
Abstract
Urban synthetic data has emerged as a transformative tool for planning research, yet its full potential remains constrained by an overwhelming focus on physical spaces and object recognition. Current digital twin analysis prioritizes built environments over human interactions, while privacy concerns in social media-based behavioral studies limit reproducibility. This commentary argues for a paradigm shift—one that integrates human vibrancy into urban synthetic data approaches to foster human-centered digital twins. By addressing key challenges of privacy, reproducibility, and technical feasibility, human-centered synthetic data can redefine urban informatics, bridging the gap between digital representations and lived urban experiences.
Keywords
Introduction
“Urban synthetic data” refers to artificially generated data sets that replicate the characteristics, distributions, and relationships of real-world urban data, created through computational models, simulations, or generative AI techniques. In an urban digital twin, such data is used to augment, replace, or anonymize actual urban data sets when real data is incomplete, sensitive, unavailable, or costly to collect. It can represent diverse urban dimensions—such as mobility flows, energy consumption, land use patterns, built environment conditions, or demographic behaviors—while preserving statistical validity without exposing individual privacy. However, these dimensions of synthetic data remain predominantly focused on physical attributes, often sidelining the role of humans in urban environments. This limitation creates a gap in understanding urban vibrancy, social interactions, and behavioral dynamics that shape cities. Similarly, digital twin technology, increasingly central to urban informatics, prioritizes the visual representation of urban spaces, often built with airborne and ground-based LiDAR data. While these representations enable fine-resolution imagery that can simulate physical appearances and pass limited Turing tests, they largely exclude dynamic human behaviors, interactions, and the city’s evolving social dimensions (Goodchild et al. 2024). At the same time, studies leveraging human data from social media face privacy challenges, limiting reproducibility and broader applicability. Synthetic urban data integrating realistic human behavior offers a solution, enhancing both urban research and human-centric digital twin development.
In this commentary, “human-centric digital twins” refer to digital twins that inclusively represent the diversity of human activities, behaviors, and needs across various socioeconomic, cultural, and demographic groups. A human-centric approach aims to move beyond physical infrastructure to integrate lived experiences, social dynamics, and behavioral diversity into urban simulations. However, we recognize that achieving full inclusivity in digital twins remains a significant challenge. As recent studies emphasize (Argota Sánchez-Vaquerizo 2025; Haraguchi, Funahashi, and Biljecki 2024), input data often reflects existing societal biases, leading to the underrepresentation of marginalized populations. Synthetic data alone does not automatically solve these challenges. Instead, we propose that synthetic data, when deliberately designed and validated, can mitigate some of these biases by generating augmented behavioral data sets that specifically account for historically excluded groups. Techniques such as reweighting synthetic populations, scenario sampling targeted at vulnerable communities, and co-designing validation protocols with diverse stakeholders are necessary to ensure more equitable representation. While synthetic data cannot eliminate all structural biases in urban systems, it provides a practical and privacy-preserving tool to address representational gaps more systematically than traditional data sources allow. Our commentary focuses on continuously refining synthetic generation processes and integrating participatory frameworks to ensure that human-centric digital twins not only simulate what currently exists but envision more inclusive urban futures.
Physical Representations over Dynamic Human Behavior
Street view analysis and digital twin applications have largely focused on the physical aspects of urban environments, leveraging techniques like semantic segmentation and object recognition to identify and map buildings, roads, vehicles, trees, and other infrastructural elements (Biljecki and Ito 2021). Semantic segmentation, which involves pixel-wise classification of urban features, has benefited significantly from advancements in fully convolutional networks and large data sets like Cityscapes and ADE20K (Cordts et al. 2016; B. Zhou et al. 2017). Similarly, object recognition techniques such as Faster R-CNN and Mask R-CNN have enabled precise detection and categorization of urban objects, including vehicles, infrastructure, and vegetation. While these methods are instrumental in creating detailed models of the built environment, they often neglect the human dimension—how people interact with and shape urban spaces. This omission is critical because it fails to capture the behavioral, social, and cultural dynamics that underpin urban vibrancy. As a result, pedestrian movement patterns, public space utilization, and crowd behaviors remain underrepresented, leaving significant gaps in understanding urban life.
The limitations of current digital twin models extend beyond the absence of human activity to include a lack of integration between physical infrastructure and social behaviors over time. This disconnect creates urban digital twins that, although accurate in replicating the physical city, fail to account for the dynamic and adaptive ways in which residents use, alter, and respond to urban spaces (Batty 2018). Without incorporating data on human mobility, social interactions, and cultural practices, these models risk reinforcing static representations of cities that are ill-equipped to address complex urban challenges or guide equitable and sustainable development. To enhance their utility, future advancements in digital twin technology must prioritize the inclusion of human activity and its interplay with the urban environment, leveraging interdisciplinary approaches and emerging data sources.
Reproducibility and privacy constraints present significant challenges in research analyzing human behavior using street view images or human mobility data. Privacy concerns—particularly those arising from regulations like the EU’s General Data Protection Regulation (GDPR), which governs the collection and processing of personal data—often restrict the sharing of raw data. Likewise, Health Insurance Portability and Accountability Act (HIPAA) data protection focuses on safeguarding individually identifiable health information, known as Protected Health Information. This limitation can hinder researchers’ ability to validate findings and collaborate effectively. This lack of access to original data sets undermines transparency and limits the reproducibility of studies, which are essential for advancing knowledge in human-centric research. Another critical barrier is the lack of standardized data sources and methodologies. The variability in data quality, collection methods, and contextual factors across studies complicates comparisons and reduces the generalizability of findings. For instance, street view imagery may differ in resolution, coverage, or temporal updates, creating inconsistencies that hinder cross-regional or longitudinal studies. To address these issues, future research must adopt standardized protocols for data collection and processing while leveraging privacy-preserving techniques such as differential privacy or federated learning to ensure data security and reproducibility.
Synthetic Data as a Human-Centric Solution
Synthetic data sets hold transformative potential for advancing digital twin applications by embedding realistic representations of human behaviors and interactions. Traditional digital twins have predominantly modeled the physical attributes of urban environments—such as infrastructure, land use, and utilities—while often overlooking the social dynamics, behaviors, and lived experiences that define urban life. Integrating synthetic human dynamics into digital twins fundamentally shifts them from static infrastructural models to dynamic, behaviorally rich simulations of urban vibrancy (Batty 2018; Yang et al. 2019).
The development of human-centric digital twins depends critically on the availability of rich, fine-grained behavioral data that reflects the diversity, complexity, and variability of urban populations. However, real-world human data collection faces significant limitations, including privacy constraints, uneven geographic or demographic coverage, and reproducibility challenges. These barriers limit the fidelity and inclusiveness of traditional digital twins, making them less capable of representing marginalized communities or predicting emergent urban dynamics. Hence, by generating synthetic pedestrian flows, public space usage patterns, transit behaviors, and social interactions, planners and researchers can model urban scenarios that incorporate a broader and more inclusive range of human behaviors.
First, synthetic data enhances the behavioral realism and diversity of digital twins. It allows urban models to simulate activities across different socio-economic groups, cultural contexts, and physical abilities, providing planners with insights into how varied communities experience and navigate the city. For instance, synthetic pedestrian data has been used in projects like the Virtual Singapore initiative, where planners modeled how elderly and disabled residents interact with the built environment under different urban design scenarios (Tan, Low, and Song 2020). Similarly, simulations of nighttime environments, informed by synthetic human dynamics, have been utilized to study the interplay between urban lighting, nightlife safety, and economic activity (Biljecki and Ito 2021).
Second, synthetic data enables rigorous testing of hypothetical interventions in ethically sound ways. By simulating diverse synthetic populations, planners can assess the impacts of proposed infrastructure projects, policy changes, or climate adaptation measures on a wide range of demographic groups without risking privacy violations or relying on limited historical data (Ye et al. 2025). For example, flood evacuation scenarios modeled in New York City have employed synthetic agent-based simulations to examine how different socioeconomic groups respond to evacuation orders under varying levels of accessibility and information dissemination (Haworth et al. 2018).
Third, synthetic data strengthens the scalability, adaptability, and reproducibility of human-centric digital twins. As urban environments evolve—due to migration, economic shifts, technological change, or climate impacts—synthetic data generation processes can be continuously updated to reflect emerging behavioral trends. This ensures that digital twins remain living, adaptive models rather than static representations. Projects such as the UrbanSim synthetic population platform demonstrate how regularly updated synthetic data sets can support long-term urban growth simulations and inform scenario planning at metropolitan scales (Moeckel 2017; Waddell 2011).
Fourth, synthetic data sets facilitate collaborative urban research by providing standardized, shareable data inputs across institutions while protecting individual privacy. By decoupling sensitive information from key behavioral and environmental features, synthetic data sets enable researchers, planners, and policymakers to exchange data without violating privacy regulations. This interoperability allows different urban agencies, research institutions, and private sector partners to collaborate more freely, accelerating innovation in fields such as transportation planning, public health, disaster resilience, and energy systems. Cross-jurisdictional learning, facilitated by synthetic data, supports the transferability of policy insights while accounting for local socio-spatial differences. Ultimately, the broad accessibility and privacy compliance of synthetic data enhance the collective intelligence of urban analytics initiatives, empowering cities to develop more inclusive, equitable, and evidence-based planning practices (Goncalves et al. 2020 Zhai, Peng, and Yuan 2020).
The rapid advancement of generative artificial intelligence (GAI) techniques has significantly enhanced the generation of human-centric synthetic data (Goncalves, Ferreira, and Stachtiaris 2020; Guo and Chen 2024). In particular, models such as generative adversarial networks (GANs) (Goodfellow et al. 2020), diffusion models (Croitoru et al. 2023), and large vision models (Liu et al. 2024) have been instrumental in advancing synthetic data applications, including image super-resolution (Tian et al. 2022), 3D reconstruction (Croitoru et al. 2023), text-to-image generation (C. Zhang et al. 2023), and video synthesis (Mogavi et al. 2024).
Recent developments have extended these techniques to human dynamics simulation through two primary approaches: kinematics-based and physics-based methods. Kinematics-based approaches leverage diffusion models to generate motion from language inputs. For instance, ReMoDiffuse, introduced by M. Zhang et al. (2023), employs a retrieval-enhanced denoising process to refine motion synthesis. This method integrates retrieval-based sample selection with multi-modal knowledge, improving the semantic coherence of generated motion sequences. Additional advancements, such as incorporating spatial control signals and language semantics, further enhance the realism of human motion generation (Wan et al. 2024; Xie et al. 2023). W. Zhou et al. (2024) introduced the Efficient Motion Diffusion Model (EMDM), which accelerates motion synthesis by reducing sampling steps while preserving complex motion distributions. In contrast, physics-based methods simulate forces, torques, and constraints governing human motion. Luo et al. (2023) proposed a humanoid controller capable of high-fidelity motion imitation and fault tolerance, even under noisy conditions. These models provide enhanced realism, particularly in dynamic environments where unexpected disruptions occur.
One of the most compelling applications of GAI in urban planning is the simulation of human dynamics in street scenes, particularly pedestrian movement. Rempe et al. (2023) developed a guided diffusion model for pedestrian trajectory prediction and full-body animation, incorporating user-defined constraints such as speed, waypoints, and group interactions within an environmentally aware framework. Extending this concept, Wei et al. (2024) introduced ChatDyn, a system that generates interactive and controllable street dynamics based on language instructions. ChatDyn employs a multi-agent LLM-based role-playing approach to plan complex interactions between pedestrians and vehicles. To achieve fine-grained motion control, it integrates PedExecutor, a multi-task pedestrian dynamics model, and VehExecutor, a physics-based policy for vehicle movements. Despite these advancements, challenges remain in fully capturing the complexities of urban human dynamics. Future research must address:
The efficient integration of diverse dynamic entities, such as cyclists and urban animals, to enhance the realism of scene simulations.
The generation of complex multi-entity interactions—such as pedestrian-vehicle interactions—to improve accuracy in scene reconstruction and event modeling.
GAI continues to push the boundaries of synthetic human dynamics generation. However, its adoption in urban analytics and planning necessitates further refinement to ensure realism, adaptability, and scalability in diverse urban environments.
Synthetic Data Generation and Validation
Incorporating the cyclical flow depicted in Figure 1, we emphasize a continuous feedback loop for refining both the AI models generating synthetic data and the urban digital twin itself. The generation of synthetic data for urban digital twins involves a multi-step, machine learning-driven pipeline that transforms real-world observations into statistically representative artificial data sets. In the case of air pollution modeling (e.g., NO₂ levels), the process begins with data aggregation from heterogeneous sources, such as ground sensors (e.g., EPA air stations), satellite imagery (e.g., Tropomi’s NO₂ maps), urban infrastructure data sets (e.g., building density, street networks), and dynamic inputs like traffic flows or weather conditions. These raw data sets are cleaned, harmonized (e.g., converting coordinate systems), and fused into a unified feature space. Next, an AI model can be trained to learn the nonlinear relationships between input features (e.g., traffic volume, street canyon effects, time of day) and target variables (e.g., NO₂ concentrations). Once trained, the model acts as a surrogate simulator, generating synthetic pollution values for locations or times lacking real measurements by extrapolating from learned patterns. For instance, it might predict NO₂ in an unsensed district by combining nearby sensor data with static urban features (e.g., building heights). Importantly, the model’s outputs are validated against held-out real data to ensure statistical fidelity (e.g., via the equality of decisions proposition) and refined iteratively to correct drift—such as retraining when seasonal pollution trends deviate from predictions. Advanced techniques like spatial lag modeling or graph neural networks can further enhance synthetic data granularity. This approach not only fills gaps in real-time data but enables “what-if” scenarios (e.g., simulating pollution impacts of new traffic policies) by perturbing input variables (e.g., reducing truck volume by 20%) and propagating effects through the model.
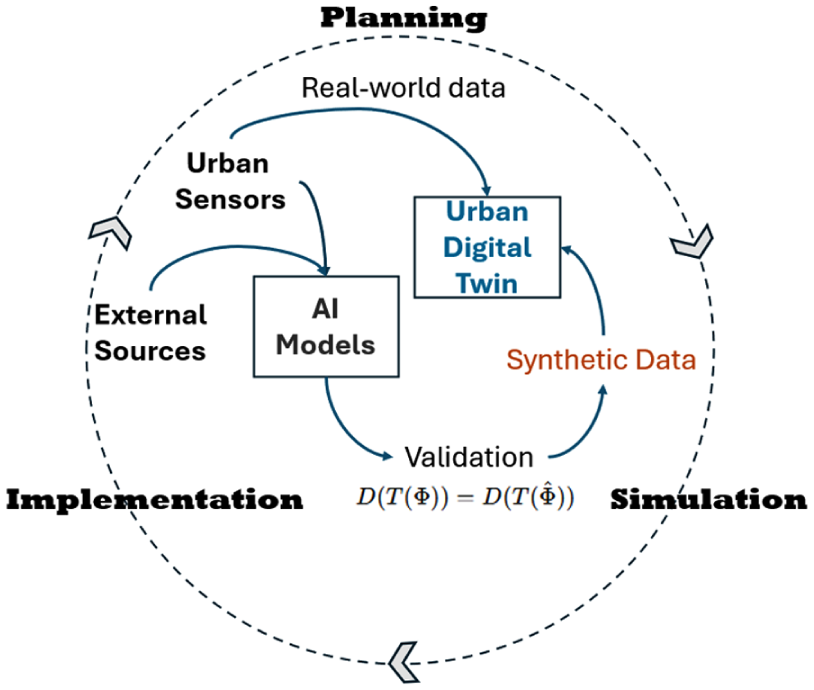
An urban digital twin fed with real and synthetic data in a planning-simulation-implementation loop (adapted from Almirall et al. 2022).
Importantly, the validation step, represented as
Despite its advantages, the synthetic data approach faces several challenges. First, the accuracy of synthetic outputs depends heavily on the quality and representativeness of the training data; gaps or biases in real-world data sets (e.g., sparse sensor coverage in low-income neighborhoods) can propagate into the model, leading to unreliable predictions for underrepresented areas. Second, the validation framework—while theoretically robust via the equality of decisions proposition (
Applications of Human-Centric Synthetic Data
Integrating synthetic data into digital twins enables more nuanced analyses of public space usage by simulating diverse human interactions. For example, pedestrian accessibility can be analyzed to identify bottlenecks, unsafe areas, or infrastructure inadequacies by simulating movement patterns across different times and populations. Additionally, synthetic data allows evaluation of social and cultural vibrancy by modeling how various demographic groups engage with and experience urban spaces, contributing to inclusive urban design strategies.
Adaptive Traffic Control. Cities can deploy digital twins to blend real-time traffic data with synthetic demand projections, enabling dynamic infrastructure adjustments. Stockholm’s traffic management system, for example, simulates thousands of congestion scenarios—factoring in variables like weather, accidents, and public transit delays—to optimize signal timings and bus frequencies in real time (Olsson and Woxenius 2014). By integrating synthetic data on future urban growth (e.g., new housing developments), the system proactively tests infrastructure resilience, reducing emissions and commute times. Companies like NVIDIA have also used synthetic data sets to train AI for autonomous vehicles, 1 simulating diverse urban environments, pedestrian behaviors, and traffic patterns to enhance safety and efficiency. By exposing AI algorithms to diverse and realistic scenarios, these simulations significantly reduce the time and cost involved in on-road testing while also enhancing vehicle safety and decision-making in real-world environments. Yet, these systems face technical challenges, such as ensuring simulation accuracy amid unpredictable human choices (e.g., ride-share trends), and ethical dilemmas, including equity in access (e.g., prioritizing high-traffic corridors over underserved neighborhoods). The opacity of “black box” AI recommendations raises accountability concerns: Who bears responsibility when a traffic algorithm causes delays for emergency vehicles? Transparency in data sources (e.g., disclosing synthetic data’s limitations) and participatory urban planning—where communities audit simulation priorities—could mitigate these risks. Without safeguards, efficiency gains may come at the cost of marginalizing vulnerable populations.
Crowd Management for Large-Scale Events. Digital twins are transforming crowd management by simulating human behavior under dynamic conditions. For instance, at major sporting events, organizers use synthetic pedestrian models—incorporating variables like walking speed, density tolerance, and emergency response patterns—to optimize venue layouts and evacuation routes. These simulations can predict bottlenecks during peak exits and test contingency plans (e.g., sudden gate closures or medical emergencies) without real-world risks. A notable example is the 2024 Paris Olympics, where planners leveraged digital twins to simulate crowd flows for over 500,000 daily attendees, adjusting signage, security checkpoints, and metro schedules to reduce congestion (Suo et al. 2024). However, such applications raise ethical questions about privacy, as anonymized tracking data must balance granularity with individual anonymity, and algorithmic bias, as synthetic profiles may not fully capture diverse mobility needs (e.g., disabilities or cultural differences in crowd behavior). The reliance on behavioral tracking data, even when anonymized, creates tension between public safety and privacy. For example, granular movement data could be re-identified or weaponized for surveillance. Synthetic profiles also risk algorithmic bias: Default “average” walking speeds might overlook disabled attendees, while cultural differences in crowd behavior (e.g., familial grouping vs. individualistic movement) could lead to flawed evacuation plans. To address this, inclusive design is critical—diverse demographic data must inform synthetic models, and privacy-preserving techniques (e.g., federated learning) should limit raw data collection. Event organizers must also disclose monitoring scope to attendees, ensuring trust in these systems.
Resilience and Disaster Preparedness: Synthetic data plays an increasingly pivotal role in the disaster preparedness domain by providing actionable insights into human behavior under crisis conditions. In Christchurch, New Zealand—prone to seismic activity—digital twin technologies model earthquake scenarios to optimize evacuation routes, assess structural vulnerabilities, and identify potential bottlenecks for emergency responders (Gralla, Goentzel, and Van de Walle 2015). By using synthetic data sets that incorporate varied demographic profiles (including age distributions and disability statuses), the simulations highlight scenarios where infrastructure upgrades or targeted communication strategies are most urgently needed. Similarly, during Hurricane Harvey in Houston, synthetic data-driven simulations helped emergency services predict flood zones, allocate rescue resources, and stage supplies in areas most likely to be affected. By calibrating digital twin models with historical flood records, real-time sensor data, and synthetic profiles of resident behaviors, authorities could identify critical evacuation points and reduce response times significantly. In the post-disaster recovery phase, digital twins help estimate rebuilding costs and prioritize neighborhoods most in need of immediate assistance, thereby promoting a more equitable distribution of resources. Cities like Kobe, Japan—which experienced extensive devastation during the Great Hanshin Earthquake—have adopted digital twins to study public space usage and mobility patterns in the wake of major disasters. By integrating synthetic human dynamics, these models reveal which communities are most affected by disruptions in public services, where commercial activity is rebounding, and how residents adapt to new travel routes or housing arrangements.
Inclusive urban planning: Synthetic data is revolutionizing inclusive urban planning by enabling hyper-realistic simulations that explicitly model diverse community needs through three transformative mechanisms. By transforming abstract policies into tactile, verifiable experiences where residents literally reshape virtual neighborhoods, synthetic data doesn’t just predict urban futures—it empowers communities to build them on their own terms. First, interactive digital twins democratize participation, as demonstrated by Singapore’s Virtual Housing Lab, where residents adjusted 3D building configurations in real-time, revealing that 20 percent more family-sized units could be added without compromising green space or sunlight exposure. Second, synthetic augmentation fills critical data gaps—Los Angeles combined cellphone data with simulated “shadow populations” of day laborers to prove that 10 percent more late-night bus service would benefit over 50,000 uncounted workers (Los Angeles City Planning 2025). Third, immersive digital twin platforms enhance active travel planning and community engagement; for instance, Watford Borough Council in the UK utilized a digital twin and virtual reality technology to involve residents in the Green Loop cycling initiative, allowing them to experience proposed routes and provide feedback, thereby fostering inclusive dialogue around transport developments (Digital Planning Directory 2024). These tools require rigorous validation—such as Amsterdam’s noise models cross-checked with live sensor data (Waag 2025)—and community co-design, exemplified by Glasgow’s wheelchair users programming virtual agents’ turning radii. The results speak for themselves: Medellín’s informal settlement residents proved through 3D simulations that a differently placed cable car station could save 90 daily commute minutes (Heinrichs and Bernet 2014), while Barcelona’s multilingual AI interface boosted non-native speaker participation by 37 percent in zoning decisions (Barcelona City Council 2025).
Ethical and Technical Considerations
The integration of synthetic human dynamics into digital twins requires careful attention to ethical and technical aspects to ensure privacy, data quality, and equitable representation. Privacy compliance is paramount and involves not only anonymizing data but also employing advanced techniques such as differential privacy and federated learning to protect individual identities while allowing valuable insights to be extracted (De Montjoye et al. 2018; Yang et al. 2019). These measures ensure adherence to regulations like GDPR, HIPAA, and other region-specific privacy frameworks, fostering trust in the use of digital twin technologies. High-quality synthetic outputs can be achieved through the use of advanced generative models, such as Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and diffusion models, to create lifelike and accurate simulations of human behavior. These models can simulate diverse scenarios, such as pedestrian dynamics in urban parks, the impact of road closures on commuting patterns, or emergency evacuation behaviors, all while maintaining the anonymity of the underlying data sources. Ensuring data quality also requires rigorous validation processes, such as comparing synthetic outputs with real-world benchmarks to ensure that simulations are realistic and reliable.
Further, engaging with community stakeholders and experts in social equity during the design and implementation of synthetic data systems can provide additional safeguards against bias. By including these voices, digital twin models can better reflect real-world complexities and serve as tools for equitable urban planning. For instance, when evaluating public transit systems through simulations, it is critical to intentionally design synthetic data models that account for the needs of marginalized populations, ensuring infrastructure investments promote equitable outcomes rather than perpetuate existing disparities. Specifically, transit placement algorithms should not rely solely on current ridership patterns, which often reflect decades of underinvestment in low-income neighborhoods, but must incorporate synthetic projections that deliberately prioritize accessibility and connectivity for underserved communities. This means modeling scenarios with enhanced service frequency in disadvantaged areas, ensuring physical infrastructure meets universal accessibility standards for disabled residents, and weighting demographic data to compensate for historical gaps in public investment. A notable example can be found in Bogotá’s TransMilenio bus system, where planners intentionally overrepresented low-income neighborhoods in demand models to justify expanded service—a corrective approach that recognized how “neutral” data often masks systemic inequities (Rodriguez-Valencia, Rosas-Satizábal, and Hidalgo 2023). Such methodologies demonstrate how synthetic data, when ethically deployed, can serve as a tool for reparative urban planning by simulating not just what is, but what should be. Without these deliberate interventions, even the most technically sophisticated models risk automating and amplifying the very inequalities they purport to address.
Another impactful application of synthetic data in digital twins lies in the realm of public health. By simulating the spread of infectious diseases within a virtual urban environment, policymakers can test the efficacy of targeted vaccination campaigns, social distancing guidelines, or school closures. High-fidelity generative models—such as agent-based simulations informed by GAN-generated movement patterns—capture nuanced interactions between individuals and populations, offering insights into how diseases propagate under varying conditions. To maintain privacy, synthetic cohorts are developed through techniques like federated learning, which trains machine learning models across multiple decentralized data sets without directly sharing sensitive personal information (Yang et al. 2019). This privacy-preserving approach enables virtual experiments that account for different demographic contexts and resource constraints, thereby ensuring that public health policies are guided by robust, ethically sourced data.
Beyond public health, synthetic human dynamics can significantly improve urban transportation networks. A city’s digital twin, for example, might model how altering a major bus route affects the commuting patterns of residents from diverse socio-economic backgrounds. By employing diffusion models that realistically simulate travel demand and time-of-day variations, city planners can project the impacts of different policy scenarios—such as the introduction of bus rapid transit lanes or dynamic toll pricing—on congestion and commuter well-being. Central to these analyses is the application of differential privacy (Dwork and Roth 2014), which protects individual travel histories even as aggregate trends are scrutinized. By safeguarding personal data, urban planners can more confidently collaborate with stakeholders, sharing key insights without exposing sensitive information. Such informed planning processes guide equitable infrastructure investments, including the prioritization of underserved neighborhoods for improved public transit access.
Disaster preparedness offers another domain in which ethically developed digital twins can make a critical difference. By combining geospatial data with synthetic human behavior models, emergency management officials can anticipate how communities might respond to disasters such as hurricanes, wildfires, or floods (Idoudi et al. 2022). In such scenarios, privacy-preserving techniques like secure multi-party computation, enable data sharing among stakeholders—health services, government agencies, and NGOs—without disclosing personally identifiable information. These virtual simulations help refine evacuation strategies, hospital surge capacities, and resource distribution systems by allowing decision-makers to test multiple approaches before a real crisis arises. Additionally, analyzing synthetic scenarios ensures that vulnerable populations, such as older adults or low-income groups, receive adequate consideration in emergency plans. The result is a data-driven process that supports timely interventions and responsible allocation of critical resources.
While synthetic data and human-centric digital twins offer transformative opportunities, ensuring their ethical deployment requires deliberate strategies to integrate participatory processes, particularly to promote equity and transparency in urban planning. Stakeholder engagement must be embedded not only in the interpretation of digital twin outputs but also throughout the entire lifecycle of data generation, model building, and scenario testing (König 2021).
One crucial strategy for fostering equity involves co-designing synthetic data sets and digital twin scenarios directly with affected communities. This participatory approach necessitates engaging residents, advocacy groups, and community organizations early in the data modeling process to collaboratively identify which behaviors, experiences, or vulnerabilities hold the most significance for simulation (Sanders and Stappers 2008). Such participatory data specification can be instrumental in ensuring that marginalized groups—including low-income residents, disabled individuals, youth, and immigrants—are meaningfully and accurately represented within synthetic urban models. Secondly, establishing transparent validation processes is paramount, allowing community stakeholders to actively participate in evaluating the alignment of synthetic data model outputs with their lived realities (O’Neil 2017). This can manifest through public workshops, community-led audits of digital twin simulations, and participatory scenario reviews that empower residents to challenge, refine, or endorse the underlying modeled assumptions. Incorporating these feedback loops into synthetic data calibration processes is vital to prevent the reinforcement of existing systemic biases and cultivate greater legitimacy of digital twin outputs. Thirdly, accessible communication tools must be integral to advanced digital twin platforms (Gurstein 2007). The deployment of interactive visualization tools, multilingual interfaces, mobile-accessible simulations, and non-technical summaries can democratize access to synthetic data-driven insights, enabling broader segments of the public to engage with urban simulations without requiring specialized technical expertise. Transparency in communicating data sources, modeling assumptions, and known limitations remains essential for building trust and fostering informed participation. Fourthly, equity audits of synthetic data models should be adopted as a routine ethical practice. Prior to deployment, synthetic data sets and digital twin outputs should undergo rigorous evaluation for potential biases or underrepresentation across diverse demographic groups. For instance, synthetic evacuation models can be audited to assess their capacity to adequately capture mobility constraints experienced by elderly or disabled residents. These audits can inform corrective actions, such as reweighting synthetic agents or incorporating previously overlooked behavioral patterns. Finally, the governance of synthetic data and digital twins must inherently be participatory (Fung 2006). Establishing citizen advisory boards, community data stewards, or participatory oversight committees can institutionalize public influence over the generation, validation, sharing, and application of synthetic data in urban decision-making processes.
Future Directions
Human-centric digital twins represent a transformative step forward in urban informatics, offering new opportunities for innovation and collaboration. Developing human-inclusive tools powered by AI can dynamically incorporate human behaviors and interactions into digital twin frameworks, enhancing their realism and utility. For instance, digital twins could integrate real-time data from public transportation systems to simulate commuter behavior during rush hours or optimize pedestrian traffic flow during large events. Additionally, AI-driven simulations can predict the impact of urban design changes, such as the addition of bike lanes or pedestrian zones, on mobility and accessibility for different demographic groups.
Open-source ecosystems for synthetic data sets and tools are essential to fostering reproducibility and enabling collaborative research across disciplines. Examples include platforms like UrbanSim, which provides open-source tools for simulating urban development, and collaborative repositories for synthetic data that simulate population dynamics in different urban contexts. Such resources not only promote transparency but also allow researchers and practitioners to test urban policies in varied environments, improving the adaptability and scalability of urban planning solutions.
Moreover, integrating these technologies into education and urban planning practices can equip planners with the skills to utilize synthetic data for participatory, inclusive, and equitable urban development. For example, digital twins enhanced with synthetic data could be used in urban design studios to enable students to simulate how different populations experience urban spaces, fostering a deeper understanding of equity and inclusion. Similarly, planning agencies could use these tools to engage communities in participatory planning workshops, allowing residents to visualize proposed changes to their neighborhoods and provide feedback based on immersive simulations. These applications bridge the gap between technology and practice, ensuring that the benefits of human-centric digital twins extend beyond research to create tangible, equitable outcomes in urban development.
Limitations and Challenges of Synthetic Data
While synthetic data offers transformative potential for advancing human-centric digital twins, it is crucial to recognize and address its current limitations as a proxy for real-world data. Recent studies (Kapp and Mihaljevic 2023; Yabe et al. 2024) have highlighted specific challenges, particularly in the domain of synthetic human mobility data. For instance, Yabe et al. (2024) demonstrate that existing synthetic mobility data sets often struggle to reproduce accurate fine-grained geolocation patterns, leading to biases in modeling pedestrian flows and urban accessibility. Similarly, Kapp and Mihaljevic (2023) report that synthetic travel data, while valuable for protecting privacy, can underrepresent rare or complex mobility behaviors, such as atypical commuting routes or dynamic multi-modal trip chains.
These challenges stem from the inherent difficulty in capturing the full heterogeneity of human behaviors, especially those associated with minority or underrepresented groups, in synthetic generation processes. When synthetic models are trained on biased or incomplete real-world data sets, they risk replicating and amplifying existing inequities rather than correcting them. Additionally, the over-smoothing of behavior distributions—a common byproduct of synthetic generation—can erase outlier behaviors that are critical for urban resilience planning, such as emergency evacuations or service access among disabled populations.
To mitigate these challenges, several strategies can be employed. First, enhancing the diversity of the training data used for synthetic generation is essential. Incorporating targeted oversampling of underrepresented groups or behaviors during model training can help ensure that synthetic data sets capture a broader range of urban experiences. Second, hybrid approaches that blend synthetic data with selective real-world observations can improve validation and correction of synthetic outputs. For example, real-time sensor data from public transport or mobile devices can be used to calibrate and adjust synthetic mobility patterns, improving their fidelity in dynamic urban contexts. Third, advances in conditional synthetic data generation—where demographic, spatial, or temporal conditions are explicitly specified—can allow for the creation of more granular and context-sensitive synthetic agents.
Finally, rigorous validation frameworks must accompany synthetic data generation. Techniques such as multi-metric evaluation (e.g., comparing spatial autocorrelation, trip length distributions, and temporal activity profiles) and participatory validation with community stakeholders can help identify and address representational gaps. While synthetic data is not a panacea, these emerging methods offer pathways for improving its accuracy, inclusivity, and utility as a foundation for human-centric digital twins.
Conclusion and Discussion
Urban synthetic data represents a transformative frontier in the evolution of digital twins, particularly in advancing human-centric modeling. By moving beyond static representations to dynamic, behavior-inclusive environments, synthetic data enables deeper insights into urban vibrancy, resilience, and development. This shift not only enhances the analytical depth of urban studies but also ensures greater inclusivity, reproducibility, and impact in urban planning research. As synthetic data techniques continue to mature, they will play a critical role in shaping the resilient and human-centered cities of the future (Ye et al. 2023).
Importantly, human-centered synthetic data offers practical implications that extend beyond technical innovation to directly support urban policy-making, participatory planning, and resilience building. By generating diverse and behaviorally realistic representations of urban populations, synthetic data allows planners to model the impacts of policy interventions with greater nuance and foresight. For instance, synthetic pedestrian flow models can assist planners in assessing the mobility equity outcomes of proposed street redesigns, enabling cities to evaluate how changes to sidewalk widths, crosswalk placements, or pedestrian priority zones might differentially affect elderly, disabled, or low-income populations. Such insights can inform targeted public policy decisions aimed at improving accessibility, safety, and social inclusion within the urban fabric.
Participatory planning processes are also strengthened through the integration of synthetic human dynamics into interactive digital twin platforms. By allowing community members to visualize proposed zoning changes, simulate their daily experiences within different design alternatives, and interact with virtual representations of future neighborhoods, synthetic data-driven digital twins foster a more intuitive and transparent engagement process. These participatory environments help lower technical barriers to public input, democratize urban design, and ensure that traditionally marginalized voices—such as immigrant communities, renters, or non-English speakers—are better represented in urban decision-making. Furthermore, by integrating multilingual interfaces and culturally relevant urban scenarios into digital twin simulations, synthetic data platforms can reach broader audiences and promote more equitable civic participation.
Beyond policy and participation, synthetic data plays a critical role in enhancing urban resilience. By simulating human responses to extreme events—such as flood evacuations, wildfire threats, or heatwave adaptations—synthetic data sets support proactive planning for emergency services, shelter allocation, transportation rerouting, and resource distribution. For example, synthetic evacuation behavior models can help emergency managers test different communication strategies or transportation options under varying demographic and infrastructural conditions, improving the speed and equity of emergency response. Similarly, long-term synthetic simulations of climate impacts on daily human activities can inform urban investments in cooling infrastructure, green space preservation, and adaptive housing strategies.
Moreover, synthetic data enables planners to explore future urban scenarios that incorporate shifts in demographics, mobility preferences, and economic activities. Rather than reacting to existing conditions alone, cities can use synthetic data sets to proactively plan for emerging trends such as aging populations, shifts toward active transportation, or remote work transformations, thereby creating more adaptable and forward-looking urban environments.
By bridging technical innovation with real-world outcomes, human-centered synthetic data becomes not only a powerful analytic tool but also a catalyst for transformative urban governance. It offers planners, policymakers, and communities the ability to simulate, visualize, and collaboratively shape urban futures that are more inclusive, resilient, and equitable. However, realizing this potential will require ongoing attention to issues of data quality, bias mitigation, participatory validation, and ethical governance in synthetic data generation and application.
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: We acknowledge the fund support from National Science Foundation (#2401860 and #2430700).