
Abstract
Online survey participants are frequently recruited through social media platforms, opt-in online access panels, and river sampling approaches. Such online surveys are threatened by bots that shift survey outcomes and exploit incentives. In this proof-of-concept study, we advance the identification of bots driven by Large Language Models (LLMs) through the prediction of LLM-generated text in open narrative responses. We conducted an online survey on same-gender partnerships, including three open narrative questions, and recruited 1512 participants through Facebook. In addition, we utilized two LLM-driven bots, each of which responded to the open narrative questions 400 times. Open narrative responses synthesized by our bots were labeled as containing LLM-generated text (“yes”). Facebook responses were assigned a proxy label (“unclear”) as they may contain bots themselves. Using this binary label as ground truth, we fine-tuned prediction models relying on the “Bidirectional Encoder Representations from Transformers” (BERT) model, resulting in an impressive prediction performance: The models accurately identified between 97% and 100% of bot responses. However, prediction performance decreases if the models make predictions about questions they were not fine-tuned with. Our study contributes to the ongoing discussion on bots and extends the methodological toolkit for protecting the quality and integrity of online survey data.
Keywords
Introduction
Online surveys have increasingly replaced traditional survey modes, especially face-to-face interviews (Callegaro et al., 2015; Schober, 2018). Many prominent survey programs, such as the European Social Survey (ESS) and the European Values Study (EVS), have adopted online data collection methods. Online surveys offer significant advantages in reducing expenses and saving time, making them a strong option for meeting the rising need for survey data (Knowledge Sourcing Intelligence, 2023). Nevertheless, online surveys face methodological challenges. A primary issue is their tendency to achieve low response rates. For instance, the meta-analysis by Daikeler et al. (2020) indicates that participation rates in online surveys are approx. 12% lower than those in other survey modes (see also Lozar Manfreda et al., 2008).
Given the challenges of low participation rates in online surveys, researchers are exploring alternative methods for recruiting participants, such as social media platforms (Zindel, 2023), opt-in online access panels (Lehdonvirta et al., 2021), website ads or pop-ups (so-called river sampling; Murray-Watters et al., 2023), and crowdsourcing platforms (Peer et al., 2022). Although these methods allow for rapid access to a vast and diverse pool of participants, concerns arise about the quality and integrity of the data collected. One major concern is bots—automated programs that interact with digital systems, including online surveys (Griffin et al., 2022; Höhne, Claassen, Shahania, & Broneske, 2025; Storozuk et al., 2020; Xu et al., 2022; Yarrish et al., 2019; Zhang et al., 2022). Bots can distort survey results, potentially biasing political and social decisions (Xu et al., 2022). This is particularly concerning given evidence of bots being used to sway public opinion, such as during the 2016 referendum on the UK’s departure from the European Union (Gorodnichenko et al., 2021) and the South Korean presidential election of 2022 (Zhang et al., 2024). The impact of bots on online surveys can be severe. First, responses synthesized by bots often differ from those of humans, introducing measurement error in the data (Xu et al., 2022). Second, the involvement of bots can erode confidence in social science research, exacerbating the impact of misinformation on public discourses (Xu et al., 2022). Finally, bots can cause both direct financial losses by exploiting survey incentives and indirect costs due to the substantial effort required for their identification and prevention (Storozuk et al., 2020; Xu et al., 2022).
Existing Strategies for Detecting Bots in Online Surveys
Most recently, an online survey on the car manufacturer Tesla was shut down early because of suspiciously high completion rates and sudden shifts in survey outcomes, pointing to potential bot infiltration (see https://www.t-online.de/finanzen/aktuelles/wirtschaft/id_100642002/tesla-umfrage-wegen-manipulationsverdacht-gestoppt-musk-teilt-artikel.html). Despite the significant threat of bots, studies focusing on bots in online surveys remain very limited. The few existing investigations mostly focus on simple prevention and identification strategies. One commonly used approach is to employ CAPTCHAs (challenge-response tests), which require participants to complete specific tasks, such as identifying objects in images, to block bots from entering online surveys (Storozuk et al., 2020). Another method involves honey pot questions. These questions are hidden queries embedded in the survey’s source code that are invisible to human participants but are captured and potentially responded to by bots, making them a tool for identifying fraudulent bot responses (Bonett et al., 2024). Furthermore, the analysis of paradata (i.e., auxiliary data describing the data collection process; West, 2011), such as response times, is considered an effective way to identify bots, as their response speed may not align with the complexity of survey questions or tasks (Nikulchev et al., 2021).
A review of research on bots in online surveys reveals a widespread underestimation regarding the capabilities of bots driven by Large Language Models (LLMs). As LLMs are trained on large text corpora, they can generate text and solve complex, text-based tasks (see Naveed et al. (2025) and Zhao et al. (2023) for basic information on LLMs). For example, Höhne, Claassen, Shahania, and Broneske (2025) demonstrate in a descriptive study that their two LLM-driven bots reliably solve attention checks (in addition to overcoming CAPTCHAs and honey pot questions). With a connection to the LLM Gemini Pro (Google, 2024), the bots can simulate human-like response behavior and provide coherent and meaningful responses to open narrative questions. Similarly, Westwood (2025) developed an automated, synthetic respondent (or bot) with a connection to OpenAI’s LLM o4-mini. Among other things, the synthetic respondent can solve various types of attention checks and provide plausible responses to open narrative questions. To ensure the integrity of future online surveys, it is thus necessary to develop new strategies for bot prevention and identification that consider the remarkable capabilities of LLM-driven bots.
A particularly promising approach is represented by predicting whether or not the text of a given response was generated by an LLM (Ghosal et al., 2023; Wu et al., 2025). Although LLMs can produce text that appears meaningful and authentic, previous research indicates that LLM- and human-generated text generally differs with respect to linguistic characteristics, including grammar and word choice (Muñoz-Ortiz, Gómez-Rodríguez, & Vilares, 2024; Reinhart et al., 2025). Various “out-of-the-box” software tools for identifying LLM-generated text have been developed in recent years, but these tools often perform poorly when put to the test (Bhushan et al., 2025; Chaka, 2023; Lebrun, Temtsin, Vonasch, & Bartneck, 2024). In contrast, fine-tuned transformer models appear to identify LLM-generated text with comparatively high reliability (Guo et al., 2023; Rodriguez et al., 2022; Sundararaj et al., 2024). This points to the importance of fine-tuning a prediction model to its respective application, such as identifying LLM-generated text in open narrative responses.
Research Question
This proof-of-concept study advances the identification of bots in online surveys by predicting LLM-generated text in open narrative responses. Specifically, we fine-tuned a series of prediction models by leveraging the “Bidirectional Encoder Representations from Transformers” (BERT) model (Devlin et al., 2019). For this purpose, we conducted an online survey on same-gender partnerships, as research suggests that such surveys have been infiltrated by bots in the past (Bybee et al., 2022; Griffin et al., 2022). Participants for this online survey were recruited through the social media platform Facebook and asked three open narrative questions. In addition, we utilized the two LLM-driven bots programmed by Höhne, Claassen, Shahania, and Broneske (2025) and synthesized open narrative responses to the same three questions. Our investigation thus addresses the following research question:
Can we identify bots in online surveys by predicting LLM-generated text in open narrative responses?
In what follows, we outline the survey data collection through Facebook and report its sample characteristics. We then describe the capabilities of the two LLM-driven bots, the data synthesis process, the open narrative questions, and the analytical strategy adopted in this study. Subsequently, we present the results and bot predictions and close with a discussion and conclusion, in which we address limitations of our study design, such as uncertainty regarding the authorship of Facebook responses, and formulate recommendations for future research.
Method
Survey Data Collection and Sample Description
We conducted a self-administered online survey on same-gender partnerships. In doing so, we selected a real-world survey topic for our proof-of-concept study because online surveys on similar topics have presumably been subject to bot infiltration in the past (Bybee et al., 2022; Griffin et al., 2022). In total, the online survey included 43 (closed and open narrative) questions, tasks, and instructions that were distributed over 28 online survey pages, with a median completion time of about 10 minutes. Importantly, for the present study, we focus on three open narrative questions. We recruited participants in Germany through Facebook ads that were placed in the newsfeed. The online survey ran from 5th February to 18th March 2024. To mitigate self-selection bias, we utilized a 3-by-2 quota design based on the German Microcensus, which is a small population census in the form of an annual household survey of official statistics in Germany (DESTATIS, 2024). Specifically, we launched six Facebook ads that were tailored to the respective combination of age and gender (e.g., “middle-male” or “young-female”). When running Facebook ads for recruiting online survey participants, researchers can set a budget for the ad campaign and Facebook automatically removes ads once the limit of the budget is reached (see Appendix A for a screenshot of the Facebook ad). In this study, we set a maximum budget of about 1700€.
The ads included information on the topic of the online survey (i.e., same-gender partnerships), incentives (i.e., raffle of 5€), expected survey time, and the link to the online survey. The first online survey page provided information on the study procedure, the probability of receiving an incentive payment, and that the study adheres to existing data protection laws and regulations. This online survey was funded by the German Society for Online Research (DGOF) and approved by the Ethics Committee of the German Centre for Higher Education Research and Science Studies (DZHW).
Sample characteristics of the Facebook survey
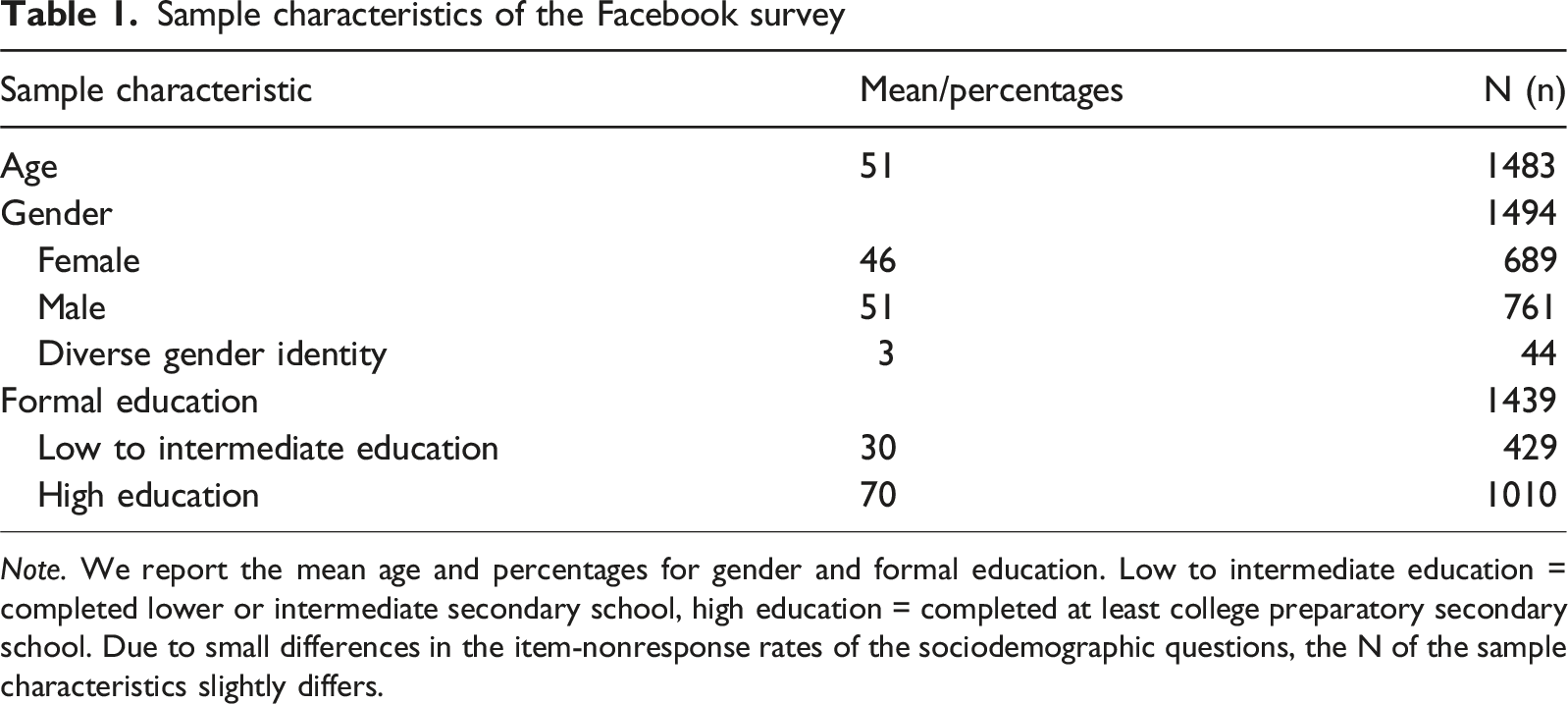
Note. We report the mean age and percentages for gender and formal education. Low to intermediate education = completed lower or intermediate secondary school, high education = completed at least college preparatory secondary school. Due to small differences in the item-nonresponse rates of the sociodemographic questions, the N of the sample characteristics slightly differs.
Bot Capabilities and Data Synthesis
We utilized the two LLM-driven bots with cumulative skillsets that were programmed by Höhne, Claassen, Shahania, and Broneske (2025, see Table 1 in their article): LLM bot (originally called “Medium-II bot”) and LLM+ bot (originally called “Advanced bot”). Both bots can deal with various online survey features, including closed questions, open (narrative) questions, honey pot questions, CAPTCHAs, and attention checks. The bots are linked to the LLM Gemini Pro (Google, 2024) and provide meaningful responses to open narrative questions. The LLM+ bot additionally keeps a history of the LLM responses to maintain consistency and is randomly assigned personas (e.g., gender and age). Figure 1 shows a screenshot of the LLM+ bot’s log output for an open narrative question. However, in contrast to Höhne, Claassen, Shahania, and Broneske (2025), we linked the bots to Gemini 1.5 Pro (version 002), which was newly released in September 2024. We also adjusted the persona setting so that it includes gender, age, education, and political party preference (see Appendix B for the persona setting). Screenshot of an open narrative question including log output of the LLM+ bot. Note. In the previous closed question on child adoption, the bot responded ”rather not good” and is now asked to explain its response in its own words. The log output, on the right, shows the history of the previous question (including closed response), as well as the open narrative response. In this trial, the LLM+ bot was assigned the following personas: male, 46 years old, low education, and preference for CDU/CSU (two united center-right parties).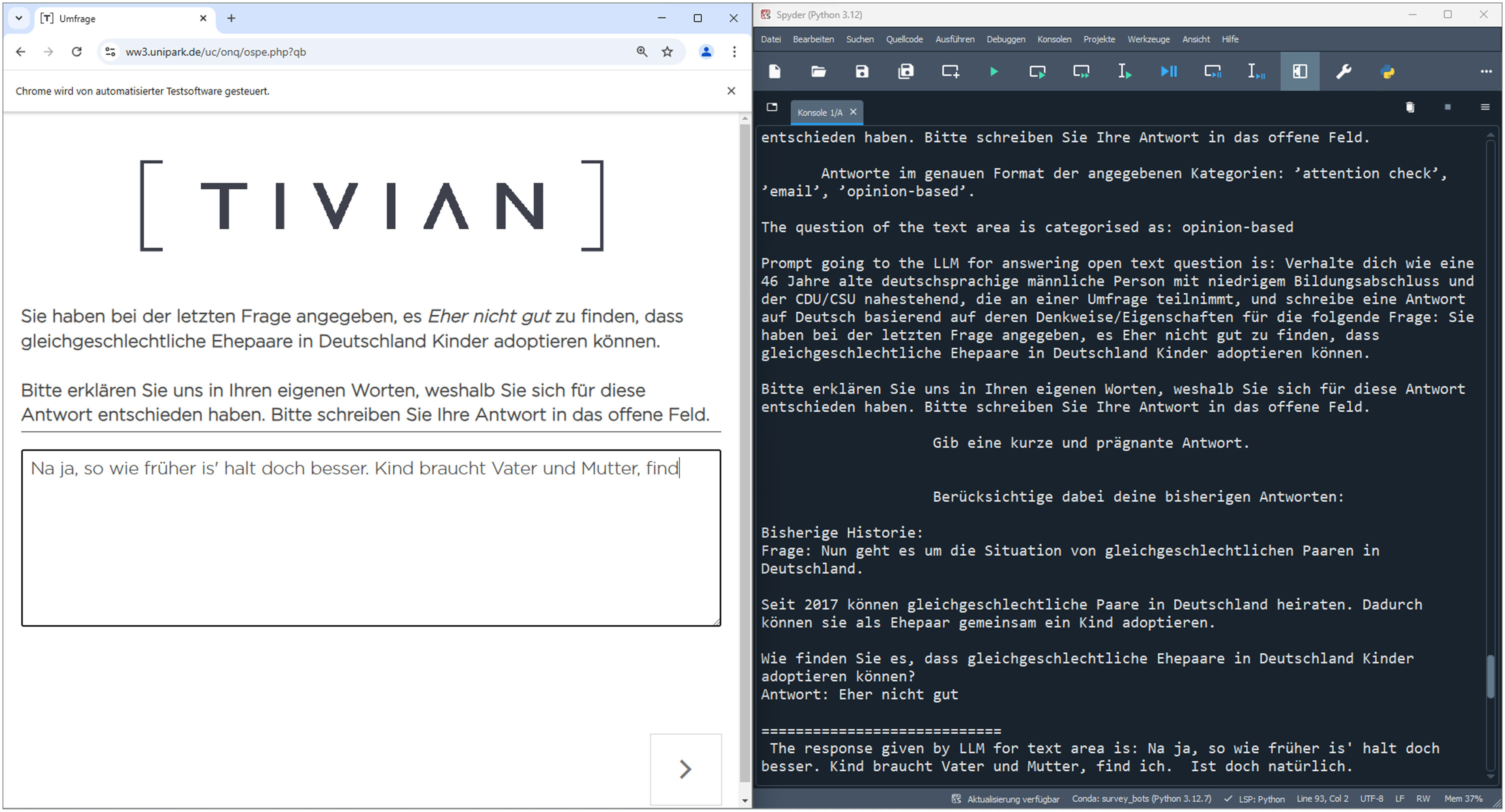
Each LLM-driven bot was instructed to respond to the three open narrative questions as well as a preceding closed question 400 times, resulting in a total of 800 bot responses to each question. In all bot runs, we logged the content of the questions, the responses provided by the bots, and all prompts for instructing Gemini Pro. Importantly, we tested two different prompt designs (Appendix B includes all prompts). First, we adopted the prompts by Höhne, Claassen, Shahania, and Broneske (2025) to have a baseline (baseline design). These prompts included the content of the questions and instructed Gemini Pro to provide meaningful responses. In case of the LLM+ bot, Gemini Pro was additionally instructed to consider the history and assigned personas. Second, we used the prompts of the baseline design but additionally instructed Gemini Pro to introduce misspellings in the bot responses (misspellings design). By introducing misspellings, we simulate human response behavior more closely, as research on open narrative questions indicates that human participants typically produce misspellings (Allamong et al., 2025). This is not necessarily the case for LLM-generated text. Based on the two prompt designs, we conducted data synthesis from 3rd February to 18th February 2025.
Open Narrative Questions
The first open narrative question (ONQ1) dealt with child adoption in same-gender partnerships and included a placeholder that was dynamically replaced with the response to the preceding closed question. 1 In particular, ONQ1 was designed as a so-called follow-up probe. The second question (ONQ2) dealt with discrimination against gay, lesbian, and bisexual people in Germany. Finally, the third question (ONQ3) was a final comment question. All three ONQs were accompanied by a five-line text field for the open narrative response (see Figure 1). Importantly, we did not restrict the number of characters in the text fields. The following formulations are English translations of the three ONQs (see Appendix C for the original German wordings):
ONQ1
In the last question, you indicated you find it [very good | rather good | rather not good | not good at all] that married same-gender partners in Germany can adopt children. Please explain to us in your own words why you chose this response.
ONQ2
In your opinion, to what extent is discrimination against gay, lesbian, and bisexual people a problem or no problem in Germany?
ONQ3
Finally, we would like to give you the opportunity to say something about our survey. Do you have any comments or suggestions on the survey as a whole or on individual questions?
Analytical Strategy
In the first step, we compared bot and Facebook responses by examining basic descriptive statistics, including item-nonresponse, unique responses (distinct or non-repeated responses), and response length (average number of words). To test whether differences are statistically significant, we estimated chi-squared tests for item-nonresponse and unique responses as well as one-way analyses of variance (ANOVA), including pairwise t-Tests with the Bonferroni correction procedure, for response length.
In the second step, we investigated whether the bots can be identified by predicting LLM-generated text in open narrative responses. We leveraged the transformer model BERT (Devlin et al., 2019) for our prediction models. BERT, although a pre-LLM-era language model, is still considered a competitive model for language classification tasks (De Santis et al., 2025). Relying on the transformer architecture, it considers word order and context, resulting in an improved natural language understanding compared to bag-of-word approaches that disregard word order and only consider word frequency (De Santis et al., 2025). For our application, we utilized the “bert-base-german-cased” model retrieved from Hugging Face (https://huggingface.co/google-bert/bert-base-german-cased) through the “Simple Transformers” library (Rajapakse et al., 2024). This version of BERT was pre-trained on German language data and is case-sensitive.
We fine-tuned this BERT version with a sample of our open narrative responses. We labeled each open narrative response based on whether it was synthesized by the two LLM-driven bots (LLM-generated text = “yes”) or collected through Facebook (LLM-generated text = “unclear”). To account for the uncertainty in response authorship, we decided to label Facebook responses as “unclear” as they may potentially contain bots themselves. This limitation is further discussed in the context of our results (see section “Discussion and Conclusion”). Using the binary label as ground truth, we fine-tuned three prediction models based on BERT, one for each ONQ. For the ONQ1 and ONQ2 models, we used all 800 bot responses and 800 randomly selected Facebook responses to create a balanced sample, respectively. In doing so, we followed previous empirical studies indicating that several hundred cases are typically sufficient for fine-tuning BERT models (Bach et al., 2025; Gweon & Schonlau, 2024). To ensure the authenticity of Facebook responses to the ONQs and limit bias in the training data, we did not apply any data cleaning procedures, such as excluding non-substantive text responses or removing stop words. Since BERT considers word order and context, cleaning the text responses may result in a loss of important (contextual) information. As only 632 participants in the Facebook survey provided a response to ONQ3, we used all Facebook responses and 632 randomly selected bot responses for the ONQ3 model. Again, this was done to achieve a balanced sample. To fine-tune each of the three prediction models, we used 60% of the responses for training, 20% for validation, and 20% for performance evaluation (previously unseen responses or “test set”). For hyperparameter tuning, we performed a grid search over all combinations of training epochs (5, 10, 15) and learning rates (1e-3, 1e-4, 1e-5).
As a post-hoc analysis, we employed the “transformers-interpret” library (https://github.com/cdpierse/transformers-interpret) to better understand the predictions of the fine-tuned models. In particular, we determined what tokens contributed most to the predictions by calculating attribution scores.
For replication purposes, data, analysis code, and the fine-tuned prediction models are available through Harvard Dataverse (see https://doi.org/10.7910/DVN/BIIZZA).
Results
Descriptive Results
Descriptive statistics
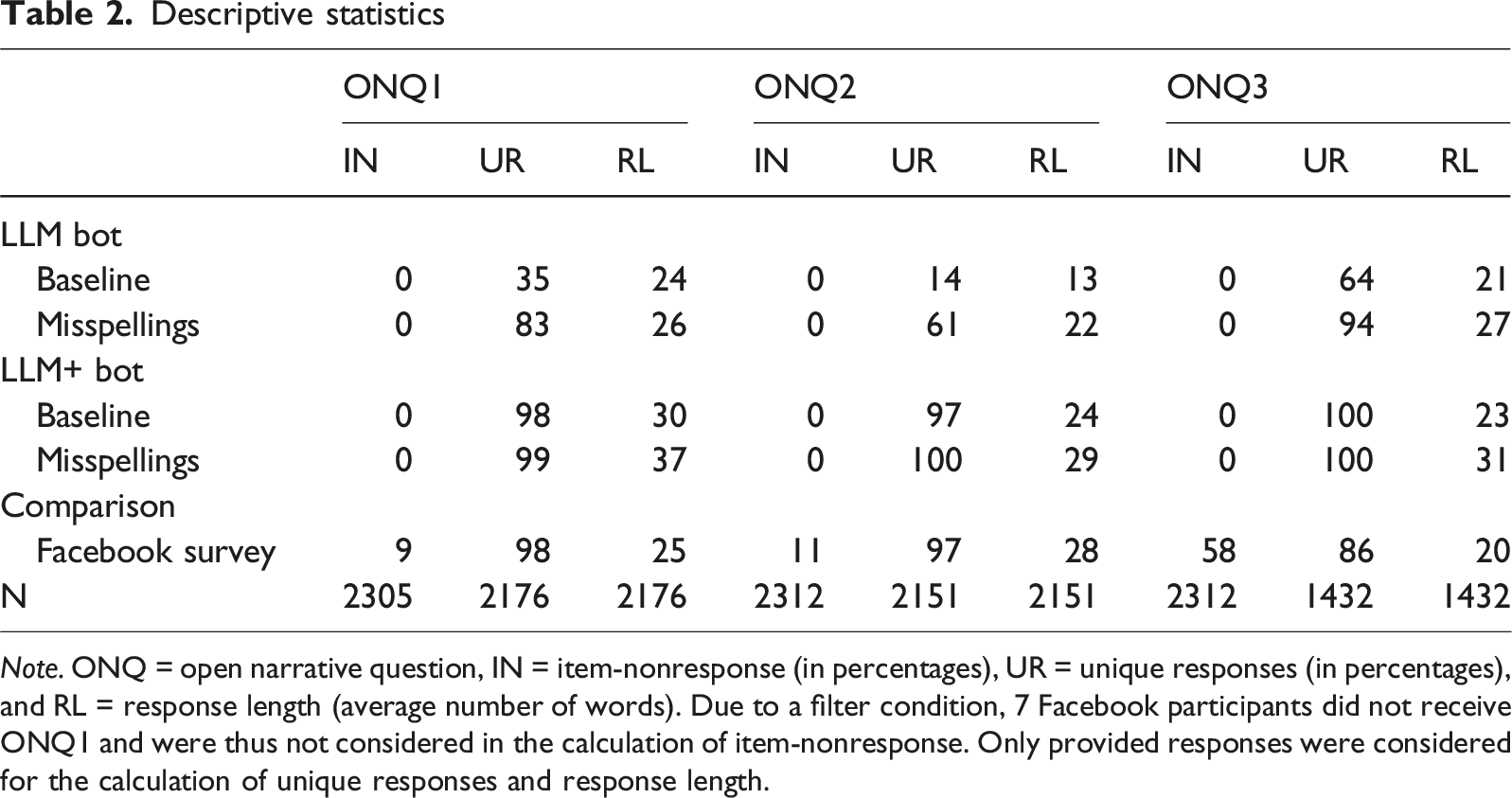
Note. ONQ = open narrative question, IN = item-nonresponse (in percentages), UR = unique responses (in percentages), and RL = response length (average number of words). Due to a filter condition, 7 Facebook participants did not receive ONQ1 and were thus not considered in the calculation of item-nonresponse. Only provided responses were considered for the calculation of unique responses and response length.
The average response length, in contrast, was similar between the LLM bot and the Facebook survey, but the LLM+ bot’s responses tended to be longer. This was more pronounced for the misspellings prompt design. Again, the differences in response length are statistically significant [ONQ1: F(4,2171) = 19.43, p < .001; ONQ2: F(4,2146) = 21.75, p < .001; ONQ3: F(41,427) = 18.38, p < .001].
Bot Predictions
Prediction performance

Note. ONQ = open narrative question. Predictions were made using fine-tuned versions (see Section “Analytical Strategy”) of the “bert-base-german-cased” model retrieved from Hugging Face (https://huggingface.co/google-bert/bert-base-german-cased). In-corpus predictions (bold diagonal) are based on the test set within the balanced samples. Cross-corpus predictions (values outside the bold diagonal) are based on all responses of the balanced samples.
Interestingly, all bot responses that were not accurately identified were synthesized by the LLM+ bot, suggesting that this bot is more difficult to identify than the less advanced LLM bot. However, recall is never lower than 0.9, even when looking at all pairwise combinations of our two bots and prompt designs separately (see Appendix D for disaggregated performance metrics by LLM-driven bot and prompt design). Overall, all three models performed extremely well, indicated by the F1 score ranging between 0.98 and 0.99.
In the second step, we examine the extent to which our models generalize to previously unseen ONQs. To this end, we used the three models to make predictions on the ONQs they were not fine-tuned with (cross-corpus predictions; see values outside the bold diagonal in Table 3). In four out of the six cases, recall was below 0.5. This indicates that less than 50% of the bot responses were accurately identified when the prediction models were not fine-tuned with the respective ONQs. Even though recall was now low, precision was still high (higher than 0.95), so positive predictions (LLM-generated text = “yes”) were almost always correct. The overall cross-corpus prediction performance of the three models was low, which is indicated by the F1 score ranging between 0.38 and 0.73. The only exception is the ONQ2 model, as its predictions on ONQ1 achieved a F1 score of 0.93. These findings indicate that cross-corpus predictions do not work well in the context of our ONQs. This especially applies when comparing them to the far superior in-corpus predictions.
Token Contributions
Top five contributing tokens by ONQ and prediction
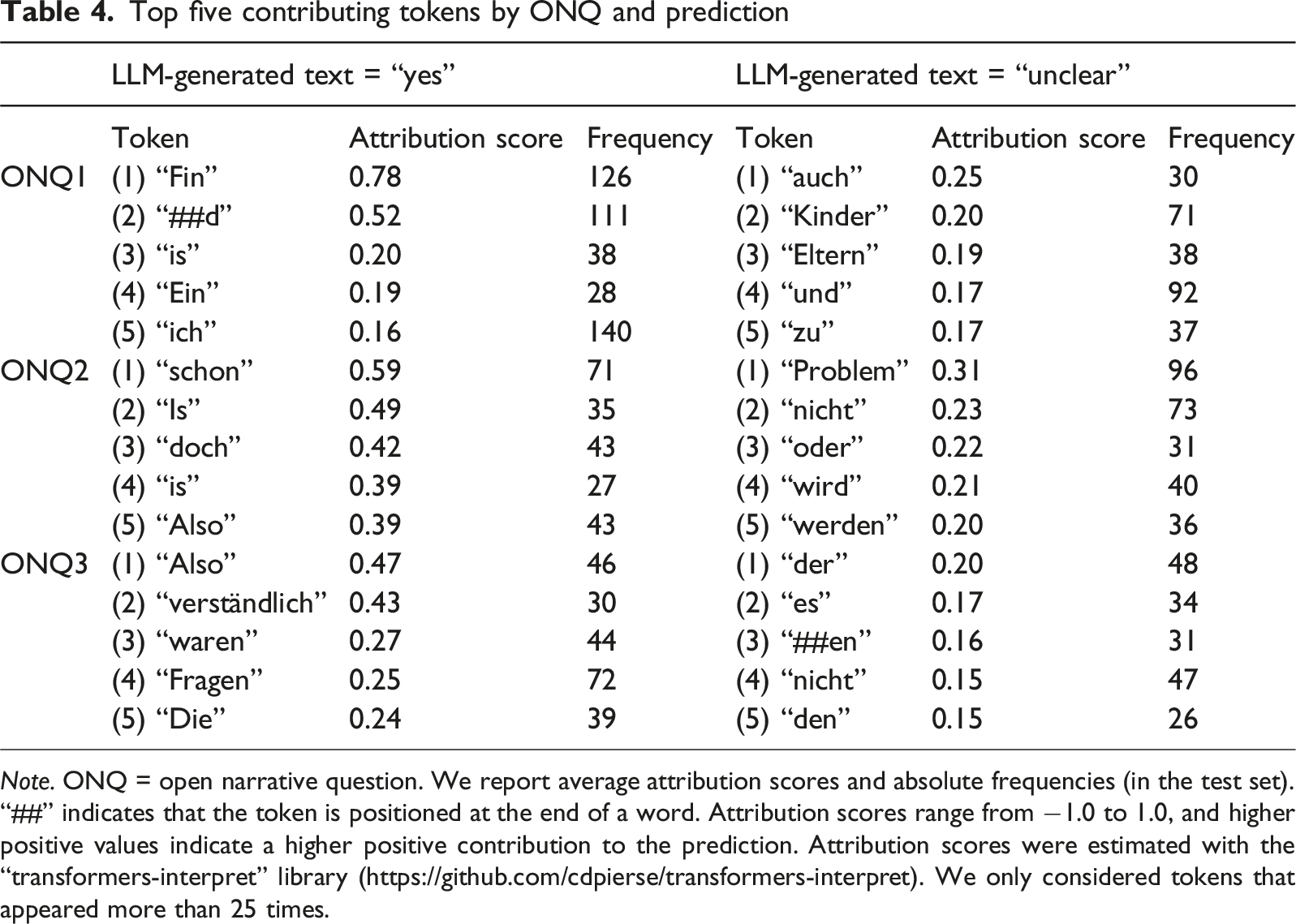
Note. ONQ = open narrative question. We report average attribution scores and absolute frequencies (in the test set). “##” indicates that the token is positioned at the end of a word. Attribution scores range from −1.0 to 1.0, and higher positive values indicate a higher positive contribution to the prediction. Attribution scores were estimated with the “transformers-interpret” library (https://github.com/cdpierse/transformers-interpret). We only considered tokens that appeared more than 25 times.
Interestingly, the top tokens for negative predictions (LLM-generated text = “unclear”) showed generally lower attribution scores. For instance, the top token for ONQ1 was “auch” (0.25), the top token for ONQ2 was “Problem” (0.31), and the top token for ONQ3 was “der” (0.20). Although contributing to the negative predictions, the latter two tokens still appeared in more bot responses than Facebook responses. This may suggest that these tokens contributed to the negative predictions only in specific contexts or word combinations.
Discussion and Conclusion
In this proof-of-concept study, we aimed to advance the identification of bots in online surveys by predicting LLM-generated text in open narrative responses. We leveraged the transformer model BERT to fine-tune a series of prediction models and analyzed responses to three ONQs on the topic of same-gender partnerships. The open narrative responses were either collected through Facebook or synthesized through two LLM-driven bots varying in their level of sophistication (LLM and LLM+ bot). Our findings highlight that the models achieved an impressive prediction performance if fine-tuned with the ONQs (in-corpus predictions). However, they were much less accurate when identifying LLM-generated text in responses to ONQs they were not fine-tuned with (cross-corpus predictions).
Main Results and Implications
Between 97% and 100% of the bot responses were accurately identified when the prediction models were applied to ONQs they were fine-tuned with. Although LLM-driven bots provide meaningful responses to ONQs, they can be distinguished from Facebook responses through specific words and formulations. Interestingly, the LLM+ bot was more difficult to identify than the less advanced LLM bot. This suggests that personas, which represent participant characteristics (e.g., education and party preference) that are emulated by the LLM+ bot (Von der Heyde et al., 2025), contribute to a greater variance in word choice and formulations used. Our descriptive findings support this, showing that the LLM+ bot synthesized almost 100% unique responses, whereas the LLM bot only synthesized between 14% and 64% unique responses (baseline design). The responses to ONQ3, which is a final comment question, shed further light on the limitations of the LLM bot. In particular, the LLM bot frequently engaged in so-called hallucinations—instances, in which the LLM-generated text was not supported by the information provided in the prompt (Mohammed et al., 2025). For example, it commented on questions that it did not previously receive (e.g., “I didn’t like the question on apples”). Unsuitable responses may thus represent an alternative bot indicator. However, this indicator does not apply to more advanced bots, such as the LLM+ bot, which are equipped with a memory feature (or history) allowing them to refer to preceding questions.
Predictive performance, especially recall, decreased substantially when the prediction models were applied to ONQs they were not fine-tuned with (cross-corpus predictions). This indicates that the LLM-driven bots used both a general set of words and formulations (irrespective of the ONQ’s topic) as well as a tailored set of words and formulations (regarding the ONQ’s topic). As the general set of words and formulations appeared in the training data of all prediction models, the models made positive predictions (LLM-generated text = “yes”) with high precision. However, the prediction models could not identify (or recognize) bot responses using the question-tailored set of words, resulting in low recall.
Limitations and Contributions
Although our study provides novel insights on the identification of LLM-driven bots, it has several limitations, opening avenues for future research. First and foremost, the findings on cross-corpus predictions highlight a major limitation of our study regarding the generalizability of our prediction models. The significant drop in recall for cross-corpus predictions indicates that the models may have overfit to question-specific patterns, rather than learning broader, question-independent features of LLM-generated text. Our training corpus is limited, consisting of one topic (i.e., same-gender partnerships), one question type (i.e., open narrative), and three questions (i.e., child adoption, discrimination, and final comment). As a consequence, the prediction models lack generalizability beyond the questions they were fine-tuned with. This poses a potential risk when applying our models in real-world settings, where bot responses may be mixed with human responses across diverse topics, questions, and question types. Thus, future research is necessary to develop methods that can reliably identify bot responses “out-of-the-box” without question-specific fine-tuning. For example, to mitigate the risk of overfitting, future research may extend our approach by fine-tuning prediction models on corpora that span multiple topics, questions, and question types, and by incorporating additional information, such as paradata (e.g., response times). When doing so, we urge researchers to carefully evaluate the performance of their prediction models on responses to unseen questions and to communicate transparently about the models’ scope and limitations. Otherwise, models might fail to identify bots in contexts that deviate from the training data, undermining the goal of improving data quality and integrity in online surveys.
Second, we drew a non-probability convenience sample by recruiting participants through Facebook ads. Although we targeted participants based on cross-quotas for gender and age, they ultimately self-selected themselves into the sample, which may cause them to deviate from the general population (Lehdonvirta et al., 2021). Furthermore, we cannot verify whether the participants are indeed human or if the Facebook responses contain bots. To account for this uncertainty, our prediction models were fine-tuned using a so-called proxy label (LLM-generated text = “unclear”). As a result, positive predictions (LLM-generated text = “yes”) for responses collected through Facebook may not represent false-positive predictions but point to actual bot responses in our Facebook survey. This would suggest a bot prevalence rate of between 1% (ONQ3) and 3% (ONQ1) in our Facebook survey, which is substantially lower than indicated by previous studies. For example, Griffin et al. (2022) estimated a rate of potential bots in their online survey that was higher than 50%. Thus, it would be worthwhile to replicate our results by evaluating the prediction models on test data that can be labeled more reliably (LLM-generated text = “yes” or LLM-generated text = “no”). To this end, it is necessary to collect verified human survey responses. For instance, this could be achieved by conducting our online survey, including the three ONQs, in a supervised lab setting in which participants need to show up in person, or by using data from before the advent of LLMs.
Finally, we analyzed responses from bots that were linked to Google’s LLM Gemini Pro. As the response behavior of LLM-driven bots heavily depends on the LLM they are connected to (Yang et al., 2024), it is key to further investigate bot responses from other state-of-the-art LLMs, such as GPT-4 (OpenAI, 2023) and Llama 3.3 (Meta, 2024). More specifically, it remains open whether and to what extent prediction models that were fine-tuned with bot responses from a certain LLM can be used to predict bot responses that were synthesized by another LLM.
Overall, our study underscores the remarkable capabilities of LLM-driven bots in terms of simulating human-like response behavior, including the provision of meaningful and coherent open narrative responses. As LLM-driven bots can overcome established strategies for bot prevention, such as CAPTCHAs and honey pot questions, our study proposes a promising and novel approach to identify LLM-driven bots in online surveys. At the same time, it highlights that more research is necessary to develop models that can detect bot responses to questions they have not seen before. By drawing on the words and formulations typically used by LLM-driven bots, our proof-of-concept study demonstrates that such bots can be identified with high accuracy by predicting LLM-generated text in open narrative responses with fine-tuned models. This is a critical first step in understanding how researchers can effectively identify LLM-generated text in open narrative responses more generally. Thus, our study makes a valuable and timely contribution to the protection of data quality and the integrity of online surveys.
Footnotes
Ethical Considerations
The online survey data collection through Facebook was approved by the Ethics Committee of the German Centre for Higher Education Research and Science Studies (DZHW).
Consent to Participate
All participants in the online survey were informed about the study procedure, probability of receiving an incentive, and our adherence to existing data protection laws and regulations, before providing informed consent.
Author contributions
Original conception of the overall study: JC, JKH, RB, and ACH; Facebook data collection: JC and JKH; data synthesis: JC, JKH, RB, and ACH; statistical analysis: JC and RB; article writing: JC, JKH, RB, and ACH.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The online survey data collection was funded by the German Society for Online Research (DGOF Online Research Fund 2023).
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
For replication purposes, data, analysis code, and the fine-tuned prediction models are available through Harvard Dataverse by Claassen et al. (2025) (see ![]() ).
).
Note
Author Biographies
Appendix A
Screenshot of the Facebook ad for recruiting online survey participants.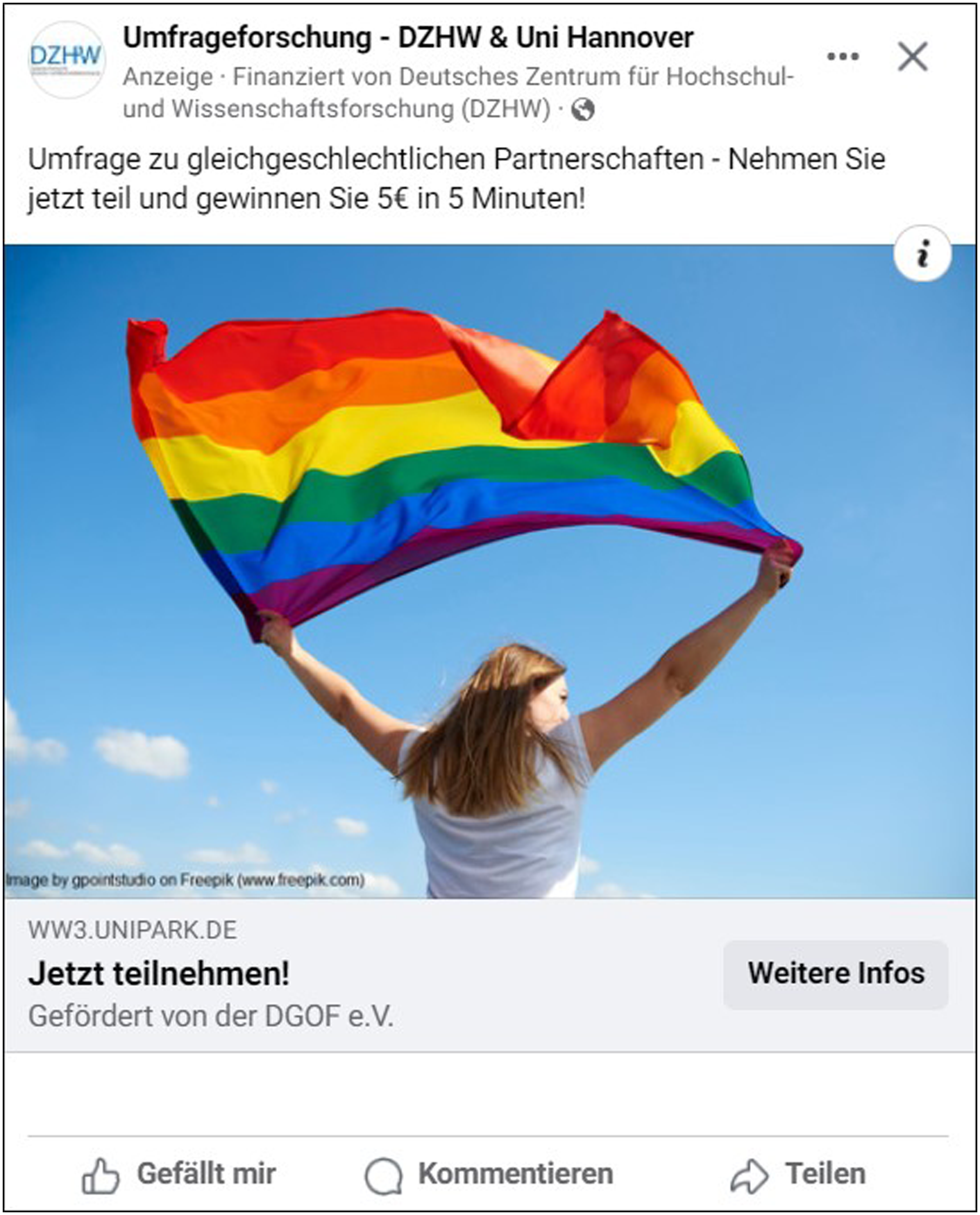
Appendix B
Prompts for open narrative questions including personas and configuration details for gemini-1.5-pro-002.
Appendix C
Original German wordings of the closed question (CQ) and the three open narrative questions (ONQs) as well as the response distribution of the CQ.
Appendix D
Disaggregated prediction performance of the two LLM-driven bots and prompt designs
Recall of in-corpus predictions by LLM-driven bot and prompt design Note. We only report recall as the prediction models were fine-tuned using a binary label (LLM-generated text = “yes” or LLM-generated text = “unclear”) that did not differ between the two bots and prompt designs. As a result, we can determine the disaggregated number of true positive predictions (required for recall) but not the disaggregated number of false-positive predictions (required for precision and F1 score) for each LLM-driven bot and prompt design.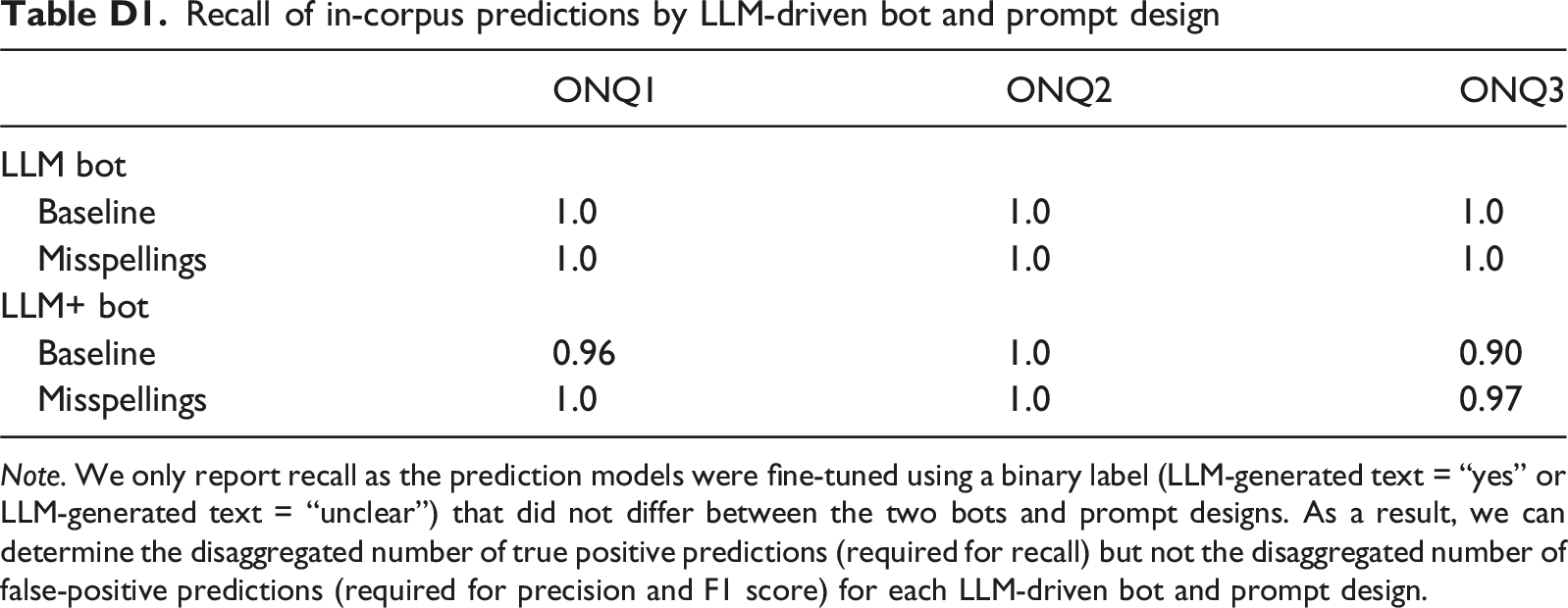
ONQ1
ONQ2
ONQ3
LLM bot
Baseline
1.0
1.0
1.0
Misspellings
1.0
1.0
1.0
LLM+ bot
Baseline
0.96
1.0
0.90
Misspellings
1.0
1.0
0.97