
Abstract
In this study, we generate prompts derived from every topic within the Journal of Economic Literature to assess the abilities of both GPT-3.5 and GPT-4 versions of the ChatGPT large language model (LLM) to write about economic concepts. ChatGPT demonstrates considerable competency in offering general summaries but also cites non-existent references. More than 30% of the citations provided by the GPT-3.5 version do not exist and this rate is only slightly reduced for the GPT-4 version. Additionally, our findings suggest that the reliability of the model decreases as the prompts become more specific. We provide quantitative evidence for errors in ChatGPT output to demonstrate the importance of LLM verification.
Introduction
Economists predict that Artificial Intelligence (AI) tools like OpenAI’s ChatGPT will make human workers more productive (Eloundou et al., 2023; Goldfarb et al., 2023; Peng et al., 2023). While acknowledging that AI tools like ChatGPT can augment human labor, we present systematic evidence of errors common in the output of large language models (LLMs) when prompted to write about and cite social science literature. Researchers should be aware of ChatGPT’s tendencies to hallucinate (i.e., generate false information or content that appears real). The problem of hallucination is significant for applications in business, policy, or wherever humans rely on text generated by AI.
We query ChatGPT (both the GPT-3.5 and more recent GPT-4 versions) about economics through prompts derived from each of the Journal of Economic Literature (JEL) categories. While acknowledging that some of the output is useful and accurate, we note the common occurrence of hallucinations. The issue of hallucination has been known to the computer science community since before the public ChatGPT product. Ji et al. (2023) warn that, “Hallucination … is concerning because it hinders performance and raises safety concerns for real-world applications. For instance, in medical applications, a hallucinatory summary generated from a patient information form could pose a risk to the patient.” Alkaissi and McFarlane (2023) document this problem in a medical context. Even though the error rate will go down as the LLM technology improves, it is unlikely that the problem could be eliminated entirely, since LLMs are fundamentally creative. AI generated content is already on the internet, including websites that users might go to for medical advice (Thompson, 2023).
To provide an objective determination of the number of hallucinations per response, we count how many of the citations provided by ChatGPT exist versus those that do not exist. There can be other types of mistakes in LLM output, however, we consider this quantitative measure to be useful data on hallucinations in social science writing. For the GPT-3.5 version of ChatGPT, the overall rate of false citations in our data is over 30%. The GPT-4 version of ChatGPT fares better, but still produces false citations at a rate over 20%. We also find that the rate of false citations increases significantly when the prompt goes from a general topic to a narrow question.
Our work supports the notion that certain creative tasks can be outsourced to LLMs, while some of the more routine work in research production still cannot be entirely entrusted to ChatGPT (Buchanan & Hickman, 2023; Cowen & Tabarrok, 2023). Our contribution does not only concern the usefulness of ChatGPT for the particular task of writing a literature review. We use citations as a proxy for factual errors because they can be counted and verified. The broader implication is that LLM output can contain falsehoods that appear legitimate because ChatGPT can mimic scientific writing.
Our goal is to present systematic evidence for this problem in a social science research context, so that researchers can use LLMs appropriately. We find, like Korinek (2023), that the LLM can produce some valid references for widely-cited books and papers, because the LLM has access to many training examples in human writing. Jungherr (2023) presents examples showing that LLM performance declines at the conceptual level when requests become more specific. Roberts et al. (2023) provide cases with geography and GPT-4. 1 Our paper provides quantitative evidence for this phenomenon.
Method
We asked ChatGPT to provide content on a wide range of topics within economics. For every JEL category, we constructed three prompts with increasing specificity. Each prompt was provided to both the GPT-3.5 and GPT-4 versions of ChatGPT. 2 OpenAI indicates that the GPT-4 version is “more reliable, creative, and able to handle much more nuanced instructions” than the GPT-3.5 version (OpenAI, 2023). The enhanced functionality of GPT-4 should lead to better results, but we demonstrate that the newer model is still susceptible to frequent hallucinations.
The three levels of prompts are as follows:
Level 1: The first prompt, using JEL Category A here as an example, was “Please provide a summary of work in JEL Category A, in less than 10 sentences, and include citations from published papers.”
Level 2: The second prompt was about a topic within the JEL category that was well-known. An example for JEL category Q is, “In less than 10 sentences, summarize the work related to the Technological Change in developing countries in economics, and include citations from published papers.”
Level 3: We used the word “explain” instead of “summarize” in the level 3 prompt, asking about a more specific topic related to the JEL category. For L we asked, “In less than 10 sentences, explain the change in the car industry with the rising supply of electric vehicles and include citations from published papers as a list. Include author and year in parentheses and journal for the citations.”
Using 19 JEL categories and three levels of prompts across the two versions of ChatGPT, we obtained 114 responses. The GPT-3.5 version responses were collected in May 2023. The responses from the GPT-4 version were collected in October 2023. Topic variety is used to demonstrate that hallucination is pervasive and not restricted to one subject. The variation in specificity allows for testing the hypothesis that hallucinations are more likely when there is less public training literature for the LLM. 3
We analyzed the responses in two ways. First, we used a measure that we argue is objective. We checked whether the citation exists. Second, we judged whether the real citations are appropriate for the answer to our question, which we acknowledge is subjective.
Real: The citation is classified as real if we could find it, as written by ChatGPT, online. Internet search tools such as Google Scholar are comprehensive. We expect that a paper or book that exists would be indexed by Google search engines. The citation is classified as not real if no such published document exists.
For example, in response to “explain how marketing in social media affects profit for businesses…” ChatGPT (the GPT-3.5 version) produced the following citation: Trusov, M., et al. (2009). Evaluating the Impact of Social Networks on Business Performance. Marketing Science, 28(2), 356-378. ChatGPT identified a scholar, Michael Trusov, who writes about social media. However, the cited paper does not exist, and ChatGPT failed to locate any of his papers that might have been a good match.
Correct: The citation is classified as correct if it is a proper source for answering the question. Consider the Level 3 prompt for JEL category R: “explain rental price changes during hurricane seasons…” ChatGPT (GPT-3.5) returned the following citation: Deryugina, T., et al. (2020). The long-run dynamics of electricity demand: Evidence from municipal aggregation. Journal of Urban Economics, 119, 103276. This citation is classified as not real because the paper with that title was not published in The Journal of Urban Economics. It would also be classified as not correct, because the subject of the paper is residential electricity demand in Illinois not hurricanes.
Although we recognize that academics might use different standards to evaluate the quality of references provided by ChatGPT, we believe that these two measures capture an important trend. The errors are significant and frequent. Readers are invited to view every response from GPT-3.5 in the Online Appendix and create metrics for errors. Figure 1 shows the response to a level 1 prompt for JEL category B. Example ChatGPT prompt and response.
The primary metric used to evaluate a GPT response is
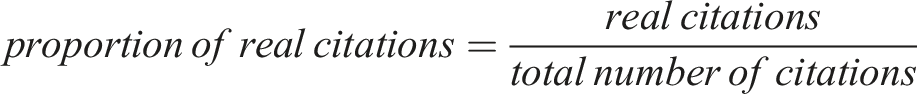
Results
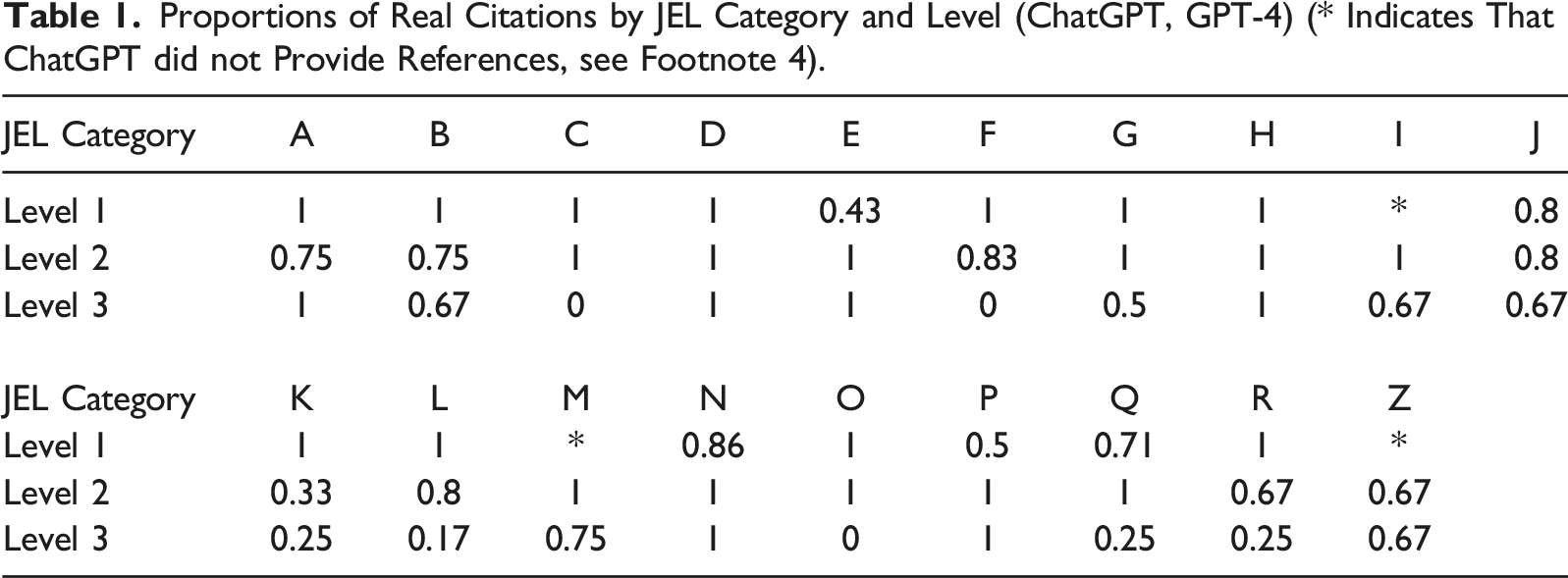
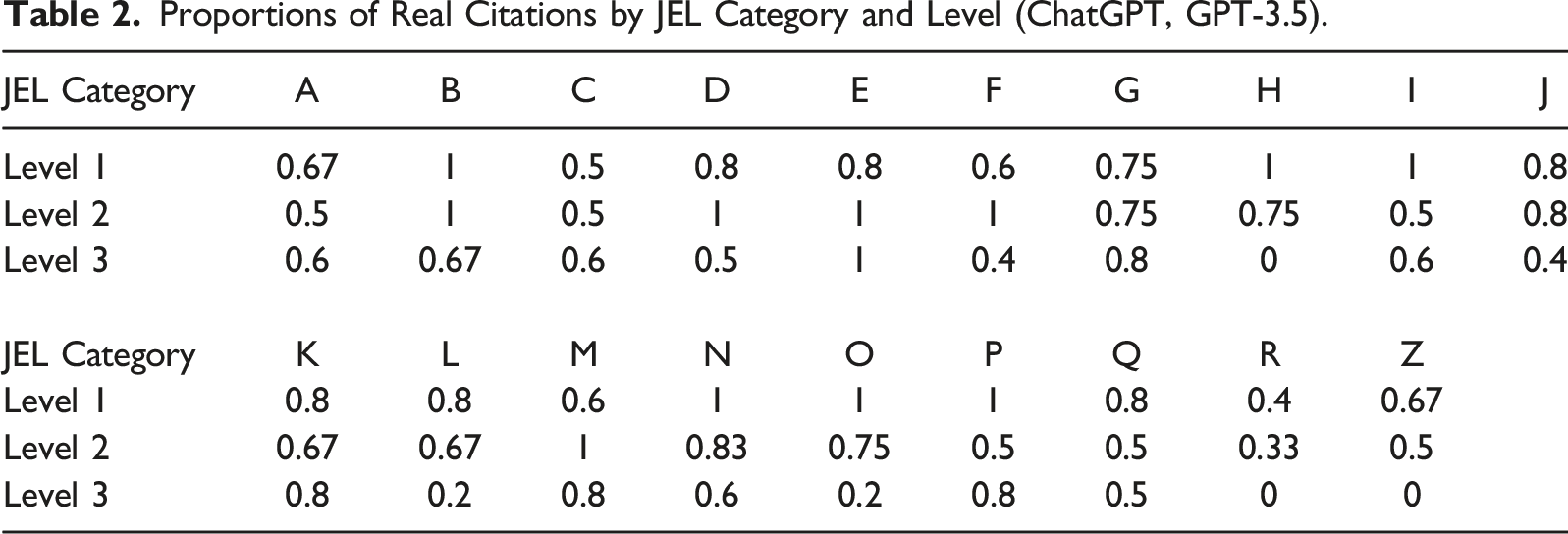
Figure 2 shows the proportion of real citations across each level of specificity. The GPT-4 version of ChatGPT outperforms the GPT-3.5 version, but both versions show a decline in the proportion of real citations as specificity increases. We report the proportion of real citations for each JEL category, by specificity level, in Table 1 (GPT-4) and Table 2 (GPT-3.5).
4
Figure 3 shows a similar result for the proportions of correct citations. Accuracy of citations provided by ChatGPT (GPT-3.5 and GPT-4) declines as the level of specificity in the prompt increases. Proportions of Real Citations by JEL Category and Level (ChatGPT, GPT-4) (* Indicates That ChatGPT did not Provide References, see Footnote 4). Proportions of Real Citations by JEL Category and Level (ChatGPT, GPT-3.5). Correctness of citations provided by ChatGPT (GPT-3.5 and GPT-4) declines as the level of specificity in the prompt increases.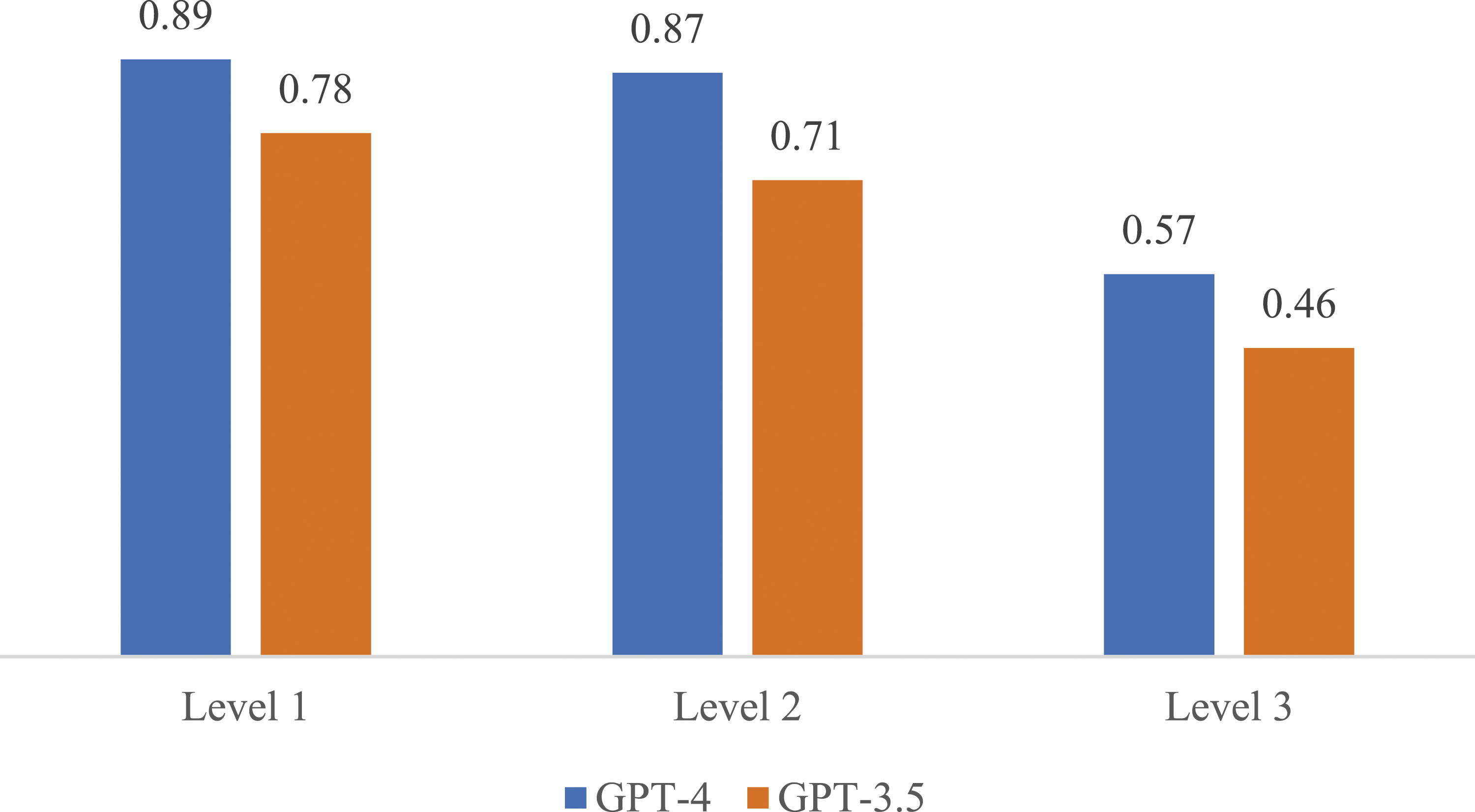
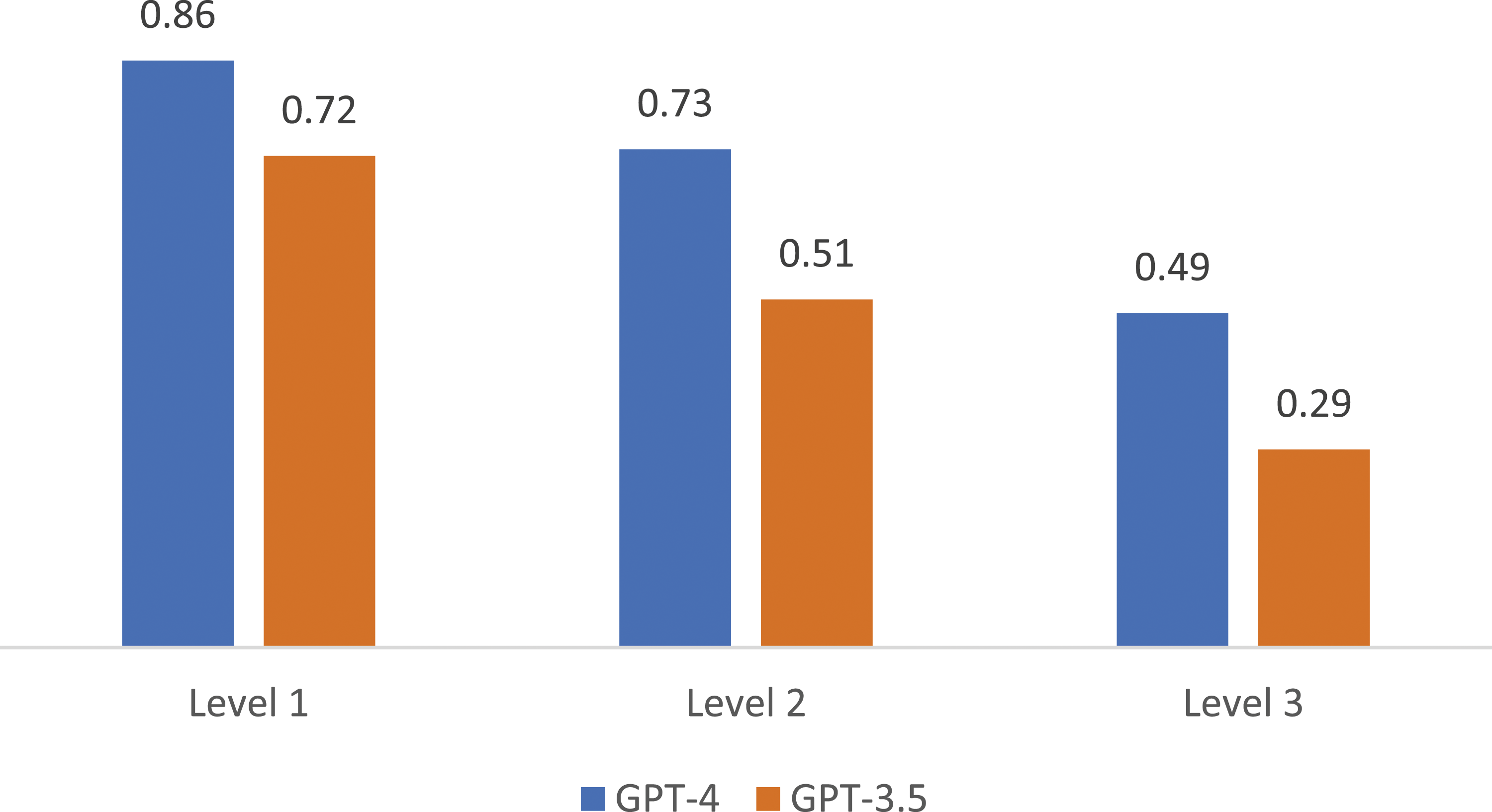
ChatGPT returns a considerable proportion of false citations, more than 30% for GPT-3.5 and 20% for GPT-4. We test for a difference in the proportion of real citations between level 1 and level 2 using a nonparametric Mann–Whitney test. For both GPT-3.5 and GPT-4 there is no significant decline (p = .29 and p = .54, respectively) in accuracy going from a description of the JEL category to a broad topic in economics. We can surmise that the prompt for Level 2 was still general and therefore ChatGPT had access to sufficient training material. Performance declined when asked to explain more specific topics with a narrower set of available documents. There is a significant decrease in accuracy from Level 1 to Level 3 for both GPT-3.5 and GPT-4 (p < .002 for both). The pattern also holds for the metric of correct citations.
We find a significant decline in accuracy from a general topic to a more specific question posed to ChatGPT (GPT-3.5 and GPT-4).
Conclusion
Academics, students, and researchers will use LLM tools (Geerling et al., 2023). We argue that fact-checking is necessary to prevent false statements from propagating in the literature. OpenAI (2022) acknowledged that, “ChatGPT sometimes writes plausible-sounding but incorrect or nonsensical answers.” We systematically document this issue in the context of citations from the economics literature.
LLMs simulate humans convincingly, but we argue that ChatGPT does not yet outperform experts in a subfield of knowledge. Researchers can study the output of LLMs as a new kind of data that provides insights into human behavior and biases, since it was trained on a vast amount of human writing (Bybee, 2023; Horton, 2023).
Hallucinations make LLMs different from previous printing and writing technologies. The issue of false academic citations might be solved if AI creators build a tool to prevent that specific type of error. Nonetheless, this article will serve as evidence that LLM output should be tested for factual accuracy and that errors are more likely to occur for obscure topics. The academic community of teachers and researchers should recognize that hallucinations are possible. The implications are equally important for management and public policy.
Supplemental Material
Supplemental Material - ChatGPT Hallucinates Non-existent Citations: Evidence from Economics
Supplemental Material for ChatGPT Hallucinates Non-existent Citations: Evidence from Economics by Joy Buchanan, Stephen Hill and Olga Shapoval in The American Economist
Footnotes
Acknowledgments
The authors declare that there is no conflict of interest regarding the publication of this article. Funding was provided by Samford University.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
Notes
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.