
Abstract
Objective
The priorities of people with mental health challenges should be reflected in the research conducted on their behalf. Quantifying alignment of priorities with the unmet needs of people with lived experience is challenging, and to our knowledge, such alignment has not been extensively studied in bipolar disorder (BD). Natural language processing approaches comparing common topics derived from public forums to those of biomedical research could help in identifying topics that are underaddressed.
Methods
We contrasted 5 years of lived experience questions posed during a Collaborative RESearch Team to study psychosocial issues in Bipolar Disorder (CREST.BD) “Ask Me Anything” (AMA) event hosted via Reddit (2019–2023) with topics labelled from abstracts extracted from PubMed with the search term BD during the same period. We applied topic modelling using BERTopic to identify dominant themes within each corpus and compared their semantic similarity using vector-based cosine similarity analyses.
Results
The Reddit AMA data included 6159 comments, and the medical literature from this period included 9188 abstracts. Topic modelling and similarity analyses indicated that shared and frequent topics in both corpuses were sleep, BD medication safety in pregnancy, and lithium treatment. Topics with comparatively higher frequency in the Reddit forums than in medical research included BD misdiagnosis, marijuana and BD, and coping with daily challenges.
Discussion
Notwithstanding limitations, comparing a corpus of lived experience questions with contemporaneous medical literature revealed areas of overlap, but some lived experience queries were not well covered in the biomedical literature. Natural language processing of public forums may facilitate identifying unmet priorities in BD.
Plain Language Summary Title:
Plain Language Summary:
The priorities of people with mental health conditions should be reflected in the research conducted on their behalf. Natural language processing approaches comparing common topics derived from public forums to that of biomedical research could help identify topics that are under-addressed. Our project used natural language processing to compare topics from 5 years of an annual online question and answer forum focused on bipolar disorder to published research about bipolar disorder in the biomedical literature. There were areas where research and public questions aligned, particularly sleep, bipolar disorder medication safety in pregnancy, and lithium treatment, but other areas were less well covered in the biomedical literature. In particular, bipolar disorder misdiagnosis, marijuana and bipolar disorder, and coping with daily challenges appeared to be unmet needs not well addressed in the scientific literature. Artificial intelligence approaches to comparing and contrasting public forums to biomedical literature could help important unmet needs in psychiatric research.
Introduction
Incorporating the perspectives and experiences of people with lived experience into research agendas holds the potential to inform the relevance of these research endeavours to those individuals and their communities.1–4 The importance of lived experience perspectives in the development of research priorities is actively being studied.5,6 Research priorities identified by people with lived experience and researchers/care providers do not always align7,8; however, when there is alignment, individuals with lived experience can experience improved access to care, trust in research and overall well-being.9–11
Among existing studies that prioritize input from individuals with lived experience of various health conditions, relatively few focus on populations with mental health concerns. 12 There is some evidence that the priorities of people with lived experience of mental health concerns are not always aligned with research priorities. For example, one study applied the James Lind Alliance methodology in three groups of stakeholders to identify a “top 10 list” of research priorities on reducing and stopping psychiatric medication, in doing so, highlighting important uncertainties and gaps in the existing evidence base in this topic area.13,14 These studies and others 15 point to the importance of including people whose lives are most directly affected by mental health conditions in discourses around unmet needs in order to most effectively shape research agendas and, ultimately, health system improvements.
When input from individuals with mental health challenges is sought out, there is the opportunity for improved care and well-being for patients and their communities.10,16,17 Collective knowledge from the research and lived experience communities has been associated with transformative change within policy and institutional realms.18,19 Seeking out user data and reflections has allowed developers of digital mental health interventions to enhance the access and utility of these tools.20,21 Engaging populations of individuals with lived experience of mental health challenges has also led to global outreach and research collaborations,22,23 improving inclusion of populations internationally. Most importantly, including lived experience can increase the likelihood that the most relevant research is being translated into clinical practice.24–26
In bipolar disorder (BD), specifically, there are only a handful of publications comparing lived experience and research community priorities; prior work has primarily been qualitative and conducted in small samples.1,2,23,27 A scoping review of consensus-setting studies in BD 28 identified only nine studies that were highly heterogeneous in terms of methodology. These studies did not directly compare in a quantitative fashion the perspectives from lived experience to the focus of the research in the scientific community. Further research using diverse methods to capture BD community input and their correspondence (or lack thereof) with biomedical research should yield insights into research questions most likely to yield impactful, clinically relevant outcomes.
Social media-based methods offer an opportunity to gather insights from posts from individuals with diverse health conditions, 29 offering an intriguing additional route to explore the research priorities. 30 Reddit, a social media service combined of “subreddits” (topical communities where anonymous users discuss specific areas of interest) 31 represents one compelling option as it readily supports health communication.32,33 While these online “subreddit” communities are often considered anonymous peer to peer conversations,34,35 they also provide a valuable opportunity to ignite conversations between diverse stakeholders in health communities. 11 Social media events on Reddit, if used effectively, can provide dynamic “crowd sourcing” 36 opportunities for questions and conversations between researchers, those with lived experience, and their wider communities, 37 and can be used to determine concerns,10,38 inform clinical care, 34 and determine priorities for research.
The Collaborative RESearch Team to study psychosocial issues in Bipolar Disorder (CREST.BD), has over the past 8 years delivered an annual Reddit “Ask Me Anything” (AMA) discussion. Held in conjunction with World Bipolar Day, the AMA serves to connect the public with a large panel of BD experts, including researchers, clinicians, and people with lived experience of BD. CREST.BD's AMA is a purposefully created space that fosters a dialogue about BD through anonymously posted questions from the community. This large data set and the unique forum generated by CREST.BD's Reddit AMA will be used in this study to develop a clearer sense of the areas of discourse that are currently prominent in Reddit BD communities. To assist in identifying research priorities, computational modelling and natural language processing will be used to identify themes from within the AMA Reddit posts. Computational modelling of text-based mental health-related Reddit posts has been conducted previously, but focused primarily on textual analysis of users with self-reported mental health diagnoses 39 or looking at particular behavioural experiences in BD. 40
In a prior study, natural language processing was used to quantify the focus areas of questions in topic modelling (specifically, BERTopic), 41 a technique that was used to algorithmically extract key themes from 5 years of the AMA conversations. Common topics identified included BD misdiagnosis/differential diagnoses, coping with daily struggles, understanding hypomania, suicidal thoughts and behaviours, medication and use of substances such as psilocybin and ketamine, and supporting loved ones with BD.
Expanding on this prior project, 42 we sought here to evaluate the alignment of the topics raised by AMA participants with that of concurrent research on BD, again using natural language processing methods. We performed topic modelling to the body of published peer-reviewed biomedical literature on BD during the same period (2019 to 2023) and then evaluated the convergence between Reddit and biomedical literature-derived topics. While this work was exploratory, we expected a range of convergent and divergent themes in comparing the Reddit and biomedical databases.
Method
Reddit Ask Me Anything Methods
All AMA events were conducted on the r/IAmA subreddit, a Reddit-based community platform facilitating topic-oriented interviews (i.e., AMAs), where users from the general public pose questions to panelists. AMAs are public facing in nature, allowing viewing of questions and responses, although only registered Reddit users may submit questions. The AMAs began each year on 30 March, World Bipolar Day, as a part of global awareness efforts for BD, and lasted 48 h. The dataset for the present study represents the AMAs held between 2019 and 2023, which engaged 159 expert panelists from 14 countries who had academic/clinical expertise in mood disorders and/or lived experience expertise in BD. Two-thirds of the panelists were existing CREST.BD members, while others joined from other mood disorder research or support networks. Taken together, the AMA events generated substantial international participation and engagement, representing the largest online BD-specific AMAs to date. Cumulatively, the five AMAs garnered 11,346 upvotes and 6,159 comments. Full details of the CREST.BD AMA methods and description of ethical considerations are provided in. 42 Briefly, since Reddit users’ profiles are anonymous and comments are shared in a public forum, this research is not governed by informed consent; ethical considerations pertaining to research on Reddit are explored in. 42
Biomedical Research Data
We performed topic modelling from the abstracts published literature available in PubMed [https://pubmed.ncbi.nlm.nih.gov]. PubMed was queried using Entrez [https://www.ncbi.nlm.nih.gov/books/NBK25501/] eSearch using an appropriate query limiting dates to the years when the CREST.BD AMA were conducted. We used the National Center for Biotechnology Information (NCBI) search term: “Bipolar Disorder,” and all data was accessed 30 April 2025, field set to “MeSH” OR “title” OR “abstract” and mindate set to 2019, maxdate set to 2023. The abstracts matching the PubMed identifiers (PMIDs) were then fetched using Entrez eFetch interface. The title, abstract content, PMID, and the date of publication were extracted. Entries which corresponded to correction, redaction, etc. that did not contain abstract text were removed from further analysis. A total of 9188 abstracts were extracted.
Topic Modelling Using BERTopic
Abstracts were treated as documents for topic modelling using BERTopic. 41 Some of the parameters for dimension reduction in Uniform Manifold Approximation and Projection (UMAP) 43 and Density-Based Spatial Clustering of Applications with Noise (DBSCAN) clustering 44 had to be modified to accommodate a larger document set. By altering some hyper-parameters (See Supplementary Material), and using frequently used words such as patient, bipolar, disorder, treatment as stop words (words to be filtered before topic modelling is performed), we achieved good clustering results with some non-cohesiveness in two large topics. The choice of hyper-parameters (Supplemental material, Table S1) was to additionally ensure 20 clusters were created with similar size and having similar distribution as our previous study. 42 For UMAP, setting metric = 'Euclidean’ and min_dist = 0.01 ensured linearity in embedding space was preserved, and points could be brought very close in the dimension reduction step. For HDBSCAN clustering, min_cluster_size = 80 ensures we had a minimum topic containing about 1% of the data; metric = 'Euclidean’ ensured linear interpretation in embedding space; cluster_selection_method = ’leaf’ was used to ensure large, diffused clusters were not created. Topic models were represented by 10 descriptive words, three exemplar documents, as well as KeyBERT 45 and ChatGPT-3.5-turbo description.
Generating Topic Labels in Biomedical Literature Using ChatGPT3.5-Turbo
Consistent with our previous study, 42 we used the following prompt to generate the topical phrase using ChatGPT 3.5-turbo on 8/22/2025: “I have a topic that contains the following documents:
Based on the information above, extract a short but highly descriptive topic label of at most 5 words. Make sure it is in the following format: topic: <topic label>”.
Constructing Topic Vectors for Matching
The focus of this article is to evaluate the extent of alignment between biomedical research with topics identified by people with lived experience, and we selected GloVe as a “common ground” between general domain lived experiences and technical biomedical perspectives in comparison to biomedical embeddings (e.g., PubMedBert). The 10 descriptive words of each topic are aggregated by summing their 300-dimensional GloVe vector.
46
Using the highest dimensional vectors available when aggregating GloVe vectors offers some advantages. Specifically, higher dimensions allow for the capture of more nuanced and complex semantic relationships between words, potentially improving the performance of downstream tasks like sentiment analysis and text classification.

where
Similarity Match Between Topics
Having constructed vectors to represent each of the model topics, similarity between two topics was computed using cosine similarity:
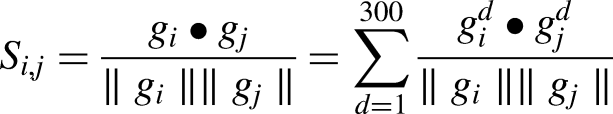
Similarity Si,j between research topics j and Reddit topic i was computed by summing respective dimensional components in the word vectors. Similarity measures and their cut-offs for titles and short texts substitutability lack a clear consensus. 47 Cosine similarity ranges from 0 to 1, and we interpreted for ease of understanding a similarity score of >0.6 as reflecting higher overlap, between 0.4 and 0.6 as modest, and <0.4 as low overlap. Although there is no widely accepted standard for cosine similarity thresholds in embedding-based topic matching, our choice was based on observation and in accordance with the few studies that explored cosine similarity in the context of embeddings. 48
Results
PubMed Topics: The results of topic modelling using BERTopic and topic representation generated by ChatGPT 3.5 Turbo are shown in Table 1. The table is sorted by the counts of abstracts belonging to the topic followed by a topical phrase generated using ChatGPT 3.5-torbo and the top defining words. In addition, we have provided the representative abstract's title and the PMID. Clustering visualization (Figure 1) shows the spatial distribution among clusters. The proximity of similar topics is apparent where clusters related to brain/cognition/ADHD occupy one region (orange/brown) next to metabolic-related (yellow/green), pharma-related ones (greens), and circadian/sleep related (blue/teal). As seen in the figure, the resultant topics cover a wide range of BD-related themes, with the most common topic “Genetic Architecture of Psychiatric Disorders,” a theme containing 728 PubMed articles, and the second most common topic was “Brain Network Alterations in Depression.” All clusters were localized and well-defined in the reduced-dimensional space (Figure 1).
Visualization of clustering of PubMed abstracts. Each publication is represented as a point in the 2D-datamap after UMAP dimension reduction. Identified colour regions represent a topic. Clusters related to brain/cognition/ADHD occupy one region next to metabolic related, pharma-related ones, and circadian/sleep related (blue/teal). The choice of “leaf” hyperparameter results in relatively even sized clusters with some gaps between them as the spatial spread of the clusters is somewhat controlled. UMAP = Uniform Manifold Approximation and Projection.
Results of Topic Modelling on PubMed Abstracts.

Topics resulting from using BERTopic on 9,188 PubMed Abstracts.
Representation of a topic generated by OpenAI's ChatGPT 3.5 Turbo Model.
Default 10-word representation generated by BERTopic.
Title of an article representative of the topic.
PubMed identifier of the representative article.
PMID = PubMed identifier.
Validation of Topic Modelling:
Topic Coherence: To assess the quality of modelled topics that correlates with human judgement, several coherence measures were calculated, each being associated with slightly different statistical and semantic properties.49–51
UMass coherence (CUMass) was −1.6; it is a word-order asymmetric corpus-based measure using document co-occurrence counts from the training corpus. The values are negative, and less negative values are better. UCI coherence (CUCI) was 1.1; it is similar to CUMass, but it uses an external corpus for co-occurrence counts, and positive values are better. Pointwise mutual information (CNPMI) was 0.142; it is a corpus-unaware measure of coherence that uses mutual information between topic word pairs, and positive values are better. Contextual vector coherence (CV) is a generally preferred metric that lies in the range [0–1] and was shown to have the strongest correlation to human ratings
50
; it was 0.67. It is a composite measure that combines sliding-window co-occurrence counts with CNPMI scores integrating direct co-occurrence with a topic-space representation to capture both local and global semantic relatedness. A higher score indicates a more coherent, meaningful topic. Scores around 0.7 are considered strong, while 0.3–0.4 indicates low coherence.
Topic Diversity: a measure of how distinct the generated topics are, was 0.77. It was computed as a fraction of all top words (across the topics) that were unique.
Model Stability: This was found to be 0.87. Rank-Biased Overlap (RBO extended), which gives greater weight to higher frequency terms, was used over five (randomly seeded) runs to compute it.
Convergence of Reddit and PubMed Topics: Our measure of convergence, cosine similarity, was interpreted as >0.6 as reflecting higher overlap, between 0.4 and 0.6 as modest, and <0.4 as low overlap. Using this metric, a third (35%) of the top 20 topics of people with lived experience exceed 0.6 (n = 6 of the topics identified through Reddit AMA topic analysis). These included Lithium therapeutic index monitoring, Bipolar Pregnancy Medication Safety, Understanding Cyclothymia, Bipolar Sleep Cycling Disorder, Marijuana and Bipolar Disorder, Bipolar Suicide Rates, and Bipolar Disorder Misdiagnosis (Figure 2 and Tables 2–3).

Sankey plot of overlap between Reddit and PubMed topics. CREST (Reddit) identified topics are on the right, and their widths are proportional to the number of postings; PubMed topics are on the left, and their widths are proportional to number of publications. The plot connects PubMed topics with matching Reddit topics that they might address. The correspondence is shown for good (cosine similarity >0.6) as well as modest matches (cosine similarities in the range 0.4–0.6). The bottom topics on either side are placeholder matches for the topics on the opposite sides with insufficient match (cosine similarity <0.4).
Reddit Topics Sorted in Order of PubMed Overlap: The Reddit Topics Clusters Labelled T1 to T20, Which Were Identified in Our Previous Study, Are Shown Sorted in Decreasing Order of Their Overlap With PubMed. The Column “PubMed Overlap” Shows the Normalized (A Value Between 0.0 and 1.0) of Cosine Overlaps with PubMed Research Topics. A Value Greater Than 0.6 Can Be Considered as a Reasonable Overlap with Specific Information Being Available to Reddit User, With Similarity Scores of 0.4–0.6 Representing Moderate, and Slow Below 0.4 Low Convergence.

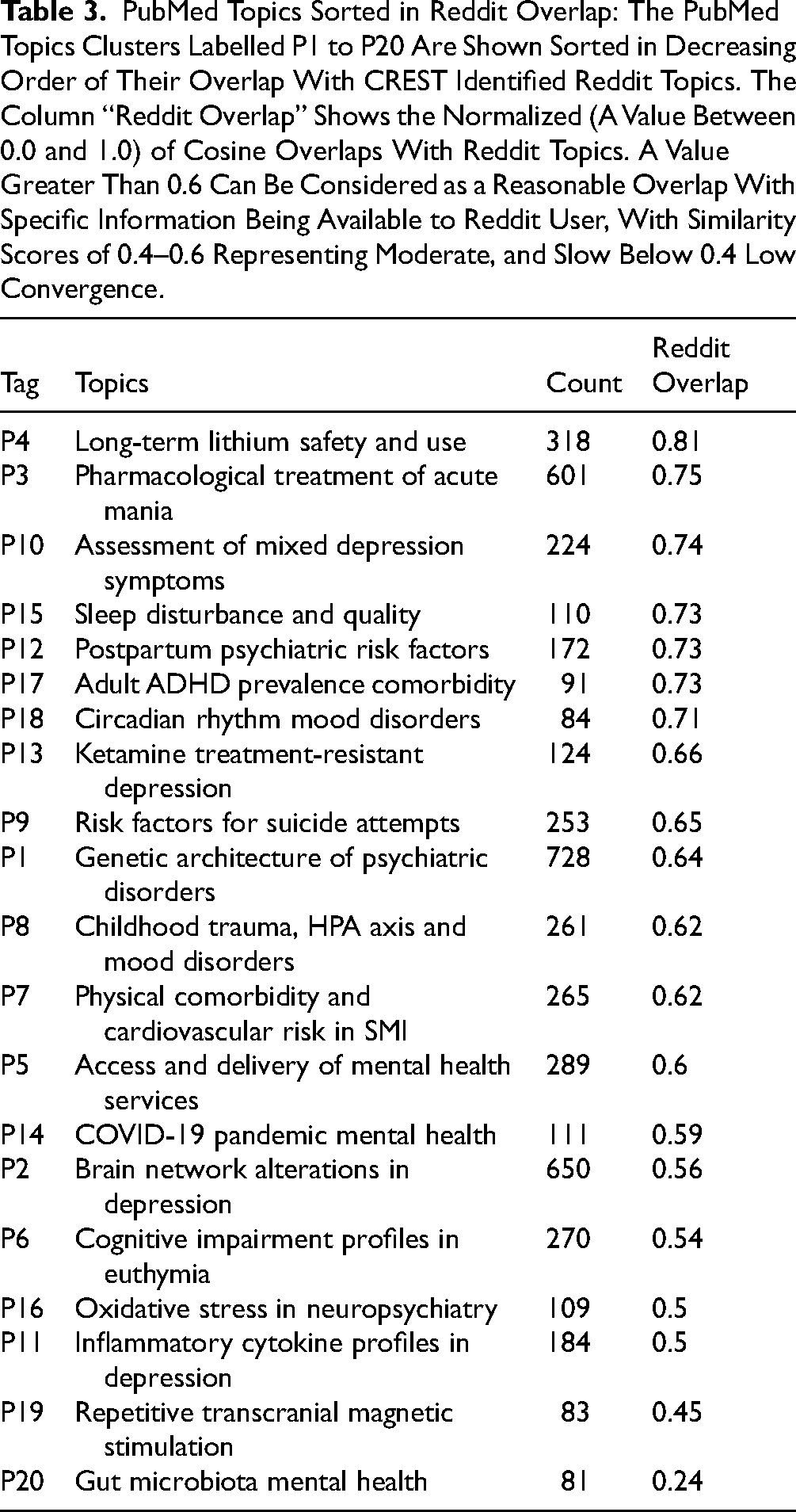
PubMed Topics Sorted in Reddit Overlap: The PubMed Topics Clusters Labelled P1 to P20 Are Shown Sorted in Decreasing Order of Their Overlap With CREST Identified Reddit Topics. The Column “Reddit Overlap” Shows the Normalized (A Value Between 0.0 and 1.0) of Cosine Overlaps With Reddit Topics. A Value Greater Than 0.6 Can Be Considered as a Reasonable Overlap With Specific Information Being Available to Reddit User, With Similarity Scores of 0.4–0.6 Representing Moderate, and Slow Below 0.4 Low Convergence.
The remaining 65% of the Reddit topics (cosine similarity in the range .28−.60) cover 42% of the Reddit responses/comments that were linked with moderate (n = 8) or low overlap (n = 5) with the biomedical literature. These topics include side effects and experiences of medications (e.g., Lamictal Lamotrigine Interactions), self-management (e.g., coping with daily challenges), and family members/caregiving.
Turning to the convergence of PubMed topics appearing in Reddit, 45% of topics evidenced higher overlap. These included Long-Term Lithium Safety and Use, Pharmacological Treatment of Acute Mania, Assessment of Mixed Depression Symptoms, Sleep Disturbance and Quality, and Postpartum Psychiatric Risk Factors. PubMed topics with very low coverage (cosine similarity <0.4) included basic biological mechanism—Gut Microbiota Health.
Finally, in Figure 2, a Sankey plot 52 visualize the match between the Reddit user topics and the PubMed topics.
To ensure we arrived at consistent topical phrases, the generated topics were reviewed by experts along with the representative words and the corresponding abstracts; results were supplemented with suggested alterations. Human review of the topic matches indicated that the thematic alignment between Reddit and PubMed topics was generally consistent with the cosine similarity values. Topic pairs with cosine similarity values greater than 0.6 typically reflected clear conceptual correspondence (e.g., lithium safety, sleep disturbance, and suicide risk), while those in the moderate range (0.4–0.6) represented broader but related themes. One partial exception was the pairing of the Reddit topic “Marijuana and Bipolar Disorder” with the PubMed topic “Pharmacological Treatment of Acute Mania” (cosine similarity = 0.65). Although these topics appear distinct, the Reddit discussions focus on recreational substances and their potential to precipitate mania, whereas the PubMed literature addresses pharmacological agents used to treat acute mania; both therefore relate to the role of psychoactive substances in manic states.
Discussion
In this study, we applied a computational approach to examine the alignment between research topics reflected in PubMed abstracts concerning BD and questions posed by individuals with lived experience during a series of large-scale Reddit AMA events focused on BD. By using natural language processing and topic modelling on both corpora, we compared the thematic focus of lived experience discourse and biomedical literature in a reproducible manner. There was some evidence for overlap, with 35% of topics in the Reddit AMA appearing in the biomedical literature and 60% of biomedical topics appearing in the Reddit forums. For areas of strong overlap, this may support the potential use of social media forums for the dissemination of scientific literature and engagement with the public. Topics with low representation in the biomedical literature but high frequency in Reddit forums included self-management and caregiving for family members. These topics could be viewed as areas of high priority for people with lived experience of BD, and unmet needs for research.
Several themes identified in the AMA questions showed considerable overlap with those prevalent in PubMed abstracts. These included topics related to diagnosis, medication use, and treatment outcomes, which have traditionally represented central foci of biomedical research and clinical management. Such convergence may reflect the ongoing emphasis on symptom management and pharmacotherapy within both professional and lived experience perspectives on BD. Sleep and circadian rhythm were also highly overlapping topics, underscoring their recognized importance as both clinical features and self-management challenges for people with BD. Taken together, these findings suggest that online communities such as Reddit could serve as useful venues for disseminating research findings on these topics in BD. Moreover, forums could provide opportunities to obtain feedback on research aims, outcomes, and or procedures in planning stages of research, as well as offer opportunities for engagement with research studies.
The areas with less overlap may also be informative for the BD research community. Firstly, it is perhaps not surprising that lived experience queries did not reflect topics in current basic science research. That said, online community forums maybe avenues for research dissemination so as to increase public awareness and potentially in discovery-oriented science. Secondly, several topics raised by AMA participants, such as self-management strategies, the experience of hypomania, and supporting family members or caregivers, appeared underrepresented in biomedical research abstracts. These domains are central to the day-to-day experience of living with BD, yet they receive comparatively less research attention.53–55 It is not quite clear why self-management, family care, or lived experience of hypomania are limited as a research focus in BD compared to public interest. One possibility is that these topics are considerations for secondary (early intervention) or tertiary (recovery) prevention, and there is some evidence that secondary and tertiary prevention research has declined in proportion of funding. 56 It may be that greater inclusion of people with lived experience in all phases of research, including priority setting and grant review, could ameliorate these gaps, and recent review has detailed the promise and challenges therein. 57 It does appear that natural language processing could be a useful tool in determining areas of unmet need, and potentially whether policy or research practice changes, such as inclusion of lived experience in research processes, mitigate these gaps over time.
Although these findings provide a preliminary perspective on how research priorities align with the lived experience of BD, several limitations should be considered. Topic modelling algorithms are imperfect, and the clusters they generate may not always represent cohesive or distinct themes. The labelling of topics therefore contains some degree of error, and our findings are best interpreted as offering a broad, “10,000-foot” overview of both data sources rather than a precise mapping of content. As with all natural language processing methods, results also depend on the linguistic patterns captured by the model and may differ from how humans would interpret meaning. The Reddit discourse data reflects questions posed by individuals rather than explicit research recommendations and therefore represent topics of curiosity or concern rather than prioritized areas for study per se. AMA questions may be shaped by the presence of experts and may differ from more spontaneous questions asked in different forums or on social media. In addition, the AMA participants may not be representative of all individuals with BD or of Reddit users more broadly, as demographic and diagnostic information were not available due to the platform's anonymity. The data were also aggregated across 5 years, and we did not have sufficient data to evaluate temporal changes in priorities among Reddit forum participants. The bioethics of social media research is a developing area with emerging frameworks for best practices. 58 Finally, some differences in results are to be expected if specialized domain-specific embeddings were used instead of GloVe embeddings for topic matching, which may be of interest from a different perspective.
We believe this study provides a foundation for integrating social media and biomedical research, more broadly, for exploring how natural language processing can be used to study the perspectives of people with lived experience and the research community at scale. Additional computational approaches, including alternative embedding methods or supervised topic models, could be examined to enhance the precision and interpretability of these analyses. Future work might also explore hybrid approaches, such as co-designing topic frameworks with lived experience partners and then applying computational methods to compare overlap with the scientific literature. Beyond BD, this approach could be adapted to other areas of mental health and chronic illness, as well as to other text sources such as patient forums, clinical documentation, or grant databases. Overall, this line of work suggests that systematic, data-driven methods may serve as useful complements to established participatory approaches, supporting efforts to ensure that research priorities remain informed by the lived experiences of the people most affected by illness.
Supplemental Material
sj-docx-1-cpa-10.1177_07067437261448751 - Supplemental material for Alignment of Lived Experience Questions with the Medical Literature in Bipolar Disorder: A Topic Modelling Approach: Adéquation entre les questions relatives à l’expérience vécue et la littérature médicale concernant le trouble bipolaire : Une approche de modélisation de sujets
Supplemental material, sj-docx-1-cpa-10.1177_07067437261448751 for Alignment of Lived Experience Questions with the Medical Literature in Bipolar Disorder: A Topic Modelling Approach: Adéquation entre les questions relatives à l’expérience vécue et la littérature médicale concernant le trouble bipolaire : Une approche de modélisation de sujets by Varsha D. Badal, John-Jose Nunez, Colin A. Depp, Adrienne Benediktsson and Erin E. Michalak in The Canadian Journal of Psychiatry
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.