
Abstract
This article presents the design, construct validation, and reliability of a self-report instrument in Spanish that aims to characterize different types of strategies that students can use to learn computer programming. We provide a comprehensive overview of the identification of learning strategies in the existing literature, the design and development of preliminary questionnaire items, the refinement of item wording, and the examination of the internal structure and reliability of the final instrument. The construction of the items was based on the educational theory of Self-Regulated Learning. The final version of the questionnaire, called the Computer Programming Learning Strategies Questionnaire (CEAPC), was administered to 647 students enrolled in computer programming courses. The data collected from the participants were used to examine the construct validity and reliability of the questionnaire. The CEAPC consists of 13 subscales, each corresponding to a different type of learning strategy, and a total of 89 items. Statistical analyses of the data indicate that the CEAPC has adequate construct validity. In addition, the results of the internal consistency analysis indicate satisfactory reliability across the different subscales of the instrument. This study contributes to the field of educational research, particularly in the area of self-regulated learning in computer programming.
Introduction
The widespread use of information technologies has led to computer programming becoming prominent not only in the software industry, but also in academia. As a result, numerous resources and websites have emerged to facilitate programming education and are accessible to anyone interested in acquiring this knowledge (Loksa & Ko, 2016). In addition, computer programming has been incorporated into the curricula of many universities, particularly within engineering programs. Despite this, there is evidence of significant dropout rates in subjects related to computer programming, primarily due to students' initial exposure to the subject matter (Juarez-Ramirez et al., 2018; Ramalingam & Wiedenbeck, 1998).
Several studies have been conducted to examine the factors that contribute to dropout rates in these subjects. The findings suggest that students, teachers, and tutors perceive programming as challenging, which often leads to difficulties in achieving satisfactory results within a limited timeframe (Tek et al., 2018). Given these challenges, it is crucial to support students in their learning processes, which requires an understanding of their self-regulation strategies. In other words, it is essential to assess their motivation levels and the learning strategies they employ (McDougall et al., 2016). Self-regulation in the context of learning refers to a self-directed process in which learners control their cognition, motivation, and behavior to achieve learning goals (Zimmerman, 1989).
In particular, the learning of computer programming has been extensively studied under the approach of self-regulation in learning through the use of self-report instruments. These instruments are questionnaires or item inventories that inquire about the learning strategies used by a student (Winne & Perry, 2000). In this context, learning strategies are defined as mental operations and behaviors that the person performs to facilitate the learning process, and their use is intended to affect how the person selects, acquires, organizes, or integrates new knowledge (Weinstein & Mayer, 1986). One difficulty, however, is that these tools are broad in scope and do not focus on a specific subject or domain of knowledge, but rather consider general learning strategies that may be appropriate for students in any subject area. In this sense, due to the peculiarities of learning programming, it is convenient to have a specific instrument for this field; considering that at the time of writing this article, a validated questionnaire to characterize the learning strategies in computer programming was not available in the literature. Thus, this work aims to answer the following research question: How can the learning strategies of computer programming students be characterized using a self-report questionnaire? In this way, the purpose of this work is to document the design and construct validation of a self-report instrument in Spanish language, called CEAPC, which stands for which stands for Cuestionario sobre Estrategias de Aprendizaje de la Programación de Computadores in Spanish (Questionnaire on Learning Strategies in Computer Programming). It was developed in response to the need to characterize the strategies that can positively influence students’ learning processes and their academic performance in the learning of computer programming.
Related Works
Self-report instruments are commonly used to assess self-regulated learning (SRL) because they directly measure how students regulate their own learning. Unlike other measurement protocols such as teacher observations or performance assessments, self-report instruments provide direct information about students' self-regulation processes (Winne & Perry, 2000). Examples of alternative measurement methods include think-aloud protocols used by authors such as Loksa and Ko (2016), visual activity logs used by Cheng et al. (2019), and activity logs collected by learning management systems (LMS) analyzed by Cicchinelli et al. (2018).
Self-report instruments aim to characterize aspects such as motivation, metacognitive strategies, and cognitive strategies that students use when learning a subject. These instruments present statements for individuals to rate and indicate the extent to which these statements apply to them (González-Torres & Torrano, 2012). Well-known self-report instruments for assessing SRL include the Motivated Strategies for Learning Questionnaire (MSLQ) (Pintrich et al., 1993), the Learning and Study Strategies Inventory (LASSI) (Weinstein et al., 1988), MAI (Metacognitive Awareness Inventory) (Schraw & Dennison, 1994), SPQ (Study Process Questionnaire) (Biggs, 1987), ALSI (Approaches to Learning and Studying Inventory) (Entwistle & McCune, 2004), and others. However, these prominent instruments were not specifically designed for a particular domain of knowledge and often do not consider the use of information and communication technologies as learning resources. This is due to the fact that most of these instruments were developed in the 1980s and 1990s (Garcia et al., 2018).
These instruments are valuable for assessing SRL because of their ease of administration and scoring, their ability to provide a comprehensive view of students' SRL behaviors and strategies, and their potential to track students' SRL development over time (Schellings, 2011; Winne & Perry, 2000). As a result, their use has spread to various domains of knowledge. In the field of computer programming, studies have identified various factors that influence learning outcomes, including motivation, cognition, attitudes, and self-efficacy. Two types of research can be distinguished: those that use or adapt the validated instruments mentioned above, and those that propose new instruments specifically tailored to computer programming research.
In the first type of research, notable work has been conducted by Bergin et al. (2005) using the MSLQ questionnaire. Their findings revealed that strategies such as organizing and generating ideas were not frequently used by students. However, they found that motivational aspects played a crucial role in positively influencing academic performance. Similarly, Tsai (2019) focused on self-efficacy expectancy and emphasized its importance. According to Bandura (2006), self-efficacy refers to an individual’s confidence in performing a particular task, such as learning computer programming concepts. In addition, Castellanos, Restrepo-Calle, González, and Ramírez-Echeverry (2017) and Ramírez-Echeverry et al. (2018) used the MSLQ-Colombia instrument, an adapted version of the MSLQ in Spanish, to assess engineering students in computer programming courses (Ramírez-Echeverry et al., 2016). The first study concluded that source code was not only associated with academic performance, but also positively correlated with motivational characteristics related to self-regulation, such as learning beliefs, task value, and self-efficacy. However, in the second study, learning strategies, as measured by the MSLQ-Colombia, did not show a significant correlation with academic performance.
Regarding the second type of research, which involves proposing new instruments, it is worth mentioning studies that have introduced instruments to characterize aspects related to the motivation to learn computer programming. For example, Ramalingam and Wiedenbeck (1998) developed a scale to assess the motivation and persistence levels of students studying object-oriented programming using the C++ programming language. The goal was to understand how students' motivation and persistence are affected in challenging situations, including distractions and uninteresting learning scenarios. In addition, Cetin and Ozden (2015) designed an attitude questionnaire with three dimensions: affect, cognition, and behavior. This instrument aimed to highlight the importance of motivational aspects, especially self-efficacy, in the process of learning computer programming. Furthermore, Tsai et al. (2019) developed the Computer Programming Self-Efficacy Scale (CPSES) based on the computational thinking framework. The CPSES consisted of five subscales with a total of 16 items that assessed students' beliefs about their own abilities in logical thinking, algorithm development, debugging, control, and collaboration. In contrast, the present study focuses specifically on exploring the learning strategies that students use to regulate their own learning process, which distinguishes it from the aforementioned works that primarily examine motivation-related aspects.
Based on the aforementioned research, and considering both types of studies, it becomes clear that there is a need to develop instruments that specifically characterize learning strategies relevant to the domain of computer programming. To the best of our knowledge, the existing studies have either proposed instruments to assess motivation to learn or have used instruments with a broad scope that do not specifically target the unique challenges of learning computer programming. This limitation may explain the difficulty in establishing clear relationships between the use of learning strategies and the academic performance of students in computer programming courses. To address this gap, not only relevant literature in the field of self-regulated learning should be considered, but also work in the broader field of computational thinking can play a crucial role in devising learning strategies that capture the specific demands and intricacies of programming education.
Among the computational thinking practices proposed by Weintrop et al. (2016), computational problem-solving practices stand out. These practices include methods that have been shown to be effective in solving problems using machines and other computational tools. This set of practices comprises seven components, including: preparing problems for computational solutions, programming, selecting appropriate computational tools, assessing different solutions, developing modular computational solutions, creating computational abstractions, and troubleshooting and debugging. Notably, a recent study by Cruz Castro et al. (2021) examined computational problem-solving practices in a first-year undergraduate engineering course. The research highlights the importance of troubleshooting and debugging as a critical practice in introductory courses that facilitates the successful and timely development of other computational thinking skills.
Materials and Methods
Research Design
To achieve the research objective, a methodology based on the self-report instrument construction scheme proposed by Carretero-Dios and Pérez (2005) was used, which consists of four stages. These stages are as follows: 1. Stage I: Identification of subscales through a comprehensive literature review. 2. Stage II: Design and construction of items with the collaboration of subject matter experts through focus groups. 3. Stage III: Initial Exploration - Analysis of the internal structure of the preliminary version of the instrument through Exploratory Factor Analysis (EFA) and conducting semi-structured interviews with computer programming students. 4. Stage IV: Final Exploration - Analysis of the internal structure of the final version of the instrument using EFA and reliability analysis.
Figure 1 provides a detailed overview of the four stages of the methodology, along with the specific activities performed in each stage. Proposed methodology for the construction of the self-report instrument.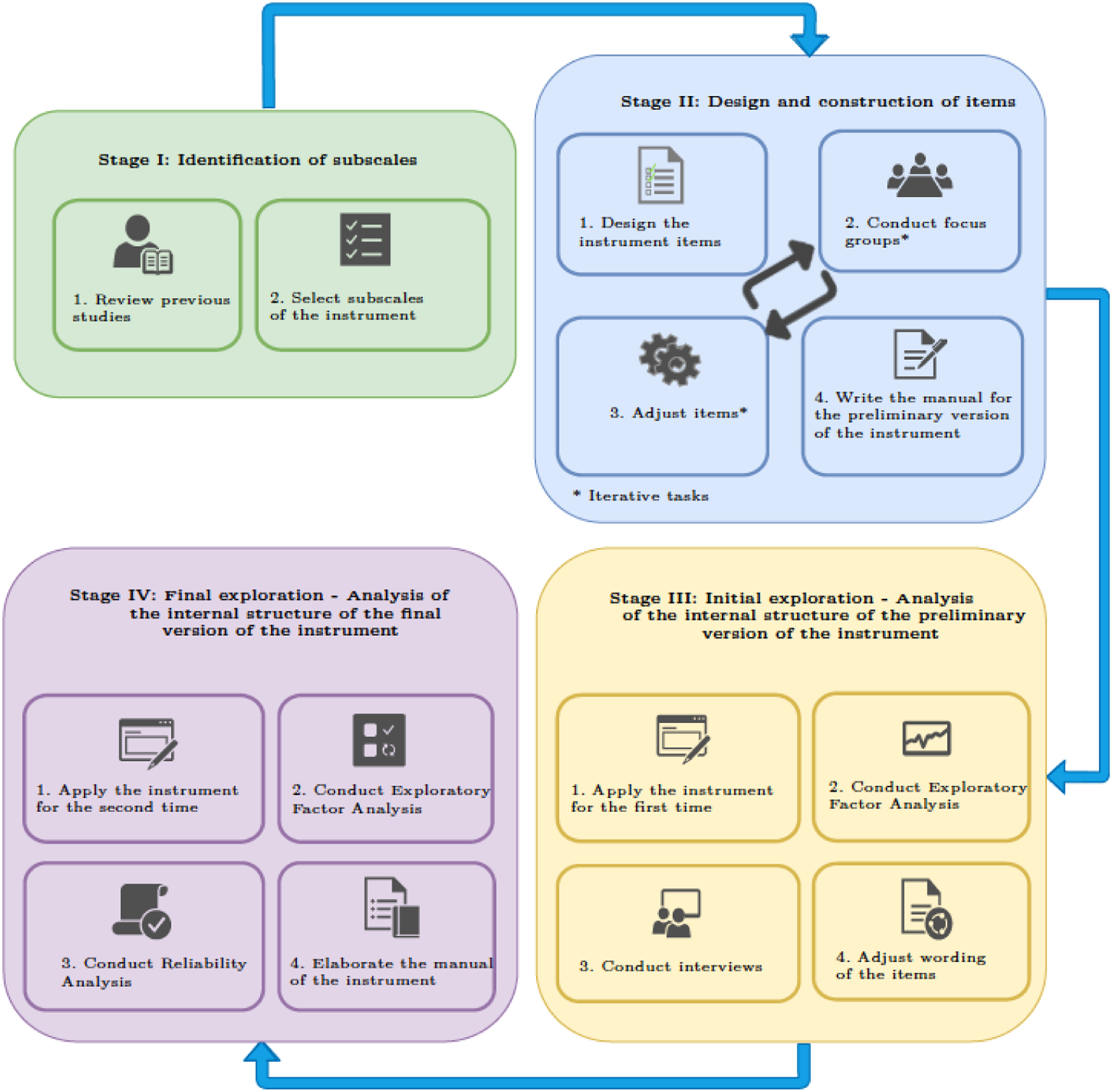
Stage I: Identification of Subscales
This stage includes the justification of the study and the conceptual delineation of the construct to be evaluated. A thorough literature review was conducted, focusing on key articles and studies related to self-regulation in computer programming learning. Through this review, we identified learning strategies that have been studied in educational contexts related to computer programming, as well as the impact of these strategies on learning outcomes. This process of identifying strategies in the literature served as the basis for proposing groupings to form the subscales of our instrument.
Categories of self-regulated learning strategies in programming, adapted from (Garcia et al., 2018) and used in this paper.
Preliminary subscales for the self-report instrument for computer programming.

Table 2 presents the name assigned to each preliminary subscale in the first column, followed by its description in the second column. The third column indicates whether it is a new subscale specific to computer programming, indicated by a check mark. The absence of a checkmark indicates that the subscale is adapted from the self-regulated learning approach, which is shared with instruments such as the MSLQ, the MSLQ-Colombia, or the Garcia et al. (2018) definitions. The fourth column indicates the number of proposed items for the subscale (in total 107 items). Finally, the fifth column lists the sources used to identify the learning strategies corresponding to each subscale.
Stage II: Design and Construction of Items
This stage involved the construction and implementation of a qualitative evaluation of the items in the preliminary instrument. The wording of each item was based on describing a technique that students can use to apply the corresponding learning strategy identified in Stage I (as proposed in the subscales in Table 2). For example, for the “Problem Solving” subscale, the items were worded as follows: (1) I engage in solving problems from different references, such as books or web platforms, and (2) I review examples of solved programming problems (Caruso et al., 2011).
Focus Groups
Before applying the preliminary questionnaire, we made a qualitative evaluation of the proposed wording of these items. The evaluation was done using the focus group method. The focus groups included three computer programming professors and between 5 and 7 master’s and doctoral students. All had previous experience in designing data collection instruments for engineering education research, which indicated their familiarity with the subject matter and their ability to provide valuable insights.
The focus groups were conducted over a period of 2 months, specifically in March and April 2020. A total of six focus group sessions were conducted. Each session lasted approximately 2 hours, allowing ample time for in-depth discussion and exploration of the topic. The focus group sessions were conducted remotely using Google Meet, a video conferencing platform. This remote format allowed for convenient participation without the need for physical presence during the COVID-19 pandemic lockdown. In addition, the use of Google Meet facilitated the recording of all participant interventions for later analysis, with participant consent. The principal investigator of the study, who is also the first author of the paper, served as the moderator for all focus group sessions. As moderator, the principal investigator facilitated the discussions, maintained the flow of conversation, and ensured that all participants had the opportunity to contribute their thoughts and ideas.
The main outcomes of the focus groups were suggestions for improving the wording of the items and recommendations for creating new items. For example, for the “Practice/Training” subscale, the experts indicated that it was important to include techniques such as repeating exercises, suggesting one’s own exercises, and using competitive programming platforms such as Codeforces or HackerRank. Similarly, for the “Resources - Digital Tools” subscale, the experts suggested techniques such as using online programming platforms and reviewing solved programming problems that explain the solution step by step. In summary, the focus groups allowed the items to be improved in both content and form.
Stage III: Initial Exploration - Analysis of the Internal Structure of the Preliminary Version of the Instrument
At this stage, the construct validity of the preliminary instrument was evaluated through a statistical analysis of the data obtained from the first administration. The instrument was administered to students enrolled in Computer Programming (CP), Object-Oriented Programming (OOP), and Data Structures (DS) courses at the National University of Colombia - Bogotá campus during the first semester of 2020. A Google Forms survey was used, which included the informed consent, instructions for completion, an explanation of the Likert scale used, and the instrument items. A 5-point Likert scale was used for the instrument with the following values: 5 - I totally agree, 4 - I agree, 3 - I neither agree nor disagree, 2 - I disagree, and 1 - I totally disagree. This scale was chosen for its readability, which is expected to increase the response rate of the questionnaire (Dawes, 2008). The items were randomly ordered to ensure separation of items belonging to each subscale. This version of the instrument took approximately 45–60 minutes to complete.
Participants
The preliminary version of the instrument was completed by a total of 244 participants, distributed among the different courses as follows: 178 students (73%) in CP, 44 students (18%) in OOP, and 22 students (9%) in DS. It is important to note that the CP course is a prerequisite for taking OOP, and OOP is a prerequisite for taking DS. Consequently, students enrolled in DS, being further along in their studies, may have had more experience in computer programming compared to those enrolled in CP and OOP.
Internal Structure of the Preliminary Version of the Instrument
First, prior to conducting the Exploratory Factor Analysis (EFA), we performed Bartlett’s test of sphericity and calculated the Kaiser-Meyer-Olkin index (KMO) to determine whether the data collected in this application of the instrument were suitable for factoring. Bartlett’s sphericity test assesses whether the correlation matrix of the variables is significantly different from an identity matrix. In other words, it tests whether there are significant relationships between the variables. If the test results in a statistical significance of less than 0.05, it indicates that the null hypothesis can be rejected, suggesting that the variables are not independent and can be factored. The KMO index is a measure of sampling adequacy used to determine the suitability of data for factor analysis. It assesses the extent to which the observed variables share common variance and can be factored. The KMO index ranges from 0 to 1, with values closer to 1 indicating better suitability for factor analysis.
First application - Results of Bartlett’s test of sphericity and calculation of the Kaiser-Meyer-Olkin index (KMO).

The internal structure of the preliminary version of the instrument was determined by means of EFA using principal axis factoring as the factor extraction method and the Oblimin rotation method. In this case, EFA was used to determine the internal structure of the instrument. It helps to identify the underlying factors or dimensions that explain the patterns of correlation among the observed variables. By conducting EFA, it was possible to gain insight into how different items or variables are related and group them based on common factors. In addition, the Oblimin rotation method allows simplifying and interpreting the factor structure obtained through EFA. It helps to obtain a more interpretable solution by allowing the factors to be correlated with each other. In this case, the objective of using Oblimin rotation was to maximize the high factor loadings of the items and minimize the low ones. By doing so, it becomes easier to interpret the relationships between the variables and assign them to specific factors (Watson, 2017). In a factor analysis, the factor loading represents the correlation between each observed variable (item) and the underlying factor. It indicates the strength and direction of the relationship between the item and the factor. Higher factor loadings indicate a stronger relationship between the item and the factor, suggesting that the item is more representative of the underlying factor. On the other hand, lower factor loadings indicate a weaker relationship between the item and the factor, suggesting that the item may not be well represented by the factor. In essence, factor loadings help determine the contribution of each item to the factors extracted in the analysis. It should be noted that in this study, an item was considered to belong to a factor if the factor loading of the item was greater than or equal to 0.3, which is considered acceptable in the literature (Hair et al., 2006).
After conducting the EFA, several notable findings emerged. First, the number of factors obtained did not match the 16 expected subscales originally proposed in the preliminary design of the instrument. In addition, certain items of the instrument were found to be grouped into unexpected factors rather than the intended ones. This was evident from the similarity of factor loadings across multiple factors, which ranged around 0.3. As a result, it was decided to limit the algorithm and define 15 factors in advance for the EFA analysis. The goal was to maximize the number of items grouped within factors that were consistent with the theoretical basis of the intended learning strategies characterized by the questionnaire. In summary, the EFA yielded the following results: • Four factors were consistent with the expected subscales: Resource - Study Environment and Time, Peer Learning, Practice and Training, and Resource - Effort. Each of these factors included the items intended for their respective subscales. • The subscale Use of Digital Tools was no longer distinct because its items were grouped into different factors. • Four unexpected factors emerged, representing new subscales for the instrument. These factors, namely Problem Solving, Consult Information, Consult Documentation, and Consult Study Resources, showed consistency when analyzed within the theoretical framework of self-regulated learning in the context of computer programming. • The remaining six factors reflected partial groupings of items intended for single subscales or included items from two or more subscales.
The results revealed instances where factors grouped items from different strategies without a plausible theoretical explanation for such grouping. In addition, certain items continued to belong to multiple factors with substantial factorial loads in each factor. As a result, 39 of the original 107 items in the preliminary version of the instrument were identified as problematic and required adjustments in wording. In order to explore the possible reasons for these unexpected results and to improve the wording of the problematic items, the subsequent phase of this research involved a qualitative analysis through semi-structured interviews with students.
Semi-Structured Interviews
The qualitative analysis of the problematic factors and items of the preliminary version of the instrument was conducted through semi-structured interviews. These types of interviews, as well as other qualitative data collection methods, provide insight into a person’s worldview and thus the subtle details that may be difficult to understand using only quantitative methods (Nassar-McMillan et al., 2010). This approach allows for a flexible yet focused conversation between the interviewer and the interviewee. The choice of this method is consistent with the goal of gaining insight into students' interpretations of the content of the problematic items.
For this research, semi-structured interviews were conducted with 35 students who had previously completed the preliminary version of the self-report instrument and voluntarily agreed to participate in this phase of the study. These students were selected because they had first-hand experience with the instrument and could provide valuable perspectives on its content. Interviews were conducted between June and July 2020.
Each interview focused on discussing the interpretation of a subset of the problematic items. Each interview involved a conversation between the principal investigator and a computer programming student, guided by pre-established questions, some other questions that arose during the activity, and the items being evaluated. The number of items discussed in each interview varied between 4 and 6, depending on the length of the conversation between the interviewer and the interviewee. On average, interviews lasted between 45 and 60 minutes, allowing sufficient time for in-depth exploration of participants' perspectives.
To facilitate qualitative data collection, an interview guide was developed. The guide consisted of a set of core questions for the interviewees. In addition, supplementary questions were included before or during the interview to explore specific aspects related to each item. The following is an outline of the core questions for each item: 1. When you read the following sentence or item, what thoughts or interpretations come to mind? 2. Based on your previous answer, how would you improve this sentence to make it easier to understand? 3. Do you use this learning strategy when you study programming? If not, do you use a similar approach?
The semi-structured interviews were also conducted remotely using Google Meet, which allowed for easy recording of the interviews with the consent of the participants. This approach facilitated the analysis of the interviews at a later stage. The recorded interviews were analyzed using thematic analysis. Through systematic coding, meaningful units of data were identified and labeled as codes derived from the words and phrases used by the participants. Common themes and patterns emerged from the coded data, representing key ideas and experiences. The researchers analyzed and interpreted the data within each theme, exploring connections, identifying evidence, and uncovering deeper meanings and implications.
By conducting semi-structured interviews, we were able to delve into the students' perspectives and gain a deeper understanding of their interpretations of the items. These insights provided valuable evidence for adjusting and refining the wording of the items to ensure greater clarity and accuracy in the subsequent version of the instrument. For example, students pointed out instances where the same word or phrase in the items was interpreted differently by different people. A specific example mentioned was the term “algorithmic elements,” which was originally used to refer to programming concepts such as variables, control structures, and methods. However, students found this term unclear and suggested that it be replaced with the phrase “programming concepts” for clarity. In addition, students pointed out ambiguities in certain words, such as the term “schema”. According to their feedback, they understood “schema” to be either a graphical method for organizing information or a method for modeling the solution to a problem before coding, especially during the design phase. This feedback highlighted the need for clearer and more precise language in the items to avoid confusion and ensure consistent interpretation across participants.
Adjustments to the Wording of Items or Deletion of Items
Based on the results of the semi-structured interviews, necessary adjustments were made to several problematic items identified in the initial application of the self-report instrument. In addition, the decision was made to eliminate 14 items. This elimination was based on observations gathered during the semi-structured interviews, as well as criteria such as the similarity of certain items, the difficulty in understanding certain items, and the presence of items that were grouped into multiple subscales. As a result of this analysis, a revised version of the instrument was obtained, consisting of a total of 93 items.
Stage IV: Final Exploration - Analysis of the Internal Structure of the Final Version of the Instrument
In this stage, the adjusted version of the instrument was evaluated to obtain the final version. The evaluation focused on studying the dimensionality or internal structure of the instrument and estimating its reliability. To achieve this, the instrument was administered for the second time using Google Forms and consisted of the 93 items derived from the previous stage. The items were randomly ordered to minimize response bias.
Participants
In this application, 647 students completed the questionnaire, about twice as many as in the first application. A total of 427 students (66%) were enrolled in CP, 181 students (28%) in OOP, and 39 students (6%) in DS. A minimum of 5 participants per item was required according to (Carretero-Dios & Pérez 2005).
Internal Structure of the Second Version of the Instrument
Second application - Results of Bartlett’s test of sphericity and calculation of the Kaiser-Meyer-Olkin index (KMO).

An exploratory factor analysis was conducted using the principal axis method and Oblimin rotation, similar to the first application. The results showed an improved factor structure of the self-report instrument when analyzed with 13 factors instead of the expected 15. Comparing these results with the EFA results of the preliminary version of the instrument, the following findings stand out: • In general, the factor loadings of each item within their respective factors increased substantially, and the conceptual relationships among the items grouped within each factor also improved. • Factors were identified that included all of the expected items for each subscale, such as Peer Learning, Resource - Effort, Organizing Ideas, and Consult Documentation. • Two factors emerged independently, including items related to Resource - Study Environment and Resource - Time. It is noteworthy that in the first application, only one factor emerged that included items from both of these learning strategies. • Items related to metacognition (Metacognition - Study Method Adaptation, Metacognition - Learning Planning, and Metacognition - Monitoring of Learning) were combined into a single factor named Metacognition in Learning Computer Programming. This factor contained 16 items with factor loadings ranging from 0.4 to 0.5. • Most of the items related to problem-solving strategies were grouped into a single factor that included strategies for analyzing, designing, coding, and testing programs. Factor loadings for these problem-solving items ranged from 0.3 to 0.5. • Some items from the original Problem Solving - Coding subscale generated another factor that grouped items with strategies specific to the coding process during learning. Factor loadings on this factor range from 0.4 to 0.6. • In addition, some items from the Organization of Ideas, Problem Solving - Design, and Problem Solving - Coding subscales were combined into one factor. These items showed a relationship with strategies for organizing important topic ideas (concepts and definitions) and organizing data to solve programming problems through diagrams and comments in the source code. • Although the first application resulted in the separation of all items from the Acquisition of Declarative Knowledge subscale, in this application all items were grouped into a single factor with loadings around 0.4. • Two unexpected but conceptually meaningful factors emerged: Programming problem-based learning (items with factor loadings between 0.3 and 0.5) and Monitoring comprehension in programming problem solving (items with factor loadings between 0.4 and 0.7). Some of these items were originally proposed for the Metacognition - Monitoring of Learning subscale. Both factors showed acceptable factor loadings. • Two factors were identified independently, including items from Organizing ideas (loadings between 0.3 and 0.6) and Resource - Effort (loadings between 0.5 and 0.7). These two subscales were initially based on the MSLQ-Colombia.
Detailed results of the final factor structure of the instrument are presented in Figure 2. Internal structure of the computer programming learning strategies questionnaire CEAPC.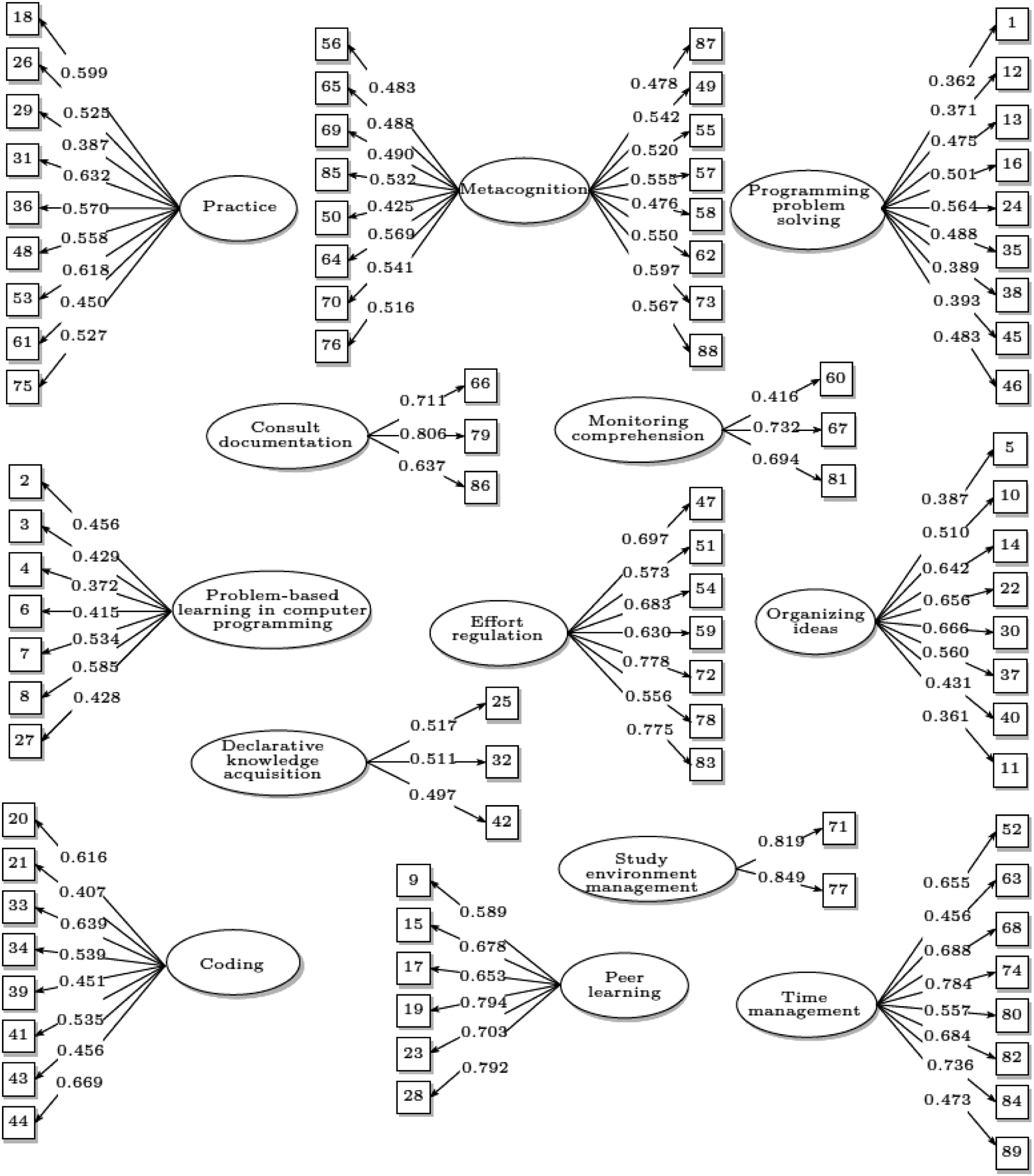
Deletion of Items From the Second Version of the Instrument
The item elimination process followed three criteria: items with factor loading around 0.2 in the expected factor, items with factor loading close to 0.3 in different factors, and lack of conceptual relationship between items within the same factor. Four items were eliminated as a result of this process. It is important to note that after each elimination, the Exploratory Factor Analysis was recalculated, demonstrating that the original 13 factors remained intact and that the remaining items within each factor retained the expected conceptual relationship. The subscales from which items were eliminated were: Problem Solving – Analysis, Problem Solving - Coding, Practice/Training, and Resource - Study Environment and Time.
The final version of the instrument, consisting of 89 items, is presented below. The statistical analysis was performed with the data from the 647 participating students, without considering the four items that were excluded.
Final Version of the Instrument
Subscales of the Instrument With Conceptual Description
Subscales and number of items of the Computer Programming Learning Strategies Questionnaire (CEAPC).

aNew subscale.
The names of certain subscales changed from those originally proposed. In assigning these names, we considered technical terms used in self-report instruments of self-regulated learning, such as the MSLQ and the MSLQ-Colombia. For example, instead of using the word “resource” with either “effort” or “time”, it was decided to use the term “regulation” in the former case, resulting in “effort regulation”, and the term “management” in the latter case, resulting in “time management.” Similarly, in the subscale “Resource - Study Environment” we used “Management” instead of the word “Resource”, thus obtaining “Study Environment Management”.
Here is the conceptual description of each subscale in the final version of the CEAPC:
Internal Structure of the CEAPC
Figure 2 illustrates the internal structure of the final self-report instrument. The ovals represent the subscales, while the boxes represent the items within each subscale, identified by their corresponding numbers in the self-report instrument. For example, the subscale labeled “Consult Documentation” consists of items numbered 66, 79, and 86 on the instrument. The values displayed next to the arcs emanating from each subscale indicate the factor loadings obtained by the respective items on that particular factor. To illustrate, item 66 obtained a factor loading of 0.711, while items 79 and 86 obtained loadings of 0.806 and 0.637, respectively.
Reliability of the CEAPC
Reliability, as measured by the Cronbach’s alpha coefficient, assesses the internal consistency of an instrument and indicates the extent to which its items consistently measure the same underlying construct (Ursachi et al., 2015). Cronbach’s alpha is a statistical measure that quantifies the interrelationship or correlation among items within a subscale or questionnaire. It produces a value between 0 and 1, with higher values indicating greater internal consistency. In essence, Cronbach’s alpha helps determine the reliability of an instrument in measuring a particular construct.
Internal consistency indices for the CEAPC subscales.

CP: Computer Programming.
CPL: Computer Programming Learning.
The subscales with the highest Cronbach’s alpha values, around 0.8, consist of items that have remained consistent and unchanged since the first application of the instrument. These subscales include “Study environment management”, “time management”, “effort regulation”, “practice in CPL”, and “peer learning in CPL”. The subscale “Metacognition” also received a value of 0.893, which places it in this group. The high alpha values indicate a high degree of consistency among the items within these subscales.
Subscales with Cronbach’s alpha values around 0.7 emerged as new subscales in either the first or second version of the instrument. For example, the subscale “Consult documentation” emerged from the first application, and the subscale “Coding” emerged from the second version. In addition, the “Organizing Ideas” subscale, although considered from the first version, had some items that were originally part of the preliminary “Problem Solving - Design” subscale. The “Problem Solving” subscale was formed by grouping items related to analysis, design, coding, and testing strategies during programming problem solving.
Finally, subscales with Cronbach’s alpha values around 0.6 were not explicitly considered in the initial research, but emerged from the results of the EFA conducted in the second application. These subscales include “Problem-based learning in computer programming for epistemological competencies” and “Monitoring comprehension when solving computer programming problems”. Furthermore, the subscale “Declarative knowledge acquisition” obtained the lowest alpha value of 0.662, but it is still considered acceptable according to the literature (Ursachi et al., 2015). It should be noted that the items of this subscale were originally grouped into different factors in the first version of the instrument. The adjustments made to the wording allowed these items to achieve the necessary consistency to characterize this type of computer programming learning strategies with the CEAPC.
Discussion
In the literature, several self-report instruments have been developed to assess learning processes from the perspective of self-regulated learning. However, most of these instruments have been designed to capture learning as a general process, without considering the specific characteristics of a particular knowledge domain, such as computer programming. During the course of this research, however, several studies were identified that made valuable contributions to the understanding of learning in computer programming. These studies focused on the design and use of self-report instruments to assess a specific aspect of self-regulated learning: motivation to learn (Cetin & Ozden, 2015; Danielsiek et al., 2017; Dorn & Elliott Tew, 2015; Ramalingam & Wiedenbeck, 1998; Tsai et al., 2019). Nevertheless, no instruments were found in the reviewed literature that specifically characterized the strategies used by computer programming students to improve their learning processes. By developing the Computer Programming Learning Strategies Questionnaire (CEAPC) as a self-report instrument, the research question of this study was answered: How can the learning strategies of computer programming students be characterized using a self-report questionnaire? This instrument addresses the need for an instrument (in Spanish-language) that can assess the learning strategies that are effective in the context of learning computer programming.
The CEAPC consists of thirteen subscales, comprising a total of 89 items, based on the self-regulated learning approach and focusing on strategies for learning to program. These subscales can be divided into two types: those that correspond to existing strategies documented in the literature and those that emerged as new strategies identified in this research. The first type of subscales includes: • • • • • • • • •
In the second type of subscale that emerged unexpectedly, we identified the following: • • • •
Finally, it should be noted that the CEAPC represents a practical contribution in the field of learning strategies for computer programming. It uses a questionnaire to assess and characterize these strategies. While some of the strategies included in the instrument are in line with the existing literature on self-regulated learning, others have emerged directly from the observations and experiences of students learning computer programming. These strategies have been identified by students themselves as valuable and effective in learning programming. Of particular note are those strategies that utilize additional resources such as digital tools, reflecting the evolving nature of learning in the digital age. By including both established and emerging strategies, the CEAPC provides a comprehensive and practical tool for understanding and evaluating learning strategies in the context of computer programming.
Conclusions and Future Works
This paper described the design, construct validation, and reliability analysis of the Computer Programming Learning Strategies Questionnaire (CEAPC), a self-report instrument for characterizing learning strategies in computer programming. The questionnaire consists of 13 subscales, each representing a specific type of learning strategy, and includes a total of 89 items that assess the techniques used by students to engage in these strategies. The identification of programming learning strategies was based on a detailed literature review, following the framework proposed by Carretero-Dios and Pérez (2005) for the construction of instruments. The development of the CEAPC was influenced by existing self-report questionnaires, such as the MSLQ (Pintrich et al., 1993) and the MSLQ-Colombia (Ramírez-Echeverry et al., 2016), as well as Zimmerman’s categories of self-regulated learning, as redefined by Garcia et al. (2018).
The CEAPC has the potential to become a fundamental reference within the field of educational research in computer programming by providing researchers and practitioners with a tool to characterize the strategies that students use when learning computer programming. This instrument offers valuable insights into various aspects, such as the actions students take to solve programming problems, as well as their planning, monitoring, and controlling of learning processes inside and outside the classroom (metacognitive strategies), among other areas of inquiry. By using the CEAPC, researchers and practitioners can gain a deeper understanding of the learning processes involved in computer programming and identify effective strategies that contribute to students' success in this domain.
The research design used in this study employed mixed methods, combining quantitative and qualitative approaches. Quantitative methods were used to determine the dimensionality of the questionnaire, assess the construct validity of the instrument, and calculate the reliability of the questionnaire subscales using internal consistency measures. On the other hand, qualitative methods were used to refine the wording of the questionnaire items and to gain a deeper understanding of the quantitative results. Semi-structured interviews allowed students to share their experiences regarding the learning strategies they use in computer programming. These qualitative insights were valuable in understanding the emergence of unexpected factors in the exploratory factor analysis, which led to the identification of emergent subscales in the questionnaire. These subscales grouped learning strategies that were not initially anticipated based on the existing literature, indicating unique approaches used by students in the context of computer programming learning.
As future work, it is recommended to expand the participant population to increase diversity and generalize the results beyond the specific context of the study. This expansion would help to further validate the internal structure of the questionnaire, refine item wording, and improve the reliability of the instrument. By including diverse populations, researchers can gather more comprehensive evidence and increase the generalizability of the findings. This line of work will contribute to the possibility of generalizing the results presented in this study to a larger scale. In addition, another limitation of this study is related to the length of time it takes to administer the CEAPC, which can be time consuming (between 45 and 60 minutes). This may be a problem for students who are under time constraints.
Moreover, future studies should explore related concepts that may influence cognitive control processes when learning programming. The use of instruments such as the CEAPC can help to characterize the learning strategies that students use, which in conjunction with information on students’ knowledge of programming, can help to better understand the cognitive control processes in this area of research. By combining data on learning strategies with assessments of students' programming knowledge, researchers can explore how these strategies interact with cognitive processes and knowledge acquisition in computer programming. This integration of information can provide valuable insights into the complex interplay between learning strategies, cognitive control, and programming proficiency, and enhance our understanding of effective instructional approaches and interventions in computer programming education.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.