
Abstract
Introduction
Research into the application of artificial intelligence (AI) to radiology is becoming increasingly popular. The number of publications on AI in medical imaging increased from about 100-150 per year in 2007-2008 to 700-800 per year in 2016-2017. 1 In 2018-2019, about 25% of published articles in Radiology were related to radiomics or AI. 2 A significant proportion of these publications assessed diagnostic accuracy; a systematic review by Kelly et al in April 2022 found that over 30% of radiology AI studies applied AI to classify lesions using medical imaging. 3 The completeness of reporting of diagnostic accuracy studies has been shown to vary. This can make it difficult for readers to assess the generalizability and sources of bias within a study and which may be a barrier to the acceptance of a study’s findings in clinical practice or as a basis for future research.4,5
In March 2020, the Checklist for AI in Medical Imaging (CLAIM) guide was published by Mongan, Moy, and Kahn Jr and endorsed by Radiology: Artificial Intelligence. 6 CLAIM is a 42-item checklist that builds upon the Standards for Reporting of Diagnostic Accuracy Studies (STARD) 2015 statement, designed to evaluate reporting completeness specific to applications of AI in medical imaging. 7 Since its release, the adherence to CLAIM has been unclear. Clarifying the uptake of CLAIM and identifying items that are infrequently reported would provide guidance to publishing platforms and investigators by identifying areas for improved reporting in future works. Understanding how reporting completeness compares between manuscripts in peer-reviewed journals and on non-peer-reviewed preprint platforms, where many diagnostic imaging AI studies are published, would alert readers to differences between these and encourage them to apply an appropriate degree of scrutiny based on the publication source. This could facilitate the acceptance and adoption of some AI models over others in practice.
The purpose of this study was to establish reporting adherence to the Checklist for Artificial Intelligence in Medical Imaging (CLAIM) in diagnostic accuracy AI studies with the highest AAS scores, and to compare completeness of reporting between peer-reviewed manuscripts and preprints.
Methods
Institutional Research Board approval was not sought as all data are available in the public domain. Reporting was per the relevant components of the PRISMA-DTA guideline. 8 The study protocol was registered (Open Science Framework: osf.io/3djma).
Data Sources
A preliminary search strategy was developed with the assistance of a librarian to search MEDLINE, EMBASE, arXiv, bioRxiv, and medRxiv to retrospectively identify diagnostic accuracy AI studies published after the release of the CLAIM checklist.
Study Selection
Given the large number of medical imaging AI studies published in the past few years, we elected to limit the search to the 100 diagnostic accuracy AI studies with the highest Altmetric Attention Score (AAS) including 50 from peer-reviewed journals and 50 from preprint platforms. The AAS is a weighted scoring system that captures the impact of a study based on more traditional sources such as citations in indexed journals but also incorporates attention on social media platforms including Twitter, public documents, online references and a variety of other sources applicable to both print and preprint articles. 9 The Altmetric Application Programming Interface (API) was queried on June 25, 2021 to retrieve the AAS to establish the impact of each study between March 25, 2020, and June 24, 2021.
Studies were included if they met the following criteria: (1) apply AI to diagnostic imaging of humans (excluding applications to histopathology images, animals); (2) English language; (3) main outcome was to determine a measure of diagnostic accuracy; (4) published after the online release of CLAIM (March 25, 2020) and before the search date of June 25, 2021; (5) AAS available via the Altmetric API. Duplicate studies, studies lacking a digital object identifier (DOI) or equivalent to query the Altmetric API, and studies that had no AAS calculated were excluded. Posters, conference presentations, and reviews were excluded as CLAIM is focused towards reporting in research manuscripts. Preprint articles were excluded if the same study was later published in a peer-reviewed journal (Figure 1). Flow diagram for included studies.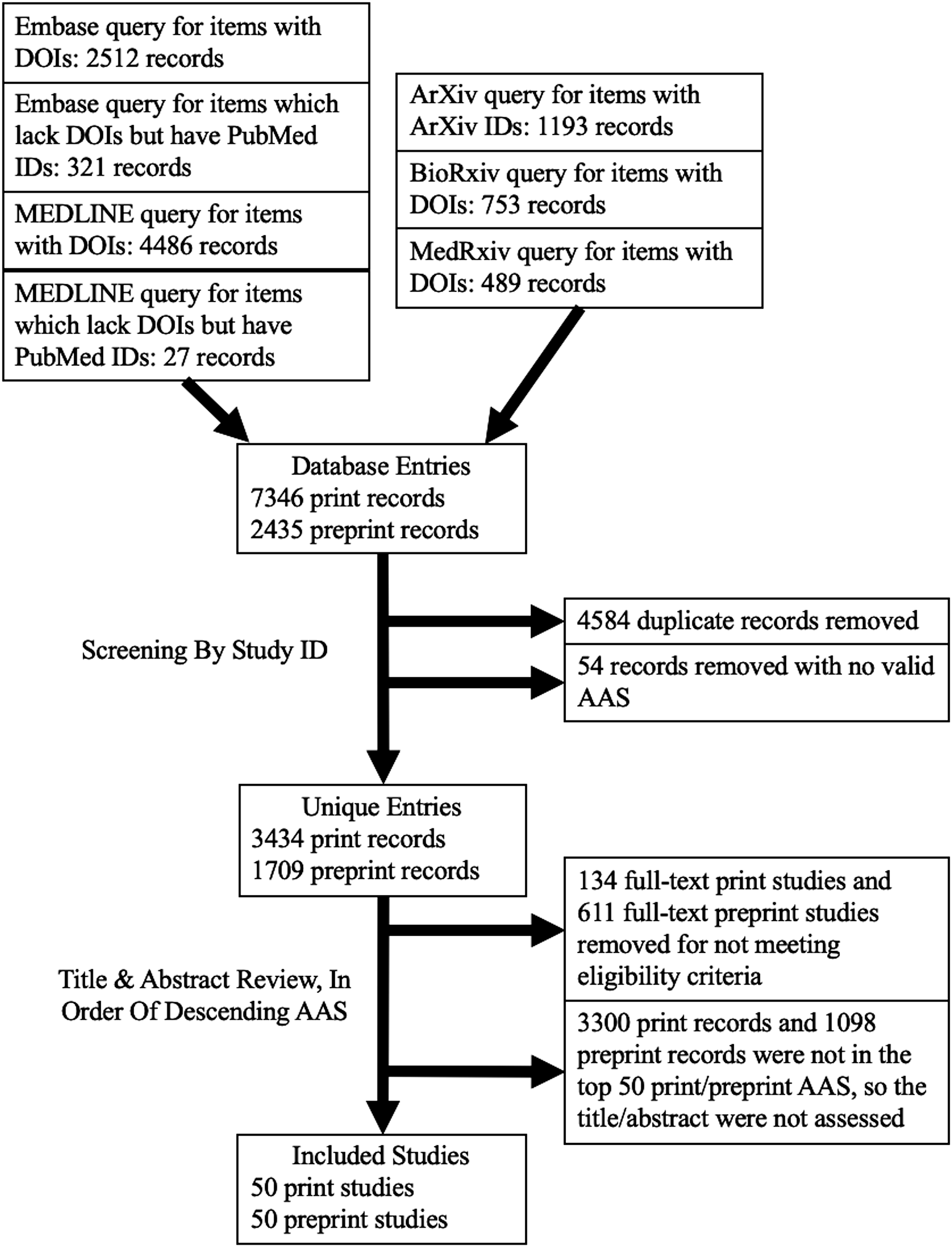
After the studies were retrieved, two authors (US, KW) independently screened the titles and abstracts in order of descending AAS according to the criteria above to identify the 50 print and 50 preprint articles with the highest AAS for inclusion. Disagreements were discussed, and in any case where consensus was not achieved, the decision was made by a more experienced third reviewer (CBvdP).
Data Extraction
Data was independently extracted by two reviewers (US, KW) using a data extraction sheet, with disagreements subsequently discussed and referred to a third reviewer if consensus could not be achieved (CBvdP). The following data were extracted for each study: title, first author, year of publication, country of corresponding author’s institution, whether the paper referenced CLAIM, imaging modality, subspecialty, body region, if the paper was related to COVID-19, if the paper involved an FDA-approved product, if the source code was available to the public, and adherence to each of the 42-items from the CLAIM guide. COVID-19 was included as a variable of interest as it was a common focus for diagnostic imaging AI research during the study period. For articles in peer-reviewed journals, the following data were also extracted: journal of publication, journal impact factor, and if the journal had formally adopted the CLAIM checklist.
Data Analysis
A CLAIM score based on the sum of the completed items from the CLAIM checklist was calculated for each article. Some CLAIM checklist items were not applicable to specific study designs, which were documented as not applicable (for example, item 27 recommends explaining any ensembles of models and is only applicable for studies that used ensembles). CLAIM score data normality were assessed using the Shapiro–Wilk test with means compared using the two-sample t test and medians compared using the Wilcoxon rank-sum test including between peer-reviewed manuscripts vs those on preprint platforms, studies that made their source code available vs those that did not, studies in Radiology: Artificial Intelligence vs all others, and studies on COVID-19 vs all others. The Fisher exact test and chi-square test were used to compare the proportion of studies that fulfilled CLAIM criteria for the CLAIM section/topics. The Kruskal–Wallis test was used to compare CLAIM scores for studies on different body regions. AAS was compared between prints and preprints using the Wilcoxon rank-sum test. Spearmen correlation was used to compare the CLAIM score with journal impact factor and AAS. P < .05 defined statistical significance. All analysis was performed using R (A language and environment for statistical computing, v4.1.3, Vienna, Austria). 10
Results
Study Search
A total of 5143 results were identified after screening, of which 3434 were print and 1709 were preprint. Print articles were assessed in order of descending AAS until 50 articles had been identified that met the eligibility criteria. To reach this threshold, 184 total print articles were examined, of which 134 were excluded for not meeting eligibility criteria. Similarly, 661 preprint articles were examined, of which 611 were excluded. This yielded the included 100 diagnostic accuracy AI studies. For print articles, 19 were from the USA, 9 China, and the remainder were from 13 other countries including 9 published in Radiology, 5 in Radiology: Artificial Intelligence, and the remainder in 26 other journals. For preprints, 12 were from the USA, 10 China, 7 India, and the remainder were from 13 other countries with 39 on arXiv, 9 on medRxiv, and 2 on bioRxiv.
Overall CLAIM Adherence
Median CLAIM adherence was 48% (20/42). Several CLAIM items were reported more often than not, including metrics of model performance (99/100), the study goal (98/100 studies), and performance metrics for optimal model(s) on all data partitions (94/100). Others were most often not reported, including de-identification methods (6/100), intended sample size and how it was determined (4/100), and where the full study protocol can be accessed (3/100). For the 44 studies published in peer-reviewed journals with an impact factor, the CLAIM score correlated with journal impact factor, rho = 0.43, P = .0040. The CLAIM score also correlated with AAS, rho = 0.68, P < .0001.
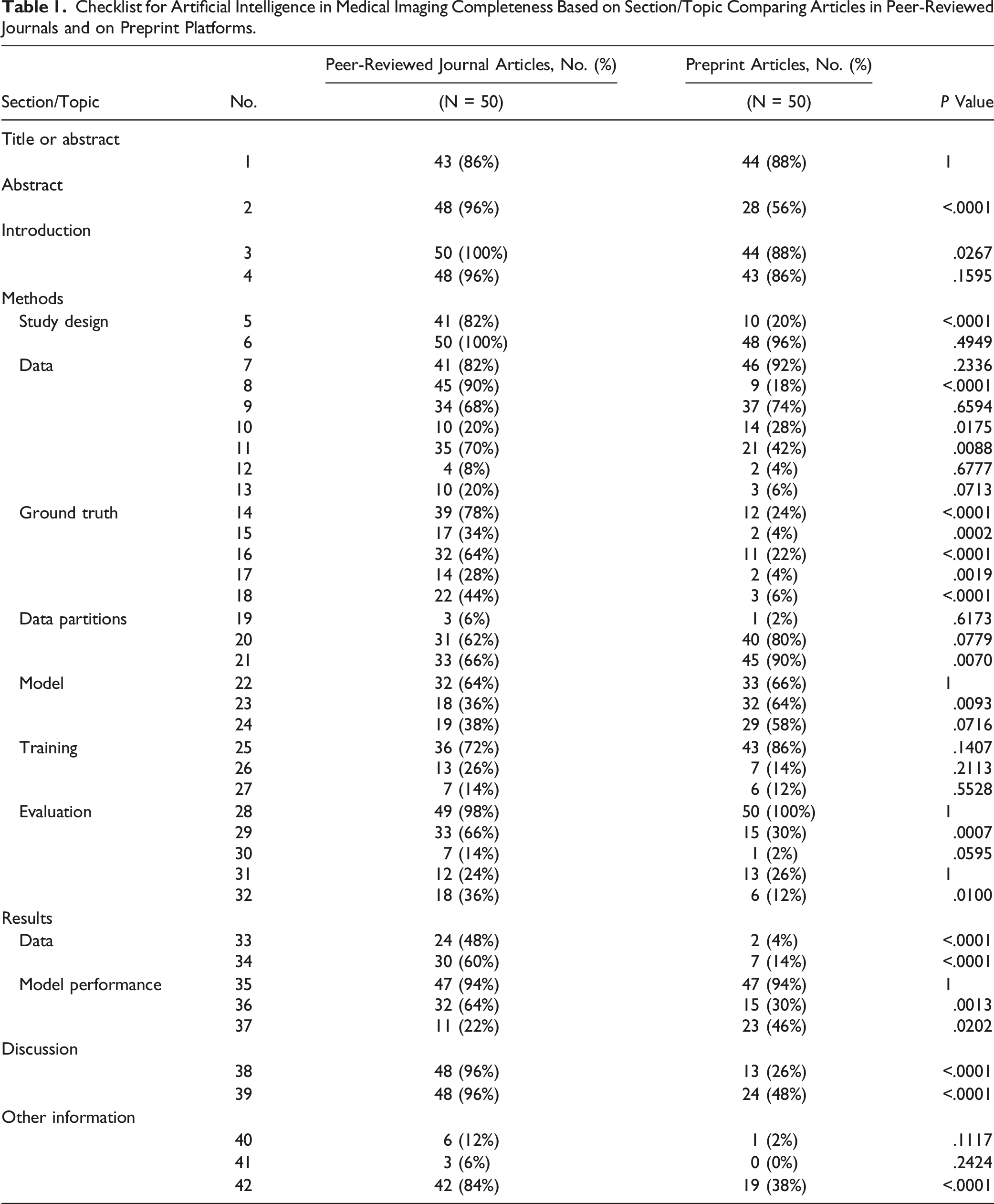
Peer-Reviewed Manuscripts vs Preprints
Checklist for Artificial Intelligence in Medical Imaging Completeness Based on Section/Topic Comparing Articles in Peer-Reviewed Journals and on Preprint Platforms.
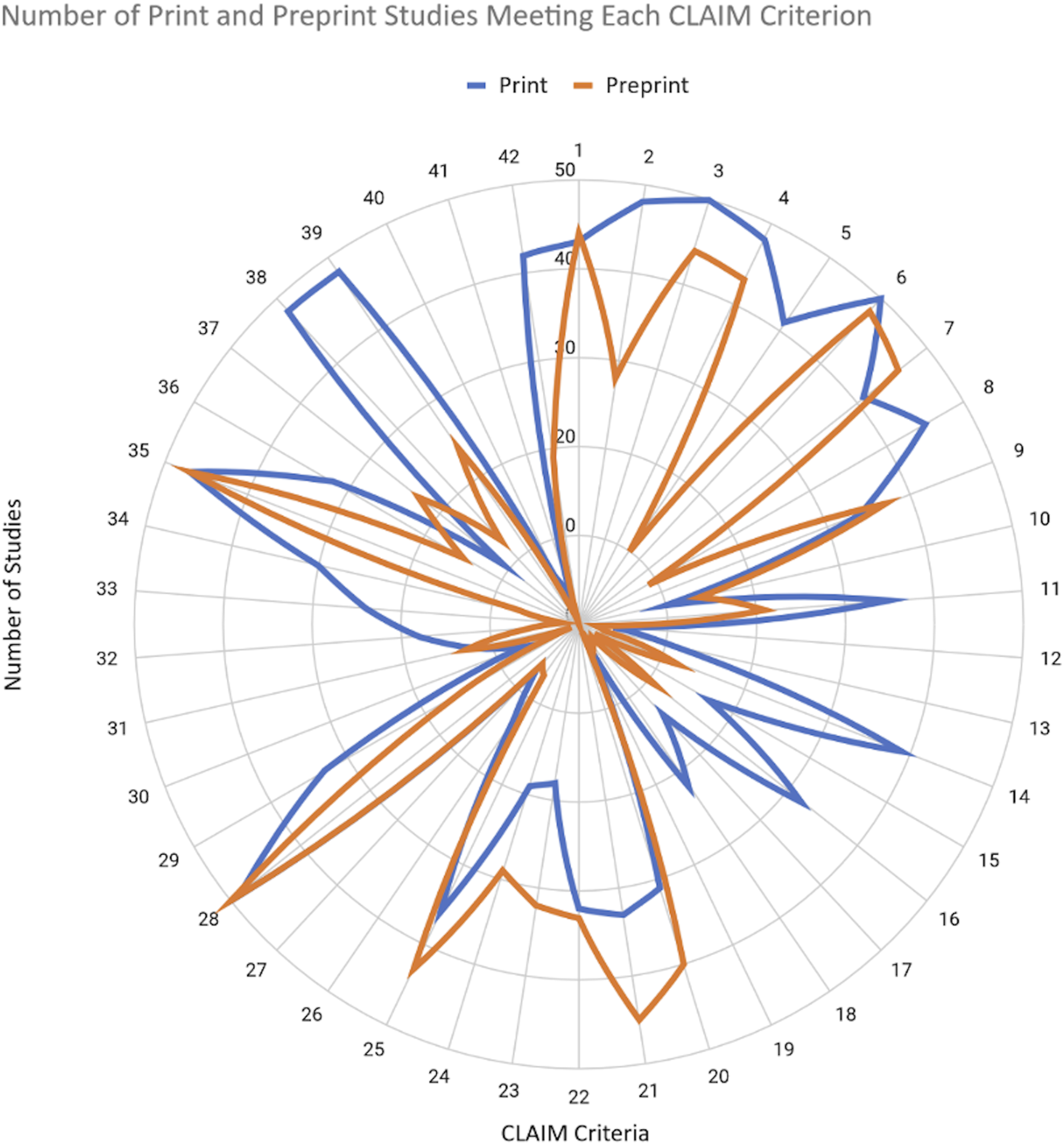
Number of print and preprint studies reporting each CLAIM item.
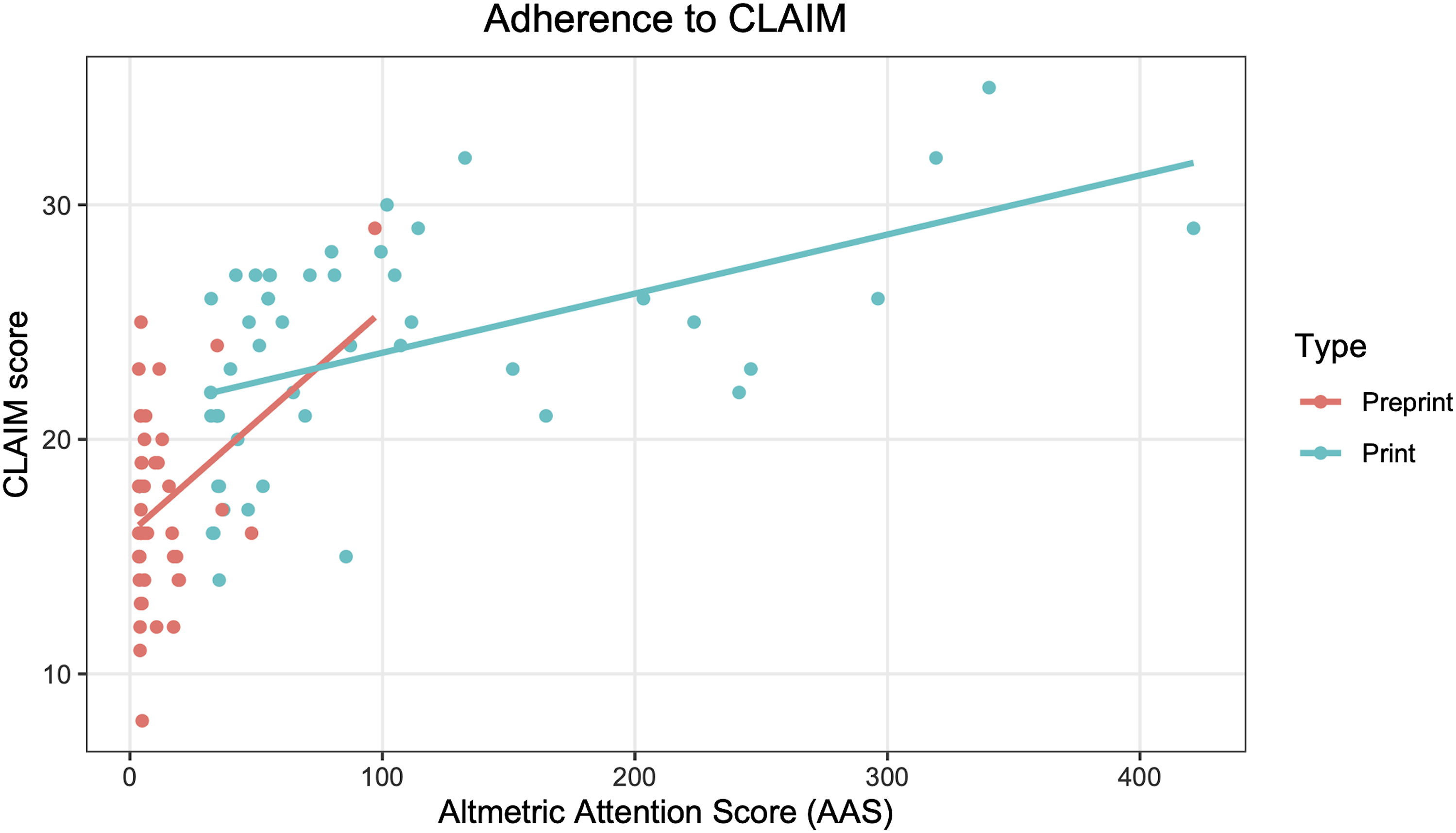
CLAIM adherence based on Altmetric Attention Score. Lines of best fit generated using a linear model.
Additional Factors
Checklist for Artificial Intelligence in Medical Imaging Scores Based on Body Region.
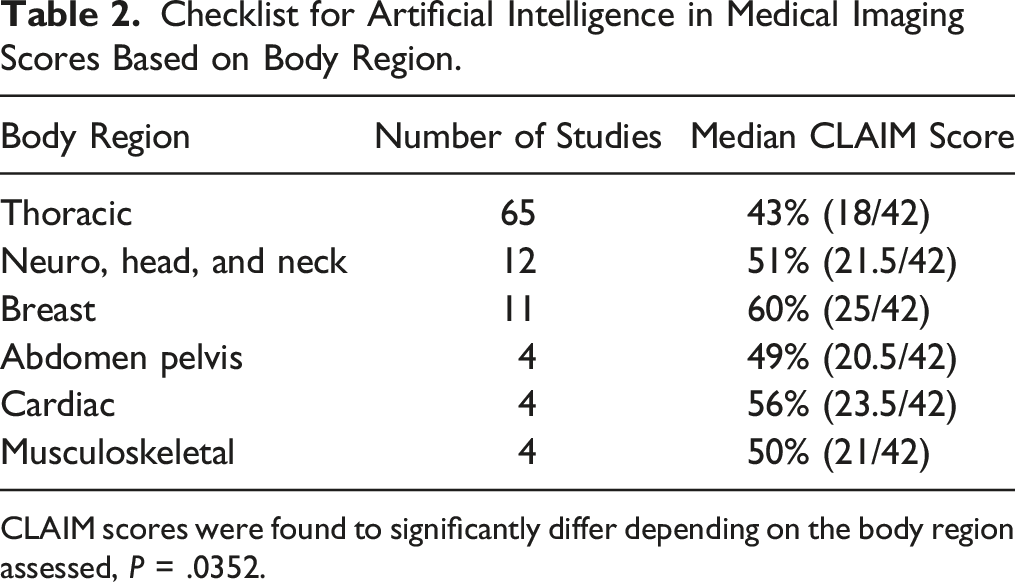
CLAIM scores were found to significantly differ depending on the body region assessed, P = .0352.
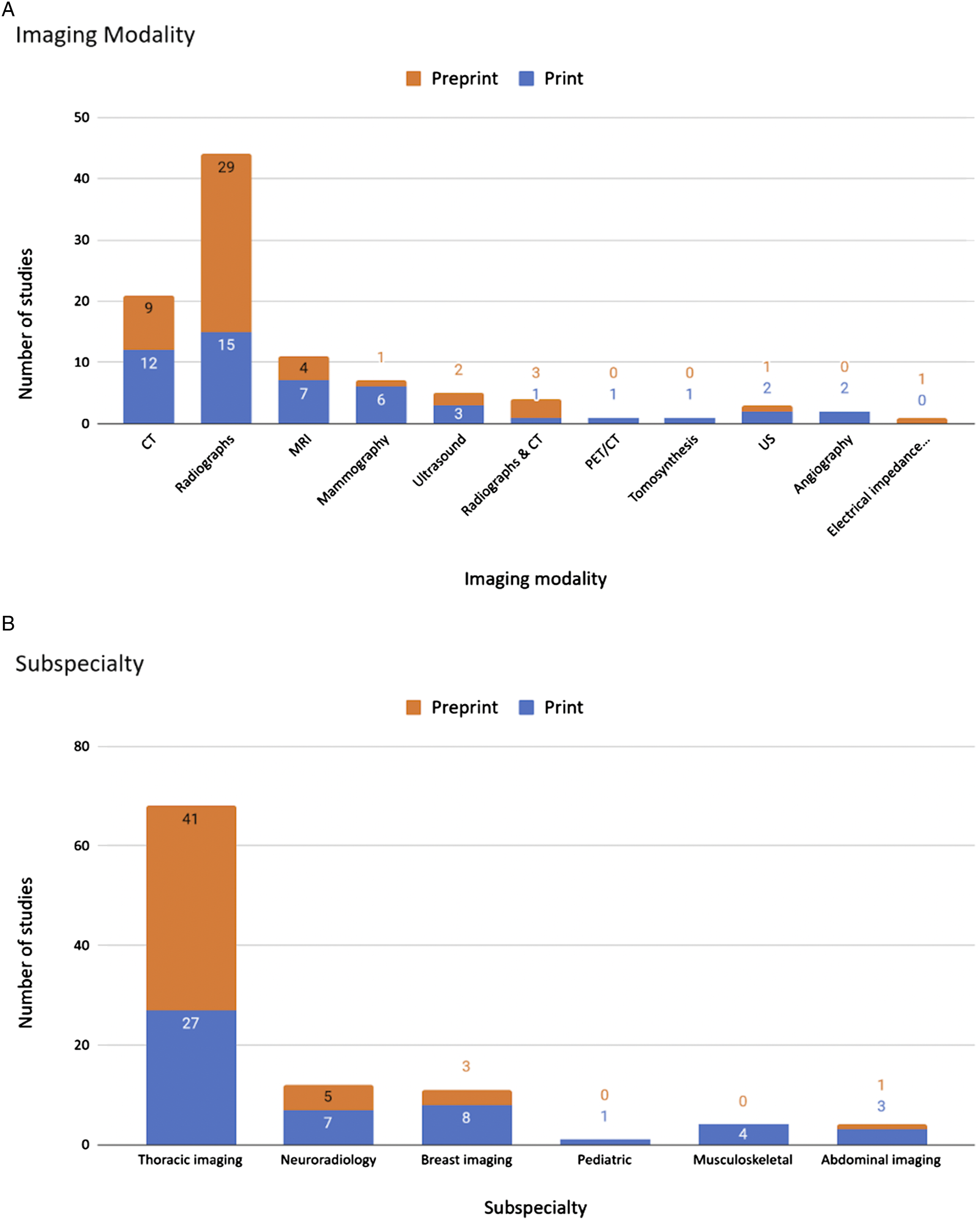
Details of 100 selected studies. (A) Imaging modality of studies (B) Radiology subspecialty of studies.
Radiology: Artificial Intelligence was the only journal to have endorsed the CLAIM guideline. The mean CLAIM score for studies published in Radiology: Artificial Intelligence was nearly but not significantly greater than those published elsewhere, 55% (23/42) vs 48% (20/42), P = .0661.
Discussion
Since the online release of the CLAIM guide, we found that the 100 peer-reviewed and preprint diagnostic accuracy medical imaging AI studies with the highest AAS had overall low reporting adherence to CLAIM at 48% of items, with preprints having less complete reporting than peer-reviewed manuscripts. This highlights the need for improved adherence to the CLAIM guide in all manuscript types, and especially in pre-prints which lack peer-review. These findings suggest that readers should exercise a higher degree of caution when reviewing articles on preprint platforms recognizing that important methodology details may be insufficiently reported. Suboptimal reporting of diagnostic imaging AI research methodology may be a barrier to embracing AI into clinical practice and may limit the ability of investigators to build upon prior works.
Preprint manuscripts were more deficient at reporting the scientific and clinical background, study objectives and goals, study limitations, including potential bias, and implications for practice, whereas print manuscripts tended to provide less detail regarding technical parameters. These differences may be attributable to the lack of peer-review for preprints. It is also possible that peer-reviewed journals attract authors who are more clinically oriented and more familiar with the reporting of non-AI medical research in traditional journals, whereas preprint platforms may attract authors from computer science who have greater experience reporting technical details pertaining to AI model development. Future research on preprint manuscripts that went on to publish in peer-reviewed journals could provide insight into the effect of the editorial practice.
There have been prior studies on reporting quality in AI studies that have also found poor aggregate reporting completeness.11,12 O’Shea et al. found comparable results to the current study with completeness percentages of 91% for identifying AI methodology and 69% for preprocessing data. 11 These items are mostly inherent in the training of AI and are usually necessary to reproduce the results. This may help to explain why these items are reported more frequently than others that are not necessary to train AI and not immediately necessary for replication. One such example is the robustness or sensitivity analysis (8/100), which often requires significant additional analysis of the model without guaranteeing any commensurate performance benefit. 12 Another example is sample size determination (4/100), especially since the amount of available medical imaging data is usually limited, so researchers simply use as much as possible rather than perform a power analysis.
During the early stages of the COVID-19 pandemic in 2020, there was a significant increase in the number of preprint manuscripts, and these manuscripts were published more rapidly than preprint manuscripts prior to the pandemic. 13 Many studies explored the application of AI to diagnose COVID-19 on chest radiographs or CT exams, and despite the remarkable efforts of researchers in this field, our results suggest that these studies were deficient in reporting completeness. This is consistent with a review by Roberts et al and another by Wynants et al which similarly found severe methodological flaws, poor reporting, and high risk of bias in these studies.14,15
Limitations
This study has several limitations. Reviewing manuscripts in the order of highest to lowest AAS may have introduced anchoring bias wherein the higher scoring articles served as the reference point for the lower scoring articles. Although using the AAS allowed us to interpret the reporting completeness of impactful studies, there is no guarantee that these findings are generalizable to other studies. While other measures of study impact could have been used, there is no ideal technique to establish a study’s true impact. For example, article citation counts can be biased by self-citations and would likely not have had sufficient time to accumulate to permit a meaningful comparison in the current study.16,17 Finally, the CLAIM checklist provides little guidance on how to holistically interpret a manuscript in conjunction with its code, which is frequently released publicly as open source software along with the manuscript. If the code is provided with the article, it provides other researchers with a wealth of information about data preprocessing, as well as the structure and training of the neural network that may be self-explanatory and reproducible but not be captured in CLAIM.
Conclusion
Overall reporting adherence to CLAIM is low in medical imaging diagnostic accuracy AI studies with a high AAS, with preprint manuscripts reporting fewer study details than peer-reviewed manuscripts. There is much room for improved adherence to the CLAIM guide, which could further promote adoption of AI into clinical practice and enhance the ability of investigators to build upon prior works.
Footnotes
Acknowledgments
Thank you to arXiv for use of its open access interoperability.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.