
Abstract
Systematic reviews are essential for evidence synthesis but often require extensive time and resources, especially during data extraction. This proof-of-concept study evaluates the performance of Elicit, an AI tool specifically developed to support systematic reviews, in the context of a systematic review on psychological factors in dermatological conditions. We compared Elicit’s automated data extraction with manually extracted data across 43 studies and 602 data points. Both were assessed against a consensus-based ground truth. Elicit achieved an overall accuracy of 81.4%, compared to 86.7% for human reviewers—a difference that was not statistically significant. In cases where Elicit and the human reviewer extracted the same information, this information was correct in 100% of instances, suggesting that agreement between human and machine may serve as a reliable proxy for validity. Based on these results, we propose a semi-automated workflow in which Elicit functions as a second reviewer, reducing workload while maintaining high data quality. Our results demonstrate that domain-specific AI tools can effectively augment data extraction in systematic reviews, especially in settings with limited time or personnel.
Keywords
Introduction
Systematic reviews are often considered the “gold standard” of evidence synthesis. They consolidate existing findings, identify knowledge gaps, and inform both policy and practice in a transparent and structured manner (e.g., Alshami et al., 2023; Gue et al., 2024; Guo et al., 2024; Li et al., 2024). By adhering to a rigorous methodological framework—including clearly defined research questions, comprehensive literature searches, systematic screening, critical appraisal, data extraction, and synthesis—they aim to provide an unbiased and comprehensive summary of the current evidence (Egger et al., 2022; Mathes et al., 2017; Wollscheid & Tripney, 2021).
The importance of systematic reviews continues to grow due to the exponential increase in scientific publications. Between 2016 and 2022, the number of published articles rose by 47% (Hanson et al., 2024), a trend that is expected to persist, with projected annual growth rates between 4% and 8% (Bornmann et al., 2021; Bornmann & Mutz, 2015). As the volume of scientific output expands, efficiently navigating and identifying relevant knowledge becomes increasingly challenging.
However, conducting systematic reviews remains inherently labor-intensive and time-consuming (Alshami et al., 2023; Borah et al., 2017; Wang et al., 2020). Estimates suggest that completing a review takes between 6 months to well over a year (Borah et al., 2017; Haddaway & Westgate, 2019) and costs in excess of $100,000 (Lau, 2019; Michelson & Reuter, 2019). Within systematic reviews, study selection and data extraction are particularly resource-intensive steps (Nussbaumer-Streit et al., 2021).
In response, a variety of technical (and nontechnical) tools have been introduced to assist in aspects of the systematic-review process (e.g., Brignardello-Petersen et al., 2024; Scott et al., 2021). And while these tools certainly streamline the process, their primary utility is to facilitate the substantial manual work that remains essential, not to replace it. They still require significant human involvement (Blaizot et al., 2022; Gates et al., 2018; Jonnalagadda et al., 2015; Schmidt et al., 2023).
However, the advent of Large Language Models (LLMs) using generative pre-trained transformers (GPTs) has introduced transformative potential for truly automating these aspects of the systematic-review process (e.g., Alshami et al., 2023; Gue et al., 2024; Mahuli et al., 2023; National Institute for Health and Care Excellence, 2024; van Dis et al., 2023). So far, research on LLM applications in systematic reviews has primarily focused on study selection (e.g., Scherbakov et al., 2025). In contrast, significantly less evidence exists regarding the use of LLMs for full-text data extraction (Hu & Geng, 2024), despite this step being both time-consuming (Gue et al., 2024; Polanin et al., 2019) and prone to cognitive strain and errors (Garousi & Felderer, 2017; Mathes et al., 2017). Reported error rates in human data extraction range from approximately 15% (Buscemi et al., 2006) to 30% (Horton et al., 2010; Zhu et al., 2023) and up to 45% (Tang et al., 2023). These findings highlight the need for alternative procedures in data extraction, a task that LLMs should theoretically be capable of performing with high accuracy (Schmidt et al., 2025).
However, evidence from recent studies (Clark et al., 2025; Gue et al., 2024; Khraisha et al., 2024; Mahmoudi et al., 2024; Reason et al., 2024; Sun et al., 2024; Tao et al., 2024; Yun et al., 2024) suggests that while LLMs can extract relatively simple, binary, or explicitly stated information with sufficient precision, they struggle with more complex, nuanced, or context-dependent data. As Sun et al. (2024, p. 2) summarize their results: “Whilst promising, the percentage of correct responses is still unsatisfactory and therefore substantial improvements are needed for current AI tools to be adopted in research practice.”
Importantly, all of the studies discussed above used a general LLM like GPT 3.5 (Gue et al., 2024; Mahmoudi et al., 2024; Sun et al., 2024), GPT 4 (Khraisha et al., 2024; Reason et al., 2024; Tao et al., 2024), Claude 2 (Sun et al., 2024), or used open source models based on general LLMs (Yun et al., 2024). Therefore, they also face the problem of “hallucinating” information, that is, the tendency of LLMs to generate incorrect, misleading, or unrelated information (Susnjak, 2023). For instance, LLMs extracted incorrect numbers of participants, hallucinated a control group when none was present in the study, or fabricated a numeric answer when the actual answer was missing (Gartlehner et al., 2024; Kartchner et al., 2023; Schmidt et al., 2025; Yun et al., 2024). This presents a significant challenge for the integration of LLMs in systematic reviews, particularly due to the rigorous demands for accuracy and reliability in this field. Even small inaccuracies can have far-reaching consequences, potentially undermining the credibility of the review process and distorting its conclusions (Susnjak et al., 2024).
To address this challenge, the current study therefore focuses on the proprietary AI-Tool Elicit, specifically designed to facilitate the (systematic) literature review process. Elicit, created within a non-profit research organization and now an independent public benefit cooperation, allows for automatic data extraction from hundreds of papers at once, creating a data-extraction table in minutes. All of the information presented in this customizable data-extraction table is backed by supporting quotes from the underlying papers (elicit.com). Combined with further mechanisms to reduce hallucinations (George & Stuhlmueller, 2023), this should—at least in theory—lead to data-extraction results similar to human reviewers, not only for simple but also for more complex data.
Furthermore, the current study does not test the AI-tool retrospectively against a well-established “ground truth” but uses the tool “in vivo” while developing a systematic review manuscript. Therefore, we were able to not only test the tool’s overall accuracy, that is, its ability to autonomously extract information, but also test whether it could serve as an independent checker for the inevitable human errors, that is, as an alternative to a second human reviewer. The current study thus follows Cochrane’s call to not only rigorously evaluate tools for automated data extraction but also investigate how those tools might fit into existing workflows (Higgins et al., 2024, Chapter 5.5.9).
Method
The current research on the effectiveness of Elicit in data extraction was integrated into a systematic review which examines psychological factors such as shame and disgust in the onset and progression of skin diseases, as well as the effectiveness of mindfulness-based and compassion-based therapies in this context (Fink-Lamotte et al., 2025). The host review follows the PRISMA guidelines to ensure methodological rigor and transparency. While conceptually akin to a “study within a review” (SWAR), our evaluation was not pre-specified or prospectively registered (see Devane et al., 2022). The final dataset comprises 46 studies that met the eligibility criteria and form the empirical basis for our analysis.
Data Extraction Process
A structured data-extraction table was created for the 46 included studies. It comprised the following seven predefined columns: • Study-Design, • Population, • Country/Region, • Participant Count, • Constructs of Interest, • Measures, and • Main Results.
Three of the authors of the systematic review independently extracted data from approximately one-third of the studies, yielding a manually curated data-extraction table with 322 data points (46 studies × 7 columns). No specialized systematic review software was used; instead, data were organized and extracted using Excel, following a predefined coding scheme. Prior to extraction, the three authors discussed and agreed upon the coding rules and extraction criteria to ensure consistency, although no formal piloting phase was conducted.
Automated Extraction Using Elicit
To evaluate the performance of the AI tool Elicit, we first randomly selected 3 of the 46 studies and uploaded their full-text PDF files via Elicit’s “upload and extract” feature. This function allows users to privately upload their own papers (which remain inaccessible to others) and specify which information should be extracted Using Elicit’s “high accuracy mode” (available during Autumn 2024). We then prompted the tool to generate a data-extraction table matching the human reviewers’ column structure. At that time, the “high accuracy mode” was an optional feature designed to enhance extraction precision by allocating additional computational resources. It has since become Elicit’s default setting for all users. During this initial trial, we observed that Elicit’s “Main Results” column contained less information than its manually extracted counterpart. Therefore, an additional column, “Interpretation,” was added to capture authors’ explanatory statements. Together, these two columns were later treated as a single “Main Results” entry for comparison purposes.
Prompts Used for Each Elicit Column

Note. Elicit-columns “Main Results “and “Interpretation” were merged before comparison with manually extracted column “Main Results.”
Comparison and Validation Procedure
This setup mirrors the dual-reviewer model commonly used in systematic reviews (e.g., Büchter et al., 2021; Mathes et al., 2017), with the human-generated table acting as Reviewer 1 and Elicit functioning as Reviewer 2. The three initial pilot studies served as a training phase for refining prompts, analogous to a calibration exercise between reviewers. Therefore, all further analyses were carried out on the remaining 43 studies (see Thomas et al., 2025).
Subsequently, all 602 data points (43 studies x 7 columns x 2 extraction tables) were independently validated by three authors of the systematic review, using the 43 full papers (46 full papers used in the systematic review minus the 3 papers used in the calibration phase).
Elicit’s extractions were exported and compared to the manually created Reviewer 1 tables in a structured, paper-by-paper format (see Supplemental Material, Table Sheet Elicit_Table). As the three evaluators were also co-authors of the original systematic review and had contributed to the initial data extraction, a blinding procedure was not applied, as it was neither feasible nor methodologically meaningful in this context. The three authors independently determined whether the corresponding data points in the two extraction tables (one manually created by human “reviewer 1” and one automatically created by “reviewer 2” Elicit) provided the same information. Then, the data points were either labeled “correct” or “incorrect.” Afterwards, a consensus decision between the three authors of the original review was reached for all data points. These consensus decisions based on three independent reviewers are considered the “gold standard” or “ground truth” the human “reviewer 1” and the artificial “reviewer 2” is compared against.
For instance, for the “Measures” column, for one study, the human rater extracted “DLQI,” whereas Elicit extracted “Dermatology Life Quality Index (DLQI),” which was rated as conveying equivalent information. In the same column, for another study, the human rater extracted “Original,” whereas Elicit extracted “Original questionnaire with 9 half-open tasks, scale from 1 to 10 for categorizing diseases by level of shame, and percentage rating of shame for own disease compared to the most embarrassing disease,” which was rated as diverging in informational content. However, in both examples, both the human as well as the automated extraction were labeled as “correct.” For a third study, the human rater extracted “QASD,” whereas Elicit extracted “Questionnaire for the Assessment of Self-Disgust (QASD), Perceived Stigmatization Questionnaire (PSQ), Brief Symptom Inventory (BSI),” which was again rated as diverging in informational content. In this example, Elicit’s extraction was labeled as “correct,” whereas the human rater’s extraction was labeled as “incorrect,” since it was incomplete and did not provide all relevant measures used in this study.
Results
Extraction of the Same Information
Comparison of Extraction Results
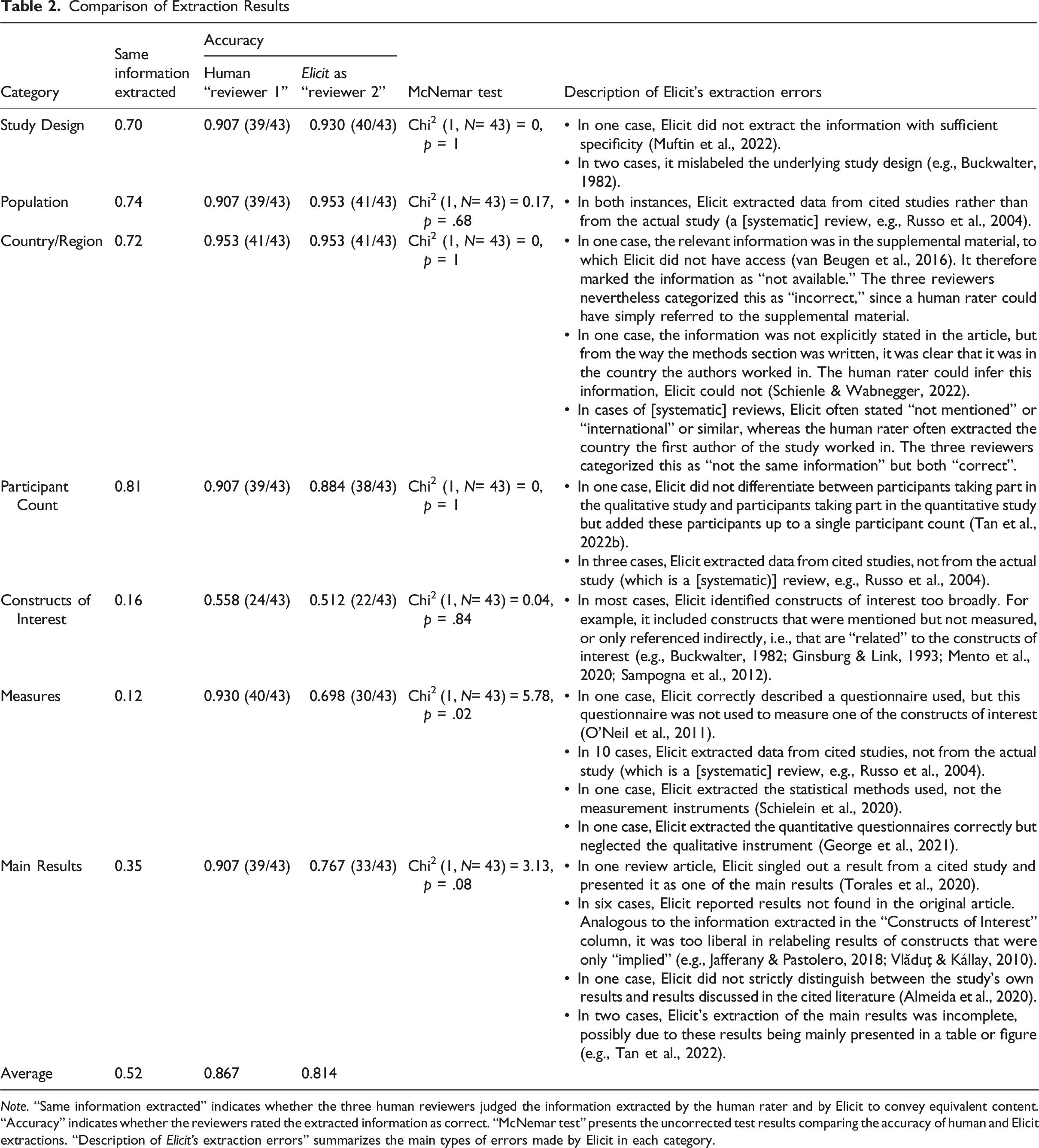
Note. “Same information extracted” indicates whether the three human reviewers judged the information extracted by the human rater and by Elicit to convey equivalent content. “Accuracy” indicates whether the reviewers rated the extracted information as correct. “McNemar test” presents the uncorrected test results comparing the accuracy of human and Elicit extractions. “Description of Elicit’s extraction errors” summarizes the main types of errors made by Elicit in each category.
Comparison of Human and Elicit Accuracy
Table 2 also shows the data-extraction accuracy of both the human “reviewer 1” and Elicit as “reviewer 2,” both compared against the ground truth as described above. On average, the human reviewer has an accuracy of 86.7%, whereas Elicit has an accuracy of 81.4%, which, as evidenced by McNemar tests, is quite similar. Although one comparison (“Measures”) yielded a nominally significant result (p = .016), this effect did not survive correction for multiple comparisons. Specifically, after applying the Holm–Bonferroni method (Holm, 1979) to control the family-wise error rate, no p-values remained significant. Similarly, applying the Benjamini–Hochberg procedure (Benjamini & Hochberg, 1995) to control the false discovery rate also resulted in no statistically significant findings. Thus, the observed effect should be interpreted with caution, as it may reflect chance findings due to multiple testing. Furthermore, both a paired-T-test (t [6] = 1.42, p = .206) and a sign test (S = 4, p = .688) also indicate that there is no difference between the accuracies of a human reviewer and Elicit.
Differences in Accuracy Between Columns
To examine whether Elicit’s accuracy varied across different columns, we conducted Cochran’s Q test on the binary accuracy data across all seven columns. The test was statistically significant, Q (6) = 46.94, p < .001, indicating that accuracy differed for at least some columns. To identify where these differences occurred, we performed pairwise McNemar tests between all column combinations, with Holm–Bonferroni correction for multiple comparisons. Consistent with the descriptive statistics shown in Table 2, accuracy for Constructs of Interest was significantly lower than accuracy for Study Design (padj = .001), Population (padj = .001), Participants (padj = .044), and Country/Region (padj = .001). In addition, accuracy in Population significantly differed from accuracy in Measures (padj = .044).
Differences in Accuracy Between Empirical Primary Studies and Other Article Types
As described in column “Description of Elicit’s extraction errors” of Table 2, Elicit occasionally encounters difficulties with articles that are not empirical primary studies (i.e., theoretical articles and [systematic] reviews). To substantiate this observation, an independent-samples t-test was conducted to examine whether articles classified as empirical primary studies (n = 30) differed from non-empirical articles (n = 13) in their total score (the sum of correct extractions over all seven columns). Results revealed a significant difference between the groups, t (20) = 3.86, p < .001, with empirical articles (M = 6.07, SD = 0.87) scoring higher on average than non-empirical articles (M = 4.85, SD = 0.99). The effect size was large, d = 1.35, 95% CI [0.62, 2.08], indicating a substantial difference between the two types of articles.
To verify the robustness of this finding, a nonparametric Wilcoxon rank-sum test was also performed, yielding a similar result (W = 314, p = .001), with a large effect size of r = .50.
Taken together, both analyses indicate a clear and practically meaningful difference: on average, empirical primary studies exhibited approximately one additional correct extraction (about six versus five out of seven possible) compared with non-empirical articles.
Discussion
Key Findings and Their Implications
This proof-of-concept study evaluated the performance of Elicit, an AI-powered data-extraction tool, within the context of a systematic review in the field of psychodermatology. Our results demonstrate that Elicit achieved an overall extraction accuracy of 81.4%, closely approaching that of human reviewers (86.7%). Crucially, in cases where both Elicit and a human reviewer extracted the same information, this information was correct in 100% of instances—suggesting that agreement between human and machine may serve as a reliable proxy for validity.
These findings suggest that Elicit is capable of supporting, and in many cases approximating, human-level performance in data-extraction tasks (e.g., Tang et al., 2023)—particularly in factual categories such as Study Design and Participant Count. In contrast, its performance declined in more interpretive categories, such as Constructs of Interest, mirroring limitations observed in other evaluations of large language models (Khraisha et al., 2024; Sun et al., 2024). Interestingly, human reviewers faced similar difficulties in extracting information for the category Constructs of Interest, achieving an accuracy of only 0.558 compared to Elicit’s 0.512. This nonsignificant difference suggests that the challenge may not lie solely in the tool’s capabilities but also in the inherent complexity of the task itself. In the social sciences, research frequently addresses nuanced, multidimensional, and context-dependent constructs that are often less precisely defined or inconsistently labeled across studies (see Belur et al., 2021; Curran et al., 2007 for related arguments). Such heterogeneity complicates the extraction of consistent information, even for trained human coders. Consequently, systematic reviews in these fields face the dual challenge of synthesizing diverse and fragmented literature while maintaining reliability and comprehensiveness (Curran et al., 2007; Davis et al., 2014)—with or without support by technical tools.
Towards a Hybrid Model of Data Extraction
Rather than replacing human reviewers, Elicit appears best suited as a complementary tool within systematic review workflows. Its greatest potential lies not in full automation but in strategic augmentation: reducing the manual workload, flagging inconsistencies, and enabling scalable quality control. This hybrid model aligns with current best practices that recommend dual independent data extraction (Higgins et al., 2024; Institute of Medicine, 2011), while simultaneously addressing the resource constraints that many research teams face (Bennett et al., 2015; Oliver et al., 2015).
A Refined Workflow Proposal
Building on our findings, we propose a pragmatic workflow that integrates Elicit as a semi-autonomous second reviewer: 1. Initial manual extraction: A single human reviewer manually extracts the data from all eligible full texts and constructs a data-extraction table. 2. Prompt calibration: The human reviewer randomly selects a small sample of these full texts (3–5 full texts, depending on the overall number of full-texts), uploads them to Elicit, extracts the same columns as in the manual data-extraction table, compares the results of the two tables for this small sample of full texts, and modifies the prompts until the reviewer is satisfied with Elicit’s data-extraction table. 3. Automated extraction: The human reviewer uploads all remaining full texts to Elicit and uses the identical prompts as before to get Elicit’s full data-extraction table. 4. Discrepancy detection: After completion of both the manual and AI-based data extraction, the two resulting tables are compared by either the initial human reviewer or an independent human reviewer who was not involved in the initial extraction. All data points in which the human reviewer and Elicit did not extract the same information are flagged for further review. 5. Targeted reconciliation: The flagged discrepancies are then reviewed and adjudicated by the person conducting the discrepancy detection. This process mirrors established arbitration procedures commonly used to resolve disagreements in systematic reviews (e.g., Higgins et al., 2024). The finalized data-extraction table incorporates these adjudicated decisions.
This workflow simulates a “dual-extraction” model while requiring fewer resources than the “single extraction with verification” strategy (e.g., Buscemi et al., 2006; Li et al., 2019). In our case, only 48% of data points required manual verification. The remaining 52%—where human and AI agreed—could be accepted with high confidence, thereby conserving resources without compromising data integrity. Such efficiency gains are especially valuable in underfunded research settings or time-sensitive projects such as policy reviews or public health interventions.
Strengths and Limitations
A major strength of our study lies in its ecological validity. By embedding the evaluation of Elicit into an active systematic review, we assessed the tool under authentic review conditions. Furthermore, the use of consensus-based ground truth ratings by three independent reviewers adds robustness to our accuracy estimates.
Importantly, the proposed workflow leverages the efficiency of automation while maintaining methodological rigor. However, it also prioritizes human oversight, ensuring verification and accountability throughout the process (Alshami et al., 2023; Huang & Tan, 2023; Kohandel Gargari et al., 2023; Scherbakov et al., 2025; van Dis et al., 2023).
Nonetheless, several limitations should be noted. First, our findings are restricted to a single domain—psychological mechanisms in dermatological conditions—and may not generalize to other fields with different data structures or conceptual frameworks. Second, while Elicit provides source references for extracted data, its performance remains limited in tasks that require nuanced interpretation, abstraction, or inferential reasoning—particularly in relation to complex psychological constructs. This mirrors broader concerns in the literature about the interpretive limits of current LLM-based tools (Gue et al., 2024; Tao et al., 2024).
Our results are also consistent with the cautious stance taken by Clark et al. (2025), who argue that LLMs are not yet suitable for autonomous use in systematic reviews. They emphasize the need for further empirical research—especially in relation to specific review tasks such as data extraction. Our findings contribute to this emerging field and underscore the value of domain-specific tools like Elicit to complement—but not replace—human expertise.
Future Directions
Future work should extend this line of inquiry in several ways. First, evaluating Elicit across multiple disciplines and review types (e.g., intervention reviews, qualitative syntheses, and scoping reviews) would help clarify its generalizability. Second, head-to-head comparisons with other AI-based tools, including proprietary and open-source alternatives, could contextualize Elicit’s relative performance. Third, studies should systematically assess not only extraction accuracy but also usability, time efficiency, and trustworthiness from the perspective of end-users.
In addition, future research should further examine whether extraction performance varies systematically by study type. In the present data, Elicit appeared to perform better on primary empirical studies than on theoretical papers or reviews—a post-hoc observation that warrants cautious interpretation. This difference could stem from the more standardized reporting structure of primary studies, from limitations in our prompting design, or from a combination of both. Systematically evaluating the interaction between study type, prompt formulation, and extraction performance would provide valuable insights into how LLM-based tools can be optimized for different forms of scientific writing.
Building on these findings, future research should also focus on improving extraction accuracy for conceptually complex or overlapping constructs. In our study, this was the category that posed the greatest challenge for both human and AI reviewers. The difficulty likely reflects not only technical limitations but also conceptual ambiguity: constructs in social sciences often overlap or are nested within each other. For instance, shame and self-stigma were both defined as distinct constructs of interest in the underlying systematic review, yet individual studies sometimes treat them as conceptually intertwined. In Ginsburg and Link (1993), for example, shame is described as one of several subdimensions of stigma-related feelings rather than as an independent construct. Such definitional overlap creates genuine ambiguity—not only for AI models attempting automated extraction but also for trained human reviewers applying predefined coding schemes. To address this, future work could experiment with adding an explicit layer of conceptual structure to the extraction process—for example, by using controlled vocabularies (predefined lists of accepted constructs and their synonyms), construct hierarchies (taxonomies clarifying how constructs relate to one another, such as whether shame is a subdimension of self-stigma), or mapping schemes (tables linking constructs to the specific measures or operationalizations used across studies; see also Kartchner et al., 2023; Gartlehner et al., 2024; Susnjak, 2023). Likewise, prompt templates that ask the model to differentiate between constructs that are measured versus merely mentioned could reduce overinclusive classifications (see Table 2). Taken together, such refinements might help AI-assisted and human coders alike handle complex conceptual categories more consistently.
Conclusion
Elicit demonstrates promising accuracy and consistency as a tool for semi-automated data extraction in systematic reviews. Although it does not yet outperform human reviewers, it significantly reduces human workload while maintaining high data quality—especially when integrated into a structured hybrid workflow. As scientific output continues to accelerate and systematic reviews grow more resource-intensive, tools like Elicit can play a pivotal role in ensuring that rigorous review methodologies remain scalable, inclusive, and timely.
Supplemental Material
Supplemental Material - Evaluating the AI Tool “Elicit” as a Semi-Automated Second Reviewer for Data Extraction in Systematic Reviews: A Proof-of-Concept
Supplemental Material for Evaluating the AI Tool “Elicit” as a Semi-Automated Second Reviewer for Data Extraction in Systematic Reviews: A Proof-of-Concept by Frederic Hilkenmeier, Marie Pelzer, Christian Stierle, and Jakob Fink-Lamotte in Social Science Computer Review
Footnotes
Author Note
The authors maintain a paid subscription to Elicit, which they fund personally. During the period in which the study was conducted, data-extraction tables generated by Elicit were obtained using a credit-based system (“tokens”). These tokens were provided free of charge to the authors by Elicit. No further interactions or exchanges took place between Elicit and the authors. In particular, Elicit did not influence the study design, nor was the company given access to any draft or preprint of this manuscript.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The data that support the findings of this study are available as electronic supplementary material alongside this article.
Supplemental Material
Supplemental material for this article is available online.
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.