
Abstract
Research in psychology can have various foci, ranging from the psychological dynamics of single individuals to the generalization across individuals, often termed idiographics and nomothetics, respectively. However, terminological ambiguities have limited communication clarity about idiographics and nomothetics. Importantly, whether studies are suitable for idiographic and/or nomothetic inferences is not categorical but rather a matter of degree. Therefore, we propose a list of concrete, better-defined methodological aspects characterizing individual studies. Specifically, we highlight 16 different decisions researchers have to make pertaining to (1) research question, (2) research design, and (3) analyses and interpretation. These decisions are introduced with a focus on personality psychology but apply to psychological research broadly. We discuss the different decisions with an emphasis on their relation to idiographic and nomothetic inferential goals. Rather than providing specific recommendations, we emphasize the importance of aligning the methodology of a given study with the research question and theory. Overall, this overview seeks to help researchers make relevant decisions more intentionally to help them tailor their studies to their inferential goals.
Plain Language Summary
Psychological research can be focused on specific individuals (often termed idiographic) or on generalization across individuals (often termed nomothetic). However, various definitions of these terms exist in the literature. Moreover, multiple different aspects of a study affect whether it allows us to understand a specific person and/or whether it allows generalization across people. To characterize individual psychological studies in a more detailed way, we propose a list of 16 decisions researchers have to make. These decisions include aspects of (1) the research question, (2) the research design, and (3) the analyses and interpretation. We discuss how these decisions are related to idiographics and nomothetics. Moreover, we emphasize the importance of a close match between the questions a study seeks to answer and the methodology used in the study. The proposed list of decisions can be used by other researchers to characterize existing studies as well as to plan new studies.
Introduction
The field of psychology spans a vast range of research foci, including intra-individual psychological dynamics of single persons as well as relatively stable inter-individual differences. One crucial distinction in classifying different research approaches is between idiographics and nomothetics. The original definition of these terms from Windelband (1998; original work 1894) emphasizes that idiographics concern the investigation of a single, specific case (e.g., event, person, group), whereas nomothetics aim for generalization across cases. Here, we focus on how this distinction most commonly manifests in the field of personality psychology where persons constitute the case(s) of interest. Personality psychology has long concentrated on the inter-individual factor structure of personality traits, which is often regarded as nomothetic (in some definitions of the word; more detail on this will be given below). However, there have been many calls for a focus on idiographic, person-specific approaches in psychology (Beck & Jackson, 2020a; Molenaar, 2004; Wright et al., 2019). Moreover, there has been a recent increase in work on personality dynamics within persons (Baumert et al., 2017; Beck & Jackson, 2021b; Kuper et al., 2021), which can be conducted using both a focus on individual persons and a focus on generalization across persons. Finally, studies may also aim to provide an integration of idiographics and nomothetics, which has frequently been called for (e.g., Beltz et al., 2016; Revelle & Wilt, 2021; Wright et al., 2019; Wright & Zimmermann, 2019).
Over the years, different meanings have become associated with the terms idiographic and nomothetic in psychology (see e.g., discussions by Lamiell, 1998; Robinson, 2011; Syed, 2022; and the overview by Phan et al., 2024). For instance, parameters that characterize populations (rather than individuals) are frequently viewed as allowing nomothetic inference. This includes correlations of variables across persons, going back to Francis Galton and hence termed the Galtonian approach (Robinson, 2011). Similarly, average effects of experimental manipulations, such as group differences between treatment and control groups (referred to as the Neo-Galtonian approach; Danziger, 1987), and average within-person phenomena (e.g., Hamaker, 2012), can be considered as characterizing populations. In this paper, we refer to this kind of inference based on population parameters as nomothetics (population approach). This can be contrasted with the view of nomothetic inference as requiring generalization to every single individual in the population, going back to the work of Wilhelm Wundt, which is closer to the original definition from Windelband (see Lamiell, 1998). This definition would, for instance, require identical (or at least similar) within-person phenomena across all individuals. In the current paper, we refer to this approach as nomothetics (generalization approach). Hence, the term idiographics will be used to refer to the focus on inferences about a single person, whereas the term nomothetics refers either to inferences about population parameters (population approach), or the generalization to every single case (generalization approach). 1
The degree to which a study is suitable for idiographic inference, nomothetic inference following the generalization approach, or nomothetic inference following the population approach, respectively, is better conceptualized as continuous rather than dichotomous. Specifically, various aspects of the research process can be differentially tailored to the focus on a single person, generalization across persons, or the population of persons, respectively. Thus, methodological approaches and single studies can in many cases not clearly be categorized as either fully “nomothetic” or “idiographic”. Instead, determining the type of inferences a study can make requires attention to multiple, more well-defined methodological aspects of the study. The consideration of these methodological aspects and their alignment with the research question allows determining which inferences are appropriate in a given study. These methodological aspects are the focus here.
The present article
The present article is one of three articles resulting from the EAPP-sponsored expert meeting “Dynamics of personality: Integrating nomothetic and idiographic approaches into a synthetic framework.” The second article (Phan et al., 2024) focuses on the conceptual distinction between different types of knowledge associated with the idiographic-nomothetic distinction. It also includes a set of criteria differentiating research approaches which are similarly discussed here. The third article (Modersitzki et al., 2024) focuses on personalization for description, explanation, prediction, and change in personality research as well as applications. Further details on the three articles are included in the mantle paper accompanying this theme bundle. The present article takes a methodological focus by providing an overview of 16 important methodological decisions that have to be made when conducting a study. By differentiating these decisions and discussing their relation to different inferential goals, we aim to provide much-needed terminological clarity. We organize the decisions into three fundamental pillars of empirical research: (1) the research question, (2) the research design, and (3) the analysis and interpretation (see Figure 1, and also Phan et al., 2024).
2
Note that we cover a broad range of decisions most relevant to the topic of the present article, but the provided list cannot exhaust all methodological distinctions that would in principle be possible. When discussing methodological options, we deliberately devote space to some methods that are not particularly common in the personality psychological literature (e.g., person-specific generation of measures and person-specific N = 1 analyses) and could be viewed as underrepresented, although some of them are gaining more traction recently. Certain highly common approaches in personality research (e.g., relying on inter-individual analyses of cross-sectional data) are included in the overview but described relatively succinctly given that readers are likely already highly familiar with them. Note that while the decisions are introduced with a focus on the field of personality psychology, they apply to empirical research in psychology more broadly. Throughout the article, we emphasize how these decisions relate to idiographic and nomothetic (population or generalization approach) inferential goals. Relevant Decisions for Research Question, Research Design, and Analyses and Interpretation. Note. Shown are decisions pertaining to different steps of the research process in psychology. For further details, see the descriptions of each decision in the main text. RQ = research question.1 See Rauthmann (2017).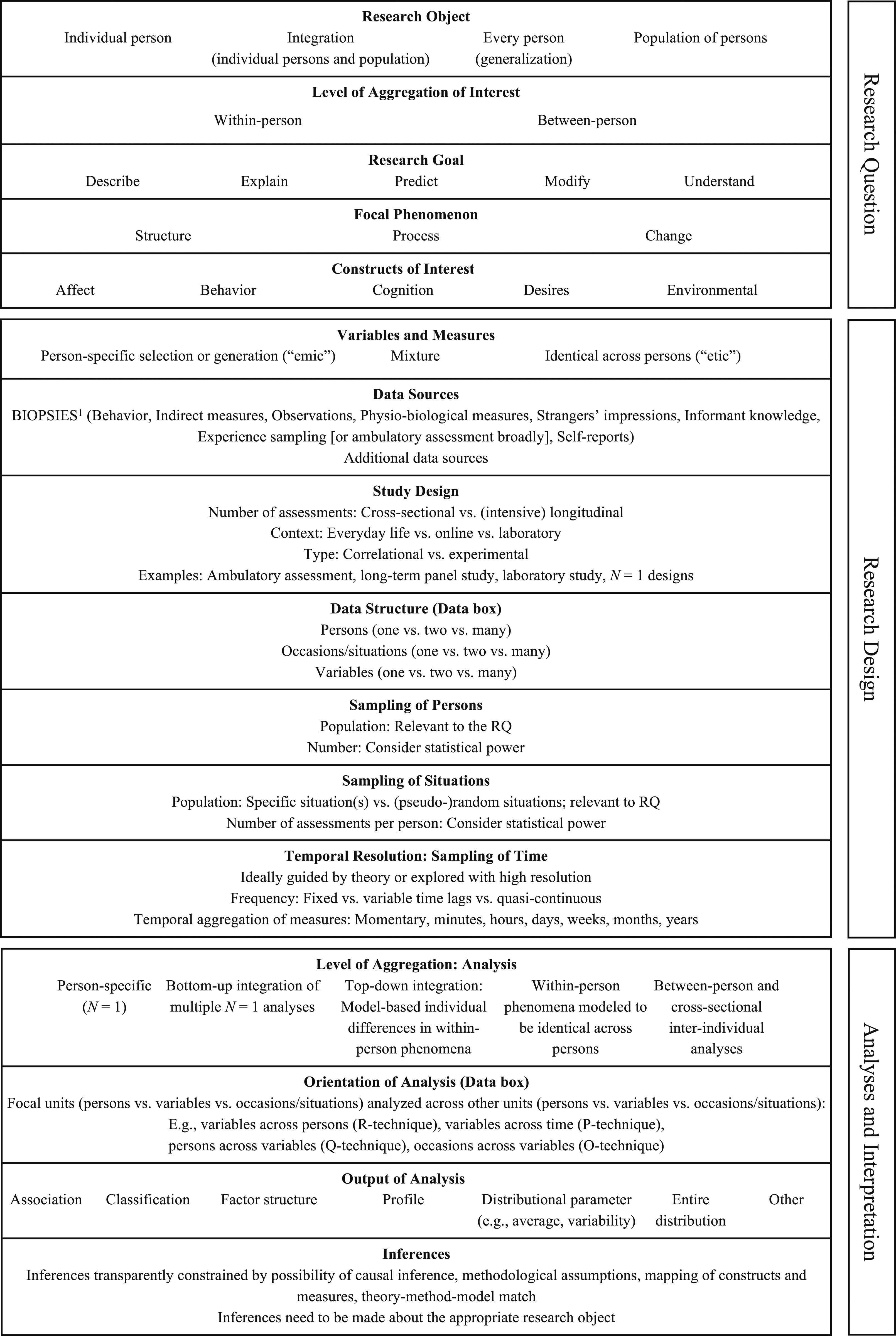
Overall, we present a framework that allows a fine-grained characterization of the methodology of a given study as well as its alignment with different aspects of the research question. In addition, the presented methodological decisions could be integrated into the research workflow to aid the planning of new studies. This would allow researchers to make relevant decisions intentionally and explicitly rather than—as is commonly the case—implicitly or without full consideration of their advantages and disadvantages. Importantly, we do not present specific recommendations for every study, but rather emphasize the importance of a match between research question (ideally guided by psychological theory), research design, and analysis and interpretation (see e.g., Collins, 2006; Hamaker et al., 2020; Hopwood et al., 2022; Howard & Hoffman, 2018; Sterba & Bauer, 2010).
Research question
When planning empirical studies, the research question dictates important decisions regarding research design and analysis that critically impact what inferences are appropriate. For instance, the optimal research methodology will be very different for the research question: “How are features of the situation and negative affect linked over time for this specific person?” compared to the research question “Which variables predict between-person differences in future job performance for potential job candidates?”. A lack of fit between research question and methodology can severely undermine the validity of the inferences drawn from a given study. For example, a central focal phenomenon in personality psychology is personality processes unfolding within-persons (e.g., Allport, 1937; Baumert et al., 2017; Costantini et al., 2021; Fleeson & Jayawickreme, 2015; Kuper et al., 2021; Mischel, 2004), and several authors have emphasized that conclusions about such processes cannot be made on the basis of inter-individual analyses of cross-sectional data (e.g., Hamaker, 2012; Molenaar & Campbell, 2009). Given this relevance of fit between research question and methodology, a clear definition of the research question is the first, important step when planning a study.
In the following, we discuss different aspects of the research question, including: (1) research object (e.g., individual person, population of persons); (2) level of aggregation of interest (i.e., within-person vs. between-person); (3) research goal (i.e., describe, predict, explain, modify, and understand); (4) focal phenomenon (i.e., structure, process, and change); and (5) constructs of interest (i.e., affect, behavior, cognition, desires, and environmental constructs). Considering each of these aspects can help authors delineate their research question in a detailed and explicit fashion. Among these aspects, especially the research object and (to a lesser extent) the level of aggregation of interest are most directly related to idiographic and nomothetic (population or generalization approach) inferential goals. The other aspects of the research question can typically be combined with multiple inferential goals, although certain combinations may be more suitable or more common.
Research object
In formulating a research question, particularly strongly related to idiographics and nomothetics (population or generalization approach) is the research object of interest. First, the research object might be a single, specific individual person. In this case, the focus would be the psychology of this person and not generalization to other persons or inferences about a population. This is typical, for instance, in applied settings where a psychologist works with a single person (e.g., in clinical practice; Wright & Woods, 2020). In psychological research, the primary aim of studies involving only one or very few participants is often not to understand those specific individuals but to showcase procedures that could be applied to any specific individual (e.g., Albers & Bringmann, 2020; Casini et al., 2020; Hopwood et al., 2016; Wright & Zimmermann, 2019). However, case studies in personality psychology exist as well. For example, Nasby and Read (1997) presented an in-depth investigation of the personality of Dodge Morgan, a famous solo sailor; Gordon Allport published “Letters from Jenny'' including an analysis of her personality (Allport, 1965); and two books have been written based on the assessments of Madeline G (Hopwood & Waugh, 2020; Wiggins, 2003). Research targeting a single individual without aiming to make inferences about the population of similar individuals might be seen as a highly idiographic form of research (e.g., Howard & Hoffman, 2018). Notably, even when the research object is an individual person, the inferences that are actually possible may be more specific. For instance, results may only pertain to a specific individual during a specific time period (i.e., not generalizing across time) when psychological phenomena are non-stationary (e.g., Albers & Bringmann, 2020; Casini et al., 2020).
In many cases, psychological research is not just focused on an individual person, but rather on the integration of person-specificity with what is shared across individuals or with average patterns in the population. This type of integration can be reached either through bottom-up or top-down approaches. For bottom-up approaches, each individual is analyzed separately and similarities across individuals are extracted subsequently. In contrast, top-down approaches model each individual from a population simultaneously (see Level of Aggregation: Analysis).
A further research object is every person (generalization), that is, the generation of nomothetic knowledge in the Wundtian sense (generalization approach) which reflects phenomena that are common to all individuals (Lamiell, 1998). Such knowledge is one possible (but not guaranteed) outcome of the integrative research described above, if the findings suggest that psychological phenomena are identical or similar across all individuals studied. Empirically, there is often a high degree of person-specificity (also termed heterogeneity between individuals; Moeller et al., 2022) in within-person dynamics. For example, individuals differ in relations between different psychological states or in effects of situation characteristics on psychological states (e.g., Beck & Jackson, 2020b; Kuper et al., 2022). Importantly, also the direction of psychological effects may differ across individuals (see e.g., Thielmann, 2021). However, in some cases, the direction (but not the strength) of effects is shared across nearly all cases from a population (e.g., positive effects of parental warmth and autonomy support; Bülow et al., 2022).
Finally, the research object may be a population of persons. This is very often the case in personality psychology as well as psychology more broadly. The corresponding inferential goal would be “nomothetic” only based on one definition of the term (i.e., population approach). Different types of population parameters may be of interest. Lamiell (1998) distinguishes two historically dominant types of parameters: associations of variables across persons within a given population (Galtonian approach) and differences between treatment and control groups in randomized experiments (e.g., clinical trials; Neo-Galtonian approach). Especially correlations of individual difference variables have long been the focus of personality psychological research (e.g., personality trait structure: Ashton et al., 2004; Goldberg, 1993; personality trait–outcome associations: Beck & Jackson, 2022a; Ozer & Benet-Martínez, 2006). In more recent years, there has additionally been high interest in average intra-individual (i.e., within-person) associations of variables over time (Hamaker, 2012). Average within-person associations can also be seen as population-describing parameters—while not necessarily generalizing to a given single individual depending on the degree of person-specificity. For a further detailed discussion of different focal entities (individual person, population of persons, other) and generalization intentions, as well as resulting research approaches, see Phan et al. (2024). 3
Level of aggregation of interest
A related aspect of the research question is the level of aggregation of interest. Here, we distinguish between-person and within-person phenomena. Between-person phenomena are the focus of work investigating personality structure as well as relations between personality traits and outcomes, which has a strong tradition in personality psychology. This perspective regards intra-individual variation across items or timepoints as measurement error (e.g., Viswesvaran & Ones, 2000).
Importantly, associations among variables between individuals have to be conceptually and statistically distinguished from associations among variables within individuals over time. Especially research questions focused on personality processes and dynamics (Kuper et al., 2021) are often concerned with intra-individual (i.e., within-person) phenomena (e.g., effects of situation characteristics on personality states: Fleeson, 2007). Phenomena of interest can be, for instance, co-fluctuations of variables (contemporaneous within-person associations) or effects of variables on each other over time (lagged within-person associations; e.g., Costantini et al., 2019; Hamaker et al., 2015).
A growing body of research shows that both the between-person and the within-person perspectives are important to further understand several personality phenomena (e.g., Di Sarno et al., 2023; Grosz et al., 2021; Kuijpers et al., 2024; McCabe & Fleeson, 2016). Notably, insights obtained from inter-individual research do not directly allow insights about phenomena unfolding within persons (e.g., Fisher et al., 2018; Hamaker, 2012; Molenaar, 2004). Moreover, cross-sectional data do not allow a pure estimation of between-person effects. Specifically, between-person effects reflect stable variance across the sampled time period, whereas cross-sectional effects are influenced by both stable and changing (i.e., within-person) variance (Hamaker, 2023a). 4 In the present article, we use the term “inter-individual” for examinations across persons, encompassing both cross-sectional inter-individual analyses as well as analyses focusing on (stable) between-person effects (see Analyses and Interpretation).
Finally, the relationship of the between-person versus within-person distinction with idiographic and nomothetic inferential goals should be noted. While sometimes treated synonymously, we want to emphasize here that these two aspects should be considered as distinct (see also Phan et al., 2024 for commonly confounded concepts). First, between-person associations and cross-sectional inter-individual associations of relatively stable variables have been regarded as “nomothetic” (population approach) in accordance with the Galtonian tradition (i.e., focus on parameters describing a population of individuals). Hence, between-person associations and cross-sectional inter-individual associations are not “nomothetic” according to the definition based on the generalization approach (i.e., general laws pertaining to each individual in a population). Second, a research question focused on within-person phenomena does not necessarily qualify as idiographic research. For instance, a lot of research is focused on average within-person effects in a population (e.g., the effect of an experimental manipulation in a within-subjects design) without focusing on (or even without modeling) individual differences in these within-person effects. This work thus yields population-level parameters, which are conceptually closer to nomothetics (population approach) rather than idiographics. Moreover, if interest lies in within-person phenomena which are identical or similar across all individuals, this is aligned with the generalization approach to nomothetics. Idiographic research, in contrast, would be more focused on person-specificity in within-person phenomena. Thus, research on within-person phenomena is not necessarily idiographic, but idiographic approaches typically require the examination of within-person phenomena (e.g., Molenaar, 2004). 5 Therefore, while the level of aggregation of interest is to some extent directly related to idiographic/nomothetic inferential goals, it needs to be considered conjointly with the research object (e.g., individual person, population of persons), and certain research objects require certain levels of aggregation.
Research goal
Having identified the research object and the level of aggregation of interest, it is important to establish the research goal. Several distinctions have been proposed (e.g., Hamaker et al., 2020; Hernán et al., 2019; Mõttus et al., 2020; Shmueli, 2010). In their overview of different research goals for personality psychology, Mõttus et al. (2020) distinguished description (i.e., comprehensively examining associations between variables without constraints from theory and without the intention to maximize prediction or to identify causes), prediction (i.e., maximizing out-of-sample prediction) and explanation (i.e., identifying specific causes or deriving coherent integrative narratives).
In addition to these goals, we further include modification (i.e., changing a given phenomenon or variable of interest such as psychopathology or personality traits; e.g., Cuijpers et al., 2013; Stieger et al., 2021). “Personalization” represents a promising and burgeoning area in which the research goal is often “modification”, combined with some form of tailoring—in the most extreme case idiographically (for an overview, see Modersitzki et al., 2024). In addition, we include the research goal understanding (i.e., a hermeneutic/interpretive approach which is more holistic and non-reductive compared to explanation and often focuses on the “understanding” of an individual person as a goal-directed entity; Dilthey, 1894; Gantt & Williams, 2016; Stern, 1917). While these different research goals can be complementary, it is important for a single study to clearly define its goal(s) and to plan the study methodology in line with it. For example, machine learning techniques maximizing out-of-sample prediction are well-suited for predictive purposes (Yarkoni & Westfall, 2017). Conversely, designing a study to allow causal conclusions (e.g., through randomization) is more relevant for testing explanatory hypotheses as compared to prediction or description.
Importantly, the different research goals can be combined with different research objects and levels of aggregation of interest. For example, personality description and prediction can be applied across individuals (e.g., Goldberg, 1993; Beck & Jackson, 2022a; often with nomothetic [population approach] inferential goals), but also idiographically to phenomena unfolding within an individual person (e.g., Beck & Jackson, 2020b, 2022b; Borkenau & Ostendorf, 1998; Renner et al., 2020).
Focal phenomenon
A further central aspect of the research question is the focal phenomenon of interest. In line with Baumert et al. (2017), we here distinguish structure, process, and change (or development). 6 In personality psychology, structure often refers to the inter-individual structure of personality traits (e.g., Goldberg, 1993), which has been regarded as “nomothetic” (population approach). However, structure can also be examined idiographically on the level of a single individual, for instance, when investigating the factor structure of psychological states over time (e.g., Borkenau & Ostendorf, 1998). In general, work on personality structure is typically descriptive in nature.
In contrast, process refers to “a series of steps […] through which some phenomenon takes place or emerges” (Baumert et al., 2017, p. 527), and research focused on processes often seeks to explain a given psychological phenomenon. Thus, research on personality processes often examines intra-individual psychological phenomena while considering the interplay between individuals and environmental factors over time. Such research can be conducted both with a focus on average (or potentially shared) processes in a given population and idiographically with a focus on processes unfolding in a single individual.
Finally, the third focal phenomenon of interest, change, refers to relatively enduring changes in psychological variables (e.g., the development of personality traits; Bleidorn et al., 2022), and can be combined with different research goals (e.g., description of change, explanation of change, prediction of change, initiating change through modification). Notably, personality change can be examined with different research objects of interest (e.g., average change in a population: Bleidorn et al., 2022; individual differences in change: Schwaba & Bleidorn, 2018; person-specific change, e.g., in the structure of psychological states: Beck & Jackson, 2022c). While findings on different focal phenomena (structure, process, change) should be integrated to yield a more comprehensive picture of personality (Baumert et al., 2017), any single empirical study should clarify its specific focal phenomenon of interest.
Constructs of interest
The last aspect of the research question refers to the specific construct of interest. Personality traits and psychological states can be investigated in terms of specific modalities, such as affect, behavior, cognition, and desire/motivation (ABCD; Wilt & Revelle, 2015). Environments and situations (Rauthmann et al., 2015) are also highly relevant to most personality phenomena (yielding ABCDE; Renner et al., 2020). Different data sources are differentially suited for the assessment of a certain construct (see Data Sources). In many studies, different modalities (i.e., ABCD) are not separated, but their distinction may be invaluable especially for process-based accounts of personality (e.g., Bleidorn et al., 2020). For instance, if state narcissism is the construct of interest in a given study, cognitive (e.g., status perceptions), emotional (e.g., pride), and behavioral (e.g., agentic behavior) states can be distinguished to investigate their relations (Kroencke et al., 2023). In general, the optimal assessment of psychological states is an area of continued development, and it remains an open question, for instance, whether and when states should be conceptualized and assessed using the same dimensions as traits (i.e., personality states: Horstmann & Ziegler, 2020). Notably, different constructs of interest can generally be combined with both idiographic and nomothetic (population or generalization approach) inferential goals. This also includes the person-specific selection of relevant constructs (see also Variables and Measures).
Research design
After defining the research question, the methodology used in a study needs to be carefully aligned with it. Concerns about the congruence between theory/research question and methods tend to overly focus on the statistical analysis applied to the data. However, the research design of the study, including who is studied; what data are collected; how the data are collected; at what time(s) they are collected; and where they are collected, are also of critical importance in aligning research questions and methods. Here, we aim to outline some of the key decisions that must be made with regard to the research design and some of their consequences for the ability to answer certain research questions (for other overviews, see Hofmans et al., 2019; Hopwood et al., 2022; Horstmann, 2021; Kuper et al., 2021; Wright & Zimmermann, 2019; Wrzus & Mehl, 2015). Specifically, we discuss the following aspects: (1) variables and measures; (2) data sources; (3) study design; (4) data structure; and (5) sampling of persons, situations, and time. Among these aspects, especially certain decisions regarding variables and measures (e.g., person-specific selection or generation vs. identical measures across persons), study design (e.g., cross-sectional vs. longitudinal), and data structure (e.g., persons: one vs. two vs. many) are most directly related to idiographic and nomothetic (population or generalization approach) inferential goals. In turn, other decisions (e.g., data sources and sampling of time) are not inherently related to certain inferential goals, but we nevertheless discuss them as important aspects of the research design and describe their relevance to idiographic and nomothetic research.
Variables and measures
Because most psychological phenomena of interest are not directly observable, one of the greatest challenges in psychology is the operationalization of psychological constructs (e.g., Cronbach & Meehl, 1955; Schmittmann et al., 2013). As a result, the measurement of such constructs can have great consequences for the degree to which a research question aligns with the research design. A thorough discussion of psychometrics is beyond the scope of this paper (see e.g., Furr, 2011). Rather, we focus on the tailoring of variables and measures to different research objects (e.g., individual persons vs. populations of persons).
To distinguish between person-specific and general tailoring of measures, it is helpful to adopt the emic-etic distinction used in cultural psychology (Cheung et al., 2011). Etic approaches typically examine certain measures developed in Western countries in other cultures, while emic (indigenous) approaches typically seek to understand the construct of interest within a given culture. For our purpose, we use etic to refer to the use of measures developed in a population of individuals for single individuals, and we use emic to refer to the tailoring of measures to a single given individual (e.g., through person-specific item selection or item generation). Thus, emic approaches to measurement include what is unique to a given individual while etic approaches focus on what is shared, common, or identical across individuals (for overviews of person-specific measurement vs. measurement standardized across individuals, see Haynes et al., 2009; Wright & Zimmermann, 2019).
Which of the two approaches is most appropriate varies by research question. For example, to answer a question about predictors of long-term outcomes such as health, well-being, or job performance, a researcher may want to use etic approaches in order to differentiate individuals on the basis of risk factors (Beck & Jackson, 2022a; Graham et al., 2017; Roberts et al., 2007; Soto, 2019). Especially when the inferential goal is nomothetic (population or generalization approach), an etic approach should typically be preferred. Relatedly, etic measurement is typically most suitable for inter-individual analyses (between-person analyses or cross-sectional inter-individual analyses; e.g., involving stable traits). However, when the inferential goal is idiographic, a researcher may consider both etic and emic approaches to measurement to examine the psychology of a single person. For instance, using an emic approach, a researcher may assess psychological states using newly generated items that are particularly relevant to the experience and behavior of this person. Notably, researchers can also integrate both approaches (Wright & Zimmermann, 2019), for instance, by selecting items or scales relevant to a given person from a larger pool of standardized measures. Ideally, these measures would be psychometrically validated and have recent norm values, both of which have several advantages for the interpretation of (individual) test scores. Moreover, researchers could include both standardized measures as well as measures newly generated for a specific person in a given study. Overall, depending on the inferential goals, emic or etic measurement approaches, or a mix between the two, may be most appropriate.
Data sources
Psychological constructs are often assessed via self-report. However, self-report is neither the only source of data available nor always appropriate for a given research question. Instead, different data sources are differentially suited to measure a certain construct of interest and it can further be informative to assess constructs multi-methodologically. One breakdown of data sources are the BIOPSIES (Behavior, Indirect measures, Observations, Physio-biological measures, Strangers’ impressions, Informant knowledge, Experience sampling [or ambulatory assessment broadly], Self-reports; Rauthmann, 2017). More broadly, data sources can be categorized into active assessments (i.e., individuals making reports or observations) and passive assessments (e.g., mobile sensing: Harari et al., 2021; Mehl et al., 2024; Wiernik et al., 2020; wearable cameras: Brown et al., 2017; audio data: Mehl et al., 2001). Passive assessments can produce Big Data that provide a rich and/or dense snapshot of individual lives (for a discussion on how Big Data can be leveraged for idiographic research, see Renner et al., 2020).
The specific research question, including the construct of interest, should determine the types of data sources used. For example, psychological experiences will likely need to be assessed using self-report; for behavior, measures other than self-report should ideally be used more frequently (e.g., behavioral observation: Back & Egloff, 2009; Baumeister et al., 2007); and situational information should ideally not only be measured subjectively (Kuper et al., 2024; Rauthmann et al., 2015). When trying to understand an individual holistically (research object: individual person and research goal: understand), researchers may include rich qualitative data (e.g., life history narrative approaches: McAdams, 2008; McAdams & Pals, 2006; McLean et al., 2020).
Notably, idiographic and nomothetic (population or generalization approach) inferential goals can be combined with various data sources. For instance, life history narrative approaches are certainly suitable for idiographic inferential goals. However, narratives are often coded for certain themes, which are then examined using inter-individual analyses (closer to nomothetics [population approach] than idiographics). Moreover, it should be emphasized that idiographic research does not require self-report and can be conducted with various other data sources (e.g., behavioral observation, mobile sensing). Generally, the common reliance on self-report renders it difficult to differentiate idiosyncratic responding (e.g., individuals differ in how they use certain scales) from unique psychological effects (i.e., individuals differ in psychological phenomena of interest; for a similar discussion, see Kuper et al., 2024). However, this differentiation is pertinent when investigating both shared effects and person-specificity (research object: integration). To allow more robust inferences, research can address this issue by using data sources other than self-report and through multi-methodological work integrating complementary data sources.
Study design
Having chosen the variables and measures as well as data sources, it is important to consider the study design required to answer a given research question. Key considerations concern the number of assessments, the context of assessments, and the study type. One basic choice is whether individuals will be assessed at one time point (often called cross-sectional assessment) or across time in a longitudinal or intensive longitudinal design. Further, researchers need to decide where assessments take place, such as in everyday life (e.g., experience sampling, mobile sensing), online, in a laboratory, or in a clinical setting, among others (Wrzus & Mehl, 2015). A third key consideration is whether a design includes an experimental manipulation or is observational/correlational. Correlational studies often emphasize associations among measured variables at a given time point or across time (e.g., research goals: description and prediction; however, there are also approaches aiming for explicit causal inference based on observational data, Grosz et al., 2020; Rohrer, 2018). In turn, experimental studies typically manipulate key variables to test possible causal mechanisms (e.g., research goal: explanation). Finally, various N = 1 study designs have been developed for single individuals as the research object (e.g., McDonald et al., 2017, 2020; Vlaeyen et al., 2022).
Different study designs are differentially suited to answer certain research questions (e.g., Hamaker et al., 2020). For example, if the structure of personality traits is the focal phenomenon, cross-sectional study designs may be sufficient (if the measures are relatively stable). If the focus lies in the long-term development or change of such traits, it is necessary to cover sufficiently long time periods using, for instance, longitudinal panel studies or more intensive study designs (e.g., Bleidorn et al., 2020). In contrast, if the focal phenomenon are processes underlying psychological states in daily life, an intensive longitudinal design (e.g., experience sampling) may be ideally suited. Similarly, other aspects of the research question are also related to the study design (e.g., level of aggregation of interest: within-person is often combined with [intensive] longitudinal designs). Finally, the study design is relevant to idiographic and nomothetic (population or generalization approach) inferential goals since different research objects are examined using different study designs. For instance, if the research object is an individual person, longitudinal designs are typically used (but see Orientation of Analysis for an example not using longitudinal data). In contrast, the research object “population of persons” can also be realized using cross-sectional designs (depending on the focal phenomenon and level of aggregation of interest). Overall, the number and timing of assessments, the study type, and the context of assessments should thus be tailored to the research question at hand (see also Data Structure and Sampling) to allow the intended inferences.
Data structure
Closely related to the study design is the structure of the resulting data with respect to the three elements of Cattel’s data box: persons, variables, and occasions/situations (Cattell, 1946). Naturally, different research questions require different data structures. For instance, if the research object of a study is a specific individual, only this single person has to be assessed, while multiple (often many) participants are required for all other research objects (i.e., integration, generalization to every person, population of persons). Regarding variables, a study may, for instance, be focused on the fluctuation of a single variable over time, on the relation between two variables across persons or across time, or on the factor structure of a large number of variables. Finally, some research questions require (intensive) longitudinal data with multiple timepoints whereas other questions can be answered using a single cross-sectional assessment (see also Study Design). Notably, the data structure determines which statistical analyses are possible (see e.g., Orientation of Analysis). In the following, we will provide further details concerning the sampling of persons, situations, and time.
Sampling
Sampling of persons
First, the sample of persons should reflect the population to which the study results are intended to generalize. This population may be characterized, for example, by certain demographics. Research in psychology is often based on convenience samples (especially undergraduate students) and on samples from highly selected socio-cultural contexts (e.g., Henrich et al., 2010), which limits generalizability. If the research object is an individual person, the sampling of persons is straightforward, although illustrative case studies still need to select a fitting individual for a given purpose. In turn, when aiming to make inferences about a population of individuals, participants should ideally be sampled while keeping the issue of representativeness for this population in mind. Moreover, statistical power needs to be considered. The required sample size depends strongly on the research question and statistical parameter of interest. For instance, when holding the number of assessments per person constant, fewer participants are typically required when estimating an average within-person effect as compared to identifying predictors of individual differences in this within-person effect (i.e., cross-level interactions; Arend & Schäfer, 2019).
Sampling of situations
The sampling of situations or contexts also needs to be aligned with the research question. Most broadly, the context of the assessments should be relevant to the aims of the study (e.g., at work when investigating productivity at the workplace). More specifically, a research question may pertain to effects of situations/situation characteristics on psychological states (e.g., Kuper et al., 2022, 2024). If specific types of situations are of interest, researchers need to ensure that these situations are captured sufficiently frequently with the sampling approach (e.g., event-contingent sampling of interpersonal situations: Geukes et al., 2019). These considerations are especially relevant when the situations of interest are relatively rare (e.g., highly stressful events). Alternatively, researchers may aim to sample a broad range of situations (e.g., standardized situations relevant to various personality traits: Kuper et al., 2024) or situations that are relatively representative of everyday life (e.g., interval-contingent prompts in experience sampling studies: Horstmann, 2021; Myin-Germeys & Kuppens, 2022).
Similar to the sampling of persons, the sampling of situations/occasions also affects statistical power (e.g., Arend & Schäfer, 2019). If the research question pertains to within-person phenomena over time, power considerations concerning the sampling of situations/occasions are relevant for all research objects (including inferences about the population such as average within-person effects). However, in particular when person-specific estimates are of interest (e.g., person-specific within-person associations or network edges), parameter estimates are often more imprecise and less reliable than desirable using currently common numbers of assessments (e.g., Kuper et al., 2022; Mansueto et al., 2023; Mejía et al., 2014). As for all statistical models, person-specific parameter estimates not only reflect the true parameters but are also affected by measurement error (which can, for instance, render the comparison of different person-specific models challenging). Overall, to yield precise parameter estimates, larger numbers of assessments are especially needed for idiographic inferential goals.
Temporal resolution: Sampling of time
In longitudinal studies, the sampling of time represents a key design component and should be guided by the research question (e.g., Hamaker, 2023b; for a detailed overview, see Hopwood et al., 2022). For example, research on the long-term development of personality traits is often carried out using relatively few assessments separated by long time periods (e.g., annual assessments; cf. Bleidorn et al., 2020). In contrast, work on momentary psychological processes often uses intensive longitudinal data (e.g., momentary or daily assessments). However, the exact temporal resolution that is most appropriate for a given research question is difficult to determine. For instance, when examining long-term lagged effects of one variable on another (e.g., predictors of personality trait change), the timing of effects—and hence the optimal time lag—may be unclear, or even differ between persons. Moreover, when investigating lagged effects in everyday life across short time periods, commonly used time lags (e.g., several hours) may be too long for the psychological effects of interest (e.g., reactions to a situation which may long be over after the time lag), leading some researchers to focus on contemporaneous rather than lagged within-person associations. Importantly, it has frequently been demonstrated that a mismatch between measurement frequency and the timing of psychological processes can lead to a distorted picture of the actual dynamics (e.g., Adolph et al., 2008; Batra et al., 2023; Schiepek et al., 2016).
Overview of Selected Statistical Approaches and Examples for Their Application at Different Levels of Aggregation.

Note. Shown are selected families of statistical approaches and examples of their application at different levels of aggregation. Additional applications of these models not depicted here are possible. The distinction of statistical approaches is pragmatic and does not imply that the approaches are non-overlapping or could not be subsumed by other approaches. For instance, many statistical approaches (e.g., MLM, factor analyses, network models) can be implemented using DSEM and several person-specific analyses can be subsumed by time series analysis. “/” = this approach is to the authors’ knowledge not commonly used to estimate this type of effect, although it may be possible to do so in special cases.
aUnless specified otherwise, integration refers to top-down integration (see Figure 2). Fewer statistical approaches explicitly employ bottom-up integration, although qualitative comparisons and quantitative bottom-up integrations (e.g., averaging and meta-analysis) are often possible.
bClassical cross-lagged panel models were not included in the table because the cross-lagged effects of interest represent a blend of between-person and within-person variance (Hamaker et al., 2015) and can thus not clearly be allocated to one column.
cWe included intra-individual personality profiles of single individuals under “person-specific analysis” and Q-technique factor analysis under “individual differences in within-person phenomena” given their historical treatment as idiographic (see Orientation of Analysis) and since a specific personality profile can be examined holistically for a given person. These approaches require intra-individual comparisons across different variables, but we acknowledge that the underlying data are not suitable for the examination of within-person relations across time, and their inclusion in these columns is not entirely unambiguous.
In addition to the frequency and timing of assessments, a further relevant consideration is the temporal aggregation of measures. For self-report measures, the temporal aggregation is often influenced through instructions or item wording (e.g., “right now”, “in the last hour”, “in the last week”, “in general”; see Robinson & Clore, 2002; Walentynowicz et al., 2018). In addition to this assumed temporal aggregation of measures via instructions or item wording, data may actually be aggregated during pre-processing for certain data sources (e.g., passive sensing: Harari et al., 2016). Overall, the temporal resolution of a study is a key consideration whenever within-person phenomena over time are of interest, which is often the case for both idiographic and nomothetic (population or generalization approach) inferential goals. The appropriateness of the temporal resolution can critically affect the quality of the drawn inferences.
Analyses and interpretation
Having discussed decisions pertaining to the research question and the research design, we now turn to the statistical analyses and interpretation part of the research process. Note that we focus on quantitative approaches in the following, although we acknowledge the utility of qualitative and mixed-methods approaches for both idiographic and nomothetic research. Here, we include the following decisions: (1) level of aggregation of the analysis; (2) orientation of the analysis; (3) output of the analysis; and (4) inferences. In particular the level of aggregation of the analysis (e.g., person-specific vs. inter-individual analyses) and the orientation of the analysis (data box) are most directly related to idiographic and nomothetic (population or generalization approach) inferential goals. Moreover, the inferences drawn from a study always pertain to a given research object (e.g., individual person vs. population of persons; closely related to idiographics and nomothetics). In turn, different analysis outputs can generally be combined with different inferential goals.
Level of aggregation: Analysis
One distinction central to idiographic and nomothetic (population or generalization approach) inferential goals is the level of aggregation of the analysis. We distinguish five different levels of aggregation which are suitable for different research objects: (1) person-specific analyses (N = 1), (2) bottom-up integration of repeated N = 1 analyses, (3) top-down integration including model-based individual differences in within-person phenomena, (4) within-person phenomena modeled to be identical across persons, and (5) between-person and cross-sectional inter-individual analyses. An overview of this classification is shown in Figure 2. Generally, person-specific approaches model data from a single person (research object: individual person), integrative approaches allow examining average/shared phenomena in a population while still modeling person-specificity (possible research objects: integration or generalization to every person), and models termed population-specific here (see Figure 2) exclusively focus on population parameters without modeling person-specificity (research object: population of persons). Classification of Statistical Analyses. Note. Shown is a classification of statistical approaches into person-specific analyses, integrative approaches (i.e., approaches allowing the examination of average/shared relations while still including person-specificity), and population-specific approaches (i.e., approaches not allowing for integration/not modeling person-specificity in within-person phenomena).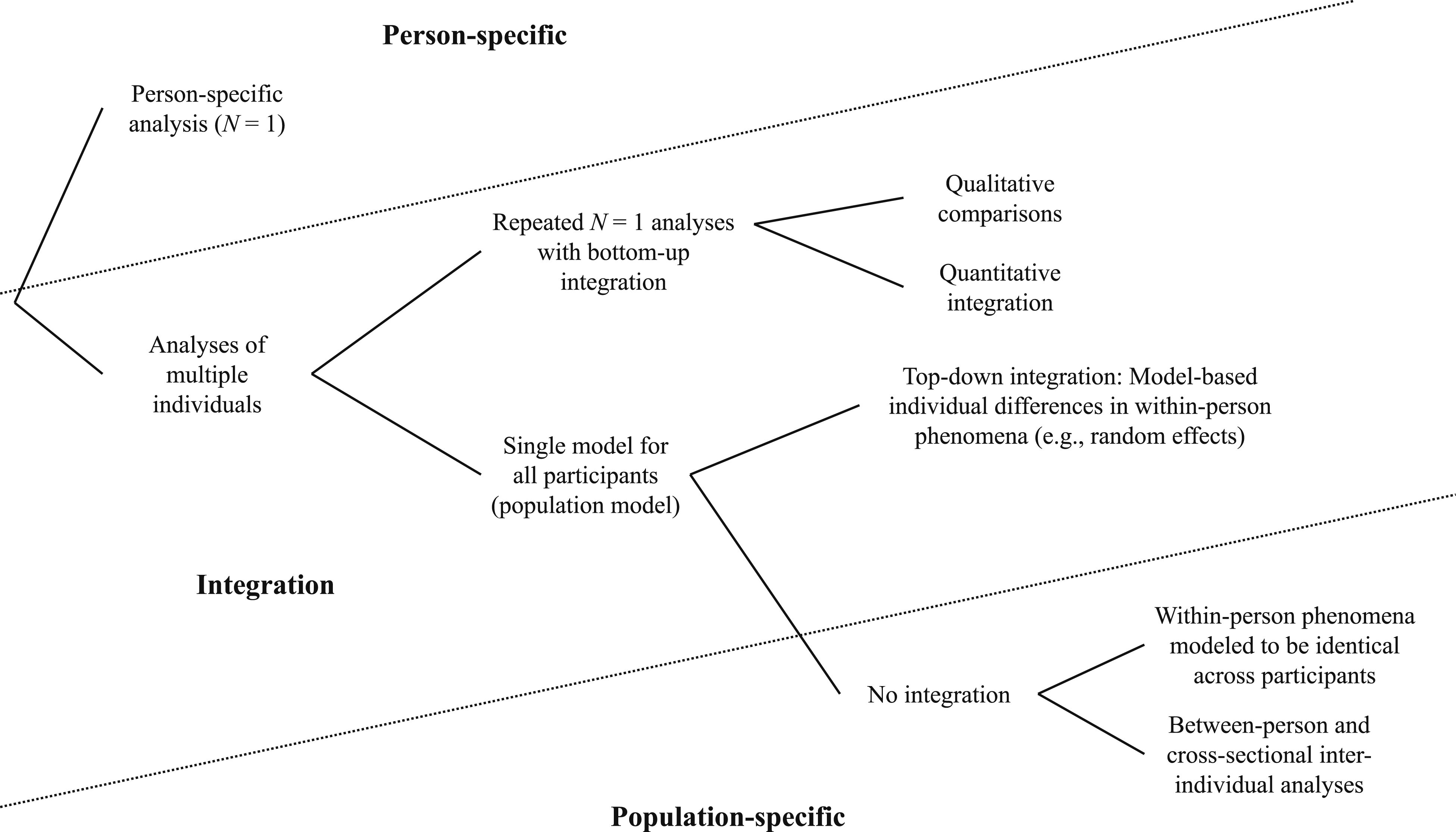
A detailed overview of specific commonly used statistical approaches and examples of their application at different levels of aggregation is shown in Table 1. As the table illustrates, several statistical approaches can generally be applied across different levels of aggregation depending on the specific research question. For previous overviews of statistical approaches (also) suitable for more idiographic research questions, see, for instance, Hofmans et al. (2019); Howard & Hoffman (2018); Molenaar and Beltz (2020); Piccirillo and Rodebaugh (2019); and Wright and Woods (2020). In the following, we describe the levels of aggregation in more detail with selected analysis approaches as examples.
Person-specific analyses
Person-specific analyses are here defined as N = 1 models using only data from a single person. Such person-specific methods have a long history in the behavioral sciences, especially if one considers individual case studies in disciplines like psychiatry and basic behaviorist psychology. In the middle part of the last century, interest grew in the idiographic study of individuals using state of the art measurement and statistical procedures (Cattell, 1952; Cattell et al., 1947; Cattell & Luborsky, 1950; Shapiro, 1961a, 1961b). This work aimed to model the psychological complexity of single individuals through multivariate statistical approaches. An important goal in this line of research was to investigate what the structure of psychological variables for a specific individual was, and whether this was similar or different from the structure that was obtained in the population using cross-sectional data.
Classical examples of these approaches include P-technique factor analysis (Beck & Jackson, 2020b; Cattell & Luborsky, 1950; Wright et al., 2016), dynamic factor analysis (Molenaar, 1985), and person-specific network models (Beck & Jackson, 2020a, 2020b; David et al., 2018; Fisher et al., 2017). The logic of these approaches is that by understanding the interrelations among relevant variables sampled intensively and repeatedly over time, the basic structure or processes of the individual’s psychology might be revealed. In the case of P-technique, the goal might be to establish the factor structure of the individual’s psychological states over time (e.g., Borkenau & Ostendorf, 1998). Dynamic factor analysis extends this goal by also accounting for lagged relations between factors at different time points, and between factors and observed variables over time. In contrast, the goal of network models is to understand how observed variables are related to each other contemporaneously and across time for a given individual, for instance, through the use of vector autoregressive models (e.g., Beck & Jackson, 2020b).
Many further statistical approaches can be applied to the N = 1 case, including latent profile analyses identifying classes of state profiles (e.g., Fisher & Bosley, 2020), change-as-outcome models (e.g., Danvers et al., 2020), (vector) autoregressive models including time-varying parameters/non-stationarity (Bringmann et al., 2017; Haslbeck et al., 2021), and machine learning models (e.g., Beck & Jackson, 2022b; Soyster et al., 2022). Several of the approaches listed for person-specific analyses in Table 1 can be subsumed by the label “time series analysis” which has a rich history in econometrics and statistics (e.g., Hamilton, 1994; Lütkepohl, 2010) as well as in personality psychology (e.g., Larsen, 1987; Larsen et al., 2009). The research question and the nature of the data guide which specific analysis approaches are best suited for a given study. Notably, in many cases, researchers may be interested both in person-specificity and in inferences regarding the population of individuals (e.g., average patterns, similarities, or even effects generalizing across all individuals). This research object requires integration across individuals, which we discuss next.
Bottom-up integration
Generating idiographic and nomothetic knowledge are not inherently opposing goals. Two basic questions are which features in person-specific models generalize to all/most individuals in a given population (nomothetics: generalization approach) and what the average model looks like in a given population (nomothetics: population approach). With a single person-specific analysis, there is ambiguity about which model features are unique to that individual, shared with some others, or common to all (or most) individuals. One way to address this concern is bottom-up integration: estimating person-specific models for a (large) number of individuals and then descriptively—qualitatively or quantitatively—comparing the models for similarities (e.g., through meta-analysis; Lee & Gates, 2023). When comparing models, it should be kept in mind that parameter estimates in person-specific models are also affected by measurement error (depending on the number of assessments, see Sampling of Situations).
An example of a quantitative bottom-up approach is Group Iterative Multiple Model Estimation (GIMME; Gates & Molenaar, 2012). GIMME is based on estimating unified structural equation models with contemporaneous and lagged regressions using the data of each person separately. It subsequently searches for paths that are present in the majority of individuals (e.g., 75%), which, if identified, are added to each individual’s model before re-estimating models (iteratively). Crucially, GIMME only ever estimates person-specific models. The “group-level” model is not a model per se, but rather the set of paths shared by all individuals in the model. These group-level paths are not fixed to equality but rather estimated separately and freely in each person’s model. Further extensions (e.g., the identification of sub-groups of participants with similar paths) are possible. For further information on GIMME, as well as its limitations, see Beltz and Molenaar (2016), Gates et al. (2017, 2020), and Nestler and Humberg (2021).
Notably, statistical modeling approaches focusing on bottom-up integration have certain basic requirements, including a sufficient sample size per participant to ensure precise parameter estimates (see Sampling of Situations), and sufficient variability on all variables. The latter can be problematic when studying rare phenomena, such that some individuals may have no variance on some variables of interest (e.g., suicidal ideation; Kaurin et al., 2022; see also Ram et al., 2017). Finally, bottom-up integration requires that identical variables were assessed across people (i.e., the variables and measures cannot be tailored to each participant; see Variables and Measures).
Top-down integration
While the bottom-up approach models each individual separately in N = 1 models and integrates across individuals afterwards, the top-down approach models all individuals simultaneously using a population model. Top-down approaches assume that individuals come from the same population, or a small number of subpopulations (e.g., in mixture or latent class analyses). The various techniques that are available in this category allow for model-based individual differences in within-person phenomena of interest. Compared to bottom-up integration approaches, these models assume that individual differences in model parameters follow a certain distribution, thus somewhat constraining person-specificity (e.g., normality assumption; Brose & Ram, 2012; Castro-Schilo & Ferrer, 2013). 8 Given this top-down integration, rather than estimating all person-specific parameters separately, only the parameters of the distribution have to be estimated in the model (e.g., the average effect and the variance of normally distributed individual differences in this effect).
A commonly used and flexible family of modeling approaches are multilevel models, also referred to as mixed effects models and hierarchical linear models. In addition to individual differences in means/intercepts (i.e., between-person variance), these models allow for individual differences in slopes (i.e., regression coefficients). For instance, individuals may have different developmental trajectories when time or age is used as the predictor (Curran et al., 2012). Moreover, random slopes can reflect individual differences in effects of a given predictor of interest (e.g., situation characteristics; Kuper et al., 2022, 2024). To focus on within-person variance in particular, predictors are often person-mean centered, removing between-person variation (e.g., Hoffman & Stawski, 2009).
Random slopes may also concern lagged regressions, such as that of a variable on itself at an earlier occasion (i.e., autoregression or inertia; Suls et al., 1998), and cross-lagged regressions between different variables. Individual differences in cross-lagged effects can be examined using, for instance, dynamic structural equation models (DSEM; Asparouhov et al., 2018), multilevel vector autoregressive models (mlVAR—i.e., network models; Epskamp et al., 2017), or multilevel continuous time models (Driver & Voelkle, 2018). In addition, multilevel models can further include individual differences in within-person variances (e.g., Hedeker et al., 2008; Jongerling et al., 2015; Nestler, 2022). Moreover, multilevel Markov models can be implemented, in which individuals are assumed to switch between distinct states over time, and transition probabilities are included as random effects (Aarts, 2019).
In multilevel models, individual differences in parameters (i.e., random effects such as individual intercepts, slopes, variances, or transition probabilities) may be predicted at the person-level, for instance, by including person characteristics as predictors of random effects. Especially in MSEM and DSEM, the random effects can be modeled with a high degree of flexibility (Hamaker et al., 2023; Sadikaj et al., 2021). The necessary sample size in terms of persons and timepoints depends on the particular research question. In many cases, multilevel models likely require fewer timepoints per person than either person-specific analyses (N = 1) or than bottom-up approaches (Liu, 2017). Notably, it is also possible to extract parameter estimates for individual persons from multilevel models, combining information from the specific person and from the population. This leads to a phenomenon called “shrinkage”, where extracted random effects are moved towards the average population effect compared to person-specific N = 1 estimates (Liu et al., 2021).
While we have here focused on multilevel modeling (and related approaches such as DSEM and multilevel VAR) as one particularly commonly used approach to top-down integration, further approaches are possible. For instance, various longitudinal structural equation models include continuous individual differences, categorical individual differences, or both in growth over time (e.g., Curran et al., 2012; Jung & Wickrama, 2008; Preacher et al., 2008).
Within-person phenomena modeled to be identical across persons
Other models focus on average within-person effects without allowing for individual differences in these effects. Such models are often implemented when there are few timepoints per person, which renders it difficult to properly estimate many individual difference parameters. These models still typically include some component to account for stable between-person differences in mean levels to distinguish between-person and within-person variance. This category includes structural equation models such as the random intercept cross-lagged panel model (RI-CLPM; Hamaker et al., 2015), as well as multilevel models including only random intercepts but no random slopes (see Barr et al., 2013, for a critical perspective). Here, it is still possible to model individual differences in within-person effects (only) to the extent that they are related to other person variables. For instance, one can estimate group differences in within-person effects using a multiple group RI-CLPM (Mulder & Hamaker, 2021), or include a person-level moderator of a within-person effect (cross-level interaction) in a multilevel model without a random slope.
Additional approaches that fall into this category of modeling within-person phenomena to be equal across persons are: Network models estimating a pooled within-person network without including individual differences in this network (e.g., Costantini et al., 2019); multilevel factor analysis with loadings of the within-person structure constrained to be equal across participants (e.g., Muthén, 1994); continuous time models without individual differences in autoregressive, contemporaneous, or cross-lagged effects (e.g., Hecht et al., 2023); and certain machine learning models pooling across individuals (see Soyster et al., 2022 for an empirical example of pooled vs. person-specific machine learning). Finally, there are also longitudinal modeling techniques that do not explicitly account for stable between-person differences. A prominent example is the classical cross-lagged panel model which requires only two waves of data but has been criticized for not purely estimating within-person effects (e.g., Hamaker et al., 2015; Lucas, 2023). Overall, the approaches discussed in this section are suitable to derive certain population parameters (e.g., an average effect; in line with nomothetics [population approach]) but cannot be used for other research objects (e.g., individual person, integration, generalization to every person).
Between-person and cross-sectional inter-individual analyses
Finally, inter-individual analyses may be of interest, such as correlations between two individual difference variables (Galtonian approach). Here, we distinguish between-person and cross-sectional analyses. For between-person analyses, multiple data points are required to estimate relations between latent or manifest person means in variables (e.g., Asparouhov & Muthén, 2019; Lüdtke et al., 2008). Possible models include between-person effects in multilevel models (e.g., Hoffman & Stawski, 2009), 9 trait associations in latent state trait models (e.g., Geiser et al., 2021a,b), between-person networks (e.g., Epskamp et al., 2018b), and between-person factor structures in multilevel factor analysis (e.g., Muthén, 1994).
In contrast, cross-sectional analyses are based on a single assessment. Cross-sectional relations between two variables reflect a blend of how the stable and the time-varying components of these variables are related (Hamaker, 2023a). Such analyses are frequently applied in personality psychology (both historically and currently). Often, they are conducted with data based on self-reported personality traits. Since people are typically asked to indicate what they are like in general in trait questionnaires, the resulting variables have a high degree of (assumed) temporal aggregation (see Temporal Resolution: Sampling of Time) and stability. Examples include cross-sectional correlations or multiple regression analysis, classical (R-technique) factor analysis, cross-sectional network analysis (e.g., Epskamp et al., 2018c), and machine learning models predicting individual difference variables (e.g., in personality computing research: Phan & Rauthmann, 2021).
Alignment with the research question
The chosen level of aggregation of the analysis needs to be closely aligned with the different aspects of the research question to ensure that inferences drawn are appropriate (see also Phan et al., 2024). For instance, if the research question concerns within-person processes (level of aggregation of interest: within-person and focal phenomenon: process), between-person and cross-sectional inter-individual analyses are not suitable. Similarly, if interest lies in individual persons or in the integration of person-specificity and shared/average effects (research object: individual person or integration), analyses modeling within-person phenomena to be identical across persons do not allow the intended inference. Such a mismatch can be avoided by integrating the explicit consideration of the different methodological decisions presented here into the research workflow.
Orientation of analysis
In addition to the level of aggregation, a further central element of the statistical analysis is its orientation. Depending on the research question and study design, the analysis of the data can be oriented towards different focal units. Three units can be distinguished in data structures according to Cattell (1946): persons, occasions/situations, and variables. These focal units can then be analyzed across other units. Most frequently, variables represent the focal unit toward which the analysis is oriented. For example, when investigating the relationship between two variables, a cross-sectional design involving one occasion allows correlating the variables across individuals (“R-technique”), whereas an intensive longitudinal design allows the variables to be associated across occasions (“P-technique”) for one individual (or for multiple individuals simultaneously using, e.g., multilevel approaches, see Level of Aggregation: Analysis). Both R-technique and P-technique are variable-centered, with the former analysis examining differences between individuals and the latter analysis examining differences between occasions. Analyses using R-technique (e.g., the factor structure of personality traits; Goldberg, 1993) are sometimes regarded as nomothetic (population approach), whereas analyses using P-technique in a single individual are typically regarded as idiographic. Thus, variable-centered approaches should not generally be equated with nomothetic inferential goals.
Historically, a different orientation of the analysis has also sometimes been regarded as idiographic. Specifically, persons rather than variables may be treated as the focal unit (Asendorpf, 2015; Howard & Hoffman, 2018; for a recent overview, see Woo et al., 2023). This is sometimes—but not necessarily consistently—termed the “person-centered” (as opposed to variable-centered) approach in the literature. For example, the question of person similarity was often examined in cross-sectional designs by correlating personality profiles across variables (“Q-technique”). This analysis is oriented toward the overall configuration of variables within an individual, aims to discover underlying personality types using procedures such as Q-factor analysis (Thompson, 2000), cluster analysis, or latent profile analysis, and sometimes also draws on corresponding data collection methods such as the Q-sort method (Block, 1961; Stephenson, 1953). Although the analysis is based on the same data structure as R-technique, it is often considered idiographic because of its orientation toward persons as the focal unit (e.g., Runyan, 1983). Interestingly, this is at odds with the fact that Q-technique cannot be carried out with data from a single person (N = 1). 10
Instead, Cattell (1951) suggested a different analysis for single individuals (in addition to variable-centered P-technique). Specifically, he suggested “O-technique”, an analysis oriented to occasions based on longitudinal data. For O-technique, state profiles of many variables are correlated for (at least) two occasions of a single person, yielding the degree of similarity of these occasions. In this vein, latent profile analyses can be used to identify classes of state profiles in a single individual (Fisher & Bosley, 2020).
Nowadays, there are numerous statistical modeling techniques using “profiles” that can handle more complex data structures and offer various forms of integration of person-specific and population-based effects. Examples include models investigating individual differences in the relation between personality profiles and prototypical profiles (e.g., “typeness”, Asendorpf, 2006), models differentiating normative and distinctive aspects of agreement in data with multiple perceivers and targets (Borkenau & Leising, 2016), models identifying categorical state profiles and classes of participants in intensive longitudinal data (Grommisch et al., 2020), and models investigating individual differences in profile stability over time (Wright & Jackson, 2023). Overall, this highlights the potential viability of considering relevant orientations of the analysis in addition to the most common variable-oriented analysis. Of course, the orientation of the analysis again needs to be aligned with the research question. Notably, however, the common reliance on specific orientations of the analysis in the literature (especially: variable-centered) has likely also affected which research questions are typically asked.
Output of analysis
The third aspect of the analysis we consider here is the output of the analysis. Ideally, the research question is formulated such that it clearly maps on a given output of interest, which then facilitates the intended inference. Possible outputs are, for instance, coefficients representing associations (e.g., correlations, regression coefficients), classifications, factor structures, profiles, distributional parameters (e.g., the average and variance), entire distributions, and more. While some outputs might occur more often for idiographic or nomothetic (population or generalization approach) inferential goals in the literature, various combinations are possible. For instance, if the research object is an individual person, relevant outputs could be a person-specific within-person association of two variables over time, a person-specific factor structure of psychological states, an intra-individual personality profile, a person-specific state distribution, and many more. For the research object integration, additional relevant outputs could be, for instance, the average within-person association in combination with its variance parameter across individuals (top-down integration using multilevel models) or the full distribution of person-specific within-person associations (bottom-up integration of repeated N = 1 analyses). In turn, if the research object is the population of persons, relevant outputs might be a between-person or average within-person association of two variables, an inter-individual factor structure of personality trait items, a distribution of trait scores in this population, and many more.
Inferences
Finally, the output of the analysis has to be interpreted in order to answer the research question. Importantly, inferences drawn from a given study have to take into account several conditions that ensure their plausibility and validity. This includes, for instance, assumptions of the statistical model (e.g., measurement invariance, distributional assumptions), the measures utilized (e.g., psychometric properties, their applicability for a given individual of interest), as well as the match of the research question with the research design and statistical analysis (e.g., Collins, 2006).
A typical problem with inference arises when a construct has only been captured by a single measure and yet the conclusions of interest are at the construct level. This is problematic because the construct and the measure are not distinguishable in such studies. In this case, conclusions should be transparently constrained by the methodology employed and, ideally, multi-methodological designs (Campbell & Fiske, 1959) should be implemented in future work.
A further central topic when drawing conclusions from a given study is the possibility of causal inference. In psychological research, causal inference is often at least implicitly of central interest (research goal: explanation), but there is a taboo against causal inference from non-experimental data in the psychological literature (Grosz et al., 2020). This taboo potentially even prevents researchers from applying more sophisticated methodologies aiming to facilitate causal inference from observational data (e.g., Rohrer, 2018). This issue is central for certain research questions in personality psychology where many variables of interest cannot be easily manipulated experimentally (e.g., Briley et al., 2018; Costantini & Perugini, 2018). Generally, even with careful design and analysis decisions, causality often cannot be inferred unambiguously, even for within-person effects (Rohrer & Murayama, 2023).
Finally, most relevant to the topic of idiographics and nomothetics, the inferences drawn from a given study are made about a specific research object of interest (individual person, integration, every person [generalization], population of persons; see Research Question and the discussion of inferential goals by Phan et al., 2024). Here, the study which was conducted (including the statistical analyses) needs to match the research object about which inferences are made. Otherwise, incorrect conclusions might be drawn. For instance, average effects of experimental manipulations might incorrectly be interpreted as pertaining to persons in general (i.e., every person), although causal effects are in fact heterogeneous across people (e.g., Bolger et al., 2019) such that the average effect only characterizes the population. Overall, the inferences from a given study should be transparently constrained by the methodology employed and its fit to the research question at hand.
Value of different methodological approaches
Given this large array of methodological options and decisions, which approaches should researchers use? That is, which approaches are most likely to yield theoretically and practically meaningful results? In our view, a central take-away is that generalized recommendations about which methods to use are not justified. Instead, the optimal methodology for a given study is highly dependent on its research question. For instance, if researchers seek to make inferences about psychological dynamics unfolding within persons, data from intensive longitudinal designs yield more meaningful results than data from cross-sectional designs. However, cross-sectional data can have a good match with other research questions (e.g., concerning personality trait structure). Thus, researchers need to carefully consider different methodological options (see Figure 1) and make intentional decisions which research designs and analyses are most suitable for their research questions.
While research in personality psychology encompasses a high diversity of methodological approaches, some methods are applied more frequently and are (perceived to be) more characteristic of the field (e.g., correlational designs and analyses; Robins et al., 2007). Research focused on nomothetic inference (population approach) makes up a very large share of personality research. In contrast, idiographic approaches, while frequently called for and potentially increasing recently, are represented less in the field (e.g., as evidenced by keyword usage; Rauthmann & Kuper, 2024). Since understanding individual persons is widely considered an important task of (personality) psychology (e.g., Molenaar, 2004; Roberts & Yoon, 2022), the comparatively rare application of methods facilitating idiographic inference could indicate that their potential to generate meaningful insights on certain research questions is not yet leveraged (as compared to more commonly applied methodological approaches). This also holds true for other less frequently applied and less well-known methodological approaches which we have devoted space to (e.g., bottom-up integration across individuals). Relatedly, several more specific methodological options may hold high potential for certain research questions but are still underrepresented (e.g., implementing a high-density measurement frequency to ensure a fine-grained temporal resolution; using data sources other than self-report—such as behavioral observation; and applying multi-methodological approaches by combining different designs and data sources with the same participants).
In general, it could thus be argued that some methodological options are still under-utilized since certain research questions with high importance for psychology could be effectively answered by them. Nevertheless, we want to emphasize that all methodological approaches can yield valuable insights as long as they are aligned with the research question at hand. Thus, the full diversity of methodological options has their place in (personality) psychology. Notably, different approaches are likely to yield complementary insights on a given phenomenon, such that their coexistence is indispensable, and psychological research fields should thus not become unduly focused on a single method.
Conclusion
When conducting empirical work in psychology, researchers have to make a myriad of methodological decisions. The present article sought to present an overview of these decisions, with a specific emphasis on their relevance to idiographic and nomothetic inferential goals. In doing so, we present clear, much needed terminological distinctions. Notably, we provide some guidance on how to align the research design, the statistical analysis, and the research question. Specifically, we reviewed decisions pertaining to the research question (research object, level of aggregation of interest, research goal, focal phenomenon, and construct of interest), to the research design (variables and measures, data sources, study design, data structure, sampling of persons, sampling of situations, and temporal resolution), and to the analyses and interpretation (level of aggregation: analysis, orientation of analysis, output of analysis, and inferences). These different decisions can be tailored to the focus of the study at hand, including the focus on individual persons, integration across persons, or average patterns in a population. Overall, we aimed to provide researchers with a list of relevant considerations to facilitate intentional and explicit decisions. This should promote the alignment between research question and methodology, ultimately helping researchers achieve their intended inferential goals.
Footnotes
Author’s note
This article is one of three articles that resulted from an expert meeting on “Dynamics of Personality: Integrating Nomothetic and Idiographic Approaches into a Synthetic Framework” sponsored by the European Association of Personality Psychology (EAPP). We have no conflicts of interest to disclose. Correspondence concerning this article should be addressed to Niclas Kuper (
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: While working on the manuscript, Niclas Kuper was supported by the project “Individualisation in Changing Environments” (InChangE), funded by the programme “Profilbildung 2020”, an initiative of the Ministry of Culture and Science of the State of North Rhine-Westphalia.