
Abstract
Psychological abuse, a form of intimate partner violence (IPV), involves non-physical behaviors meant to control, humiliate, punish, or threaten a partner. Despite its strong link to other forms of abuse, scholarly disagreement makes its definition ambiguous. Data-driven approaches, particularly machine learning (ML), remain underutilized in IPV research but offer advantages such as uncovering hidden patterns, efficiency, and scalability. This work applies natural language processing (NLP) modeling techniques (traditional modeling, fine-tuning, and few-shot learning) to classify six types of psychological abuse on a dataset of 1,500 labeled Reddit posts. Our LLaMA-3.70 few-shot model establishes a state-of-the-art baseline for this dataset. Not only does our study reveal that it is possible to employ NLP modeling to detect psychological abuse, it also demonstrates how some computational methods can make use of very limited datasets to produce high-quality results within the social sciences. We also apply an explainability measure (LIME) to surface model biases. This technique deepens understanding of model behavior, contextualizes performance, and sets a precedent for using computational methods in nuanced, human-centered social science research. This study demonstrates how ML paired with explainability measures can advance rigorous, responsible research in social disciplines involving ethical or semantic uncertainty.
Keywords
Introduction
Psychological Abuse
Intimate partner violence (IPV), a form of gender-based violence also known as domestic abuse, includes physical, sexual, and psychological harm inflicted by a partner or personally connected perpetrator, such as a former spouse or cohabiting family member (Refuge, 2017; Women’s Aid, 2024b; World Health Organization, 2024). Although anyone can experience IPV, women are disproportionately affected, particularly in cases involving serious injury or homicide (Office for National Statistics, 2025; Walby & Towers, 2017).
Psychological abuse, a type of IPV, involves non-physical aggression aimed at humiliating, punishing, or controlling a survivor (Follingstad, 2007). 1 It can occur alone or alongside other forms of violence, taking forms such as intimidation, verbal harassment, or exploitation (Martín-Fernández et al., 2019; Murphy & O’Leary, 1989). Similar to coercive control, psychological abuse can include emotional manipulation, verbal insults, and isolation to dominate a survivor of abuse (Breiding et al., 2015; Women’s Aid, 2024a; Zavala & Guadalupe-Diaz, 2018). Psychological abuse has severe mental health consequences, including post-traumatic stress disorder, depression, anxiety, and substance use disorders (Coker et al., 2002; Dye, 2020; Pico-Alfonso, 2005). Survivors of psychological abuse are also at an increased risk of physical and sexual IPV (EU Agency for Fundamental Rights, 2014; Murphy & O’Leary, 1989). Psychological abuse can be as damaging to survivors as physical abuse (Dye, 2020) and is linked to suicidal ideation (Li et al., 2019; Wolford-Clevenger et al., 2017). Both psychological abuse and coercive control are legally recognized forms of IPV. Non-physical forms of abuse are explicitly included in the UK’s 2021 Domestic Abuse Act and are criminalized under the UK’s 2015 Serious Crime Act 2015 (UK Public General Acts, 2015, 2021).
Defining Psychological Abuse
The formal study of psychological abuse is relatively new. Until recently, scholars viewed it as a consequence or side effect of other forms of IPV (Arias & Pape, 1999; Astin et al., 1993; Doherty & Berglund, 2008). While the research landscape, and partially the policy and legislative landscapes, now acknowledges psychological abuse as a distinct form of IPV, key questions about its definition—such as how to address subjectivity of experience and how to distinguish it from aversive interpersonal behavior—remain unexplored and unanswered (Follingstad, 2007). Due to these ambiguities, expert definitions vary, leading to inconsistencies in measurement strategies and intervention approaches. As a result, prevalence and severity estimates range widely. Reports of psychological abuse rates range from as low as 10–20% to as high as 80–90% (Martín-Fernández et al., 2019).
Traditional social science methods to study psychological abuse, such as surveys, interviews, and questionnaires, are commonly used to attempt to define or quantify psychological abuse (Neubauer, 2023). Though these approaches offer nuanced qualitative insights and allow for follow-ups, they are often expensive, time-consuming, and difficult to scale.
The Promise of NLP
Machine learning (ML) is a computational approach in which computer systems, or models, learn to perform tasks by analyzing large amounts of data, rather than by following explicitly programmed rules (Jordan & Mitchell, 2015). Natural language processing (NLP), a type of ML, enables computers to process and understand human language (Stryker & Holdsworth, 2024). In recent years, the development of the transformer architecture and of large language models (LLMs) has increased computational capabilities across a series of NLP tasks, such as reading comprehension, language understanding, and predictive reasoning (Roser, 2022; Vaswani et al., 2017).
NLP research can complement social science research in the IPV field by addressing some of its key pitfalls (Neubauer, 2023; Soldner et al., 2021). NLP methodologies may involve more authentic and unprompted data, uncover patterns missed by human annotators, reduce the work’s psychological burden, and be further developed into automated abuse detection and content moderation tools (Grimmer et al., 2021; Molina & Garip, 2019).
Considering these opportunities, we developed and evaluated NLP modeling strategies to classify psychological abuse. We tested a range of models (traditional, fine-tuned, and few-shot learning) and applied explainability techniques to better understand the behavior of our most successful one. While prior work has focused on applying ML techniques toward social issues related to IPV (e.g., hate speech and cyberbullying), our study is the first to successfully apply such methods to classify psychological abuse.
By focusing on a notoriously complex and ambiguous form of harm, we shed light on how algorithmic systems can navigate moral and semantic uncertainty. We demonstrate how modern computational methods can be applied toward the study of socially sensitive issues and thus advance efforts to design survivor-centered technologies (e.g., chatbots and safety agents) that are both technically robust and attuned to lived realities of abuse.
Related Work
NLP for IPV
NLP has proven effective in detecting a range of harmful online behaviors. Researchers have already applied such methods to analyze a range of online harms, including criminal networks and financial fraud (Ferrara et al., 2014; Soni et al., 2023), hate speech and cyberbullying (Badjatiya et al., 2017; Galán-García et al., 2016; Iranzo-Cabrera et al., 2025; Iwendi, Srivastava, Khan et al., 2023), sexism and sexual harassment (Liu et al., 2019; Parikh et al., 2021; Suvarna et al., 2020), and child grooming and exploitation (P. Anderson et al., 2019; Cook et al., 2023; Razi et al., 2023). This growing body of work establishes a strong precedent for applying NLP to study psychological abuse in digital spaces.
Focusing more narrowly on NLP methodologies for studying IPV, the research is generally split between ML models trained on institutional data (Botelle et al., 2022; Karystianis et al., 2021; Soldner et al., 2021) and those trained on social media data (Adeeba et al., 2023; Soldevilla & Flores, 2021; Subramani et al., 2019; Wang et al., 2022). Institutional data used in NLP research generally comes from electronic health records and police reports. These records are used for various IPV detection tasks, such as perpetrator classification and time-series offense prediction (Botelle et al., 2022; Karystianis et al., 2021; Soldner et al., 2021).
Social media is also a valuable data source for NLP-based IPV detection. Researchers leverage data from platforms like Twitter/X, Facebook, and Reddit to train models capable of identifying patterns in IPV-related discourse. Both Adeeba et al. (2023) and Soldevilla and Flores (2021) demonstrated how modern ML models can differentiate between violent and non-violent content on Twitter/X and Reddit. Similarly, Subramani et al. (2019) found deep learning models particularly effective in the classification of IPV-related Facebook posts. Recognizing the urgency of crisis situations, Wang et al. (2022) adapted this dataset to develop models for crisis recognition, expanding the role of NLP beyond classification to potential intervention. These studies illustrate how NLP can be used to analyze, classify, and respond to online narratives of IPV.
NLP Applications in Industry
Despite the limited amount of academic research applying NLP methods toward IPV detection, similar models are being developed for active commercial deployment. These models are commonly used in two areas: as content moderation algorithms on social media platforms and as abuse prediction tools sold to law enforcement agencies.
Content moderation is the process by which online platforms regulate user-generated content to minimize online harm (West, 2018). While it was once led by human annotators who would sift through and remove harmful content, today it is typically automated (Gillespie, 2020; Gorwa et al., 2020). Though automation enables scalability, it also introduces a host of challenges (Broussard, 2018). For one, online content is often multimodal, meaning it combines data from text, images, videos, and audio. As such, semantic meaning can depend on context or the interplay of these elements; individual components of a post may appear benign or harmless in isolation, but may be hateful or abusive when viewed in combination (e.g., text and image combination in memes) (Lin et al., 2024). Furthermore, the informal, fast-evolving nature of online discourse (e.g., sarcasm, slang, and coded language) makes detection even harder; machine systems miss these nuances that human moderators catch with ease (Röttger & Vidgen, 2021). Finally, automated tools are embedded within commercial ecosystems that prioritize profit. As such, transparency is often deprioritized to protect proprietary algorithms and business models, resulting in opaque moderation processes and limited avenues for accountability (Gorwa et al., 2020).
Algorithmic abuse detection systems are also adopted by law enforcement agencies around the world. One high-profile example is VioGén, a risk assessment algorithm used by Spain’s police force to evaluate the likelihood of repeat IPV (Eticas, 2024). Despite its widespread use, VioGén faces scrutiny for misclassifications with devastating outcomes: over half of the women who had been assessed and subsequently killed by a partner had been labeled low or negligible risk by the algorithm (Satariano & Pifarré, 2024). While VioGén is currently the largest of its kind globally, similar tools are being rolled out elsewhere, such as ODARA, which is used to predict IPV risk in Canada, the United States, and Germany (Department of Justice, 2021; Lulamae, n.d; Ojeda, n.d). Advocates of these systems often highlight their potential to help overburdened agencies triage urgent cases, but the reliability of such tools is undermined by data limitations and deployment risks. Training data often reflects only the subset of cases that are formally reported, excluding survivors who fear retaliation, face immigration-related barriers, or experience psychological abuse that goes unrecognized (Satariano & Pifarré, 2024). As a result, models may produce skewed representations of abuse that fail to capture its full complexity. Moreover, algorithmic bias based on race, gender, and other identity markers is well-documented in adjacent domains (Allhutter et al., 2020; Dastin, 2018; Larson et al., 2016; Luo et al., 2024), calling into question the claim that automation necessarily reduces bias.
NLP for Psychological Abuse
In 2023, Neubauer (2023) became the first to apply ML methods to classify psychological abuse, contributing a high-quality dataset and classification framework. However, their models failed to perform well across evaluation metrics and forms of psychological abuse. Our study builds on their final research question: “How successfully do ML models learn to classify psychological abuse?”
In revisiting this question, we aimed to determine whether NLP modeling strategies are effective at and appropriate for detecting psychological abuse. To achieve this, we set our objective to design a model that meets or exceeds Neubauer’s (2023) baseline performance across six classification tasks, with at least one classification significantly surpassed. We then applied explainability techniques to contextualize our findings and evaluate whether the observed performance is sufficient for practical use. We contribute a novel comparison of ML methods for psychological abuse classification and a high-performing model for this task. Our work provides critical insights for the application of ML methods for the study of socially sensitive issues, especially those navigating moral and semantic ambiguity.
Methodology
Data
We made use of Neubauer’s (2023) Reddit dataset on psychological abuse (see Data Availability and Appendix A1). The dataset includes 1,500 annotated posts using binary labels across six non-mutually exclusive categories: (1) Rules, control, and micro-regulation (2) Justifying, minimizing, and denying abuse (3) Threats, intimidation, and punishment (4) Shaming, degrading, and ignoring (5) Isolation (6) Surveillance, monitoring, and harassment
Each post was labeled by at least two annotators. The dataset includes wide (any annotator selected a label) and narrow (at least two agreed) formats. All six binary labels are imbalanced, meaning that they include far more examples of non-abuse than abuse (Appendix A4 Table 1).
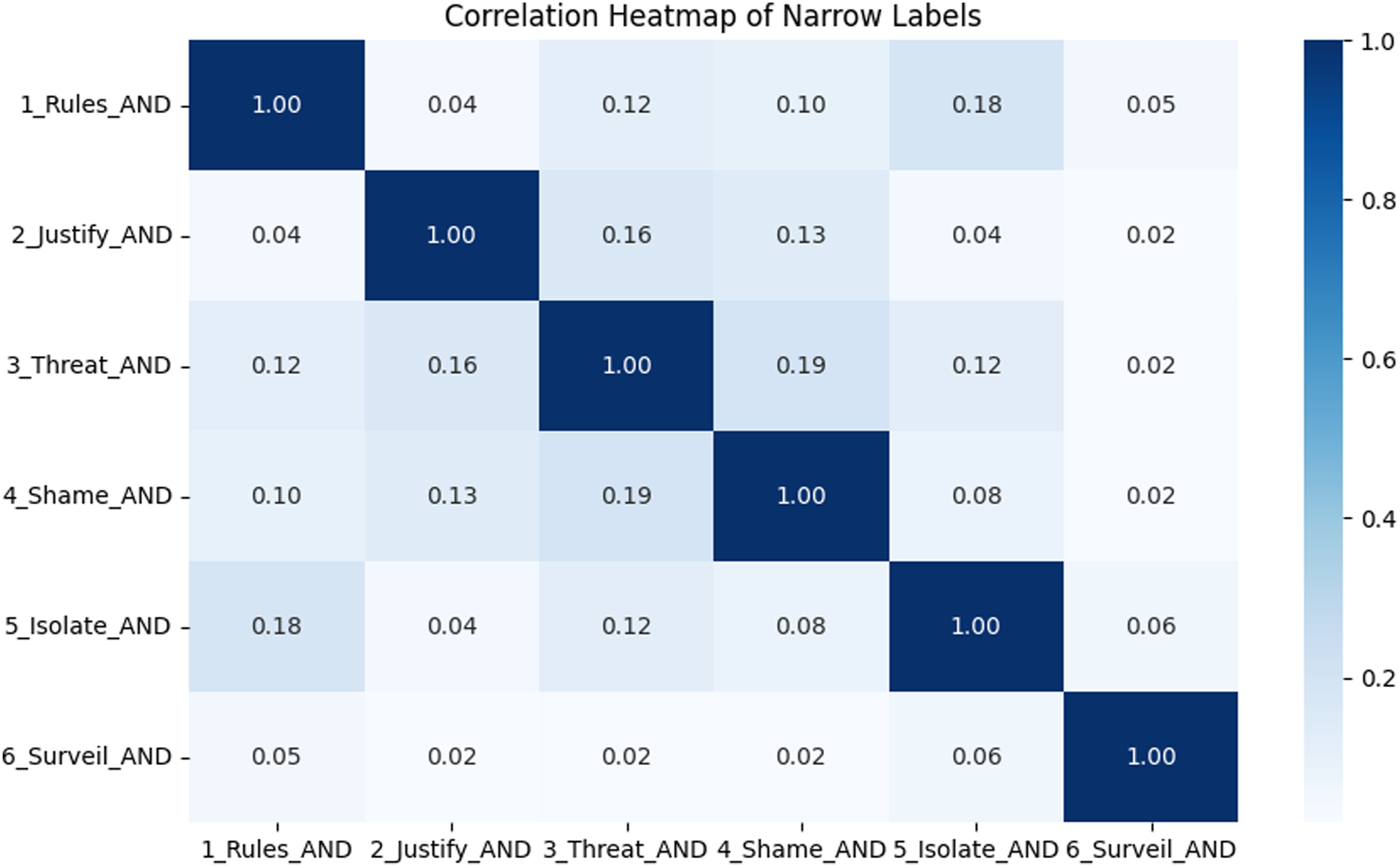
Although Neubauer (2023) noted some overlap during labeling, our exploratory data analysis revealed weak correlations between their abuse labels (Figures 1 and 2). This suggests that their annotation scheme effectively distinguishes between forms of psychological abuse. Heatmap of wide label correlations. Correlations are low, indicating that each label captures a distinct aspect of psychological abuse. Heatmap of narrow label correlations. As in Figure 1, correlations are low, indicating label distinctiveness.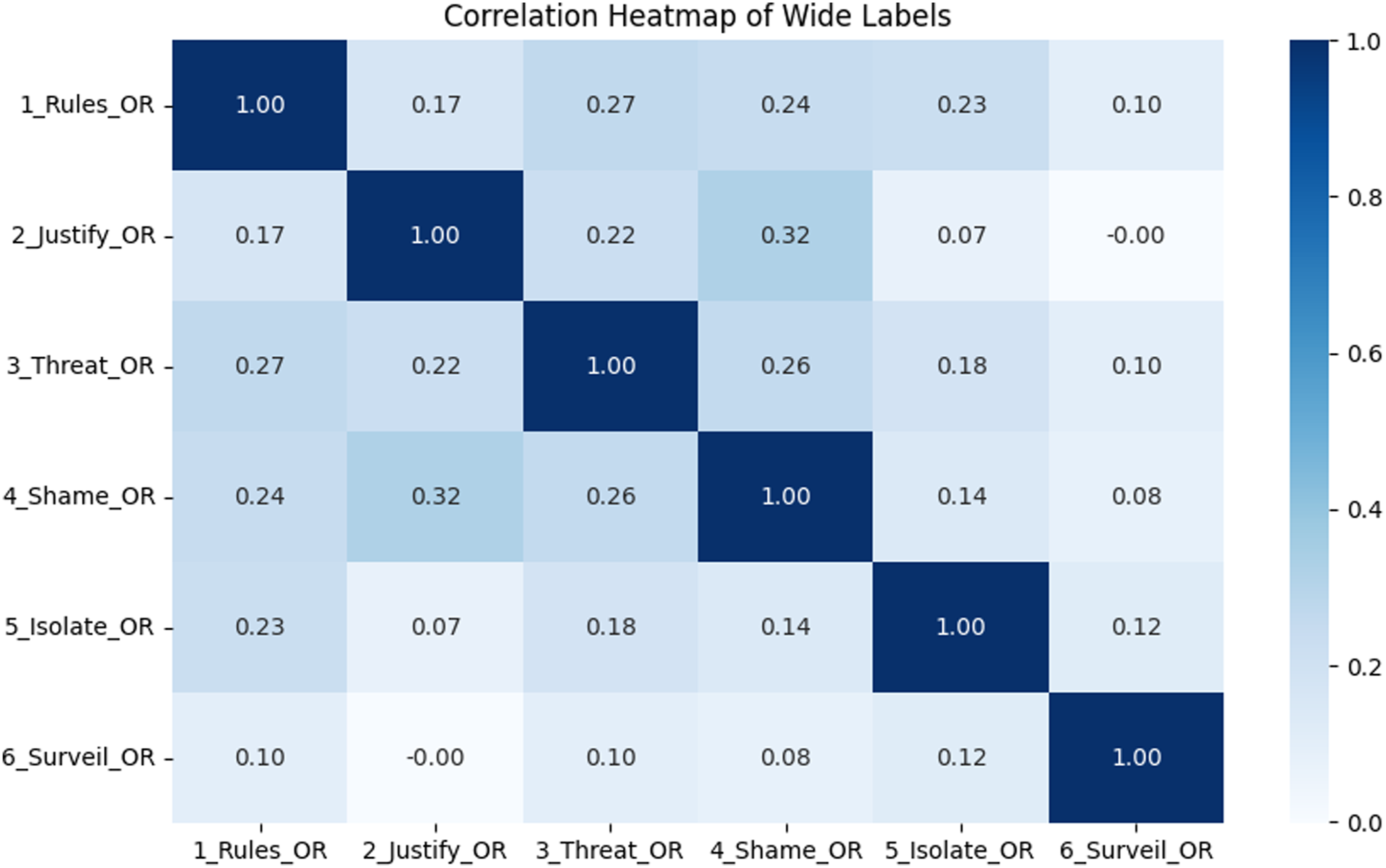
Modeling
To ensure a well-rounded assessment of ML methods, we tested a range of models’ performances (traditional modeling, fine-tuning, and few-shot learning). We calculated accuracy, precision, recall, and F1 scores to evaluate model performance across all experiments. All models were trained and tested separately on both wide (any annotator selected a label) and narrow (at least two agreed) labels.
Traditional Models
Traditional ML uses well-established algorithms to find patterns in data and predictions without relying on complex deep learning models (Janiesch et al., 2021). We trained four traditional ML models: Random Forest (RF), Logistic Regression (LR), Linear Support Vector Classifier (Linear SVC), and Multilayer Perceptron (MLP). Our traditional modeling experimentation extended beyond Neubauer’s (2023) by (1) testing data augmentation techniques, (2) applying Grid Search Cross Validation (GSCV) for hyper-parameter tuning, and (3) implementing an additional inherently multilabel model (MLP).
Preprocessing
Data preprocessing is a crucial step of the ML modeling process, where data is cleaned and transformed into a format a model can understand (Albahra et al., 2023). Following ML convention, we designated 80% of our dataset for training and 20% for testing (Joseph, 2022). We used a stratified split to preserve class distributions in both train and test data. After splitting the data, we developed a preprocessing pipeline 2 that (1) converted all text to lowercase, (2) removed punctuation and URL links, (3) tokenized the text, and (4) removed stop-words. 3 Although Neubauer’s (2023) models were first preprocessed and then split into train and test data, we reversed the order of these steps to avoid data leakage, specifically train-test contamination (Sasse et al., 2025).
Modeling
Pipelines for all four models followed the same four steps: embedding, sampler, dimensionality reduction, and classifier. First, we used an embedding transformer to convert text into a numerical format that our models could understand and work with during training and evaluation. 4 To handle data imbalance, we included a sampling step which allowed us to test different methods that either increased the number of examples in the minority class (oversampling) or decreased examples from the majority class (undersampling). 5 Finally, we reduced the size of the numerical text representations to retain essential information from the data while reducing computational cost. 6
Fine-Tuned Models
Fine-tuning is an NLP method where a small, expert dataset is used to adjust the weights within a commercial LLM. The benefit of fine-tuning is that it leverages LLMs’ rich semantic understanding (Parthasarathy et al., 2024). In this phase, we fine-tuned two transformer models (RoBERTa and GPT-2) on both label representations using cross validation.
Preprocessing
We first used a custom function to break the text data into smaller pieces called tokens. We then used truncation and padding to ensure a uniform input length. 7 Maintaining a consistent length is common practice in NLP workflows to balance the need for sufficient context with the need for computational efficiency (Mutasodirin et al., 2023).
Modeling
For our fine-tuned RoBERTa, we froze all layers but the final to optimize efficiency and reduce computational cost. In contrast, our fine-tuned GPT-2 updated all layers to better adapt its generative architecture to the classification task, despite higher training costs. Both models trained for three epochs with a learning rate of 2e-5 and employed cross validation to ensure generalization.
Few-Shot Learning
One of the limitations Neubauer (2023) mentioned is the small size of their dataset. Few-shot learning is a method where an LLM is exposed to a very small amount of labeled training data in order to learn to generalize to new, unseen examples. Unlike traditional and fine-tuned methods, few-shot learning enables advanced models to adapt with minimal data, making it ideal when labeled data is scarce (Parnami & Lee, 2022).
Case Selection
To make sure each of the six psychological abuse categories was included, we used a sampling method that randomly chose one real, labeled example for each of the six classes of psychological abuse. This approach ensured our model was exposed to a balanced and representative set of cases, each grounded in real, human-annotated cases of abuse. Random selection reduces selection bias while maintaining coverage across all categories.
Prompting
We used a standard function for all few-shot promptings. 8 We first prompted the model as “an expert on psychological abuse” and then presented six sampled case-response pairs. Using the same template, we prompted the model on all remaining data points and recorded its predictions (Appendix A2).
Modeling
We ran our few-shot promptings on four versions of Meta’s LLaMA: LLaMA-2 (7b and 13b) and LLaMA-3 (8b and 70b). 9 Although the textual data comes from publicly available Reddit pages, the labels are from a private, human-annotated dataset that the models would not have seen during pretraining. Using multiple versions allowed us to assess the effects of model versions and sizes on performance. We executed our few-shot experiments twice per model, once using each label representation. We ran our few-shot experiments using our university’s high-performance computing system to ensure consistent runtime conditions and sufficient computational resources for handling large models.
Output Cleaning
To make processing and evaluation simpler, we standardized all labels into a consistent format by converting them into binary values (1s and 0s), instead of using words or True/False values. For example, in cases where the model’s predictions included a True/False label and additional detailed text, we manually mapped responses to the appropriate True/False value. Detailed text responses with no explicit mention of True or False were only positively labeled if there was no ambiguity in the response, such as “Writer is isolated from family and friends” for (5) Isolate. In the rare case where the model did not respond, such instances were treated as missing values and excluded from metric calculations. This choice, known as listwise deletion, aligns with standard evaluation practices in ML (IBM, 2021). Like with our previous modelings, we evaluated performance on accuracy, precision, recall, and F1.
Explainability
After evaluating all models and selecting the highest-performing one, we used a tool called Local Interpretable Model-Agnostic Explanations (LIME) 10 to better understand how the model made its decisions. We chose LIME for its ability to provide clear explanations for individual predictions. LIME works by creating simple approximations of the model’s behavior for each input and highlighting the words or phrases that most influence its decision (Ribeiro et al., 2016). In our case, LIME helped us see which parts of a Reddit post the model relied on most when identifying psychological abuse.
For our LIME analysis, we were specifically interested in studying instances where the model erred. We randomly selected five false positives and five false negatives from each abuse category to manually review, resulting in 60 total posts. The analysis served an exploratory, hypothesis-generating purpose, providing context for the performance metrics of our highest-performing model, rather than yield generalizable or definitive conclusions.
Results
We evaluated three modeling strategies (traditional, fine-tuned, and few-shot) against established baselines to assess their effectiveness in detecting psychological abuse. In addition to overall performance, we examined how the labeling strategy and the level of agreement between annotators (inter-annotator agreement, or IAA) affected model results. Finally, we used LIME to explore the language patterns that influenced the model’s predictions, providing insight into which words or phrases most affected whether abuse was detected. Our findings emphasize the potential of modern computational methods to study even linguistically ambiguous and ethically nuanced social issues.
Modeling
Our findings highlight that across all approaches, models trained with wide labels consistently outperform narrow labels. This suggests that broader, more inclusive data representations of psychological abuse may offer a stronger foundation for ML model training. While both traditional and fine-tuned models performed similarly to existing baselines, the few-shot learning experiments showed statistically significant improvements. Importantly, the few-shot model using LLaMA-3.70 and wide labels marks a new performance threshold for the automated classification of psychological abuse.
Traditional Models
Comparing our traditional models with Neubauer’s (2023) baselines, we found that the majority of the F1 scores were near-equal to Neubauer’s (2023) (13/24, difference within 0.05) or slightly under-performed (9/24, difference greater than 0.05). These results may stem from variations in modeling workflows. Notably, we chose to preprocess our text data only after conducting the train-test split to avoid contamination (Sasse et al., 2025). Neubauer (2023), by contrast, applied preprocessing prior to splitting the data, which may have caused data leakage and inflated performance scores. While our approach may have resulted in slightly lower metrics, it adheres more closely to best practices in ML methodology (Sasse et al., 2025).
We also find that, across the six tasks, the wide labels vastly outperformed the narrow for all traditional models (RF: mean difference = 0.178, 95% CI [0.040, 0.316], p = 0.021, Cohen’s d = 1.35, Appendix A3 Figure 5; LR: mean difference = 0.139, 95% CI [0.074, 0.204], p = 0.003, Cohen’s d = 2.25, Appendix A3 Figure 6; LinSVC: mean difference = 0.137, 95% CI [0.038, 0.235], p = 0.016, Cohen’s d = 1.45, Appendix A3 Figure 7; MLP: mean difference = 0.179, 95% CI [0.038, 0.319], p = 0.022, Cohen’s d = 1.34, Appendix A3 Figure 8). All traditional models show statistically significant differences and large effect sizes, confirming that wide labels consistently outperform narrow labels.
The superior performance of the wide labels could be explained by the larger number of positive labels included. Because psychological abuse is subtle and context-dependent (Follingstad, 2007), capturing a wider range of expression may give models more informative data to learn from, even if the examples are noisier. This theory is further supported by performance correlations with label distributions and IAA. Correlations between label distribution and traditional models’ performance were strong for both wide and narrow labels, at 0.796 and 0.678, respectively. However, correlations between IAA and F1 scores ranged from very weak for the wide labels at 0.168 to moderate for the narrow labels at 0.4444.
Fine-Tuned Models
Like with the traditional models, the fine-tuned models (RoBERTa and GPT-2) failed to outperform Neubauer’s (2023) baseline. However, the reasons for their underperformance likely differ between the two. In the case of RoBERTa, we fine-tuned only the final layer to conserve computational resources. Deeper fine-tuning of the model might be necessary to yield performance gains. Our approach was a pragmatic decision, shaped by resource constraints, and should not be taken as conclusive evidence against the effectiveness of fine-tuning.
For GPT-2, the lower performance may stem from the architectural differences between our GPT model and the BERT-model used by Neubauer (2023). While BERT is typically well-suited for tasks requiring understanding of linguistic context, GPT is primarily designed for text generation. Overall, we present these results as a preliminary exploration rather than a definitive assessment of fine-tuning approaches.
As with the traditional models, the wide labels consistently outperformed the narrow for the fine-tuned RoBERTa (mean difference = 0.168, 95% CI [0.104, 0.232], p = 0.0011, Cohen’s d = 2.75, Appendix A3 Figure 9) and GPT (mean difference = 0.171, 95% CI [0.113, 0.229], p = 0.00064, Cohen’s d = 3.09, Appendix A3 Figure 10). This finding further suggests that a broader range of experience can improve model performance.
Echoing the traditional models, we witnessed strong correlations between performance and label distribution (r = 0.984 for both wide and narrow labels) and weak correlations between performance and IAA (r = 0.124 for wide and r = 0.336 for narrow).
Few-Shot Learning
The few-shot models returned the greatest performance, when compared both with previous modelings and with Neubauer’s (2023) baselines (Figure 3; Appendix A.3 Figure 11). The highest performing few-shot model, using LLaMA-3 with seven billion parameters and wide labels, matched or surpassed Neubauer’s (2023) model’s performance on all six classifications (Figure 3). Few-shot (wide) F1 scores on all six classifications. Our highest performing model (in blue) uses LLaMA-3 with 70 billion parameters.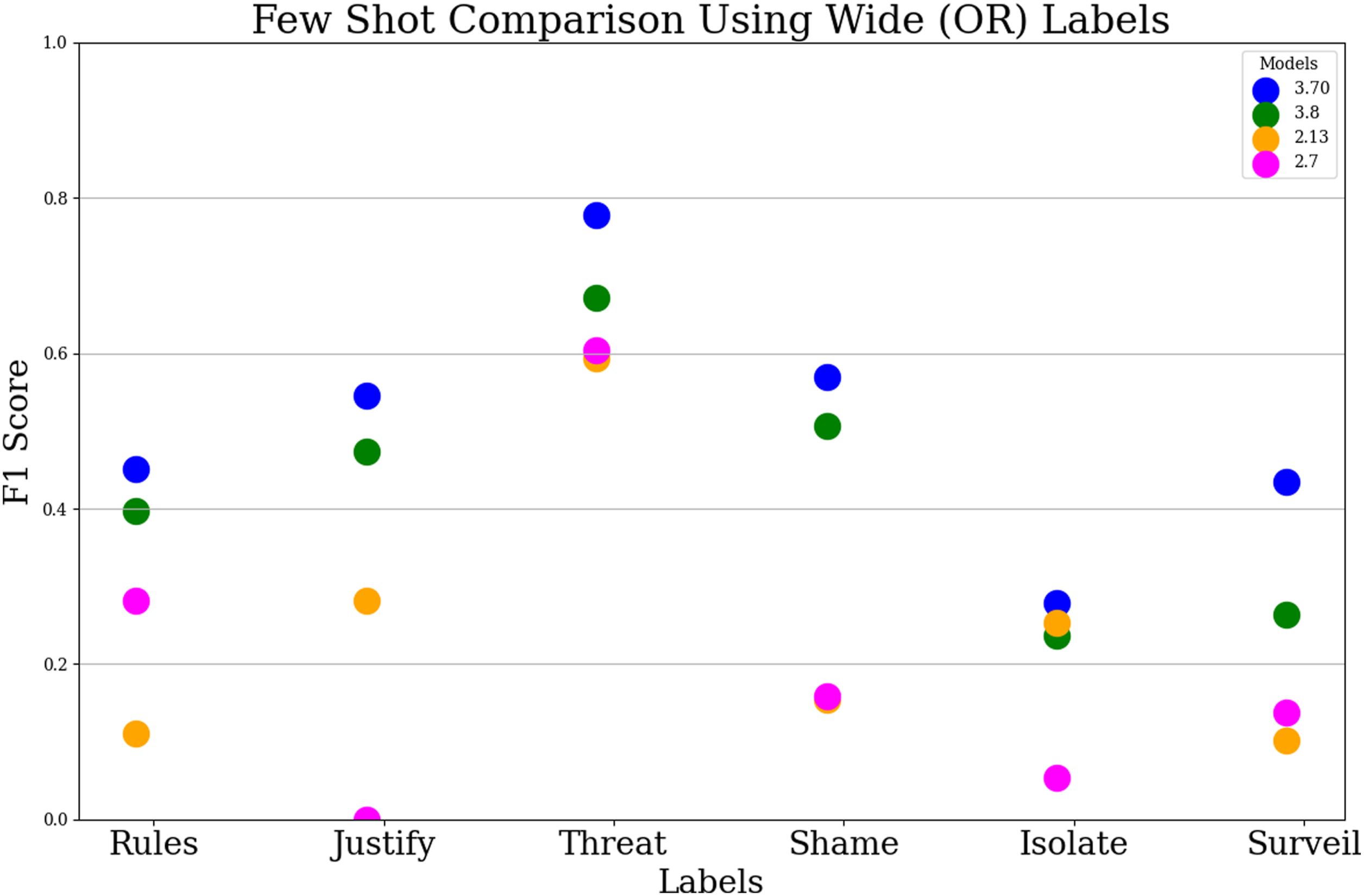
Markedly, the impact of label representation was much less prominent for our highest-performing few-shot model, compared with previous experiments. For this model, wide labels did not significantly improve performance (mean difference = 0.014, 95% CI [−0.018, 0.045], p = 0.33, Cohen’s d = 0.45). It appears that powerful LLMs, which have already been trained on an extremely large set of online data, can work well with very few instances of labeled data.
However, while this model sets a new performance baseline overall, not all six abuse categories were classified with equal effectiveness (Figure 3), underscoring the need for further refinement and caution in deployment.
Explainability
In our analysis, LIME revealed which words or phrases in each post most heavily influenced our highest performing model’s classification of abuse. By inductively aggregating patterns across 60 explanations in cases of model misclassification, we were able to identify two key linguistic features that may have shaped the model’s decision-making.
First, the model appeared to be less likely to classify posts as abusive when survivors used cautious or tentative language. Explicit expressions of fear increased the likelihood of an abuse prediction, while hedging phrases (e.g., “maybe”) shifted the prediction toward non-abuse.
Second, the model seemed to prioritize mentions of physical abuse over psychological ones. In posts that mentioned both, the presence of psychological abuse appeared to dilute the abuse signal, reducing the overall likelihood of an abuse classification (Figure 4). An example using LIME. Green text nudges model toward an abuse prediction and blue text nudges model against.
Discussion
This study applied a range of NLP modeling strategies to classify psychological abuse in Reddit posts. We tested traditional, fine-tuned, and few-shot models, and then used explainability techniques to evaluate how well the models captured this subtle and complex form of harm. Our key contributions are as follows: (1) We present the first systematic comparison of diverse NLP modeling techniques (traditional vs fine-tuning vs few-shot) for psychological abuse detection. (2) We present the first documented use of few-shot learning for psychological abuse classification, showing strong performance in low-resource, high-stakes settings. Our top-performing model (few-shot, LLaMA-3.70, wide labels) achieves high F1 performance across abuse categories, furthering research on safety and support applications. (3) We pair model performance evaluation with explainability measures to reveal potential biases: the model appears to struggle with cautious language and to prioritize physical over psychological abuse cues. This approach deepens understanding of our findings and encourages future research to adopt similar interpretability standards.
Importance of Dataset Richness
Across all tested NLP methodologies, the wide labels outperformed the narrow. This suggests that datasets capturing a broader variety of experiences may be more effective than those limited to narrowly defined, expert-agreed labels.
In their work, Neubauer (2023) proposed that model performance across psychological abuse subtypes might be influenced by label distribution and IAA. Specifically, they suggested that labels which are more common and clearly defined should yield better results. Our findings offer only partial support for this hypothesis.
While we observed strong positive correlations between label distribution and F1 scores, IAA correlations with performance were weak to moderate. This finding is somewhat unexpected. Previous work has raised concerns that machine learning models struggle with socially complex categories (Bacciu et al., 2019; Neubauer, 2023), which typically have lower IAA. If that were the case, we would expect models to perform significantly better on less socially complex issues (higher agreement) than more complex ones (lower agreement).
Instead, our results suggest that model performance may be influenced more by the volume and richness of training data than by annotator agreement alone. While the quantity of positive examples appears to play a role, further experiments are needed to establish causality and control for confounding factors, such as class prevalence and class difficulty.
Our study emphasizes the importance of evaluating the impact of dataset characteristics on performance when conducting computational research in the social sciences. Embedding this finding in the broader literature is challenging; whereas most existing work focuses primarily on evaluating model performance (Adeeba et al., 2023; Badjatiya et al., 2017; Iwendi et al., 2023; Karystianis et al., 2021; Soldevilla & Flores, 2021; Subramani et al., 2019), only a smaller body of research examines how dataset characteristics shape outcomes (Liu et al., 2019; Razi et al., 2023). Our study shows how dataset factors (e.g., the trade-off between label richness and consistency) affect performance, underscoring the need to evaluate data quality alongside model metrics. Future work should systematically examine how factors such as data complexity and IAA influence model performance across diverse datasets and domains.
For practical applications such as social media companies’ automated abuse detection tools or law enforcement agencies’ case flagging systems, the importance of dataset richness is particularly relevant. Many algorithms rely on narrow, skewed datasets (Dastin, 2018; Larson et al., 2016) that exclude survivors who cannot officially report abuse due to factors such as safety concerns and financial or immigration status dependence (Satariano & Pifarré, 2024). While Reddit data also excludes some survivors, such as those without internet access or under device surveillance, it captures many unreported experiences. As an early support outlet for survivors, such user-generated content platforms offer broader, real-world insights that can capture the complex nature of abuse and strengthen detection models (Amaya et al., 2021; Proferes et al., 2021).
Success of Few-Shot Learning Techniques and Points of Caution
While more dated ML approaches like traditional and fine-tuned modeling struggled to classify psychological abuse, our few-shot learning experiments outperformed both of these methods and existing baselines. This finding challenges the common assumption that strong model performance necessarily depends on having large amounts of labeled training data (C. Anderson, 2008; Hughes et al., 2021; Neubauer, 2023). With the availability of pre-trained LLMs, researchers can spend less time and effort on large-scale data collection and instead concentrate on high-quality annotation and thorough model analysis. Our few-shot models accomplished high performance using only six case examples, compared to the 1,200 training cases required by the traditional and fine-tuned models. Based on available evidence, we believe our few-shot model which uses LLaMA-3.70 and wide labels is currently the most effective ML classifier of psychological abuse. Our findings suggest that few-shot learning may offer a more effective and scalable strategy for research in contexts where labeled data is scarce or difficult to obtain, echoing earlier work which applies few-shot learning toward similar aims (Mozafari et al., 2022; Stappen et al., 2020; Sui et al., 2021).
Although the results are promising, we advise against the immediate practical use of our model. For one, the model struggles to generalize across a wide range of abuse types. This finding is complemented by our LIME-based explainability analysis, which revealed that our model appears to struggle with posts containing hedging language or referencing subtle forms of abuse. Given the high-risk nature of this application, misclassifications carry serious ethical and practical consequences and must be addressed with caution.
Further, our highest performing model relies on an LLM trained on vast amounts of internet data, which can encode harmful biases in representations of IPV (Du et al., 2021; UNESCO & IRCAI, 2024). As such, for deployment in real-world contexts, similar ML systems must be accompanied by safeguarding measures (e.g., uncertainty estimation and survivor support). In fact, such decision-making algorithms have faced serious criticism, and in some cases, removal from public use, for reinforcing existing biases. Automated hiring tools have favored language more commonly used by male applicants and have penalized references to women’s colleges (Dastin, 2018). Recidivism prediction tools used in U.S. criminal courts have exhibited racial bias against non-white defendants (Larson et al., 2016). Similarly, X-ray classifiers have underdiagnosed patients from underserved, intersectional groups (Seyyed-Kalantari et al., 2021). These high-profile failures underscore the need to evaluate model generalizability and ethical risks before high-stakes deployment. Technical performance is not equivalent to ethical adequacy, particularly in domains where decisions impact survivors’ safety, autonomy, or legal outcomes (Abercrombie et al., 2023; Broussard, 2018).
Our LIME-based explainability analysis was especially important in complicating the picture of model performance, revealing blind spots that would have been obscured by accuracy metrics alone. While caution is essential in applying computational methods in social science research, tools like LIME offer hopeful ways to ensure further richness and interpretability. By highlighting what the model picks up on and overlooks, explainability measures like LIME help researchers begin to assess whether model predictions align with meaningful social patterns.
Limitations
Just as with most research, our work has several limitations. First, the dataset is relatively small (1,500 entries) and imbalanced. This may lead to unreliable p-values and correlation estimates. Because the method involves many observations and repeated measures, these statistics can overstate confidence. As such, they should be interpreted alongside effect sizes and confidence intervals for a more accurate understanding. The small size and skewed distribution of the dataset may also hinder the ability of ML models to identify meaningful patterns. Additionally, the data is limited to English-language Reddit posts. This means that all text samples come from users with internet access, who are able to write in English, and who share experiences they believe will be supported by the Reddit community. Consequently, it may be that some forms or expressions of psychological abuse may be underrepresented or misrepresented by this sample (Dimaggio et al., 2004). Such skewed data often causes algorithmic biases in task-specific decision-making ML models (Dastin, 2018; Larson et al., 2016) and also for commercial LLMs, including models such as the GPT, RoBERTa, and LLaMA used in the fine-tuning and few-shot experiments. Future work could address these limitations by applying transfer learning from related tasks (e.g., hate speech detection) or by re-evaluating our model’s performance against datasets from other sources to determine generalizability (Belz et al., 2023).
Second, although our LLaMA-3.70 model outperformed Neubauer’s (2023) best model, its performance is still not suitable for applied settings due to the safety and privacy risks of misclassification in this context and should be viewed as exploratory. While our results are promising, further validation on external datasets is needed to establish a generalized benchmark for psychological abuse classification. Future research may explore different LLMs, promptings, and sampling methods. Performance is both prompt- and exemplar-dependent, and results may vary across runs; to better understand this variability, sensitivity analyses could examine how different exemplar selections affect model stability. Additionally, incorporating multimodal data could enhance model performance and adaptability, particularly for applications like social media content moderation or automatic criminal behavior detection (Lin et al., 2024).
Finally, the explainability technique employed in this study relied on a fundamentally retrospective form of reasoning; patterns in model behavior are inferred after the fact, based on observed outputs rather than direct insight into the model’s internal processes. As such, interpretation of these patterns is inherently subjective, shaped by our own perspectives, assumptions, and potential biases. As a result, while these methods provide valuable insights into model behavior, they also carry the risk of over-interpretation or misattribution, particularly in the absence of ground truth about the model’s internal reasoning. We intend for these findings to be understood as exploratory and hypothesis-generating, rather than as definitive conclusions.
Conclusion
In this research, we compared traditional modeling, fine-tuning, and few-shot learning for classifying psychological abuse. This marks the first comparison of its kind and the first application of few-shot learning to this task, achieving high performance for psychological abuse classification. We also used LIME to identify linguistic features’ influence on predictions, unveiling potential model biases against uncertain or subtle expressions of abuse. Despite the limitations outlined, our work is still relevant, as it is the first to compare the performance of a range of NLP modeling techniques toward the classification of psychological abuse and the first to employ few-shot learning toward this aim.
We challenge the assumption that large, labeled datasets are essential for effective use of ML in social science. Advanced pre-trained LLMs, when paired with appropriate prompting, can extract meaningful patterns from small or noisy datasets, reducing the need for extensive annotation. As such, ML methods can advance social science research by enabling rigorous analysis with limited data.
Explainability is critical in socially sensitive domains. Our use of LIME to explain model predictions helped uncover biases and patterns that accuracy metrics alone would miss. This emphasis on explainability is crucial for social science research, ensuring that computational methods are trustworthy and aligned with the complexity of human experience.
Yet, as algorithmic solutions gain traction in institutional and industry settings, it is essential to interrogate what such systems can and cannot achieve. NLP is not a cure for IPV, but one tool among many in understanding and addressing societal ills (Abercrombie et al., 2023; Broussard, 2018). As proprietary, or “black box,” models grow more opaque (Gorwa et al., 2020), explainability and uncertainty measures become vital for ensuring accountability and preventing misuse (Shin, 2021).
This work demonstrates how integrating advanced computational methods with explainability tools can provide more nuanced insights into sensitive social issues. We encourage researchers to explore creative computational approaches (e.g., testing dataset characteristics and using explainability measures) to strengthen the rigor and responsibility of their social science research.
Future work may focus on (1) validating our models across varied datasets (e.g., from various social media or institutional databases) to confirm generalizability; (2) exploring novel modeling techniques for a more comprehensive IPV representation (e.g., different LLMs, system prompts, and multimodal approaches); and (3) developing robust explainability and uncertainty measures to ensure the safety and trustworthiness of ML classifiers for IPV detection.
Supplemental Material
Supplemental Material - Decoding Psychological Abuse: A Comparative Study of Natural Language Processing (NLP) Classifiers Using Reddit Data
Supplemental Material for Decoding Psychological Abuse: A Comparative Study of Natural Language Processing (NLP) Classifiers Using Reddit Data by Maya Ashkenazi, Jessica Lilly Neubauer, María Pérez-Ortiz, Enrico Mariconti, Leonie Maria Tanczer in Social Science Computer Review.
Footnotes
Acknowledgements
The authors would like to thank Lifang Li, Meghan Knittel, and Demelza Luna Reaver for their time, commitment, and knowledge while labeling the dataset we used; their contributions were foundational to this work. We also extend our sincere thanks to the Gender and Tech Lab at UCL Computer Science for their feedback and enthusiastic support throughout this project.
Ethical Considerations
This study received formal approval from our university’s Institutional Review Board/Ethics Committee (Project ID 791) prior to commencement and was conducted in accordance with established ethical standards. To minimize the risk of traumatizing individuals affected by IPV, we did not attempt to contact any Reddit users whose posts were analyzed. All usernames were replaced with anonymized identifiers to protect and preserve privacy. This approach follows established best practices for safeguarding the privacy and safety of survivors in digital contexts (Bellini et al., 2023; Markham, 2012). Unlike qualitative methods such as interviews or focus groups, the use of scraped Reddit data shifts the burden of exposure to distressing content primarily onto the researchers. To mitigate the psychological impact of this work, researchers participated in weekly one-on-one supervisory check-ins and monthly reflective group practices with a licensed psychotherapist. Optional individual therapy sessions were also made available. Reading of sensitive content was restricted to designated workspaces, and researchers were encouraged to take regular breaks throughout the annotation process.
Author Contributions
M.A.: Conceptualization, formal analysis, funding acquisition, investigation, methodology, software, and writing (original draft, review, and editing)
J.L.N.: Conceptualization, data curation, resources, and software
M.P.-O.: Conceptualization, methodology, project administration, supervision, and writing (review and editing)
E.M.: Conceptualization, data curation, resources, and supervision
L.M.T.: Conceptualization, funding acquisition, methodology, project administration, resources, supervision, and writing (review and editing)
Funding
Parts of this research were supported by multiple funding sources. The data underpinning this study were generated through an EPSRC studentship in Cybersecurity (grant number EP/S022503/1). Subsequent analysis was partially enabled by an Ofcom OVAWG Secondary Data Analysis and Literature Review tender (tender reference C20242113). The salary of Dr. Leonie Tanczer was supported by a UK Research and Innovation (UKRI) Future Leaders Fellowship (FLF; grant number MR/W009692/1) and the UK Prevention Research Partnership (Violence, Health and Society; grant number MR/V049879/1). The findings, interpretations, and conclusions expressed in this article are solely those of the authors and do not necessarily reflect the views, policies, or positions of the funders.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
All datasets used in this study are publicly available and can be accessed via the UCL Research Data Repository at: https://doi.org/10.5522/04/31587925.v1. The data is anonymized and excludes duplicate, empty, and deleted posts. For more information on data collection and annotation, see ![]() .
.
Supplemental Material
Supplemental material for this article is available online.