
Abstract
Introduction
Large language models (LLMs) have generated considerable interest in the medical community for their potential to transform clinical decision-making and patient care. 1 Their capacity to rapidly generate coherent responses makes them attractive for tasks ranging from summarizing research findings to synthesizing complex patient data.2,3 However, when applied to specialized clinical contexts, general-purpose LLMs often reveal shortcomings as they rely primarily on publicly available data and may not be trained on proprietary or region-specific guidelines. 4 Consequently, they can produce outputs that lack alignment with expert consensus or fail to account for subtleties relevant to a particular patient population or healthcare system.5,6
One critical challenge is the management of incidental findings, such as incidental hepatobiliary lesions, which occur in up to 30% of radiological investigations.7-9 These findings range from a spectrum of clinical significance, from benign cysts to potentially malignant masses warranting further investigation. Accurately providing management recommendations for these scenarios is essential to preventing misdiagnosis and avoiding unnecessary interventions.
Guidelines from the Canadian Association of Radiologists (CAR), building on the body of work produced by the American College of Radiology,10,11 offer a structured approach to handling incidental hepatobiliary findings. 9 Tailored to Canada’s healthcare system, they are a valuable resource for radiologists. However, their evolving and specialized nature makes it unlikely that any general-purpose LLM has been comprehensively trained on them, underscoring the potential risk of relying on a model’s “internal” knowledge alone.
Retrieval-augmented generation (RAG) has emerged as a compelling strategy to overcome these limitations. By integrating an external retrieval mechanism into the generation process, RAG systems enable LLMs to access domain-specific content in real-time. This approach retains the broad linguistic and inferential strengths of LLMs while mitigating their knowledge gaps. As a result, RAG-enabled models may reduce the likelihood of inaccuracies, hallucinations, and deviations from evidence-based practice.
This is the first study to evaluate RAG with two distinct LLMs for adherence to the CAR guidelines for incidental hepatobiliary findings. The primary objective was to assess adherence rates with and without RAG, while secondary objectives included evaluating reading complexity and response times of generated outputs. By addressing these objectives, this study seeks to advance the application of artificial intelligence in radiology, illustrating how RAG-enabled systems may bridge the gap between broad language processing capabilities and the specialized demands of clinical practice.
Methods
Clinical Case Construction
Clinical cases were systematically constructed to capture a diverse spectrum of incidental hepatobiliary findings frequently encountered in imaging studies.9-11 Guided by the CAR recommendations for incidental hepatobiliary findings, the guidelines were deconstructed to identify key variables affecting clinical decision-making. These variables included patient demographics (eg, age, sex), relevant clinical history (eg, underlying hepatobiliary disease, risk factors), and imaging characteristics (eg, lesion size, margins, homogeneity, attenuation). By systematically varying these factors, the constructed cases encompassed a wide range of presentations and patient demographics, each following a standardized template. An iterative review process was then undertaken in which a focus group of radiologists and clinicians external to the study team evaluated the cases. Their feedback helped refine the cases to more accurately represent actual clinical presentations.
Large Language Model Selection
Two LLMs, GPT-4o and o1-mini, were selected for evaluation based on their distinct capabilities relevant to the study’s objectives. GPT-4o (version gpt-4o-2024-08-06) was chosen for its general-purpose language understanding, contextual reasoning, and broad knowledge base, making it well-suited for diverse linguistic and conceptual tasks. This model, trained on data up to October 2023, represents one of the most widely adopted and advanced LLMs in real-world applications. Its selection ensures the inclusion of a state-of-the-art model with strong generalization abilities across multiple domains. The model was accessed through OpenAI’s Application Programming Interface (API), 12 with prompts submitted programmatically and responses retrieved in text format. The default temperature (0.7) used in web-based interactions was preserved to maintain consistency between test conditions. 12
In contrast, o1-mini (version o1-mini-2024-09-12), was selected for its specialized training in science and mathematical reasoning, prioritizing efficiency and domain-specific accuracy. 13 While also trained on data up to October 2023, o1-mini’s smaller architecture and targeted training corpus allow for a comparison between a domain-focused model and a broader general-purpose model in structured tasks. Prompts to o1-mini followed the same standardized input format as GPT-4o, with outputs similarly retrieved for analysis.
RAG Architecture Development
A custom RAG architecture was developed and implemented in Python to provide the two LLMs with external information (Figure 1). The CAR guidelines for incidental hepatobiliary findings were digitized into a structured format and embedded using a text-embedding model (text-embedding-ada-002 developed by OpenAI 14 ) to allow for high-fidelity vector representations. The guideline texts were tokenized and chunked using the LangChain library into sections of 1000 characters, with an overlap of 100 characters to preserve context across section boundaries. These chunks were then stored in a vector database, indexed using cosine similarity to facilitate retrieval of the most relevant text. For each clinical case, the RAG system executed a similarity search to retrieve the top five most relevant guideline chunks. This retrieved text was automatically appended to the prompt via a Python script before being passed to the LLM for inference. This RAG architecture was selected for its ability to control chunking granularity, maintain transparency in retrieved context, and facilitate API calls for automatic text processing.
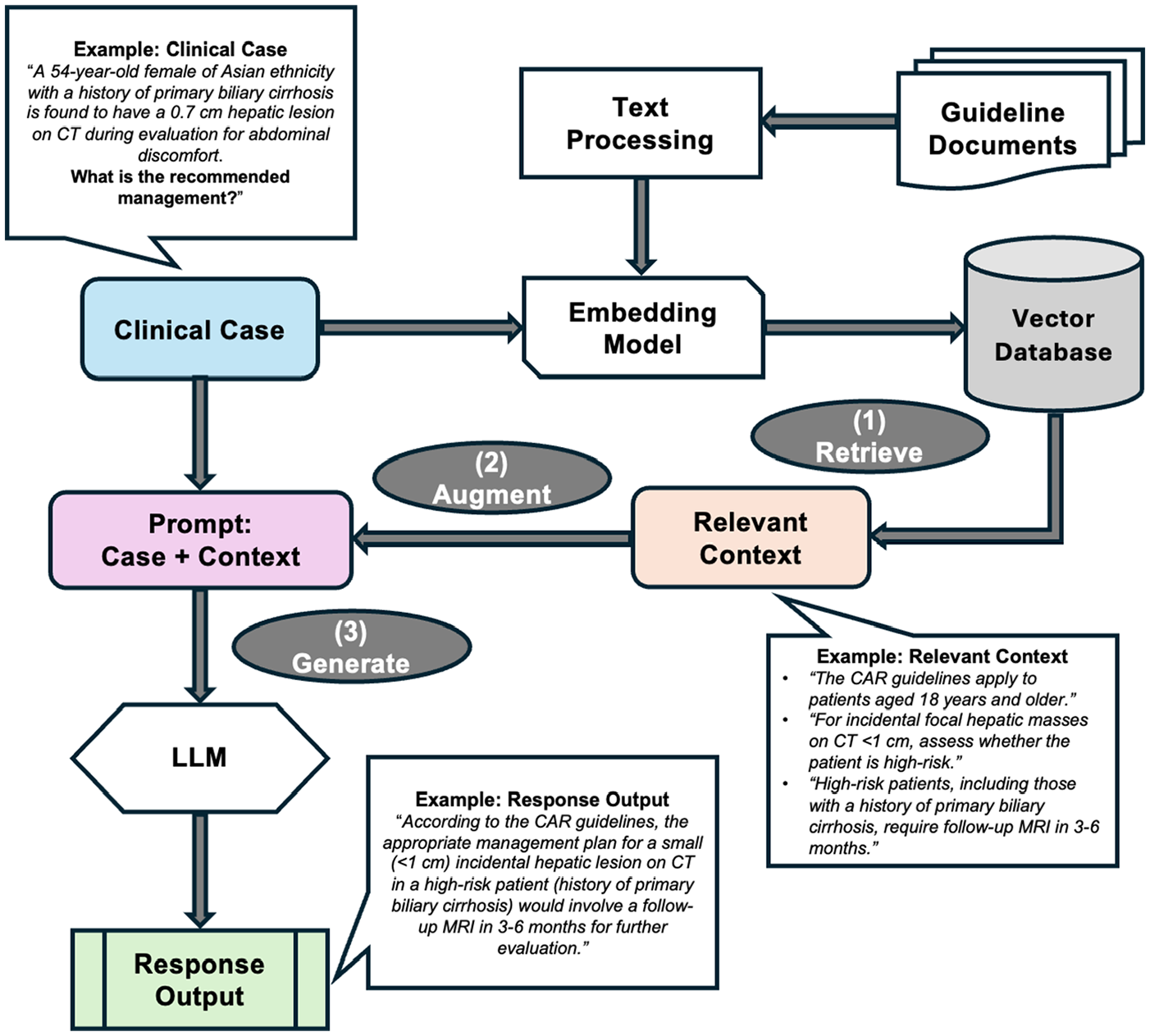
Overview of customized RAG architecture for processing clinical cases and generating response outputs.
Prompt Engineering and Development
Prompts were carefully engineered to standardize input structures. Each prompt contained a concise task description, the clinical case, and a specific request for management recommendations aligned with CAR guidelines. For cases utilizing RAG, the retrieved guideline recommendations were included within the prompt to provide external context. Non-RAG prompts relied solely on the model’s pre-trained knowledge. The API calls for all prompts were executed synchronously, with each request waiting for the previous one to complete before starting the next. Figure 2 shows an example prompt with a clinical case with and without embedded RAG context.
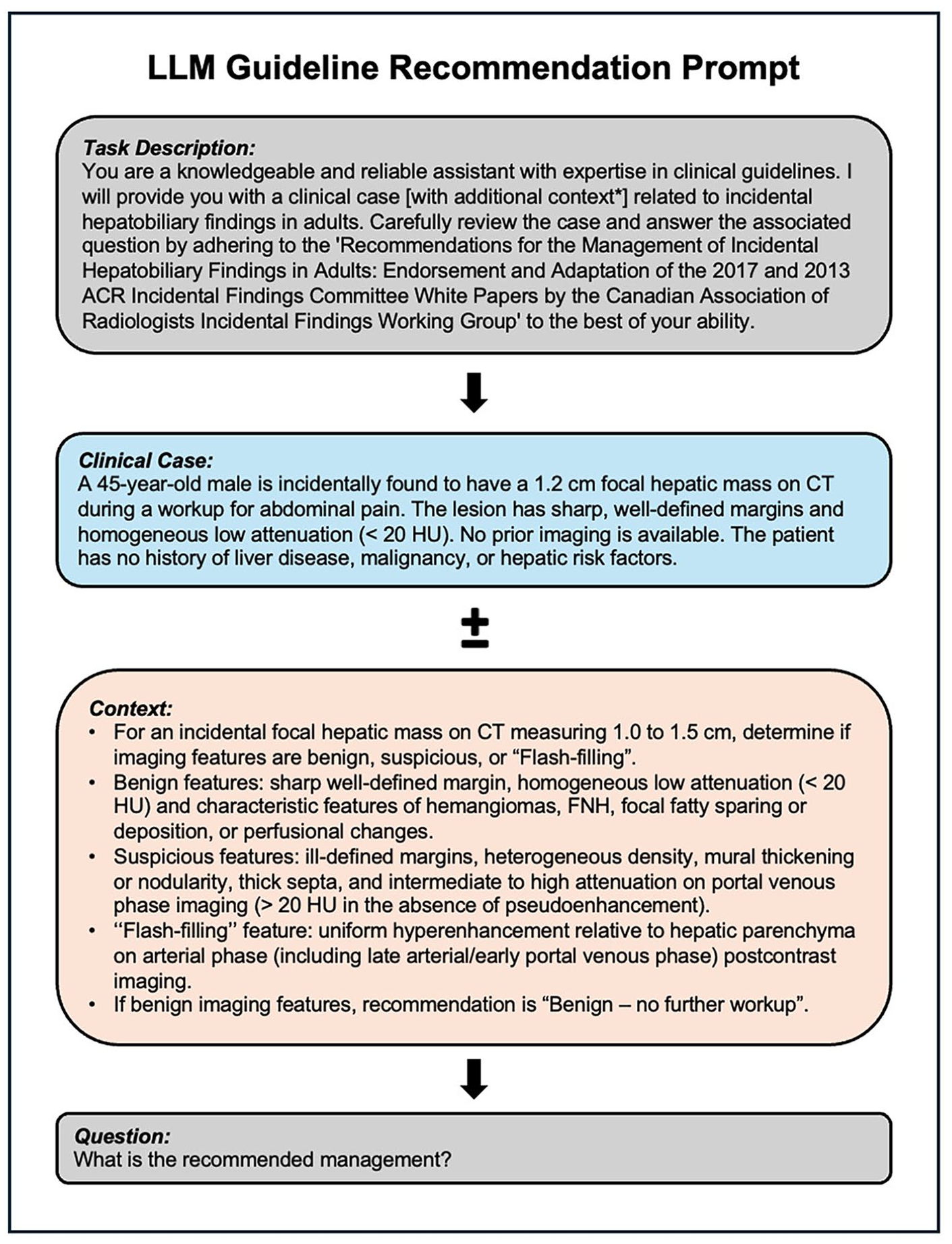
Example prompt for clinical case with and without RAG context.
Guideline Adherence Evaluation
Adherence to CAR guidelines was evaluated using a three-tiered scoring system, as employed in previous studies.15,16 Outputs deemed fully compliant with the recommended management received a score of 1 (full adherence). Those that aligned partially but contained minor inaccuracies or omissions (eg, factually correct information but incomplete recommendations), were assigned a score of 0.5 (partial adherence), and those that deviated substantially (ie, included information that was factually incorrect) from the guidelines were scored as 0 (non-adherence). Two independent, blinded reviewers with formal medical training rated each LLM output, and inter-rater reliability was determined via Cohen’s kappa (κ). Discrepancies in scoring were resolved through consensus discussions. A working group of three board-certified experts in radiology or hepatobiliary surgery provided input and guidance on the evaluation process.
Statistical comparisons of adherence rates were performed using the Kruskal-Wallis test. When significant differences were identified, Dunn’s post-hoc test with Bonferroni correction was applied to adjust for multiple comparisons, analyzing adherence across the models with and without RAG. To characterize deviations from guideline adherence, partial and non-adherent responses were systematically reviewed, and categorized into recurring error patterns based on observed trends.
Additional subgroup analyses were conducted to assess for potential demographic or contextual biases in LLM outputs. These analyses were stratified based on age (<50 or ≥50 years), sex (male or female), and imaging modality used to detect incidental findings (ultrasound or CT). For the subgroup analyses, the same statistical approach using the Kruskal-Wallis followed by Dunn’s post-hoc test was applied to compare performance across models.
Output Readability Scoring
The readability of each model’s output was evaluated using the Flesch Reading Ease and Flesch-Kincaid Grade Level scores.17-19 The Flesch Reading Ease score measures text readability on a scale from 0 to 100, where higher scores indicate greater ease of reading. The Flesch-Kincaid Grade Level score assesses the U.S. school grade level of a text, ranging from 0 to 18, with higher scores indicating a greater level of comprehension required. Both metrics have demonstrated excellent validity and reliability in evaluating linguistic complexity across various domains, including medical communication. 17 The scores were generated by analyzing the outputs from each model with and without RAG using the textstat package from the Python Package Index. 20 A one-way analysis of variance (ANOVA) was conducted to compare the mean differences in readability scores across the four model configurations, with statistical significance set at a P-value of .05. Post-hoc analysis using Tukey’s Honestly Significant Difference (HSD) test was performed to identify statistically significant pairwise differences among the groups.
Output Response Time Benchmarking
The response time performance of the LLMs was tested. All models were run in the same API environment and used the same local hardware over a stable Wi-Fi connection. While inference was performed on OpenAI’s cloud infrastructure,12,13 the local machine facilitated API requests and logging. For each prompt, the time from API request to response was recorded, excluding post-processing. For API calls involving RAG, the total response time included the time spent on retrieval and preprocessing before inference. The response time per clinical case prompt, total response time for all clinical case prompts, and the contribution of RAG-specific processes (retrieval and preprocessing) were calculated and reported as mean ± standard deviation (SD) in seconds. To account for differences in the length of output, response times were adjusted based on the mean number of tokens generated per model. A one-way ANOVA was conducted to compare mean response times between configurations, with post-hoc Tukey’s HSD test identifying pairwise differences (P < .05).
Results
In total, 319 clinical cases were analyzed to evaluate the performance of the LLMs with and without RAG. The mean patient age across all cases was 52.4 ± 11.8 years. The dataset included 160 male patients (50.2%), and 159 female patients (49.8%). Incidental radiographic findings were identified on CT scan in 195 cases (61.1%), and on ultrasound in 124 cases (38.9%).
Adherence Rates
GPT-4o achieved an adherence rate of 81.7% without RAG and 97.2% with RAG. The adherence rate of o1-mini without RAG was 79.3% and 95.1% with RAG (Table 1). The Kruskal-Wallis test revealed a statistically significant difference in adherence rates between all four groups (H(3) = 90.44, P < .001). Post-hoc pairwise comparisons using Dunn’s test indicated that RAG-enabled configurations outperformed their non-RAG counterparts (adjusted P < .001). No significant difference was observed between GPT-4o+RAG and o1-mini+RAG (adjusted P = .81), or between standalone GPT-4o and o1-mini (adjusted P = .73). Inter-rater reliability for adherence scoring was excellent, with a κ of 0.92 (95% confidence interval [CI]: 0.87-0.97), 0.93 (95% CI: 0.82-1.00), 0.91 (95% CI: 0.86-0.96), and 0.90 (95% CI: 0.85-1.00) for GPT-4o without RAG, GPT-4o+RAG, o1-mini without RAG, and o1-mini+RAG models, respectively.
Adherence Rates of GPT-4o and o1-mini With and Without RAG.
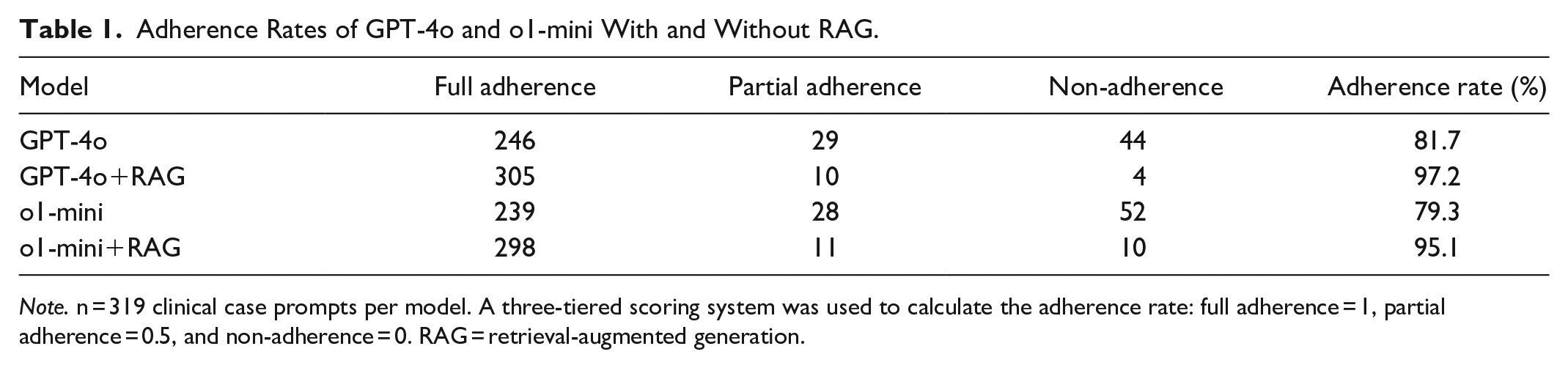
Note. n = 319 clinical case prompts per model. A three-tiered scoring system was used to calculate the adherence rate: full adherence = 1, partial adherence = 0.5, and non-adherence = 0. RAG = retrieval-augmented generation.
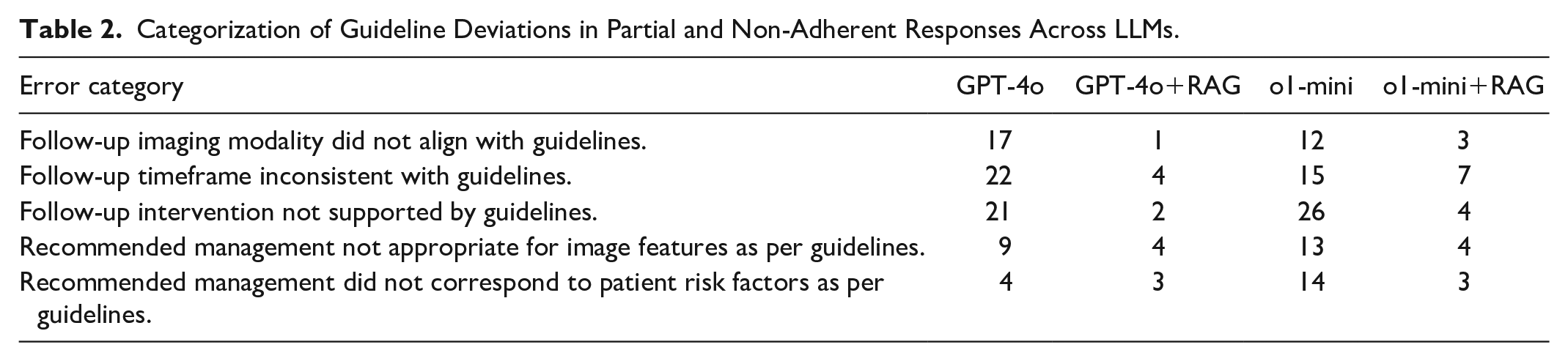
Analysis of partial and non-adherence responses revealed that guideline deviations most commonly involved inappropriate follow-up interventions (eg, recommending surgical management instead of further imaging) and incorrect follow-up timeframes (eg, suggesting MRI in 1 year instead of 3-6 months). Less frequent deviations included the use of an incorrect imaging modality for follow-up (eg, recommending CT instead of MRI) and misinterpretations of imaging features (eg, classifying suspicious lesions as benign) or patient risk factors (eg, categorizing high-risk patients as low-risk). Table 2 categorizes deviation patterns for each LLM.
Categorization of Guideline Deviations in Partial and Non-Adherent Responses Across LLMs.
Subgroup analyses demonstrated that RAG-enabled models consistently outperformed non-RAG LLMs, with results in keeping with the overall adherence findings. Tables S1 to S6, show the performance of the LLMs with and without RAG stratified based on age, sex, and imaging modality used to detect incidental findings.
Readability Scores
For ease scores, GPT-4o+RAG achieved the highest mean (36.13 ± 12.16), followed by standalone GPT-4o (24.26 ± 9.04). In contrast, o1-mini+RAG (21.54 ± 10.96) scored significantly lower, followed by o1-mini with the lowest 11.78 ± 9.56. ANOVA indicated significant differences in ease scores between configurations (F(3,315) = 493.27, P < .001), with Tukey’s HSD tests confirming that all pairwise comparisons were statistically significant (P < .05).
For grade scores, standalone models achieved higher means, with o1-mini scoring the highest (16.66 ± 1.96), followed by GPT-4o (16.11 ± 1.98). In contrast, RAG-enabled models showed lower mean scores with o1-mini+RAG achieving a mean score of 15.28 ± 2.40, and GPT-4o+RAG scoring the lowest (13.75 ± 2.63). One-way ANOVA revealed significant differences among configurations (F(3,315) = 454.41, P < .001), and Tukey’s HSD tests indicated significant pairwise differences (P < .05) between all groups.
Response Time Performance
The mean response time per prompt for each model was 4.80 ± 1.67 seconds for GPT-4o, 3.48 ± 1.37 seconds for GPT-4o+RAG, 5.16 ± 1.74 seconds for o1-mini, and 6.22 ± 2.31 seconds for o1-mini+RAG. The total response time to process all 319 cases was 1532 seconds for GPT-4o, 1110 seconds for GPT-4o+RAG, 1645 seconds for o1-mini, and 1984 seconds for o1-mini+RAG. The response time ANOVA revealed significant differences among the four model configurations (F(3,315) = 125.13, P < .001). Post-hoc Tukey’s HSD test revealed that all pairwise comparisons were statistically significant except for GPT-4o versus o1-mini without RAG (adjusted P = .064), where the null hypothesis could not be rejected. The contribution of RAG-specific processes, including retrieval and preprocessing, demonstrated that the mean response time attributable to RAG was 298 milliseconds per prompt, with an SD of 110 milliseconds. The total duration of RAG-specific computations across all 319 cases was 95.16 seconds.
Additionally, the mean number of tokens generated per prompt for each model was 235.79 ± 67.63 for GPT-4o, 150.51 ± 58.86 for GPT-4o+RAG, 495.19 ± 105.45 for o1-mini, and 361.63 ± 97.34 for o1-mini+RAG. After response times were adjusted for token output, results indicated that GPT-4o with RAG was about 9.5% times slower than without RAG, and o1-mini with RAG was about 50.8% slower without RAG (P < .05).
Discussion
This study demonstrates that RAG significantly improves adherence to the CAR guidelines for incidental hepatobiliary findings compared to non-RAG models. Adherence rates increased by about 15% with RAG integration for both GPT-4o and o1-mini models, with subgroup analyses demonstrating similar improvements. Adherence agreement was high across all outputs, underscoring the reliability of the scoring system. In addition, RAG-enabled models generally improved the readability of outputs, with processing times remaining clinically acceptable.
For guideline deviation, five errors patterns were identified across models. While overall error frequency was similar, RAG-enabled models exhibited fewer deviations in follow-up imaging modality recommendations. Despite the added context, these deviations may have resulted from insufficient contextual capture, misinterpretation of domain-specific terminology during retrieval, or conflicts between retrieved and pre-existing training data. However, the limited explainability of LLM responses makes it difficult to determine the exact cause of errors.
This study’s findings align with and expand upon previous studies evaluating the performance of RAG-enabled general-purpose LLMs in medical applications.16,21-23 For example, studies evaluating RAG in medical oncology and hepatology have demonstrated moderate improvements in adherence to clinical guidelines, although the magnitude of improvement observed in this study exceeds those previously reported.16,21 This improvement suggests that radiology guidelines may be particularly well-suited to the integration of dynamic retrieval mechanisms, such as RAG. Prior studies employing RAG in radiology have also shown RAG enhances decision-making,22,23 with Bhayana et al, 22 reporting improved GPT-4 performance on radiology board questions and Ranjit et al, 23 demonstrating better clinical metrics for report generation using RAG-enabled GPT-3.5 and GPT-4.
Findings showed that GPT-4o had a higher mean reading ease score than o1-mini with and without RAG. RAG-enabled outputs were also rated as easier to read compared to their non-RAG counterparts for both GPT-4o and o1-mini modes, consistent with previous work. 24 Despite this, all models had a mean Flesch reading ease score below 40, indicating that the generated outputs were difficult to read. For grade level, both RAG-enabled LLMs produced outputs at a lower grade level, but all outputs were at the postgraduate level. While such complexity may be suitable for clinical experts, readability optimization may be needed for patients-facing applications. Notably, the prompt did not explicitly instruct the model to adjust for readability. While this approach may help assess the “inherent” readability of generated text, incorporating such guidance could serve as a modifier to enhance output readability.
For model benchmarking, findings revealed that RAG-enabled models were slower than their standalone counterparts. These results align with prior literature,25,26 given the additional data retrieval and processing steps required in RAG-enabled systems. However, all outputs were generated within a few seconds of each other, representing a clinically acceptable trade-off for improved guideline adherence. In addition, GPT-4o+RAG generated nearly a 40% reduction in generated tokens, compared to GPT-4o alone, supporting how RAG can enhance efficiency in models with well-optimized retrieval pipelines. Future research should explore approaches to streamline RAG processing to reduce model latency and optimize output token generation.
The potential of RAG extends beyond its application in this study. Future iterations of RAG could explore alternative retrieval mechanisms that do not rely solely on vector embeddings, such as hybrid approaches combining rule-based retrieval with vector embeddings or leveraging graph-based architectures.27,28 Additionally, LLMs with native RAG integration, such as models trained with access to continuously updated databases, have shown promise to streamline clinical decision support. 29 Moreover, collaborations with guideline development organizations could facilitate the creation of structured, machine-readable guidelines optimized for integration with RAG systems.
Fine-tuning, which involves adjusting pre-trained models for specific use cases, is another approach for domain specialization. Like RAG, it has demonstrated improved performance on targeted tasks, 30 however, it requires large, labelled datasets, substantial computational effort, and re-training to integrate new knowledge. Recent research has shown that combining fine-tuning with RAG could offer a powerful hybrid approach, leveraging the robust specialization of fine-tuning alongside the scalability of RAG for real-time updates. 31
In addition to customized systems, future research may explore existing RAG-enable tools, like NotebookLM (https://notebooklm.google/), which allows users to upload data for context-aware responses. While promising, this approach was not used in this study due to limited API access and data-handling concerns. In any case, the use of externally hosted models raises concerns related to data privacy and ownership, especially for sensitive health information. Given the comparable performance of both RAG models in this study, smaller, locally hosted models augmented by RAG may offer a viable alternative. Future research should focus on validating their performance in clinical settings, with prospective studies assessing feasibility and workflow integration.
This study was not without its limitations. First, this study focused on adherence to the CAR guidelines, which represent only one aspect of clinical-decision-making. Evaluating the RAG-enabled models against other clinical guidelines may provide insight into their broader applicability. Furthermore, the clinical cases were constructed rather than derived from real-world patient data, which may limit the generalizability of findings. However, all cases were rigorously designed and followed an approach that has been successfully validated in previous studies.32,33 Additionally, the use of this dataset ensured that the models were tested on scenarios for which they were not pre-trained, reducing bias in output generation. Lastly, model performance may be influenced by prompt design, a challenge inherent to any LLM-based process. 34 However, all prompts were standardized to minimize variability and uniformly processed by the LLMs.
Conclusion
This study demonstrated that RAG-enabled LLMs significantly improved adherence rates to CAR guidelines for incidental hepatobiliary findings, while maintaining readability and acceptable response times. These findings underscore RAG’s potential as a scalable approach for advancing AI-driven decision support, warranting further investigation and validation across diverse clinical settings.
Supplemental Material
sj-docx-1-caj-10.1177_08465371251323124 – Supplemental material for Evaluating Adherence to Canadian Radiology Guidelines for Incidental Hepatobiliary Findings Using RAG-Enabled LLMs
Supplemental material, sj-docx-1-caj-10.1177_08465371251323124 for Evaluating Adherence to Canadian Radiology Guidelines for Incidental Hepatobiliary Findings Using RAG-Enabled LLMs by Nicholas Dietrich and Brett Stubbert in Canadian Association of Radiologists Journal
Footnotes
Data Availability
The code used to develop the RAG framework is available from the corresponding author, upon reasonable request.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.