
Abstract
In many assessment problems—aptitude testing, hiring decisions, appraisals of the risk of recidivism, evaluation of the credibility of testimonial sources, and so on—the fair treatment of different groups of individuals is an important goal. But individuals can be legitimately grouped in many different ways. Using a framework and fairness constraints explored in research on algorithmic fairness, I show that eliminating certain forms of bias across groups for one way of classifying individuals can make it impossible to eliminate such bias across groups for another way of dividing people up. And this point generalizes if we require merely that assessments be approximately bias-free. Moreover, even if the fairness constraints are satisfied for some given partitions of the population, the constraints can fail for the coarsest common refinement, that is, the partition generated by taking intersections of the elements of these coarser partitions. This shows that these prominent fairness constraints admit the possibility of forms of intersectional bias.
Introduction
Individual identity is multifaceted. Hannah, for instance, is a woman, an American, from New York City (specifically the Upper West Side), but a resident of the South, a person who spent several formative years in England, a Cambridge graduate, a philosophy DPhil, an academic, from an upper middle class background, an advocate of risk literacy, a runner, a violist, Jewish, a flexitarian, heterosexual, an effective altruism enthusiast, a mother, a sister, a wife, and a fan of Andrei Tarkovsky and Townes van Zandt. Any one of these properties applies to a large number of other people, defining a subgroup of a general population of individuals. For a given individual, different social contexts may make membership in different groups more or less salient. The relative importance attached to membership in such groups is also a matter of individual discretion, at least to some degree. But one and the same individual can be a member of all of these groups without contradiction. Since similar remarks apply to any individual, there are many legitimate ways to group individuals in a population, from marital status or nationality to religion or taste in music.
Fair treatment of different groups is an objective common to many domains of assessment including aptitude testing in psychometrics (Borsboom et al., 2008), hiring decisions in the labor market (Fang and Moro, 2011), risk assessment in the criminal justice system (Kleinberg et al., 2017; Pleiss et al., 2017), and evaluation of the credibility of testimonial sources in epistemology (Stewart and Nielsen, 2020). 1 Consider the case of risk assessment. Using the same actuarial techniques that are used to calculate insurance premiums, statistical software is employed in the U.S. criminal justice system to assess an individual’s risk of re-offending. Given the type of crime committed, age, sex, employment status at the time of arrest, criminal history, etc., an individual is assigned (what can be thought of as) a probability of recidivism. Such scores are used in sentencing and parole decisions among other things. A 2016 ProPublica analysis of the risk scores of the COMPAS statistical tool for Broward County, Florida found a form of bias in the data on the tool’s predictions (Angwin et al., 2016b). The rate of false positives—the percentage of non-recidivists given a high risk score—was roughly twice as great among black defendants as among white. And the rate of false negatives—the percentage of recidivists being given a low risk—among whites was roughly twice as great as among blacks. 2 The bias is that these types of errors were asymmetrically distributed across black and white sub-populations, affecting the lives of black and white people in very different ways.
Research on algorithmic fairness studies the prospects of unbiased assessment. Bias in error rates is one form of bias, but not the only form and often considered not the most important form. Can bias in error rates and other important forms of bias be simultaneously eliminated? One lesson that emerges from some of these studies is that eliminating one form of bias can mean that it is impossible to eliminate another. Sometimes, then, we face a conflict between eliminating different forms of bias. Here, I argue that, not only do we face a conflict in eliminating different forms of bias, we also face a conflict in eliminating one form of bias across different groupings. Eliminating a certain form of bias across groups for one way of categorizing people in a population can mean that it is impossible to eliminate that form of bias across groups for another way of classifying them. This conflict is significant to the extent that multiple classifications are relevant. And they often are: consider the various classes mentioned in standard non-discrimination clauses, for example. 3 Moreover, even if our assessments are unbiased for certain ways of classifying people—say for both a race classification that includes black and white categories and a gender classification that includes categories for women and men—bias can persist for the coarsest common refinement of these classifications—in this case, the single classification that includes the groups of black women, black men, white women, and white men. In other words, forms of intersectional bias are possible for the prominent fairness constraints in the fair algorithms literature. Given the conceptions of fairness encoded in these constraints, and confronted with the sorts of limitations in achieving fairness across various classifications discussed below, we must reconcile ourselves with lingering bias against some groups.
Identity and Population Partitions
In any assessment problem, there is a particular population of individuals that is relevant. For instance, in parole decisions in Broward County in 2015, there are the people coming before the parole boards in the county that year. In SAT testing in the U.S. for the last decade, there is the population of people who took the exam in that time frame. In Faceboook’s assessment of the trustworthiness of its users in an effort to combat “fake news,” there is the set consisting of nearly
Any population can be divided into groups according to various individual properties or identities. For the question of fair treatment in assessment, certain groups are more customary to consider than others. Often, history and social context make salient particular categories. In the ProPublica story mentioned above, the focus is on the disparate treatment of different races. In particular, black and white defendants were treated differently. My interest here is in the possibility of fair treatment across various partitions of a population. A partition of a (finite) set
Why should we be concerned about the multiple group memberships of any given individual and the multiple possible ways a population can be partitioned? In his book Identity and Violence, Sen argues that there is moral urgency to considering the various aspects of individual identity. Reckoning with “the power of competing identities,” says Sen, “leads to other ways of classifying people, which can restrain the exploitation of a specifically aggressive use of one particular categorization” (Sen, 2007, p. 4). Sen has in mind the way in which considering one’s humanitarian or religious affiliations might weaken the pull of a violent nationalistic or racist movement, for example. Throughout the book, Sen criticizes the idea that there is a uniquely appropriate or privileged partition. The insistence, if only implicitly, on a choiceless singularity of human identity not only diminishes us all, it also makes the world much more flammable. The alternative to the divisiveness of one preeminent categorization is not any unreal claim that we are all much the same. That we are not. Rather, the main hope of harmony in our troubled world lies in the plurality of our identities, which cut across each other and work against sharp divisions around one single hardened line of vehement division that allegedly cannot be resisted. (Sen, 2007, p. 16)
My concern is a bit different from Sen’s, but there is a relevant lesson in the passage quoted just above. To wit, a single, fixed partition is overly constraining, and may frustrate our goals and lead to sub-optimal outcomes. The goal in assessment that is our focus is the fair treatment of different groups. But since there are various legitimate ways to partition a population into groups, restricting our attention to a single partition potentially commits us to ignoring important forms of group bias. 7
Consider once again the bias found against black people in the COMPAS data. In that same Broward County data set, there is a similar amount of bias in error rates against women compared to men, as a companion piece in ProPublica makes clear (Angwin et al., 2016a). Bias against either group is ethically relevant. Satisfying certain central fairness constraints (described in the following section) for a race partition does not imply that those constraints are satisfied for a gender partition. Still other partitions could be pertinent. The relevant social identities cannot be decided a priori, without appeal to contingent social context and values. Sen points out that even intuitively unimportant aspects of personal identity can become important. Consider, for example, those who wear a size 8 shoe, or those born between nine and ten in the morning, local time. If size 8 shoes were to become extremely difficult to find—think “high noon” of Soviet civilization or broken supply chains due to a novel coronavirus pandemic—then being someone who wears that shoe size may become an important part of one’s identity and grounds for solidarity with those similarly unshod. Likewise, if an authoritarian ruler were to elect to severely curtail the freedoms of people born between nine and ten in the morning due to some supernatural belief or other, then the hour of one’s birth and the persecution it entails for some is, again, likely to become an important aspect of one’s identity and grounds for solidarity (Sen, 2007, pp. 26–27). In either case, new forms of bias become pressing considerations. The priority of particular partitions in eliminating bias might reasonably depend not just on past history of discrimination, but also on current deprivation. What groups suffer discrimination and deprivation is a matter to which we may frequently need to reattend. They may well depend in part on the particular assessment problem confronting us, or on the particular population, as I explain at the end of Section 4. In general, and more to the point for this essay, there can be bias against many different groups.
Fair Assessment
In order to foreground the issue of different population partitions, let’s assume that there is just a single property
In order to talk about population proportions or frequencies, let’s introduce a uniform probability distribution
The interesting issue concerns what properties
Why does it make sense to think of calibration as a fairness constraint? One reason is that it guards against a form of bias in confidence. If it rains on
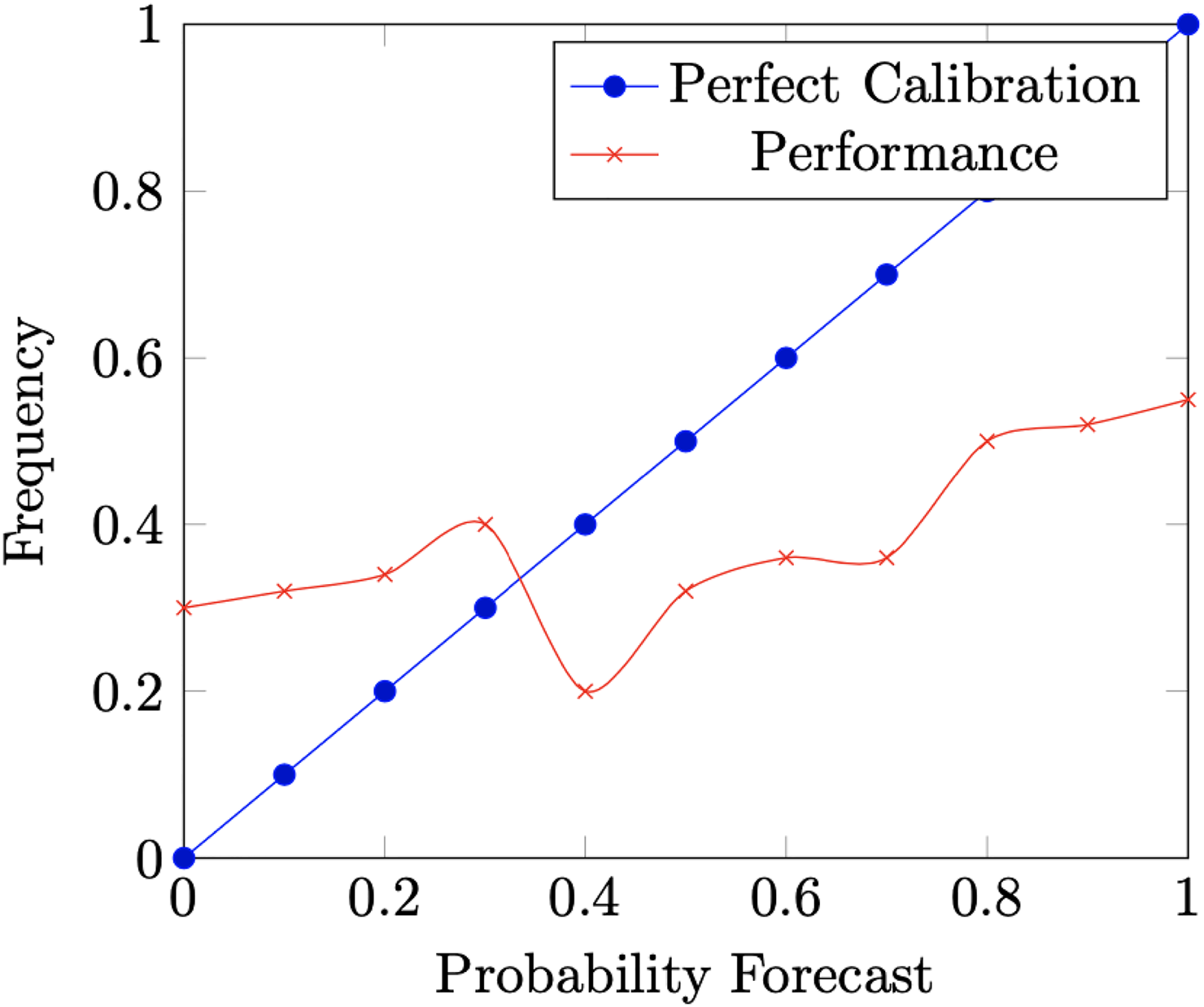
Calibration Curve.
I think there are some reasonable concerns one might have about construing calibration as a fairness property. It seems to me that this latter line of motivation in terms of meaning—and to some extent even the previous one in terms of under- and overconfidence—fails to fully motivate calibration as a fairness constraint. Scores for individuals in different groups can mean the same without the assessor satisfying the full calibration constraint. Calibration implies that
There are at least two cautions about relaxing calibration to predictive equity worth considering. The first is that fairness is not the only goal in assessment. We also care about the property being assessed after all. We care about maintaining public safety, admitting a talented class of freshmen, trusting credible testimonial sources, making prudent loan decisions, etc. That is, there is typically a purpose for which an assessment is conducted, with fairness acting as a sort of constraint. So, it may be reasonable to retain the form of accuracy that calibration adds to predictive equity. Not only should it be the case that
Rather than considering ways to relax calibration, we might consider alternative fairness constraints, ones that might potentially supplement calibration. Even if calibration is necessary for unbiased assessment, it may not be sufficient. An assessor that simply predicts the group base rate for everyone in the group will be calibrated. Yet, an innocent person in a group with a high recidivism base rate, for example, might have grounds for complaint when he receives a higher risk score than his counterpart in a group with a lower base rate. Similarly, it is consistent with calibration for a recidivist in a low base rate group to receive a lower risk score than a non-recidivist in a high-base-rate group. One reading of these points is that there are other forms of bias to consider besides the one calibration attempts to eliminate. This reading seems supported by ProPublica’s analysis of the COMPAS data. The sort of bias that they charge the statistical tool with is not a failure of calibration, but a disparity in error rates across groups. I turn now to a constraint meant to eliminate for exactly this type of bias.
To introduce the constraint, we need a few auxiliary definitions. The false positive rate of an assessor
In this essay, I will grant that calibration and equalized odds are prima facie compelling fairness constraints, though I consider it legitimate to subject them to further scrutiny in general and plan do to so in future work. On the one hand, the reader might agree that the properties are important formalizations of unbiased assessment. Many have found them to have considerable intuitive plausibility. So, the consequences of the properties would seem ethically important for such readers. On the other hand, because of the prominence of these sorts of statistical properties in theories of algorithmic fairness, it is crucial to scrutinize them, to explore their consequences and their limitations. So, even if the reader is unconvinced of the normative status of the properties, the consequences of these properties are relevant to a sober evaluation of them. 13
Unfortunately, there are limits to the extent assessments can be unbiased. Let’s look at one central limitative result. An assessor is perfect if
(Kleinberg et al., 2017) Let Either i) the base rates in all groups are exactly the same or ii)
Theorem 1 is widely regarded as an impossibility or triviality result for fair assessment. Corbett-Davies et al. report that Kleinberg et al. “prove that except in degenerate cases, no algorithm can simultaneously satisfy” calibration and equalized odds (Corbett-Davies et al., 2017, p. 799); on the basis of this result, journalists at ProPublica published a followup article entitled “Bias in Criminal Risk Scores Is Mathematically Inevitable, Researchers Say” (Angwin and Larson, 2016). The idea is that perfection, as discussed, is very rarely achievable in real-life, interesting assessment problems. Similarly, that the base rates for the relevant groups are exactly the same is only very rarely the case. As a result, outside of very rare circumstances, it is impossible to achieve both fairness properties. Results like Theorem 1 give us reason to explore ways to relax or modify the fairness constraints.
Each of calibration and equalized odds is meant to eliminate a certain form of bias. What Theorem 1 establishes is that, for a fixed way of carving the population into groups, eliminating one form of bias makes it impossible to eliminate another. Next, I consider requiring the individual fairness constraints on assessment hold for all partitions of the population. Clearly, we cannot expect these constraints to be jointly satisfied in assessment for multiple partitions since, by Theorem 1, they cannot be simultaneously satisfied for a single partition. Instead, I consider each property on its own. Under the assumption that each fairness constraint eliminates a form of bias that is desirable to eliminate, I study the possibility of eliminating one form of bias across multiple ways of dividing the population into groups.
Let’s consider each constraint in turn, starting with calibration. An alternative way to strengthen calibration for a single partition is to require it for multiple partitions rather than imposing a different sort of fairness constraint like equalized odds on the same partition. Again, Theorem 1 gives us reason to seek such alternatives. When confronted with the limitation expressed in Theorem 1, a number of people have suggested to me in person that calibration is clearly the more compelling condition. Perhaps bias of types that calibration fails to exclude—for example, some version of bias in error rates—could be reduced by requiring calibration for multiple partitions. The best case would be for calibration to hold for all partitions, since that would exclude bias in confidence against any group and maybe other forms of bias to boot. Observation 1 states a limitation on this strategy.
Let
Calibration for all partitions, then, is only achievable in the typically unrealistic case of perfect assessment (cf. Hébert-Johnson et al., 2018, p. 1940). 15 In other words, outside of the unrealistic case of perfect assessment, there will be bias in confidence against some group. Observation 1 complicates any automatic inference from failure of calibration for some group to intentional bias on behalf of the assessor (for further discussion of this point, see Stewart and Nielsen, 2020, Sec. 5).
Next, let’s consider the weaker predictive equity property. Say that an assessor
Let
Aside from assessors that make perfect distinctions, scores will not “mean” the same thing for all groups; there will be bias against some group. In large populations, perfect distinctions is very difficult to achieve—not as difficult as perfect assessment, but difficult nonetheless. Observations 4 and 5 below relate perfect distinctions to perfection.
Say that
Let
Here is another way to think about perfect non-discrimination. A higher bar than making perfect distinctions would be making perfect distinctions while limiting assessments to just two scores. Then, the binary assessor perfectly sorts the population into two groups: those having property
Certain mathematical relationships between the limitations in Observations 1, 2, and 3 are easy to state. For instance, a simple numerical transformation can convert an assessor that makes perfect distinctions into a perfect assessor.
Let
Barocas et al. point out that, for any assessor that satisfies predictive equity, there is a transformation of it that is calibrated (Barocas et al., 2019, Proposition 1, p. 52). On the basis of this observation, they conclude that predictive equity and calibration are “essentially equivalent notions” (Barocas et al., 2019, p. 52). In my view, such an interpretation is unwarranted,
16
but these sorts of transformations at least succinctly state a type of connection between concepts. The existence of a transformation to a perfect assessor characterizes those assessors that make perfect distinctions and so characterizes assessors that satisfy predictive equity for all partitions. For non-homogeneous populations, the existence of an injective transformation to a perfect assessor characterizes those assessors whose scores sort the population into a
Using the limitations, we can also easily mark some logical relationships between the fairness constraints when they hold for all partitions for non-constant assessors.
Let If If
Since the observation is a fairly immediate consequence of preceding ones, I will just sketch a quick supporting argument here. If
We could think of what happens when a constraint is satisfied for all partitions as revealing what ideal of fairness the constraint is committed to. As satisfying one of the constraints is supposed to represent a form of fair assessment for the groups in a partition, satisfying a constraint for all partitions represents fair assessment for all groups. This is, plausibly, the ideal case. For the three criteria under consideration here, the ideals are very simple and so are the relationships between them (Figure 2).

Relations among Fairness Ideals for Non-Constant Assessors.
I want to consider two objections to the significance of the foregoing limitative results. Both concern the potentially overly exacting nature of what is being asked for in avoiding bias completely against all groups. First, we might consider satisfying certain fairness constraints approximately rather than exactly. That is, we could confine the amount of bias to which any group is subject to a certain margin of tolerance. Second, we might consider avoiding bias for a certain collection of partitions, even if that collection is not the set of all partitions. I discuss these objections in turn.
One potential source of stringency that could be driving the limitative results is the requirement that a constraint has to be satisfied exactly. Instead, we could consider requiring that an assessor satisfies a fairness constraint approximately. Kleinberg et al. consider such a possibility for satisfying multiple fairness criteria approximately in light of Theorem 1. On this approach, an assessor is approximately fair for some margin of tolerance if, for each group, the assessments are within that margin. The guiding idea is that the fairness standards are relaxed to requiring only that assessors are unbiased “enough” for each group. Only sufficiently small amounts of bias, in other words, are tolerated. Let’s look at each constraint in turn.
Say that
Let
Put another way, relaxing calibration in a continuous fashion is equivalent to relaxing perfection in a continuous way. Small deviations from calibration allow only (equally) small deviations from perfect assessment. Observation 1
Say that
Let
Observations 2 and
Finally, say that an assessor satisfies
Let If
On the basis of Observations
When we require, not that the criteria hold exactly for all partitions, but only that they hold approximately for all partitions, the logical connections between the characterizing conditions are a bit different. These connections are represented in Figure 3. We can take any

Relations among Approximate Fairness Ideals for Non-Constant Assessors.
The second objection councils restraining our ambitions in a different way. One might be inclined to think that, while (a particular type of) unbiased assessment for multiple partitions is often desirable, we have overshot the mark by requiring it for all partitions. Consider calibration. There are simple examples of populations that allow for a imperfect assessor that is simultaneously calibrated for, say, two different non-trivial ways of partitioning the population.
Calibration for Two Binary Partitions.
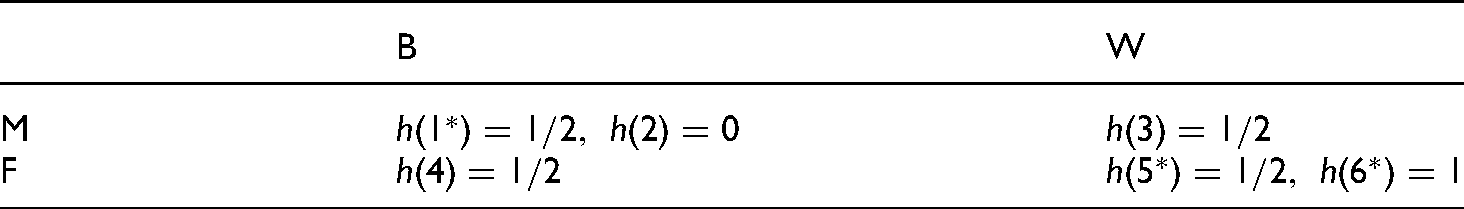
So one idea might be that there is a small set of relevant partitions
No Calibration for Two Binary Partitions.

One feature of Example 2 that may incline some to regard it as a corner case is that the base rate for property
Still, it makes sense to investigate conditions that are both necessary and sufficient for the existence of an imperfect but calibrated assessor, for example, for all partitions in a set
To summarize, on the one hand, requiring the satisfaction of a fairness constraint for some single partition is generally unsatisfactory since we may care about the fair treatment of groups from different partitions. On the other hand, requiring any of the fairness constraints considered here be satisfied for all partitions of the population or all partitions of some cardinality places unrealistically high demands on assessment as Observations 1, 2, and 3 establish. Kearns et al. make a similar point: “we cannot insist on any notion of statistical fairness for every subgroup of the population: for example, any imperfect classifier could be accused of being unfair to the subgroup of individuals defined ex-post as the set of individuals it misclassified. This simply corresponds to ‘overfitting’ a fairness constraint” (2018, p. 2565). The foregoing observations refine this point, providing, for each fairness constraint, an explicit characterization of when the constraint holds or holds approximately for all partitions. What about imposing the fairness constraint on only some set of partitions? There are at least three problems with resisting the limitative nature of Observations 1, 2, or 3 by relaxing the assumption that the relevant fairness constraint holds for all partitions (or all partitions of a given cardinality) to the assumption that it holds for just multiple partitions. First, by the observations above, bias against some group is a foregone conclusion. Which and how many partitions are ethically relevant is not invariant across assessment problems and cannot be decided a priori, so the implied bias may be more or less ethically relevant. As Examples 2 and 4 show, for some assessment problems, we can run into impossibilities even for small sets of partitions. These examples can be adapted to show that this sort of limitation emerges even for approximate versions of the fairness constraints. Second, for some given set of partitioning categories, certain populations may admit non-trivial fair assessments while others do not. For example, it could be the case that the population of Broward County defendants in 2015 admits non-trivial fair assessment for races and genders, while the 2016 population does not. This raises yet further concerns about fair treatment: some populations can be treated fairly, while others cannot unless the assessment meets the highest bar of perfection. The third problem that arises for resisting the limitative nature of the foregoing observations by focusing only on a set of pre-determined partitions is the prospect of intersectional bias, which I turn to next.
We have seen that membership in multiple social groups is universal and is, in a sense, a truism. Intersectionality theory is concerned with membership in multiple socially disadvantaged groups, and with how membership in multiple socially disadvantaged groups can compound disadvantage in a nonlinear way, so to speak. Calibration, predictive equity, and equalized odds each presents a particular conception of unbiased assessment. A natural question to ask is whether any of these conceptions of unbiased assessments admits the possibility of intersectional bias. Do the intersectionality theorist’s concerns emerge here?
Kimberlé Crenshaw, who introduced the term “intersectionality,” makes use of a court case to explain how bias against black women, for example, is consistent with the lack of that form of bias against black people or against women (Crenshaw, 1989). In DeGraffenreid v. General Motors, five black women alleging discrimination by General Motor’s seniority-based system sued the company. Prior to 1964, General Motors did not hire black women. All of the black women hired after 1970 lost their jobs through a seniority-based layoff during a later recession. The district court rejected the plaintiffs’ attempt to bring a suit on behalf of black women in particular rather than on behalf of black people or women. According to the court, the suit must present “a cause of action for race discrimination, sex discrimination, or alternatively either, but not a combination of both” (qtd. in Crenshaw, 1989, p. 141). The court noted that, while General Motors did not hire black women prior to 1964, they did hire female employees for a number of years prior to 1964. So there was no sex discrimination. And what if General Motors had hired black people—specifically black men—for a number of years prior to 1964? Crenshaw’s point is that that would not really absolve General Motors of the charge of discrimination against black women. It certainly does not follow that there could be no discrimination against black women.
To address the spectre of intersectional bias in the fair assessment setting considered here, we need to introduce the notion of the coarsest common refinement of a set of partitions. As technical work that deals with partitions has shown, the coarsest common refinement of a set of partitions is a very handy concept (e.g., Aumann, 1976).
18
A partition
How does the fairness framework under consideration in this essay bear on the issue of intersectionality? It is not true that if
Let
, and let
for
. Again, having property
is represented by an asterisk in Table 3. Consider two binary partitions, one for gender,
, and one for race,
. The partitions and assessments scores are also displayed in Table 3. The assessor
is calibrated for both the
partition and the
partition. In all of those groups, two thirds of those who receive an assessment of
have property
. The coarsest common refinment is the four-cell partition
composed of the groups of black men, black women, white men, and white women. Since
,
is underconfident in (and so not calibrated for) black women. At the same time,
is overconfident in both black men and white women.
Intersectional Bias.
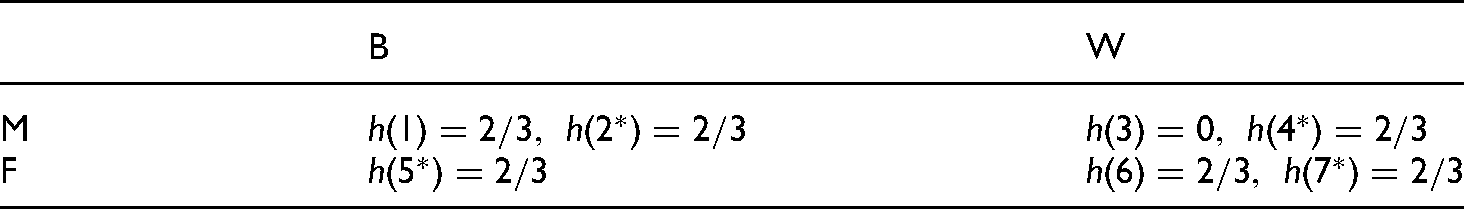
Intersectional Bias.
Two further points are worth emphasizing. First, the example also shows that it is conceptually possible for membership in multiple socially disadvantaged groups to lead to favorable assessment bias. This could be the case if
Let
Even if Even if Even if
I end on at least a slightly more positive note. Suppose that we manage to specify some number of population partitions for which unbiased assessment is most ethically relevant in a particular assessment problem. The next observation provides one consideration in favor of focusing on unbiased assessment for the coarsest common refinement of the relevant partitions.
Let
If If If
Observation 7 assures us that, if we can specify the population partitions that are ethically relevant in an assessment problem, then satisfying a particular fairness constraint for the coarsest common refinement implies that the constraint is satisfied on all of the relevant partitions. The constraint only needs to be satisfiable in the coarsest common refinement in a non-trivial way. This contrasts with the lack of a corresponding guarantee, indicated in Observation 6, when we focus on unbiased assessments for the coarser partitions as the district court did in DeGraffenreid v. General Motors. Nevertheless, satisfaction of one of these fairness constraints on the coarsest common refinement of a set of partitions is only a sufficient condition for the constraint’s satisfaction for all partitions in the set; it is not necessary, as simple examples illustrate. As a result, focusing only on the coarsest common refinement unduly restricts the set of fair assessors. Furthermore, we generally do not know at the time of assessment whether non-trivial unbiased assessment is possible for the coarsest common refinement.
There are multiple ways to carve a population, multiple social identities, for which it may be important to avoid biased assessments. Fixing a single partition of identities is overly restrictive, committing us to ignoring both relevant forms of bias against other groups and changing social context. Allowing even a set of partitions to ossify into the relevant partitions may fail to make us sufficiently attentive. In the DeGriffenreid v. General Motors decision, the court resisted the idea that relevant classifications are open to reconsideration or refinement: “The prospect of the creation of new classes of protected minorities, governed only by the mathematical principles of permutation and combination, clearly raises the prospect of opening the hackneyed Pandora’s box” (qtd. in Crenshaw, 1989, p. 142). Pandora’s box or not, the alternative seems to be refusal to confront different possible forms of group bias. If Sen is right, such dogmatism also “makes the world much more flammable.”
But we confront limitations in taking the relevant classes in fair assessment to be “governed only by the mathematical principles of permutation and combination.” Requiring that certain forms of bias be avoided for all possible social groupings is overly constraining, placing unrealistic demands on assessment as Observations 1, 2, and 3 attest. Put another way, bias against some group is inevitable for non-trivial assessment problems. Requiring only that an assessor be “close” to bias-free for all groups does not change this picture much (Observations
Where does this leave us? What the foregoing analysis helps us to make clear is that, not only is there a conflict between eliminating different forms of bias, but there are serious limits to the extent to which a given form of bias can be eliminated across different partitions. Often, many partitions are important. In “auditing” an assessor for bias (e.g., Kearns et al., 2018), outside of some rather restrictive cases, we are guaranteed to find bias against some group. While that is pertinent data for the ethical evaluation of an assessor, what are the prescriptive implications for assessment? Some have recently argued for rejecting nearly all of the statistical criteria of fairness proposed in the literature for reasons of a different nature than those I have considered (e.g., Hedden, 2021). Do the observations recorded here add to this case? It seems there are two broad approaches we might pursue. First, we could reconcile ourselves with bias against some groups since it is essentially inevitable on this way of understanding fair assessment, hoping and doing what we can to ensure that implied forms of bias minimally impact what we take to be the most relevant protected classes for the given time and place (cf. Hébert-Johnson et al., 2018). Second, we could seek a different conception of fair assessment.
Footnotes
Acknowledgements
Thanks to Marshall Bierson, Mike Bishop, Yang Liu, Michael Nielsen, Ignacio Ojea Quintana, Shanna Slank, Tom Sterkenburg, Reuben Stern, Borut Trpin, audiences at the Center for Advanced Studies (CAS) at LMU Munich and the Faculty of Philosophy at the University of Groningen, three anonymous referees at Social Choice and Welfare, and two anonymous referees at the Journal of Theoretical Politics for helpful conversations and feedback. I am grateful to CAS and Longview Philanthropy for providing research leave, and to the Cambridge-LMU Strategic Partnership for funding the Decision Theory and the Future of Artificial Intelligence group.