
Abstract
The urban planning profession is increasingly challenged to analyze extensive text data, from plans to public feedback. While natural language processing (NLP) has promising potential for aiding this analysis, its applications and purpose in planning remain unclear. This article reviews current planning research using NLP, seeking to highlight key themes and challenges, and suggesting a coherent future research agenda. The results reveal that existing research is primarily exploratory with a fragmented research landscape. Future studies should focus on sharing data, benchmarking NLP techniques, fostering collaborative research tailored to planning, and addressing ethical implications to harness NLP's full potential in planning.
Introduction
Urban planners traditionally have generated and engaged with large amounts of text such as plans (e.g., land use plans, transportation plans, and hazard mitigation plans), policies (e.g., zoning and land use ordinances and building codes), and reports (e.g., housing reports and traffic analysis). They also conduct public meetings to engage stakeholders and community members throughout the planning process and undertake public submissions and surveys to collate public input, such public engagement activities will generate extensive amounts of textual data for planners to process to inform better decisions. Additionally, the problems facing planners are also becoming increasingly complicated and interconnected in the complex urban systems, notwithstanding new emerging challenges such as the global pandemic and climate change (Anguelovski et al. 2016; Florida, Rodríguez-Pose, and Storper 2021; Fu 2020; Glaeser 2022; Shi and Fitzgerald 2023). As a result, planners today not only have to deal with the traditional planning tasks that already involve large numbers of texts, but they also need to digest massive amounts of new information to keep pace with international best practices (French, Barchers, and Zhang 2017; Grimmer 2015; Thakuriah, Tilahun, and Zellner 2017). A critical challenge, and a major opportunity, for planning lies in how to process increasing amounts of textual data more efficiently and effectively.
Natural language processing (NLP), a subfield of artificial intelligence (AI) aiming to enable machines to understand and generate human language, has recently gained much attention. This is especially due to the recent launch of ChatGPT, 1 with rapidly advancing capabilities to learn, analyze, and process human language content (Chowdhary 2020; Khurana et al. 2023). The theorization of NLP has extensively utilized the premise of parsimony, as epitomized by George Zipf's Principle of Least Effort, in human ecology (Zipf 1949). This principle suggests that human natural language is fundamentally a constellation of cooccurring words with inherent patterns, such as simplicity in linguistic structures and words tending to cluster around specific, recurring topics. In NLP, it means developing algorithms to mine these patterns, including analyzing word frequencies, cooccurrences, and relationships to capture the semantic relationship and nuances of human language (Piantadosi 2014). In fact, many widely used NLP techniques such as topic modeling and word embedding are developed based fundamentally on Zipf's law (Blei, Ng, and Jordan 2003; Gerlach, Peixoto, and Altmann 2018).
NLP has already shown promise in aiding planners to deal with big textual data, with research proliferating in leveraging NLP techniques in the planning literature. For example, planning researchers have applied NLP techniques to social media data (e.g., Twitter) to mine public sentiment and opinions toward specific events or topics over time and space (Hu, Deng, and Zhou 2019a; Kong et al. 2022; Zhai, Peng, and Yuan 2020); others have applied it to the planning literature to track research areas and trends (Fang and Ewing 2020; Sun and Yin 2017), and a few others have used it on the actual planning documents to extract useful information without having to read them manually (Bickel 2017; Brinkley and Stahmer 2021; Brinkley and Wagner 2022; Fu, Li, and Zhai 2023; Fu, Wang, and Li 2023). This offers an exciting opportunity for urban planning research and practice.
Despite the growing interest, the application of NLP in planning research is still at an early stage. Hence, it is critical to understand to what extent NLP is being used in planning research and to explore how to better leverage its rapidly advancing capability in both research and practice. To fill this gap, this article undertakes a review of the existing planning literature involving NLP methods to provide a snapshot of the existing progress. It also compares the existing use of NLP techniques in planning against the state-of-the-art development in the field of NLP to further identify future research areas and opportunities. Specifically, the objectives of this research are: (a) to provide a brief review of the latest development in NLP, (b) to synthesize existing NLP applications in planning research through a scoping review of the literature, and (c) to identify challenges and opportunities and develop a future research roadmap for maximizing the uptake of NLP techniques in planning. To this end, this article begins with a brief history of NLP and a review of the latest developments. Next, I describe the review methodology, followed by discussions of results and findings. Finally, I build on the exciting progress in planning research to discuss future challenges and opportunities.
The Past and Present of NLP
NLP is a collection of theory-motivated computational techniques to automate the analysis and representation of natural human languages (Chowdhary 2020; Liddy 2001). NLP research focuses on understanding how human beings comprehend and use language, and on developing tools and techniques to emulate such processes so that computer systems can also perform tasks involving natural language (Chowdhury 2003).
The development of NLP dates to the late 1940s and early 1950s at the intersection of AI/computer science and linguistics, and it has also been strongly influenced by many other disciplines such as psychology and mathematics (Nadkarni, Ohno-Machado, and Chapman 2011). In the beginning, NLP research was focused on machine translation (MT; such as from Russian to English) by solving word-to-word translation and tackling language syntax, through which researchers attempted to develop vocabularies and rules of human language for computers (Jones 1994). This endeavor proved to be difficult, which manifested in the need to resolve syntactic and semantic ambiguity for human natural language as a result of its variability, ambiguity, and context-dependent characteristics (Jones 1994; Liddy 2001). To this end, in the subsequent phases of NLP (between late 1960s and late 1980s), researchers were focusing on developing computationally semantic representations of natural language and, along with such theoretical development, built NLP systems that could be useful and applied in a broad, real-world context (Liddy 2001). Since the early 1990s, NLP research has been transformed by the introduction of statistical NLP approaches, building language models over large quantities of empirical language data, due to the increased availability of electronic textual data on the internet (Hirschberg and Manning 2015).
With more advanced algorithms and computing power, NLP research has significantly evolved from using punch cards and batch processing that could take up to 7 min to analyze a sentence, to the word processing and searching of millions of pages, like Google does, in less than a second (Cambria and White 2014). In fact, NLP is already deeply integrated into our daily lives, often without us being aware of its existence, in tools like language translators, spam filters, spell checkers, voice-recognizing smart assistants like Siri, and chatbots. This field is rapidly developing, and the potential applications are spreading across various disciplines, including urban planning. Hence, it is meaningful for cutting-edge planning practitioners and researchers to engage with the latest developments and continue exploring how to leverage the power of NLP to improve planning research and practice. In the following, I will try to summarize the latest NLP applications that are potentially relevant to planning. It should be noted that the following summary is hardly exhaustive, as the field of NLP is so vast and developing at such a speed that “even a book is not sufficient to present in detail all the available techniques” (Chowdhary 2020, 609).
Current NLP applications can be broadly categorized into two core subfields: natural language understanding (NLU) and natural language generation (NLG). As their names suggest, NLU focuses on understanding human language and making sense of it, whereas NLG deals with generating human-like language based on certain input (Skrodelis et al. 2023). While they can be distinctly differentiated by these two categories, modern NLP applications such as ChatGPT require both NLU and NLG.
A primary NLU application is information extraction and summarization (IES). IES aims to quickly provide useful information that humans can digest from a much larger dataset, particularly powerful in this digital era when data is expanding every second (Grimmer 2015; Khurana et al. 2023; Thakuriah, Tilahun, and Zellner 2017). Some of the main applications of IES include extracting useful information (e.g., places, names), analyzing sentiments and emotions, and identifying common topics from vast quantities of textual data available online, such as academic and gray literature, social media data, and news articles. As for now, IES is perhaps the most useful and relevant application to the field of planning, utilizing multiple established techniques, such as sentiment analysis, and topic modeling.
MT is another key application that necessitates understanding the source language (NLU) and generating text in the target language (NLG). It can be invaluable for planners worldwide to communicate and coproduce knowledge without language barriers (Hirschberg and Manning 2015). Planning, like much other research, is dominated by English-speaking scholars and ideologies (Ferguson 2007). It means that roughly 80% of the world's population that does not speak English (Statistics & Data 2023) is unable to engage in or contribute to the field of planning, which limits the capacity for knowledge codevelopment and transfer around the world. For example, planning scholars cannot directly investigate plans or planning practices from other languages, and it also limits their ability to conduct comparative studies between two or more countries with differing languages. Although recent progress in MT using deep-learning models is quite promising, accurate translation between human language pairs (particularly for the minor languages) remains challenging, as it requires a humanlike understanding of world knowledge and context (Hirschberg and Manning 2015), especially for specialized fields like planning that often involves ambiguous concepts like sustainability and resilience as well as terminologies.
One other key application in planning is the dialog systems (DSs). Similarly, DSs also employ NLU to understand the user's input, and NLG, to generate relevant responses. It has already been widely adopted, from the text-based DSs such as the customer service chatbots answering preset frequently asked questions, or the spoken DSs like Apple's Siri helping people with simple manual tasks, to the latest large language models (LLMs) like ChatGPT allowing human-like conversational dialog. In a planning context, DSs have the potential in streamlining planning processes, boosting public engagement, and enhancing accessibility by providing information retrieval, decision support, education, and multilingual communication. In fact, many global cities, such as Singapore and Dubai, have already started to explore the potential of the latest DS, ChatGPT, to improve institutional and work efficiency in the public sector such as, but not limited to, researching and drafting policies and plans, summarizing information from news and reports, helping citizens navigate city services, and answering public queries about regulations and policies (Wray 2023). While there are still many limitations with the latest DSs, the potential of applications like ChatGPT, as well as other LLMs like Bard and LLaMA, remains significant. What they might achieve in the future is likely to surpass our current imagination.
Review Methodology
This review aims to provide an overview of how NLP has been utilized by planning scholars and shed light on how this emerging technology can be better harnessed to improve planning research and practice. To this end, considering that NLP is still quite new to planning and much research is still in the making, I adopt the scoping review method to provide a snapshot of this subfield of planning as well as an overall summary of what has been done so far (Munn et al. 2018).
In this scoping review, I followed a four-step methodology to (1) establish inclusion criterion, (2) search for and identify relevant literature, (3) assess literature quality and eligibility, and finally, (4) identify additional studies through backward searching, being those studies that the included literature cited, and forward searching, which are studies that cited the included literature (Xiao and Watson 2019).
Specifically, for the inclusion criterion, I only included peer-reviewed studies written in English that applied NLP to textual data relevant to urban planning. This includes studies that have urban/city planning as a keyword, are published in an urban planning journal, 2 and are deemed relevant by the author. References were retrieved from Web of Science by searching keywords “natural language processing” or other common NLP techniques, including “text mining,” “topic modeling,” “word embedding,” and “sentiment analysis,” in combination with key terms that limit the results to the planning domain including “urban planning” and “city planning.” The initial search yielded 54 records of individual articles. I then read through the abstracts of these articles to decide their relevance to urban planning. After careful review, a total of 37 articles were deemed eligible. Five articles were excluded because they were applying NLP techniques to nontextual data (e.g., taxi data), three articles were excluded because they were irrelevant to urban planning (e.g., purely methodological), and another six articles were excluded because they were not published in peer-reviewed journals (e.g., conference proceedings). Next, I obtained the full text for these articles and skimmed through them to further assess their eligibility. After careful review, three articles were further excluded because they were either too narrowly focused on methods and/or lacked relevance to urban planning. Lastly, I identified 18 additional relevant studies through forward and backward searching from the 37 articles, which involves a two-staged process whereby I first identify a relevant article based on its title and then decide whether to include the study after reading through its abstracts and keywords. One additional relevant study, suggested by a reviewer, was also added to the review sample. In total, 55 studies were included.
NLP in Urban Planning Research
Planning studies using NLP techniques have significantly proliferated in the last few years, with most papers (85%, or 47 out of 55) included in this review published within the last 5 years 3 (Figure 1). These studies were published in 32 different journals, covering a broad range of topics. They ranged from exploring the evolution of planning research over time and discovering the spatial and temporal patterns of buildings, to gauging public perceptions and awareness during disasters and extracting key information from plans and policy documents. Seven planning journals published one-third of the sampled articles (18/55). These planning journals are Cities (5), Landscape and Urban Planning (3), Computers, Environment and Urban Systems (2), Journal of American Planning Association (4), Environment and Planning B (2), Journal of Planning Research and Education (1), and Urban Studies (1).
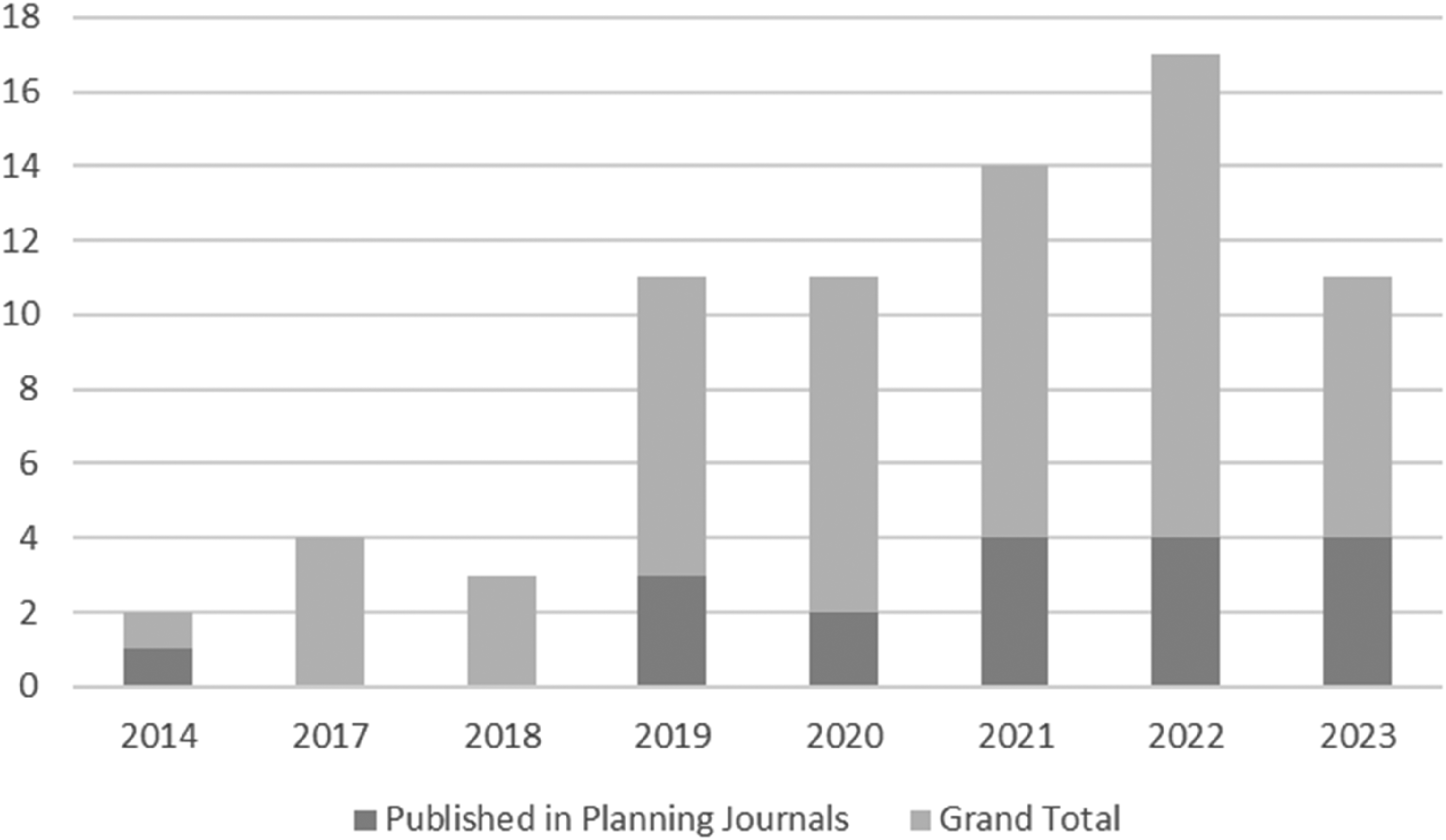
NLP research trend in the review sample.
NLP is primarily used for IES in the existing planning studies. As illustrated in Figure 2, the most used method is topic modeling (27%), followed by sentiment analysis (19%), Word2Vec (17%), latent semantic analysis (12), and others. Existing studies applied these NLP techniques to a wide range of datasets, such as social media data (e.g., Twitter), plans and reports, online advertisements and reviews, and news articles. Despite the diversity of studies in this review, there emerged common themes of applications to planning from the NLP methodologies and the problems they were trying to solve.
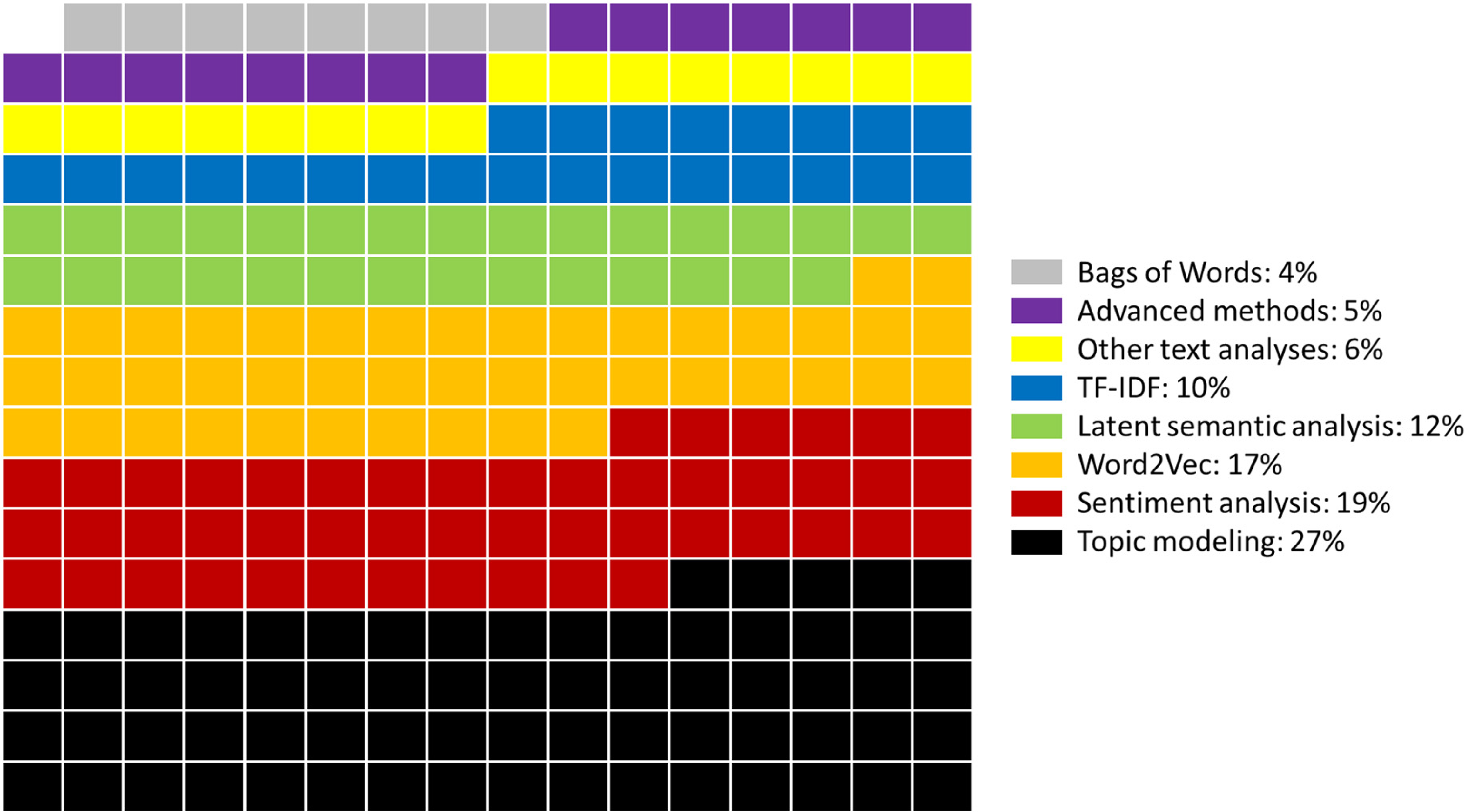
Proportions of NLP methods used in the sampled literature.
Sentiment Analysis
A major theme is assessing public sentiments on relevant planning topics because public opinions have been highly valued in planning (Arnstein 1969; Davidoff 1965; Lalli and Thomas 1989), and sentiment analysis (an NLP technique) offers an alternative way to efficiently collect such information. Planners constantly gather public input through community meetings, public workshops, and requests for public submissions. This is usually from a small, self-selected group of community members, involves a lag in time and is very costly and time-consuming (Einstein, Palmer, and Glick 2019; Tighe 2010). However, the development of social media platforms and the vast amount of data available now offers a promising way to mine public sentiment and opinions over a large population across space and time, in almost real-time, and at very little cost (Liu, Yuan, and Zhang 2020; Ilieva and McPhearson 2018).
There are mainly three approaches for sentiment analysis, including the lexicon-based approach, the machine-learning approach, and the hybrid approach (Wankhade, Rao, and Kulkarni 2022). In planning research, the lexicon-based approach is the most used method due to its ease of use and flexibility, whereas the other methods will require training data that is very difficult to obtain. The lexicon-based approach aims to identify the positive or negative orientation of textual language based on a sentiment/opinion lexicon, such as Liu (2012). Basically, it assigns a polarity score (e.g., −1, 0, +1 for negative, neutral, positive) to each token of the text based on a predefined lexicon or dictionary, and then aggregates the scores of all tokens in the text separately by polarity to identify the highest value polarity scores to denote the overall sentiment. A key disadvantage of this approach is that it is domain-dependent, and words may have different meanings in different domains, thus rendering this approach to be less reliable and accurate in some circumstances (Moreo et al. 2012). Additionally, the machine-learning approach involves training a model on a labeled dataset containing texts with their associated sentiment, and the hybrid approach combines the lexicon-based and machine-learning methods to take advantage of the strengths of both (Wankhade, Rao, and Kulkarni 2022). Furthermore, instead of just analyzing the overall sentiment, there are other approaches like aspect-based sentiment analysis, which identifies specific aspects mentioned in the text and their associated sentiments, and emotion detection, which categorizes text into specific emotions (e.g., happy, sad, anger, etc.), allowing a more granular understanding of the sentiments (Schouten and Frasincar 2015).
Sentiment analysis has been applied in different planning contexts. The dominant context is measuring public perceptions of their living environments to provide the needed empirical evidence in supporting better planning and decision-making for improving urban livability. For example, Hu, Deng, and Zhou (2019a) analyzed reviews online to understand the public sentiments toward the different aspects of their neighborhoods. Huai and Van de Voorde (2022) as well as Kong et al. (2022) analyzed online reviews of parks to investigate environmental features that contribute to the positive and negative perceptions of them. Meanwhile, Tan and Guan (2021) used Twitter tweets to examine the spatiotemporal relationship between public sentiment (i.e., happiness) and housing prices. Another context is to understand how public sentiment evolves over time and space during special events, such as understanding what landscape features of urban greenspace helped alleviate people's negative emotions during the pandemic (Guo et al. 2022), and how public emotions changed over space during the different phases of a disaster event in order to inform better design and implementation of emergency management responses (Yuan, Li, and Liu 2020; Zhai, Peng, and Yuan 2020). One last context worth noting involves analyzing the sentiments of governmental documents (e.g., plans, policies) and/or public officials’ social media accounts to explore planning priorities and potential implementation barriers (Fu, Li, and Zhai 2023; Han, Laurian, and Dewald 2021; Han and Laurian 2023; Puri, Varde, and de Melo 2022).
As previously discussed, sentiment analysis can yield inaccurate results primarily due to methodological limitations; errors may also arise from the poor quality and inherent noise in large datasets. Thus, it is critical to understand the performance of this approach before adoption in research and practice. Two studies compared sentiment results from social media data and survey data, finding a high correlation overall (Huai et al. 2023; Lock and Pettit 2020). However, there's a caveat: the new approach should be seen as complementary to the survey method at this stage due to sample and technique limitations.
Semantic Analysis
Besides sentiment, it is also crucial to understand the actual meanings of natural language, the semantics, from the emerging big data. Semantic analysis, a subfield of NLP, deals with the meaning of sentences and words by grouping them based on their underlying structures created by syntactic analysis (Khurana et al. 2023; Salloum, Khan, and Shaalan 2020). The main objective is to minimize the syntactic structures in order to derive meanings and find synonyms from natural language (Salloum, Khan, and Shaalan 2020). In a planning context, semantic analysis enables us to derive more meaningful information from the big data and, for example, rather than only understanding whether the public is positive or negative about an issue, it can provide further insights into the meanings and reasons related to the sentiments. Although there exists a wide range of NLP techniques to analyze semantics, three common techniques emerged from the planning literature from this review: Word2Vec, latent semantic analysis (LSA), and latent dirichlet allocation (LDA) topic modeling.
Word2Vec is a popular word embedding technique, an approach for transforming individual words into a vector (i.e., a numerical representation of the word), which applies neural networks over a large corpus of text to train a model to learn word associations and contexts (Mikolov et al. 2013a, 2013b). In simpler terms, a model is trained by projecting words from a large corpus of text onto a vector space, with semantically similar words located closer to one another and vice versa. To this end, coupled with other clustering/classification methods (e.g., k-means, random forest, support vector machine) can help extract patterns from the training dataset or be applied to find patterns from other datasets (Guo et al. 2022; Zhai 2022). While Word2Vec provides representations for individual words, it can also be extended to represent sentences (Setence2Vect), paragraphs (Paragraphy2Vec), and even entire documents (Doc2Vec; Jebari, Cobo, and Herrera-Viedma 2018).
In the planning literature, Word2Vect has been used to identify topics such as land uses from online point-of-interest labels (Yao et al. 2017), disaster impacts from social media data (Dou et al. 2021), and textual contents from plans (Kaczmarek et al. 2022). Researchers also used it to automatically detect and classify new information from new datasets. For example, Vargas-Calderón and Camargo (2019) trained a citizen topic model by applying Word2Vect and K-means algorithms to over 2.6 million tweets for automatically classifying new tweets into relevant topics and dynamically tracking public opinions. Similarly, Kim et al. (2021) used Word2Vect with a machine-learning classification method, namely random forest, to train a model using 160,000 civic queries a city collected to automatically classify future public complaints for improving the efficiency of public engagement. Word2Vect can also be applied to undertake sentiment analysis by classifying the words into positive or negative space, such that Chang, Rhee, and Jun (2022) used this approach to analyze public opinions on the built environments using online reviews. In comparison to the lexicon-based sentiment analysis discussed previously, Word2Vec can potentially generate more accurate results as it is trained using domain-relevant dataset, but it is computationally more expensive and requires training data that is generally scarce in planning.
Another popular technique is topic modeling, a suite of statistical models that aim to discover topics from a collection of text documents (Blei 2012; Ramage et al. 2009). The basic assumption behind topic modeling is that documents consist of multiple hidden or latent topics and each topic consists of a collection of words. Hence, the goal of topic models is to uncover these latent topics from the text document collections (Vayansky and Kumar 2020). This is a very useful NLP technique for planners because it can not only extract meaningful information from a large body of contextually relevant texts, but it is also an unsupervised machine learning model, thereby performing contextual analysis without the need for labeled training data. LSA and LDA topic modeling are two of the foundational techniques in topic modeling that are based on different algorithms (i.e., LDA uses a probabilistic approach, while LSA does not, Kherwa and Bansal 2019) to find topic clusters, and they are also the most used techniques in the sampled planning literature.
Similar to the application of Word2Vec, planning research using LSA and LDA topic modeling is also studying social media data (e.g., Twitter tweets) and online texts (e.g., reviews, news articles, housing advertisements) to identify common topics across the collection of text datasets. The differences are that the Word2Vec approach determines the contextual representation of each word by the surrounding terms, disregarding the context of the document, 4 and requires an additional step of clustering in order to identify topics, whereas topic models like LSA and LDA use the documents as context to identify common topics from the document collections (Esposito, Corazza, and Cutugno 2016). Hence, topic modeling not only can automatically extract topics from documents but also allows us to examine the distribution of these topics across and between documents. The document-based analysis of topic modeling is particularly useful for analyzing various governmental documents, such as plans, which share similar addressed topics as well as planning context (i.e., common planning issues and terminologies), yet vary greatly in terms of the breadth and depth of the topics covered and how they are addressed between plans. This is fundamentally because each individual plan is locally developed and contextual to local conditions. There are significant variations between localities (e.g., socioeconomic characteristics of the population, geographic location, environmental resources, etc.), and therefore each locality faces a different set of problems and may also address them using different approaches, as evidenced by the rich body of plan evaluation literature (Berke and Conroy 2000; Berke and French 1994; Fu et al. 2017; Fu and Li 2022; Lyles, Berke, and Smith 2014; Wheeler 2008; Woodruff and Stults 2016).
Several recent studies in our sample attempted to apply topic modeling to a range of governmental documents, which included India's national plans and policies on COVID-19 (Debnath and Bardhan 2020), Calgary's (Canada) local plans (Han, Laurian, and Dewald 2021), council meeting minutes and staff reports from 25 of Canada's largest cities (Lesnikowski et al. 2019), Californian (USA) cities’ general plans (Brinkley and Stahmer 2021), and resilience plans from the 100 Resilient Cities Network (Fu, Li, and Zhai 2023). All the studies considered topic modeling as an effective tool to offer rapid insights into vast planning documents, including useful findings that are otherwise hard to observe. For example, Brinkley and Stahmer (2021) examined the convergence of topics following the identification of topics from 461 Californian city-level general plans, and they found that the topics of housing had little overlap with other planning topics, thereby calling for a more coherent planning framework to build a stronger linkage between highly interconnected planning elements, such as housing, transportation, economic development, and hazard planning (e.g., fire). Building on the topic modeling results, Brinkley and Wagner (2022) further examined how environmental justice was incorporated into a subset of these plans, and Banginwar et al. (2023) developed an interactive database to access and map the different topics across all the 461 Californian plans in real-time. This interactive Californian plan database offers a real use case of leveraging NLP techniques to allow researchers, practitioners, and even the general public to easily access and interact with the lengthy and technical planning documents across the entire state, which are otherwise scattered throughout each of the individual jurisdictions’ websites.
Although topic modeling is quite efficient and effective as an alternative approach to gain useful information from the big text data (i.e., Fu, Li, and Zhai 2023 found that topic modeling results coincided largely, 80%, with those from manual content analysis), all studies agreed that there are several major limitations: (a) topic modeling performs better where there are many long documents and it also requires arbitrarily deciding an appropriate number of topics to be generated, which will significantly influence the performance of the model; (b) topic modeling does not know what the topics mean, as it only generates the groups of words to be later interpreted by humans, so there exist large margins for errors where the model can generate groups of words with no obvious meanings and/or groups of words are misinterpreted by humans; and (c) topic modeling can only extract some of the main information, missing the more in-depth details from the big text data.
Other Approaches
There are several other NLP applications found in the planning literature not mentioned previously, from simple methods used to prepare data for more advanced NLP analysis, such as part-of-speech tagging, dependency parsing, term frequency-inverse document frequency, and bag-of-word model (Jacinto, Reis, and Ferrao 2020; Markou, Kaiser, and Pereira 2019; Zhang, Barchers, and Smith-Colin 2022). Less popular methods are semantic network analysis and named entity recognition model (Han and Laurian 2023; Hu, Mao, and McKenzie 2019b; Su et al. 2021), and there are more advanced techniques such as bidirectional encoder representation from transformers and decomposable attention model (Fan and Zhang 2022; Hu, Wang, and Zhai 2023). Since explaining all these methods is beyond the scope of this review, I urge interested readers to read the cited references or do their own research to find out more about these methods.
None of the planning studies reviewed used only one NLP technique in their research. Usually, multiple NLP techniques are applied together to provide insights into the big text data from various angles. For example, sentiment analysis is very commonly used with Word2Vect or topic modeling to analyze perception and sentiments on the respective topics generated (Fu, Li, and Zhai 2023; Hu, Deng, and Zhou 2019a; Han and Laurian 2023; Su et al. 2021). It should also be noted that NLP in planning research is at a very nascent stage that researchers are currently exploring potential applications as well as examining their reliability and robustness. Most NLP techniques used in the planning literature are the foundational NLP techniques, thus hardly reflecting the latest development in NLP, which is advancing and evolving very rapidly. This suggests a large research gap and potential uptake. Nevertheless, this review offers an initial insight into the current state of NLP research in planning literature, serving as a baseline for future comparisons and highlighting upcoming research challenges and opportunities.
Challenges and Opportunities
Although NLP demonstrates great potential in processing the explosive amount of digital text data, we are admittedly still in the early stage of the product life cycle. In parallel to the introduction of many other potential innovations disruptive to urban planning, such as autonomous vehicles and digital twins, critical challenges accompany the opportunity to improve and possibly transform planning research and practice in the future (Duarte and Ratti 2018; Ye et al. 2023). This review of the 55 articles provides an opportunity to identify these critical challenges and aims to initiate an important academic discourse on NLP applications in planning, in order to lay a coherent research agenda. As such, the following section discusses two key challenges facing NLP application in planning research and practice.
Lack of Result Validation
A critical challenge before mainstreaming NLP techniques remains the need to validate the methodology and the resulting findings. Although NLP techniques hold great promise in obtaining rapid insights from big text data, existing studies are mostly exploratory research that aims to test the various NLP techniques on planning topics and propose methods to gain new information. Very few of them have attempted to validate their results from the NLP approaches. This validation problem is not unique to the NLP application but, in fact, is very common across the adoption of advanced methodologies, particularly those involving black-box algorithms like machine learning, and big data (Grimmer 2015).
I consider this validation problem to be twofold: (1) a methodological problem and (2) a data problem. Many of the NLP techniques involve machine learning, such as topic modeling. As such, the modelers manipulate the source data and the model hyperparameters to find the “best” performing model, but they are unable to explain why this is the case, and nor can they open the “black box” to find out how the results are generated. Another example is the wide presence of sarcasm, metaphors, and colloquial language in social media data that is methodologically challenging for existing NLP techniques, which can be especially problematic for the lexicon-based approach that is commonly used in the planning literature to extract reliable sentiments (Khurana et al. 2023). Hence, this significantly hinders the potential uptake of NLP in urban planning where best evidence and transparency are highly valued to inform decision-making (levy 2016). Despite the appeal of the NLP approach for efficient processing of big data, such methods must be first validated in various planning contexts before they can be actually usable for planners. More research is needed to identify the best practice, by comparing the performance of the latest NLP techniques in various planning contexts, and to provide guidance on a more coherent and consistent approach to utilize these cutting-edge methodologies.
Additionally, another challenge lies in the use of big data such as social media and crowdsourced data in planning research (i.e., 36 out of 55, or 65% of the articles in this review used some types of social media or crowdsourced online data). Such big data does allow us to gain rapid insights into public opinions over a very large spatial and temporal scale at a very little cost, as compared to the conventional surveying approach that is fixed in time and space, expensive, and time-consuming (Thakuriah, Tilahun, and Zellner 2017), but it is also important to acknowledge the key limitations inherent in the big data. One key limitation is regarding the data representation of the population (Ilieva and McPhearson 2018). On the one hand, people who participated in social media or contributed to online reviews only represent a proportion of the population, which is negatively correlated with age and poverty, thereby exhibiting sample bias. On the other hand, there is inevitably noise or bad quality data in the big datasets, such as tweets created by a single person with multiple accounts and computer bots or irrelevant tweets that are wrongly mined due to the generic searching criteria. Some of these biases can be mitigated but not eliminated, so when one works with a huge dataset, how reliable the results are remains uncertain. Hence, it is also crucial for more planning researchers to design studies that compare the results from big data analysis, and not limited to NLP, to those from the traditional survey methods to calibrate the accuracy of applying certain techniques to certain types of big data. Lastly, existing NLP research often uses piecemeal data, and collecting such data can also be highly costly and onerous. For example, many websites, like LinkedIn and Google Scholar, prohibit data scraping. Other essential data, such as good-quality social media data like Twitter, can be quite expensive when purchased from a third-party data provider, and the planning documents are generally dispersed across local sites, making data collection time-consuming. This data fragmentation problem will also hinder colearning and cross-validation, which are crucial steps for refining and validating NLP techniques and applications in planning and other fields. In the future, researchers should aim to publish their data open-access or invest in building data-sharing platforms such as the California General Plan Database Mapping Tool (Banginwar et al. 2023) to better facilitate knowledge sharing and coproduction.
Need for Collaborations
Planners are not conventionally trained to code or analyze big data, which are both required for conducting NLP analysis. However, this is evolving due to a growing recognition of the need for planners to analyze and visualize urban data to achieve improved urban outcomes. This shift is evident in the emergence of degree programs that intersect urban planning and computer/data science, like the Urban Science Degree at the Massachusetts Institute of Technology. However, most existing planning researchers and practitioners still lack such technical capacity, which is also reflected by the representation of planning scholars in the literature reviewed. Out of 55 articles, 19 (35%) are authored by scholars from a planning school and the rest of the articles are mainly authored by researchers from the school of geography, engineering, and science. Additionally, 15 articles (27%) have a planning scholar as the first author and only three of them have coauthors from a nonplanning discipline.
The composition of authorship as well as the content of the articles reviewed offer two important implications. Firstly, planning researchers need to work more collaboratively beyond their own discipline, especially in the case of developing NLP applications, which planners are not trained for. This, in part, explains the use of mostly foundational and simplistic NLP techniques in the planning literature. To this end, the presence of computer scientists who are experts in the NLP field is generally missing in our review sample, including those authored by nonplanning researchers. Collaborative research with computer scientists is crucial for utilizing advanced techniques, such as the state-of-the-art generative pretraining transformer (GPT) behind ChatGPT, or for codesigning tailored methodologies for planning research and practice. Secondly, the planning practitioners’ presence in these articles is also missing, which is critical for designing accessible and useful methodologies for professional planners to build a strong link between planning research and practice (Krizek, Forysth, and Slotterback 2009). Accessibility and trust are the two barriers to adopting such advanced techniques in planning (Ramage et al. 2009). Accessibility refers to the technical barriers facing planners, whereas trust refers to planners’ lack of understanding and experience of the various NLP techniques and data sources. Both barriers can be reduced by involving planning practitioners to (a) improve accessibility by educating them about how and why specific NLP techniques work, (b) earn trust by working with them to explore and validate NLP models to discover or test a hypothesis and, more importantly, to codesign NLP applications that are directly applicable to the needs of practitioners and the communities in which they are serving.
Opportunities: A Research Agenda
Despite the potential high reward, the integration of NLP in urban planning is still at a nascent stage. Most current studies are predominately exploratory, thereby leading to a somewhat fragmented research landscape in this domain. This underscores the need for a structured research agenda to prioritize efforts collectively on tackling key challenges, guiding future research directions, and, ultimately, seeking to harness the full potential of NLP technologies to transform the profession. Below is my perspective on charting a future research trajectory, hoping to serve as a stepping stone for stimulating further research and dialog in this rapidly growing field of research.
As NLP technologies advance, it is imperative for future research to continue exploring novel methods and their potential use in planning, but such work should be undertaken in a more coherent and strategic manner. Specifically, future research needs to emphasize a more consistent data-sharing protocol, ensuring data being used in one study can be reused to facilitate further research as well as cross-validation across various studies. This is because data collection for NLP is often time-consuming and even costly. Ideally, if datasets used in published research are all made open access, it will drive faster research development and greater innovation by allowing other researchers to easily build upon previous discoveries to produce new findings as well as reducing the overall costs from data collection for the discipline. It will also foster interdisciplinary research by making data from planning accessible to other fields and promote equality in research and knowledge distribution by removing barriers and paywalls that hinder research access and productivity for researchers in smaller institutions or developing countries. Additionally, future research should also benchmark the performance of different NLP techniques, particularly now with the latest developments in LLMs like ChatGPT. For example, future studies can evaluate how well ChatGPT can undertake certain NLP tasks such as topic modeling or sentiment analysis as compared to the more conventional NLP techniques, as well as to its competitors such as Google's Bard and Meta's LLaMA. More research is also needed to compare the performance of NLP techniques in certain planning-relevant tasks, such as public engagement and plan evaluation, using conventional methods like surveys and content analysis. Such benchmarking studies can identify areas where NLP can be specifically improved for urban planning and establish best practices, guiding researchers and practitioners in choosing the most appropriate tools for their specific planning objectives. There is an urgent need to collaborate closely with professional planners to genuinely comprehend the use cases of NLP and to adopt an interdisciplinary approach in creating dedicated tools, specifically for urban planners. Bridging the gap between NLP researchers and urban planners is of utmost importance, especially considering the professional nature of our field. This suggests that future research should involve professional planners, to deepen our understanding of the actual challenges and nuances in planning practice, help prioritize research areas, and select the appropriate NLP tools tailored to planners’ specific needs. For example, researchers can work with planners in local governments to explore the use of NLP tools like ChatGPT in processing public feedback data and to examine how and to what extent such tools can aid them in analyzing citizen input. Because no NLP methods have been developed specifically for planning, these general-purpose NLP tools are unlikely to yield satisfactory results, making them unsuitable for direct use in current practice. This is especially the case with the recent developments in LLMs, where researchers have increasingly found that the general-purpose LLM, ChatGPT, underperforms in specific domains such as law and biomedical engineering (Pal et al. 2023; Shen et al. 2023). Researchers from almost all different disciplines are calling for the development of their domain-specific version of LLM, and urban planning should be no exception. Theoretically, a PlanGPT can be potentially developed in two ways, either by training a planning-specific LLM from scratch, or by fine-tuning an existing LLM like ChatGPT to perform better in the planning context. Fine-tuning is currently more realistic. Although building an LLM is expected to perform better overall, it requires daunting amounts of resources, expertise, and time. Nevertheless, both approaches will require extensive, well-structured training data, and expertise beyond the planning domain. Future research should consider how we, as planning researchers, could collectively build a planning-specific dataset through various studies over time, seeking to train a future AI model specifically for planning. We should also actively seek collaboration with computer and AI scientists to design dedicated NLP tools that truly cater to the complex needs of urban planning. The critical ethical and social implications of NLP applications are missing from the existing literature and therefore should be further explored in future research. Future studies should delve deep into understanding the possible ramifications of widespread NLP adoption in urban planning. Issues like data privacy, bias in algorithms, and equitable access to planning tools need to be at the forefront of discussions. For example, can NLP methods produce fair results to inform equitable planning decisions? Like most AI models, many novel NLP methods, trained on extensive digital data, can perform extremely well in certain cases while poorly in others. A vivid example is the wrongful arrest of an African-American, Robert Willams, in June 2020 due to an error made by a facial recognition algorithm, which was trained mainly using white faces (Maxwell and Clémençon 2020). Understanding and mitigating these implications is essential to ensure that NLP technologies benefit all stakeholders in the urban planning process, without inadvertently perpetuating existing societal inequalities.
Conclusion
This article provides a first review of the emerging NLP applications in planning research and identifies critical challenges facing the planning research community in the widespread adoption of this novel methodology. NLP has undeniably huge potential to improve planning research and practice. It can efficiently process vast text data for rapid insights across extensive temporal and spatial scales, potentially help underscore key research gaps, design research frameworks, develop improved plans and policies, and promote critical reflection on the current state of planning theory and practice. Meantime, we must also acknowledge the large limitations of these methods and pay extra caution to their results, as well as the degree to which we can trust them. However, the field of NLP is developing better methods and advancing at an unprecedented speed, so new techniques may become more effective, with fewer limitations, and would be trustworthy and usable in planning research and practice, especially if they are to be codeveloped with planning researchers and practitioners.
Existing planning research primarily uses foundational NLP techniques to extract sentiments and semantic themes from various text datasets, including social media data, online reviews, and governmental plans and policies. In other words, these studies mainly aim to understand the (public) perception of a specific planning issue, such as transportation services or a major disaster, and/or to extract key themes/topics discussed from a large collection of documents. From the review, in order to fully harness the power of NLP, two major challenges emerge: the first is the need to better validate results from the NLP techniques by specifically designing research to compare them to the conventional methodologies such as survey and content analysis, while the second is to work more closely with computer scientists and planning practitioners to adopt the latest NLP techniques and/or codevelop methods that meet the actual needs of planning research and practice. While solutions to these challenges outlined here remain open and how much progress NLP can make in the future may be beyond our imagination, one overarching theme is clear: the demand for NLP techniques in planning, and more generally social science, is high and growing.
Supplemental Material
sj-docx-1-jpl-10.1177_08854122241229571 - Supplemental material for Natural Language Processing in Urban Planning: A Research Agenda
Supplemental material, sj-docx-1-jpl-10.1177_08854122241229571 for Natural Language Processing in Urban Planning: A Research Agenda by Xinyu Fu in Journal of Planning Literature
Footnotes
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
Notes
Author Biography
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.