
Abstract
Digital platforms now serve as crucial archives for analysing societal trends, yet their research APIs pose methodological challenges. This study critically evaluates TikTok Research API through comparative analysis of 6,373 videos from 14 creators in the United States and United Kingdom (2020–2022), contrasting API-derived outputs with manual collection and third-party analytics. The API demonstrated scalability, retrieving more videos than alternative methods and providing 22 variables, including eight unavailable elsewhere. However, limitations were substantial: transcriptions covered about 10% of the content, with more transcripts returned from American male creators. Engagement metrics exhibited inconsistent accuracy across data sources, with the API showing systematically lower view counts but higher comment and share counts compared to manual collection. The number of videos varied depending on sample composition, indicating that small changes in inclusion criteria could shift outcomes disproportionately. These results highlight systematic inconsistencies, showing why multi-method approaches remain necessary despite automation. While TikTok Research API offers valuable scale and ethical compliance, its demographic biases and metadata inconsistencies compromise validity. The study advocates integrated auditing protocols and targeted API refinements to improve representativeness and accuracy in platform-based research.
Introduction
Digital platforms have become integral to contemporary social life, producing vast datasets that can be systematically examined to address pressing research questions. Social media (SM) platforms generate digital traces that offer unprecedented opportunities to study societal trends (Reisach, 2021) and human behaviour across diverse contexts. These data enable researchers to explore phenomena ranging from conflict dynamics (Zeitzoff, 2011) to polarisation in voting behaviour (Sharma et al., 2022), underscoring their relevance to computational social science (Lazer et al., 2021). The dynamic interplay of platform algorithms, user interactions, and societal events necessitates robust open science practices to ensure transparency and reproducibility (Bezjak et al., 2018; Mosnar et al., 2025). Application programming interfaces (APIs) provide structured protocols for accessing these data, facilitating large-scale analyses of networked behaviours (Acker & Kreisberg, 2020; Davidson et al., 2023; Perriam et al., 2020).
Among social media platforms, TikTok has emerged as a focal point for researchers due to its rapid growth and appeal to younger demographics. Access to TikTok’s Research API necessitates an endorsement letter, a requirement that has grown common, though the frequency of approvals remains unclear due to limited public data on application outcomes. By late 2023, TikTok expanded its Research API to European countries, offering a more permissive approach compared to platforms like Meta Transparency Centre (2024) and X Developer Platform (2024), which have curtailed academic access (Chang, 2018; TikTok, 2024a, 2024b). TikTok’s substantial revenue growth, reaching £875 million by October 2022 (Sweney, 2022), underscores its expanding influence across cultural and political domains (Literat, 2021; Rejeb et al., 2024). The platform’s rich, multimodal data, encompassing videos, audio, text, and engagement metrics, support a diverse array of research methodologies, ranging from thematic analysis (Moir, 2023; Lu & Shen, 2023) and digital ethnography (Entrena-Serrano, 2025; Haime & Biddle, 2025; Yang, 2022) to interviews (Klug et al., 2021; Liang, 2021), surveys (Chen & Zhang, 2021; Kirkpatrick & Lawrie, 2024), and machine-learning applications (Agrawal, 2024; Parisi et al., 2023). However, platform-imposed restrictions arising from Terms of Service (ToS), such as data retention, pre-production, post-publication, and risks of indemnity, often constrain research validity and replicability Bak-Coleman, 2023; Venkatagiri, 2023; related items in Appendix 1).
Additionally, significant methodological and ethical challenges continue to limit the validity of societal insights derived from TikTok research. Small sample sizes, often the result of manual scraping (e.g. Cervi & Divon, 2023), restrict representativeness. Ethical concerns also arise when data collection contravenes TikTok’s Terms of Service, whether through manual or automated scraping (Thole, 2022). Unstable API performance can return data inconsistent with webpage information (Ruz et al., 2023), while reliance on third-party tools frequently produces incomplete datasets requiring extensive cleaning and validation (Mimizuka et al., 2025). Meanwhile, despite the widespread use of API-driven data, little is known about potential algorithmic biases favouring certain demographics or about inconsistencies in metadata accuracy. This lack of understanding undermines the ability to assess the generalisability and validity of current acquisition methods, and, by extension, the robustness of findings based upon them.
Existing research highlights persistent technical and ethical challenges in using TikTok’s Research API. There are three key limitations: inconsistent data delivery, rate restrictions on video retrieval, and restricted API access for independent researchers, which undermines the quality of societal insights that can be derived from platform data during critical events such as the COVID-19 pandemic. Notably, algorithmic curation and demographic disparities, including gender and cultural skews, introduce biases that call into question the fairness of trend analyses on the platform. Crucially, integrating multi-method approaches, such as combining API data with manual collection or external analytics, offers a means to address these inconsistencies. This is consistent with calls to enhance the reliability of social media research by triangulating sources, particularly when examining time-bound phenomena such as lockdown periods.
This study critically evaluates TikTok Research API by comparing API-derived data with manual collection and third-party analytics, using a dataset of 6,373 videos (after manual calibration) from 14 U.S. and U.K. creators (2020–2022). Videos were selected for their relevance to social commentary, humour, and public discourse during the COVID-19 period. This study addresses key research questions:
This paper proceeds as follows: it first examines the functionalities of the TikTok Research API, then evaluates its limitations, and finally proposes methodological refinements. The literature review synthesises prior scholarship on social media APIs, covering data collection practices, the affordances and constraints of the TikTok Research API, and associated issues of data quality, governance, and ethics. The methodology outlines data acquisition from three sources, such as API retrieval, paid datasets, and manual calibration, followed by statistical evaluation of data quality across these streams. The findings present the results of the comparative analysis. The discussion then interprets these outcomes considering the research questions, drawing out implications for platform-based data acquisition strategies. The paper concludes with recommendations to strengthen methodological rigour in future social media research.
Literature Review
Data Collection in Computational Social Science
Computational social scientists typically employ one or more of four approaches to data collection: web scraping, commercial analytics services, data donation, and platform-provided APIs, with the choice shaped by participant consent and the researcher’s technical expertise. Among these, APIs offer a sanctioned and legally compliant route to structured, large-scale public social media data, with clear advantages over manual collection and unofficial scraping (see Figure 1; Table 1). Official APIs, such as those provided by TikTok, can grant access to archived content not visible on public-facing interfaces, thereby ensuring a degree of compliance with platform terms (Davidson et al., 2023; Sato, 2023). However, restrictive usage agreements, including rate limits and potential costs, can narrow the research scope and hinder open dissemination (Ohme et al., 2024). Manual collection remains accessible to those without advanced technical skills, but is labour-intensive, error-prone, and poorly suited to large datasets (e.g., Cervi & Divon, 2023). Unofficial scraping and some third-party crawlers present an alternative yet may breach terms of service and raise significant ethical and legal concerns (Bruns, 2019). Taken together, these constraints underscore the need to critically evaluate API-based methods for fairness, validity, and their capacity to support robust social media research. Accessing SM Data. Note. The diagram is built on Davidson et al. (2023) Description of each route from Figure 1 with the types of data that are typically obtained from that route Note. The table is built on Davidson et al. (2023).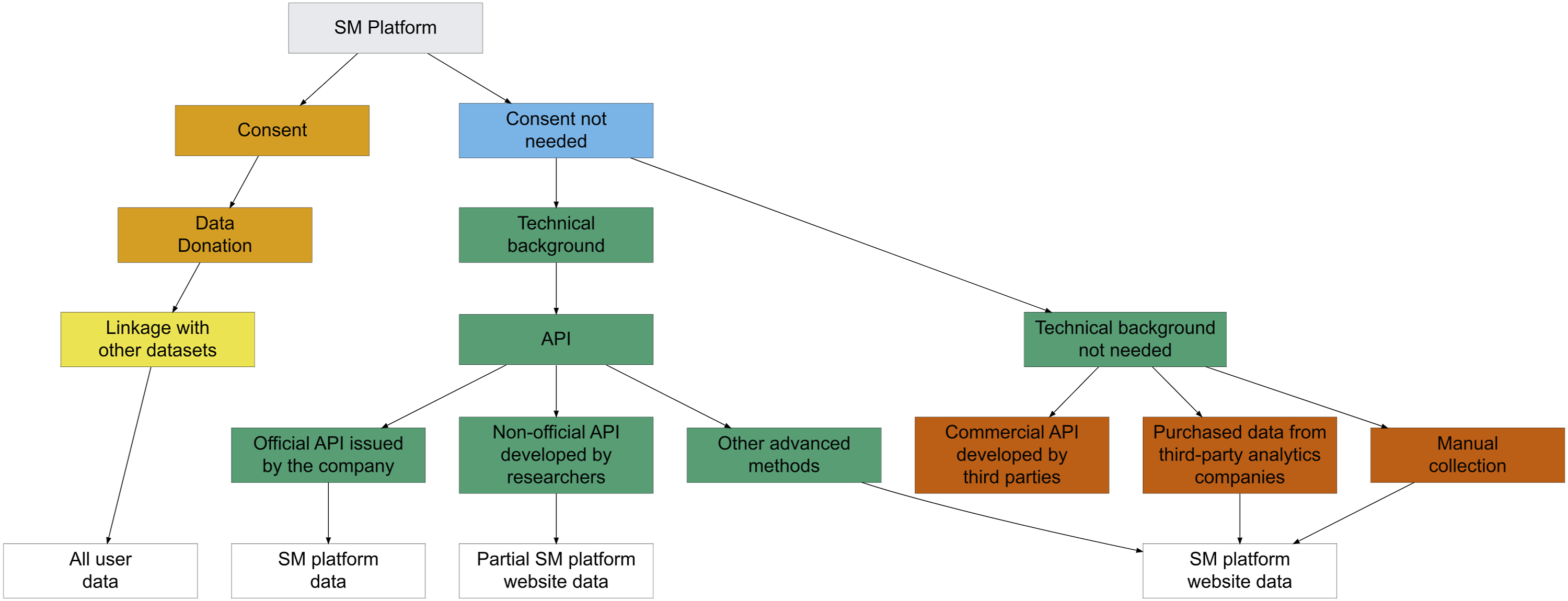

The TikTok Research API: Promise and Pitfalls
Launched in 2023, the TikTok Research API represents a milestone in platform transparency and academic collaboration. Initial applications of the API have enabled researchers to analyse political communication, content virality, and algorithmic demographic bias through machine-learning models (Corso et al., 2024; Pinto et al., 2024a; Pinto et al., 2024b). The structured provision of multimodal data, including text, video, and audio metadata, marks a significant step forward compared to earlier TikTok studies reliant on ad hoc methods (Rogers & Zhang, 2024). This has enabled analyses ranging from content engagement statistics to semiotic and linguistic interpretations (Leedham et al., 2020; Parikh, 2025).
Nevertheless, the practical implementation of the API is far from seamless. Scholars have reported incomplete and inconsistent data delivery, often receiving only a fraction of the requested materials. Burnat and Davidson (2025) note that TikTok Research API imposes highly selective access criteria and suffers from documented data quality issues, corroborating reports of inconsistent data delivery (Corso et al., 2024; Ruz et al., 2023). Pfeffer et al. (2018) demonstrate that streaming sample APIs are neither random nor immune to distortion: deliberate flooding can manipulate topic coverage, while rate limits and batching introduce temporal artefacts and omit low-activity content. Furthermore, high-engagement posts are over-represented, challenging the notion that API data provide a faithful snapshot of platform dynamics. These constraints do not only limit the API’s utility for comprehensive societal trend analysis but also can severely impact dataset completeness, thereby compromising analytical accuracy and interpretive robustness (Pfeffer et al., 2018). Additionally, server instability and unreliable pagination further undermine the reliability of automated data extraction processes (Mimizuka et al., 2025). If API workflows encourage fragmented or low-fidelity datasets, then the integrity of empirical findings is inevitably weakened.
Data Quality, Governance, and Ethics
Concerns over the epistemological trustworthiness of API-derived data extend beyond purely technical limitations. TikTok’s internal moderation algorithms and content-curation systems introduce layers of bias and obfuscation rarely addressed in dataset evaluations. These ‘black-box’ mechanisms can distort both the authenticity and representativeness of retrieved data, creating systemic blind spots in research outputs (Corso et al., 2024).
Governance frameworks further shape who can access platform APIs, often reinforcing epistemic privilege for university-affiliated researchers. Under the European Union’s Digital Services Act, applicants must demonstrate formal affiliation with a recognised academic or non-profit institution to obtain ‘vetted’ status for internal datasets (European Centre for Algorithmic Transparency, 2025). In practice, this requirement compels independent researchers, freelance journalists, and civil society organisations to partner with universities, think tanks, or research consortia to meet eligibility criteria. As a result, API access remains largely confined to academic investigators, excluding many non-academic actors from direct engagement with platform data (Mimizuka et al., 2025).
Burnat and Davidson (2025) identify critical ‘audit blind-spots’ in platform APIs, including TikTok’s, where moderation and algorithmic processes remain opaque, an ‘accountability paradox’ in which platforms control both the data and the terms of its release. This lack of transparency, coupled with epistemic asymmetries favouring platform operators, raises significant ethical challenges for ensuring fairness and validity in computational social science.
A further point of contention concerns user consent and data privacy. The granularity of engagement metrics available through the API, when combined with other datasets, can enable inadvertent re-identification of individual users. Such risks create potential legal liabilities and challenge the ethical legitimacy of research reliant on these data (Mimizuka et al., 2025), especially for those who are not qualified as public figures.
In sum, while the TikTok Research API represents a notable advance in platform-based research, the literature depicts its utility as mixed. Technical constraints, governance opacity, and ethical exclusions collectively limit its broader adoption and impact. These unresolved issues form the rationale for this study’s central aim: to conduct a robust, comparative audit of TikTok’s Research API against alternative data collection methods, including web scraping, and commercial analytics services, thereby contributing to methodological best practices in computational social science and informing future platform policy.
Methodology
This study adopts a mixed-method design to evaluate the efficacy and limitations of TikTok Research API in analysing societal trends, with a specific focus on comedic content during the COVID-19 pandemic. Data were obtained from three sources, the official TikTok API, a third-party analytics service (Analisa.io), and manual calibration, enabling a comparative assessment of accuracy, completeness, and representativeness. In doing so, the research addresses persistent gaps in platform-based studies (Davidson et al., 2023). The following subsections outline the sampling strategy, data acquisition procedures, and analytical approach, with particular attention to methodological robustness and ethical compliance.
Sample Selection
The COVID-19 pandemic offers a critical context for examining societal responses under conditions of collective stress, revealing patterns of isolation, mental-health strain, and the circulation of misinformation (Davidson et al., 2023). Comedy on TikTok, often rooted in shared social truths, provides a distinctive lens through which to interrogate cultural narratives and patterns of user engagement. As neuroimaging research indicates, the brain’s response to vividly presented content can mirror real-world experiences, harnessing neuroplasticity to capture attention and reflect the prevailing zeitgeist (Nishimoto et al., 2011; Pearson, 2019; Pearson et al., 2015). Against this backdrop, prominent comedic creators were selected as a purposive sample for examining real-time societal discourse.
Total number of videos of selected content creators
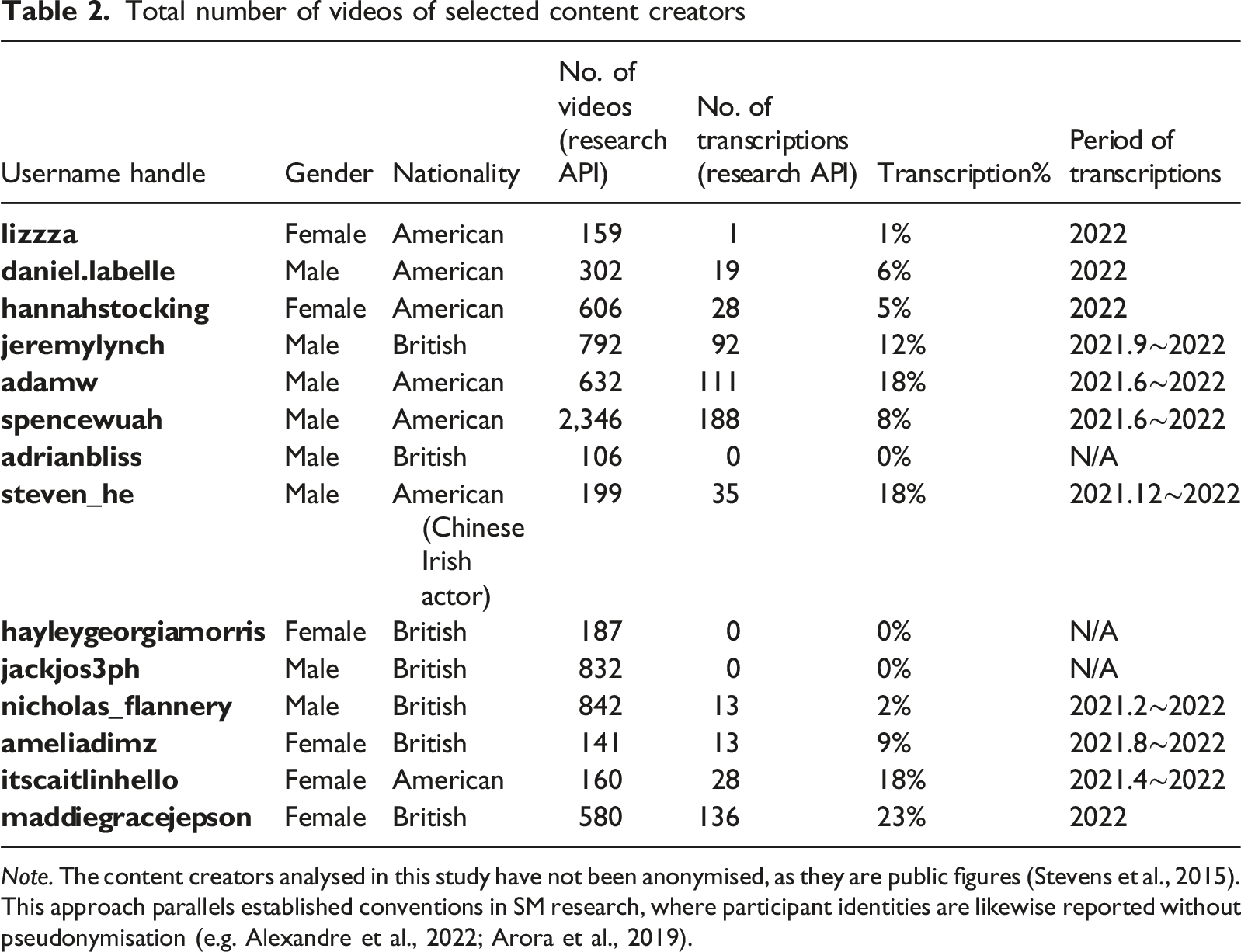
Note. The content creators analysed in this study have not been anonymised, as they are public figures (Stevens et al., 2015). This approach parallels established conventions in SM research, where participant identities are likewise reported without pseudonymisation (e.g. Alexandre et al., 2022; Arora et al., 2019).
The core analytical materials comprised video metadata (e.g. upload date, video description) and engagement metrics (e.g. views, likes, comments, shares) (see Figure 2). These provided both quantitative indicators and discursive content, enabling a multi-layered analysis of comedic expression and audience interaction during a period of significant social disruption.
Data Acquisition and Annotations
Data Description from Three Data Sources
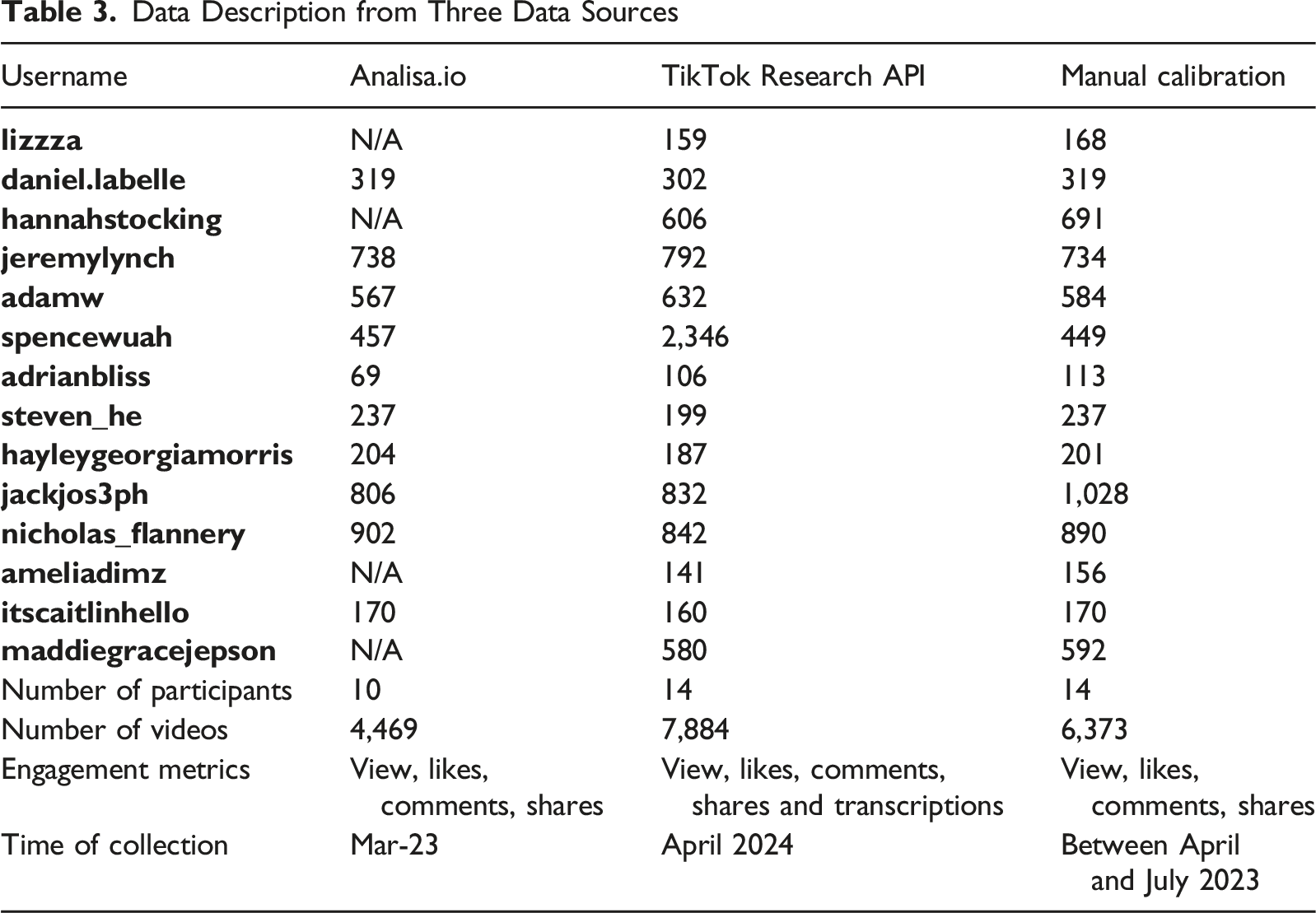
The first dataset was obtained in March 2023 from Analisa.io, a commercial social media analytics service (Lachief, 2023). However, access to several creator profiles, including @lizzza, @ameliadimz, @maddiegracejepson, and @hannahstocking, was subsequently lost following the service’s closure, resulting in partial discontinuity.
The second dataset was collected in April 2024 via the official TikTok Research API (the raw data are shown in Figure 3), accessed in R using packages such as Example output from API. Note. The screenshot is intended solely to illustrate the workflow and data structure, not to expose raw data. Only a partial view is shown to minimise any risk of unnecessary disclosure
As is typical for behavioural trace data, raw API output required extensive preprocessing. Technical constraints, including rate limits, pagination handling, emoji decoding (Figure 2), and incomplete exposure of video-level features, restricted both the volume and granularity of extractable data. Every cleaning step was systematically documented, with derived variables cross-checked against supplementary metadata sources (Lazer et al., 2021; Salganik, 2018). This approach ensures transparency, reproducibility, and interpretability in subsequent modelling. Sample video by @itscaitlinhello. Note. ‘favourite_count’ is not included in this paper due to its unavailability by the time of data collection (April 2024)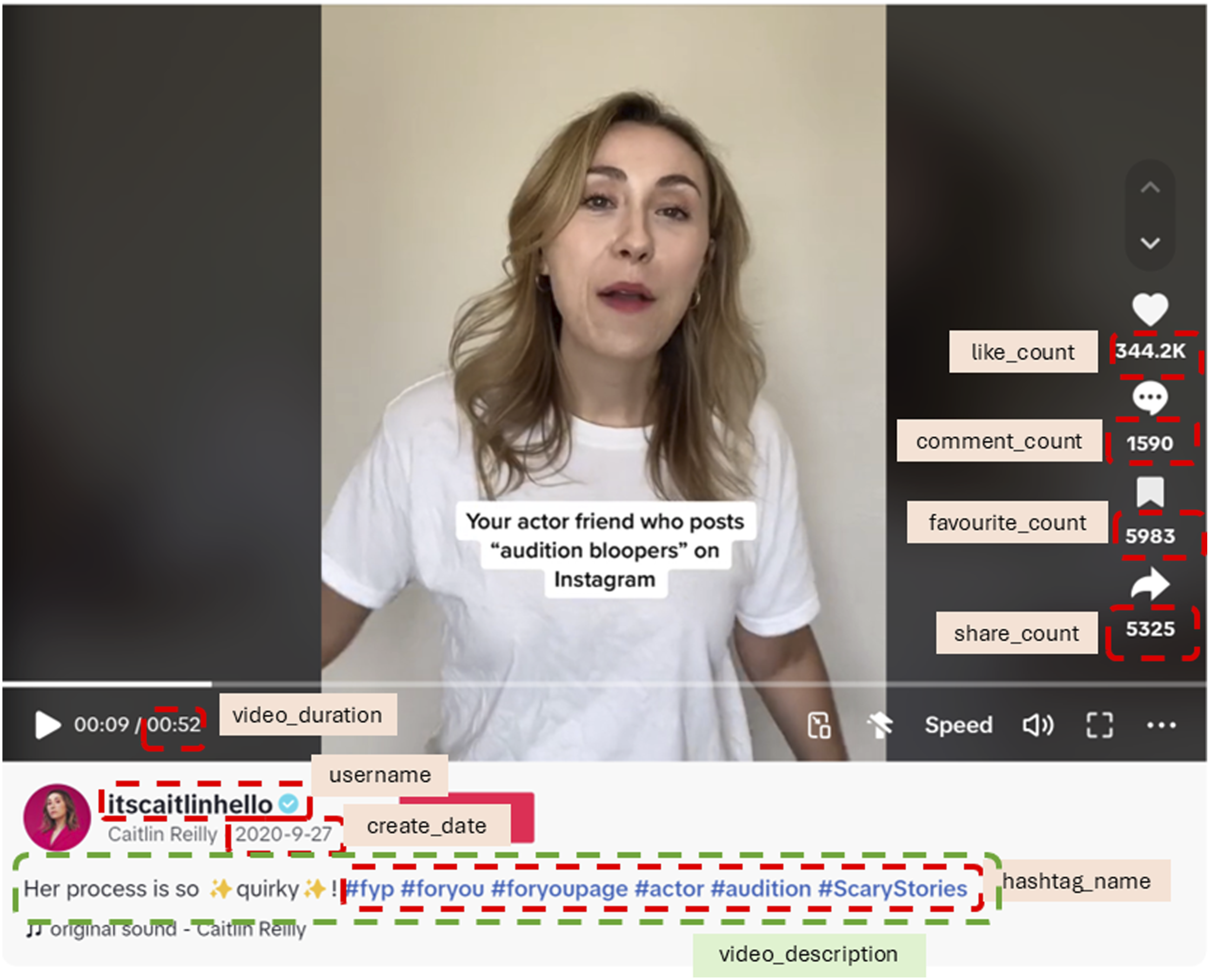
Finally, manual calibration was undertaken between April and July 2023, with videos verified and collected directly from TikTok.com. This step was designed to check whether there were missing videos between actually available metadata on the website and the purchased source or API source. Therefore, it is reasonable to compare the number of videos from three sources. This served as a benchmark against which to evaluate the completeness and accuracy of both API- and analytics-based retrieval. Research-ready version is presented in Figure 4. Cleaned dataset from manual calibration built on purchased data
Data Analyses
To evaluate the TikTok Research API’s efficacy for computational social science, the analysis proceeded in two phases, addressing both macro-level data coverage and micro-level metric precision (Figure 5). This dual approach aligns with RQ1 by assessing the API’s technical capacity for multimodal data collection and with RQ2 by examining whether systematic discrepancies across data sources could introduce demographic or algorithmic biases that compromise the fairness of societal insights. In other words, if certain groups or content types are systematically under- or over-represented due to data source effects, subsequent interpretations of societal trends risk being skewed. Workflow diagram illustrating the two-phase data analysis process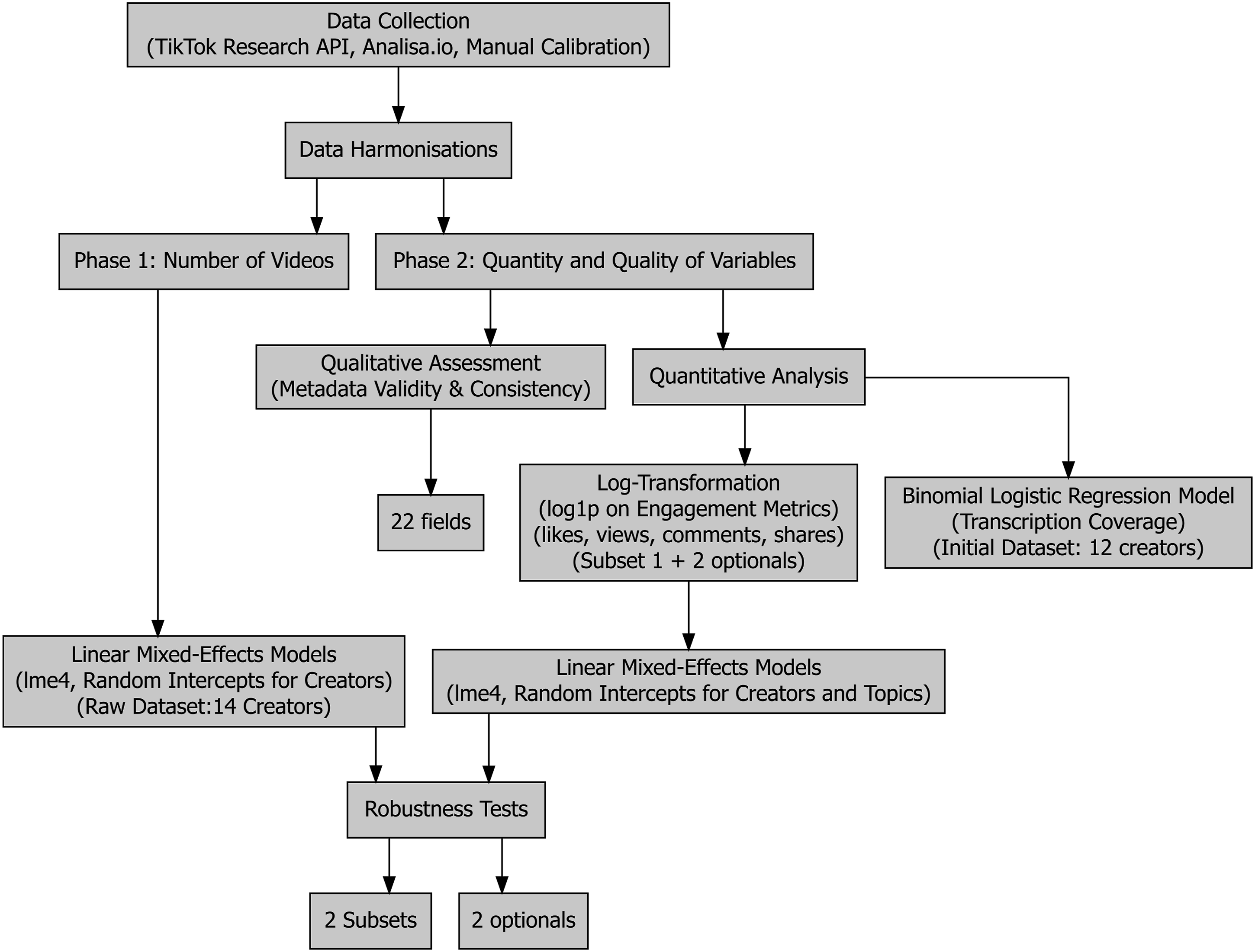
Phase 1: Number of Videos
The first phase compared the monthly total number of videos (dependent variable) retrieved from the three data sources (API, manual calibration, and Analisa.io) to assess the API’s ability to provide a comprehensive dataset. Raw dataset included 14 creators over 36 months including two optional candidates (@steven_he and @nicholas_flannery), and then initial specification included 12 creators, yielding a balanced panel of 1,251 observations.
After data harmonisation, linear mixed-effects models were fitted using the
Robustness analyses were conducted in two subsets (1) excluding four creators lacking purchased-source data, leaving 829 observations across eight creators, and (2) excluding both the four creators with missing purchased data and one high output outlier, yielding 733 observations across seven creators.
Phase 2: Quantity and Quality of Variables
The second phase examined data completeness and accuracy. First, the number of available metadata variables per video was compared across sources to provide a holistic measure of coverage. Next, the accuracy of key engagement metrics, like count, view count, comment count, and share count, was assessed, as these are widely used indicators of content impact in social media research. Their reliability is critical: systematic under- or over-reporting could distort comparative analyses and, by extension, the fairness of societal interpretations.
For comparability, only videos present in both sources were retained; those unique to a single source were excluded, thus leaving paired videos from 10 participants in total. Engagement analyses were restricted to API and manually calibrated data, as Analisa.io’s rounded outputs closely mirrored manual counts, limiting their utility for precision testing. Notably, engagement metrics of @lizzza, @ameliadimz, @maddiegracejepson, and @hannahstocking from manual calibration are unavailable due to their lack of purchased source.
Linear mixed-effects models were also used, but with log-transformed outcome variables (via
Additionally, the newly introduced voice_to_text (transcription) variable was evaluated for validity, given its potential to introduce further demographic or linguistic bias. A binomial logistic regression was used to compare the differences in proportion of videos of having a transcription (dependent variable: whether a video had a transcription) as a function of gender and nationality (independent variables).
Preliminary Findings
Number of Videos
Descriptively, on average each month, the API Video count by data source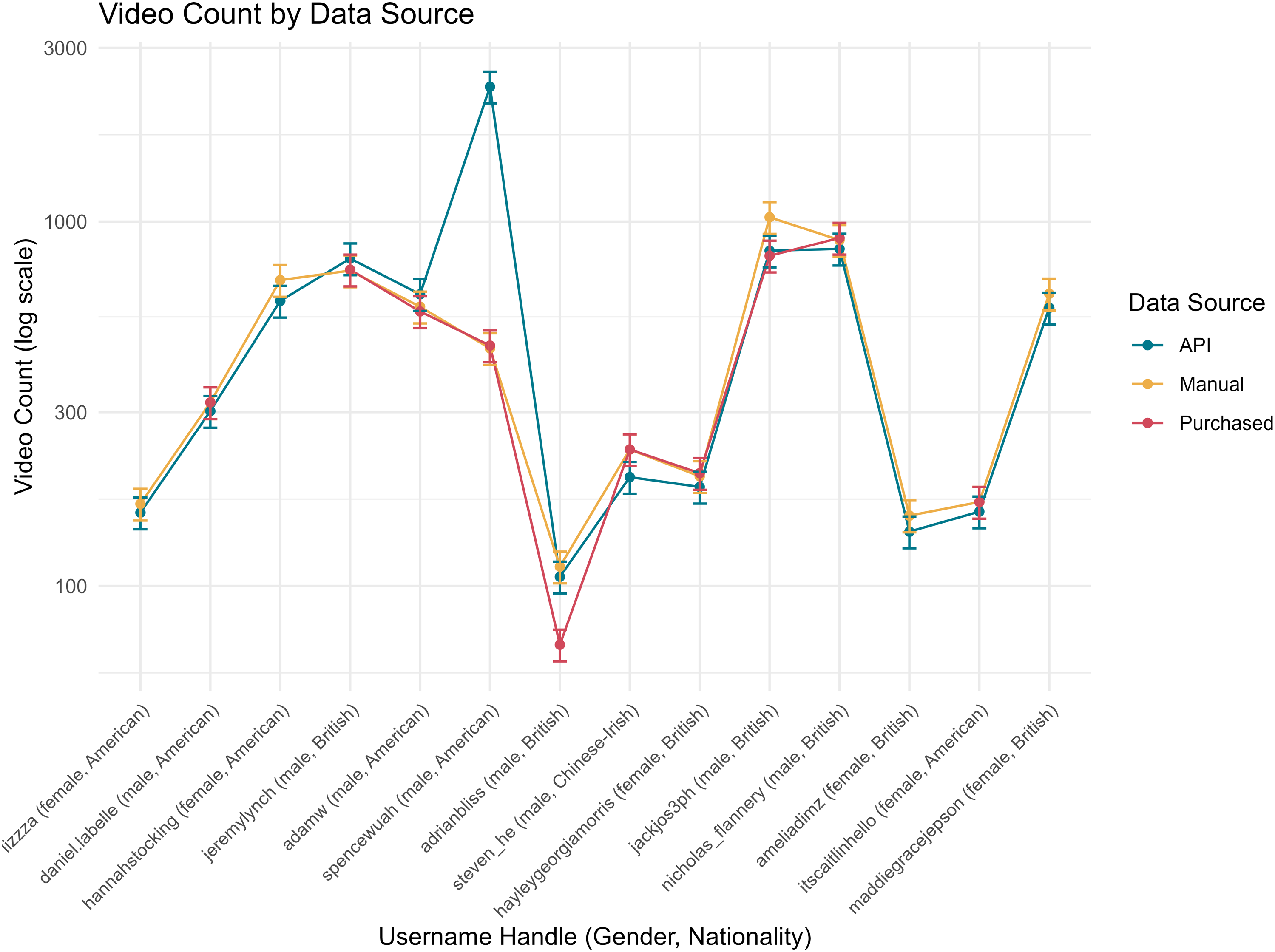
The linear mixed-effects analyses revealed consistent differences in estimated upload counts between data sources. In the full model including all 14 creators, both the purchased dataset (
When the two optional candidates (@steven_he and @nicholas_flannery) were excluded, the pattern persisted, with larger estimated differences for purchased (
As shown in Figure 6, there is an outlier of API (@spencewhuah). Thus, in a more restricted but balanced subset (e.g. excluding four creators absent from purchased data, two optional candidates, and the outlier, finally seven creators), the negative coefficients for purchased and manual sources were smaller and statistically insignificant (e.g. purchased:
Quantity and Quality of Variables
Variable Quality from Three Sources
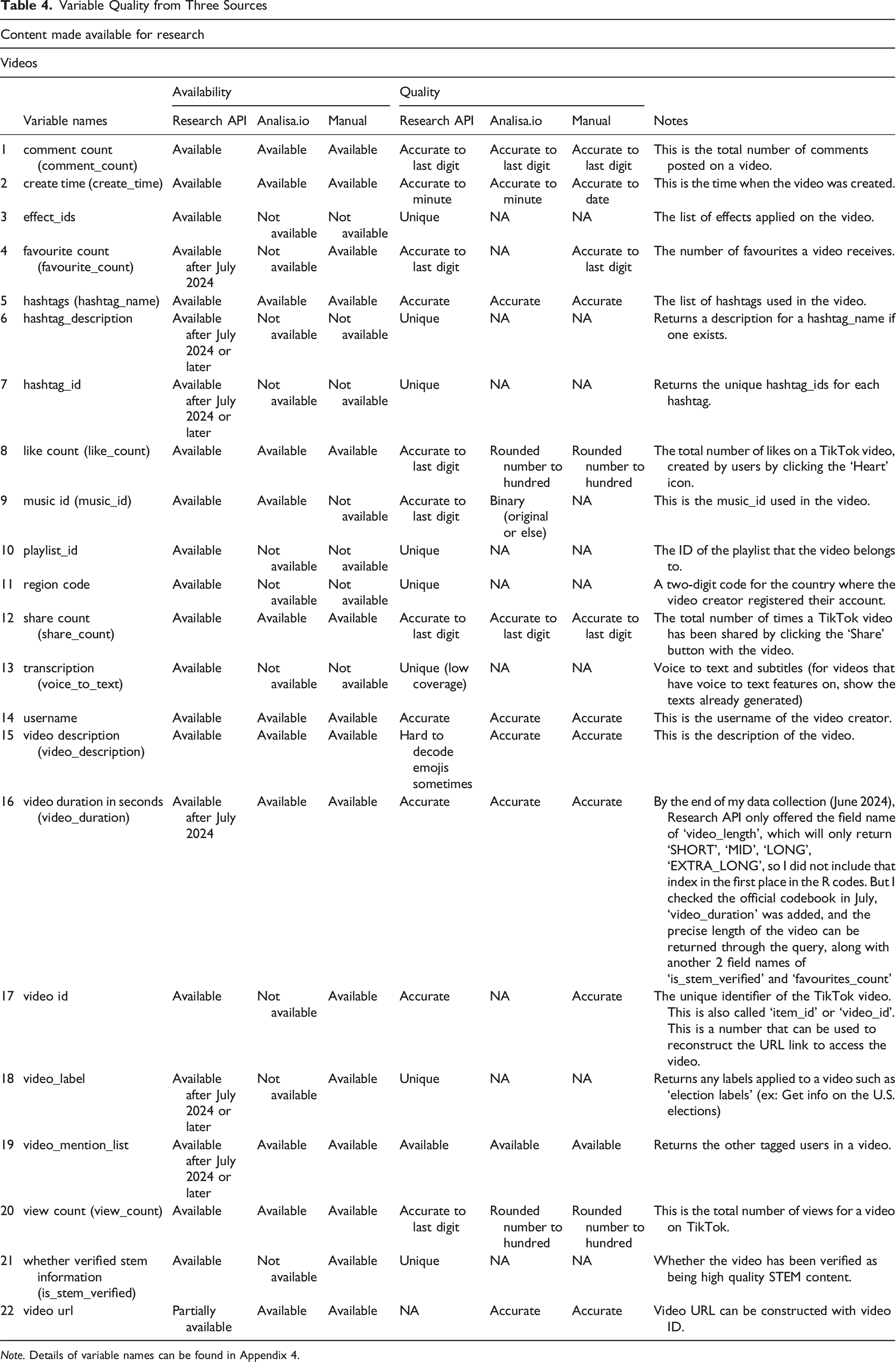
Note. Details of variable names can be found in Appendix 4.
Nonetheless, the API has limitations; for example, it fails to decode emojis in video descriptions but showed ‘garbled text’ or ‘mojibake’ (Kita et al., 2022) when data are exported into CSV or Excel formats, requiring manual correction and extra online tools (Faust, 2017/2024) during cleaning. Furthermore, some variables (e.g. favourite count, hashtag description, and video duration) were introduced incrementally after the API’s initial release.
Variable Quality: Like Count
Across both manual and API sources (N = 10 creators, 8,424 observations), the average like count per observation was Monthly like count by data source (manual and API)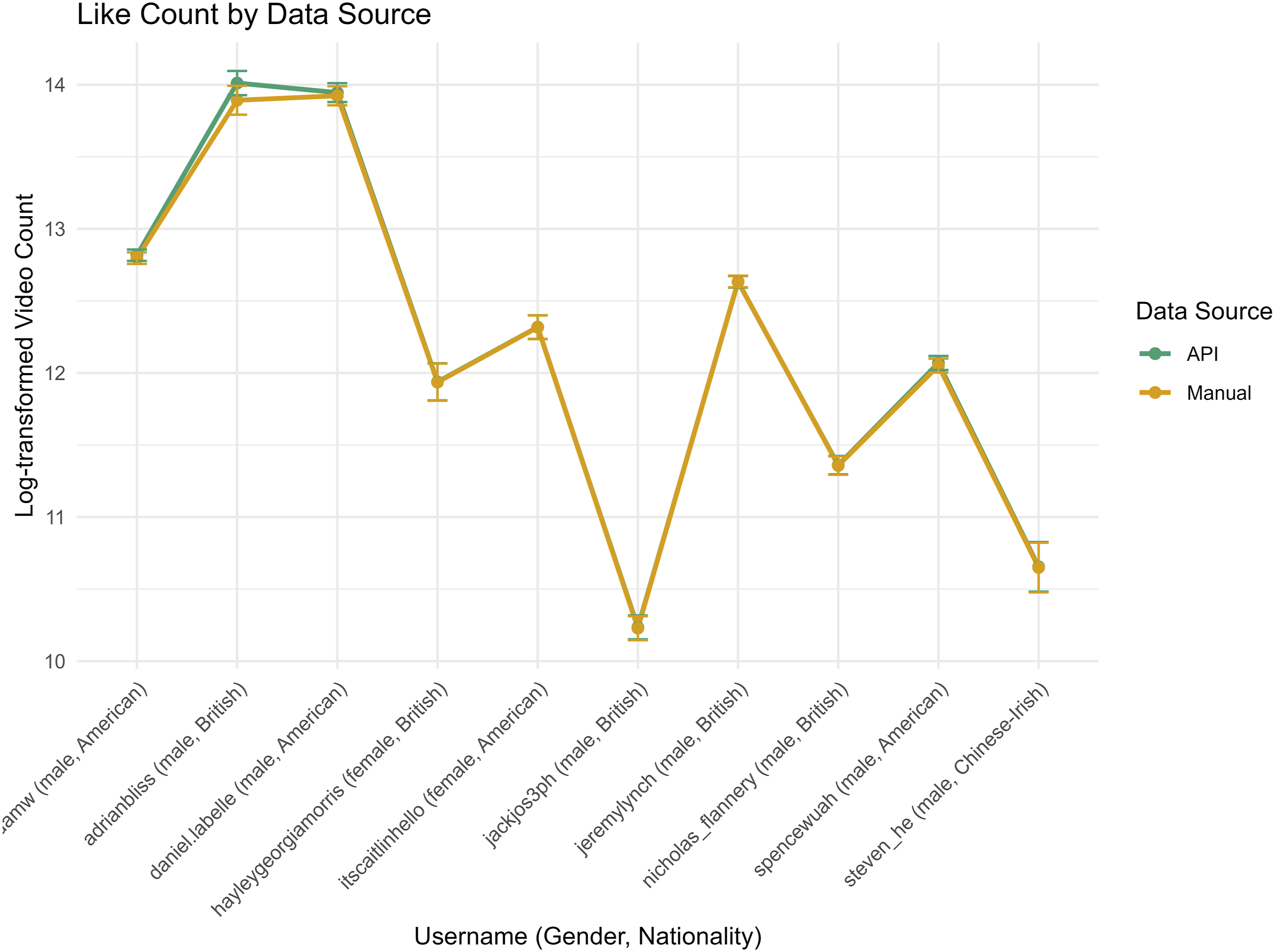
In the model including all 10 creators (excluding those without purchased data), the year of posting emerged as a significant predictor of like counts: relative to 2020, like counts were higher in 2021
When the two optional candidates were excluded, the pattern persisted. Data source effects remained negligible (
Variable Quality: View Count
As for the view count ( Monthly view count by data source (manual and API)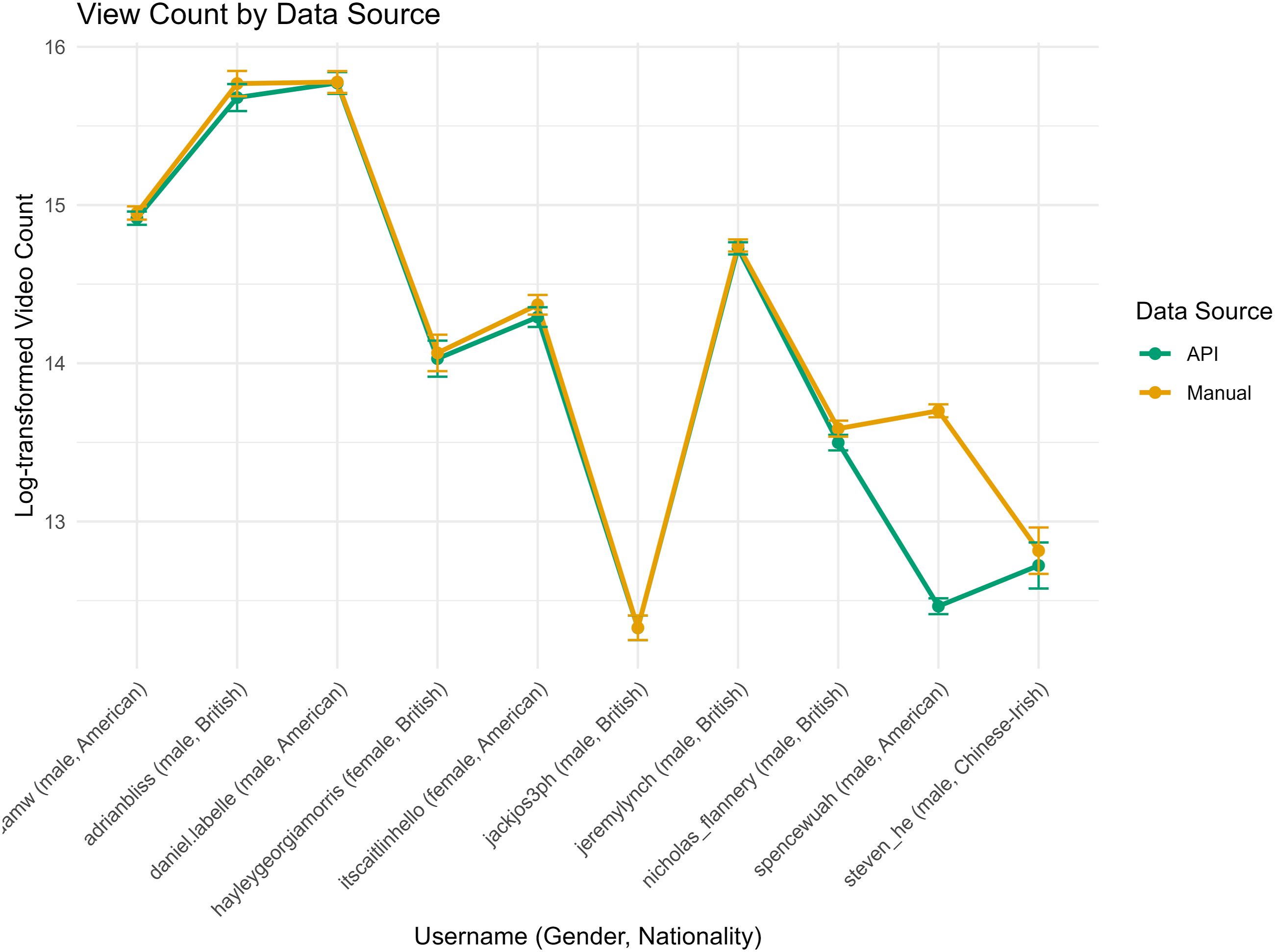
An analysis including all 10 creators showed that API-sourced counts were significantly fewer than manual counts (
Variable Quality: Comment Count
In terms of comment count ( Monthly comment count by data source (manual and API)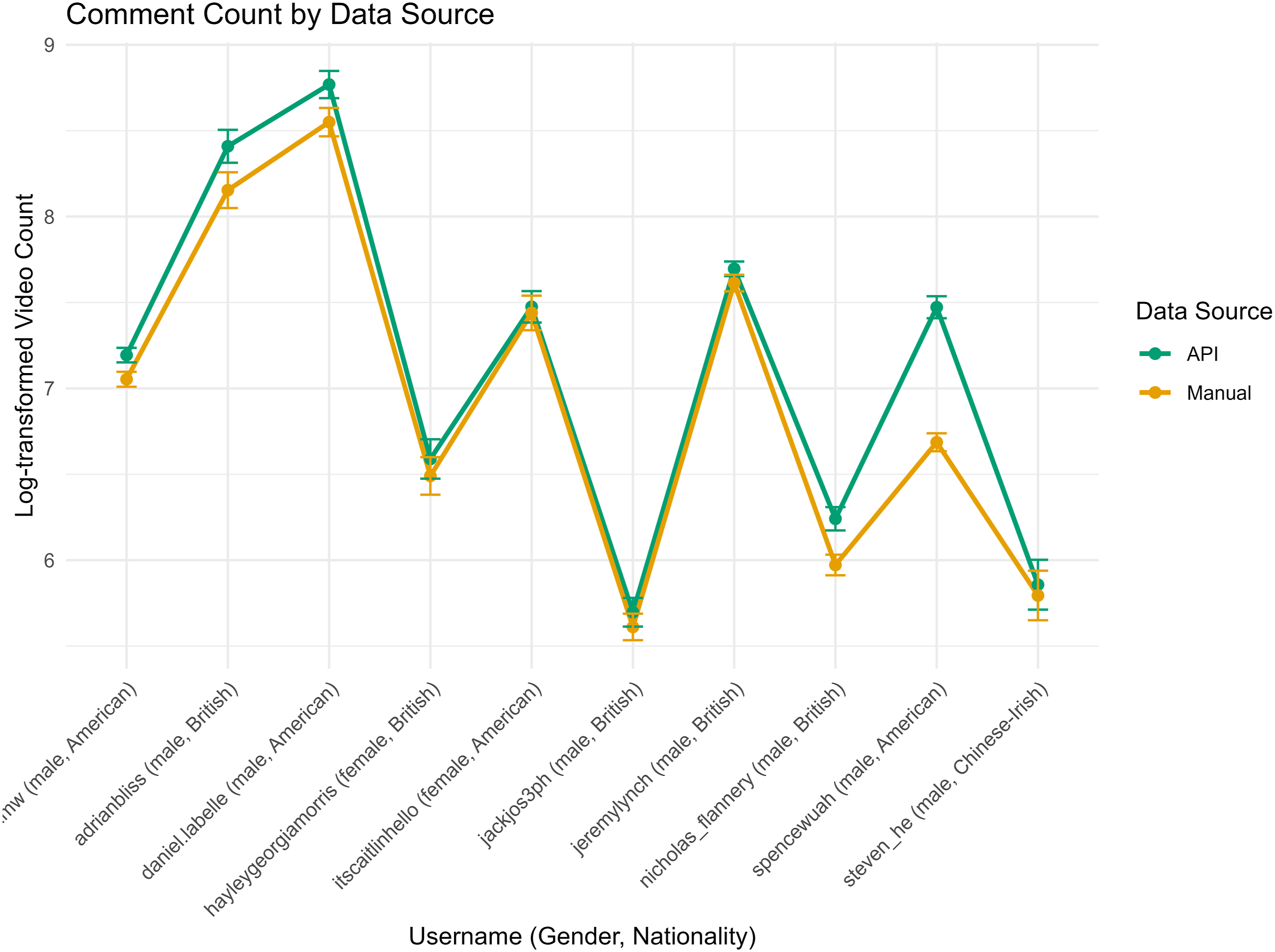
The data source predicted comment counts: API-sourced counts were significantly higher than manual counts (
Variable Quality: Share Count
As for share count ( Monthly share count by data source (manual and API)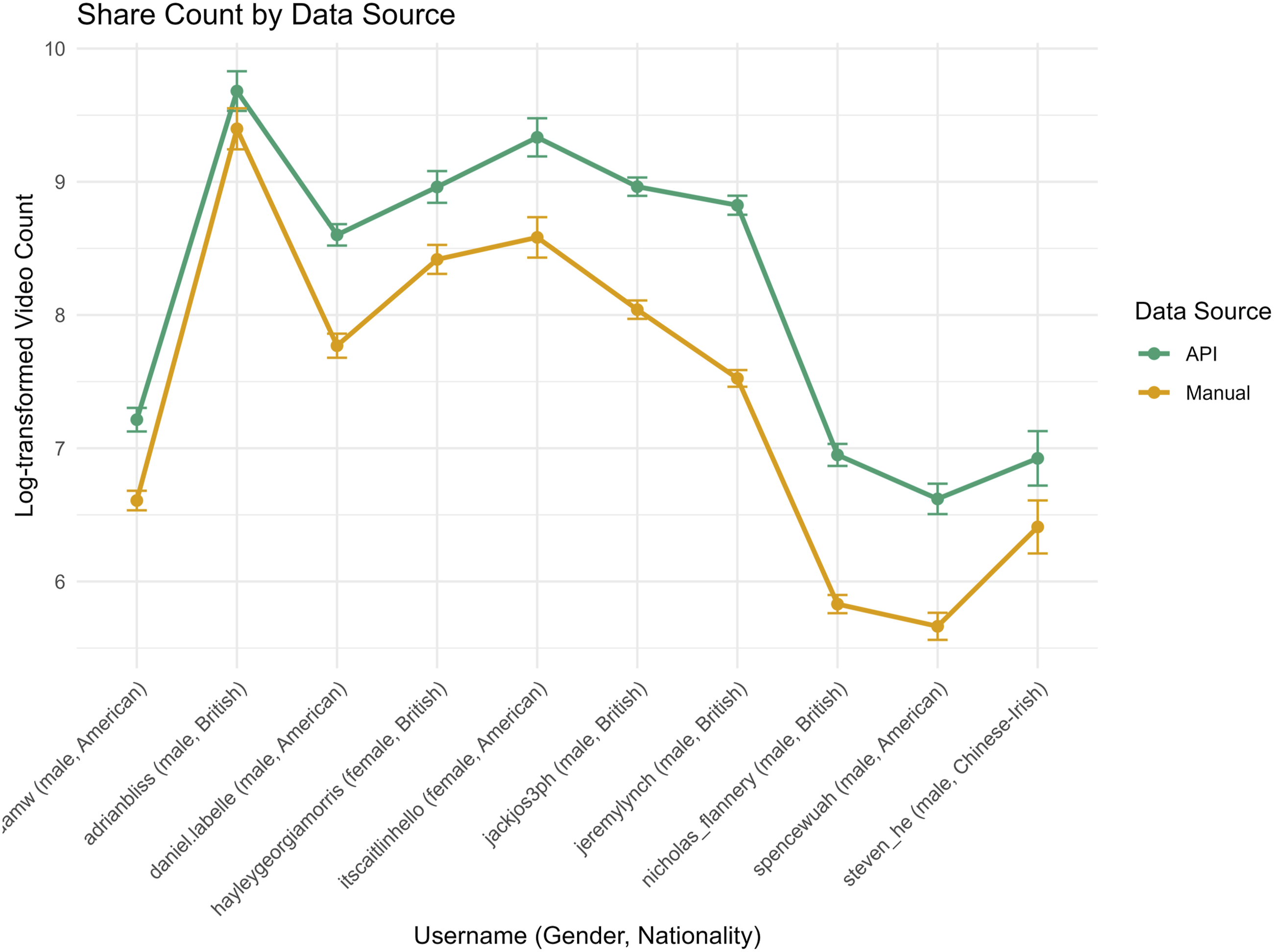
Similar to comment counts, the analysis confirmed that API-sourced share counts were substantially higher than manual counts (
Variable Quality: Transcription
The API returns voice-to-text transcriptions, one of its unique fields, though only for approximately 10% of videos on average (Figure 11) out of API-driven dataset. A binomial logistic regression model (n = 12) was fitted to examine whether transcription percentages (number of transcriptions divided by the number of videos) varied by creator nationality and gender, excluding two optional candidates (@steven_he and @nicholas_flannery). Main effects suggested that British creators had higher odds of transcription than American creators ( Transcription rate of research API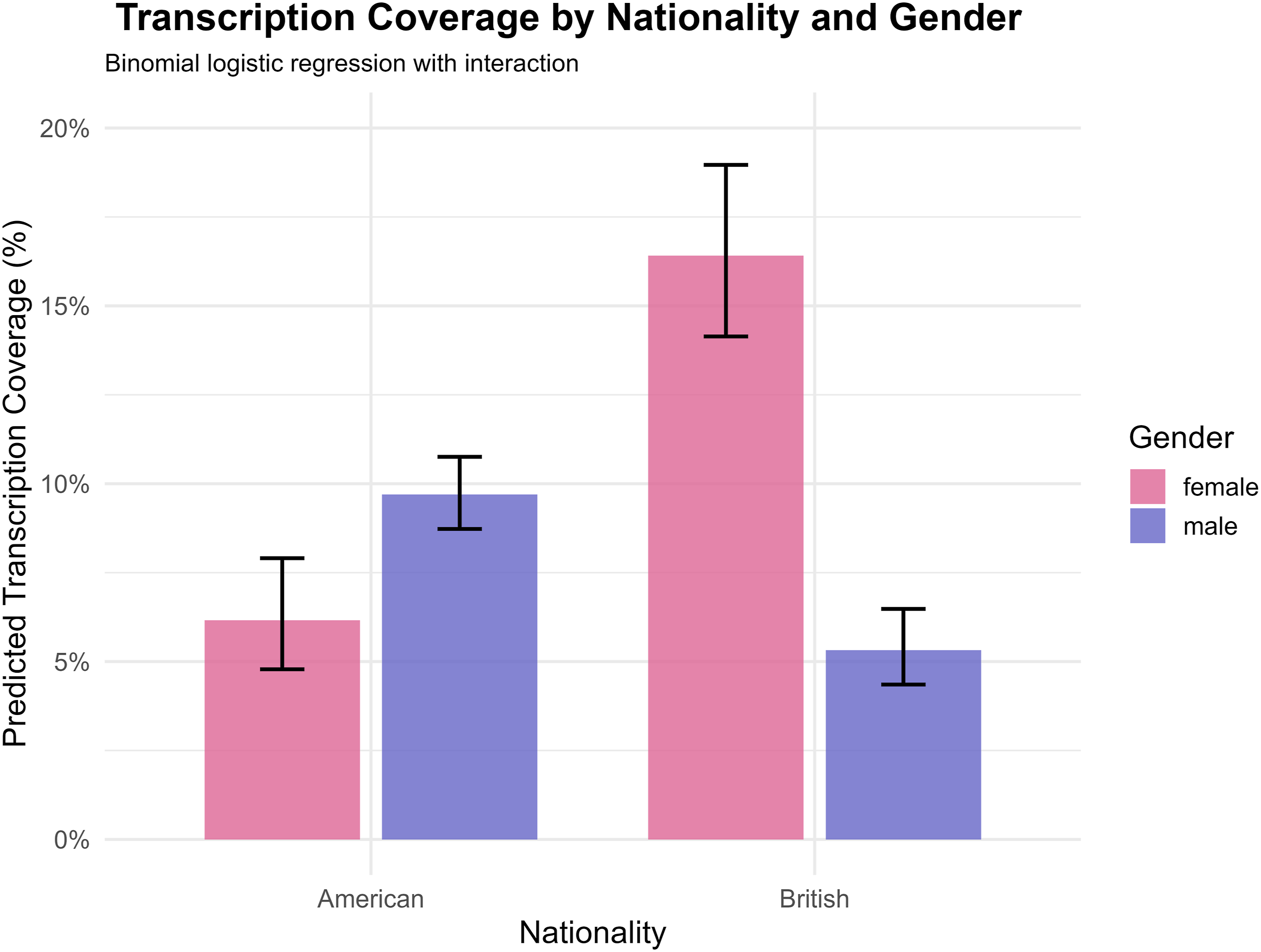
Post-hoc Tukey-adjusted pairwise comparisons revealed that British females had significantly higher odds of transcription coverage than American females (odds ratio =
Discussion
This study has critically evaluated the TikTok Research API’s capacity to support computational social science, addressing its effectiveness for multimodal data collection (RQ1), the manifestation of biases in retrieved data (RQ2), and the potential of multi-method integration to mitigate these challenges (RQ3). Drawing on a dataset of 6,373 videos collected via multiple methodologies, the findings depict a nuanced landscape: the API offers clear strengths, notably scalable, ethically compliant retrieval, yet these are offset by inconsistent metadata and systematic demographic biases.
The analysis reveals marked variability in video counts, engagement metrics, and transcription coverage across creators, with patterns strongly influenced by data source, nationality and gender for transcriptions. First, the Research API retrieves marginally higher video volumes than alternative methods whilst providing access to unique variables unavailable through manual collection or third-party services. However, this advantage proves uneven, as differences between data sources appear concentrated among specific creators rather than reflecting universal measurement biases. Second, whilst data source and year exert a substantial influence on engagement metrics, gender and nationality do not. The consistent API advantage in engagement metrics raises questions about whether this reflects genuine behavioural differences or artefacts of the retrieval process.
Third, observed differences in transcription rates require careful interpretation. It is important to note that TikTok’s Automatic Captions feature was only introduced in April 2021 (TikTok Newsroom, 2021), during the middle of our study period (2020–2022). Because creators had the option to enable captions, this may explain why transcripts generated via the API appear predominantly after that launch date and are absent beforehand. The decision to activate voice-to-text functionality rests with individual creators rather than the API itself. However, the uneven distribution of transcripts across demographic groups suggests that uptake patterns may reflect broader systemic factors. It is plausible that American creators adopted this functionality at higher rates than their British counterparts, which could account for regional variation. Similarly, differential adoption rates between male and female creators may point to underlying inequalities in platform literacy, technical confidence, or community norms around accessibility features. Whilst the API faithfully returns whatever transcriptions creators have enabled, these creator-level choices may themselves be shaped by demographic and cultural contexts. This raises important questions about equity in platform feature adoption and the extent to which automated systems can perpetuate existing social disparities even when those systems function as designed.
These results carry important implications for future research employing multiple data collection strategies in computational social science. While the API’s quantitative advantages are evident, they are compromised by technical inconsistencies and demographic skews that raise fundamental questions about validity and representativeness in societal trend analyses. Addressing these limitations will require methodological designs that integrate complementary sources, apply rigorous bias detection, and ensure transparency in reporting.
Multimodal Data Collection: Capabilities and Constraints (RQ1)
Quantitative Superiority and Scalability Advantages
The analysis indicates that the TikTok Research API is highly effective for large-scale data acquisition, outperforming purchased datasets and manual collection in quantitative terms. Linear mixed-effects models confirm that it retrieves more videos overall, though results remain sensitive to sample composition. Meanwhile, the study suggests that API-sourced data systematically capture higher viewing, commenting, and sharing activity. Crucially, its advantage extends beyond volume: the API grants access to unique variables – including transcriptions, effect identifiers, and precise metadata fields – that remain unavailable through alternative approaches. These affordances enable rapid assembly of large longitudinal datasets, facilitating both quantitative modelling and qualitative content analysis.
This scalability marks a significant advance for computational social science. It enables the rapid assembly of datasets that would be prohibitively resource-intensive to collect manually. The ability to retrieve historical content spanning multiple years further enhances its value for longitudinal studies, particularly those examining temporal dynamics during crisis periods such as the COVID-19 pandemic. These capabilities support a wide range of analytical approaches, from quantitative modelling of engagement metrics to qualitative content analysis.
Technical Constraints Undermining Data Validity
Yet these strengths are tempered by technical shortcomings that compromise validity. Unstable API performance, consistent with Ruz et al. (2023), produces inconsistent data volumes across collection periods. Content visibility and access issues arise through deletion or privacy settings, rendering content inaccessible via the API (TikTok for Developers, 2024), whilst manual calibration remain limited to publicly available videos. The outlier ‘@spencewuah’ illustrates marked discrepancies in video counts between API and manual sources.
Further distortions occur because the API includes archived videos, such as drafts, inflating counts relative to platform-visible data. More data returned by the API does not necessarily represent better quality but may compromise results when researchers focus on platform-accessible content. Transcription coverage is particularly sparse; voice-to-text data exist for around 10% of videos, predominantly from 2021 onwards. This temporal skew excludes much of the early pandemic period from linguistic analysis, potentially obscuring shifts in discourse during initial lockdowns.
Metadata inconsistencies, notably the API’s failure to decode emojis, produce mojibake (Kita et al., 2022) and require manual correction (Faust, 2017/2024). As Cohn’s foundational work on the visual language of sequential images (2013) demonstrates, pictorial elements, whether in comics or digital media, operate within structured semiotic systems. Subsequent research on emoji sequencing (Cohn et al., 2019) extends this framework, showing that emoji, like other visual modalities, often lacks fully developed grammatical structures yet still interacts systematically with accompanying text. Such issues challenge Tromble’s (2021) assertion that minimal programming suffices for API research, as specialist intervention is often essential.
Additionally, the Research API cannot return or store video or audio data, which must be obtained through third-party services (see a list of possible services in Appendix 7). Prosody, captured through speech rhythm, intonation, and emphasis, offers cues to stance and affect otherwise absent from purely textual analysis (Arvaniti, 2020; Mauchand et al., 2020). In multimodal contexts, prosodic contours synchronise with gesture, jointly signalling pragmatic meanings such as information status, stance, and (im)politeness (Brown & Prieto, 2021; Kendon, 2004; McNeill, 2005). This integration supports the view that prosody and gesture operate as sister systems in sociopragmatic marking (Ambrazaitis & House, 2017; Prieto & Espinal, 2020). In short-form video, these systems work in concert with visual symbols including emoji, to form a tightly integrated semiotic ensemble.
Ethical Constraints and Access Limitations
Regional restrictions shape content availability through government bans, platform moderation, and algorithmic filtering (Zhao, 2024). In this study, some U.S.-origin videos were inaccessible from the United Kingdom, reducing dataset completeness and constraining cross-national comparison. These constraints expose the API’s limitations for longitudinal analysis and point to the need for multi-method calibration to safeguard validity. The API can increase data volume, but doing so demands substantial computational resources for processing and verification.
Technical and ethical constraints compound these issues. Strict retrieval limits and the requirement for formal ethical approval impede reproducibility, echoing earlier critiques of API-based research (Freelon, 2018). Access policies that privilege university-affiliated researchers raise equity concerns and appear misaligned with the EU’s Digital Services Act commitment to transparency (Burnat & Davidson, 2025). Challenges in data dissemination and retention derived from ToS still haunt open science (Bak-Coleman, 2023; Venkatagiri, 2023). Collectively, these barriers not only narrow the empirical scope but also shape the wider conditions under which regulated digital research is conducted.
Algorithmic and Demographic Biases: Compromising Research Equity (RQ2)
The analysis identifies pronounced disparities within TikTok Research API that compromise research equity. Transcription coverage systematically varies across demographic groups, with American and male creators demonstrating higher rates than their U.K. and female counterparts. Whilst the choice to enable TikTok’s Automatic Captions feature rests with individual creators, the observed patterns suggest that adoption may be influenced by broader structural factors.
Several mechanisms may account for these disparities. American creators may have adopted auto-captioning functionality at higher rates than British creators, potentially reflecting earlier exposure to the feature, stronger platform literacy, or differing community norms around accessibility. Similarly, gendered differences in transcription availability may stem from variations in technical confidence, awareness of accessibility tools, or expectations regarding content presentation. Research on digital inequalities has consistently demonstrated that platform feature adoption is rarely neutral but often reflects pre-existing social stratifications (Feng et al., 2021; Markl, 2022; Sari et al., 2021).
Moreover, even when creators do enable captions, the accuracy of automated speech recognition systems may vary systematically across demographic groups. ASR models are typically trained on datasets that over-represent certain dialects, accents, or demographic groups, leading to differential performance (Wassink et al., 2022). Creators whose speech patterns align with dominant training data enjoy greater transcription accuracy, whilst those outside these norms may experience lower quality outputs, potentially discouraging further use of the feature. This creates a feedback loop wherein initial technical disparities become reinforced through user behaviour.
These demographic skews have significant implications for the fairness and validity of societal trend analyses. Unrepresentative samples risk distorting interpretations of cultural phenomena, particularly in policy-relevant contexts where findings might inform interventions. In such cases, conclusions may disproportionately reflect the perspectives of privileged groups, limiting generalisability in global or gender-diverse settings. The marked attenuation of effects following outlier removal further indicates that extreme observations can disproportionately shape perceived differences between data collection methods. This underscores the importance of examining distributional properties and identifying influential cases before drawing inferences about data quality.
Multi-Method Integration: Mitigating Inconsistencies for Enhanced Validity (RQ3)
In light of the challenges identified in RQ1 and RQ2, the analysis demonstrates that integrating multiple data collection methods, combining API-derived data with manual calibration and third-party analytics, offers a robust means of improving validity. This triangulated approach mitigates inconsistencies such as video-count discrepancies and enhances completeness through cross-validation of engagement metrics. In doing so, it addresses both technical limitations and bias-related distortions, thereby strengthening the evidential base for subsequent interpretation.
The comparative analysis reveals systematic differences in how engagement metrics are captured across methods. Data source exerts a significant influence on reported values: videos obtained via the API exhibit lower log-transformed view counts than those gathered manually, yet higher comment and share counts. This asymmetry suggests that platform-specific definitions or calculation procedures for engagement metrics may differ between collection routes. In other words, the same video can appear to perform differently depending on the method used, a non-trivial complication for comparative research.
Multi-method integration also proves critical for examining temporal engagement patterns. The year of posting emerged as a consistent predictor across metrics, with videos from 2021 recording markedly higher engagement than 2020 content. It is reasonable that established creators benefit from a larger reach over time, also known as ‘cumulative advantage’ (De Oliveira Santini et al., 2020). These temporal shifts underscore the importance of accounting for contextual factors when interpreting engagement trends. Encouragingly, as of 15 August 2025, TikTok Research API includes a batch compliance task 10 feature (TikTok for Developers, 2024), allowing researchers to submit lists of video or comment identifiers for validation. This process enables verification of whether each identifier remains publicly accessible, supporting accurate reporting of dataset availability at the time of analysis.
By incorporating alternative transcription services such as Happy Scribe (see a list of possible services in Appendix 7) and cross-checking outputs, this methodological pluralism reduces the impact of incomplete coverage and demographic skew. Crucially, it enables researchers to distinguish findings that are robust across methods from those that are artefacts of a particular collection strategy. In periods of rapid social change, when data quality assumes heightened importance, such integration is not merely desirable but essential for producing credible, equitable, and generalisable insights.
Data Accessibility, Methodological Transparency, and Ethical Considerations
The empirical patterns identified in RQ1–RQ3 reinforce the existing literature on the tension between data legitimacy and research reproducibility in computational social science (Davidson et al., 2023), including demographic and algorithmic biases, metric inconsistencies across collection methods, and the benefits of multi-method integration. While the API enables structured, large-scale data retrieval, its utility is constrained by platform-imposed rate limits and post-hoc deletions by content creators. Such constraints, consistent with Ruz et al. (2023) and Entrena Serrano et al. (2025), undermine data completeness, particularly in longitudinal studies of temporally sensitive phenomena such as pandemic-related humour. Echoing Pfeffer et al. (2018), sample-streaming endpoints also exhibit non-random omissions, manipulation, and popularity bias, necessitating corrective measures such as stratified sampling or weighting to preserve representativeness.
Discrepancies in engagement metrics further complicate interpretation. API-sourced videos tend to report lower view counts, but higher comment and share counts than manually collected equivalents, aligning with Pearson et al. (2025), who show that both data source and year significantly influence TikTok viewership. Notably, no significant effects emerged for data source in like-count analyses, suggesting that likes may be more consistently measured across methods. These asymmetries highlight the need for methodological transparency when comparing engagement metrics derived from different pipelines.
Ethical considerations compound these methodological challenges. The API’s exclusivity disadvantages independent scholars and civil society groups, reinforcing structural inequities in research access. Moreover, its granular engagement data, including comment histories, raise privacy risks such as potential deanonymisation, even within TikTok’s consent frameworks (Mimizuka et al., 2025). These risks are magnified in high-stakes contexts such as public health or political discourse, where the digital divide exacerbates disparities in who can produce, access, and analyse data (Bezjak et al., 2018; Rossi & Lenzini, 2020). Robust ethical protocols and transparent governance are therefore imperative to balance analytical utility with accountability.
By leveraging a large, balanced dataset spanning two nations and genders, this study addresses the limitations of prior TikTok research, which often relied on smaller, non-systematic samples (e.g. Cervi & Divon, 2023). It complements emerging machine-learning applications of the TikTok Research API in political and behavioural domains (Corso et al., 2024; Pearson et al., 2025), while applying a critical social science lens to issues of methodological rigour and representational equity. The findings affirm the API’s potential as a scalable, compliant tool for computational social science, but also underscore the necessity of multi-method strategies to mitigate its shortcomings. Balancing its strengths (volume, unique variables) against its weaknesses (quality, bias) offers a framework for best practice in ensuring validity and fairness, contributing to the ongoing discourse on platform-based methodologies.
Study Limitations
Whilst this study offers valuable insights into TikTok Research API for social science research, several limitations must be acknowledged. First, the restricted sample of creators poses a notable constraint. With data drawn from only 14 creators based in the United States and the United Kingdom, the findings may not fully represent the diverse TikTok creator population. This limitation restricts the generalisability of the results, particularly for creators from other regions or with varying audience demographics (Herring, 2009; Lomborg & Bechmann, 2014).
Second, the discrepancies between API and manual coding are unlikely to be attributable solely to time accumulation. Although the API data were collected several months after the manual coding, potentially inflating shares and comments by allowing more time to build up, uploads within a fixed past period are not changed, yet the API still reports more uploads (suggesting manual under-coverage rather than a timing artefact). Moreover, despite this timing advantage, the API shows fewer views, indicating that view differences are not explained by timing alone and likely reflect differences in coverage or measurement.
Additionally, the TikTok Research API introduced challenges affecting data quality. Transcriptions were available for approximately 10% of videos, limiting the scope of linguistic analysis. Inconsistent metadata accuracy, such as discrepancies in engagement metrics, further complicates the reliability of the findings. Finally, methodological constraints warrant consideration. The study’s timeframe (2020–2022) may not reflect longer-term trends, whilst the integration of manual calibration with API data risks introducing inconsistencies. These limitations suggest caution in interpreting the results and highlight avenues for future research, such as expanding the sample diversity and refining data collection methods.
Conclusion
This study set out to interrogate the reliability, representativeness, and ethical dimensions of TikTok Research API, using a large, balanced dataset to examine how methodological choices shape the validity of social media research. By systematically addressing RQ1–RQ3, it has shown that while the API offers unprecedented opportunities for structured, large-scale analysis, its outputs are neither neutral nor complete. Algorithmic and demographic biases, metric inconsistencies, and coverage gaps are not peripheral flaws but structural features of the data environment, features that, if left unexamined, risk distorting scholarly narratives and policy-relevant insights. Yet these limitations are tractable: multi-method integration, bias-aware modelling, and transparent reporting can materially improve both the equity and reproducibility of platform-based research.
This critical assessment highlights the API’s dual character. On the one hand, it provides compliant and scalable access to multimodal data, and offers a legally sanctioned means of integrating quantitative and qualitative analyses (Nguyen & Diederich, 2023). On the other hand, it exhibits technical instability, systematic biases towards American and male creators, and restrictive ethical constraints. Whilst the API enhances computational social science by enabling diverse analytical approaches, its shortcomings in data quality, transparency, and accessibility necessitate a multi-method strategy to ensure valid and equitable insights. By doing so, this research contributes to ongoing debates on platform governance and methodological pluralism, demonstrating how comparative strategies can offset the deficiencies of single-source datasets. Enhancing the reliability and representativeness of social media data remains essential for robust societal understanding and for fostering a more equitable digital research ecosystem.
Future work should adopt integrated approaches, combining API data with manual scraping or third-party platforms to cross-validate findings and address coverage gaps. Documenting discrepancies enhances transparency (Bezjak et al., 2018), while post-weighting adjustments can counter demographic biases (Ohme et al., 2024). Platform developers, for their part, should increase retrieval limits, expand transcription coverage, clarify metric definitions, and broaden access beyond academic institutions to promote inclusivity.
Finally, these findings open pathways for comparative API studies, for example, across Douyin, YouTube Shorts, and Instagram Reels, and for deeper examination of transcription biases and algorithmic opacity, particularly in relation to misinformation and political mobilisation. Leveraging automated tools or language models offers further potential, provided ethical standards are upheld. In this way, social media research can evolve to meet contemporary challenges while remaining methodologically rigorous, transparent, and fair.
Supplemental Material
Supplemental Material - Harnessing Big Data, Hindered by Bias: Evaluating TikTok Research API for Fair and Optimal Social Sciences
Supplemental Material for Harnessing Big Data, Hindered by Bias: Evaluating TikTok Research API for Fair and Optimal Social Sciences by Dan Bai and Yan Gu in Social Science Computer Review.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
Notes
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.