
Abstract
This article presents the development of a specialized data set for analyzing Estonian metadiscourse markers in academic usage, extending Hyland's interpersonal metadiscourse model to a non–Indo-European language. Our goal is to show how metadiscourse, as a feature of a writing tradition, can reveal aspects of writing in languages other than English, complementing the traditionally Anglo-centric perspective in metadiscourse research. By analyzing 21 Estonian linguistics research articles, we offer a transparent procedure to address methodological issues in metadiscourse studies and demonstrate the need for language-specific adjustments in the framework. We introduce statistical methods for analyzing multidimensional associations among marker categories, linguistic level, and rhetorical text structure. The findings suggest that Hyland’s metadiscourse model can be adjusted for specific languages, highlighting the influence of language structure on metadiscourse category variation and linguistic expression levels. The study reinforces that the distribution and manifestation of metadiscourse are shaped, among other factors, by unique writing traditions.
Keywords
Introduction
This study gives an overview of metadiscourse (MD) markers and strategies in Estonian academic text, as exemplified through linguistics research articles. Academic texts and the process of writing academic texts have long interested researchers, including interest in structural, linguistic, and discursive aspects (e.g., Aull, 2015, 2020; Flowerdew, 2020; Hyland, 2005; Swales, 1990, 2004) as well as cultural aspects (e.g., Connor, 1996; Fløttum et al., 2006; Kaplan, 1966; Lillis & Curry, 2010). For the latter, cultural aspects embedded in academic texts, it is important to recognize how writing traditions (see also Leijen et al., 2024a) differ from each other and how these differences may be made visible at the various levels of texts, for example, micro, meso, and macro levels.
Currently, there is a lack of visibility of local standards for research publications, especially in smaller national language communities, and the diversity in writing traditions are underresearched and in need of acknowledgment and support. As a result, these smaller writing communities are at risk of losing their agency, voice, and identity amid the global English-centered academic discourse. Similar concerns are also echoed by Gentil (2005), who emphasizes that maintaining academic literacy in more than one language is overlooked in L1 and L2 writing research when compared to the considerable attention L1 and L2 literacy development in English has been given. We believe that researching smaller academic writing languages helps to empower those communities and incentivizes writers to consider publishing their research in their language of choice. A clear necessity for such empowerment emerges from a 2021 overview of the language preferences in Estonian PhD theses that showed a decrease in the number of PhD dissertations written at one Estonian university by Estonians (Vallikivi, 2021). We stress the importance of fostering a more inclusive perspective to broaden our understanding of the various academic writing traditions and communities, which can be obtained through ethnographic studies (Lillis, 2008; Lillis & Curry, 2010), or as in our case, by entering the conversation to better understand the local writing tradition through corpus analysis of published articles.
To support more culturally and linguistically diverse research on academic writing, we have proposed transposing a feature model of (academic) writing traditions (see Leijen et al., 2024a, for a detailed overview) on understudied academic writing languages. The model enables a systematic procedure to identify distinct and common patterns of recurring features of a writing tradition irrespective of language or culture, thereby fostering the application of such procedures in similar replication studies across various languages. The model integrates three main theoretical frameworks: (1) contrastive rhetoric (Kaplan, 1966) and intercultural rhetoric (Connor et al., 2008); (2) genre theory (Bazerman, 2009), including English for academic purposes (Swales, 1990); and (3) discourse analysis (Hyland, 2004; Upton & Cohen, 2009). Altogether, currently, the model combines five features: rhetorical structure, argumentation, stance, authorial presence, and coherence (Table 1). While all these features have been quite well researched and described for English academic writing, less research has been conducted in other languages, resulting in a situation where it is difficult to describe what a specific writing tradition in many smaller languages looks like.
Simplified Feature Model (Leijen et al., 2024a).
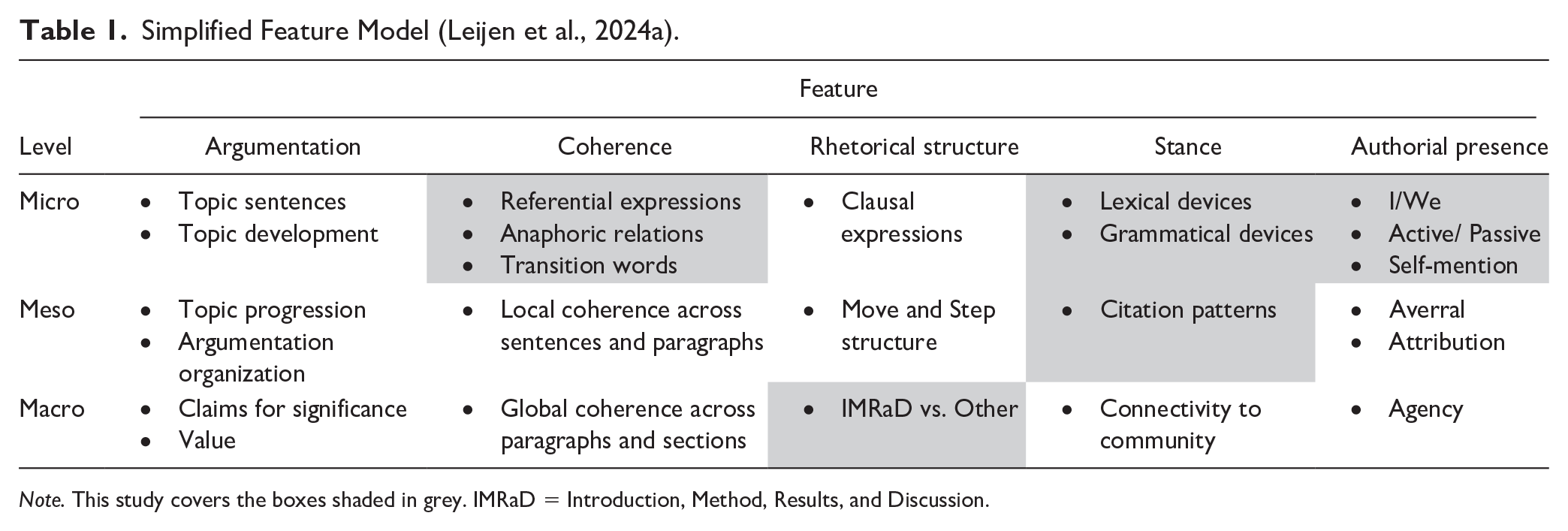
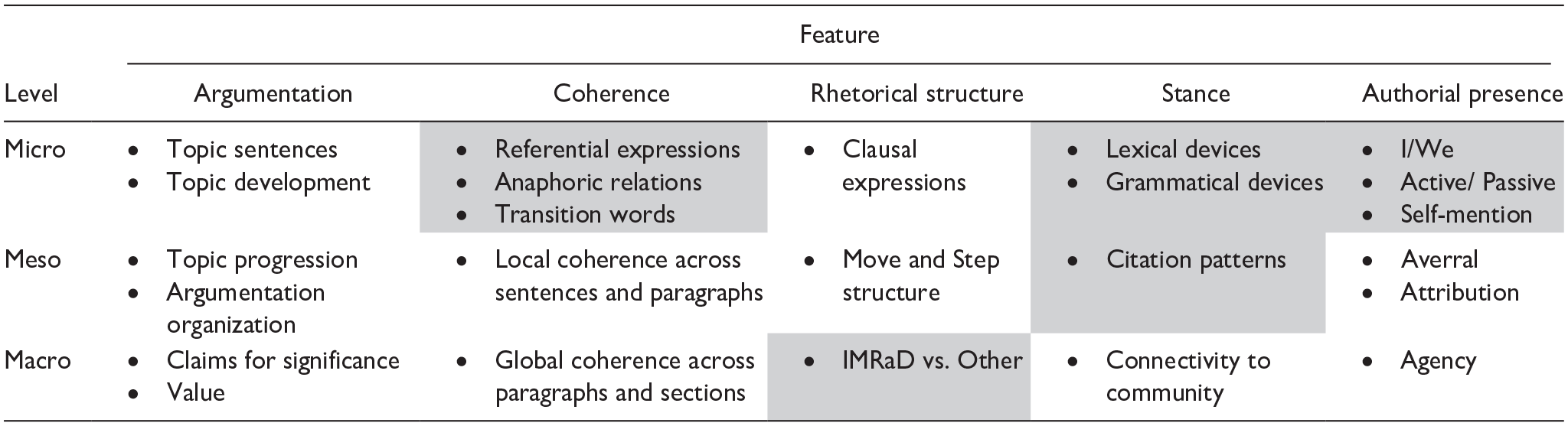
Note. This study covers the boxes shaded in grey. IMRaD = Introduction, Method, Results, and Discussion.
In this article, we make a leap toward a better understanding of the Estonian academic writing tradition. We do so by systematically describing the, as yet, underinvestigated aspect of Estonian writing, namely, MD features (see the next section for an in-depth description of MD features). In the context of the proposed feature model, MD covers several aspects under stance, authorial presence, and coherence.
Over the last two decades, MD features have gained increased research attention. However, the general English-centered perspective in academic writing research is also reflected here as the conversation is heavily biased toward English and contrastive studies between currently dominant languages in the academic context. As a result, English is probably the most extensively investigated language in the MD framework (Ädel, 2010; Aull, 2015; Hyland, 2005), accompanied by Mandarin Chinese (e.g., Hu & Cao, 2011; Kim & Lim, 2013; Mu et al., 2015), Persian (Gholami et al., 2014; Khabbazi-Oskouei, 2016), and Spanish (Mur-Dueñas, 2011; Navarro et al., 2022). Many MD studies compare the use of MD markers either across languages or between varieties and proficiency levels of languages, where one of the languages is typically English (e.g., Ädel, 2010; Bax et al., 2019; Dahl, 2004; Dontcheva-Navratilova, 2016; Mur-Dueñas, 2011), or across disciplines (Dahl, 2004; Hyland & Jiang, 2016; Ngai et al., 2018), and across genres in first and second language (e.g., Hyland, 2004).
Given the dominance of English as a lingua franca of academic writing and writing research, the use of MD markers in smaller languages within the academic community may benefit from comparable systematic investigations. Though there are studies available that tackle MD aspects of lesser-used languages such as Lithuanian (e.g., Šinkūnienė, 2018, 2019), Norwegian (Dahl, 2004), 1 and Finnish (Crismore et al., 1993; Mauranen, 1993), these studies often build their argumentation on models and approaches that are developed based on English academic writing. The importance of variability in local writing traditions and the cultural discourse context may strongly affect the patterns of academic texts (see, e.g., Ruskan et al., 2023). The present article aims to augment our current understanding of academic writing with insights from writing traditions in lesser-used languages analyzed through the lens of statistical associations.
We emphasize a comprehensive approach of the use of all MD markers across the whole text to determine the connectivity across all MD markers and between the features in the feature model. Typically, studies report primarily the frequencies and functions of certain MD devices and provide lists of various common MD markers available in a language (Hyland, 2005, 2017). However, it is rare to find detailed information about the methodological procedures used in MD studies and how they are influenced by language and writing traditions. For example, Hyland’s interpersonal model of MD is based on English data (as noted, e.g., in Bal-Gezegin, 2016; Çandarlı et al., 2015; Hyland, 2005), but it is still unclear if and how the structure of language affects the overall system of MD. Other languages may provide more insights.
This article has two goals. First, we aim to comprehensively describe a full inventory of MD markers in the discourse of academic Estonian, a language with about 1.2 million speakers. That is, we aim to map the system and distribution of Estonian MD markers, using linguistics research articles as an example. We build on Hyland’s (2005) MD model as one of the most influential ones in the field of research. The model was also chosen for its comprehensiveness when compared to other MD models (e.g., Ädel, 2006; Ädel & Mauranen, 2010; Mauranen, 1993). As mentioned above, our interests for this study include the author’s stance and presence, as well as text coherence. Hyland’s model encompasses both the writer’s perspective and stance, unlike models with a narrower, that is, text-reflexive view.
Our goal, however, is not to directly apply Hyland’s model to Estonian, but rather to adapt the model so that it reflects the conventions of Estonian academic writing traditions. In earlier research, various adaptations of MD models have already been explored. Bouziri (2021), for example, combined reflexive and interactional approaches in MD research of spoken academic discourse by non-native English speakers in Tunisia, proposing a more flexible and comprehensive interpersonal MD model. Burneikaitė (2008) also developed an alternative three-dimensional model for analyzing MD in texts produced in Lithuanian academic settings in English. These studies suggest the importance of modifying existing models to meet the needs of specific research projects and data.
An additional benefit arises by applying a comprehensive analysis through the entire text since this allows us to estimate the relationship between the functions of different text sections and the preferred MD devices in these sections. As such, we combine four features (Coherence, Rhetorical Structure, Stance, Authorial Presence) from a larger writing tradition model (Table 1), to show that it is necessary to analyze the features of a text in a larger framework, to understand the intricate connections between features, and how these form the writing tradition. In other words, we examine how the distribution of MD markers, which serve rhetorical functions, correlates with the sections of the IMRaD 2 format, a widely used structure in scientific writing. Many factors, such as writing tradition, journal guidelines, but also individual preferences may affect the distribution of MD markers across different parts of text. Previous research has shown the connection of MD markers and article subsections to be present in English academic articles, but culture-specific conventions may be inconsistent with the patterns characteristic of English writing (Abdi, 2011). Thus, we expect that the use of MD, as a rhetorical strategy, is influenced by the rhetorical structure of a text, and conversely the use of certain MD devices supports the rhetorical function of a text part. However, cultural conventions may result in different applications of MD markers across various languages, highlighting the need for a nuanced approach to analyzing rhetorical strategies within diverse academic traditions.
Second, we offer a transparent, step-by-step procedure for MD analysis, to facilitate replication in future studies, and an operationalized empirical approach and statistical techniques for (semi)automatic large corpus analyses. For example, when both the rhetorical structure and the MD markers can be identified fully automatically, it will become increasingly feasible to use their distribution as a kind of fingerprint for a writing tradition. We, thus, provide a guideline for future systematic studies of languages and writing traditions without the need for comparison. The guideline sets a reference point, or baseline, for future studies on Estonian MD, aiming to inspire other investigations of lesser studied academic languages.
Literature Review: Understanding Metadiscourse
As a starting point, the term metadiscourse was initially used to refer to the linguistic elements in a text that are used to “talk” about the text itself (Vande Kopple, 1985). In that sense, MD is a necessary component of the text that always accompanies the propositional content (i.e., what is talked about). Despite the seemingly simple explanation of the term, MD has now been recognized as a complex combination of various linguistic features that the writer uses throughout the text to both structure and comment on the text, give hints to the readers about the intended reception of the text, and to express the writer’s own stance toward the propositional content presented in the text (cf. Crismore et al., 1993; Mauranen, 1993; Vande Kopple, 1985).
As a result of the contributions of numerous authors, there are currently two predominant traditions in MD studies: the interactive (also known as broad or integrative) approach and the reflexive (narrow or nonintegrative) approach. The main contributors to the interactive approach have been Vande Kopple (1985), Luukka (1992), Crismore et al. (1993), and Hyland (2005). On the other hand, Mauranen (1993), Ädel (2006), Dahl (2004), and Toumi (2009) are known as the proponents of the reflexive approach instead. With both sides applying the functional approach, the main difference between these two models appears to be the disagreement on the rhetorical categories that can be qualified as MD, specifically interpersonal categories such as stance (Ädel, 2006).
Since 2005, Hyland’s interpersonal model of MD has gained a substantial following among the researchers who consider MD as textual interaction, surpassing any other approaches (for an overview, see Pearson & Abdollahzadeh, 2023). The model is originally derived from the earlier works of Vande Kopple (1985), Crismore et al. (1993), and Thompson and Thetela (1995). On the other hand, some researchers have preferred the reflexive, so-called narrow approach, for example, for providing clearer criteria to identify MD (e.g., Li & Xu, 2020; McKeown & Ladegaard, 2020). However, while the reflexive approach includes only material that reflects the aspects directly related to the ongoing text, Hyland’s model offers a more inclusive analysis of the whole text.
With full awareness of the work of various researchers who have attributed quite different boundaries to MD, we are utilizing the potential of the broad concept of MD to investigate several aspects of our feature model (see Table 1) that align with the linguistic devices available for MD. According to the broader approach to MD, by using various markers of MD, writers organize the text for readers (i.e., pay attention to coherence), express their stance, engage the readers in discourse, and make decisions on how to present themselves as authors in the text (Hyland, 2005).
Thus, we use one of the most widespread models of MD that represents the broad approach, namely, Hyland’s (2005) interpersonal model of MD (see also Hyland & Jiang, 2022; Hyland & Tse, 2004). This model combines (a) the interactive dimension of MD that is about organizing the discourse and anticipating readers’ knowledge and (b) the interactional dimension of MD that is concerned with the writer’s attitudes and engagement in the expressed arguments and involving the reader in the argument (Hyland & Tse, 2004). The interactive dimension includes the categories of transitions, frame markers, endophoric markers, evidentials, and code glosses. The interactional dimension comprises hedges, boosters, attitude markers, self-mentions, and engagement markers. The categories, with explanations and examples, are summarized in Table 2.
An Interpersonal Model of Metadiscourse by Hyland (Hyland, 2005, p. 49).
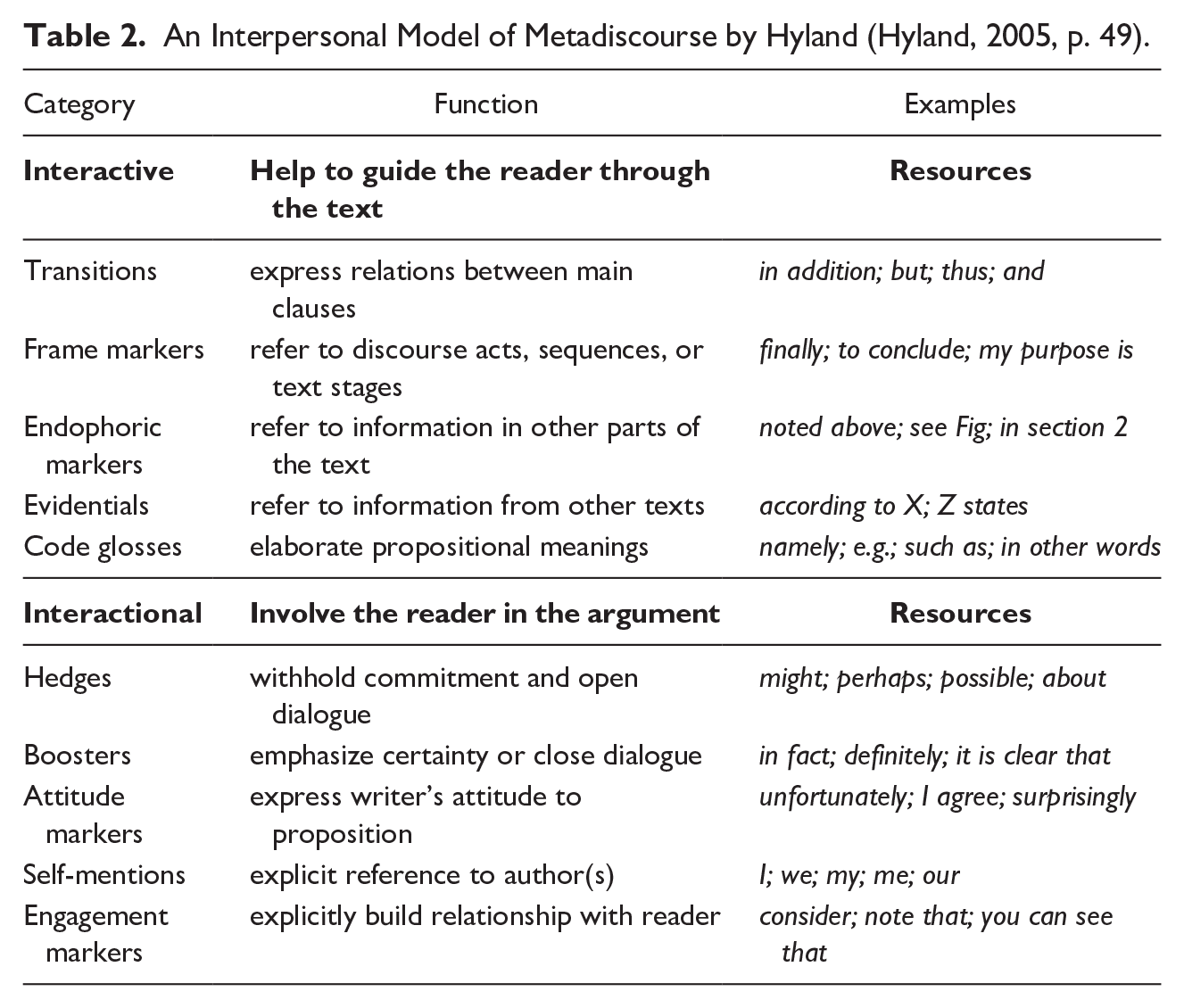
In his works, Hyland has focused on lexical items, that is, words and chunks of words (i.e., constructions). Other MD studies often follow the word lists offered by Hyland as a starting point. There might be several reasons for this practice. First, this method is quite straightforward, offering results that are in line with the results for English. Second, the particular language under study may have a similar linguistic structure to English (e.g., Germanic or Romance languages). Third, a predetermined list facilitates automated search methods (as has been proven successful by Aull, 2015; Aull & Lancaster, 2014; Bax et al., 2019; Yoon & Römer, 2020). However, to get a full picture of MD markers across languages, it is important to include different kinds of linguistic items in addition to lexical ones, to take into account, for example, grammatical categories such as gender, case, and aspect morphology (see also Bal-Gezegin, 2016; Dahl, 2004; Mauranen, 1993). The rich morphology of a Finno-Ugric language like Estonian is, thus, a good test case. In Estonian, until now, the concept of MD has been used only in the context of investigating the strategic text choices made by citizens in their written complaints to authorities (Reinsalu, 2017b). While some recent studies have analyzed the forms and functions of self-mentions in Estonian academic texts (Lemendik, 2022; Reinsalu, 2017a; Šmidt & Reinsalu, 2021), the full system of MD markers has not gained attention yet.
Our study takes a comprehensive approach to MD markers, aiming to analyze all available MD markers. As such, we determine MD markers from the bottom-up, coding the text containing all aspects of MD, rather than the top-down approach where MD markers have been determined and we only find these. Our study aims to determine all potential MD markers through careful manual annotation of a small selection of texts, before turning to a large-scale semiautomated analysis, and thus avoids using a predetermined list of MD markers (cf. Aull, 2015). A similar approach (i.e., retrieving the markers for analysis in two steps) has been taken by Mur-Dueñas (2011), for example, although it is not specified if the scanning procedure was guided by the aim of finding those markers that could easily be used in the second step, namely, automatic extraction of the markers.
Two aspects of MD make analyzing MD markers and their functions difficult for researchers and especially difficult in computational corpus-driven approaches. First, the line between propositional and metadiscursive meanings is vague, and it might be difficult to clearly separate them from each other (Khabbazi-Oskouei, 2013). Second, one marker can carry more than one MD function in a particular place in a particular text (Hyland, 2005). For example, quite can be a hedge or a booster, or possibly both (quite poor, quite tricky) (Hyland & Jiang, 2024). Therefore, the interpretation of the functions of MD markers requires a rigorous analytic approach and clear annotating principles (see Bax et al., 2019, for a similar discussion). We aim to heighten awareness of these difficulties.
Method
Step 1: Collection of the Corpus
We analyzed the use of different MD markers in research articles (RAs) written in Estonian. We compiled a corpus of 21 RAs from one discipline, namely, linguistics. Considering that we analyzed full texts of the RAs rather than only some selected sections, 21 RAs is optimal for a task requiring extensive manual annotation. We intentionally tested only one discipline for this baseline study as we aim to initially restrict the number of factors that can influence our results. Linguistics was deemed as the most suitable discipline for two reasons. First, in a previous study (Hint et al., 2024) we have found that linguistics is an interesting test case between “soft” and “hard” sciences. Linguistics does represent the “traditional” features of a humanities discipline, but it also expresses certain patterns of “hard” sciences, for example a strong connection between images and text in reporting findings (see also Hyland & Jiang, 2018, p. 24). In an earlier study, Dahl (2004) has also shown that while linguistics RAs in English, French, and Norwegian are very different from medicine RAs, they are in several aspects quite similar to economics RAs. Therefore, we expect linguistics as a discipline to reflect a more balanced use of MD markers compared to more restricted disciplines (e.g., medicine) and, at the same time, present a nuanced picture of disciplinary conventions that underscores the complexity and diversity of strategies within a specific academic discourse. Second, the field of linguistics is perhaps one of the most well-covered in terms of the publications available in Estonian. Thus, linguistics is a representative baseline for both MD and rhetorical structure.
The RAs were published over ten years between 2011 and 2020 in three Estonian sources, seven RAs from each: a monthly journal Keel ja Kirjandus, and two yearbooks, Estonian Papers in Applied Linguistics, and The Yearbook of the Estonian Mother Tongue Society. We adopted the following selection criteria. (a) Single-authored RAs were included in the corpus for better identification of self-mentions and engagement markers. (b) All the RAs in the corpus are written by Estonian academics. (c) Each author is represented in the corpus with only one RA, to avoid a possible author bias in the data. (d) Since two of the selected journals publish only one issue per year, we aimed to keep the time span of the RAs as equal as possible. Thus, not more than one RA per year from each journal/yearbook was selected into the corpus.
Step 2: Preliminary Close Reading and Devising an Annotation Scheme
We started the annotation process with an exploratory close reading of a selection of five RAs from our corpus in order to get an understanding of the available MD markers and how they are used in Estonian academic texts. In this preliminary stage, we included three annotators. One RA was inspected by all three annotators; plus each annotator studied one or two individual articles. After the close reading stage, the three annotators had a 2-day discussion session to systematically consider the MD marker candidates. Based on these discussions, a detailed annotation scheme was devised.
The resulting annotation scheme builds on Hyland’s (2005) interpersonal model of MD. All MD marker categories from Hyland’s model are included in the study, that is, both interactive and interactional markers are analyzed. Each MD marker found in the corpus is annotated for three variables: (a) marker category, (b) linguistic level, and (c) section in the text. The variables are explained and illustrated in Table 3.
Variables and Their Values Annotated in the Study.

During the preliminary annotation, certain conceptions under some categories needed to be changed or adjusted to make the model suitable for Estonian data. The underlying reasons for these adjustments fall into two groups.
In the first group, the adjustments are related to the grammatical structure (e.g., first-person verb endings, impersonal forms) and/or pragmatic usage patterns (e.g., discourse clitic, conditional mood) of certain linguistic devices in Estonian that are inherently different from the structure of English, that is, the language based on which the model was originally developed. Therefore, while Hyland’s model includes only lexical items and constructions as MD markers, we also added a grammatical level to the analysis because certain grammatical forms in Estonian inevitably involve metadiscursive meaning, that is, the author’s perspective toward the expressed propositional content. In our study, these markers include the following.
In addition to first-person pronouns as self-mentions, we annotated all first-person verb endings as instances of self-mention. This change is important because first-person and second-person pronouns can be freely omitted in Estonian, but the corresponding verb ending still explicitly marks the person. Note that some researchers (Ädel, 2010; Toumi, 2009) have previously claimed that only some uses of first-person forms are metadiscursive (i.e., the author commenting on arguments and text), while others are only propositional and should not be considered as MD (i.e., the author commenting on what she did in the research process, that is, the actions and events in the past). However, we did not exclude any first-person markers from the study, because they always realize authorial agency (i.e., construe researcher as an active participant in the process), and, thus, are central to the writing (Wilcox & Jeffery, 2018).
All implicit references (i.e., impersonal verb forms and constructions) to the author are included under the category of self-mentions. It is crucial to note that impersonal constructions are grammatically different from passive constructions in Estonian, so treating impersonal verb forms simply as passives would be misleading and English-biased. More specifically, while Estonian impersonal construction lacks a subject, it conveys an active, indefinite meaning where the suppressed subject retains its syntactic relevance (Torn-Leesik, 2009). For example, the proper translation of an impersonal sentence Teises peatükis
The choice between the personal or impersonal form is generally a conscious decision made by the author (Hyland, 2005, p. 53), and thus both forms deserve equal attention (see also Akbas & Hardman, 2017; Balažic Bulc, 2020, for a similar reasoning). Because of the inclusion of impersonal forms, it might be necessary to reconsider the category label, since “self-mention” points only to explicit forms, whereas by using implicit (impersonal) forms the author consciously avoids mentioning oneself. However, a straightforward concept of “avoiding a person” can probably be attributed to languages with less complex pronoun systems, such as English, where there is a more direct link between personal pronouns and personal reference (Laitinen, 1995, p. 342). Building a whole theory based only on one language (or language family) strongly biases the analysis results for other languages; therefore, a theory that claims to represent universal categories must allow itself to language-specific adaptations.
3. The discourse clitic -ki/-gi, that functions as an emphasis marker, is always considered as a booster (e.g., nii selgu-b-ki; gloss: “so become clear-3SG-CL” 3 “so it [really] becomes clear”). In Estonian, this form is morphologically a bound morpheme, but it carries a discourse-pragmatic function. As it is expressed at the level of grammar in Estonian, it is another indication that grammatical level must also be considered in the analysis of MD.
4. Verb forms in conditional mood are always considered as hedges (e.g., või-ks üldista-da; gloss: can-COND generalize-INF “could be generalized”), as conditional forms express either a hypothetical or unreal situation and they also function as politeness markers.
The second group of adjustments relates to the difficulties in deciding the exact MD category of a certain device or making a distinction between propositional and metadiscursive meaning. Therefore, to limit subjective decision-making about the metadiscursive function of such markers and to reduce inconsistencies in the annotation process, we decided to always include certain types of markers as metadiscursive. Because of this decision, we added two separate categories in our study, which were not originally included in Hyland’s model (1 and 2 below). We also decided to restructure the content of three interactive categories (3, 4, and 5 below), to promote transparency in the annotation and integrity of the analysis.
Modal constructions overall express meanings that are related to the writer’s cognitive perceptions and attitudinal qualifications about the propositions as well as interactional and textual aspects (i.e., they add the writer’s perspective to the text) (Cornillie & Pietrandrea, 2012). It is generally possible to say whether a modal construction has a hedging (e.g., with verbs like paistma and tunduma, both translated as “seem”) or rather boosting (e.g., pidama “must, have to”) function in a specific context. However, it is often the case that in a modal construction, another (grammatical) element occurs that has a different, even contradictory, metadiscursive meaning (e.g., tundu-b-ki, gloss: seem-3SG-CL “it (really) seems,” where tundub “seems” could be analyzed as a hedge and the clitic -ki as a booster). Therefore, we decided to include modal markers (e.g., constructions with modal verbs) in the analysis as a separate category of its own.
Adverbs of degree and frequency (hereafter “frequency markers”) in academic text definitely add the author’s perspective to the text and express author’s stance, but it is often difficult to say whether they express the hedging or boosting function, or whether they function as attitude markers (e.g., ainult “only”). Therefore, such adverbs were annotated, but kept in the analysis as a separate group of markers.
Transitions proved problematic in the annotation process, because separating between propositional and metadiscursive meanings is often impossible in actual data (see also Ebadi et al., 2015). In response to this difficulty, sentence connectives and conjunctions that work above the phrase level were included, and no attempt was made to leave out transition markers from sentences expressing “purely propositional” content.
Markers indicating discourse goals (such as Siinne artikkel annab ülevaate “The article gives an overview” or Selle uurimuse peamine eesmärk on “The main goal of this study is”) are not, in this article, considered as frame markers, but instead, we annotated these as endophoric markers referring to the whole text (see also Cao & Hu, 2014, for a similar approach). Thus, we treated these markers the same way as we treated any other marker that referred back to the preceding text or to the text yet to come. The reason behind this decision was that these markers also refer to the text itself, although on a more comprehensive level.
Under the category of evidentials, we counted all integral citations, that is, citations that explicitly emphasize the author of the cited work and use a reporting verb construction or a postposition to introduce the reference (e.g., PN järgi “according to PN”). Nonintegral citations with author name and publication year in brackets were also annotated when an additional linguistic element—usually a reader-engaging device—was added to the reference (e.g., vt nt PN “see e.g., PN”).
The described annotation scheme was then followed to comprehensively annotate the whole corpus, including the five RAs from the initial exploratory annotation, which were revised according to the devised scheme.
Step 3: Preparing the Data for the Analysis
After the article selection process, all the texts were cleaned, that is, we removed abstracts, tables, figures, linguistic examples, other illustrative material, lists of references, extended quotations, and longer indented quotations from all RAs. Titles and section headings were not removed, because these are important elements that provide necessary information during the annotation process; however, MD markers in titles and headings are not analyzed in this study. Footnotes were considered to contain both propositional and metadiscursive meanings, so they are also included in the corpus. We then collected all texts into one Excel sheet, one sentence per line. We used Notepad++, a free text editor, to arrange the texts to follow the necessary structure. Table 4 presents the quantitative overview of the corpus content and size.
Description of the Cleaned Corpus.

Step 4: Automatic Data Extraction and Annotation
We combined automatic data annotation with manual annotation. For the automatic annotation, we collected a list of the most common and clear-cut examples of Estonian MD markers, based on the results of the preliminary annotation process (Step 2). There were several challenges in this process. As far as we know, there is no existing reference corpus or list of MD markers for Estonian. Thus, we had to find out what to mark up, how to mark up, and the conditions and delineations for the different markers. This demanded manual resources and cross-checking between annotators. While the first versions would still need extensive manual revision before coverage is satisfactory, the result is a first step toward a reference corpus for Estonian MD markers, which can be used to train fully automatic models using machine learning in further studies. The MD markers encode high-level functions, such as the intention of the writer for using the constructions. Such high-level functions are notoriously difficult to infer automatically from the text and it is also difficult to make formal rules based on text features that would inform about high-level functions. However, many patterns are recurring and provide good predictive cues.
Altogether, 106 MD markers were deemed suitable for automatic annotation. These included lexical units and constructions as well as grammatical units (e.g., first-person pronouns, verb endings, and clitics). Using a Python script, these markers were then automatically searched for through the whole data set and annotated in the worksheet. When a sentence (i.e., a row in Excel) contained more than one MD marker, additional rows for each individual marker were added to the worksheet during the annotation process.
Step 5: Manual Data Annotation
Since the use of MD devices is very context sensitive, it is necessary to include human checking and adjustments in the analysis. After the automatic MD markers extraction and annotation, we carefully checked and, when necessary, corrected the pre-filled Excel sheet. In addition, we manually added into the table each MD marker from the data that had not yet been added in the automatic phase. The manual annotation resulted in 8,870 lines of annotated MD markers. Three annotators were responsible for this task: two authors of this article and one student annotator. The annotations by the student were later confirmed and revised by the two primary researchers, where necessary.
Step 6: Interrater Reliability
After we finished annotating the entire data set, we checked the reliability of the annotations, using Cohen’s kappa interrater reliability measure between two primary researchers, and Fleiss’s kappa for the overall agreement per rating category. Given the multivariate nature of the data, two questions guided our double coding. First (Q1), do we have a similar understanding about the MD markers overall and per category, that is, do we agree with the selection of markers (i.e., yes/no answers)? Second (Q2), do we agree on the decisions about the category of a particular marker (i.e., blindly annotating the categories and comparing the agreements).
First, we made two separate subsets, each containing only data with one annotator’s decisions. The size of both these subsets was about 5% (i.e., around 300 MD markers) of the whole data set. We made sure that the distribution of MD categories in both subsets represented the distribution in the whole data set. Then, both annotators made the decisions about the agreement of counting the device as a MD marker, and about its specific category, without foreknowledge of the first annotator’s choices. For calculating Cohen’s kappa and Fleiss’s kappa, we used the R (R Core Team, 2022) package psych (Revelle, 2023). The interrater reliability measures across all the categories showed almost perfect agreement between the two annotators across all the categories (Table 5). The interrater reliability measured per rating category between the two annotators shows that some categories achieved greater reliability scores (self-mentions, modal constructions, and transitions) and others showed lower reliability scores (engagement and attitude markers, and boosters) (Table 6). Finally, we discussed both the disagreements between annotators and the discrepancies across the data, and we agreed on the most acceptable solution. We then refined the annotation, to eliminate all inconsistencies from the annotation.
Cohen’s Kappa Interrater Reliability Across All Categories for the Manually Coded Data.

Note. 621 subjects/items and 2 raters/measurements. Confidence intervals (CIs) are asymptotic.
Fleiss’s Kappa Interrater Reliability per Rating Category Measures for the Manually Coded Data.

Note. 621 subjects/items and 2 raters/measurements. Confidence intervals (CIs) are asymptotic.
Step 7: Data Analysis
Data analysis was carried out in two stages. First, we determined the overall descriptive statistics of the data (i.e., the frequencies of the categories and the number of devices in each category). We also qualitatively described the data by presenting the five most characteristic MD markers for each category. Second, to explain the patterns in our data and associations between the variables included in this study, we used association plots (Cohen, 1980; Friendly, 1992; Meyer et al., 2003) and multiple correspondence analysis (MCA). These techniques allowed us to clearly represent the patterns in our multidimensional categorical data. The data analysis was handled on the popular R platform (R Core Team, 2022). R is a general framework for statistical analysis, including a programming language, and a framework for sharing packages that implement methods for analysis and graphing. Specifically, we used packages ggplot2 (Wickham, 2016),vcd (Meyer et al., 2006), and FactoMineR (Lê et al., 2008) for the analysis. 4
Results
Descriptive Statistics: Overall Quantity of Markers and Marker Categories
Altogether, our corpus includes 5,058 sentences. In 1,253 sentences, no MD markers were present; therefore, the following analysis is based on 3,805 sentences. The ratio of sentences that include MD markers versus sentences without MD is roughly 3:1, meaning that about 75% of the sentences included at least one MD marker. Among the sentences that include MD, there were on average 3.7 MD markers per sentence. There were on average 361 MD devices per article, with a maximum of 15.7 markers per 100 words, and a minimum of 5.0 markers per 100 words in a single article. The total number of MD markers in this analysis is 7,586.
Overall, interactive markers were much more frequent in Estonian annotated data compared to interactional markers (Figure 1). Crucially, the three most frequent categories all belonged to the interactive dimension. Especially frequent were transition markers (2,025 occurrences) that were twice as frequent as the next two categories, code glosses (1,074) and endophoric markers (1,031). The use of evidentials, that is, mostly integral citations (411), and frame markers (227) were less substantial and comparable to the use of interactional categories. Also relatively frequent were the two categories that we added to Hyland’s original model, that is, frequency markers (694) and modals (502). In the interactional dimension, the category of self-mentions (511) was the most frequent, followed by boosters (417) and hedges (373), whereas attitude markers (222) and engagement markers (99) were the least used MD devices in our data. These patterns indicate various distinctions when compared to results obtained from English and other languages.
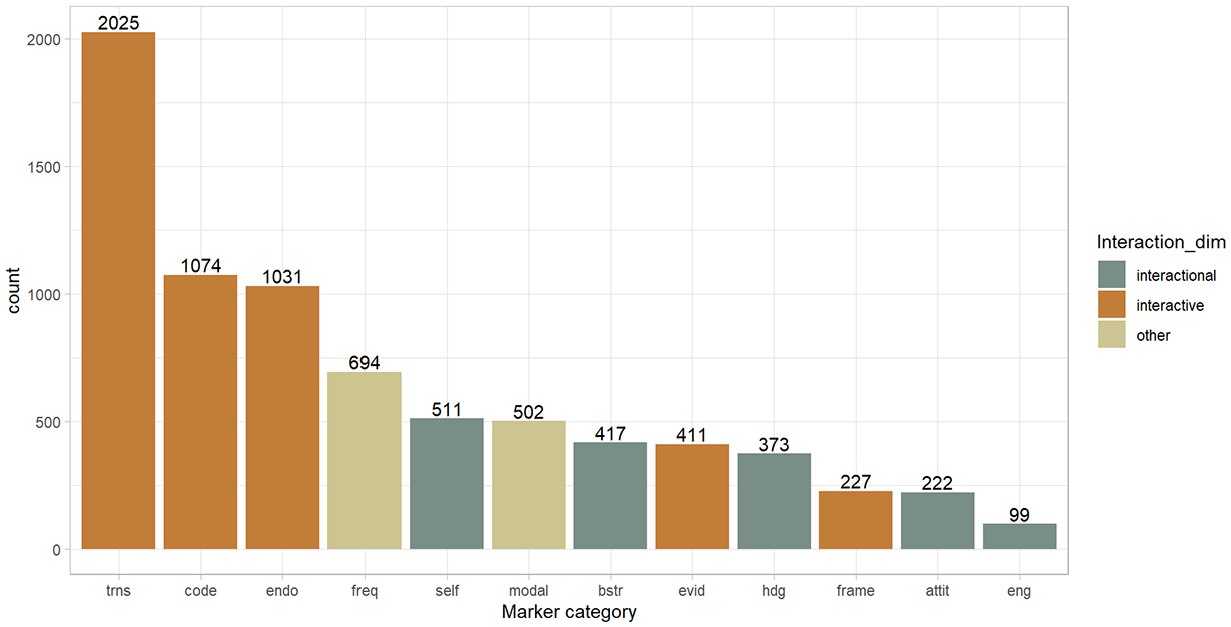
Most used MD categories in Estonian.
The number of different MD items available in each category varied considerably (Table 7). Endophoric markers were the most versatile group with 269 different items used in our data. Evidentials (176), transition markers (151), and frequency markers (142) also had a rather wide array of items for a writer to choose from. On the other hand, engagement markers (39), modal constructions (27), and self-mentions (11) had a smaller range of different items. Importantly, it must be noted that usage frequencies of categories and the number of individual MD items in each category do not necessarily correlate; for example, while code gloss is the second most frequent MD category, there were only 75 different items of code glosses used in our data. By contrast, there were altogether 222 instances of attitude markers in our data, with as much as 118 individual items used.
The Number of Different MD Items Available Across Categories.
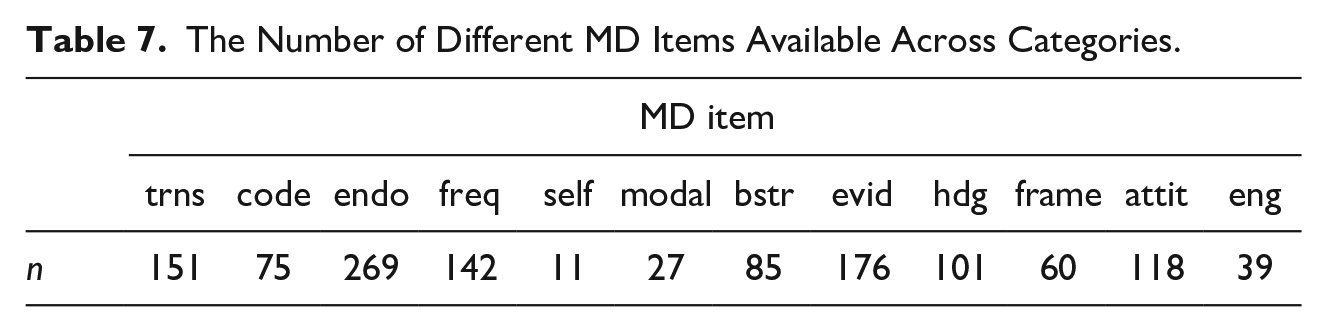
The majority of MD markers were realized either on the lexical or constructional level in Estonian (Figure 2). Importantly, these two levels were represented across the whole range of MD categories, although with certain categories, constructions (frequency markers, boosters, hedges) as well as lexical markers (self-mentions, evidentials, engagement markers) occuring only infrequently. Grammatical level expressions were most strongly connected to self-mentions as well as to hedges and boosters. Punctuation marks had the most restricted functions, occurring only in two categories: most often as code glosses, but also as frame markers.
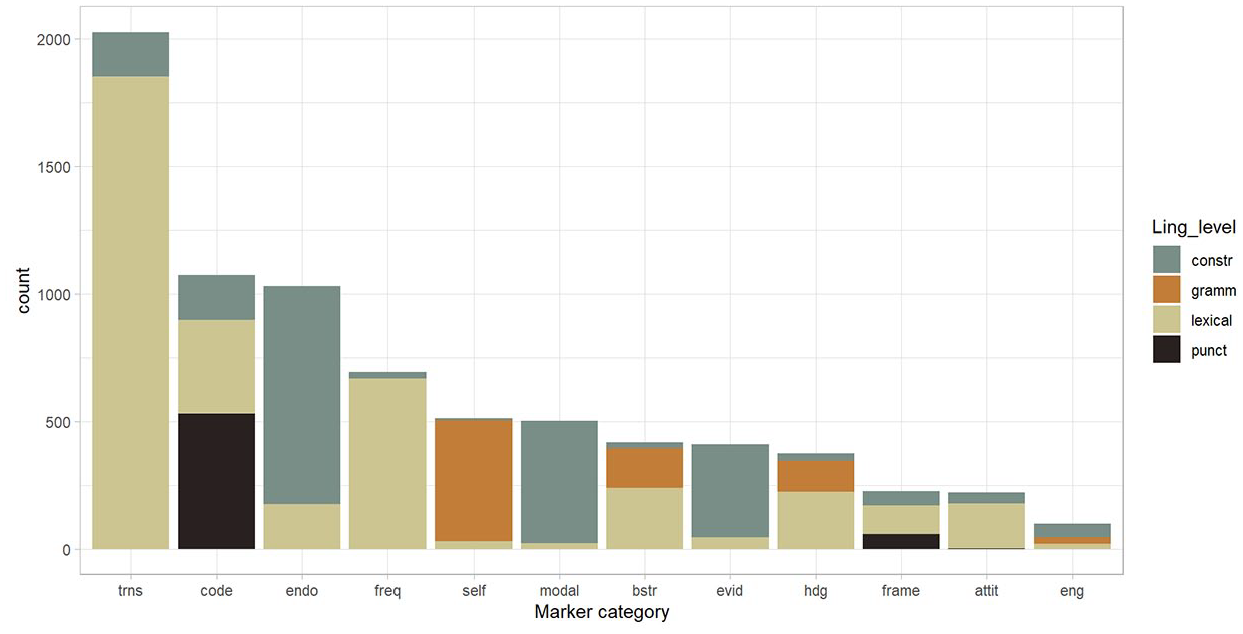
The distribution of MD markers from different linguistic levels across MD categories.
In Table 8, we present the five most frequent markers used in each category. English translations have been added to lexical and constructional items; for presenting grammatical items, glosses are used. Punctuation marks and combinations of other internationally known characters are presented without additional comments.
Five Most Frequent MD Items in Each Category.

Note. Counts are presented in brackets.
Two aspects deserve further elaboration when interpreting the results of this section. First, the number of different items available in each MD category relates to the linguistic level that most closely connects to the expression of the functions of that category. In other words, when a category is mostly expressed with grammatical items (1SG for self-mentions, but also conditional verb forms for hedges and clitic -gi/-ki for boosters), then the number of possible devices is limited, since the amount of grammatical category member is always finite and rather small. The argument for code glosses is similar in that they heavily rely on various punctuation marks (e.g., colons, dashes, parentheses) that also form a limited set in a language. On the contrary, categories where lexical items are more important also have a larger variability in the available devices (e.g., attitude markers, hedges and boosters, frequency markers, transitions). Furthermore, the categories with most variation are usually expressed with various constructions, which is intuitively expected, because there are so many possible combinations (especially in a language with free word order and rich morphology, as is the case with Estonian).
Second, the results presented here are affected by our aspiration to apply the automatic analysis procedure on MD markers. To be able to automatically detect all the necessary MD markers, it is first essential to identify all possible patterns within the data, even when the conceptual differences between these patterns are negligible to the human reader. For example, the meaning and function of code glosses such as s.t, st, (s.t), (st), all meaning “i.e.,” are conceptually identical, but they differ in incidental surface-level presentation. This surface-level variation explains why we counted so many different endophoric markers, evidentials, and transition markers in our data, whereas self-mentions and modals constitute rather restricted sets.
Exploratory Analysis of MD Categories
The Associations Between Text Sections and MD Markers
In this subsection, we analyze the patterns of MD markers. We place the patterns of the MD marker in the context of the relevant features in the writing tradition mode (Leijen et al., 2024a). More specifically, we explain whether and how MD categories relate to the conventional rhetorical structure, to the IMRaD sections in academic text. In the association plot in Figure 3, we investigated associations by looking at the Pearson residuals resulting from the contribution toward a deviation from the assumed or expected statistical independence of rows (sections) and columns (MD categories). Red in a cell marks a strong underrepresentation (i.e., lower frequencies than expected if independence were true). Blue marks an overrepresentation (i.e., higher frequency than would be expected if independence were true). The base of each bar is relative to the support for the association, and the height of it is proportional to how significant it is. Significance is understood as marking a pattern that is hard to explain by random chance.
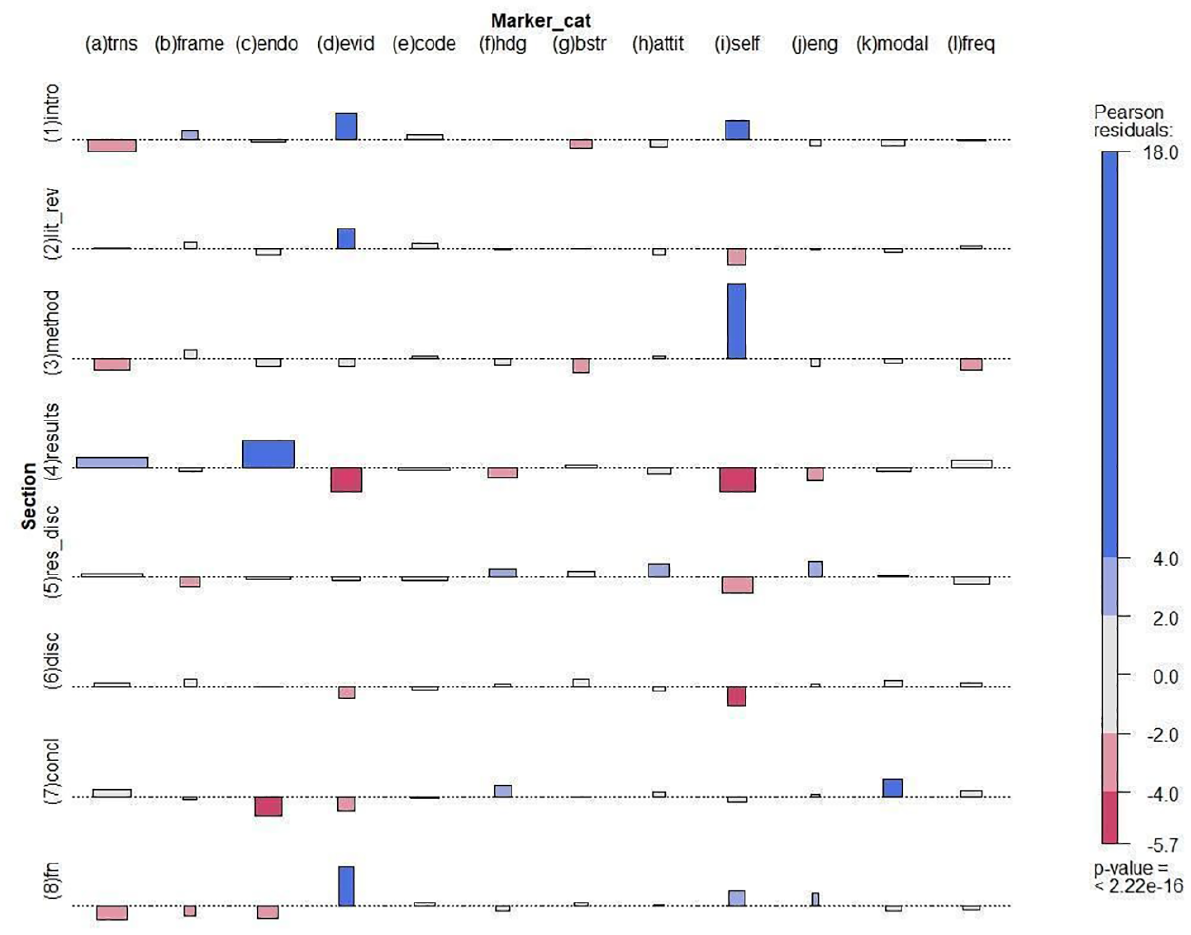
Association plot for section and marker category in the data.
We concentrate on the MD categories that have strong preferences for which sections they will be observed in, that is, we focus on those bars with a relatively large support, as they are more likely to repeat. First, the endophoric markers (c in Figure 3) showed up significantly in the results section (4 in Figure 3) but were avoided in the conclusion (7) and in the footnotes (8). Second, evidentials (d) were associated with the introduction (1), literature review (2), and footnotes, but dissociated with results (4), discussion (6) and conclusion (7). Third, the category of modals (k) had an association with the conclusion, where the results are interpreted for their meaning in the study. Fourth, self-mention (i) is an interesting category as there were strong preferences where self-mention is observed, namely method (3), introduction (1), and to some extent footnotes, but the category is avoided for results (4), discussion (6), and the literature review (2). Finally, transition markers (a) were used in results but were less prominent in the introduction, methods, and footnotes. In contrast, hedges (f) were used more in the conclusion and results-discussion but avoided in the results. In addition, there were some weaker associations and dissociations in the graph.
The results from the association plot suggest that each section in an RA, in particular each IMRaD section, is associated with specific MD categories. Specifically, these results show that while authors often start and support their studies with their own methods and motivations, the results, discussion, and conclusions are driven more by the actual findings than by the authors’ initial motivations or opinions. Separating the authorial presence from the results and conclusions may be considered an indication of good scientific practice in the Estonian writing tradition, especially within the discipline of linguistics. The overall impression is that different MD categories are associated, and also dissociated, with different sections in a RA. To further illustrate these associations, we turn to correspondence analysis in the following section.
The Associations Between All Variables
To combine all the variables in our study (Table 3) and explain how they associate with MD categories across the whole data set, we use multiple correspondence analysis (MCA) (Glynn, 2014), which compresses a multidimensional analysis into its principal components, that is, the projected dimensions that best explain the variance. Variables that appear near the origin (0) of both axes in the graph are considered to be as expected in the data set, whereas variables further away from the origin contribute to the observed variance or inertia as it is calculated through eigenvalues. Furthermore, when variables cluster together in the graph at a similar angle to the origin, they show a stronger association than when they co-occur further from the origin.
Three important observations can be made from the MCA graph (Figure 4). First, regarding MD interaction dimensions, we can see that the interactive and interactional dimensions, as well as the “other” dimension for the two categories we added, are clearly distinct from each other. The clear separation among these dimensions supports existing approaches in discourse analysis that propose different roles for MD markers (e.g., Abdi, 2011). This separation provides empirical evidence that these categories are not only theoretically distinct but also functionally and practically separable in actual text analysis. Furthermore, this distinction is supported by the observation that the corresponding MD markers cluster together (i.e., endophoric markers, evidentials, transitions, frame markers, and code glosses in the bottom left in the graph; modal and frequency (other) at the top left; and attitude markers, engagement markers, hedges, and boosters at the right side close to 0 on the second dimension). The two principal dimensions correspond nicely to the interactive, interactional, and “other” dimensions. The distinction between interactive and interactional is realized in principal component dimension 7 1 (represented by the x axis), which is discovered by the statistical principal component analysis.
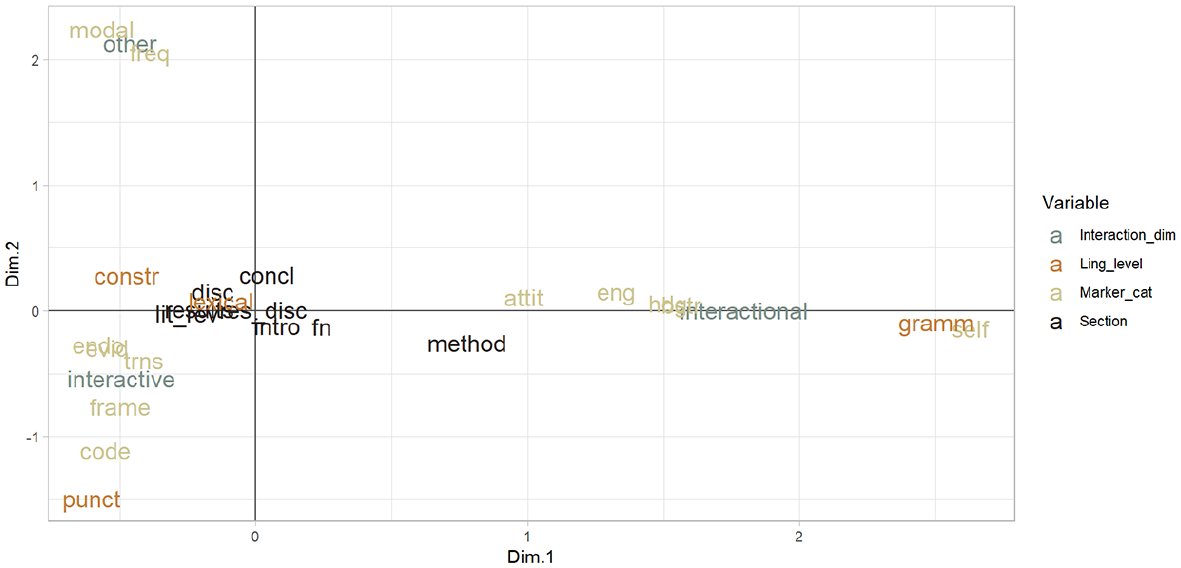
Results of the multiple correspondence analysis (Interaction_dim = interaction dimension, Ling_level = linguistic level, Marker_cat = marker category; see Table 3 for other abbreviations).
Second, the variable of linguistic level also significantly contributes to the first principal component axis. This is especially visible in the distinction between grammatical and lexical markers, and the punctuation has a further association with code glosses and frame markers, which help span the second principal component axis. Certain MD categories are closely associated with linguistic levels: self-mentions with grammar markers and punctuation with code glosses, and the statistical analysis discovers this structure without knowing about it. Discovering these associations without prior parameterization underscores the robustness of the analytical methods used. It shows that the statistical models are capable of detecting nuanced relationships in the data, which might be overlooked or assumed not significant in models trained specifically on English or any particular linguistic framework. Furthermore, the distinction between grammatical and lexical markers and their association with specific MD categories like self-mentions and code glosses provides insights into how different linguistic elements function in academic writing.
Third, we can observe that almost all sections cluster around the origin, and closer to the interactive side of the graph, which is associated with devices to guide the reader, rather than engage the reader and express the author’s stance. The method section is further to the interactional side of the graph, an indication that including the author’s personal perspective, as a way of motivating methodological choices made in a particular study, may be more important in that section. Thus, this finding provides a clear visualization of how various sections of academic papers in Estonian writing tradition typically function with respect to MD usage. Most sections focusing on guiding the reader indicate a general trend toward facilitating understanding and navigation through the text. More specifically, the distinct positioning of the method section toward the interactional side suggests that this part of academic papers may play a unique role in integrating the author’s personal perspective or voice. In other words, the method section often underpins the validity of the research.
Discussion and Conclusions
In this article, we have provided insights into the features of the Estonian academic writing tradition from the perspective of MD markers in linguistics RAs, written by expert writers in Estonian. This study is the first overview of the overall system of MD markers in Estonian. MD markers offer an “initial indication of writer intention and communicative purpose” (Bax et al., 2019, p. 81), but categories can often be flexible enough to adapt to language and genre. We tested the fit of the interpersonal model of MD (Hyland, 2005) in a new context, Estonian.
Our analysis suggests three general conclusions. First, our data align well with Hyland’s original model in that the distinction between interactive and interactional dimensions emerges clearly. The addition of two categories, modals and frequency markers, to the model is justified by the results of multiple correspondence analysis, since they form a distinct cluster in the analysis, and, thus, they express some homogeneity.
Second, we can conclude that in terms of the level of linguistic expression, MD categories can vary considerably, with some categories relying more on lexical markers (e.g., transitions), some categories relying more on constructions (e.g., evidentials), and some categories relying more on grammatical markers (e.g., self-mentions). This variation probably largely depends on the structure of the language and on its morphological and syntactic complexity.
Third, particular sections of the text do not select for particular MD categories exclusively, that is, in each section, the whole range of MD categories can be used freely. However, as illustrated by the associations between MD markers and text sections, certain MD categories can be more or less associated with certain sections, indicating that the use of MD markers often depends on the function and objectives of a specific part of the text. This may be different for example in more essayistic texts, with different affordances in terms of structure and norms.
Overall, these results highlight that the application of MD is a complex process with many choices left to the authors of academic texts. Various MD categories have rather different functions in the text, and they help the writer to build the rhetorical structure of the text. Furthermore, MD markers have probably more dimensions than just the two proposed by Hyland, that is, the distribution is an analytical feature that may vary between authors, disciplines, genre, and writing traditions. With our extended model, we aimed for greater flexibility to respond to language-specific variability and issues related to vagueness of certain MD categories.
Similar challenges are addressed by Bouziri (2021), who highlighted the necessity for certain MD categories to alternate between organizational (interactive) and evaluative (interactional) dimensions, introducing a third, so-called bidimensional aspect to accommodate the model’s flexibility. Similarly, Burneikaitė (2008) has developed her original three-dimensional model for functional analysis of MD when investigating the texts produced in Lithuanian academic settings in English, showing that the difference in the use of MD markers in L1 and L2 English writing is statistically insignificant, which suggests that the optimal pattern for using MD markers within a single discipline remains consistent across various cultural contexts. These studies by Burneikaitė (2008) and Bouziri (2021) show that the use of any rigid model is not obligatory; instead, depending on the context, it might be necessary to modify previous models to meet the needs of a specific research project and its data.
In addition, our results emphasize that different parts of RAs, especially those characteristic of the IMRaD format, encourage various ways of argumentation. This observation aligns with the study by Bertin et al. (2016), which studied the distribution of references in the four main sections of the IMRaD format and found that the distribution was an invariant across (biology related) articles, and that there were also strong correlations for where to find the oldest references (methods and introduction). In another study, Thelwall (2019) found significant variance between disciplines for how IMRaD headings were labeled, and which labels were included. For example, “Introduction” and “Materials and Methods” were far more common headings in natural science and engineering than in the humanities. Similarly, our study identifies specific patterns in the use of MD markers across IMRaD sections. While there are associations for when the authors typically want to guide the reader to factual information, and when the authors want to engage the readers, there are also other considerations the authors have to weigh in, such as reflections and attitudes toward the certainty of factual claims and the moderation of magnitude. As shown in this article, these dimensions and markers tend to be used differently in different parts of the text, depending on factors that have to do with guiding the reader, engaging the reader and evaluating the results. On a larger scale, the distribution of MD markers is to be seen as an indication of a specific writing tradition, and it is likely to see different variations in other languages. Expanding the corpus (e.g., with a variety of disciplines and a variety of languages) and scaling up the analysis using the same approach is necessary in future research to confirm our assumption.
Estonian findings in a cross-linguistic context
As the first comprehensive investigation of MD markers in the Estonian language, this study provides a deeper understanding of language-specific aspects of a phenomenon that has been so far studied in a rather restricted set of languages. Importantly, we have indicated a relatively lower presence of the interactional dimension (i.e., expressions of the writer’s stance and engagement) in Estonian linguistics texts, while the interactive dimension (i.e., organizing the discourse) is much more visible. To better understand how Estonian MD differs from MD resources and practices in English, we went through some most influential studies in the field to compare and reflect our studies against the earlier ones, specifically focusing on linguistics discipline and on English writing.
Mu and his colleagues (2015) used applied linguistics articles to compare MD markers in English and Chinese. They, too, found that overall, interactive MD markers in English as well as Chinese are used more than interactional MD markers. The most frequent interactive MD markers in both English and Chinese are transitions, a feature also characteristic of Estonian. However, the distributional patterns of other interactive markers exhibit more variation in terms of frequency; for example, Estonian uses relatively more endophoric markers but relatively fewer frame markers than English and Chinese. Interactional MD devices are much more often used in English and occur less in Chinese (Mu et al., 2015). Most common interactional markers in English and Chinese are hedges. In Estonian, however, the most frequent interactional markers are self-mentions, followed by boosters and then hedges. Therefore, although the overall ratio of interactive versus interactional markers seems to remain constant across languages, there exist noticeable differences in the usage patterns of marker categories within languages.
Nevertheless, quite different results have emerged in Hyland and Jiang (2018), who conducted a diachronic study to observe the changes in English academic writing across 50 years in four disciplines. When contrasting our results with those from Hyland and Jiang’s (2018) most contemporary group of articles, we can see that the distribution of interactive versus interactional markers in contemporary English linguistics articles does not reflect Estonian linguistics’ patterns. In Estonian, interactive MD markers tend to be considerably more frequently used than interactional markers, whereas in English, a similar distribution is observed within biology articles, whereas in linguistics, the distribution of interactive versus interactional devices is more balanced.
However, one should approach such comparisons with caution, because of significant limitations. This is even more crucial because of some conflicting results, for example, evidence about the interactional dimension being more prominent than interactive is available for English and Spanish in business management articles (Mur-Dueñas, 2011). Although it is beyond the scope of this article to reconcile these opposing outcomes, it is necessary to be aware that the presentation of the results of MD analysis can be very sensitive to the choices made during the analysis process. Similar concerns have been pointed out in previous research; for example, there is no consensus about what units (words, constructions or sentences) are usually coded as MD (Ädel, 2023; Mu et al., 2015). Given such differences in methodologies and our lack of more specific knowledge about which MD exactly were included in these studies, the above generalizations may suggest some tendencies, but undoubtedly need more thorough investigation in future research. In the context of this study specifically, comparison with previous results loses some important detail because of the lack of information regarding the language structure–related and rhetorical structure–related variation. Furthermore, our cautious stance on such comparisons is guided by potential misinterpretation and oversimplification of complex linguistic phenomena when cross-linguistic comparisons are made without a nuanced understanding of differences in language structures and methodological contexts.
A Closer Interpretation of Estonian Results
The dominance of interactive dimension in Estonian should be interpreted with some caution, since the high frequency of transitions can result from our coding decisions (i.e., to include all sentence connectives and conjunctions that work above the phrase level). However, transitions being the most frequent MD markers in academic writing seems to be a universal tendency (e.g., Bax et al., 2019; Hyland & Tse, 2004; Mu et al., 2015). It has already been discussed in previous studies that the distinction between propositional and nonpropositional is fuzzy and subjective (Khabbazi-Oskouei, 2013), and therefore often difficult to decide (Hyland & Tse, 2004, p. 160). In natural data, and especially when manual annotation is used, it is impossible to guarantee an objective detection of purely propositional content, particularly since the same markers do occur in both propositional and metadiscursive contexts. Therefore, to avoid inconsistencies in the analysis, the set of transition markers is kept as constant as possible. Furthermore, the functions of transition markers are rather different from all other MD markers, that is, they connect ideas and sentences and thus help to build the coherence in the text, but their prime function is not to express the writer’s evaluation and commitment to the content. Therefore, it could have been useful to separate the category of transition markers from the overall framework of MD in future studies. An alternative would be to exclude all simple connectives (also, intra-sentential connectors) that work on the surface level of the text (i.e., connections between sentences), and only consider more complex connective phrases (also, inter-sentential connectors) that connect arguments and ideas on the deep level (Cao & Hu, 2014; Liu, 2008).
Zooming into the interactional dimension, expressing the author’s stance is a rather underused practice in the Estonian writing tradition, at least, as exemplified by our test set of linguistics RAs data. This result is best seen in a relatively low use of hedges and boosters, when compared to English (Hyland & Jiang, 2016; Yoon & Römer, 2020), and Spanish (Mur-Dueñas, 2011). Furthermore, attitude markers and engagement markers, both having a lower category agreement (Table 6) and as the two most powerful means of expressing one’s authorial voice and communicating with the reader, are the two least used MD categories in our corpus. This finding suggests that in the Estonian writing tradition, it is not common to explicitly promote the writer’s personal opinion as well as explicitly address the reader. Another support for this conclusion would be the preference to use grammatical constructions as more implicit means in the category of self-mentions as well as hedges and boosters.
The Importance of Methodological Considerations
In this article, we have also stressed the methodological considerations in the analysis of MD. First, it is important to pursue methodological rigor in MD analysis. This rigor is crucial since MD has been considered as a highly subjective matter, with frequent overlaps between categories (Bax et al., 2019; Hyland, 2005; Hyland & Tse, 2004; Toumi, 2009). It becomes especially problematic when one wishes to run an automated analysis on MD markers. While there might be clear identification criteria available in a particular context for a human annotator, computers are not capable of understanding subtle differences in meanings and functions without prior training (see, e.g., Fort, 2016; Hovy & Lavid, 2010). Furthermore, some decisions about the category membership of particular MD devices can be idiosyncratic and be based only on one or a few researchers’ personal impressions rather than facts. Therefore, to prove that meaningful variance really exists in the use of certain MD markers, the data annotation principles must be very clear and applied rigorously. Furthermore, to enable comparisons and replication across languages, it is necessary that the analysis procedures are kept as constant as possible across languages (as an example, see Hint et al., 2024, and Leijen et al., 2024b, for a comparison of MD markers in Estonian, Latvian, and Lithuanian RAs).
Second, to map the significant patterns and the range of possible variation in the use of MD categories and individual markers, it must be shown statistically. The methodology in this article suggests that statistical techniques, such as association plots and multiple correspondence analysis, help to guide us toward aspects and associations of MD that may be overlooked in previous studies. Many differences on the deeper levels of the text (e.g., the importance of certain MD categories or individual markers in certain text sections) might not be meaningful for the human annotator/reader in a particular text, but when generalized over a larger data set, certain patterns emerge. An individual article might be reduced to its MD markers, but such markers used across a genre or a collection of articles, can reveal useful patterns.
Suggestions for Future Research
Two lines of future research could provide more in-depth knowledge about the use and behavior of MD markers. First, at the micro level of language structure, the combination of MD markers with other sentential elements deserves more attention. So far, most of the research on MD has focused on the usage frequencies and functions of MD markers and/or categories per se. However, research is needed to reveal more usage-based perspectives on the use of MD, for example the collocations of certain MD markers, especially in cases where the marker is considered to have more than one metadiscursive meaning (e.g., Aull, 2015). Also, it could be useful to detect the verbs or verb categories that are associated with particular MD markers and categories, in order to understand whether and how argumentative structures in the text relate to certain metadiscursive functions.
Second, further studies are needed on the higher levels of language use to assess the variation across writing traditions and their relation to different disciplines. Further questions may also include differences in MD categories across languages and their relation to text structure. The markers may differ in their linguistic form and representation between languages, but different traditions may also have different preferences for how to apply such markers. For example, there could be different preferences for how visible the authors are in an article, with implications for other constructions, such as the use of passives and the use of tense and aspect markers. The norms associated with the text structure may also vary. For example, the labeling of sections may differ substantially between traditions, and we want to investigate this further using and developing the methodology introduced here across traditions and, in particular, in less studied academic languages.
Extensions of the presented work may include comparisons to other methods, and investigations into other languages and genres. In addition, it would be necessary to approach this research using empirical methods to validate (or challenge) previous MD models, rather than rely on just one single model. 8 Practical implications are, for example, the identification of text sections from the distribution of MD markers and the identification of genres and origin of articles from the distribution of such markers within the sections of a text. The implementation of such extensions and applications are left for future researchers and would demand more resources, such as access to larger data sets, large language models, and careful analysis for selecting the optimal models.
Taken together, we have shown that the complex phenomenon of MD can benefit from broadening the scope of analysis and reconsidering the individual markers, depending on the language under study. While Hyland’s (2005) interpersonal model of MD offers a solid base for understanding the core aspects of the phenomenon, it is also necessary to add further nuance into the framework. Further nuance can offer more sophisticated and consistent explanations to, as yet, fuzzy areas in the study. It is also crucial to understand the typological aspects and variation in the use of MD markers, as compared to the giants of English, Spanish, or Mandarin, by explaining the patterns found in other languages, such as Estonian.
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by the project Bwrite: Academic Writing in the Baltic States: Rhetorical Structures through culture(s) and languages EMP475, funded by Iceland, Liechtenstein, and Norway through the EEA Grants and Norway Grants.