
Abstract
Rapid automatized naming (RAN) is a powerful predictor of reading fluency, and many digitized dyslexia screeners include RAN as an essential component. However, the validity of digitized RAN has not been established. Using a sample of 174 second-graders, this study tested (1) the comparability between paper and digitized versions of RAN and (2) the validity of the digitized version. We found that paper and digital versions were highly correlated, and such correlation was consistent across students’ reading levels. Further, the digital RAN predicted children’s word reading proficiency as well as the paper version. Moreover, the constructs measured by paper and digital versions of RAN were comparable. We conclude that the digitized RAN is a valid alternative to the traditional paper version for this age group.
Introduction
Although not universally acknowledged, rapid automatized naming (RAN), how quickly an individual can name a visual array of alphanumeric or non-alphanumeric stimuli in a serial fashion, is one of the best predictors of dyslexia (e.g., McWeeny et al., 2022). RAN’s robust prediction capacity for reading fluency has made it an essential part of screening for reading challenges. Many states now mandate dyslexia screening, and most include the RAN. That said, many scholars underscore that RAN is considered as only one of several major predictors of later reading proficiency, including phonological awareness, vocabulary, and letter-sound correspondence knowledge, that should be used in any early prediction battery. Intervention studies have shown the crucial importance of early interventions that target weaknesses like RAN and PA, particularly when data from assessments including RAN assessments guide the instructional emphases (Gotlieb et al., 2022; Lovett et al., 2017; Morris et al., 2012).
Differences Between Paper and Digital Assessment Formats
Digital screeners are being deployed to allow for efficiency in administration and interpretation of test results. Digital assessment tools often offer automatic scoring; a dashboard that is quickly updated with student scores; and efficiency in administration for teachers. Many of these kinds of assessments allow children to complete tests with little to no adult supervision.
Several studies have shown the digital versions of various academic assessments to be equivalent to the paper and pencil versions. For instance, one study found that there were no significant differences between fourth grade students’ performance on a standardized assessment, Trends in International Mathematics and Science Study (TIMSS), when students took a paper and pencil version or a version on a tablet (Hamhuis et al., 2020).
The problem is that there are no known comparisons between children’s use of digitally administered RAN tests and the original paper-administered, classic RAN Tests (Denckla & Rudel, 1976; Wolf & Denckla, 2005). To date, comparisons of digital and paper versions of naming speed tasks have only been conducted with adult samples with varied versions of RAN tasks (Howe et al., 2006; Park et al., 2022). For instance, Park et al. (2022) found that the two mediums measuring naming speed showed high agreement (.92–.94) but they used a naming instrument specifically developed for concussion screening, not the classic RAN. Similarly, Howe and colleagues (2006) found a high agreement (.95) across mediums using researchers-created RAN tasks.
Given the proliferation of these screeners and the paucity of data on comparisons of print-based and digitized RAN in children, we investigate the assumption that these two mediums provide the same information with a newly digitized version of the classic RAN Letters and RAN Objects subsets. In other words, the overall aim of this study is to test whether a digitized version of the RAN test is a valid alternative to the original version. Therefore, we examined the following research questions: 1. Are the digital version and the paper version of the RAN test equivalent? 2. Is the degree of equivalency across the two mediums consistent across students’ levels of reading proficiency? 3. Is RAN’s predictive power of children’s reading proficiency equivalent across the two mediums? 4. Does the construct measured by the Letters and Objects subtest of the RAN, respectively, converge across the two mediums?
The implications of these results have critical importance for whether digitized RAN tasks can inform the emphases in instruction and intervention, particularly for struggling readers.
Methods
Participants and Setting
Race/Ethnicity Composition of the Sample.

Demographic Characteristics of the Sample by Schools.
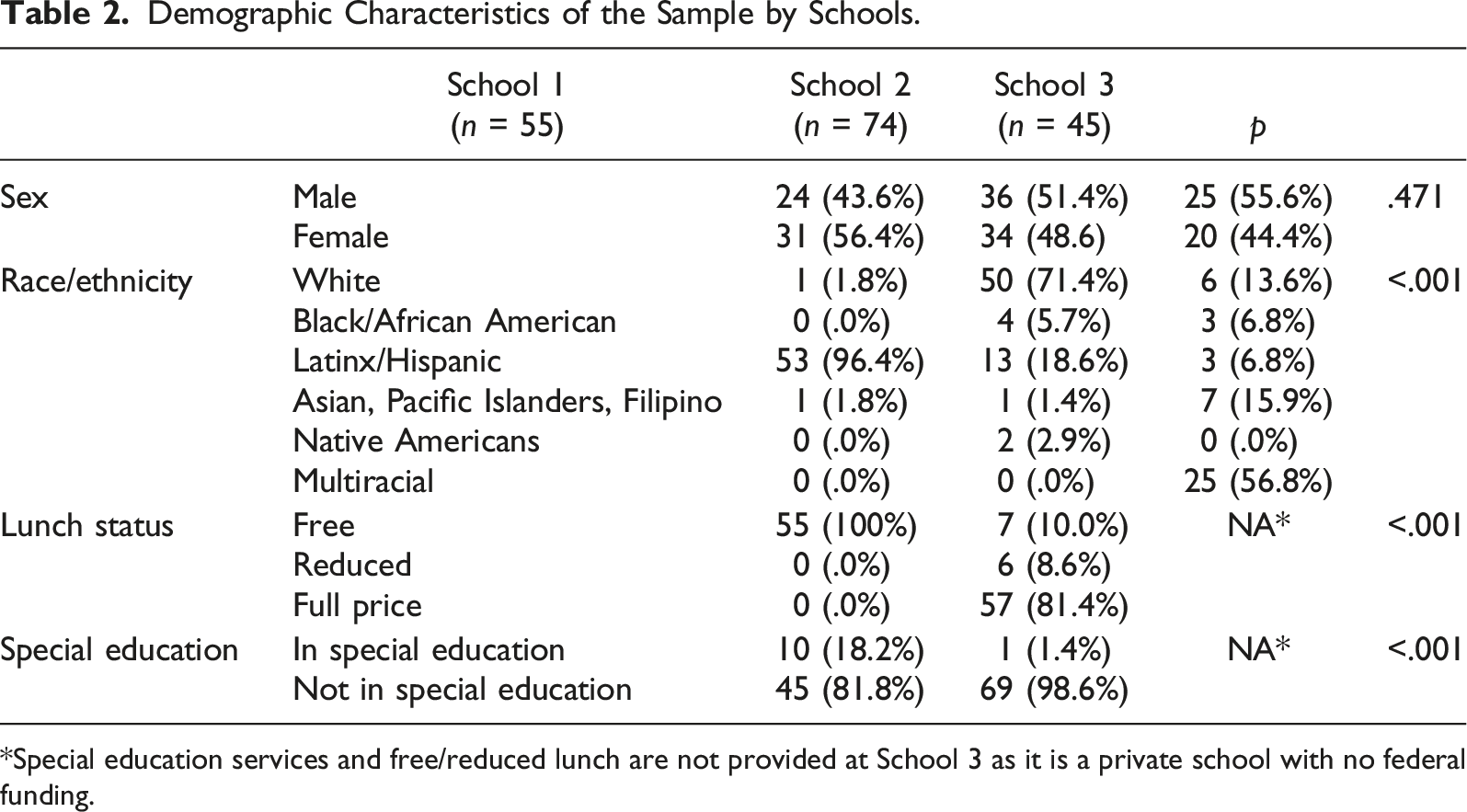
*Special education services and free/reduced lunch are not provided at School 3 as it is a private school with no federal funding.
Measures
RAN Paper
The Letters and Objects subtests of the classic RAN test were administered in their original paper forms (Wolf & Denckla, 2005, Pro-Ed). Five rows of 10 letters or objects, a total of 50, were printed on a sheet of paper (17 × 11 inches). Students were asked to name an array of letters or objects as quickly and accurately as possible. A short practice task was provided before the actual test in order to confirm students’ understanding of the instruction and basic letter knowledge, so that only retrieval speed, not letter knowledge is measured. The reliability of the classic RAN test ranges from .84 to .92.
RAN Digital
The exact copy of the Letters and Objects subtests of the RAN test were digitized, and these digitized versions were accessed through an iPad app developed for this study that had a timer function embedded in it. The RAN tests were displayed in 8.5 × 6.5 inches screen on the iPad. As with the paper version, the testers controlled when the stimuli progressed from the practice image to the test image.
Test of Word Reading Efficiency—Second Edition (TOWRE-2)
The Real-Word subset of the TOWRE-2 was administered to measure decoding and word reading proficiency among students. The reliability of the TOWRE-2 ranges from .87 to .90.
Procedures
Each student completed both the paper and digitized versions of the Letters and Objects subtests of the RAN in one sitting. Testers used a handheld timer to record RAN completion time for the paper version and used either the handheld timer or the embedded timer for the digital version.
Randomization groups.
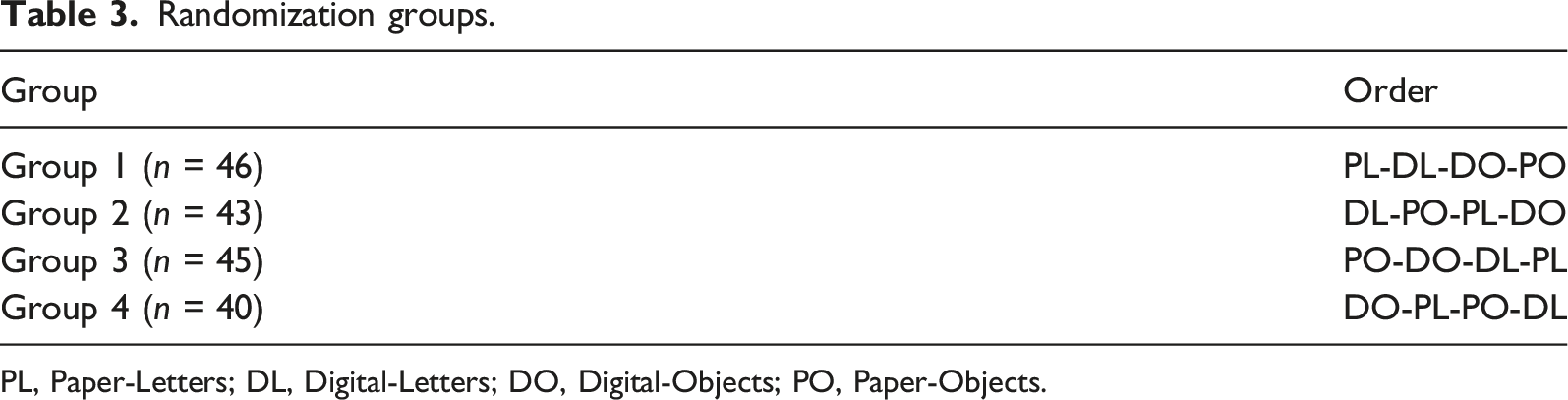
PL, Paper-Letters; DL, Digital-Letters; DO, Digital-Objects; PO, Paper-Objects.
On the same day, the TOWRE-2 Real-Word subset was administered to each student. Students were asked to read the list of the words as fast as they can in 45 seconds. The number of words read correctly within the given time was recorded.
Statistical Analysis
To measure the equivalency between the paper and digital versions of the RAN, a parallel form reliability test was conducted by calculating Pearson r between the two mediums for both Letters and Objects subtests.
To examine the consistency of the correlations (Pearson r) across students’ reading proficiency, Fisher’s z was calculated within reader groups. The reader group was determined by the students’ quartile scores in the TOWRE Real Word test. Students were identified as struggling readers (N = 52) if they scored below the 25th percentile on the national norm in the TOWRE Real Word test (Torgesen et al., 2012). Those who scored above the 25th percentile in the TOWRE Real Word test were identified as non-struggling readers (N = 122).
To compare the predictability of RAN for children’s word reading fluency between the two mediums, the correlation between the TOWRE score and the paper versions of RAN was compared to the correlation between the TOWRE score and the digital versions. Such a comparison was made for both the Letters subset and the Objects subset using Fisher’s z.
Lastly, to measure if the validity of the Letters and Objects subsets converges across mediums, the correlation between the Letters subset score and the Objects subset score of the paper RAN was compared to the correlation between the Letters subset score and the Objects subset score of the digital RAN. This comparison was also made using Fisher’s z.
All statistical analyses were conducted using SPSS version 28.
Results
Parallel Form Reliability
Descriptive Statistics.
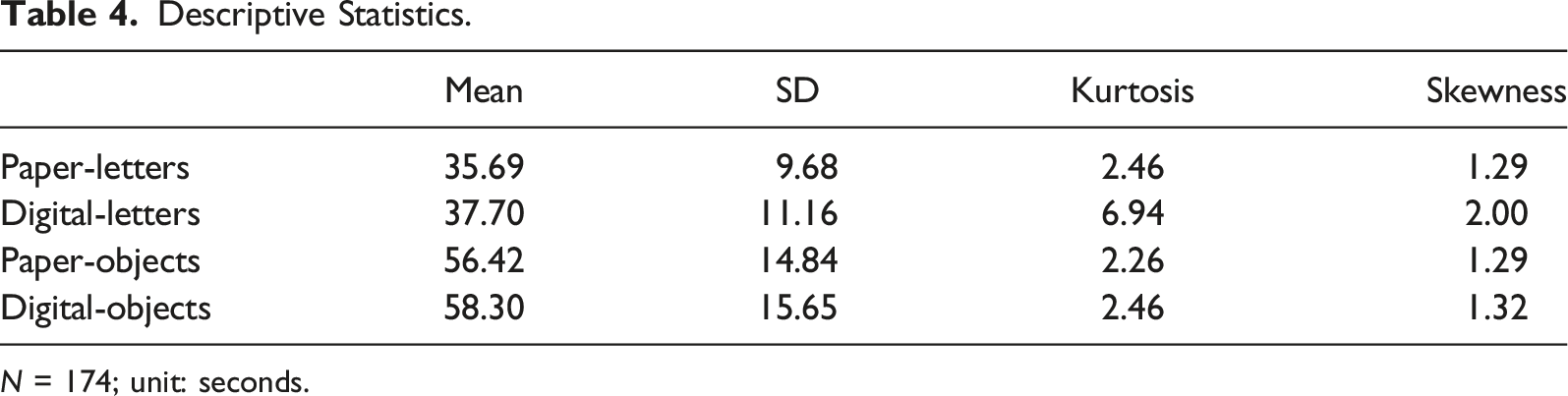
N = 174; unit: seconds.
Parallel Form Reliability.

Consistency Across Reading Proficiency Groups
The Pearson r between versions of the Letters subset was moderately to highly positive among both struggling and non-struggling readers. These two correlations were statistically significant (p < .05). Fisher’s z for these two correlations were non-significant (p > .05), indicating a non-significant difference in the correlations across the two groups.
Correlation Comparison Between Reading Proficiency Groups Across RAN Versions.
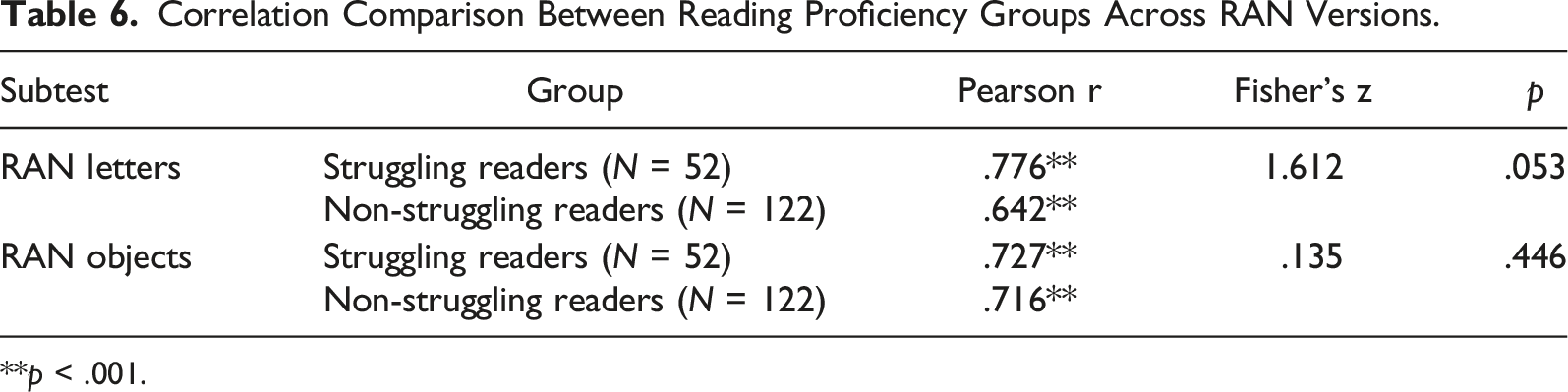
**p < .001.
Association Between RAN on Word Reading Proficiency
The correlations between the Letter subset of the RAN and the TOWRE score were moderately negative for both paper and digital versions. These relationships were statistically significant (p < .05). Fisher’s z for these two correlations was not significant (p > .05), indicating a non-significant difference in the correlations across the mediums.
Correlation Comparison Between RAN and TOWRE Across Mediums.
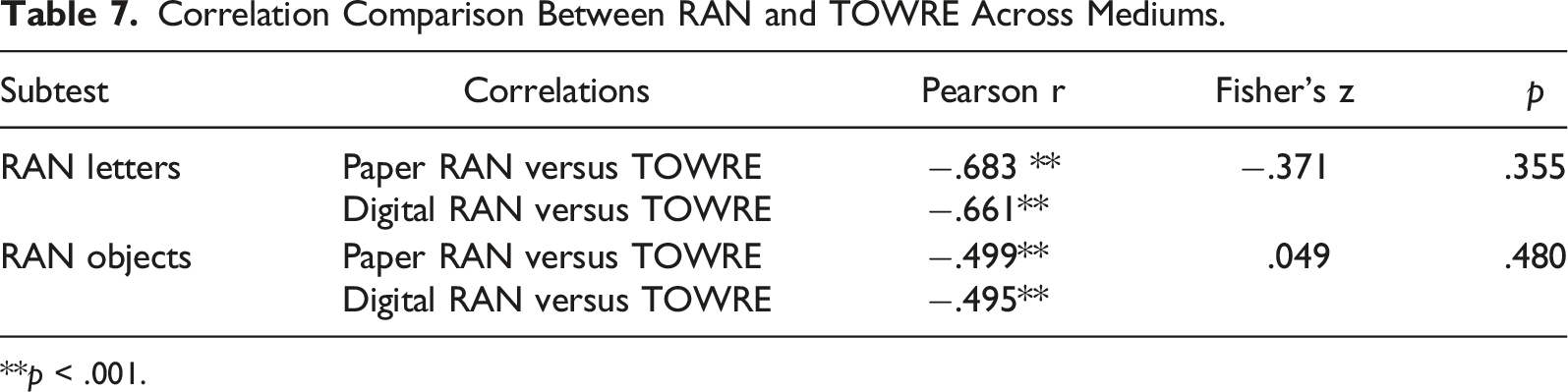
**p < .001.
Convergent Validity and Effects of Medium
Correlation Comparison Between RAN Letters and RAN Objects Across Mediums.

**p < .001.
Discussion
Most states in the U.S. currently require some form of early literacy screening for students (National Center on Improving Literacy, 2022), and increasingly screening may take place using digital devices. Many of these screeners include naming speed, ideally using RAN. Although RAN is one of the best early predictors of reading challenges (McWeeny et al., 2022), previous research has not demonstrated the efficacy of a digital RAN and its comparability to the traditional paper version of RAN in children. Here, we demonstrate that a diverse sample of second grade students’ performance on a digitized version of the Letters and Objects subsets of RAN administered via an iPad and on the traditional Letters and Objects RAN test is equivalent. More specifically, we found that the digitized version and the original paper version of the RAN were highly correlated, and such correlations were consistent across students’ levels of reading proficiency. In addition, we found that the digital version of the RAN was just as powerful a predictor of word reading proficiency as the traditional version. The digital version of the RAN measures the equivalent construct as the paper version does.
Although no previous research to our knowledge has compared the traditional and digitized RAN in children, our findings accord with previous research showing comparability of the RAN across mediums in healthy adults (Howe et al., 2006; Park et al., 2022). In addition, the high correlation found across mediums (.805) in the Letters subset of the classic RAN in our study aligns with the similarly high correlation (.85) found in the alphanumeric naming tasks between the classic RAN and an alternative RAN test developed by Decker (1989) (Compton et al., 2002). Together, findings from the current study suggest that the digitized version is a valid alternative to the original in this age group.
Wide-spread use of a digitized RAN requires that the test is a fair instrument across students with different levels of reading proficiency and that differences as a function of RAN test medium are not related to reading proficiency. Our findings suggest that the digitized RAN is equivalent to the traditional RAN for students who are poor readers and for average or above readers. Results offer preliminary assurances of its usefulness.
It is important to note that children in our sample performed better in the Letters subset of the RAN compared to the Objects subset. This in fact supports the previous finding by Norton and Wolf (2012) that RAN latencies are related to how automatized the naming process was, not how early the children learned the names of the stimuli. For this reason, young children ages 5–6 years often name non-alphanumeric stimuli (e.g., objects) faster than alphanumeric stimuli (e.g., letters). However, automatization increases with more exposure and practice with letters in the school setting, and by first grade, alphanumeric stimuli become much more automized than non-alphanumeric stimuli. In our sample of second-graders, the alphabet appears to be much more automatized than object names as we would expect. Such a difference in the level of automatization between letters and objects explains the relatively low correlations between the Letters and Objects subset across both mediums.
Aside from reducing the size of the stimulus to fit on an iPad, we underscore that we kept the same layout as the classic RAN test, only varying the medium. Many existing naming-speed tests have varied the number and type of stimuli. Emerging readers, particularly struggling readers, require a substantial number of stimuli before their system is taxed sufficiently so as to expose challenges to automaticity in their retrieval processes. The fifty-item structure has proven more efficacious in discriminating children with fluent retrieval weaknesses than measures with fewer stimuli (O’Rourke et al., 2001). We urge, therefore, caution in generalizing the present results to naming-speed tests that have reduced the number of stimuli, despite the advantage of efficiency in administration.
We used a moderate-sized sample from three substantially different schools and demonstrated equivalence across RAN mediums. As complete demographic data were not available, we plan future research to test the equivalence of the traditional and digitized RAN for a larger sample with other sub-populations of students. Further, future research should investigate affordances and challenges of digital RAN screening as a function of various socio-cognitive aspects of the student, and investigate various other reading measures, in addition to the TOWRE used here, to provide a more comprehensive understanding of individual differences in students’ reading competencies.
Summary
RAN represents one of the most universal predictors of reading and is a component in many dyslexia screeners. As digital screeners for dyslexia become increasingly common, the data presented here indicate that a digitized RAN screener that adheres to basic principles around assessing retrieval can be an effective alternative to the traditional, print-based RAN for most young children, including struggling readers.
Footnotes
Declaration of conflicting interests
The author(s) declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: One of the authors in this report is a co-author of the RAN test, which was studied in the current manuscript.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Office of Special Education Programs, Office of Special Education and Rehabilitative Services, (H326M190005).
Appendix
One-Way ANOVA to Test Randomization Group Differences.
Tests
Sum of squares
df
Mean square
F
p
Paper-letters
Between groups
93.55
3
31.183
.329
.805
Within groups
16,127.692
170
94.869
Total
16,221.241
173
Paper-objects
Between groups
1169.56
3
389.853
1.796
.15
Within groups
36,910.814
170
217.122
Total
38,080.374
173
Digital-letters
Between groups
401.285
3
133.762
1.076
.361
Within groups
21,129.175
170
124.289
Total
21,530.46
173
Digital-objects
Between groups
881.646
3
293.882
1.203
.310
Within groups
41,512.814
170
244.193
Total
42,394.46
173