
Abstract
Although assembly line balancing problem has been an attractive field of research in many industries over the past decades, few researches focused on the problems in shipbuilding. In this contribution, we deal with a more realistic assembly line for sub-block in shipbuilding, through which lots of small different products were produced. Thus, the problem becomes more complex, which can be regarded as a variant of the classical assembly line balancing problem, batch-model assembly line balancing problem with space and sequence constraints. Our goal is to find the optimal division of the total assignment into different production batches based on the balance of the station workloads and higher efficiencies of the workers and equipments. We solve the said problem with a memetic algorithm, which is illustrated in detail. The validity of the proposed algorithms is tested using the real data of the sub-block assembly in shipbuilding, and the experiment results demonstrate that the proposed algorithm outperforms highly the existing standard genetic algorithm in terms of ability to find the optimal solutions.
Keywords
Introduction and literature review
An assembly line is a special product system which consists of a serial workstations aligned in the fixed manner. According to the different configurations, each station can perform the total or some specific assembly operations. In the assembly process of the products, the components visit stations consecutively from the first one to the next by certain transportation systems, for example, a conveyor belt or a serial platform connected to each other, and some specific operations allocated to each station are performed in the required time. In the end, the finished products flow from the last station. Most assembly lines can produce only one type (single model) of product; with the demand of making the production more versatile and flexible, many lines had been forced to change from the fixed assembly lines to mixed-model or multi-model ones, in which different products can be produced. 1
On the batch-model assembly line, the set of assignments allocated to a station constitutes its station load. Each assignment i requires a determined operation time STi,k on the k station, and the cumulated operation time in the same station of the assignment set is called station time. In paced assembly lines, the cycle time of all stations is equal to the same value CT, which is also regarded as the interval time between two batches of products flowing out from the line. As a consequence, all station times of a feasible allocation may never exceed CT, as otherwise the assigned operations cannot be finished before the components leave the station. However, station times can be smaller than the CT; in this circumstance, a station may have an idle time in each cycle, that is, it is unproductive for this time span. Obviously, in order to enhance the productivity of the line, we should reduce the total idle time of the stations as much as possible.
The decision problem of optimally partitioning (balancing) the assembly operations among the stations subject to some constraints with respect to some objective is known as the assembly line balancing problem (ALBP). 1 It exists in many production stages, such as configuring, redesigning or adjusting about an assembly line. The classical ALBP involves determining an optimal assignment of a subset of tasks to each station of the plant fulfilling certain time and precedence restrictions. 2 An optimal solution of the ALBP can help the practical assembly line configuration or production planning by offering the optimization models. Due to this reason, ALBP has been an active field of research over more than half of century and a large number of achievements have been attained.3–5
According to the number of items produced on the line, the ALBP is classified into three types: single model, batch model and mixed model. Single model assembles only one type of product, whereas a batch model assembles two or more types of product. Each model is produced in batches on the same assembly line, and there may be one or more models in one production batch.6,7 Although the mixed-model assembly lines can also produce multiple products, the different products are being produced separately rather than in batches. This article solves batch-model line balancing problem with real application. The single-model assembly line is the easiest one among the three types of lines. The most ordinary objective of the single-assembly line balancing problem (SALBP) is to maximize the efficiency of the assembly line. This goal can be attained either by minimizing the number of workstations given a fixed CT or by minimizing the CT given the number of stations.3,5 However, in the mixed-model or batch-model lines, there are many different models to be assembled, and each model may require different operations with individual STi,k. Additionally, the precedence relations and space constraints also need to be considered when allocating the assignments to stations. In general, the problem of determining production sequence and subset of models produced on the line by optimizing a certain performance measure is called mixed- or batch-model ALBP.
Since the first mathematical formalization of ALBP published by Salveson, 8 the problem of designing and balancing assembly lines has been examined extensively in the literature. However, most of these articles focus on the SALBP. Recently, assembly line balancing research evolved toward formulating and solving more complex problems with various additional characteristics such as cost functions,9,10 equipment selection, paralleling, 11 U-shaped line layout 12 and mixed-model production.4,6,13 Reviewing the literature on ALBP shows that it is a class of non-deterministic polynomial-time (NP)-hard optimization problem. Like other NP-hard problems, there are a number of exact procedures that are suitable for some small-size instances of the problem, such as branch and bound,9,14,15 integer linear programming 16 and dynamic programming. 1 However, further algorithmic improvement is necessary to deal with the realistic and large-scale instances. Consequently, many heuristic/meta-heuristic algorithms have been used to obtain the optimal or even near-optimal solutions about the complex ALBP. These approaches include genetic algorithms (GAs),17–20 the simulated annealing approach, 21 tabu search, 22 Petri-net heuristic, 23 memetic algorithm (MA) 24 and some experimental heuristics such as the computer method of sequencing operations for assembly lines (COMSOAL) method, 25 the greedy randomized adaptive search procedure (GRASP) algorithm 26 and the FTALB heuristic algorithm. 27
From the literature review, it is easy to see that almost all studies focus on finding the optimal allocation of the operation tasks to the stations. However, we deal with the special ALBP, where the outputs are a great deal of diversified products, which have the same processing procedures and smaller size relative to the capacity of stations. Usually, in the multi-level production system, these products are the sub-assemblies, which will be transported to the high-level assembly line and the final products are assembled there. A just-in-time (JIT) philosophy, which requires producing only the necessary products in the necessary quantities at the necessary time, 28 can be used to control the batch-model multi-level production system. In order to catering for this pull production system, some specific products cannot be started before all its predecessors are completed. Additionally, the batches’ partition of the total assignments is feasible only if the cumulated space occupied by the raw materials of each batch is not exceeding the available space of the platform.
Thus, given a mix of products to be produced, the objective of the balancing and sequencing problem is to allocate different assignments to production batches with the precedence and space constraints so as to balance the station workloads and gain the high efficiency of line capacity. Consequently, the sequencing, balancing, time and space factors must be taken into account simultaneously when solving the said ALBP. Due to the complex constraints and combinatorial optimization objective of the problem, further algorithmic improvement and specific procedures must be employed. In this article, the MA is proposed, which is a kind of evolutionary algorithm using a local search algorithm to exercise exploitation. Therefore, it can avoid falling into the local optimum and gain the optimal or near-optimal solutions in a short computational time. 29
The rest of this article is organized as follows: section “Detailed description of the problem” gives the detailed explanation about the ALBP of sub-block in shipbuilding. The design and realization of the proposed MA are introduced in section “Proposed algorithm.” The validity of the algorithm is verified by some computational experience using the real date, and subsequently, the discussion about the test is given in section “Computational experiments and results.” The main conclusions of the study and some future researches are outlined in section “Conclusion and future research.”
Detailed description of the problem
Hull assembly system belongs to the typical multi-level production system. In general, a ship hull is built with hundreds of blocks. A block is composed of several subassembly blocks. And each sub-block is composed of steel panels and sections that are cut or bent. We deal with the sub-blocks’ assembly line balance problem in this article. One hull consists of many various sub-blocks, which may be different from each other in size and structure. But all sub-blocks have the same production process, which is separated into five main phases as shown in Figure 1: Uploading, Fix Position, Welding, Polishing and Hot processing. The components of the products need to be uploaded to the platform in the first station and then visit the rest of stations one by one; the finished products flow from the last station. There may be different required areas or station times for each product to be assembled on the line. In addition, there are precedence relationships among all products according to the JIT ideology. Therefore, our goal is to find the optimal cycle time and batches’ partition of the total given assignments with some constraints satisfied and predesigned objectives attained.
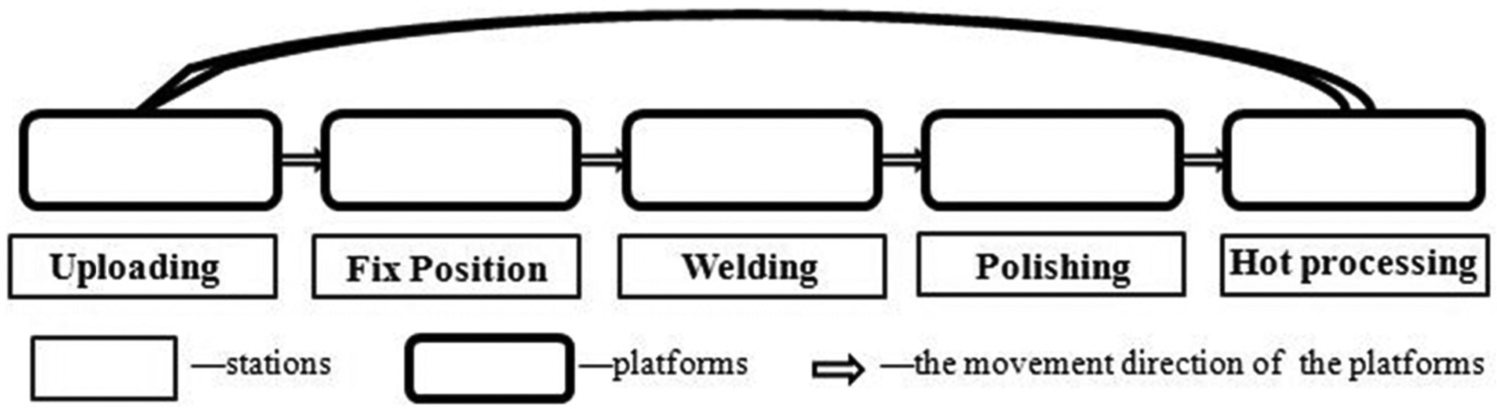
The constitution of the sub-block assembly line.
Problem analysis
There are three main elements of the whole assembly line, namely, assignments, stations and workers. Before description of the assembly line problem, the detailed analysis about each factor is given as follows.
Assignments
Each sub-block to be assembled is regarded as the assignment (Ai) on the assembly line; the total assignments to be manufactured is typically expressed as a set V = {A1, A2, …, An} of n products. The set of assignments in each production batch is expressed as BA, and the total number of batches is represented as nBat. Consequently, the relations among them are shown as follows
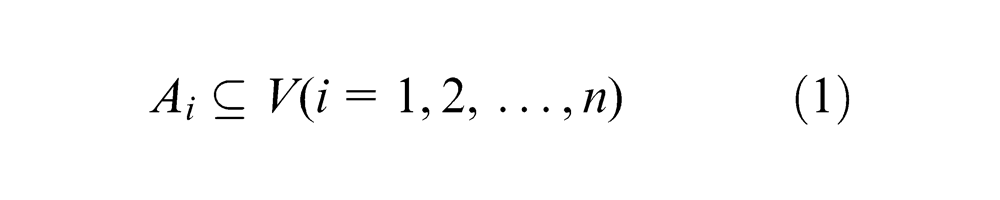
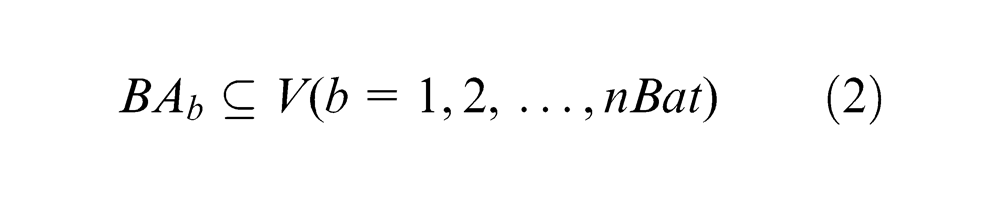
As mentioned above, there are precedence relations among the assignments to be manufactured. These precedence constraints can be depicted in a precedence graph, where the nodes of the graph represent assignments, and every arc represents a precedence relation between two assignments. For example, arc (i, j) indicates that assignment j should not be finished before finishing assignment i. This precedence relation can also be expressed as matrix form, which is defined in equation (3). Using this definition, the precedence graph can be converted into the precedence matrix conveniently. An example of a precedence graph and its matrix form with 10 assignments is given in Figure 2

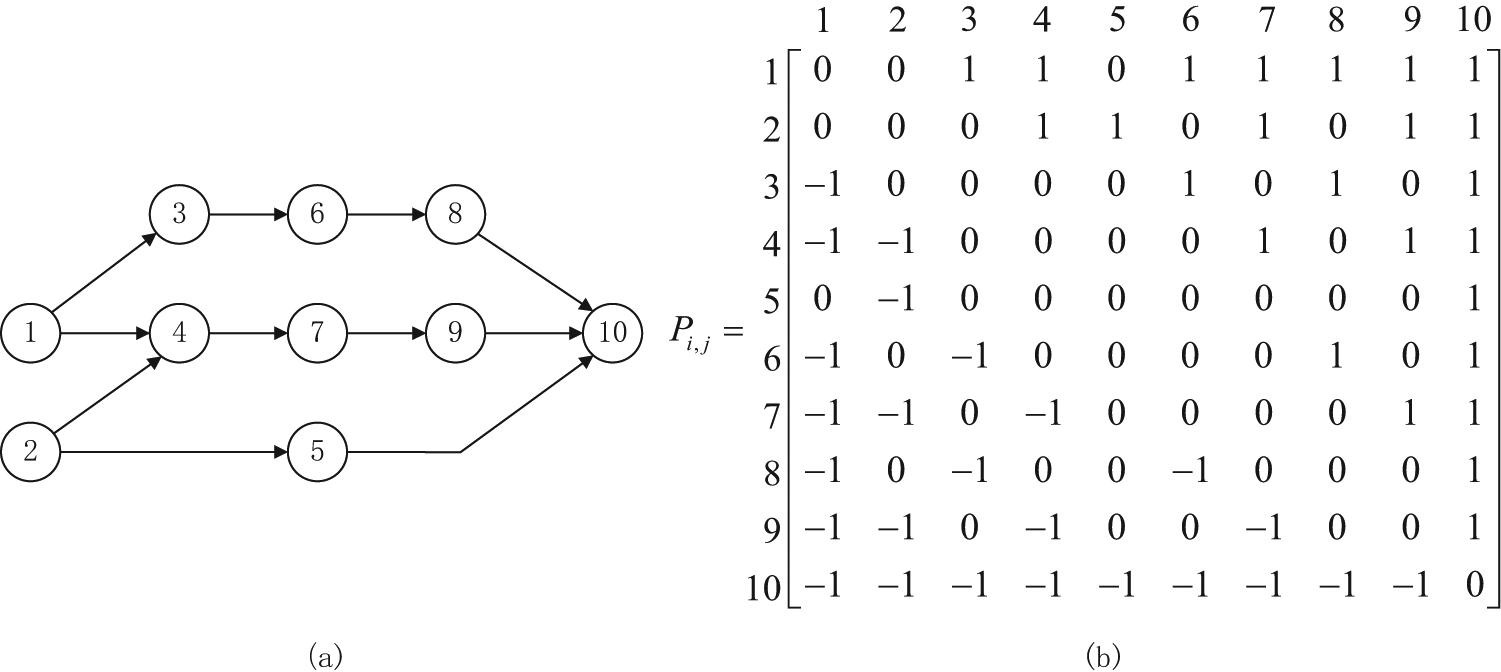
(a) Precedence graph and (b) precedence matrix.
For reasons of homogenization and simplification, we assume that the available space of all platforms is equal to S. And Si is used to represent the required space of the assignment i, which may be different from each other because of their different structures. However, all the assignments must go through every station in the same order to finish the assembly process.
In order to increase the utilization efficiency of the platform, it is better to allocate as many assignments as possible to the same production batch. Let us introduce the following decision variables di,b to express the allocating result of each assignment, where nBat represents the total number of batches

Stations
The assembly line consists of m stations, which are arranged in the straight-line layout, and there are no buffers around every station. In addition, the only specific operations can be finished on given station. For example, the welding station cannot fulfil the polishing work. We define the assembly line as the paced line. Consequently, at the end of each cycle time, the platforms move simultaneously in the fixed direction, and the time consumed for moving the platforms cannot be neglected.
Workers
As mentioned above, different assignment may stay at different times on the same station, and there may be different values of station time to the same assignment when it visits the different stations. But the total station time is constant to the whole assignment. The reasonable arrangement of station workers can help ensuring the continuity and balancing of the assembly line. The number of workers to each station can be identified using equation (5). Here, k denotes the station, TST represents the total station time of the assignment set V and WN represents the worker number assigned to workstation.
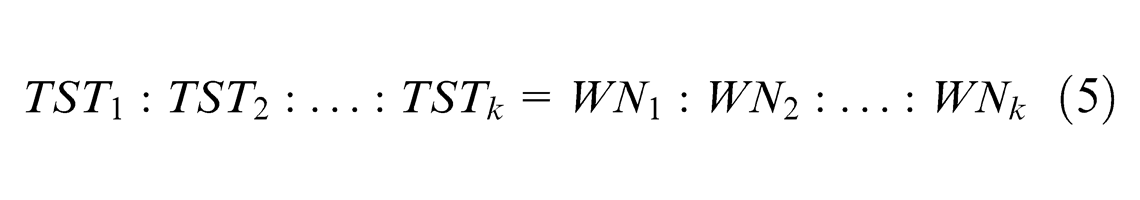
Problem assumption and formulation
Problem assumption
In order to give a detailed problem description in mathematical formulae, the following symbols are introduced in Appendix 1.
Before representing the mathematical formulae, certain basic assumptions must be stated in order to define the problem completely:
The precedence relationships among assignments, required area and the duration of an assignment visiting each station are known deterministically.
It is supposed that there are no unexpected factors to disturb the smooth flow of the platforms, such as machine breakdowns or worker absence.
For any assignment, the processing time and required area are independent.
We define a paced serial line where buffers are not considered.
Every product should be allocated to only one production batch, that is to say, the product cannot be divided into different batches.
The number of workers in each station is specified, and all the workers have the same technical ability. In addition, working across the stations’ boundaries is not acceptable.
Each station can only perform the particular operations, and the platforms with components only move in the fixed direction. In this study, we assume that the platforms move from left to right as shown in Figure 1.
Consequently, we confront the batch-model assembly line balance problem (BMALBP), which may be stated in the following way: given the fixed line configuration (m and WNk) and a set of n assignments with their temporal and spatial attributes (STi,k, Si) and a fixed precedence relationship (PRi,j) among them, each assignment i must be allocated to one production batch b such that (1) all the precedence constraints are satisfied and (2) no station time BSTb,k exceeds the cycle time CT, and no area required by the components of each production batch is greater than the available area of the platform (S).
Problem formulation
On the basis of the assumptions mentioned above, the combinatorial optimization model for the problem is given as follows
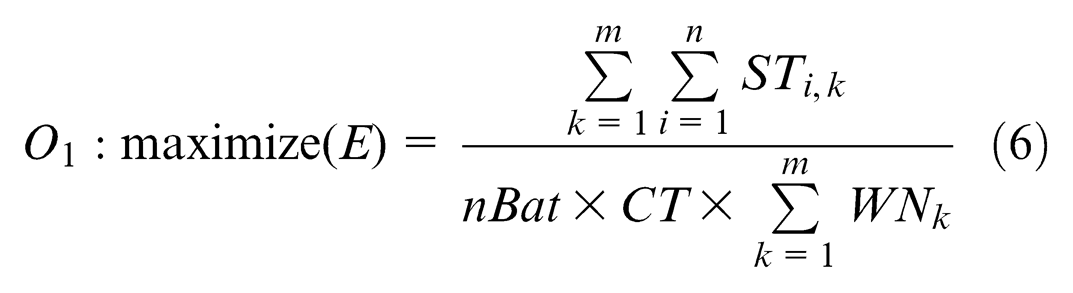
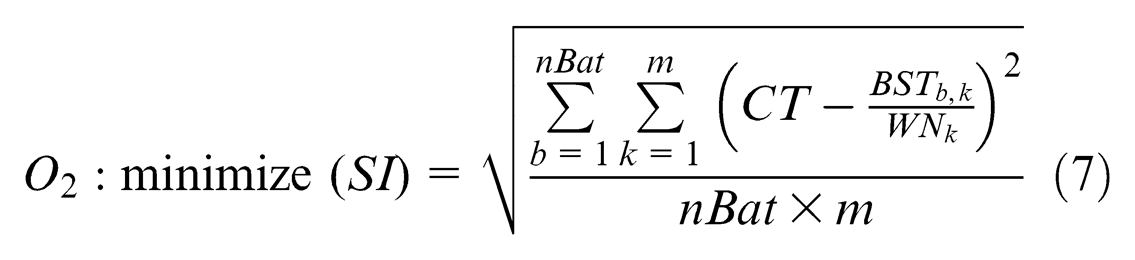
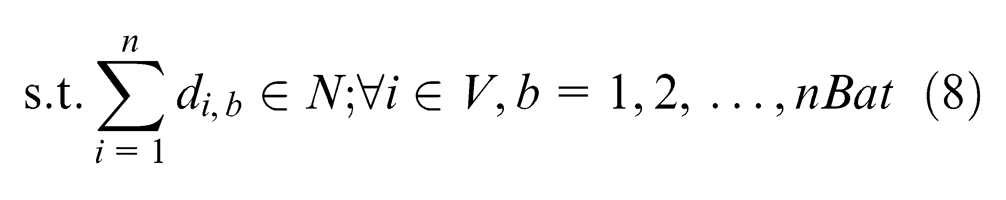
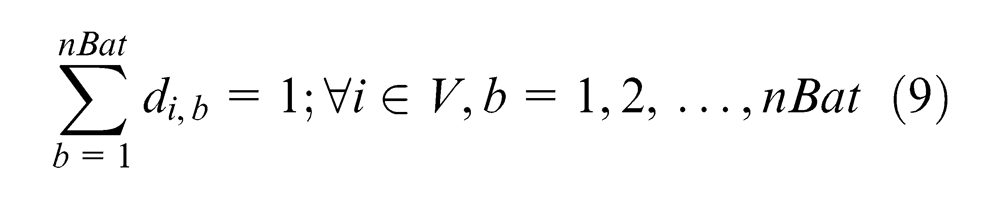
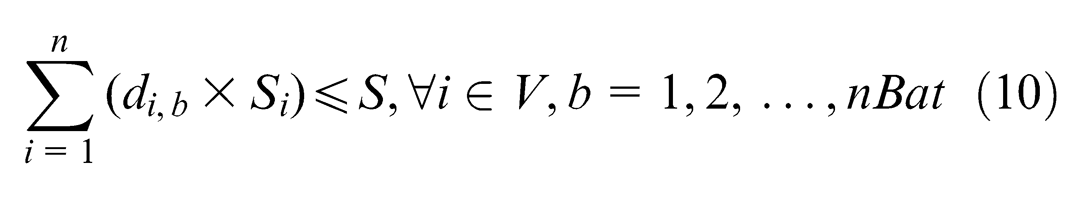
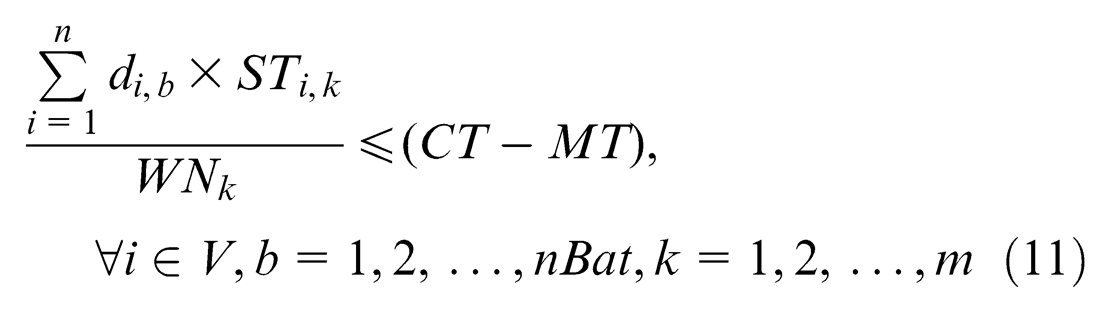
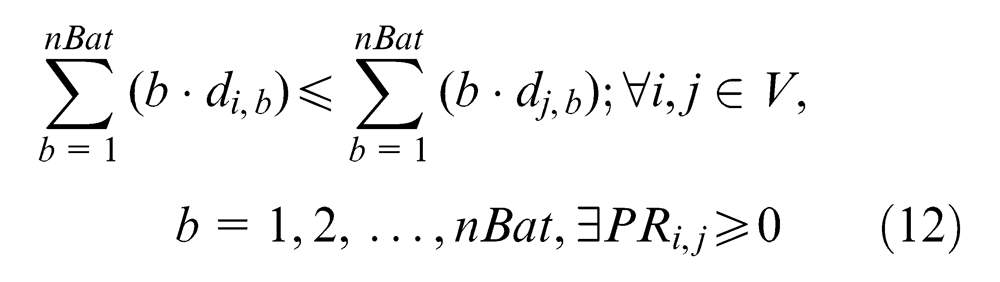
Equations (6) and (7) are the objective functions. Equation (6) is defined to maximize the production efficiency of the assembly line for a given number of workstations. Where the total station time of all assignments (
From the above analysis, one can see that the problem to be solved involves balancing and sequencing problems about a batch-model assembly line in a JIT production system, which contains a number of different constraints and a set of objectives. This kind of problem belongs to the combinatorial optimization problems. Recently, many exact or heuristic algorithms have been proposed to solve this type of problems in the literatures. Here, we propose a new heuristic approach based on the MA, which integrates local search with global search in finding the optimal solutions. The overall schema and the main operators of the algorithm are introduced in the next section of this article.
Proposed algorithm
As mentioned above, BMALBP is known as a classical NP-hard problem, which mixes the bin packing problem, the partition problem, the sequencing problem and the balancing problem. To cope with this type of complex problem, the MA is proposed. As we know, GAs hybridized with local search techniques are categorized as MAs, which is population-based search algorithm used to solve combinatorial optimization problems. 31 In the following section, we present the detailed schema and procedures of a new MA.
Algorithm scheme
MA is a robust meta-heuristic algorithm used in many combinatorial optimization problems. In the MA, every individual is encoded by a structure that represents its properties. Here, it represents a sequence of the assignments to be assembled. Each population of individuals is produced stochastically, so there may be some conflicts between the individuals and the predetermined precedence relations. The reorder procedure is necessary to ensure the feasibility sequence of the assignments in each individual. Next, the batch splitting procedure is introduced to allocate a sequence assignment of individual to the production batches. And then, the division result of each individual in the populations is evaluated by a fitness function, and a fitness value is assigned to it. This value represents quality of the individual, that is, the higher fitness value, the better solution. Afterward, on the basis of a selection procedure, a set of individuals are selected as parents for crossover and mutation to produce a new population. After each evolution operation, the reorder procedure must be implemented to repair the sequence of genes in the individual. As mentioned above, after some iteration in algorithm, the population diversity may be sufficiently low to stall around a local optimum. To overcome this issue, the local search is used. This process, which is called generation, is iterated until the stopping criteria are met and output the individuals with the highest fitness value. The flowchart of the proposed MA is shown in Figure 3.
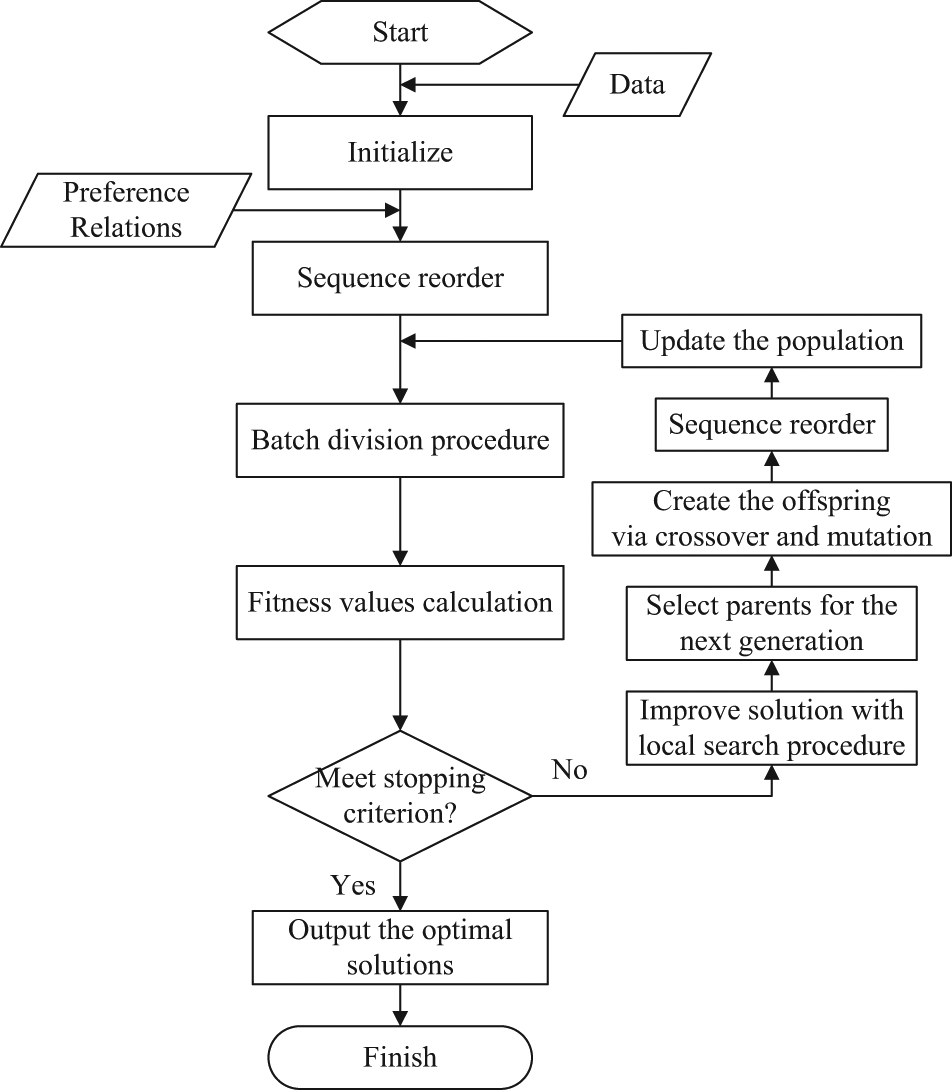
Flowchart of the memetic algorithm.
Sub-procedure of the algorithm
Initialization
Initial population generation is the first step in the MA (Figure 3). A set of N chromosomes is generated stochastically as an initial set of populations. The chromosome is defined as a vector containing a sequence of genes (assignments). Each gene denotes one assignment to be assembled, and the position of a gene in the chromosome represents the sequence of the assignment to be launched to the assembly line. An example of the chromosome with 10 genes is illustrated in Figure 4.

Chromosome encoding.
Reordering procedure
As we know, the set of chromosomes is produced randomly in the initialization procedure, and the crossover or mutation may also disorganize the sequence of the genes in the chromosome. Consequently, the resulting solutions are often infeasible. The reordering procedure is introduced to transform an arbitrary vector into a feasible sequence according to precedence relations. Detailed description of the procedure is illustrated in Figure 5, and then, a simple example is given in Figure 6, which explains the adjustment process using this procedure. Here, Ci and Cj represent the genes (assignments) in the ith and jth positions of the chromosome, respectively. Besides, the Num(C) represents the total number of the genes in one chromosome.
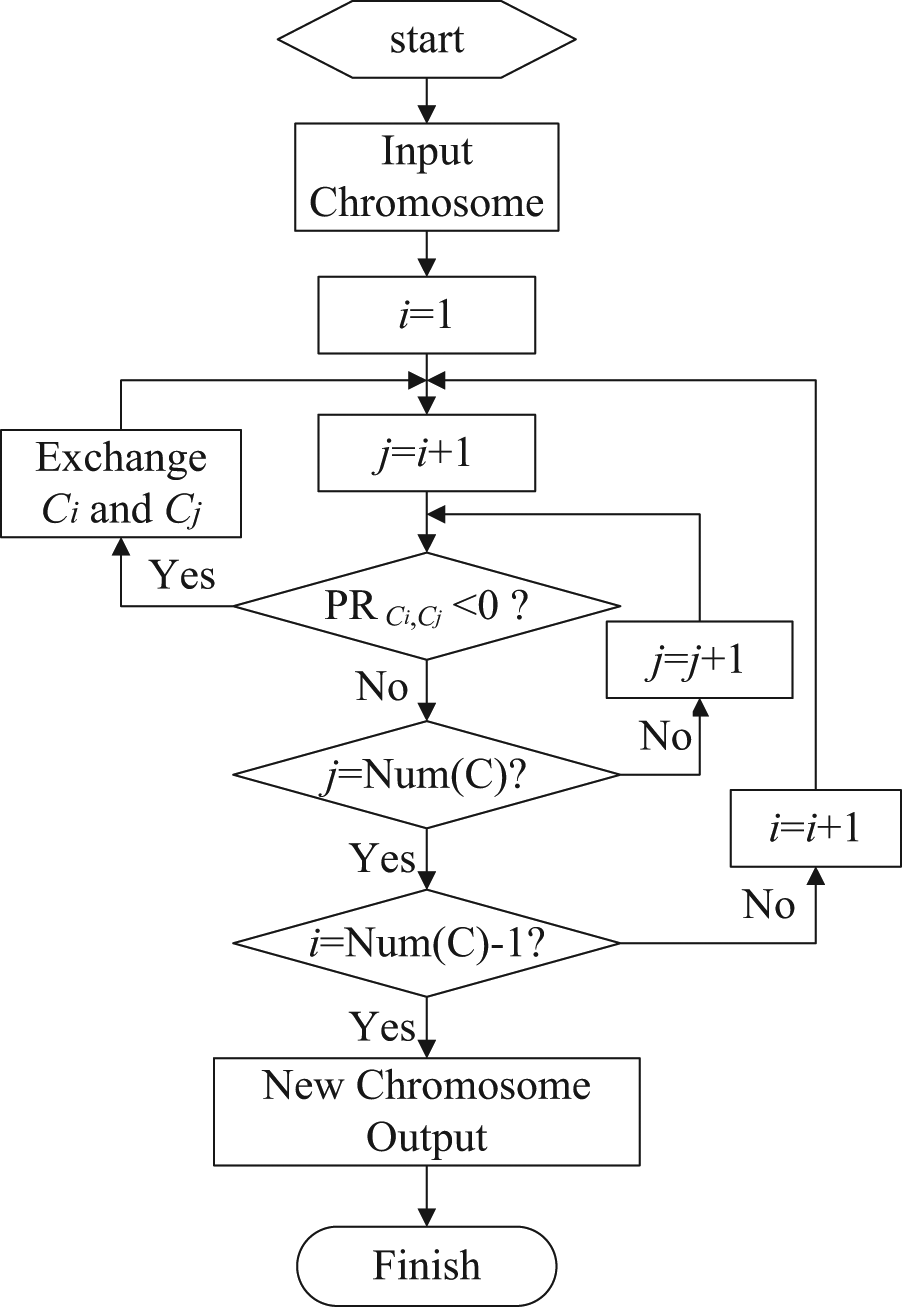
Flowchart of the reorder procedure.
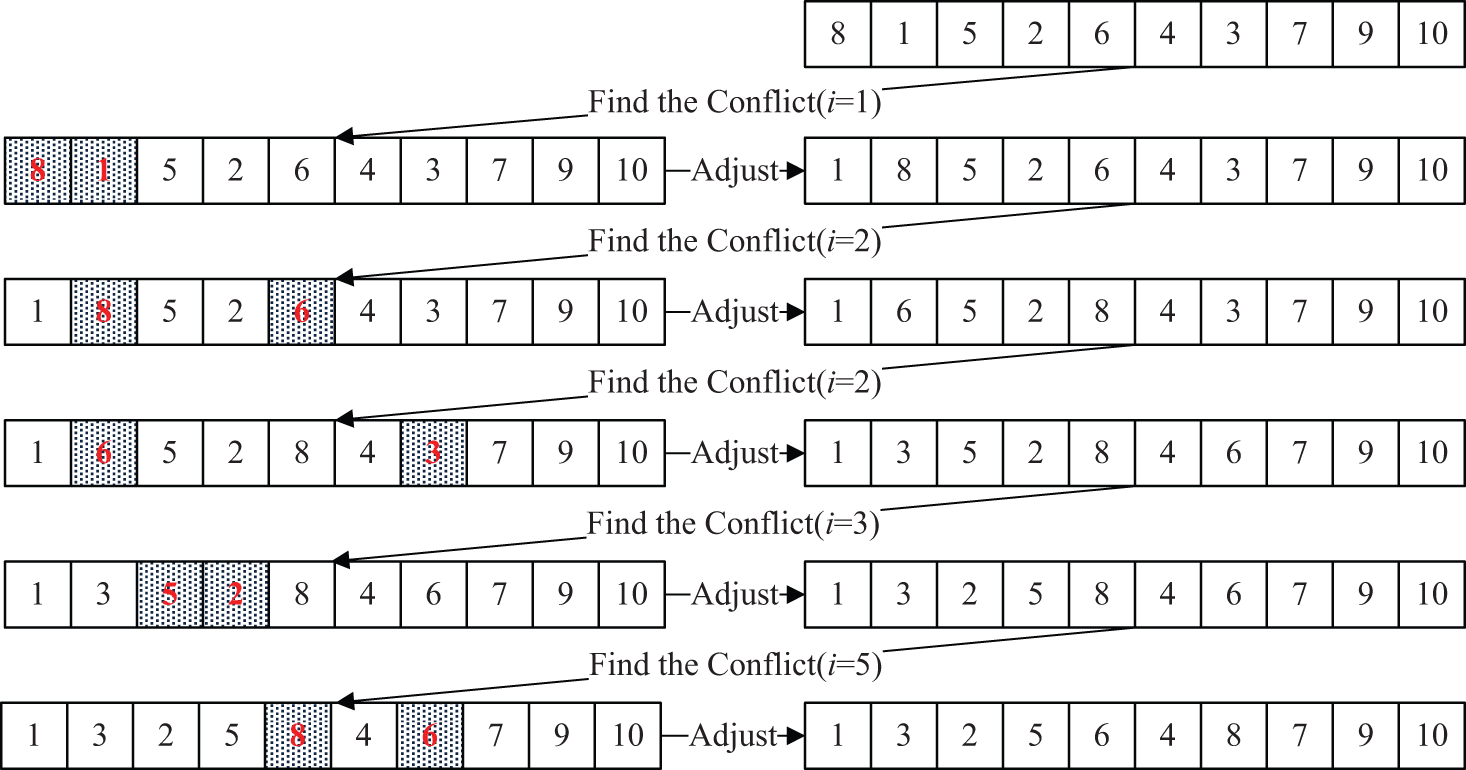
Reordering process of the example.
In the following example, we assume that the launching sequence of the assignments must satisfy the precedence relations predefined in Figure 2. The operator will not stop inspecting the assignment, and it follows from the first gene of the chromosome until there is no conflict with the precedence relations between any two assignments. When the conflict occurs, the operator will exchange their positions automatically and continue the inspection procedure.
Batches’ division procedure
Because the occupied area of each assignment (sub-block) is smaller than the effective area of the platform, the multiple assignments can be manufactured simultaneously as a batch. Obviously, if the batches can be divided as few as possible, the utilization ratio of platform will be improved as a result. This procedure aims to divide each chromosome (assignments set) with all assignments into different production batches, without changing the feasible sequence that was attained by the reordering procedure. The following division procedure was developed to achieve this goal.
The procedure begins with the opening of a first batch (b = 1). Assignments are then successively assigned to this production batch until the next assignment cannot be assigned, so the space constraint defined as equation (10) can be satisfied. In this circumstance, the batch b is closed and a new batch (b = b+ 1) is opened. In each iteration, the candidate assignments with the greatest priority to the remaining assignments are assigned to the current batch, and the platform load of the current batch reaches as the highest value as possible. The procedure ends when there are no more assignments left to allocate. An example demonstrating how the division procedure works for a feasible chromosome with 10 assignments is given in Table 1. In this example, we assumed that the available area of the platform is given as 50 m2, and the result of the batches’ division is shown in Table 2.
The process of the batches’ division.
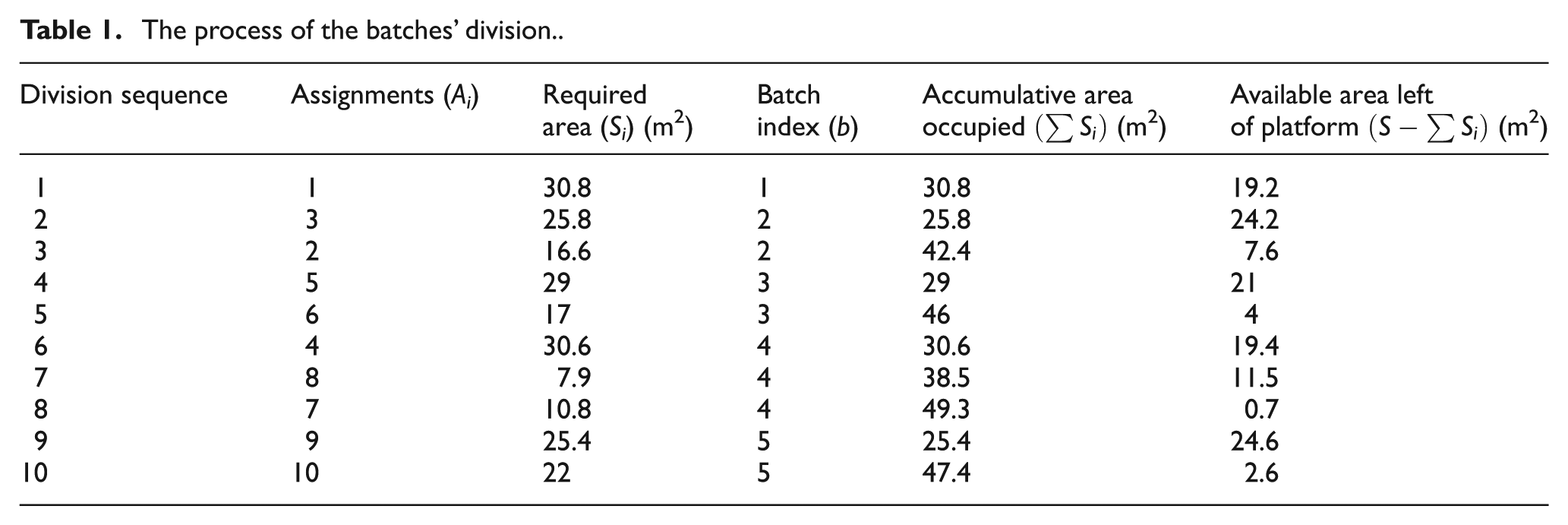
The results of batches’ division.
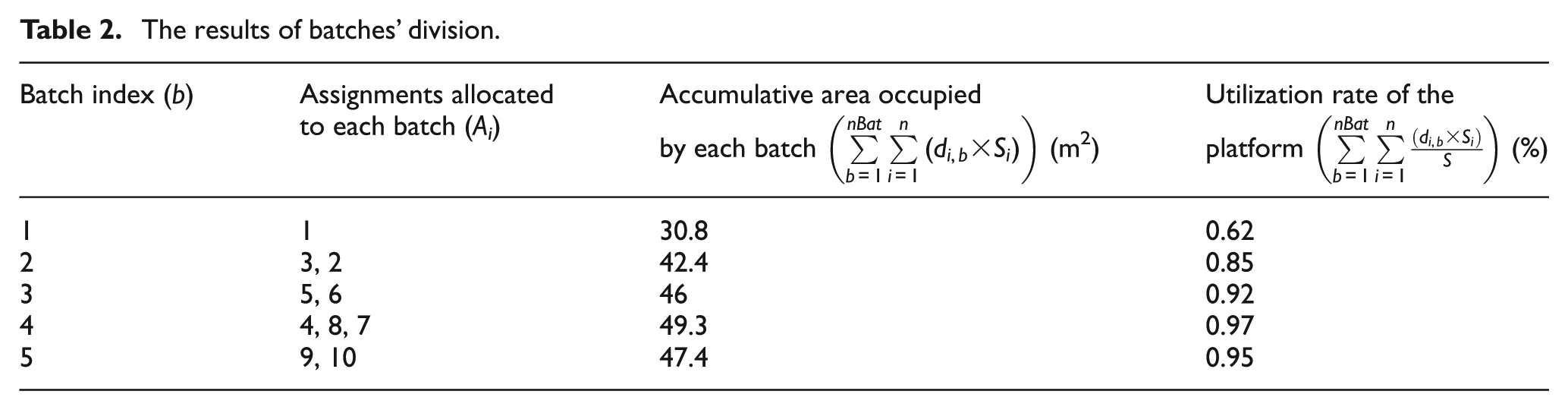
Fitness function
Fitness function is used to evaluate the performance of a solution. In this study, our goal is to find the optimal allocation of the given assignments to be assembled. The objective functions are defined as equations (6) and (7), which is applied to maximize the production efficiency and minimize the workload smoothness index simultaneously. Nevertheless, there is no conflict between the two objectives. The maximum E can be regarded as the global optimization. And the minimum SI intends to distribute work among stations as evenly as possible (balancing). It is a kind of local optimization used after the global one. In other words, the maximum E does not necessarily result in the line balancing. But the balancing of the line definitely leads to the highest production efficiency. So, we can combine the two objective functions into a single composite one using the weighted sum method 32 and search the optimal solutions using the mono-objective algorithm. The fitness function value (FFV) of the combinational problem can be calculated using equation (13) shown as follows
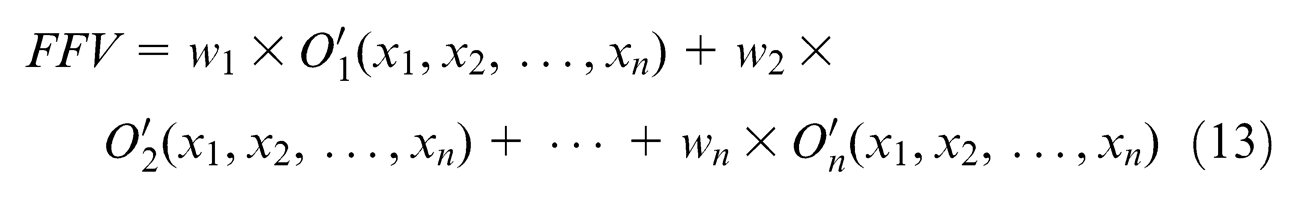
where ∑wi = 1 and
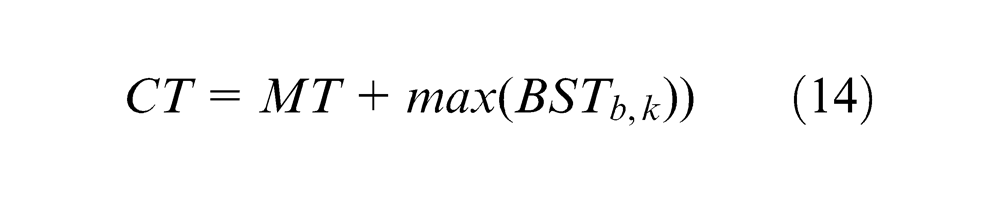
Local search
In this study, the insert procedure (IP) local search is presented to improve the quality of the solutions, which can help the algorithm avoid falling into the local optimum. In IP, an assignment is removed from the current position and inserted into another position, by which a neighbor is randomly generated from the neighborhood of the current solutions. The neighbor will replace the current solution if it is better than the current one. After the first replacement, the local search will not stop working in the same manner until there is no better solution than the current one.
Genetic procedures
Reproduction is the process in which a number of individuals are selected according to their bigger fitness value to participate in creating and forming the next generation. This increases the quality of the individuals in the next generation and therefore leads to better solutions of the optimization problem. First, the fittest individual of current population will be chosen by using the elitism selection. And then, the Roulette wheel method will be used to select rest N− 1 individuals. All the N selected individuals will form a mating pool for the crossover and mutation. The procedure of the Roulette wheel selection is presented as follows (f(x) is the fitness of x):
Step 1. Calculate the cumulative probability of qx for each individual x
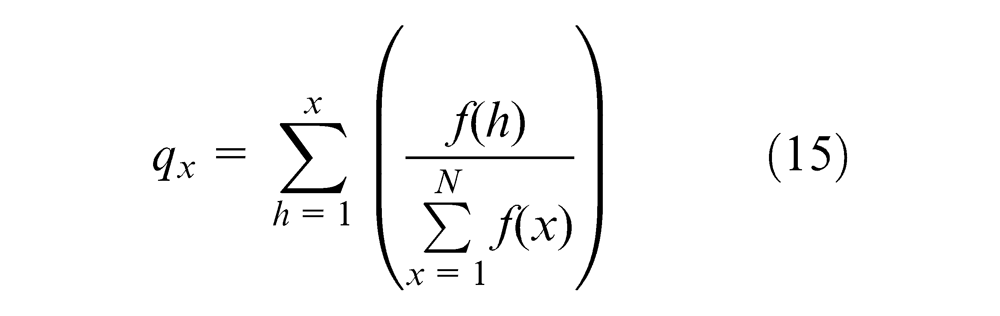
Step 2. Generate a random number r from the interval (0, 1].
Step 3. If r < qx, then select the first individual; otherwise, select the xth individual such that qx−1 < r ≤qx.
Step 4. Replay steps 2 and 3, until N− 1 individuals are selected.
In addition, we assume that each chromosome must be selected only one time. According to this assumption, the diversity of mating pool will increase.
After selecting procedure, the partially mapped crossover (PMX) combines the selected parents to generate the new offspring of the population. The aim of this procedure is to maintain inheritance of adjacency and relative order of elements in the solution structure. 33 An example is shown in Figure 7(a) to illustrate how the procedure works.
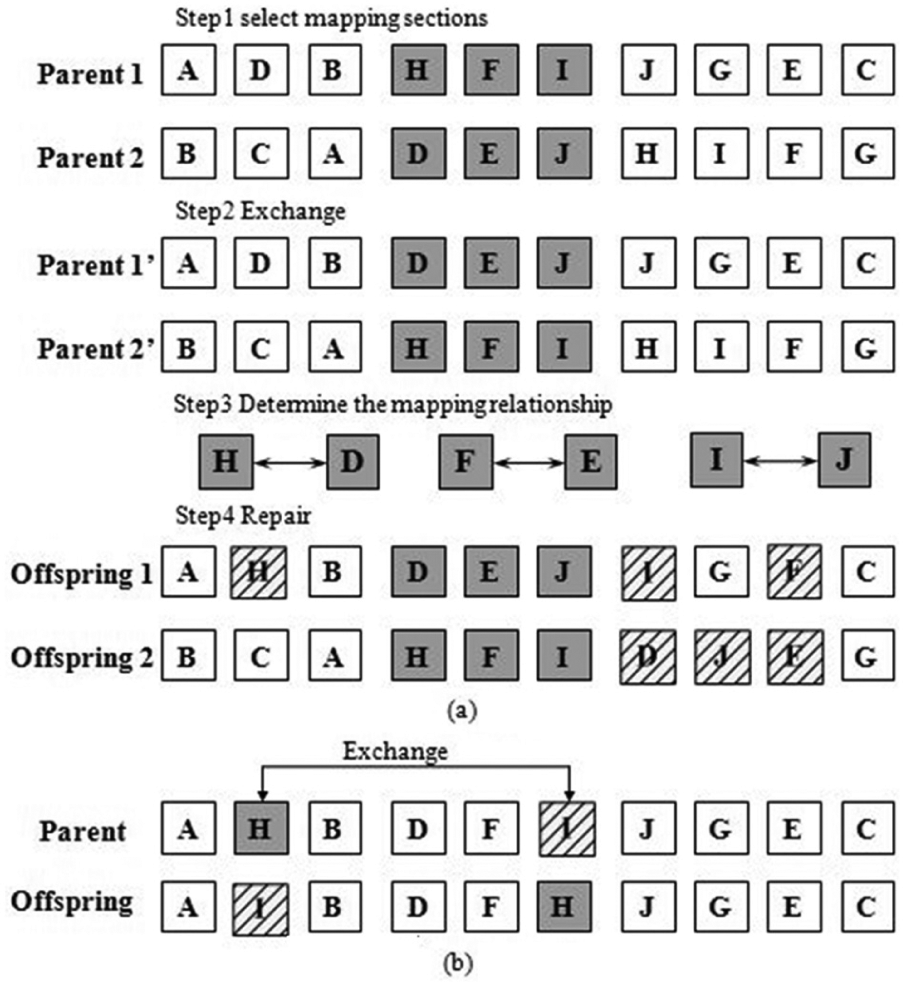
Genetic operators: (a) sequencing crossover and (b) sequencing mutation.
Next, the mutation procedure is offered to change the structure of the offspring. Select two arbitrary assignments located at positions i and j in the chromosome, i ≠ j, and interchange them to generate a new solution. Sequencing mutation of the chromosome is explained in Figure 7(b).
These procedures introduced above can increase the diversity of the chromosome and avoid premature convergence of the algorithm to a local optimum. The search process will not stop working until the stop criterion is attained.
Computational experiments and results
The real data of the sub-block assembly line are used to test the efficiency of the proposed algorithm, which is provided by a big shipyard in China. An instance with 50 assignments is illustrated in Appendix 2. It shows the assignment number, duration times of the assignment in each station and required area in Table 6 of Appendix 2. The precedence relationship constraints among these assignments are shown in Table 7 of Appendix 2. From this instance, we can see that the required areas of each assignment and all their operation times through every station are independent. In addition, the number of assignments and stations is larger and the required areas of assignments are not equal to each other. As a result, the complexity of problem is increasing. We assume that the platforms have an available area of 50 m2, and the time for platform movement (MT) is equal to 600 s. Additionally, the population size, crossover probability (Pc), mutation probability (Pm) and termination criterion of MA are fixed to 50, 0.6, 0.07 and 100 generations after many tests. The worker number allocated to each station is specified referring to equation (5).
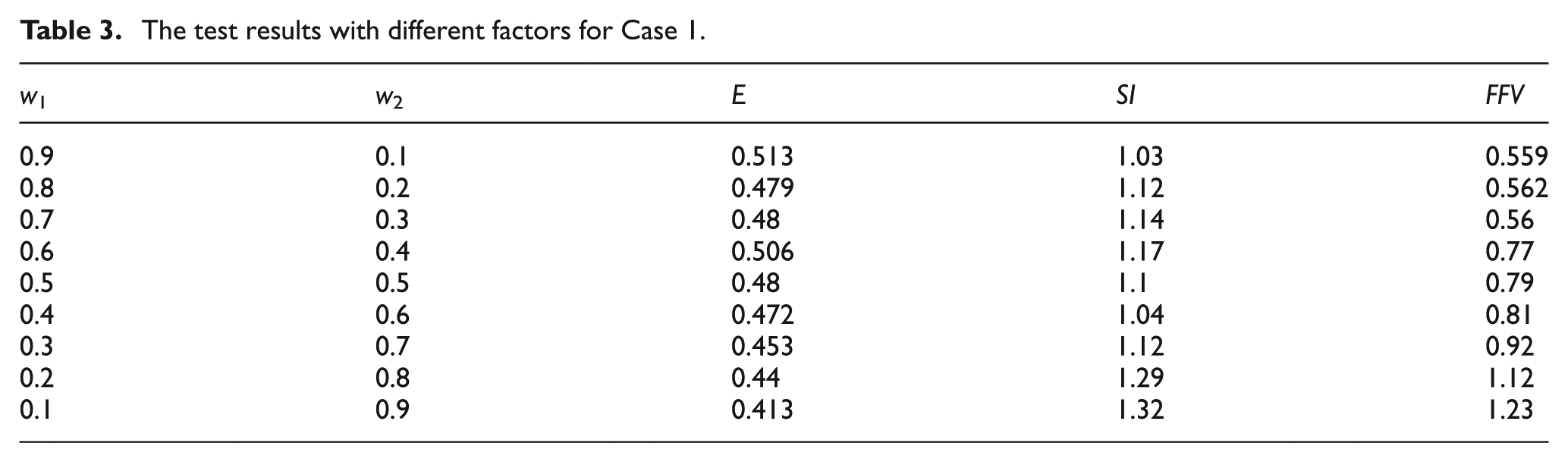
The weighted factors (w1 and w2) of the fitness function in the MA are obtained by conducting a sensitivity analysis. Case 1 with 50 assignments is used for the analysis, and the different combinations of the two factors are set to simulation. The results of the analysis are given in Table 3. As mentioned above, we know that the maximum E of the line is regarded as the global optimization and the minimum SI only as the local optimization. So, the factor for the objective O1 is fixed as 0.9 and the factor for O2 as 0.1.
The test results with different factors for Case 1.
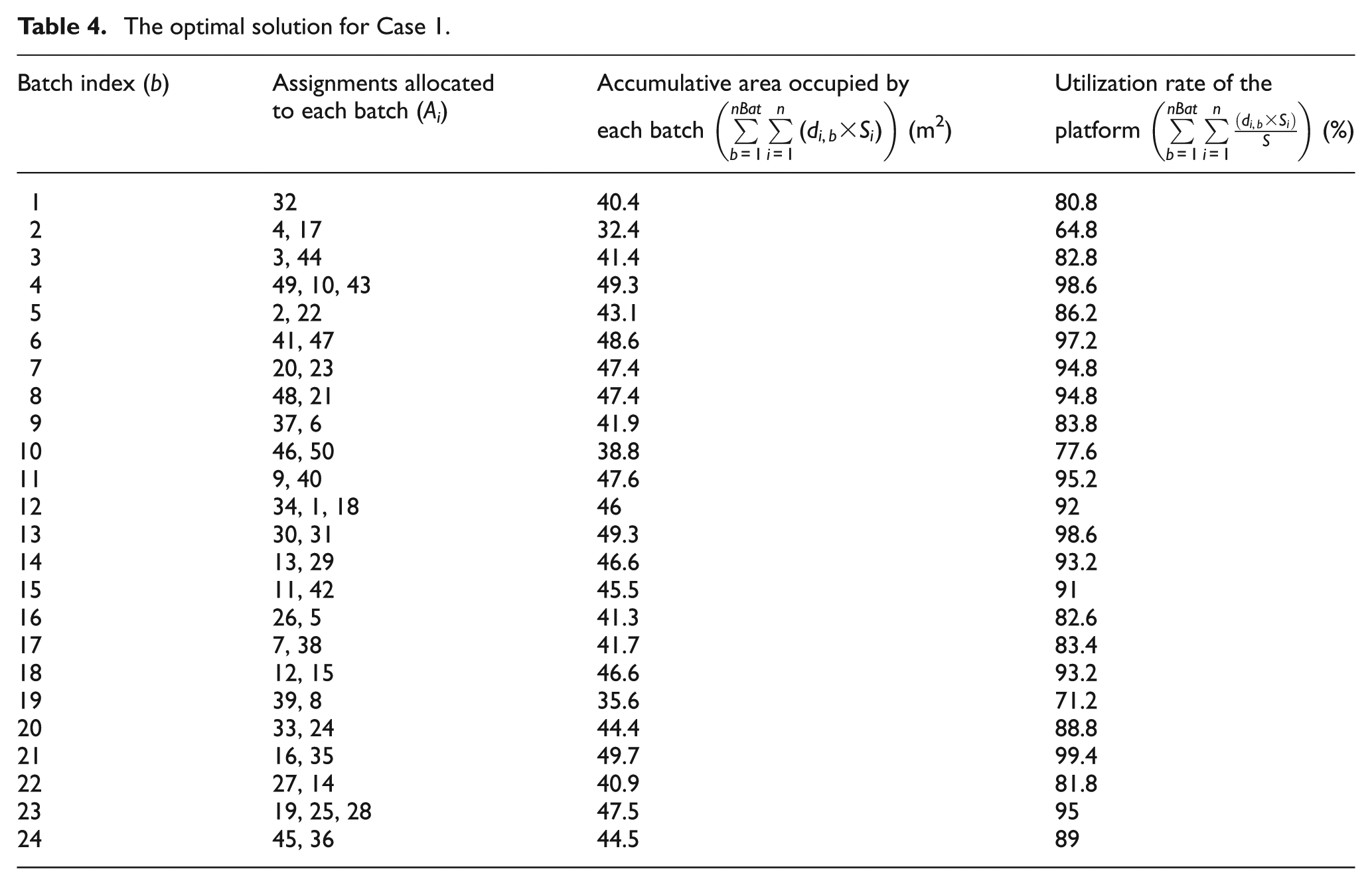
The result of simulation using the proposed MA for this instance is shown in Table 4. And the changes in some design variables through different generations are illustrated in Figures 8–10. When the optimal solution is found, the total assignments were divided into 24 production batches, which can satisfy the precedence relations among them and achieve the objectives predetermined. Correspondingly, the cycle time (CT) of the line is equal to 39.5 min, which can be seen in Figure 8. And Figure 9 describes the changing process about the FFV and its mean. Obviously, the algorithm converges after about 75 iterations. Figure 10 gives the changes about two objective values.
The optimal solution for Case 1.
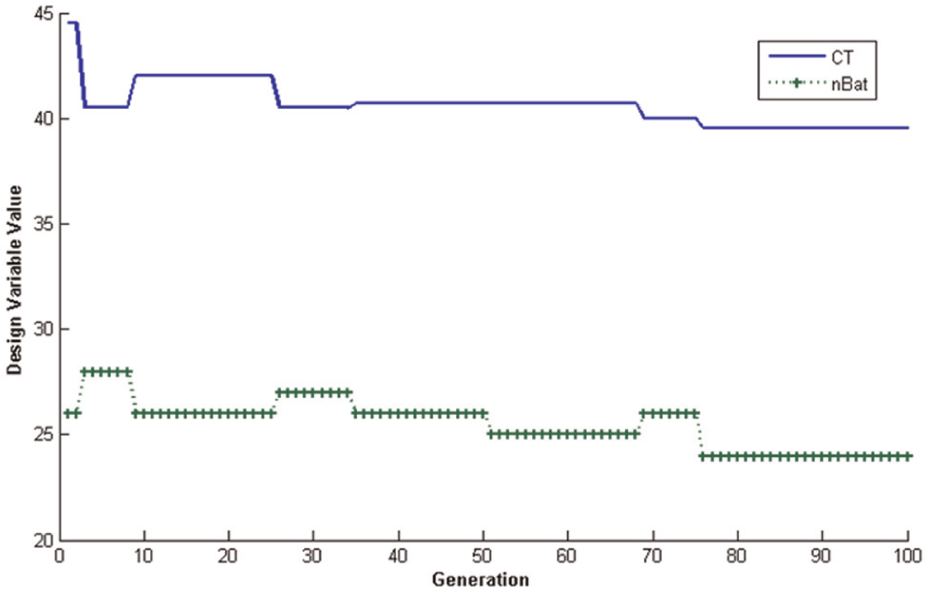
Changes in design variable value through generations.
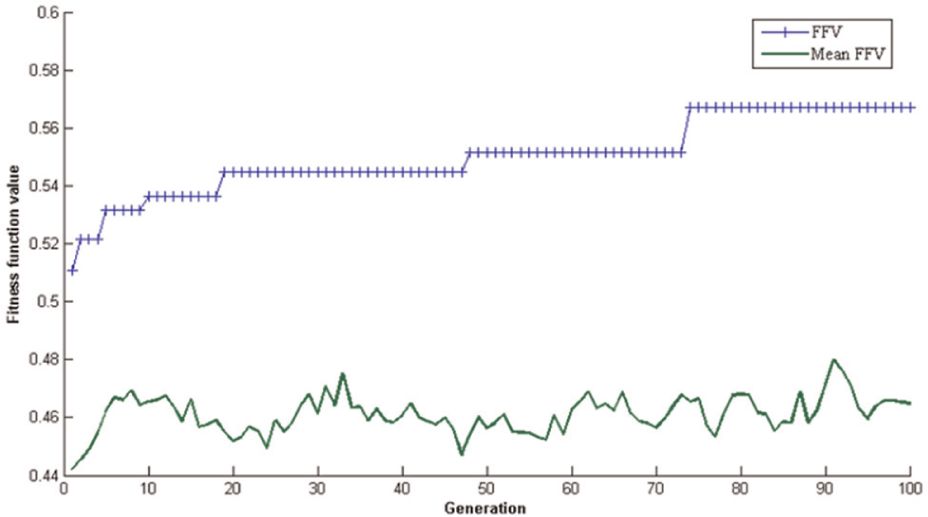
Changes in fitness function value through generations.
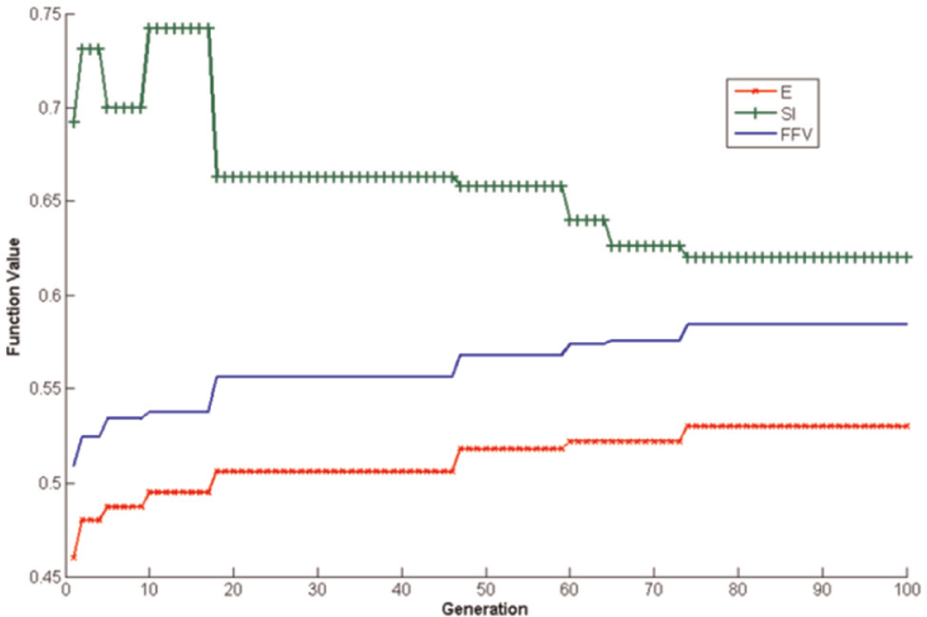
Changes in objectives and fitness function value through generations.
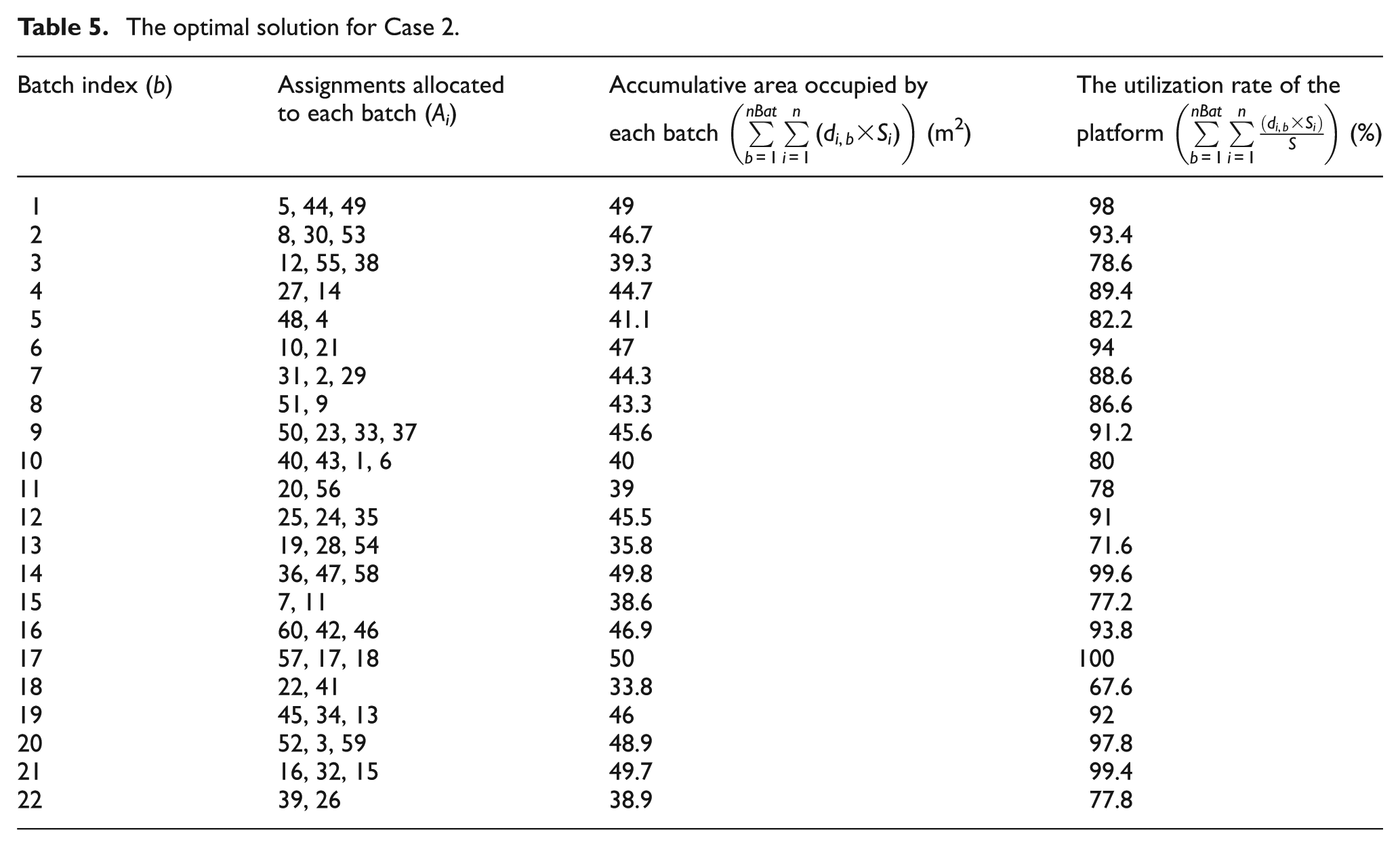
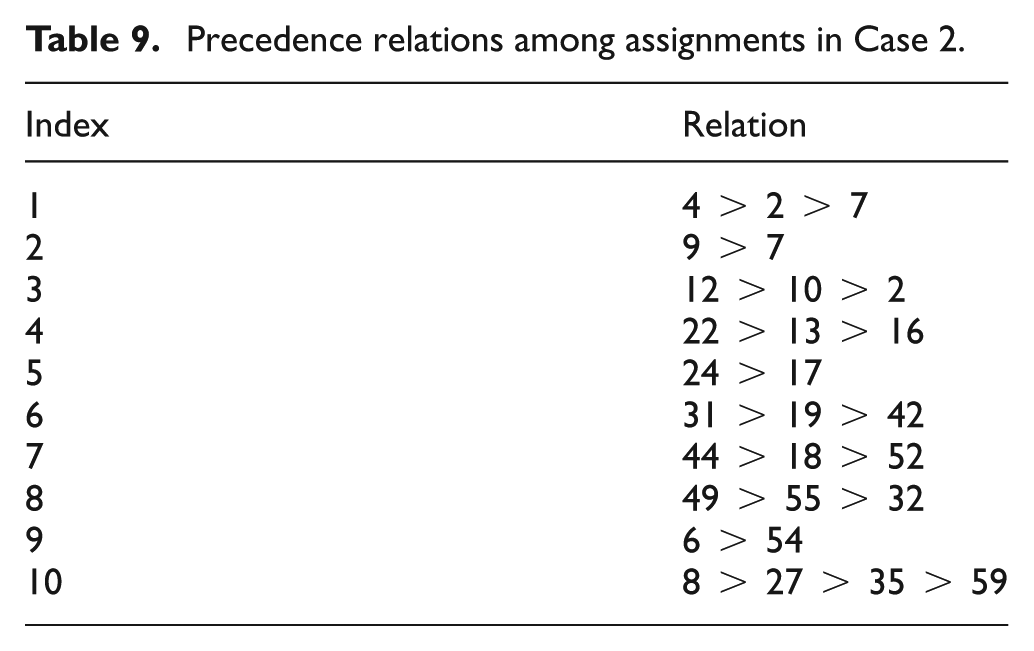
To verify the effectiveness of the algorithm, we have done plenty of experiments using different data sets. Here, another instance is given. Similarly, the assignment sets and their precedence relations are listed in Tables 8 and 9 of Appendix 2. The optimal division of the total assignments is shown in Table 5 and the CT is equal to 37 min.
The optimal solution for Case 2.
The algorithms utilized here are written in MATLAB R2007a and the test environment is that of a Pentium 1.73-GHz PC at 1 GB RAM. In order to improve the non-deterministic nature of the algorithms, it usually runs at least 10 times. Results indicate that the MA converges after about 75 iterations and it takes 30 s or so for the whole computing. Nevertheless, the GA converges only after 20 iterations, and it takes 50 s at least for the total 100 generations. In addition, the MA can find the optimal solution with the bigger FFV than GA. The performance of the proposed MA is compared with the GA in Figure 11. This comparison was made based on the two cases mentioned above. Obviously, the MA can quickly find the global optimal solution with the maximum fitness value in the specified generations. It also demonstrates that the local search operator in proposed MA plays an important role in solving this large-scale batch-model ALBP.
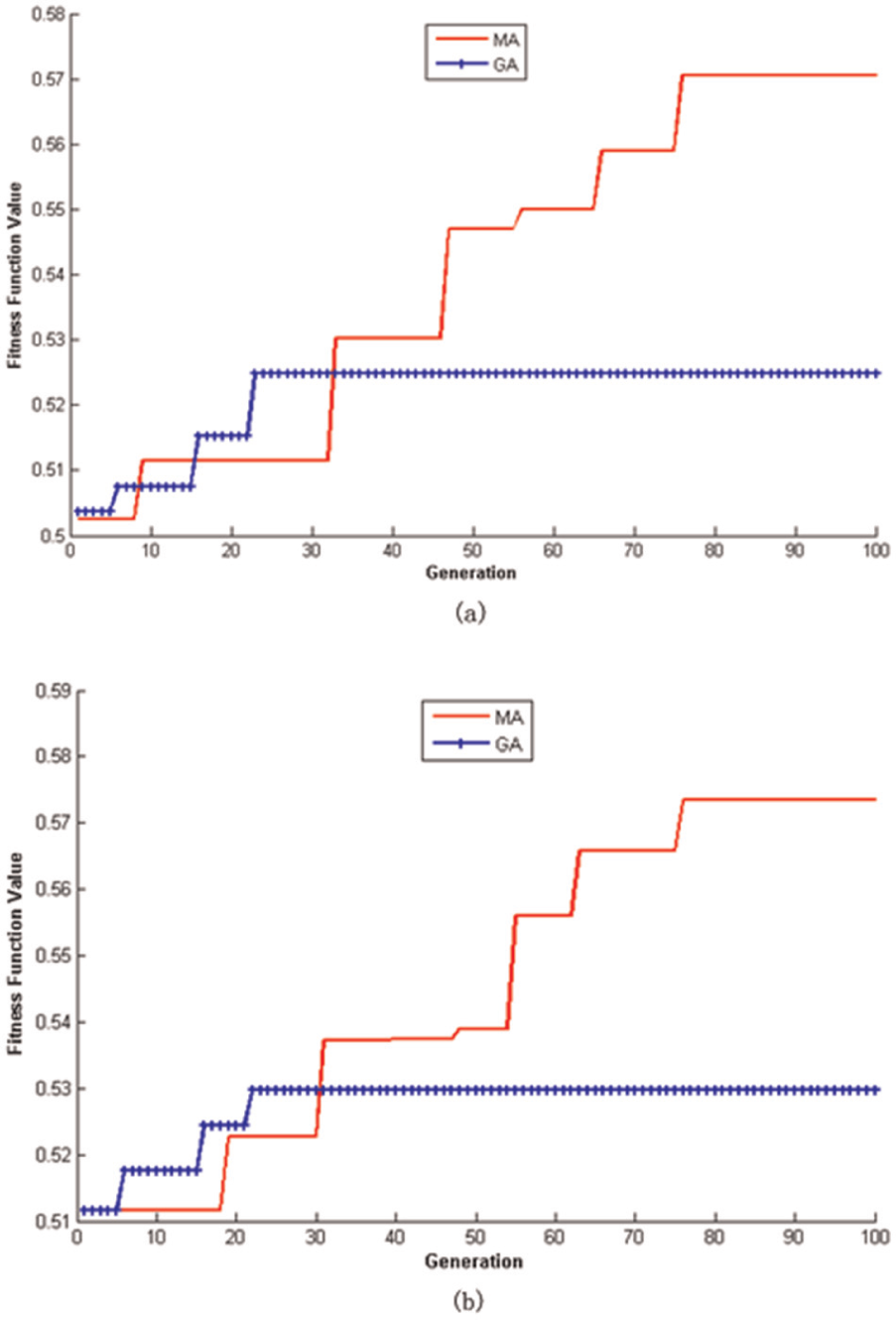
The comparisons of two algorithms: (a) based on Case 1 and (b) based on Case 2.
Conclusion and future research
In this work, we have introduced and modeled a real-world ALBP in shipyard. It belongs to the batch-model ALBP, which is difficult to solve because it involves many different models to be assembled and a great deal of constraints (space, time and precedence relations). Moreover, it was a combinatorial optimization problem, which is to maximize the production efficiency and minimize the workload smoothness index. These objectives could only be achieved by the optimal batch division to the assignments. Due to the complexity of this problem, the MA has been proposed, which integrates the local search operator with the classical GA. Computational experiment based on real data sets in shipbuilding indicates that the proposed algorithm can obtain the global optimal solutions quickly. Moreover, it is shown that the MA outperforms the current standard GA in finding optimal or at least near-optimal solutions. Further research is required to analyze the more complex problems, such as the U-shaped or two-sided lines, which may have more complicated constraints and multiple objectives.
Footnotes
Appendix 1
Appendix 2
Precedence relations among assignments in Case 2.
| Index | Relation |
|---|---|
| 1 | 4 > 2 > 7 |
| 2 | 9 > 7 |
| 3 | 12 > 10 > 2 |
| 4 | 22 > 13 > 16 |
| 5 | 24 > 17 |
| 6 | 31 > 19 > 42 |
| 7 | 44 > 18 > 52 |
| 8 | 49 > 55 > 32 |
| 9 | 6 > 54 |
| 10 | 8 > 27 > 35 > 59 |
Declaration of conflicting interests
The authors declares that there is no conflict of interest.
Funding
This research received no specific grant from any funding agency in the public, commercial or not-for-profit sectors.