
Abstract
Computational thinking (CT), an essential 21st century skill, incorporates key computer science concepts such as abstraction, algorithms, and debugging. Debugging is particularly underrepresented in the CT training literature. This multi-level meta-analysis focused on debugging as a core CT skill, and investigated the effects of various debugging interventions. Moderator analyses revealed which interventions were effective, in which situations, and for what kind of learner. A significant overall mean effect of debugging interventions (
Keywords
Computational thinking (CT) is an analytical approach that incorporates the key concepts of computer science; it is considered by some to be an essential 21st century skill (Wing, 2006). Shute et al. (2017) defined CT as the collective knowledge and skills needed to solve problems effectively and efficiently by designing algorithms that are applicable to different contexts. Computational thinking consists of various skills, such as the ability to construct algorithms, abstract, and debug (Shute et al., 2017). Among these, debugging is an often overlooked and underrepresented skill in CT research and training (Gao & Hew, 2023; Liu et al., 2017; Wong & Jiang, 2018).
Debugging - the process of locating and fixing errors in code - is a core competency of computational thinking and an essential skill for computer programmers to master (e.g., Brennan & Resnick, 2012; Kong & Wang, 2023; Shute et al., 2017). Researchers have emphasized training and improving debugging skills as a key CT practice (Kong & Wang, 2023; Kutay & Oner, 2022; Zeng et al., 2023). Programs rarely work the first time they are run, and even experts claim to spend more than half of their time debugging code (Contreras-Rojas et al., 2019; Zeller, 2009). Moreover, debugging is a multifaceted skill, requiring sophisticated domain, systems, procedural, strategic, and experiential knowledge (Jonassen & Hung, 2006). To be successful, a programmer must balance the dual demands of maintaining a high-level view of code structure and abstractions while also flexibly focusing to locate and fix any bugs. Given its complexity, debugging is especially challenging for novices (Lee & Wu, 1999; McCauley et al., 2008). Although findings suggest that beginners do employ rudimentary debugging strategies, such as trial and error, these often are limited, and prove to be ineffective and inefficient (Lee & Wu, 1999; Li et al., 2019). For example, rather than systematically exploring the problem space as experts do, novices jump to fixing bugs without taking time to understand the overall program first (Fitzgerald et al., 2008). Moreover, beginners find it challenging to execute the procedural aspects of debugging, such as conducting thorough code tests, using debuggers, and interpreting error messages. The centrality of these skills in bug localization makes it challenging for novices to identify the causes of errors, resulting in a process marked by frustration and stress (Whalley et al., 2021).
The complexity of debugging makes it challenging not only to learn, but also to teach. We still lack guidelines for teaching debugging skills (Whalley et al., 2021). Because debugging involves a diverse set of nuanced subskills, such as program comprehension and hypothesis testing, significant instructional time is required to cultivate mastery in each of its component skills. Bugs also vary in context and form, so instructors must personalize support for the specific bugs used in instruction while also teaching general debugging principles. In practice, computer-science courses mostly focus on programming content knowledge and syntax, with little time allocated to debugging practice (Lee & Wu, 1999).
A first step towards providing guidelines for instructors and helping researchers to better facilitate debugging is to synthesize the existing literature on debugging interventions. In this meta-analysis we analyze studies and report on their findings regarding the efficacy of such interventions. We also conduct moderator analysis on eight factors—intervention type, programming medium, control-group activities, type of outcome, participant characteristics, study design, and features of the source documents (publication year and type)—in order to distinguish factors that influence the effect size of the intervention. The goal of this work is to synthesize existing research on debugging interventions to feature effective approaches and highlight opportunities for future research.
Our research questions are: (1) Are interventions for increasing debugging skills effective on average at raising scores on measures of debugging? (2) How variable are the effect sizes for interventions for increasing debugging skills, and what portion of effects, if any, shows detrimental effects? (3) Do characteristics of the interventions and learners, or features of the studies themselves, relate to the effectiveness of debugging interventions?
Literature Review
Interventions for Fostering Computational Thinking
Due to the interconnectedness between CT and computer science, much of the literature has focused on improving CT via teaching programming or coding knowledge (e.g., Angeli & Valanides, 2020; Berland & Wilensky, 2015; Papert, 1980). Papert (1980) proposed to use constructionism as a framework for learning CT. He built LOGO, which provided a microworld in which students construct programs and improve their own understandings of numerical and computational concepts. This effort inspired the creation of other CT learning environments, such as Scratch (MIT, https://scratch.mit.edu). Scratch is a visual programming tool where students can create their own artifacts (e.g., interactive stories, animations, and games) by dragging and dropping blocks of code to write programs. Such visual programming tools are frequently used to improve CT (Hsu et al., 2018). Studies have shown consistent evidence that designing artifacts using Scratch can foster CT skills among preschoolers (e.g., Bers, 2018; Falloon. 2016; Sung et al., 2017), elementary students (e.g., Jun et al., 2017; Sáez-López et al., 2016; Zhang & Nouri, 2019), middle-school students (e.g., Grover et al., 2015; Kutay & Oner, 2022), and even college students (e.g., Cetin, 2016). Grover et al. (2015) provided evidence that students can transfer their programming skills from Scratch to text-based programming environments. Moreover, educators can use Scratch to teach subject-matter content by creating simulations and games. For example, Garneli and Chorianopoulos (2018) taught students science knowledge and CT skills via Scratch.
Other approaches to teaching CT include incorporating robotics and digital games. Robotics are generally used to help young students learn CT. Studies have investigated how pre-elementary students interact with educational robotics, and provide evidence that preschoolers can acquire essential CT skills such as debugging and sequencing (Angeli & Valanides, 2020; Bers et al., 2014). Robotics can also support middle-school and high-school students in learning CT skills including abstraction, generalization, and algorithm development (Atmatzidou & Demetriadis, 2016; Berland & Wilensky, 2015). Fun digital games can also maintain student attention and interest in CT development, and provide support when needed. Various games have been developed to foster student CT skills, including RoboBuilder (Weintrop & Wilensky, 2012), Penguin Go (Zhao & Shute, 2019), and aMazeD (Tikva & Tambouris, 2023). Research has found that using digital games can help students develop targeted CT skills, such as problem decomposition, algorithmic thinking, abstraction, and debugging.
Assessment of Computational-Thinking Skills
A key issue in the CT literature relates to the assessment of CT across studies. The assessments used have largely been based on researcher-developed rubrics or tests of programming knowledge and skills. Few of these scales have been validated as measures of CT. Often their reliabilities are not reported.
Home-grown tests generally target the domain knowledge associated with the intervention used to encourage CT (e.g., Chen et al., 2017; Grover et al., 2017). However, few CT tests have undergone psychometric evaluation. One exception is the scale of Korkmaz et al. (2017). The authors characterized CT as using five associated skills: creativity, algorithmic thinking, cooperation, critical thinking, and problem solving. They reviewed the literature on scales assessing these five skills and selected 29 items to be included in their CT scale. They initially administered 29 five-point Likert-scale items (with responses from “never” to “always”) to a sample of undergraduates. The scale was further tested among secondary students (Korucu et al., 2017).
Another exception is the CT assessment developed by Román-González et al. (2017). The scale includes 28 multiple-choice items targeting knowledge of sequences, loops-repeat times, loops-repeat until, if-simple conditional, if-else-complex conditional, while conditional, and simple functions. These researchers have conducted various empirical studies to validate their test, especially among middle-school and high-school students. The downsides of their test pertain to its emphasis on programming concepts and the exclusion of an important CT skill – debugging. Debugging is an integral part of CT skills when a solution plan does not work as expected; however, both CT interventions and assessments have often failed to include debugging as a component of CT.
Interventions for Fostering Debugging Skills
Debugging interventions can generally be categorized into two types, those that teach debugging and those that support debugging. Ardimento et al. (2019) have argued that these are “inherently different tasks.” Debugging instruction explicitly introduces students to the skills and strategies of debugging. This commonly takes place in the form of online or offline curriculum-based approaches, using a series of scaffolded steps or by examining pre-defined bugs. On the other hand, some tools support students as they encounter bugs in their own programs. These tools are typically embedded within an integrated developmental environment (IDE) for coding. Traditional debuggers, visualization tools, hint-generation systems, enhanced error messages, and intelligent tutoring systems most often fall into this category. These two approaches are not always mutually exclusive, as some tools that support debugging have been shown to improve general debugging skills as well (Ardimento et al., 2019; Price et al., 2020).
Based on the observation that debugging skills are rarely explicitly taught in computer science (CS) classes, some researchers have explored the effectiveness of improving students’ skills through direct instruction. Such interventions focus on systematically teaching the debugging process (e.g., Chou, 2020; Wong & Jiang, 2018). For example, Michaeli and Romeike (2019) developed and taught a procedure for debugging that emphasized repeated hypothesis formation and experimentation for different error types: compile-time, runtime, and logical. They presented this procedure on a poster to tenth-grade students and discussed each step using an example. Learning this procedure improved both self-efficacy expectations and debugging performance in the experimental group as compared to the control group.
While the previously mentioned intervention was conducted during in-person training sessions with paper materials (a poster), online learning tools support other promising approaches to systematically teaching debugging. Ladebug (https://github.com/EmandM/ladebug), an online tool that allows students to step through scaffolded pre-defined bugs, garnered initial positive feedback from introductory programming students (Simon et al., 2019). Similarly, online games designed to foster debugging skills have also shown preliminary positive effects (Deitz & Buy, 2016; Liu et al., 2017), though these authors did not conduct comparative experiments as part of their investigations.
A separate yet related category of interventions aims to support students when they encounter bugs while writing their own programs. A major obstacle for beginning programmers is deciphering messages about errors that prevent code compilation. Denny et al. (2014) note that compiler messages are notoriously difficult for novices to understand and can hamper their progress while increasing frustration. Based on this observation, an active area of research is the enhancement of error messages to make them easier to read, more encouraging, and more helpful. Along a similar vein, researchers have also explored the integration of hints that guide students in locating bugs and implementing solutions in their code. For example, Price et al. (2020) explored the efficacy of embedding data-driven hints in student code. These hints annotated which lines should be deleted, replaced, or inserted and provided further explanations and examples. Thus far, enhanced error messages and hint-generation approaches have shown mixed effects on improving student debugging ability (e.g., Becker et al., 2019; Price et al., 2020), suggesting that the design of these messages heavily influences their utility.
Although syntax bugs are a major obstacle for students, they are typically easier to fix compared to semantic bugs which compile but produce incorrect output (Fitzgerald et al., 2008). Traditional debuggers, which allow students to set breakpoints and systematically check variable values at each step, assist in locating semantic bugs. However, these tools have a steep learning curve (Becker, 2019) and often don’t address high-level struggles novices encounter while debugging, such as during hypothesis formation and decomposition. Attempts at enhancing traditional debuggers to cater to novices assume a variety of forms. Ko and Myers (2004) developed the Whyline (https://www.cs.cmu.edu/∼NatProg/whyline.html), an interrogative debugging tool that visualizes users’ “why” questions about their code. Similarly, many intelligent-tutoring approaches to debugging gradually scaffold the debugging process by encouraging students to ask questions and develop hypotheses (Lane & VanLehn, 2005). General features observed in these enhanced debuggers are the use of visualizations to reduce the cognitive load of code processing and provisions for user input to guide the debugging process.
Assessment of Debugging Skills
In addition to the diverse interventions designed to address debugging, assessment methods that measure the impact of these interventions vary greatly. One common evaluation approach is based on the correctness of student code. This includes measures such as qualitative or quantitative ratings of code quality and number of errors generated (e.g., Chung & Hsiao, 2020; Denny et al., 2014). Additionally, researchers have used various measures of debugging skills, such as number of attempts to create correct code, numbers of lines of code edited (e.g., Liu et al., 2017; Price et al., 2020) and time taken to solve the bug (e.g., Ko & Myers, 2004; Lin et al., 2017; White, 2009). These evaluation metrics are most commonly assessed on pre-defined debugging tasks within controlled environments (e.g., Ko & Myers, 2004; Lane & VanLehn, 2005), or on student-generated code in an ecologically valid environment, such as an introductory CS course (Becker et al., 2016; Price et al., 2020). There is little consensus, though, on validated measures of debugging ability, making generalizations across the field potentially difficult. The wide variety of assessment approaches further highlights the need for a meta-analysis of findings in the literature.
Previous Meta-Analyses on Computational Thinking and Debugging
Meta-analysis facilitates synthesis of findings from previous studies and assessment of their generalizability. CT researchers have examined a variety of interventions using diverse assessment methods, often with smaller samples. Meta-analysis allows for increased power via the accumulation of such smaller diverse studies (Cohn & Becker, 2003), and provides a means for assessing whether differences in effectiveness appear across the varied approaches and contexts that have been studied. Recent meta-analyses on CT have focused mainly on the impact of specific intervention types (e.g., collaboration, educational games, etc.) on general CT skills. For example, collaboration was associated with an overall positive effect on CT programming knowledge (
Meta-analyses have also examined component CT skills as outcomes. Sun et al. (2021) examined the impact of programming activities on K-12 students' CT skills and found an effect of 0.60 standard-deviation units (SE = 0.05). Li et al. (2022) also examined general CT skills following one of two types of intervention. An overall effect size of
While a handful of in-depth reviews have examined specific interventions related to debugging such as enhanced error messages (Becker et al., 2019) or code visualizations (Egyed et al., 2003), a comparative overview of the many diverse approaches is lacking. McCauley et al. (2008) briefly addressed interventions in their review of the literature on debugging, but their analysis was limited to explicit debugging instruction. Additionally, Li et al. (2019) and Luxton-Reilly et al. (2018) presented cursory reviews of debugging tools, but their reviews do not include quantitative analyses of study results.
Our synthesis aims to investigate debugging as an essential but often neglected CT skill. Our quantitative meta-analysis is designed to identify which types of debugging interventions are effective, and for whom. We investigate our three research questions via overall analyses of effectiveness and variation in effects, and by examining eight moderators of intervention effects. Our results have implications for guidelines for debugging instruction, and for future research.
Methods
Study Selection
The databases used for our data collection included ProQuest (including its dissertation compendium), EBSCOhost, Web of Science, and PsycInfo. In each database, we used the same keywords and criteria for searching for sources. We first identified empirical studies appearing between January 1, 2002 to December 31, 2021 (the most recent two decades) with abstracts including the keywords: “computational thinking”, “computer science”, debug*, intervention, effect*, and experiment*. We sought sources in English, not other languages. Our search included journal articles, dissertations, theses, conference papers, and proceedings. The initial search generated 234 papers to screen. We removed duplicate papers. In addition, we conducted snowball searches for additional papers by examining the references of previous meta-analyses on CT and the references of screened papers for other relevant studies. In response to reviewer comments we updated our searches through by additional snowballing and thus added three more studies to our original collection of fifteen.
We screened papers using the inclusion and exclusion criteria listed below. 1. The research outcome should be debugging skills. 2. The source should specify the instruments/evaluation tools used to test students’ debugging skills. 3. The source should report on a comparative study to test the effects of an intervention. 4. Research that described the development of an intervention without providing quantitative data on its efficacy was excluded. 5. The research report specifically described the participants and methods. 6. The report provided sufficient data for computing the effect size for the treatment versus control comparison.
After careful review, 18 papers (see Figure 1) were included for the final meta-analysis, including two dissertations, eleven conference papers/proceedings, and five journal articles. PRISMA chart of the study-selection process.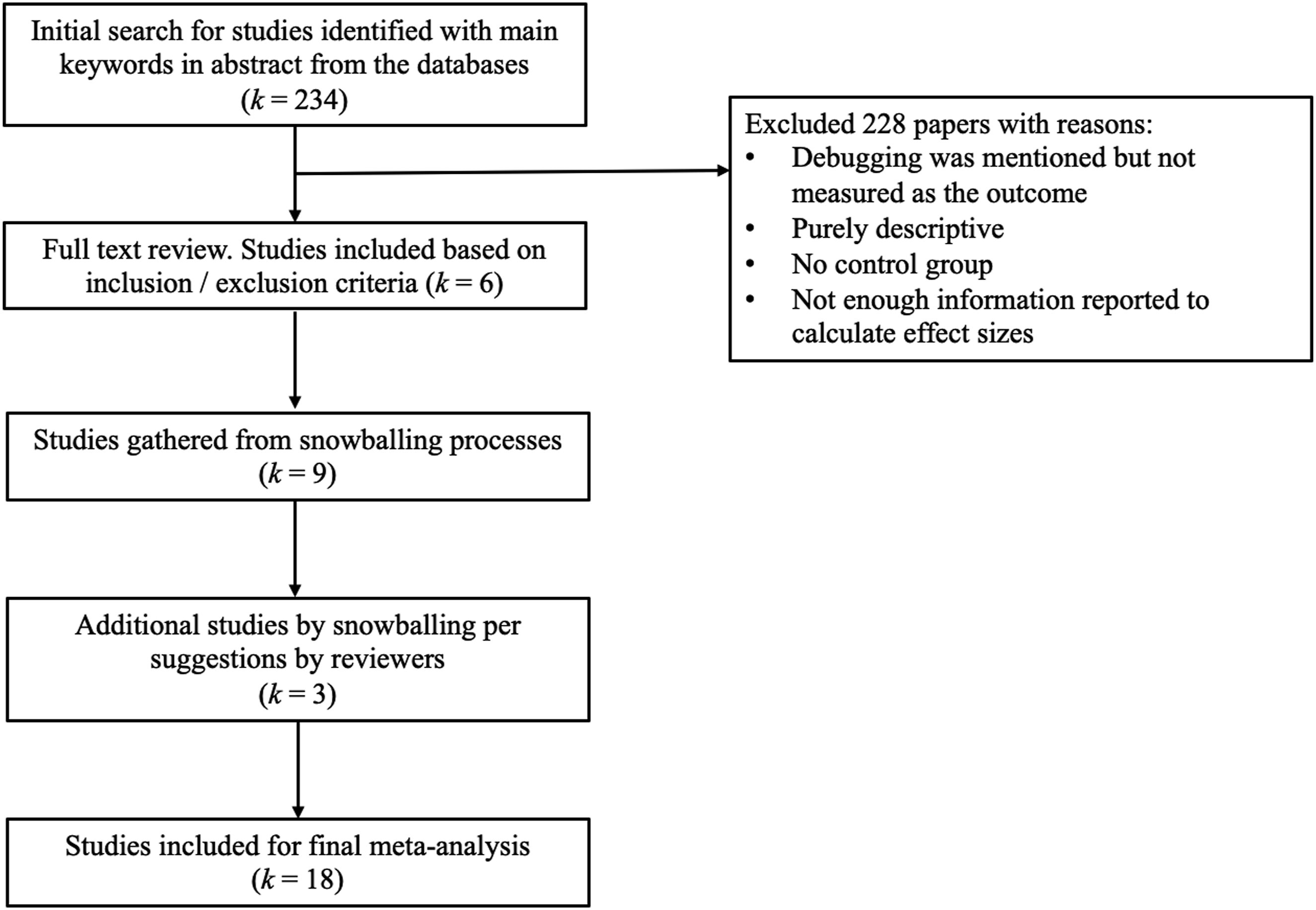
Coding Procedures
After the set of study features (i.e., sample size, test used, use of randomization, etc.) was identified, two coders independently coded the study features and effect sizes for each sample. Two coders went through three rounds of coding to establish inter-rater reliability. Two randomly-selected studies were coded for the first round, and one study was randomly selected for coding training for each of the next two rounds. After each round of coding, the coders met to compare extracted data and resolve any differences until reaching 100% agreement on all the 20 variables. In the first round, the two coders had complete agreement for one paper, and some disagreement for the other paper on three variables related to statistics, such as the values of debugging measures, and what other types of statistics should be included. Thus across all variables the percentage agreement was 92% (37 out of 40 variables) for the first round. The inter-rater reliability, in the form of percentage agreement for the two studies examined in the next two rounds was 95% (19 out of 20 variables) and 100%, respectively. Therefore, the inter-rater reliability was about 96% on average for the three rounds of training, which is high enough for separate coding. Afterwards, the two coders coded the remaining fifteen studies and obtained the data set for analysis. The final inter-rater agreement was 100% across all the 18 papers included in the analysis.
Effect Sizes
For each source, we calculated standardized-mean-difference effect sizes for all possible group comparisons. None of the studies presented results for multiple sub-samples. When debugging was measured by several tests or tasks, an effect size was calculated for each test or task. The effect sizes were corrected for bias and within-study variances were computed, as described below.
Hedges (1981) derived the unbiased standardized mean difference, denoted as g, which is adjusted using the correction factor J(m) – a function of sample sizes, with m = nT + nC - 2. In larger samples, the factor J is close to 1, and for smaller sample sizes it is lower, reflecting and correcting for small-sample bias (Hedges & Olkin, 1985). The formula to calculate Hedges’ g is
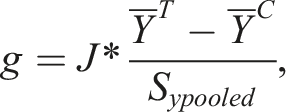
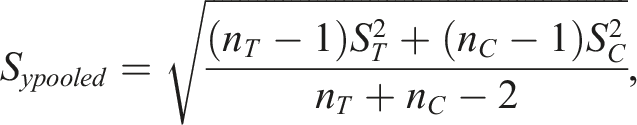
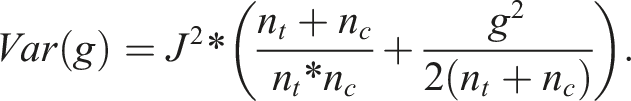
Hedges’ g is referred to as the corrected or unbiased effect size compared to the value of Cohen’s d. The difference between Hedges’ g and Cohen’s d is very small for studies with samples of 19 or more, as J(m) ≥ .96 in that range (Hedges, 1981).
Features Coded for Moderator Analysis
In addition to examining the overall effect of debugging interventions, we investigate how eight factors relate to the effects of interventions on student debugging skills. Four of the factors concern the nature of the intervention (i.e., intervention types, programming medium, control-group activities, and type of outcome), and four focus on participants, study design, and features of the source documents. We examine all eight study features for confounding or collinearity with other factors.
Intervention Types
As the literature review shows, debugging interventions have assumed different forms, as no consensus exists on how to best enhance debugging skill. Studies have explored a wide range of interventions, such as instructional/curriculum designs (e.g., Chou, 2020; Michaeli & Romeike, 2019), intelligent tutoring systems (e.g., Ko & Myers, 2004; Simon et al., 2019), and digital games (e.g., Deitz & Buy, 2016; Liu et al., 2017). Providing hints and enhanced error messages has shown inconsistent effects on debugging learning (e.g., Becker et al., 2019; Price et al., 2020). Given the large amount of variance in the design of interventions, we compared effect sizes from different types of interventions. By identifying effective interventions, we hope to provide implications for future intervention designs.
We categorized the debugging interventions into five types. Enhanced debuggers are interactive systems developed to help programmers to visualize their code input as part of the debugging process, especially when searching for semantic bugs. Enhanced error messages and hints are messages carefully designed to help programmers comprehend error messages and locate and resolve bugs; these are not interactive as are enhanced debuggers. Systematic-instruction interventions included curricula developed to teach debugging skills in courses. These may or may not have digital components. Digital games and virtual-reality systems are the fourth type – these can be leveraged to improve students’ debugging skills, help them visualize code, and increase their motivation and interest. Lastly, collaborative programming may play a role in enhancing debugging abilities collectively through team interactions. However, data based on collaborative activities have inherent dependencies and do not cleanly parse out individual students’ competence levels.
Intervention duration was also coded, but only seven studies (38.9%) reported it in a clear and usable form.
Programming Medium
The programming medium is the channel through which students interact with coding activities. We examined three types of medium. Text-based programming focuses on programming languages, such as Java and Python, where students need to write syntax to create programs. A typical example of block-based programming is Scratch where students drag and drop code blocks to build programs such as games and simulations. The last medium uses physical objects to program, such as in studies of robotics (Bers et al., 2014; García-Valcárcel-Muñoz-Repiso & Caballero-Gonzales, 2019). The programming medium also influences the types of bugs students encounter. Notably, syntax errors are minimized and even absent by design in block-based languages. If different programming media are associated with more or less effective interventions, we may gain insight about the most useful type of medium for training debugging skills.
Control-Group Activities
In some studies, the control group consisted of simple and regular programming instruction without any intervention or support for debugging. On the other hand, some control groups received a modified/lesser version of the treatment-group activities (e.g., paper version of computerized feedback), or a different but weaker approach aimed at training debugging. If one type of control-group activity leads to more learning of debugging than the other, effect sizes will be reduced for studies with that sort of control.
Type of Outcome
The literature contains a great diversity of assessments of debugging skill, and of specific dimensions that constitute the construct of debugging skill. Based on the literature we coded four types of outcome: time spent to debug or complete tasks, correctness of program code, number of bugs solved, and efficiency (i.e., number of compiles or edits taken to arrive at the correct solution). Two common measures of debugging skill include accuracy of code (e.g., Chung & Hsiao, 2020; Denny et al., 2014), and time spent on problem solving (e.g., Ko & Myers, 2004; Lin et al., 2017). Students are expected to spend less time to debug and complete tasks after training, and to make fewer edits or attempts at corrections compared with students who did not receive any training or received less training; effects from studies using these types of measure were reverse coded so that positive effects represented better performance (e.g., less time spent) by treated samples. In the same vein, debugging interventions should help students to construct programs with higher levels of correctness, and to resolve more bugs. Thus, investigating effect-size differences between assessment methods can reveal the efficacy of interventions across debugging success measures.
School Level
Students who participated in studies of debugging interventions ranged from kindergarteners to graduate students. Debugging interventions are tailored to students based on their age or grade level, often by modifying the type of programming language students encounter. K-8 students are commonly introduced to programming through block-based languages as opposed to text-based languages, while the same is not necessarily true for college-aged students. This suggests potential confounding of programming medium and student age/school level. Additionally, Rich et al. (2019) suggest that younger learners rely more on basic debugging strategies and may have difficulty employing cognitively complex strategies such as strategically choosing between debugging techniques.
Prior knowledge and experience with programming may also matter, and this often comes with age. That said, some older students may still be programming novices whereas some younger students may be able to create advanced programs. Given the anticipated large range of grades and ages, we differentiate effect sizes among different grade or school levels.
Unfortunately no studies explicitly measured level of coding experience of participants, aside from a few that characterized the overall experience level of the sample (e.g., students in an introductory CS class). Thus level of coding experience was not investigated.
Use of Randomization
In true experiments, participants are randomly assigned to control and experimental groups, for the purpose of minimizing biases and enhancing causal inferences (Creswell, 2009). However, as Lipsey (2003) noted, this design feature may be confounded with other study features, such as whether the intervention is a research or demonstration program versus one that has been put “into the field”; the latter may be more difficult to study using randomization. We include both true experiments and studies using nonrandom assignment. Thus, it is worth checking the effect-size difference between the two different assignment methods.
Publication Year
Year of publication is often examined as a moderator in meta-analyses. It can be used to detect trends over time, which reflect advances and improvements in the interventions used as the literature builds upon prior research, and as those developing interventions enhance their approaches.
Publication Type
Much of the literature on debugging has been shared via conference proceedings, such as those of the Association for Computing Machinery (ACM). Thus many of the papers in our review were from conference proceedings. Our meta-analysis also includes studies published in peer-reviewed journals and dissertations. The quality of research can vary greatly across peer-reviewed journals, conference proceedings, and dissertations, though we note these outlets are a poor proxy for true study quality. Also, prior meta-analyses have found differences between published and unpublished sources consistent with publication bias, or the censoring of weaker or nonsignificant findings (e.g., Mathur & VanderWeele, 2021). Thus, we will compare effect sizes of debugging interventions across these publication types.
Analyses
In total, 62 effect sizes from eighteen studies of interventions aiming to improve students’ debugging skills were included in the final meta-analysis. We used the R package “metafor” (Viechtbauer, 2010) to conduct the meta-analysis, and adopted random-effects models with restricted maximum likelihood (REML) estimation. All but four studies provided more than one effect size. The number of effect sizes ranged from 1 to 16 across the 18 studies, with a mean of 3.6. As such, many subsets of effect sizes are dependent on each other. Thus we employed multi-level modeling techniques to handle the nested data structure resulting from the use of multiple outcome measures, using the study’s first author as the nesting variable. We examined the overall mean and variance of the effects and meta-regressions for each study feature. We also examined the data for the presence of publication bias using Egger’s test and the funnel plot with the trim-and-fill technique.
Results
Study Description
Characteristics of Studies in the Meta-analysis.

aCounts of types of outcome are based on the total of 62 effect sizes.
Overall Analyses: Research Questions 1 and 2
Our first goal was to examine the overall effectiveness of the collected interventions, regardless of their features or the characteristics of participants. First, we examined the effect sizes to determine whether a random-effects model was appropriate, and if so to estimate the variance of the effects. Random-effects models assume a population of effect sizes, wherein each sample effect size may represent a unique participant population. Thus the collected effect sizes are expected to show a degree of true variability around the mean effect size. The I2 value, an index of between-studies heterogeneity as a portion of total variability is 81.54%, indicating that a high percent of the variance comes from between-studies differences. The test of homogeneity is highly significant with Q(61) = 203.93 (p < .0001). The two indices show that a random-effects model is appropriate for the analysis.
The forest plot of confidence intervals (Figure 2) for all effects confirms that the effect sizes are heterogeneous. Intervals are ordered by study author(s) and plotted using within-study standard errors. Some studies (e.g., Lin et al., 2017; Ko & Myers, 2004; White, 2009, outcome 3) reported very large effect sizes with large standard errors resulting from their small samples (ns of 16, 9, and 7 respectively). The plot also reveals that most studies provided more than one effect size. These represent effects for measures tapping different skill outcomes (e.g., Zhong & Li, 2020, with effects for time, correctness, and number of debugging tasks completed) or multiple measures of the same skill dimension, such as Denny et al.’s (2014) counts of different kinds of errors. Effect sizes appear very similar across the measures collected within most studies. Forest plot of the effects of interventions on debugging skills.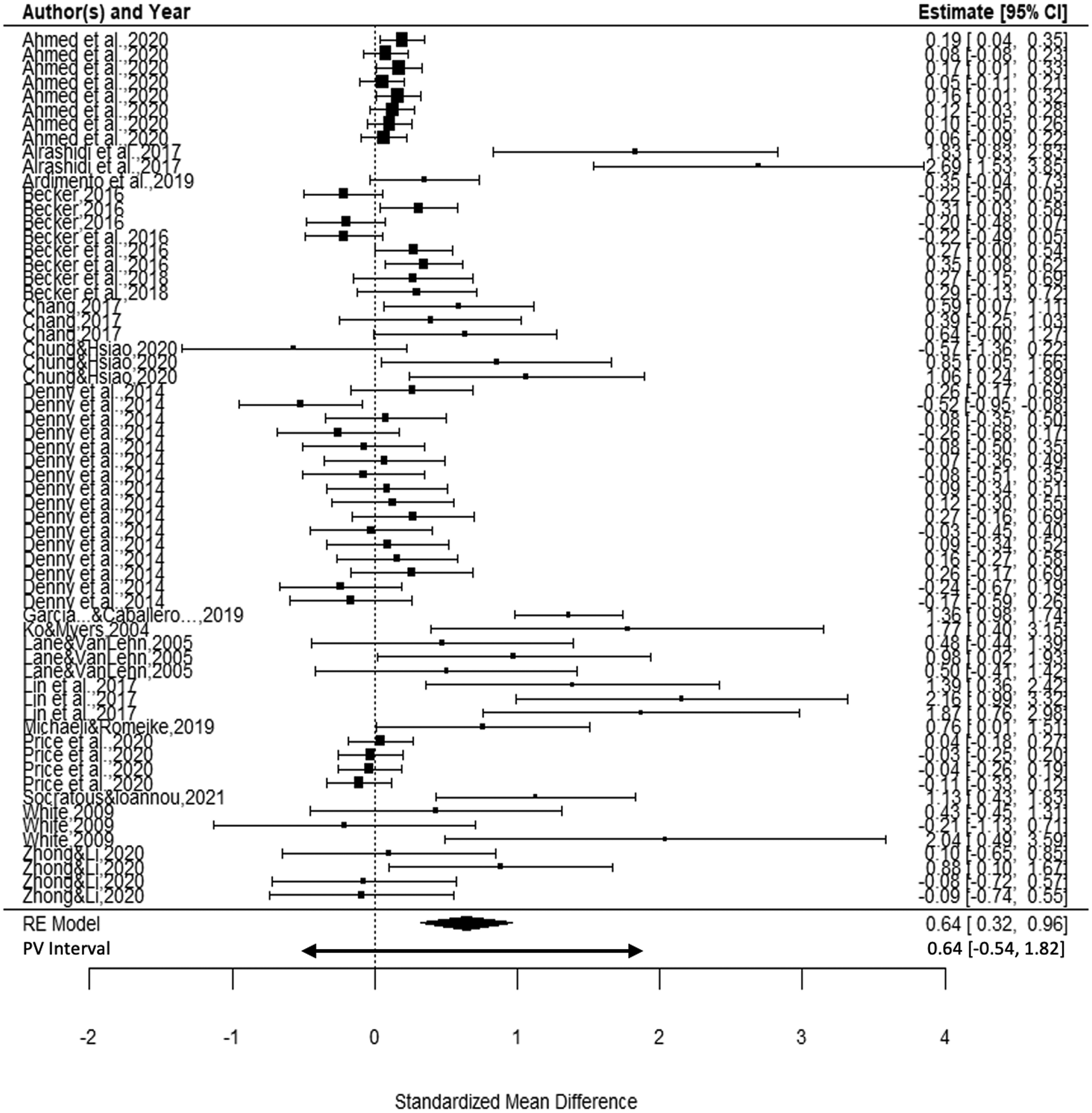
Overall Mean Effect: Research Question 1
The overall mean effect size across all interventions from the multilevel analysis is shown as the center of the diamond at the bottom of the forest plot in Figure 2. Across all debugging-skills studies the mean is
The forest plot reveals that most large effects are from smaller studies, as reflected in their wide confidence intervals. Thus any one large effect will not have an overly large influence on the mean, but the sheer number of large effects has contributed to the large mean effect.
Overall Variation: Research Question 2
The forest plot also shows that effect sizes vary widely around the mean effect, with eleven g values larger than one standard deviation in size, and three above two standard deviations. The between-studies variance for the full set of effects has two components. The between-studies (i.e., between-authors) variance is 0.361, and the variance among effects within studies is 0.002, which is negligible. Summing these, the variance among all effects is 0.363, leading to a plausible values interval for 95% of the population of effects ranging from −0.54 to 1.82. This interval is shown as a wider arrow just below the diamond for the CI in Figure 2.
As the lower end of the plausible values interval is negative, it is apparent that some interventions are from populations that suffered deleterious effects from the interventions. If the population effects arose from a normal distribution, roughly 86% of effect sizes would be expected to be positive, and the remaining 14% negative. However, in our data 17 effects or 27% of the 62 effect sizes fell below zero, and a histogram showed the distribution effects to be positively skewed (skewness coefficient = 1.47) with a median of 0.17. The mean effect appears to have been strongly influenced by the upper tail of the distribution.
Publication Bias
Among the 18 included papers, 11 (61.1%) were peer-reviewed high quality conference papers (such as ACM), 5 (27.8%) were from academic journals, and 2 (11.1%) were dissertations. All the papers were accessible. However, it is still important to check for potential publication bias in the studies of debugging interventions. Egger’s test for the funnel plot (Figure 3) shows notable asymmetry in the effects from debugging interventions (z = 6.20, p < .0001). The trim-and-fill technique using the L0 estimator with the REML estimated variances added 14 potentially missing studies to the left side. The addition of these potentially missing studies leads to a greatly reduced estimate of the mean effect, of 0.08 (SE = 0.08) which does not differ from zero. However, this analysis is not hierarchical thus does not account for dependence. Funnel plot for the 62 effect sizes from debugging interventions with 14 added studies as suggested by trim and fill.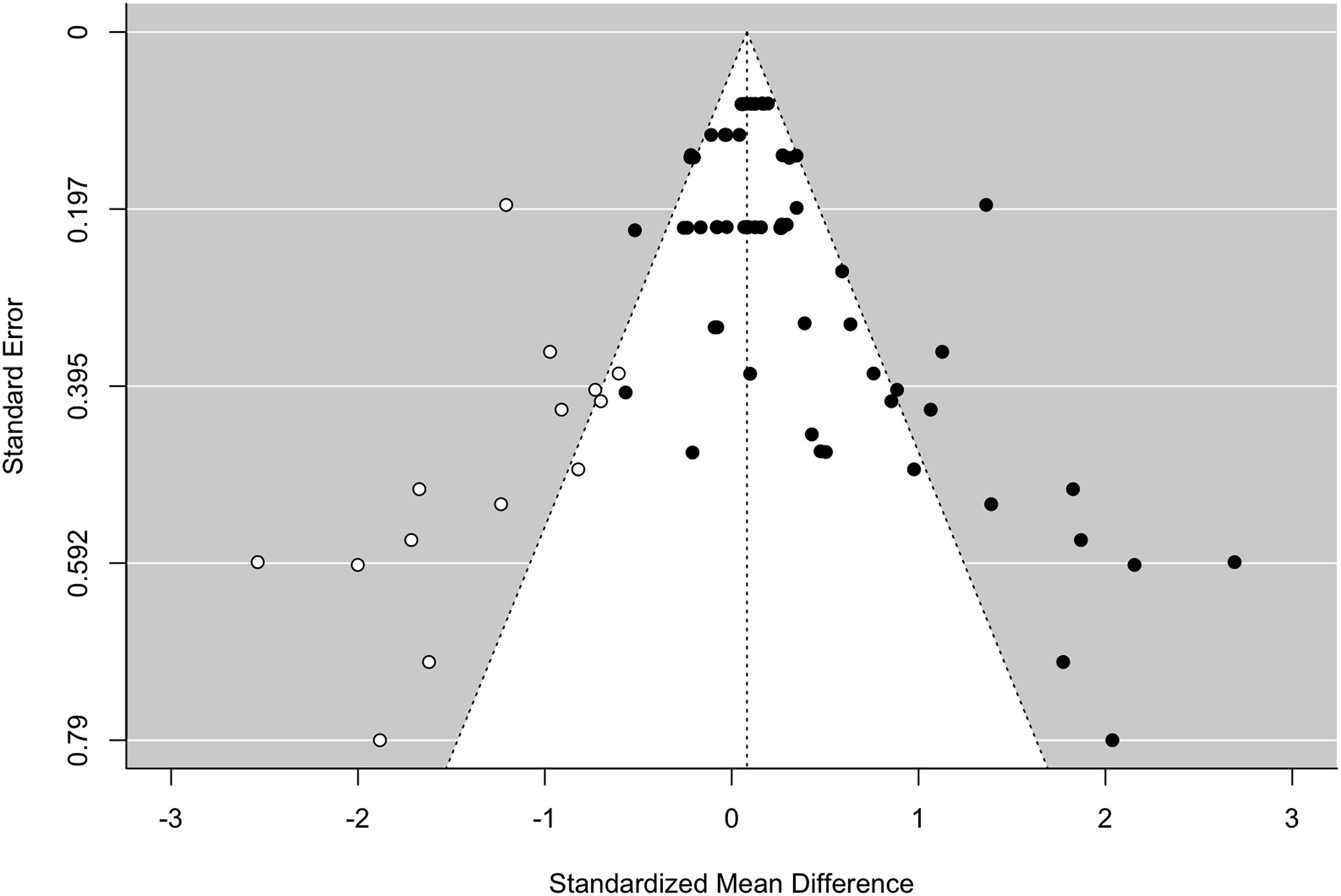
Moderator Analyses: Research Question 3
CT researchers have designed different types of interventions and employed various measures to assess student debugging skills. Given the heterogeneous nature of the studies, with many intervention types, assessment tools, and research designs, we conducted moderator analyses to examine possible sources of the variation in the effectiveness of debugging training. Before proceeding we checked for evidence of confounding by examining cross-tabulations among the eight moderators. Several interesting patterns emerged.
Potential Confounding
Meta-analyses are especially subject to confounding of study features because in most cases the set of studies is not planned (Lipsey, 2003). Also, unlike participants in primary-study experiments, studies are not “assigned” to have specific features. Study features may be confounded by chance, or due to decisions common to a field of study. If several predictors that explain significant amounts of effect-size variation are confounded, we cannot assign a unique interpretation to any one predictor.
To examine the study features for confounding/collinearity we computed correlations among quantitative variables and dichotomies, otherwise we crosstabulated pairs of features. The eight features have 28 pairwise relationships, thus to reduce the chance of detecting spurious associations we used a reduced alpha level of .0018. None of the six correlations among the two dichotomies (randomization and control type) plus year and school level reached significance with alpha = .0018. The largest was r = .39 (p = .114) between school level and control group. 1 Also the two dichotomies, control-group type and randomization, correlated with r = 0.11 (p = .653).
The other 22 relationships were examined using crosstabulations and chi-square tests. However, all tables had many empty cells because of the relatively small number of studies, and because most variables had the same value for all effects within study. The exception to this was the type of outcome, which varied within some studies. Only four of the 22 relationships were significant; we discuss these below when relevant to a specific moderator analysis. 2
Intervention Types
Moderator Analysis of Different Debugging Interventions.
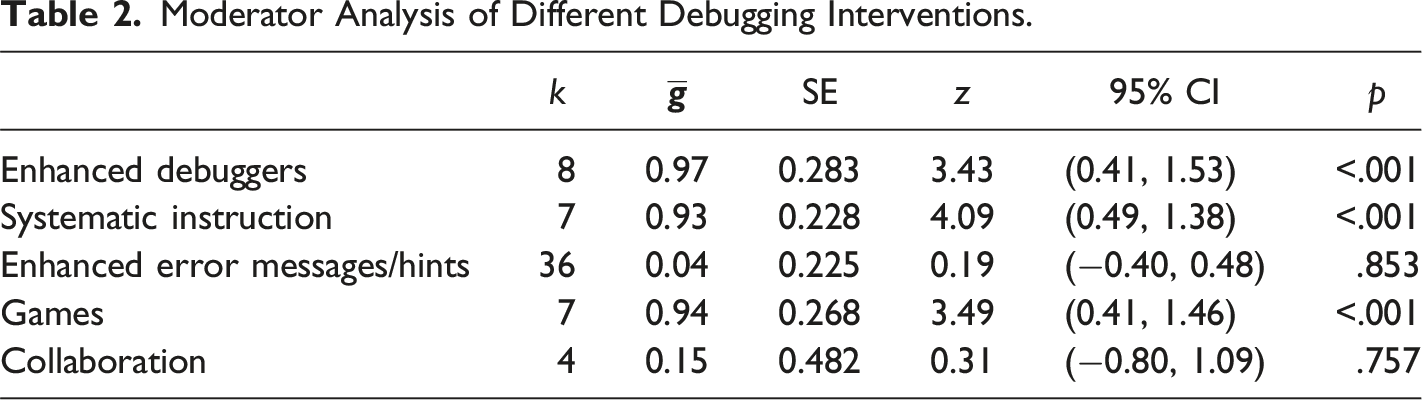
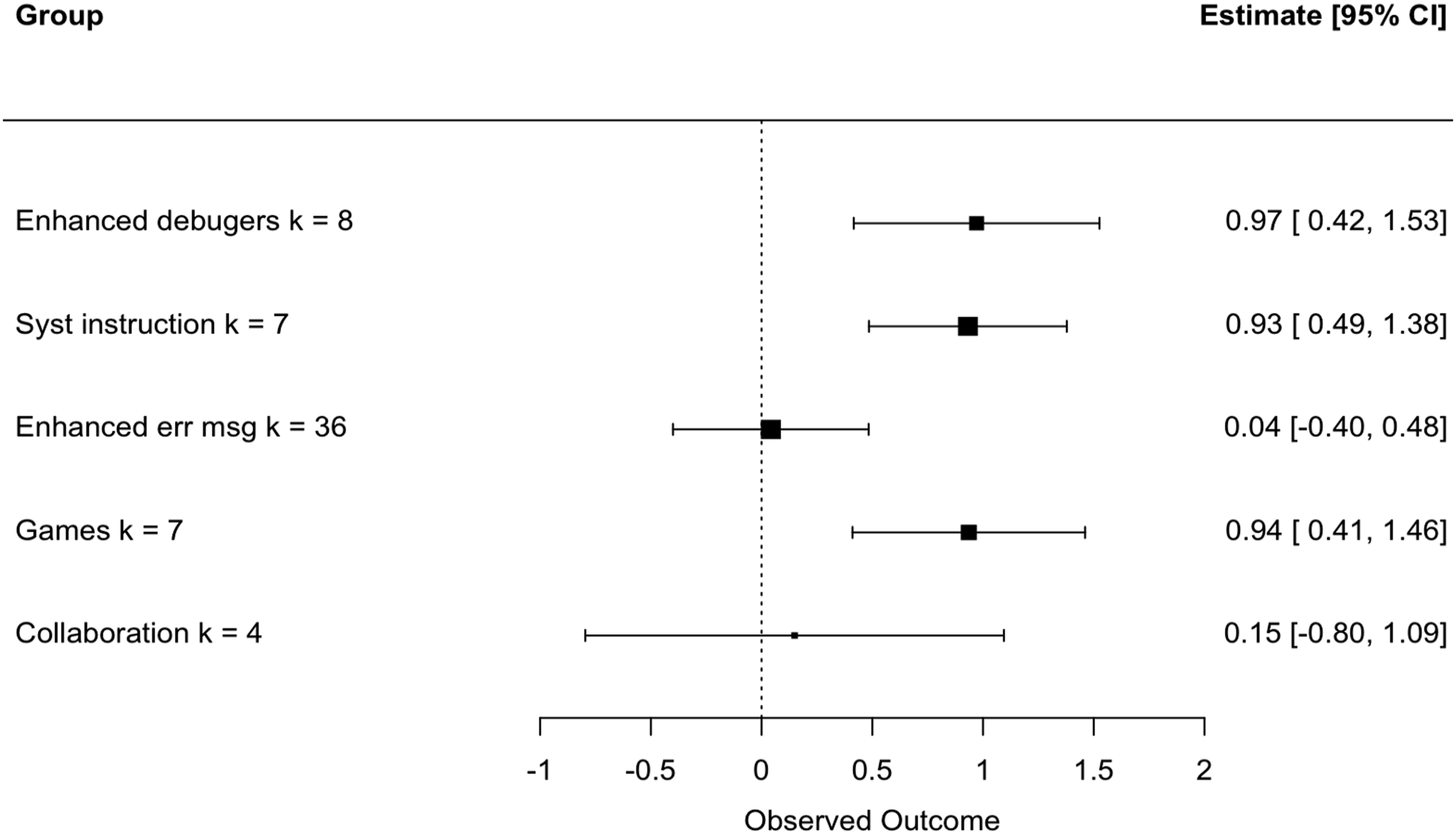
Forest plot of group means by type of intervention.
In contrast, enhanced debuggers and systematic instruction had significant and large effects on students’ debugging skills. The mean of enhanced debuggers was close to one standard deviation in size.
Programming Medium
Moderator Analysis of Programming Medium.
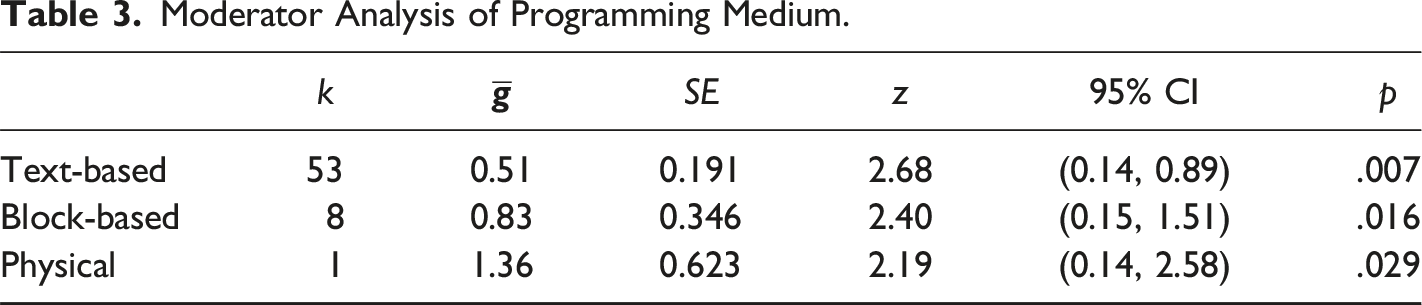
This one study of physical based programming examined the only kindergarten sample, and our analyses of confounding confirm a significant association between program medium and school level (χ2(8) = 26.37, p = .0009). This p value reaches significance by our stringent rules. Essentially, younger students are very unlikely to be able to use text-based programming. Some kindergartners cannot yet read, so researchers have quite limited options for the programming medium that can be applied for the youngest coders. None of our studies of kindergarten or elementary samples used text-based programming. Because of this we cannot fully disentangle the impact of coding with physical objects from the role of age without further studies that use physical-object-coding experiences with older participants. Forest plot of group means by type of programming medium.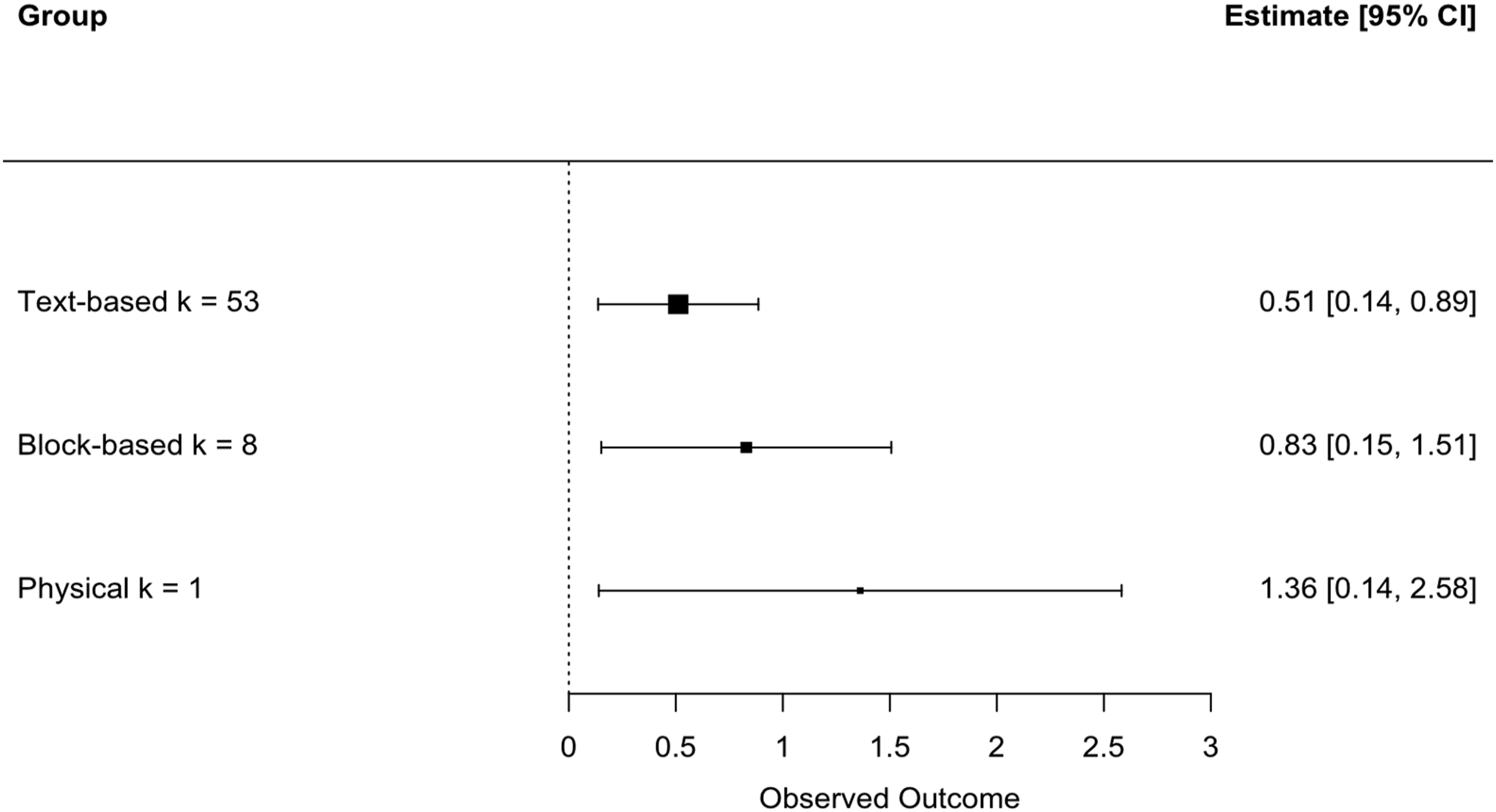
Control-Group Type
Moderator Analysis of Control-Group Type.

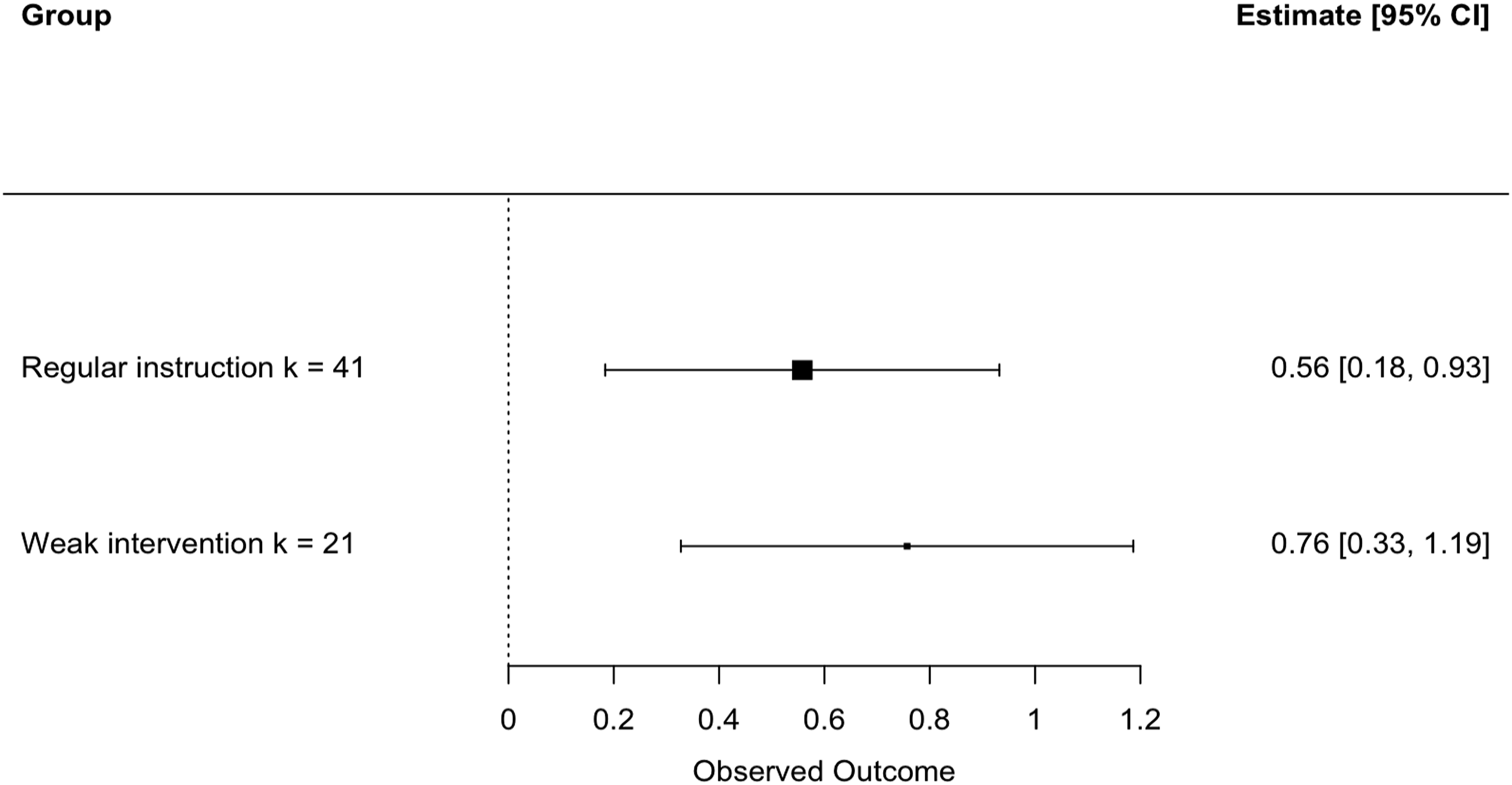
Forest plot of group means by type of control group.
Outcome Type
Moderator Analysis of Outcome Types.
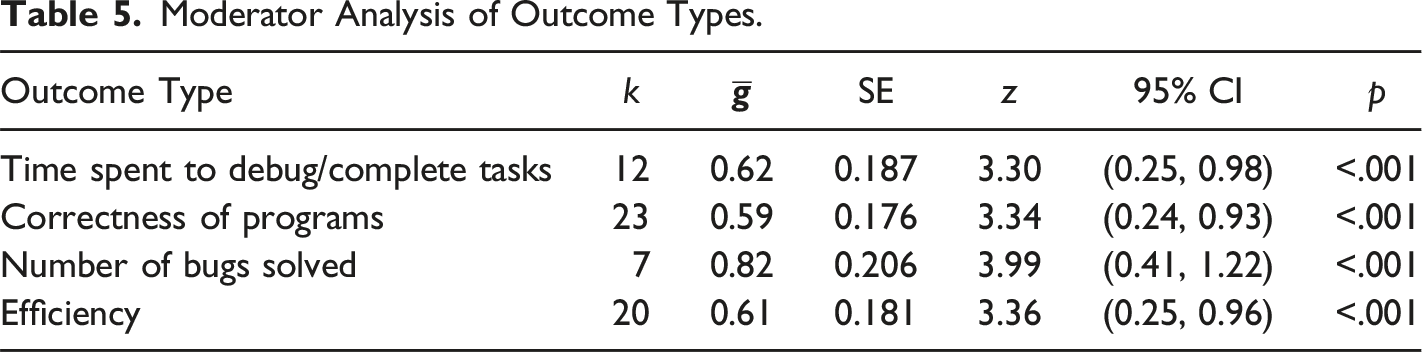
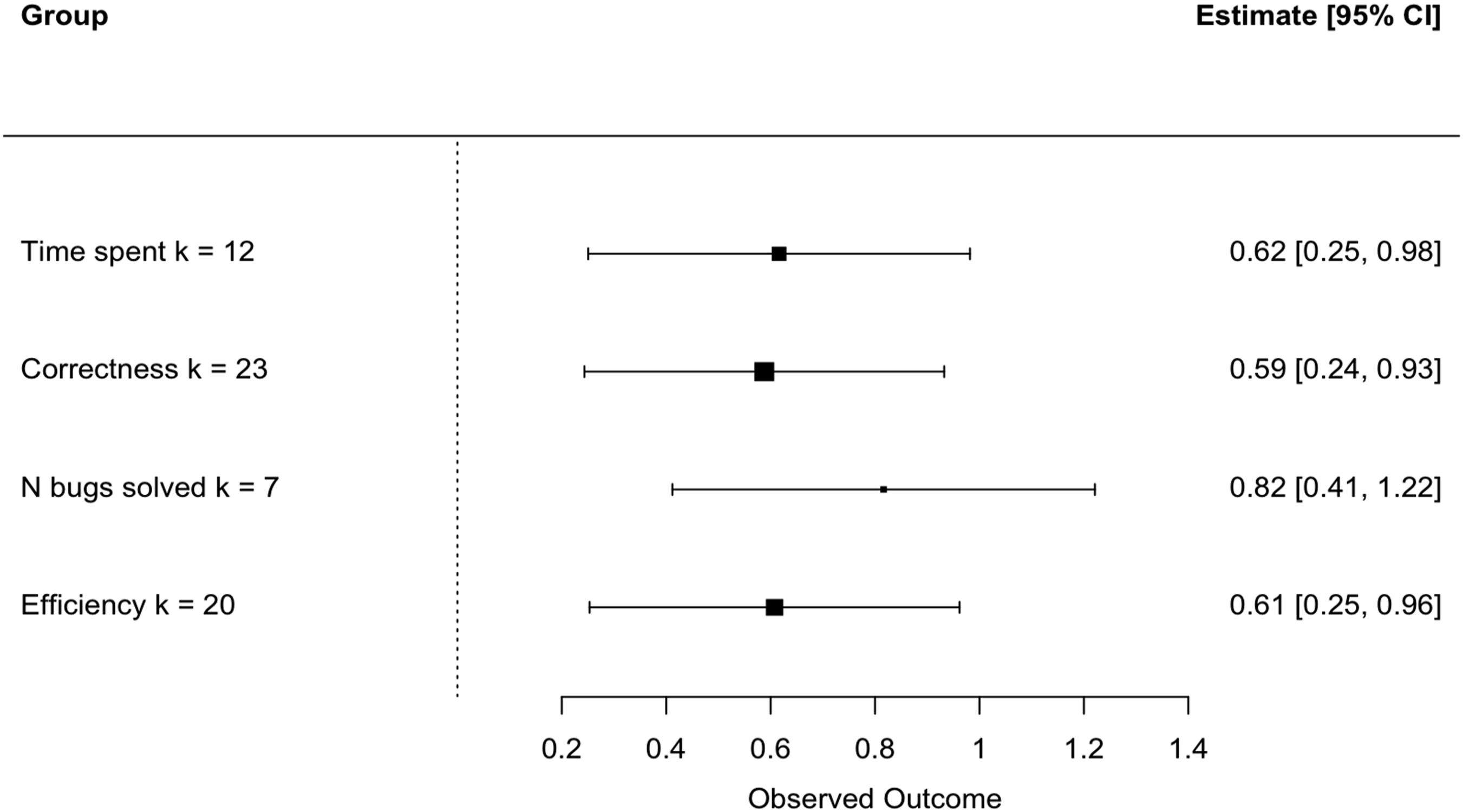
Forest plot of group means by type of outcome.
Our analysis of confounding also revealed that type of outcome used was significantly associated with randomization (χ2(3) = 17.9, p = .0005), year (χ2(27) = 82.08, p < .0001), and school level (χ2(12) = 34.93, p = .00048). Though the reason is unclear, efficiency of coding was measured only in randomized studies, and nonrandomized studies were more likely than randomized ones to track the number of bugs solved. The pattern of association for outcome type with year is not interpretable. Correctness was measured at all school levels except graduate study, but number of bugs solved was only tapped at the high-school and college levels; perhaps these choices relate to the cognitive levels possible for young children, or the constraints of what can be measured given the programming mediums used for younger children. Last, certain outcomes are measured only or primarily for specific interventions. Efficiency was measured in the main for studies of enhanced error messages. In contrast, time spent was measured largely in studies of enhanced debuggers and systematic instruction, and correctness and number of bugs solved were used in at least 4 of the 5 types of interventions.
School Level
Moderator Analysis of School Levels.
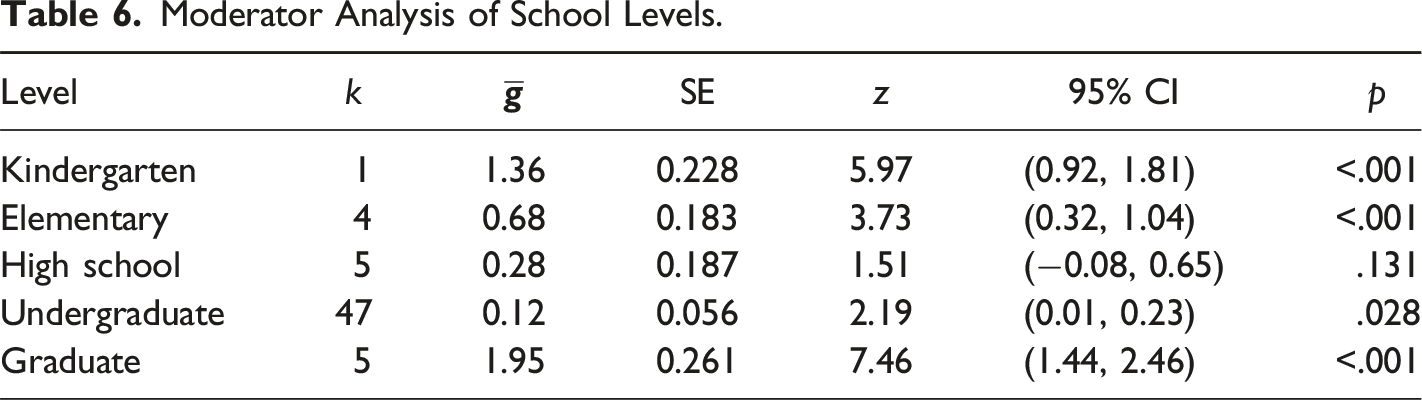
Forest plot of group means by school level.
Use of Randomization
Moderator Analysis of Randomization.

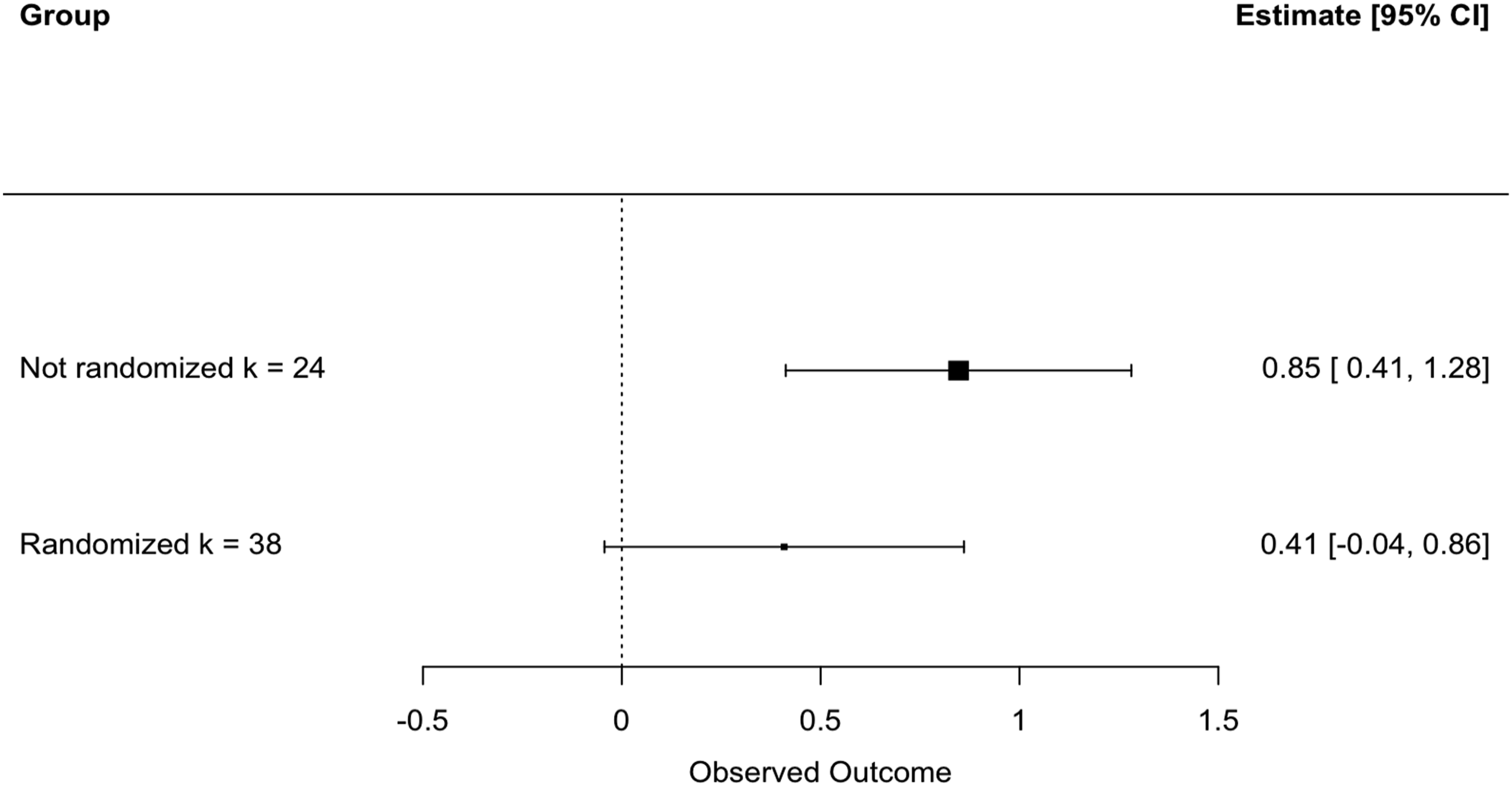
Forest plot of group means by randomization.
Year of Publication
Studies in our sample were published between 2004 and 2021. Because only a few years saw the publication of more than one study, publication year is highly confounded with study authorship. The scatterplot of year versus effect size in Figure 10 shows no discernible pattern of effects. A linear model with the predictor year did not reach significance (b = −0.02, SE = 0.021, p = .321). Scatterplot of year versus effect size.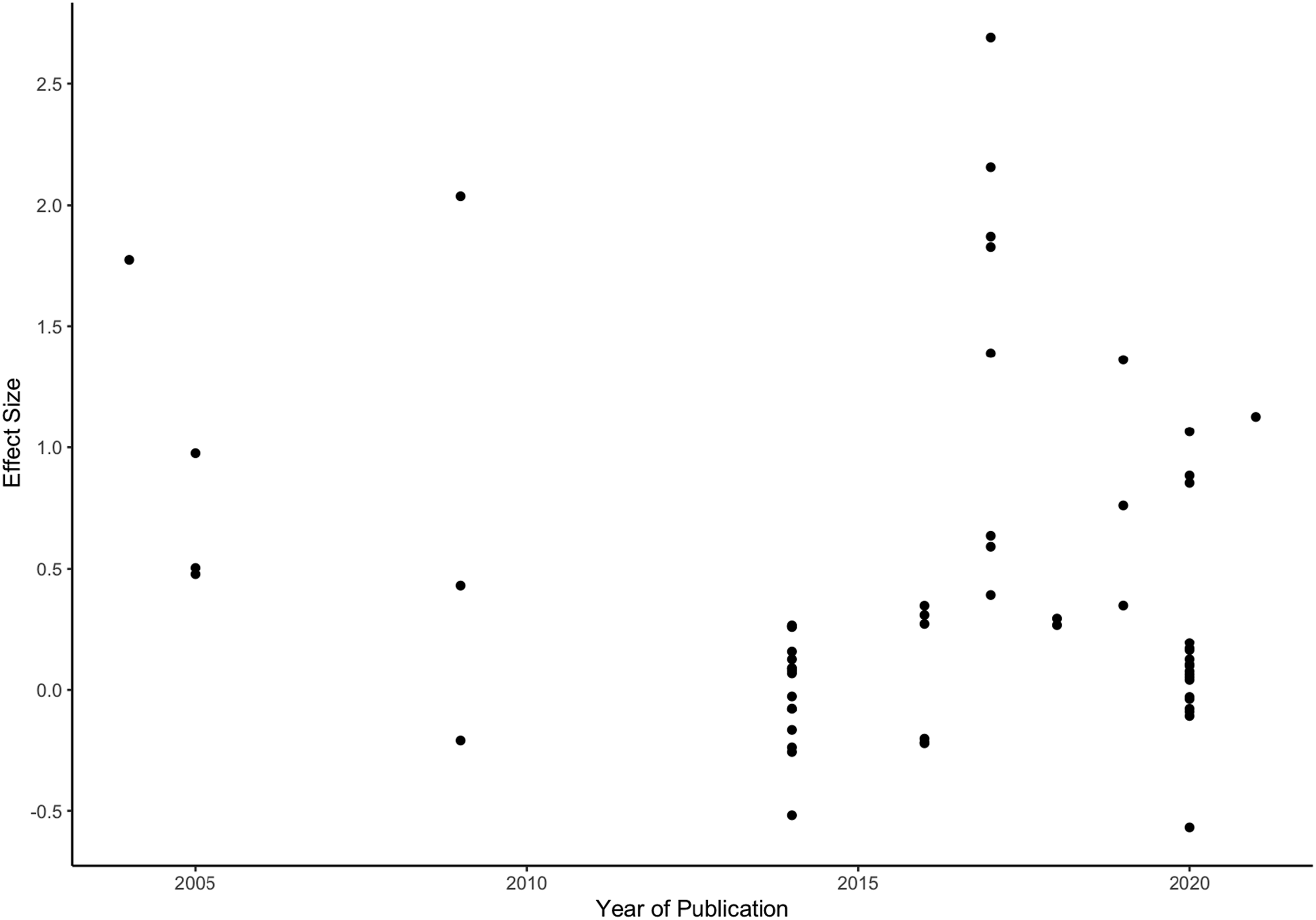
Publication Type
Moderator Analysis of Publication Types.
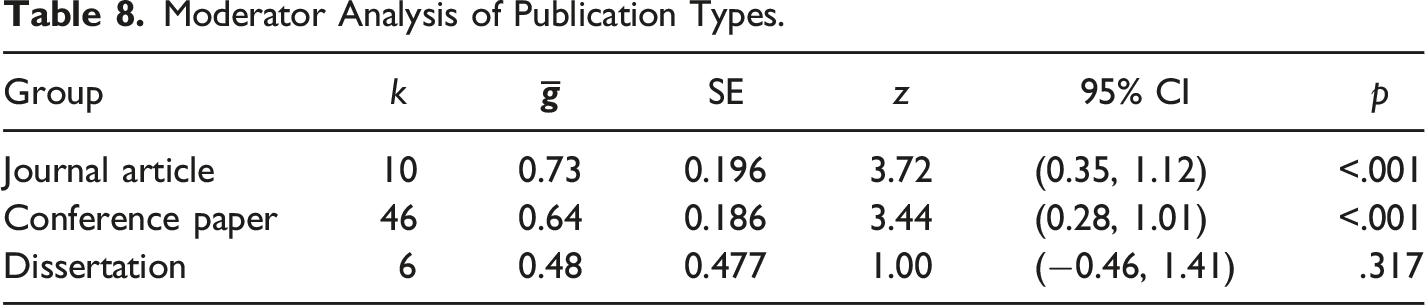

Forest plot of group means by type of publication.
Effect sizes did not differ on average between the three different publication types (Q = 0.86, df = 2, p = 0.652), with dissertation studies showing a small, nonsignificant mean. This may reflect some degree of publication bias, wherein significant results and high effect sizes are more likely than weaker effects to be published in peer-reviewed journals (and here, conference proceedings).
Sensitivity Analysis
Three effect sizes in the dataset are larger than 2, which is unusual in most studies of educational interventions. Large effect sizes influence meta-analysis results. As a result, we removed the three largest effect sizes and performed a sensitivity analysis of the overall results. With the remaining 59 effect sizes, the overall mean effect reduced to
Discussion
This meta-analysis investigated intervention effects on students’ debugging-skill development. We found a nascent field, but one where nearly all studies provided information on multiple measures of debugging skill. Our results provide compelling evidence that interventions can have a positive impact on students’ debugging skills, with a significant overall mean effect of
Our analysis adopted multilevel-modeling techniques to account for the fact that multiple effects came from the same research groups, and included several moderator analyses to explore the impacts of intervention and participant characteristics on the effectiveness of interventions for debugging. First, we investigated which types of interventions were most effective in training debugging skills. Enhanced debuggers (
Second, we analyzed the intervention effects for various measures of debugging skills. We found significant effects of interventions for all four debugging measures. Thus, it is safe to conclude that on average, training for debugging improves students’ debugging skills in terms of all four types of debugging measures.
Third, debugging skills were significantly improved regardless of programming medium. A majority of studies implemented interventions in text-based languages. The effect size of text-based programming (
Fourth, we categorized the control groups used based on their strength of intervention. That is, some control groups applied a weaker form of the focal intervention but others adopted regular learning or instruction. The results confirmed the advantage of debugging interventions over both control groups; and on average weak interventions and regular instruction were equally inferior. This again showcases the promising of debugging interventions to facilitate students’ ability to resolve bugs better than those who either received a weaker version of an intervention or did not receive any at all.
We further investigated whether intervention effectiveness varied by participant population. Debugging interventions were particularly effective for kindergarten and graduate students, but not for high-school populations. However, the single effect size for kindergarten students suggests an area for more empirical investigation. Our findings suggest that interventions may be most effective for older students. However, we also noted that different sorts of outcomes and different programming media were used across the school levels in our collection. This makes sense, as younger children are less likely to be able to code using text, or even process text as part of the interventions and outcomes that were assessed.
Next, we checked whether randomizing participants influenced the effects reported. The results revealed that studies with randomization and without randomization both had significant mean effects. However, the mean effect size from randomized studies was more moderate. The difference due to this aspect of method was not significant, thus our findings only hint at the potential bias existing in non-experimental designs which can in turn result in differences in effectiveness. One further finding was that when we examined the between studies variation separately for randomized and nonrandomized studies, we found almost 30% more variation among the nonrandomized studies (
We also checked the possible influence of publication bias in effect sizes. Our overall publication-bias analyses – the funnel plot, Egger’s test, and trim and fill – suggested asymmetry that was manifest in underreporting of small and/or negative effects. Also, while both journal articles and conference papers reported significant and large mean effect sizes of (0.73 and 0.64 respectively), dissertations generally reported smaller and more dispersed results. However, caution is needed in interpreting the results because the bulk of our sources were conference papers appearing in proceedings outlets. Our analysis also indicates a potential publication bias, in that researchers have predominantly published their debugging research in conference proceedings related to computer-science fields, rather than in traditional journals. This is likely due to the rapidly changing environment of computing and computer-science research.
Conclusions
This meta-analysis focused on debugging interventions in the context of fostering students’ computational thinking skills. The review included 18 sources, many with multiple effect sizes. Most of the various interventions supported debugging-skill development, but to different degrees. Some studies reported remarkably large effects, of over two standard-deviation units, whereas in contrast a notable portion of the effects were also negative. We aim to direct more researchers’ attention to debugging skill, an often-neglected but integral area of computational-thinking skills, particularly for researchers in non-computer science fields. The increased interest in computing-intensive fields such as artificial intelligence and data science prompt a dire need to assess and facilitate students’ debugging skills.
Future studies need to more fully investigate the best practices for improving debugging abilities for whom and under what circumstances. Future research calls for investigations of how to design more effective enhanced error messages/hints, and more empirical evidence is required to test the effects of enhanced debuggers and digital games. Future researchers should investigate the effects of block-based programming in cultivating debugging skills, with the caution that text-based programming usually exerts high requirements on syntactic accuracy which may be problematic for non-CS students.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.