
Abstract
This is a visual representation of the abstract.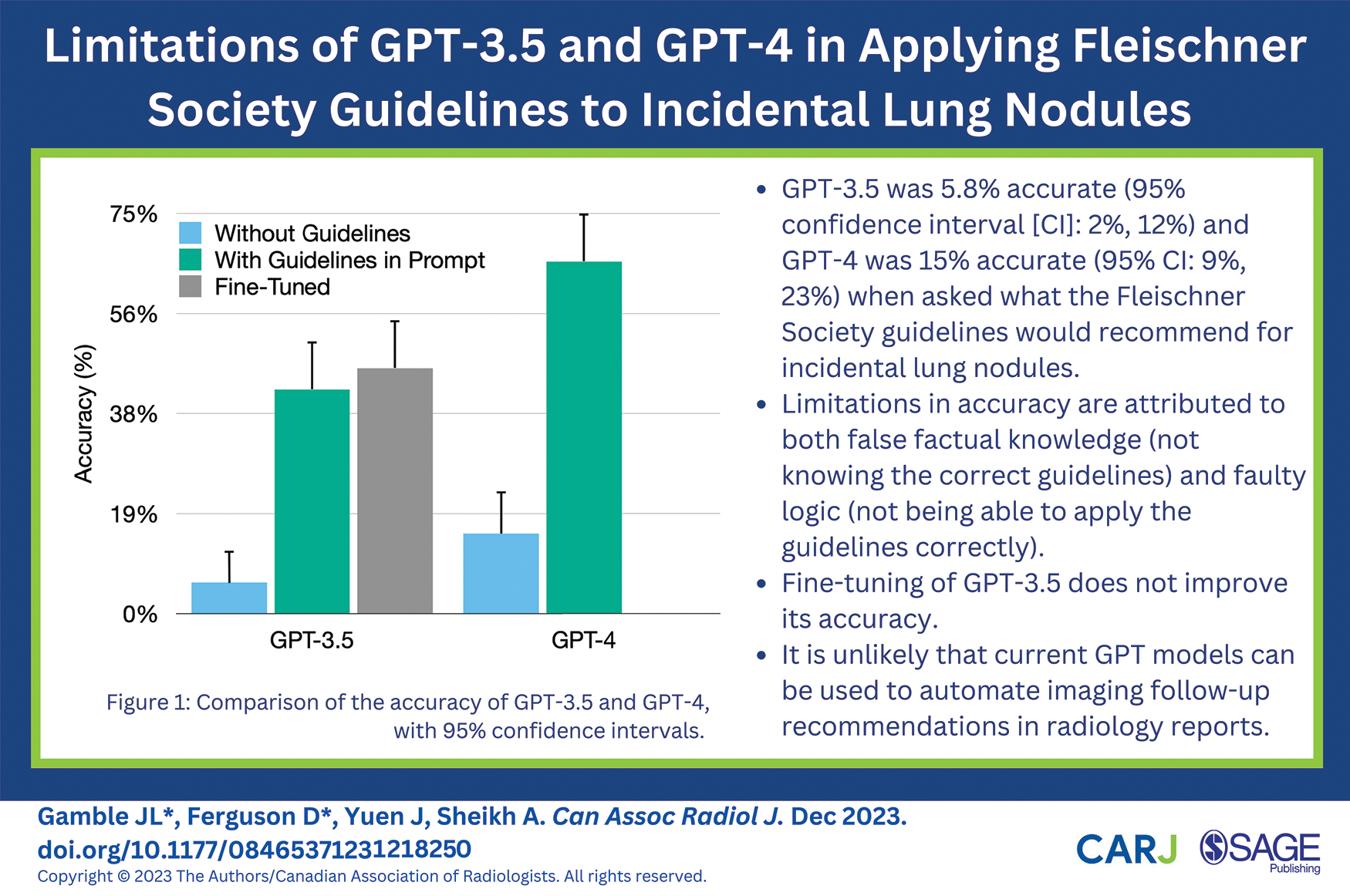
Introduction
Generative pre-trained transformer (GPT) is a type of large language model (LLM) created by OpenAI that underlies its popular chatbot, ChatGPT. GPT models are trained on volumes of unlabeled text data, and they learn to predict the next word from the preceding words. They rely on transformers, a type of neural network architecture distinguished by their self-attention mechanism, which allows them to weigh the importance of different parts of the input sequence and make predictions. 1 Consequently, LLMs can generate coherent, human-like responses to natural language prompts. Careful construction of the input prompt is required to achieve optimal results from LLMs. Fine-tuning, the process of customizing models by feeding them sample ideal data, also boosts performance for certain tasks. 2
GPT-3.5 and GPT-4 are the most recent publicly available versions. Both included medical literature in their training datasets, with GPT-4 being advertised to have significantly improved medical knowledge. 3 Previous studies have shown that GPT-3.5 fell just short of, while GPT-4 exceeded, the passing threshold on radiology board-style exam questions.4,5 Rogasch et al. 6 also found that ChatGPT could appropriately answer basic questions about PET-CT. However, there remain concerns about the propensity of LLMs including GPT to “hallucinate” and use confident language even when incorrect. 7 In a recent study prompting GPT-3.5 for cancer-related treatment recommendations, one-third of cancer-related treatment recommendations were guideline-discordant, and 12.5% were hallucinated. 8
Automatic generation of radiological report impressions has been proposed as a use-case for GPT. 9 For this to work, GPT would need to accurately make evidence and guideline-based recommendations, given the text findings from a radiological report. However, it remains uncertain whether GPT can aid in this task, since there is limited research on the use of GPT in real-world radiological scenarios, outside of basic and exam-style questions.10,11 Finally, fine-tuning is newly launched feature of GPT-3.5, and the potential gains of fine-tuning are untested in the medical context.
We explore the comparative performance of GPT-3.5 and GPT-4 in applying the widely used 2017 Fleischner Society guidelines for management of incidental pulmonary nodules, 12 and we assess whether fine-tuning can improve GPT-3.5’s performance in this knowledge and reasoning-based task.
Methods
Institutional ethics board review was not required since no patient data was used. We programmed a Python application to generate descriptions of incidental lung nodules for each of the 12 nodule categories in the Fleischner Society guidelines. These descriptions were incorporated into a single fictitious report for an otherwise normal CT pulmonary angiogram. Within each category, the nodule size and lobar location were randomly generated. One hundred twenty reports were generated, 10 from each category. We designed prompts instructing GPT to act as a radiologist and make specific recommendations for the nodules mentioned in these reports, according to the 2017 Fleischner Society Guidelines.
Using the OpenAI API, we submitted the prompts to GPT-3.5 and GPT-4, each in turn. We then tested GPT’s logical reasoning, while controlling for its potentially incorrect knowledge of the guidelines, by incorporating the complete 2017 guideline recommendations into the prompts and re-submitting them. Finally, we fine-tuned a GPT-3.5 model using 600 generated lung nodules (50 per category); the fine-tuning prompts included the full guidelines, chain-of-thought steps in how to apply the guidelines to the given nodule, and the correct follow-up recommendation. Chain-of-thought is a technique that asks LLMs to think logically through their answers and has been shown to improve performance on complex math and reasoning problems. 13 We re-submitted the prompts incorporating the full guidelines to this fine-tuned model. At time of study, fine-tuning was not available for GPT-4. All prompt submissions used a temperature parameter of 0.1 for more deterministic, less random responses. Prompts are included as a supplement (Supplemental Table 1). Our complete code is available at https://github.com/joelgamble/gpt-fleischner.
Statistical Analysis
We compared GPT’s recommendations to the Fleischner Society recommendations using binary accuracy analysis. “False positive” was assigned if GPT inappropriately recommended biopsy, too short a follow-up interval, or follow-up when none required. “False negative” was assigned if GPT recommended too long a follow-up interval or no follow-up when follow-up was required (Table 1). We chose accuracy as the metric for evaluating overall performance, since it is intuitive to interpret, and since true positive and true negatives are equally relevant. However, F1-score was chosen for PET-CT/biopsy recommendations, since the objective in this case was to minimize false positive and false negatives.
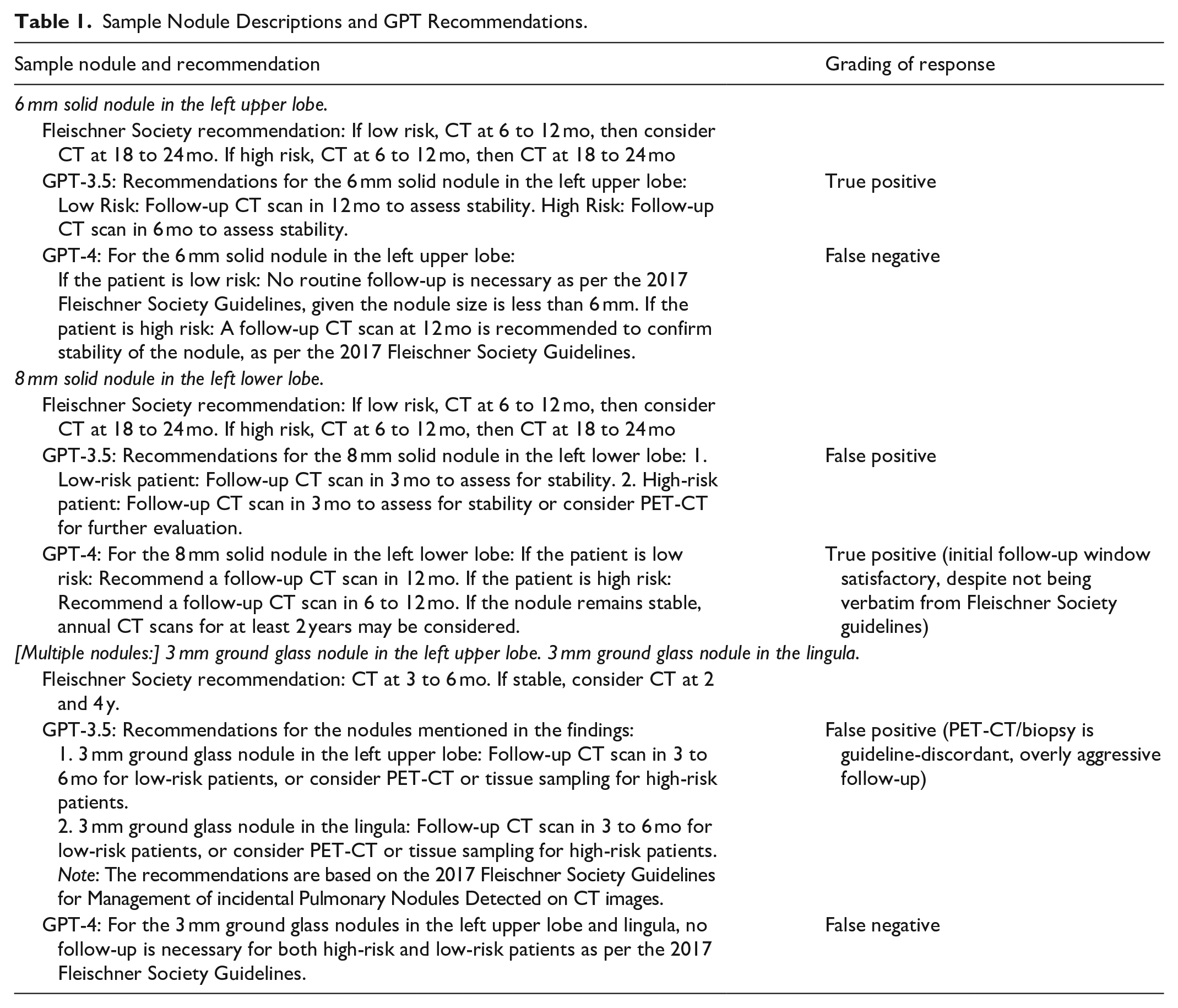
Sample Nodule Descriptions and GPT Recommendations.
Statistical analysis was performed in R, version 4.3.1. 14 Metrics and confidence-intervals were obtained using the caret package. 15 Comparative accuracy was tested using McNemar’s test, given the paired data. A sample size of 118 was required for 80% power at alpha .05 to detect a 20% difference in accuracy between GPT-3.5 and GPT-4, calculated using the sampleSizeMcNemar function.
Results
GPT-3.5’s accuracy in applying Fleischner Society guidelines was 0.058 (95% CI: 0.024, 0.12). GPT-4 accuracy was significantly greater at 0.15 (95% CI: 0.091, 0.23; P = .02, χ2(1) = 5.26). For 76% (86/113) of GPT-3.5 and 38% (39/102) of GPT-4’s incorrect recommendations, the answer stated that they were based on 2017 guidelines. In recommending PET-CT and/or biopsy, both GPT-3.5 and GPT-4 had an F1-score of 0. GPT-4 also illogically stated 3 times that nodules ≥6 mm should not be followed because they were <6 mm.
After incorporating the guidelines directly into the prompts, the accuracy of GPT-3.5 and GPT-4 improved to 0.42 (95% CI: 0.33, 0.51; P < .001, χ2(1) = 38 for test of improvement) and to 0.66 (95% CI: 0.57, 0.74; P < .001, χ2(1) = 52 for test of improvement), respectively (Figure 1). GPT-4 remained significantly better than GPT-3.5 (P < .001, χ2(1) = 16). In recommending PET-CT and/or biopsy, the F1-score was 0.06 for GPT-3.5 and 0.53 for GPT-4. A persistent shortcoming in the improved GPT recommendations was incorrectly applying the single-nodule guidelines to multiple nodules individually, rather than applying the multiple-nodule recommendation (Table 1). In a subgroup analysis including only multiple nodules, accuracy was reduced to 0.18 for GPT-3.5 (95% CI: 0.10, 0.30) and 0.47 for GPT-4 (95% CI: 0.34, 0.60).
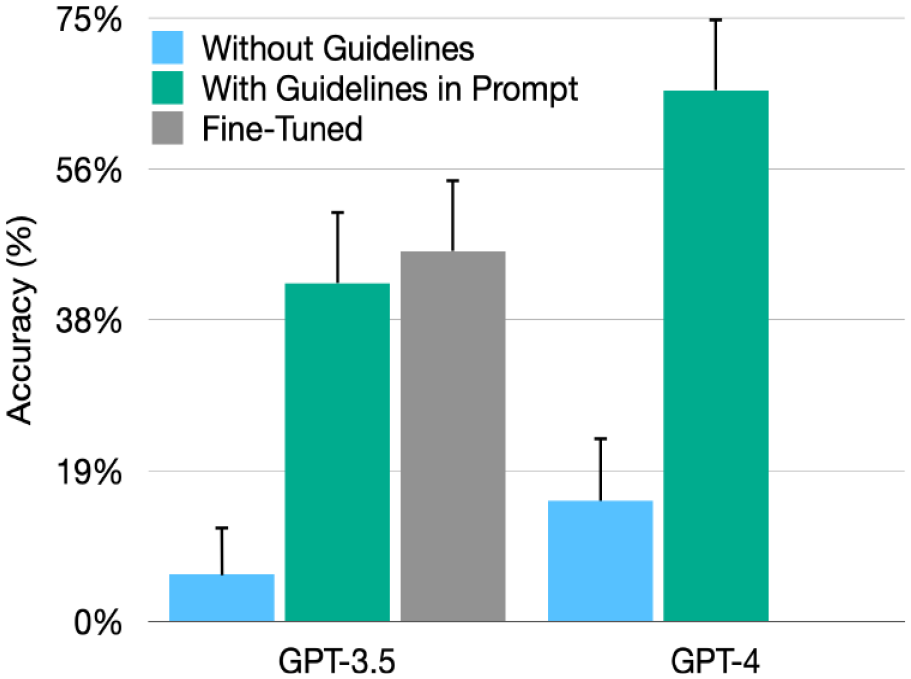
Comparison of the accuracy of GPT-3.5 and GPT-4, with 95% confidence intervals.
Finally, the fine-tuned GPT-3.5 model accuracy was 0.46 (95% CI: 0.37, 0.55), which did not significantly differ from the GPT-3.5 model with guidelines included (P = .53; χ2(1) = 0.39) (Table 2).
Metrics for Model and Prompt Performance.
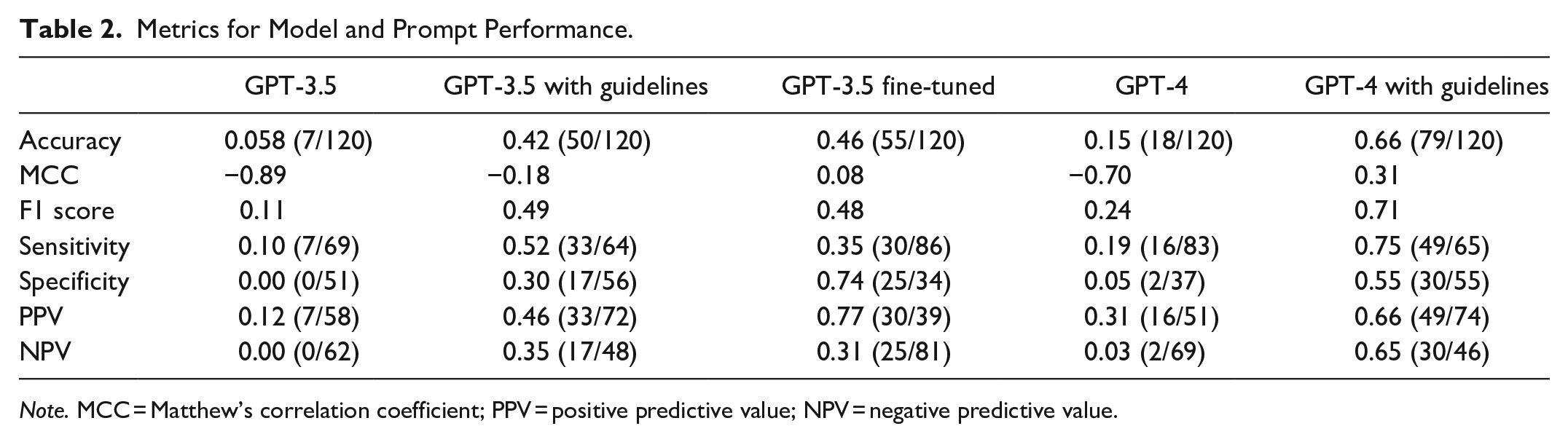
Note. MCC = Matthew’s correlation coefficient; PPV = positive predictive value; NPV = negative predictive value.
Discussion
Our study tests GPT-3.5 and GPT-4 in a real-world radiological task well-known to all radiologists: applying clinical practice guidelines. We chose the Fleischner Society guidelines for lung nodules since they are widely used, readily available, and relatively unambiguous, and they have the added complexity of multiple versions.12,16,17 Applying the Fleischner Society guidelines requires a composite of knowledge and reasoning. The user must use the most recent version and logically deduce the correct recommendation for given nodule(s). In this study, GPT-3.5 and GPT-4 were less than 20% accurate in recommending appropriate follow-up when asked to apply the 2017 guidelines. Despite this, GPT-3.5 and GPT-4 exhibited false confidence, frequently citing the 2017 guidelines as the basis for their incorrect recommendations. Importantly, biopsy is the most invasive test, and ensuring high performance for this category is imperative. Neither GPT-3.5 nor GPT-4 correctly recommended PET-CT or biopsy (F1 score = 0), indicating how restricted GPT’s “knowledge” is, despite its ability to answer simple questions about PET-CT. 6
We hypothesized that GPT’s poor performance may be due to incorrect knowledge of the 2017 guidelines and/or to flawed reasoning. To control for lack of knowledge, we incorporated the guidelines directly into the prompts. With the guidelines provided, GPT’s sole task was to logically determine which recommendation applied to the specified nodule(s). The models’ performance significantly improved, but GPT-3.5 was still less than 50% accurate. GPT-4 was significantly more accurate (P < .001), consistent with previous research. However, its accuracy only reached 67%, which is unacceptable for clinical use. GPT-3.5 and GPT-4 ’s inability to apply the provided guidelines highlights their fallible logic. For example, both models failed to consistently interpret multiple nodules as belonging to the multiple-nodule category in the Fleischner Society guidelines. It seems likely that GPT’s performance would also perform poorly on more complex guidelines, such as the Bosniak classification or -RADS systems. These findings, based on current GPT models, raise doubts about GPT’s proposed utility in helping generate radiological impressions. 9
We attempted to improve accuracy by fine-tuning, a recently launched capability for GPT-3.5. 2 The purpose of fine-tuning is to optimize model performance at specific tasks. The accuracy of the fine-tuned model (46%) was not significantly different from the non-tuned GPT-3.5 model (42%; P = .53), suggesting that fine-tuning will not improve GPT’s medical factual knowledge or reduce its hallucinations. The likely explanation is that fine-tuning is optimized for refining GPT’s output formatting and tone, but not augmenting or correcting its underlying knowledge.2,18 Additionally, fine-tuning is unlikely to help GPT “unlearn” incorrect information, a pressing problem for LLMs and neural networks. 19
While we endeavoured to simulate a real-world scenario, one study limitation is that our fictitious reports did not include nodules from multiple categories (eg, both ground-glass and solid nodules in the same report). Although this differs from real-world reports, this was an intentional study design choice to ensure that the correct guideline-directed follow-up was unambiguous. Additionally, we only evaluated the latest GPT models at one time point. Both GPT-3.5 and GPT-4 performed slightly worse on USMLE questions in June compared to March 2023, and it is possible that performance on our study’s task may have been better with earlier model versions. 20 Finally, GPT was not designed for medical purposes, and it is unreasonable to hold it to the standard of a purpose-built model.
Our study demonstrates that GPT-3.5 and GPT-4 are not well suited to applying clinical guidelines to real-world input, due to a combination of false knowledge and fallible reasoning. GPT’s language processing functions differently from both human cognition and other machine learning methods. While the type and frequency of GPT’s mistakes may be unsurprising to machine learning researchers familiar with its model architecture, these errors can be very misleading to end users. It is questionable whether large language models, including fine-tuned models, can be safely incorporated into clinical practice.
Supplemental Material
sj-docx-1-caj-10.1177_08465371231218250 – Supplemental material for Limitations of GPT-3.5 and GPT-4 in Applying Fleischner Society Guidelines to Incidental Lung Nodules
Supplemental material, sj-docx-1-caj-10.1177_08465371231218250 for Limitations of GPT-3.5 and GPT-4 in Applying Fleischner Society Guidelines to Incidental Lung Nodules by Joel L. Gamble, Duncan Ferguson, Joanna Yuen and Adnan Sheikh in Canadian Association of Radiologists Journal
Footnotes
Abbreviations
AI Artificial intelligence
CI Confidence interval
LLM Large language model
MCC Matthew’s correlation coefficient
PPV Positive predictive value
NPV Negative predictive value
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.