
Abstract
This article offers a new account of rising inequality by providing a new explanation for the observed correlation between computerization and earnings. The argument is that as computers transformed work into a more knowledge-intensive activity, occupations located at critical junctions of information flow have gained greater structural power, and thereby higher wages. Combining occupational measures for location in the information flow based on the Occupational Information Network with the 1979–2016 Current Population Surveys, the analyses reveal a rising wage premium for occupations with greater access to and control of information, independent of the spectrum of skills related to computerization.
Social science explanations for rising wage inequality have reached a dead end. Most economists argue that computerization is primarily responsible, while on the other side of the argument, sociologists and political scientists stress the role of political forces in the evolution process of wages. This article highlights the complex dynamics between technology and politics (broadly defined) in order to progress in solving an unsettled question regarding the role of computerization in rising wage inequality: What are the mechanisms behind the well-known observed positive correlation between computers and earnings? To provide a possible answer to this question, I explicitly theorize how computerization has transformed the labor process 1 in a way that had profound effects on workplace power relationships. I argue that computers have opened up new opportunities for enhancing the earnings of the already privileged by placing already well-rewarded occupations at critical junctions of information flow, capitalizing their access to and control of information on the labor process. This has led to an increase in their bargaining power, hence also in their relative earnings. In other words, while Google and Facebook have made fortunes from controlling personal information on their users, and spreading of organizational information to workers increases their earnings (Rosenfeld & Denice, 2015), this article maintains that it is mainly high-wage workers who have benefited from computers transforming work into a more knowledge-intensive activity.
This new structuralist theory on wage inequality developed in this article rests on what have become two stylized facts in the landscape of widening inequality. The first is that the computer revolution in the workplace fulfills an important role in rising wage inequality (Kristal & Cohen, 2017), and some would argue for a critical role (Acemoglu & Autor, 2011). The second stylized fact is that rising wage inequality is increasingly driven by the between-occupation component of inequality (Autor et al., 2006; Liu & Grusky, 2013; Mouw & Kalleberg, 2010; Williams, 2013) in parallel with high-wage occupations being increasingly sorted into high-wage firms (Song et al., 2015). One way to theorize the relation between these two stylized facts is the Skill-Biased Technological Change (SBTC) thesis. This posits that computers have increased the productivity of, and demand for, high-skilled workers and occupations, thereby raising their wages above those of the less skilled (Autor et al., 2003). To be specific, the argument is that work with computers complements cognitive tasks (sometimes also termed abstract and analytic tasks); therefore, they will tend to expand their labor demand. Because it is impractical to quantify the concepts of productivity and market forces, most evidence relates to the relation among computers, individual or occupational skill, and wages.
This article theorizes and empirically tests an additional relation between computerization and expanding between-occupation wage inequality. Like the SBTC thesis, it assumes that computer-based technology has affected wage distribution not only by the use (or nonuse) of computers at work but also by transforming work into a more knowledge-intensive activity. The SBTC thesis underlines a productivity-enhancing mechanism observable by comparing returns on skill group or use/nonuse of computer; by contrast, this article underlines a power-enhancing mechanism observable by estimating wage payoffs on occupations that differ in their structural location in the information flow (see Figure 1).
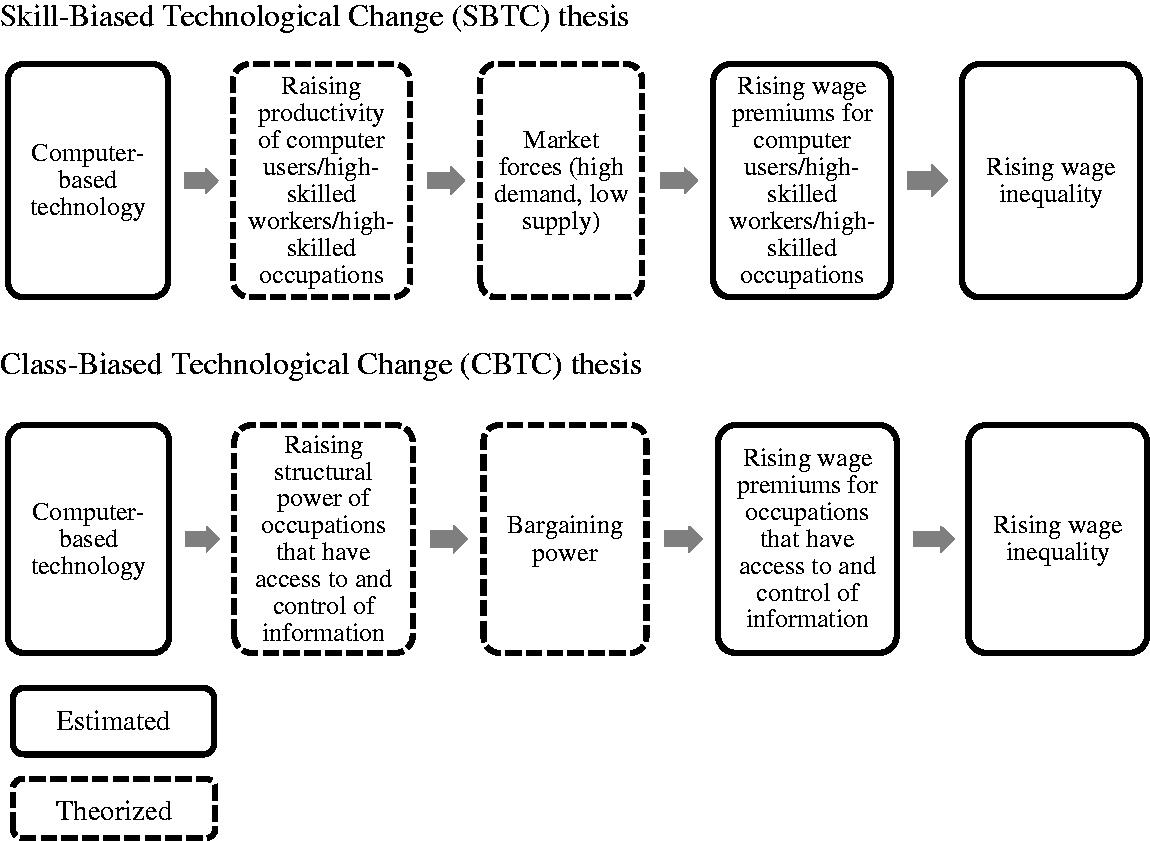
SBTC and CBTC Hypotheses on the Mechanisms That Link Computerization and Rising Wage Inequality.
Where does occupational structural power come from in the age of the computer revolution? The general argument is that computerization provides a structural basis for the further enrichment of already well-rewarded occupations through their control of and access to information. At the same time that digital computers made information more available and important, digitization eased the commodification of information. Like other economic goods with some scarcity and value, information thenceforth became more controlled and asymmetric, an asymmetry that particularly plays between occupations. Occupations differ in their access to (e.g., through the retrieval of outputs of computerized technology) and control of (e.g., through the design of computer systems) information on the production process, hence in their structural location in the labor process’s information flow. Occupations located at critical junctions of information flow will have a greater structural power than other occupations, workers’ and occupations’ skills regardless. This greater structural power, which is embedded in workers’ location in the labor process’s information flow, makes them indispensable, with greater consequences riding on the choices made by the workers who do these jobs. All these factors combine to produce considerable resources with greater bargaining power to extract higher wages. Certainly, occupations located at critical junctions of information flow are also likely to call for higher cognitive and technological skills than other occupations. Still, I expect to find a wage payoff for powerful occupations above the payoff for their technological skills.
Three main baseline assumptions, shared by many researchers studying inequality through a structural lens, are at the core of this conceptual framing. First, between-occupations earnings distribution is partly an outcome of the social relationships among occupations, where relatively powerful occupations get more money (Gorman & Sandefur, 2011; Grusky & Sørensen, 1998; Weeden, 2002). The second assumption is that occupational power, which can be thought of as the capacity of workers to realize their interests, partly results from the location of occupations within the economic system and production relations. 2 As past research demonstrated for social relations within workplaces (Choi et al., 2008; Tomaskovic-Devey & Avent-Holt, 2019; Wright, 1997) and hierarchical relations among workplaces (Kalleberg et al., 1981; Perrone et al., 1984; Wallace et al., 1989; Wilmers, 2017), structural locations in the economic system and production relations shape earnings distribution. The third and last idea explains why structurally powerful occupations get more money. It is simply because they have considerable resources, with greater bargaining power to extract rent in the form of higher wages (Avent-Holt & Tomaskovic-Devey, 2010; Tomaskovic-Devey & Avent-Holt, 2019).
To evaluate the theoretical argument, I estimate the wage premium in tasks related to entering, managing, and utilizing information and knowledge of the labor process. First I utilize the rich information from the Occupational Information Network (O*NET) to build measures at the occupational level for location in the information flow—from entering data to managing and utilizing data. I combine these representative data on occupational features with large samples of wage and salary workers from the monthly outgoing rotation group (MORG) supplement to the 1979–2016 Current Population Surveys (CPS-ORG) and with the CPS’s Annual Social and Economic Supplement (ASEC). The combined data make it possible to estimate the wage premium in tasks related to entering, managing, and utilizing information. To preview the main results, the analyses reveal a wage premium for occupations with greater access to and control of information, independent of workers’ education enrollment, time-invariant unmeasured abilities, computer use, and abstract occupational skills and that this information wage premium has increased over time. Importantly, I find that measures for structural location in the information flow grow to be more important for wages than a spectrum of skills related to computerization.
Why Study Information Wage Premiums Among Occupations?
Before delving into the relations between technological change, information, and wage inequality, it is important to explain the conceptual and empirical decision to study information wage premiums at the occupational level. The theory specified in the following contends that structural processes in organizations lead to an increase in already well-rewarded occupations’ social capital, and thence to a rise in their relative earnings. On one hand, the ideal data set for testing these propositions lies at the point where the work takes place. Detailed organizational data on workers’ location in the organizational information network and their relative earnings will enable a close estimation of the social capital mechanisms at play.
At the same time, the main aim of this article is to explain large-scale social and economic changes among salaried workers over several decades, a goal that cannot be reached with cross-section detailed organizational data, even if these data are available for several organizations. I therefore chose breadth rather than depth. Due to the availability of large and longitudinal data sets on occupational features in the United States, conducting a research at the occupational level makes it possible to study changes over time in wage inequality that stems from differences in information rather than differences in skill levels. The downside of this kind of study is that it cannot really specify causal mechanisms but only show associations between predictors of locations in the information flow and earnings, which gesture toward causal mechanisms.
No less important, conceptually, is that an occupation, not only a job, can be critical in the information flow in an organization. This is a result of the well-documented process termed by Steven Barley (1996) the technization of existing work in a postindustrial economy. Importantly, information digitization through computer technologies has transformed existing occupations whose work has become more abstract and symbolic, associated more with information and less with physical phenomena. Barley (1996) stresses that an important outcome of the technization of work is a shift to a more horizontal division of labor based on substantive expertise, which undermines the logic of a vertical division of labor in organizations based on authority relations. As detailed later, this shift constitutes a more controlled and asymmetric distribution of workplaces’ information in which, according to this article’s argument, some specific occupations located in critical junctions have benefited the most.
Because I focus on occupation positional power to clarify that computers are biased in favor of powerful occupations, and not only in favor of high-skilled workers, my argument suits the term Class-Biased Technological Change coined by Kristal (2013, 2019), in which the concept of “class” is used explicitly for location within employment relations. The term Power-Biased Technological Change coined by Peter Skott and Frederick Guy (2007, 2013) to illustrate that technologies have profoundly affected the relative power of firms and corporate executives is also closely articulated with my argument.
What We Know and Do Not Know About Computers and Rising Inequality
That computerization partly explains rising inequality is widely agreed. Direct evidence on the connection between computerization and wages (but not necessarily on the mechanisms behind it) comes from Krueger’s (1993) widely cited study. He found that highly skilled workers—especially those with more schooling—were more likely to use computers on the job and that those who did so earned 17% more than nonusers, net of standard human capital variables. Large wage differentials for on-the-job computer use were found in other liberal countries as well (Kristal & Edler, 2020). The effect of computerization may proliferate from the individual who does or does not use a computer at work to the entire arena of the labor market. Abundant quantitative and case-study evidence documents a strong correlation between the adoption of computer-based technologies and a rise in the relative wages of college-educated labor (Acemoglu & Autor, 2011).
Less accord is found regarding the precise mechanisms whereby computerization affects the structure of inequality, particularly in the upper tail (90/50), which led to the overall rise in wage inequality in the 1990s and 2000s. Recently, a few studies have questioned the assumption that the invisible hand of the market is the only mechanism through which computerization increases inequality. DiMaggio and Bonikowski (2008) show that internet use at home enhanced workers’ earnings, suggesting that web users may have benefited from better access to job information or from the signaling effects of using a fashionable technology. Liu and Grusky (2013) assert that the changes in payout on skill were driven in part by institutional sources, such as the “low-road” strategy of intensive supervision, as opposed to narrowly technological ones. These and other studies (Fernandez, 2001; Hanley, 2014; Kristal, 2019; Shestakofsky, 2017; Skott & Guy, 2007, 2013) suggest that while SBTC certainly has a role in explaining rising inequality, it is rather restrictive to assume that computers have impacted the labor market and wage inequality solely via SBTC.
Computers, Information Flow, and Social Capital
This article develops a new conceptualization, grounded in network and social capital theory, of the advantage stemming from computerization created by interactions with information in general, not necessarily computers. The general argument is that computerization provides a structural basis for the further enrichment of already well-rewarded occupations through their control of and access to information. In the following sections, I strip this argument down to its two components by providing greater detail on the central concepts and reasoning in which the argument is grounded and elaborate on the mechanisms that may link computerization, the labor process, social capital, and earnings. In the next subsection, I elaborate how computer-based technologies have changed workplaces’ information flow. Thereafter, I discuss who benefit most from the distribution of workplaces’ information becoming more controlled and asymmetric.
Computerization and Flow of Information
The term digital computer, which historians Martin Campbell-Kelly and William Aspray (1996) aptly label an “information machine,” encompasses personal computers and many other information-centric technologies. But how does the digital computer differ from preceding business-information-processing instruments (e.g., telephones, typewriters) to generate an unequal impact on the wage structure? The answer lies in the opportunity to digitize information, which in turn, according to Barley and Orr (1997), gave to the notion of information the meaning of an economic good. The digitization of information centered on “the translation of symbols into digital impulses that could be stored, manipulated, transferred, and decoded in electronic form” (p. 9). As a result of digitization, information in general (such as a Facebook user’s personal data), and information on the labor process in particular, became a commodity that could be produced, bought, and sold. 3 In other words, computerization through digitization has enabled the commodification of information.
As information on the labor process became a commodity, like other economic goods with some scarcity and value, it became more controlled and asymmetric. Specifically, digital computers should have played an important part in reconfiguring power over information in different occupational groups: accentuated information asymmetry between experts/managers and rank-and-file workers. For example, through the retrieval of outputs of computerized technology and the design of computer systems, some workers have gained privileged access to and control of information on the production process; on the other hand, some simply enter data. Well-known examples of the latter are factory employees who use a plastic card to punch job data directly into a computerized time clock; employees who work with barcodes and scanners to tap corporate data into tablets for production or warehouse operations; stock clerks who enter raw data on inventory; data labelers who label or categorize various pieces of information and perform data entry of information into databases; tellers who use computers to receive and pay out money; and word processors who are required to input data into computers at a very efficient speed. Such occupations that handle input data at low-, medium-, and high-tech firms generally do not have access to output data processed by the computer.
In the next section, I explain how information asymmetries, which result from computerization, privilege certain actors or groups of actors over others in the claims-making process for organizational revenue.
Information Flow and Social Capital at Work
To theorize on how the aforementioned changes in the labor process and power relations due to computerization turn into an earnings advantage, I apply network concepts and reasoning (but do not utilize a network analytical method). But first, it is necessary to define a central concept of this study: “networks of production.” According to network theorists, social structures can be described as configurations inscribed by the relations among the incumbents of specified positions. Accordingly, I conceptualize “networks of production” as relations among occupations with respect to the flow of information on the production process, and what workers can do with it, typically within a broader market or organization. Based on the analytical frame of networks of production, one advantage that may lead to higher occupational earnings is “social capital”—capital that exists where people have an advantage because of their location in a social structure (Bourdieu, 1986; Burt, 1992; Coleman, 1988; Lin, 2002; Portes, 1998).
Networks of production in the age of the computer revolution involve at least two mechanisms that affect social capital of occupations and thereby their earnings. The first is brokerage across “structural holes” (Burt, 1992, 2000) as a source of added value. The implementation of computerized technology and advanced information systems creates structural holes in the production process between clusters of occupations, mainly of “input workers,” where workers on either side of the hole circulate in different flows of information. For example, two workers use a computer at work in an automated warehouse. One of the main tasks of a counter is to use computer applications to account for inventory, to generate daily out-of-stock and shipping-confirmation reports, to report damage, and to complete data sheet entries. Another worker, who drives a vehicle that stores and retrieves cases of all sizes, usually wears a headset and is instructed by a computerized voice on where to go in the warehouse to gather or store products. Either of these two workers circulates in a different flow of information. Each has limited access, if any, to the data produced by the other worker.
This situation has opened up new opportunities for the interpretation and manipulation of data on production. Which occupations lead to “the occupancy of a structural position that links pairs of otherwise unconnected actors” (Fernandez & Gould, 1994)? In other words, which occupations mediate the flow of information between two other jobs that are not directly linked? I argue that it is mainly workers who have the technology to reorganize, aggregate, and transfer the information (e.g., computer programmer, information systems specialist), and those who know how to translate, interpret, and manipulate the data and receive the information flow after its processing by the computer and use the output to make decisions (e.g., managers, engineers). Thus, workers who manage and utilize data have gained an opportunity to broker the flow of information among “input workers,” exploiting their superior position in the information flow as a device to extract higher wages. Accordingly, the concepts of social capital and brokerage yield the following hypothesis: H1a: Workers who manage and utilize data will obtain higher wages than will other workers, including those who enter data, due to their prominent bargaining power that has derived from their brokerage structural position in the information flow, and their wage advantage should have grown over time due to computerization.
But they are not the only occupational group involved in brokering practices. Outputs from the centralized computer are available to managers and professional workers such as engineers who know exactly what different groups of workers do and are familiar with the information they produce. They also translate and interpret information but in the broader workplace context. Moreover, while the information available for “input workers” is mainly from specific and anecdotal observations of the labor process, and workers who manage data have access to comprehensive but still observation-based information, workers who utilize data retrieve observation-based information that has been processed into business information. Workers who utilize data also gain access to substantive, professional-based information and knowledge not only from coworkers or from computer-based technologies but also based on their professional networks. It is reasonable to assume that both business and professional information can be leveraged more effectively than observation-based information in wage negotiations.
The second mechanism that “can be essential to realizing the value buried in the holes” (Burt, 1992) is closure within a network of production as a device to extract higher wages. Here too, organizational (Barley, 1986; Bechky, 2003; Burkhardt & Brass, 1990; Vallas, 1998, 2001) and historical (Hanley, 2014) studies show that by closing ranks on access to and control of information when new computerized technologies are adopted by an organization, experts gain power at the expense of rank-and-file workers. Accordingly, the concepts of social capital and social closure yield the following hypothesis: H1b: Workers who manage and utilize data will obtain higher wages than will other workers, including those who enter data, due to their prominent bargaining power that has derived from their closure structural position in the information flow, and their wage advantage should have grown over time due to computerization.
To recap, this study argues that the advantage stemming from computer-based technology is created by interactions with information in general, not necessarily from computers. Occupations doing data management or data utilization should receive higher wages than other occupations due to their structural position in the information flow, which through the mechanisms of brokerage across structural holes and social closure enable extraction of higher wages. At first, the distinction among occupations doing data management or data utilization and other occupations seems to parallel Castells’s (2000) differentiation between “self-programmable labor,” characterized with decision-making autonomy and the ability to retrain themselves and adapt to new tasks, and “generic labor,” which encompasses exchangeable and disposable occupations that primarily execute instructions. Yet it is important to emphasize that unlike Castells (2000) and other scholars who emphasize skill as a foil for developing a set of expectations about the effect of computerization on between-occupation income inequality, this study emphasizes structural location as the main explanatory concept, and the empirical estimates detailed in the following are aligned with the study’s thesis.
Empirical Strategy
Following what has become a conventional research strategy in studying the sources of rising wage inequality, I utilized large and longitudinal data sets on occupational features. This confined me to looking for aggregate empirical evidence consistent with the hypothesis of higher returns on occupations with greater access to and control of information, but with only indirect evidence of why it yielded returns, to track changes over time in a large sample of workers and occupations. Paired with large annual income surveys, the breadth of the data provides a good empirical test for the wage payoff over time for differential locations in the information flow.
To study if occupations located at critical junctions of information flow are related to higher wages and if the wage returns increased over time, I used three research strategies. In the main analyses, I used annually repeated cross-sectional data to estimate for each year between 1979 and 2016 the returns on occupations with greater access to and control of information. To better distinguish whether time-invariant unmeasured abilities or location itself are driving wage effects, I utilized a short-term panel of individuals and a long-term panel of occupations. The longitudinal individual data enables examining if workers that switch from a noncritical information job to a critical information job receive a wage premium. Last, the longitudinal occupational data enable studying if occupations that switch from low-information jobs to high-information job obtain, on average, higher wages.
Data
Available data on occupational activities and tasks from the Department of Labor’s Dictionary of Occupational Titles (DOT) and its recent successor the O*NET are utilized in this article for the first time to measure use of a computer at work and location in the information flow. The DOT was last updated for most occupations in 1977 (based on data collected between 1966 and 1974) and for a small subset in 1991 (based on data collected between 1981 and 1990); the O*NET has been continually updated since 2003. To maximize the longitudinal quality of the occupational data, three versions were used: (a) O*NET 4.0 (consisting of the DOT “analyst database” that was revised into the O*NET data structure and recorded into the 2000 Standard Occupational Classification [SOC] system), (b) O*NET 9.0 (released December 2005), and (c) O*NET 20.0 (released August 2015).
The O*NET classified about 1,000 occupations according to the characteristics of a typical worker (knowledge, skills, and abilities) and—most importantly for the current study—according to occupations’ activities and tasks, with variables defined to measure significant aspects of these domains. To analyze the effect of occupational features on occupational wages over time, I merged the rich occupational information from O*NET with a large representative household data source: the MORG supplements to the 1979–2016 CPS-ORG and the CPS’s ASEC. The former provides more accurate measures of the hourly wage distribution, and the latter enables a short-term panel of individuals.
Based on the 1989–2017 waves of the CPS-ASEC (covering earnings from 1988 to 2016), I constructed a series of 2-year (biennial) panels. The CPS has a rotating sample design whereby respondents are in-sample for 4 months, out-of-sample for 8 months, and then in-sample for 4 more months. This makes it possible to match up one half of the sample from one ASEC interview to the next, and thus create a series of 2-year panels. To help ensure I am matching ASEC households properly, I matched individuals based on five variables (see Rivera Drew et al., 2014): unique household identifier, unique person identifier, month in sample (Months 1–4 for Year 1, Months 5–8 for Year 2), gender, and race. I deleted observations as incorrect matches if the age of the person drops, or if it increases by more than 2 years. I also forego observations if state of residence changes because the CPS is an address-based survey and thus does not follow movers. Appendix A presents sample sizes of CPS respondents linked across two consecutive years for 27 years of matched data (due to major survey redesigns in the mid-1990s, it was impossible to match the 1995–1996 waves).
I merged the rich occupational information with the CPS using a crosswalk between the federal government’s more detailed SOC used in O*NET and the less detailed Census Occupational Codes used in CPS. I started by using a Bureau of Labor Statistics (BLS) crosswalk between ONET-SOC 2010 codes and ONET-SOC 2000 codes. 4 I then used a BLS crosswalk to assign a three-digit Census 2000 occupation code to each of the ONET-SOC 2000 codes. Next, I used a further crosswalk created by Autor and Dorn (2013) that matched three-digit Census 2000 occupation codes to earlier Census codes and an additional BLS crosswalk that matched 2010 occupation codes to census 2000 codes. Using these four crosswalks, I created a consistent set of 330 occupations matching the 1980, 1990, 2000, and 2010 Census codes and ONET-SOC 2000 and ONET-SOC 2010 codes.
I followed established conventions by restricting the CPS samples to civilian wage and salary workers who were currently working, aged between 18 and 65 years, with a valid occupation, who reported hourly wages more than 2 dollars (in 2015 dollars). Following the conventional practice, I measured earnings as hourly wages; top-coded wages were replaced by 1.5 times the top-coded value. Wages were converted into constant 2016 dollars (to account for inflation) using the Consumer Price Index for All Urban Consumers Research Series (CPI-U-RS). Because wage allocations in the CPS-ORG data suppress the amount of between-occupation inequality (Mouw & Kalleberg, 2010), I excluded 1994 and 1995 from the analyses because of lack of documentation on whether wages were imputed and eliminated all cases in other surveys with missing wage data. 5 The pooled samples were very large, containing on average about 120,000 workers per year (18,000 in the 2-year panels), to yield a grand total of 4,306,351 cases (493,450 in the 2-year panels).
Occupational Variables
Following previous studies that created summary indices ranking occupations based on the DOT and O*NET data, I used factor analysis to compute measures for three locations in the information flow: “data entry,” “data utilization,” and “data management.” Table 1 details the variables and their loading. The resulting loadings are based on a confirmatory factor analysis of the O*NET variables for 330 occupations. Versions of the O*NET data being collected and coded in different ways led to two empirical decisions. First, based on the results of the factor analysis, I created three dummy variables. I coded occupations as doing data entry, data utilization, or data management if they were ranked at the upper third of each variable for each version of O*NET. 6 Second, I assumed that occupational ratings were constant for all years preceding the O*NET versions. Hence, O*NET 4.0 ratings were applied to the years 1979–2001, O*NET 9.0 to the years 2002–2011, and O*NET 20.0 to the years 2012–2016. 7
Occupational-Level Variables Computed Based on O*NET Data for Location in Information Flow.
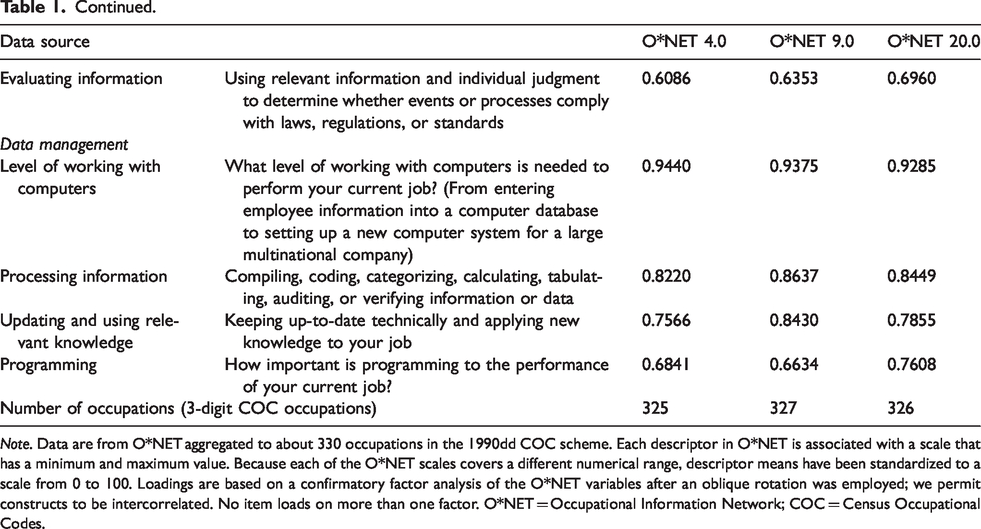
Note. Data are from O*NET aggregated to about 330 occupations in the 1990dd COC scheme. Each descriptor in O*NET is associated with a scale that has a minimum and maximum value. Because each of the O*NET scales covers a different numerical range, descriptor means have been standardized to a scale from 0 to 100. Loadings are based on a confirmatory factor analysis of the O*NET variables after an oblique rotation was employed; we permit constructs to be intercorrelated. No item loads on more than one factor. O*NET = Occupational Information Network; COC = Census Occupational Codes.
The 10 top-ranked occupations in locations in the information flow are presented in Table 2. Workers in occupations for which data entry is important (e.g., registered nurses, meter readers, bank tellers, human resource clerks) are those who enter, transcribe, record, store, or maintain information in written or electronic/magnetic form. Workers in occupations that manage data or utilize data do some brokerage and closure at work. Workers in occupations for which data management is important (e.g., computer software developers, computer system analysts and computer scientists, physical scientists, mathematicians, and statisticians) are those with access to and control of information through their expertise in computer technologies (closure) and those who process information across organizational boundaries (brokerage). Workers who utilize data (physicians, chief executives, financial managers) are involved in making decisions based on getting, analyzing, and evaluating information (closure), as well as in the translation and interpretation of information (brokerage).
Top-Ranked Occupations in the Three Locations in the Information Flow.
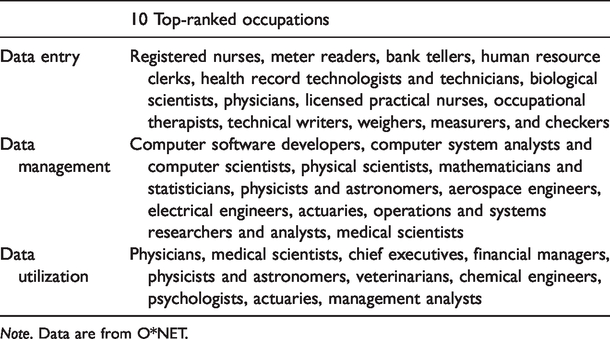
Note. Data are from O*NET.
A required question is whether the “data entry,” “data management,” and “data utilization” categories represent locations in the flow of information (as this article argues) or variation in the skills needed to work with computers at varying levels. One way to rule out the skill explanation is to measure skill level across occupations and to estimate the wage payoff for locations in the information flow independently of their skill level. To this end, I construct two measures for occupational skill: abstract skill and computer use. These skills exert significant and increasing effects on wages according to both sociological (Liu & Grusky, 2013) and economic (Acemoglu & Autor, 2011) accounts. The concept of abstract skill was measured according to the most influential paper that used this perspective and data source to test the SBTC thesis; Appendix B details the variables used by Autor et al. (2003) and their loadings. Like other occupational variables, I coded an occupation as being high skilled if it was ranked in the upper third of the abstract skill variable. 8 Table 3 presents descriptive statistics for all the occupational variables.
Correlation Matrix of Occupational-Level Variables in O*NET 4.0 (Lower) and O*NET 20.0 (Upper).
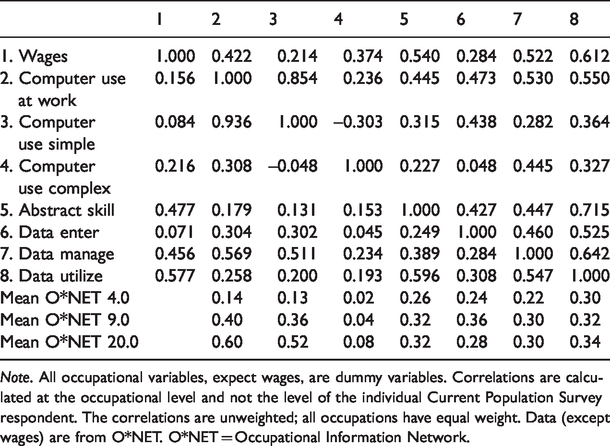
Note. All occupational variables, expect wages, are dummy variables. Correlations are calculated at the occupational level and not the level of the individual Current Population Survey respondent. The correlations are unweighted; all occupations have equal weight. Data (except wages) are from O*NET. O*NET = Occupational Information Network.
To identify occupations that use a computer at work, I relied on the O*NET variable of “Interacting with Computers,” which identifies occupations that use computers and computer systems (including hardware and software) to program, write software, set up functions, enter data, or process information. Workers who reported that in their occupation working with computers was important, very important, or extremely important for performance of the current job were defined as those who used a computer at work (computer use = 1). Workers who reported that in their occupation working with computers was not important or somewhat important were defined as not using a computer at work (computer use = 0). Comparing the percentage of workers who directly used a computer at work based on the O*NET (matched to CPS-ORG) to individual-level data on using a computer at work (available from the October supplements to the CPS) revealed similar results (data not shown).
Measuring computer use at work as a dummy variable (i.e., whether a worker does or does not use computers) has become common practice in research on the association between computerization and wages (see DiMaggio & Bonikowski, 2008). But because computers are used at work in a wide variety of tasks and activities, and to put the study’s argument to a more compelling test, I went a step farther and distinguished two levels of computer use according to the O*NET variable of “Interacting with Computers.” Occupations that use a computer at work for simple tasks are those who process digital or online data or operate computer systems or computerized equipment. Occupations that use a computer at work for complex tasks are those who resolve computer problems; set up computer systems, networks, or other information systems; implement security measures for computer or information systems; and program computer systems or production equipment. Analyzing wage returns on different computer usages, assuming that they reflect different skill levels, is coherent with the rationale of the SBTC. Hence, in doing that, I put the article’s structural argument to the most demanding test: Is there or is there not a wage premium for occupations involved in data management and data utilization above the returns on a spectrum of skills related to computerization.
Method
To estimate the wage payoff over time for differential locations in the information flow, I analyze hierarchical linear models that take into account the nonindependence of the observations, partition the variance of wages into in- and between-occupation components, and thereby generate more efficient parameter estimates (Raudenbush & Bryk, 2002). Most importantly for the current purpose, hierarchical models make it possible to estimate occupational-level effects on wages while controlling for cross-occupation differences in the characteristics of the individuals nested in them. Therefore, for each year from 1979 to 2016, I estimate a random-intercept hierarchical model (in multilevel modeling also termed an intercept-only model) to predict logged hourly wages. The two-level model can be represented by a set of equations:
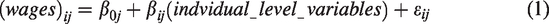
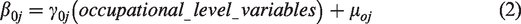
On the individual level, the dependent variable is the (logged) hourly wages of individual i in occupation j, and βo j is the intercept denoting average wages. The vector of individual-level explanatory variables includes race, gender, marital status, southern region, metropolitan residence, education (four categories), potential years of work experience (i.e., age – years of schooling – 6), employment status, sector, and manufacturing operationalized in standard ways (Table 4). 9 β denotes their coefficients, and εij is the error term. This equation allows the intercept to vary across occupations (i.e., to be random), while the effects of all the other variables are constrained to be the same across occupations (i.e., to be fixed). On the second level, occupation-level characteristics explain this random effect, as presented in Equation 2. The main interest of this study is Equation 2, which estimates the between-occupation variance in the Level-1 intercept (β0 j ).
Means and Standard Deviations of Individual-Level Variables.
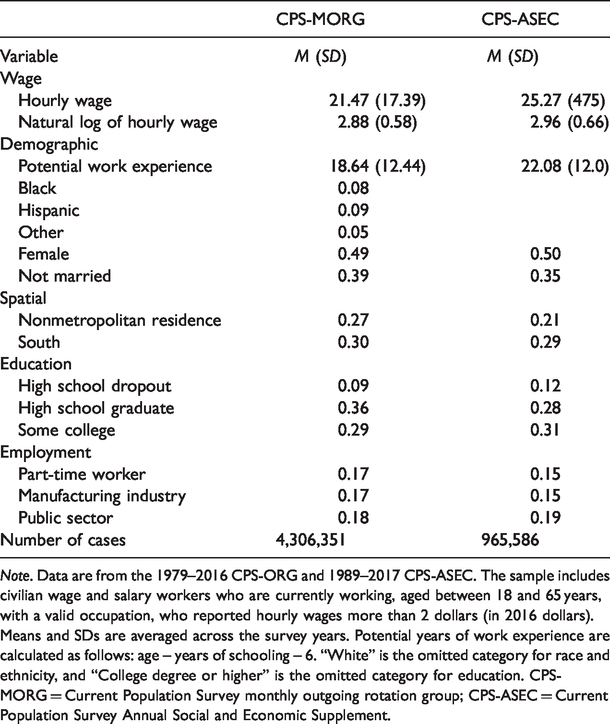
Note. Data are from the 1979–2016 CPS-ORG and 1989–2017 CPS-ASEC. The sample includes civilian wage and salary workers who are currently working, aged between 18 and 65 years, with a valid occupation, who reported hourly wages more than 2 dollars (in 2016 dollars). Means and SDs are averaged across the survey years. Potential years of work experience are calculated as follows: age – years of schooling – 6. “White” is the omitted category for race and ethnicity, and “College degree or higher” is the omitted category for education. CPS-MORG = Current Population Survey monthly outgoing rotation group; CPS-ASEC = Current Population Survey Annual Social and Economic Supplement.
From the results of these analyses, it is possible to portray the trends in wage premiums associated with tasks related to processing the information and to knowledge of the production process. By analyzing within-group inequality in earnings among workers with similar education and work experience, the key argument can be tested. That is, a significant and growing wage premium accrues on occupations whose workers have privileged access to, and control of, information on the production process, independent of workers’ education enrollment and occupational skills. To further evaluate the robustness of the results, I estimated if there is a wage payoff for differential locations in the information flow above the payoff to time-invariant unmeasured abilities. To this aim, I analyzed OLS regressions with individual fixed-effects on a short-term panel of individuals (2 years) and OLS regressions with occupation fixed-effects on a longer-term panel of occupations (37 years).
Results
Researchers of technology conceive of the digital computer as an information machine. I therefore begin by considering whether in parallel with the diffusion of computers across workplaces and occupations, more workers engage in information, located in at least one of the three places outlined earlier: enter, manage, or utilize data. Figure 2 shows for each major occupational group and in two time periods (1970s–1980s, 2010s) the percentage of occupations doing data entry, data management, or data utilization and the percentage using computers at work. Comparing occupational groups in the first time period, it is evident that professional and management occupations were more likely to be located at a critical junction of information flow—doing data management or data utilization—as early as the 1970s, partly, but not only, due to their advantage in computer use. As argued earlier, computerization of the labor process should have made these critical locations even more powerful in recent years. Comparing the time periods, the results show that all occupations became more likely to use a computer at work and that all occupations, except operators and laborers, also engaged more in information, located in at least one of the three locations.
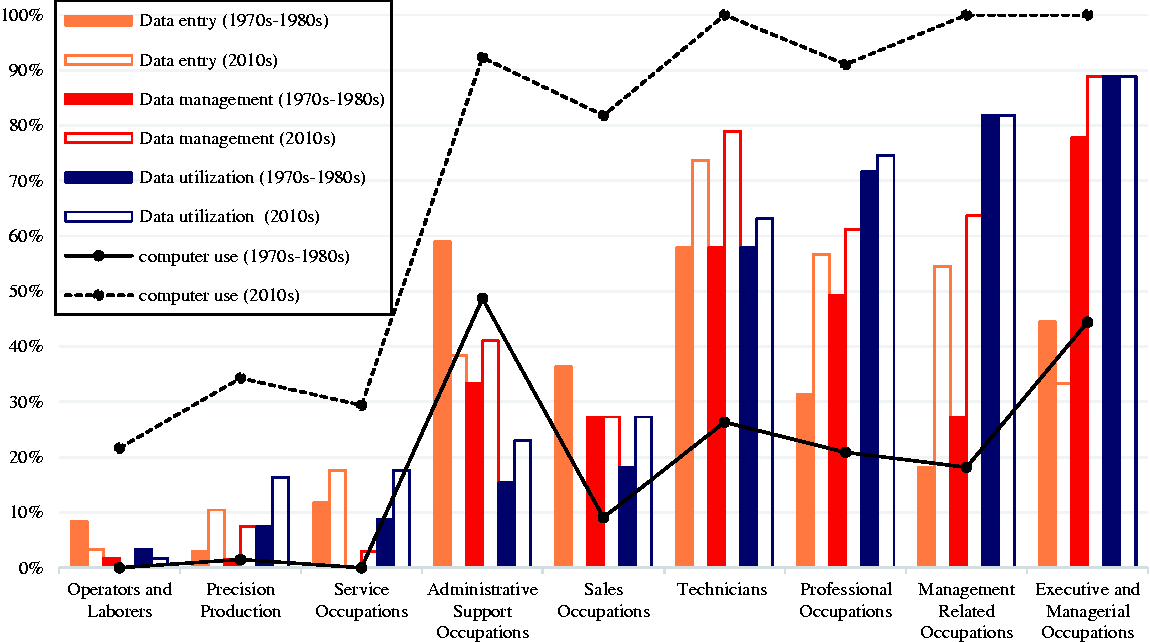
Percentage of Occupations Doing Data Entry, Data Management, and Data Utilization and Percentage of Occupations Using a Computer at Work by Major Occupational Group (1970s–1980s, 2010s).
As more workers become involved in the information flow, is there any wage payoff for occupations located at critical junctions of information flow? And have wage payoffs risen over time? To answer these questions, I estimated a random-intercept hierarchical model to predict logged hourly wages. Full results for the wage payoffs to the three locations in the information flow, controlling for computer usages and abstract skill, are shown in Table 5. To study more closely the trend over time, I also estimated the same model for each year from 1979 to 2016, and the results are graphically presented in Figure 3. To take into account changes over time in workforce occupational composition, and to facilitate generalization to national inequality trends, the results at the occupational level in Table 5 (Models 1, 3, 5, and 7) and in Figure 3 are weighted by the occupation’s contribution to the total work hours. However, to be sure that the explanatory power of the occupational variables is not driven by sizable occupations that are outliers, I estimated the same models assuming that all occupations have equal weight. That is, each occupation’s contribution to the total work hours is the same as that of other occupations and is constant over time (Models 2, 4, 6, and 8 of Table 5).
Selected Coefficients From Multilevel Random Intercept Regressions of Wages on Individual-Level and Occupation-Level Covariates, 1979–2016; Dependent Variable: Natural Log of Hourly Wages.
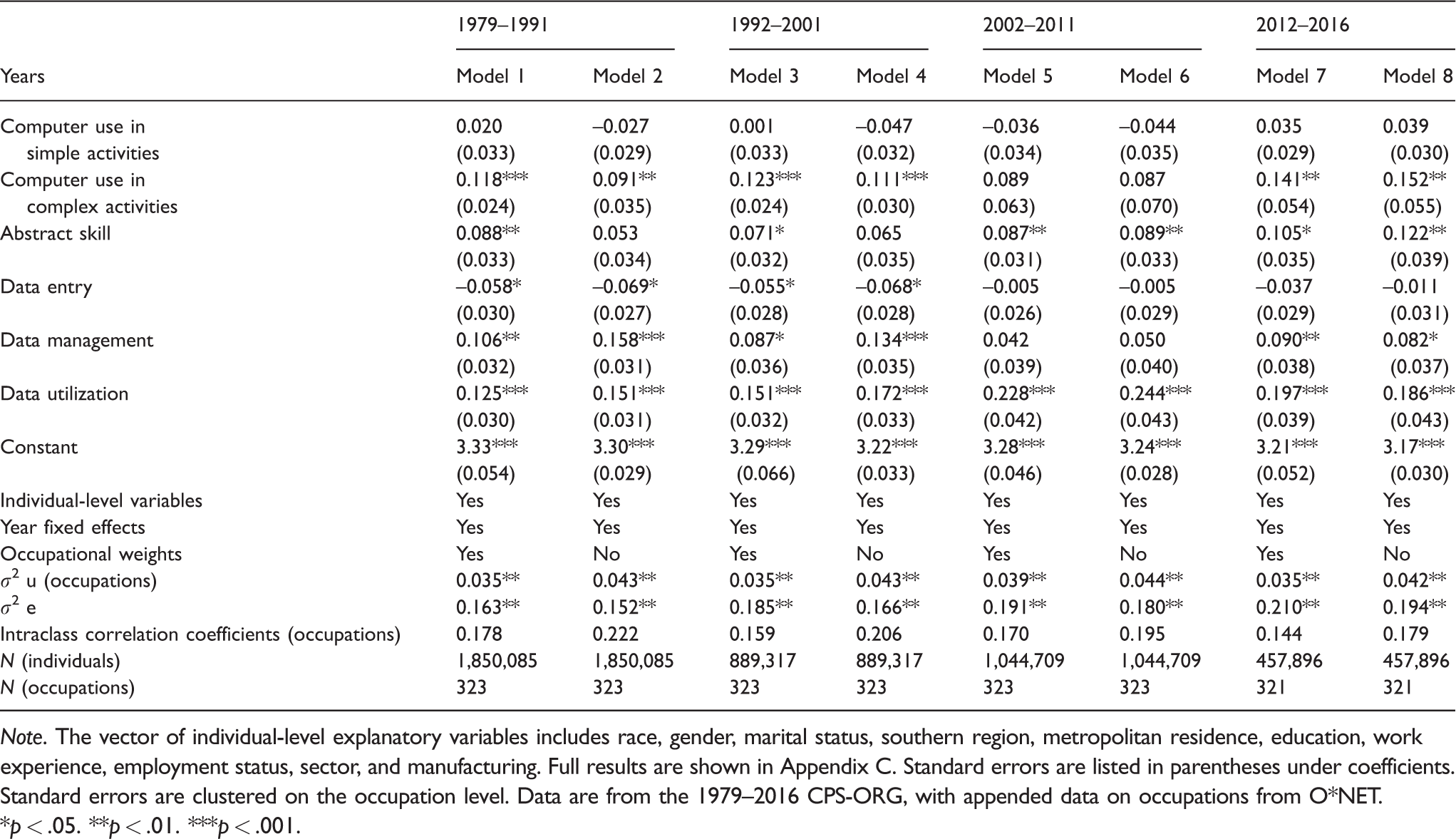
Note. The vector of individual-level explanatory variables includes race, gender, marital status, southern region, metropolitan residence, education, work experience, employment status, sector, and manufacturing. Full results are shown in Appendix C. Standard errors are listed in parentheses under coefficients. Standard errors are clustered on the occupation level. Data are from the 1979–2016 CPS-ORG, with appended data on occupations from O*NET.
*p < .05. **p < .01. ***p < .001.
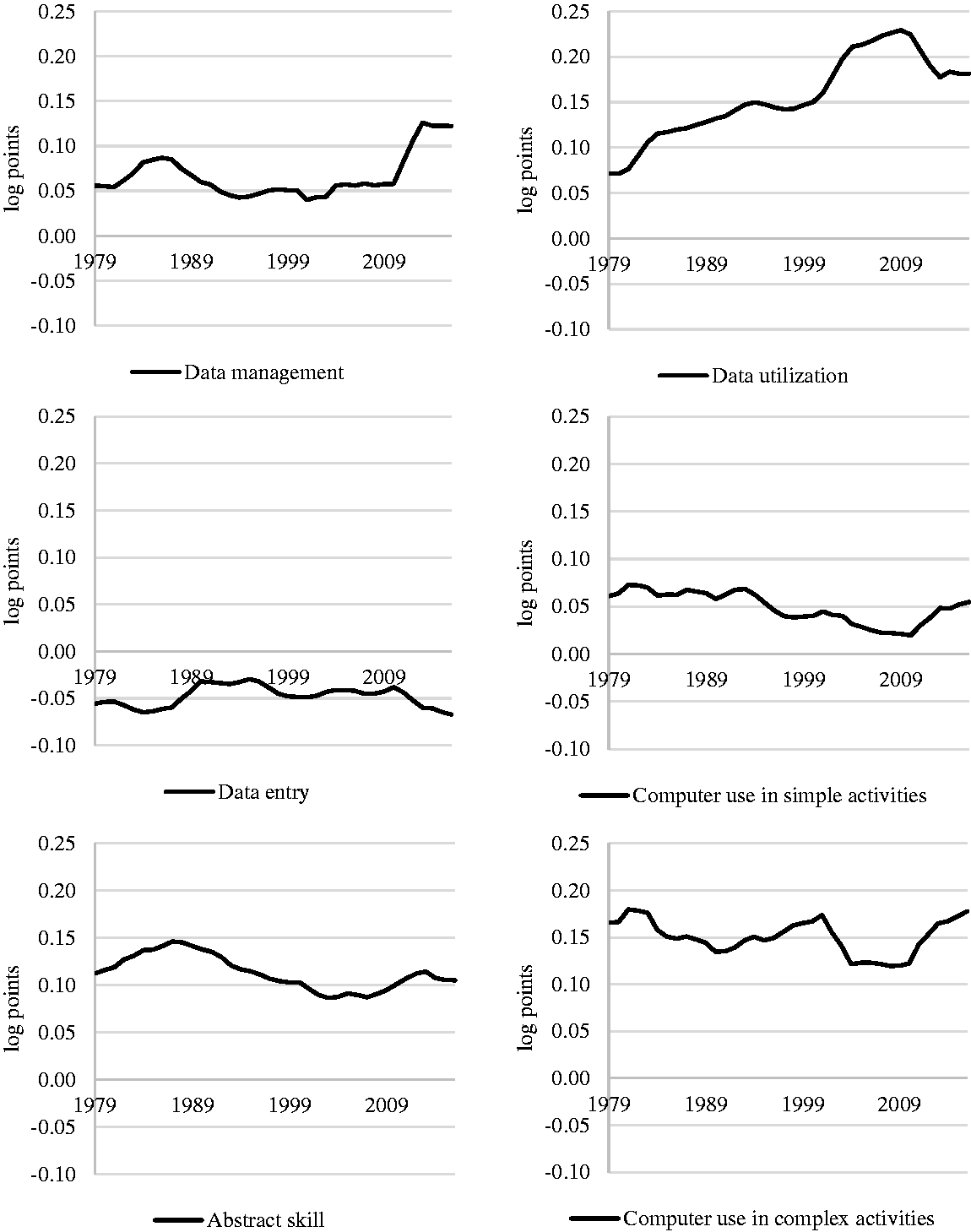
Results From Multilevel Random Intercept Regressions for the Wage Premiums for Data Entry, Data Management, Data Utilization, Computer Usages, and Abstract Skill, 1979–2016; Dependent Variable: Natural Log of Hourly Wages.
To recap, this study argues that the advantage stemming from computer-based technology is created by interactions with information in general, with occupations doing data management and data utilization extracting higher wages, above the returns to their skill. This argument won strong empirical support. Independently of workers’ and occupations’ abstract and technological skills, the returns on occupations involved in data management are large (about 5%–13%) and even larger on those doing data utilization (about 7%–24%), and generally increase over time. While the wage premium for data utilization has continuously increased over the years, the takeoff in the wage premium for data management was not entirely linear but occurred over the 1980s and again from the late 2000s. The results are also consistent with the SBTC thesis, which anticipates a wage premium for abstract skill and using a computer at work, in particular for complex usages of computers.
A second main conclusion is that the earnings premiums from information-based work disproportionately benefit those who are already advantaged in the labor market. This conclusion arose from observing the adjusted predicted wages for occupations doing data entry, data management, or data utilization over the period 1979 to 2016 (Figure 4). With all control variables held constant, the only factors that changed were measures for location in the information flow—if occupations were (or were not) doing data management or data utilization. 10 As expected, occupations involved in data management and data utilization had higher wages as early as the early 1980s, and their earnings advantage over other similar occupations that were not involved in data management and data utilization had increased over time. Doing data utilization in particular had an increasing earnings advantage. In 1979, occupations involved in data utilization earned 2.4% more than occupations not involved in data utilization (20 dollars per hour compared with 18 dollars); by 2008, this advantage had risen 8% (23 dollars per hour compared with 18 dollars) and had somewhat declined to 5.8% by 2016.
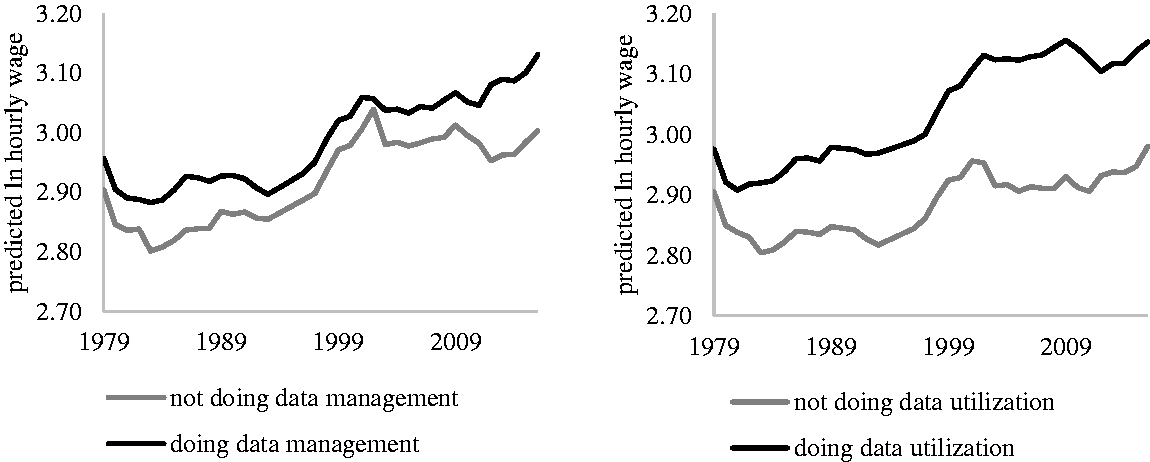
Adjusted Predicted Hourly Wage for Occupations Doing Data Management and Data Utilization, 1979–2016.
A third conclusion, which is particularly important for testing the thesis elaborated in this study against the SBTC thesis, is that measures for location in the information flow increasingly matter more for earnings than occupational skill. Taking the yearly returns for doing data management and utilization together (see Table 5 and Figure 3), the wage premium is on average 23% (29% since the early 2000s), while the return on using a computer at work together with an abstract skill is about 20% lower. In fact, not taking into account occupation’s contribution to the total work hours, and how it changed over the years, the findings for the returns on occupations involved in data management were even stronger in the 1980s and 1990s. This is the result of large occupations such as secretaries and registered nurses, which lower the returns on data management.
Robustness Analyses
The findings described so far reveal wage premiums for occupations doing data management or data utilization above the returns on a spectrum of skills related to computerization. But can these information wage premiums result from other important occupational features?To obtain a net as possible effect of locations in the information flow on occupational wages, I first added in Table 6 controls for other occupational features related to occupational wages, including quantitative and social skills (Appendix B details the variables used to construct these variables and their loadings), occupational gender and ethnic composition (i.e., percentage of women in an occupation and percentage of non-Hispanic White workers), and unionization that captures an important aspect of institutionalized sources of closure that is known to generate a wage premium for workers employed in such protected positions (Bol & Weeden, 2015; Drange & Helland, 2019). The results, seen in Table 6, show what we already know from previous research. Everything else being equal, a heavily unionized occupation has higher mean wages than a nonunionized occupation, a high share of women in an occupation decreases wages, while a high share of non-Hispanic White workers increases wages. More importantly, the main results of this study, shown in Table 5, do not change with the inclusion of other occupational features that are related to occupational wages.
Robustness Analyses: Selected Coefficients From Multilevel Random Intercept Regressions of Wages on Individual-Level and Occupation-Level Covariates, 1979–2016; Dependent Variable: Natural Log of Hourly Wages.
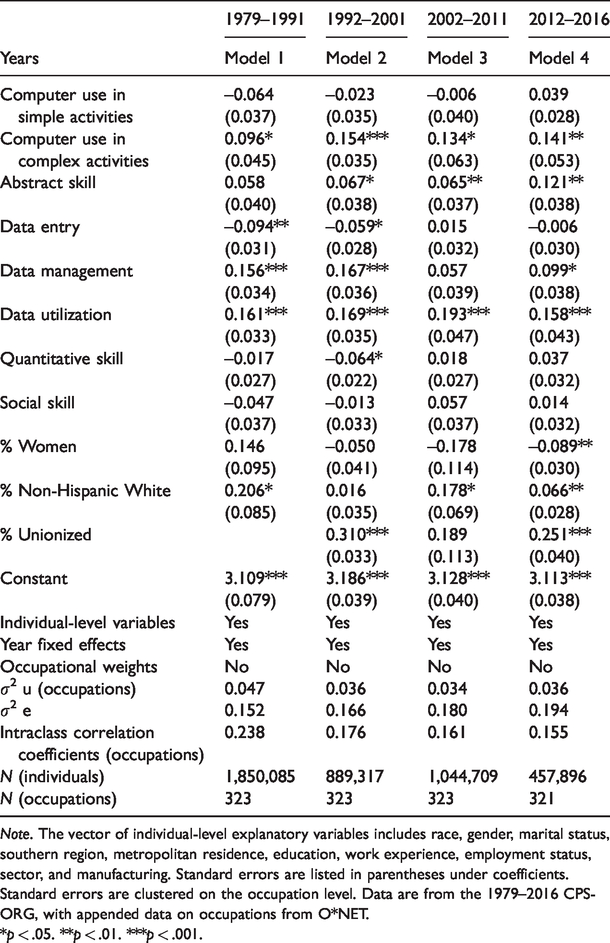
Note. The vector of individual-level explanatory variables includes race, gender, marital status, southern region, metropolitan residence, education, work experience, employment status, sector, and manufacturing. Standard errors are listed in parentheses under coefficients. Standard errors are clustered on the occupation level. Data are from the 1979–2016 CPS-ORG, with appended data on occupations from O*NET.
*p < .05. **p < .01. ***p < .001.
To better distinguish whether time-invariant unmeasured abilities or location itself are driving wage effects, I first utilized the longitudinal feature of the O*NET occupational data from the 1970s (O*NET 4.0) through the early 2000s (O*NET 9.0) to recent years (O*NET 20.0). Three versions of the O*NET data with appended individual data from the CPS-ORG enabled studying a central part of the study’s argument—occupations that switch from low-information jobs to high-information jobs should obtain, on average, higher wages. The results shown in Table 7 support this argument. I found that the switch of occupations to data utilization, and even more to data management, is related to a wage increase, even for occupations with similar technological skills. This is the only analysis in which I find that the coefficient for data management seems to be higher than for data utilization. One likely explanation is that occupations doing data utilization are characterized by higher levels of autonomy and authority than occupations doing data management. Therefore, in models that control for such time-invariant occupational features, the effect of data utilization should be smaller than that of data management.
Robustness Analyses: Selected Coefficients From OLS Regression of Mean Wages on Occupational-Level Covariates, Occupational-Panel Design 1979–2016; Dependent Variable: Natural Log of Mean Hourly Wages.

Note. The vector of occupational-level explanatory variables includes race, gender, marital status, southern region, metropolitan residence, education, employment status, sector, and manufacturing. Standard errors are clustered on the occupation level and listed in parentheses under coefficients. Data are from the 1979–2016 CPS-ORG, with appended data on occupations from O*NET.
*p < .05. **p < .01. ***p < .001.
Perhaps the strongest support for the main argument on a wage premium for occupations located at critical junctions of information flow comes from utilizing a biennial panel design of individuals, which enable checking if workers that switch from a noncritical information job to a critical information job receive a wage premium. Results shown in Model 1 of Table 8 support this study’s argument that occupations doing data management or data utilization increase earnings independently of workers’ measured (i.e., education, work experience) and time-invariant unmeasured abilities (captured by individual fixed-effects). Models 2 to 4 further show that location in the information flow yield higher earnings even within occupations with similar levels of computer use and abstract skills, and within the same industry (Model 4).
Robustness Analyses: Selected Coefficients From OLS Regression of Wages on Individual-Level Covariates, Biennial Individual-Panel Design 1988–2016; Dependent Variable: Natural Log of Hourly Wages.
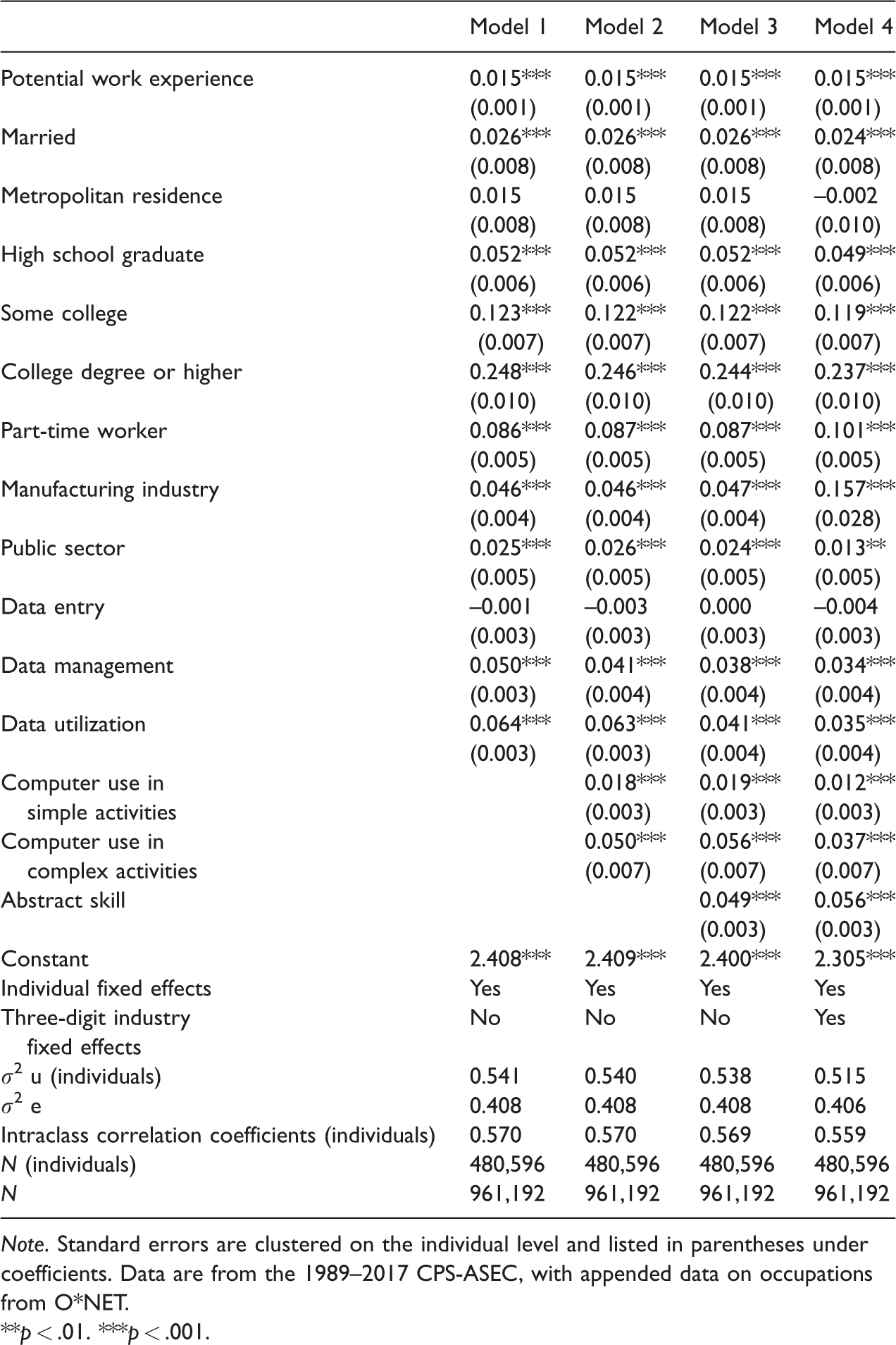
Note. Standard errors are clustered on the individual level and listed in parentheses under coefficients. Data are from the 1989–2017 CPS-ASEC, with appended data on occupations from O*NET.
**p < .01. ***p < .001.
Discussion
The main argument of this study is that computerization increases wage inequality by expanding the unequal control of the production and distribution of information on the labor process. Consequently, a large part of the wage premium associated with computerization has to be concentrated in the hands of privileged workers, particularly managers and specialist workers, who have superior access to information on the labor process and substantial control over it. In support of the study’s hypothesis, estimations over time and sensitivity tests for returns for different locations in the information flow show the following. First, a significant wage premium exists for occupations that have privileged access to and control of information on the labor process, measured by occupational activities and tasks describing data management and data utilization, when workers’ human capital and occupational technological skills are controlled for. Second, this wage premium has increased over time. I assess sensitivity of the results to empirical decisions with four additional analyses showing that the results are not driven by a handful of occupations, by other occupational features related to occupational wages, or by time-invariant unmeasured occupational skills and individual abilities.
Conclusions
This article’s objective is a better understanding of the role of computer technology as an engine of income inequality. Previous studies advocating the SBTC thesis allocated a central role to the use of computers at work and to abstract skill as driving inequality. However, focusing solely on computer usages and abstract skills neglects an important feature of computerization: Computer-based technologies are information-centric, hence are critical to the operation and allocation of information on the labor process. By extending, both theoretically and empirically, the consequences of computerization behind computer use and occupational skill to locations in the information flow, this study seeks to offer an important critique of the SBTC thesis. Theoretically it underlines the interactions between technology and politics in the wage-determination process, emphasizing that computerization power on the wage structure is governed by power relations among jobs and not only by workers’ skills and productivity. Empirically, I find that rewards associated with using computers on the job and with having abstract skills, as specified in the SBTC literature, are like or somewhat lower than rewards associated with the greater structural power accruing to some occupations due to their access to and control of information.
Unexpectedly, I find that rewards are higher on occupations doing data utilization than on those doing data management (but net of time-invariant unmeasured occupational skills, the findings are inverse). The research strategy employed in this article does not permit direct testing of the social capital mechanisms, inherent in the relations between occupations, through which I expected that computerization had increased between-occupation income inequality. I assumed that occupations that manage and utilize data obtain higher wages than other occupations due to their prominent bargaining power, deriving from their brokerage and closure structural positions in the information flow. The findings, assuming that measuring data utilization and data management by occupational tasks and activities is adequate, suggest that doing data utilization is related to a more powerful position. This may be due to the importance of gaining access to business and professionally based information over access to observation-based information in making brokering and closure practices. Network data from specific organizations on the location of jobs in the information flow and their relative earnings will furnish a better test for why there are higher rewards for occupations doing data utilization than on those doing data management. It would enable a more explicit measurement of structural locations compared with the use of O*NET secondary data collected and coded in different ways along the years, and a closer estimation of the social capital mechanisms at play.
In linking computerization to information asymmetry and structural locations within the economic system and production relations, this study also suggests that organizational processes will be important determinants of the configurations of information asymmetry and occupational structural power, as well as their related outcomes. This study was based on observations of variation across occupations within one country over time. Researchers may develop further insights into the dynamics between computerization, information asymmetry, and income inequality by drawing comparisons between organizations. Organizational contexts that might moderate such effect of computers on income inequality could be an adoption of a “high-road” strategy for implementing new technologies (Fernandez, 2001), the dissemination of organizational information from managers to workers (Rosenfeld & Denice, 2015), and the use of emotional labor aimed at helping workers adapt to software systems (Shestakofsky, 2017). On the other hand, organizational restructuring including outsourcing and the expansion of performance-pay practices might have led not only to rising inequality between workplaces but also to a more asymmetry in information within workplaces and therefore to a sizable impact on inequality.
All in all, this article contributes to the ongoing debate over the causes of rising income inequality over the past 40 years and can generally advance stratification research and economic sociology in four important ways. First, it explicates the well-known positive correlation between the computer revolution and the surge in wage inequality by clarifying the question of mechanisms. Second, it links structural models of inequality with network models of competition in explaining sources of rent production; and third, it shows that progress can be made in understanding rising inequality by availing of insights from economic sociology theory and research to further our understanding of the income determination process.
Last, the middle-range theory developed in this article on why computerization increased wage inequality can also contribute to the labor process tradition in the sociology of work, which has long seen technology powerfully influencing social relations in the capitalist firm (Braverman, 1974; Noble, 1984). As discussed herein earlier, information asymmetry has been related to new technologies also in the precomputer organizations. The embodiment of organizational memory in corporate enterprises independent of individuals was initiated back in the early 20th century by the systematic management movement (Yates, 1989). However, in this article, I argue that as computers transformed work into a more knowledge-intensive activity and as digitization has enabled the commodification of information, workplace information plays a more crucial role than ever in power dynamics and consequently in generating wage inequality. This circumstance has amplified the influence of the complex dynamics between technology and politics of production in generating social and economic inequalities.
Supplemental Material
sj-pdf-1-wox-10.1177_0730888420941031 - Supplemental material for Why Has Computerization Increased Wage Inequality? Information, Occupational Structural Power, and Wage Inequality
Supplemental material, sj-pdf-1-wox-10.1177_0730888420941031 for Why Has Computerization Increased Wage Inequality? Information, Occupational Structural Power, and Wage Inequality by Tali Kristal in Work and Occupations
Footnotes
Acknowledgments
The author wishes to thank Yinon Cohen, Asaf Darr, Ilan Talmud, the editor, and anonymous reviewers for helpful comments and discussions on earlier drafts. Alina Rozenfeld-Kiner provided excellent research assistance. The author would also like to thank Uri Even Ezra who is a constant source of inspiration for his excellent insights.
Author’s Note
Earlier versions of this article were presented at the Intergenerational Mobility and Income Inequality Workshop held at the University of Haifa (in 2018) and the SPP1764 conference on “Technology, Demographics, and the Labor Market” held at University of Cologne (in 2019).
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Support for this project came from the European Research Council (ERC), ERC Starting Grant Agreement Number 677739/2015, and from the Israel Science Foundation Grant Number 394/15.
Notes
Supplemental Material
Supplemental material for this article is available online.
Author Biography
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.