
Abstract
This article considers the problem of scheduling n jobs on m identical parallel processors where an optimal schedule is defined as one that produces minimum makespan (the completion time of the last job) and total tardiness among the set of schedules. Such a problem is known as identical parallel processor makespan and total tardiness problem. In order to minimize makespan and total tardiness of identical parallel processors, improved versions of particle swarm optimization and harmony search algorithm are proposed to enhance scheduling performance with less computational burden. The major drawback of particle swarm optimization in terms of premature convergence at initial stage of iterations is avoided through the use of mutation, a commonly used operator in genetic algorithm, by introducing diversity in the solution. The proposed algorithm is termed as particle swarm optimization with mutation. The convergence rate of harmony search algorithm is improved by fine tuning of parameters such as pitch adjusting rate and bandwidth for improving the solution. The performance of the schedules is evaluated in terms of makespan and total tardiness. The results are analyzed in terms of percentage deviation of the solution from the lower bound on makespan. The results indicate that particle swarm optimization with mutation produces better solutions when compared with genetic algorithm and particle swarm optimization in terms of average percentage deviation. However, harmony search algorithm outperforms genetic algorithm, particle swarm optimization, and particle swarm optimization with mutation in terms of average percentage deviation. In certain instances, the solution obtained by harmony search algorithm outperforms existing clonal selection particle swarm optimization.
Keywords
Introduction
Scheduling is a decision-making process primarily concerned with allocation of operations on machines in such a manner that some process performance measures such as makespan, tardiness, earliness, and flow time can be minimized.1,2 The scheduling procedures available today are not only quite realistic but also possess fast solution-generating capability. It finds widespread applications in both manufacturing and service industries.
1
The parallel processor scheduling is one of the scheduling scenarios that arise when a set of n jobs available at time 0 needs to be processed on m identical parallel processors (IPPs; machines). Each job has to be processed without interruption on one of the available m machines with processing time pij where jth job is processed on machine i. Each machine can process only one job at a time. Furthermore, the jobs cannot be processed more than one machine at the same time. The objective is to find a job schedule that can minimize the makespan and total tardiness. The problem of scheduling n jobs on m IPPs where an optimal schedule is defined as one that gives the smallest makespan (the completion time of the last job) and minimum total tardiness among the set of schedules is known as IPP makespan and total tardiness problems (IPPMST). Using the standard three field notations, makespan is normally denoted as
In this article, smallest position value (SPV) rule proposed by Tasgetiren et al., 18 originally borrowed from the random key representation of Bean, 19 is used for problem representation in PSO for sequencing the jobs in IPPMST. Moreover, a non-uniform mutation operator is incorporated when it is observed that search procedure starts losing diversity and tends toward premature convergence. 20 The results obtained from particle swarm optimization with mutation (MPSO) have further been validated using HSA with SPV rule problem representation integrating Mahdavi et al.’s 21 fine tuning schemes.
Literature review
In order to solve identical parallel machine scheduling problem, Lawler 2 has proposed a transportation problem model when the job processing times are identical. Dogramaci 3 has proposed a dynamic programming algorithm to minimize total weighted tardiness. Elmaghraby and Park 4 have used a branch and bound (B&B) technique to minimize some penalty functions of tardiness considering identical due dates and processing times. Later, this method is modified by Barnes and Brennan, 5 Azigzoglu and Kirca, 6 and Yalaoui and Chu 7 to reduce the computational burden. Tanaka and Araki 8 have proposed a solution strategy based on B&B algorithm with Lagrangian relaxation technique to obtain a tight lower bound (LB). Most of the exact methods are limited to solve generalized IPPMST because they consider either equal processing times or common due dates or both. Therefore, a number of heuristic methods have been proposed to solve the problem. To minimize mean tardiness on a single machine, Wilkerson and Irwin 22 have presented a heuristic method based on neighborhood search. This method has been extended to solve the parallel machine case by Baker and Scudder. 23 Kim et al. 24 have considered the problem of determining the allocation and sequence of jobs on parallel machines for the objective of minimizing total tardiness. Kumar et al. 25 have proposed a SA-fuzzy logic approach to select the optimal weighted earliness–tardiness combinations in a non-identical parallel machine environment. Dogramaci and Surkis 26 have implemented a heuristic method based on list algorithms designed for parallel machine problem. Ho and Chang 27 have proposed a new measurement technique called traffic congestion ratio combining processing time and due dates to obtain traffic priority index for job assignment. Simon and Andrew 28 and Patrizia et al. 29 have compared various heuristics on similar instances to study the effectiveness of heuristics. With the development of evolutionary computing techniques, meta-heuristics procedures are used to solve IPPMST problems to generate approximate solutions close to the optimum with considerably less computational effort. GA has been applied by Bean 19 to solve IPPMST where a representation technique called random keys is proposed to maintain feasibility from parent to offspring in GA. With the objective of workflow balancing, Rajakumar et al. 30 used GA to solve parallel machine scheduling problem. Chaudhry and Drake 31 have presented a GA approach to minimize total tardiness of a set of tasks for identical parallel machines and worker assignment to machines. Koulamas 32 has proposed a polynomial decomposition heuristic and a hybrid SA heuristic for the problem. Kim and Shin 33 have implemented TS algorithm that schedules jobs on parallel machines when release times and due dates of jobs are known a priori and at sequence-dependent setup times. Bilge et al. 34 have developed a TS approach to solve the IPPMST with sequence-dependent setups on uniform parallel machines. Anghinolfi and Paolucci 35 have proposed a hybrid meta-heuristic approach that integrates several features of TS, SA, and variable neighborhood search (VNS) for solving IPPMST.
For minimizing the makespan, Graham 9 has used well-known longest processing time (LPT) rule for assigning the list of jobs to the least loaded machines. Coffman et al. 10 have proposed the MULTIFIT heuristic and proved the close relation between the bin-packing problem and maximum completion time problem. Lee and Massey 11 have proposed COMBINE heuristic that utilizes the LPT rule for an initial solution and improves the schedule by MULTIFIT algorithm. Gupta and Ruiz Torres 12 have proposed LISTFIT heuristic for minimizing makespan in identical parallel machines with new LB). Kurz and Askin 36 have investigated a hybrid flexible flow line environment with identical parallel machines and non-anticipatory sequence-dependent setup times with an objective to minimize the makespan.
Min and Cheng 13 have proposed GA for solving large-scale identical parallel machine scheduling problem with too many jobs and machines to minimize makespan. Kennedy and Eberhart 37 have proposed PSO algorithm having the capability of updating of position and velocity of particles and quick convergence to obtain near-optimal solutions. Tasgetiren et al. 18 have proposed a PSO for permutation flow shop scheduling problem. Liao et al. 38 and Liu et al. 39 have also used PSO in flow shop scheduling problem. Niu et al. 40 have proposed a clonal selection algorithm to improve the swarm diversity and avoid premature convergence. Geem et al. 41 have proposed HSA, a nature-inspired algorithm, mimicking the improvisation of music players. The harmony in music is analogous to the optimization solution vector, and the musician’s improvisations are analogous to the local and global search schemes in optimization techniques. It has been successfully applied to various optimization problems such as sequential quadratic programming, structural optimization, and so on.21,42–44 Zhang et al. 45 have addressed the dynamic job shop scheduling problem with random job arrivals and machine breakdowns. Renna 46 has adopted a pheromone-based approach in creating schedules for the job shop environment in cellular manufacturing systems. Rui et al. 47 have developed bidirectional convergence ant colony algorithm to solve the integrated job shop scheduling problem with tool flow in flexible manufacturing system (FMS). Kim and Lee 48 have considered the scheduling problem in hybrid flow shops with parallel machines at each serial production stage where each job may visit each stage several times, called the re-entrant flows. Marimuthu et al. 49 have addressed the problem of making sequencing and scheduling decisions for n jobs in m machine flow shops with a lot-sizing constraint. Pan et al. 50 have presented a novel multiobjective particle swarm optimization (MOPSO) algorithm for solving no-wait flow shop scheduling problems with makespan and maximum tardiness criteria. Rossi and Dini 51 have presented a GA for generalized job shop problem-solving, and the generalization includes feeding times, sequences of setup-dependent operations, and jobs with different routings among work centers including “multi-identical” machines. Wang and Brunn 52 have proposed an effective GA for job shop sequencing and scheduling where a simple heuristic rule is adapted and embedded into the GA to avoid the production of unfeasible solutions.
Scheduling on IPPs
The scheduling of IPPs is regarded as one of the most-studied classical scheduling problems that involve the assignment of multiple jobs onto the machines. Among the performance measures considered, makespan, total tardiness, and earliness are commonly used to test the schedules. The problem can be stated as follows: there are n jobs waiting for being scheduled on m IPPs so as to minimize makespan and total tardiness. The basic assumptions need to be considered for solving IPPMST problems are as follows:
All jobs can be processed on any of the parallel machines.
Each of the parallel machines can process at most one job at a time.
Each job has to be processed without interruption on one of the machines.
All jobs are available to be processed at time 0.
No job can be processed by more than one machine.
The processing time and the due date of the jobs, the number of jobs, and the number of machines are given and fixed.
No downtime is considered, and setup time is included in processing time.
A set N = {J1, J2, …, Jn} of n jobs are to be scheduled on a set M = {M1, M2, …, Mm} of m identical parallel machines. The first objective is to find the optimal schedule S = {S1, S2, …, Sm} where Sj is a subset of jobs assigned to machine Mj such that max{C1(S), C2(S), …, Cm(S)} = Cmax(S) is minimum where
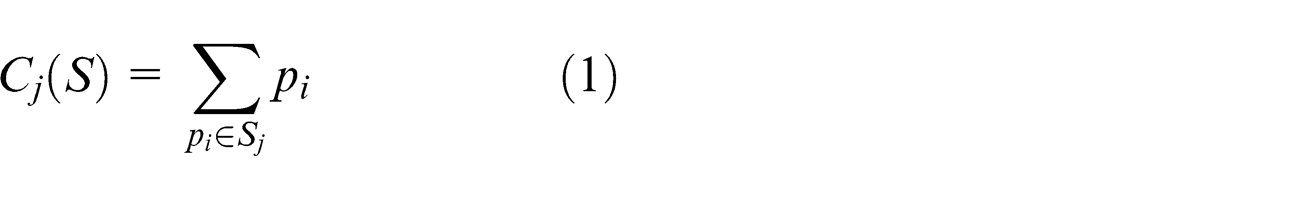
The following notations have been used for finding total tardiness: i is the index of machine, i = 1, 2, …, m, where m is the number of machines;
The IPP total tardiness can be represented mathematically in the following manner

Constraint (2) describes the starting time of the machine is equal to 0
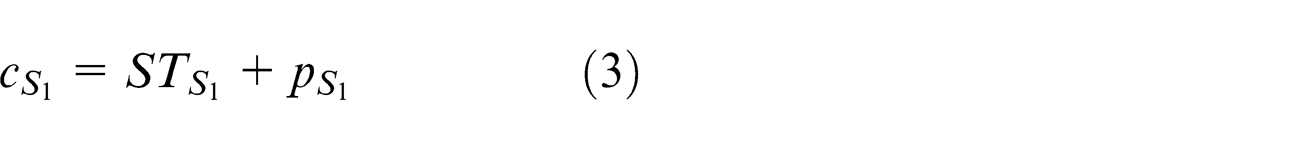
Constraint (3) denotes the completion time of the job in the sequence which is the summation of starting time and the processing time of the particular job in the sequence

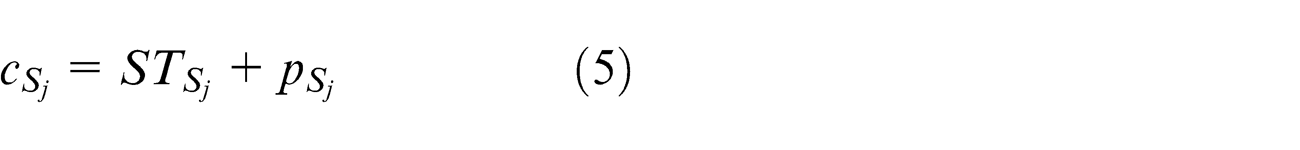
The tardiness time of job Sj is calculated using the following equation
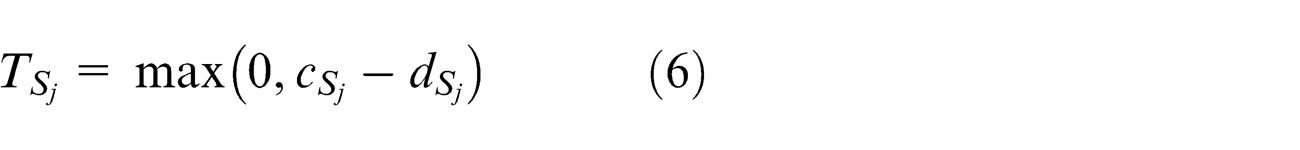
The second objective of this article is to minimize total tardiness which is defined using equation (7)

The mixed-integer programming approach for IPP machine scheduling problem formulated above can be solved by B&B technique, but computational efforts are prohibitive for large-scale problems.
PSO
PSO is inspired by the social behavior of bird flocking and fish schooling. It is a population-based, bio-inspired optimization algorithm originally introduced by Kennedy and Eberhart. 37 In PSO, particles are called as potential solutions; each particle adjusts its position based on its own experience as well as the experience of a neighboring particle by utilizing the best known position in the search space as well as the entire swarm’s best known position. By adapting the global and local exploration capabilities, PSO has maintained its flexibility toward reaching the global optimal solutions. The particles in PSO have their own memory that enables to retain good solutions among all particles. But in case of GA, the previous knowledge of the problem has been destroyed once the population changes and chromosomes share their information with each other. In PSO, previous best value is called as Pbest of the particle and the best value of all the particles among the Pbest in the swarm is called as Gbest. Compared with GA, all the particles in PSO tend to converge to the best solution quickly even in the local version in most cases, and it does not require any kind of classical optimization methods such as gradient descent and quasi-Newton to solve optimization problem. Due to its simplicity, easy implementation, and quick convergence, PSO has gained much attention among the researchers and has been successfully applied to a wide range of applications in almost all fields of engineering.18,20
The basic elements of PSO are summarized as follows: The particle
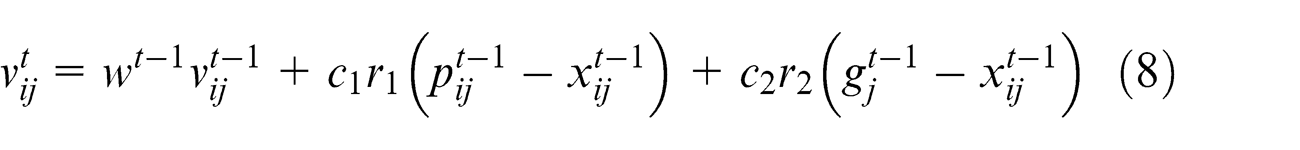

where c1 and c2 are social and cognitive parameters and r1 and r2 are uniform random numbers between (0, 1)
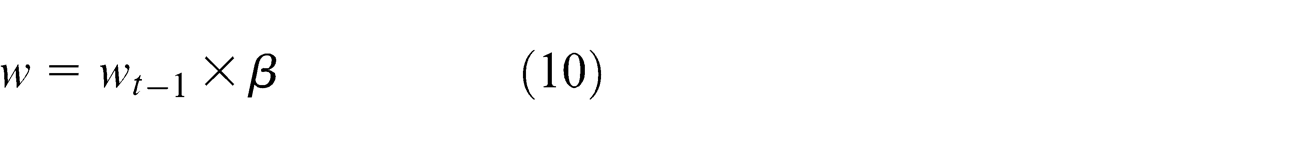
where β is the decrement factor. The updation of equations (8) and (9) may lead the particles moving toward compound vector of global and local optimal solutions.
Proposed PSO algorithm
Solution representation
The solution representation is one of the important issues when designing PSO. To maintain the bonding between the problem domain and PSO particles for IPPMST, D number of dimensions is represented for n number of jobs. The particle
SPV rule.

SPV: smallest position value. The bold values shows the smallest position value.
The smallest position in the table is
Processing times for the jobs.

For example, there are two machines (m = 2) and six jobs (n = 6). From the SPV rule, the fourth job occupies the first position in the initial sequence. The corresponding processing time of the particular job has been taken from Table 2 and placed in the first machine as shown in Table 3. Similarly, the sixth job in the initial sequence occupies the second position. So, the corresponding processing time for the sixth job from Table 3 has been placed in the second machine. Both the machines have been assigned with two different jobs. Among these machines, the machine that completes the assigned job first is assigned with a new job from the sequence in Table 1. In this case, second machine assigned with job number 6 completes the job first as processing time for the job is 7 units of time. The third position in the sequence is job number 3 having the processing time of 10 units of time. Hence, the second machine is occupied by the job number 3. This process is repeated until all the jobs are assigned to machines. From Table 3, it is evident that job completion time of first machine is 27 units of time and that of second machine is 25 units of time. Hence, the makespan has been considered as the maximum of the completion time in all the machines. In this case, makespan is considered as 27 units of time. From Table 3, pij denotes the processing time of the jth jobs in ith machine where 9(4) represents fourth job is processed having 9 units of time.
Assignment of jobs using SPV rule.

SPV: smallest position value.
Mutation operator
Mutation operator adopted from GA tends to alter one or more gene values in a chromosome from the initial state. This leads to the generation of new gene value that is being added to the gene pool. Moreover, GA can be able to attain better solution than the previous one through these newly generated genes. Hence, mutation is an important operator of the genetic search as it helps to avoid local optimal by preventing the population of chromosomes. In case of PSO, the lack of population diversity among the swarms is considered as a factor for the convergence on local minima. Hence, the PSO has been incorporated with mutation operator to enhance its global search capacity and to improve performance. In this article, a non-uniform mutation operator by Michalewicz
20
has been incorporated in PSO which helps to mutate some particles selected randomly from the swarm. If the number of iterations with no diversity in the solution exceeds, mutation is carried out. This operator works by changing a particle position dimension (
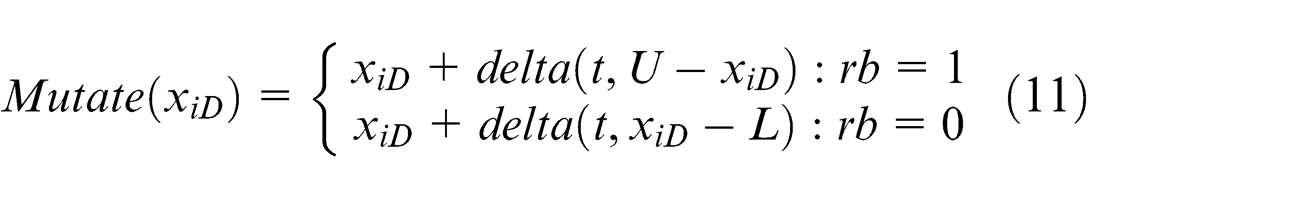
where t is the current iteration number, U is the upper bound value of the particle dimension, L is the LB value of the particle dimension, rb is the randomly generated bit, and delta (t, y) returns the value in the range [0:y]
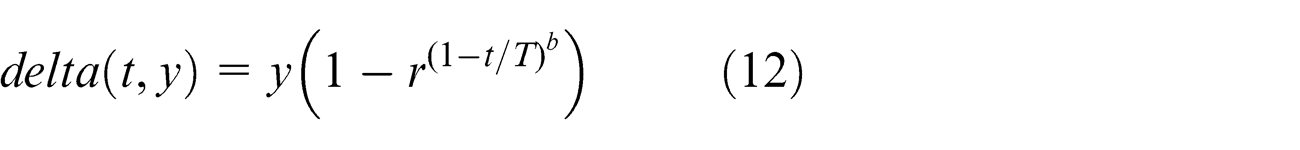
where r is the random number generated from the uniform distribution range [0:1], T is the maximum number of iteration, and b is the tunable parameter which is set as 5 by Michalewicz. 19 The pseudo-code for the proposed MPSO is given as follows:
Initialize the parameters, including swarm size, maximum number of iteration, w, c1, c2
Initialize particle’s position and velocity stochastically;
Apply SPV rule;
Evaluate each particle’s fitness using the objective function;
Initialize pbest position;
Initialize gbest position with the particle with lowest fitness in the swarm;
Update the velocity of the particles by equation (8);
Update the position of the particles by equation (9);
Apply SPV rule;
Evaluate each particle’s fitness using the objective function;
Perform mutation if t < (Tmax* PMUT) where Tmax is maximum number of iteration and PMUT is probability of mutation;
Find the new gbest and pbest values by comparison;
Update gbest of the swarm and pbest of each particle;
The pseudo-code has been further explained with the introduction of flow chart as shown in Figure 1.
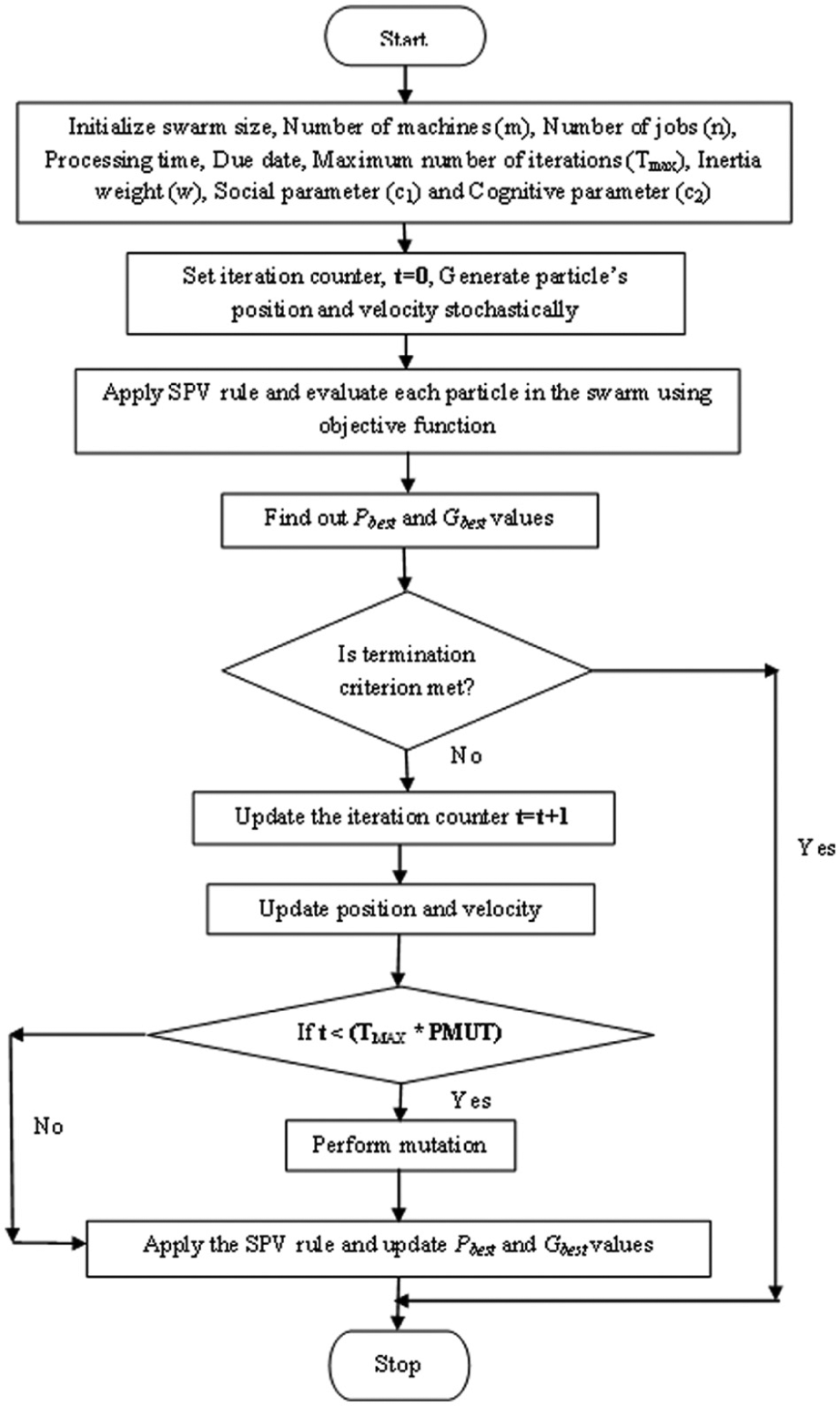
Flow chart for MPSO algorithm.
HSA
Geem et al. 41 introduced an interesting meta-heuristic algorithm called HSA. It is population based and mimics the musical process of searching for a better state of harmony such as jazz improvisation. It has its own advantages over traditional optimization techniques by having great power in global search and its simplicity in both concept and implementation. Due to its advantages and novelty, HSA has received increasing attention among the researchers and has been vigorously applied to various engineering optimization problems. One of the finest qualities of HSA is the identification of high-performance regions of the solution space at a reasonable time. However, while performing the local search for numerical application, it is not able to withstand at its best. Hence, fine tuning the HSA characteristics becomes inevitable. In order to improve such fine tuning characteristics and convergence rate, Mahdavi et al. 21 have proposed an improved harmony search which has the fine tuning feature of mathematical techniques having the potential of outperforming traditional HSA. This algorithm uses harmony memory considering rate (HMCR) and pitch adjusting rate (PAR) for finding the solution vector in the search space. The optimization procedure of HSA is given in the following steps.
Initialization of the harmony memory (HM);
Improvisation of a new HM;
Updation of the HM;
Checking for the stopping criteria. Otherwise repeat steps 2 and 3.
Initialization of HM
A set of initial solutions of harmony memory size (HMS) is generated to build the HM, which is represented by a matrix of two dimensions where rows consists of a set of solutions xi (population size), while columns consists of the variables of each solution (jobs). Each solution xi is considered as a one-dimensional array. The size of the array can be designed by the maximum number of jobs considered in the problem instance. HM is represented as given in equation (13)
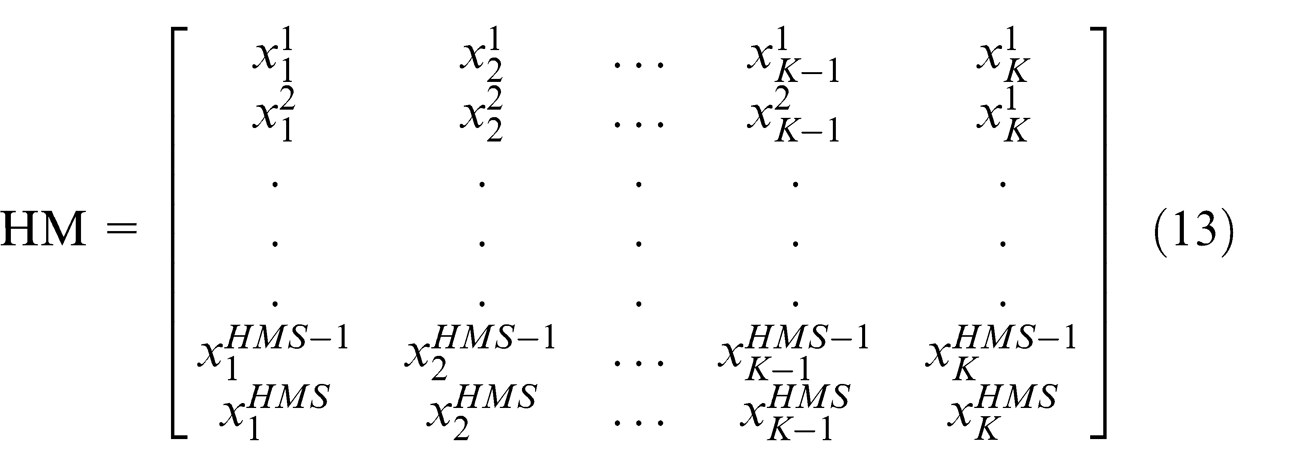
Improvisation of new HM
The divergence and convergence of the search in HSA has been maintained during this process. HMCR and PAR are considered as the main parameters for convergence or divergence of the search capability by Mahdavi et al.
21
Here, the new solutions are constructed stochastically using one of the following three operators: (1) memory consideration (based on the HMCR), (2) random consideration (based on 1 − HMCR), and (3) pitch adjustment (based on the PAR). For the memory consideration, the value of the first decision variable (
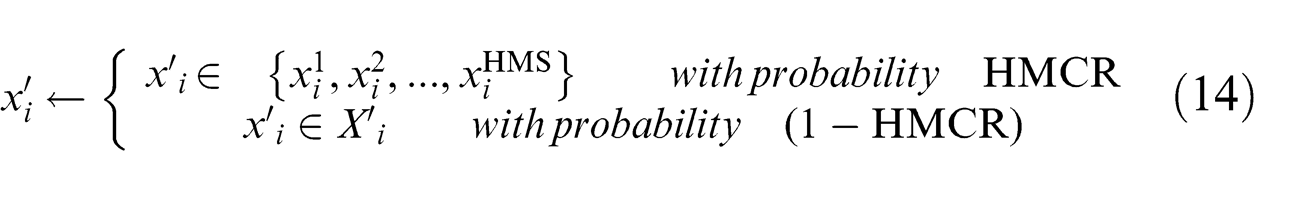
Each and every component obtained by the memory consideration is analyzed to determine whether the pitch should be adjusted
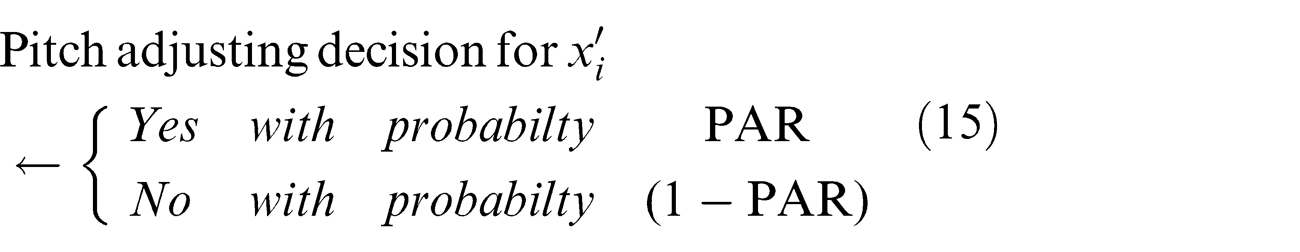
If the pitch adjustment decision for
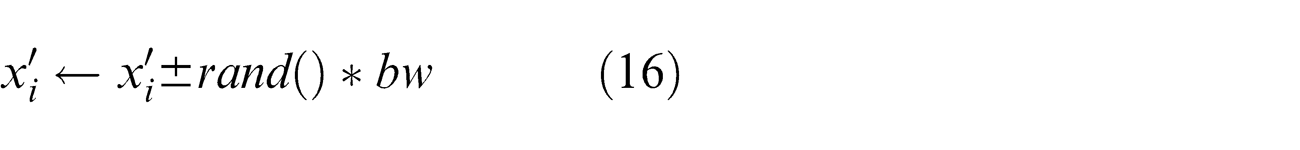
where bw represents an arbitrary distance bandwidth and rand() represents random number between 0 and 1.
By considering HM, pitch adjustment has been applied to each variable of the new HM vector. These improvisation steps are almost similar to reproduction in GA which uses crossover and mutation operators. Thus, the improvisation utilizes the full HM to construct the solutions, but in case of GA, new chromosomes are generated by crossover of two parents or mutation. While considering the operators in GA, it needs to be carefully designed for highly constrained problems for reaching out its optimal solutions.
Updation of HM
If the new harmony vector, (
Check for stopping criteria
If the maximum number of improvisations (stopping criterion) is satisfied, computation is terminated. Otherwise steps 2 and 3 will be repeated.
Proposed HSA
In HM vector, each member in the population pool is converted to job schedule using SPV rule–based problem representation discussed in section “Solution representation” for getting the initial sequence of jobs and assignment of jobs to the machines to calculate the objective function. The traditional HSA only uses fixed values for both PAR and bw. These values have been adjusted in the initialization step and not been changed during new generations. This has been considered as the main drawback of traditional HSA. Hence, the need has been raised to sort out these issues. However, by fine tuning the optimized solution vectors using the parameters such as PAR and bw, convergence rate has been increased, and this leads to optimal solution. Still there has been a probability of having a dispute by assigning small and larger values for PAR and bw or vice versa. Hence, the parameter values need to be selected judiciously. Fesanghary et al. 42 have developed one of such fine tuning parameters for PAR and bw for reducing the dispute among the values given to their parameters. It has been reported that using equation stated below for PAR and bw, these issues have been sorted out
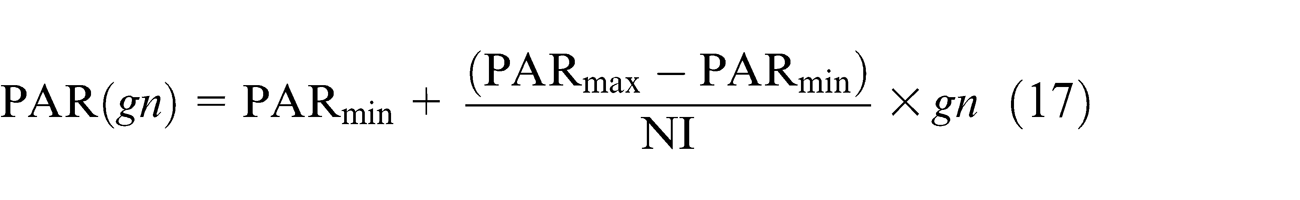
where PAR represents the pitch adjusting rate for each generation,
For bandwidth, tuning has been done using the following equation
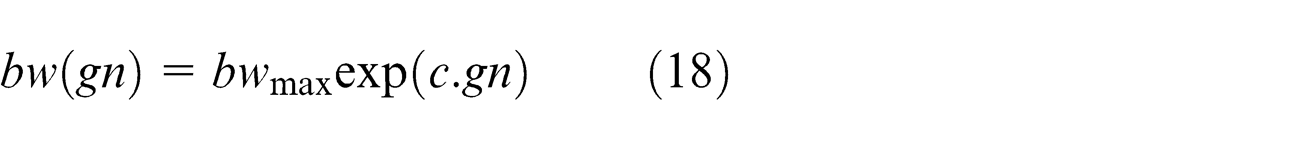
where
Results and discussions
The computation study aims to analyze the performance of MPSO and HSA to minimize makespan and total tardiness for the IPP scheduling. The algorithms are coded in MATLAB R2010a and executed in Intel® Core™ i5 CPU M430 at 2.27 GHz with 4 GB RAM. The benchmark problems have been taken from Tanaka and Araki
8
and are also available at https://sites.google.com/site/shunjitanaka/pmtt. Fisher
53
has proposed the standard method for generating these problems. The integer processing times pj (1 ⩽ j ⩽ n) of these problems have been generated from the uniform distribution between [1, 100]. The total processing times have been computed by
The MPSO algorithm has been tested with GA and PSO. In all the cases, the percentage deviation (PD) of MPSO is better than GA and PSO. HSA has been tested with the same benchmark problem where the PD value of HSA is better than GA, PSO, and MPSO. The results are represented in terms of PD of the solution from the LB reported by Gupta and Ruiz Torres. 12 The LB has been calculated using the equation given below
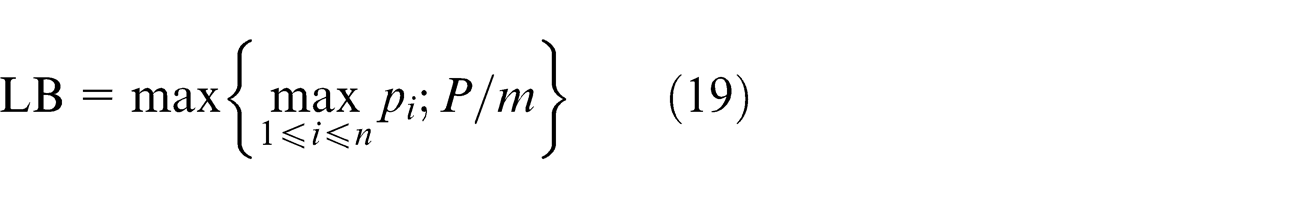
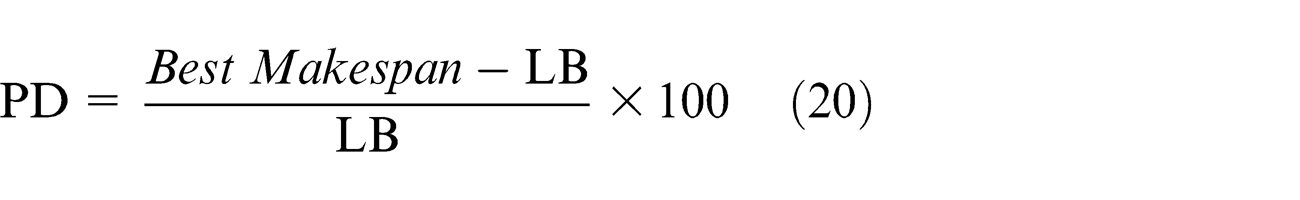
The average percentage deviation (APD) of the proposed MPSO has been tested with GA and PSO in IPPMST. The APD can be calculated as follows

where I is the total number of problems and L stands for index of the problem.
From Table 4, it is observed that the calculated value of APD for GA is 0.2686 and PSO is 0.1385. The APD value obtained by using MPSO is 0.0851. Based on APD comparisons, MPSO turns out to be superior to GA and PSO, whereas the performance of GA is worst among all algorithms. The APD value for HSA is 0.0523. It clearly shows HSA is superior to GA, PSO, and MPSO.
APD values for makespan.
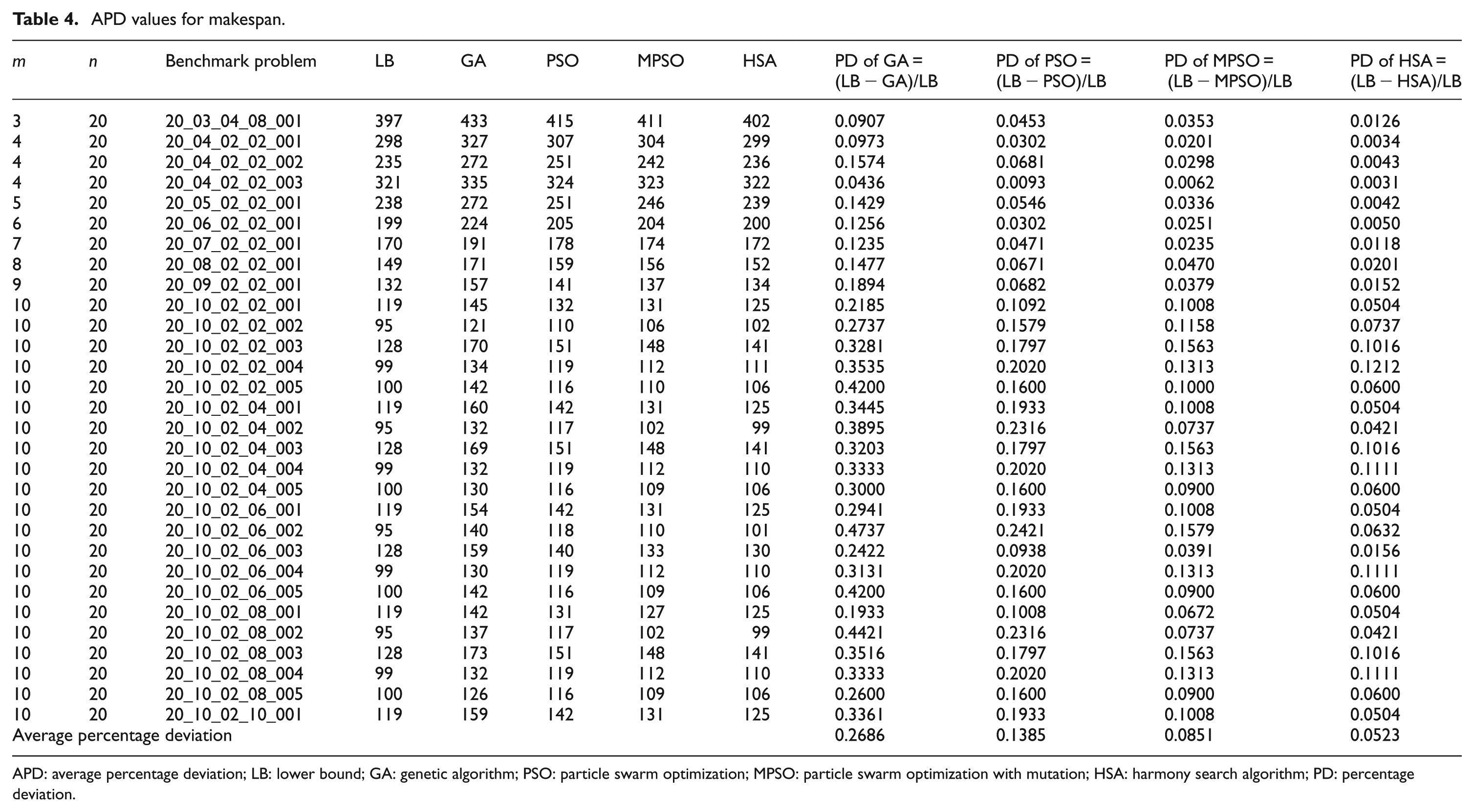
APD: average percentage deviation; LB: lower bound; GA: genetic algorithm; PSO: particle swarm optimization; MPSO: particle swarm optimization with mutation; HSA: harmony search algorithm; PD: percentage deviation.
The improvement rate in APD using MPSO can be defined as follows
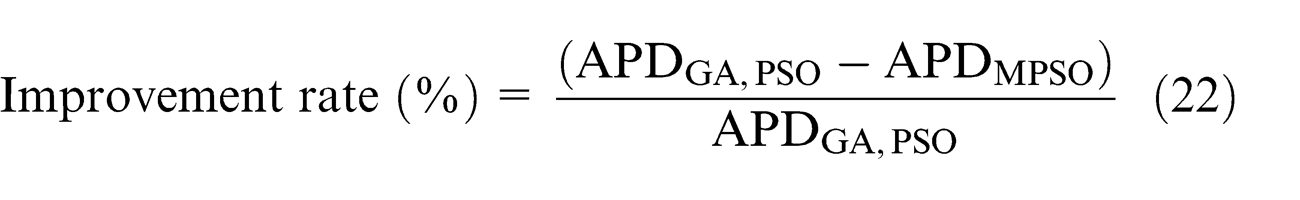
The improvement rate of MPSO with respect to GA is 68.3% and with respect to PSO is 38.5%. The convergence curve for makespan with MPSO is presented in Figure 2.
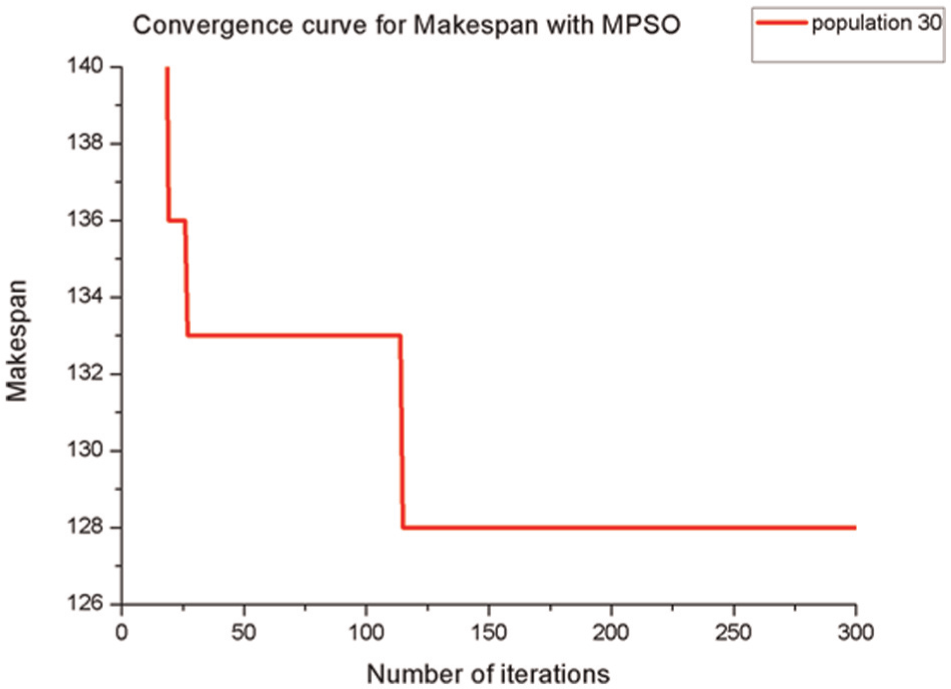
Convergence curve for makespan with MPSO for the problem 20_10_02_08_001.
Similarly, the improvement rate for HSA can be defined as follows

The improvement performance of HSA with respect to GA is 80.5%, with respect to PSO is 62.2%, and with respect to MPSO is 39.9%. The convergence curve for makespan with HSA is presented in Figure 3. The results of GA, PSO, MPSO, and HSA for makespan and their corresponding APD values are shown in Table 4.
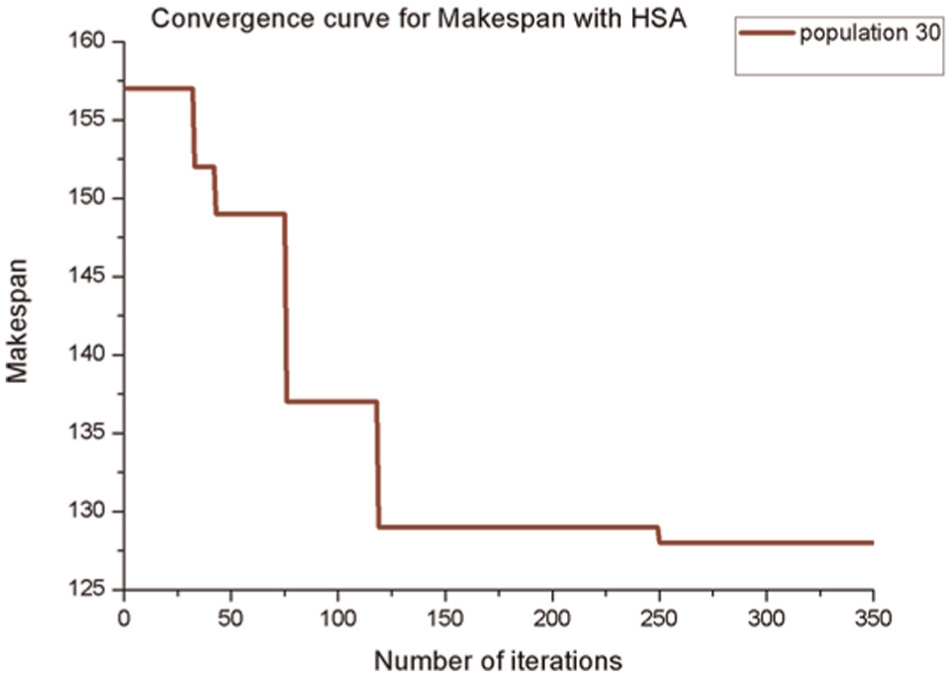
Convergence curve for makespan with HSA for the problem 20_10_02_08_001.
The same benchmark problem has been tested with total tardiness, and same instances of the problems have been compared with clonal selection PSO (CSPSO) reported by Niu et al. 40 and also the optimal solution (OPT) reported by Tanaka and Araki. 8 The results for total tardiness are shown in Table 5. The comparison with instances by Niu et al. 40 indicates that the total tardiness value by HSA is either exactly matching or better for eight instances out of nine instances. For instances 20_04_02_02_002 and 20_10_02_02_004, total tardiness value by CSPSO are 105 and 180, respectively, and same values are obtained by HSA. For the instance 20_10_02_02_002, the average total tardiness value by CSPSO is reported as 136.6, whereas the corresponding value by HSA is 136. For the instance 20_10_02_04_002, total tardiness values by CSPSO and OPT are 86.5 and 85, respectively, whereas HSA results in total tardiness of 85. For instances 20_10_02_04_004, 20_10_02_06_002, and 20_10_02_06_004, total tardiness values by HSA are better than CSPSO. However, in case of the instance 20_10_02_08_004, CSPSO results in better total tardiness value as compared to HSA. This is to be noted that total tardiness value produced by HSA is similar or superior to GA, PSO, and MPSO. Out of 30 instances, the total tardiness value for 9 instances is comparable with results produced by HSA. The convergence curves for the total tardiness are shown in Figures 4 and 5. PSO, originally proposed by Kennedy and Eberhart, 37 is mainly used in continuous optimization problems due to quick solutions. However, it has an inherent drawback of premature convergence at initial stage of iterations. The limitations of the PSO can be overcome by the use of mutation, a commonly used operator in GA, through introduction of diversity in the solution. The proposed algorithm is termed as MPSO. MPSO is found to perform better than GA and PSO, in both continuous and combinatorial optimization problems. However, a newly developed meta-heuristics known as HSA is simple in concept and easy for implementation. HSA needs only few parameters to be tuned like PSO. Since HSA is a population-based meta-heuristic, the multiple harmonic groups can be used in parallel. This parallelism technique usually leads to better establishment with higher efficiency. Hence, fine balance of intensification and diversification as well as the good combination of parallelism with elitism is the key to the success of HSA and, in fact, to the success of any meta-heuristic algorithm. Thus, HSA performs better than GA, PSO, and MPSO.
Total tardiness value comparison.
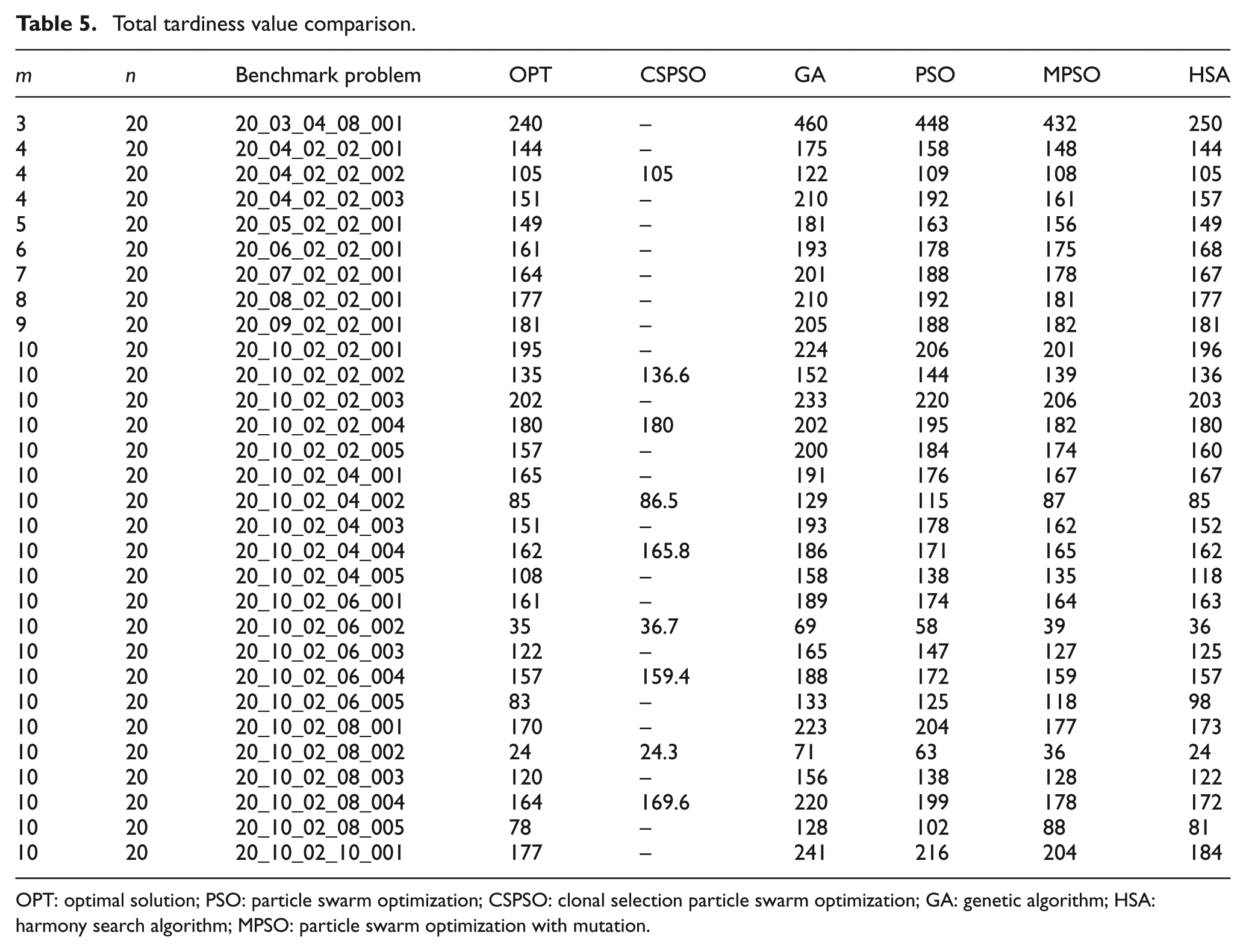
OPT: optimal solution; PSO: particle swarm optimization; CSPSO: clonal selection particle swarm optimization; GA: genetic algorithm; HSA: harmony search algorithm; MPSO: particle swarm optimization with mutation.
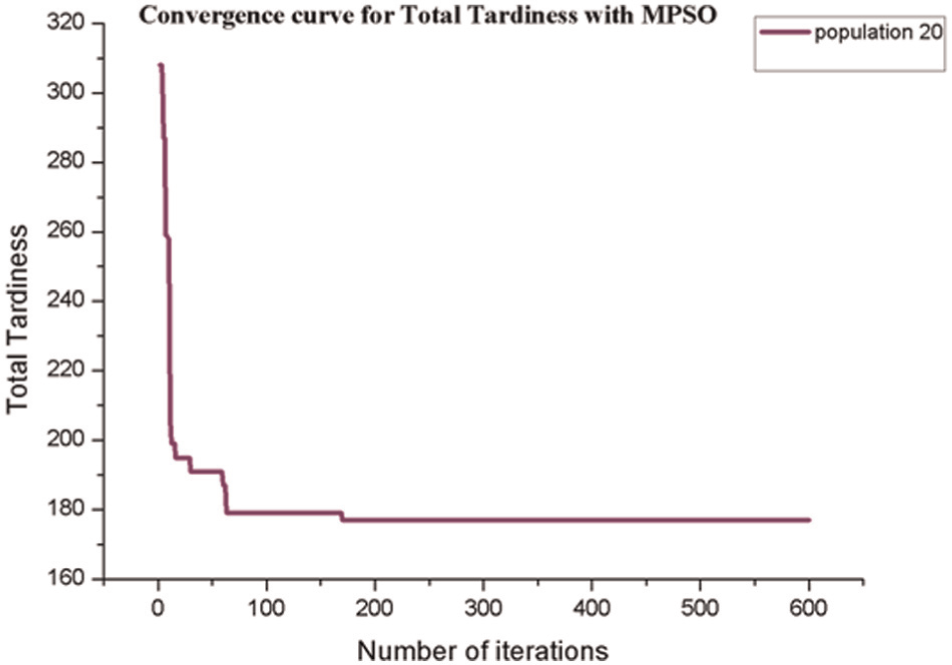
Convergence curve for total tardiness using MPSO for the problem 20_10_02_08_001.
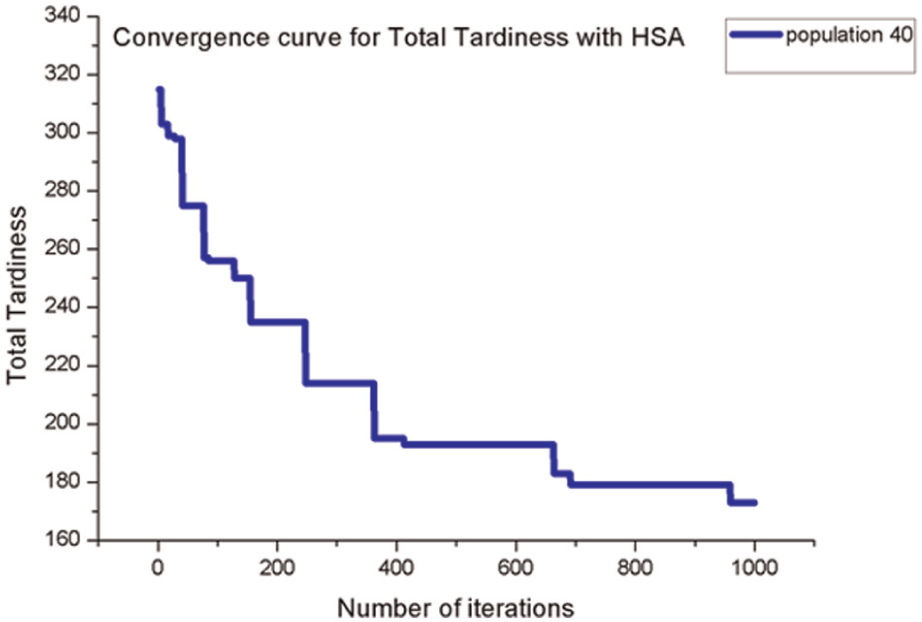
Convergence curve of total tardiness using HSA for the problem 20_10_02_08_001.
Conclusion
In this article, two new meta-heuristic approaches have been presented for minimizing makespan and total tardiness in IPP scheduling problems. In the first approach, PSO has been modified using a mutation operator and job sequence using SPV rule. In the second approach, HSA has been improved using the Mahdavi et al. 21 parameter in PAR and bw, and the sequence of job has been obtained through SPV rule. The scheduling performance by both the algorithms has been compared with GA and PSO. It is found that the performance of MPSO is superior to GA and PSO. However, it is to be noted that HSA outperforms GA, PSO, and MPSO. Both the algorithms happen to be novel in the field of scheduling. The study provides a framework for practicing engineers and managers to schedule large-scale IPP with less computational burden. However, tuning of algorithmic parameters is vital to obtain best schedules. Both the algorithms are extremely simple to implement. Although the proposed algorithms have been tested in IPPMST, the approach can be extended to flow shop, job shop, flexible low shop, flexible job shop, FMS, and resource-constrained project scheduling problem. The mapping of continuous position values of PSO or HM vector of HSA to schedule can be made with application of SPV rule with little modification. In case of continuous optimization problems, for example, process optimization, both the proposed algorithms can be applied without the need of application of SPV rule. However, combinatorial problems require the generation of combination by the use of SPV rule. Application of the proposed algorithms to combinatorial case makes problems more complex than continuous counterpart, and preservation of diversity of solution becomes an important issue. In this study, the processing time is assumed to be deterministic and machines are perfectly reliable. In future, the algorithms may be modified to incorporate stochastic processing times and machine unreliability for solving IPPMST. Although the study applies SPV rule for generation of job schedule, other mapping methods may be explored in conjunction with the proposed algorithm to study the performance of the algorithms in IPPMST.
Footnotes
Declaration of conflicting interests
The authors declare that there is no conflict of interest.
Funding
This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.