
Abstract
With the emergence of Industry 4.0 and the widespread use of smart computing, there is an increasing demand for lightweight, corrosion-resistant, high-performance materials in intelligent manufacturing, attracting extensive attention to researching new composite materials. Intelligent-driven composite material performance analysis and prediction based on big data and machine learning have become important means for research on new composites. However, previous studies on composite performance analysis often focused on material characteristics, neglecting the combined influence of processing parameters, structure, and application environments. On the other hand, in actual factories, the process of obtaining the above auxiliary data is very difficult and time-consuming. Therefore, this article focuses on carbon fiber reinforced composites (CFRP), takes advantage of transfer learning to achieve high accuracy in smaller datasets, and proposes a data-driven framework which can not only use the characteristics of the material itself but also increase the material structure and processing parameters to improve the prediction accuracy of the tensile strength of new composites. After comparing four commonly used base learning models, the coefficient of determination (R 2 ) of the ElasticNet model is improved by 7.67% and the mean absolute error (MAE) is reduced by 55.53%. For other models, please refer to results and discussion.
Keywords
Introduction
The emergence of Industry 4.0 and the widespread use of smart computing have attracted widespread attention to developing new composites. The demand for lightweight, corrosion-resistant, environmentally friendly, low-cost, and safe materials is increasing in intelligent manufacturing, as represented by aerospace and new energy vehicles. 1 According to relevant analysis, 2 the global aerospace composites market is expected to grow by 33%. Due to the long time and high cost of traditional material development methods, intelligent-driven composite material performance analysis and prediction based on big data and machine learning have become important means for research on new composites.3,4
Currently, research on predicting the mechanical properties of composites can be classified into two main categories: finite element analysis (FEA) and machine learning. In studies on predicting mechanical properties using the FEA, Zhang et al. 5 have successfully predicted the static mechanical strength of fabric fiber-reinforced composite laminates with varying porosity. Wang et al. 6 developed a predictive model to evaluate the performance variation with temperature of carbon fiber reinforced composites (CFRP). Although many researchers have used the FEA to predict the mechanical properties of composites,7,8 most of them only consider a limited number of parameters for prediction. The mechanical properties of composites are influenced by various factors, including materials and processing parameters, making finite element modeling challenging. Using the Monte Carlo method, Gao et al. 9 established a fiber network model based on a three-dimensional microstructure to represent the statistical and random properties of the material. They proposed a tensile performance prediction method based on the microstructural properties in the model. However, the model error obtained by this simulation method is relatively large.
On the other hand, machine learning methods have been employed to predict the mechanical properties of composites. 10 For instance, Pathan et al. 11 proposed a supervised machine learning approach to accurately predict unidirectional composites’ macroscopic stiffness and yield strength under lateral loading. Similarly, Qi et al. 12 used a decision tree regression model to establish the relationship between the performance variables of carbon fiber monofilament and the macroscopic mechanical property parameters of composites. Divakarraju et al. 13 considered different fiber and matrix properties, volume fractions, and fiber distributions and obtained a prediction model for carbon fiber’s transverse and shear modulus. Zhao et al. 14 proposed a machine learning assisted multi-scale modeling strategy, which used a low computation cost model in conjunction with molecular dynamics simulation to predict the mechanical properties of CFRP based on the resin molecules. However, most of these studies relied on data generated by FEA, which introduces errors due to its limitations. These errors, when combined with those of the machine learning models, can lead to reduced prediction accuracy.
Compared to the above methods, fitting real data using machine learning methods can help address the limitations of theoretical modeling. For instance, Vineela et al. 15 used an artificial neural network model to predict the tensile strength of composites for different composition ratios. Sharan et al. 16 employed an artificial neural network model to predict the tensile strength of unidirectional carbon fiber reinforced composites, considering parameters including fiber strength and matrix strength. However, incorporating microstructure parameters like porosity into predicting process outcomes often results in poor practical applicability.
Furthermore, many existing prediction models neglect the effects of practical application environments and processing parameters, leading to predictions that deviate significantly from real-world outcomes. On the other hand, different machine learning models are often trained and evaluated to select the model with the highest accuracy due to the lack of dataset analysis and model analysis. 17 For example, Shirolkar et al. 18 selected a suitable prediction model for the mechanical properties of carbon fibers by comparing different machine learning models. However, the characteristics of the composite material itself vary with the composition content and the processing environment, making it difficult for this method to select the optimal learning model. In the process of material development, apart from the characteristics of the composite material itself, the additional environmental factors generated during the processing and the composition ratio structure of the composites will also bring significant changes to the strength of the material. As a typical material in composite research, CFRP has shown wide application value in strengthening various and optimizing structures. 19 Among the many indicators of material performance, tensile strength plays a critical role in determining the ability to withstand tensile forces and resist damage. At present, several application cases have emerged in the field of material performance research using machine learning algorithms to predict tensile strength, such as fused deposition modeling. 20 Therefore, we chose the tensile strength of CFRP as our prediction object.
This paper first aims to determine the various factors that affect the mechanical properties of CFRP through correlation analysis between data. Secondly, more effective transfer learning for smaller data sets can provide accurate prediction of the mechanical properties of CFRP. Finally, through the data-driven framework we proposed, an optimized prediction method is provided to select the most appropriate relearning model in accordance with user requirements. This makes the prediction method of composites not only more suitable for the characteristics of small data sets, but also maintains its accuracy or improves its prediction accuracy and reduces processing time without reducing the prediction accuracy of traditional machine learning methods, thereby improving the overall development efficiency of the system. After comparing 4 commonly used base learning models, the coefficient of determination (R 2 ) of the ElasticNet model is improved by 7.67% and the mean absolute error (MAE) is reduced by 55.53%. For other models, please refer to results and discussion.
The major contributions of this study can be summarized as follows: 1) To solve the problem of limited datasets. We used the generative adversarial networks (GAN) method, which is commonly used in data augmentation technology, to improve the dataset. 2) We proposed a data-driven framework based on specialized machine learning models to predict the tensile strength of CFRP. 2-1 First, our framework can provide users with a variety of requirements, such as sample prediction accuracy, execution location, and available computing resources minimization, to adapt to different composite usage scenarios and provide customized solutions. 2-2 Second, our framework can use data correlation analysis to determine the establishment of multiple factors such as processing parameters, structure, and application environment, which is convenient for accurate parameter adjustment of learning models. 2-3 Finally, our framework is based on transfer learning, which can achieve high accuracy even with a small amount of data. By selecting a base learning model and adding highly relevant data, the framework can re-learn from the existing model to optimize the accuracy and processing time.
Framework design and implementation
Methodology
Scenario and problem statement
In our study, we considered the scenario shown in Figure 1. We can collect multiple influencing factors and target mechanical properties of composites from factory A and define them according to user requirements, so as to select the optimized base learning model of factory A as the target, and use a small amount of learning data obtained from factory B or the learning data fitted by the GAN method to generate a re-learned model for factory B to predict the mechanical property. The issues considered in this research paper are as follows: Scenario for the prediction of mechanical properties of composites. Case A is when there is sufficient data, and case B is when there is not enough data.
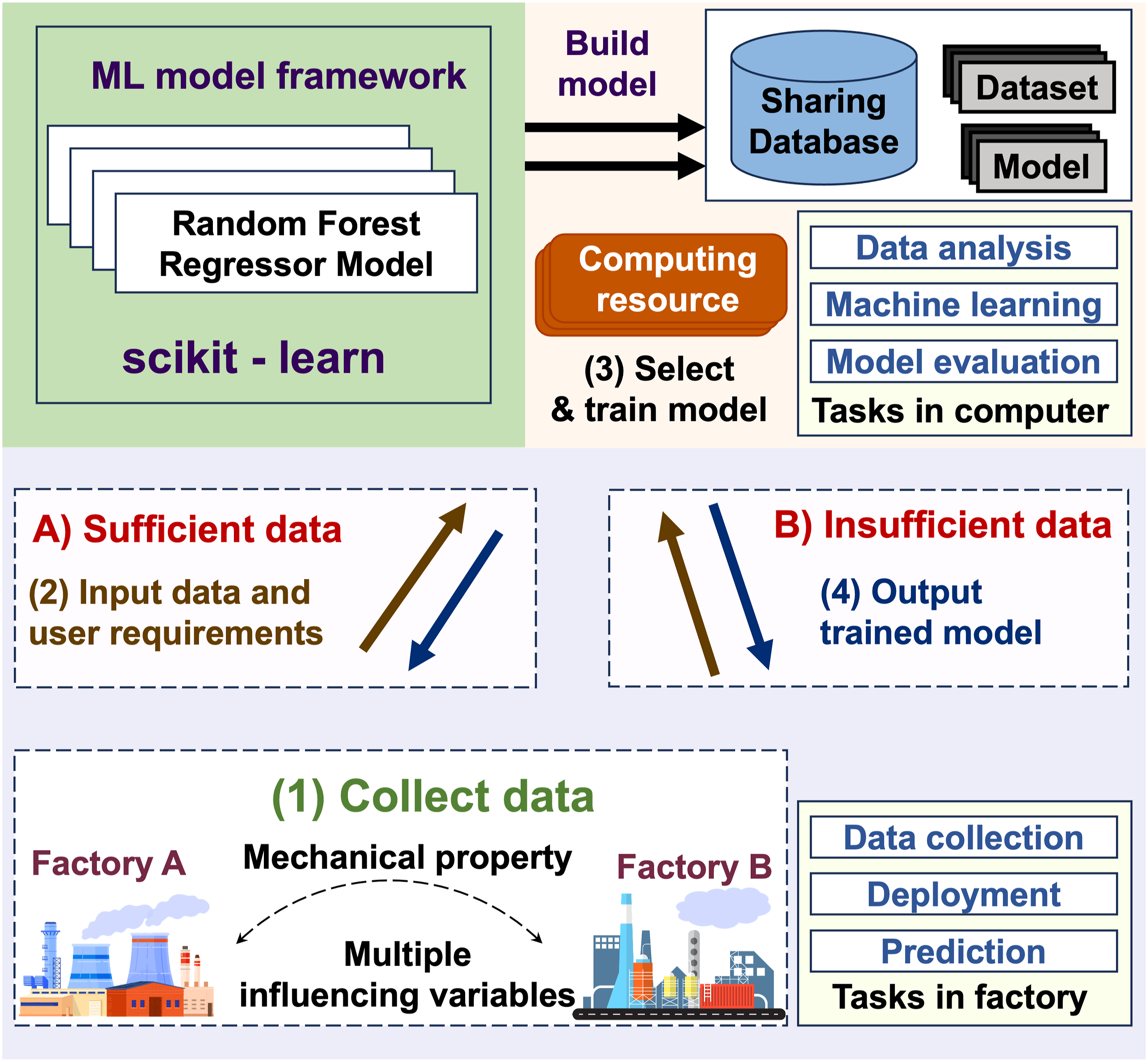
Requirements
Based on the scenario outlined above, we can summarize several key requirements for predicting mechanical properties of composites as follows:
Approach
Our approach is illustrated in Figure 2. First, we proposed a model selection policy. We establish a knowledge-sharing database to store trained models and performance metrics of Factory A, such as model accuracy, execution time and size. Our framework can define corresponding user’s policy according to the user requirements, and our framework can use our model selection algorithm to select the base model that meets the user’s conditions from the database. Second, users only need to import the data obtained from Factory B or the synthetic data into our framework. Thirdly, through data correlation analysis, we can determine the factors affecting the target variables, screen reasonable data, and pre-process and optimize the dataset of Factory B. Fourthly, combined with the optimized data of Factory B, our framework can use the base model of Factory A to quickly create a re-learning data model belonging to Factory B. Fifthly, according to the user’s requirements, we select reasonable computing nodes to quickly deploy the computing environment of the re-learning model of Factory B and implement performance prediction and model evaluation. Overview of approach for mechanical property prediction of composites.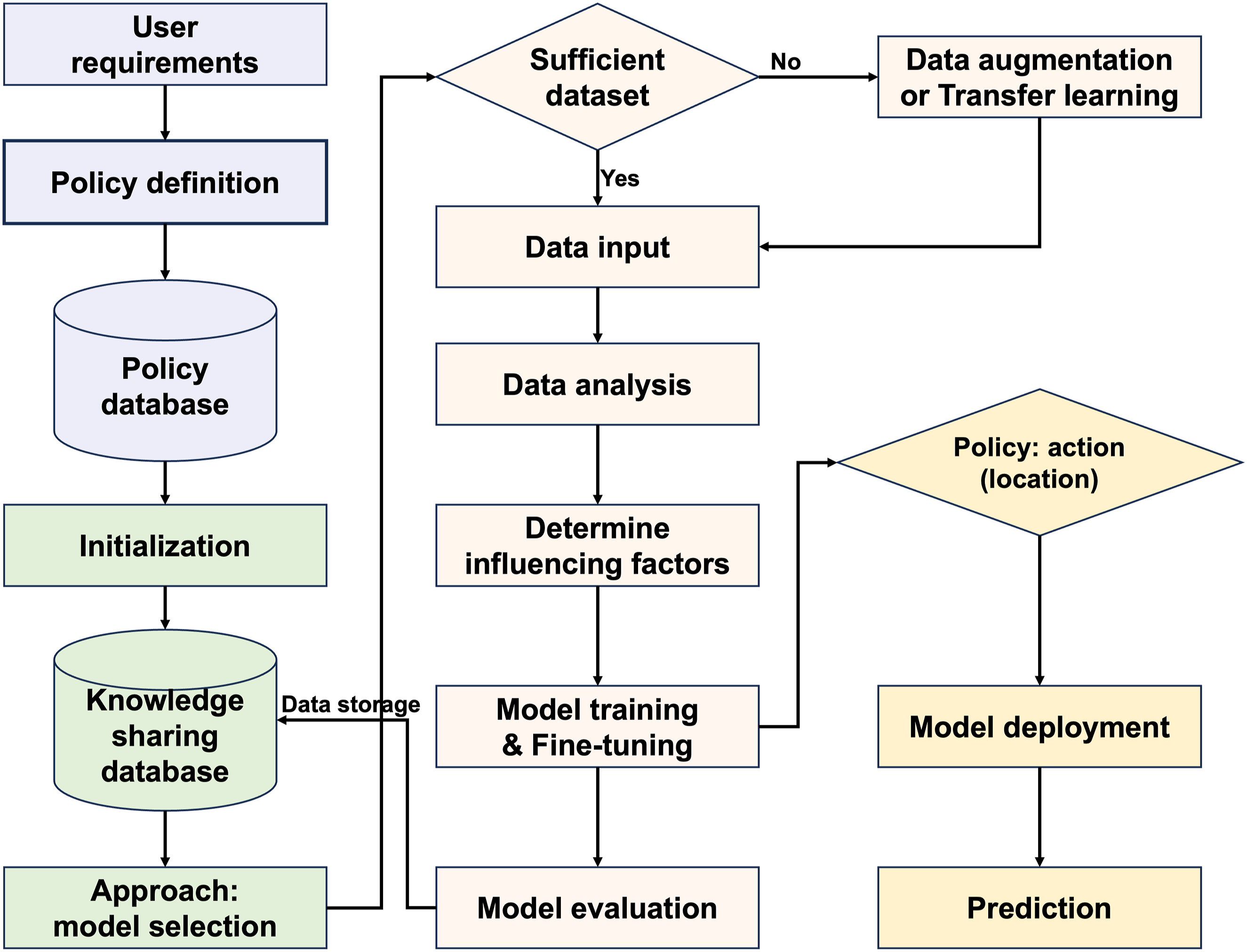
In addition, to address the issue of insufficient data samples and generate high-precision learning models, we use the GAN method to create synthetic data to compensate for the lack of sufficient actual data. When sufficient relevant data samples are available, we can directly use transfer learning to retrain the learning model selected as the base model of our framework. Moreover we use Bayesian optimization to fine-tune and retrain the model. The evaluation results, including performance metrics, are stored in the database for future reference, further improving the adaptability and reusability of the framework.
Design of data-driven framework
This section discusses the design of our data-driven framework. The proposed framework is shown in Figure 3 Overview of data-driven framework proposed in this study.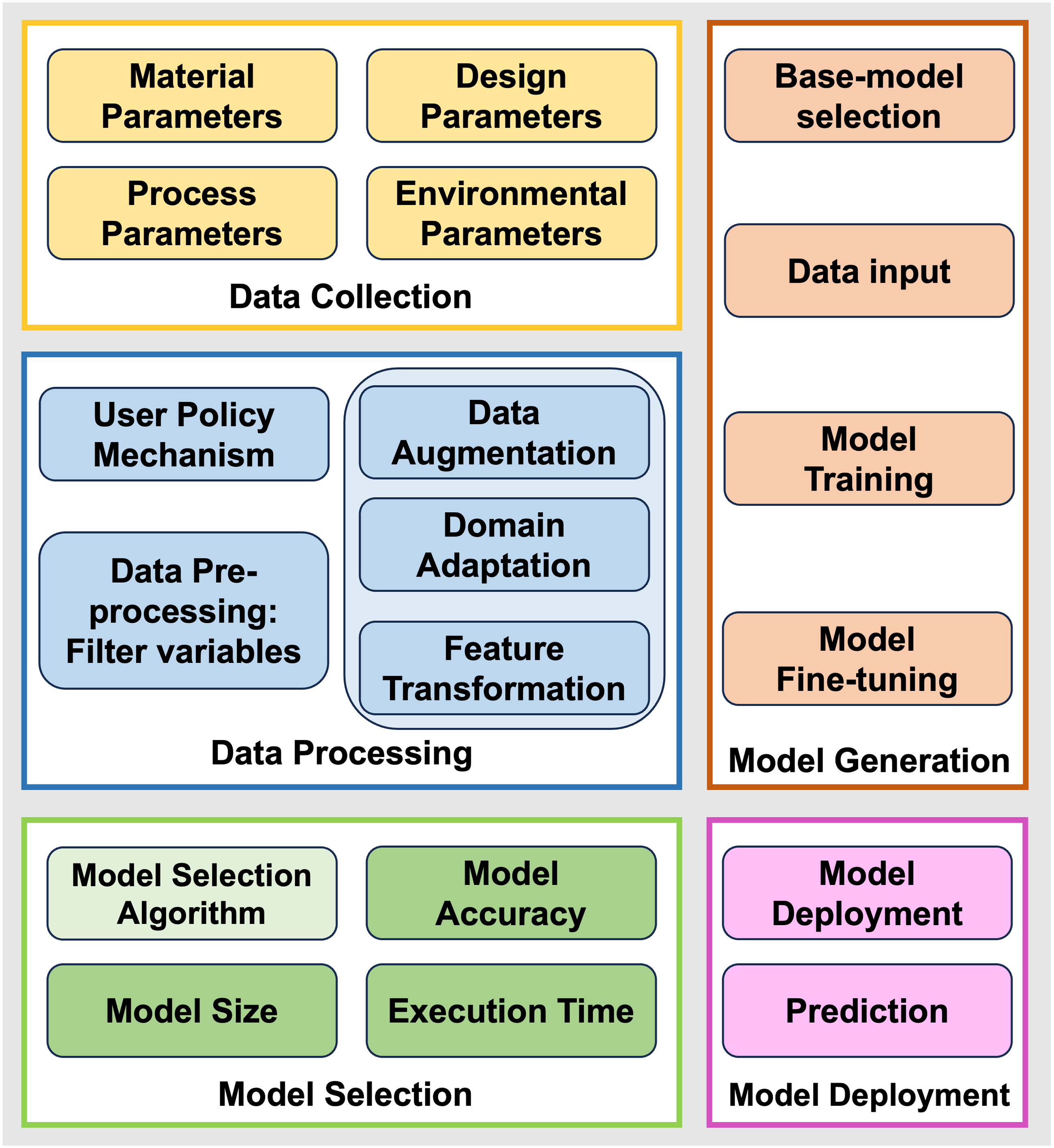
Data collection and processing
Regarding material selection, factors such as fiber strength, matrix density, fiber content, are considered to ensure the appropriate materials and configuration ratios are chosen during the prediction process. For structural design, parameters like the number of plies can affect composite materials' strength, stiffness, and stability. Regarding processing parameters, defects can be minimized, and the performance of composite materials can be improved by optimizing process parameters such as temperature, pressure, and processing time. In terms of environmental factors, the performance of composites may vary under different environments, such as ambient temperature, necessitating the selection of appropriate materials and design solutions for specific application scenarios.
First, to address the challenge of selecting influential factors for prediction, we employ the maximal information coefficient (MIC) to measure the correlation between two variables. MIC allows us to assess the degree of association between variables without assuming a linear relationship. We define the correlation based on the MIC coefficient: less than 0.3 corresponds to a weak correlation, values between 0.3 and 0.7 are defined as moderate correlation, and greater than 0.7 is considered a strong correlation. By applying MIC, we screen out factors strongly related to the target variables. Secondly, in the case of insufficient data, we use GAN method to generate synthetic data to improve the model’s prediction accuracy. For cases where there are relevant and sufficient datasets, our framework can utilize transfer learning to select the base model from the source database. It can be transferred to the processing nodes in the target domain according to user needs, waiting for the optimized dataset established after correlation analysis to predict the target model for further learning. Finally, we use Bayesian optimization to fine-tune the retrieved model to maintain better performance and improve the accuracy and processing time of the underlying model.
Model selection

Model generation and deployment
After selecting a base model, the next crucial step is to generate a predictive model through training and fine-tuning to obtain a fully trained and optimized model. At the same time, the model and its complete evaluation results are stored in the shared database for future reference. To reduce the risk of overfitting and improve the model’s generalization ability, we use sequential Bayesian optimization to optimize the model’s hyperparameters. This method combines sequence models with Bayesian optimization, gradually optimizing the model by selecting the optimal hyperparameters at each step. Once the prediction model has been thoroughly evaluated and optimized, it can be deployed to the user-specified computing node, for example, on the cloud or edge nodes near the user’s device specified by the user. After deployment, users can borrow their computing power on designated computing nodes to accurately predict the mechanical properties of fiber-reinforced composites (FRP), thereby promoting practical applications and engineering decisions.
Implementation
Data augmentation
During the manufacturing process of FRP, data collection is always a time-consuming and labor-intensive task. To handle this problem, we employ deep generative models to generate synthetic data. 21 These models are designed to learn the underlying distribution of real data and generate new data points with similar characteristics. We use conditional tabular generate adversarial networks (CTGAN), 22 a variant of deep generative models designed to create synthetic tabular data. CTGAN is based on the framework of GAN. It consists of a generator network that creates synthetic data and a discriminator network that evaluates the similarity between synthetic and real data. Through iterative training, CTGAN generates synthetic data that closely mirrors the statistical properties of real data. The primary advantage of using CTGAN to create synthetic data is that it can greatly reduce the workload and cost of data collection. Researchers can quickly obtain large data samples for model training, optimization, and evaluation by generating synthetic data. This approach provides a more efficient and economical way to obtain data for research in FRP.
Transfer learning
In the context of FRP, where rich relevant data sets exist, employing domain adaptation techniques can be very effective. One such method, transfer component analysis (TCA), 23 aims to bridge the gap by modeling the distribution differences between the source and target domains. TCA can be leveraged to map the source and target domain data into a shared feature space which aligns the data distributions, enabling the model to adapt to the target domain. The application of TCA in FRP is of great significance. First, it allows the transfer of knowledge learned from the source domain to the target domain even if the data distribution is different, overcoming the common issue of limited labeled data in the target domain. Second, TCA helps to effectively utilize the rich and relevant data sets in the field of FRP. We perform feature alignment on the tabular data of the source domain and the target domain, and then incorporate the aligned feature data into the model for joint training to improve the training accuracy of the model. By using TCA, our approach can maximize the use of relevant data sets, improving the performance and applicability of the model in the field of FRP.
Policy definition

Experiment
Experiment dataset
Examples of representative data.
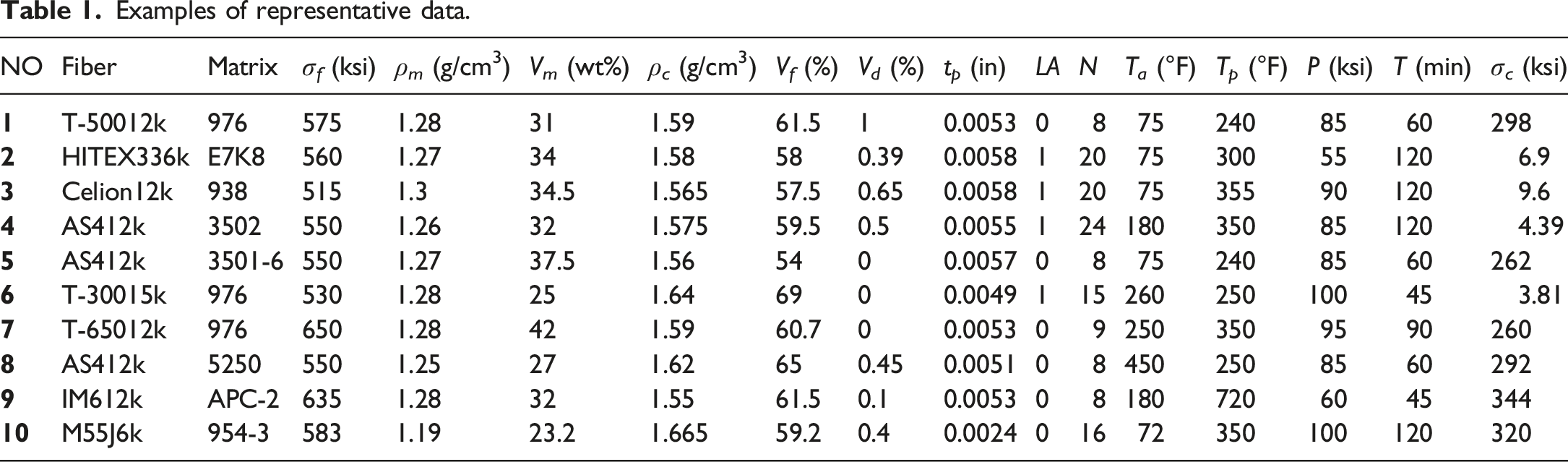
In this experiment, the ultimate tensile strength of CFRP is selected as the prediction target, which is an important indicator of the unidirectional tape mechanical performance. The types of CFRP include carbon-epoxy, carbon-bismaleimide, carbon-peek, and carbon-cyanate ester, and these type differences have a significant impact on the performance of CFRP. The distribution histogram of each variable is shown in Figure 4. Our data includes nine types of fibers and 11 types of matrices (indicated by numbers in Figure 4). In addition, it is worth noting that when the tensile direction is consistent with the fiber direction (LA = 0), the tensile strength is above 150 ksi, and when the tensile direction is perpendicular to the fiber direction (LA = 1), the tensile strength is within 50 ksi. Distribution histogram of each variable.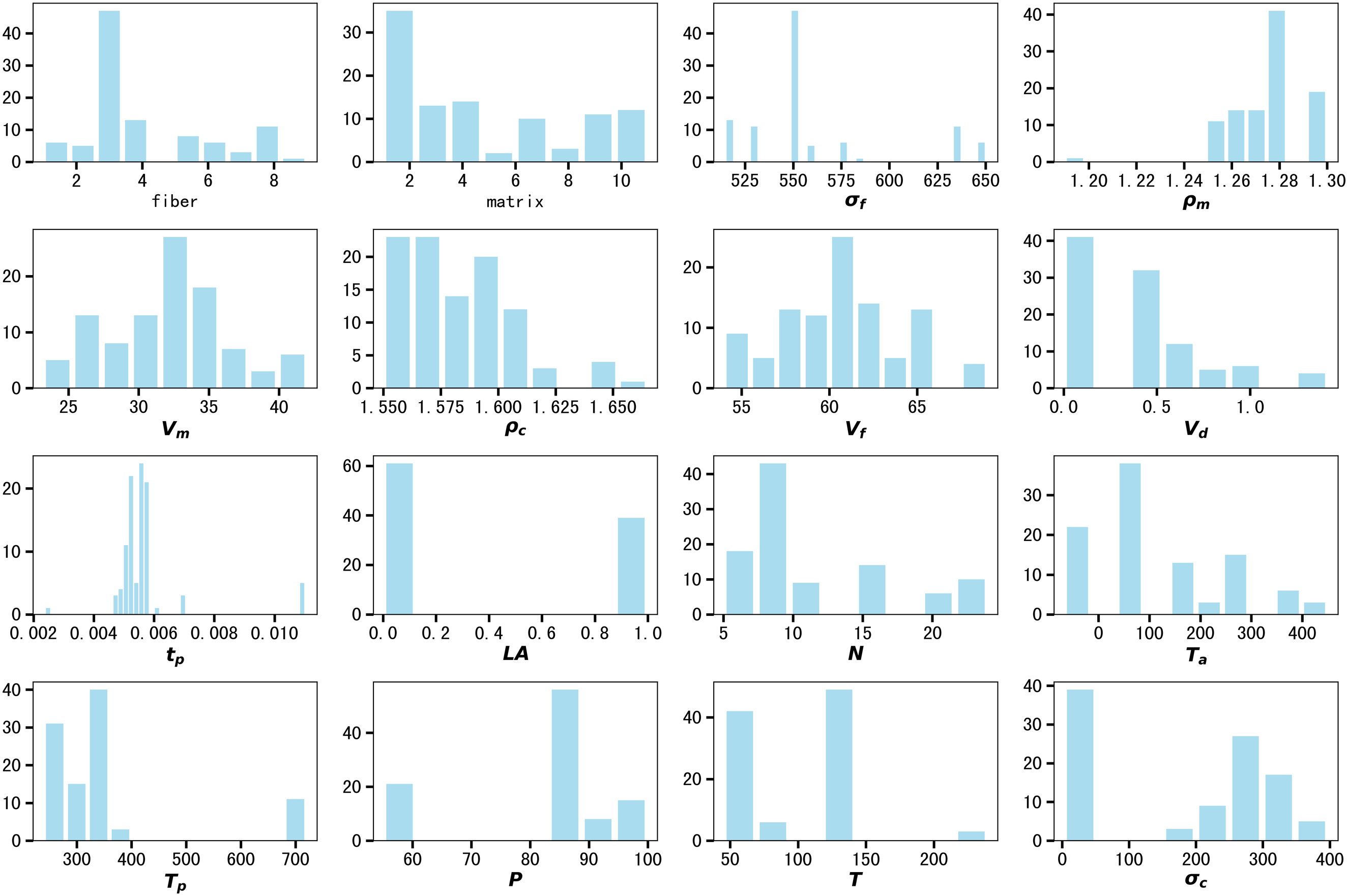
Representative model
The model used in the experiment.

Evaluation metrics
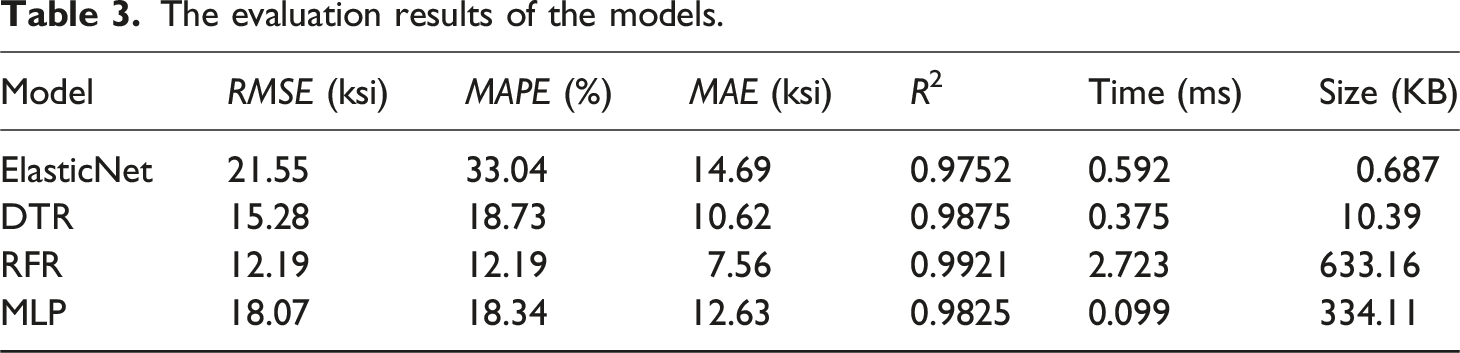
Four commonly used statistical analysis metrics were employed to evaluate the accuracy of our mechanical property prediction model, including root mean squared error (RMSE), mean absolute percentage error (MAPE), Mean Absolute Error (MAE), and R
2
. The expressions for these metrics are given in Equations (1)–(4), where 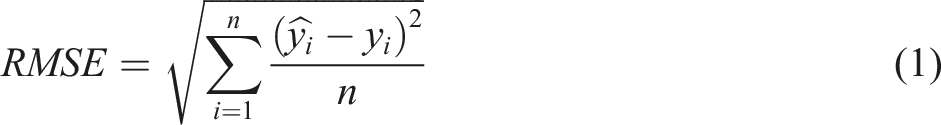
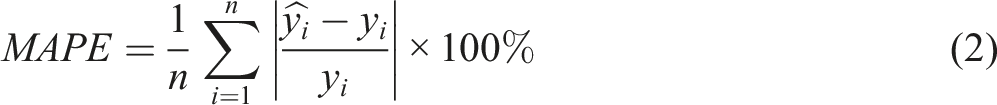

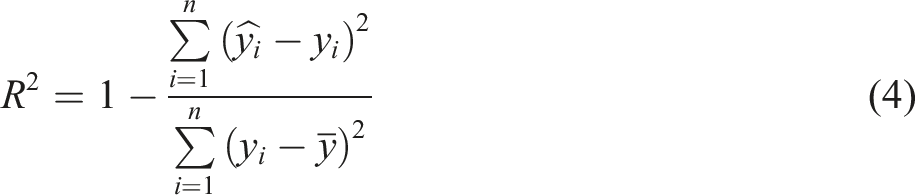
Results and discussion
Data analysis results
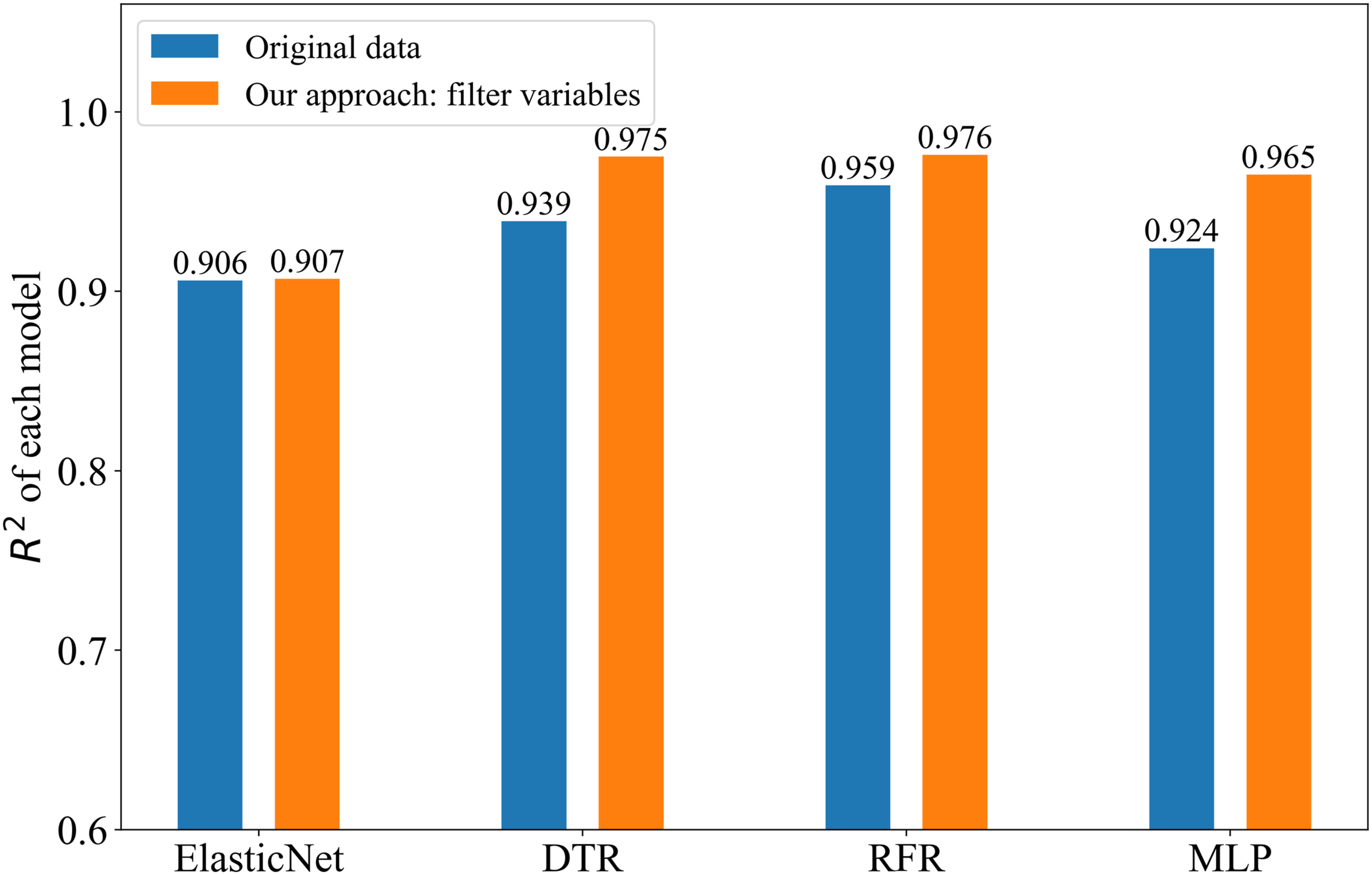
The results of data analysis, as illustrated in the MIC heat map in Figure 5, highlight the correlation between influencing factors and the target variables, as well as the interrelationships among different influencing factors. Based on these results, we selected influencing factors with MIC value greater than 0.3 relative to the target variable and used them as feature variables for model training. The comparison results in Figure 6 demonstrate that the R2 of each model has improved. The overall increase of the DTR model is 3.8%, the overall increase of the RFR model is 1.77%, and the increase of the MLP model is 4.43%. In addition, feature selection reduced the complexity of the models, enhancing their practicality and applicability in real-world forecasting scenarios. This has important implications for the actual forecasting process. Meanwhile, the error of the four models was reduced by 18.3%, further validating the effectiveness of this approach in improving model accuracy and efficiency. Heatmap of MIC matrix. The results of removing variables with little correlation.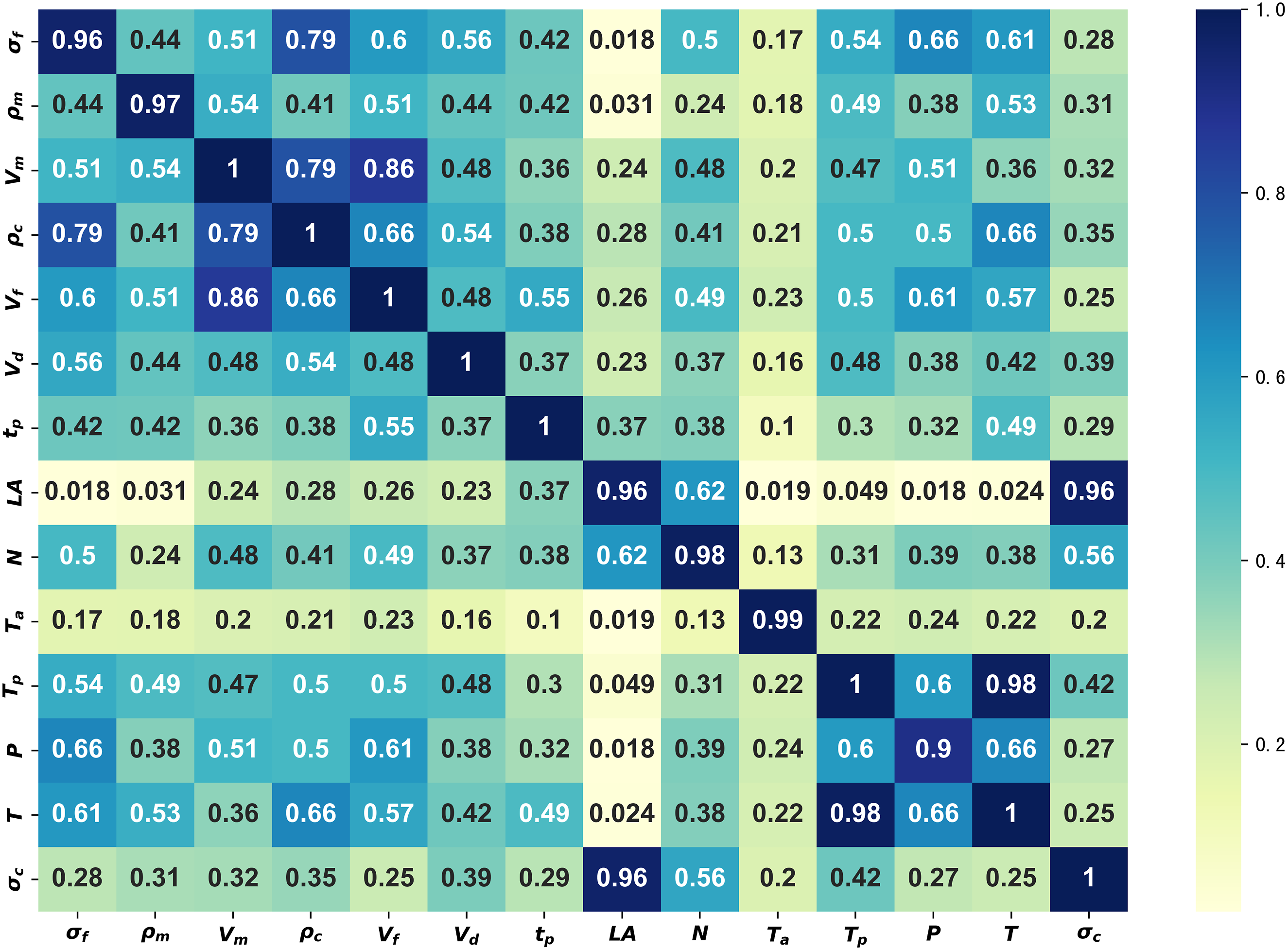
CTGAN and transfer learning
When using CTGAN for data augmentation, we divide the data set into 80% training set and 20% test set to simulate the situation of small data sets. Each model was evaluated 10 times, and the average results were recorded. By using CTGAN to generate synthetic data, it can be observed from Figure 7(a) that the MAE is reduced in all models. Among them, the MAE of the DTR model is reduced by 25.72%, the MAE of the RFR model is reduced by 24.56%, and the MAE of the MLP model is reduced by 30.88%. These results show that the synthetic data generated by CTGAN effectively enhances the models’ ability to fit the real data, providing more meaningful information and improving prediction accuracy. Comparison of MAE of four models with (a) data augmentation using CTGAN, and (b) transfer learning using TCA.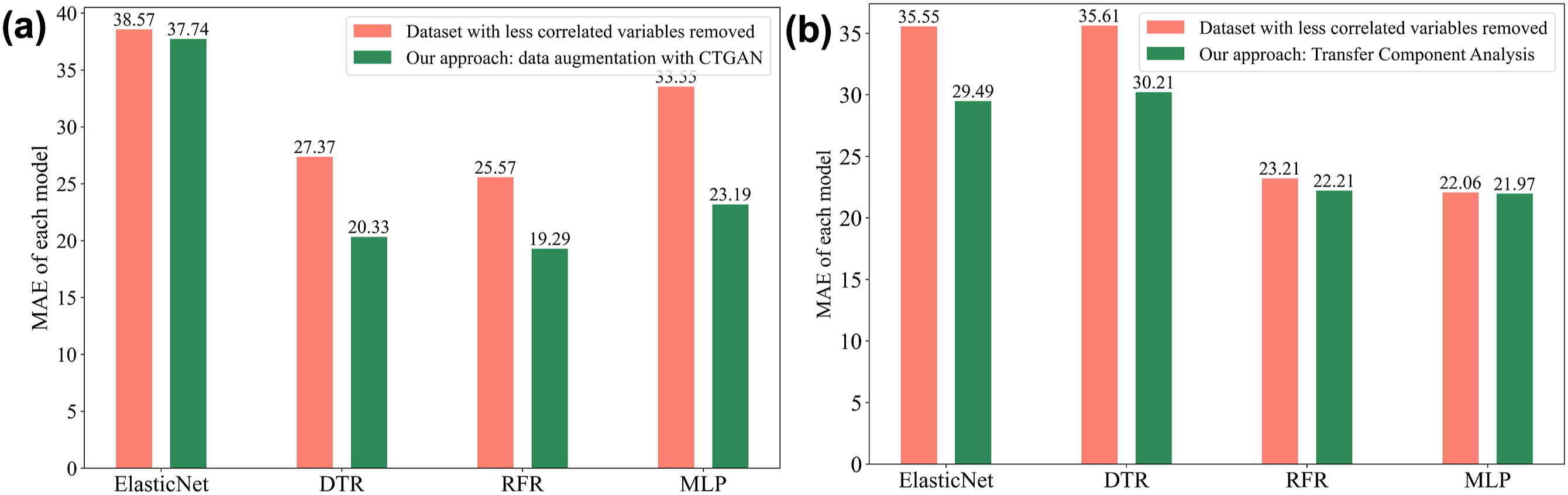
When using TCA for transfer learning, the real data set was used as the target domain and 1040 synthetic samples generated by CTGAN were used as the source domain. As shown in Figure 7(b), the ElasticNet and DTR models exhibit a more significant reduction in MAE, while the reduction in the RFR and MLP models is relatively smaller. This can be attributed to the high quality of synthetic data generated by CTGAN, which allows the models to learn more effective information. In addition, the MLP and RFR models inherently have better learning capabilities. The MLP model has powerful feature extraction capabilities and performs better when processing complex data; while the RFR model reduces the noise interference of a single tree through the averaging of multiple trees, improving the accuracy and generalization ability of the model and robustness. Overall, the TCA method effectively improves model accuracy for small data sets, demonstrating its value in leveraging synthetic and real data for enhanced performance.
Through the above analysis, it can be concluded that both the CTGAN method and the TCA transfer learning method can improve the accuracy of the model on small data sets. The synthetic data generated by CTGAN provides more effective information, while TCA method improves the generalization ability of the model by transferring model knowledge. According to different actual scenarios, we can choose one of the methods to optimize the small data set model.
Model evaluation
The evaluation results of the models.
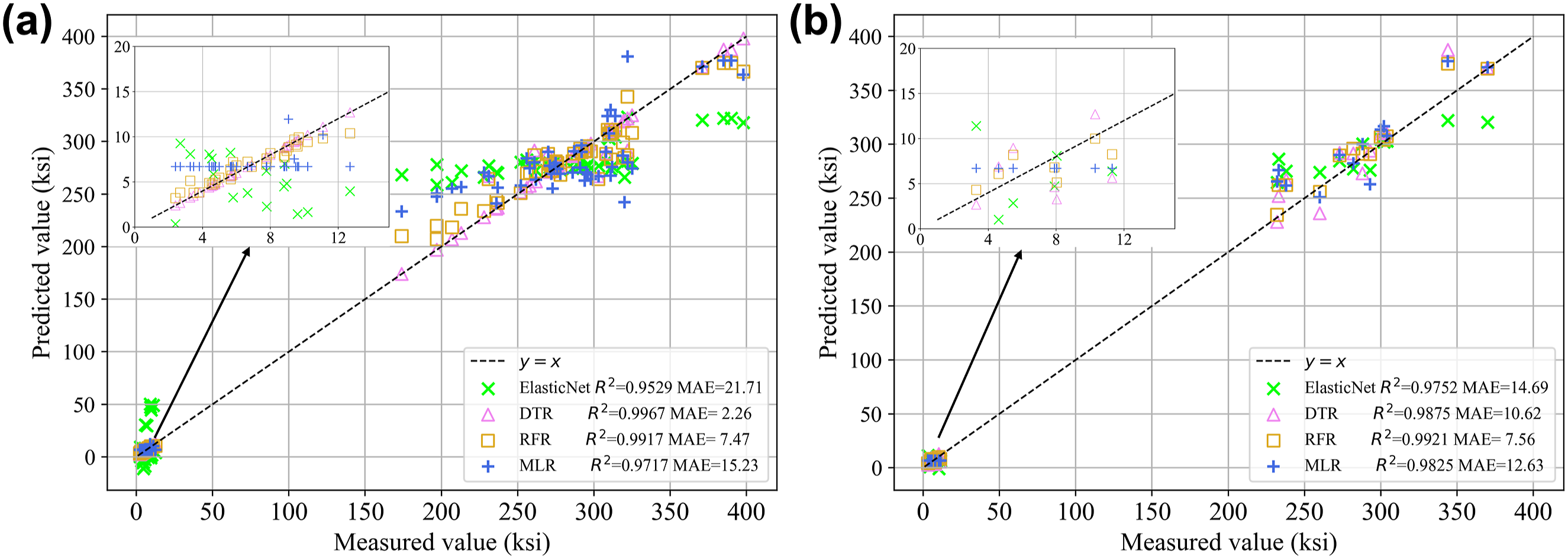
Scatter distribution of prediction results for each model on (a) train set and (b) test set.
By comparing Figure 8(a) and (b), we can observe the MAE differences between the various models on both training and test sets. Since tensile properties are affected by many factors and there may be complex non-linear relationships, the ElasticNet model, using a simple linear combination, may not be able to capture the detailed changes in the data well. Its large MAE could result from regularization, which helps prevent overfitting but also limits the ability of the model to learn complex data relationships, resulting in a large average absolute deviation between the predicted and true values. The DTR model suffers from overfitting because the noise and details in the training set may be over-learned during the training process, thus performing poorly on the generalization ability and resulting in high MAE. On the other hand, the RFR model mitigates overfitting by employing an ensemble of multiple decision tree models, each built using random features and samples. This ensemble approach helps to reduce the impact of overfitting from any single decision tree, leading to better performance on the test set. The MLP model has only three neurons in the hidden layer, which may be relatively small for capturing the complex relationships in the data, especially for tensile strength, that may have complex non-linear relationships. The activation function, ReLU, although helps alleviate the gradient vanishing problem, the structure of the model may limit its ability to fit the data. Different models have different characteristics. We can define different policies to select base model based on actual user requirements and user scenarios.
Discussion
We used some material parameters and processing parameters, combined with data augmentation and transfer learning methods, to obtain four machine learning models with different characteristics. Through our data-driven framework, we can train machine learning models that meet the needs of different scenarios based on historical data. For example, in the creation of high-performance composites for critical aircraft components like wings and engines, the framework facilitates the selection of optimal fiber-matrix ratios and processing parameters, ensuring mechanical properties are met economically. Similarly, in the automotive industry, where lightweight materials are essential, our prediction model can identify material parameter combinations with minimal fiber content while meeting design requirements. However, challenges remain. Data quality and quantity are crucial as inaccurate or insufficient data can lead to unreliable predictions. Model interpretability is another concern, especially in safety-critical applications. Continuous model validation and updating are necessary to account for evolving materials and manufacturing processes. Future research should focus on refining data collection and management, enhancing model interpretability, and establishing robust validation frameworks.
Conclusion
Accurate predictive models are paramount in the field of composite materials, where understanding and predicting mechanical properties are crucial for applications ranging from aerospace to automotive industries. This paper presents a comprehensive data-driven framework designed for rapid deployment and prediction in a machine learning environment tailored for composite materials. The framework seamlessly integrates data processing, model selection, and model generation, enabling the selection of influential factors that enhance prediction accuracy while reducing model complexity. By addressing the challenge of generating high-precision models from small datasets, we have incorporated the CTGAN method to synthesize effective data and utilized the TCA method in transfer learning to leverage knowledge from large datasets. Our framework was successfully applied to predict the tensile strength of carbon fiber-reinforced composite materials, significantly reducing MAE and improving R 2 , thereby demonstrating its effectiveness and practicality. This work significantly contributes to the field by providing a robust and efficient approach to predictive modeling in composite materials.
In the future, our research will delve into the intricate relationship between fiber state parameters—such as residual fiber length, dispersion, and orientation—and the mechanical properties of FRP. By building a machine learning model to explore this influence, we aim to further enhance the predictive capabilities and understanding of composite materials, paving the way for more sophisticated and accurate models in future studies.
Footnotes
Author contributions
Zengda Yu: Conceptualization, Investigation, Software, Formal analysis, Writing – original draft, Writing – review & editing. Jingtao Sun: Methodology, Validation, Writing – review & editing. Ankun Xie: Writing – review & editing. Siqi Yan: Writing – review & editing. Danyang Zhao: Supervision, Funding acquisition, Writing – review & editing. Sai Ma: Supervision, Funding acquisition, Writing – review & editing.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors greatly acknowledge the support of the National Natural Science Foundation of China (Grant No. 52205339), the National Key R&D Program of China (Grant No. 2023YFB4605301 and Grant No. 2022YFB3806203) and the Fundamental Research Funds for the Central Universities (Grant No. DUT22RC(3)061).