
Abstract
Robots are projected to affect healthcare services in significant, but unpredictable, ways. Many believe robots will add value to future healthcare, but their arrival has triggered controversy. Debates revolve around how robotics will impact healthcare provision, their effects on the future of labor and caregiver–patient relationships, and ethical dilemmas associated with autonomous machines. This study investigates media representations of healthcare robotics in Norway over a twenty-year period, using a mixed-methods design. Media representations affect public opinion in multiple ways. By assembling and presenting information through stories, they not only set the agenda by broadcasting values, experiences, and expectations about new technologies, but also frame and prime specific understandings of issues. First, we employ an inductive text-mining approach known as “topic modeling,” a computational method for eliciting abstract semantic structures from large text corpora. Using Non-Negative Matrix Factorization, we implement a topic model of manifest content from 752 articles, published in Norwegian print media between 1.1.2000 and 2.10.2020, sampled from a comprehensive database for news media (Atekst, Retriever). We complement this computational lens with a more fine-grained, qualitative analysis of content in exemplary texts sampled from each topic. Here, we identify prominent “frames,” discursive cues for interpreting how various stakeholders talk about healthcare robotics as a contested domain of policy and practice in a comprehensive welfare state. We also highlight some benefits of this approach for analyzing media discourse and stakeholder perspectives on controversial technologies.
Introduction: Why Media Representations of Healthcare Robotics Matter
The field of healthcare robotics has evolved considerably over the past decades. Robots, at various levels of technical maturity, are slowly entering our hospitals, care facilities and homes to assist in healthcare delivery. Surgical robots now furnish operating rooms. In experimental interventions, care robots are being piloted as service assistants for healthcare staff and for supporting independent living among the elderly. In hospitals, data are handled autonomously by new information processing algorithms, and chatbots promise to offer relational support and replace human dialogue in mental health and adjacent fields.
Originally conceived by writers Josef and Karel Čapek from the word robota, a Czech expression for “forced labor,” the term “robot” was popularized in the latter’s influential science-fiction play R.U.R. (Rossum’s Universal Robots) from 1921. Karel told the story about a group of artificial humanoids who rebel against their overlords, becoming an existential threat to humankind. Today, robot is a family resemblance term, designating a vast array of automation technologies, from machines performing physical movement in their environment by sensing and acting, to “disembodied” algorithms for ubiquitously processing information to execute computing tasks (e.g., “bots”). While formal definitions are debated (Calo et al., 2016; Thring, 1966), we here use the term in accordance with the colloquial for automated machines that replace human efforts.
Broadly construed, healthcare robotics is an instance of “technoscience” (Michael, 2006): a form of healthcare practice based on the application of scientific knowledge driven by technological developments. Technoscience stands apart from ideal-typical science, as the epistemic goal is not mainly to represent the world through novel theories and models (Hacking, 1983), but to intervene in society (Etzkowitz & Leydesdorff, 2000; Nowotny et al., 2003). As a knowledge domain, healthcare robotics co-evolves with political, economic, and other cultural issues, and there is a close interface between science, technology, and social contexts of care. Healthcare robotics also instantiate “post-normal science” (Funtowicz & Ravetz, 2008): stakes are high, facts are uncertain, values disputed, and decisions about how to proceed have some urgency.
While healthcare robotics is heralded as potentially revolutionary, the implication of large-scale implementation remains uncertain. Additionally, communications about these technologies and their implications, inevitably faces the problem that various stakeholders have diverging knowledge bases and assumptions, and therefore attribute different meanings and values to robotic interventions. This creates conflicting visions of a future where healthcare is provisioned with the help of intelligent machines.
Background and Research Questions
As an affluent and comprehensive welfare state that consistently perform on the top of life quality rankings, Norway has become a testbed for promising healthcare technologies. Having mass-digitized, the Norwegian public is economically able, digitally literate,1 and willing to experiment with technology-assisted health solutions.
From the academic literature on healthcare robotics we can identify three salient “sticking points” (Hacking, 1999), which are likely to characterize public debates on healthcare robotics in the coming years. The first, concerns robotic applications for improving the quality of care. In the medical domain, robot-assisted surgery is well-established (Gerhardus, 2003; Vyas & Cronin, 2015). Although benefits, challenges and cost-effectiveness remain vital topics for research (Lawrie et al., 2019), robot-supported minimally invasive surgery may reduce the risk of complications and post-surgical pain caused by human errors, resulting in fewer inpatient hospital days. Current applications of social robots in healthcare that emulate human features, on the other hand, are based on more immature technologies for language processing and human-robot interactions in real-world situations. Some preliminary studies, however, indicate that certain forms of robot companionship can positively contribute to life quality, improving psychological and physical well-being (Góngora Alonso et al., 2019; Pu et al., 2019).
A second issue in the literature revolves around robots and the future of labor. Robot technologies could radically change the nature of working life. This is a topic with a long intellectual history going back to the dawn of industrialization (e.g., Keynes, 2010), which remains pertinent today (Paus, 2018). Advancements in robotics are occasionally construed as a labor issue, with some projections suggesting machines, at some point, can lead to redundancies for many healthcare workers. Such fears about technology’s consequences, including losing one’s job, co-varies with factors like educational and income level, gender, and age (McClure, 2018), with some being “technophobes”; pessimists displaying exacerbated levels of fear for unemployment and financial insecurity (p. 152).
The third sticking point revolves around healthcare robotics as a source of ethical dilemmas. Robots in healthcare raises deep questions about responsibility and accountability, trust and deception, patient safety, privacy, and data protection (e.g., Santoni de Sio & van Wynsberghe, 2016; Sharkey & Sharkey, 2012). On argument suggests that healthcare robots for the aging population must be designed to “actually benefit the elderly themselves,” not just “reduce the care burden on the rest of society” (Sharkey & Sharkey, 2012, p. 28). Widespread domestic use of assistive robots for the elderly, for instance, may result in reduced human contact, instilling a sense of objectification and alienation among users. Conversely, it is possible that some applications could increase the autonomy of an aging population, by decreasing dependencies on other human caretakers.
Considering these issues, it is highly interesting to investigate how journalists, elites and various communicators represent the ascent of robotics in healthcare. In this article we therefore ask: what topics are most prominent in reports about healthcare robotics in Norwegian print media over a twenty-year period? Secondly, we consider what is gained by leveraging an approach that integrates quantitative topic modeling with qualitative content analysis for examining media representations of healthcare robotics? A deeper understanding of media accounts of healthcare robotics over this 20-year period is important because such representations may affect public opinion via a range of mechanisms that influence how information is processed by the reading public (Cacciatore et al., 2016). Media representations broadcast values, experiences, and expectations of journalists and the stakeholders they write about. When information is assembled and highlighted through salient news stories, these representations may exert media effects that activate reference frames and prime specific interpretations of controversial issues, like robots in healthcare. As such, news media are agenda-setting participants, and not impartial spectators in public discourse.
In democratic societies, public understanding of socially significant scientific issues is also premised on a delegation of epistemic trust, whereby citizens expect news reports to contain reliable information about matters of concern
Technoscience is an important driver of social change, and its potentials are frequently mobilized for various political, cultural, and economic agendas. In the case of healthcare robotics, imaginaries about the wonders of new technology are mobilized for making decisions and solving social challenges that are predominantly non-technical in nature (Šabanović, 2010, p. 442). One challenge for Norway and other affluent countries is the projected shortage of healthcare providers and increases in healthcare expenditure due to a rapid demographic shift towards an aging population. This dynamic is a source of significant controversy, since problems in healthcare must be redefined in ways that makes technical interventions salient and socially feasible. Such processes raise a myriad of difficult questions about the consequences of enrolling machines in healthcare delivery across stakeholder groups (Riek, 2017); contentious topics residing at the intersection between health science, politics, economics, and not least: machine and medical ethics. It is also interesting to investigate how media discourse align with academic debates on the subject.
Methods
To address these questions, we adopt a mixed-methods approach to content analysis that combines statistical topic modeling with a manual content analysis of exemplary texts, identified through keywords sampled from each topic (see Figure 1 Model of the study’s mixed-methods design.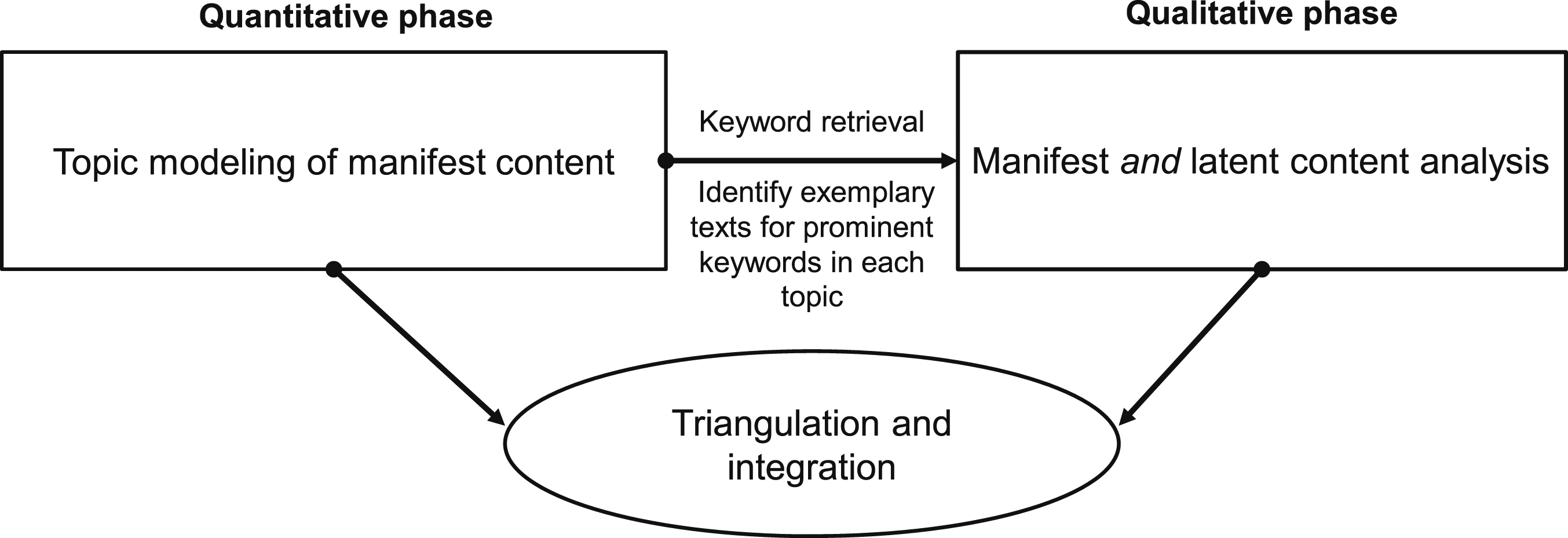
Instead of relying on a semantically “blind,” quantitative validation of the model, this integrative move helped establish coherent interpretability for each topic first identified through text-mining. Notably, computer software supported both steps (Wordstat 8, https://provalisresearch.com). By combining “distant” (quantitative) and “close” readings, letting the former guide our attention in the qualitative phase, we could triangulate substantive meanings of media representations of healthcare robotics. 2 Having mutually validated our abstract, computational model of content topics across the journalistic corpus with layered meanings identified through a textual hermeneutics of discursive samples, we hope to avoid pitfalls associated with relying on a single approach. As such, our disposition to combine computational objectivity of latent patterns in complex text-data with contextualized interpretation was done in the spirit of “dialectical pragmatism” (Teddlie & Tashakkori, 2012, p. 780): an effort to combine seemingly disparate epistemic commitments to address concrete research questions. 3
On Topic Modeling
Computationally speaking, topic models comprise a family of methods for probabilistic modeling that use algorithms to explore and identify thematic structures in large swathes of text. A manual approach to media representations based on direct reading might involve using a colored marker to highlight and code salient key words for certain themes in a few texts (Brett, 2012). Such approaches can be used in both qualitative and quantitative designs. Topic modeling, in contrast, approaches the “abundance of evidence” in text corpora by using computer software for the coding job, thereby constraining the researcher’s degrees of freedom to make spurious interpretations and confirm their own biases and preconceptions about contents (Underwood, 2017, p. 19). While topics are word distributions, a topic model is a distribution of word distributions across many documents. As such, they are higher-level abstractions, specified from underlying structural relationships between co-occurring words that can be identified using statistical methods. The result is a “set of substantively meaningful coding categories” (Mohr & Bogdanov, 2013).
Within a family of methods for automated text analysis, this approach can be classified as a “mixed membership model” for automated clustering (Grimmer & Stewart, 2013, pp. 283–284). Based on the text input (a corpus), a topic model is constructed by a computer program of recurrent themes, based on parameters selected by the analyst. This includes defining the number of topics to be extracted (a value known as K), specifying the statistical method, a level of segmentation (whether co-occurrences of words are measured on the level of document, paragraphs, or sentences), and the factor loading. Defined as a number between .0 and 1.0, this is the minimal factor loading a word must have to be kept in the factor solution for the sample.
An attractive feature of topic modeling is its capacity to handle the “heteroglossia” of journalistic discourse (DiMaggio et al., 2013, p. 590), a concept originally coined by the literary scholar Bakhtin to describe how individual texts may accommodate multiple perspectives or voices. Instead of assigning texts to topics deduced from theory, topic modeling is based on the premise that texts contain a mixture of topics at different levels of granularity, with the model inductively tracing interrelations and distributions between these across the corpus. The appeal of this approach for our study should be evident, as the data are sampled from a journalistic archive. Except for opinion pieces, Norwegian journalists and editors are obliged to abide by professional norms, 4 including a declared commitment to provide readers with a balanced variety of perspectives on controversial issues. Consequentially, many reports in the corpus reflect multiple sentiments about the state of healthcare robotics. We therefore consider sentiment classifications at the level of whole articles as positive or negative to be unproductive, with results dependent on the coder’s prior beliefs about robots, potentially yielding poor intersubjective agreement on classifications. In the language of machine learning, topic modeling offers an “unsupervised” alternative to manual approaches, as there is no need for human coding, training, or annotation beyond the metadata used to individually label files in the corpus (source, date etc.). As Mohr and Bogdanov points out, topic modeling may thus appear as a fully inductive and data-driven approach (2013: 546, note 2). They do, however, remind us that while topic models appears fundamentally inductive, the approach is not “theory-free.” It is based on presumptions about the organization of texts and meanings, like which units of discrete data exist (e.g., words), their organization, and distribution in and across documents.
Data and Data Processing
As described in Figure 2, our corpus was created from a broad search in the Norwegian database Atekst (https://www.retrievergroup.com), which indexes major national, regional and local newspapers in a digital archive, using the keywords “health” (helse) and “robot” (robot) for the period between 1.1.2000 to 2.10.2020. Having identified 2914 articles from the database, we screened each manually for eligibility, excluding 2152 articles. Articles that did not mention robots in the context of healthcare, including articles on agricultural robotics and animal health, movie and book reviews, and articles where the word robot was primarily used as a figure of speech, were removed from the sample, along with pure duplicates (artefacts). The final version included 752 PDF-articles in Norwegian, indexed according to title and date of publication, organized per year. This corpus represents a mixture of news outlets ranging from national newspapers and professional magazines to regional and local newspapers. Notably, these latter publications play a crucial role in the Norwegian media ecology, as decentralized news outlets serving informational and communal functions. Pipeline for identifying and screening relevant articles in the corpus. Boolean operators (AND, *) are used to capture variances in search terms. For example, in the screening phase, we discarded multiple articles on the use of robots in animal husbandry appearing in the search, as these frequently contain terms related to animal health (Norwegian: “dyrehelse”).
This corpus was imported to Wordstat 8 (Version 8.0.33, Provalis Research). Following common practice, texts were pre-processed using lemmatization for Norwegian. Additionally, we used a standardized exclusion list based on common words. To this list, we added words generated by Atekst from textual metadata pertaining to copyrights, institutional affiliation, and login data, as well as random letters and symbols generated by the PDF-extraction process. Appearances of such artefacts throughout the dataset can add noise and potentially overwhelm topic variability.
Computations for the topic model were performed using Wordstat’s topic extraction feature. This tool combines the methods of natural language processing and statistical analysis to “uncover the hidden thematic structure of a text collection” (Provalis, 2018). The extraction process in Wordstat 8 first computes a word-by-document frequency matrix, and then extracts a smaller number of factors from this. Processing can be accomplished using two analytical techniques: Non-Negative Matrix Factorization (NNMF), and factor analysis with a varimax rotation (see: Peladeau & Davoodi, 2018 for a comparison). Arguably, both are stable probabilistic methods, with results comparable to other modeling techniques, such as Latent Dirichlet allocation (LDA). Here, we adopted NNMF, which yields similar results (Peladeau, 2020).
Topic extraction we excluded low frequency words to ensure stable factoring, as recommended. Ideally, this means removing words occurring less than 10 to 50 times from the corpus, depending on the dataset’s size. Here, we removed words occurring with a frequency less than 40 times, using Wordstat’s post-processing options. Co-occurrences were segmented on the level of whole documents rather than paragraphs, due to the relative brevity of journalistic articles in the sample (compared to genres like political speeches, books, etc.). Factor loading value was set at a default .3.
Inspired by DiMaggio et al.’s work on newspaper representations in the policy domain of arts funding (2013), we created a model with twelve topics (K = 12). Ultimately, the adequate number of topics, model granularity (K), is decided heuristically by the researcher, and will depend on the field of inquiry (Jaworska & Nanda, 2016, p. 383). 5 The appropriate number must thus be judged pragmatically, on basis of usefulness (Murakami et al., 2017, p. 250). Interpretative differences between models with varying topic numbers are often minimal, with the K-value primarily affecting the specificity or generality of a given topic (Munksgaard & Enghoff, 2018, p. 74).
Topics are generated from a probability distribution over a fixed vocabulary, where certain words are more likely to appear under one topic (i.e., Norwegian working life), than another (Digital solutions). Words can then be ordered in a list, according to the probability of co-occurrences. A guiding metaphor is that topics, as patterns of word co-occurrence, are akin to “bags of words” (Murakami et al., 2017). These “bags” do not discriminate on basis of syntactical or narrative features of language, but evinces a latent structure based exclusively on probabilities. Taking the container-metaphor further, ordering these containers by decreasing probabilities yields a list appearing to human observers as an inventory of meaningful and coherent topics or themes (Mohr & Bogdanov, 2013, p. 547). Since the topic model is constructed from a probability distribution, these bags of words are not mutually exclusive and display some overlap. For instance, words appearing in topic X and Y may, to a lesser extent, appear in topic Z. While naming topics is partly an intuitive process (Jaworska & Nanda, 2016, p. 383), Wordstat 8 uses an algorithm to suggest a label based on the frequency of co-occurring keywords. These suggestions were edited for intelligibility.
Results: Exploring a Topic Model of Healthcare Robotics
In Table 1, we display the solution for a model based on twelve extracted topics from the corpus. The rank order of topics is based on the highest percentage of cases (% CASES) with at least one of the items listed in the KEYWORD column. In terms of absolute and relative numbers of cases, the most prominent topic is Norwegian working life (329 cases, 45.19%), with the least prominent being Artificial intelligence (AI) (131 cases, 17.99%).
Gross Result of a Topic Model With Twelve Topics.
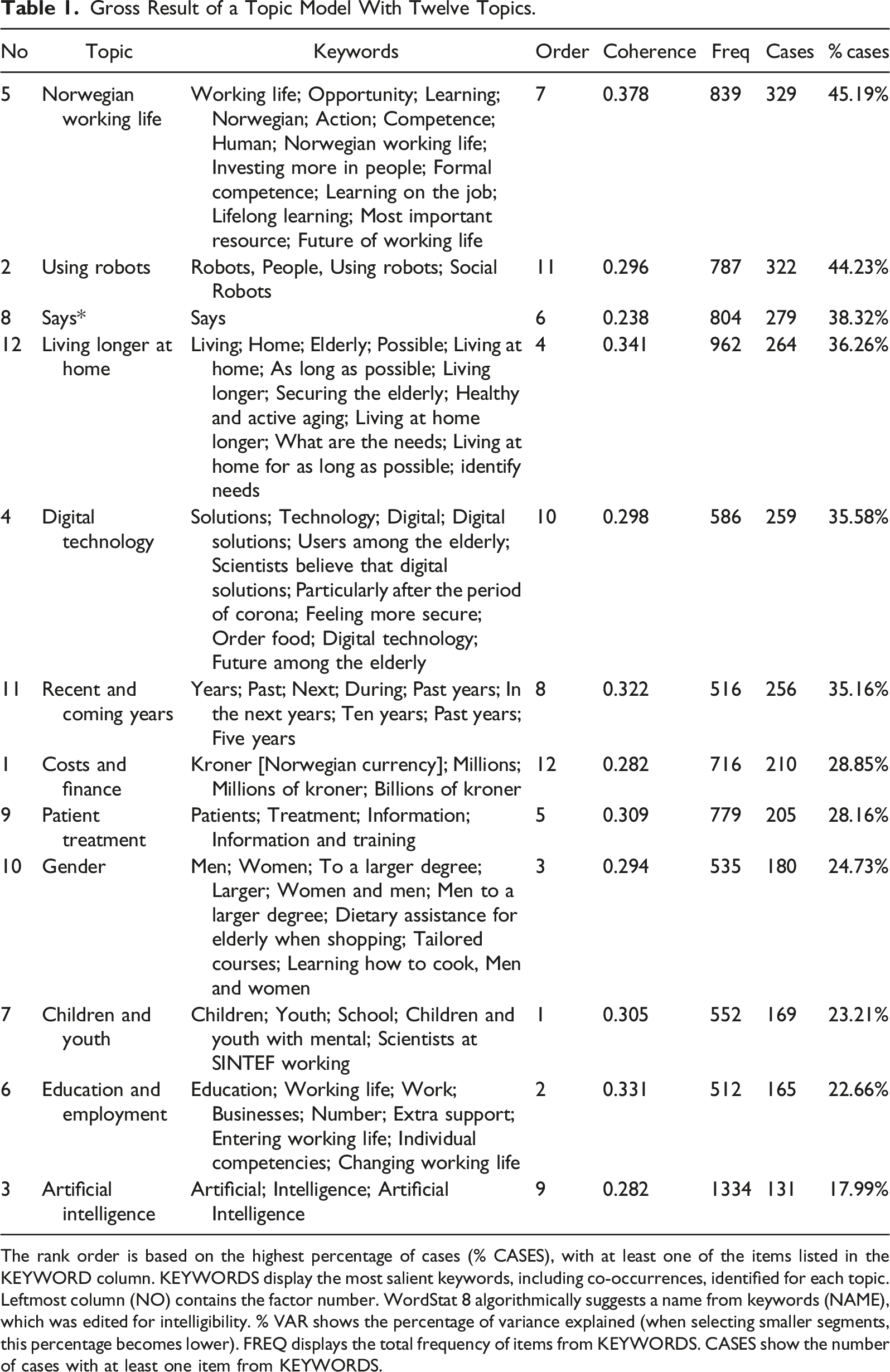
The rank order is based on the highest percentage of cases (% CASES), with at least one of the items listed in the KEYWORD column. KEYWORDS display the most salient keywords, including co-occurrences, identified for each topic. Leftmost column (NO) contains the factor number. WordStat 8 algorithmically suggests a name from keywords (NAME), which was edited for intelligibility. % VAR shows the percentage of variance explained (when selecting smaller segments, this percentage becomes lower). FREQ displays the total frequency of items from KEYWORDS. CASES show the number of cases with at least one item from KEYWORDS.
In a conventional approach to content analysis, the reader first acquires insight about text fragments by scrutinizing it, one paragraph after another. Here, we temporally displaced this subjective interpretative work to the “post-modeling phase” (Mohr & Bogdanov, 2013). In contrast to “close” readings, where understandings of significant issues emerge from deep narrative familiarity, we began with a distant reading of the corpus. In other words: we counted first, and then did the interpretative work. This enabled a mutual bootstrapping between the inductive topic model, our prior horizons of understanding, and emergent themes in specific texts. Here, our quantitative model reduced complexity and productively constrained the number of meaningful dimensions to look for, transcending our individual biases and tendencies to oversimplify content. It also helped identify key documents for qualitative investigation. In turn, our hermeneutic inquiry of samples from the digital archive, where meanings were interpreted based on conjectures about part-whole relationships of specific texts, corroborated the quantitative topic model. A benefit of this cross-over design is that human interpretation can invalidate meaningless topics and locate spurious artefacts.
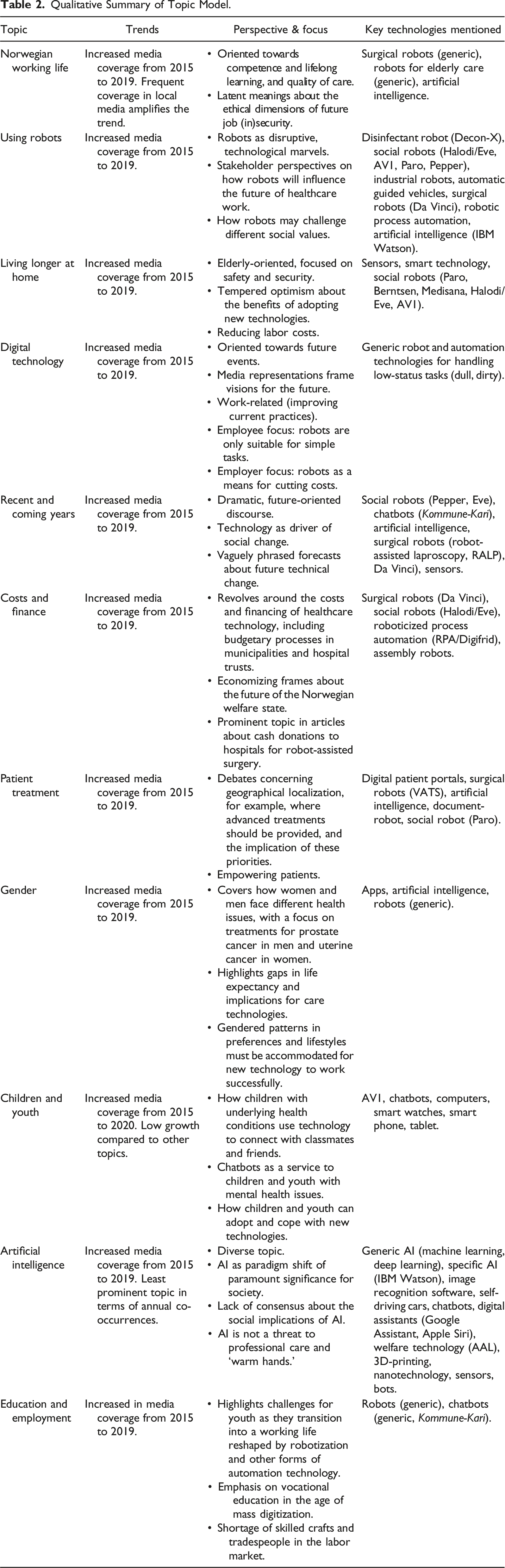
Having statistically “unitized” informative elements in the corpus through modeling (Krippendorff, 2018, p. 5.1), we subjected the topics to a more fine-grained qualitative content analysis. In this section, we explore the thematic structure of our model in more detail by interpreting the meaning and significance of the eleven remaining “net” topics. In the model, a topic is a pattern of word-use across a selection of texts. These patterned words tend to occur together across the corpus, and there are variations to the extent to which any individual document in the sampled text represents a topic. This characterization differs from the use of “topic” in everyday speech, as a subject of discourse. Following DiMaggio et al., we consider the topics in our model as “frames” (2013: 593), discursive cues that help identify and interpret how various stakeholders construe healthcare robotics as a meaningful but contested domain of policy and practice through talk (Entman, 1993; Gamson, 1989). While recognizing the need for precision about the conceptual underpinnings of frames and other “media effect mechanisms” (Cacciatore et al., 2016, p. 20), we here use the term pragmatically to designate categories of talk whereby figures of speech, keywords, and phrases are recruited to organize and set the agenda, and make certain aspects of healthcare robotics salient.
Qualitative Summary of Topic Model.
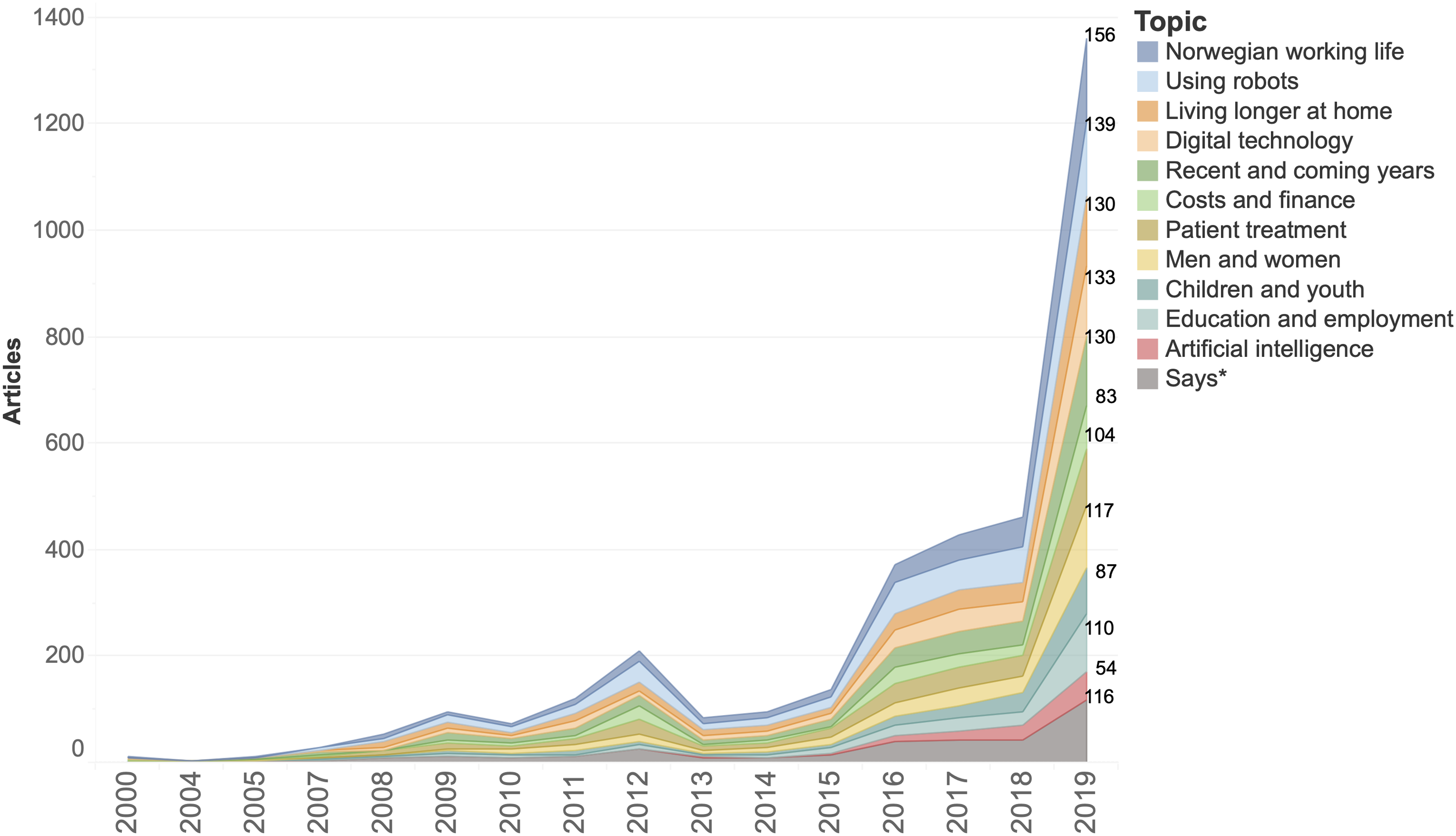
Distribution of all topics 1.1.2000 – 31.12.2019. A stacked area chart represents the topic distribution in news reports, based on crosstabulation of case occurrences for each topic per year over two decades. There is an increase in all topics between 2015-2019. Data from 2020 is not represented in the figure since we do not have access to a complete record for this year.
Norwegian Working Life
The first topic, Norwegian working life, revolves around how new technologies like robots might influence healthcare work (coherence .378, frequency 839, cases 329, % cases 45.19). When novel technology enters the workplace, tasks change, and new competencies are required to perform the job. For some stakeholders, this development presents an opportunity to work more efficiently, provide better services, and so on. Other actors, including some professionals and labor unions, voice their concerns about the implications of new technologies on care quality and job security. Central for this latter frame, is the question of whether formal competencies are required to transition over to work with new healthcare technologies, and the extent to which professionals can acquire such novel skills on the job or if they need additional schooling. Considering tomorrow’s challenges, many Norwegian stakeholders exhort the pursuit of “lifelong learning” as an ideal for healthcare workers since investments in human capital remain a most important resource for any organization, despite robots at some point may enter the workplace as efficient colleagues. The following proposition, sampled from an opinion piece in a local newspaper, exemplify this issue. Here, a conservative member of parliament calls for a nationwide “competence reform” due to new technologies like robots: “To ensure that no one expires in Norwegian working life and to give everyone a second chance, we must invest more in people” (Helgelendingen, 4.6.20).
Using Robots
Automation and robotization is already widespread in industry, and some stakeholders consider the healthcare domain to be the next frontier, ripe for technical disruption. Terms constituting the second topic, Using robots, comprise stories about how these marvels of engineering change the practice of healthcare delivery (coherence .296, frequency 787, cases 322, % cases 44.23). These stories describe experiences from technical interventions in the present (e.g., robotic platforms like DaVinci Surgical Systems, and the robotic pet Paro for dementia care) or engage with technoscientific imaginaries about how interactive social robots and AI could become significant for healthcare at some undisclosed future time. This topic also deals with robot agency, their capabilities, and associated challenges. Potential conflicting interests and values are highlighted in the following segment describing the experimental prototyping of novel care-bots: “The prospect of future robot-colleagues in elderly care does not excite Kjellfrid Blakstad, leader of the division for health and social care in Fagforbundet [a labor union]. What is lacking in municipal care is people who can provide the elderly with care and security. Can new technology do that, she asks rhetorically, and answers with a resounding no” (Kommunal Rapport, 6.2.2008). This frame emphasizes both the potential alienation of elderly recipients of care, and the unique competencies of healthcare professionals.
Living Longer at Home
In the context of Norwegian healthcare robotics present many opportunities, but also faces obstacles. Being a comprehensive and generously funded welfare state based around primary care delivery administered through municipalities, 6 there is willingness to adopt new and costly technologies, if these can offset other expenditures or add quality to the service. However, working life is highly organized, with comprehensive labor rights and a very high degree of unionization. With unions playing a key role in policy making, the example above illustrate potential tensions between trade union interests (e.g., recognition of skills and qualifications, job security and labor conditions), and employer federations, who envision robotization as attractive and a potentially cost-effective measures to the problem of staff shortage in care delivery, or an instrument for reducing labor costs.
Terms constituting the topic Living longer at home addresses how new technologies such as robots may enable the elderly to reside in their homes for a longer period, without being institutionalized due to increasing needs for care (coherence .341, frequency 962, cases 264, % cases 36.26). Conceptually, key terms about this issue occupy multiple frames. One frame is economizing, embodied by the following lead from a regional paper: “New technology makes it possible for elderly to live longer at home. This can save municipalities a lot of money” (Drammens Tidende, 23.2.2012). However, the same article reveals a competing frame construed from the same keywords, based on values like autonomy, dignity and coping despite the inevitability of aging: “We need a rethink. Both young and elderly persons in need of care want to manage on their own for as long as possible. Technology can help, says Navarsete [then Minister of Local Government from the Center Party].” This latter frame emphasizes technology’s potential to improve quality of life, instead of merely promoting its economic benefits. Overtly promoting the efficacy of healthcare robots, which are disputed due to the formidable challenge of standardizing care practices, raises politically unpopular questions about replacing human care with machine care, and the potential consequences of “technology-driven austerity” on care quality.
Digital Solutions
The fourth topic contains terms dealing with the general category of digital solutions and the process of digitizing health services in Norway (coherence .298, frequency 586, cases 259, % cases 35.58). Again, the topic embodies stories about what may occur sometime in the future. It is prominent in articles from local papers, national news, and professional magazines. An example is the following segment from Nationen, a daily focusing on economic affairs in rural Norway: “As expected, in particular after the coronavirus pandemic, scientists believe that digital solutions by 2030 will have even more users among the elderly, technology that can help them feel more secure and help them remember.” Figuring in techno-optimistic frames like this one, the topic also appears in frames that challenge such future visions. A salient example is an article about a high-profile seminar, where the director of Stavanger municipality (Norway’s fourth largest) made controversial statements about the inevitability of deploying robots for cutting labor costs in municipal care. Recapitulating from the seminar, the journalist asked: “Politicians and municipal directors all point in the same direction—with the help of robots and digitization, tasks will be solved better and cheaper. We ask: is this realistic? How can technology give us better and more effective services? And: are robots a threat to Norwegian jobs? Or can we expect a massive re-schooling of our healthcare workers and people with IT-skills?” (Stavanger Aftenblad, 17.8.2019). Commenting on the director’s controversial statements, a regional head from the Nursing Association underscored how robots cannot outperform trained professionals in this domain: “We believe that robots may perform simple routine tasks, so that we can have more capacity to do other things. Caring for a patient, for instance, consists of many phases, where observing and talking to the patient are the most important. Robots will never be able to perform such tasks. On the other hand, robots can help make beds, and fold towels.”
Recent and Coming Years
Time construal is central for reasoning and meaningful debate about the pace and nature of technical change. Labeled Recent and coming years, topic five is composed of terms used to represent time, mainly on the temporal scale of years, like in the “past” or “next” years, up to decades into the future (coherence .322, frequency 516, cases 256, % cases 35.16). Like with the construal of space by human minds, time construal is central to experience and comprehension, for abstract concepts and concrete issues like technological developments. Terms encompassing this topic exemplify what Evans calls the “common-place view” of time as a cosmic property, a tangible part of the physical world and its fabric (2003). 7 Terms represented by this topic construe healthcare robotics, and other forms of technoscience, as a process extending through time (see Elster, 1983). Time concepts recruit linguistic resources for describing time as motion or location in three-dimensional space. 8 Moreover, time is objectified through language (i.e., spatial metaphors like “coming years,” whereby a year is a physically approaching entity) and measurement devices, like clocks and calendars (that become meaningful by anchoring conceptual ideas in physical materials). These structures help quantify time, separate past from present, and anticipate what comes next. Temporal concepts that construe time as both a process and object with an inherent structure, are elaborated and structured by conceptual content from non-temporal domains.
Many instances of these terms describe recent changes brought about by new technology, along with economic or political changes in the healthcare landscape. Other uses are distinctly future-oriented; forecasts about when and how technical change shall occur. Interestingly, despite hype and exuberance about technologies like robots, predictions in the corpus about desirable or undesirable consequences of this technical change are seldom dated. Neither do they specify conditions for future events in detail. Instead, predictions are expressed in vague statements, such as “every third job may be replaced by a robot within the next 20 years” (Harstad Tidende, 21.6.2014). Technological forecasts, however, tend to underestimate the complexity and uncertainty of bringing innovations from concept to practical fruition, and those peddling such predictions often lack accountability (Tetlock & Gardner, 2016). Instead, predictions about healthcare robotics appear to work as “floating” or “empty” signifiers (Lévi-Strauss, 1987, p. 63), vaguely quantified outlines of a dramatic future without probability estimates, that can be attributed different meanings to.
Costs and Finance
Terms in Costs and finance mainly refer to cardinal numbers enumerating prices of various technologies, services, or investments in Norwegian currency (coherence .282, frequency 716, cases 210, % cases 28.85). At first glance, these may appear uninformative, like the discarded topic “says.” A more nuanced interpretation suggests this topic revolves around costs and financing of new healthcare technology. In Norway, this predominately happens via public sector budgets. Critical issues, like whether the costs of new technology are worthwhile investments for municipal healthcare or hospital trusts, are therefore central to public debate about the scope of healthcare robotics. This topic represents an economizing frame about the future of the welfare state, and asserts a “technological imperative” in healthcare (see Hofmann, 2002). It is prominent in descriptions of budgetary processes in municipalities and hospital trusts, stories about investments in new facilities, and local or national research and innovation projects. Casting light on public spending on new healthcare technology, these articles also question the merits of some investments.
Costs and financing reoccur in an interesting subclass of articles dealing with monetary donations to hospitals for advanced healthcare robots and particularly, the role of two affluent investors in central and southern Norway. These events are likely contributors to a prominent spike across multiple topics, observable from Table 1 in 2012. Noteworthy, this topic appears in a spate of articles on a controversial donation of roughly 25 million NOKs by the businessman Ole G. Ottersland to the Hospital of Southern Norway. As a condition for his gift, the donor stipulated that the hospital in Arendal would use the money to purchase a costly platform for advanced robotic surgery. This contradicted the hospital trust’s contested long-term strategy of centralizing its cancer surgery unit in Kristiansand city. Installing the robot in Arendal conflicted with the board’s decision, requiring additional spending on skilled personnel and infrastructure to utilize the machine for patient treatment. This triggered extensive debates about localization, the utility of surgery robots, and the ethics of donating costly technology that potentially disrupts the priorities of public decision-makers. Some stakeholders questioned whether the robot’s medical benefits were sufficiently documented. Others argued that the prestigious machine would help recruit patients and staff to the hospital. By not keeping abreast with technical developments, the surgical unit risked becoming unattractive. Finally, the hospital accepted the donation.
Patient Treatment
Patient treatment is what the business of healthcare is all about (coherence .309, frequency 779, cases 205, % cases 28.16). Keywords include patients, treatment, information, and training, with healthcare robotics having implications for each. Generally, the topic is abundant in articles discussing general trends and developments in patient treatment. Like the previous topic, many news articles in local and regional papers covers localization debates about where specialist treatments should be provided, and the implications for patients, debates where robotization and automation are recurring motives.
An attractive feature of automation and robotics technology is the potential to revolutionize how information propagate between stakeholders in the healthcare system. In one news report, the reader is introduced to “document-robots” as a promising application of machine learning techniques to assist doctors in making sense of medical records: “Computer software that can read hundreds of records can extract critical information. The program gets smarter and smarter the more records it is given access to. With an average of 180 documents per patient, this can be a good tool” (Flekkefjords Tidende, 20.9.2017). In another, we learn that machine learning increases diagnostic precision, as a tool for decision-support: “Automation and robotization is on the rise: physical presence is no longer necessary to the same extent as before. Patients can monitor themselves at home, doctors can supervise each other virtually, images and information can be considered by colleagues elsewhere on the planet, without time delay” (Aftenposten, 17.7.2019). Texts encompassing this topic also highlight how automated systems, like “document-robots,” empower patients and caretakers by democratizing knowledge formerly reserved for care professionals.
Gender
Applications of healthcare robotics are inextricably linked to gender issues. In the corpus, Gender surfaces in several contexts, including articles on the gendered character of healthcare professions, and news stories about how men and women face different health issue (coherence .294, frequency 535, cases 180, % cases 24.73). One set of articles, from 2020, spotlights the report Food Plate 2030 and predictions about diet and healthy aging, including possible dietary interventions for aging men. Its authors are not confident that robot butlers will be widely used in households within a decade. Additionally, the topic appears in several articles describing developments in robot-assisted surgery, with a focus on treatments for prostate cancer in men and uterine cancer in women. Some cover issues like long waiting times for treatment, due to a lack of capacity for robot-assisted surgery in hospitals. Another group of texts addresses the gap in life expectancy between Norwegian men and women, with women living longer. Despite a significant reduction of gender differences in life expectancy, the remaining gap may have implications for technologies of care, like robots. For example: “Karen Dolva, the founder of the technology company No Isolation, who makes robots that enable those with serious illnesses to participate in communal life, says that women are as lonely as men” (Klassekampen, 26.10.2019). An underlying premise is that gendered patterns in preferences and lifestyles must be accommodated for new technology to work successfully for different stakeholders.
Children and Youth
Like gender, the next topic Children and youth also calls attention to a social category (coherence .305, frequency 552, cases 169, % cases 23.21). Articles about three kinds of issues deserve mentioning. The first describe novel uses of a commercially available robot known as AV1, designed to be an avatar for children and young adults with long-term illness. Providing live audio and video, AV1 is used in classrooms and other places where usual interactions with peers are not possible: “Today, 300 children with long-term illness in Norway has been given the robot, that participates in school instead of the child” (Budstikka, 17.1.2018). These articles span a five-year period, covering the first trials when the robot was a novelty in 2016, with more recent materials from 2020 on how AV1 helps children with health conditions connect with classmates during the coronavirus pandemic.
Another salient group of articles outlines efforts by scientists to create a new chatbot as a service to children and youth with mental health issues. In a string of opinion pieces in local and regional newspapers from February 2018, a charity working with at-risk youth voice concerns about the long-term consequences of these services. While recognizing that such technology may have positive benefits, the author argues that no technical quick fix can replace the critical work of volunteers: “Kirkens SOS appreciate that researchers and authorities use their resources on youth and mental health issues. But is the answer a chatbot? Most of all, the youth need another human being that cares and have the time to listen” (Nordlys, 3.2.2018).
A third cluster of articles addresses how children and youth can adopt and cope with new technologies, such as artificial conversational agents, more generally, outlining potential consequences for schooling, higher education, and work-life preparation.
Education and Employment
The next topic appears across a swathe of articles about challenges for youth as they transition into a working life that is reshaped by robotization and other forms of automation technology (coherence .331, frequency 512, cases 165, % cases 22.66). One cluster of texts, for instance, deal with unemployment rates and school dropouts. A subclass here investigates the value of vocational education in the age of mass digitization, and the shortage of some groups of skilled crafts and tradespeople in the labor market. It overlaps with Norwegian working life, the first topic described in Table 1.
Notably among these cases, we also find the opinion letter by the conservative MP appearing in topic one. Published in multiple local newspapers in late May and early June 2020, the opinion piece calls for a “competence reform” for lifelong learning to guarantee that the nation’s workers remain competitive on the labor market: “to ensure that people will have work in the future, adults need to refill their competencies, both when they have a job and when they do not” (Rogalands avis 26.5.2020).
Artificial Intelligence
AI is the last topic (coherence .282, frequency 1334, cases 131, % cases 17.99). Unsurprisingly, AI intersects with other topics on the list, appearing across a variety of articles. Originally, the term referred to a variety of engineering techniques and algorithms in computer science with rather narrow applications, but is now a buzzword in public discourse. As observed by two notable scientists in the field of human and machine intelligence: “despite a history of missed milestones, the rhetoric of AI remains almost messianic” (Marcus & Davis, 2019, p. 5).
Several texts from the corpus frame even minute advances in AI as paradigm shifts of paramount significance for the future of human health. This point is illustrated in the introduction to an otherwise tempered opinion piece by one profiled academic: “The Beast from Revelation or Messiah? Artificial intelligence (AI), different computer systems capable of self-learning, are considered by many to be the most radical man-made revolution” (Aftenposten, 13.2.2019). Notably, texts construe the potential of AI in healthcare as promissory, something to be cashed in at some undisclosed point in the future: “Artificial intelligence could analyze data about many people, in order to identify diagnoses and treatments that work” (Aftenposten, 30.12.2019). These articles do not reflect consensus about the implications of AI-advances for different healthcare professions. Some cases also contain a competing conceptual frame stressing the uniqueness of human cognition and emotion as central for quality healthcare delivery. In the words of the secretary general in a major Christian charity for mental health: “Artificial intelligence can never replace volunteers. Warmth and presence will always depend on beating hearts. Human intuition can never be programmed into a robot” (Dagens Perspektiv, 17.01.2020).
Similar sentiments are echoed by a spokesperson for the national trade union for radiographers and radiation therapists. He rejects prospects about the profession soon becoming redundant, despite advances in image processing: “It is easy to get overwhelmed by the thought of the opportunities made possible by artificial intelligence, but according to chief advisor Håkon Hjemlys’ report from the European Society of Radiology’s AI-seminar in Barcelona, there is still no reason to fear that the new technology will cause mass-unemployment among those at work in imaging departments” (Hold Pusten, 24.6.2019).
Arguably, the topic illustrates significant gaps between the rhetoric and reality of AI in Norwegian healthcare and reveals a problem of trust in healthcare robotics. Public discourse on this subject appears to conflate the potential of general (or “broad”) machine intelligence in the future, and functional applications of current systems, which are useful only for very narrow domains, requiring close human supervision and maintenance. Marcus and Davis call this feature of contemporary discourse “the AI Chasm” (2019). While the field of AI has made substantial progress, the public may arguably overestimate the capabilities of these systems, partly because media reports tend to misrepresent the actual capacities of current AI-applications. Another salient example appearing in the corpus, is the rise and fall of IBM Watson Health, a bold effort to revolutionize medical diagnostics by using AI to analyze patient records and the medical literature. Heavily marketed in the press, this dazzling effort eventually fell flat, when its limitations came to light in the healthcare community. Contrary to popular opinion, argues Marcus and Davis, such systems are brittle and lack “robustness,” as their applications do not transfer across even modestly different contexts from the situations which they have been trained for.
Discussion
As a Proxy for Measuring the Media Exposure of Political Parties in the Corpus, We Computed the Total Number of Independent Cases Where the Political Parties Currently Represented in Norwegian Parliament are Mentioned.

The number of cases is the sum of independent articles were party name plus its abbreviation (see parentheses) appear as a keyword. Note that a single case may include either the party’s full name, its abbreviation, or both. This yields a different number than the absolute frequency of a keyword in the corpus, which does not discriminate between mentions within and across independent cases (a party may appear several times in the same article).
In the introduction, we identified three sticking points in the academic literature on healthcare robots: applications for improving the quality of care, the future of labor, and robotics as a source of ethical dilemmas. Having explored our topic model numerically and qualitatively, our model of media representations reveals an alternative, fine-grained inventory of eleven key topics on healthcare robotics in Norway. Instead of mapping neatly onto the main themes in the academic literature, our topic inventory rather crosscut these. Ethical dilemmas, for example, comprise a latent pattern across several topics in the model, but do not manifest explicitly. Surprisingly, concerns about robot-induced job loss do not manifest in the model, beyond latent worries about their influence on future work-life.
Disputes about the proper role of healthcare robots also change substantially over time, as some technologies mature, while others become obsolete or fail to deliver on initial promises. An influential Norwegian Official Report published in 2011, which mentions robots 49 times, 9 presents a compelling example. Offering a rich tapestry of predictions, Innovation in Care argued the case for robots in healthcare delivery for an aging demographic in the next decades, spanning use-domains such as safety and security, compensatory applications, and well-being, social contact, treatment, and care. Our topic model reveals that, despite a proliferation of articles on the subject, few of these predictive assertions about healthcare robotics on a large-scale in Norwegian healthcare have come true. As such, our model of Norwegian media representations highlights gaps between discourse on the feasibility and promise of robotics, and its empirical realization and mass implementation.
Robot technologies promising paradigmatic or revolutionary shifts in healthcare delivery are frequently spotlighted in the corpus, due to their novel features and future potentials. But newsworthiness also depends on how the technology intersects with other social concerns. We saw that the topic Patient treatment foregrounded how a relatively mature technology, namely, robot-assisted surgery, was entangled in regional disputes about the localization of advanced hospital treatments. During a tug of war for local access to finite resources, news representations of healthcare robotics proliferated in the period before decision-makers concluded where the robot should be located. But when the final decision was made, newsworthiness dropped, and reporting about the technology ceased.
As revealed by multiple topics, including Norwegian working life and Education and employment, debates about robots and healthcare labor frames the technology as mainly entailing changes in working life, focusing less on the question of job loss per se. For instance, the topic Norwegian working life is represented across a swathe of articles about the future landscape of healthcare work. These stories, which include both mature technologies such as Apoteca Chemo (a robotic system for pharmacological cytostatics, Farmasiliv, 25.2.2016) and more immature technologies like IBM Watson for AI-based medical decision-making (Aftenposten, 4.9.2016), stresses how machines will work side by side with humans to support and assist them, rather than take their jobs. One hypothesis is that this absence of worries over job loss can be explained by the high standing of workers’ rights in Norway, where healthcare is predominantly a public sector enterprise. Being technology-intensive, this sector recruit personnel with high formal competence, and there is a projected staff shortage on the labor market.
The relative brevity of frames emphasizing job displacement from robotization can also be explained by the fact that much healthcare work takes form as personal care delivery. Based around human interactions, these services are highly correlated with labor inputs. As such, this sector is less amenable to standardization and mechanization than industrial commodity production, and there are few examples of widespread diffusion of robots in care delivery where people become redundant (Lloyd & Payne, 2019). Future research should investigate this aspect more thoroughly, by examining the attitudes of different Norwegian healthcare professionals towards robotics and the future state of labor. This also raises a question about whether similar patterns are prominent in media representations sampled from more market-oriented healthcare systems.
Until now, healthcare robotics has mostly been framed as an assistive tool, yet to replace human-to-human patient care. But many stakeholders believe that advances towards more agile and autonomous technologies will increasingly affect the nature of manual work, for better or worse. Presumably, coming debates about robot futures will depend on the technology’s role in solving healthcare problems on a mass scale, and whether it is possible to document positive effects from this. Our topic model suggests that representations of healthcare robotics in the Norwegian media landscape reflects the abundance of political and dilemmas associated with such developments. These issues are lodged at the intersection between robotics technology, labor, and employment rights, voicing the hopes, aspirations and concerns of workers, healthcare managers, and union-representatives alike.
The ascent of healthcare robotics into the public sphere pits different values and visions of healthcare futures against each other, since many of the problems the technology promises to solve are social and political, and not technical per se. Unsurprisingly, then, our model suggests that the future of robotized healthcare is politicized and on the agenda across the Norwegian policy spectrum (see Table 3). In our corpus, major parties on both sides of the political isle are keen to stage themselves as optimists about technology’s potential to solve healthcare challenges. But despite cautious optimism from political elites, our model reveals that what is at stake is not identical for all stakeholders, who perceive the future of healthcare robotics through divergent risk-frames. Based around notions of harm and chance, risk-frames become salient when something of human value, such as job security, or quality in healthcare, is at stake. Unsurprisingly, there is much uncertainty about the outcome of introducing intelligent machines into the workspace of highly trained professionals, where patient safety is a main priority. The question of what role different political parties see for healthcare robotics in the Norwegian welfare state deserves more attention in future research.
Challenges and Caveats of Topic Modeling
Argument against computational topic modeling for content analysis targets its apparent simplicity since the method is primarily based on two plain ingredients: a corpus of text and a specific software. In Jockers and Mimno’s words, the worry is that “algorithmic techniques will turn scholarship into a mechanistic process that converts texts into facts, leaving no room for interpretation, or for dissent” (2013: 768). As they, we think this concern is unwarranted and based on faulty assumptions. Our sequential, cross-over design suggests, to the contrary, that “ample room” for interpretation remains. An inductive, quantitative model of objective features in the corpus instead highlights representations apt for focused, hermeneutic exegesis on actionable and thematically coherent meanings (Baumer et al., 2017).
A related challenge is articulated by Brookes and McEnery, who question the utility of topic models, because they are founded on an inadequate “theoretical underpinning of what a topic actually is” (2019). They stress that the “qualitative analytical phase” of topic modeling in fact begins at the very moment when the researcher decides to discard thematically incoherent topics, as happened for the topic “says” in our proposed model. We agree with this observation. But as remarked by Mohr and Bogdanov, generic critiques based on a criteria of simplicity can, ultimately, be leveled at any research method (2013). What matters is not the method’s degree of sophistication or complexity, but whether its practical implementation help acquire new, robust insights about phenomena. Under no circumstance is the word-clusters offered by topic modeling a replacement for substantive understandings of multivalent discourse. As our qualitative exploration show, the statistical model is simply a tool for making some analytical problems tractable, which is particularly helpful for large datasets based on journalistic content, where boundaries between analytic categories, actors and perspectives can be fuzzy.
A third issue concerns technical adequacy. In this case, that meant preparing the data to fulfill the method’s formal constraints. Only when the quantitative and qualitative is properly intercalated, can the analysts attain an epistemically sound grasp of the discourse at hand. In our case, we gained some initial familiarity with the corpus by manually reading and systematically coding all articles from 2000 to 2018, in an early phase of the project, before adopting a topic modeling approach. Formalization is therefore a supplement, not a replacement for close readings. Since data cannot speak for itself, hermeneutics remains a central ingredient in topic modeling work and should be explicit about its limitations. Jockers and Mimno illustrates this point with the analogy of satellite imagery of forests (2013). Just like images of forests captured from space cannot show the fine micro-level details of individual trees in all biological richness, topic models cannot represent the full meaning of individual texts. But the view from a distance, whether from a satellite or a topic model, offers a complementary perspective, compared to that up-close. As such, the cross-over between topic models and close readings helps us understand contextual trends in media discourse about healthcare robotics, differently than each method alone affords. Consequentially, topic modeling may be useful for some inquiries into patterns of meaning, but less so for others.
Conclusion
Topic modeling provides an empirically grounded method for automated coding of manifest content in large, domain-specific text corpora sampled from public discourse. When combined with close readings of latent meanings in exemplary texts, it offers a novel approach to using digital archives for mapping public controversies in healthcare, and our model illustrates how technoscientific disputes can be represented and explored in a compact and legible way. Applied to news media, the method provides insight into prominent topics in public discourse about healthcare robotics, and how journalists, opinion leaders, and other stakeholders, frame key issues in this field from their own standpoint. These public representations potentially affect sentiments about healthcare robotics in a wider readership, through a variety of mechanisms beyond the scope of this study (Cacciatore et al., 2016).
Like other methods in quantitative content analysis, topic modeling offers a formal and transparent approach to measure change in meanings and frames over time, to chart differences between actors and groups, and assess relationships between sentiments and attitudes of various stakeholders. It is thus compatible with the epistemic goals that motivated seminal work on content analysis by Berelson, Lazarsfeld, Lasswell, and others, namely, answering questions about “who says what, through which channels, to whom and with which effects” about a given issue (Lasswell 1960, cited in Krippendorff, 2018, pp. 3–4). Ending on a methodical note, we suggest that a cross-over design, like we applied to this case of healthcare robotics, extends the empirical scope for mapping the composition of controversies over technoscience in novel directions (Marres, 2015). Social negotiations over healthcare robotics, unfold over large timespans, engaging a variety of actors whose local meanings are represented across a diverse media landscape. As a tool, topic models can help researchers cash in on the “data deluge” of contemporary knowledge society, where close readings of the massive amounts of circulating information from many stakeholders are beyond the capacities of a single reader. Notably, our model of media discourse on healthcare robotics demonstrates that Norwegian society is not comprised of passive onlookers, who simply conform and adopt to new technological innovations in a deterministic fashion. Instead, it illuminates a wide cast of characters, interest groups and communities who are actively engaged in the struggle to shape the future of welfare by negotiating the professional, epistemic, social, and political life of healthcare robotics.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.