
Abstract
Research on social bots aims at advancing knowledge and providing solutions to one of the most debated forms of online manipulation. Yet, social bot research is plagued by widespread biases, hyped results, and misconceptions that set the stage for ambiguities, unrealistic expectations, and seemingly irreconcilable findings. Overcoming such issues is instrumental toward ensuring reliable solutions and reaffirming the validity of the scientific method. Here, we discuss a broad set of consequential methodological and conceptual issues that affect current social bots research, illustrating each with examples drawn from recent studies. More importantly, we demystify common misconceptions, addressing fundamental points on how social bots research is discussed. Our analysis surfaces the need to discuss research about online disinformation and manipulation in a rigorous, unbiased, and responsible way. This article bolsters such effort by identifying and refuting common fallacious arguments used by both proponents and opponents of social bots research, as well as providing directions toward sound methodologies for future research.
Introduction
Human decision-making processes depend on the availability of high-quality information and a healthy society requires a shared understanding of issues and values. Misinformation and disinformation erode trust and emphasize divisions. Moreover, the presence of divergent or incompatible beliefs can hinder reaching consensus and taking effective collective action. The repercussions could be so severe as to delay responses to a deadly pandemic (Pierri et al., 2022) or endanger democratic processes (Pennycook et al., 2021).
The science of misinformation seeks solutions to these problems (Lazer et al., 2018). However, this paramount endeavor can itself incur the same problems that it aims to overcome (Altay et al., 2023; West & Bergstrom, 2021). For example, scientific articles and publishers engage in a fierce competition for attention, much like mainstream news outlets. As a consequence, sensationalist claims and hyped results are sometimes used as shortcuts to publication and scientific recognition (West & Bergstrom, 2021). Confirmation bias is also making its way into science, in the form of citation bias: the preference for citing articles that support one’s results over those that challenge them (West & Bergstrom, 2021). And again, over-generalizations of scientific results and poor understanding of methodological and conceptual limitations give rise to multiple misconceptions about misinformation (Altay et al., 2023). These and other problems currently undermine the efficacy and credibility of our research efforts. Therefore, for the science of misinformation to benefit our society, we must first solve the problems within the science itself.
The present study concerns one of the many forms of online manipulation: social bots. Among the many diverse existing definitions (Gorwa & Guilbeault, 2020), here we define social bots as social media accounts that are totally or partially automated. Hereafter, we use the terms “social bot” and “bot” interchangeably, always in line with the aforementioned definition.
Due to their automation, simplicity, and low operating cost, social bots can be easily used as expendable tools for spreading problematic content. Understanding the role and activity of bots in large-scale manipulation campaigns is important, as it can inform strategies to curb mis- and disinformation (Shao et al., 2018). For this reason, social bots have attracted considerable scholarly and media attention (Allem & Ferrara, 2018; Assenmacher et al., 2020; Chen et al., 2021; González-Bailón & De Domenico, 2021). A recent example is the public dispute over Twitter’s bot count preceding Elon Musk’s acquisition (Varol, 2023). However, despite many years of research, the science of social bots is replete with the same problems that also plague the science of misinformation. These originate from uncorrected biases in how scientific results are cited and discussed, and a wide array of methodological and conceptual issues that set the stage for ambiguities, misunderstandings, and unrealistic expectations, as well as contrasting and seemingly irreconcilable findings (Hays et al., 2023; Rauchfleisch & Kaiser, 2020).
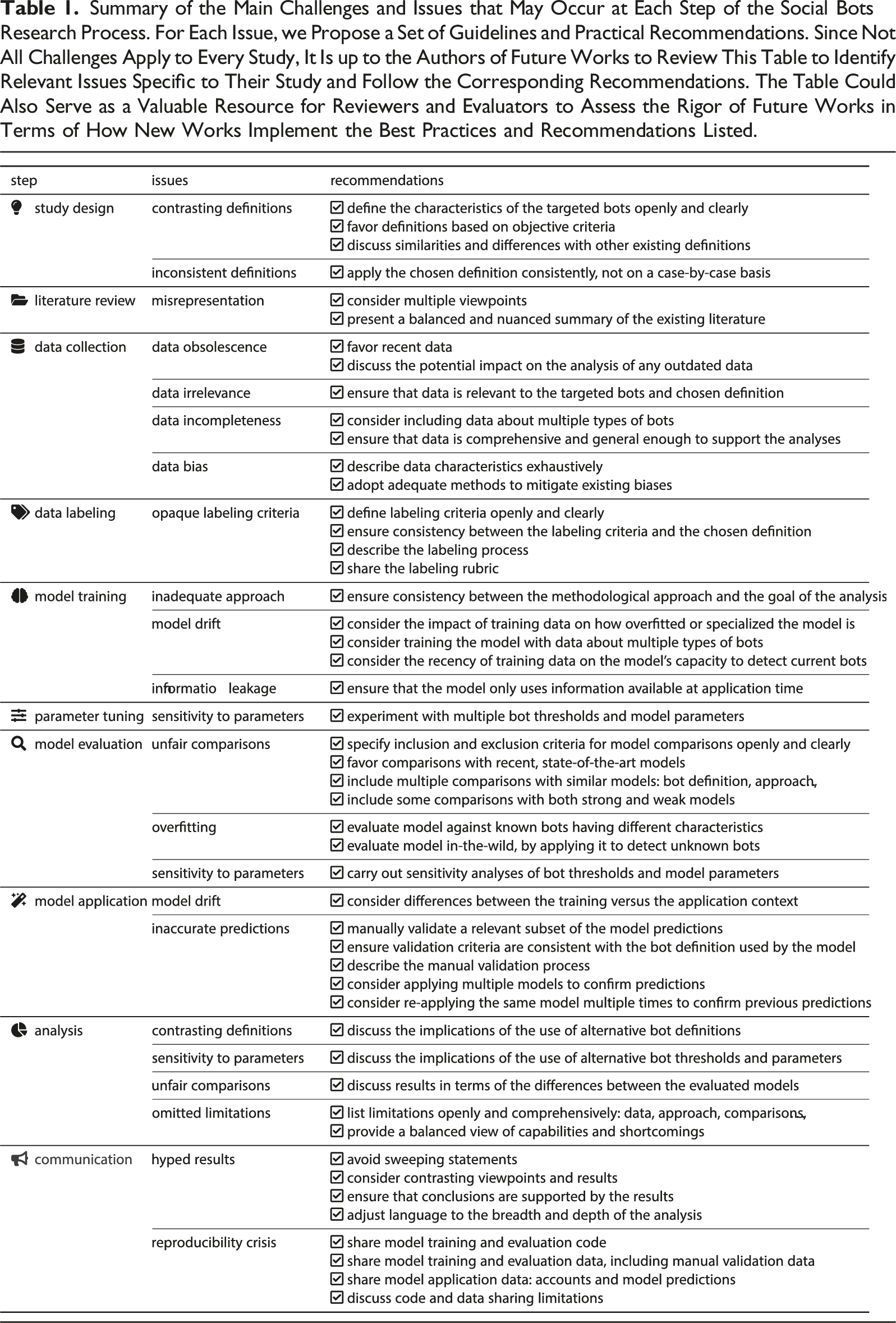
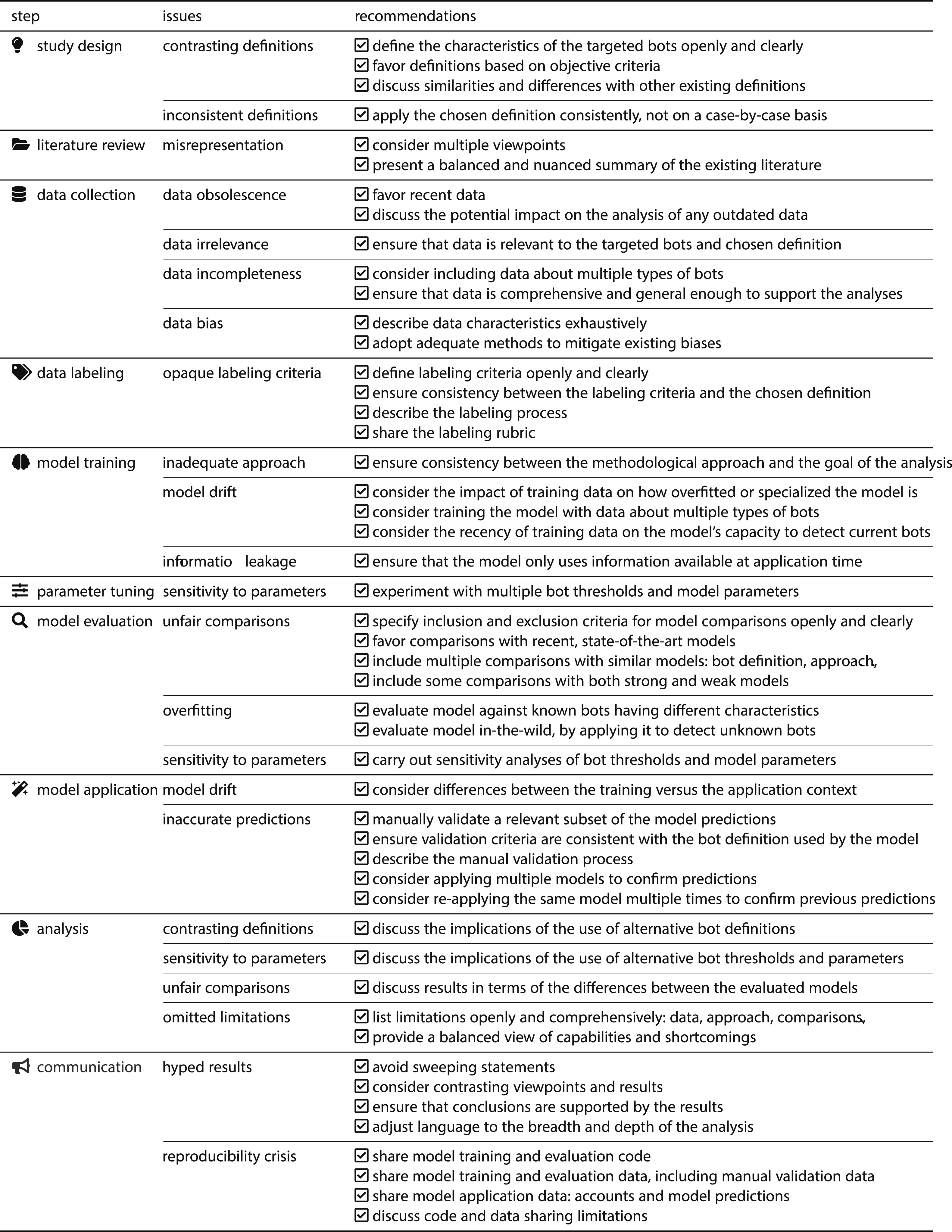
Summary of the Main Challenges and Issues that May Occur at Each Step of the Social Bots Research Process. For Each Issue, we Propose a Set of Guidelines and Practical Recommendations. Since Not All Challenges Apply to Every Study, It Is up to the Authors of Future Works to Review This Table to Identify Relevant Issues Specific to Their Study and Follow the Corresponding Recommendations. The Table Could Also Serve as a Valuable Resource for Reviewers and Evaluators to Assess the Rigor of Future Works in Terms of How New Works Implement the Best Practices and Recommendations Listed.
Methodological Issues
In this section, we focus on issues that arise from how social bots research is conducted and evaluated, covering aspects such as data selection, model training, and the dissemination of results.
Social bot detection is a challenging task in the realm of online safety and cybersecurity (Cresci, 2020). In practice, it often involves the use of machine learning algorithms in a binary classification setting, with the goal of distinguishing human-operated accounts from automated ones—the social bots. The machine learning models are trained on features extracted from user profiles, behaviors, network interactions, and linguistic patterns acquired from user posts, with the goal of detecting subtle differences between authentic users and automated entities. Methodological issues in social bots research include a mix of typical machine learning pitfalls and unique issues inherent in the evolving nature of online social ecosystems, which we exemplify in the following sections.
Model Drift
Model drift arises when the features a model relies on differ between training and prediction data—whether due to gradual shifts over time or inherent dataset differences. It can erode accuracy or falsely suggest strong performance by exploiting training-specific patterns absent at prediction time. In bot detection, the problem may surface when knowledge of some peculiar characteristic of the accounts is known beforehand and exploited at training time, allowing for near-perfect detection performance. For example, each botnet typically exhibits some peculiar characteristics resulting from the bot creation process, their goals, or any other shared characteristic (Mazza et al., 2022; Zhang et al., 2016). These peculiar characteristics might set the bots apart from the average behavior of human-operated accounts (Cresci et al., 2020). However, typically such characteristics are known only for botnets that have already been identified and are instead unknown for still undetected botnets. Here we recall that a classifier’s detection performance on a held-out portion of known data serves merely as a proxy for its real-world detection performance in-the-wild. In fact, the end goal of any bot detector is to accurately detect unknown bots from a set of never-seen-before data. However, if a bot detector exploits known characteristics at training time for classifying instances of known bots, it might learn correlations that do not generalize to the unknown bots that the classifier will be tasked to detect later on.
A specific instance of model drift in bot detection is when a detector exploits knowledge of how the accounts were collected—be them the malicious bots or the genuine ones—as a means to predict their class (i.e., automated or otherwise). The correlation between the information on how certain accounts were collected and their class is spurious with respect to the task of bot detection, which makes features based on such information dangerously misleading. Consequently, a detector exploiting these features would achieve excellent performance on known data but would exhibit poor capacity to generalize to new data with different characteristics. Leveraging features used to select and label the data can also be framed as a feature leakage issue, since those features would unfairly advantage the detector. Such a situation can lead to the proposal of ostensibly superior models, which, however, represent a regression rather than an advancement in addressing the bot detection problem. In addition, the same models could also be exploited to unduly undermine the performance of other models. For example, some scholars trained simple but unrealistic bot detectors using features tightly bound to the training dataset, such as whether an account was verified by Twitter—which was among the features used to select and label the data—to exaggerate the limitations of more general state-of-the-art models (Gallwitz & Kreil, 2022; Hays et al., 2023).
Unfair Evaluation
Other challenges arise from the multitude of disparate definitions, detectors, and benchmark datasets (Cresci, 2020). For example, a critical issue in evaluating bot detectors is the possible inconsistency between the bot definition assumed by the detector and that used by the evaluator. This inconsistency can lead to biased and unfair evaluations, as it is conceptually flawed to evaluate a detector using a different definition than that employed by the detector itself. A tool trained to identify a specific type of bot should be assessed based on its ability to detect that specific type, not alternative ones for which it was not designed. This misalignment in definitions can result in evaluations that misrepresent the detector’s true performance and capabilities. Therefore, while it is perfectly acceptable to discuss—and even criticize—the social bot definition used by a detector, evaluators must ensure that the definition used to evaluate a detector aligns with the detector’s, or be very clear about the differences and their implications toward the results of the evaluation. However, there exists an important trade-off between the need for consistency in using definitions and the necessity of assessing the detector’s generalizability, which requires testing it against bots with different characteristics (Cresci, 2020). Striking this balance depends on multiple factors, including the practical context in which the detector is used and whether the detector is specialized toward specific types of bots or general-purpose.
In addition, the existence of many bot detectors creates an environment where authors introducing new detectors can selectively engage in favorable comparisons. The issue is exacerbated by the difficulty of delineating a clear state-of-the-art in bot detection, as the sheer volume of existing models makes it arduous to discern the most effective ones. The lingering uncertainty around the performance of even established bot detectors (Rauchfleisch & Kaiser, 2020) makes it possible to cherry-pick competitors and evaluation scenarios, allowing proponents of a novel detector to demonstrate its superiority only against a small subset of detectors and datasets, conveniently omitting those against which it may not perform as well.
The evaluation landscape is further complicated by the seemingly excellent performance achieved by models that overfit to specific evaluation datasets. 1 The issue arises from the inappropriate comparison of a general-purpose model with an extremely specialized—potentially overfitted—one. As an example, Hays et al. (2023) selected some datasets to train trivial classifiers with a very small number of features. Then, they compared the trivial classifiers to more complex, general, state-of-the-art models, on the same dataset where the trivial models had been trained, suggesting that very few features are sufficient to identify bots. While this approach can highlight biases in certain datasets, the comparison itself is unfair and should not be used to undermine the utility of general-purpose detectors or to criticize their performance.
Attention should also be devoted to the data used for the evaluation. As an example of problematic use of evaluation data, Gallwitz and Kreil (2022) challenged the accuracy of a widely used bot detector based on its results on a small dataset of public figures’ accounts. However, these accounts—typically managed by social media teams—do not represent the broader platform user base, possibly leading to under- or overestimation of the detector’s performance. While useful in a specific context, such evaluation does not justify generalized conclusions about the detector’s effectiveness. More broadly, since bot detection methods—whether based on machine learning or on human annotation—have inherent error margins, accuracy results can be manipulated by carefully choosing test examples.
In light of the pervasive challenges in evaluating results about social bots, a common recommendation is to always manually check a subset of the data after classification (Yang et al., 2022), as this often allows detecting outright misclassifications and possible underlying problems. Moreover, evaluating detectors should not only involve rigorous testing during training but also continuous validation when using pre-trained models, irrespective of their established reputation.
Cherry-Picking
The issue of cherry-picking extends beyond unfair comparisons. A concerning trend involves selectively including, excluding, or misrepresenting prior literature to propose a narrative that aligns favorably with one’s own findings. Recently, this has been done to cast seemingly new criticism against certain bot detectors (Hays et al., 2023). However, the impression of novelty in such criticism can only be made by omitting a significant amount of literature (Cresci, 2020; Sayyadiharikandeh et al., 2020; Varol et al., 2017; Yang et al., 2019, 2020). An opposite—but equally misleading—practice involves repeatedly citing one’s own unpublished results, which could give a false impression of prior research supporting one’s claims (Gallwitz & Kreil, 2022). Selective referencing can not only distort the perceived reliability and novelty of a work but also skew the representation of the state-of-the-art. While citing unpublished work is not always bad per se, by self-citing under different forms multiple unvetted claims about the results of a single analysis, authors may create an illusion of authority. And by omitting works that have already made certain contributions or conclusions, authors may create an illusion of originality, potentially overshadowing a substantial body of pre-existing research that has contributed comparable insights. This not only undermines the integrity of the academic discourse but also detracts from the collective acknowledgment and recognition owed to the broader community of scholars who have previously advanced the field.
Addressing the cherry-picking issue necessitates a reliance on expert reviewers deeply versed in the nuances of the field, capable of discerning the strategic omission of relevant literature, definitions, methods, or data. Paradoxically, the escalating trend of publications (Haghani et al., 2022), particularly in hot topics like bot detection (Cresci, 2020), poses a formidable challenge, as the growing demand for reviewers outpaces the available pool of experts. This discrepancy surfaces a crucial tension in maintaining the quality and rigor of peer review processes within rapidly evolving research landscapes (Van Noorden, 2023). The field is now confronted not only with the difficulty of establishing a definitive benchmark but also with the challenge of navigating through a heterogeneous literature landscape, where discerning genuine advancements becomes a complex task amid the noise produced by contributions of varying quality.
Straw-Man Methodology
The straw-man fallacy consists of misrepresenting someone else’s research and then criticizing the misrepresentation instead of the original research. A common manifestation is the claim that bot detection is exclusively a supervised machine learning task. This wrong assumption could perhaps be explained by the fact that supervised machine learning is the traditional way in which the task was tackled, and by the multitude of existing supervised bot detectors (Cresci, 2020). Despite their prevalence, however, a robust body of literature highlighted that supervised detectors suffer from lack of generalizability and transferability (Cresci, 2020; Dimitriadis et al., 2021; Echeverría et al., 2018; Rauchfleisch & Kaiser, 2020; Sayyadiharikandeh et al., 2020; Yang et al., 2020). A variety of unsupervised and semi-supervised detectors were proposed as possible solutions to these problems, considering groups instead of single accounts and studying features like the temporal patterns of their actions or the structures of their graph representations (Cresci, 2020). Nonetheless, some studies specifically focus on evaluating the generalization capabilities of bot detectors, but only consider supervised detectors with known generalization deficiencies. The unsurprising result is that the considered detectors fail to generalize, which is used to criticize the whole field—a textbook example of circular reasoning. For instance, Hays et al. (2023) criticize the generalization capabilities of all bot detectors, despite having experimented only with a narrow set of supervised methods. Similarly, Gallwitz and Kreil (2022) conclude that «the field of social bot research is fundamentally flawed», despite having investigated only a tiny fraction of the research based on one single bot detector. The issue lies in the broad conclusions of such studies, which are unsupported by their methodology and results. Neither of the two aforementioned works made distinctions between the different types of bot detectors proposed to date. A further example is the claim that a systematic evaluation of bot predictions in real-world scenarios have never been done (Gallwitz & Kreil, 2022). The accusation points to a lack of manual validation and publicly available datasets. However, the majority of existing bot detectors have indeed been evaluated on training and test datasets, with many of these datasets being publicly available. While we acknowledge that such evaluations may have inherent limitations, and that it is important to manually validate bot labels and to share this validation data, the generic criticism that no systematic evaluation has been done before is unwarranted and potentially misleading.
Therefore, future work should avoid oversimplifying social bot detection as a solely supervised task. Instead, works that propose new detectors, that use already existing ones, or that discuss the state-of-the-art, should acknowledge the multitude of approaches to the task, with their strengths and weaknesses. Then, the type of evaluation, as well as the type of bot detector to develop, use, or discuss in a given study should be chosen so as to be adequate and consistent with the objective of the study.
Data Biases
In machine learning and data science, high-quality data is the linchpin for robust model development and insightful analyses (Halevy et al., 2009). As mentioned above, numerous datasets of bot and human accounts have been published over the years. On the one hand, this made it easier to thoroughly test the performance of new bot detectors. On the other hand, it introduced the risk of cherry-picking favorable datasets, potentially distorting reported performances and introducing bias. Furthermore, the temporal heterogeneity stemming from the availability of datasets spanning varying time periods—ranging from recent to decade-old—can pose additional challenges when detectors are trained on outdated data, undermining the relevance of their performance in contemporary settings. When considering the representativeness of published benchmark datasets with respect to the bots that currently inhabit online platforms, the readers should be aware that the accounts included in a dataset are likely a few years older than the publication date of the dataset itself. Hence, the publication date of a dataset should be considered as a generous upper bound of the recency of the accounts therein. Even under this relaxed assumption, in consideration of the rapidly evolving landscape of online harms and the availability of more comprehensive and recent datasets (Feng et al., 2021), we risk relying on datasets that are no longer representative of the actual state of the platforms. This is particularly troublesome in light of the known evolutionary behavior of social bots, typical of adversarial settings, which requires constant updates of data and methods (Cresci et al., 2021). However, many newly published bot detectors are at least partially based on obsolete training data.
Annotations of accounts as humans or bots, or any other category, can introduce further bias when the annotation process is opaque or incoherent. As a practical example, cyborgs—accounts that are partly automated and partly managed by humans who can step in as needed to avoid detection—can be labeled as “humans” if one only considers their capacity to reply to a message. However, many bot detectors are based on the definition that any account with partial automation is a bot. When evaluating such bot detectors, labeling cyborgs as humans would unfairly inflate the false-positive rate due to the mismatch between the definition adopted by the bot detector versus that of the evaluator. In other cases, the authors change criteria for labeling bots multiple times within the context of the same study, without disclosing any annotation rubric (Gallwitz & Kreil, 2022). First, they label accounts that automatically post news headlines—such as those associated with major newswire agencies—as humans. Then, they ignore suspended accounts or consider them to be human, depending on the analysis. Finally, they label accounts that cross-post tweets through software apps as humans.
As exemplified above, the use of obsolete or biased datasets with unclear, inconsistent, or shifting definitions and opaque labeling schemes are among the malpractices that affect this field. To avoid bias, account labeling should be performed by multiple independent annotators following a shared and openly accessible rubric, and based on a consistent definition of social bot. Moreover, continuous scores representing the different degrees of “botness” (i.e., automation) should be favored in place of binary labels, as the former are better suited to capture nuances in the use of automation.
Practical Recommendations
Table 1 summarizes the main methodological issues that may occur at each step of the social bots research process, and proposes a set of best practices, guidelines, and practical recommendations to mitigate them.
One significant challenge is the use of contrasting definitions of social bots, which leads to incomparable results and confusion in research. To mitigate this, future studies should openly and clearly define the specific characteristics of the social bots they are targeting. Moreover, future research should adopt definitions consistently, without changing bot criteria and definitions case-by-case. Furthermore, favoring definitions based on objective characteristics—such as the use of automation—over subjective ones, will boost clarity and consistency. When discussing results, researchers should also compare their definitions with existing ones to highlight similarities and differences, also exploring how different definitions could impact the results. A related pressing issue is the use of inconsistent or opaque bot labeling procedures, as these hinder the clarity, comparability, and reproducibility of results. Researchers should document and publish their labeling procedures, including the criteria and tools used to carry out the annotation. Sharing labeled datasets with comprehensive metadata will further enhance transparency, reproducibility, and collaborative efforts.
A further set of recommendations involves the evaluation procedures of social bot detectors. Newly trained bot detectors are often tested on well-known and old bots, which does not accurately reflect their performance in real-world scenarios. Researchers should prioritize using the most up-to-date datasets for their evaluations, as these are likely to better reflect the evolving nature of social bots. Performance assessments should include tests on bots with different and unknown characteristics, to better gauge the detectors’ real-world applicability and to ensure that detectors are robust and effective in dynamic online environments. In addition, attention to validation should not only be the focus of the training and testing phases of a new bot detector, but should also be devoted when using a pre-trained detector developed by others, even if it is well-known and established. A subset of automatically assigned labels and scores should always be manually validated, rather than accepted at face value. This ensures their accuracy and reliability in the given context, which might be different than that on which the detector was developed. As with the aforementioned manual labeling procedures, also this manual validation process should be clearly and openly documented, detailing the criteria and methods used for manual verification of the assigned labels.
Another issue in the evaluation of bot detection performance is the possibility of cherry-picking competitors in such a way to purportedly demonstrate the superior performance of a newly proposed detector. To mitigate this issue, future research should benchmark bot detectors against a comprehensive set of existing detectors, including both strong and weak performers. Moreover, the criteria for the selection of the comparisons should be stated clearly and openly. Sharing evaluation scripts and datasets used in benchmarking will further promote transparency and reproducibility in performance comparisons. In addition, sensitivity analyses should also become a standard practice to address the possible sensitivity of detectors to thresholds and other model parameters, which are often overlooked when reporting bot detection results. These analyses should be reported alongside the main results to provide a clearer picture of the robustness and reliability of the detectors, aiding in the identification of optimal settings and limitations.
Lastly, data availability and documentation are crucial for the progress of bot detection research. The lack of shared and well-documented datasets impedes reproducibility and comparison and slows down the development of new detectors. Researchers should make their datasets publicly available whenever possible, ensuring they are well-documented with comprehensive metadata, including how the data was collected and labeled. This recommendation does not only involve the datasets used to train or evaluate a detector, such as those labeled manually, but also the datasets on which pre-trained detectors are applied. For the latter, it is crucial to share the data together with the labels or scores automatically assigned by the detectors. If data sharing is constrained by privacy or other issues, researchers should at least provide detailed descriptions of their datasets and the procedures for obtaining them. This practice will support reproducibility and facilitate more rigorous comparisons and advancements in bot detection research.
Conceptual Issues
Beyond methodological challenges, the field is also intricately intertwined with a variety of potentially more subtle—yet profoundly influential—conceptual issues. These concern how social bots and related phenomena are defined, framed, and understood within the research discourse. These nuanced challenges, if left unaddressed, have the potential to exert an even more insidious influence on the development of the field and its reception.
Failure to Account for Context
In discussing the limitations that currently hinder progress in bot detection, some recent research pointed at flawed data collection practices that fall short of capturing the complexity of the bot space (Hays et al., 2023). This interpretation of the limitations of the existing datasets implicitly assumes the possibility to encode the full complexity of the bot detection problem space in a dataset. More specifically, this criticism subsumes that building unbiased and comprehensive bot datasets is possible, and perhaps even convenient. Unbiased datasets are needed so as to avoid that peculiar bot and human characteristics leak into the data allowing simple models to achieve good performance on the collected data, while showing poor performance in real scenarios. Furthermore, comprehensive datasets are needed so that expressive models can learn to generalize to all types of existing social bots. Unfortunately, the assumption of the existence of an unbiased and comprehensive dataset is fallacious.
Regarding bias, many bot datasets were found to contain biases, in that the accounts therein featured some peculiar characteristics (Hays et al., 2023). However, this is largely unsurprising since such characteristics are the inevitable consequence of the bots being organized in botnets: groups of accounts created and controlled by a central entity who collectively operates the bots to reach some predefined goal (Zhang et al., 2016). Given that all bots belonging to the same botnet are created or operated by the same entity, and pursue the same common goal, they tend to share similarities. When compared to other accounts, the botnet thus appears to have some peculiar characteristics, as highlighted in Figure 1(b). Thus, in most cases, the presence of biases in the existing bot datasets should not be blamed on the creators of the datasets, but rather traced back to the very nature of the social bot phenomenon. The ecology of online accounts: Social bots and humans. Differences between naïve and realistic models, and their implications for data collection. (a) Simplistic and naïve model of social bots (black-colored) and human-operated accounts (gray-colored). Here, all bots are alike, they are evenly distributed, and we have complete knowledge of their numbers and characteristics. According to this model, collecting unbiased and comprehensive bot datasets is possible. (b) Realistic model of social bots and human-operated accounts, and of the related knowledge gaps. Here, social bots are organized in botnets, each with peculiar characteristics (color-coded). Among the missing information is the number of bots in known botnets, as well as the number, size, and characteristics of all unknown botnets.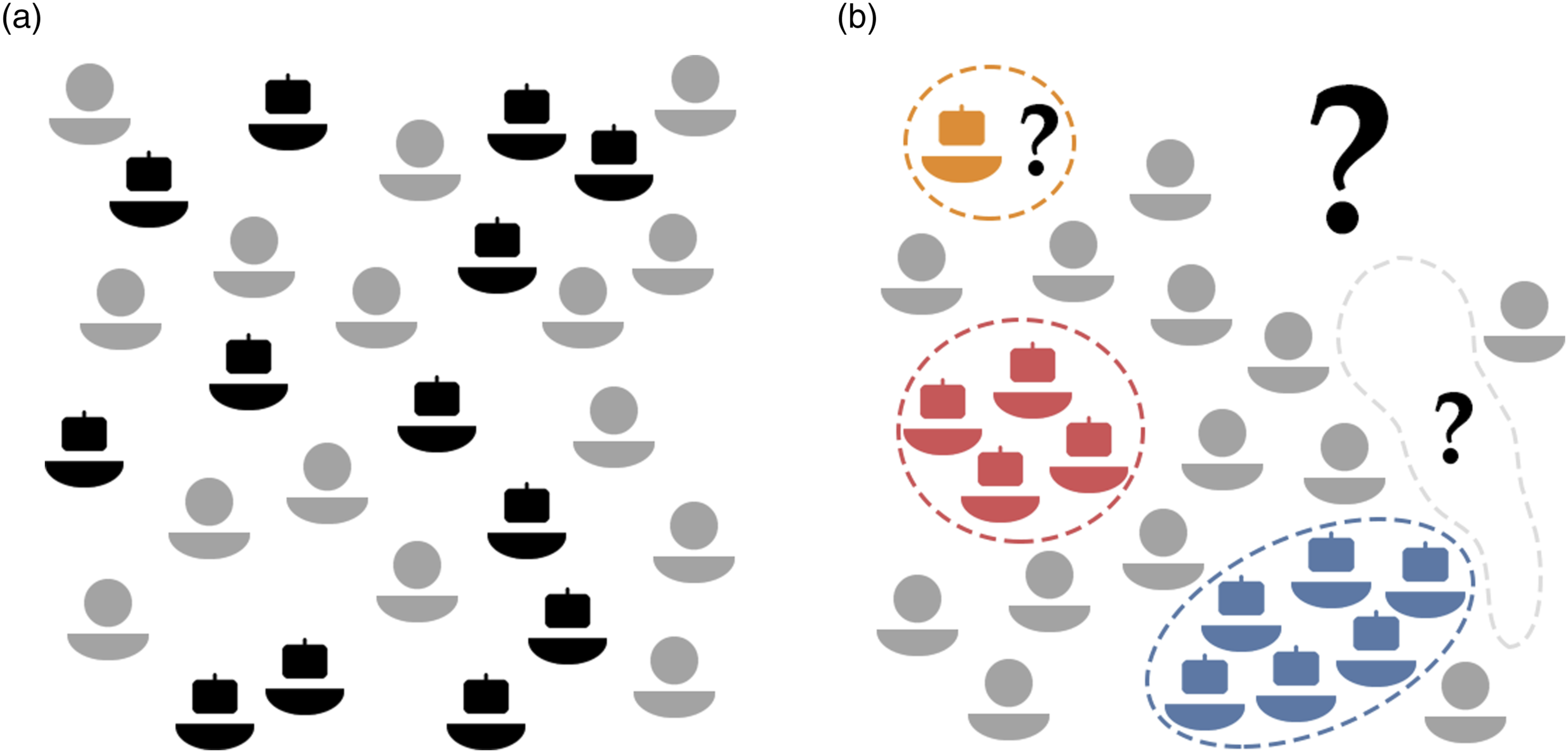
The assumption about the possibility to build comprehensive bot datasets is equally flawed. Creating such datasets would require a uniform and random sample of an adequate number of accounts from the complete distribution of existing bots. This would allow obtaining an accurate representation of the bot landscape that captures the full complexity of the problem space. However, performing a uniform and random sample of the whole population of bots is extremely problematic—if not outright impossible. The task of detecting social bots partly belongs to the fields of information security and open-source intelligence, which are intrinsically characterized by the presence of adversaries who are strongly motivated to remain hidden (Cresci et al., 2021). There has always been limited knowledge of the real extent of the bot problem, which makes it hard to track bots on a platform, quantify their numbers, and assess their impact (Mendoza et al., 2020; Tan et al., 2023; Varol, 2023). We only have a partial understanding and visibility of the botnets that operate on our online platforms. 2 Figure 1 provides a conceptual view of the landscape of social bots and human-operated accounts: firstly according to a naïve interpretation (Figure 1(a)) and then in a more realistic representation (Figure 1(b)). Figure 1(b) highlights the knowledge gaps related to the presence of bots in online platforms. These include known unknowns: the exact number of bots belonging to known botnets. But they also include unknown unknowns: information about the hidden botnets operating on a platform. How can we create unbiased and comprehensive datasets when we largely ignore the types and numbers of bots populating online platforms? This fundamental question is currently unanswered.
Common Misconceptions in Social Bots Research

The above evidence shows that despite significant efforts devoted for a prolonged time, bot detection is nowhere near to being a solved problem—quite the contrary.

For many years, we witnessed to a whack-a-mole game between bot developers, with their increasingly sophisticated accounts (Yang et al., 2024; Yang & Menczer, 2023), and bot hunters, equipped with a variety of different detectors (Sayyadiharikandeh et al., 2020; Yang et al., 2019, 2020). Looking back at how this arms race has unfolded, we can conclude that none of the technological advances we have experimented with have significantly mitigated the challenges posed by malicious social bots in the long term. It is reasonable to assume that future advances will suffer a similar fate. Social bots are adversarial, fast-moving targets, characterized by a fast adoption of cutting-edge technology (Cresci et al., 2021). Bot detection is therefore an intrinsically challenging task, made even more daunting by the lack of accurate information on the targets of the analysis, the limited collaboration from online platforms, and the rapidly evolving nature of online harms.


Both scholars and the general public often assume that a bot detector performing well on some bots will perform equally well on any bot detection task. This assumption is problematic given that there are a plethora of diverse bots, each with its own characteristics (Mazza et al., 2022). Consider, for example, the differences between the bots used to boost the popularity of certain public figures—so-called fake followers (Cresci et al., 2015)—and those that manipulate trending topics—astroturfers and spammers (Abokhodair et al., 2015). Or the differences between bots involved in political manipulation (Caldarelli et al., 2020; Shao et al., 2018) versus those aimed at fooling automated trading systems (Bello et al., 2023; Tardelli et al., 2022). Some scholars addressed this heterogeneity by designing detectors that aim for generality and broad applicability, such as Botometer, especially in its latest releases (Sayyadiharikandeh et al., 2020; Yang et al., 2020). Others have developed detectors specifically designed to detect certain types of bots. The latter trade generalizability and portability for detection accuracy, and their performance depends heavily on the characteristics of the bots they are designed to detect. For example, a detector designed to detect time-synchronized retweeting actions (Mazza et al., 2019) would likely be useless at detecting mass-following bots (Cresci et al., 2015). However, this should not be regarded as a limitation of the bot detector—let alone one deliberately unstated by its developers in order to pass it off as a good product—but rather as an inappropriate use of the detector itself. Limitations in generalizability and portability also affect general-purpose bot detectors, although to a lesser extent than specialized ones. In fact, even general-purpose detectors rely on a limited number of features to estimate whether an account is a bot. Therefore, in general, any detector, specialized or otherwise, has variable performance and its detection capabilities depend on the characteristics of the accounts it is applied to. In conclusion, no single bot detector is capable of detecting all types of bots.

An unbiased analysis of the existing literature paints a dubious picture of the role of social bots. For example, while some studies have concluded that bots play a prominent role in the spread of problematic content (Shao et al., 2018; Stella et al., 2018), others have reached the opposite conclusion (González-Bailón & De Domenico, 2021; Seckin et al., 2024; Vosoughi et al., 2018). The existing literature has focused almost exclusively on detecting bots and characterizing their behavior, leaving the fundamental task of measuring the impact of bot malfeasance largely unexplored (Cresci, 2020). For these reasons, we currently lack scientific consensus and conclusive evidence about the role of social bots and their effectiveness in influencing online users. What we do know, however, is that bots are only one of many agents involved in the spread of mis- and disinformation (Roth & Pickles, 2020; Starbird, 2019). Examples of other agents are state-sponsored trolls, users who collude and coordinate for malicious purposes, superspreaders, and even willing but unwitting individuals (DeVerna et al., 2022; Starbird, 2019). Each of these agents represents a potential threat to safe and trusted online platforms, and a thriving area of research and experimentation. It is therefore critical to balance efforts in all of these directions, avoiding the pitfall of overstudying some while overlooking others, based on unsupported decisions.

There exist at least three strong arguments against this thesis. First, despite the limitations of bot detectors, there are several glaring examples of bot studies that were able to bring to light demonstrably harmful campaigns. For example, detectors developed as part of some scientific efforts were later deployed on online platforms and used to remove large numbers of malicious accounts (Yang et al., 2014). Similarly, the results of some studies led platforms to remove accounts identified as malicious bots (Ferrara, 2022; Yang & Menczer, 2023). In several other cases, scientific findings about bot activity were later found to be consistent with independent platform removals of malicious accounts (Nizzoli et al., 2020; Tardelli et al., 2022), confirming the accuracy of the scientific findings. These cases represent just some of the success stories of social bot research. Therefore, even if no universal bot detector exists, and despite the many caveats to consider in bot detection, being able to detect some malicious bots puts us in a more advantageous position than being able to detect none.
Second, the methodological rigor and practical usefulness of some social bots studies are evidenced by corrective actions taken by government agencies based on academic research. For instance, in November 2014, the U.S. Securities and Exchange Commission (SEC) issued an alert to raise awareness about stock market manipulations exacerbated by social bots, 6 following the findings of earlier studies (Hwang et al., 2012). Subsequent research confirmed these suspicions on multiple occasions (Cresci & Lillo et al., 2019; Nizzoli et al., 2020), contributing to calls for greater government oversight of social bots (Gorwa & Guilbeault, 2020; Yan et al., 2023) and discussions on regulating bot freedom of expression (Lamo & Calo, 2019). Both the 2018 and 2022 EU Code of Practice on Disinformation, as well as investigations by the U.S. Congress and the UK Parliament’s Digital, Culture, Media and Sport Committee, have also been informed by research on social bots. Furthermore, the concern over bot infiltration was highlighted when Elon Musk initially decided to abandon his purchase of Twitter, citing misleading information about the platform’s financial health and bot prevalence (Varol, 2023)—a claim also supported by Peiter Zatko, Twitter’s former head of security, who exposed serious deficiencies in the company’s security. 7
Third, the benefits of social bot research extend beyond the detection of malicious bots. For example, research and experimentation on social bots led to the development of neutral bots used to assess the level of political polarization and bias on a platform (Chen et al., 2021); “news bots” used for journalistic purposes to curate, aggregate, and distribute content gathered from multiple sources (Lokot & Diakopoulos, 2016); and even bots used for content moderation (Askari et al., 2024; Bilewicz et al., 2021). In addition, social bot research has contributed to the early development of other neighboring fields. The early research on social bots, which dates back to 2010 (Cresci, 2020), provided an important foundation, allowing the field to draw upon several years of accrued experience when widespread concerns regarding misinformation, state-backed trolls, and coordinated inauthentic behavior surged in 2016 and subsequent years. In other words, early results on detecting and characterizing social bots informed strategies for detecting and mitigating other related forms of online manipulation. In light of these considerations, research on social bots—imperfect as it is—seems far from useless. In fact, social bots research perfectly exemplifies the process leading the general advancement of science: the accumulation of knowledge resulting from certain research efforts, other than solving local problems, also fertilizes the broader scientific ecosystem, providing data, methodologies, tools, and insights for further scientific advancements in close—and sometimes not so close—fields.
Challenges in the Post-API Era
In addition to the widespread biases and misconceptions detailed above, the field of social bot research confronts significant obstacles due to changes in social media platform policies. In the API era, most social bot studies have focused on Twitter/X due to its free API and the ease of large-scale data acquisition. This hyperfocus on X has led to the neglect of other platforms, creating a bias in social bots research that largely ignores other platforms. However, this data policy ceased in 2023 when X terminated free data access for researchers. 8 Similarly, Reddit restricted free data access, and Meta announced the discontinuation of CrowdTangle, a crucial tool for researchers studying Facebook and Instagram. 9
The lack of access to fresh social media data severely hampers researchers’ ability to monitor bot activities and assess their influence. It significantly impedes the collection of new bot samples necessary for studying their characteristics and training novel machine learning classifiers. Even if researchers can develop new classifiers, deploying them at scale is challenging, exposing social media users to potential manipulation. Bot operators, on the other hand, remain largely unaffected. Leveraging burner and virtual cellphones, they can manage bot accounts across platforms directly, bypassing API restrictions. The advent of AI-powered social bots, which evade current bot detection models (Yang et al., 2024; Yang & Menczer, 2023), further emphasizes the importance of data availability in support of social bot research.
Despite these setbacks, Europe’s Digital Services Act (DSA) has offered some hope by mandating large social media platforms to grant researchers data access upon reasonable requests. 10 Platforms like TikTok, Meta, and Google have initiated new data access programs. However, these programs are significantly limited compared to previous access levels. Their opaque and stringent application review processes also leave their efficacy in question (Jaursch et al., 2024). Besides traditional social media, the rise of decentralized platforms such as Mastodon and BlueSky introduces new dynamics. Their openness facilitates data access for researchers but also exposes them to exploitation by malicious actors. The decentralized nature of these platforms complicates efforts to combat threats such as malicious social bots, presenting novel challenges to both users and the research community. Moreover, the limited number of participants, which has not yet reached a critical mass, and the difficulty in creating a reliable ground truth, further contribute to hindering bot detection research on these platforms. Overall, the new data accessibility landscape and the change in the underlying technologies, represent an opportunity and a call for further research in social bot detection.
A Call for Moral Responsibility
Our analysis of the drawbacks and limitations of recent studies brought to light the need for responsibility when discussing results about social bots. The way in which new findings are presented in this and in neighboring fields can influence not only the next iterations of research but also industry practices, policymaking, and public opinion. To this end, it is paramount to avoid repeating the mistakes and propagating the common misconceptions that currently haunt the social bot literature and that fuel ambiguities, generalized misunderstandings, and friction among scholars.
The everyday challenges that we face as researchers in the broad area of misinformation are an accurate reflection of those faced by our society. As authors, reviewers, and readers of new research in this field, we have the moral obligation of refraining from falling for the same biases, and exacerbating the same issues, that we frequently encounter in our analyses. Misinformation often surfaces as «an accurate fact set in a misleading context» (Starbird, 2019). Perpetuating the methodological and conceptual issues addressed in this paper contributes to creating flawed or unreliable research. Cherry-picking data, references, claims, or results from a cited article are examples of misleading context in which misinformation thrives (West & Bergstrom, 2021). Similarly, while making hyped or sensationalist claims can help publish a paper and accrue citations, such claims also contribute to creating misleading contexts and unrealistic expectations, as well as to increasing scientific tribalism.
Making tangible progress in the science of misinformation requires that we address many conceptual, practical, and ethical challenges. Doing so involves embracing the intrinsic complexity of the phenomenon, considering multiple viewpoints, and providing nuance rather than naivety. Sweeping statements such as “the creators of bot datasets are responsible for the failure of the field,” “all social bots research is flawed or useless,” or even “this new bot detector has flawless performance” do not contribute to achieving these goals.
In conclusion, should we fail to respect our moral obligation, we would produce biased and unreliable research, further worsening the problems that currently undermine the credibility of our field (Altay et al., 2023; West & Bergstrom, 2021). In a 2019 piece published in Science, Derek Ruths compared contrasting findings about social bots, commenting that «research on misinformation has come to resemble the very thing it studies» (Ruths, 2019). It is our moral responsibility to reverse this fatal course. This can only be achieved via responsible research that fosters nuanced, unbiased, and balanced viewpoints, and by a review process that adheres to the same principles. This article aims to make a contribution in this direction by debunking common fallacious arguments adopted by both proponents and opponents of social bots research, as well as providing directions toward sound methodologies for future research in the field.
Footnotes
Acknowledgement
Marinella Petrocchi and Angelo Spognardi are supported by project SERICS (PE00000014) under the MUR National Recovery and Resilience Plan funded by the European Union - NextGenerationEU.
ORCID iDs
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Stefano Cresci is supported by the European Union – Next Generation EU, Mission 4 Component 1, for project PIANO (CUP B53D2301 3290006) and by the ERC project DEDUCE under grant #101113826.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.