
Abstract
Purpose
To develop and assess the performance of a machine learning model which screens chest radiographs for 14 labels, and to determine whether fine-tuning the model on local data improves its performance. Generalizability at different institutions has been an obstacle to machine learning model implementation. We hypothesized that the performance of a model trained on an open-source dataset will improve at our local institution after being fine-tuned on local data.
Methods
In this retrospective, institutional review board approved study, an ensemble of neural networks was trained on open-source datasets of chest radiographs for the detection of 14 labels. This model was then fine-tuned using 4510 local radiograph studies, using radiologists’ reports as the gold standard to evaluate model performance. Both the open-source and fine-tuned models’ accuracy were tested on 802 local radiographs. Receiver-operator characteristic curves were calculated, and statistical analysis was completed using DeLong’s method and Wilcoxon signed-rank test.
Results
The fine-tuned model identified 12 of 14 pathology labels with area under the curves greater than .75. After fine-tuning with local data, the model performed statistically significantly better overall, and specifically in detecting six pathology labels (P < .01).
Conclusions
A machine learning model able to accurately detect 14 labels simultaneously on chest radiographs was developed using open-source data, and its performance was improved after fine-tuning on local site data. This simple method of fine-tuning existing models on local data could improve the generalizability of existing models across different institutions to further improve their local performance.

Introduction
Chest radiographs are commonly used in emergency departments worldwide to help diagnose common and potentially life-threatening conditions. 1 As imaging of patients in emergency departments has become increasingly common, the workload of emergency radiologists has increased exponentially. 2 Prompt communication of findings on radiographs is critical for reducing the risk of adverse clinical outcomes. Hence, radiographs with critical or time-sensitive findings must be read promptly to provide optimal patient care. Machine learning (ML) models can assist radiologists in detecting and reporting time-sensitive pathology by prioritizing life-threatening conditions. 2
ML models have been shown to be very useful in medical imaging analysis.2,3 While many previously developed models achieve high accuracy, relatively few of these have been implemented into clinical workflows. 4 Some reasons for the lack of implementation include limited clinical usefulness of models designed to detect only a single or a handful of pathologies, and a decrease in accuracy when a model is used across different institutions (lack of generalizability).1,5-10 This may be due to differences in hardware, resolution, artifacts, and patient demographics. 8 A very large dataset which includes images from various institutions and geographic regions is required to create a model with good generalizability. 11 However, such large datasets are difficult to acquire in practice.
Fine-tuning a model on a small set of local data helps adjust the model to local reporting practices, patient demographics, and image quality. 6 Acquiring the hundreds of thousands of studies required for training a neural network with data from a single institution is prohibitively time-consuming; therefore, the use of a ML model trained on open-source data and fine-tuned with local data is promising for increasing the adoption of ML models.6,10-12
The purpose of this study was to develop and assess the diagnostic performance of a ML model which screens chest radiographs for 14 labels simultaneously, and to determine whether fine-tuning the model on local data improves its performance. We hypothesized that fine-tuning a neural network by training it with local radiographs will improve its diagnostic accuracy at the same local institution.
Methods
Study Design
This retrospective study was approved by the local institutional review board, with a waiver for consent. All patient data was downloaded, anonymized, and encrypted using institution-approved software. This study involved model creation as well as feasibility testing of our fine-tuning method.
Architecture
The ML model was made up of two large neural networks, one for use with single view studies (SoloNet), either anteroposterior (AP) or posteroanterior (PA) views, and another model for use with studies including both a lateral and either an AP or PA view (DuoNet), shown previously to perform better than single view networks. 13 All networks were implemented using PyTorch 1.4.0 in Python 3.6. 14
SoloNet is an ensemble network that averages the outputs of three convolutional neural networks (CNNs), DenseNet-121, ResNext50, and MobileNetV2 for multi-class classification.15-17 Each network was initially designed to accept 3-channel RGB images and classify 1000 classes. For use with grayscale chest radiograph images, the initial layer of each network was modified to accept 1-channel inputs. The final fully connected layer was replaced in each network to output 14 classes instead of 1000.
DuoNet is an ensemble network similar to SoloNet but differs by having two identical network backbones which each accept either one of PA or AP, and one lateral view image. 13 As in SoloNet, the input layer of each backbone was modified to accept 1-channel grayscale image inputs. The two backbones were combined by removing the final layer from each backbone and introducing a new layer that received the extracted features from each backbone as inputs, and output 14 classes.
Open-Source Training
Open-source dataset.
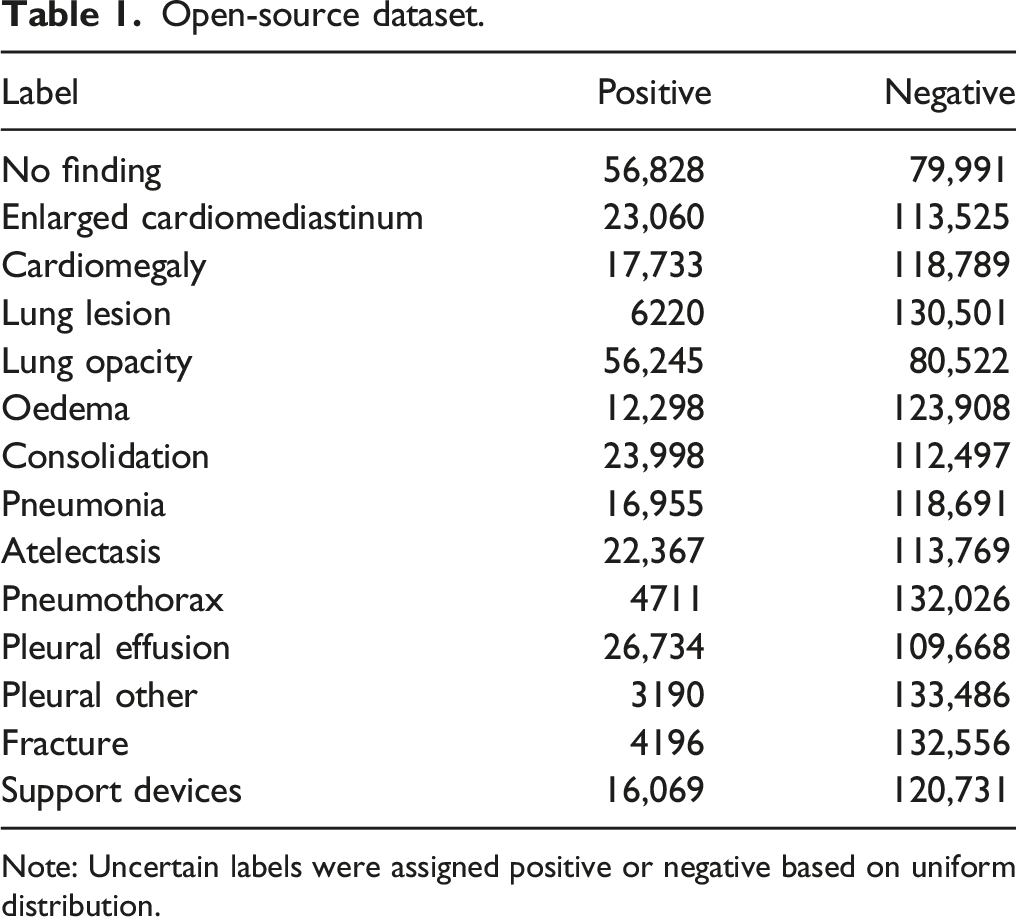
Note: Uncertain labels were assigned positive or negative based on uniform distribution.
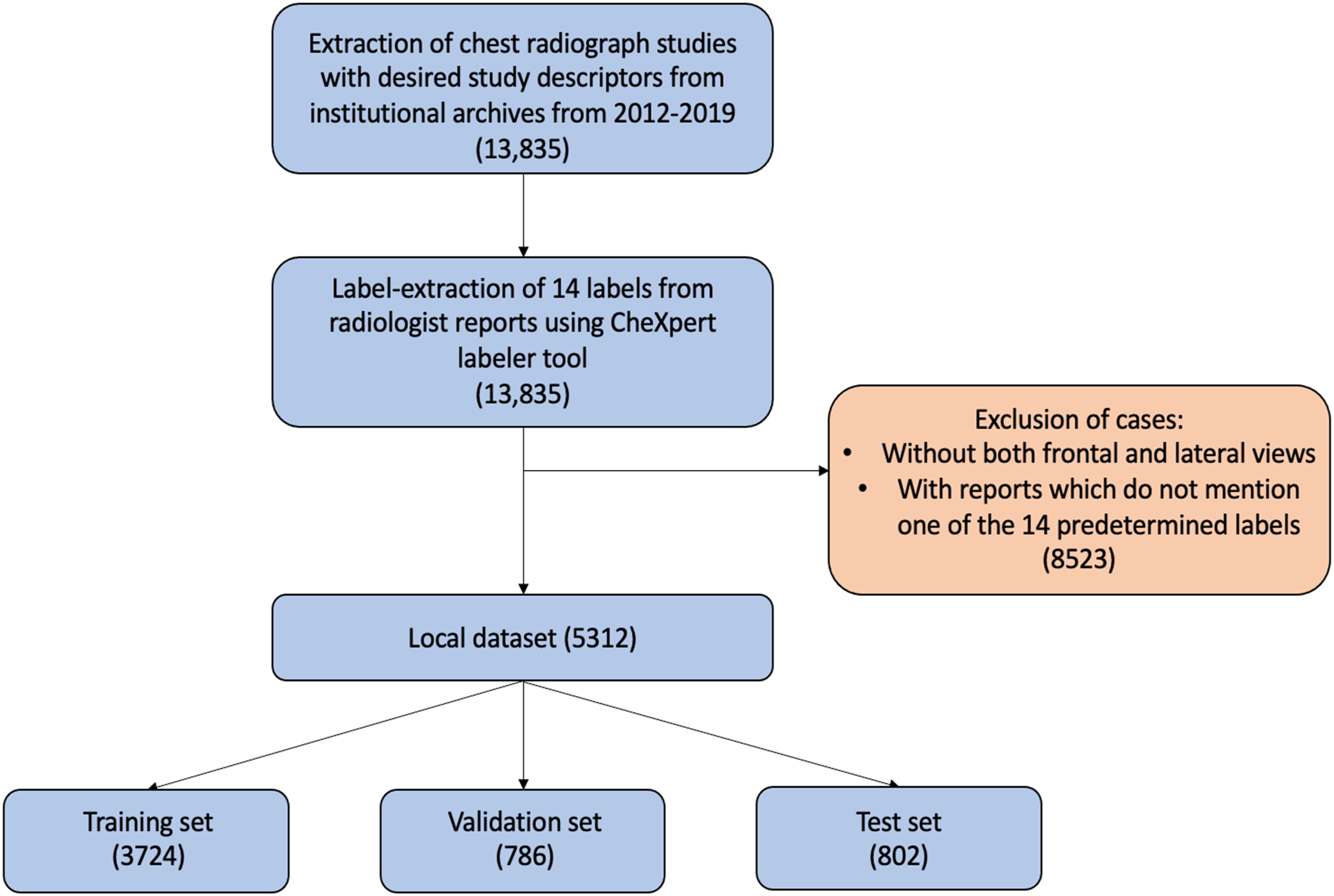
Summary of local dataset acquisition. Desired study descriptors included: atelectasis, cardiomegaly, oedema, mass, nodule, opacity, normal, pleural effusion, pleural thickening, pneumonia, and pneumothorax.
Local Dataset
Local dataset.
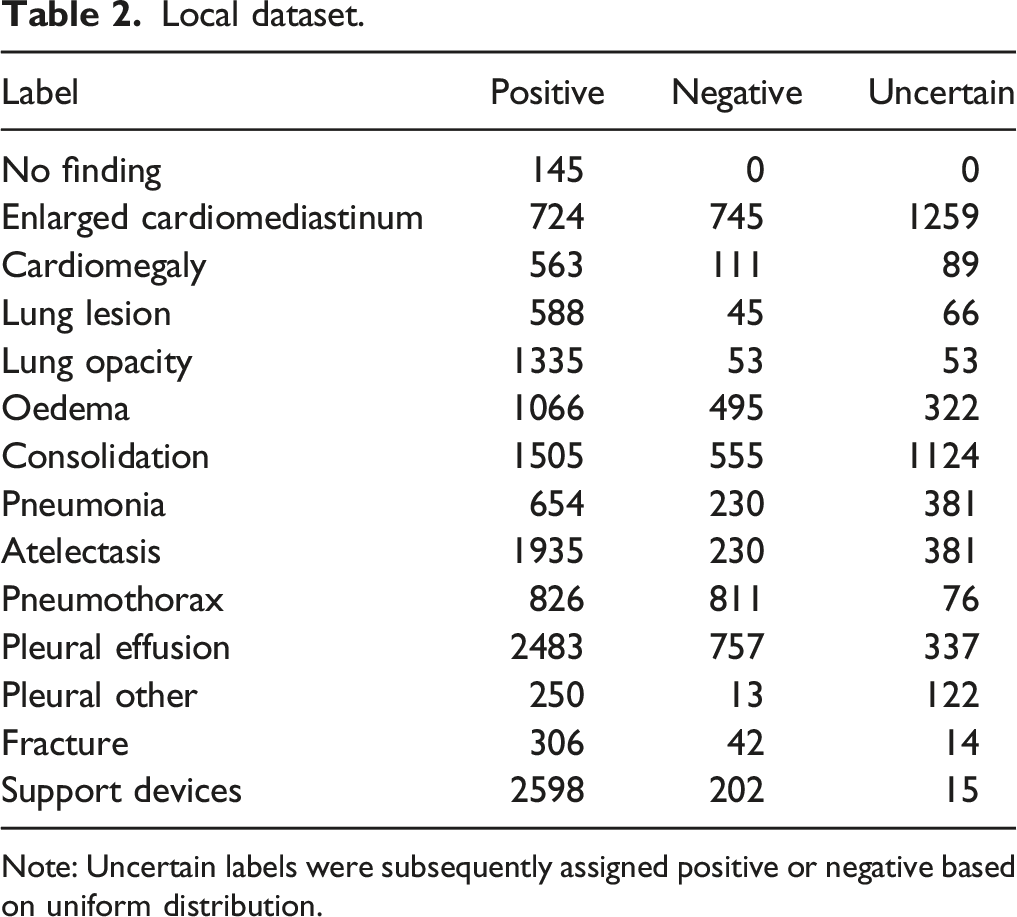
Note: Uncertain labels were subsequently assigned positive or negative based on uniform distribution.
Local Fine-Tuning
The local training and validation sets were used to further train, or “fine-tune” the individual networks. Stochastic gradient descent optimizer with learning rate of .001, minibatches of 88 images, and dropout of .8 were used during training. Training was stopped after 10 epochs without improvement in binary cross entropy loss on the validation data. The resulting machine learning model is referred hereafter as the “fine-tuned model” (Figure 2). Summary of the training and fine-tuning process.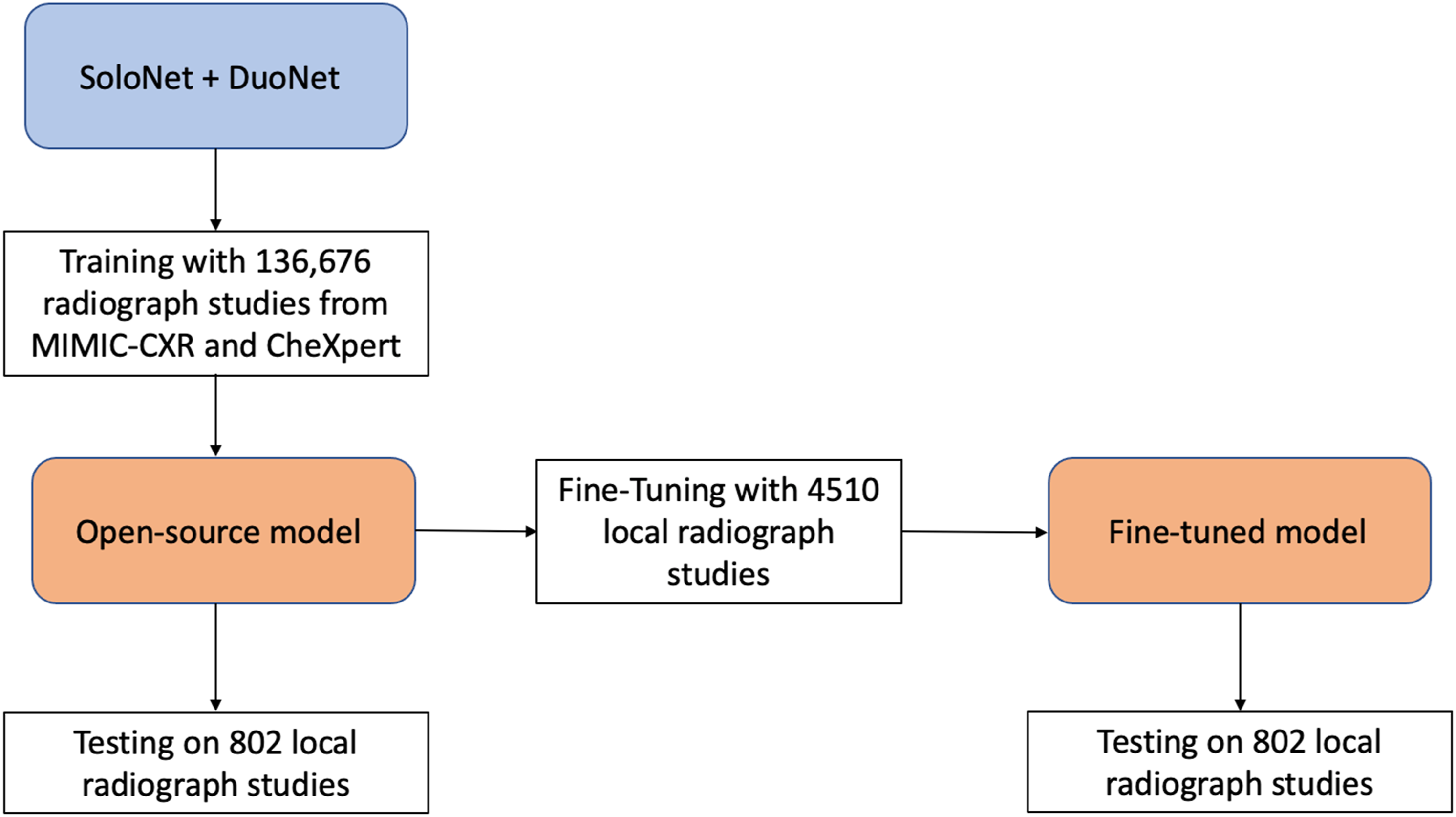
Class Imbalance
Due to class imbalance within the dataset, positive weights were calculated as the ratio of negative case counts to positive case counts. Iterative stratification was applied, which ensures that the proportion of each label present in each dataset (training, validation, and testing) is approximately equal.
Image Processing
High resolution grayscale images were first cropped of black borders, then resized to 512 × 512 pixels. Images were then normalized using the ImageNet normalization parameters, adjusted for grayscale images. 20
Label Processing and Augmentation
Unmentioned labels were treated as negative labels. Label smoothing was applied to all uncertain labels. 21 Briefly, uncertain labels were assigned a soft label randomly selected from a uniform distribution between .55 and .85. 21 Labels were corrected to account for lung disease hierarchical dependencies as outlined by Irvin et al. 19 For example, oedema, consolidation, pneumonia, lung lesion, and atelectasis labels required a label of lung opacity. Pneumonia required a label of consolidation, and cardiomegaly required a label of enlarged cardiomediastinum. 19
Data Augmentation
For improving generalizability and orientation invariance, horizontal flips, and rotations between −10 and 10 degrees were randomly applied with a 50% probability to input images during training.
Visualization
GradCAM was used to visualize class activation mappings and to localize important regions within each chest radiograph, contributing to the predicted class labels. 22
Evaluation
The open-source and locally fine-tuned models were evaluated on a test set consisting of 802 locally acquired radiograph studies, dating from 2012-2019. Radiologist reports were label-extracted using the CheXpert labeller. 19 Receiver-operator characteristic curves and area under the curve (AUC) were calculated for each model’s detection of each label. The overall AUC of each model was also calculated, representing the mean AUC of all 14 labels. DeLong’s method was used as the statistical test for comparison of each model’s AUC for detection of individual labels. 23 Statistical significance of overall AUC of the two models was calculated using a Wilcoxon signed-rank test, as outlined by Demsar. 24 Statistical significance was defined as P < .01. SciPy 1.4.1 was used in Python 3.6 for statistical analyses. 25 Sensitivity and specificity were calculated using individual threshold values from the AUCs for each model’s detection of each label. The threshold was chosen such that the sum of sensitivity and specificity was the highest possible.
Results
Model Training
Open-source training runtime ranged from 6 hours to 12 hours. Fine-tuning runtime ranged from 1 hour to 4 hours (Supplemental Appendix 1,2).
Model Testing
Comparison of area under the receiver operating curve of open-source and fine-tuned models for 14 labels.
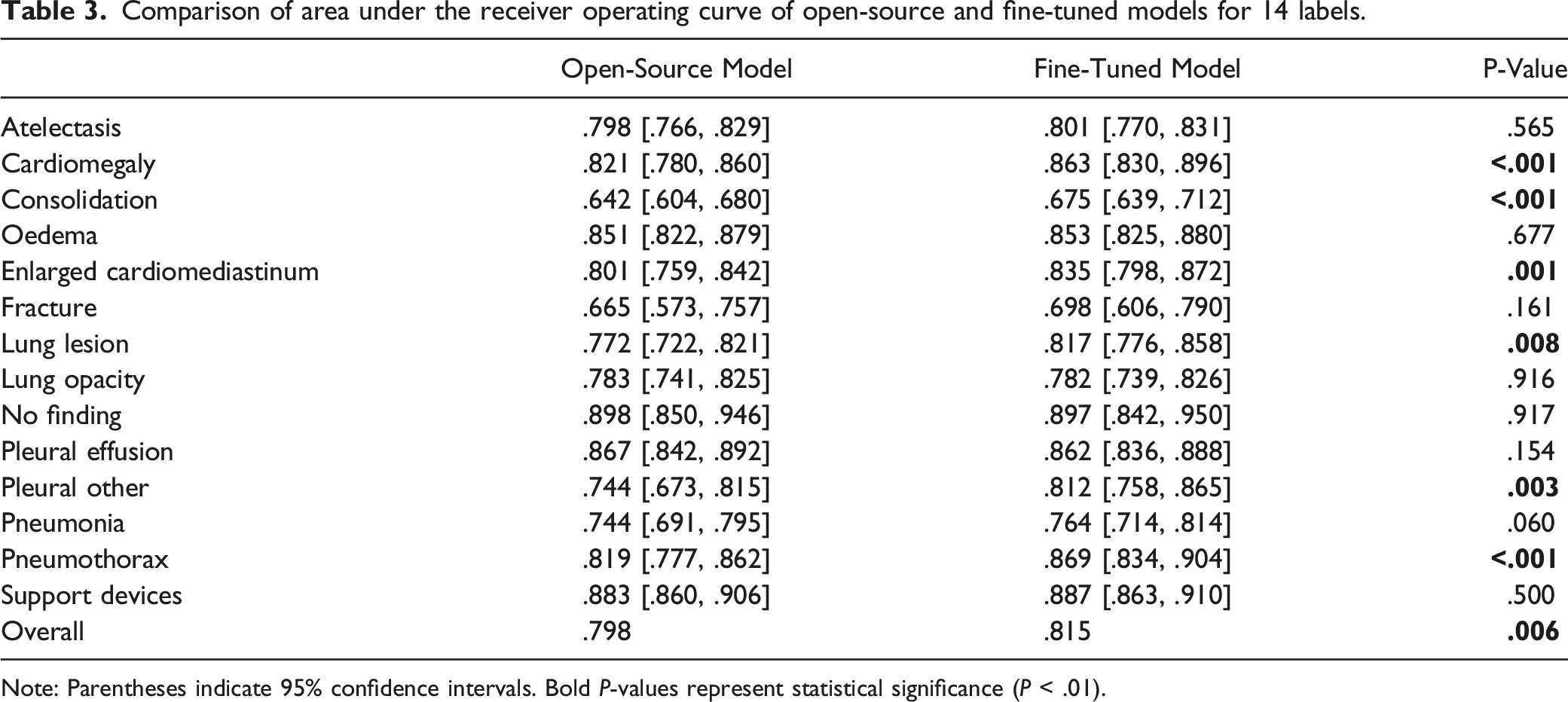
Note: Parentheses indicate 95% confidence intervals. Bold P-values represent statistical significance (P < .01).
Sensitivity and specificity of open-source and fine-tuned models for 14 labels.
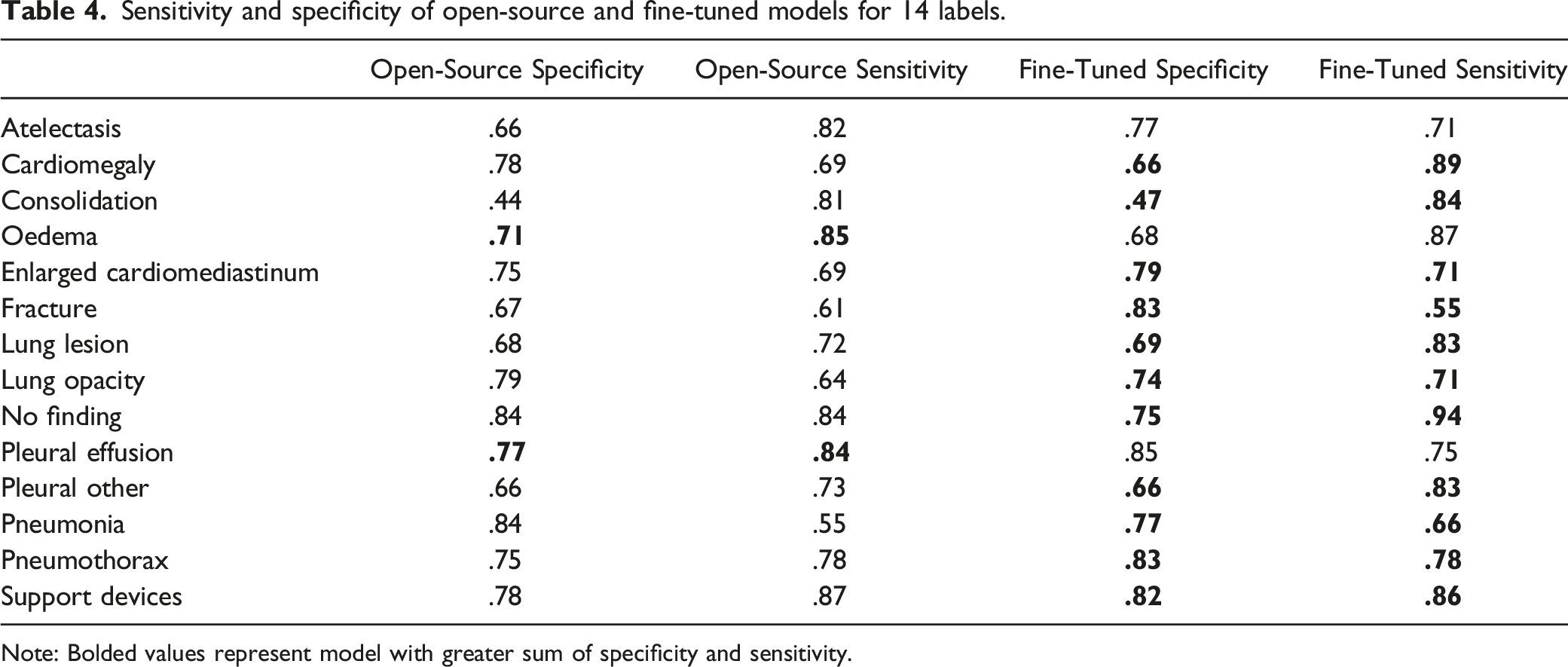
Note: Bolded values represent model with greater sum of specificity and sensitivity.
GradCAM was used to localize important regions within each chest radiograph in the testing dataset. An example of GradCAM results is shown (Figure 3). Example of GradCAM results for one tested radiograph, highlighting the areas with abnormalities detected; a) Original chest radiograph; b) identification of pneumothorax; c) identification of pleural effusion; d) identification of atelectasis; and e) identification of support device (chest tube).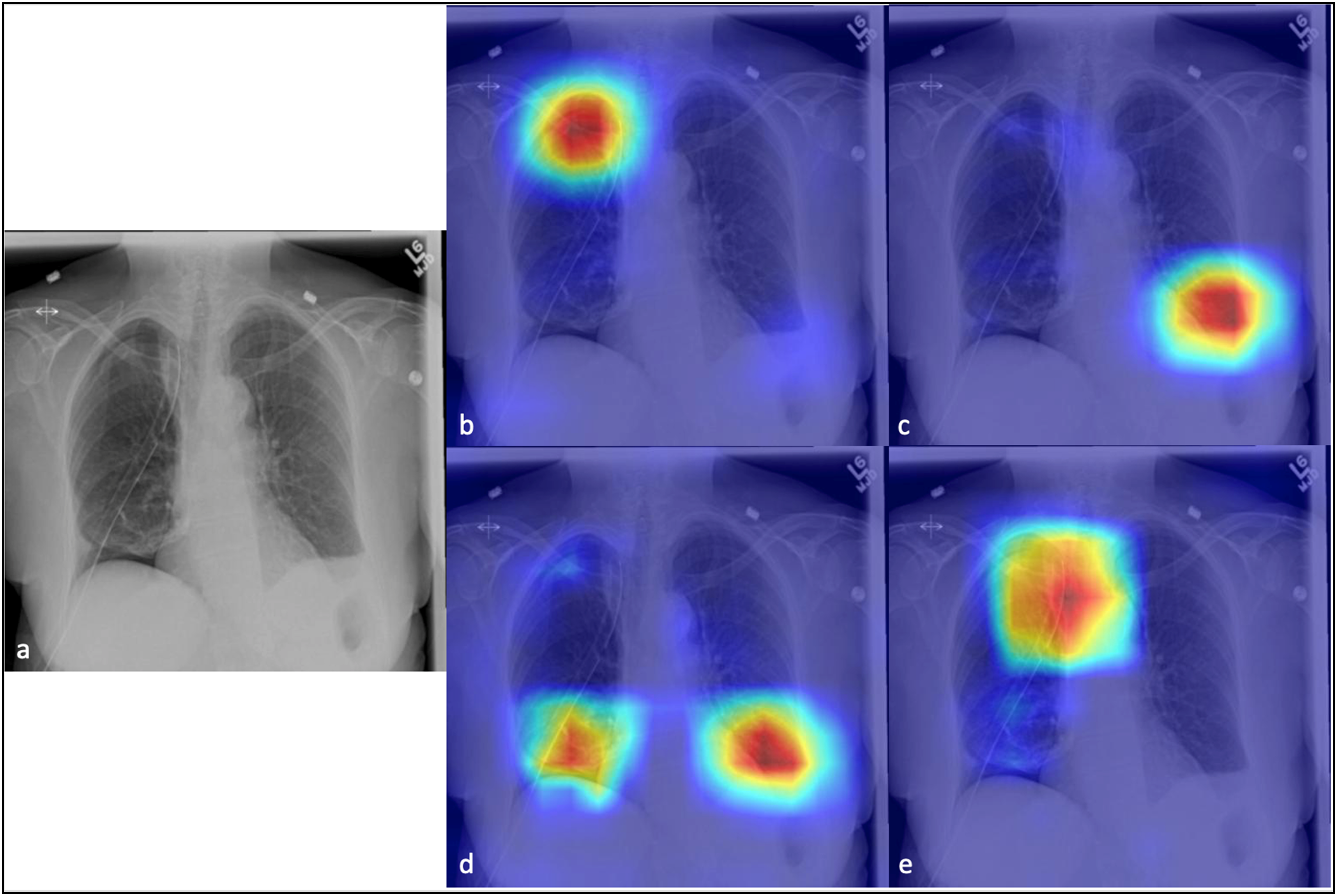
Discussion
Performance of ML models can decrease when used at institutions different than the ones where they were developed.5,7,8 We demonstrated that fine-tuning using a small local dataset may be a solution for adapting models across different institutions. Fine-tuning may improve performance by biasing the model towards our local institution’s image specifications, techniques, protocols, and equipment as well as biasing towards local radiologist reporting practices. 6 While this bias is usually undesirable, as it decreases a model’s generalizability, it is useful for training a model for use at one specific institution. This approach could be used to adapt available models for use in institutions that do not currently develop their own models.
Currently, there are few Health Canada approved ML models for chest radiograph analysis. ClearRead Xray has two algorithms available, one for lung nodule detection with an AUC of .558, and one that highlights tubes and catheters for reduction of study interpretation time. 26 One algorithm, xrAI, detects pulmonary abnormalities with heatmaps, but there are limited publicly available results other than 20% improvement in diagnosis. 26 There are more algorithms with Federal Drug Agency approval in the United States, including algorithms for detection of pneumothorax exclusively, pleural effusion exclusively, and 10 abnormalities on chest radiographs. 26 While these models perform with high accuracy, many have limited utility as they only detect a small number of chest pathologies. Additionally, these can be quite costly to an institution. Therefore, using an open-source model fine-tuned to a specific institution’s needs provides a more cost-effective option.
Previously in the literature, transfer learning has been used to adapt a machine learning model previously trained on natural images (non-radiological images) for applications in radiology by re-training the model with a relatively small number of radiological images.11,27,28 There exist very few examples of a fine-tuning method like ours which fine-tunes a model originally trained with medical images with local data, with the goal of improving its performance at a specific institution. One example by Rauschecker et al. used a similar fine-tuning method to optimize a brain MRI lesion segmentation algorithm trained at one institution by fine-tuning the model with data from 51 patients from a second institution. 29 Another example by Kitamura and Deible used a model trained to detect multiple pathologies on chest radiographs and retrained it specifically for the detection of pneumothorax at their local institution. 30 Similarly to ours, both of these studies found that training with a small data subset from the second institution increased performance.29,30 Therefore, our study adds to the small body of literature showing that local fine-tuning is an effective method for improving an open-source model for use at a specific institution.
Accuracy of the fine-tuned model is likely affected by the size and quality of the local dataset. The AUCs for detection of 14 different labels varied between .642 and .898 for the open-source model and between .675 and .897 for the fine-tuned model. The wide ranges in our AUC values for each label show that the models have higher diagnostic accuracy in detecting certain labels compared to others. For example, they are less accurate at identifying fractures than pleural effusions, perhaps because chest radiographs are not optimized for fracture detection and old fractures are commonly not mentioned in the reports used to train the model. There were also a low number of cases positive for fractures in our datasets. For example, only 3.1% of the open-source dataset and 5.8% of the local dataset had positive labels for fracture (Tables 1 and 2). To further improve the diagnostic accuracy of the fine-tuned model, one could continue the fine-tuning process with a larger dataset of local radiographs. We were able to achieve a statistically significant improvement for multiple pathologies with a modest dataset of only 4510 local studies. By increasing the size of the local dataset, one could potentially further improve performance.
Using multiple radiologists to label the local dataset rather than labels extracted from existing reports by the CheXpert labeller could offer another avenue for improving diagnostic accuracy. The CheXpert labeller is limited by only using labels mentioned in the radiologist report. For example, a report may read only “no interval change” for a chest radiograph showing a pleural effusion unchanged from prior studies, even though that pathology is present on the image. Automation of labelling saves time, but accuracy of the model may be improved if each radiograph in the local dataset is read and labelled by a radiologist for the purpose of the study.
Our next step is to integrate this model into the emergency radiology workflow to triage incoming radiographs, identifying those for immediate interpretation by the radiologist. We plan to undertake a study to determine the clinical impact of this model by determining whether using it for triage in our emergency radiology department decreases time to interpretation of radiographs with urgent findings. Currently, radiographs are read chronologically.
In our fine-tuned model, diagnostic accuracy of identifying a chest radiograph without pertinent findings was high with an AUC of .897 (Table 3) and sensitivity of .94 (Table 4). High sensitivity for detecting radiographs with no findings is important in the context of screening for acute findings and prioritizing worklists. 31 Although higher individual AUC values have been reported in detection of the some of these chest pathologies in the literature, these models usually only detect a few pathologies. 1 Lower AUCs were deemed an acceptable trade-off for our model’s ability to detect a wide range of pathologies for triaging purposes. In addition, the threshold used to calculate sensitivity and specificity values from the ROC was selected to maximize the sum of sensitivity and specificity values (Table 4). However, when applied clinically, a threshold value representing different points on the ROC could be used to favour different sensitivity and specificity values, depending on the clinical application. For example, for the purpose of prioritizing radiographs with urgent findings it is important to minimize false negatives; therefore, lower specificity may be accepted to prioritize high sensitivity values.
One main limitation of our study is that we have only shown improvements by fine-tuning of one model at one institution. It is unclear whether this method would be effective for multiple other ML models and at multiple other institutions. Another limitation is the use of the NLP labeller as described above. As our objective was to test whether our relatively simple and time-effective process of fine-tuning was a viable method for an individual institution to improve an open-source model’s accuracy for local use, we used an NLP labeller because it is less time and resource-intensive than labelling by expert radiologists. However, for optimal results, the local datasets would ideally be labelled by at least two expert radiologists, eliminating the potential errors introduced by using NLP labellers. In the future, the accuracy of NLP labellers may improve and eliminate the bottleneck of manual labelling. Finally, while our fine-tuned model is designed specifically for use at our institution, other institutions could use our fine-tuning method to adapt an open-source model for their clinical workflow if a small set of local radiograph studies and existing radiologist reports are accessible.
In conclusion, we have successfully fine-tuned a model originally trained on open-source data with a relatively small amount of local data, to accurately detect 14 labels on chest radiographs at our local institution. We have shown that our fine-tuning process significantly improved the overall diagnostic accuracy of the model. This method is much less time and resource-intensive than creating a new model as the initial training process requires hundreds of thousands of labelled radiograph studies. 8 Our fine-tuned model could potentially be useful in the emergency department for worklist prioritization but could also be applicable to inpatient and outpatient radiology.
Supplemental Material
Supplemental Material - Machine Learning Model for Chest Radiographs: Using Local Data to Enhance Performance
Supplemental Material for Machine Learning Model for Chest Radiographs: Using Local Data to Enhance Performance by Sarah F. Mohn, Marco Law, Maria Koleva, Brian Lee, Adam Berg, Nicolas Murray, Savvas Nicolaou, and William A. Parker in Canadian Association of Radiologists Journal
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Summary Statement
Fine-tuning a machine learning model with a relatively small amount of local site imaging data is a feasible method for adapting machine learning models for use at individual institutions.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.