
Abstract
Rapid automatized naming (RAN) powerfully predicts word-level reading fluency in the first 2 years of school as well as further reading development. Here, we analyze various RAN stimuli (objects and digits) and oral/silent word reading (OWR/SWR) modalities to find feasible measures for predicting early reading development. The RAN performances of 127 children starting first grade were assessed. The children’s oral and silent word reading skills were then reassessed in the second grade. Linear regression models and relative weight analysis were used to compare reading and screening modalities and further precursors of reading such as phonological awareness and nonverbal IQ were controlled. Scores from the first grade RAN assessment did not differentially predict second grade OWR versus SWR levels. RAN digits predicted word reading development more strongly than RAN objects, which contributed uniquely when predictions used only RAN variables. However, when different precursors of reading were controlled, only RAN digits helped to predict early reading performance.
Introduction
Fluent word reading is a crucial skill for comprehension, imagination, and learning (McLaughlin et al., 2014). The first 2 years of schooling are pivotal in developing this skill, as it predicts future reading levels (Cook, 2003; Juska-Bacher et al., 2021). To prevent children from failing, early screening is essential to implement specific intervention (Jenkins et al., 2007; Vaughn & Fuchs, 2003). Various potential predictors for fluent word reading have been studied, such as phonological information processing (Bowers, 1995; Kirby et al., 2003; Manis et al., 2000) and language (Juska-Bacher et al., 2021; Silverman et al., 2021). This study aims to examine another predictor, rapid automatized naming (RAN), which is seen as a universal precursor of reading throughout different orthographies (Landerl et al., 2021). RAN refers to the ability to quickly decode well-known stimuli (e.g., familiar objects) and spell them out rapidly. It is of special interest for education as it allows for a quick and economic assessment with high predictive power to detect potential children at risk for reading failure.
This paper examines the differences in the predictive power of different types of RAN stimuli (alphanumeric vs. nonalphanumeric) assessed at the beginning of grade 1 for word reading and in two different reading modalities (oral vs. silent reading) at the beginning of grade 2. The study focuses on a phase where the significance of the RAN stimuli may be subject to change (i.e., non-alphanumeric stimuli lose significance while alphanumeric ones gain significance). The results are important for early school-based screening purposes to determine which type of RAN stimuli is predictive for further reading development. The study takes up the distinctions between alphanumeric and nonalphanumeric RAN stimuli and between oral and silent reading modalities, which arose in a longitudinal study (project SCHNAPP) that aims to identify specific risk patterns for school-based learning to read and write in the first weeks of first grade. Screenings should be of good predictive power, feasible, and ecological.
Predictors of Word Reading
Predictors of word reading can be divided into environmental and child-centered factors. Environmental predictors include poor socioeconomic background and disadvantaged family circumstances, which have been found to have negative effects on reading ability (Carroll et al., 2014; Hart & Risley, 2003; Rutter & Yule, 1975). However, Law et al. (2014) found that the number of books in a household was positively correlated with early reading ability, even after controlling for family income. Similarly, Wolf (2008) found that the amount of talking, listening, and reading young children are exposed to predicts reading development through prerequisite language skills.
Child-centered predictors of word reading can be further divided into linguistically based skills (such as phonological knowledge and vocabulary) and visual skills (such as visual attention). Grainger et al. (2016) provide an overview on the predictive power of these skills. Linguistically based predictors, such as letter knowledge, phonological awareness, and RAN, have been found to be robust predictors of word reading across different orthographies (Landerl et al., 2021). Phonological working memory also frequently supplements these predictors (Pinto et al., 2015). Snowling et al. (2021) recently carried out a longitudinal study showing the influence of basic levels of linguistic competencies, such as vocabulary and grammar, on the development of specific learning disorders. Additionally, linguistic deficits in children with diagnoses of reading problems are observed retrospectively by parents more often than in average or good readers (Price et al., 2021). Nonverbal IQ has been found to have little direct predictive power for word reading performance in previous longitudinal studies (Ozernov-Palchik et al., 2017). However, it must still be controlled due to the developmental relationship between nonverbal IQ, vocabulary, and reading (Blaga et al., 2009; Gustafsson & Undheim, 1992).
This study focuses on child-centered predictors of word reading and analyzes a specific language-related predictor that has the most predictive power for reading across different orthographies. Additionally, transparent orthographies and specific predictive conditions will be highlighted.
Word Reading in Transparent Orthographies
Word reading comprises several components, including phonological analysis of written words (Ehri, 1995), orthographic processing for forming storing, and accessing orthographic representations (Stanovich & West, 1989), and lexical access to word meaning. Differences in reading acquisition are well documented among languages, with children learning to read more easily in transparent orthographies with high symbol-sound consistency, such as Italian, compared to complex and opaque ones, such as English. A large European network analyzing 13 different languages revealed hardly any reading errors after 1 year of schooling in transparent orthographies, while children acquiring more complex orthographies struggled more (Seymour et al., 2003).
In German orthography, which is characterized by low complexity and high transparency, reading difficulties manifest early as reduced word reading speed without difficulties in reading accuracy (Esser et al., 2002; Gasteiger-Klicpera et al., 2006; Kohn et al., 2013; Moll et al., 2014; Schulte-Körne, 2010). These reading differences across languages and orthographies suggest different underlying neurocognitive processing mechanisms and associated predictors. As a result, phonological awareness is less important as a predictor of later reading skills in transparent orthographies, and RAN and letter knowledge are more important (Landerl et al., 2013; Share, 2008).
In German-speaking countries, children typically enter school as nonreaders or prereaders without formal phonic instruction (Landerl, 2009). German kindergartens and preschools generally provide minimal literacy content (Kuger et al., 2013), with teaching often limited to phonological awareness exercises and first encounters with the written language, such as learning to write one’s name). However, written language knowledge varies greatly among children due to differences in family promotion of literacy skills. Thus, at the beginning of grade 1, children’s knowledge of phonological awareness, letter knowledge, reading, and spelling skills can be quite diverse. A key goal of early schooling is to read words accurately and fluently. In transparent orthographies like German, reading accuracy is typically mastered after a few months of systematic instruction (Aro & Wimmer, 2003; Seymour et al., 2003; Wimmer & Hummer, 1990), even among relatively poor readers (Landerl & Wimmer, 2008). However, nonfluent readers may still be present among these students, showing rather slow and laborious reading (Landerl, 2001). Therefore, it is crucial to identify precursors for pinpointing reading difficulties as early as possible.
In contrast to complex orthographies where phonological knowledge is the best predictor of reading performance, RAN has even more predictive power to identify non-fluent readers in transparent ones.
RAN and its Predictive Power for Reading
The RAN task involves quickly naming familiar visual stimuli, such as alphanumeric characters (e.g., digits or letters) or non-alphanumeric items (e.g., objects or colors) presented in a random order. This assessment is typically done by having children name a set of limited items as quickly as possible. Although there are different paradigms used for assessing RAN, the total response time for sets of items (digits, objects, letters, colors) has been shown to be a significant predictor of reading fluency. Even after controlling for IQ, children with low reading rates perform significantly worse than those with average reading fluency, as demonstrated in the original task by Denckla and Rudel (1974). Although other paradigms for assessing RAN exist (e.g., pause time versus articulation times; Georgiou & Parrila, 2020), they are not feasible for daily school use.
RAN involves several processes that are closely related to reading, including perceptual analysis of the symbols or objects, memory retrieval (comparison with previously experienced symbols or objects), semantic mapping of the stimuli, and cross-linking of visual processing with language information (verbal comprehension), followed by the phonological response of naming the word aloud.
In a meta-analysis of 137 studies, the correlation between RAN and reading performance was found to be moderate to strong across multiple languages (see Araújo & Faísca, 2019 for a review; Araújo et al., 2015). Specifically, RAN was found to strongly and significantly correlate with reading speed for words (r = .43 to r = .47) and nonwords (r = .38 to r = .42), with the highest impact on reading fluency (r = .49), followed by reading accuracy (r = .42). Furthermore, RAN correlated with word reading (r = .45) and nonword reading (r = .40). Nonetheless, this study has not examined the unique impact of RAN on reading. In other studies, however, RAN was found to predict word reading independently of other predictors, such as processing speed (e.g., Georgiou et al., 2008), phonological awareness (e.g., Manis et al., 2000), orthographic and morphologic knowledge (e.g., Georgiou et al., 2009), a combination of these factors (e.g., Georgiou et al., 2016; Poulsen et al., 2017), and IQ (Duzy et al., 2014). Additionally, a recent meta-analysis focusing on kindergarten children showed that RAN had a unique predictive association with reading (r = −.25) even after controlling for phonological awareness (McWeeny et al., 2022). However, it remains to be seen whether this unique predictive power remains when RAN is assessed at school entry level as well as kindergarten.
Effects of Different RAN Stimuli
RAN tasks are commonly used in screening procedures to predict reading achievement. However, there are variations in mode of presentation (serial vs. discrete), output (overt articulation vs. simple motor responses), and stimulus type (alphanumeric vs. non-alphanumeric stimuli) among RAN tasks. Previous research has indicated that the number of items used does not influence RAN-reading regressions (Araújo et al., 2015).
Regarding the mode of presentation and output, studies with Greek-speaking second graders indicated that serial RAN tasks and overt articulation seem to optimize the prediction of reading development (Georgiou et al., 2013). This finding is supported by a recent literature review (Landerl et al., 2021).
Non-alphanumeric RAN stimuli such as pictured objects and colors are powerful predictors of reading development in preschool settings (De Jong et al., 1999; Kirby et al., 2003; Lervåg & et al., 2009; Huschka et al., 2021 for German orthography). In contrast, alphanumeric stimuli such as letters and digits are better predictors from primary school age onward (Araújo et al., 2015; Georgiou & Parrila, 2020). Norton and Wolf (2012) also highlighted the temporal relationship between the predictive power of these two types of stimuli. Through formal reading instruction and exposure to letters and numbers, alphanumeric stimuli become more significant over time.
Similar to the results obtained for English orthography, when RAN was assessed with Italian children aged 4 years, colors and objects were better predictors of later reading skills. However, 1 year later, as students were increasingly exposed to numbers and letters, the difference between nonalphanumeric and alphanumeric stimuli disappeared (Ceccato et al., 2019). Mayer’s study (2018) produced similar results for first-to-fourth-graders in German when RAN was measured at the end of each academic year. The correlations of word reading with RAN digits and RAN colors were r = .79 and r = .47, respectively. Nonetheless, nonalphanumeric stimuli such as RAN objects can also predict later reading skills for children beginning formal reading instruction in German-language settings. For example, the assessment of RAN objects among first grade students predicted their level of reading fluency up to grade 8 (Landerl & Wimmer, 2008).
Landerl et al.’s recent review (2021) suggested that RAN tasks should be assessed before actual reading instruction begins to clarify the influences of reading acquisition itself when used to predict reading skills. Although these authors recommended using alphanumeric RAN stimuli, there is still no consensus about whether to use alphanumeric or nonalphanumeric stimuli at the earliest stages of formal reading instruction.
Prediction of Oral and Silent Reading by RAN
Reading skills can be assessed using two different methods as follows: oral reading, typically carried out one-to-one with reading lists of words or nonwords in a speed condition, and silent reading, which is applicable in group settings and requires connecting a given word to a target word out of a variety of pictures in a time frame. Established tests for oral reading include the SLRT-II (Moll & Landerl, 2014; rtt = .91; for further instruments and overview of psychometric properties see Galuschka et al., 2015) for German and the TOWRE-2 (Test of Oral Reading; Torgesen et al., 2012; for psychometric properties see Tarar et al., 2015) for English, while the ELFE-II (Lenhard et al., 2017; rtt = .83 on word level; for further psychometric properties see Renner & Scholz, 2020) and TOSWRF-II (Test of Silent Word Reading-II; Mather et al., 2004) are examples of tests for silent reading. Although oral and silent reading are closely related, they consist of distinct sets of skills (Kim et al., 2011).
Several studies have compared the influence of RAN on oral versus silent reading. Desimoni et al. (2012) found that RAN (alphanumeric: letters) was more closely related to reading aloud than to reading silently in second grade Italian children. van den Boer et al. (2014) also found that RAN (alphanumeric: letters and digits) was more strongly correlated with oral than silent reading among Dutch fourth graders. However, the differences were small, suggesting that both modalities represent similar reading processes. More recently, Georgiou and Parrila (2020) reported differences in the predictive power of RAN (alphanumeric stimuli: letters) for silent and oral reading in English-speaking second graders and university students, with higher correlations for oral reading (r = −.56) than silent reading (r = −.40) in second grade.
Aims and Research Questions
In this study, we aim to investigate the relationship between reading skills (oral vs. silent) and RAN modes (serial digit naming vs. serial object naming), and to examine the predictive validity of different RAN modes for later development of word reading skills. Specifically, we aim to answer two research questions.
The first research question (RQ1) is whether RAN, assessed at school entry, correlates differently with second grade oral and silent fluent word decoding. We aim to investigate the predictive validity of RAN modes related to reading modes. Previous studies have suggested that RAN would be more strongly correlated with oral than silent word reading fluency (Desimoni et al., 2012; Georgiou and Parrila (2020)), or that there would be little difference (van den Boer et al., 2014). However, to our knowledge, no prior study has tested whether the differences in the correlations for RAN modes and reading modes are statistically significant. Therefore, we will explicitly test for the significance of correlation differences.
The second research question (RQ2) is whether serial object naming (RAN objects), assessed at the beginning of first grade, can add to the predictive power of serial digit naming (RAN digits) in predicting second grade word decoding, that is, whether there is incremental validity. Prior studies have shown that nonalphanumeric stimuli (objects and colors) are better predictors of later reading acquisition among preschoolers, but alphanumeric stimuli (digits, letters) are more powerful predictors for children’s reading skills from second grade onwards (Araújo et al., 2015). However, it remains unclear whether non-alphanumeric stimuli, such as objects, can provide unique contributions to the prediction of word decoding in the presence of alphanumeric stimuli, such as digits. Therefore, we will investigate the unique predictive power of RAN objects by controlling for RAN digits.
Methods
Sample and Procedure
At the end of September 2018 (t1), shortly after their schooling had begun, we assessed several precursors of reading ability in a sample of n = 143 first grade children (6 classes) from two Austrian elementary schools; one from an urban area and one from a rural area. For pragmatic and organizational reasons, schools with a large number of first graders (by Austrian standards) and with principals open to research projects were selected. The sample of n = 134 amounts to 93% of the total number of first graders of the two schools. The parents of the remaining 7% of first graders (n = 10) did not gave their written consent to participate in the study. Moreover, 13 children attending a preschool or preparatory school year and 12 children with incomplete assessments were excluded from the statistical analyses. Finally, 118 first graders participated at t1. In December 2019 (t2, i.e., second grade), silent and oral word reading was reassessed in 113 of the 118 children (2 children had moved to another school; one child was repeating the first class, and two children were not in school on test day). The mean age of the final sample used in this study (n = 113; (64.6% girls and 35.4% boys) was 6 years and 9 months (SD = 7.2 months). 26% of the children were bilingual.
All tests were administered by trained teacher education students. The screening measures at t1 and t2 were assessed in one-on-one settings, except for the silent word reading at t2, which was administered to the whole class as a group assessment. All assessments took place on school mornings.
Measures
RAN
Two different naming speed tasks (objects and digits) were used at t1. A paper copy of the task was distributed to the participants, whose responses were evaluated in parallel on Ipads. Each participant was given a test run in which they named five monosyllabic stimuli (pictures of a hand, a cow, a tree, a mouse, ice) together with the investigator, thus ensuring the children knew these high-frequency words. Where children were unable to recall the object names with confidence, the practice session was repeated as often as necessary. The child was then asked to repeat the pictures, arranged in six lines in different orders, as quickly as possible. The total time of articulation was measured with a timer in the evaluation app on the Ipad, which, like a stopwatch, was started by the investigator with the first word mentioned by the child and stopped after the last. The number of errors was recorded by the investigator by clicking on the wrongly named item. In a second run, five monosyllabic digits were offered in place of the objects. RAN in the digit condition was based on the work of Denckla and Rudel (1974), with the construction of the test following Landerl et al. (2013) for more details. Items (digits 1, 2, 3, 6, 8) were again arranged in six lines of five items each. Shorter articulation times reflected higher RAN competences. The tests items are depicted in the supplement. The average processing time for both RAN tasks was about 35 seconds (SDdigits = 12.5; SDobjects = 8.4; see Supplementary Table S1 in the supplement).
Outcome Measures: Silent Reading Fluency
The standardized and recently re-normed word reading test ELFE II (A Reading Comprehension Test for First to Seventh Graders–Version II; Lenhard et al., 2020) was used to measure children’s silent reading word decoding competencies (SWR) at the end of second grade (t2). For each picture, the appropriate word had to be selected from four alternatives and underlined. Processing time is limited to 3 minutes. Representative norm values for grades one to seven are available. The number of correct items (i.e., raw score) was used as the dependent variable and serves as a robust score for the following sentence and text reading competencies (Richter & Christmann, 2002). The odd-even-split-half reliability of the paper test for the second grade was r = .98 (Lenhard et al., 2020).
Oral Word and Nonword Reading Fluency
The DiLe-D test (Differentiated Reading Test–Decoding; Paleczek et al., 2017) was used to assess decoding skills in oral reading at t2. The DiLe-D test was developed and validated for first to third graders, and provides grade-specific norm scores. Children are asked to read aloud, as accurately and as fluently as possible, line by line. The test time is limited to 1 minute for real words (OWR) and nonwords (ONR). The retest reliability for second grade children was rtt = .96. For the analyses of this paper, we used raw scores.
Control Variables
We used the following control variables that are known precursors of reading ability and are also associated with RAN in German (Ennemoser et al., 2012; Gellert & Elbro, 2017; Juska-Bacher et al., 2021; Landerl et al., 2021): 1) letter knowledge, 2) nonverbal IQ, 3) phonological awareness (PA), and 4) language skills. For details see supplement section “control variable measures.”
Methods of Analysis
To answer RQ 1, we estimated the correlations between RAN and the reading modes. To statistically compare the correlations, we estimated confidence intervals (CI) for their differences (e.g., rRAN-Objects, Reading aloud - r RAN-Digits, Reading aloud) applying the method proposed by Zou (2007) and implemented in the cocor R-package (Diedenhofen & Musch, 2015). We measured effect sizes using Cohen’s q (Cohen, 1988) to quantify differences in correlations. Following Cohen, r and q-values are interpreted as follows: q/r < 0.1 = no effect; 0.1 ≤ q/r < 0.3 = small effect; 0.3 ≤ q/r < 0.5 = moderate effect; q/r ≥ 0.5 = large effect.
To answer RQ 2, we used hierarchical regression analyses (for information on assumption checks see supplement). In order to assess the incremental contribution of RAN objects in predicting reading, we entered RAN digits in a first step (i.e. Reading = b 0 + b 1 RAN digits + e) and additionally entered RAN objects in a second step resulting in the following model: Reading = b 0 + b 1 RAN digits + b 2 RAN objects + e. The change in R2 (ΔR2) associated with entering RAN objects indicates whether RAN objects explain variance in reading above and beyond RAN digits and thus, ΔR2 is a measure of incremental validity. However, any shared explanatory variance of the two RAN measures is credited to the variable first entered in the regression model (i.e., RAN digits). Therefore, ΔR2 is not suitable to assess how much variance explained in reading can be attributed to the two RAN measures, that is, ΔR2 does not inform about the relative importance of RAN digits and RAN objects in predicting reading. Similarly, standardized regression coefficients are flawed estimates of predictor importance, when the predictors are correlated (the two RAN measures correlate with r = .616, p < .001).
As LeBreton et al. (2007, p. 477) note, a regression based incremental validity analysis may show only a small (insignificant) increment in the prediction, even when the overall contribution of the entered variable (here RAN objects) in predicting the outcome is as large or even larger than the contribution of the step 1 predictor (here RAN digits). Relative weight analysis (RWA), which has been proposed as a supplement to regression analysis (Tonidandel & LeBreton, 2011), overcomes these issues. RWA properly partitions the explained variance among correlated predictors and thus allows us to better understand the role of the two RAN modes in predicting reading ability.
In detail, RWA partitions the total R2 of a model (i.e., the model of step 2) into parts (raw relative weights, RRW) explained by the respective predictors. RRWs can also be rescaled to reflect the percentage contribution of a predictor to the total R2. Moreover, a bootstrap procedure (we used 10,000 bootstrap samples) additionally allows for estimating a 95% confidence interval (CI) for the RRWs and also for the difference in the RRWs of two predictors. Thus, it is also possible to test whether the importance of two predictors—in our case, the two RAN modes—significantly differ.
As the association between RAN and reading may be confounded by other precursors of reading, we ran a second set of analyses (regression and RWA) considering the control variables described above. Focusing again on the incremental validity of RAN objects in the regression analyses, we entered the control variables together with RAN digits in step 1 and RAN objects in step 2. RWA was conducted with all predictors of step 2. We used the Relative Importance Shiny App (Tonidandel & LeBreton, 2015) for RWA. Regression analyses were conducted using Jamovi 2.2.5 (The jamovi project, 2022).
Results
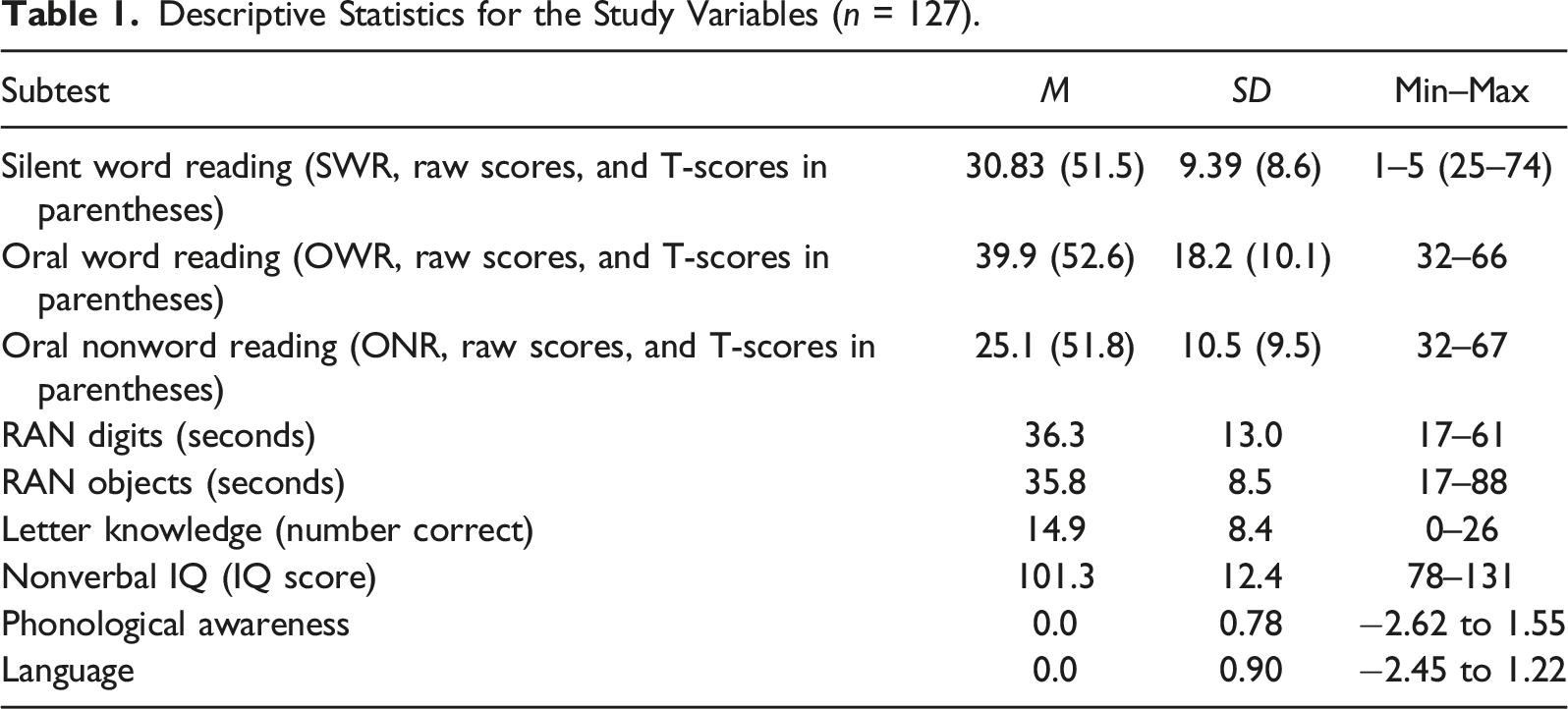
Descriptive statistics and correlations for all study variables are presented in Supplementary Table S1 in the supplement. The means for the reading measures, for which norm scores (t-scores) are available, indicate that the word reading abilities in the sample are slightly – for OWR significantly – above the population mean of 50 (MSWR = 51.2, SDSWR = 8.56, deviation from the population mean d = .15, p > .05; MOWR = 52.6, SDOWR = 10.01, d = .26, p < .01; MONR = 51.5, SDONR = 9.05, d = .17, p > .05). As expected, reading is significantly correlated with most other variables, whereas correlations between reading and RAN, and reading and letter knowledge are among the highest (r-values between −.243 and −.471). Moreover, the RAN modes are also significantly (up to r = −.472 for RAN digits and letter knowledge) correlated with the other precursors of reading.
Research Question 1
Descriptive Statistics for the Study Variables (n = 127).
Research Question 2
Regression and RWA Results.
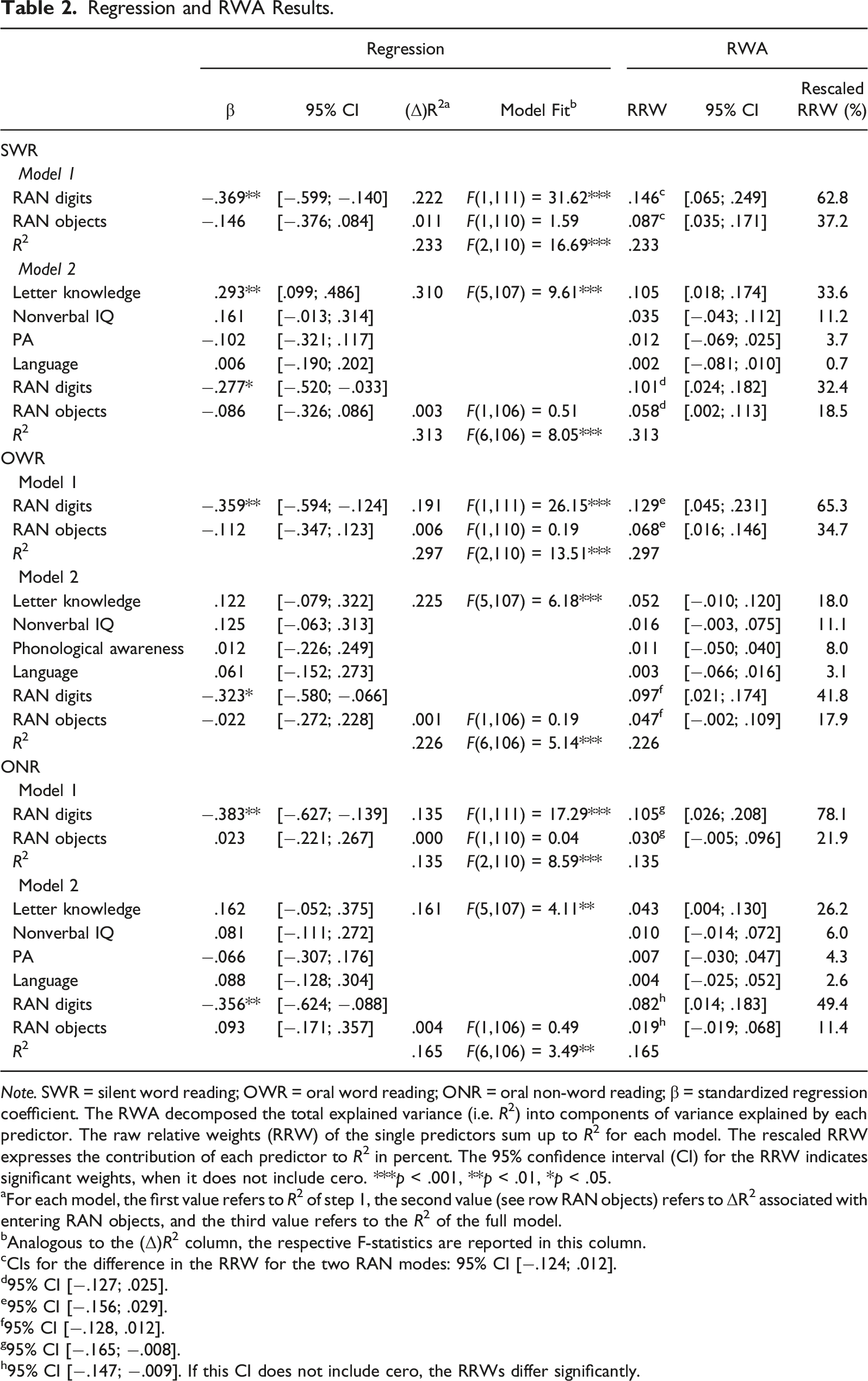
Note. SWR = silent word reading; OWR = oral word reading; ONR = oral non-word reading; β = standardized regression coefficient. The RWA decomposed the total explained variance (i.e. R2) into components of variance explained by each predictor. The raw relative weights (RRW) of the single predictors sum up to R2 for each model. The rescaled RRW expresses the contribution of each predictor to R2 in percent. The 95% confidence interval (CI) for the RRW indicates significant weights, when it does not include cero. ***p < .001, **p < .01, *p < .05.
aFor each model, the first value refers to R2 of step 1, the second value (see row RAN objects) refers to ΔR2 associated with entering RAN objects, and the third value refers to the R2 of the full model.
bAnalogous to the (Δ)R2 column, the respective F-statistics are reported in this column.
cCIs for the difference in the RRW for the two RAN modes: 95% CI [−.124; .012].
d95% CI [−.127; .025].
e95% CI [−.156; .029].
f95% CI [−.128, .012].
g95% CI [−.165; −.008].
h95% CI [−.147; −.009]. If this CI does not include cero, the RRWs differ significantly.
Notably, in contrast to the regression results, the RWA indicated that RAN objects explained a significant proportion of the variance in SWR (raw relative weight [RRW] = .087, 95% CI [.035, .171]) and OWR (RRW = .068, 95% CI [.016, .146]), accounting for one-third of the total R2 (SWR rescaled RRW = 37%; OWR rescaled RRW = 35%). RAN digits accounted for the remaining two-thirds of the variance explained. Moreover, the RWA also indicated that the shares of variance explained did not differ significantly between the RAN modes for SWR and OWR. However, for ONR, RWA – in line with the results of the regression analysis – indicated that only the effect of RAN digits was significant. The RWA additionally showed that the effect of RAN digits (RRW = .105, 95% CI [.026, .208]) was significantly stronger than that of RAN objects (RRW = .030, 95% CI [−.005, .096]; 95% CI for the RRW difference [−.165, −.008]). When the set of reading precursors was controlled for (Model 2 in Table 2), regression analyses again indicated that RAN objects did not make an incremental contribution in the prediction of reading. For SWR, the RWA again indicated that RAN objects accounts for a significant share of variance of the outcome (RRW = .058, 95% CI [.002, .113], rescaled RRW = 19%). For OWR and ONR however, both RWA and regression analyses showed no effect of RAN objects. Notably, out of all predictors of Model 2, only letter knowledge significantly contributed to the prediction of reading beside the RAN measures (see regression and RWA for SWR and RWA for ONR).
Discussion
Early identification of reading disabilities in children is crucial for providing timely and effective support. While RAN is recognized as the best predictor of word and nonword reading (McWeeny et al., 2022; for German: Landerl & Wimmer, 2008; Moll et al., 2009), questions remain regarding its implementation in school screening procedures. This study investigated whether RAN stimuli (digits vs. objects) have differential correlations with different reading modalities (oral vs. silent) when formal reading instruction begins in grade 1 (RQ1). Thus, the study aimed to determine whether RAN’s predictive validity for reading fluency varies by RAN stimuli and reading mode. Additionally, the study examined whether RAN objects incrementally contribute to the prediction of word reading when controlling for RAN digits (RQ 2).
For RQ 1, our study found stronger correlations between RAN and silent word reading (digits: r = −.47; objects: r = −.40) compared to oral word reading (digits: r = −.44; objects: r = −.36), but these differences were not significant. This supports previous research that found minimal differences between reading modalities (van den Boer et al., 2014), but contradicts studies reporting higher correlations between RAN and oral reading (e.g., Desimoni et al., 2012; Georgiou & Parrila, 2020; Papadopoulos et al., 2016). Notably, as prior studies did not test whether correlations between reading modes and RAN differ significantly, conclusions about correlation differences might have been misleading.
Moreover, as expected, RAN digits had slightly stronger correlations with reading than RAN objects, but these differences were small (qs < .137) and not significant. This contradicts previous studies that found significantly higher correlations between reading and RAN digits than for RAN objects (Araújo et al., 2015; Mayer, 2018). The difference in results may be due to our focus on the start of formal reading instruction, where—just as in the preschool phase (Ceccato et al., 2019)—RAN objects may be more important predictors of reading. Our findings are consistent with a study of Greek speaking children (similarly transparent language as German) by Papadopoulos et al. (2016), who found similar results, even for RAN tested at mid of first grade. The non-significant differences in our study, however, may also be due to a lack of statistical power due to small sample size.
For RQ 2, we found that RAN digits consistently predicted reading and accounted alone for 14% (ONR) to 22% (SWR) of the variance in the reading measures. RAN objects did not explain variance in reading above and beyond RAN digits. All changes in R2 associated with entering RAN objects as predictor in the regression equation were insignificant. Thus, from an economic screening point of view, our results suggest that RAN objects is not needed to predict reading problems when RAN digits is already considered as a predictor. However, if we take a somewhat different perspective and ask for the unique explanatory power of RAN objects (i.e., relative importance) in the presence of RAN digits, the results of relative weight analyses indicated that RAN objects accounted for a unique explained variance of about 7–9 % in silent and oral word reading (i.e., about one-third of the total variance explained), whereas RAN objects explained about 13–15%. Therefore, the two RAN measures might tap into different aspects of the RAN-reading association (Georgiou & Parrila, 2020).
Furthermore, we found that RAN digits predicted oral nonword reading significantly better than RAN objects, based on different aspects the stimuli have in common with reading. Again, this result is an indication for the preference of RAN digits when the choice between digits and objects should be made, confirming the recommendation made by Landerl et al. (2021) to use alphanumeric instead of nonalphanumeric stimuli at school entry for predicting later reading.
Practical implications
In summary, our findings indicate that RAN assessed at the beginning of grade 1 has similar predictive validity for second grade word and non-word reading. The selection of RAN stimuli is crucial for the construction of effective and economic assessment tools. RAN digits appear to be the first choice, given the somewhat higher correlations with reading and the insignificant incremental contribution of RAN objects in the prediction of reading. However, for effective screening, a broad set of reading precursors should be considered (e.g., Schöfl et al., 2021; Silverman et al., 2019) in order to detect risk patterns for reading development early on and provide adequate interventions.
Limitations
The study has found significant correlations between RAN assessed at the beginning of Grade 1 and reading performance in second grade. However, other factors such as cognitive aspects of RAN stimuli, reading socialization via parents, school, and friends, and macrolevel social influences should be considered as potential predictors of reading development. Additionally, the small convenience sample size limits the statistical power and generalizability of the results. Future research should use larger representative samples to test for differences in predictive and incremental validity using more RAN modes.
Supplemental Material
Supplemental Material - Are Both Object and Alphanumeric Rapid Automatized Naming Measures Required to Predict Word Reading Fluency in German Prereaders?
Supplemental Material for Are Both Object and Alphanumeric Rapid Automatized Naming Measures Required to Predict Word Reading Fluency in German Prereaders? by Martin Schoefl, Susanne Seifert, Gabriele Steinmair, and Christoph Weber in Journal of Psychoeducational Assessment
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.