
Abstract
In organizational theory, institutionalists generally make predictions of corresponding context and policy outcome based on structural processes. Psychoanalytic theory, in contrast, focuses on the rhetorical framing rather than the environment of a policy for predictive outcomes. This study aims to explore the debate over policy prediction by developing a supervised machine learning model to predict for policy success and context in the United Nations (UN). Through data collected with a python web scraper on all UN meetings in the General Assembly (GA) and Security Council (SC) between 1994 and 2020, we parse motions, policies, and conflict indicators, before passing meeting records through the Linguistic Inquiry and Word Count (LIWC) psycholinguistic algorithm. Next, we build 12 different machine learning models to predict for policy passage and context using preprocessed motion and LIWC data; results demonstrate that the psychoanalytic models better predicted for both context and policy outcomes than the institutionalist models, suggesting that the classical political axiom, “actions speak louder than words,” may not be supported by the empirical evidence.
Keywords
In 1955, US Secretary of State Dean Rusk first observed that, as contrasted to the 19th century bilateral “backroom deals,” large international institutions were rapidly coming to resemble the multilateral factionalism of domestic parliaments (Fiott, 2011, p. 1; Rosenbaum, 1967, pp. 218–9); as a consequence, Rusk noted, new formalized methods that “equalized” the decision-making power of actors in adjudicating policy disputes were changing traditional diplomacy into “an exercise in building and managing the coalitions required to secure the minimum number of votes” (Smith, 2007, pp. 3–4). Since then, theorists on UN decision-making have generally sorted into two schools: first, institutionalists argue that the processes of the UN, by governing interaction and policy drafting, act as gatekeepers for determining which policies pass and under what circumstances (Berliner & Prakash, 2014, pp. 218–20; Monteleone & Oksamytna, 2020; Smith, 2007, p. 278; Jessup, 1957). In contrast, political psychologists, rather than focusing on the available tools or interests of such actors, pivot to a constructivist viewpoint in emphasizing how rhetoric and cultural pretexts shape the tools, policies, and appraised contexts of a given situation (Bode, 2015, pp. 16–9; Kertzer & Tingley, 2018; Winther & Lindegaard, 2020, pp. 232–3233).
Regardless, the existing literature of both schools tends to analyze voting patterns (Voeten, 2013, pp. 55–8). Others such as Kaufmann (1988) and Smith (2007) focus on a qualitative review of historical cases that represent actors’ manipulation of the process to further specific policy goals. 1 Notably, both methods result in context-orientated case studies that while attractive in addressing pressing issues such as “why the UN did nothing in Rwanda” fail to empirically demonstrate systemic phenomena (Braun et al., 2018; Holsti, 2016). And finally, in contrast to the traditional “realist” or “liberal” approaches, which deem decision analysis as a “black box” that adds little definitive knowledge to international politics thereby justifying a pivot to analyzing vague state intentions, this paper aims to tangibly identify approaches within the institution that can affect real life policy making (Mearsheimer, 1994; Finel, 2001). In this paper, we build on early research by providing a parameter of inputs between 1994 and 2020, rather than a series of individual case studies, to illustrate systemic phenomena. Next, we compare our psycholinguistic model to the traditional institutionalist model to determine which better predicts for policy outcome and contexts. As a result, we make three contributions: first, we employ a new machine learning methodology to test for predictions based on large sets of variables, which allows for large sets of data to be more accurately modeled (Marsland, 2015; Montavon, et al., 2018). Second, we engineer 12 models—six for the GA and six for the SC—to compare and contrast predictions and determine the most accurate model. Third, we implement an empirical strategy focused on identifying meaningful distinctions in policy: rather than recording only votes, we account for the Kaufmann (1988) “death by committee” strategies by also recording events in which votes are not taken (Freixas & Zwicker, 2003; Rasch, 2009). As our conflict indicators further illustrate, we aim to determine when the UN is likely to tangibly intervene, rather than just issue vague statements or discords. As a result of both, we demonstrate that the psycholinguistic model is a stronger predictor than suggested by the current literature.
Literature Review
General Assembly and Security Council
Differences in the General Assembly and Security Council.
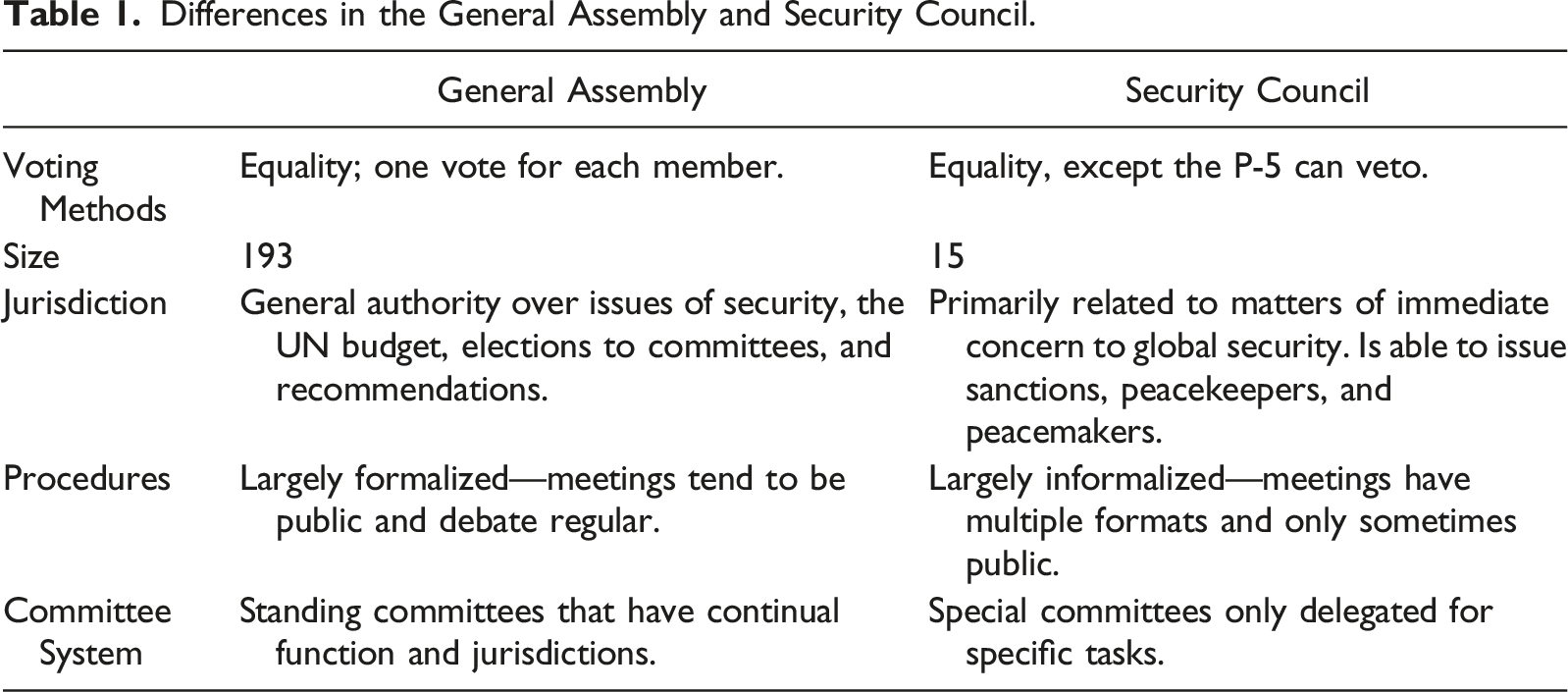
In terms of important distinctions, much academic discourse tends to focus on the SC’s veto power; the effect of this difference, however, is empirically complicated. As Kim and Rusett (1996) notes, the actual use of the veto has changed little since the 1970s, with Thalakada (1997) similarly observing that the actual use of the veto has been reserved since the 1960s. More contemporarily, scholars have noted that the use of veto power is more implicit, being instead utilized to threaten a block of policy, forcing lengthy debates that result in a de facto “veto” (Zaccaria, 2021). Finally, even those scholars who do allege the veto power has been used extensively to the detriment of UN agree that the actual use of the veto is less apparent than its threat (Smith, 1999); and even under these cases, certain “norms” have emerged that minimize its impact for certain cases that threaten international security (Wenaweser & Alavi, 2020, pp. 65–6).
The Institutionalist Model
Characteristics of Motion Classes.

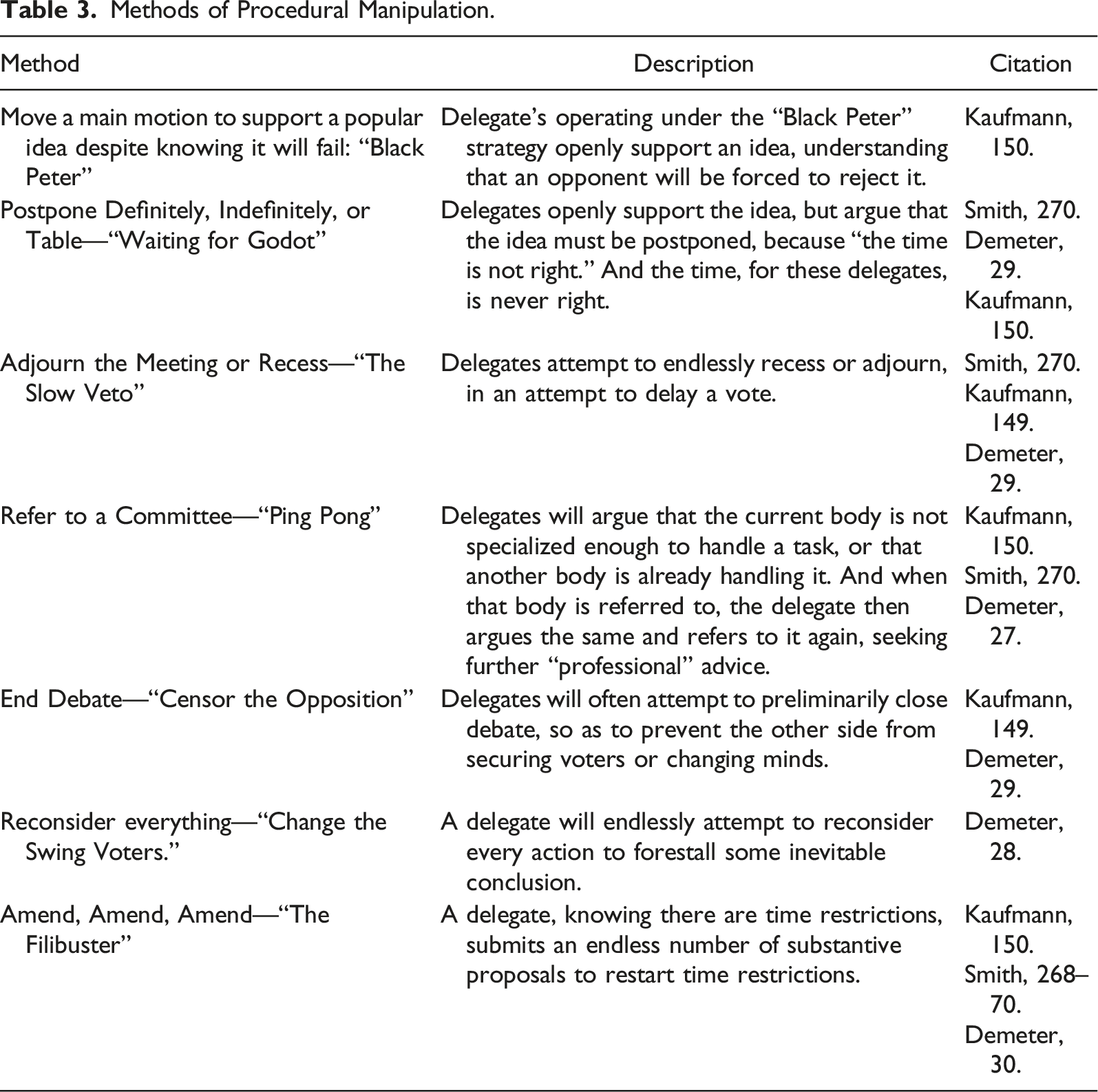
Methods of Procedural Manipulation.
In essence, institutionalists propose that policy outcomes and context predictions are a function of the ordering of an institution, which in turn modifies the transaction cost of taking action (Wood & Bohte, 2004). Moreover, in contrast to output orientated theories of institutional policy, such as a realist analysis of voting for a specifically beneficial resolution, institutionalism observes that even in an environment of selfish actors, policies are often “debilitated” rather than “defeated” through a filter of processes that select for actual outcomes (Kaufmann, 1988, p. 143; Smith, 2007).
Finally, for institutionalists the type of deliberative body matters: indeed, while delegates in the GA have equal voting rights, the “veto power” in the SC introduces inequality among members, which in turn differentiates the cost of transacting policy in either body (Bourantonis, 2010; Smith, 2007). Institutionalists predict, as a result, that the perception of a policy outcome is dependent on the processes used to reach it (Haftendorn et al., 2004); for example, institutionalists would point to use of numerous amendments to “filibuster” and the corresponding defeat of the Razali SC reforms in the GA as evidence of institutional process affecting outcomes (Smith (2007), p. 272). 3 For this reason, institutionalists would predict that not only does accuracy differ in both the GA and SC, but that ordering of the institution, and corresponding use by delegates, better predicts policy than what those actors allege to politically and normatively represent.
Psycholinguistic Models
In many democratic institutions, as Smith (2007) notes, policy construction is simply a reflection of voting coalitions. How these coalitions form, and under what criteria they change, is subject to decades of research with various psycholinguistic explanations; Chong and Druckman (2007), for instance, suggest that disputes can often simply be resolved by a contextual view of an argument’s merits. Other scholars suggest that the relative strength of arguments can be traced to broader cultural themes, cognitive biases, and heuristics built into certain rhetorical arguments, both at the domestic and international level (Bayes et al., 2020; Peterson & Arceneaux, 2020, 1129). The UN, moreover, highlights a particularly interesting case study because convincing arguments must transcend traditional regional or cultural borders to establish international representations of norms (Shannon et al, 2014). As a result, the general theses of psycholinguistic models emphasize how arguments for a policy are framed, rather than just what tools are used to further a policy (Manstead, 2001); in effect, this framing modifies how individual delegates appraise a policy or context (Almohammad, 2016, pp. 8–15; Jones, 2020, pp. 649–52). In particular, numerous empirical studies have indicated the validity of “dictionaries,” or built-in algorithms of certain psychological phrases, in transcribing verbal expressive emotions from text documents (Kahn et al., 2007; Mcdonnell et al., 2020). More specifically, as Hacker (1996) points out, linguistic analysis excels at providing evidence for the deliberate use of language to manipulate or coerce a desired outcome. In totality, the psycholinguistic model suggests that the syntax and diction that an individual uses affects the psychological state of both the subject engaged in the discourse and those listening, in turn reflecting their corresponding opinion on policy and context (Gagné, 2011; Martynyuk & Ponikaryova, 2018).
Neural Networking and Classification
To solve the problem of sorting through enormous sets of data, this study employs machine learning models to predict outcomes (Hindman, 2015, pp. 48–52). Functionally, a deep neural network (DNN) algorithm creates a network of layers. Each unit in a layer is called a “neuron.” Each multilayer network of neurons creates numerous nonlinear relationships to defined parameters, similar to the human brain (Grill-Spector et al., 2018). In doing so, as illustrated by Figure 1, the algorithm attempts to generate nonlinear functions that most efficiently select for the given criteria demanded by the output parameter (Hussain & Jeong, 2016, pp. 1–3; Sullivan 2019, pp. 2–11). Deep neural network (DNN) model.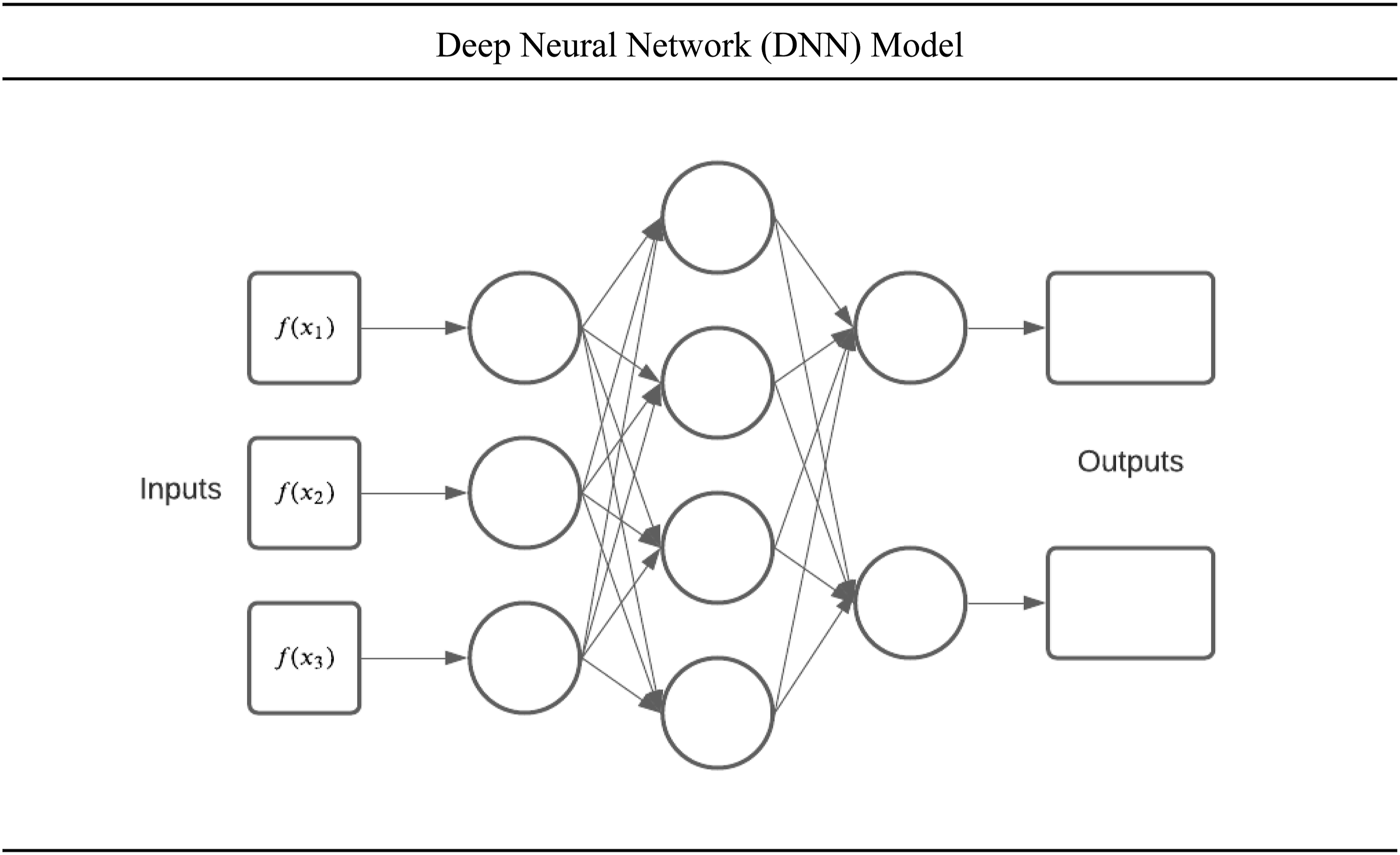
The above model shows a simple DNN model designed to portray three concepts: First, the inputs from a defined “training” set of data relay information to the first layers of neurons. Second, the first layer of neurons computes the input data using an activation function designed to calculate a desired output, which is then transmitted to the next layer of neurons. Moreover, each input to the second layer is signaled by a weight given to each variable, allowing the neurons to slowly prioritize or “learn.” Deep neural network models then continue to pass the corresponding weighted values through each layer, slowly “learning” how to prioritize the importance of variables, similar to biological neurons. Finally, the last layer of neurons produces an output function which is then tested against a series of the data not used in the training set, which can then be translated into a number of usable metrics.
In political science specifically, DNN models have become increasingly important for interpreting large sets of data (Hindman, p. 49). Rapid advances in DNNs promise not only to automate technical functions but to augment traditional human interpretations of data (Li et al., 2017, pp. 12–4). While the proprietary nature of these algorithms often prevented their review by scholars, their impact is nevertheless self-evident by their successful implementations. In the UN specifically, as Sovrano et al. (2020) notes, artificial intelligences have already been able to classify UN resolutions according to related Sustainable Development Goals, effectively monitoring state compliance. As a result, DNNs allow for researchers to not only theorize but make tangible predictions for a massive range of factors, and are well suited for previously inaccessible comparisons of psycholinguistic models that utilize hundreds of interacting variables (Kratzwald et al., 2018, p. 24).
Methodology
The architecture of our proposed framework to predict policy passage operates in five central units, as illustrated by Figure 2. First, the web scraper downloads and mines the UN meeting documents, either through a fuzzywuzzy program for motions, policy, and context, or the Linguistic Inquiry and Word Count (LIWC) API (Hu et al., 2021; United Nations, 2021). Second, the database is stress-tested, with finalized data preprocessed before being returned to the database for analysis. Finally, the data is fed to the tensorflow neural network to compute the probability of the labels; that is, the probability of policy passage and the presence of conflict indicators.
4
Framework: An architectural view of the data pipeline.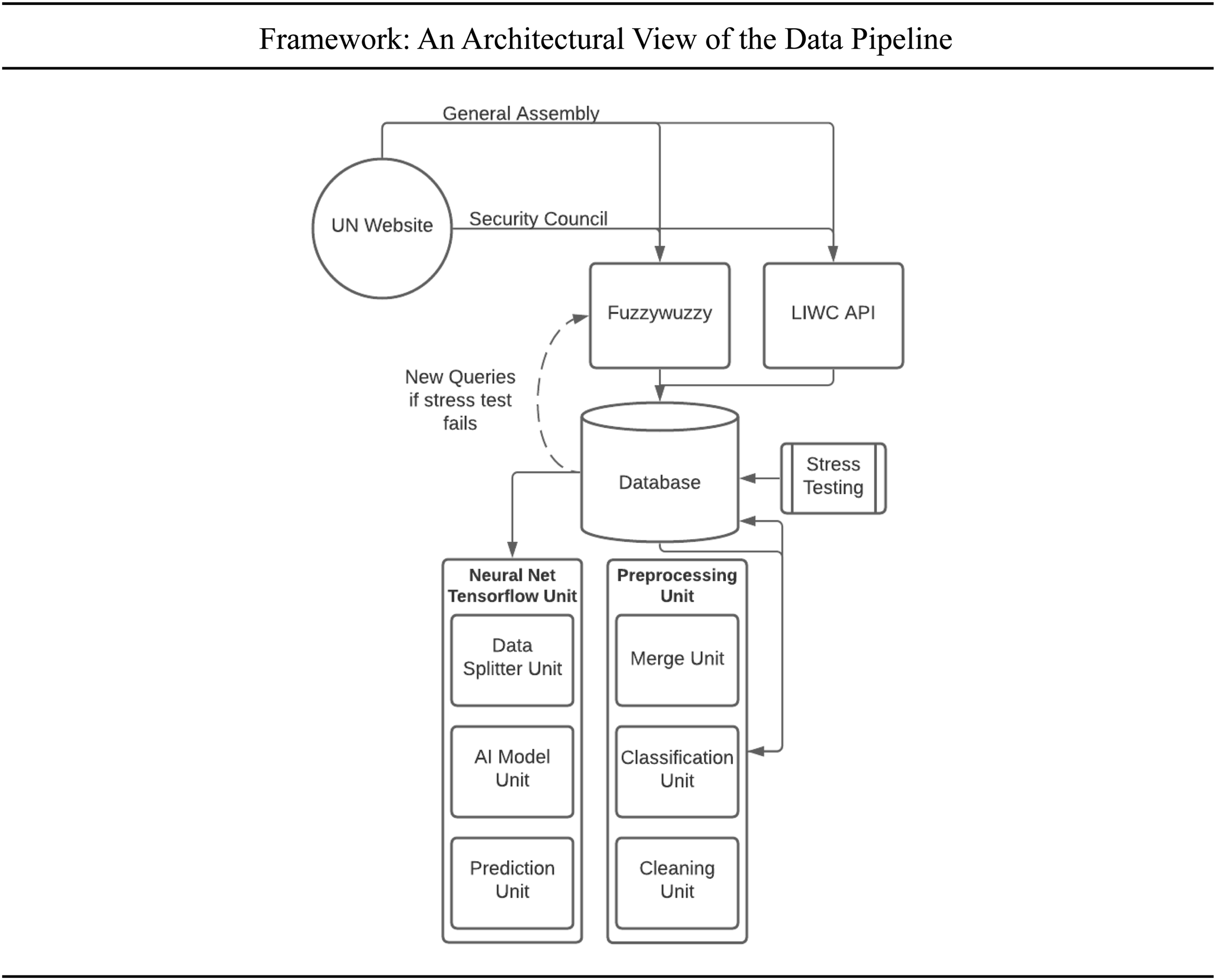
Variables
First, all meetings are sorted by type of assembly: namely, the GA or SC. These two bodies have several distinctive procedural differences, such as the number of motions, voting rights (i.e., presence of veto), and jurisdictions.
Second, meetings were categorized by conflict prevalence (CP), as recorded by a dummy variable (no conflict = 0, conflict = 1). In this paper, CP refers to the presence of forceful intervention in any given topic as defined by Chapter VII of the UN Charter. This includes three potential situations: “peacekeeping,” “peacemaking,” and “sanctions.” These situations conform with the 2005 “Responsibility to Protect” (R2P) doctrine and UN charter (526) as outlined by Burkle (2018).
Third, the number of politics passed in any given meeting was counted. For this paper, the definition of a “policy” is a resolution passed or rejected by a given set of rules governing a main motion. To measure this, our queries in the GA searched for “The draft resolution was adopted.” In the SC, our queries searched for “The draft resolution has been adopted.” 5
Fourth, the total number of motions per meeting is recorded. These motions are then sorted into the aforementioned five ordinal classes: main motion (M), subsidiary motion (S), privileged motion (P), incidental motion (I), and motions that bring a question before the deliberative assembly (B). 6 These classes represent every possible procedural action that can occur in a deliberative assembly. Each of these motions holds a specific characteristic that infers an interaction with another motion (Appendixes A and B).
Linguistic Inquiry and Word Count (LIWC) API Categories.

Data Collection
This study will review a population of United Nations (UN) meeting records in the GA and SC between 1994 and 2020.
First, a python web scraper took UN records from online databases and converted the files to a portable document format (PDF). The files were then converted into readable text files and sorted by date.
Second, the documents were analyzed both through a fuzzywuzzy analyzer and LIWC. For fuzzywuzzy, key phrases for policy passage and conflict indicators were run against the text files computing similarity of statements through the levenshtein distance formula at 95% confidence. Fuzzywuzzy data was then stress tested for accuracy. 7 Thereafter, the program records each query and sums the total frequency of queries per text file. For LIWC, every document was run and results recorded. The queries for both are then placed into a csv file for preprocessing.
Analysis
Our neural network models the transformed data to accurately predict either the probability of policy passing or the presence of conflict indicators. We used the Tensorflow python environment to simulate models (Dillion et al., 2017). For both the GA and SC, the models were divided into three categories: 1. Psychology: the probability of a label given only LIWC input variables as features. 2. Motion: the probability of a label given only motion input variables as features. 3. Mixed: the probability of a label given both LIWC and motion input variables as features.
For both the GA and SC, all parameters, including density, testing and training data allocation, dropouts, and epochs were tuned for optimal accuracy and to fortify against overfitting (Hssayni, 2020). All variables were set as features, with the exception of “Policy Passed” and “Conflict Indicators,” which were set as the labels depending on the model tested. To tune, we simply used the trial and error method, as noted by Bielza et al. (2013).
In both the SC and GA, the model first splits the data into two categories: training and test (test proportion: GA = .2; SC = .15). Second, using a sequential function, hidden layers were added using the Rectified Linear Unit (ReLU) activation function 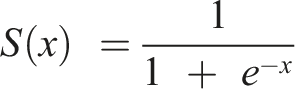
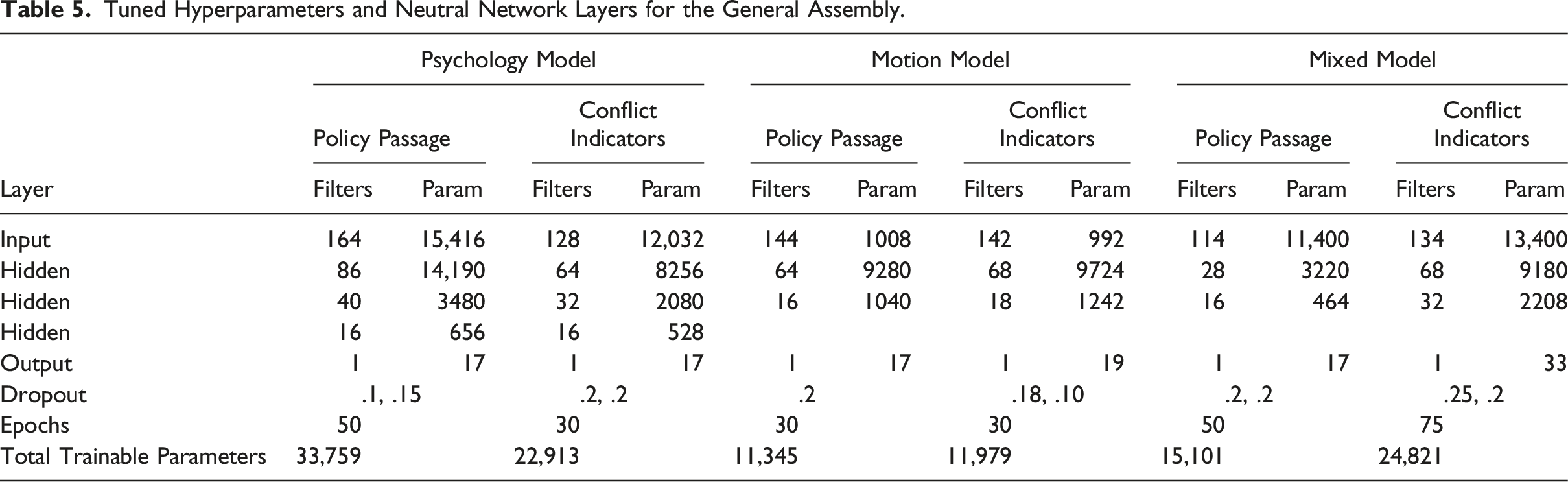
Tuned Hyperparameters and Neutral Network Layers for the General Assembly.
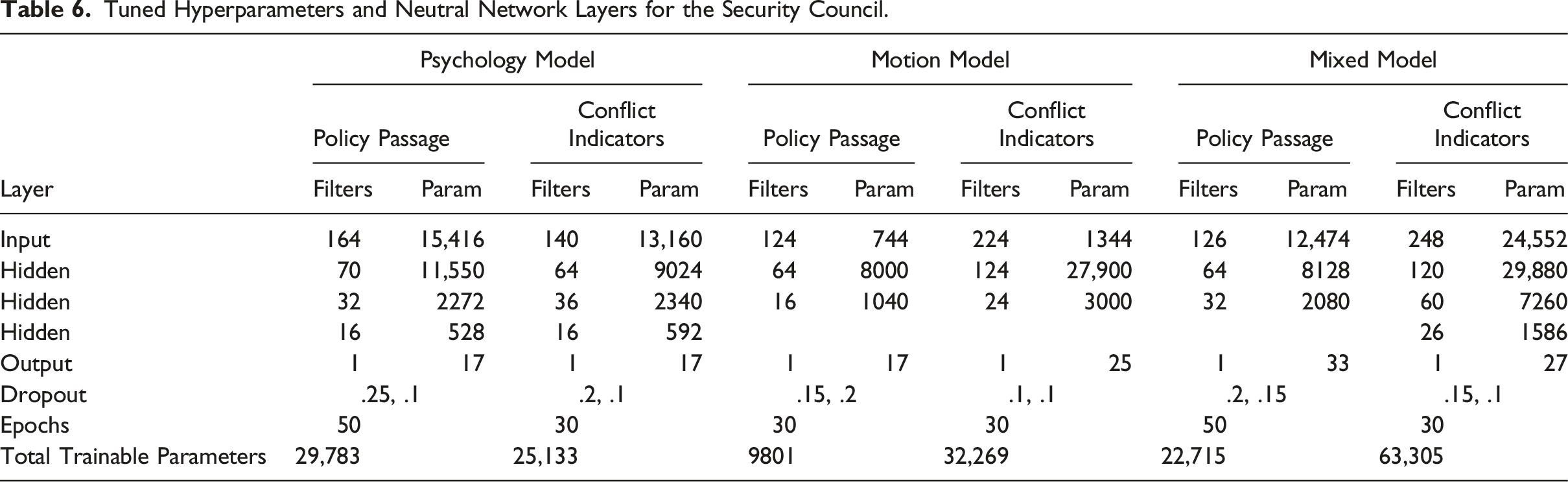
Tuned Hyperparameters and Neutral Network Layers for the Security Council.
Finally, to simulate reproducibility in the stochastic environment of Tensorflow, we modeled the average metrics of 30 models. Due to data imbalance, label classes were weighted for.
Results
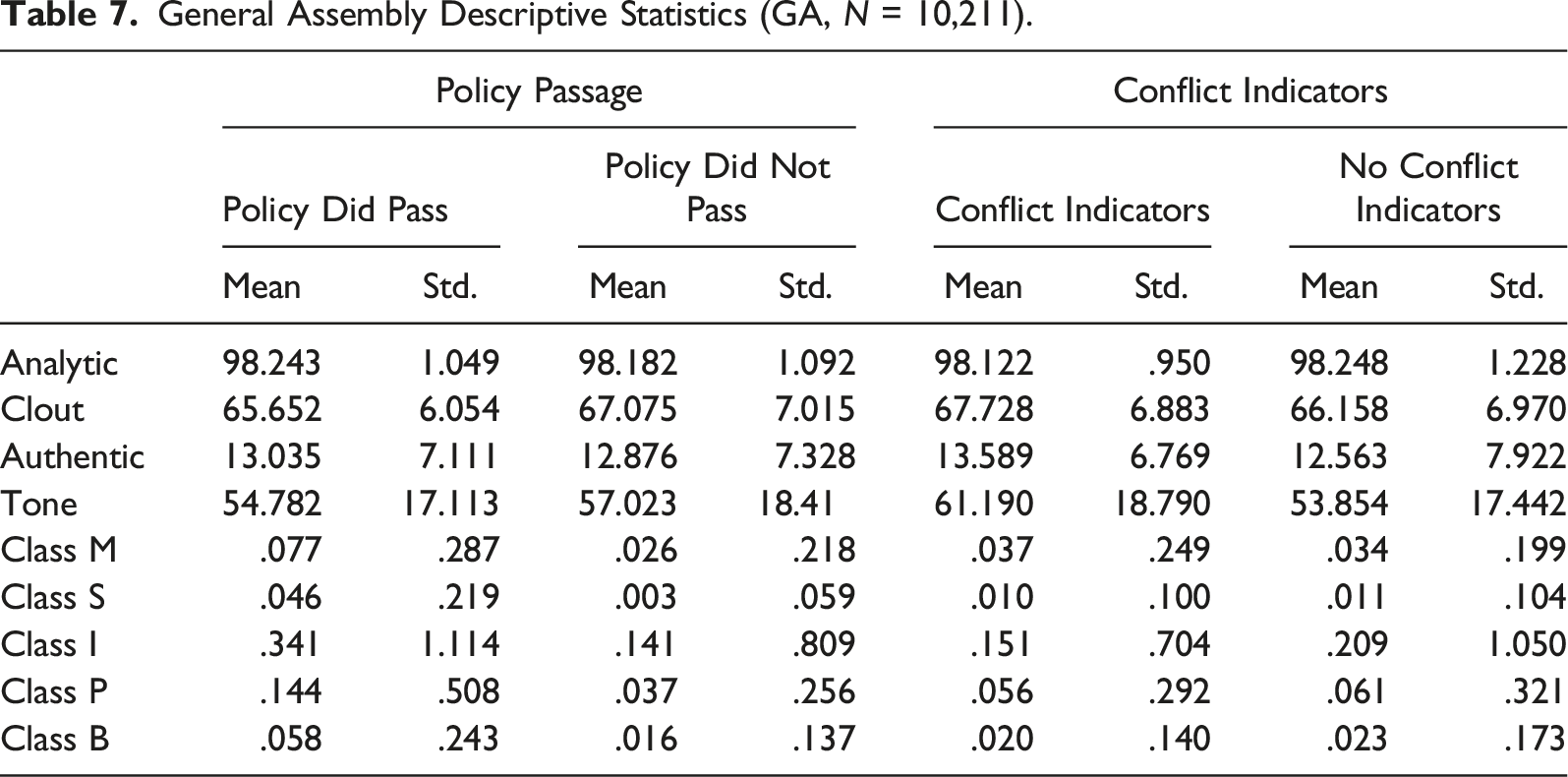
General Assembly Descriptive Statistics (GA, N = 10,211).
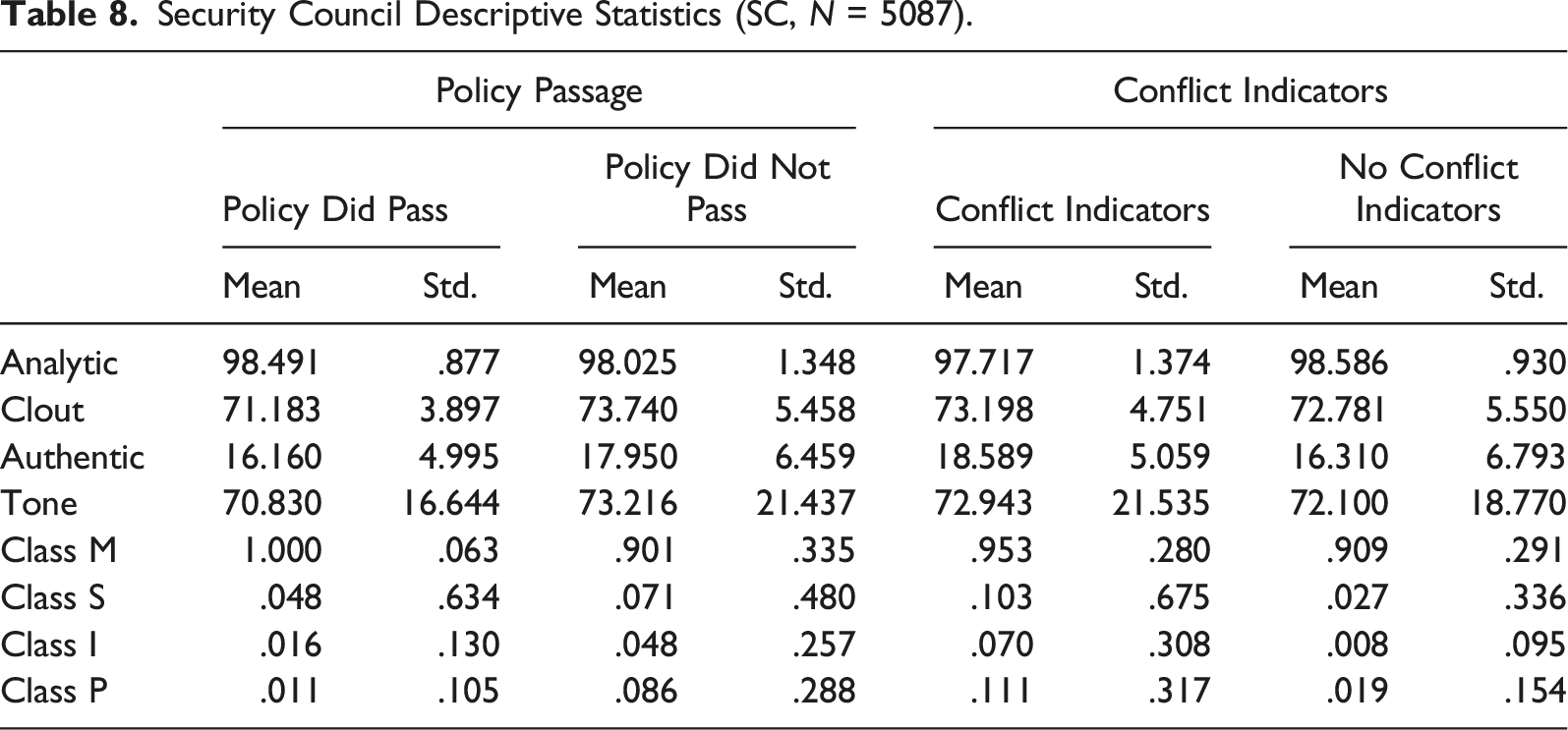
Security Council Descriptive Statistics (SC, N = 5087).
Model Performance
Average Prediction Outputs for the General Assembly.
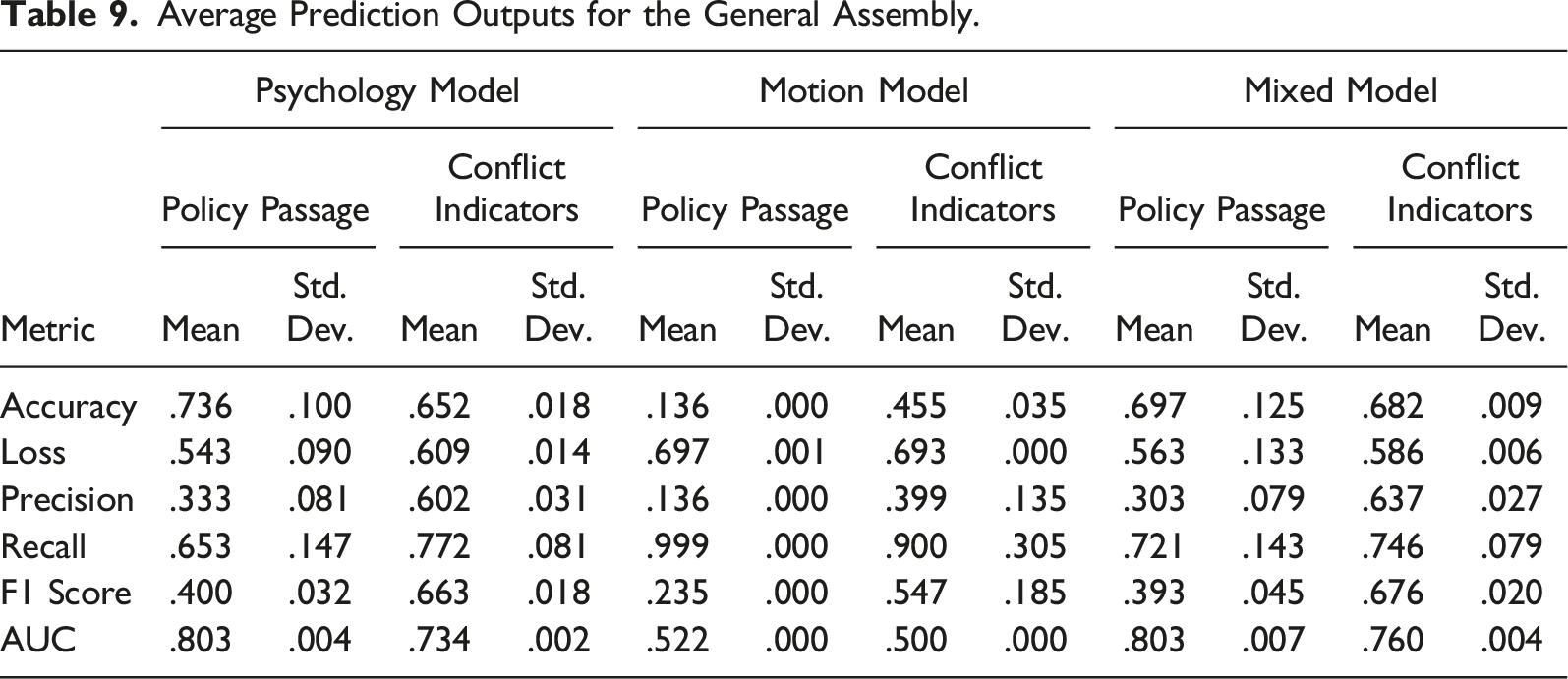
For both policy passage (AUC = .803) and conflict indicators (AUC = .734), the returns demonstrated the model was more accurate than randomization. In contrast, the motion model scores were, for policy passage (AUC = .522), barely better than randomization, and for conflict indicators, no better (AUC = .5). Finally, the mixed model scores displayed at the right, with policy passage (AUC = .803) and conflict indicators (.760) more accurate than randomization.
Next, results demonstrated convergence of the training and validation data, inferring generalization was applicable. Figures 3(A)–3(C) illustrate convergence of training loss and validation scores, relatively recorded for each of the 30 models over time. For each figure, the data was recorded using a smooth loss function (loss on the y-axis and time on the x-axis). Using tensorboard, we smoothed the loss function at .6. Each model was checked for convergence, demonstrating that accuracy results were optimized to control against underfitting and overfitting. Results can therefore be generalized. Figures 3(A) to 3(C) represent the General Assembly Psychology Loss Model, Motion Loss Model, and Mixed Loss Model, respectively. Likewise, 3(D) to 3(F) represent the Security Council Psychology Loss Model, Motion Loss Model, and Mixed Loss Model, respectively. Convergence represents validation and training meeting.
Average Prediction Outputs for the Security Council.
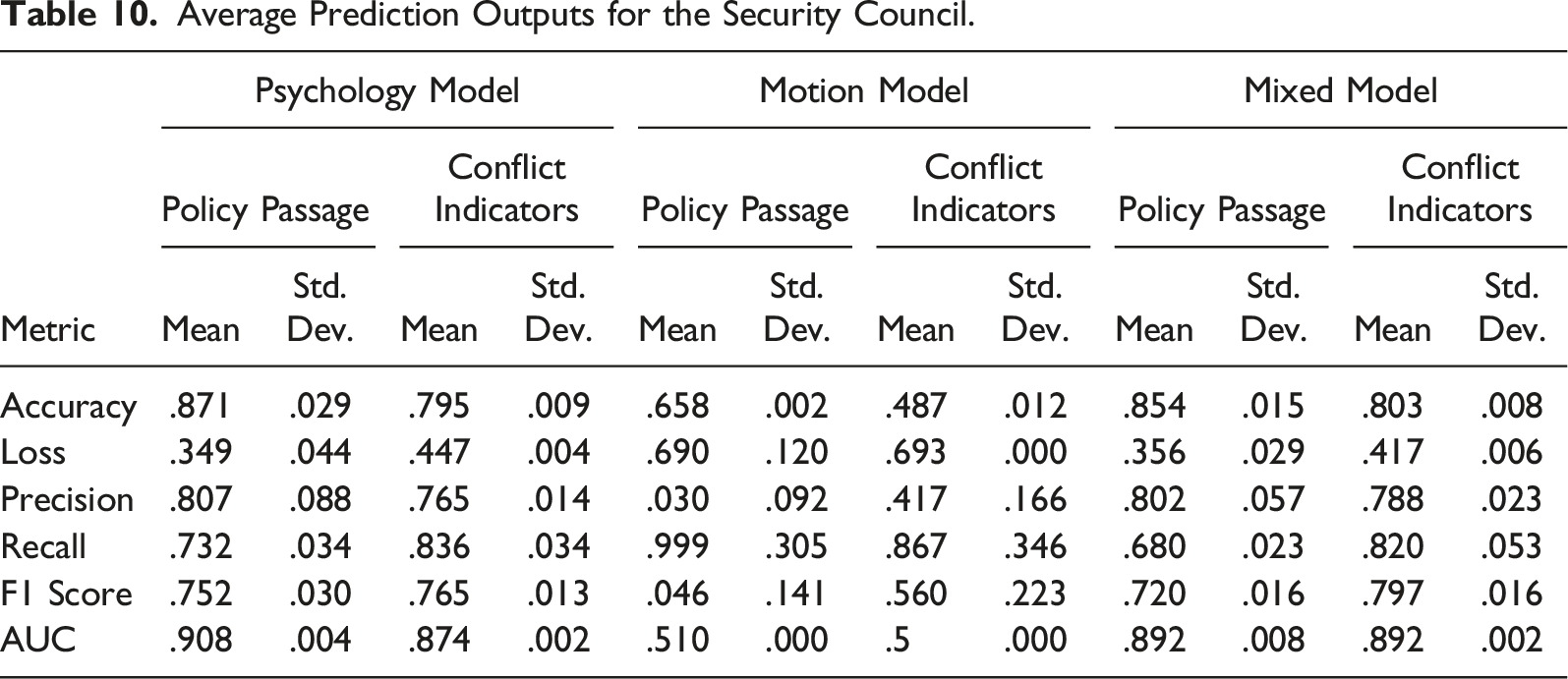
For both policy passage (AUC = .908) and conflict indicators (AUC = .874), the returns demonstrated the model was more effective than randomization. The motion models, however, performed significantly worse, with policy passage (AUC = .510) barely better than randomization, and conflict indicators (AUC = .5) performing no better than randomization. Finally, the mixed model scores displayed at the right, had differing results, with policy passage (AUC = .892) better than randomization but weaker than the corresponding psychology only model. In contrast, the mixed conflict model (AUC = .892) was the stronger of the series.
Next, results demonstrated convergence of the training and validation data, inferring generalization was applicable. Figures 3(D)–3(F) illustrate convergence of training loss and validation scores, relatively recorded for each of the 30 models over time. For each figure, the data was recorded using a smooth loss function (loss on the y-axis and time on the x-axis). Using tensorboard, we smoothed the loss function at .6. Each model was checked for convergence, demonstrating that accuracy results were optimized to control against underfitting and overfitting.
Discussion
In general, the results suggest that psychological indicators are stronger predictors for policy passage and context than the actual actions of the delegates to either implement or pass a policy. Moreover, while institutionalists may be inclined to connect rhetorical acts to institutional pressures that predetermine the probability of policy or context, these same pressures do not relate to the actual procedural actions of delegates (Wood & Bohte, 2004). Indeed, the actual action of delegates, ranging from committee hearings, to amendments, to procedural debates was a significantly weaker predictor than the rhetoric those delegates employed, regardless of the type of deliberative body they were based in. The specific results of the study, furthermore, aimed to identify how predictions manifested: namely, whether features better predicted for presence or absence of policy passage or certain contexts. As our results indicated, modeling in both the GA and SC overwhelmingly predicted better for a lack of policy passage or conflict indicators, suggesting that when the UN does pass policy or use a form of coercion in such policy discussions there is a weaker link to rhetoric and action. For this reason, when faced with debates on pressing crises—such as genocide—other factors, such as unannounced state interests, may project a stronger influence.
In the GA specifically, policy predictions for the psychology model were more accurate than the motion model; moreover, because even the mixed model, which analyzed both the rhetoric and actions of delegates in predicting policy passage, was not significantly more accurate than just the psychology model, rhetoric used by delegates was a stronger predictive factor. However, while accuracy was relatively high for predicting policy results, the low precision scores weighed down the overall F1 score, inferring that the model was poor at correctly predicting the presence of policy passage. Likewise, an amplified result of the same trend emerged with predicting for conflict indicators, with the psychology model producing stronger predictions than the motion model. Furthermore, similar to the policy models, the conflict indicator models had poor precision but high recall, indicating the models were better at predicting when sanctions or peacekeeping would not be utilized, rather than when they would be.
Rhetoric in the SC, while following a similar pattern to the GA, was a stronger predictor; indeed, for policy passage, the psychology model was likewise a stronger predictor than the motion model, the latter of which could not even surpass random selection. Both the psychological and mixed models, while with the latter slightly less accurate than the former, demonstrate strong predictability for policy. The SC, however, differentiates largely from the GA in terms of precision scoring across the psychology and mixed models, indicating that predicting the probability of policy passage was more accurate in the former. This supports a more transparent view of the SC: when a delegate says something, it more strongly relates to the actual passing of a given policy. Institutional differences between the SC and GA, moreover, may contribute to this difference; indeed, as the literature suggests, delegates have less reason to use “behind the scene” manipulation when the veto is always an alternative (Kaufmann, 1998). Thus, despite arguments from Hovell (2009) and Wenaweser and Alavi (2020) that procedures in the SC incentivize policies to fail, it may also paradoxically induce transparency, thereby lending to broader range of rationalizations for policy amendments and subsequent passage (Norris, 2017); in layman’s terms, delegates that are more open may be better able to compromise and adjust positions, wherein GA procedures—which value each individual vote—may also make individual delegates harder to discern, and thereby decrease transparency (Kaufmann, 1998). The size of both institutions may also reflect the transparency of rhetoric on either policy or context, given that scholars have already noted an increased pool of interests may obfuscate the actual positions of the majority (Smith, 2007, pp. 162–5); that is, because even a few dissenting delegates in the SC may prove fatal to a policy, and thus bump predictability, the same situation in the GA may be overcome by a “silent majority” (Panke, 2013, pp. 15–22, 120–5).
The trend of policy success as a function of psychological response persists across the spectrum of policy contexts. That is, for both the GA and SC, the presence of sanctions, peacekeeping, and peacekeeping could be accurately predicted by the models. Both bodies, however, had varying degrees of conflict indicators explained by the model; in the GA, precision was lower than recall, inferring that the model was relatively better at predicting the lack of a policy context. The SC mirrored a similar trend, albeit similar to actual policy success, held both high recall and precision, inferring the model, while relatively worse at predicting for a specific policy context, was a strong fit regardless. As a result, the psychology and mixed models were able to, especially in the SC, both predict for the probability of a policy successfully passing and the type of policy that would pass, given only the input of rhetoric used in the meeting. This suggests, in contrast to prior supported expectations by Kaufmann (1998) and Smith (2007), that the type of policy passed could be controlled for when making predictions about policy success.
Limitations and Future Research
The present study had several important limitations. First, while fuzzy analysis allows for more efficient processing of large data, string-matching that is too complex can result in disjunctions between actual motions and recorded motions, increasing the probability of type II error (Noh et al., 2015, pp. 4348–51). Alternatively, strings that are too short, as in some cases the query selected for class B motions, can yield false positives and increase the probability of type I error (4349). Until public libraries of fuzzy algorithms are able to interpret contextual use of certain terms, the very nature of data mining will contain error. This error, however, is mitigated by the presence of a large sample size (4348).
Second, as already noted, DNN models are extremely complicated, lending to a lack of interpretability for two reasons: first, machine functions fail to report on how it arrived at a conclusion, and second, DNN models are inherently stochastic, making reproduction difficult (Wang & Shang, 2014). While the models can accurately predict policy outcomes and context at a rate far stronger than traditional methods, it is nearly impossible to exactly know the reasoning of how it arrived at a conclusion (Hicks et al., 2018, pp. 363–4). While researchers could, hypothetically, examine functions individually to derive the model’s reasoning, doing so would require investigating hundreds of thousands of intricate relationships, many of which are codependent (Reimers et al., 2020). Second, the models, along with all machine learning models, are stochastic—that is, the model generation is non-deterministic due to random initialization of layer weights, shuffling of data when splitting, and CPU multi-threading (Chen et al., 2016; Huang et al. 2016, pp. 646–8). While some research has suggested that machine learning models can be reproduced through seeding, this equally undermines the very strength of machine learning: computation optimization (Dahl et al., 2013). We still preferred this method, however, because direct human involvement necessarily detracts from engineering efficient algorithms that can explain relationships between the over 100 variables used in our study (Yalcin, 2021). Conclusions drawn on the models, while accurate in probability of prediction, must therefore be carefully tailored to a difficulty in applying extensive theoretical implication (Li, 2017).
Third, LIWC has several limiting functions: first, because the LIWC algorithm simply parses phrases rather than learns from the use of words in context, researchers should not interpret strong variables to mean that such sentiment causes certain outcomes; indeed, words associated with “anger,” for example, can be applied to various contexts not related to actual anger (Crespo & Fernández-Lansac, 2015). Second, the LIWC algorithm cannot detect all forms of language, such as sarcasm, and thus lacks a truly encompassing view of the human language. While the literature generally supports a consensus that rhetoric and norms within the United Nations limits the aforementioned expressions, coded language, such as Baton’s (1991) qualitative observation of racial rhetoric embedded in discussions of previous colonies, will need further investigation in future studies (Wiseman, 2011).
Conclusion
Institutionalists often adopt an “actions speak louder than words” paradigm when predicting policy; but as our results suggest, such an insight is unfounded in actually predicting policy passage. The model outcomes support the academic hypothesis that the psychological effects on appraisal, rather than substantive barriers provided by structural features, best predicts for policy outcomes. This conclusion may not, however, be mutually exclusive with the institutionalist worldview; Kaufman, Smith, and Demeter’s “Black Peter” and “Waiting for Godot” strategies (Table 3), for example, seem presuppose the necessity of a psychological response in frustrating structural outcomes. In context, this often means using procedural blocks to wear down an opponent’s morale or broad consensus. As a result, the institutionalist view is still potentially useful in prescribing actions to affect a vote, even if not accurate in predicting the actual outcome of the vote. Furthermore, given the inherent difficulty of understanding how a DNN comes to conclusions, institutionalism’s alternative—to manipulate the where and when speeches will be given—may be easier for policymakers to use.
The algorithm simply represents the underlying variables that best predict for policy outcomes. In the SC and GA, the empirical evidence demonstrates both policy passage and the conflict indicators can be better predicted given the rhetoric of delegates, rather than the actual substantive action of any delegate; our mixed models, moreover, suggests that substantive action only played a minor role on predicting for context. Thus, the evidence tends to support the psycholinguistic view of policy analysis, with speech generally predicting for corresponding policy outcome.
Ultimately, further work will be needed to properly implement the program to a workable interface. This may manifest, for example, in easily accessible application programming interfaces (API) that can be fed speeches to produce predictions. Our models, furthermore, can provide policymakers a valuable insight into the strength of the opposition given the rhetoric of individual delegate speeches.
Footnotes
Acknowledgments
We extend our thanks to Dr. Sereseres, whose general guidance allowed us to pursue this study. We would also like to thank Keoni Gandall, who assisted in the programming. Finally, we extend our thanks to the University of California, Irvine, Undergraduate Research Opportunities Program (UROP), who funded this study.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research is funded by Undergraduate Research Opportunities Program, GF11210.
Notes
General Assembly Motion Queries.
Motion Class
Standardized Motion
UN Rule
Query
M
Adoption of the agenda
13
May I take it that the assembly wishes to take note of those items that remain open for consideration
M
Adoption of the Agenda (general order)
21
The agenda was adopted
S
Amend
22
Amend the agenda to
M
Adopt, accept, or agree to a report
64
I have been authorized to make the following statement on behalf of the assembly
M
Committee, to refer a matter that is not pending
65
Refer the matter
M
Adopt Special Rules of Order
66
Report of the Committee
I
Point of Order
71
Point of Order
I
Point of Order
73
Right of reply
S
To postpone indefinitely
74
To adjourn the debate
S
Previous Question
75
May I take it that it is the wish of the General Assembly to conclude its consideration
P
Recess
76
To suspend the meeting
P
Adjournment
76
To adjourn the meeting
S
Amendment
78
To introduce a draft amendment to the draft resolution
M
Main Motion
78
The Assembly will now take a decision on draft resolution
I
Objection to consideration of the question
79
Objection to consideration of the question
I
Withdraw or modify a motion, to grant maker permission to, after motion has been stated by the chair
80
To withdraw
B
Reconsideration
81
Reconsideration of the
M
Main Motion
96,100
Appoint a Committee
I
Division of the Assembly
87,127
A recorded vote has been requested
I
Division of a question
129
A paragraph-by-paragraph vote on the draft resolution
Security Council Motion Queries.
Motion Class
Standardized Motion
UN Rule
Query
M
Adoption of the Agenda (general order)
9
The agenda was adopted
M
Main motion or question
28
appoint a committee
M
Adopt, accept, or agree to a report
29
I have been authorized to make the following statement on behalf of the committee
M
Adopt, accept, or agree to a report
29
May I take it that the draft report as corrected is adopted by the council
I
Point of Order
30
point of order
S
Amend a pending motion
31
amendment
I
Division of a Question
32
A paragraph-by-paragraph vote on the draft resolution
S
Commit, Refer, or Recommit a pending question
33
refer the matter
S
Postpone definitely
33
postpone discussion to
S
Postpone indefinitely
33
postpone discussion indefinitely
P
Recess, to take a, if moved while business is pending
33
The meeting was suspended
P
Adjourn, ordinary case in societies
33
the meeting be adjourned
I
Withdraw or modify a motion
35
To withdraw the draft resolution
M
Adopt Special Rules of Order
37
In conformity with the usual practice, I propose, with consent of the council, to invite those representatives to participate in discussion
S
Previous Question
S/2010/507 and other interpretations.
It is my understanding that the security council is ready to vote on the draft resolution before it