
Abstract
Background
We aimed to determine the post-hoc power of randomized controlled trials (RCTs) in critical care, and describe the implications for long-term positive (PPV) and negative predictive value (NPV) of statistically significant and non-significant findings respectively in the research field.
Methods
We reviewed three cohorts of RCTs. “Adult-RCTs” were 216 multicenter RCTs with a mortality outcome from a published systematic review. “Pediatric-RCTs” were 120 RCTs with a mortality outcome, obtained by search of picutrials.net. “Consecutive-RCTs” were 90 recent RCTs obtained by screening publications in 6 journals. Post-hoc power for each study was calculated at α 0.05 and 0.005, for measures of small, medium, and large effect-size, using G*Power software. Long-run expected PPV and NPV of critical care research field findings were then calculated.
Results
With α 0.05, post-hoc power for small effect-size was very low in all RCT-cohorts (eg, median 24% in Adult-RCTs). For medium effect-size, post-hoc power was low, except for Adult-RCTs (eg, median 9% in Pediatric-RCTs). For large effect-size, post-hoc power for non-human-animal Consecutive-RCTs was low (median 32%). With α 0.005, post-hoc power was even lower. The corollary was that both PPV and NPV were poor for small effect-size, unless α 0.005 was used. Even with α 0.005, with realistic (vs. optimistic) prior probability of the alternative hypothesis, the PPV was low (eg, in Adult-RCTs 57.1% vs. 92.3%). Adding mild bias (0.1) reduced the PPV even further. For medium effect-size both PPV and NPV were better; nevertheless, with α 0.05 and realistic prior probability of the alternative hypothesis the PPV was poor, and with α 0.005 and mild bias (0.1) the PPV was very low (eg, Adult-RCTs median 44.1%).
Conclusions
To improve the predictive value of findings in the critical care research field, RCTs should be designed to have 80% power for realistic effect-size at α 0.005.
Keywords
Study power is the long-run probability (Pr) that a null-hypothesis statistical test will correctly reject the null hypothesis (Ho) when the Ho is false (see Table 1 for definitions of terms used). 1 A low-powered study is one with low sample size and/or small effects, and has several consequences. First, by definition, a reduced probability of finding a true effect when one exists (ie, lower negative predictive value, NPV; a statistically non-significant finding has a higher probability of having incorrectly rejected the alternative hypothesis H1, and thus a lower probability of having correctly accepted Ho). 1 Second, a reduced probability that an observed effect that reaches “statistical significance” reflects a true effect (ie, lower positive predictive value, PPV).1–1 Third, exaggerated estimates of the magnitude of an effect (“Winners Curse” or “effect inflation”; only those small low-powered studies that, by chance, overestimate the magnitude of the effect will pass the “statistical significance” threshold).1–1 Fourth, a higher incidence of “vibration of effects” (ie, different estimates of the magnitude of effect depending on the analytical options implemented), publication bias (ie, smaller low-powered studies with negative findings more easily disappear into the file drawer, unavailable to contribute to evidence synthesis using meta-analysis), “Proteus phenomenon” (ie, the first study obtains an extreme result, followed by replication studies finding smaller or no effect), and lower quality (ie, less funding and personnel to examine study conduct).1–1
Glossary of Terms and Methods.

Power and α (the long-run probability that a null-hypothesis statistical test will incorrectly reject the Ho when the Ho is true) never compute the probability of a hypothesis. 6 The obtained p-value is a random variable, and should not be confused with α. 7 To compute the long-run probability of the alternative hypothesis given “statistical significance” (ie, PPV, Pr[H1│significant finding]), and of the null hypothesis given “statistical non-significance” (ie, NPV, Pr[Ho│non-significant finding]) across all studies run in a field one must use Bayes Theorem [ie, consider α, power, and pre-study prior Pr[Ho]).8,9
We aimed to determine the power of RCTs in the critical care literature in order to describe the implications of observed power for PPV and NPV of findings in the field. In addition, we aimed to explore predictors of the power of RCTs that might suggest subgroups of RCTs that may require the most attention. Across three cohorts of representative critical care RCTs we found that the power for small and medium effects was low, producing surprisingly low PPV and NPV. In addition, NHA-RCTs may be at particularly high-risk of low power.
Materials and Methods
As only publicly available published data was recorded, this study did not require ethics board approval.
Included Randomized Trials
We examined three cohorts of RCTs in critical care, chosen to be relevant for clinicians and researchers of diverse backgrounds (eg, adult critical care, pediatric critical care, non-human-animal researchers), and to improve generalizability of findings. “Adult-RCTs” were the 216 multicenter RCTs that examined mortality as an outcome from a published systematic review. 10 This was the largest list of systematically reviewed adult critical care RCTs available, which precluded a repeat exhaustive search of the literature for this study. “Pediatric-RCTs” were 120 RCTs that reported an obtained p-value for a mortality outcome; the list was developed by search of https://picutrials.net using the terms “mortality” or “multicenter”, followed by screening of the abstracts (and full text if necessary). 11 This already maintained database of PICU trials precluded a repeat exhaustive search of the literature for this study. “Consecutive-RCTs” were 90 recently published RCTs obtained by screening the title and abstract of all publications in 6 journals (NEJM, JAMA, Critical Care, Critical Care Medicine, Pediatric Critical Care Medicine, and Intensive Care Medicine) starting backwards from January 2019 until 15 publications were included from each journal. Eligibility was defined as: topic involves critically ill patients; and RCT comparing groups with respect to some interventional exposure to report an outcome effect size (ES) and p-value. We excluded studies if the primary outcome had a p-value ≥0.10 (because in a separate study we aimed to explore the reverse-Bayesian implications of obtained p-values, which are most relevant to studies obtaining lower p-values), 12 or the full text did not explicitly report an exact p-value. This cohort was intended to represent a contemporary recent cohort of critical care RCTs in high-impact journals that most critical care clinicians are likely to read. In addition, this cohort allowed us to examine predictors of post-hoc power in a cohort of studies that included all of adult, pediatric, and NHA RCTs.
Data Recorded
A study instruction manual was used, giving detailed explanations (with references) of all study variable definitions, calculations of missing RCT variables, calculations of post-hoc and sensitivity power, and calculations of long-run values of PPV and NPV in the critical care research field based on different chosen ES thresholds, α, prior odds of the Ho, and amount of study bias (Supplemental Material 1). A glossary of term definitions and methods used is shown in Table 1.
We obtained descriptive information from each RCT, including: category of primary outcome; study size; study outcomes with numbers, proportions, means, and standard deviations as appropriate; ES (for studies with obtained p-value ≤0.10, assuming studies with higher p-values had negligible ES) including as relative risk (RR) and standardized mean difference (d), with 95% CI; power calculation numbers if reported; and obtained p-value. In the Consecutive-RCTs we also recorded the main secondary outcome and associated information as above. When not reported, we calculated ES based on the values reported in the published study (Supplemental Material 1).
Outcomes
Power of RCTs
Power for each RCT was calculated based on sample size, and generally accepted (sample size independent and scale-free) measures for what are small, medium, and large ES.13–13 For categorical outcomes (eg, mortality), small, medium, and large ES was defined as RR of 0.81, 0.54, and 0.33 respectively. For continuous outcomes, small, medium, and large ES was defined as d of 0.2, 0.5, and 0.8 respectively.
Post-hoc power was calculated, using G*Power, by entering the RCT sample size (assuming equal allocation to each group to maximize power), the desired two-sided α (0.05 or 0.005), and, for RR calculations, the obtained control group proportion, and the expected proportion for the desired RR (Supplemental Material 1).16,17 This was not a retrospective power analysis, which would have used the obtained ES to calculate the “observed power”, a value determined solely by the observed p-value and thus adding no further information to the p-value.4,18–18 Sensitivity power was calculated, using G*Power, which determined the minimum ES a study was sufficiently sensitive to detect with power of 80% given the RCT sample size and desired two-sided α (0.05 or 0.005).16,17
Long-run Values for the Research Field
Based on median [interquartile range] post-hoc calculated power for small and medium ES we calculated values of interest over the long-term for the critical care research field (Supplemental Material 1).1,2,5,8,9 False report probability and true report probability (PPV), false negative report probability and true negative report probability (NPV) were calculated as shown in Table 2. Values were calculated for α of 0.05 and 0.005, and for pre-study odds Ho:H1 that were optimistic (1:1) and more realistic (9:1).1,2,5,8,9 Bayes Factor (BF), the extent to which the observation that p ≤ α changes the prior odds that H1 rather than Ho is true, was calculated as power/α.
Calculations of Predictive Values Based on Prior Odds of the Hypothesis, Power, Alpha, and Bias. a

FN: false negative; FP: false positive; Ho: the null hypothesis; H1: the alternative hypothesis; O: the pre-study odds of Ho:H1 in a research field; TN: true negative; TP: true positive; α: Type I error (this is not equivalent to the p-value); β: Type II error (such that 1-β = Power).
Calculations of outcomes are as follows: PPV = TP/(TP + FP); NPV = TN/(TN + FN). Note that NPV does not change with changes in bias [ie, the (1-bias) in numerator and denominator cancel out].
The effects of bias on PPV and BF was calculated as shown in Table 2. Bias was defined as “any kind of implicit or explicit technique, manipulation, or error which can result in the outcome that a certain proportion of results which would otherwise be reported as statistically non-significant will be reported as statistically significant”. 5 Bias of 0.1, 0.2, and 0.3 were used, as suggested by others.2,5,8 The BF was calculated as (Power + bias[β])/(α + bias[1-α]).
Statistics
Descriptive results are presented using counts and percentages, median, interquartile range [IQR], and range (minimum to maximum). We explored predictors of post-hoc power and sensitivity power at alpha 0.05 and 0.005 using univariate and (after excluding multicollinearity) multiple variable linear regressions for each RCT cohort. Although we initially planned to explore predictors of post-hoc power for small ES in all RCT-cohorts, because we found that post-hoc power for small ES was very low and with little variability for non-Adult-RCT cohorts, we decided to instead explore predictors of post-hoc power for medium ES in these RCT-cohorts. The three RCT cohorts were considered too different to allow pooling for this analysis; for example, Adult-RCTs did not include Pediatric or NHA studies, Pediatric-RCTs did not include Adult or NHA studies, and Consecutive-RCTs were not always based on mortality or binary outcomes. The possible predictors for univariate analyses were pre-specified: field of sepsis (the most common category for Adult-RCTs and Pediatric-RCTs), mortality as primary outcome, study year 2011 to 2019 (for Adult-RCTs and Pediatric-RCTs), multicenter study or number of centers (>20 for Adult-RCTs, >10 for Pediatric-RCTs), number of patients, mortality in control group (for Adult-RCTs and Pediatric-RCTs), p-value category, study RR, and higher mortality in intervention group (for Adult-RCTs with p ≤ 0.05). For Consecutive-RCTs we added study continent of Europe (47.8% of included studies), higher impact journal (NEJM or JAMA), species non-human-animal (NHA), power calculation reported, and d. In multiple regressions variables were included if p-value in the univariate regression was <0.10, while forcing “multicenter study” (for Pediatric-RCTs and Consecutive-RCTs), and NHA (for Consecutive-RCTs). We considered p ≤ 0.05 as statistically suggestive.
Results
Description of Included RCTs
The 216 Adult-RCTs, described in E-Table 1 (Supplemental Material 2), had a median power calculation control group mortality of 40% [29, 50], median obtained control group mortality of 31.5% [24.1, 41.7] and intervention group mortality of 30.4% [21.1, 39.4]. For the 57 RCTs that obtained p-value ≤0.10, the median obtained absolute risk difference (ARD) was 13.8% [8.6, 20.3]. The obtained ES was trivial in 10 (18%), small in 34 (60%), medium in 9 (16%), and large in 5 4 (7%).
We searched the 444 RCTs in the EPICC database; after exclusions, we included 120 Pediatric-RCTs described in E-Table 2 (Supplemental Material 2). For the 25 RCTs that obtained a p-value ≤0.10, the obtained median ARD was 19.1% [9.1, 30.3]. The obtained ES was trivial in 2 (8%), small in 7 (28%), medium in 3 (12%), and large in 13 (52%).
We screened 269 studies in 6 journals, and after exclusions (E-Table 3, Supplemental Material 2) included 90 Consecutive-RCTs described in E- Table 4 (Supplemental Material 2). These were RCTs in NHA in 21 (23%), and in children or neonates in 20 (22%). The obtained ES were trivial in 10 (11.1%, all Human-RCTs), small in 31 (34.4%, 29 [42%] of Human-RCTs and 2 [9.5%] of NHA-RCTs), medium in 14 (15.6%, all Human-RCTs), and large in 33 (36.7%, 16 [23.2%] of Human-RCTs and 17 [81%] of NHA-RCTs). The included Consecutive-RCTs are listed in Supplemental Material 3.
Power of RCTs
Post-hoc and sensitivity power of Adult-RCTs, Pediatric-RCTs, and Consecutive-RCTs (for primary and secondary outcomes) are shown in Table 3.
Post-hoc and sensitivity power of Adult-RCTs, Pediatric-RCTs, and Consecutive-RCTs using α of 0.05 and 0.005.
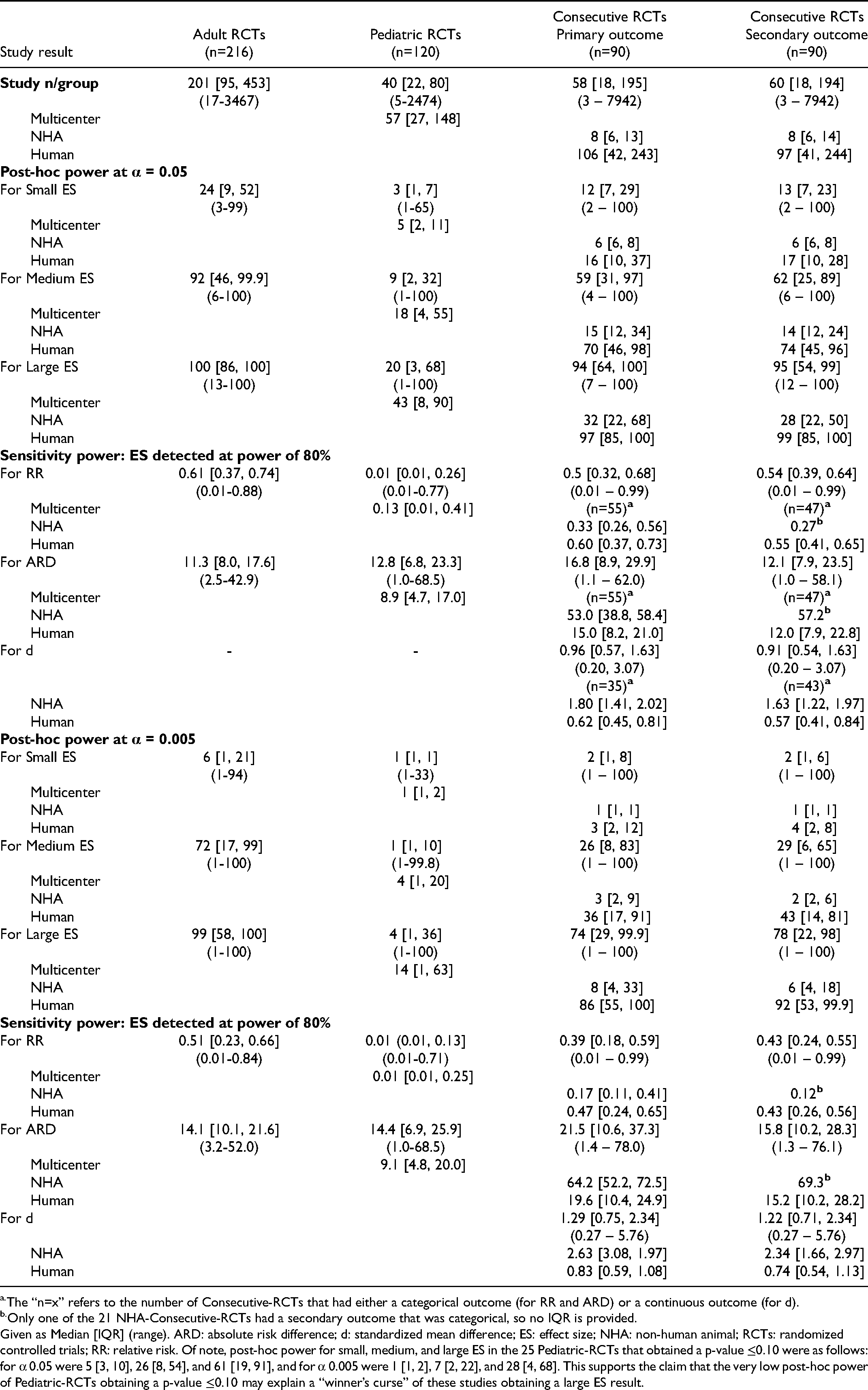
The “n=x” refers to the number of Consecutive-RCTs that had either a categorical outcome (for RR and ARD) or a continuous outcome (for d).
Only one of the 21 NHA-Consecutive-RCTs had a secondary outcome that was categorical, so no IQR is provided.
Given as Median [IQR] (range). ARD: absolute risk difference; d: standardized mean difference; ES: effect size; NHA: non-human animal; RCTs: randomized controlled trials; RR: relative risk. Of note, post-hoc power for small, medium, and large ES in the 25 Pediatric-RCTs that obtained a p-value ≤0.10 were as follows: for α 0.05 were 5 [3, 10], 26 [8, 54], and 61 [19, 91], and for α 0.005 were 1 [1, 2], 7 [2, 22], and 28 [4, 68]. This supports the claim that the very low post-hoc power of Pediatric-RCTs obtaining a p-value ≤0.10 may explain a “winner’s curse” of these studies obtaining a large ES result.
Post-hoc power for small ES was low in all RCT cohorts using α 0.05: 24 [9, 52], 3 [1, 7], 12 [7, 29], and 13 [7, 23] respectively. Post-hoc power was better for medium ES at α 0.05, at 92 [46, 99.9] for Adult-RCTs, but still low for Pediatric-RCTs and Consecutive-RCTs at 9 [2, 32], 59 [31, 97], and 62 [25, 89] respectively. Post-hoc power was far lower at α 0.005, including for medium ES was far lower at α 0.005, where even for Adult-RCTs post-hoc power was at 72 [17, 99]. Post-hoc power for even large ES was low at α 0.05 for Pediatric-RCTs and Consecutive-NHA-RCTs, at 20 [3, 68] and 32 [22, 68] respectively.
Sensitivity power (ie, the ES detectable at power 80%) was for a medium or greater ES in Adult-RCTs and Consecutive-Human-RCTs; even for the best cohort of studies, Adult-RCTs, a median RR 0.61 and (corresponding to an ARD 11.3%) at α 0.05, and median RR 0.51 and (corresponding to an ARD 14.1%) at α 0.005. This sensitivity power was markedly worse for Pediatric-RCTs, at α 0.05 median RR 0.01 and ARD 12.8%. Sensitivity power was also poor for Consecutive-NHA-RCTs, at α 0.05 median RR 0.33, ARD 53%, and d 1.80.
We explored predictors of post-hoc power for small ES in Adult-RCTs, and for medium ES in Pediatric-RCTs and Consecutive-RCTs for primary outcome (E-Tables 5–8, Supplemental Material 2). On multiple variable linear regressions consistent predictors of higher post-hoc power in Adult-RCTs and Pediatric-RCTs were higher number of centers, number of patients, and control group mortality. In Consecutive-RCTs predictors were NHA-RCT (at α 0.05, coefficient −39.3
Long-run Values for the Critical Care Research Field
Small ES: Values are given for Adult-RCTs in Table 4, and Pediatric-RCTs and Consecutive-RCTs primary outcomes in E-Tables 9 and 10 (Supplemental Material 2; we did not calculate these for secondary outcomes as post-hoc power was similar to that for primary outcomes). Adult-RCTs had the best values, at α 0.05 with PPV and NPV median 82.8% and 55.6% respectively. Pediatric-RCTs had the worst values, at α 0.05 with PPV and NPV median 37.5% and 49.5% respectively (somewhat better for multicenter studies, with PPV and NPV median 50%; in what follows we focus on these better values for multicenter Pediatric-RCTs). Consecutive-Human-RCTs had values similar to Adult-RCTs, while Consecutive-NHA-RCTs had lower values, at α 0.05 a median PPV 54.5% and NPV 50.3%. The PPV was higher with α 0.005 (reaching median 92.3% for Adult-RCTs and 66.7% for multicenter Pediatric-RCTs and NHA-Consecutive-RCTs), without much change in NPV.
Long-run Values for the Critical Care Research Field for Small Effects in 216 Multicenter Adult-RCTs with a Mortality Outcome.
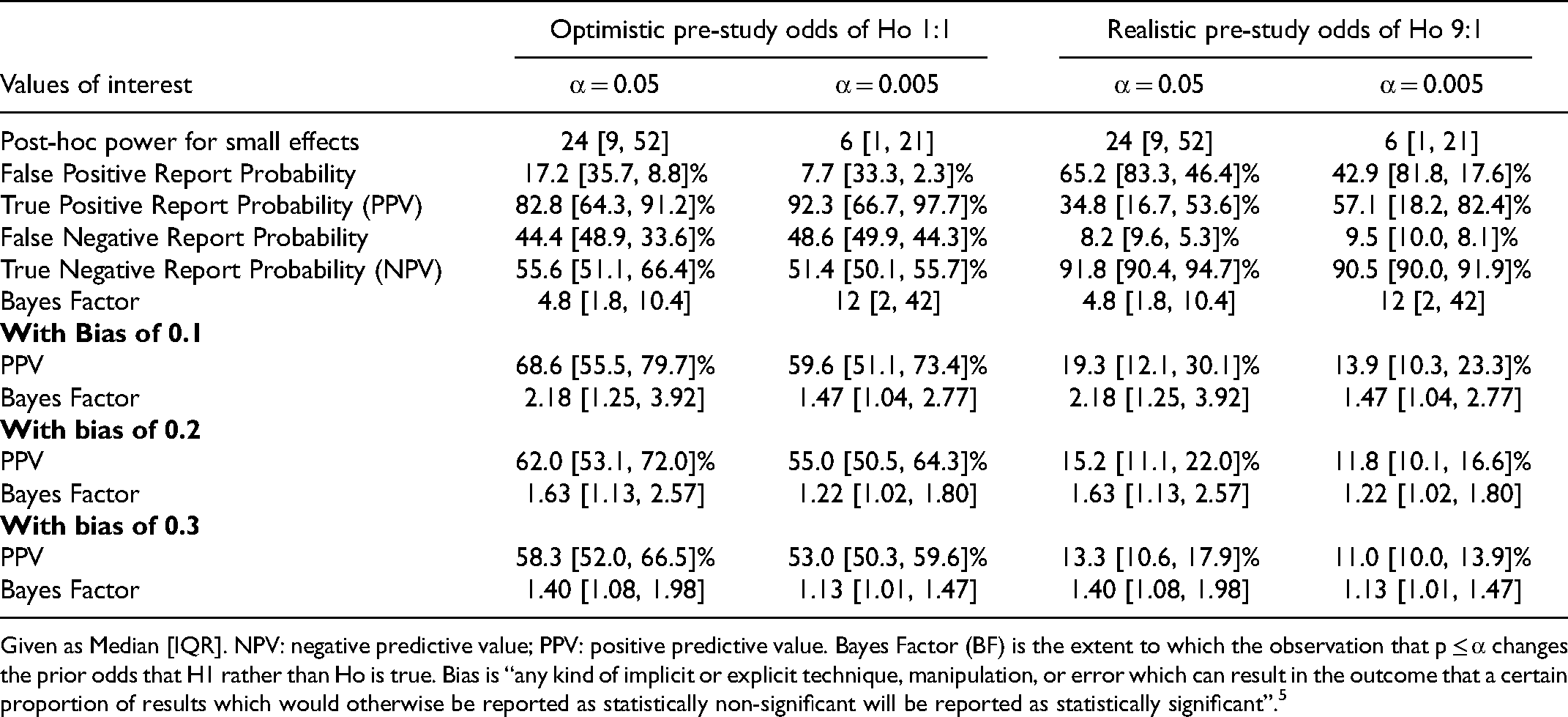
Given as Median [IQR]. NPV: negative predictive value; PPV: positive predictive value. Bayes Factor (BF) is the extent to which the observation that p ≤ α changes the prior odds that H1 rather than Ho is true. Bias is “any kind of implicit or explicit technique, manipulation, or error which can result in the outcome that a certain proportion of results which would otherwise be reported as statistically non-significant will be reported as statistically significant”. 5
The PPV was markedly lower, and NPV much higher, when using a realistic prior Pr(H1). For Adult-RCTs at α 0.05 and 0.005, the PPV was median 34.8% and 57.1%, and the NPV was 91.8% and 90.5% respectively. For multicenter Pediatric-RCTs the respective values were, for PPV median 10% and 18.2%, and NPV 90% and 90%. Similarly, for Consecutive-Human-RCTs the PPV was median 26.2% and 40%. Adding mild bias (of 0.1) reduced the PPV and BF markedly; in Adult-RCTs the PPV at α 0.05 and 0.005 reduced to median 68.6% and 59.6%, and with a realistic prior Pr(H1) to 19.3% and 13.9 1% respectively.
Medium ES: Values are given in Tables 5–7 for respective RCT-cohorts (and E-Table 11 for Consecutive-RCT secondary outcomes, Supplemental Material 2). Overall, the PPV and NPV were higher than for small ES. Using realistic prior Pr(H1) for Adult-RCTs the PPV at α 0.05 and 0.005 were median 67.2% and 94.1% respectively. In multicenter Pediatric-RCTs these values were median 28.6% and 47.1%. In Consecutive-Human-RCTs these values were 60.9% and 88.9% for primary outcome and 62.2% and 90.5% for secondary outcomes. Again, PPV was higher with α 0.005 and lower when using a realistic prior Pr(H1), and NPV was higher with realistic Pr(H1), always >90%. Adding mild bias (0.1) reduced the PPV and BF markedly; in Adult-RCTs, with realistic Pr(H1), median PPV at α 0.05 and 0.005 were 41.3% and 44.1% respectively.
Long-run Values for the Critical Care Research Field for medium Effects in 216 Multicenter Adult-RCTs with a Mortality Outcome.
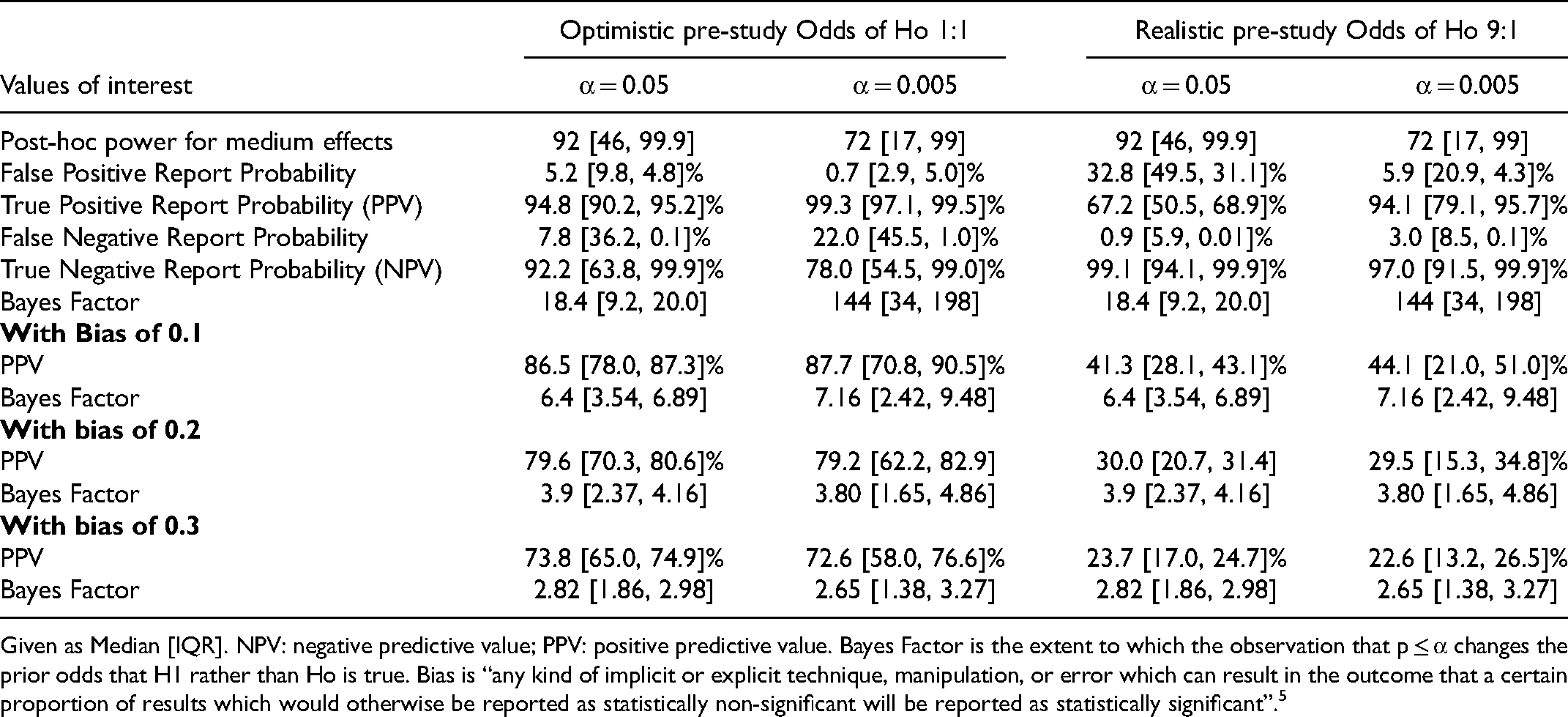
Given as Median [IQR]. NPV: negative predictive value; PPV: positive predictive value. Bayes Factor is the extent to which the observation that p ≤ α changes the prior odds that H1 rather than Ho is true. Bias is “any kind of implicit or explicit technique, manipulation, or error which can result in the outcome that a certain proportion of results which would otherwise be reported as statistically non-significant will be reported as statistically significant”. 5
Long-run Values for the Pediatric Critical Care Research Field for medium Effects in Pediatric-RCTs with a Mortality Outcome.
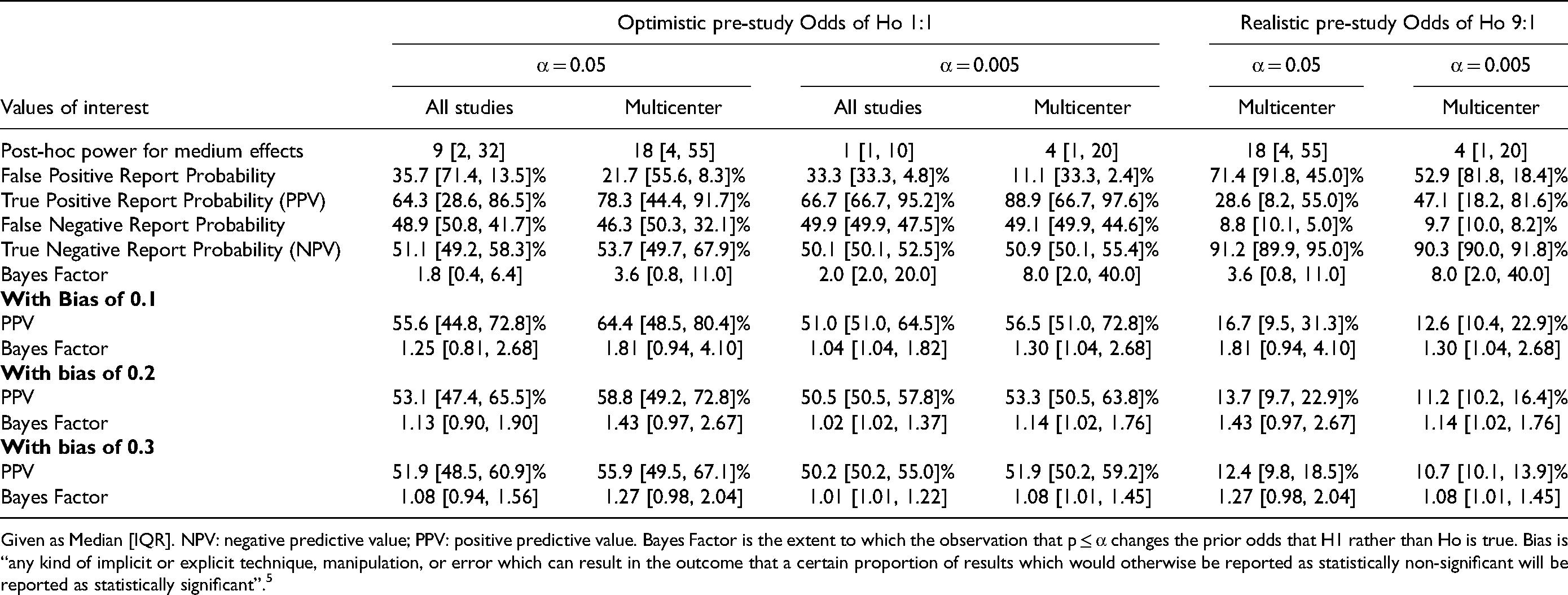
Given as Median [IQR]. NPV: negative predictive value; PPV: positive predictive value. Bayes Factor is the extent to which the observation that p ≤ α changes the prior odds that H1 rather than Ho is true. Bias is “any kind of implicit or explicit technique, manipulation, or error which can result in the outcome that a certain proportion of results which would otherwise be reported as statistically non-significant will be reported as statistically significant”. 5
Long-run Values for the Critical Care Research Field for medium Effects in 90 Recently Published Consecutive-RCTs with a Primary Outcome.
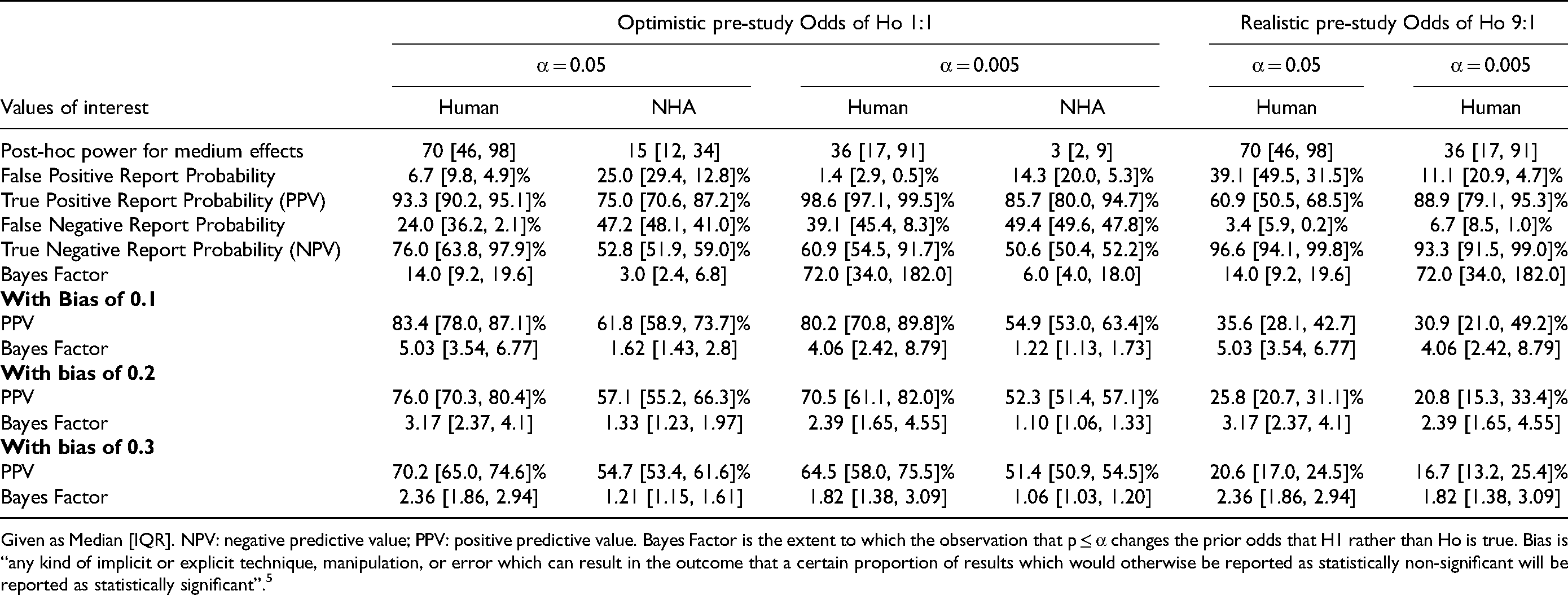
Given as Median [IQR]. NPV: negative predictive value; PPV: positive predictive value. Bayes Factor is the extent to which the observation that p ≤ α changes the prior odds that H1 rather than Ho is true. Bias is “any kind of implicit or explicit technique, manipulation, or error which can result in the outcome that a certain proportion of results which would otherwise be reported as statistically non-significant will be reported as statistically significant”. 5
Discussion
We examined three cohorts of critical care RCTs in order to demonstrate the implications of low-powered studies. The Adult-RCTs (multicenter, with mortality outcome) and Consecutive-RCTs (published in relatively high-impact journals) may represent some of the best RCTs in the critical care research field. The Pediatric-RCTs (published in many different journals, and often not having mortality as the primary outcome) may be more representative of RCTs in the research field. Our main findings include the following.
First, most RCTs often overestimated control group mortality, and most obtained high ARD, and obtained trivial or small ES. Exceptions were the Pediatric-RCTs and Consecutive-NHA-RCTs that often obtained large ES (likely due to Winner's Curse, as these RCTs had the lowest post-hoc power).1,5,9 Second, with α 0.05, post-hoc power for small ES was low in all RCT-cohorts (eg, the highest was median 24% for Adult-RCTs), for medium ES was low except for Adult-RCTs (eg, median 9% in Pediatric RCTs), and for large ES was low in Consecutive-NHA-RCTs (median 32%) and Pediatric-RCTs (median 20%). With α 0.005 the post-hoc power was even lower. An exploratory analysis suggests that low power was a general phenomenon in the field, as multivariate analysis did not find consistent predictors of post-hoc power.
Third, the corollary of low post-hoc power was that the PPV and NPV were poor for small ES. These values improved when unless α 0.005 was used; nevertheless, even with α 0.005, when using a realistic prior Pr(H1) the PPV was low, while the NPV improved. The PPV and NPV were better for medium ES; nevertheless, with α 0.05 and realistic prior Pr(H1) the PPV was poor, and with α 0.005 and little bias (0.1) the PPV was also low (eg, Adult-RCTs median 44.1%). Adult-RCTs and Consecutive-Human-RCTs most often found small ES; with realistic Pr(H1) and small ES, at α 0.05 or 0.005 these RCTs had PPV median 34.8% and 57.1%, and 26.2% and 40.0% respectively. Pediatric-RCTs, with realistic Pr(H1) and medium ES, had PPV median 28.6% and 47.1% respectively. Adding even small amounts of bias (0.1) markedly reduced these PPV values, without affecting NPV.
Others have reported similar findings in different research fields. Median power in neuroscience papers was 21% to detect medium to large ES, and in recent cognitive neuroscience and psychology literature 12% and 44% to detect small and medium ES, with no sign of increase in power over six decades.1,2,21 The authors of those papers discussed implications of low power on study PPV (or its complement, the false positive risk).1,2 In critical care RCTs, overestimation of control group mortality and “delta inflation” (defined as biased overestimates of predicted treatment ES during trial design, with delta-gaps averaging up to 8.7%) is common; this results in RCTs that have sample sizes too low and hence low power.22–22 The authors of those papers did not report the exact power for different ES obtained in the RCTs, and only suggested that inadequate power may account for falsely negative RCTs (ie, low NPV).22–22 In critical care RCTs a low fragility-index is common, defined as the minimum number of reversals in outcome that need to occur for the result to no longer be statistically significant; this reflects the relatively small sample sizes and unrealistic treatment ES.25–25 The fragility index is based on the obtained p-value and can be said to simply be “repackaging of the p-value”; 29 it reflects the instability of obtained p-values between 0.05-0.005. In contrast, our method considered the long-term reliability of studies done in a research field with a certain empirical power and, crucially, designed with a certain α level and a specified prior Pr(Ho). This reflects what to expect long-term from studies done in a research field that uses that specified design; importantly, after the data is in and an exact p-value is obtained, the credibility of that individual study requires a different analysis, and these reverse Bayesian implications of the cohorts of RCTs we have reported elsewhere.12,30 Modeling of incentive structures in science determined that to maximize scientists’ fitness they should “spend most of their effort seeking novel results and conduct small studies that have only 10-40% statistical power [such that at least] half of the studies they publish will report erroneous conclusions”. 31 To our knowledge, the current study is the first to present detailed implications of low power for a research field, and particularly in the field of critical care. By determining the surprisingly low empirical post-hoc and sensitivity power of representative cohorts of RCTs in critical care we detail many implications including low NPV (of a non-statistically significant finding), low PPV (of a statistically significant finding), and how these vary with the chosen α, ES to be detected, defensible Pr(Ho), and even small amounts of bias. Based on these findings, we suggest that, to improve the credibility of findings in the critical care research field, RCTs be designed to have at least 80% power for realistic (likely small) ES at α 0.005. Importantly, this will guard against overly-optimistic estimates of Pr(H1).
The optimistic Pr(H1) we used was 50%, reflecting clinical equipoise that is considered to justify blinding and randomization. 32 The realistic Pr(H1) we used was 10%, suggesting that only 10% of all interventions studied in critical care RCTs are found to be useful. This choice can be defended. First, 10% (and often lower) has been suggested by others as a realistic estimate of the proportion of interventions tested in a field that prove successful.5,33 Second, systematic reviews of adult and pediatric critical care RCTs consistently find that <10% of tested interventions prove successful with wide implementation in practice.10,11,24 Third, reviews of translation from NHA studies to human clinical practice consistently find that <10% (and often closer to 0%) of interventions succeed.34,35 Fourth, even interventions thought useful in human critical care RCTs often turn out to have been false-positive findings, with few proven interventions that improve outcomes.10,36–39
The suggestion that RCTs be designed to have at least 80% power for realistic ES at α 0.005 will require attention to realistic control group outcome rates (to avoid over-estimation), realistic expected treatment ES (to avoid delta inflation), and design based on a more stringent α of 0.005.22–22,33 To achieve this goal, the sample size of many RCTs (especially Pediatric-RCTs) would need to increase, often requiring larger multicenter studies; using α 0.005 instead of 0.05 while maintaining 80% power would require an increase in sample sizes of about 70%. 33 This may result in fewer and costlier RCTs being performed. We believe the many benefits of this approach will outweigh these costs. First, low powered RCTs have both poor PPV and NPV (as shown here), yield inflated ES estimates, and are more prone to publication and other biases as shown by others.1–1 This makes results less credible individually and in meta-analyses, and may lead to premature abandonment of promising therapies, to premature adoption of false-positive or overly optimistic findings, and to falsely optimistic future studies based on misleading ES estimates. Second, low powered RCTs expose research participants to risk without sufficient benefit of expanding knowledge and improving care of future patients. Third, low powered RCTs may consume scarce research resources without resulting in sufficient scientific or clinical value.
This study has limitations. First, we did not consider all RCTs in critical care, limiting generalizability of findings. Using three cohorts of RCTs to represent the field somewhat mitigated this concern. Second, we did not assess bias in the included RCTs, and thus do not know if the bias factors considered were accurate. A bias factor of 0.1 is thought to be small, and when assessing an individual RCT determining potential biases can inform the relevance of this estimate.5,33 Third, we only included RCTs, and only mortality outcomes for the Adult-RCTs and Pediatric-RCTs; our findings may not generalize to observational studies and non-mortality outcomes. Observational studies provide more opportunity for bias to influence results.40–43 Non-mortality outcomes sometimes are more subjective, also providing opportunity for bias; non-mortality outcomes were included in the Consecutive-RCTs with similar results.9,43 Fourth, mortality was not the primary outcome for 26.9% of Adult-RCTs, and 84.2% of Pediatric-RCTs, potentially reducing the calculated post-hoc power. Mortality as the primary outcome was not an independent predictor of post-hoc power for small ES in Adult-RCTs, nor of post-hoc power for medium ES in Pediatric-RCTs or Consecutive-Human-RCTs. Fifth, excluding Consecutive-RCTs obtaining a p-value ≥0.10 may have given non-generalizable results for this cohort of RCTs. Findings for Consecutive-Human-RCTs were similar to those for Adult-RCTs, and better than for Pediatric-RCTs, where we did not exclude studies based on p-value. In addition, p-value category was not a predictor of post-hoc power in Adult-RCTs or Pediatric-RCTs.
This study had several strengths. First, we examined three large cohorts of RCTs, representing some of the best critical care RCTs. Second, we used a detailed instruction manual to guide recording data and calculate outcomes. Third, we calculated not only post-hoc and sensitivity power, but also determined the implications of post-hoc power for the PPV and NPV of findings in the critical care research field.
Conclusions
Post-hoc power was low, particularly for small ES, at α 0.005, in NHA-RCTs and Pediatric-RCTs, or when RCTs may have mild bias. This translated into low PPV and often low NPV of RCT findings. We suggest that, to improve the reliability of findings in the critical care research field, RCTs be designed to have as minimal bias as possible, and with 80% power for realistic (likely small) ES at α 0.005. Otherwise, the field is likely to find that “most published research findings are false”. 5
Supplemental Material
sj-docx-1-jic-10.1177_08850666221077203 - Supplemental material for Critical Care Randomized Trials Demonstrate Power Failure: A Low Positive Predictive Value of Findings in the Critical Care Research Field
Supplemental material, sj-docx-1-jic-10.1177_08850666221077203 for Critical Care Randomized Trials Demonstrate Power Failure: A Low Positive Predictive Value of Findings in the Critical Care Research Field by Sarah Nostedt and Ari R Joffe in Journal of Intensive Care Medicine
Supplemental Material
sj-docx-2-jic-10.1177_08850666221077203 - Supplemental material for Critical Care Randomized Trials Demonstrate Power Failure: A Low Positive Predictive Value of Findings in the Critical Care Research Field
Supplemental material, sj-docx-2-jic-10.1177_08850666221077203 for Critical Care Randomized Trials Demonstrate Power Failure: A Low Positive Predictive Value of Findings in the Critical Care Research Field by Sarah Nostedt and Ari R Joffe in Journal of Intensive Care Medicine
Supplemental Material
sj-docx-3-jic-10.1177_08850666221077203 - Supplemental material for Critical Care Randomized Trials Demonstrate Power Failure: A Low Positive Predictive Value of Findings in the Critical Care Research Field
Supplemental material, sj-docx-3-jic-10.1177_08850666221077203 for Critical Care Randomized Trials Demonstrate Power Failure: A Low Positive Predictive Value of Findings in the Critical Care Research Field by Sarah Nostedt and Ari R Joffe in Journal of Intensive Care Medicine
Footnotes
Funding
This work was supported by a University of Alberta, Department of Pediatrics Resident Research Grant awarded to Dr Sarah Nostedt. The funding agency had no role in design and conduct of the study; collection, analysis or interpretation of the data; preparation, writing, review, or approval of the manuscript; or the decision to submit the manuscript for publication.
Author's Contributions
SN and ARJ contributed to conception and design of the work; acquisition, analysis, and interpretation of the data; and substantial critical revisions of the manuscript for important intellectual content; have approved the submitted version; and have agreed to be accountable for all aspects of the work in ensuring that questions related to the accuracy or integrity of any part of the work are appropriately investigated and resolved. ARJ wrote the first draft of the article.
Ethics Approval and Consent to Participate
Not applicable. This study used only data from published studies, and thus was exempt from requirements for ethics board approval.
Availability of Data and Material
The datasets used and/or analyzed during the current study are available from the corresponding author on reasonable request.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.