
Abstract
Reading practice is crucial for students with reading difficulties, but locating texts for reading practice can be time-consuming for teachers. Artificial intelligence (AI) tools (e.g., ChatGPT) can rapidly create text according to specified parameters, but the application of creating content for reading intervention has not been examined. We used six AI tools to generate text based on simple prompts (grade level specified), detailed prompts (grade level and science-related topic specified), and decodable text prompts. Results showed that the readability and text complexity of most texts were higher than the grade levels requested in the prompts, and their syntactic simplicity was lower than human-written grade-level science reading materials. Further, holistic ratings found that texts generated with simple and detailed prompts were largely free from odd or contradictory elements and would be appropriate for instruction and practice opportunities. However, several problems were observed with the texts generated through the decodable prompts, such as being too difficult or unnatural for beginning readers.
To become fluent readers, students must progress from effortful decoding of individual words to reading and comprehending connected text with greater ease. Explicit instruction in the alphabetic code is necessary for most students to acquire reading skills, but the development of reading proficiency depends on extensive practice in reading text (Cunningham & Stanovich, 1997; Mol & Bus, 2011; O’Connor et al, 2007; Stanovich et al, 1995; Taylor et al, 1990). Students employ self-teaching processes as they develop their knowledge of the alphabetic code, learning new words through reading experience (e.g., Share, 1995, 2008; Tamura et al, 2017; Wang et al, 2011).
Extensive reading practice is especially important for students with or at risk for reading difficulties and disabilities. Estimates indicate that, for students on a typical trajectory of reading development, several opportunities to read a printed word correctly are necessary to link the spelling to a pronunciation (Nation et al, 2007) and, in some cases, more exposures are better (e.g., Bowey & Muller, 2005; Tamura et al, 2017). Students with lower literacy skills may require two to three times as many exposures (Ehri & Saltmarsh, 1995; Reitsma, 1983; Steacy et al, 2020). Experience reading connected text offers opportunities to develop efficient word recognition skills, and practice reading new words. Repeated practice allows students to build new knowledge and vocabulary to facilitate reading achievement (Biemiller, 2003).
When providing reading instruction and practice opportunities to their students, teachers often have to identify text according to a certain level of difficulty (e.g., grade level), or passages with specific characteristics (e.g., genre, topic, inclusion of specific words). Locating texts with specific features can be difficult and time-consuming. Core reading curricula and commercially developed reading intervention programs typically include text used for instruction and practice; however, many teachers across grade levels report that they rely on materials created themselves or by a colleague with resources such as Teachers Pay Teachers or internet search engines (Prado Tuma et al, 2022). Even when core curricula or intervention programs include text for practice, teachers may encounter situations in which the provided text is insufficient, not matched to their students’ skills, or irrelevant in terms of genre or content area.
Teachers and interventionists may also need to identify alternative text options on short notice in response to student needs. Additionally, teachers and interventionists may wish to find decodable text (i.e., texts written to contain a high percentage of words with phonetically regular spelling-sound relations) to allow emergent readers and students with reading difficulties to practice applying recently taught decoding skills. In short, sourcing and curating text can be time-consuming and labor-intensive.
Artificial Intelligence Tools in Education
Advances in generative artificial intelligence (AI) tools, such as OpenAI's Generative Pre-Trained Transformer (i.e., “ChatGPT”), offer advanced text-generating capabilities that could be used to support instruction. Such tools use natural language processing and large language models (LLMs) to understand and generate human-like dialogue and text. The use of AI tools has made its way into the classroom. Surveys conducted in late 2023 found that sizeable proportions of educators were using or planned to use AI tools in their teaching (Diliberti et al, 2024; Langreo, 2024). One survey found that one-third of teachers reported using AI tools in the classroom, and more than 50% were either currently using or had plans to use AI tools in the future (Langreo, 2024).
AI Tools for Generating Text for Reading Practice
The use of AI tools in education should be considered cautiously, but with a recognition of their potential to make teachers’ jobs easier. AI tools can generate coherent and contextually relevant text from user prompts and, thus, rapidly generate text for intervention and student reading practice. Further, this immediate generation of content can be tailored to specific parameters, such as text consistent with a desired subject or topic, genre, text structure, level of complexity, or frequency of letter combinations or spelling patterns. As such, AI tools may allow for the creation of texts that could be used to support a wide range of teaching and learning activities, such as reading practice and content acquisition. A particular benefit is that teachers can acquire text immediately, even mid-lesson, that is tailored to features that are important for a lesson or that they want their students to practice.
However, despite their capabilities, it is not clear whether AI tools can be effective for generating text that is useful for student reading practice. For example, it is not clear whether AI tools adjust the complexity of text based on a requested level of difficulty (i.e., a specific grade level) or specified topic. LLMs, which power many AI tools, are typically trained on internet content, books, and academic papers written for adult readers (Brown et al, 2020), raising questions about whether these tools can create text appropriate for less skilled readers. In addition, AI-generated text may include odd, peculiar, or distracting elements that could contribute to an “unnatural” feel (i.e., it is apparent that it was not written by a human). Finally, with several generative AI tools freely available, the extent to which AI tools compare in their ability to generate text according to specific prompts is unclear.
In sum, the challenge lies in generating content that is not only factually correct but also tailored to a diverse range of linguistic and reading abilities, requiring an understanding of language and reading development processes that current AI tools might not have. To that end, we conducted this study as an initial step in examining how generative AI tools can be used to support teaching and intervention activities. Specifically, we compared several AI tools on their ability to generate text that could be used to support students’ reading practice.
Rationale for Choice of the Aspects we Evaluated
We evaluated text generated by several generative AI tools in response to a set of “prompts” (i.e., requests) that reflected how educators might interact with AI tools. These included “simple” prompts that only asked for text at a specific grade level, “detailed” prompts that requested text at a certain grade level about a specific science topic, and “decodable” prompts that requested decodable text that could be used for emergent readers. We used grade level in some of these prompts, not as an endorsement of text-leveling systems, but because referring to the difficulty of text in terms of grade levels has been a common practice in instruction and assessment. Additionally, requesting text at a particular grade level provided an opportunity to evaluate the complexity of the text the AI tools generated relative to the requested grade level.
In comparing and evaluating the text generated by the AI tools, we did not aim to exhaustively quantify the text across numerous dimensions on which text can be evaluated; instead, we focused on a few aspects relevant to how teachers might use AI tools in generating text for reading instruction or practice for students with reading difficulties.
First, because generative AI tools have only recently become available and many educators are unfamiliar with their capabilities, we examined basic features of the text generated by the tools in response to the different prompts, such as the length of the text when prompts did not specify that parameter. Our aim in evaluating text length was to provide information on what to expect when using AI tools; an ideal text length will vary based on the situation in which it will be used (e.g., some situations might require a shorter text, and others a longer text).
Second, we examined the difficulty or complexity (sometimes referred to as “readability”) of the text generated by AI tools. When choosing reading practice opportunities in interventions for students with reading difficulties, a primary area of interest is the difficulty or complexity of the text. The ideal level of text difficulty varies by student and situation but, generally, text that is too difficult can result in student frustration and inadequate reading progress (Rodgers et al, 2018). Conversely, in some situations providing students with opportunities to read text that is somewhat more challenging text may be important (Shanahan, 2020; Vaughn et al, 2022). The aim of the current study was not to debate what level of text difficulty is best for reading practice; that decision is often idiosyncratic and can vary by student, situation, or even the same student in different situations (e.g., in some instances, easier and less complex text may be needed to bolster a student's confidence and offer more opportunity for independence; in other situations, adding challenge to the level of text may be important for learning new skills). Rather, the study was about evaluating the text produced by generative AI tools in terms of its difficulty and complexity overall, whether AI tools adjust difficulty based on a different requested grade level, and how different tools compare in terms of the complexity of text they generate.
Efforts to evaluate the difficulty, complexity, and “readability” of text have been going on for more than 100 years and over 200 metrics and formulae have been developed for that purpose (DuBay, 2004). Some of the best known metrics of text difficulty are readability formulae that often express the difficulty of a text at a U.S. grade level, such as Dale-Chall readability (Chall & Dale, 1995; Dale & Chall, 1948) and Flesch-Kincaid grade level (Kincaid et al, 1975). These formulae are based on text characteristics such as sentence length combined with the number of “difficult” words, as in the Dale-Chall (i.e., words not included in a predefined “Dale” list of 3000 that were familiar to most fourth grade students), or the number of syllables per word, as in the case of Flesh-Kincaid. Although readability formulae have been critiqued since their origin (DuBay, 2004), studies have indicated that they offer basic indices of text difficulty that correlate with reading comprehension and oral reading fluency (e.g., Begeny & Greene, 2014; DuBay, 2004; Toyama et al, 2017).
We used readability formulae in evaluating the text generated by the AI tools not because they are an exceptionally valid method of evaluating text difficulty, but because they have been widely used over the years across a variety of settings, including education, health care, and the military (DuBay, 2004; Wang et al, 2013). Additionally, they are expressed in a grade level that is readily understood. In short, these readability formulae provided a way to compare text across AI tools in terms of estimated grade level in relation to the requested grade level for text that teachers gather for practice reading to build accuracy and fluency.
In addition to “first-generation” readability formulae in Dale-Chall and Flesh-Kincaid, we two used other metrics of text complexity: The Lexile Framework and Coh-Metrix. The Lexile Framework (MetaMetrics, 2024) was developed to match readers with text they could comprehend adequately. Based on word frequency and sentence length averaged across smaller sections, the Lexile level of a text is intended to reflect the difficulty of text in which a reader, with a corresponding Lexile level, would be able to comprehend with at least 75% accuracy. For example, a typically achieving reader at the beginning of third grade would be expected to comprehend a text with a Lexile of 520 (expressed as “520L” in the Lexile system).
Another means of evaluating text that is different from traditional readability formulae is the Coh-Metrix software (Graesser et al, 2004). Coh-Matrix analyzes text on more than 200 measures of complexity, language, and cohesion characteristics. We focused on the syntactic simplicity metric (PCSYNz) from Coh-Metrix, which is a composite score based on several factors, including the number of words per sentence, the number of clauses per sentence, and the number of words before the main verb of the main clause of the sentence. Syntactic simplicity is lower in more complex texts, and has been shown to decrease linearly as grade levels increase across language arts, science, and social studies texts (Graesser et al, 2011).
In summary, the difficulty or complexity of a text is relevant when considering whether text may be useful for reading practice for a given student or situation. We used multiple indices of text complexity because (a) no single metric is universally agreed upon as the most trustworthy index of text difficulty; and (b) multiple indices permit examining consistency across metrics in comparing the text generated by different AI tools.
Finally, we evaluated the texts generated by the AI tools on a holistic basis. Generative AI tools use LLMs trained on text written by humans, but what they produce is still generated by technology. We were curious to determine whether the text generated by AI tools would contain “unnatural” elements such as odd or irrelevant information, jarring transitions, or other features suggesting that it was not written by humans.
Research Rationale and Questions
The first widely available AI chatbot ChatGPT was released in November 2022, and since that time, the use of AI tools has increased rapidly across many aspects of everyday life, including education (Diliberti et al, 2024; Langreo, 2024). Several studies have examined the readability and appropriateness of AI-generated texts for medical patient education and communication (e.g., Eid et al, 2024; Gordon et al, 2024; Hancı et al, 2024), but to our knowledge, no research has specifically evaluated the capacity of AI tools to generate reading content, based on different types of prompts, that could be appropriate for reading practice for children in educational settings.
In this descriptive study, we compared the ability of six publicly available AI tools to generate text for reading practice. We evaluated generated text using a set of prompts that teachers might use when interacting with AI tools with varying parameters such as grade level, topic, or decodability and specific letter combinations in words. One research question guided our study: What is the length, text difficulty/complexity, and holistically rated naturalness of text generated by different AI tools based on a set of prompts with varying specificity?
By answering this question, we aimed to (a) equip educators with an understanding of whether available AI tools can produce text suitable for instruction and reading practice given user prompts, (b) provide practical guidance on which AI tools are preferable, and (c) identify prompt formats and frameworks that are the most effective in generating useful text. A better understanding of the abilities and limitations of available AI tools will empower educators to integrate AI-generated content into their teaching more efficiently and effectively.
Method
Identification of AI Tools and Prompts
To identify AI tools and prompts for this study, we considered how teachers might seek and access AI technology.
AI Tools
We considered tools that (a) could generate text on request, (b) were publicly available, and (c) were free to use. We identified five tools that fit these criteria: ChatGPT 3.5, Google AI Bard (which has since been renamed as Google Gemini), two platforms for Meta's Llama 2 (Llama 2: https://www.llama2.ai/ and Llama 2 Huggingface [Llama 2_HF] https://huggingface.co/chat/), and Diffit (https://web.diffit.me/). As we were identifying AI tools, we learned of the recently released ChatGPT 4.0, accessible through a $20 monthly subscription. Based on reports that ChatGPT 4.0 is superior to 3.5 in its ability to comprehend prompts and generate text, we included it in the set of tools compared in the study.
Prompt Design
We compared the ability of AI tools to generate text based on three types of so-called zero-shot prompts (giving a task in natural language without providing any specific training or examples). Each was designed to simulate teachers’ interaction with an AI tool in different situations.
Simple Prompts
Simple prompts included only the requested grade level and were stated as: “Give me a passage at a [third/ninth]-grade reading level.” These types of prompts were used because we were interested in evaluating the characteristics of generated text when the prompt included no guiding information other than a target grade level. The simple prompt also might resemble what a teacher might use to generate a wide variety of grade-level-aligned materials without specifying topics, genre, or length, or other parameters. The simple prompt might also reflect how educators, having recently learned about AI tools, might request text.
Detailed Prompts
Our detailed prompts were more specific and included a designated topic, in addition to grade level, and were written as follows: “Give me a passage at a [third/ninth]-grade reading level about [topic].” This mimicked what a teacher might request for more specific instructional goals, such as reinforcing comprehension of a recent history lesson or providing practice in a specific topic area, such as science. We chose five topic areas commonly seen in third- and ninth-grade science curricula: the life cycle of a butterfly, extreme weather, the water cycle, states of matter, and the decomposition of plants. The same five detailed prompts were used for each AI tool, at both the third- and ninth-grade levels.
Decodable Prompts
Finally, each AI tool was used to generate decodable prompts. The term “decodable” refers not to the readability of the prompt itself; rather, the goal was for AI tools to generate text that would be decodable for emergent readers or students with reading difficulties. Decodable text contains more phonetically regular words or those with a particular letter combination. Especially in the case of emergent readers and students with significant reading difficulties, teachers might request text that is closely aligned with their phonics instruction when the available curricula or intervention materials do not include text with these specific letter combinations or when supplemental materials are needed.
We chose 10 common letter combinations for each AI tool to generate texts: sh, th, ch, wh, ck, ou, ea, ee, ow, oo. The prompt “Give me a highly decodable passage that includes several words with [letter combination]” was used with each AI tool. Grade level was not specified, nor did we request a specific number of decodable words, to avoid potentially limiting what the AI tool output. We also did not provide the AI tools with other information about “decodability” to evaluate the textual outcome when each AI tool was given a prompt that teachers might use.
Rationale for Grade-Level Specification
Grade levels for the simple and detailed prompts were specified to evaluate the difficulty and text complexity of the AI-generated texts. Referring to text difficulty in terms of grade level is a commonly used practice in education, and likely the primary way teachers might interact with AI tools to generate text with a desired level of complexity. We used two grade levels, third and ninth grade, with the same prompt language to evaluate whether the AI tools adjusted text difficulty and complexity accordingly. Third grade was selected because it is a time when reading intervention is commonly implemented, and fluent reading and comprehension are common goals of instruction. We selected ninth grade because it is likely different enough from third grade, and any adjustment by the AI tools to adapt to reading level would be apparent. Additionally, ninth grade is a time when some students struggle with text reading (Brassuer-Hock et al, 2011), reading intervention is still highly relevant, and text is often needed for practice in building fluency and comprehension (Scammacca et al, 2015; Vaughn et al, 2015).
Passage Generation With the AI Tools
Simple Prompts
As mentioned, the simple prompt did not request parameters other than grade level. This might be akin to a situation in which a teacher or interventionist seeks reading content at a particular grade level, such as for student reading fluency practice, but is less concerned with the topic of the text. Because the simple prompt did not specify anything other than grade level, the generated text might vary widely each time the prompt was run, and we were curious about which level of variability was present in the resulting output when we ran the prompt multiple times for each AI tool. Therefore, to have a robust sample of passages for evaluating the variability of the generated text, we issued the simple prompt 30 times across each AI tool at both the third- and ninth-grade levels. Diffit was not used in this step, because the tool requires the input to specify a topic. Issuing the simple prompts across the other AI tools resulted in 150 passages for each grade level, for a total of 300 simple prompt passages.
Detailed Prompts
Each of the five detailed prompts—which specified grade level and topic—were issued once for each AI tool, for both the third- and ninth-grade reading levels. This allowed us to assess how well the AI performed when given more detailed, subject-specific instructions. Unlike with the simple prompts, repeating the same specific prompt with the same AI tool would result in text that was highly similar to the previous output. The objective of the detailed prompts was to observe variation across prompts about specific topics (and across tools with these prompts); therefore, it was not necessary (or useful) to repeat these prompts with each tool multiple times. This resulted in 30 passages for each grade level, totaling 60 detailed prompt passages.
Decodable Prompts
Finally, we issued the decodable prompts 10 times across each AI tool, one passage for each of the 10 letter combinations, resulting in a total of 50 passages. We wanted to capture the overall trend of the text complexity and writing quality when the tools were given a prompt oriented around the production of decodable text (i.e., a potentially common request for teachers and interventionists working with emergent readers or students with reading difficulties). Because these prompts specified a letter combination, it was not necessary to generate more than 10 passages per AI tool because the constant was the decodable aspect contained in each prompt.
Text Evaluation
Passage Length
Passage length was determined through simple word counts for each passage. We reported passage length to provide (a) practical information for educators on the length of passages that users might expect when using prompts that did not specify a target length; and (b) to compare differences between AI tools in the length of the passages they generated.
Text Difficulty and Complexity
We evaluated AI tools by analyzing the readability and text complexity of the passages they generated. As discussed earlier, a primary consideration in selecting text for reading instruction and practice, particularly for students with reading difficulties, is the difficulty of the text (Rodgers et al, 2018). It is unclear to what extent generative AI tools can scale the difficulty of text up or down based on information in the request (e.g., a request for text at a specific grade level). Additionally, because generative AI tools are trained on LLMs primarily derived from text written for adults, it is not clear if AI tools generate text that is more difficult and complex than desired for providing reading practice materials. We used a set of readability and text complexity metrics studied and discussed in prior literature (e.g., Begeny & Greene, 2014; Graesser et al, 2004, 2011; Newcomer, 1985; Smith et al, 1989; Stenner, 2022; Toyama et al, 2017) that differed in their formulae and thus reflected somewhat different elements of the text.
Readability Formulae
Dale-Chall readability, one of the oldest and best known readability formulae (DuBay, 2004), is calculated based on average sentence length and the frequency of difficult words in a given passage. Studies indicate that Dale-Chall is predictive of students’ reading fluency across different texts (Begeny & Greene, 2014). Flesch-Kincaid grade level is calculated based on average sentence length and the frequency of multisyllabic words. It is one of the most widely used formulae for estimating grade-level readability (DuBay, 2004), and is even included as a tool in common word processing programs such as Microsoft Word.
We used an online calculator (https://readabilityformulas.com) to obtain Dale-Chall and Flesh-Kincaid readability estimates for the texts generated by the AI tools, which are expressed as grade levels. We first calculated means and standard deviations of readability estimates for each AI tool and prompt type and then compared these metrics against the grade level specified in the prompt.
Lexile
The Lexile level of a text is calculated using word frequency and sentence length across many smaller sections of a text. Within each section, words are compared to a word-frequency database, as well as the average length of each sentence. Scores from each section are averaged to result in a Lexile level for the text. Scores are expressed on a continuous scale and are intended to reflect the difficulty of text in which a reader with a corresponding Lexile level would be able to comprehend with at least 75% accuracy (Lennon & Burdick, 2004). For example, a typically achieving reader at the beginning of third grade would be expected to comprehend a text with a Lexile of 520. Lexile scores are expressed as a score range, so we coded the upper and lower bounds for each passage and calculated means and standard deviations for the upper and lower Lexile bounds for each AI tool and prompt type (scores retrieved from http://www.Lexile.com/analyzer/). We compared these ranges to the benchmarks provided by Lexile using the middle-of-year 25th to 75th percentile ranges for third and ninth grade. For third grade, the middle-of-year benchmark range is 415L to 760L; for ninth grade, it is 1040L to 1345L. By comparing the Lexile ranges of the AI-generated passages to these benchmarks, we determined the extent to which the average Lexile score range of the passages generated by each AI tool fell within the range estimated for the grade level specified for the prompt.
Coh-Metrix Syntactic Simplicity
We analyzed syntactic simplicity using Coh-Metrix 3.0 (McNamara et al, 2014), which is calculated based on the number of words per sentence, the number of clauses per sentence, and the number of words before the main verb of the main clause of the sentence. High scores indicate text with simpler syntactic structures, characterized by fewer words, shorter sentences, and fewer embedded clauses—features that reduce cognitive load during reading comprehension (Graesser et al, 2011). Syntactic simplicity is expressed as a z-score (M = 0, SD = 1) and corresponding percentile scores based on a comparison with the Touchstone Applied Science Associates (TASA) corpus, a large body of 37,651 texts from different content areas (e.g., English/language arts, science, social studies) commonly used in K-12 education. Syntactic simplicity norms in each grade level across English/language arts, science, and social studies are provided for corpora comparison (see McNamara et al, 2014).
These normative values are calculated based on a random sample of passages from TASA corpus. This was advantageous in our case, because it allowed us to contrast AI-generated text from detailed science prompts with human-written science texts from specific grade levels in the TASA corpus. Following McNamara and colleagues’ (2014) recommendation, we used z-score to perform the statistical analysis and derive a corresponding percentile score for interpretation. We first compared the syntactic simplicity scores across AI tools and then evaluated these scores against the TASA corpus grade-level norms provided by McNamara et al (2014).
Holistic Evaluation of “Naturalness”
Generative AI tools are designed to simulate human creativity and productivity. Although they are built on extensive and sophisticated LLMs, what they produce is still generated by machines. Thus, we were curious about the extent to which the AI tools generated reading passages that felt “natural” in that they did not contain odd, unnatural, nonsensical, or contradictory features that suggested they were not written by humans, and whether that differed across the different prompt types and AI tools.
Therefore, we holistically evaluated the naturalness of language in the passages (i.e., are there elements of the passage that seemed unnatural, odd, or contradictory?). Naturalness was rated on a scale from 1 (many/pervasive) to 3 (very few/none). Passages were distributed equally and systematically among the five authors, all of whom had prior experience implementing interventions for struggling readers across various grade levels. Ratings were given to all passages generated from the detailed and decodable prompts (n = 60 and 50, respectively), and we randomly sampled 33% (n = 100) of the passages generated by the simple prompts (passages were evenly sampled from each AI tool and grade level). A total of 210 passages were rated and a randomly selected 60 passages were double-rated. Interrater agreement on the double-rated passages was 83% and Cohen's Kappa (for two raters) was 0.56, indicating moderate agreement.
Results
Quantitative Evaluation
Data on passage length, readability, syntactic simplicity, and naturalness for each AI tool and prompt type are reported in Table 1.
Means and Standard Deviations for Word Count, Readability Estimates, and Lexile Levels for AI-Generated Passages and Prompt Types (N = 30 for Simple Prompts, N = 5 for Detailed Prompts, and N = 10 for Decodable Prompts).
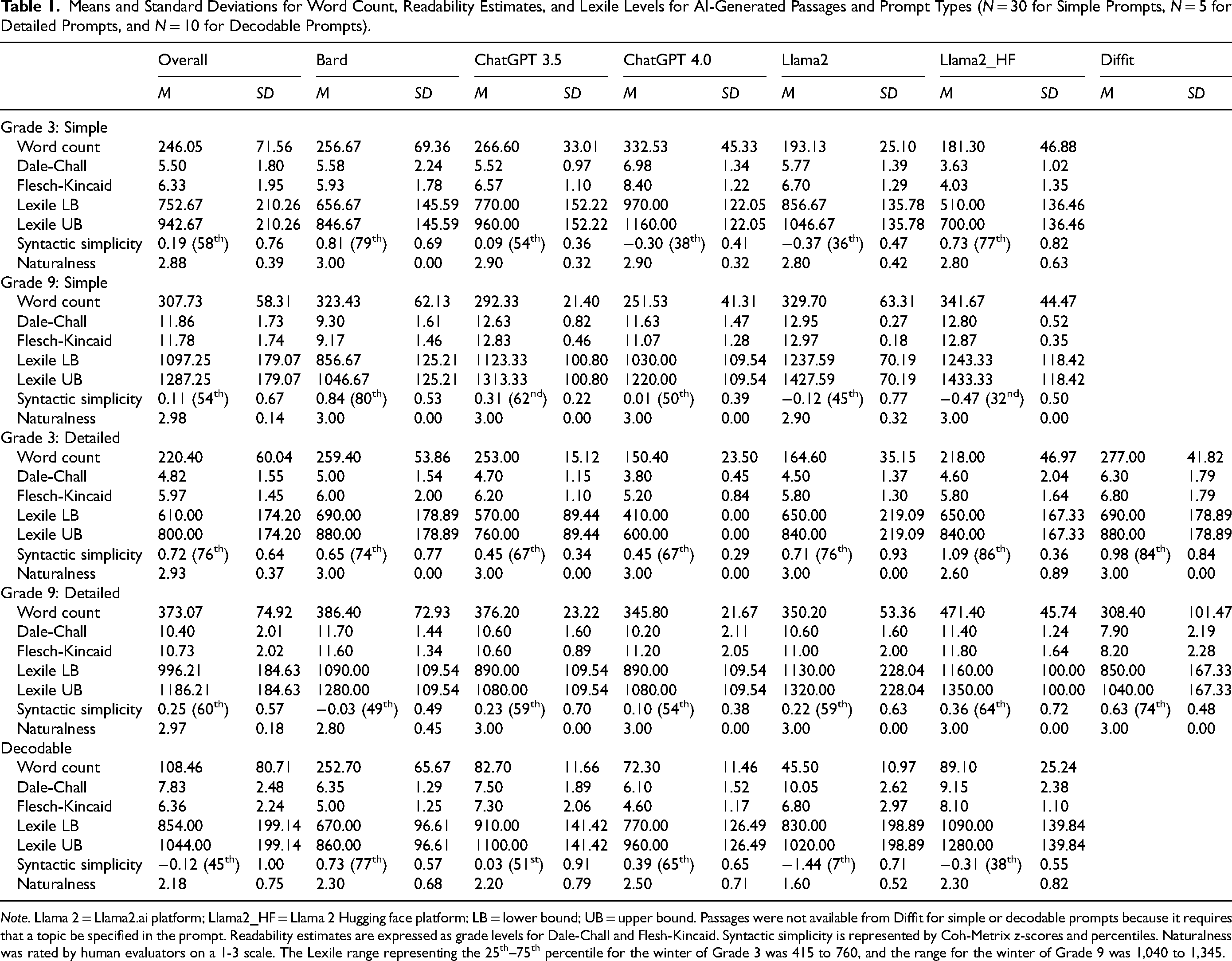
Note. Llama 2 = Llama2.ai platform; Llama2_HF = Llama 2 Hugging face platform; LB = lower bound; UB = upper bound. Passages were not available from Diffit for simple or decodable prompts because it requires that a topic be specified in the prompt. Readability estimates are expressed as grade levels for Dale-Chall and Flesh-Kincaid. Syntactic simplicity is represented by Coh-Metrix z-scores and percentiles. Naturalness was rated by human evaluators on a 1-3 scale. The Lexile range representing the 25th–75th percentile for the winter of Grade 3 was 415 to 760, and the range for the winter of Grade 9 was 1,040 to 1,345.
Passage Length
As reported in Table 1, across all AI tools, the average length of passages generated by simple prompts requested for third grade was 246.05 (SD = 71.56), and slightly greater for ninth-grade requests (M = 307.73, SD = 58.31). The average length of passages generated by the detailed prompts was similar to the simple prompts; mean length and standard deviations for third-grade requests were 220.40 (SD = 60.04), and for ninth grade were 373.07 (SD = 74.92). In contrast, passages generated by the decodable prompts were shorter (M = 108.46, SD = 80.71) with mean passage length for most tools falling between 45.50 and 89.10 words. Although ideal passage length varies by situation, these results indicate that, without prompting for passage length, AI tools produce passages that might generally be considered a practical length for use in instruction or reading practice.
Type of Passages
For simple prompts, third-grade passages were predominantly narrative, except for Bard, which generated 80% expository texts (24 out of 30). All ninth-grade simple prompt passages were expository. Detailed prompts yielded exclusively expository passages for both third and ninth grades across all AI tools, which would be expected given the science topics we requested. Decodable prompts consistently yielded narrative passages across all grade levels and AI tools.
Readability and Text Complexity
Simple Prompts, Third Grade
When third-grade passages were requested with simple prompts, the overall mean estimated grade level was 5.50 (SD = 1.80) for Dale-Chall and 6.33 (SD = 1.95) for Flesh-Kincaid. The overall mean lower and upper Lexile bounds were 752.67L (SD = 210.26) and 942.67L (SD = 210.26), respectively. For reference, Lexile reports the lower and upper Lexile bounds representing the 25th to 75th percentiles in the winter of third grade as 415L to 760L (MetaMetrics, 2024), indicating that AI-generated passages were more difficult than what a typically achieving third grader would be expected to comprehend. For Coh-Metrix syntactic simplicity, higher scores mean greater syntactic simplicity (i.e., sentences with fewer words and simpler syntactic structures, and thus easier to read; Graesser et al, 2011). When the third-grade text was requested with simple prompts, the overall mean syntactic simplicity z-score was 0.19 (SD = 0.76), which corresponds to 58th percentile of syntactic simplicity in the TASA corpus of human-written texts. For reference, the average z-score of human-written grade 2-3 language arts passages in the TASA corpus is 0.89 (81st percentile, SD = 0.63), and 1.48 (93rd percentile, SD = 0.63) for human-written Grade 2-3 science passages, which means the AI-generated texts were more syntactically complex than human-written texts aimed at the same grade level and content area.
Simple Prompts, Ninth Grade
The passages generated using ninth-grade simple prompts were consistently estimated as more difficult than those generated using third-grade level prompts, which suggested that the AI tools recognized the need to adjust text complexity based on the grade level specified in the prompt. The overall mean estimated grade level for ninth-grade text was 11.86 (SD = 1.73) for Dale-Chall and 11.78 (SD = 1.74) for Flesh-Kincaid. The overall mean lower and upper Lexile bounds were 1097.25L (SD = 179.07) and 1287.25L (SD = 179.07), respectively. For reference, the lower and upper Lexile bounds representing the 25th to 75th percentiles in the winter of ninth grade are 1040L to 1345L (MetaMetrics, 2024), indicating the estimated Lexile range of AI-generated passages is close to the benchmark range. The overall mean syntactic simplicity z-score of all AI tools was 0.11 (SD = 0.67), which corresponds to 54th percentile in the corpus of human-written text in the TASA database. As for the other metrics, the AI tools tended to generate text that was more syntactically complex for ninth-grade prompts than for third-grade prompts. The mean syntactic simplicity for human-written science texts for Grades 9-10 in the TASA database is 0.72 (77th percentile), meaning that, overall, the AI-generated texts were more syntactically complex than human-written content intended for the same grade level.
Detailed Prompts, Third Grade
When third-grade passages were requested with the detailed prompts, the overall mean estimated grade level was 4.82 (SD = 1.55) for Dale-Chall and 5.97 (SD = 1.45) for Flesch-Kincaid. The overall mean lower and upper Lexile bounds were 610L (SD = 174.20) and 800L (SD = 174.20) respectively. For reference, Lexile reports the lower and upper Lexile bounds representing the 25th to 75th percentiles in the winter of third grade as 415L to 760L (MetaMetrics, 2024), indicating the estimated Lexile range of AI-generated passages is close to the benchmark range. The overall mean syntactic simplicity z-score was 0.72 (SD = 0.64), which corresponds to the 76th percentile in the TASA database of human-written science texts. In the TASA corpus, Grade 2-3 passages have an average syntactic simplicity score of 1.48 (93rd percentile, SD = 0.63), which indicates that the AI-generated passages were more syntactically complex.
Detailed Prompts, Ninth Grade
When ninth-grade text was requested with the detailed prompts, the overall mean estimated grade level was 10.40 (SD = 2.01) for Dale-Chall and 10.73 (SD = 2.02) for Flesch-Kincaid. The overall mean lower and upper Lexile bounds were 996.21L (SD = 184.63) and 1186.21L (SD = 184.63), respectively. For reference, the lower and upper Lexile bounds representing the 25th to 75th percentiles in the winter of ninth grade are 1040L to 1345L (MetaMetrics, 2024), indicating the estimated Lexile range of AI-generated passages was close to the benchmark range. The overall mean estimated syntactic simplicity z-score was 0.25 (60th percentile; SD = 0.57). For comparison, the average syntactic simplicity score for human-written Grade 9-10 science texts in the TASA corpus is 0.72 (77th percentile, SD = 0.74), which again indicates the AI-generated passages were more syntactically complex than human-written science texts for the same target grade.
Decodable Prompts
The passages generated with the decodable prompts represented a broad range of text readability and complexity estimates. The overall average grade-level estimates were 6.36 (SD = 2.24) for Dale-Chall and 6.36 (SD = 2.24) for Flesch-Kincaid. The average lower and upper Lexile bounds were 854L (SD = 199.14) and 1044L (SD = 199.14), respectively. According to Lexile norms, the average difficulty of the text generated through the decodable prompts is consistent with the 25th to 75th percentile range for the winter of sixth grade (855L to 1160L; MetaMetrics, 2024). Passages generated using decodable prompts showed lower syntactic simplicity than passages generated by the other prompt types. The overall mean was −0.12 (SD = 1.00) across the AI tools. The text generated by the AI tools in response to decodable prompts were also more syntactically complex compared to human-written Grade 2-3 language arts passages in the TASA corpus. In that database, Grade 2-3 narrative passages had a mean syntactic simplicity score of 0.89 (63rd percentile, SD = 0.63).
Statistical Comparisons of Readability and Text Complexity
One-way ANOVA tests were conducted to compare the readability and text complexity estimates from the AI tools. The ANOVA and post-hoc results are reported in the Supplemental online file and are briefly summarized here.
Significant differences in readability levels were observed across AI tools for Dale-Chall, Flesch-Kincaid, Lexile, and syntactic simplicity metrics at both grade levels (all ps < .001). After applying the Benjamini-Hochberg procedure (Benjamini & Hochberg, 1995) to control for the false discovery rate across multiple comparisons, all results remained statistically significant. Although nearly all the passages generated by all the AI tools were estimated to be more difficult than the requested grade levels, for third-grade simple prompts, the passages generated by Llama 2_HF had the lowest grade estimates of difficulty whereas the passages generated by ChatGPT 4.0 had the highest estimates of difficulty. The syntactic simplicity index suggested that Bard had the highest syntactic simplicity and Llama 2 and Llama 2_HF had the most complex syntactic structures. For ninth-grade simple prompts, Bard generated passages with the lowest difficulty estimates and highest syntactic simplicity, and Llama 2 generated passages with the highest estimated difficulty and the most complex syntactic structures.
Given the limited sample sizes for decodable and detailed prompts, with only 10 passages per tool for decodable prompts and 5 for detailed prompts, there was insufficient statistical power to conduct a meaningful ANOVA. Consequently, we focused on descriptive statistics to summarize and compare the data across different AI tools and prompt types.
Holistic Evaluation of “Naturalness”
Across all AI tools, the passages generated from simple and detailed prompts at both requested grade levels were rated as highly natural, and there were very few odd elements (the mean scores were all higher than 2.88). In contrast, passages generated from decodable prompts were scored much lower (the mean scores ranged from 1.60 to 2.50). These passages tended to contain unnatural elements, such as surreal scenes or unusual word choices, which resulted in lower scores on the language rating. They also exhibited weaker overall organization. The passages generated by the decodable prompts all included several examples of words with the letter combination specified in the prompt. However, many passages contained several complex and multisyllabic words. Given that decodable texts are typically used for beginning readers and students with reading difficulties, the high frequency of detailed words and considerably higher level of text complexity in these AI-generated texts makes them less useful for emergent readers or students with significant reading difficulties.
Discussion
For students with reading difficulties, frequent opportunities to practice reading text is a critical component of intervention, regardless of whether the goals of the intervention are to build basic reading skills or develop reading comprehension (Foorman et al, 2016; Vaughn et al, 2022). Unfortunately, teachers may encounter situations in which curriculum or program materials lack sufficient text for practice, or they may wish to use text about a specific topic or of a particular difficulty level. Locating text for reading practice in these situations requires time teachers seldom have. Generative AI technology offers a way to generate text immediately, even mid-lesson. However, the ability of AI tools to generate student-facing reading content in an educational context has not been previously evaluated. This study examined the text generated by several AI tools based on different prompt types that educators might use.
AI-generated text was examined using simple prompts specifying grade-level readability (i.e., third or ninth grade), detailed prompts that requested passages about specific topics and specified a grade level, and prompts for decodable text including words with specific letter combinations. Across prompt types and requested grade levels, AI tools tended to generate text that was more difficult than requested, based on readability and text complexity estimates from several formulae. Further, the texts generated using the simple and detailed prompts were rated as highly natural across the different AI tools. The AI tools also demonstrated an ability to adjust text difficulty and complexity based on a requested grade level, as texts generated from requests for ninth-grade text were estimated as more difficult than content generated from requests for third-grade text.
The AI tools were much less successful in responding to requests for decodable texts. That is, the texts generated using decodable prompts were far more complex than would be expected, contained several odd and unnatural elements, and frequently contained words that would be too challenging for emergent or struggling readers (i.e., the population for whom decodable text is most relevant).
Simple and Detailed Prompts
Although the AI tools exhibited some capability to generate text at different difficulty levels, the readability of the generated passages seldom matched the requested grade level. That is, the readability levels were often two to three grade levels higher than requested based on common formulae for estimating text readability and complexity. They were also more syntactically complex than human-written grade-level passages based on Coh-Metrix results. These differences were observed across AI tools, and no AI tool consistently performed much better or worse than the others.
The fact that the AI tools generated text that was more difficult than expected should not preclude their use for generating text for reading practice, however. The fact that the AI tools demonstrated the ability to scale text complexity based on the prompt (i.e., requests for ninth-grade text resulted in text that was consistently more complex than text generated from third-grade requests) means that users may adjust the requested grade level in their prompts with the understanding that AI tools may overestimate readability levels. For example, a user may ask an AI tool to provide text two grade levels below the intended grade level. However, the effectiveness of this strategy is uncertain and requires confirmation through future research. Additionally, there are situations in which more challenging text is advantageous for reading practice. Vaughn et al (2022) recommended periodic and supported opportunities for students with reading difficulties to read “stretch text”—text that is slightly above their current reading level—which offers exposure to greater diversity in word types, syntax, vocabulary, and background knowledge than they would have been exposed to with easier reading content.
Despite the discrepancies in text difficulty levels, the overall quality of the AI-generated texts was very good when using simple prompts, and of remarkably high quality when using prompts targeting a specific topic. Passages were well organized, made sense, and were informative. There was typically no indication the texts were not written by a human. Even though we did not specify the length of the passage in our prompts, the AI tools generated texts with lengths that would generally be appropriate for reading lessons (i.e., texts were not too brief or prohibitively long).
Decodable Prompts
Although there is not extensive research support to suggest that using decodable texts is superior to using authentic text in instruction or intervention (Jenkins et al, 2004; Mesmer, 2001; Price-Mohr & Price, 2018), many scholars and practitioners agree that some use of decodable texts is a helpful scaffold to support beginning readers and students with reading difficulties in applying newly acquired decoding skills to connected text.
To be useful in these situations, one would expect decodable texts to contain a high proportion of words that could be read using previously taught letter-sound correspondences and simple sentence structures. However, in response to our prompts for decodable text, the AI tools failed to produce passages that met these characteristics. The generated passages had average difficulty levels estimated at a fourth-grade reading level or above, with some even reaching ninth- or tenth-grade levels, making them unsuitable for early readers. Moreover, many passages contained difficult, low-frequency words and exhibited unusual and complex syntactic structures, resulting in stories that lacked coherence and contained numerous unnatural elements. Consequently, these texts would be considered inappropriate for reading instruction or practice with emergent readers or students with significant reading difficulties.
One explanation of the poor performance of the AI tools in generating decodable text is a lack of decodable texts in the datasets used to train them. Decodable materials are highly specialized and often created by educational experts who carefully control the selected words, spelling patterns, and sentence structure to be accessible for beginning readers. If the training data for the AI tools do not include sufficient high-quality decodable passages, the tools may struggle to replicate the unique features of these materials. Moreover, the AI tools may not have been explicitly trained to recognize and prioritize the specific constraints and guidelines that define decodable texts.
Our decodable prompts also involved requests to include several words with a specific letter combination. This is a common feature of decodable texts, which are often written to accompany phonics lessons that target specific letters or spelling patterns. All the AI tools included several words with the targeted letter combination; however, the words represented a broad range of length and complexity and would not be consistent with how a teacher would use the text to provide practice for beginning readers practicing word reading with targeted spelling patterns. It is possible that the AI tools overselected on this aspect in “forcing” any words with specific letter combinations into the passage, which may have been a reason for including complex and multisyllabic words, and the more frequent occurrence of odd elements in the passages they generated. Anecdotally, we experimented with decodable prompts without the specified letter combinations, and the resulting text was still more difficult and complex than would be expected for the situations in which they would be intended.
These findings point to two issues in need of future consideration: (a) if decodable text is sought for beginning readers, the prompts will need to be altered in ways that the AI tools will understand (ways that are not currently known to us); and (b) AI tools may need specific training to understand these types of requests and adjust the text accordingly. Given the ability of AI technology to accomplish a remarkable number of tasks, we expect that language models can be tuned to provide decodable text appropriate for beginning reading instruction or intervention.
Limitations and Recommendations for Future Research
Our study was limited by the availability of AI tools at the time. AI is rapidly evolving, tools and models are continually emerging, and these changes and updates may result in different outcomes in text generation. Future research should continue to evaluate the performance of newly created or updated versions of previously used tools as they become available. Ongoing research on newly evolved versions of AI tools could provide up-to-date insights and recommendations for educators and researchers. In addition, future studies should test a wider variety of AI tools. Evaluating a diverse set of AI tools will support researchers in comparing performance output, identifying best practices, and providing more specific recommendations for educators and content creators. This will help to identify AI tools that show promise for generating educational content and guide the development of more advanced and education-focused AI models.
Other limitations of our study involved the ratings of “naturalness.” The scale was created for this study for exploratory purposes and had not been previously validated, and it is possible our three-point scale was too limited to capture a greater range. Although interrater agreement and Kappa were acceptable, we did not double-score all the passages or resolve all disagreements in scoring. Furthermore, ratings were completed by the study authors, who were aware of the sources of the passages, but raters were not aware of the passages’ readability and text complexity data and the lack of variation in ratings across passages should mitigate concerns about higher or lower ratings for a specific tool.
Despite these limitations, these ratings provide an initial view of the degree to which the AI-generated text could be viewed as passable for having been written by a human or at least free of odd elements that might be distracting to readers. Additional studies might consider a more extensive evaluation of the writing quality of AI-generated text or other AI-derived content for educational purposes.
We used metrics of readability and text complexity that have been criticized for as long as they have existed (DuBay, 2004). In doing so, we do not endorse leveled-text systems or any one particular text complexity formulae; rather, we sought a basis for evaluating the overall difficulty and complexity of text generated by AI tools. We encourage future research that considers this and other methods for evaluating the complexity and quality of text generated by AI tools when used in educational contexts.
This study only represents one specific use case (i.e., zero-shot prompting) among the many possible ways teachers might interact with AI tools. While readability metrics such as Flesch-Kincaid are widely known among educators, we did not explicitly incorporate them in our prompting strategy, as our goal was to examine AI-generated text in a minimal-instruction context. Future studies should investigate how various interaction patterns affect the readability and naturalness of the generated content. For instance, prompts could include specific feedback, examples, or explanations to guide the AI, such as a detailed definition and parameters for a third-grade reading passage, potentially incorporating readability metrics into prompts. After generating output, researchers could offer precise suggestions to adjust the content to better match a third grade reading level. Exploring few-shot prompting, where the AI is provided with a small set of examples and feedback tailored to specific grade levels, could further enhance our understanding of its ability to generate grade-level-appropriate content. By clarifying the relationship between prompt design and the resulting passage features, researchers and educators can craft more effective prompts that enable AI tools to generate passages tailored to individual students.
Future research should also investigate whether the readability levels of typical instructional materials written for children in third or ninth grade would similarly exceed their intended grade levels when assessed using the readability tools employed in our study. Such a comparison would provide more context for interpreting our findings on AI-generated content. Additionally, future research could recruit third- and ninth-grade students to read and evaluate the difficulty of these AI-generated texts, providing a more comprehensive understanding of their appropriateness by and for the target audience. Moreover, future research should investigate a broader range of grade levels. This will provide a more comprehensive understanding of how AI tools perform in generating texts across a greater grade range.
To improve the quality and suitability of AI-generated texts for educational purposes, collaboration between AI experts and educators should be fostered. Such interdisciplinary collaboration could enable the development of large, high-quality training datasets that include a wide range of text difficulty, genres, and topics, ultimately resulting in the development of AI tools that are better aligned with the needs of teachers and their students. Educators can also provide valuable insights into the characteristics of high-quality decodable texts, which can then be incorporated into the training data used to fine-tune AI models.
Implications and Recommendation for Practice
Based on the findings of this study, we believe that it is not premature to suggest that teachers could utilize AI tools to generate text about specific topics. Although teachers must be mindful that the generated text will likely be more difficult than requested, AI-generated texts can serve as valuable resources for providing students with diverse and engaging reading materials that align with the content they are taught or that cater to their interests. Scholars have emphasized the importance of providing extensive opportunities to read expository and informational texts, especially for students with reading difficulties (e.g., Swanson et al, 2017; Vaughn et al, 2022), as they provide a context for teaching both basic reading and reading comprehension in text types that students are expected to learn from as they progress through school. One of the most promising ways AI could help improve instruction and intervention delivery is by providing the nearly instantaneous ability to generate text that aligns with skills or knowledge a teacher wants to build with their students, helps students integrate knowledge, and motivates them to read.
Certain differences in the structure of the texts generated by the different AI tools in response to the detailed prompts have implications for practice. For example, ChatGPT 3.5 and 4.0, Llama 2, and Diffit generated passages in a traditional paragraph or multi-paragraph format, whereas Bard structured text as a series of numbered points or bullets and often provided images with the text, similar to what might be found in some science texts or other informational resources.
At this time, we cannot recommend that AI tools be used to request decodable text, at least in the manner prompted in this study. There may be other ways of prompting that AI tools would more clearly understand, and it is also possible that language models require specific tuning or access to a large corpus of decodable text to “learn” its characteristics. Thus, when decodable text is desired, we recommend that educators continue to rely on professionally created materials, as these have been carefully designed to support the unique learning needs of emerging readers.
Conclusion
The potential applications of AI to education are just beginning to be understood. For example, AI tools might enhance teachers’ work via their ability to instantaneously generate text based on a requested set of parameters that could be used to support student reading instruction and practice. Although users may need to request text at grade levels lower than anticipated, AI tools are particularly effective at generating authentic text about specific topics. Additional work is needed to determine if and how AI tools can be used to generate decodable text. Future research on the usability of AI tools for generating text for reading practice (as well as other applications of AI to education and special education) is recommended as technology continues to evolve.
Supplemental Material
sj-pdf-1-ldr-10.1177_09388982251352564 - Supplemental material for Can Artificial Intelligence Tools Generate Text That is Useful for Reading Practice?
Supplemental material, sj-pdf-1-ldr-10.1177_09388982251352564 for Can Artificial Intelligence Tools Generate Text That is Useful for Reading Practice? by Linling Shen, MPhil, Jessica Kane-Cabello, MEd, LDT, CALT-QI, Patricia Y. Candelaria, MEd, CALT, NBCT, Dianne Stratford, MSEd, and Nathan H. Clemens, PhD in Learning Disabilities Research & Practice
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
ORCID iDs
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.