
Abstract
In recent years, researchers have emphasized the relevance of data about commonsense moral judgments for ethical decision-making, notably in the context of debates about autonomous vehicles (AVs). As such, the results of empirical studies such as the Machine Moral Experiment have been influential in debates about the ethics of AVs and some researchers have even put forward methods to automatize ethical decision-making on the basis of such data. In this paper, we argue that data collection is not a neutral process, and the difference in study design can change participants’ answers and the ethical conclusions that can be drawn from them. After showing that participants’ individual answers are stable in the sense that providing them with a second occasion to reflect on their answers does not change them (Study 1), we show that different conclusions regarding participants’ moral preferences can be reached when participants are given a third option allowing AVs to behave randomly (Study 2), and that preference for this third option can be increased in the context of a collective discussion (Study 3). We conclude that design choices will influence the lessons that can be drawn from surveys about participants’ moral judgments about AVs and that these choices are not morally neutral.
Introduction
Online platforms have become a common way to collect and quantify political and moral opinions to inform decision-makers, conduct research, or even automate decision-making. However, critical sociology has highlighted the non-neutrality of quantification methods used for statistical analysis, resulting in numerous controversies statisticians have debated (Desrosières, 2008). A famous example of this critique is Bourdieu’s claim that “public opinion does not exist” because opinion surveys are associated with political constructions strongly determined by their methodology, the questions’ framing and goals (Bourdieu, 1972). However, this call for prudence, which characterized the social sciences’ adoption of statistical methods, was unheeded by those who developed computational approaches to social choice based on machine-learning models. Indeed, despite relying on copious amount of data about people’s moral and social preferences, these approaches have been particularly blind to the extent to which design choices and methodological limitations in surveys’ design may shape researchers’ conclusions. As such research typically aims to play a crucial role in shaping public debate and policy-making, our goal in this paper is to draw attention to the way design choices can impact the conclusions of computational approaches to social decision-making.
More precisely, we focus on recent attempts at automatizing social and moral decision-making around autonomous vehicles (AVs). Through three studies, we provide experimental evidence that subtle choices in survey design do impact participants’ replies and the conclusions machine-learning algorithms would draw while trying to deduce a general picture of social preferences from their answers. Our results allow us to refute the conclusions of foundational experimental works about people’s moral opinions on AVs dilemmas, demonstrating that more data does not necessary lead to more accurate results, as attempts to aggregate moral opinions can fall in critical pitfalls. In doing so, we also suggest better designs for online survey makers to collect accurate moral opinions.
The recent development of AVs led academics to engage in numerous debates about the ethical questions raised by this technology. However, most of these debates have focused on how AVs should behave when they have to choose between courses of actions that would all lead to inflicting harm on others. For example, should AVs decide to harm an animal rather than a human being? One person rather than two? A young person rather than an old person?
One reason these questions have drawn so much attention is because such dilemmas have been at the center of ambitious empirical studies. The Moral Machine Experiment (MME, Awad et al., 2018) presented participants with a series of dilemmas involving AVs, in which they had to choose whether an AV should go ahead and harm certain people, or swerve and injure other people. They collected c. 40 million decisions from people in 233 countries and territories, what probably makes it the largest available dataset on people’s intuitions about moral dilemmas. Based on this unprecedented wealth of data, Awad and colleagues found several patterns in people’s preferences, including preferences to save human beings rather than pets, several people rather than one person, young people rather than old people and people who are healthy rather than people who are not.
As authors of the MME have stressed in several places (e.g., Bonnefon, 2019), these conclusions are supposed to be descriptive, not prescriptive: they describe how people prefer AVs to be programmed, not how we should program them in the end. However, they still argue that these data are relevant to normative debates about the way AVs should be programmed. A “modest” argument in favor of this relevance relies on pragmatic considerations: if policymakers want people to adopt AVs, then they should make sure that the behavior of AVs does not conflict with people’s sense of morality. For example, Awad and colleagues (2018) write that “we need to have a global conversation to express our preferences to the companies that will design moral algorithms, and to the policymakers that will regulate them,” and that “we can embrace the challenges of machine ethics as a unique opportunity to decide, as a community, what we believe to be right or wrong; and to make sure that machines, unlike humans, unerringly follow these moral preferences.” Thus, results of the MME are morally relevant because they allow people to express their preferences in the context of a collective ethical decision about the way AVs should be programmed.
A more “ambitious” version of this approach proposes to automatize ethical decision-making by collecting people’s judgments about such ethical issues and using aggregation methods to reach “credible” ethical decisions. Thus, Noothigattu et al. (2018)’s Voting-based system (VBS) aims to automatize moral decision-making in the context of dilemmas involving AVs: rather than providing AVs with general ethical principles people have agreed upon, we should simply provide them with people’s opinion on ethical dilemmas and have the AV learn from these individual choices to make their decisions. This more ambitious proposal has been resisted on several grounds. For example, it has been criticized for being based on morally fallacious methodological axioms—for example, endorsing Conitzer’s assumption (2017) that aggregating moral agents’ judgments “may result in a morally better system than that of any individual human, for example, because idiosyncratic moral mistakes made by individual humans are washed out in the aggregate” (Etienne, 2021; Greene et al., 2016).
Despite their differences, both approaches rest on the assumption that the data collected in the context of the MME and similar studies accurately reflect participants’ attitudes—and, more importantly, the type of attitudes that might be relevant to the public reception of AVs. However, the behavioral economists’ literature on nudges, reminds us of the great sensitivity of respondents’ replies to survey designs (Thaler & Sunstein, 2008), emphasizing the critical importance of collecting responses that accurately reflect people’s opinions. As such, there are at least five dimensions on which the kind of data collected by the type of approach illustrated by the MME might fall short of being relevant to ethical decision-making.
A first dimension is perspective (PT). Indeed, past research has suggested that moral intuitions can be shaped by the point of view from which we approach moral issues. For example, research on moral dilemmas suggest that participants’ intuitions might depend on whether they approach this problem from a first- or third-person perspective (Nadelhoffer & Feltz, 2008; Tobia et al., 2013; but see Cova et al., 2021 for failure to replicate). Similarly, research on moral and political reasoning suggests that people’s judgments can be modified by asking to take them certain specific perspectives on moral and political issues—such as the perspective of an “impartial spectator” (see Allard & Cova, forthcoming for a review of this research). In the context of AVs, Bonnefon and colleagues (2016) observed that, though participants were supportive of AVs that might sacrifice passengers to save others, they were reluctant to ride in vehicles designed to follow this moral principle. Moreover, Frank and colleagues (2019) found that participants were less likely to answer that AVs should sacrifice their passengers when asked to adopt the perspective of an AV passenger (compared to the perspective of a pedestrian or observer). This suggests that what seems acceptable might depend on the perspective participants adopt when reflecting about AVs. However, we do not know which perspective participants naturally endorse when participating in such studies, and whether this is one relevant to public discussion at large.
A second dimension is deliberation time (DT). Past research on moral intuitions have emphasized that our responses towards moral dilemmas sometimes pit against each other a quick, intuitive answer and a slower, reflective one (Greene, 2014). In line with this “dual-process” approach to moral judgment, it has been shown that people’s responses to moral dilemmas can change when they are asked to take time to reflect before answering (Capraro et al., 2019; Suter & Hertwig, 2011). Accordingly, recent research suggests that people’s response to moral dilemmas involving AVs can change depending on whether they are asked to answer quickly or not: in a dilemma asking participants whether the AV should sacrifice pedestrians or its passengers, participants who had to answer quickly (within 5s) were more likely to answer that it should sacrifice its passengers (Frank et al., 2019). However, quick answers are not necessarily those relevant to public debates, in which people are supposed to take the time to reflect and ponder different factor. Additionally, most research on people’s judgments about AVs probe participants’ intuitions when first exposed to a certain problem. But people engaged in public deliberation are more likely to be repeatedly exposed to the questions they are asked to answer, giving their more time to deliberate. Thus, it might be that answers collected by the MME only reflect quick, intuitive answers based on a single exposure and not the slower, more reflective answers based on repeated exposure that are more relevant to public debate.
A third dimension is whether people reflect about abstract principles or concrete cases (AvC). While public debates about AVs are likely to be framed in terms of abstract principles (e.g., “should we take age into consideration?”), most studies have focused on participants’ responses to particular cases. However, past research in moral psychology and experimental philosophy have emphasized the fact that people can give radically different answers depending on whether questions are about abstract principles or concrete cases (Freiman & Nichols, 2011; Nichols & Knobe, 2007; Sinnott-Armstrong, 2008; Struchiner et al., 2020).
A fourth dimension is the number of options, and more precisely the presence of a third option (3O). Past research has shown that introducing a third option in a moral dilemma can dramatically switch participants’ moral preferences (Wiegmann et al., 2020). In the context of moral dilemmas including AVs, Bigman and Gray (2020) have shown that introducing a third option allowing the AV to make a decision at random drastically reduced the relevance of certain factors such as age, gender or social status. Awad and colleagues (2020) argued that participants’ answers were biased by the formulation of the Bigman and Gray’s third option, which made it more ethically attractive (“Treat the lives of X and Y equally”). However, Bigman and Gray also ran a study in which the third option was formulated in a more neutral way (“To decide who to kill and who to save without considering whether it is X or Y”) and participants still showed a wide preference for this option. Awad and colleagues (2020) also argued that, when they offered their participants to indicate their preference between two options using a slider, very few participants chose to put the slider at the middle, which would indicate that they are indifferent between two options. However, this counterargument rests on a confusion: preferring that the choice between A and B be random is not the same as being indifferent between A and B if one is forced to choose between A and B. This confusion is based on the assumption that preference for a choice at random must be grounded in indifference, while it is more likely to be grounded in a moral preference for impartiality. Finally, recent studies have shown that participants are much more likely to be outraged by AVs that makes decisions based on criteria such as age, gender or moral status, compared to AVs that makes decisions at random (De Freitas & Cikara, 2021). This suggests that allowing participants to have AVs programmed to choose at random might lead to a very different picture of public consensus compared to the two-options method used by studies such as the MME.
A fifth and last dimension is the presence of a series of objections and a collective discussion (DISC). Most people arguing for the relevance of empirical approaches to ethical debates on AVs argue that such methods allow non-experts to take part in the collective discussion about the ethics of AVs. However, most of the time, the data collected do not reflect the outcome of a public discussion, but the aggregation of individual differences, formed in isolation. But psychological studies show that the outcome of collective discussions is not similar to the mere aggregation of individual answers, and that the results of public discussion are generally more efficient (Balliet, 2010). This is why some have argued that discussion might lead people to converge on “better moral judgments” (Mercier, 2011). Thus, if one’s goal is to identify the moral principles on which people would converge, it might be more interesting to collect judgments that have been formed as the result of a discussion, rather than in isolation, and challenged by the review of objections.
For all these reasons, it might be that public opinion as it has been measured through studies such as the MME might not be the most relevant to ethical decision-making about AVs, and that changing some of the aforementioned parameters might lead people to converge on very different options. If this is the case, then programming AVs so that they learn to make decisions based on the answers people gave to the MME might not lead AVs to make “credible” decisions, but rather to go against the ethical principles that are likely to be endorsed as the result of public discussion. To investigate this possibility, we conducted three exploratory studies. In the first study, we explored the impact of PT and DT, and had people answer dilemmas about AVs quickly and slowly. In the second study, we explored the joint impact of AvC, 3O and DISC by comparing participants’ answers when collected according to the methods of the MME and when collected at the issue of a collective discussion on abstract principles including the possibility of the third option. In the third study, we explored how robust is participants’ preference for their third option, and whether it is favored by collective discussion.
Study 1: The Effect of Time Constraint on Participants’ Judgments
First, we wanted to determine to which extent answers collected following the MME methods were robust, or changed (i) depending on the perspective participants were asked to adopt, and (ii) when participants were given more time to reflect on them.
Materials and Methods
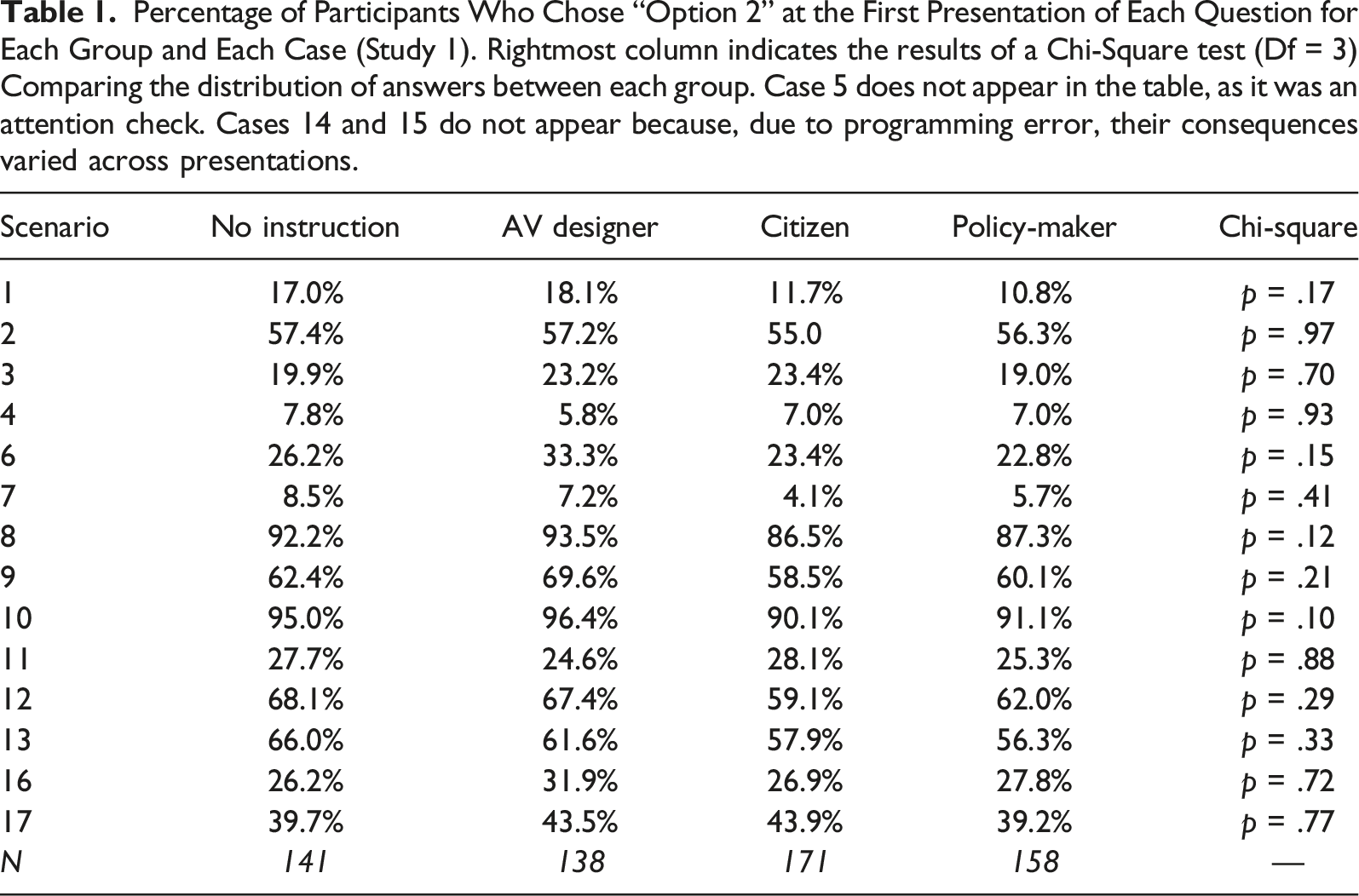
We used an experimental paradigm similar to the one used by the MME. Participants were presented with 16 (+1 control) moral dilemmas in which an AV experiences a brake failure, preventing it from stopping safely on time. Respondents then had to choose whether the AV should keep straight or swerve into the other lane, resulting in various consequences involving at least one individual’s death (see Figure 1). Each scenario required respondents to arbitrate between different categories of victims according to nine criteria: gender (male vs. female), age (young vs. adult vs. aged), body size (fat vs. fit), social status (executive vs. homeless, doctor vs. criminal), nature (humans vs. pets), number (1 vs. 2 vs. 3 vs. 5), role in the dilemma (pedestrian vs. AV passengers) and lawfulness (jaywalkers vs. lawful pedestrians) (see Table 1 for the full list of combinations). Participants had to indicate their answer by choosing between two options: Continue (Option 1) or Swerve (Option 2). Example of scenario in Studies 1 and 2 Percentage of Participants Who Chose “Option 2” at the First Presentation of Each Question for Each Group and Each Case (Study 1). Rightmost column indicates the results of a Chi-Square test (Df = 3) Comparing the distribution of answers between each group. Case 5 does not appear in the table, as it was an attention check. Cases 14 and 15 do not appear because, due to programming error, their consequences varied across presentations.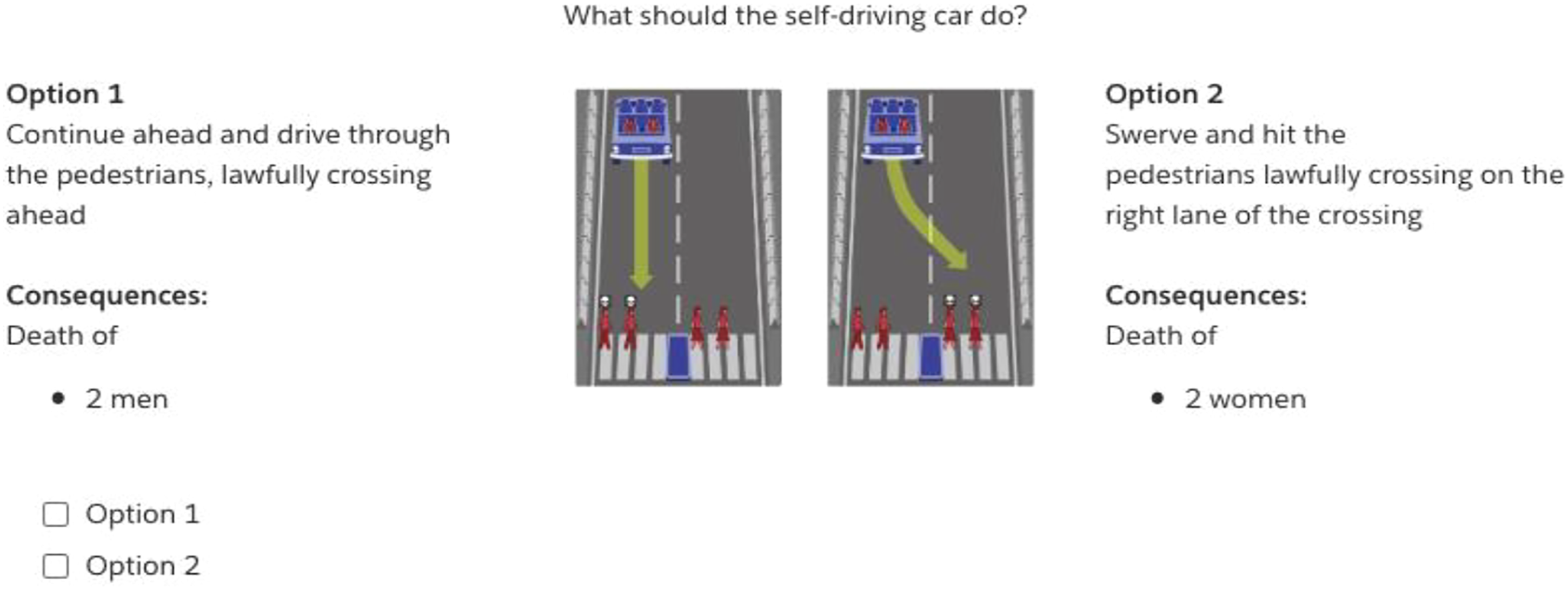
Participants were presented with the full set of scenarios twice. For the first presentation (Set 1), participants were instructed to answer questions “as quickly as possible.” For the second presentation (Set 2), they were instructed to “take time to think about their answer.” To force them to take time to think, there was an invisible time counter at the bottom of the vignette and participants could not submit their answer before the counter reached zero. To investigate whether the effect of a second exposure on participants’ answers would depend on how much time they were asked to think about their answer, the time they were asked to wait before answering varied across participants (10s, 20s, 30s, or 40s).
The way questions were framed varied across participants. One fourth of participants were asked to answer as if they were designers of AVs, another fourth as if they were citizens answering a national public consultation on AVs, and another fourth as if they were policymakers preparing the regulation for the self-driving industry. The last fourth did not receive specific instructions.
Results
Participants were US and UK residents recruited through Prolific Academic. After excluding 46 participants who failed the attention check, we were left with 608 participants (278 women, 324 men, 6 “others”; Mage = 30.69, SDage = 11.22).
Perspective-Taking
We first assessed the effect of perspective-taking on participants’ answers. For each vignette, we compared the proportion of participants’ answers across all four conditions using chi-square tests. Results are presented in Table S1 in Supplementary Materials. As can be seen, we found no significant effect of condition.
First vs. Second Exposure
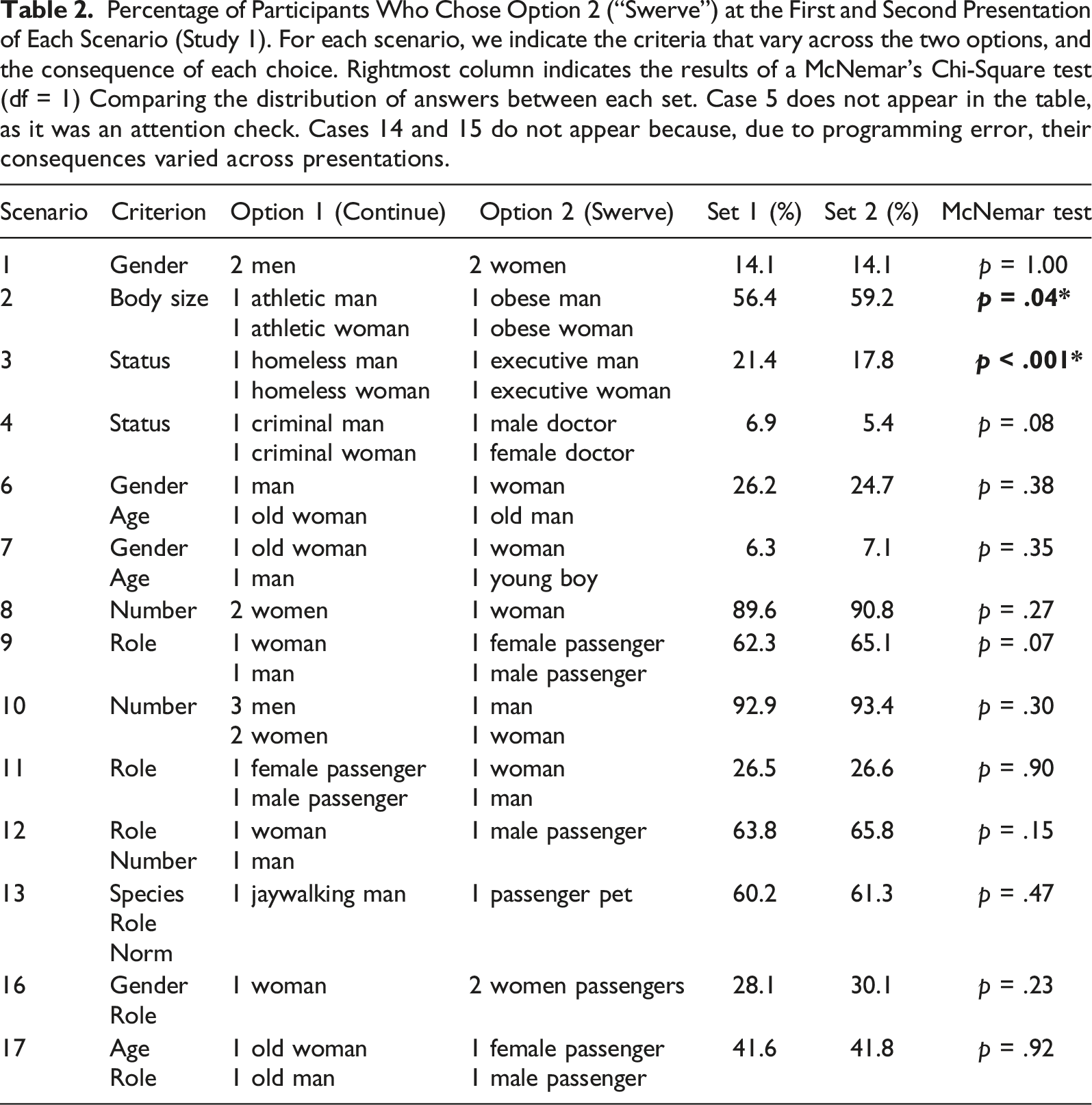
Percentage of Participants Who Chose Option 2 (“Swerve”) at the First and Second Presentation of Each Scenario (Study 1). For each scenario, we indicate the criteria that vary across the two options, and the consequence of each choice. Rightmost column indicates the results of a McNemar’s Chi-Square test (df = 1) Comparing the distribution of answers between each set. Case 5 does not appear in the table, as it was an attention check. Cases 14 and 15 do not appear because, due to programming error, their consequences varied across presentations.
Discussion
In this first study, we investigated whether people’s answers to AVs dilemmas were robust against two potential sources of variations: (i) perspective-taking, and (ii) repeated exposure providing participants with more time to reflect on their answers. Overall, we did not observe a significant effect of perspective-taking. However, our results are not at odd with the previous literature, which focused on the passenger vs. pedestrian perspective. Here, we were more interested in perspectives that were directly relevant to the public debate. The fact that participants in the “no instruction” condition did not significantly differ from the “citizen” or “policymakers” conditions suggests that the perspective participants naturally endorse does not impact their answers in a way that make them irrelevant to public deliberation.
Presenting participants a second time with the AVs dilemmas and forcing them to take time to reflect on their answer did not substantially alter their responses either. This absence of effect might seem at odd with previous results (Capraro et al., 2019; Suter & Hertwig, 2011). However, it should be noted that these studies were not concerned with AVs dilemmas (but dilemmas involving human agents) and that they used a different methods: they compared participants that were exposed a single time to dilemmas (and manipulated the time of this first exposure). The only study that focused on AVs dilemmas was the one by Frank and colleagues (2019), but this study contrasted very short response times (<5s) with more “usual” ones (<30s). Here, if we were interested in contrasting participants’ “normal” answers to MME-style experiments with longer public deliberation that typically involve several exposures, we rather asked participants to think longer than usual, where Frank and colleagues asked them to think shorter than usual. Our results are thus compatible. However, our results suggests that giving participants an occasion to reflect more on their answer by presenting them a second time with a given AV dilemma did not make a substantial difference, and thus that their answer to the first presentation already is robust.
Study 2: Participants’ Judgments after Collective Discussions the Moral Relevance of Different Factors
In Study 2, our goal was to study participants’ judgments about the ethics of AVs in a context that would be closer to a public deliberation about the principles of AVs ethics. That is, participants were asked to (i) have a collective discussion (DISC), about (ii) general abstract principles (AvC). Because our means were limited, we did not systematically manipulate these factors but rather introduced them all at once, to see whether the conclusions our study would yield would differ from the one yielded by Study 1 and MME-style experiments at large.
Materials and Methods
At the beginning of the study, participants were presented with the same 16 + 1 scenarios as in Study 1, and asked to answer them “as quickly as possible.” This was made to acquaint participants with the kinds of dilemmas that are considered relevant for ethical debates about the ethics of AVs.
After that, participants were immediately invited to join a video call to engage in a collective online discussion with seven to fifteen other participants (discussions lasted around 15 minutes). Participants were asked to discuss the relevance of nine criteria: gender (male vs. female), age (young vs. adult vs. aged), body size (fat vs. fit), social status (executive vs. homeless, doctor vs. criminal), nature (humans vs. pets), number (1 vs. 2 vs. 3 vs. 5), role in the dilemma (pedestrian vs. AV passengers) and lawfulness (jaywalkers vs. lawful pedestrians) (see Box 1). In each question, respondents were asked whether they thought the criterion was “morally relevant to make life arbitrations in such situations” and, if so, which category should be sacrificed to spare the other (e.g., sacrifice men to save women). After the collective discussion, each participant was asked to indicate their answer by indicating for each criterion whether the criterion was morally relevant or whether it was morally irrelevant and AVs should be programmed to choose at random, without taking this criterion into account (see Box S1 in Supplementary Materials for the exact wording). For half of participants, we asked them how confident they were about their reply (0 = Not confident at all, 1 = Not much confident, 2 = Quite confident, 3 = Very confident), and how much they understood that someone might feel differently about this criterion (0 = Not at all, 1 = Not much, 2 = Quite, 3 = Very much). Some of you answered that everything else being equal, [X] should be saved over [Y], and others replied the opposite. Please use the next 90 seconds to discuss whether you think [Z] is a morally relevant criterion to make such arbitrations, or not. And if so, should [X] or [Y] be spared and why? 1.X = “men,” Y = “women,” Z = “gender” 2.X = “younger people,” Y = “older people,” Z = “age” 3.X = “fit,” Y = “larger,” Z = “body size” 4.X = “people with higher social status,” Y = “people with lower social status,” Z = “social status” 5.Some of you answered that humans should always be saved over pets, while others replied it may depend on the situation. Do you think some circumstances may allow for exceptions or not? 6.Some of you answered that everything else being equal, lawful drivers and pedestrians should be saved over jaywalkers, and others replied it should not make a difference. Do you think abidance by the law is a morally relevant criterion to make such arbitrations? And if so, would you allow for exceptions to this? 7.X = “pedestrians,” Y = “AV passengers,” Z = “that this” 8.Some of you answered that everything else being equal, the AV’s action of swerving versus keeping straight is morally relevant, while others replied that it does not matter. Would you change any of your replies if reaching the same outcome implied the AV swerving instead of keeping straight and why? 9.Some of you answered that the AV should always be operated in a way to save the greater number of people, while others disagree, arguing that it depends on the situation, which should be assessed based on the criteria previously discussed. What do you think about it?”Box 1. Instructions for Collective Discussion (Study 2)
Results
Participants were US and UK residents recruited through Prolific Academic. After excluding 10 participants who failed the attention check, we were left with N = 190 participants (96 women, 94 men; Mage = 31.4, SDage = 10.8).
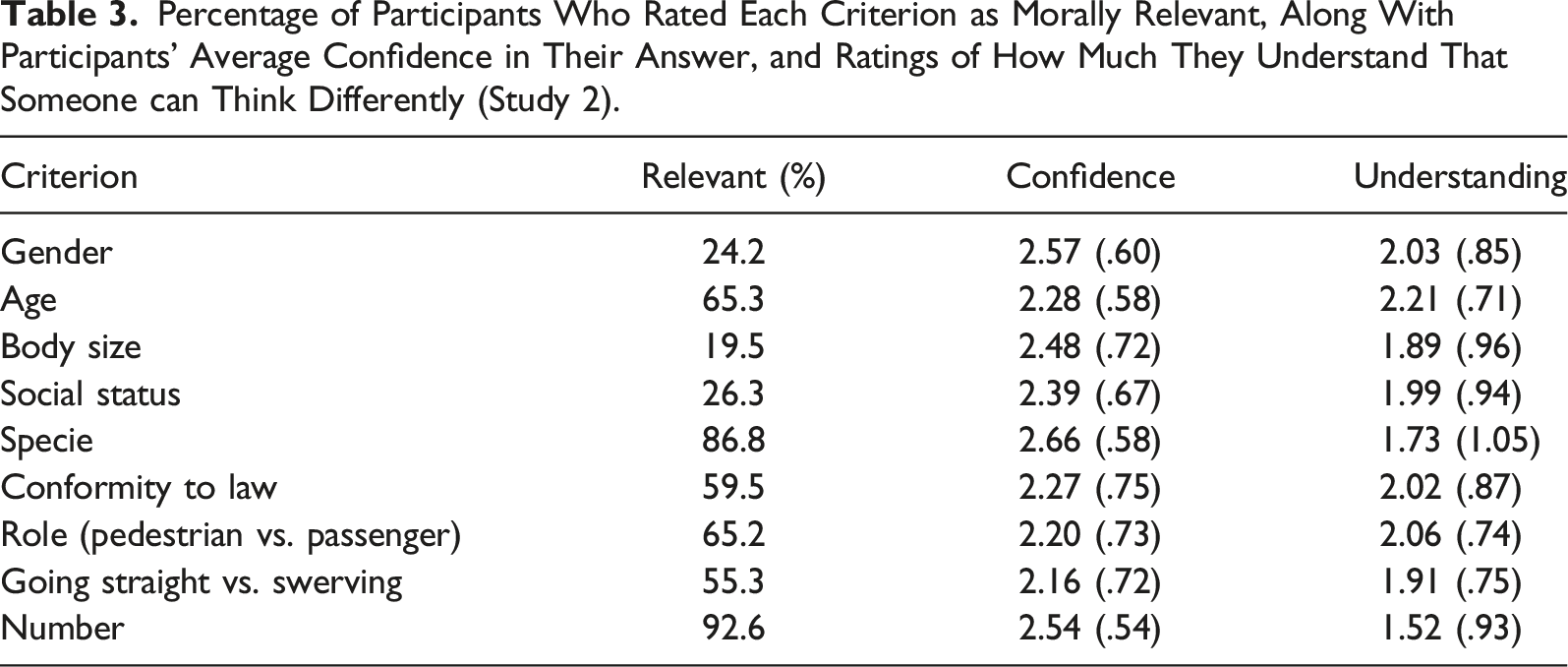
Percentage of Participants Who Rated Each Criterion as Morally Relevant, Along With Participants’ Average Confidence in Their Answer, and Ratings of How Much They Understand That Someone can Think Differently (Study 2).
Discussion
Our results suggest that there was a strong consensus in our participants on the relevance of two criteria: number of persons saved (saving the most people) and species (saving humans rather than pets). Two thirds of participants also considered age to be a relevant criterion. This is in line with the results of the MME, which suggested that these two criteria had the most weight. However, there was also a strong consensus on certain criteria being morally irrelevant: gender, body size, and social status. For these criteria (which are the ones Etienne, 2021 identified as the least morally relevant), most participants considered it best to leave the AV’s decision at chance.
However, training AVs to make decisions on the data collected by the MME would lead AVs to take such criteria into account, leading them to go against the perceived consensus. This is because the methodology of the MME only allows participants to signal indifference between two outcomes, and not to express their commitment to impartiality and their preference for random choices. Thus, an AV that would be trained on the kind of data we collected would behave in a substantially different way from an AV trained on the data collected by the MME. This means that design choice can substantially influence the outcome of data-driven, automated decision-making.
One question raised by our study is what drives people’s judgment that criteria such as gender, body size and social status are irrelevant? Is it only the fact of offering participants a third option that allows them to express their preference for random choice? Or did the fact that we presented participants with abstract principles (rather than concrete cases) and that we offered them the possibility to discuss with each other play a role? In Study 3, we investigated the impact of introducing a third option (random choice) in concrete cases, rather than in abstract ones. Moreover, we collected participants’ answers before and after collective discussions, to determine to which extent participating in a collective discussion led participants to favor this third option.
Study 3: The Impact of Collective Discussion on Participants’ Preference for Random Choice
In Study 3, we still offered participants a third option (random choice) but presented this option in the context of concrete scenarios rather than abstract principles. We then had participants read arguments against the relevance of several criteria and engage in a collective discussion with other participants.
Materials and Methods
Participants were US and UK residents recruited through Prolific Academic. We asked 331 participants, of which 324 passed the attention check, to address the same set of 11 randomized dilemmas (+1 control question) three different times (Set 1, 2 and 3). Between Set 1 and Set 2, participants were presented with seven objections to the main arguments that were brought up in group discussions in Study 2 and are based on Etienne (2022)’s counterarguments. For example, the objection against the relevance of gender to AV’s decisions was: You may think that gender is a morally relevant criterion here. If so, and to be consistent with your answer, you should be ready to either state that white people should be spared versus black people or the contrary, that Muslims should be spared versus Catholics or the contrary, that homosexuals should be spared versus heterosexuals or the contrary, or to explain what makes gender different from skin colour, religious belief and sexual orientation so that the former one is morally relevant here whereas the others are not.
(All seven objections can be found in Supplementary Materials.) After each objection, participants were asked to rate the objection’s strength on a 5-point scale. Between Set 2 and Set 3, they participated in a group discussion to express and justify their replies (as in Study 2).
Contrary to the abstract principles we used in Study 2, the concrete cases we used in Studies 1 and 2 present one disadvantage: when participants choose the Option (“Keep straight”), we do not know whether this choice reveals a preference for saving people on the other tracks, or a mere preference for inaction. As we saw in Study 2, 44.7% of participants answered that they considered this a relevant criterion. To correct for this shortcoming, we used concrete cases in which participants had to choose between “turning left” or “turning right” (or “choosing at random”). An example is presented in Figure 2. Example of scenario in Study 3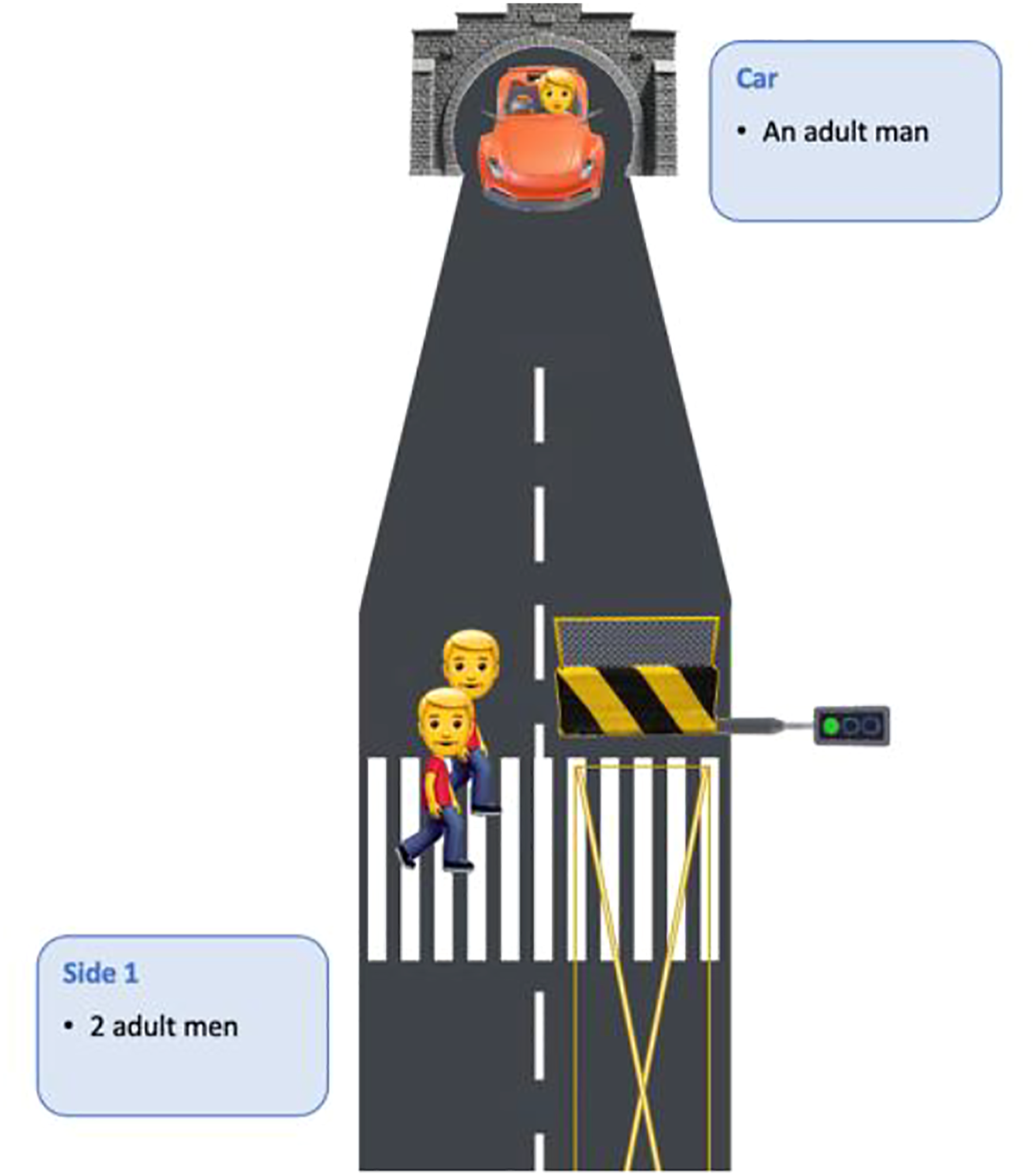
Finally, in Study 2, we have seen that the third option (“choosing randomly”) was the most often selected for certain criteria. However, one could object that participants might be drawn towards this answer because they feel like it does not need to be justified (contrary to other answers). To test for this, a third of participants were asked to provide a justification for their answer to all three sets (JUST). Another third received no particular instruction (CONTROL), and the last third were asked to communicate a degree of confidence (DOC) for their replies (“how confident do you feel about your reply?”) as well as a score of perceived consensus (“how much do you think that others would agree with you?”) for each of the three sets.
Results
Frequency of “Random” Choice
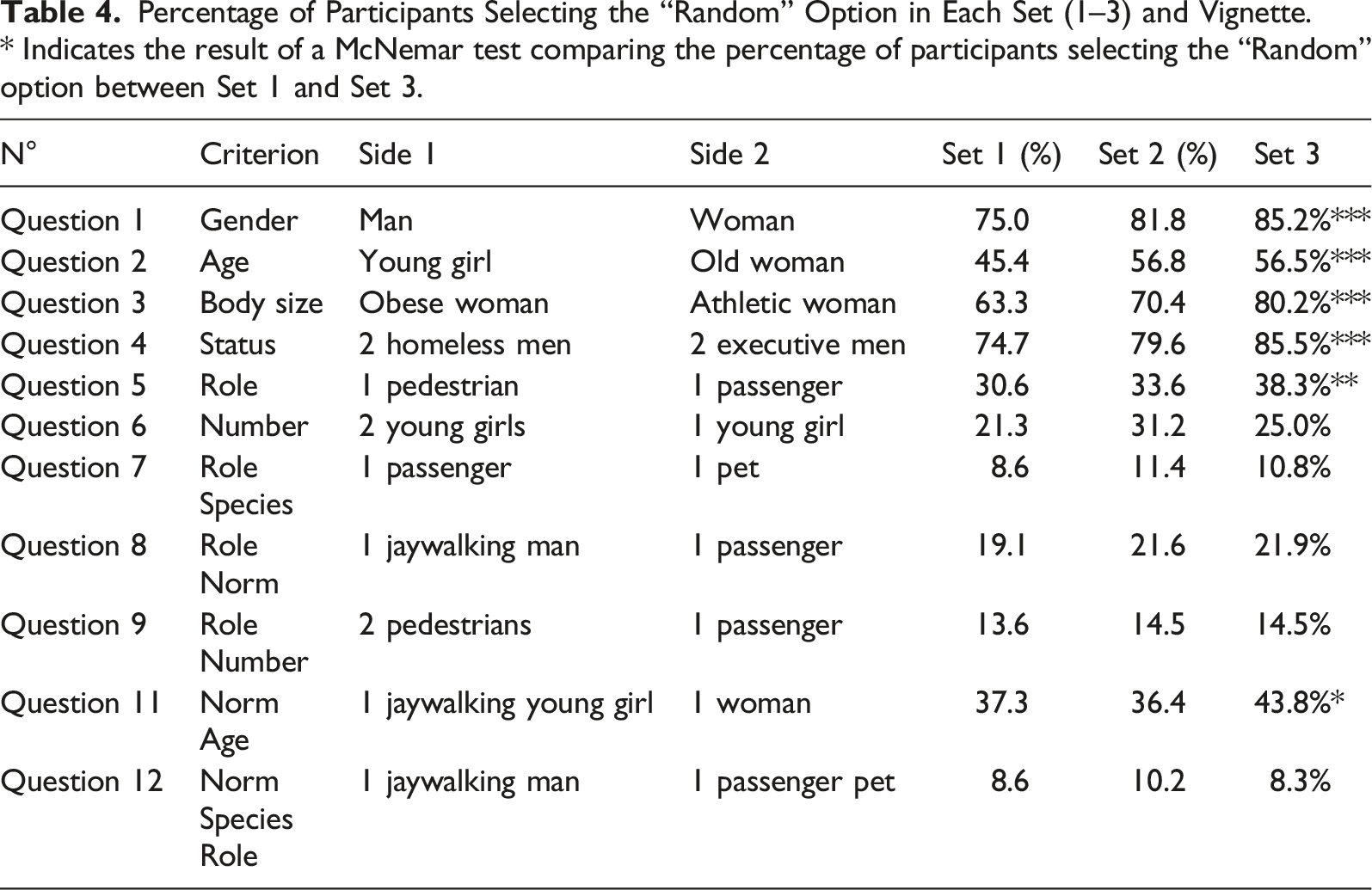
Percentage of Participants Selecting the “Random” Option in Each Set (1–3) and Vignette. * Indicates the result of a McNemar test comparing the percentage of participants selecting the “Random” option between Set 1 and Set 3.
Effect of Condition
We used 11 chi-square tests to investigate the impact of condition (CONTROL, DOC and JUST) on distribution of participants’ answers to Set 1. Out of 11 tests, only the one for vignette 3 (obese woman vs. athletic woman) came out significant. However, this was not because the percentage of “random” answers significantly varied across conditions (p = .15), but because participants asked to justify their answer were more likely to choose to kill the athletic woman (see Table S3 in Supplementary Materials). Thus, participants’ tendency to choose the “random” option was robust and remained even when participants were asked to justify their answer.
Effect of Objection and Discussion
We compared participants’ answers across the three sets (Set 1: initial answers, Set 2: after objections, Set 3: after discussion). We found that, for all 11 vignettes, variance in participants’ answers was lower in Set 3 compared to Set 1: t(10) = 5.31, p = .0003. This means that the procedure increased consensus across participants (see Table S4 in Supplementary Materials).
As can be seen in Table 4, the procedure (objection + collective discussion) produced significant changes in participants’ judgments. Overall, 30% of answers were modified at least once across the three sets (see Section 3.4 in Supplementary Materials). For the four most controversial criteria (age, gender, body size, and status), the procedure led more participants to endorse the third option, and thus to treat these criteria as irrelevant. However, for role and norm-compliance, it led more participants to consider these criteria as relevant, showing that the procedure did not always favor the “random” option.
Confidence and Consensus Perception
Participants’ Degree of Confidence and Perceived Consensus for Each Set (Study 3).

Discussion
In Study 2, we found a pattern of answers that suggested that criteria singled out as relevant in the MME were deemed mostly irrelevant once a third option was introduced. However, it was not possible to determine whether this was due only to the introduction of a third option, or whether this was mostly due to the fact of presenting choices in an abstract and/or having participants engage in a collective discussion. In Study 3, we found a similar pattern of answers in a concrete setting, suggesting that this was not only due to the abstract presentation of Study 2 (though we cannot exclude that presentation style might have effects, see Table S2 in Supplementary Materials). Moreover, we found that engaging in a collective discussion tended to increase the choice of the “random” option for the criteria judged more irrelevant. Still, the pattern of answers we spotted in Study 2 was already visible before the collective discussion (in Set 1).
Participants’ choice of the “random” option was not affected by their having to justify their answer or indicate their degree of confidence. Moreover, participating in the collective discussion raised participants’ confidence in their answers. Overall, this suggests, against Awad and colleagues (2020)’s suggestion, that participants’ choice of the “random” order is not the result of mere bias that could be overcome by more reflection.
Conclusion
In this paper, our goal was to show that attempts at automatizing ethical decision-making by aggregating participants’ answers to moral dilemmas face a serious methodological difficulty: data collection is anything but a neutral process. Indeed, participants’ replies can vary with experimental designs, so that the way experiments are framed can lead machine-learning algorithms to reach very different conclusions about what is the most “plausible” ethical answer to a dilemma.
More precisely, our goal was to explore whether collecting data using an experimental design that more faithfully mirrored the context of a public discussion about AVs might change the conclusions one could draw from such experiments. Indeed, most empirical studies on people’s moral judgments about AVs are focusing on quick intuitions, generated in isolation by a single exposure to each case, and with a limited range of options. However, these conditions differ widely from the ones in which citizens engaging in a public debate would form their opinion about the ethics of AVs. As the results of these experiments are increasingly used to bear on social decisions, with the claim that they represent public opinion, this is problematic.
Thus, we sought whether changing the conditions in which participants’ judgments are generated to more closely mirror the conditions of public deliberation resulted in different conclusions regarding the “social consensus” about which factors should be relevant to AVs’ behavior. For example, in Study 1, we had participants take more time to think about their answers by exposing them a second time to each vignette and forcing them to wait some time before answering, and by asking to endorse them different perspectives beyond the mere perspective of driver or passenger (such as policymaker or citizen). In this case, these changes did not make a difference.
However, in Studies 2 and 3, we showed that giving participants the possibility to mark certain criteria as “morally irrelevant” and to express their preference for AVs to make random choices led to a pattern of answers (and to a picture of “social consensus”) that differed from the one observed by previous studies offering only two options: we observed a strong consensus on the moral irrelevance of certain criteria such as gender, body size, and social status. For gender, our results paint a picture in which a minority of participants express a preference for saving women and a majority (around 75% in Study 2 and 75–85% in Study 3) expresses a preference for random choice. This is very different from a situation in which 60% prefer to save a woman compared to a man, and 40% prefer to save a man compared to a woman—a situation in which there is no clear consensus. However, both situations will be treated in a similar way by algorithms trained on data that do not provide participants with the possibility to express their preference for random choices: in both cases, such algorithms will compute a small preference, at the scale of the population, for saving women, while there seems to be a strong consensus for not taking gender into account and allowing AVs to make a random decision. It will thus go against the moral consensus by allowing AVs to favor women, even in a slight way.
The dismissal of a third, “random” option in previous studies about AVs dilemmas might be due to a tendency to understand moral deliberation on the model of rational decision theory. From the standpoint of rational decision theory, a choice at random between two options A and B can only express one thing: indifference between A and B. However, in ethical decision-making, choosing at random is not necessarily an expression of indifference—rather, it can express a strong endorsement of moral values such as impartiality, or the commitment to treat all human beings as having the same moral status, independently from their individual differences. Thus, rejecting the need for a third, random option under the pretext that the same information can be obtained from two-options survey (because it will manifest itself as indifference at the level of population) already commits oneself to a particular view of ethical decision-making, according to which ethical decision-making is similar to economic decisions.
Additionally, the assumption that preference for random choices (and thus impartiality) will manifest itself as indifference in two-options surveys is unwarranted. When forced to choose between two options, participants who favor impartiality on moral grounds (and would select the “random” choice in a three-options survey) might choose to rely on non-moral preferences. After all, participants in the MME are simply asked what the AV should do—without specifying that this “should” be a moral one (see Cova et al., 2019 on this particular methodological issue). Thus, the two-options design might force participants to rely on personal preferences that they would not themselves consider morally appropriate, thus increasing dissensus.
Moreover, decisions about AVs are not likely to be made in isolation: rather, as most people in this literature emphasize, such decisions need to be the outcome of a public discussion. Thus, in Study 3, we used a design that, in addition to providing participants with a random option, tried to imitate the context of a public discussion: participants were provided with simplified versions of arguments provided by ethicists against the relevance of certain criteria, and were asked to discuss their answer with each other. We found that this procedure led participants to be more confident of their individual answers, while reducing variance in participants’ answers. Thus, the deliberative process participants were invited to engage in allowed them to reach more stable and confident replies they may better relate with and, thus, feel more responsible for.
Crucially, this procedure also led participants to significantly change their minds about the relevance of certain criteria. For example, this procedure led them to reach an even stronger consensus on the moral irrelevance of gender, body size, and social status. It also led to significant difference in their assessment of the relevance of age: while more than half of participants endorsed age as a morally relevant criterion at the beginning of the study, less than half did so at the end of the study. Together, these results show that the consensus people are likely to reach through a collective discussion cannot be reduced to the aggregation of individual answers made in isolation, no matter how many individual answers have been collected.
Overall, the results of our studies suggest that we should be wary of using the empirical results of studies such as the Moral Machine Experiment as a guide for ethical decision-making. On the one hand, the design of these studies rests on unquestioned assumptions about the nature of ethical decision-making, which might lead them to ignore clear popular consensus on “impartial” options. On the other hand, the data are collected in a setting that cannot be considered equivalent to the setting of an informed, collective discussion in which people might come to reject as unwarranted and morally irrelevant the various biases identified by these studies. As we observed it, introducing a third option severely challenges Awad and colleagues’ conclusions, showing that surveys’ design can either bring out dissensus which do not accurately capture people’s opinions, or reveal consensus which better reflect them.
Finally, because surveys’ design influence participants’ replies, our studies also fall under this limitation. Forcing people to take more time before submitting their responses does not necessarily lead them to question these further, what could explain that we do not observe significant effect of the reflection time when other works do. The convergence effect of the collective discussion could also partly result from a pressure to conform to the majority opinion, rather than from a genuine revision of one’s opinion. Therefore, distributing participants across discussion groups based on their previous replies may either reinforce their opinions, if groups are formed to be likeminded, or encourage them to revise these latter, if groups are built to represent diversified opinions and participants explicitly asked to defend their previous replies. Overall, these limitations only support our claim that surveys’ design influence the way participants grow an opinion about a topic, therefore the replies they provide. Further studies should investigate the opportunity to frame their design to support respondents’ critical thinking and develop more robust and meaningful opinions. Such an effort is crucial nowadays as surveys are being increasingly used by a wide range of actors to represent a so-called public opinion, and that such biased representations of people’s opinions influence their actual opinions (e.g., by pressure to conform), as well as it is used by decision-makers to justify societal choices.
Supplemental Material
Supplemental Material - Performative Quantification: Design Choices Impact the Lessons of Empirical Surveys About the Ethics of Autonomous Vehicles
Supplemental Material for Performative Quantification: Design Choices Impact the Lessons of Empirical Surveys About the Ethics of Autonomous Vehicles by Hubert Etienne, and Florian Cova in Social Science Computer Review
Supplemental Material
Supplemental Material - Performative Quantification: Design Choices Impact the Lessons of Empirical Surveys About the Ethics of Autonomous Vehicles
Supplemental Material for Performative Quantification: Design Choices Impact the Lessons of Empirical Surveys About the Ethics of Autonomous Vehicles by Hubert Etienne, and Florian Cova in Social Science Computer Review
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by Facebook Inc.
Supplemental Material
Supplemental material for this article is available online.
Author Biographies
Hubert Etienne is a researcher in AI ethics in Meta's Responsible AI team in New York.
Florian Cova is a postdoctoral researcher at the Centre Interfacultaire en Sciences Affectives, University of Geneva.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.