
Abstract
High-quality online dialogues help sustain democracy. Deliberative theory, which predates the internet, provides the primary model for assessing the quality of online dialogues. It conceptualizes high-quality online dialogue as civil, rational, constructive, equal, interactive, and for the common good. More recently, advances in computation have driven an upsurge of empirical studies using automated methods for operationalizing online dialogue and measuring its quality. While related in their aims, deliberative theory and the wider empirical literature generally operate independently. To bridge the gap between the two literatures, we introduce Textual Indicators of Deliberative Dialogue (TIDDs). TIDDs are defined as text-based measures of online dialogue quality under a deliberative model (e.g., disagreement, incivility, and justifications). In this study, we identified 123 TIDDs by systematically reviewing 67 empirical studies of online dialogue. We found them to have mid-low reliability, low criterion validity, and high construct validity for measuring two deliberative dimensions (civility and rationality). Our results highlight the limitations of deliberative theory for conceptualizing the variety of ways online dialogues can be operationalized. We report the most promising TIDDs for measuring the quality of online dialogue and suggest deliberative theory would benefit from altering its models in line with the broader empirical literature.
Keywords
Humanity faces increasingly global problems requiring large-scale coordination. Online dialogues offer a public space where people can discuss issues of common concern. Deliberative theory argues that when online dialogues are high quality, they maintain healthy democracies (Dahlberg, 2001; Friess & Eilders, 2015; Graham & Wright, 2014; Janssen & Kies, 2005; Sunstein, 2018). Advances in computation have led to an upsurge in empirical studies using quantitative text analysis methods for analyzing online dialogues (Lampe, 2013). Deliberative theory currently operates independently from this growing literature, mainly employing manual coding methods that are difficult to scale to large datasets (Beauchamp, 2020).
We present a systematic review of 67 empirical studies of online dialogue to identify Textual Indicators of Deliberative Dialogue (TIDDs). TIDDs are defined as text-based measures of online dialogue quality under a deliberative model (e.g., disagreement, incivility, and justifications). TIDDs aim to bridge deliberative theory with the growing empirical literature using online dialogue data. Each TIDD measures a single construct using machine learning, manual coding, or rule-based automatic text analysis. TIDDs are reviewed for their reliability, criterion validity, and construct validity for measuring six deliberative dimensions: rationality, interactivity, equality, civility, constructiveness, and common good reference (Friess & Eilders, 2015).
The review’s goal is to identify TIDDs and evaluate their applicability for deliberative theory. TIDDs provide a snapshot of what is measurable in online dialogue and, therefore, a list of text-level variables available to researchers for predicting desirable post-dialogue outcomes. We identify 123 TIDDs, evaluating them as having mid-low reliability, low criterion validity, and high construct validity for measuring civility and rationality in online dialogues. Our results demonstrate the variety of text-based variables used for studying online dialogue while highlighting the limitation of the deliberative model for conceptualizing them.
Background
In 2019, for the first time in history, a majority (51%, 4 billion people) of the world’s population were using the internet (International Telecommunications Union, 2020). Many internet users are communicating, either publicly through social networking sites, or privately through semi-synchronous “chats” (Yao & Ling, 2020). Social networks are viewed through a normative lens by the social science literature. Optimists view social networks as a place for discussing the world’s problems from multiple perspectives and finding consensus on courses of action (e.g., Bohman, 2004). Pessimists view social networks as entrenching existing political binaries through “echo chambers” that undermine any meaningful consensus (e.g., Sunstein, 2018). These opposing views demonstrate the need for understanding how certain dialogue structures lead to desirable (e.g., consensus) and undesirable outcomes (e.g., echo chambers).
Online dialogue produces behavioral trace data (Lampe, 2013). Trace data are unobtrusive, meaning behaviors are observed in naturally occurring contexts (Webb et al., 1966; Wu & Taneja, 2020). Trace data are normally recorded digitally and, therefore, predominantly relate to people behaving on the internet through a computing device (Howison et al., 2011). Using behavioral trace data enables the empirical study of social processes in near real-time (Lampe, 2013), including how and why the observation of certain online dialogues may lead to positive or negative outcomes. This review asks how textual trace data can be operationalized for measuring online deliberation. Specifically, what constructs are currently measured in online dialogue and how applicable are they to deliberative theory.
Online Dialogue and Deliberation
A dialogue is defined as a minimum of two people using a semiotic system to communicate about something (Linell, 2017, p. 302). This is conceptualized as a Self-Other-Object relationship, where two or more selves come together to discuss any object of interest. A dialogue, therefore, comprises all Self and Other observable communicative behaviors on one or several discussed topics (Object).
“Online” dialogue is used as shorthand for public, asynchronous, text-based dialogues that happen on the internet. These dialogues involve people coming together with strangers to openly discuss a topic. Online dialogues are asynchronous because participants are not required to immediately reply to each other. They are public because most people can freely observe or participate in them. Finally, they are text-based because participants use written language to communicate with each other.
The term “online dialogue” is preferred over the commonly used “computer-mediated communication” (e.g., Atai & Chahkandi, 2012; Chua & Chua, 2017; Di Blasio & Milani, 2008) due to the public connotation. Computer-mediated communications include private messaging, video conferencing, and emails, which are not necessarily public, asynchronous, or text-based. We focus on online dialogues as their quality is relevant to deliberative theorists, who argue that democratic societies are partly sustained by dialogues conducted in the public sphere (Dahlberg, 2001; Friess & Eilders, 2015; Graham & Wright, 2014; Janssen & Kies, 2005; Sunstein, 2018).
Habermas, who conceptualized contemporary deliberative theory, argues that a healthy democracy is maintained by a public sphere where dialogues strive toward an “ideal speech situation” (1981). The ideal speech situation has four principles (Habermas, 2008, p. 50): (1) “publicity and inclusiveness,” nobody should be excluded if they can contribute; (2) “equal rights to engage in communication,” everyone should have the same opportunity to speak; (3) “exclusion of deception and illusion,” participants should mean whatever they say; (4) “absence of coercion,” nobody should try to silence others for their own merit. According to Habermas, when citizens work towards these ideals, their dialogues can generate solutions to societal problems.
Habermas’ ideal speech situation concerns deliberation, “a process where people, often ordinary citizens, engage in reasoned communications on a social or political issue in an attempt to identify solutions to a common problem and to evaluate those solutions” (Stromer-Galley, 2007, p. 3). Deliberation has an “input,” “throughput,” and “output” stage (Friess & Eilders, 2015; adapted from Wessler, 2008). Input refers to the social, cultural, and physical context where a dialogue takes place. Throughput refers to the quality of dialogue as it is procedurally achieved. Finally, output refers to the outcomes of dialogues independent of the process.
Friess and Eilders dimensions of dialogue indicating deliberation (2015, p. 323).

Dialogue Research Approaches
Dialogue research can be “descriptive” or “prescriptive” (Stewart & Zediker, 2000). Prescriptive approaches define dialogue in terms of desirable outcomes (Kim & Kim, 2008; Stewart & Zediker, 2000). Prescriptive approaches, including deliberative theory, view dialogue as essential to “growth, development, and positive change” for individuals, communities, and societies at large (Cooper et al., 2013, p. 82). Dialogue, under this view, always produces positive societal outcomes.
Descriptive approaches, in contrast, view dialogue as a “pervasive” feature of human behavior that should be described empirically (Stewart & Zediker, 2000, p. 225). The descriptive approach does not tie specific dialogue structures to ideal outcomes. Instead, it regards dialogue as the primary mechanism for coordinating human social behaviors (Gergen et al., 2004). Dialogue, under this view, produces many societal outcomes, both positive and negative.
A key problem with prescriptive approaches is that high-quality dialogue is defined independent of context, thereby prescribing what communicative behaviors are desirable regardless of outcomes. Descriptive approaches avoid this problem by studying the diversity of potential outcomes without making any prior normative recommendations on communicative behaviors (Gillespie et al., 2014). A prescriptive approach instead obfuscates the possibility that non-ideal communicative behaviors may lead to desirable outcomes.
Deliberative theory exemplifies the prescriptive approach by arguing that when dialogue is not “fair and equitable,” the outcomes will necessarily be distorted (Cooper et al., 2013, p. 80). Habermas’ ideal speech situation has been criticized for being prescriptive despite his assuming a descriptive approach elsewhere (Kim & Kim, 2008, p. 56). Nonetheless, deliberative theory has remained focused on prescription, developing Habermas’ ideals for deliberation into manual coding frameworks to identify “good” dialogue (e.g., Graham, 2008; Graham & Witschge, 2003; Steenbergen et al., 2003).
Manual coding, however, is impractical for the scale of online dialogue. We agree with Beauchamp (2020, p. 323) that adopting Natural Language Processing (NLP) in deliberative theory would enable more rigorous testing of its conceptual frameworks than is currently done. NLP is concerned with studying organic human communication and the automatic analysis of text (Boyd et al., 2020; Boyd & Schwartz, 2021). This includes extracting information, applying classifications, and measuring the frequency of observable variables (Mehl & Gill, 2010, p. 109).
Automatic measurement provides three improvements over manual coding. First, manual coding takes substantial time and resources to complete, even on small datasets. In contrast, automated measurement, once developed, is cost-effective and scalable. Second, a manual coding framework may have difficulties replicating when used by new researchers, diminishing the reliability of findings. In opposition, automated measures are perfectly reliable, producing identical results when applied to the same data. Third, automated measurement enables the possibility of real-time monitoring of the quality of online dialogues, which would be impossible with manual coding.
Empirical studies using NLP represent the descriptive approach to studying dialogue quality. When operationalizing online dialogue, NLP studies are not constrained by deliberative theory (see Beauchamp, 2020, p. 331). Instead of using a conceptual framework to derive measures, they can do so by observing dialogues. Thus, identifying measures from a wide empirical literature (including NLP studies) benefits deliberative theory by providing alternative constructs for predicting desired outcomes. To conceptualize and review the diversity of measures from the empirical literature, we introduce the concept of Textual Indicators of Deliberative Dialogue.
Textual Indicators of Deliberative Dialogue
Textual Indicators of Deliberative Dialogue (TIDDs) are text-based measures of online dialogue quality relevant to a deliberative model. TIDDs can be measured either within a turn, between turns, or across the whole dialogue by aggregating turns. TIDDs exclude trace data that occur independently of the dialogue text or is domain-specific, such as likes or click-through rates. TIDDs include structural features of online dialogue (e.g., number of turns, number of replies) that are universal in text-based communication. TIDDs are conceptualized as a bridge between the deliberative (prescriptive) and empirical (descriptive) literatures.
TIDDs can be measured using manual coding, fully automated methods, or supervised machine learning. Manual coding refers to people annotating text data for the presence of target phenomena, formalized as “content analysis” (Krippendorff, 2018). Fully automated methods refer to non-machine learning automatic text analysis, such as dictionary methods. Dictionary methods—such as the Linguistic Inquiry and Word Count tool (LIWC, Pennebaker et al., 2001)—measure a construct in text by counting the occurrence of relevant words (e.g., people’s emotions as indicated by emotional words). Finally, supervised machine learning methods fall between automated and manual coding traditions. They require a manually coded dataset to “learn” the best way to predict a response variable based on hand-coded data. This includes newly trained algorithms for a specific context, or pre-trained algorithms such as Google’s Perspective Application Programming Interface (API, 2021), which identifies uncivil communicative behaviors in text.
The Present Study
We systematically review TIDDs for measuring dialogue quality under a deliberative model. Our study is unusual in reviewing constructs from the empirical literature, rather than examining their results. Therefore, we did not use a specific protocol but followed the PRISMA guidelines (Page et al., 2021) where applicable.
The review has three research questions to assess the viability of using TIDDs as indicators of deliberative dialogue. Combined, these three research questions help identify synergies between the deliberative and empirical literatures.
What is the reliability of the TIDDs? Reliability reflects the degree to which results obtained by a measurement process are reproducible (John & Benet-Martínez, 2014, p. 342; Shrout & Lane, 2012, p. 302). This research question addresses the replicability of a TIDD’s measurement method employed by the studies: manual coding, fully automated methods, or supervised machine learning.
What is the criterion validity of the TIDDs? Criterion validity reflects how accurately a measurement (or scale) correlates with a relevant outcome (Bryant, 2000, p. 106). This research question addresses how well TIDDs correlate with outcomes external to the dialogue text.
What is the construct validity of the TIDDs? Construct validity reflects how accurately a variable measures a target concept (Cronbach & Meehl, 1955). This research question addresses how well TIDDs fit the deliberative dialogue model (table 1, Friess & Eilders, 2015). Accordingly, RQ3 addresses the extent to which the identified TIDDs measure rationality, civility, interactivity, constructiveness, equality, and common good reference.
Methods
Search Strategy
Our target literature was any empirical article with a systematic operationalization of online dialogues. We targeted studies using NLP but also included those using manual coding. We identified the studies through two searches on three databases—Scopus, PsychInfo, and EmBase—in October 2020. The first search focused on Friess and Eilders (2015) dimensions and the second focused on the quality of dialogue. To further constrain the searches, we developed three additional lists of words. The first identified studies using online data. The second identified studies about dialogue. The third identified empirical studies with a systematic methodology. The full lists of search terms are in the supplementary materials (A – 1).
For a study to appear in the results, a word from each of the three lists needed to be in the “title, abstract, or keywords” for the Scopus search, or the abstract for the PsychInfo and EmBase searches. We chose the latter search option as it most resembled the Scopus option. All searches were limited to articles published in English with no time-period constraints.
Inclusion/Exclusion Criteria
Studies were included if they were empirical, published in a journal or conference proceedings, and used online dialogue data. A study was considered empirical if it reported a clear and systematic method in either the abstract or body of the text. Online dialogue data was defined as public, asynchronous, text-based, and naturally occurring interactions involving two or more individuals.
Studies were excluded if they were published as a book chapter, did not include any text-level variables, or examined dialogues that were not online. We, therefore, excluded studies using exclusively private computer-mediated communications (direct messaging, emails, etc.), dialogues elicited through experimental conditions, or surveys about online dialogues. Detailed inclusion/exclusion criteria are in the supplementary materials (A – 2).
Data Extraction and Analysis
For each TIDD, we extracted a definition, the unit of analysis, the measurement methods and associated statistics, and the results of the analyses conducted. Once the TIDDs were identified, we grouped identical (or highly similar) measures under an umbrella term.
TIDDs Evaluation method.
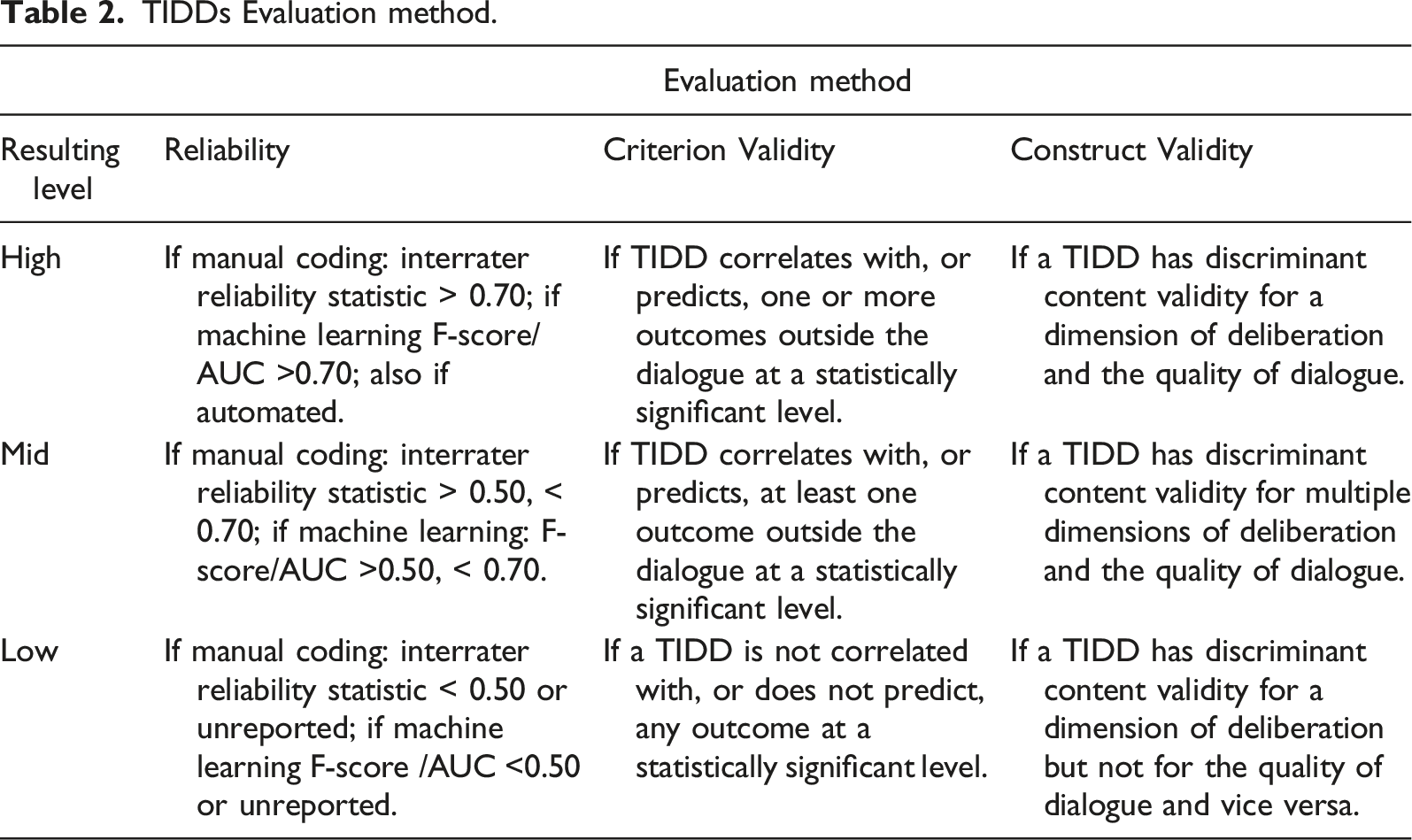
We scored all automated TIDDs reliability as “high” because, when applied to the same dialogue, the TIDD will always produce identical results. We assessed manual coding TIDDs’ reliability according to reported interrater reliability statistics (e.g., Krippendorff (1970), Cohen (1960), or Scott’s pi (Scott, 1955)) and machine learning TIDDs according to their reported accuracy statistics (e.g., Area Under the Curve, F-score). For both, TIDDs with relevant statistics above 0.70 were classed as high reliability, those between 0.50 and 0.70 as mid reliability, and those under 0.50 as low reliability. These cutoff levels were chosen to provide a comparable estimate of reliability across different research traditions.
For RQ2, the criterion validity of the TIDDs was established by examining the studies’ results and the variables predicted by TIDDs. The process of determining criterion validity is summarized in Table 2. We first noted whether a TIDD correlates with any outcome variables independent of the dialogue text. The strength of these correlations then determines the TIDD’s criterion validity rating. We do not consider instances where a TIDD is an outcome (i.e., dependent variable) as demonstrating criterion validity.
For RQ3, the construct validity of the TIDDs is determined by whether they have discriminant content validity (Johnston et al., 2014) for measuring the six dimensions of deliberative dialogue. In big data research, construct validity is difficult to establish as studies normally use naturally occurring behavioral trace data (e.g., online dialogues) instead of survey data (Braun & Kuljanin, 2015; Xu et al., 2020). For standard survey data, researchers typically employ a Confirmatory Factor Analysis (CFA) to estimate the construct validity of their measures (Bryant, 2000). CFA requires a minimum of three measures of a construct to obtain a model (Anderson & Rubin, 1956). This is easily done with a survey, where new items can be added and tested at will. With naturally occurring trace data, however, behaviors will likely occur at varying frequencies, resulting in lots of missing data for behaviors that are not regularly observed (Braun & Kuljanin, 2015, p. 523). This often renders CFA untenable.
As an alternative to conventional methods of assessing construct validity in big data contexts, the literature recommends using “subject matter experts (SMEs) to rate the relevance of behavioral trace variables or measuring a construct of interest” (Braun & Kuljanin, 2015, p. 525). To make this process more robust, we propose using discriminant content validity (Johnston et al., 2014) to assess how well the TIDDs discriminate between a set of conceptually relevant dimensions. Eleven coders (of MSc level in psychology or linguistics and including both authors) assigned the TIDD to one of the six dimensions or an “other” category and provided a confidence score. We also had raters assess how well a TIDD measures the quality of dialogue independent of the dimensions. These confidence scores allowed us to test the viability of the deliberative dimensions for conceptualizing the TIDDs.
Results
Descriptive Statistics
Figure 1 shows a PRISMA flowchart (Moher et al., 2015) for determining the final list of studies included in the systematic review. The results of the searches were first combined (n = 3908) and any duplicates removed (n = 3185). We then examined the titles and abstracts to determine whether studies should be included (n = 208). Additional studies (n = 20) were subsequently added manually after being identified in bibliographies as relevant for the review. The remaining studies (n = 225) were then assessed for their viability using the entire text. This produced the final list of studies (n = 67). Both assessment stages used the same inclusion and exclusion criteria. PRISMA flowchart (Moher et al., 2015).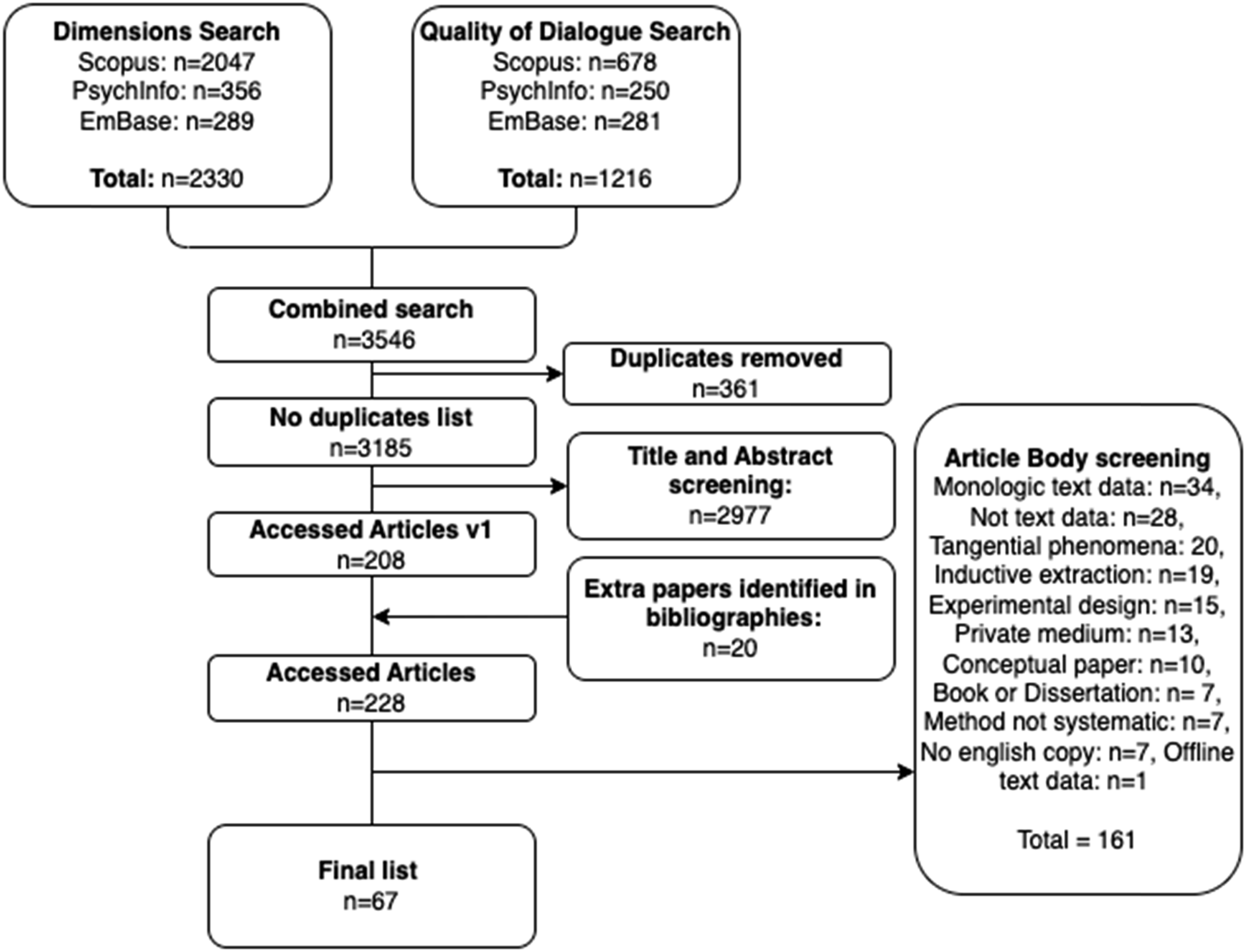
Most studies were published in peer-review journals (n = 40, 60%), with the remaining being conference papers (n = 25, 37%) or preprint studies on the arXiv database (n = 2, 3%). Figure 2 plots when the studies were published and whether they involved a social science, computer science, or a combined approach to deliberative dialogue. We categorized a study based on the journal of publication and the “subject area and category” listing on the Scimago JR database (SJR, n.d.). Most of the studies were published after 2010 (n = 65, 97%). We find an equal number of studies from social science and computer science traditions (n = 24, 36%) and 19 studies (28%) from journals taking a mixed approach. Figure 2 shows the sharp increase in interest from both social science and computer science approaches in the 2010–2020 time-period. Distribution of empirical studies by year and discipline.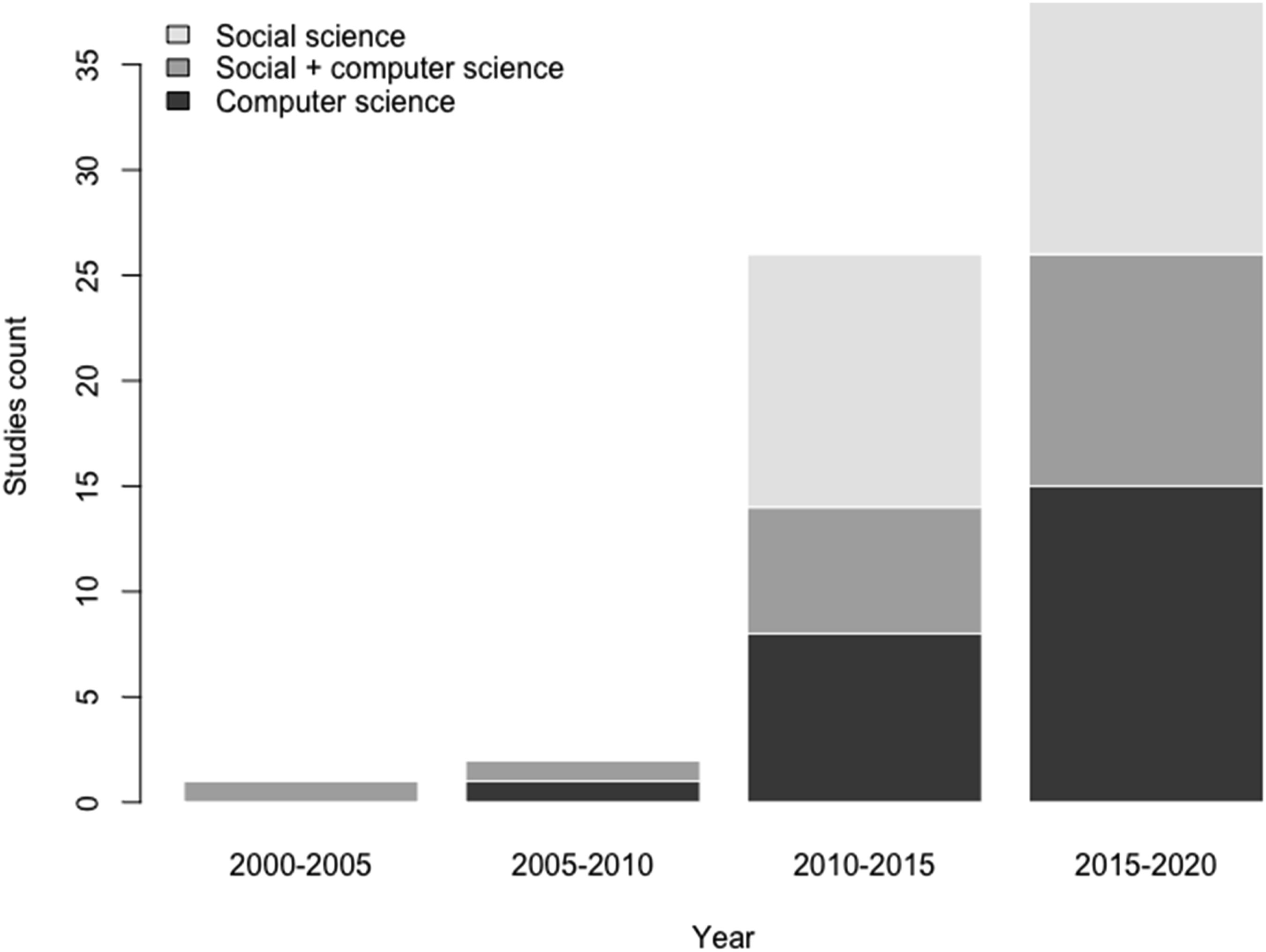
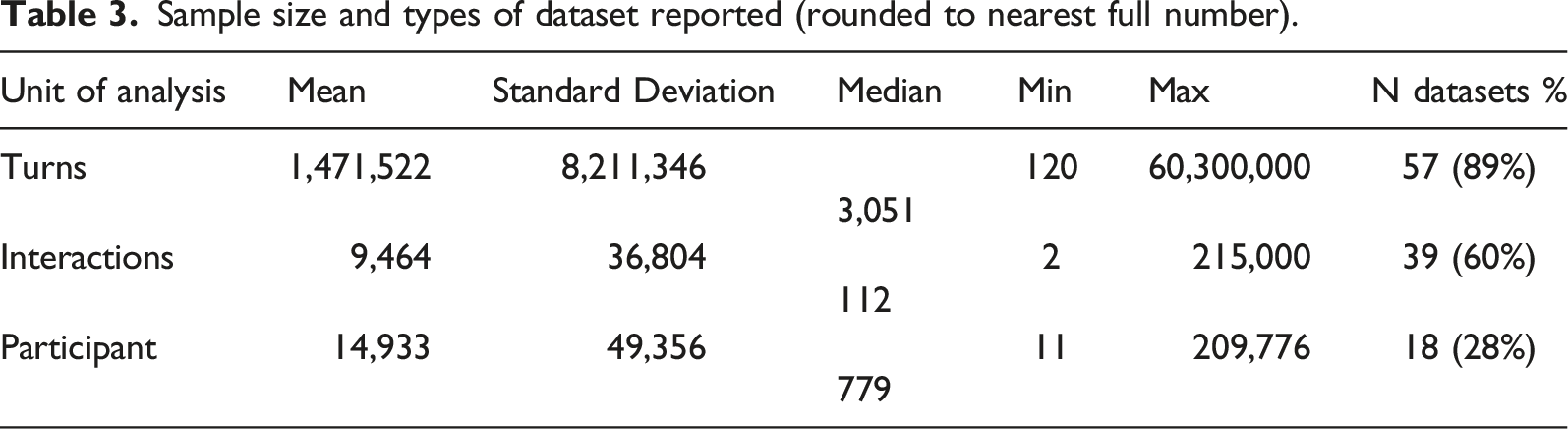
In the 67 studies (see supplementary materials A – 5), we initially identified 221 TIDDs. Of these, the majority were measured using manual coding frameworks (n = 170, 77%), with 32 (14%) using a machine learning algorithm, and 19 (9%) using a fully automated method.
Sample size and types of dataset reported (rounded to nearest full number).
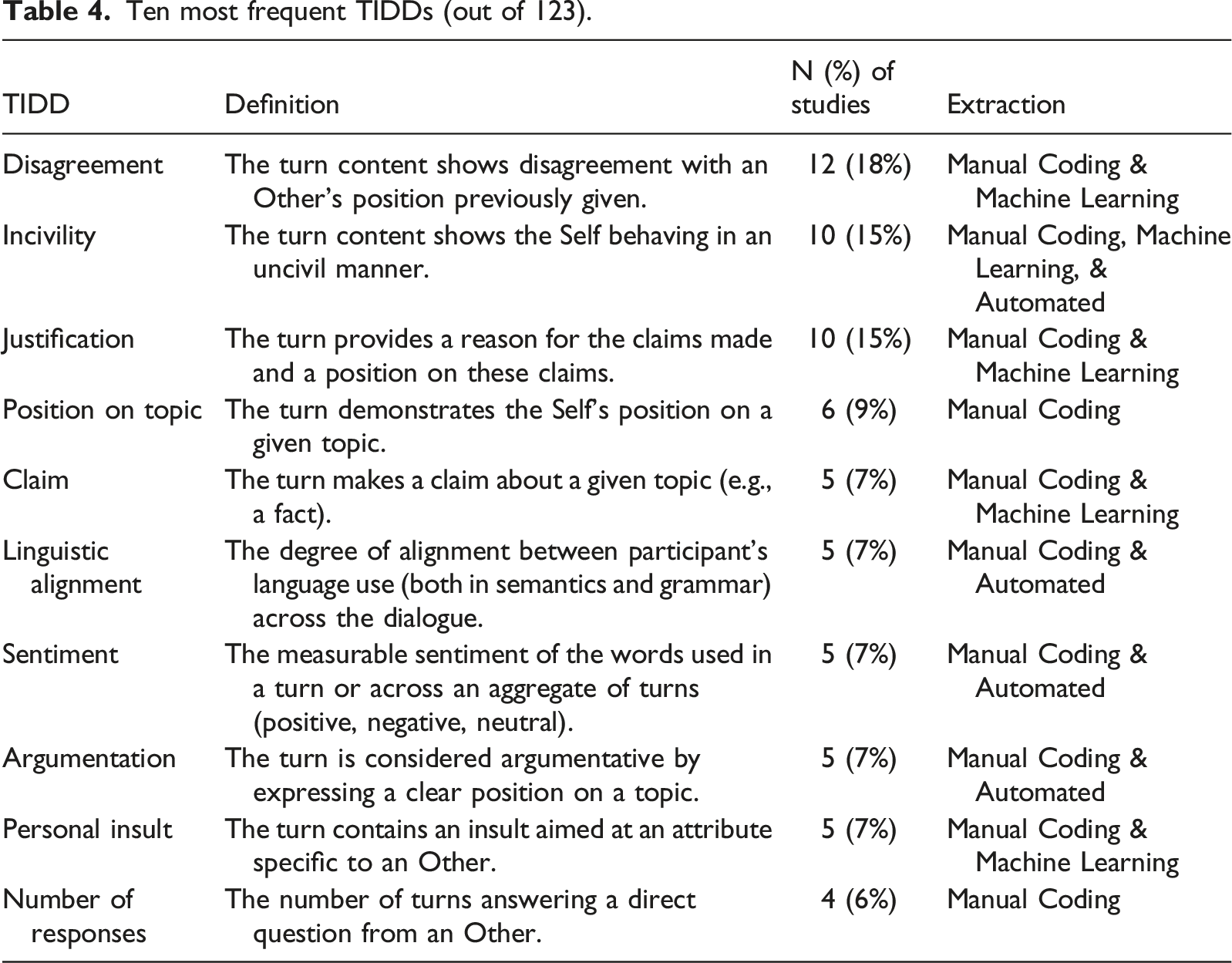
Ten most frequent TIDDs (out of 123).
RQ1—What is the Reliability of the TIDDs?
Reliability of TIDDs and measurement method.
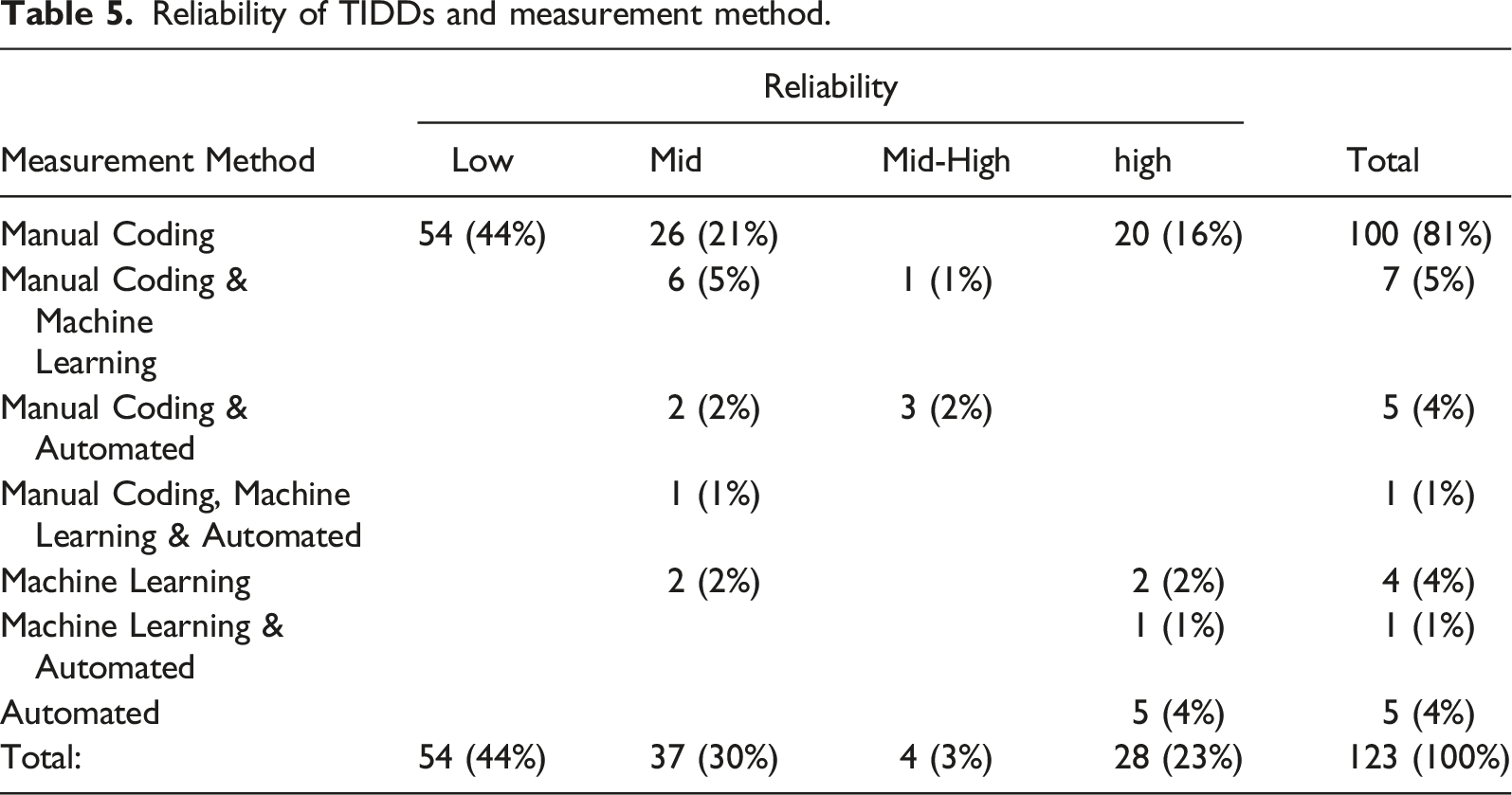
A majority of the TIDDs (n = 100, 81%) were measured using exclusively manual coding. This includes 54 low reliability TIDDs, which either had no reported interrater reliability statistic or a statistic of value below 0.50. We found that 4 (3%) TIDDs were measured exclusively with machine learning and 5 (4%) using exclusively automated measures. The remaining 14 TIDDs were measured using multiple measurement methods.
Interrater reliability statistics were identified for 61 TIDDs with 121 associated values. These interrater reliabilities range from 0.32 to 1.00, have a mean of 0.78 and a standard deviation of 0.12. Of the 121 reported values, 72 (59%) report Krippendorff’s α, 30 (25%) report Cohen’s κ, and the remaining 19 (16%) use an alternative statistic such as Maxwell’s RE, Scott’s Pi, or the Pearson product-moment correlation. Machine learning accuracy statistics were identified for 13 TIDDs with 29 reported values. The F-score was the most reported statistic (n = 22, 76%), ranging from 0.49 to 0.91, with a mean of 0.73 and a standard deviation of 0.12.
RQ2—What is the Criterion Validity of the TIDDs?
High and Mid rated criterion validity TIDDs.
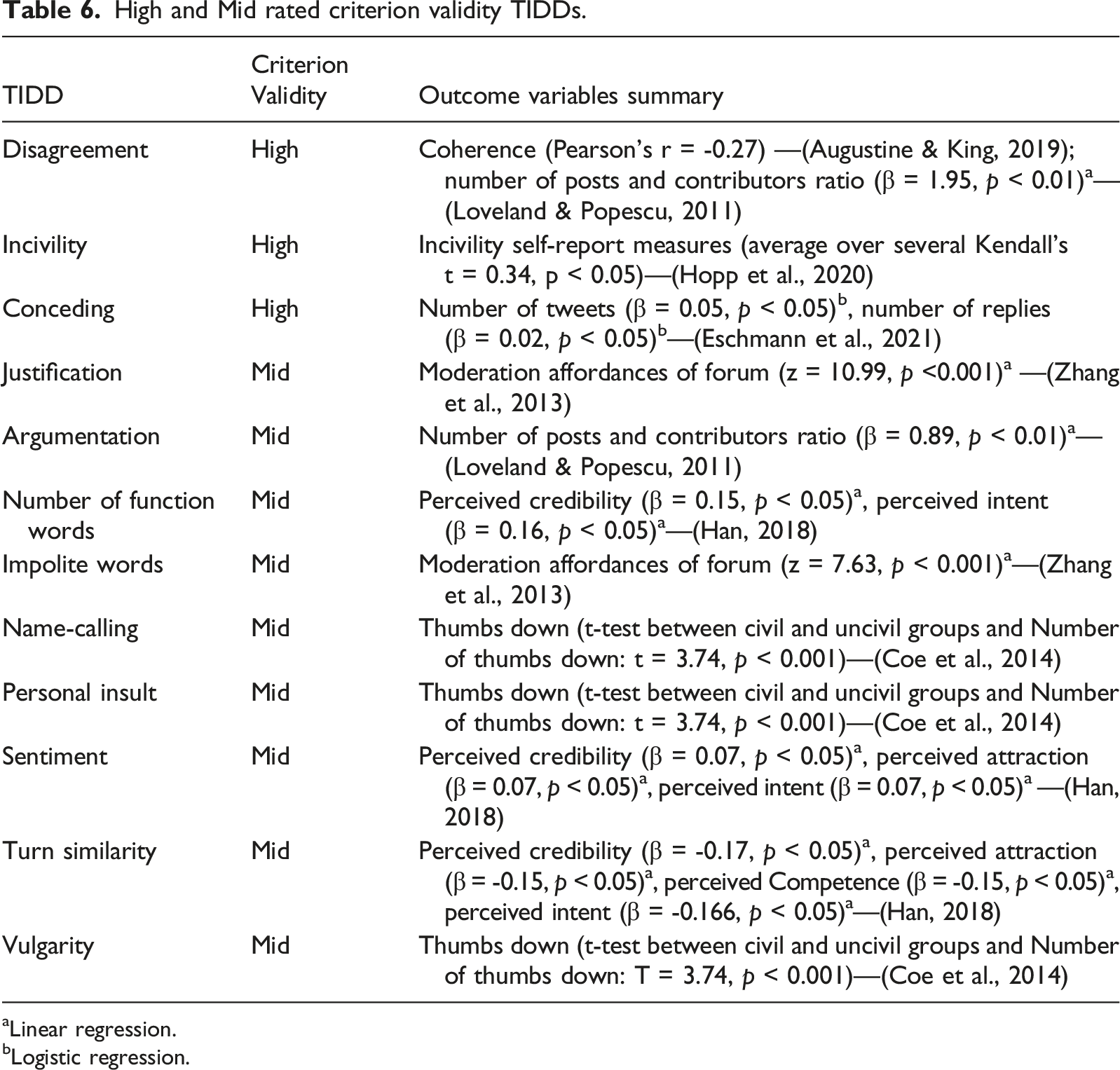
aLinear regression.
bLogistic regression.
Three studies are notable for their consideration of criterion validity in their research designs. First, Han (2018) had individuals rate the quality of Twitter dialogues through a survey along four dimensions (Credibility, Attraction, Intent, and Competence) and proceeded to explore whether TIDDs measured in the text predict the results. Despite their results showing modest associations between the TIDDs measured and perceived quality variables, this method of evaluating criterion validity appears robust.
Second, Hopp and colleagues (2020) find positive and statistically significant correlations between self-report and text-based measures of incivility. The authors use Google’s Perspective API to automatically identify uncivil political communication in Facebook and Twitter data, collected from participants who reported on how frequently they engaged in uncivil dialogue.
Finally, Loveland and Popescu (2011) create a “quality of deliberation” metric which involved a ratio between the number of contributions and contributors (see p. 693). They then use this metric to explore whether specific TIDDs (e.g., disagreement and argumentation) predict this ratio. While it is useful to see these correlations, the reason why the ratio represents “quality” is unclear.
RQ3—What is the Construct Validity of the TIDDs?
Across all the TIDDs, the 11 coders had a Krippendorff (1970) of 0.39 and 15% agreement. This indicates that many TIDDs were allocated to more than one dimension. Despite this, we still found the majority of TIDDs (n = 77, 62%) to have high construct validity in measuring a single deliberative dimension and the quality of online dialogue. Only five (4%) TIDDs were evaluated as having mid construct validity and the remaining had low construct validity (41, 33%).
Discriminant content validity results.

All p < 0.05 for dimensions (rationality, civility & equality) and quality with Wilcoxon (one-sided) sample-rank test.
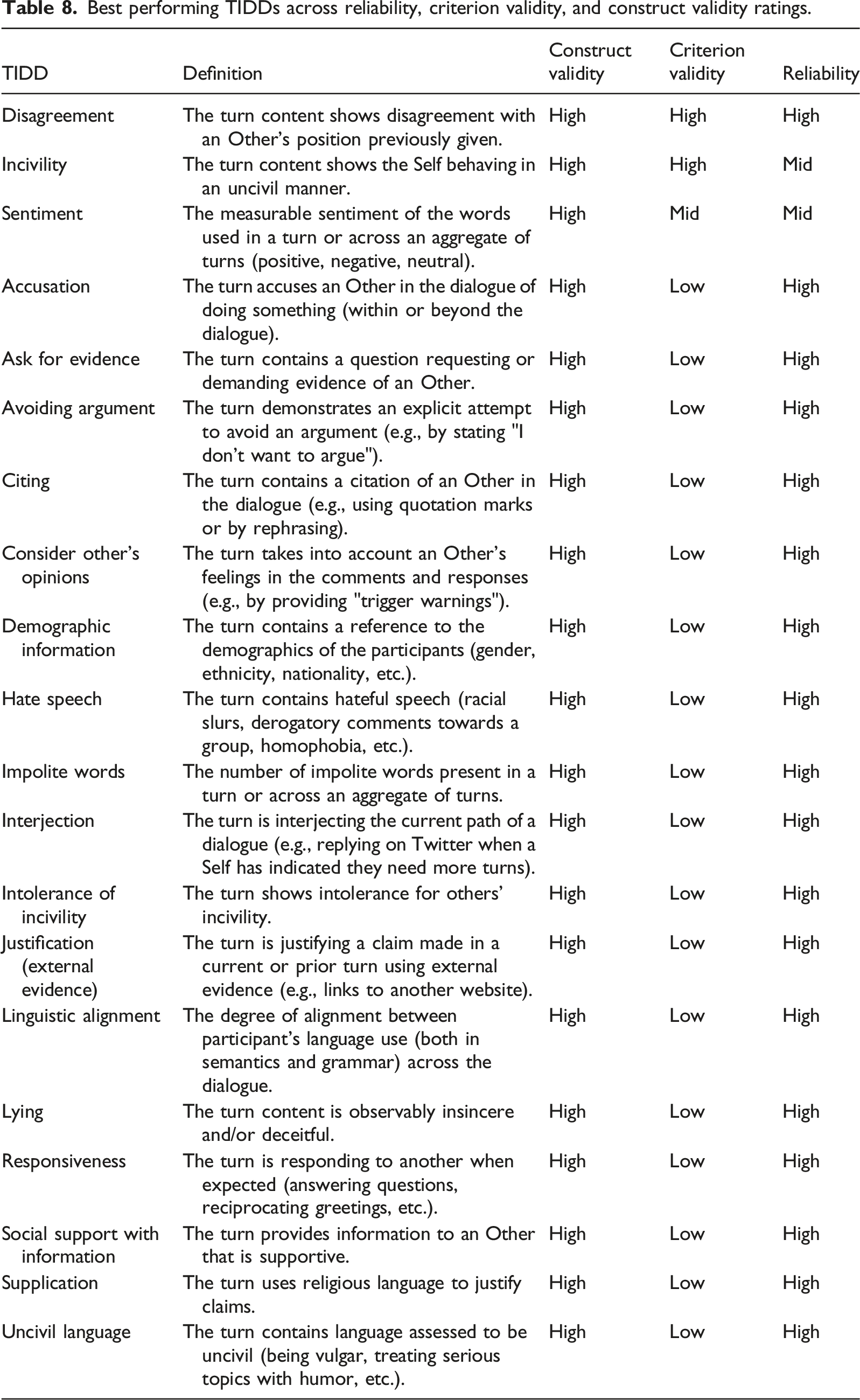
Best performing TIDDs across reliability, criterion validity, and construct validity ratings.
Discrimination failures between dimension pairs for low construct validity TIDDs (full version in supplementary materials A – 3).

Discussion
This review introduces TIDDs and assesses the viability of using automated text analysis to assess the quality of online deliberative dialogue. The review employs a novel use of Discriminant Content Validity (Johnston et al., 2014) to estimate the construct validity of behavioral trace measures. Discriminant content validity was designed to test the face validity of survey items before pretesting their statistical construct validity; however, it is effective for testing the construct validity of measures designed for behavioral trace data.
We identified 123 TIDDs from 67 studies and found that, on average, they have weak to medium reliability (RQ1), low criterion validity (RQ2), and high construct validity in measuring civility and rationality (RQ3). These findings reflect the viability of using textual measures to assess the quality of deliberation and the usefulness of deliberative theory for conceptualizing them.
Examining the reliability of the TIDDs (RQ1), we find that the empirical literature studying online dialogue is primarily using manual coding to measure constructs. Automatic extraction—both by rule-based (e.g., dictionary methods) or machine learning algorithms—are currently not the norm. The use of pre-existing manually coded datasets was common in studies focused exclusively on training a machine learning classifier. While preexisting datasets are useful for model design, they can have validity problems because a machine learning classifier will replicate any biases present in the original data. This limitation is demonstrated by Hoffman et al.’s (2017) attempt to validate Danescu-Niculescu-Mizil and colleagues’ politeness classifier (2013). In the study, the tool does not perform as expected, failing to classify instances of politeness in contexts that were dissimilar to the initial training data. They conclude that future machine learning algorithms will likely improve the prediction of politeness, but current models are limited (Hoffman et al., 2017, p. 12).
The overall reliability of the indicators can be improved in three ways. First, by developing new standardized tools for measuring TIDDs. Any automated tool (such as LIWC and the Perspective API) has high reliability as it produces identical results when used repeatedly on a document. Second, the validity of existing tools should be continuously tested on unseen data to confirm the continued accuracy of results. This could be achieved by checking a machine learning algorithm’s predictions against human coders (Hoffman et al., 2017) or focusing on the construct validity of linguistic features extracted before training (see Sao Pedro et al., 2012). Third, researchers should work collaboratively to create and maintain open source databases of online dialogue, manually coded with relevant constructs. This would help train supervised machine learning algorithms, which would facilitate automation in future analyses.
Examining the criterion validity of the TIDDs (RQ2), we identify more instances of TIDDs being used as dependent variables than independent. This demonstrates a premature assumption in the empirical literature that certain TIDDs are definitive indicators of an online dialogue’s quality. This shows how both the deliberative and empirical literatures need to test widespread assumptions about online dialogue outcomes. For instance, incivility can be used to combat oppressive conditions or express familiarity in a community. Incivility, therefore, does not necessarily correlate with undesirable outcomes and low-quality dialogue in all contexts (Chen et al., 2019).
Another example of assuming an outcome is Loveland and Popescu’s (2011) “deliberative quality” metric to measure the effects of civility TIDDs on online dialogue. This metric is a ratio of the number of posts divided by the number of contributors to the thread and multiplied by the “proportion of thread posts which responded to a prior post” (p. 695). While civility TIDDs may correlate with this metric in these contexts, the assumption that the metric represents the quality of dialogue is unverified.
We propose three methods for future studies to determine whether TIDDs can be used as outcome measures. First, researchers could employ the method employed in Han’s (2018) study. Participants first rank and rate naturally occurring dialogues for their perceived quality. TIDDs are then extracted from the dialogues to test whether they predict the ratings. Second, participants take a survey before and after taking part in online dialogue, rating their attitudes at each stage. This would allow testing of whether attitudes correlate with target TIDDs. Finally, researchers may choose to correlate TIDDs with self-report measures of the same constructs (as done by Hopp et al., 2020).
Examining the construct validity of the TIDDs (RQ3), we found they could only be reliably classified into three of the six Friess and Eilders (2015) dimensions of deliberative dialogue. Of these three dimensions, rationality and civility are the best represented, associated with 74 (60%) TIDDs in total. In contrast, equality is only associated with three (2%) TIDDs. There were also a high number of TIDDs with good discriminant content validity for measuring a broad dialogue quality category but did not measure any of the deliberative dimensions (n = 40, 33%).
This suggests the deliberative model is limited for conceptualizing the current ways online dialogues are operationalized by the broader empirical literature. This is likely a result of conceptual crossovers between dimensions. For instance, the opposite of both civility and constructiveness appears to be antisocial behaviors. Civility is about people treating each other with respect and constructiveness is about working towards constructive shared outcomes. Therefore, being antisocial appears to be both uncivil and unconstructive.
Our results evidence the need for the prescriptive deliberative literature to adapt their model according to the variety of TIDDs present in the wider empirical literature. Overall, the deliberative model, derived from coherent but abstract principles, does not operationalize parsimoniously when used to analyze actual dialogue. Therefore, we recommend altering the model using principles from descriptive approaches to dialogue (Stewart & Zediker, 2000).
A descriptive approach better represents the current state of the empirical literature and emphasizes the communicative behaviors participants employ toward each other. This model is implicit in Détienne and colleagues’ (2016) study, where they focus on the “dialogic functions” of turns in Wikipedia conversations. This involves describing each turn in terms of what it is doing for the participants and their social-cultural context. We recommend developing a model using the axiomatic definition of dialogue as a Self and Other communicating on an Object. Each TIDD indicates a combination of Self-Other-Object components in a tripartite model: object-focused, other-focused, and intersubjective-focused.
Object-focused TIDDs concern a Self providing information or attitude on the Object of conversation. Prototypical Object-focused TIDDs include conceding, counterclaim, claim, justification, diversity of perspectives, position on topic, and balanced view. These TIDDs concern the justifications participants are making about the topics discussed, and any other TIDDs directed at the exchange of information.
Other-focused TIDDs concern the Self’s behaviors towards Others in the dialogue. Prototypical other-focused TIDDs include incivility, judgment of ideological positions, accusation of incompetence, and criticizing others’ talk. These TIDDs concern any instance of other-directed communicative behaviors produced by a single individual.
Intersubjective-focused TIDDs concern the overall relationship between Self and Others as they interact over an Object. Prototypical intersubjective-focused TIDDs include disagreement, metatalk, social support, and reciprocation of self-disclosure. These TIDDs pertain to meta dialogue, that is, dialogue that coordinates the perspectives of Self and Other vis-à-vis the Object.
Conclusion
This study introduces TIDDs to conceptualize the growing need to measure the deliberative quality of online dialogues. The review provides a practical and theoretical contribution. At a practical level, the TIDDs (supplementary materials B & A – 4) can be applied across a variety of datasets as they are context-independent. They may therefore facilitate automatic comparison of dialogue quality across social media platforms. If embraced and developed, TIDDs might enable more multidisciplinary research using large-scale online dialogue datasets.
At a theoretical level, we suggest deliberative theory conceptualize TIDDs using a model of Self-Other-Object interactions instead of ideal speech situations. Based on a descriptive definition of dialogue, a Self-Other-Object model better reflects empirical reality than abstract theoretical constructs such as rationality and civility. Adopting this model can help broaden current empirical measures used for predicting desirable outcomes of deliberation and, in turn, understanding how online dialogues can be improved for maintaining democracies.
This systematic review has three important limitations. First, the review did not follow a prospective registration before being conducted. Second, only three databases were used for identifying relevant literature. Future studies should seek to expand on the current TIDDs by targeting databases that were not included in the review (e.g., Web of Science, Google Scholar). Third, because the review focused on measured constructs, we only performed a minimal quality check of studies’ analysis methods and results during the screening process. Future reviews may expand on our review by assessing how well TIDDs are analyzed in the target studies. This would provide additional insight into the criterion validity of the TIDDs and, therefore, how they might robustly predict dialogue outcomes.
Computers have become integral to the functioning of societies by enabling previously unimaginable dialogues. With these new dialogues come many unanswered questions about the role of communication in democracies. We have shown how the deliberative literature, which conceptualized dialogue quality before widespread computation, benefits from adapting methods and findings from the wider empirical literature. The TIDDs provide a step towards reliable and valid measures of deliberative dialogue. With refinement, TIDDs have the potential to help monitor and improve the quality of online dialogue and, as a result, the future of global democracy.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.