
Abstract
Language learning has increasingly benefited from Computer-Assisted Language Learning (CALL) technologies, especially with Artificial Intelligence involved in recent years. CALL in writing learning acknowledged as the core of language learning is being realized by technologies like Automated Writing Evaluation (AWE), and Automated Essay Scoring (AES), which have developed considerably in both computer and language education fields. AWE has effectively enhanced EFL students’ writing performance to some extent, but such technology can only provide an evaluation in the form of scores, the majority of which are based on holistic scoring, resulting in the inability to provide comprehensive and detailed content-based feedback. In order to provide not only the writing multiple trait-specific evaluation scores, but also detailed writing feedback, we proposed a computer-assisted EFL writing learning system incorporating the neural network models and a couple of semantic-based NLP techniques, MsCAEWL, which fully meets the requirements of writing feedback theory, i.e., multiple, continuous, timely, clear, and multi-aspect guidance interactive feedback. The results of comparison experiments with the AWE baseline models and human raters demonstrated the superiority and the high correlation contained by the proposed system. The independent-sample t-test and paired-sample t-test results of the experiments on MsCAEWL effect validation suggested the significant impact of our proposed system in enhancing students’ EFL writing proficiency.
Keywords
Introduction
Computer-Assisted Language Learning (CALL) technologies have profited greatly from the quick development of Artificial Intelligence and have been increasingly involved and developed in language learning. Writing to learn and writing to learn is identified as essential component in ESL/EFL (Zhang, 2013), the Computer-assisted writing evaluation technology thereby has drawn adequate attention both in computer science and language education.
Writing learning has traditionally been viewed as crucially dependent on writing evaluation or feedback (Lloyd-Jones, 1977). Writing feedback helps improve learning outcomes, draws L2 learners’ attention to the gap between the target language and the interlanguage, and stimulates L2 learners to internalize L2 knowledge. At the same time, teachers can also adjust the teaching method through feedback (Zamel, 1982). Effective feedback is supposed to include multiple modifications and reciprocating processes and to indicate revision instructions covering dimensions such as organization, content, and mechanics (Cohen & Cavalcanti, 1990; Ferris, 1995; Hedgcock & Lefkowitz, 1994).
For many non-native English-speaking countries, EFL/ESL writing is the least gratifying task for both teachers and students, especially in China (Mo, 2012). EFL teachers in Chinese high schools or colleges have to face 40-80 students in one class, which is the only one of 2–5 classes he or she teaches in a semester. Thus, the workload of the TEFL is abnormally high. Moreover, in China, the largest English learning group is non-English majors, and there is no exclusive course for writing in high schools and universities for this group. The large class size makes it almost impossible for teachers to assign enough writing tasks, not to mention providing detailed evaluations or individual instructions. Most of the writing feedback students receive is vague, overall, or inconsistent (Beach & Friedrich, 2006).
Recently the TEFL, especially writing teaching, has remarkably benefited from the rapid development of CALL technologies. Computer-assisted writing evaluation technology, known as Automated Writing Evaluation (AWE), Automated Essay Scoring (AES), and Computer essay grading, has emerged and flourished since the 1960s. In addition to scoring compositions, computer-assisted writing evaluation technology can also provide diagnostic feedback concerning content, logic, vocabulary, grammar, spelling, etc., which is personalized, timely, objective, and constant (Li et al., 2015; Polio, 2012). With the AWE or AES system, students can receive timely and detailed writing feedback and freely modify articles at unlimited times, so as to achieve the purpose of internalizing knowledge and improving cognitive and speech ability. The existing AWE technologies or products can provide effective vocabulary and simple syntax modification suggestions. Their feedback on complex syntax errors is, however, less satisfactory (Fang, 2010).
The existing AWE/AES technologies or applications provide feedback that is capable of increasing the composition mechanics, such as accuracy, complexity of words, and average length of sentences (Li et al., 2017). Nevertheless, there is little help they can offer in feedback on content, organization, and unity, which does not accord with the requirements of writing feedback of second language acquisition theory. Furthermore, neural network-based AWE models rely too much on labeled training data. At present, more than 90% of AWE models use scored corpora from Kaggle ASAP (2012), which may lead to less objective scoring results. In addition, lacking the ability to evaluate the content relevance, the AWE models are vulnerable to spoofing or attacks of adversarial texts (Higgins & Heilman, 2014; Kabra et al., 2021; Parekh et al., 2020).
In this study, following the guidance of writing feedback theory and adopting the analytical scoring method, we proposed a Multi-strategy Computer-assisted EFL Writing Learning System (MsCAEWL) incorporating a variety of semantic-based NLP technologies and models, including deep learning in writing evaluation in order to provide not only the writing evaluation score but also the detailed writing feedback. Its introduction is able to overcome the limitation of previous AWE/AWE technologies which are powerless to evaluate texts from content-based dimensions, such as assessment of content and organization. Moreover, it addresses the problem that the improvement of writing ability benefited from AWE/AES models is limited due to their common implementation of holistic scoring. The proposed system is capable of providing evaluation sub and total scores from multiple traits while outputting the improving and correcting writing instructions for students writing learning.
Our contributions are summarized as follows: 1) Following the writing feedback theory, our model provides timely, detailed, multiple trait-specific, accurate analytic evaluation feedback on compositions utilizing multiple indicators, rather than the commonly used holistic evaluation in prior AWE models. 2) A package strategy of the Natural Language Processing technologies including neural networks is introduced and modified to yield multiple trait-specific evaluations of an essay based on the sentiment, such as thesis, fluency, and content. 3) Grammatical Error Correction (GEC) and Grammatical Error Diagnosis (GED) are introduced to provide revision and evaluation feedback. 4) A novel method is introduced to assess the competence of complexity of word and syntax usage and provide detailed lexical and syntactic usage suggestions in accordance with the level of the writer’s language abilities.
Literature Review
On top of scoring compositions, Automated Writing Evaluation (AWE), Automated Essay Scoring (AES), Computer essay grading, Computer-Assisted Writing Evaluation, and other computer-assisted writing evaluation technologies can also provide diagnostic feedback on content, logic, vocabulary, grammar, and spelling. Furthermore, AWE/AES technologies are distinguished by their uniqueness, timeliness, impartiality, and consistency (Li et al., 2015; Polio, 2012). With the AWE or AES system, students can receive timely and detailed writing feedback and freely modify essays with no limit of rounds, thus realizing the requirements and goals of the process-oriented writing approach and achieving the purpose of internalizing knowledge and improving cognitive and speech abilities. Students can use automated feedback to assist them improve their linguistic correctness by employing automated writing evaluation (AWE) technology (Saricaoglu & Bilki, 2021). AWE/AES technologies and their effects have elicited vehement debates. The findings of extensive research and quantitative analyses concerning the effects of AWE/AES improvements in various aspects of writing have demonstrated that there have been noteworthy long- and short-term improvements in accuracy, learn autonomy, and interaction (Link et al., 2022; Wang et al., 2013). Especially in grammatical error correction, the errors of certain categories were demonstrated to be greatly decreased when AWE was used (Saricaoglu & Bilki, 2021). Note that improvements like these may occur during the later stages of a period of sustained use of AWE for writing assistance (Liao, 2016). The utilization of AWE systems has been shown to generate not only positive effects on students’ writing performance, but also to significantly enhance the quality of teacher feedback in several dimensions, including mode, amount, types, and levels of feedback (Jiang et al., 2020). Thus, teachers’ attitudes and methods of use of AWE systems are positively associated with the performance of such systems in the context of writing learning., underscoring the importance of teachers’ roles in successful integration of these systems (Li, 2021), besides, different combinations of multi-approach writing teaching integrating AWE yield varying effects on writing performance (Tang & Rich, 2017).
In the industry, a large number of commercial AWE and AES products have emerged, including E-rater, Project Essay Grade (PEG), Writing Roadmap, My Access, Intelligent Essay Grade (IEA), Criterion, Write to Learn and Summary, pigai.org, Youdao Writing, I-write, Bingo English, etc. The early stage of AES/AWE development is dominated by the traditional machine learning technologies based on Bayes’ theorem (Rudner & Liang, 2002), linear regression (Phandi et al., 2015), rank preference learning (Chen & He, 2013; Yannakoudakis et al., 2011), reinforcement learning (Wang et al., 2015), etc. In recent years, the accelerated development of deep learning, especially neural network technology, has also greatly benefited the field of writing evaluation, such as Recurrent Neural Networks (Cai, 2019), Long Short-term Memory (Alikaniotis et al., 2016; Jin et al., 2018; Liu et al., 2019; Taghipour & Ng, 2016), Convolutional Neural Networks (CNN) (Dong & Zhang, 2016; Dong et al., 2017; Farag et al., 2017), BERT-based approach (Sharma et al., 2021). The introduction of attention mechanisms also significantly improved AES SOTA performance (Dong et al., 2017). Automated Writing Evaluation also benefited from pre-training strategies implemented at the forefront of natural language processing (Cai, 2019; Farag et al., 2017; Mim et al., 2021). Many studies adopted a variety of solutions based on neural networks, such as generating adversarial samples for learning (Farag et al., 2018; Liu et al., 2019), Multitask Learning (Cummins & Rei, 2018), and Self-Supervised Learning (Cao et al., 2020), Graph Algorithms (Jiang et al., 2021). Some studies proposed different approaches to address the problem of scarce training data for writing evaluation (Li et al., 2020; Ran et al., 2018). There are also scoring models that integrate multiple neural network models and schemes (Beseiso et al., 2021).
Grammatical Error Correction (GEC) or Grammatical Error Detection (GED) is an independent track of NLP missions, which is capable of automatically correcting or detecting the mechanical error of composition. The task content of GEC/GED overlaps with the parts of AES/AWE. AWE tasks are always accompanied by a diagnosis of grammatical errors, most of which need to be pointed out in their correct form. However, the AWE studies pay little attention to the GEC approaches, and only a few studies introduced the early GEC model into the AWE works (Liu et al., 2019). The initial research on GEC and GED mostly adopts N-gram (Xie et al., 2015; Zhang & Wang, 2014), Confusion Set (Lin & Chu, 2015; Rozovskaya & Roth, 2010), and language model (Brockett et al., 2006) including BERT (Devlin et al., 2019; Hong et al., 2019; Zhang et al., 2020) to diagnose and correct grammatical errors. However, the above solutions hardly solve problems such as disorder and component omission. Encoder-decoder architecture (Ge et al., 2018; Sutskever et al., 2014) has achieved similar success in GEC by end-to-end addressing the issues that other models fail to address at one time. It is worth noting that most recent advanced GEC architectures exploit the advantages of multiple models to solve different kinds of problems (Chollampatt & Ng, 2018; Rozovskaya & Roth, 2010; Zhang & Wang, 2014), including the Transformer-based approaches (Lichtarge et al., 2019; Zhao et al., 2019).
Writing Feedback and ESL riting
Zamel defines feedback as teaching information that helps the writing revision process and improves language learning (Zamel, 1982). Writing feedback is regarded as input information about second language writing provided to authors to improve their accuracy of expression (Arndt, 1992), and also as information provided to authors to modify their interlanguage (Keh, 1990). The function of feedback is generally considered to be to confirm, understand and clarify requirements (Ellis, 1994). Modification serves as its theoretical core. Learners use modification feedback as a clue to conduct exploratory and open learning, and gradually form scaffolding instruction.
Good and effective writing feedback not only needs to point out whether it is correct or not but also provides suggestions for modifying or improving performance (Zamel, 1982). Based on the practice and verification of generations of pedagogics and linguists, writing feedback is essential to the success of writing instruction, and a few key requirements should be met in order to ensure its effectiveness (B. Chen & J. Zhang, 2022).
To be more effective, writing feedback should cover all aspects of writing, including content, organization, grammar, and mechanics (Cohen & Cavalcanti, 1990; Ferris, 1995; Hedgcock & Lefkowitz, 1994). Holistic scoring, in which an overall score is set to reflect the writing performance, is traditional and widely adapted by AWE models or teachers. Under this circumstance, single-trait holistic scoring cannot provide diagnostic information (Cohen, 1994) and is not adequate as ideal writing feedback. Comparatively, analytic scoring assigns separate sore from different dimensions as mentioned above to assess writing performance, thus can provide adequate diagnostic information of splendor or insufficiency in particular performance and detailed guidance for the development of students’ writing (Bauer, 1981; Klein et al., 1998; Weir, 1988).
Theoretically,
However, in ESL teaching, the writing feedback students receive is mostly vague, global, or inconsistent (Beach & Friedrich, 2006), and in most cases delayed. Especially in China, it is difficult for teachers to follow writing feedback in the teaching process. In the context of poor educational resources, it is impossible to require teachers to provide personalized, continuous, and detailed feedback for each student each time they write or modify an essay.
In accordance with the requirements of writing feedback theory for writing evaluation, this study, therefore, seeks to propose an easy-to-operate automatic machine writing evaluation method, which aims to enable users to obtain immediate responses and use them to revise their compositions repeatedly, and the response are supposed to contain the specific suggestions of organization, use of grammar and vocabulary, cohesion, etc.
Methodology
Grading Criteria
Definitions of Evaluation Categories.

According to the table above, in the proposed computer-assisted writing learning, we set five modules to execute the above five evaluation requirements for writing: The mapping between evaluation modules of MsCAEWL and the evaluation categories of composition properties. The proposed computer-assisted EFL writing learning system consists of five main modules which function following the requirements of the general EFL writing evaluation categories, that is, unity, organization, content, fluency, vocabulary, grammar, and mechanics.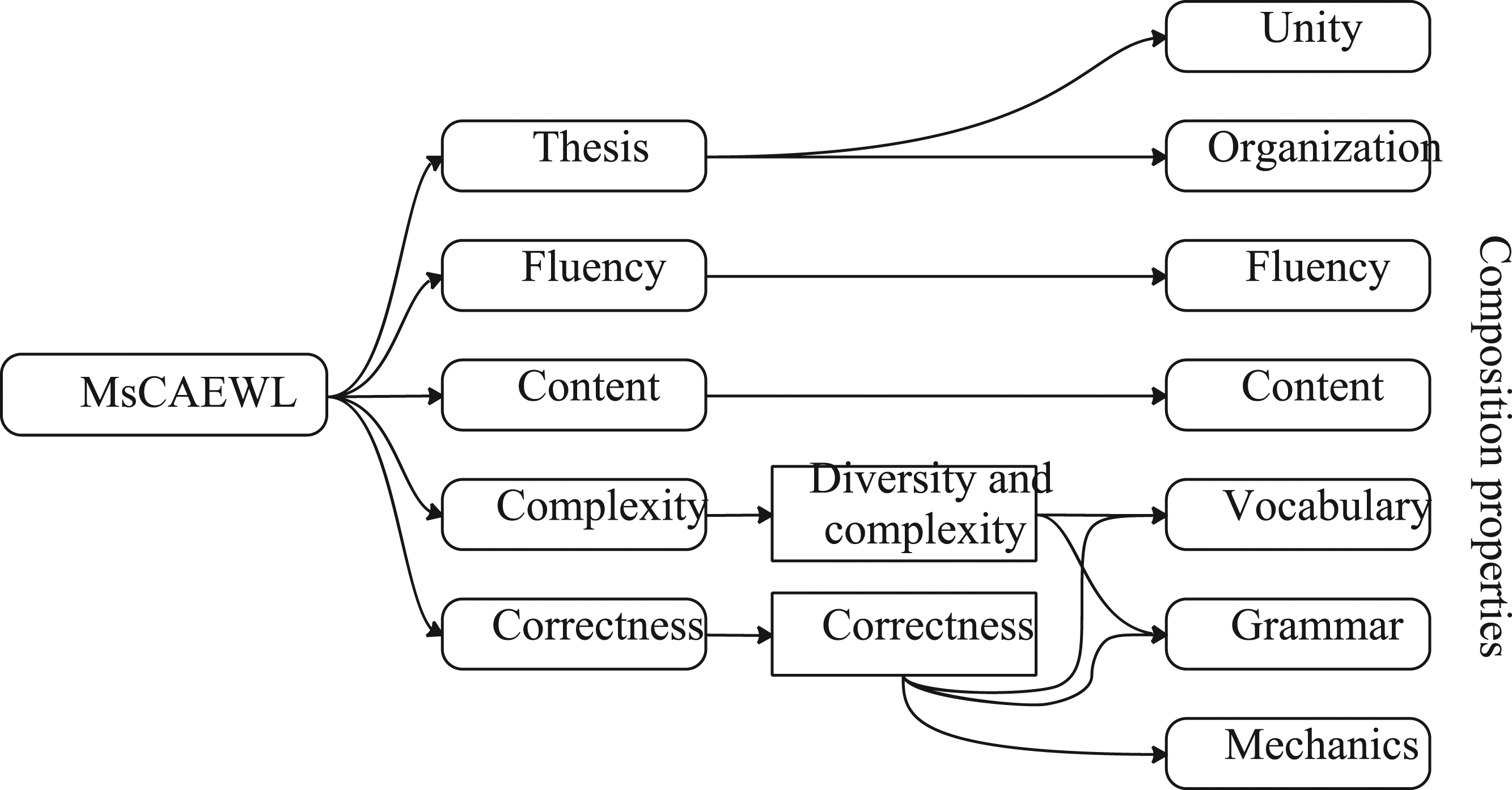
Task Definition
In accordance with the requirements of writing feedback on the EFL writing teaching, this paper proposes a novel multi-strategy automatic computer-assisted EFL writing learning system MsCAEWL. The flow chart of the proposed system is shown in Figure 2. The flow chart of MsCAEWL. Essays and prompts are combined as inputs into MsCAEWL. The Theory, Fluency and Content modules generate the corresponding scores respectively. In the complexity module, sub-scores will be provided for each of the sentence and vocabulary levels, with the final completion score being driven by a combination of the two sub-scores. In addition to detecting and scoring syntactic and lexical errors, the Correction module also provides suggestions for error correction.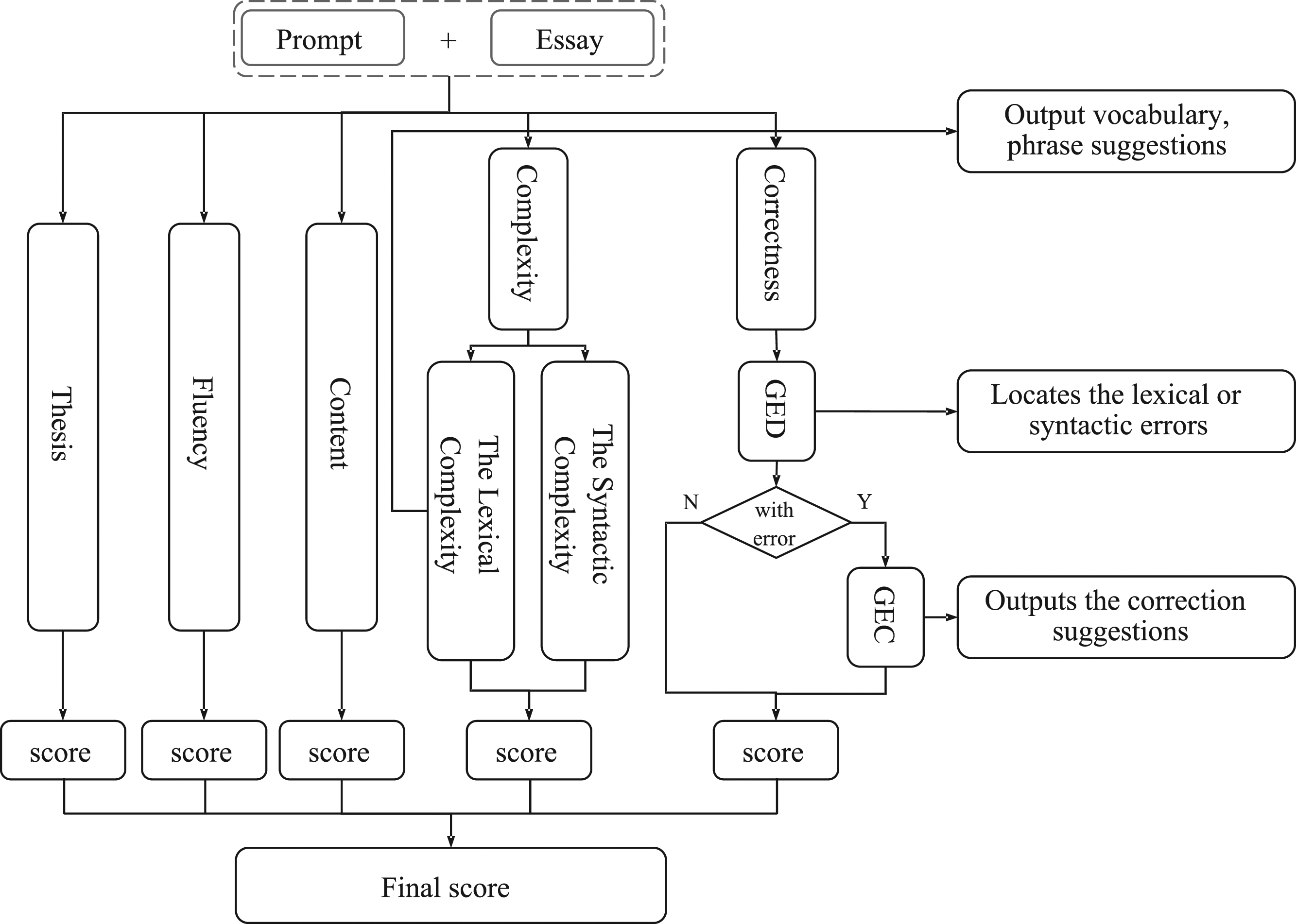
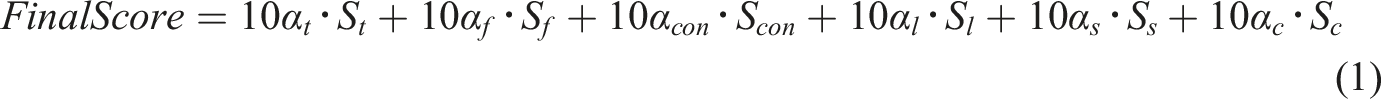


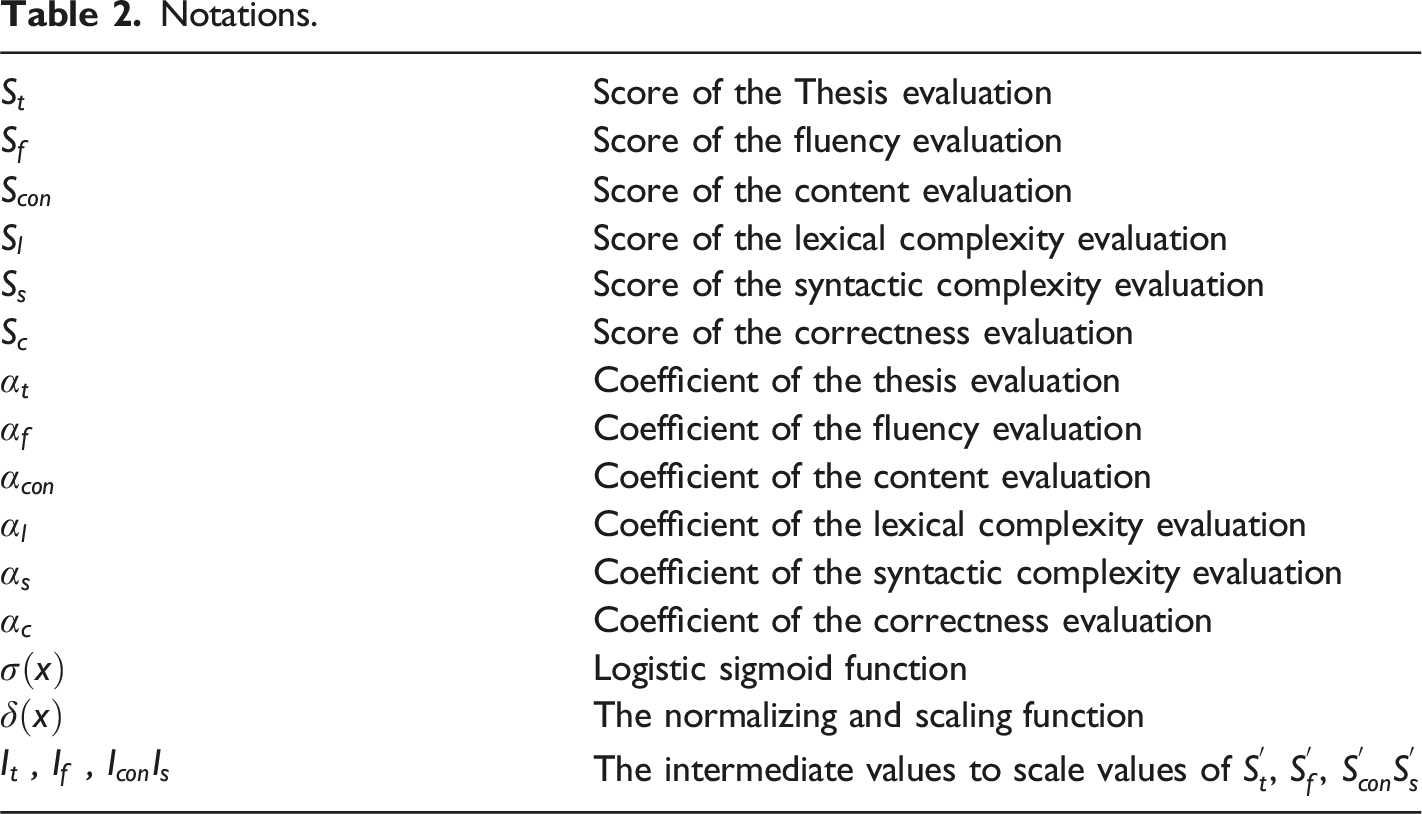
Notations.
In the proposed model, each evaluation module possesses different approaches to modeling and calculating in scoring compositions, the ranges of scores of the Thesis, Fluency, Content, and Syntactic Complexity modules vary, thus the functions are implemented to normalize and scale the above sub-evaluation sores. The logistic sigmoid function
Value Range of the Scoring Modules or Functions.

The Score Assignment and Coefficient Setting.

The Thesis Module
The majority of EFL writing exams contain opinion/discussion writing tasks essentially with prompts in them. The writing prompt students must respond to in the writing task of EFL is a compact set of writing instructions that assist students to focus on a certain topic, task, or goal. Writing prompt is the key to achieving Unity.
Quality of Organization is related to whether ideas are arranged logically and accurately. Each part of the essay is supposed to be clearly organized and flow smoothly. An essay with good organization indicates that paragraphs should support the thesis of the paper.
However, the EFL students often fail to grasp the topic or have problems in developing content with regard to the prompt, thus possibly resulting in digression or failure to arrange the ideas or statements to support the thesis. Due to incapacity in identifying the content of texts, the prior AWE models do not attend to this issue and are inadequate to address it. Much worse, students tend to cheat models with fancy expressions and words while leveraging automatic writing evaluation means, which is inevitable given the current state of the art.
This module is incorporated to check the accordance between the prompt and the main body, and the unity of each paragraph, i.e., the Thesis module merges the 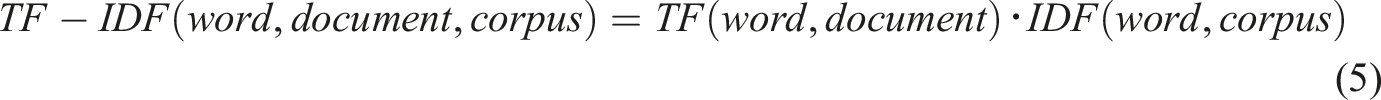
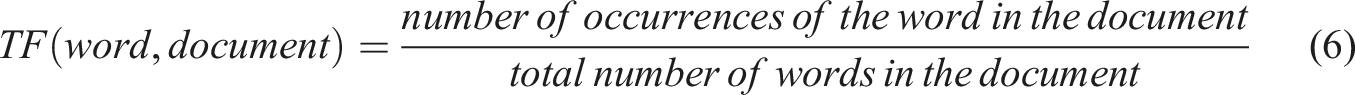
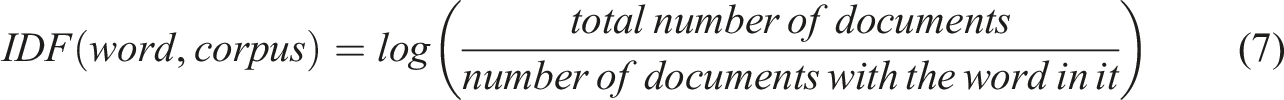
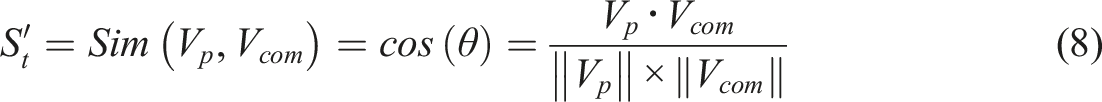
The Fluency Module
Writing Fluency refers to a student’s ability to write with a natural flow and rhythm, utilizing appropriate word patterns, vocabulary, and content. Syntactic fluency refers to the extent to which a writer constructs a sentence containing linguistically complex structures (Shapiro, 1999). More specifically, fluent composition flows smoothly from word to word, phrase to phrase, and sentence to sentence. In Natural Language Processing the N-gram-based metrics carry a similar function achieving the above requirement for Writing Fluency.
As an automatic evaluation metric of text generation or machine translation BLEU (Bilingual Evaluation Understudy) measures the closeness by comparing the machine output against the human reference and is well-known for its strong correlation with human evaluation in adequacy and fluency. Its calculation is as follows: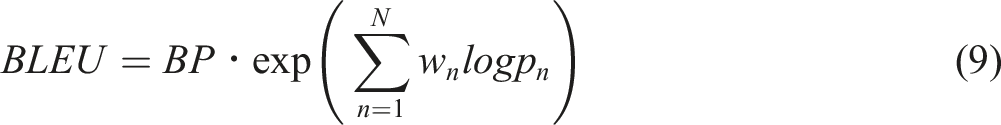
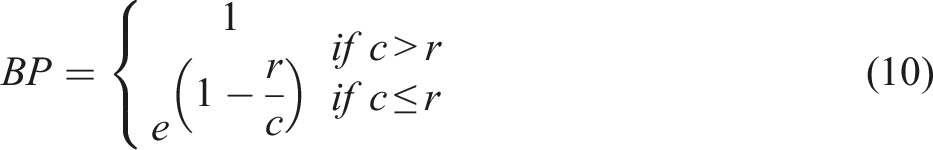
BLEU compares the n-gram of the candidate with the reference corpus to count the number of overlaps that are independent of the word positions. This n-gram precision scoring captures two aspects of translation: adequacy and fluency. The longer n-gram overlaps between the candidate and reference account for fluency, which means the generated sentences are well-formed and mature in length and structure compared with the reference.
In this study, BLEU with 4-g is utilized for writing fluency evaluation matric. We take compositions as system output candidates in machine translation, and a standard corpus with sufficient capacity is used as a reference. Considering that EFL writing requires writing with standard English, we choose a news set as the reference corpus. The Fluency score is the average BLEU score of each sentence from the essay against the news corpus (All The News, see section “Datasets”). The calculation is shown in equation (11).
The Content Module
In essence, grading the content of writing is a comprehensive evaluation of whether the thesis and purpose are clear, whether expectations and development are in a consistently excellent manner according to the viewpoint, whether the structure and word choice and use are fluent and graceful, and so on. Content evaluation is the core of the human judgment of an essay; thus, it regularly presents as holistic scoring.
The AWE/AES models assign holistic scores based on the writing content. More than 90% of AES models are trained and tested leveraging the ASAP (The Automated Student Assessment Prize) (see section “Comparison experiments”) corpus and its scoring labels. Based on the ASAP corpus as well, this article established an LSTM-based model to assess the writing content. Recurrent Neural Network (RNN) has been widely applied in various NLP tasks for their outstanding time series feature extraction capability. Long-short-term memory (LSTM) (Hochreiter & Schmidhuber, 1997) (the formula is as follows) is an improvement to solve the problems such as the disappearance of the RNN gradient. LSTM is introduced in this section to extract sequential features from essays with different scores in the training set so as to predict the holistic score of the essays to be tested.
In an LSTM cell, the hidden state is split into two vectors: 

The Complexity Module
As stated in section “Grading Criteria.” Complexity checks the lexical and structural diversity and complexity, i.e., the proficiency in vocabulary and grammar of writers. Two sub-modules are incorporated to achieve this end: the Lexical Complexity and the Syntactic Complexity.
The Lexical Complexity
The existing AWE research and products give improving feedback on vocabulary choice or usage by listing the possible synonyms of words or phrases in the essays, merely based on dictionary-matching technology. The listed words or phrases will not be changed according to the learners’ level. Most students can’t benefit from feedback and learn new-to-them vocabulary and usage. Thus, the word list scales based on the EFL learners’ lexical knowledge are introduced to address this problem. The New JACET 8000 (Committee, 2016) is the scaled list of basic words established by the Japan Association of College English Teachers (JACET). Eight levels are divided among 8000 words conforming to the lexical profile of Japanese EFL learners, and each level contains 1000 words. On the basis of the author’s vocabulary level being positioned leveraging the word scales, the gap between the author’s level and the writing requirements is judged and corresponding evaluation and suggestions on vocabulary use are given accordingly.
According to the learners’ level, a higher vocabulary set and a lower vocabulary set are established. The words or phrases in the composition are replaced by the synonyms from the higher and lower vocabulary sets respectively using the thesaurus. If the replacement occurs in the higher vocabulary set, it indicates that the author still has room for improvement in the use of this replaceable word or phrase. The system will output the words in the higher vocabulary set as improving suggestions, and at the same time reduce the score of Lexical Complexity. On the contrary, the replacement can only be found in the lower vocabulary set, the system will output no suggestions, and the score is increased.
A novel model for scoring lexical complexity is proposed in this study. We use the ratio of the total number of edits that can be replaced to the weighted total number of words after deduplication as the basis for the vocabulary complexity score. The calculation is as follows:
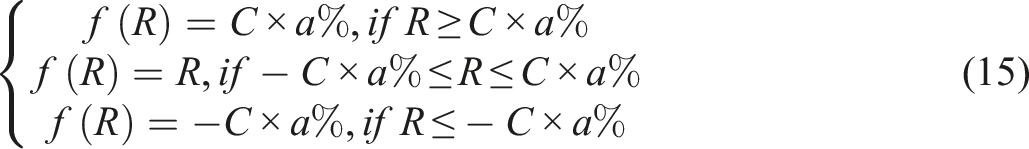

The syntactic complexity
The Syntactic Complexity mainly depends on the diversity of structural patterns and the flexible application of the grammar, such as the diversity of active and passive sentences, clauses, participles, etc. From the linguistic point of view, these syntactic phenomena have their own characteristic function words. These function words are selected into a set, such as: which, when, copular verbs, adverbs, etc. TextRank in NLP is incorporated to calculate the representation of function words in the set based on lexical relations, i.e., the appropriateness of the syntax use represented by the function-word-centered lexical relationship. The TextRank values based on function words in the news corpus (All The News, corpus from Kaggle in section “Datasets”) and each composition are calculated and compared respectively. The higher the similarity between the two, the better the Syntactic Complexity, and the higher the score. The Syntactic Complexity is calculated based on a real-world corpus, there are thus no worries about being cheated by adversarial samples.
TextRank, as an application of graph algorithm, takes words of text as graph nodes, constructs a graph model, and then calculates the importance of each word based on the weights between words. That is, the ratio of the weight 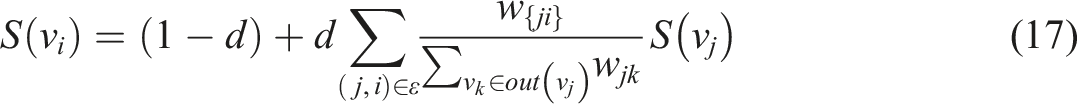
The Syntactic Complexity score is the average TextRank score of each sentence from the essay. The calculation is shown in equation (18).
The Correctness Module
As stated in section “Grading Criteria,” Correctness checks the proper use of vocabulary, mechanics, and grammar, i.e., whether the compositions are written in correct standard English. Two sub-modules are incorporated to achieve this goal: the GED module locates the lexical or syntactic errors, and the GEC module corrects them and outputs the correction suggestions.
The Grammatical Error Diagnosis module
Grammar error detection (GED) can be analyzed as a Sequence Tagging task, that is, the task of predicting labels based on sequential features. Although BERT and Transformer techniques are popular in all aspects of NLP, the RNN family is more dominant in the extraction of sequential features. Therefore, this study adopts Bi-directional Long-short term memory neural networks (Bi-LSTM) to detect grammatical errors.
A large number of experimental studies and applications have proved that the BERT model pre-trained based on a huge multilingual corpus can obviously improve the effect of various downstream tasks because of its excellent semantic/syntactic representation ability (Devlin et al., 2019; Herzig et al., 2020; Sun et al., 2019; Zhu et al., 2019). In this study, BERT’s pre-training strategy is implemented to Fine-tune the training data, and then the task of grammar error detection is carried out.
After the text enters the BERT model for fine-tuning, a new semantic vector representation is obtained, which is then processed by Bi-LSTM and conditional random field (CRF) to finally output the error type tags. The calculation process is shown in Figure 3: The diagram of the Grammatical Error Diagnosis model. This vector representation is used to make predictions regarding the type of errors within the text, utilizing both Bi-LSTM and CRF for the task. The BERT model is fine-tuned with the text, resulting in a new semantic vector representation. This vector is then processed with Bi-LSTM and CRF, ultimately outputting the error type tags.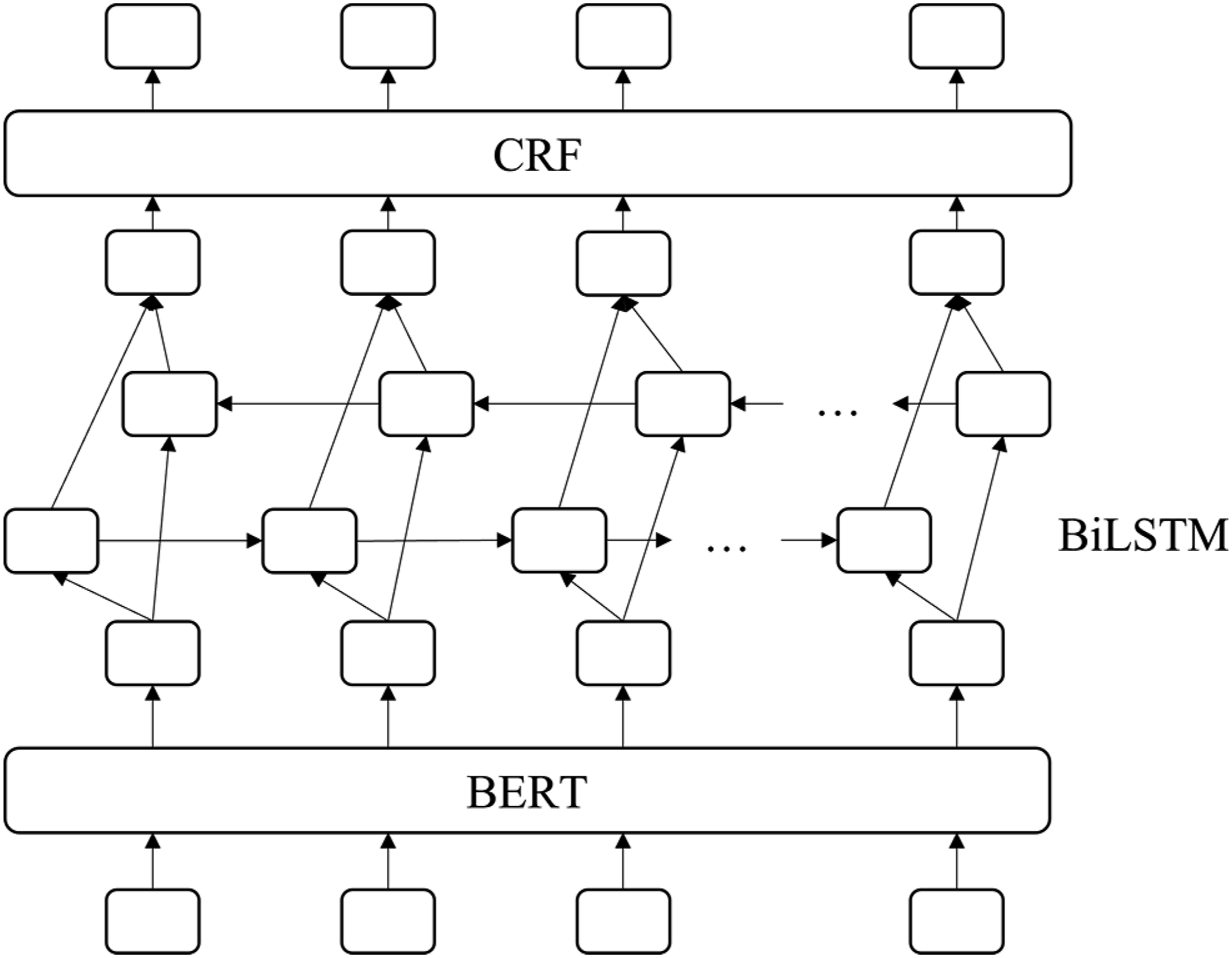
The Grammatical Error Correction module
Grammatical Error Correction models with SOTA scores mostly regard Grammatical Error Correction as a machine translation task and often adopt an Encoder-decoder structure. In this study, a novel Grammatical Error Correction architecture is inspired by the previous study (B. Chen & J. Zhang, 2022). As the neural networks in the Grammatical Error Diagnosis module, the training text obtains a new semantic representation after pre-training via BERT, and then enters the Encoder-decoder model with Global attention, where the Encoder involves a uni-direction LSTM, and the Decoder takes Bi-LSTM as the core. The specific architecture is depicted in Figure 4. The Architecture of Grammatical Error Correction Model. In the Grammatical Error Diagnosis module, the training text is pre-trained using BERT to obtain a new semantic representation, which is then fed into the Encoder-Decoder model with Global Attention. For the Encoder, a uni-directional LSTM is employed. The Decoder, on the other hand, utilizes a Bi-LSTM as its central component.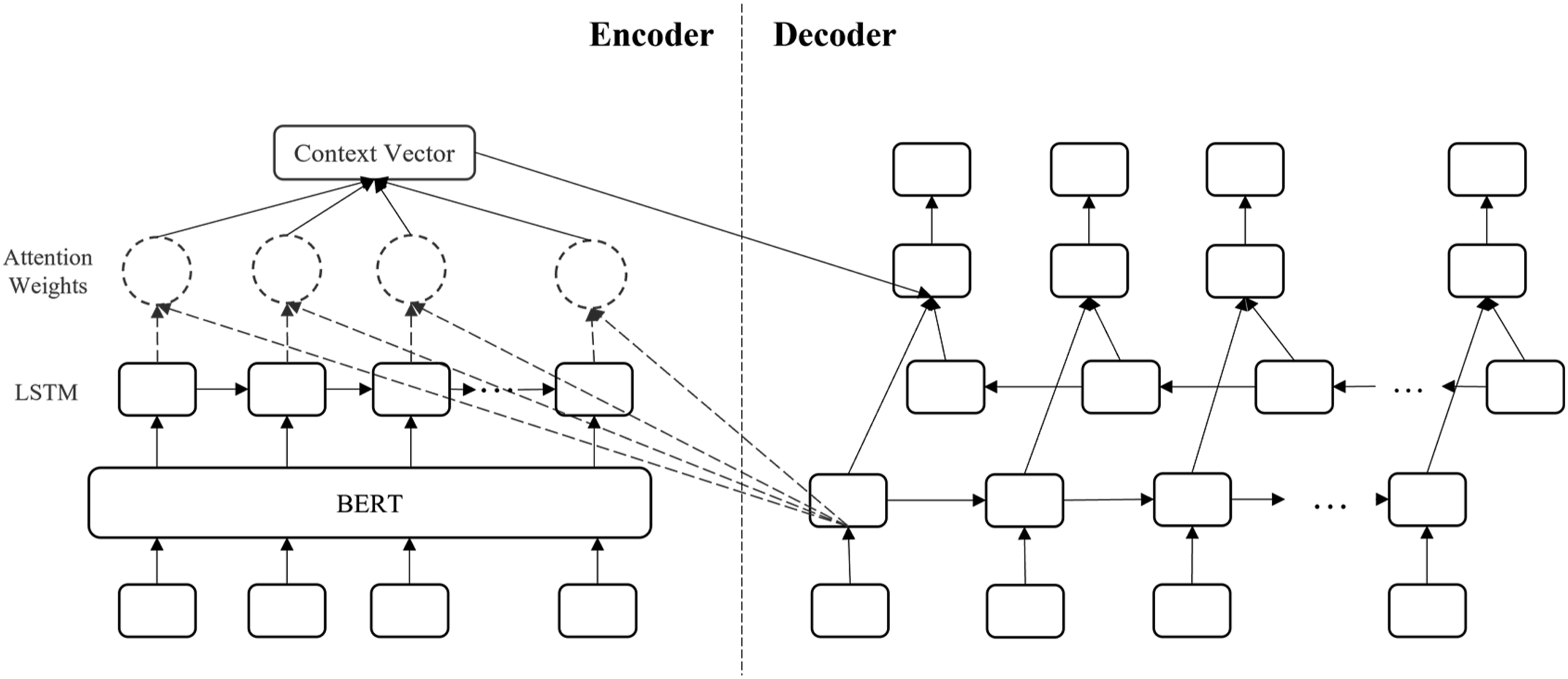
The scoring method of the correctness evaluation
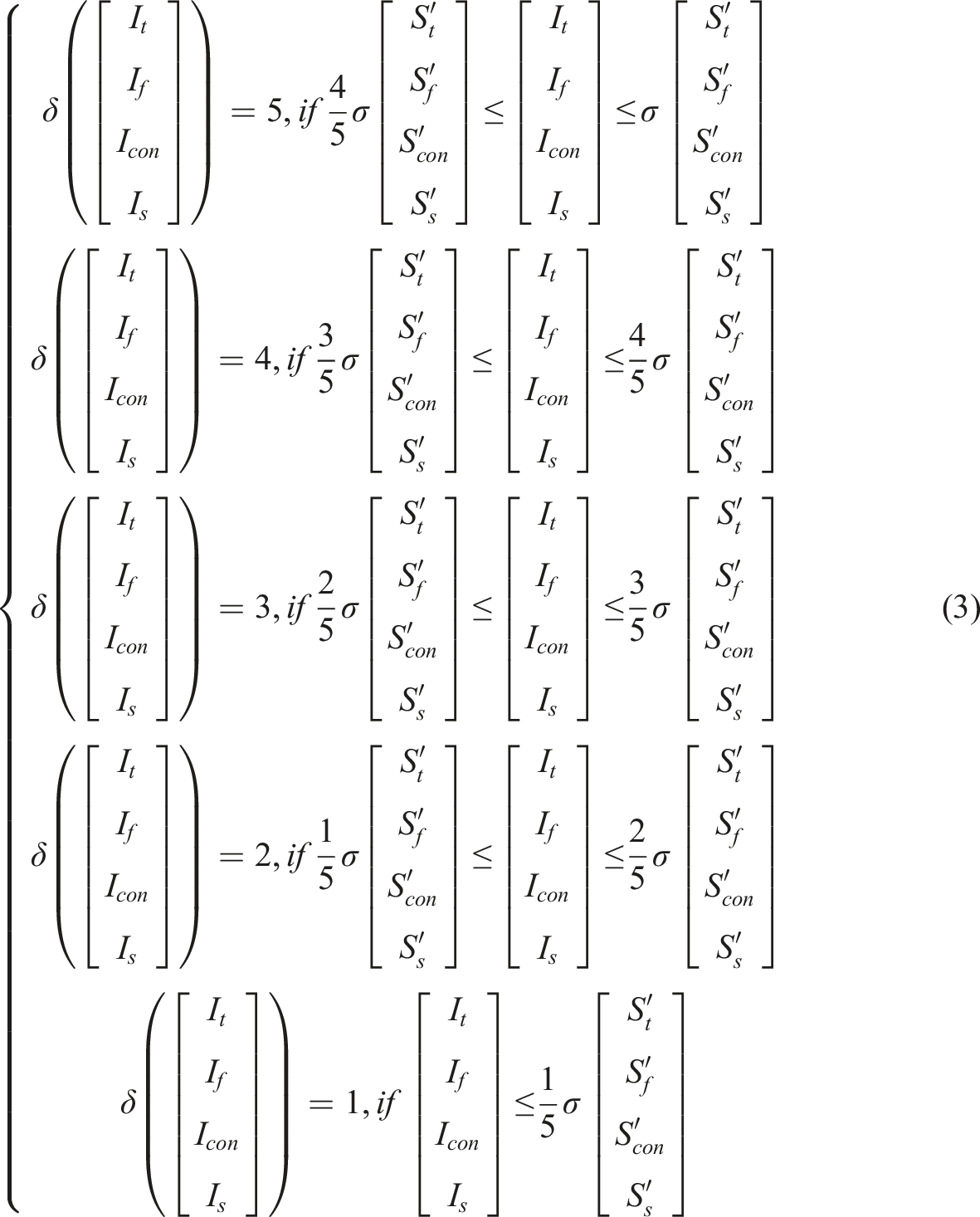
The Grammatical Error Diagnosis module charges for identifying and showing the errors to the users, meanwhile, the Grammatical Error Correction module is responsible for correcting the located errors. The errors located and corrected are supposed to be marked as the candidate items of losing credits. The mechanic of penalty credits for grammatical errors is depicted in equations (19) and (20).
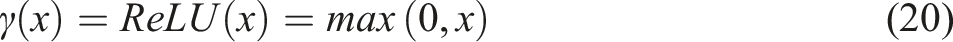
Experiments
Datasets
a) Reference corpus in the model
In sections of the Thesis, Fluency module, and the Syntactic Complexity of the Complexity module, the role of the reference corpus is essential. The quantity and quality of the corpus will lead to a change in scores, making the scores unreliable, which means a massive and error-free corpus is required. Most EFL writing tasks focus on elaborating or discussing opinions and examining the author’s proficiency in standard English. Therefore, the writing style requires written language rather than spoken language. In view of this, the news texts with rigorous terms are adopted as the basic dataset.
The All The News
1
from Kaggle consists of 143,000 news articles covering a wide range of topics from 15 American publications including the New York Times, Breitbart, CNN, Business Insider, etc. This reference corpus derives from the news from 2016 to 2017, with a total size of about 1.2 Gb. b) The scored essay corpus
The Statistics of the ASAP Corpus.
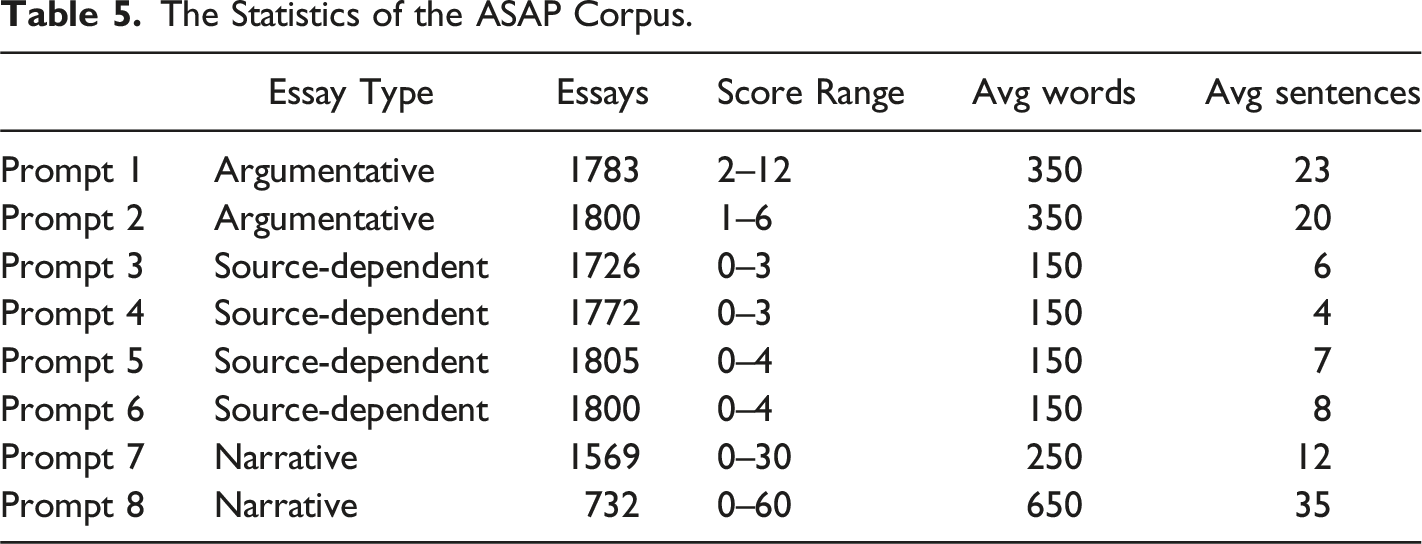
Comparison Experiments
Evaluation metric
Quadratic Weighted Kappa (QWK) which is the official metric of the Automated Student Assessment Prize and regarded as the major metric of the performance of AWE models is introduced as the evaluation metric in this section. It measures the agreement between the prediction score set and the label score set. The QWK value ranges from 0 to 1, which indicates the agreement arises from arbitrariness to completeness. In this sense, the human annotator rating set is considered as the labels, and the system outputs present as the prediction scores.
An N-by-N quadratic weight matrix 

Comparison based on holistic scoring
The Descriptions of the Baseline Models.

ASAP corpus with holistic scores as training labels serves as experiment data set in this section. Although more than 10 years have passed since the Kaggle AES competition, the labeled data set continue to benefit the AWE/AES field. Remarkable models have been emerging, especially for ones with neural networks incorporated, long after the competition event.
However, there are two issues that do not fit the requirements of our experiment and need to be modified in the pre-processing.
First, the number of human annotators in each essay is not consistent. Most essays contain two rater scores while some of them have three rater scores. More, given that one set of essays adopts trait scoring evaluation, i.e., the analytic scoring, while the others incorporate the holistic scoring method, the resolved score is obtained inconsistently: either the higher rater score is directly elected, or the composite score is calculated by relevant equations. The score range of each prompt thus differs. In this section, we take the resolved scores as baseline scores or labels regardless of the acquiring method. Before experiments, the score range should be normalized into (0, 1).
Second, out of privacy protection, the competition organizer has removed any personal information and replaced the relevant entities with marks, such as @ORGANIZATION1, @PERSON1, etc. It is worth noting that the replacements often act as vital sentence constituents like subjects or objects. For people and machines, this is obviously a huge obstacle to reading or understanding, especially for machine learning methods with semantic-based models as their backbones. Since all the modules of the proposed model are highly semantic-dependent, these marks will infect the performance to a different extent. Hence, we randomly choose words under the marked categories to restore the sentence, such as replacing @ORGANIZATION1 with “bank” and @PERSON1 with “Jackson.”
The Comparison with the Baseline Models on Holistic Scoring.
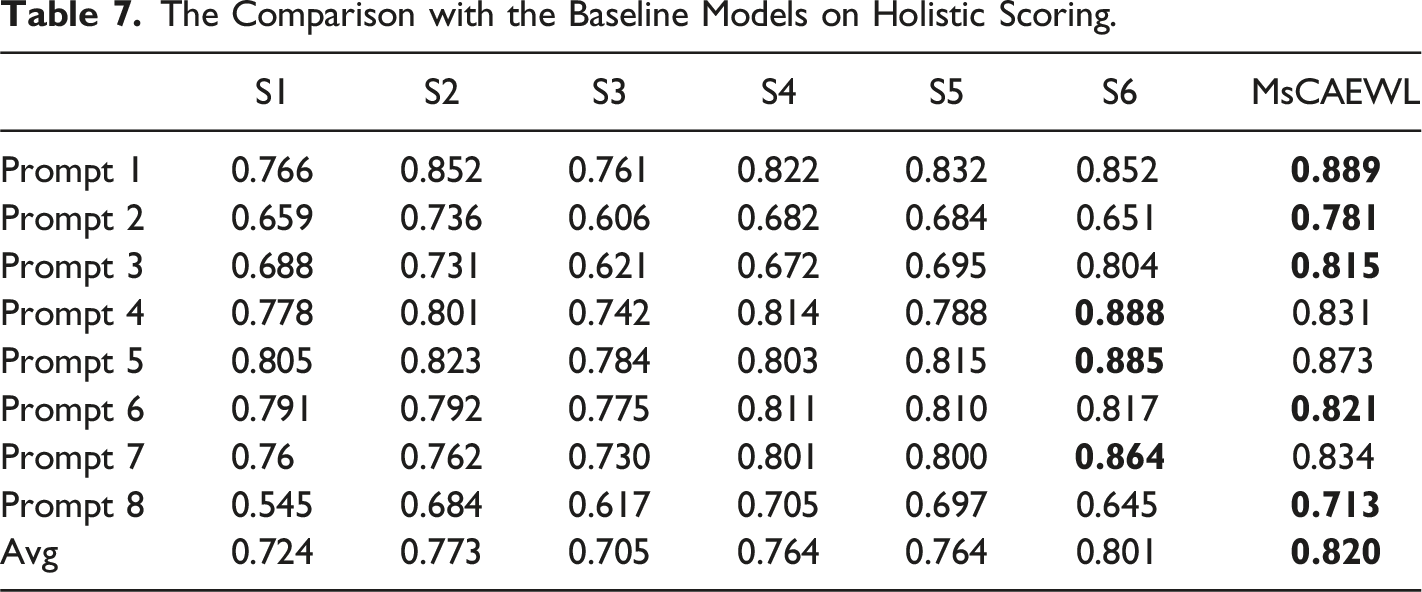
The comparison results show that MsCAEWL gains the five top accomplishments out of eight prompts and the optimal performance in the track of average QWK score. On the whole, S6, S2, and S4 have achieved relatively satisfactory in part of the tracks. From their experimental results and the model architecture, it can be concluded that the sentiment-oriented structures based on the cutting-edge language models greatly boost the experimental results, such as LSTM, BERT, and attention mechanism. Though the S6 obtains astonishing results in most prompts, the two obvious weakness items occur in prompts 2 and 8 which contain the biggest average length of the essay, 350 words. However, in these two tracks, the top models including ours are based on RNN serial models, namely, LSTM. That is, the RNN architecture remains the superior ability to capture sequential semantic features, especially in a long text, despite the fact that S6 particularly adapts the BERT to fit the large-scale text mission.
Owning to the multiple strategies incorporated in NN, the proposed system can benefit from the advantages of various technologies so as to meet different challenges. There is an obvious superiority in tackling long text, the proposed model dominates in almost all essay sets with more than 150 words size, which mainly leads to the superiority in average score.
Comparison based on the analytic scoring
In this section, we aim to verify the analytic scoring of the proposed system. Hence the dataset with trait-specific scores as labels is primary to the validation experiments. Though the ASAP corpus provides the trait-specific scores on part of sets, there are two obstacles making the dataset unsuitable for the experiments. Only two prompts are presenting the analytic scores, prompts 7 and 8. However, the trait categories differ from each other. The scoring of prompt 7 evaluates Ideas, Organization, Style, and Conventions, while Ideas and Content, Organization, Voice, Word Choice, Sentence Fluency, and Conventions involves in the assessment of prompt 8. That means, the evaluation rubrics of each prompt are different, and the focus on parts of writing ability from the examiners are different. Moreover, the compositing methods of total scores are distinct. The final total score on each essay is simply obtained by adding 2 raters’ sum scores of all traits in prompt 7, rather than the weighted sum of scores on each trait by 2 taters in prompt 8. Since the traits and compositing methods of MsCAEWL are not consistent with any prompts above, it reveals unlikely to be utilized as the basis of the analytic scoring comparison.
By all accounts, a new validation experiment is set as follows. A group of college students is asked to write an essay according to a prompt. The essays then are scored by human raters and MsAWE as well following the detailed analytic scoring instructions concretely categorized as Thesis, Fluency, Content, Complexity, and Correctness. Accordingly, the trait-specific and total scores between human and machine raters are obtained eventually to be leveraged to reveal the analytic scoring ability of the proposed writing computer-assisted writing learning by statistical analysis.
Writing Prompt From TEM 4.

The Statistical Results of Trait and Total Scores From Human Raters and MsCAEWL.
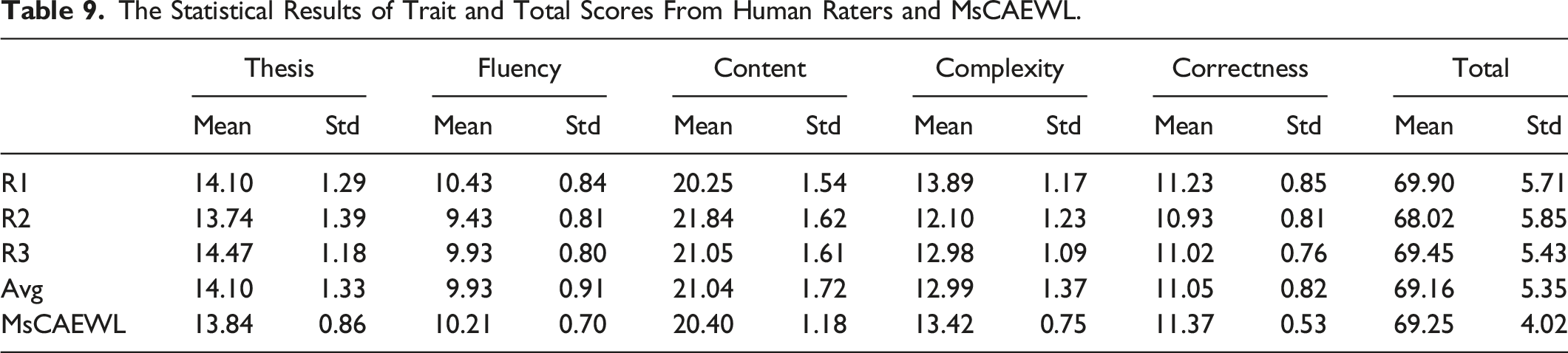
The box-plot diagrams in Figure 5 depict the distribution of rating scores of MsCAEWL and human annotators. It can be seen that, overall, the machine rating keeps constituent with the average rating of three human raters, which is also consistent with the QWK results in section “Comparison based on holistic scoring.” That is, MsCAEWL is reliable in scoring in comparison with the overall human level. Box-plot diagram of score distribution by MsCAEWL and human raters. The box-plot diagrams show the distribution of rating scores of MsCAEWL and human annotators. Comparison of the diagrams indicates that the machine rating is consistent with the average rating of three human raters. This implies that MsCAEWL is reliable for scoring in relation to the overall human level.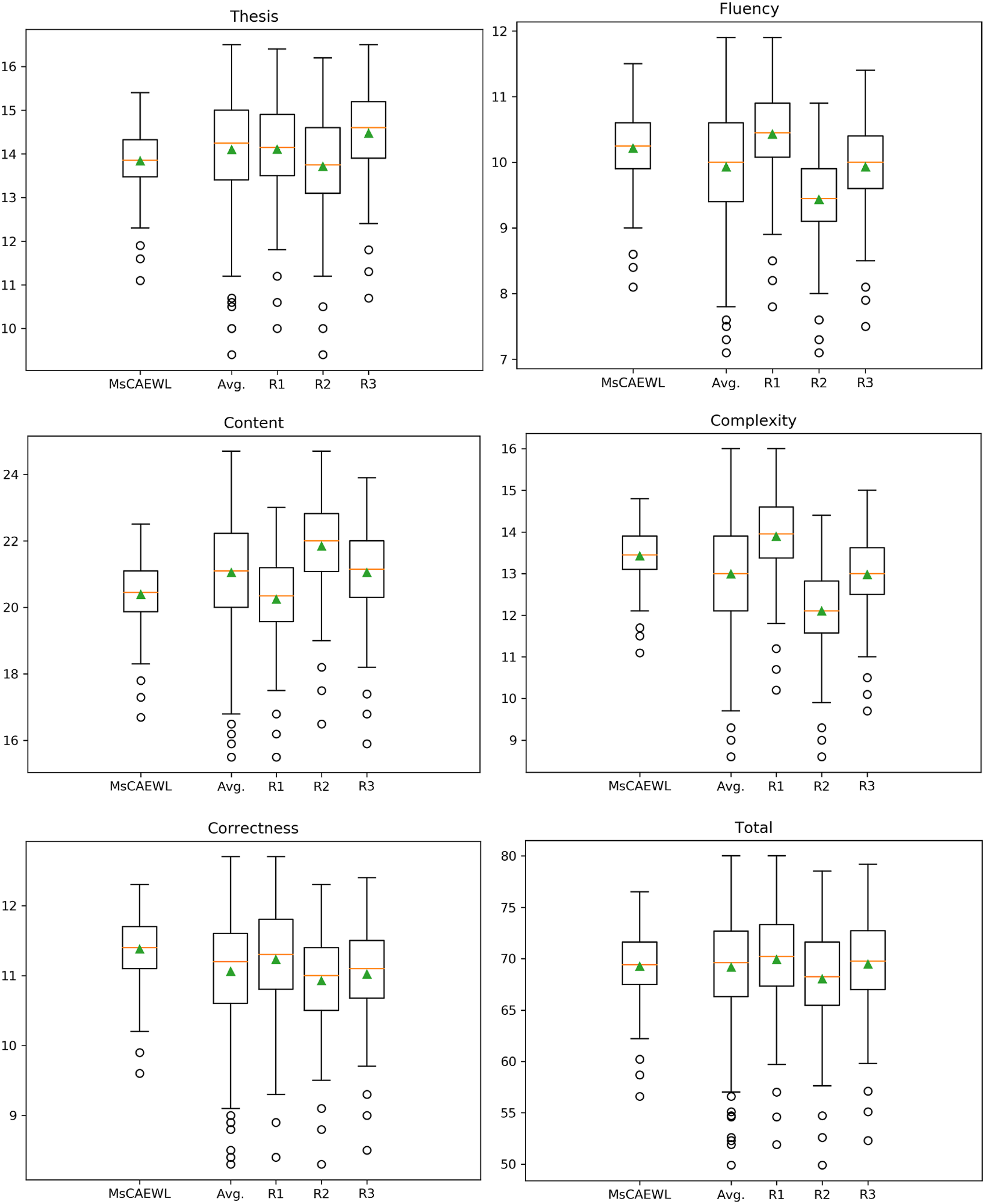
It should be noted that the data distribution of MsCAEWL ratings is significantly less volatile than that of the human ratings. More important, human ratings vary widely from one another, and it is difficult to maintain consistency under each category. The opinions of human raters keep the relative agreement in thesis and correctness. It shows that human raters are easier to reach an agreement at judging digression and quality of organization. Furthermore, the review of grammar, spelling, mechanics, and other errors is more objective, and human judges are less likely to disagree on such issues. However, for evaluations that need multi-dimensional consideration, such as fluency, content, and complexity, human ratings are prone to diverge. To recap, the scoring of MsCAEWL is more robust.
Validation of effects on writing learning assistance of MsCAEWL
The aforementioned experiments can only compare model performance based on their scores. Our model may offer not only scores, but also feedback such as improvements in vocabulary and grammar, error correction, and so on. Scores are solely used as a reference for validation of improvements in writing ability, the major priority of the proposed system is to enhance students’ writing skills. By that means, in this part, we devised experiments to verify if MsCAEWL can increase students’ writing abilities.
Method
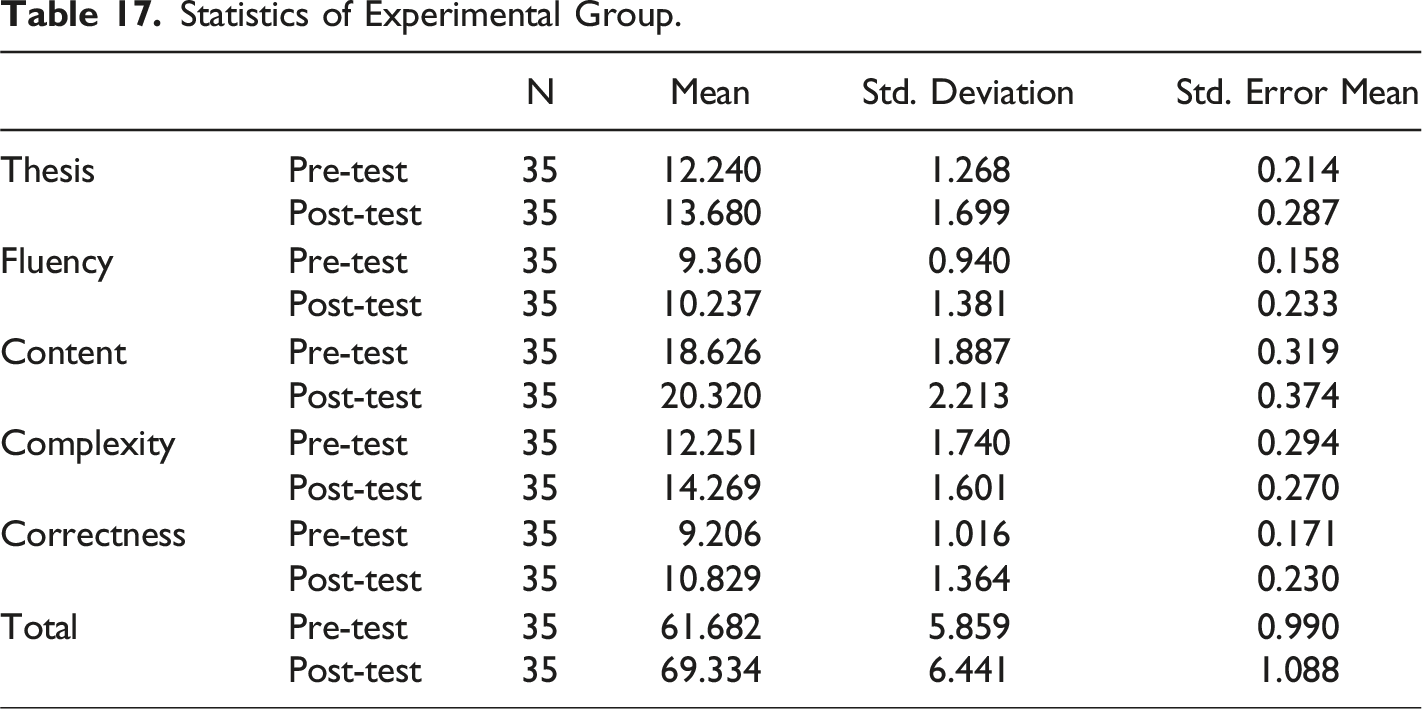
In this section, 70 high school sophomores with comparable scores in a high school in Guizhou province were selected as subjects for a 60-day writing learning experiment. Among them, 35 were randomly assigned to the experimental group and 35 to the control group. There was no significant difference in writing proficiency between the two groups. The experimental group and the control group received ordinary face-to-face writing instructions from the same teacher during the experiment. Differently, in the experimental group, the MsCAEWL is adopted to assist writing learning. According to the writing feedback by MsCAEWL, the experimental group students revise their essays by themselves. A pre-test was performed before the experiment, and a post-test was performed after the experiment for the experimental and the control group. The performances of the two groups are analyzed by independent-sample t-test and paired-sample t-test with SPSS 26.0 to verify the effects of MsCAEWL in improving students’ English writing proficiency. All compositions in the experimental and control group were scored by MsCAEWL.
Participants
Participants
Materials
In the writing learning experiments, several essay prompts from the former National Matriculation English Tests are adopted as the writing learning and teaching materials. Given the short period of the verification experiment, the familiar materials are more beneficial for students to achieve better writing performance. Moreover, the prompt design of the National Matriculation English Tests is more rigorous, and the difficulty of each prompt varies slightly, so it is more suitable for the experiment of this study. The prompts are selected randomly as follows:
Procedure
Prompts Adopted in Writing Learning.

Thus, in order to simulate the real writing teaching and learning scene, each instruction is within 15 minutes. For the control group, the students will receive a holistic score, marks for grammatical and lexical errors, and a general comment just like the daily teaching. With regard to the evaluation in the control group, the raters are also asked to finish the review of each composition within 10 minutes. In this way, the marks of errors and the comment may be rough, inadequate, or even faulty. Note that only the holistic score by the teacher will be presented to the writer. Even though MsCAEWL will review each essay and output the sub and overall scores as experimental data which are completely blind to the control group.
As for the experimental group, besides the ordinary writing instructions, their essays are completely evaluated by the system rather than the teacher. After finishing the writing and evaluation, the students may revise each composition according to MsCAEWL’s multiple trait-specific scores and writing feedback. The revision effect can be checked because the revised essay can be scored again immediately. This computer-assisted English writing learning round is without limitation of times. However, in this experiment, the revision shall not stop unless at least three rounds are completed, or the score stops rising. All writing tests are carried out according to the requirements of The National Matriculation English Test, with a full score scope of 100 credits.
Results and discussions
a) The Effects of Writing Learning Assistance of MsCAEWL on Overall Performance
Group Statistics of Pre-Test Scores in Experimental Group and Control Group.

Independent-Sample t-Test of Pre-Test Scores of Experimental Group and Control Group.
Group Statistics of Post-Test Scores of Control and Experimental Group.

Independent-sample t-Test of Post-Test Scores of Experimental Group and Control Group.
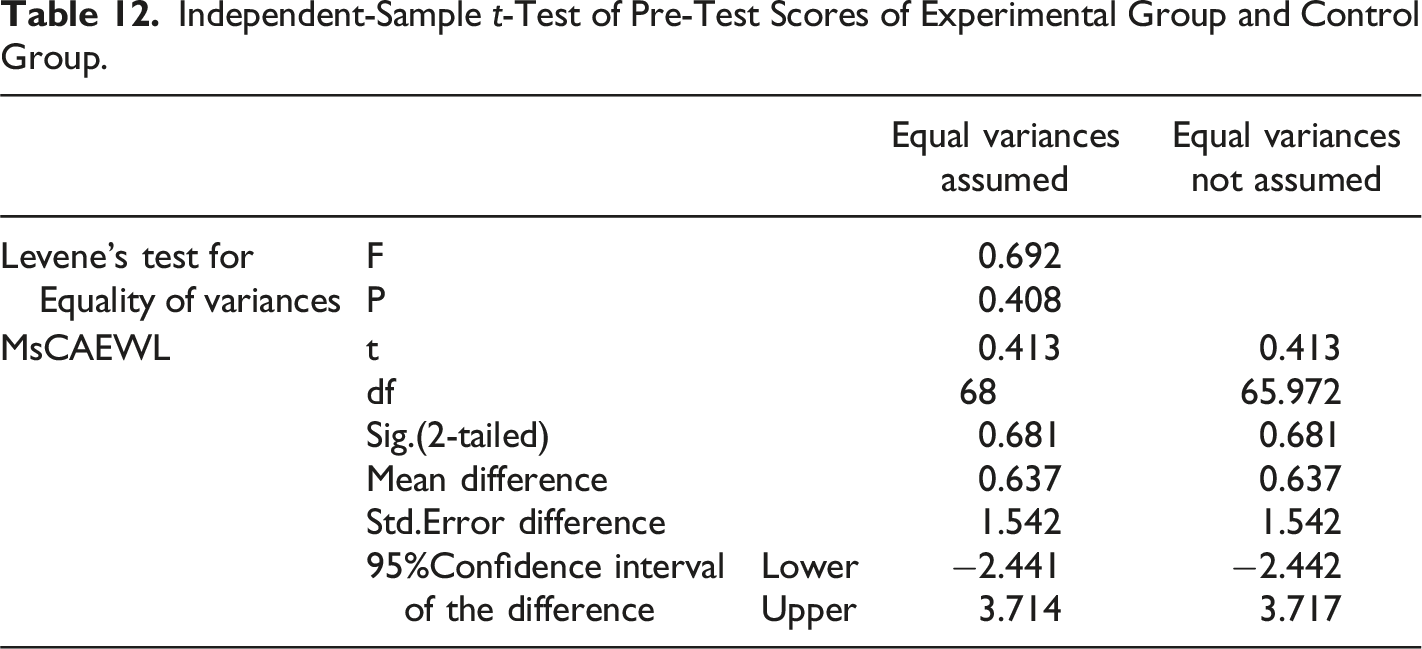
The results of the independent-sample t-test for the pre-test in Tables 11 and 12 showed that there was no statistically significant difference in the scores for the control group (
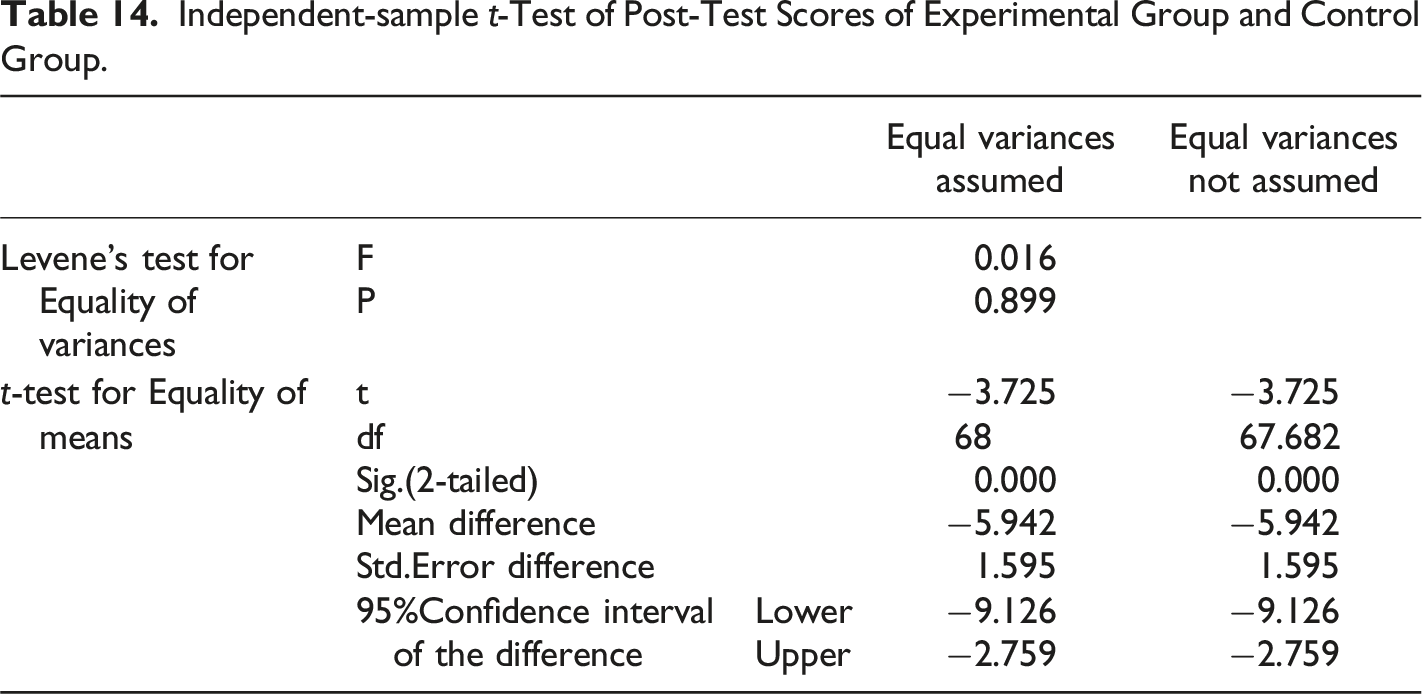
In order to examine if the effects of writing learning assistance of MsCAEWL took place at the end of wringing instructions in the experimental group and the control group, after the experiment, the post-test scores of the two groups were investigated by independent-sample t-test.
The results in Tables 13 and 14 revealed a statistically significant mean difference between the control ( b) The Effects of Writing Learning Assistance of MsCAEWL on Trait-specific Performance
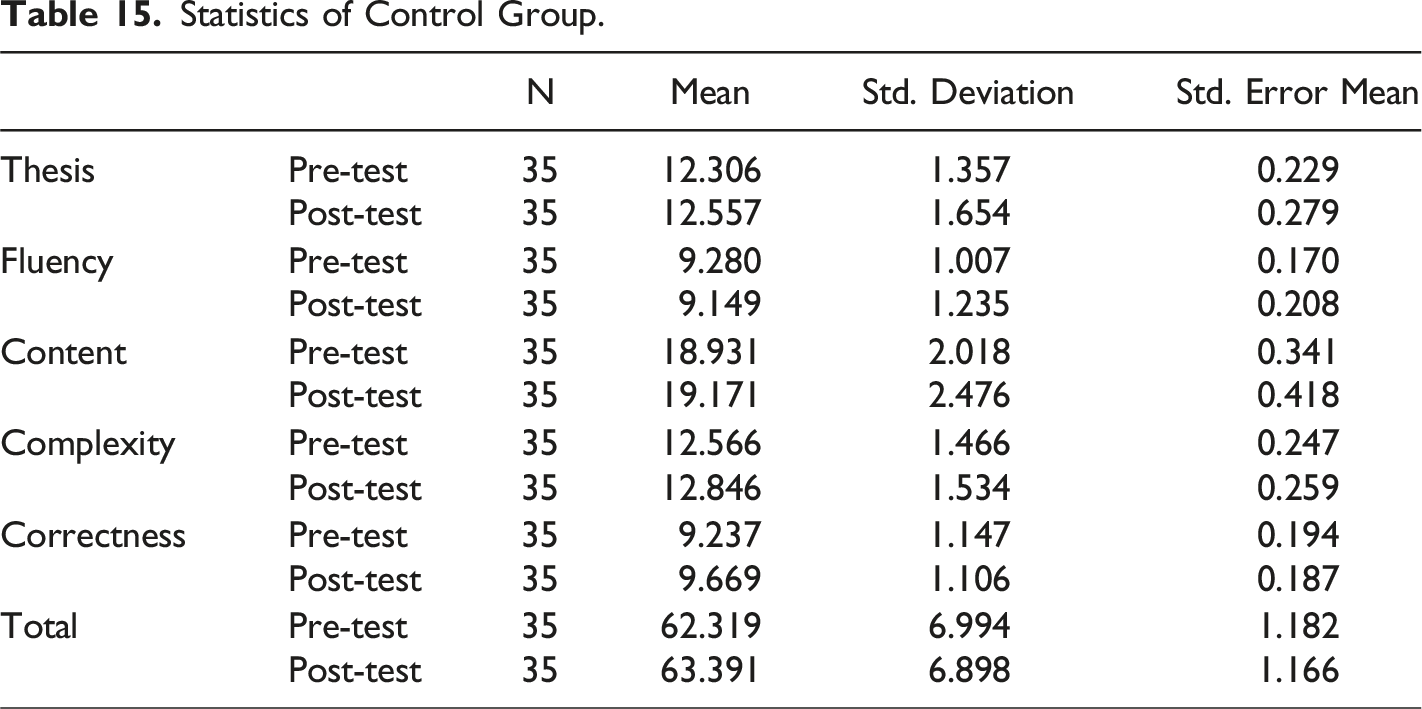
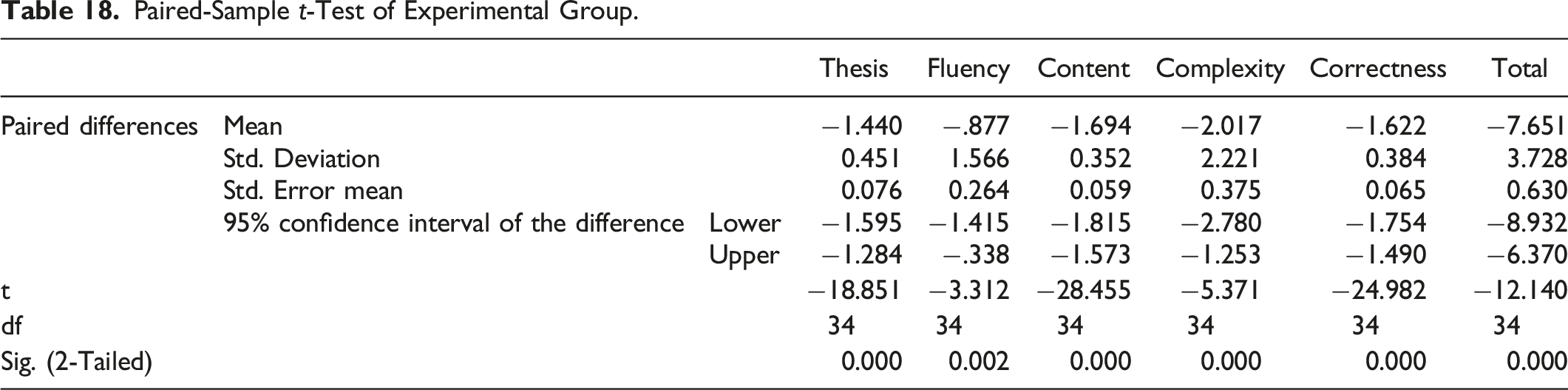
On the basis that MsCAEWL can effectively assist students in learning English writing, in order to have a deeper understanding of which aspects of writing learning and to what extent our system has produced positive effects, paired-sample t-tests were conducted to compare pre-test and post-test scores in each trait of writing, i.e., Thesis, Fluency, Content, Complexity, Correctness, and total score.
Statistics of Control Group.
Paired-Sample t-Test of Control Group.
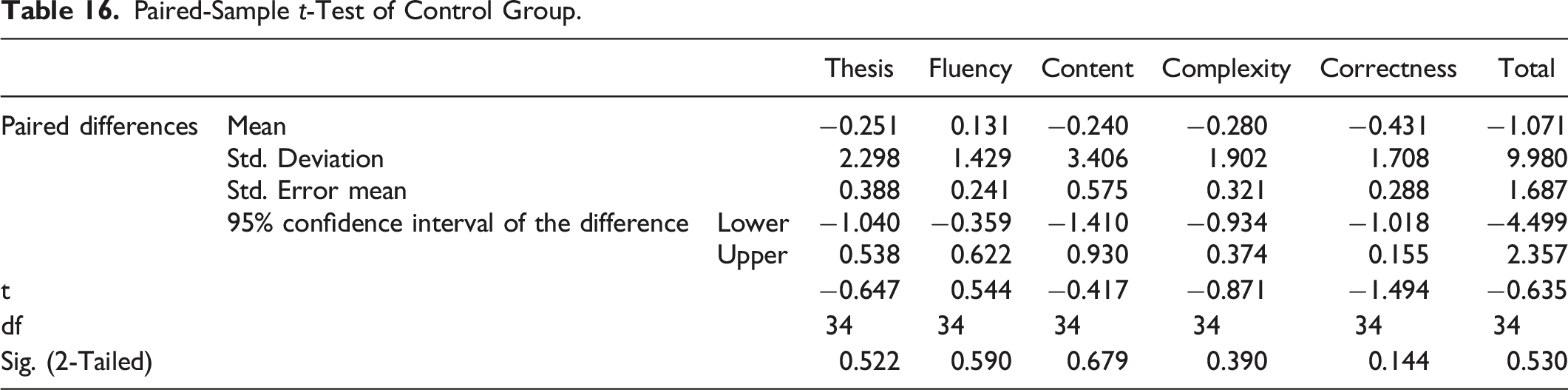
In order to whether and on which trait MsCAEWL yields writing learning assistance, a paired-sample t-test was conducted to compare the writing scores between the pre-test and the post-test of the experimental group.
Statistics of Experimental Group.
Paired-Sample t-Test of Experimental Group.
Conclusion and Future Works
How MsCAEWL Can Benefit Writing Learning Under the Guidance of Writing Feedback
In this study, we proposed a computer-aided writing learning system that integrates the neural network models and a couple of semantic-based NLP techniques. Different from the previous AWE or AES models, which mostly adopt the holistic scoring method, the concept of our proposed system follows the writing feedback theory. Combining the advantages of the AWE or AES model, neural networks, and multiple NLP technologies, our proposed system can provide a package of writing feedback that fully meets the requirements of writing feedback theory, namely, multiple, continuous, timely, clear, and multi-aspect guidance interactive feedback.
More specifically, as with the other AWE models, MsCAEWL is designed for easy operation, allowing students and teachers to use it multiple times without burden and obtain feedback immediately. The analytic scoring method, multiple trait-specific evaluations, is adopted in MsCAEWL in order to provide the multi-aspect guidance feedback. Thank to this, a temporal matrix of writing assessment can be easily formed based on feedback on each trait-specific evaluation after each revision of a composition. Students and teachers can intuitively observe the continuous changes in the composition and provide dynamic feedback.
Users can also use the scores of trait-specific evaluations in this system (rather than all of them) to compose different assessment matrices, thereby achieving different teaching or learning goals. It is worth noting that the utilization of writing feedback theory or AWE models is predicated upon a fundamental principle, namely that learners possess sufficient self-regulation to execute or teachers can oversee multiple careful revisions of a writing task. In our observation, even in instances where AWE or teachers proffer detailed and constructive feedback, the benefits derived from such feedback are exceedingly circumscribed if the author only revises once without attending to the feedback thereafter.
Conclusion
In this article, following the guidance of writing feedback theory, we designed a Multi-strategy Computer-assisted EFL Writing Learning System (MsCAEWL) in order to provide the writing multiple trait-specific evaluation scores and the detailed writing instructions.
In the comparison experiment of holistic scoring, MsCAEWL achieved the best performance on multiple prompts and the final average score. Due to the introduction of various semantic-based NLP technologies, our proposed system outperformed other outstanding baseline models incorporating the single model in their backbone structure.
The experiment of analytic scoring proves that in multiple trait-specific scoring, our system is more reliable and more robust than human raters. In other words, MsCAEWL is more suitable as a reference standard for writing verification experiments. It can not only provide more comprehensive multi-aspect assessments but also avoid individual differences in human scoring and inconsistent rating due to fatigue.
However, scoring compositions are only one of MsCAEWL’s capabilities. The most valuable task is to improve the author’s writing ability through multiple rounds of writing revision based on the interactive and all-around feedback provided to the author. In the validation experiment of assistance effect in writing learning, learners may utilize MsCAEWL’s writing feedback to edit their compositions without the restriction of use times, and they can immediately acquire the score changes after one round of modification to lead the next round of modification. With the assistance of our system, learners’ writing skills may be greatly enhanced over time, indicating that the writing feedback theory assisted by the computer is more effective.
Future Works
In the future, we will focus on text evaluation based on paragraph and text intention extraction, as well as evaluating the continuity between paragraphs and support for the topic based on paragraph intention. We will strive to bring the model closer to human thought in works of writing evaluation and feedback. Simultaneously, we will consult with second language acquisition specialists on the weight allocation and rationality of the traits in writing assessment.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the National Social Sciences Foundation of China (21BYY162); The Research Project of Introducing High-level Talents of Qiannan Normal College for Nationalities (2021qnsyrc09).