
Abstract
Background
It is fundamental for accurate segmentation and quantification of the pulmonary vessel, particularly smaller vessels, from computed tomography (CT) images in chronic obstructive pulmonary disease (COPD) patients.
Objective
The aim of this study was to segment the pulmonary vasculature using a semi-supervised method.
Methods
In this study, a self-training framework is proposed by leveraging a teacher-student model for the segmentation of pulmonary vessels. First, the high-quality annotations are acquired in the in-house data by an interactive way. Then, the model is trained in the semi-supervised way. A fully supervised model is trained on a small set of labeled CT images, yielding the teacher model. Following this, the teacher model is used to generate pseudo-labels for the unlabeled CT images, from which reliable ones are selected based on a certain strategy. The training of the student model involves these reliable pseudo-labels. This training process is iteratively repeated until an optimal performance is achieved.
Results
Extensive experiments are performed on non-enhanced CT scans of 125 COPD patients. Quantitative and qualitative analyses demonstrate that the proposed method, Semi2, significantly improves the precision of vessel segmentation by 2.3%, achieving a precision of 90.3%. Further, quantitative analysis is conducted in the pulmonary vessel of COPD, providing insights into the differences in the pulmonary vessel across different severity of the disease.
Conclusion
The proposed method can not only improve the performance of pulmonary vascular segmentation, but can also be applied in COPD analysis. The code will be made available at https://github.com/wuyanan513/semi-supervised-learning-for-vessel-segmentation.
Keywords
Highlights
Pulmonary vessels are meticulously annotated in CT images through an interactive approach.
A self-training framework is proposed that utilizes a teacher-student model to minimize the need for annotations.
A strategy of pseudo-label selection effectively reduces false positives in vessel segmentation.
Quantitative analysis of the pulmonary vessels in COPD offers original insights.
Introduction
Chronic obstructive pulmonary disease (COPD) is a prevalent and progressive lung disorder characterized by persistent respiratory symptoms and airflow limitation. 1 As reported by global initiative for chronic obstructive lung disease (GOLD), CT imaging plays an increasingly important role in diagnosis and evaluation of COPD patients. 2 Spirometry is a broad assessment tool that detects the presence of disease according to GOLD but have some limitations. 3 While CT imaging enhances the information gained from spirometry and enriches the understanding of diseases by pinpointing their anatomical locations, characterizing airway disease and emphysema, 4 categorizing the subtype of emphysema, 5 and investigating manifestations of COPD outside the lungs.6,7 Also, the extraction of pulmonary vessels from CT images can provide valuable insights into the micro-vascular structure and perfusion of the lungs. 8 These insights can facilitate identifying subtle pathological changes associated with COPD and ultimately contribute to a more comprehensive understanding of the disease's underlying mechanisms.
Deep learning has emerged as a vital tool for the early detection and assessment of pulmonary diseases.9–11 The extraction and analysis of pulmonary vessels from CT images have gained increasing attention in recent research. Pulmonary vascular analysis can provide valuable insights into the microvascular structure and perfusion of the lungs, which are closely related to the pathophysiology of COPD. For example, disruption of pulmonary microvasculature has been linked to the development of emphysema and impaired gas exchange. Advanced imaging techniques and computational algorithms now allow for precise segmentation and quantitative analysis of pulmonary vessels, facilitating the identification of subtle pathological changes that may not be apparent through traditional diagnostic methods.
These insights contribute to a more comprehensive understanding of the underlying mechanisms of COPD, including the interplay between airway remodeling, emphysema, and vascular pathology. Furthermore, they hold potential to enable personalized treatment strategies by identifying specific phenotypes of COPD, predicting disease progression, and monitoring therapeutic outcomes. As such, CT imaging, combined with advanced quantitative techniques, represents a critical development in COPD research and clinical practice, paving the way for more precise and effective management of this complex disease. 12
As for segmentation of pulmonary vessel in COPD patients, the accurate annotation of small pulmonary vessels poses significant challenges due to their intricate morphology, diverse orientations, and varying levels of contrast against surrounding lung parenchyma (shown in Figure 1). Manual annotation is not only time-consuming and labor-intensive but also prone to inter- and intra-observer variability. Furthermore, the high level of expertise required to accurately identify and annotate these vessels often leads to a scarcity of comprehensively labeled datasets. This limitation hinders the development and training of robust models for the precise segmentation of the pulmonary vessel, particularly the smaller vessels.
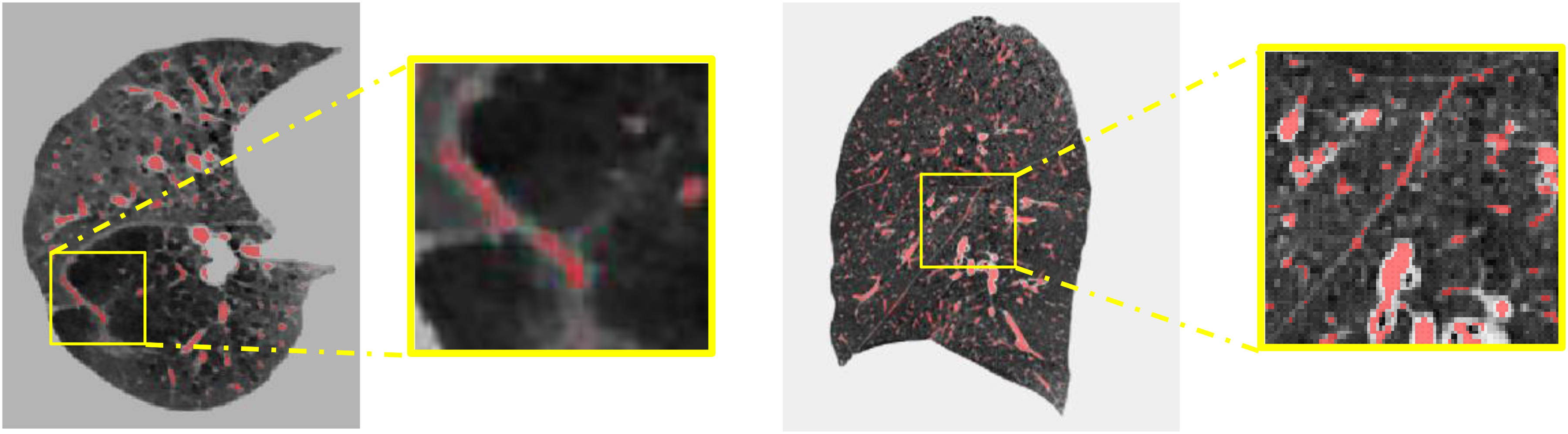
The challenge of pulmonary vessel annotation and segmentation in COPD patients. (a) Axial view of CT image; (b) sagittal view of CT image. The yellow boxes represent zooming in on local details.
Another challenge is the pulmonary vessel in the chest CT images of COPD patients and healthy individuals usually shows several differences. 13 It could be summarized into four aspects: (1) Reduced lung tissue density: The lung tissue of COPD patients is typically looser than that of healthy individuals, leading to a decrease in lung tissue density in CT images. (2) Airway dilation: The airways of COPD patients may dilate due to chronic inflammation and fibrosis, which is manifested as thickening of the internal airways in CT images. (3) Emphysema: Emphysema is the most common pathological manifestation in COPD patients. It refers to the inability of lung gas to flow smoothly due to airway obstruction or reduced elasticity of lung tissue, causing over-expansion of the alveoli. In CT images, emphysema usually appears as areas with many gas-containing vesicles, and these areas also have lower lung tissue density. (4) Pulmonary vascular abnormalities: The pulmonary vessels of COPD patients usually show thinning, obstruction, and small vessel pruning. These imaging abnormalities make the annotation and segmentation work more complex and increase the difficulty of model learning.
Thus, the development of more reliable annotation and more efficient segmentation method is necessary. Interactive annotation offers a promising solution to this problem by involving domain experts in a semi-automated annotation process. By providing initial annotations and allowing the system to learn and adapt, experts can guide and correct the system interactively. This reduces the burden of full manual annotation while still leveraging the expertise of professionals. 14 Moreover, semi-supervised learning has emerged as a promising approach to overcome these challenges, as it leverages labeled and unlabeled data to train deep learning models. Furthermore, semi-supervised learning has demonstrated its potential in various medical imaging applications, including brain tumor segmentation, 15 airway segmentation, 16 and vessel segmentation. 17
Various deep learning-based methods have been proposed for pulmonary vessel segmentation in recent years, demonstrating significant advancements. Numerous studies have applied convolutional neural networks (CNNs) to tackle the problem of pulmonary vessel segmentation, achieving considerable success.17–20 More recently, the introduction of transformer networks, including nnFormer 21 and Swin Transformer, 22 has revolutionized the field of computer vision by demonstrating remarkable performance in various applications, including medical image analysis.23–25
With these advancements, the study proposes to harness the power of interaction annotation, semi-supervised learning, and transformer networks for accurate pulmonary vessel segmentation in CT images of COPD patients. Moreover, the study also focuses on assessing pulmonary vessel parameters in COPD patients. The main contributions of this study are as follows: First, the high-quality pulmonary vessels are annotated in CT images of COPD patients by an interactive way. Second, a self-training framework is employed to reduce the need for labeled data. A Transformer-based network is introduced to develop a robust and accurate segmentation method, which leverages the rich global context and long-range dependencies. Finally, the segmentation results of the proposed method are utilized for quantifying pulmonary vessel parameters among COPD patients, which ultimately contributing to assessing the development of the disease.
Related work
Traditional vs. deep learning methods in vessel segmentation
In traditional methods, intensity thresholding is the most common method for pulmonary vessel segmentation in CT images. 26 This technique hinges on the use of a specific threshold value to distinguish pulmonary vessels from adjacent tissues, leveraging the variance in pixel intensities. Other segmentation methodologies encompass region growing,27,28 edge detection, 29 and morphological operations. 30 Kaftan and his colleagues proposed a unique concept of fuzzy segmentation, which amalgamates the benefits of threshold information and the fuzzy connectedness approach. 31 As an illustration, Wu and his team applied regulated morphological operations to binarized data, thus generating a fuzzy spherical model of the vessels. 32 However, these conventional methods often suffer from limitations such as high sensitivity to parameter settings, difficulty in handling intensity inhomogeneity, and poor performance in segmenting small or low-contrast vessels.
In recent years, deep learning has been widely used in medical image analysis.9,33,34 Deep learning has surpassed traditional methods, becoming a potent and widely-used tool for vessel segmentation in CT images. Various approaches, including CNN methods.18–20,35 generative adversarial networks, 36 and transformer-based networks, 37 were proposed for vessel segmentation in CT images. Utilizing sophisticated architectures like 3D contextual transformers and channel-enhanced attention modules, these methods enhance both accuracy and efficiency. For instance, CNNs are proficient at automatically extracting and processing features from CT images, which are then used for precise segmentation of pulmonary vessels. Several groundbreaking deep learning architectures, such as U-Net, 38 V-Net, 39 and 3D U-Net, 40 have been proposed for pulmonary vessel segmentation. Zhai et al. leveraged CNNs to extract the vascular skeleton and generate an adjacency matrix for vessel segmentation. They used Graph Convolutional Network (GCN) to obtain the weights using features learned during CNN training, achieving effective artery and vein separation post-training. 41 Cui et al. presented a novel 2.5D segmentation network. This approach, facilitated by three orthogonal axes, allowed for the integration of multiple planes. 35 Pang and colleagues proposed synthesizers for mutual synthesis of Non-Contrast Computed Tomography (NCCT) and Contrast-Enhanced Computed Tomography (CECT) images, demonstrating their efficacy in pulmonary vessel segmentation. 36 Similarly, Wu et al. developed a transformer-based network for vessel segmentation and artery-vein separation, evidencing high precision and utility in CT images. 37 Qin et al. introduced a feature recalibration module that amplified the features learned by the neural network, thus exhibiting superior sensitivity to the peripheral tubular structure. They employed U-Net as the backbone in their research. 42 Gu and his team designed a two-stage CNN model, where the initial stage screened high-intensity structures, capturing both vascular and non-vascular tissues like nodules. The subsequent stage differentiated between blood vessels and non-vascular tissues. 43 Xu and his team applied the Unet++ algorithm to extract lung parenchyma and used nnU-Net to segment blood vessels within that parenchyma. 44 Despite these advancements, these existing deep learning-based methods also exhibit certain drawbacks. Many models require large amounts of annotated data for training, which can be costly and time-consuming to acquire. They are often computationally intensive, necessitating high-performance hardware, and may struggle with generalizability across different datasets or imaging protocols. Some architectures, particularly those based on CNNs, have limited ability to capture long-range dependencies and global contextual information, which can affect the segmentation of elongated and complex vascular structures. Collectively, these techniques represent significant strides in the field, offering novel solutions for efficient and precise vessel segmentation in medical imaging.
Semi-supervised learning in medical image segmentation
Semi-supervised learning is a learning method that sits between unsupervised learning and supervised learning.45–47 Unlike supervised learning, which requires labeled data to guide learning, semi-supervised learning utilizes limited labeled data and a large amount of unlabeled data for training and prediction. The key idea of semi-supervised learning is to use the information in the unlabeled data to improve the performance of learning algorithms. Information in unlabeled data can be obtained through unsupervised learning on unlabeled data, such as clustering, dimensionality reduction, generative models, etc.
The self-training methods are reviewed the in this section, which is a label-propagation-based semi-supervised learning method where a model is first trained with labeled data. Then it uses this training model to predict labels for unlabeled data. The model is then retrained (or updated) using a combination of the original labeled data and the newly labeled data. The idea is that the model can learn more about the underlying data distribution from its own predictions. In medical image analysis, self-training methods have been used for various tasks, such as segmentation, classification, and detection. Huang et al. used a self-training approach to segment brain tumors in MRI scans. The model was initially trained on a small amount of labeled data, then used to predict labels for the remaining unlabeled data. 48 Wang et al. used a self-training approach to classify multiple diseases in chest X-ray images. The model was first trained on a small set of labeled data, then used to generate labels for the remaining data. The model was subsequently retrained on the combined original labeled and newly labeled data, leading to improved performance. 49 Shen et al. introduced a semi-supervised learning framework for subcutaneous vessel segmentation that uses a multi-scale recurrent neural network and two auxiliary branches for detail enhancement and prediction alignment. Using a novel alternate training strategy, the proposed method can effectively perform segmentation tasks with limited labeled data and abundant unlabeled data, and its effectiveness is demonstrated across a variety of tasks including subcutaneous vessels, retinal vessels, and skin lesions. 17
Methods
The overview of the proposed method
Figure 2 provides the workflow of the proposed semi-supervised learning method. First, an initial teacher model is trained on the labeled CT images. In this phase, the model is trained to learn the mapping from input images to their corresponding labels. Next, the trained teacher model is used to predict pseudo labels for the unlabeled images. The teacher model applies its knowledge to the unlabeled data to generate these pseudo labels. Then, inspired by, 50 a pseudo-label selection strategy is implemented to select reliable pseudo labels. Finally, a student model is retrained on a mix of labeled images and unlabeled images, together with the corresponding pseudo labels. This step aims to refine the model's understanding and improve its performance. The above steps are iterated, with the student model becoming the teacher model in the next iteration, until the best results are achieved. The goal is to automatically extract the pulmonary vessels from lung CT images.
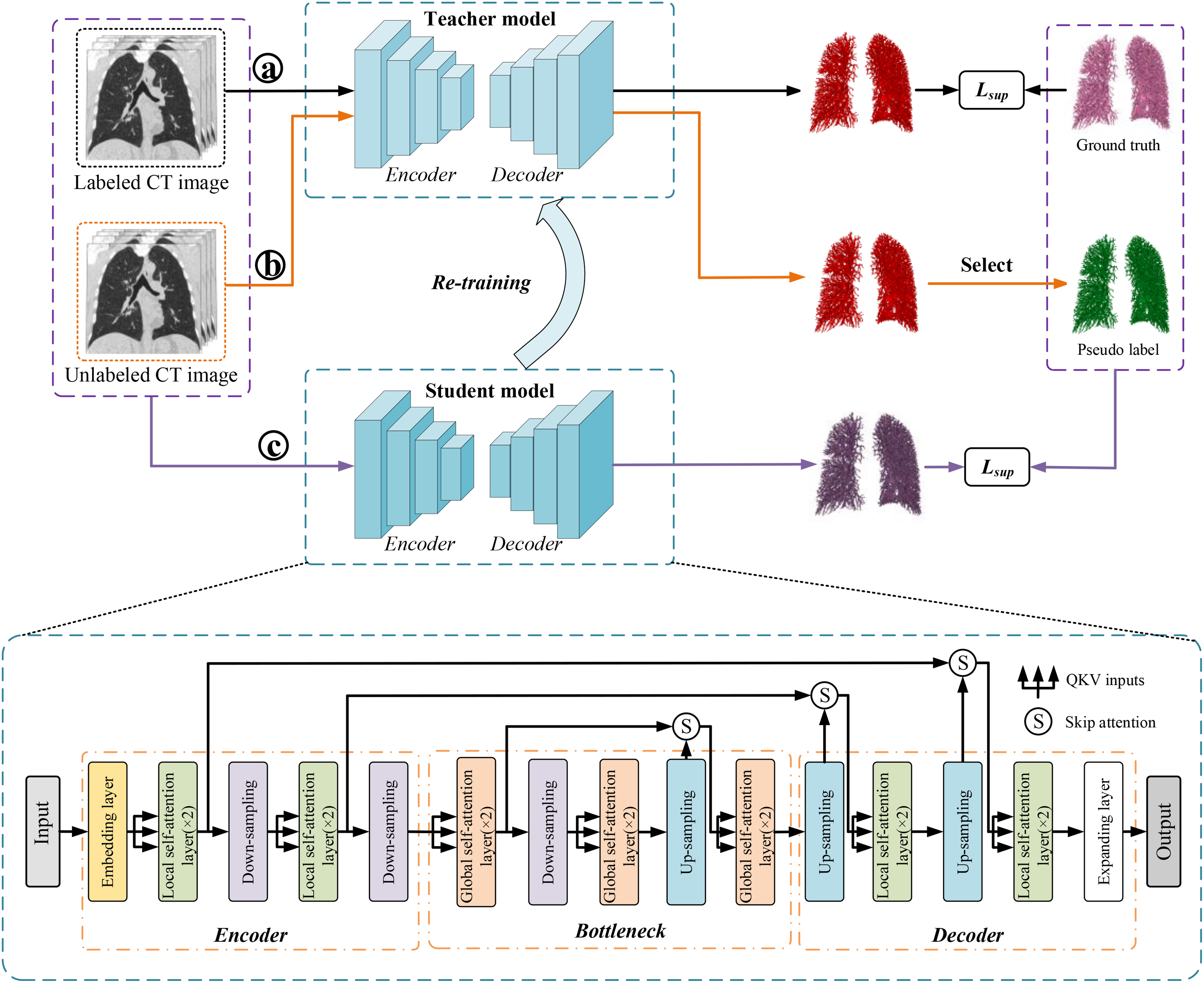
The workflow of the proposed method. The nnFormer model is employed as the fundamental structure of the mean teacher framework. The a, b, and c in the circle represent different training process, ⓐ is training the teacher model, ⓑ is producing the pseudo labels, and ⓒ is training the student model with ground truth and pseudo labels.
Interactive learning for annotating pulmonary vessels
As shown in Figure 3, the interactive learning workflow involves with a pre-trained model in the previous study 51 and a trained model with VESSEL12 dataset (provided by the VESSEL12 challenge at https://vessel12.grand-challenge.org/) that generates preliminary annotations of the pulmonary vessels. These initial annotations are then combined and presented to a trained radiologist for review. The radiologist interacts with the generated results, making necessary corrections and adjustments to the vessel boundaries and classifications. Each correction is fed back into the learning algorithm, refining its accuracy with each iteration. The details of the annotation procedure are given as follow.
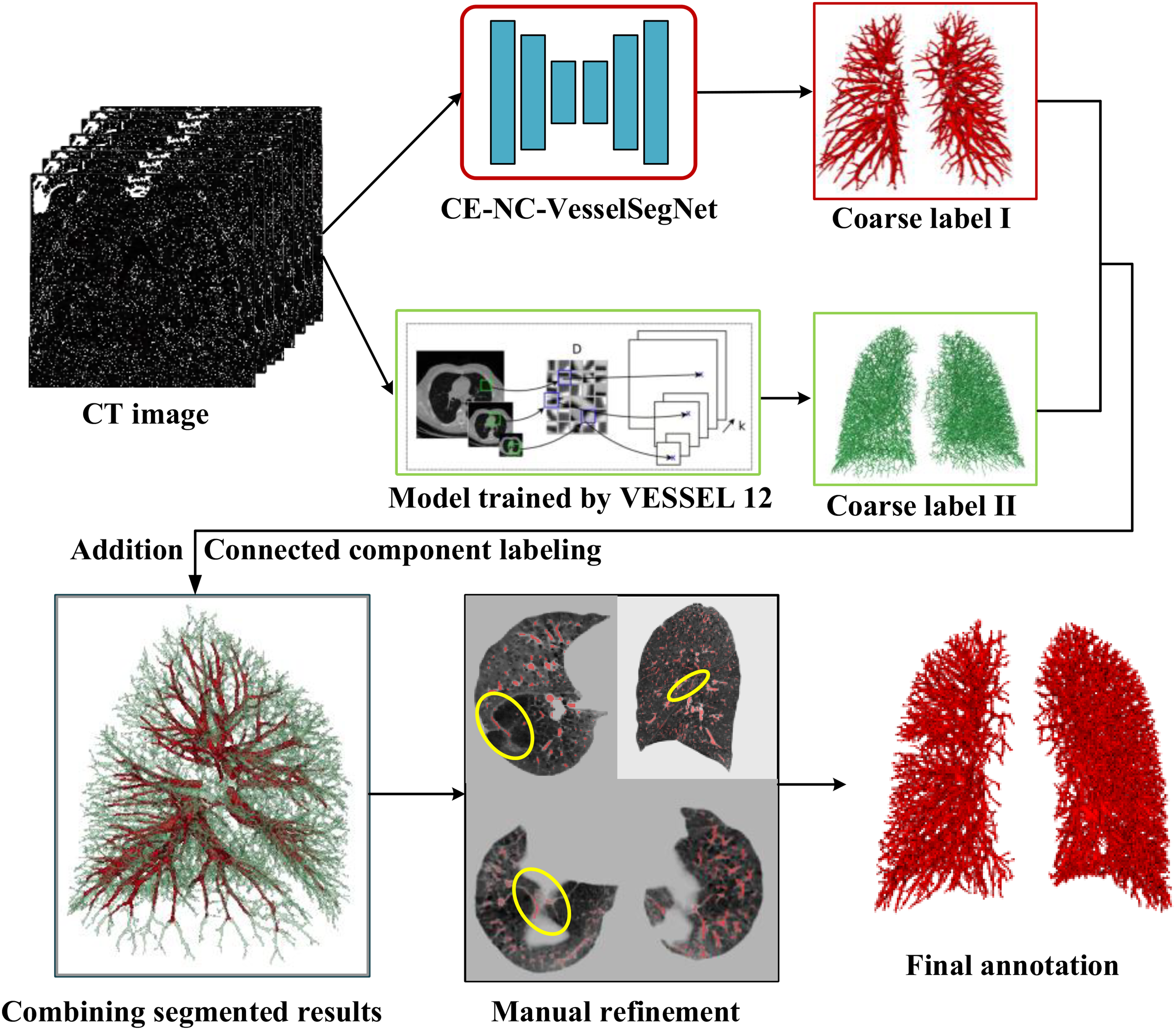
The interactive learning workflow for pulmonary vessel annotation.
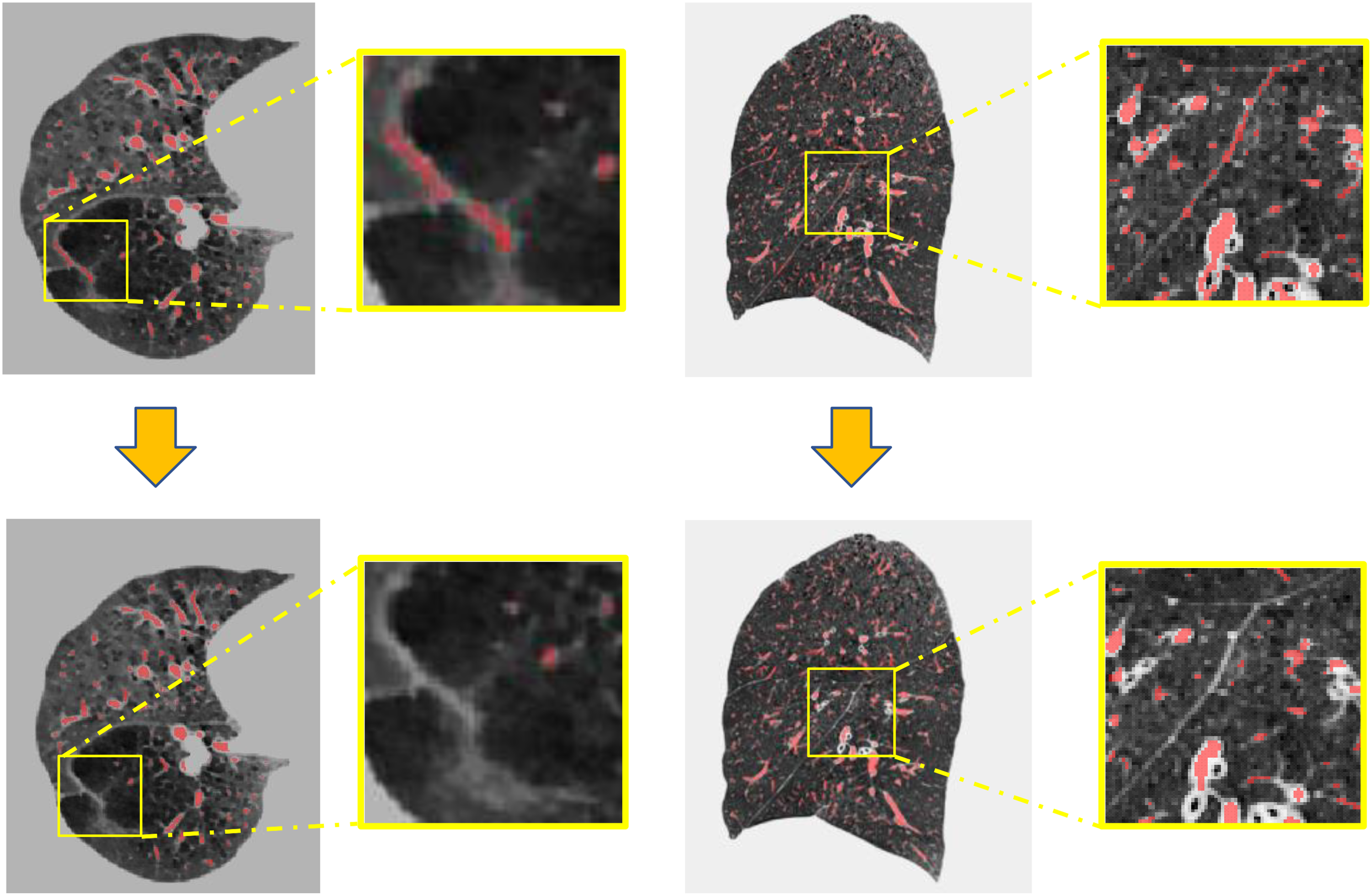
The annotations before and after manual refinement.
As illustrated in Figure 3(b), there are still inaccuracies in the lung vessel annotations after fusion (by the yellow ellipses). For instance, fissures caused by emphysema, interlobar spaces, etc., need to be manually corrected. In the manual refinement process, ITK-SNAP (http://www.itksnap.org/pmwiki/pmwiki.php) is employed to correct the labels. After manually correcting the inaccuracies in the lung vessel annotations, isolated small connected areas are removed. This process ensures that the final vessel annotations are accurate and reliable (Figure 4).
Model architecture
The nnFormer is employed as based model in the framework. 21 As described in Figure 2, the nnFormer model retains the U-Net structure and can be divided into three main blocks: the encoder, bottleneck, and decoder. The encoder in nnFormer has a lightweight convolutional embedding layer, two local self-attention layers, and two down-sampling layers. This embedding layer encodes pixel-level spatial information into lower-level but high-resolution 3D features. After the embedding blocks, the model alternates between transformer and convolutional downsampling blocks. This alternation allows the model to fully integrate long-term dependencies and high-level, hierarchical object concepts, thereby improving the generalizability and robustness of the learned representations. In the bottleneck, there are three global self-attention layers, a down-sampling layer, and a up-sampling layer. Moreover, two up-sampling layers, two local self-attention layers, and an expanding layer are in decode path. As shown in Figure 5(a), the nnFormer introduces volume multi-Head self-attention (V-MSA) to learn representations on 3D local regions, which are then aggregated to produce predictions for the entire dataset. Moreover, the concatenation/summation is replaced with skip attention (in Figure 5(b)) in this paper.
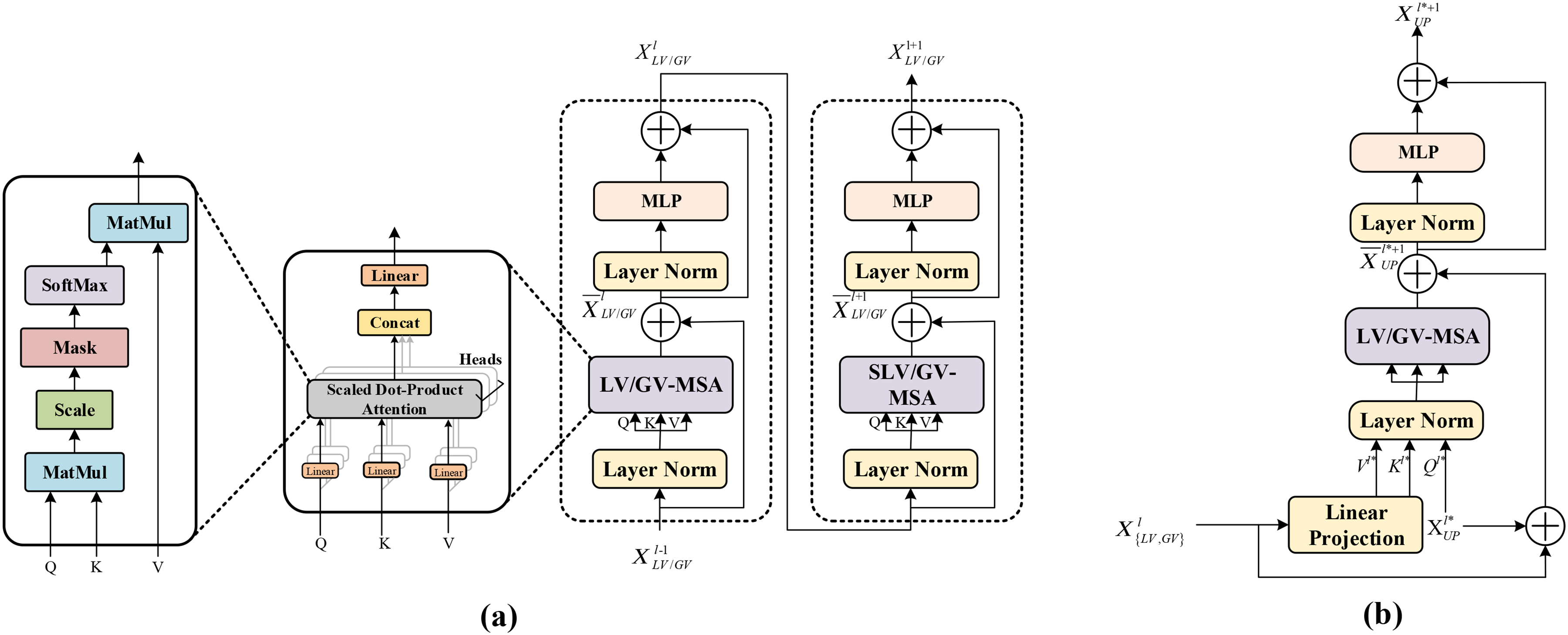
Modules in the network architecture. (a) LV-MSA/GV-MSA; (b) skip attention.
The nnFormer model is a hybrid model that combines convolution and self-attention mechanisms. It leverages the strengths of both mechanisms and proposes a computationally efficient method to capture dependencies between slices.
Loss function
The methodology incorporates a novel loss function, hard region adaptation (HRA) loss,
52
which dynamically identifies regions that are challenging to segment by evaluating the segmentation quality of results in real-time. This ensures a dynamic equilibrium of class representation. Traditional approaches that utilize standard cross-entropy loss do not differentiate between complex and simple regions, uniformly distributing attention and often leading to pronounced class imbalance issues. Conversely, HRA loss approach pinpoints difficult areas such as vessel borders and minute terminations by calculating the L1 norm between the segmentation output and the ground truth, followed by the application of a threshold to isolate the hard-to-segment region mask. Subsequently, the cross-entropy loss is computed selectively within these identified regions, as delineated in Equation (1).
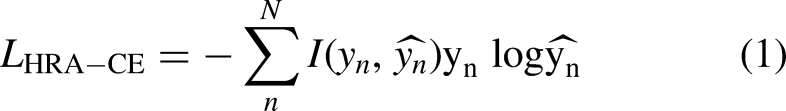
Semi-supervised learning train strategy
A semi-supervised learning strategy is introduced known as "teacher-student training" inspired by Self-training Scheme.
50
As illustrated in Figure 6, first, a teacher model T is trained on a labeled dataset The pipeline of semi-supervised learning method in the study.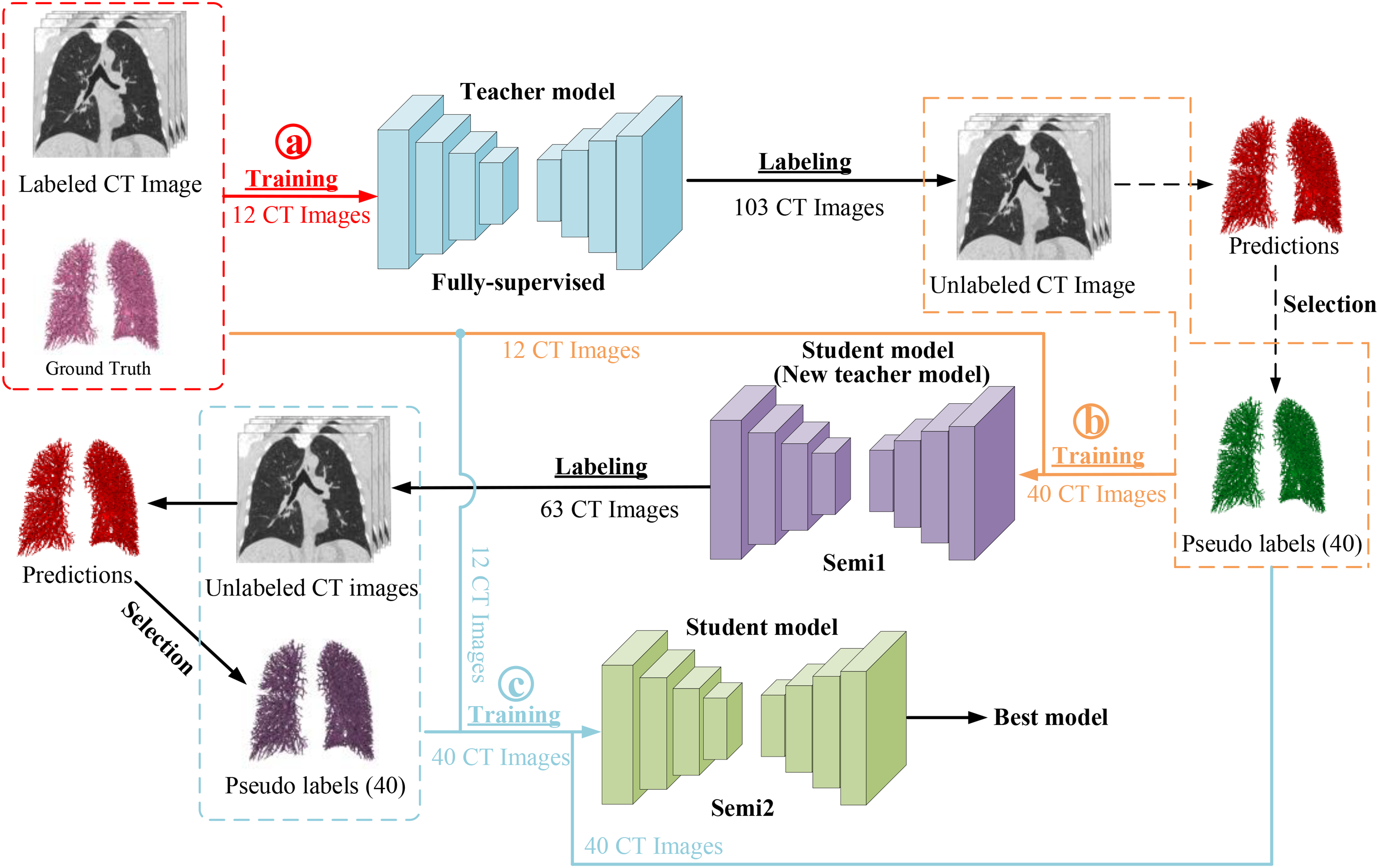

Experiments
Datasets
All participants willingly provided their informed consent, adhering to the ethical principles outlined in the Declaration of Helsinki (2000). The medical ethics committee of the First Affiliated Hospital of Guangzhou Medical University thoroughly reviewed and approved the study, ensuring that it met the highest standards of ethical conduct and safeguarded the rights and welfare of all involved subjects. Inclusion criteria were that participants met the diagnostic criteria for COPD according to the GOLD 2023 guidelines, which include exhibiting signs and symptoms of COPD and a forced expiratory volume in the first second (FEV1) / forced vital capacity (FVC) ratio of less than 70% following the inhalation of a bronchodilator. And participants were excluded if they had active pulmonary tuberculosis; concomitant bronchial asthma; death during hospitalization or follow-up; malignancies under treatment or with a life expectancy of less than one year without treatment; recent surgical history; or severe liver or kidney diseases.
The dataset comprises 125 cases of non-enhanced CT scans, including 34 cases of GOLD 1, 35 cases of GOLD 2, 35 cases of GOLD 3, and 21 cases of GOLD 4. All CT scans have a thickness of 1.0 mm and a slice size of 512×512. This dataset provides a valuable resource for developing and evaluating the semi-supervised iterative training approach for lung vessel segmentation and vessel parameters calculation in COPD patients.
Comparative experiments
To find a fully supervised training network that is more suitable for blood vessel segmentation, some segmentation networks, including UNETR, Swin UNETR, and nnU-Net, are employed in the experiment. UNETR utilizes Vision Transformer (ViT) as its encoder, instead of relying on CNN-based feature extractors. This architecture uses pure Transformers as encoders to learn serial representations of the input volume and effectively capture global multi-scale information. 53 It also follows the successful "U-shaped" network design of encoders and decoders, with the Transformers encoder directly connected to the decoder via jump connections at different resolutions to calculate the final semantic segmentation output. Swin Transformers 22 were proposed as a hierarchical vision Transformer, calculating self-attention within an effective shifted window partition scheme. Therefore, Swin Transformers are suitable for various downstream tasks where multi-scale features extracted can be further processed. Following this, Swin UNETR was proposed, which uses a U-shaped network with Swin Transformers as the encoder and connects it to a CNN-based decoder with different resolutions through jump connections. This network demonstrated its effectiveness in the multi-modal 3D brain tumor segmentation task of the 2021 Multi-modal Brain Tumor Segmentation Challenge. 24
Experiment setup
In the fully supervised learning, 12 lung CT scans with corresponding refined labels for training, and 10 CT scans for testing. From each CT image case, the lung region is automatically segmented according the previous study, 54 and the labels for vessels within the lung region along with the lung region CT image is obtained. Then, the data is resampled to the median voxel spacing of all cases (1×0.74×0.74 mm3). The data is then cropped to rectangular prisms of size 128×112×160 and used for network training. The training epoch is initially set to 1000. The batch size is 2. The initial learning rate is set at 0.01. The optimizer used is Stochastic Gradient Descent (SGD), with momentum set to 0.99. The weight decay is set to 3e-5. After the completion of the fully supervised training, a teacher model is obtained, which is used for subsequent semi-supervised iterative training.
Random rotations, random scaling, random elastic deformations, gamma correction augmentation and mirroring are utilized in data augmentation. All experiments are conducted on a workstation with a central processing unit of Intel(R) Xeon(R) Silver 4114 CPU, 128 GB RAM, and four NVIDIA GeForce RTX 2080Ti Graphical Processing Units (with 11 GB memory). The popular PyTorch framework is utilized, and the code is written in Python.
Segmentation evaluative metrics
The model's efficacy is assessed through four evaluative metrics. These metrics comprise the Dice Similarity Coefficient (DSC), Intersection over Union (IoU) ratio, sensitivity, and precision. For the experimentation, the study implements voxel-based evaluative criteria as outlined in,
51
with the specific metrics detailed in Equation (2)-(5).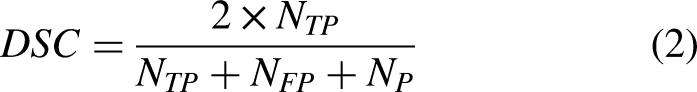
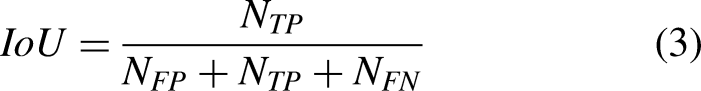
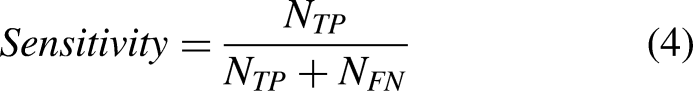
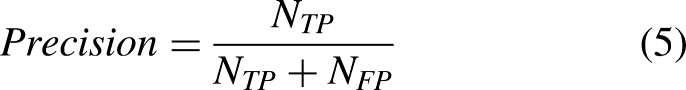
Vessel parameter calculation for COPD
The calculation of vessel parameters is based on the VesselVio, 55 including total blood volume (TBV), surface area, number of segments, branch count, endpoint count, tree length, aggregate vessel volume for vessels less than 5 mm2 in cross-sectional area (BV5), BV5/TBV, and the total number of vessel segments with different radius, including R(0-1mm), R(1-2mm), R(2-3mm), and R(3-4mm). The detailed procedure is given as described in. 55
To analyze the differences of vessel parameters among different severities of COPD, a one-way analysis of variance (ANOVA) was initially carried out to determine if there were statistically significant differences in mean values among any of the groups. If the ANOVA results were statistically significant, Bonferroni-corrected post-hoc tests would be employed to identify specific group differences.
In all analyses, a p-value below 0.05 was considered to indicate statistical significance. The analyses were performed with SPSS version 23.0 (IBM, Armonk, NY, USA).
Results
Performance comparison of different fully supervised learning methods
Table 1 presents the comparison of segmentation performance across four fully supervised learning models, including nnFormer, UNETR, Swin UNETR, and nnU-Net. The nnFormer model achieves best performance, with a Dice coefficient of 0.855 and an IoU of 0.747, suggesting it is the most effective at capturing the true positive area while maintaining overlap accuracy. It also leads in precision of 0.880, indicating a higher true positive rate relative to false positives, and showcases commendable sensitivity of 0.832, reflecting its ability to detect positives accurately. Following nnFormer, the nnU-Net model is a strong contender, with a notable Dice coefficient of 0.835 and an IoU of 0.739, both metrics underscoring its robustness in segmentation accuracy. Its sensitivity and precision scores are competitive, but marginally lower than nnFormer.
The segmentation performance of nnFormer, UNETR, Swin UNETR, and nnU-Net.

Performance comparison of semi-supervised learning methods
Semi-supervised iterative training was completed twice, with the first iteration model represented as Semi1 and the second iteration model as Semi2. The fully supervised model is represented as Fully. The test set consists of 10 COPD patients with pulmonary vessel annotation. Table 2 shows the segmentation performance of the three models.
Performance of fully supervised model and two semi-supervised models.
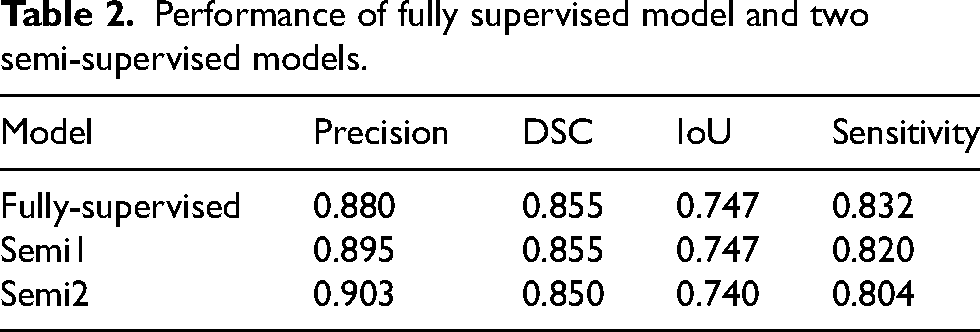
The purpose of semi-supervised iterative training is to improve the precision of segmentation and reduce false positive segmentation. As can be seen, the precision of Semi2 reached 0.903, which is a 0.023 improvement over the 0.880 of the fully supervised method, achieving the expected effect. It's a normal phenomenon that sensitivity would decrease as precision increases. Given the complex structure of pulmonary vessels, with their ends being too small in diameter and varied in size, it's less important for the segmentation result to contain all the gold standard for the analysis metrics. What matters most is that the segmentation result includes as few non-vessel areas as possible. In addition, the Dice and IoU metrics of the three models are very close.
The results indicate that semi-supervised iterative training can effectively improve the precision of segmentation without significantly affecting other performance metrics, making it a viable strategy for this task.
Figure 7 displays the visualization of the segmentation results in axial, coronal, and sagittal view of CT images among three models and label. In this visualization, blue represents the gold standard for pulmonary vessels, green denotes the segmentation results from the fully supervised model, red illustrates the results from the first iteration of the semi-supervised model (Semi1), and yellow depicts the second iteration of semi-supervised training (Semi2). It is observable that the fully supervised model, trained with the refined labels, generates complete and uninterrupted segmentation inferences. Similarly, the inference results from the semi-supervised model with two iterations of reliability-based pseudo labeling are also clear in their branchpoints, without any discontinuities.
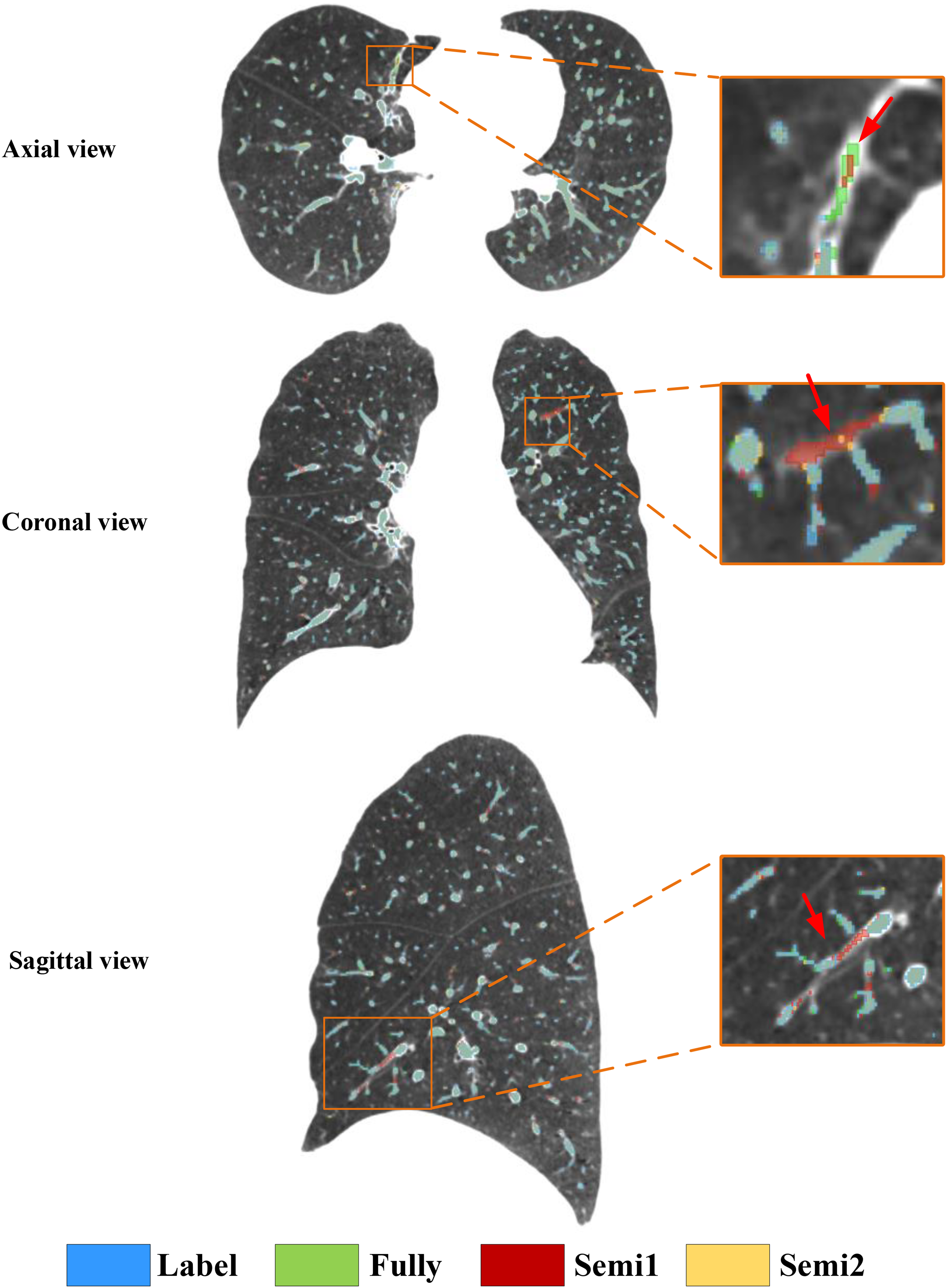
The example visualization of the label and vessel segmentation results of three models, including Full, Semi1, and Semi2, in axial, coronal, and sagittal view of CT images.
By overlaying the four masks onto the same CT image, a clear comparison of the segmentation effects of the three models is possible. Within the orange rectangular frame in axial view, it is evident that the false-positive regions segmented by fully-supervised model and Semi1 have been improved by the Semi2. It is also apparent that the false positives segmented by the fully supervised model and Semi1 in coronal and sagittal view of CT images.
Visualization of vessel segmentation in different severity of COPD
Figures 8 presents the visualization results for GOLD 1-4 of COPD patients, including the segmentation of the vessel tree and visualized computed branch points with the vessel radius size serving as a reference in the legend. Due to the minor variations in GOLD 1 and GOLD 2, no significant abnormalities are evident in the 3D visualization results. For GOLD 3, which exhibits more severe mutations, there is a noticeable decrease in the BV5/TBV metric (Tables 3 and 4). The segmentation results clearly show a sparser right lung vessel. In the case of GOLD 4, marked by severe mutations, there is a significant decrease in the BV5/TBV metric (Table 4). The segmentation results and branch points all reveal a conspicuously sparse vessel tree in the lower left lobe of the lung.
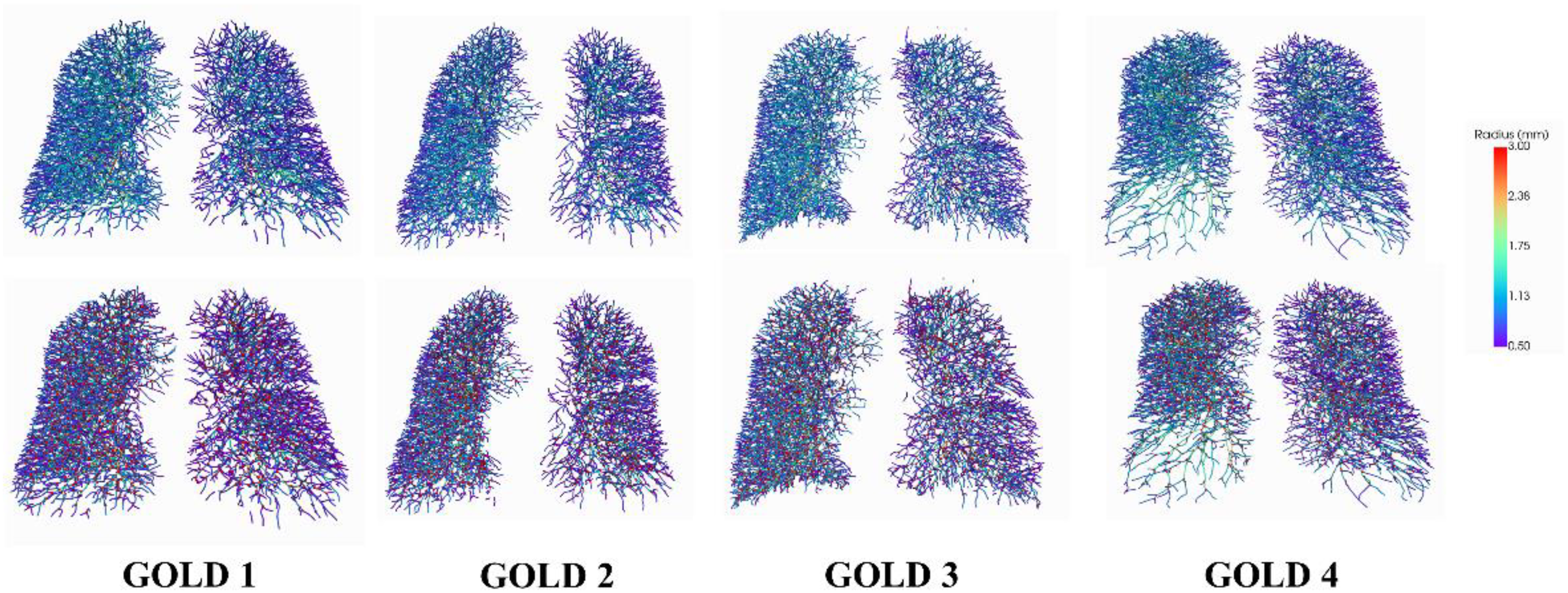
Visualization results for GOLD 1-4 of COPD patient. The first row is the segmentation of the vessel tree. The second row is the computed branch points.
Results for TBV, surface area, number of segments, number of endpoints, number of branchpoints, BV5, and BV5/TBV.

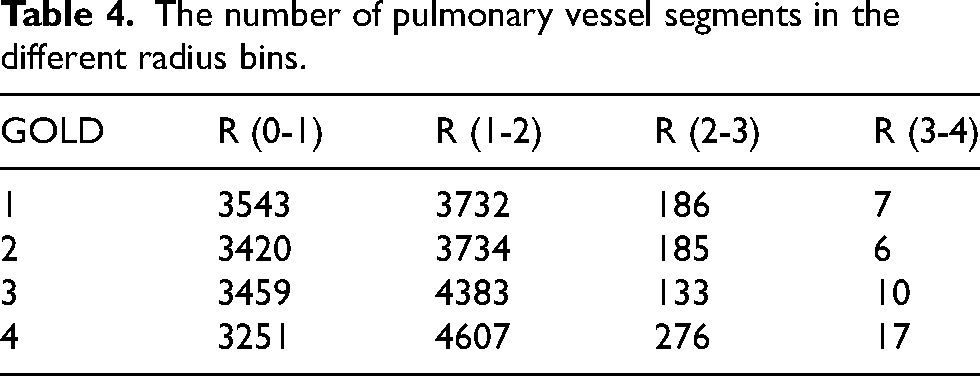
The number of pulmonary vessel segments in the different radius bins.
The results and statistical analysis of vessel parameters
Based on the segmentation results, we performed quantitative analysis using VesselVio. 55 Table 3 shows a progression of metrics across four GOLD grades. From GOLD 1 to GOLD 4, there is a notable increase in both TBV and surface area, suggesting that lung vasculature may be expanding or becoming more engorged as the disease worsens. Interestingly, while the TBV and surface area increase with disease severity, the BV5 does not keep pace, resulting in a decreasing BV5/TBV ratio. Specifically, from GOLD 1 to GOLD 4, the BV5/TBV ratio drops from 0.5701 to 0.5213, indicating a relative decrease in the proportion of blood within the smallest vessels compared to total blood volume. This could imply that as COPD progresses, there is a relative shift of blood volume away from smaller vessels, potentially reflecting the pathological changes in the lung's microcirculation. The number of segments and branchpoints generally increases from GOLD 1 to GOLD 3 and then stabilizes or slightly decreases at GOLD 4. However, the number of endpoints, which represents the terminal points in the vessel tree, decreases from GOLD 3 to GOLD 4 despite an overall increase in segments and branchpoints. This could suggest more advanced disease features such as vessel pruning or more severe airway obstruction.
Table 4 presents the distribution of pulmonary vessel segments across different radius bins for various GOLD grades of COPD severity. As the GOLD grade increases from 1 to 4, there's a notable trend in the distribution of vessel segments across the radius bins: In the smallest radius bin (R0-1), the number of segments decreases slightly as GOLD grade increases, suggesting a reduction in the number of the smallest vessels with higher COPD severity. For the R1-2 radius bin, there's an increase in the number of segments with increasing GOLD grade. This could indicate a compensatory dilation or an increase in the number of medium-sized vessels with advancing disease. In the R2-3 bin, the pattern is less clear, with GOLD 1 and 2 showing similar counts, a decrease at GOLD 3, and then an increase at GOLD 4. This fluctuation could suggest varying changes in the vasculature not directly correlated with disease severity or could reflect different pathological processes at work at different stages of the disease. The largest radius bin (R3-4) shows an increase in the number of segments as the GOLD grade increases, possibly indicating vessel dilation or the formation of new, larger vessels in response to the progressive disease.
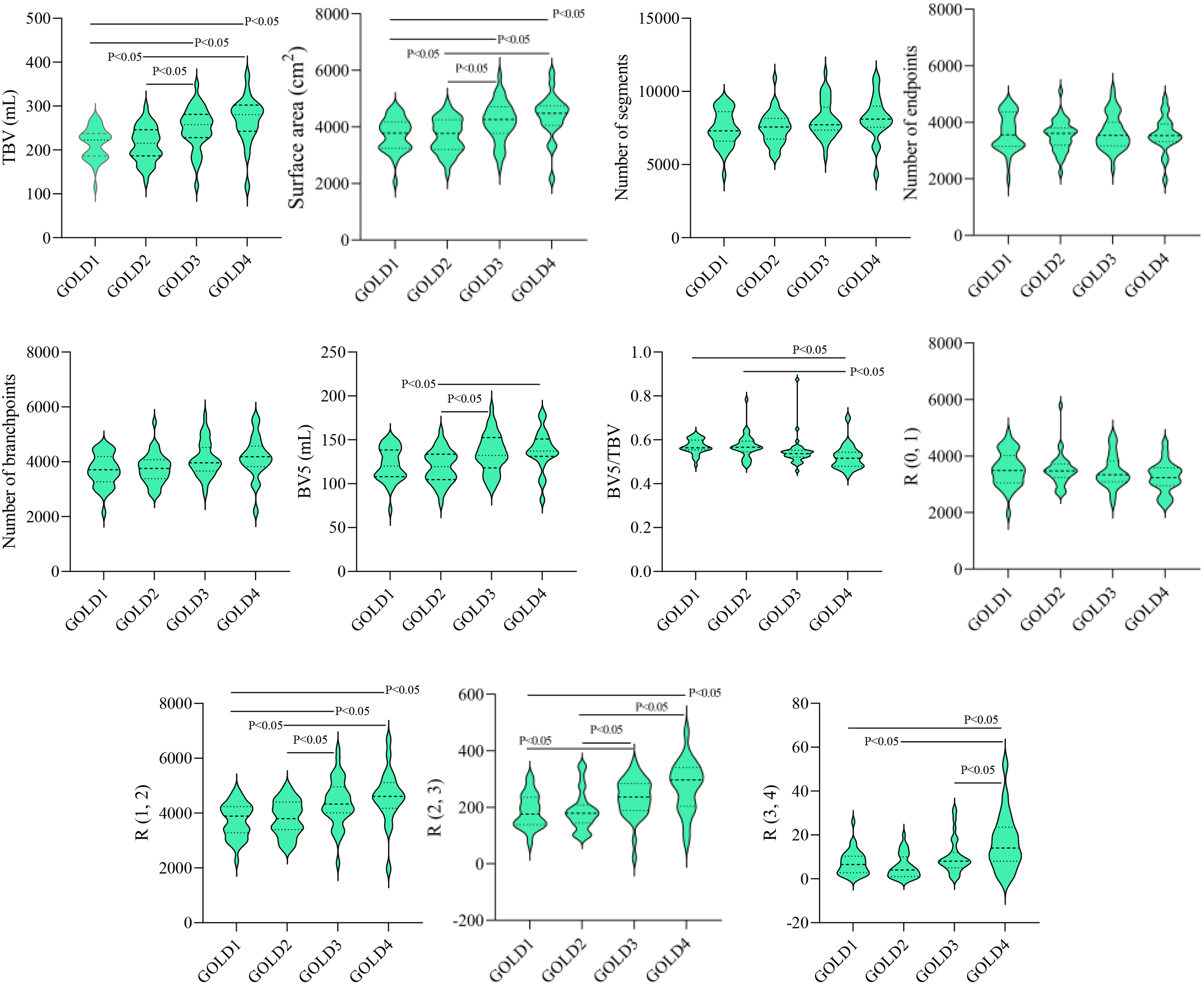
As shown in Figure 9, the results of ANOVA showed that there was a statistical difference (p<0.05) between the four different severities of COPD (i.e., GOLD 1, GOLD 2, GOLD, and GOLD 4) in some of the vessel metrics, including TBV, surface area, BV5, BV5/TBV, R (1-2), R (2-3), and R (3-4). There are no statistical differences in metric of number of segments, number of endpoints, number of branchpoints, and R (0-1) radius bin across any GOLD grade comparisons.
Statistical differences in vessel metrics across GOLD 1-4.
To further explore the differences between groups, subsequent multiple comparisons were performed using Bonfroni correction. After Bonfroni correction, for volume, surface area, R (1-2), and R (2-3), there were statistically significant differences between GOLD 1 and 3, 4, as well as between GOLD 2 and 3, 4 (p<0.05). Moreover, the BV5 value shows significant differences when comparing GOLD 2 to GOLD 3 and 4. The ratio of BV5 to TBV is significantly different when comparing GOLD 1 to GOLD 4, and GOLD 2 to GOLD 4. In addition, on the different severity of COPD, there was a statistical difference between GOLD 1, 2, 3, and GOLD 4 in terms of R (3-4) radius bin (p<0.05).
Discussion
In this work, we propose a semi-supervised learning framework designed significantly to improve the segmentation of the full pulmonary vascular tree, with particular emphasis on capturing the intricate structures of smaller vessels. The method leverages high-quality interactive annotations and a robust segmentation model, which together provide a foundation for accurate quantification of pulmonary vasculature. Such quantification plays a crucial role in the clinical assessment of COPD patients.
Precision serves as the primary evaluation metric for segmentation performance, especially concerning small pulmonary vessels in COPD patients. It is defined as the proportion of true positive segmentations out of all predicted positives. As summarized in Table 2, the Semi2 model achieves a precision of 0.903, demonstrating a notable improvement over the Fully-supervised model, which attains a precision of 0.880. This advancement is particularly meaningful in clinical contexts, where accurate vessel segmentation is essential for reliable evaluation of pulmonary vascular architecture. The heightened precision of the Semi2 model indicates a superior capability to identify vessel boundaries correctly—a critical advantage given the complex and often entangled nature of pulmonary vessels in COPD.
Furthermore, as illustrated in Figure 8, the proposed method effectively identifies vessels affected by disease-related alterations, thereby providing essential insights into disease severity and potential treatment strategies. Despite challenges posed by airway distortion and emphysematous changes typical in advanced COPD, our approach maintains robust segmentation performance. The visual results confirm not only high precision in vessel segmentation but also the model's capacity to delineate finely detailed and pathologically altered vessels, which are key indicators of disease progression.
The novelty of the proposed framework is established through comprehensive comparative analysis, highlighting its effectiveness and generalizability in the challenging context of COPD imaging.
The focus on small vessel segmentation represents a pioneering stride in the field. Small vessels are often the most challenging to label and segment due to their diminutive size and the potential for partial volume effects, yet they play a vital role in the pathophysiology of COPD. Correctly identifying and quantifying changes in these small vessels can lead to better understanding and management of the disease. While the Dice coefficient and IoU are slightly lower for the Semi2 model compared to the Full and Semi1 models, this does not diminish the significance of the work. The sensitivity of the Semi2 model, despite being lower than the Full model, still indicates a high true positive rate which, when combined with the model's high precision, underscores its ability to accurately segment small vessels. When compared to other works in the field, such as those by Wu et al., 37 which provided advanced Transformer-based frameworks for vessel segmentation, or the more recent deep learning approaches by Wu et al. 18 that improved segmentation accuracy, the proposed method stands out. It not only advances the precision but also emphasizes the clinical relevance of accurately segmenting small vessels. This is a substantial leap forward from previous methodologies that either did not focus on or struggled with small vessel segmentation due to technical constraints (Figure 10).
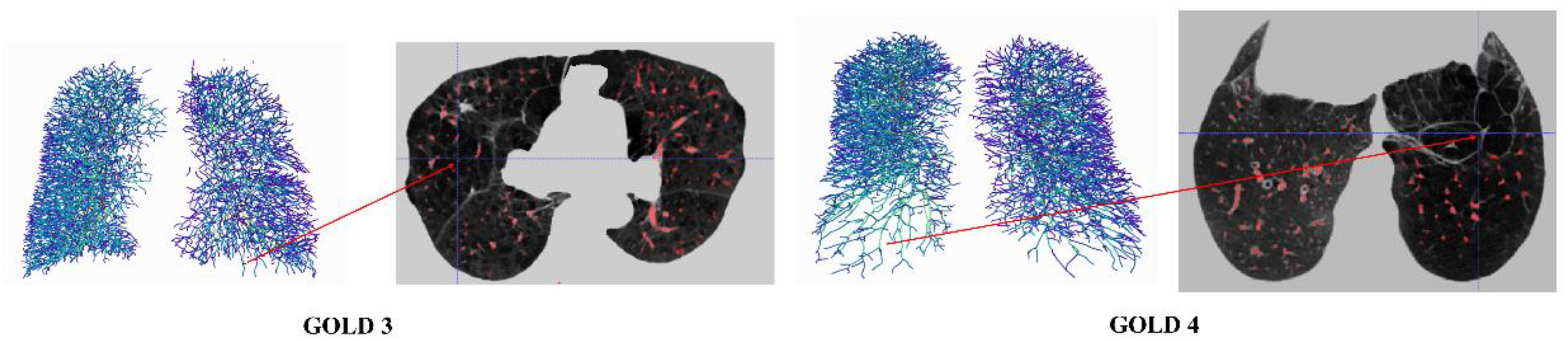
Visualization example results for GOLD 3 and 4 of COPD patient.
From Table 3, as COPD developed from GOLD 1 through GOLD 4, there is a trend toward increased TBV and surface area, possibly due to the disease's impact on the lung's structure. There is also a suggestion of reduced micro-vascularity in the later stages of COPD, as indicated by the BV5 and BV5/TBV values., In summary, as COPD severity increases, there is an expansion in lung vasculature but a concerning decrease in the proportion of blood in the smallest vessels, possibly reflecting compromised microcirculation. Additionally, the changes in the number of segments, branchpoints, and endpoints may indicate more complex structural changes in the lungs as the disease advances. Moreover, Table 4 suggests that as COPD becomes more severe, there is a decrease in the number of the smallest vessels and an increase in the number of larger vessels. This may reflect pathological changes in the lung's vasculature, such as inflammation and remodeling, that occur with the progression of COPD.
There are some limitations in the work. First, it is important to note that COPD is a complex disease, and the measures in the results alone cannot capture its full pathophysiological impact. Other factors like patient symptoms, exacerbation history, and FEV1/FVC ratios are also important in assessing disease severity and progression. Second, the dataset is collected only from one hospital. In the future, more hospitals and centers should be enrolled. Finally, there are more advanced deep learning method, 56 such as self-supervised learning57,58 and diffusion models.59,60 They should be employed in the future work.
Conclusions
This study presents a semi-supervised learning framework based on nnFormer for pulmonary vessel segmentation using CT images from patients with chronic obstructive pulmonary disease (COPD). By incorporating interactive annotation and a teacher-student consistency training strategy, the proposed method effectively mitigates the challenge of limited annotated data, achieving a Dice Similarity Coefficient (DSC) of 0.850 and a precision of 0.903. These results outperform fully supervised approaches including UNETR, Swin UNETR, and nnU-Net. Moreover, compared to the fully supervised version of nnFormer, the proposed approach improves segmentation precision by 2.3% while maintaining comparable DSC performance. The framework demonstrates a enhanced capability to delineate the complete pulmonary vasculature, particularly finer vessels, which is expected to facilitate more accurate quantitative analysis of pulmonary vessels across different stages of COPD, thereby offering valuable insights for diagnosis and treatment planning. Despite the promising segmentation performance, this study has several limitations. First, the interactive annotation process still requires manual intervention, and its initial quality may be influenced by subjective expert input. Second, all data used in this study were acquired from a single center with specific scanning protocols; thus, the generalizability of the model across different devices and acquisition parameters remains unverified. Finally, the high computational and memory demands of the Transformer architecture during training may restrict its application in resource-constrained environments.
On the other hand, the iterative self-training mechanism and the Transformer-based network architecture exhibit strong generalization potential, indicating promise for broader applications in segmenting tubular structures in other biomedical imaging contexts, such as retinal vessels and coronary arteries. Several directions merit further investigation. Future work could explore fully unsupervised or self-supervised pre-training strategies to reduce reliance on manual annotations. External validation across multiple centers and imaging devices is essential to assess the model's generalization capability and robustness. Additionally, model compression techniques such as knowledge distillation and network pruning could be applied to increase inference speed and meet the requirements of real-time clinical processing. Although the current model does not yet support real-time inference, its high accuracy provides a solid foundation for subsequent optimization. Integration with hardware acceleration and lightweight model techniques will be crucial to promoting its application in clinical decision-support systems.
Footnotes
Acknowledgements
This study was supported by the National Natural Science Foundation of China (Nos. 82472076 and 82270044) and the Fundamental Research Funds for the Central Universities (N25BJD013).
Consent to participate
Informed consent was obtained from all individual participants included in the study.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.