
Abstract
We draw on a general model of the governance of organizations to analyze the dynamics among various actor types given the present ubiquity of evaluations in and around universities. Regulators demand evaluations to assess the return on taxpayers’ money. Market actors, particularly publishers of academic journals, promote different metrics, including citation scores and impact factors. Scrutinizers, such as media companies, professions, auditors, and nongovernmental organizations, create further evaluations by developing university rankings, accounting systems, and investigative reports. There are also initiatives for evaluations inside universities: vice chancellors, department heads, and other academic leaders launch voluntary internal assessments, and researchers assist regulators, market actors, and scrutinizers throughout their evaluations. We conclude that multiple actors are responsible for the current evaluation regime in academia, and that none of them is responsible alone. Rather, it is in the dynamic relationships among actors at different levels that we find the strongest processes driving a seemingly ever-increasing number of evaluations in contemporary academia.
Introduction
Continuous performance evaluations of individuals have always been a basic feature of academia. Evaluations start at the undergraduate level with oral and written examinations, and continue at the graduate level, with the doctoral dissertation defense constituting the ultimate step (Lindberg, 2022). For those staying in academia, reviews of manuscripts, grant proposals, and job applications are common (Langfeldt and Kyvik, 2011; Musselin, 2013). The procedures for assessing academics are particularly transparent in the US higher education system, where fresh PhDs are first hired as assistant professors, and then evaluated for tenure 6 years later (Finkin, 1996). US universities thereby apply the consultancy principle: ‘Up or out.’
Although evaluations are endemic to academia, they have taken new paths over time. One such path is a movement from evaluations concentrating on individual researchers to the current plethora of evaluations that also consider departments, universities, and other higher education organizations. Another new path is a movement from evaluations as intra-academic procedures to the increasing use of bibliometric figures and organizational rankings, which are readily available to both academic and non-academic audiences.
Some 40 years ago, a literature had already developed exploring various approaches to evaluations in academia. Attention was first directed to the relationships between resource input and output (Cook and Campbell, 1979), followed by an emphasis on the qualitative aspects of research (Lincoln and Guba, 1985). Later, there were calls to combine quantitative and qualitative approaches (Chen, 1990). Since then, evaluations have increased in scale and scope, generating important developments and stimulating crucial debates, as recently articulated by Hallonsten (2021) and his commentators (Wagner, 2021). An appropriate and rather evident question concerning these debates is how we ended up in the present-day situation. As expressed in the title of this special section: ‘Causes and consequences of the current evaluation regime in (academic) science.’
In this article, our aim is to develop new perspectives on the likely causes underlying the current evaluation regime. We address our aim by means of a general model of organizational governance (Engwall, 2018). This model provides us with opportunities to explore how various dynamic relationships among multiple actors in and around universities fuel new and further evaluations.
After this introduction, we present the model, which focuses on the external governance demands facing organizations in general, universities included. Then, we discuss the specific features of universities as well as how these features may affect evaluations. Moving on, we apply our model to both external and internal actors that fuel evaluations in and around universities. We conclude that multiple actors are to blame for the present ubiquity of evaluations in academia, and that none of these actors bears the blame alone.
The governance of organizations
In principle, classical approaches to governance identify two modes of governing: politics and markets. The political science literature (Lindblom, 1977) thus tends to distinguish collective decisions made by politicians representing their electorates in constituencies from those individual decisions made by actors pursuing their interests in markets. The economics literature (Coase, 1937; Williamson, 1975, 1985) makes a similar distinction regarding the organization of transactions, focusing on whether they occur within firms or between buyers and sellers on markets. In both of these governance modes, regulators and market actors play significant roles. In modern societies, scrutinizers − auditors, professions, media companies, and nongovernmental organizations (NGOs) − also affect the governance of organizations. Together, the mentioned three actor types play an important governance role, and they are fundamental components in the analytical model (Engwall, 2018: Chapter 2) we use throughout this article.
As shown in Figure 1, international, national, and local regulators (R) govern organizations (O) through rules (R1) regarding behavior and resource allocation, as well as through punishments (R2) if rules are broken. Moreover, market actors, such as resource providers, competitors, and customers (M), govern organizations through market signals (M1) regarding standards for prices, contents, and offerings, and sanction deviations through market verdicts (M2), which, in the worst of cases, may lead to closures. Finally, scrutinizers, including the media, NGOs, auditors, and professions (S), govern organizations through norms (S1) regarding socially accepted conducts, and, if norms are broken, condemn transgressions through naming and shaming (S2).
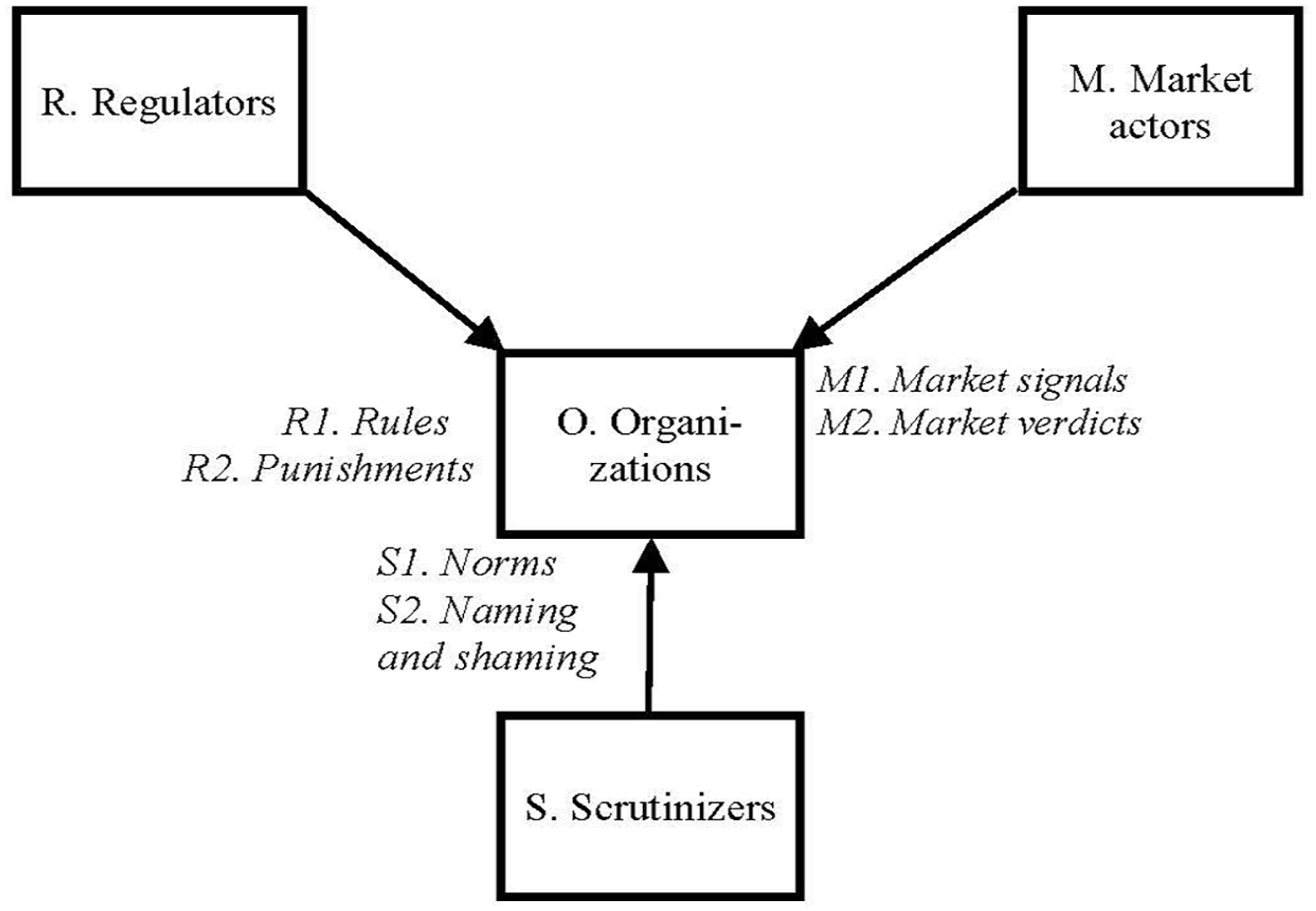
External pressures in the governance of organizations.
The governance relationships summarized above generate, to a varying extent, internal effects in organizations. As demonstrated by the two-way arrows in Figure 2, organizations (O) tend to apply three strategies (in italics) in response to external governance pressures. In relationships with regulators (R), organizations employ persuasion (O1), signifying various efforts to demonstrate that these organizations are performing well, but also to influence regulators in the creation of rules and allocation of resources benefiting the focal organizations. Similarly, in relationships with market actors (M), organizations utilize promotion (O2) to flaunt their merits and capabilities toward clients, investors, employees, and other resource providers. Finally, in relationships with scrutinizers (S), organizations deploy protection (O3), signifying various efforts to prepare for potential inspection. Throughout all three response strategies, organizations tend to establish boundary-spanning units, including legal, branding, and communication offices, as well as collaborations with consultants, interest associations, and other intermediaries.
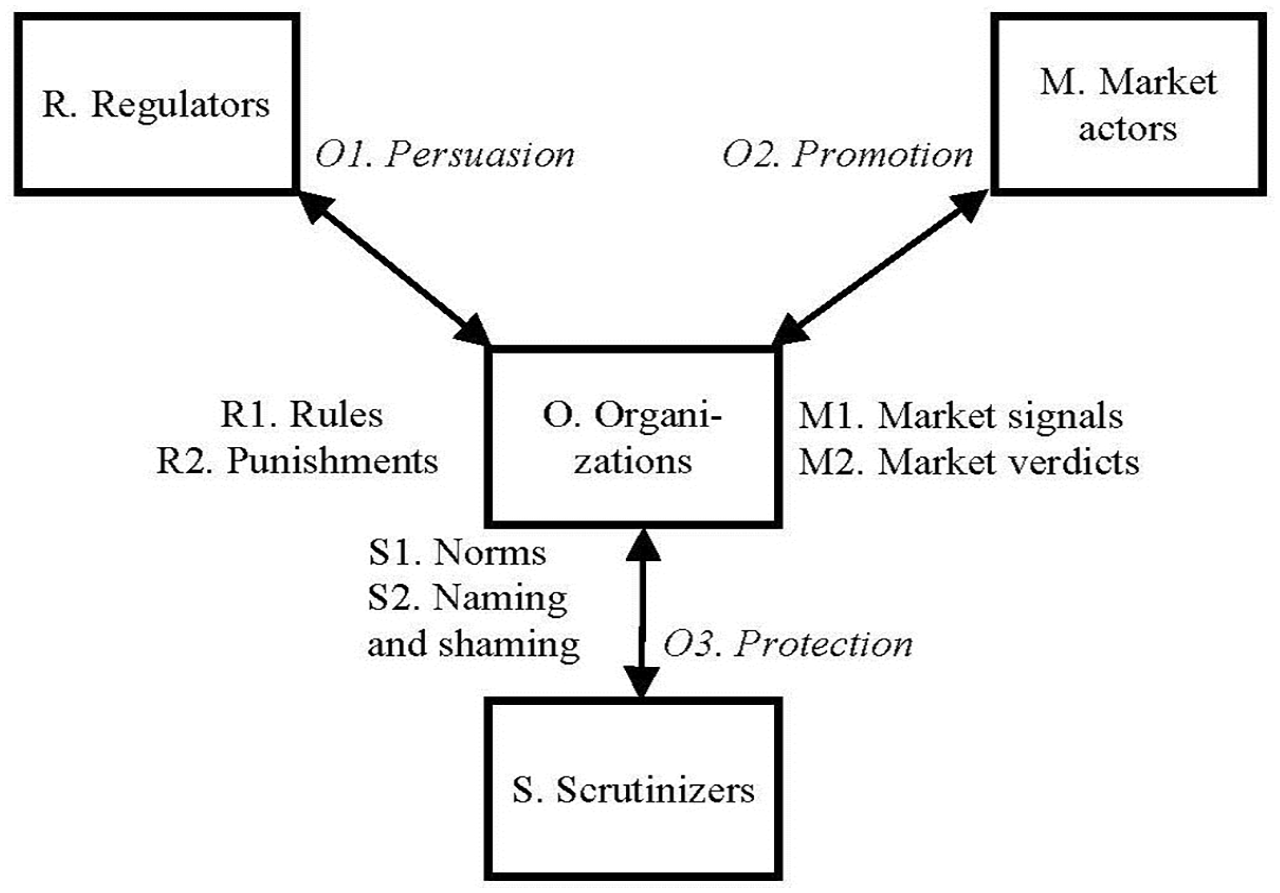
Organizations responding to regulators, market actors, and scrutinizers.
The model presented thus emphasizes the pressures organizations face from regulators, market actors, and scrutinizers, which govern through rules, signals, and norms, respectively. In case of breakage, deviance, or transgression, the three types of actors sanction by punishments, market verdicts, and naming and shaming, respectively. These governance pressures and sanctions correspond closely to what DiMaggio and Powell (1983) have called coercive, mimetic, and normative forces. To handle such forces, organizations use three strategies as responses: persuasion, promotion, and protection.
This model constitutes the basis of our efforts to analyze how governance pressures and sanctions apply to universities as organizations, and how the delegation of regulation to market actors and scrutinizers shapes new governance relationships that affect evaluations in and around higher education organizations. Before that, however, we use the following section to identify some basic features of universities that are significant for understanding evaluations in academia.
Universities as organizations
Although other organizations than universities also conduct research, universities constitute dominant actors in this domain of activity. Some universities emerged in the Middle Ages, but most were founded in the 20th century, particularly after the Second World War (see Geiger, 1993, 2015, for the United States; and Rüegg, 1992–2011, for Europe). As an organizational form, universities have been very successful: many have been established and few have been closed. This means that many countries nowadays hold not only one university but several. This growth of universities can be interpreted as the success of a brand that has made other forms of higher education organizations, including university colleges and polytechnics, eager to gain university status (Dee, 2022; Hemmings et al., 2015). This has led to a large, dynamic, and heterogeneous field of universities within which units differ in scale and scope as well as in performance. The features of this field suggest that universities as organizations have an interest in differentiating themselves to compete for economic and cultural capital. In terms of economic capital, it is a matter of attracting donations, tuition fees, block grants, and project grants, whereas the competition for cultural capital is a matter of recruiting excellent students and faculty members (Marginson, 2006; Münch, 2014). The more successful a university is in these competitions, the more opportunities it has to perform its basic tasks. Better performance is also associated with better chances in the continued competition for economic and cultural capital.
To understand the dynamics of this competition, it is important to pay attention to the characteristics of the three basic tasks that universities perform. First, they provide education of different kinds: undergraduate (for Bachelor’s degrees), graduate (for Master’s and Doctoral degrees), and continuing education. In all these types of education, the reputation of universities is important, although particularly so at the undergraduate level. This is because most first-year students have limited and uncertain information about their upcoming courses. By definition, students should not know the contents of their education in advance; if students did, they would not enroll in them. In addition, after finishing a course, even if they liked it very much, students do not take it once again – unlike various other services, which may be used or purchased repeatedly. Adding to this, alumni are unlikely to spread negative information about their education, because doing so could damage their careers. As a result, students tend to choose their education based on the images of universities communicated by families and friends, admission grades, and alumni careers (Espeland and Sauder, 2016; Stevens, 2007). Reputation is thus a core feature of university competition.
A second basic task of universities is research. This task began to take off with the development of the natural sciences in the 18th century. However, it was the founder of the University of Berlin, Wilhelm von Humboldt, who established the ideal of combining education and research in one organization (Östling, 2018). Like education, research has characteristics associated with uncertainty. A central notion in research is that it should follow established norms and common knowledge; simultaneously, another central notion is that research should produce new insights, which, by extension, may require challenging established norms and common knowledge (Merton, 1942). This leads to tensions that representatives of the academic profession attempt to handle by carefully and continuously screening research output through peer reviews (Merton and Zuckerman, 1971). Such screening may lead to the rejection of innovative research as well as to the acceptance of fraudulent research (Engwall, 2014). Nevertheless, quality control in the form of peer review remains the most common procedure for screening research output, and academic journals play a significant role.
In addition to education and research, universities are expected to interact with their surrounding communities. This third task tends to be even more uncertain than education and research. Here, labels like the ‘new production of knowledge’ (Gibbons et al., 1994; Nowotny et al., 2001) and ‘the triple helix’ (Etzkowitz and Leydesdorff, 1997) have put community interactions on the agenda over the past few decades. Moreover, politicians have emphasized the need for universities to communicate research output toward wider audiences than just academic ones. Such emphases are also behind open-access efforts and movements that strive to make all research output publicly available (Suber, 2012). This increasingly creates a public audience for university research output, and generates an additional dimension to competition as universities vie for reputation beyond academia.
The processes referred to so far highlight universities as complex organizations that interact with different audiences and compete on several dimensions. Reputation at the organizational level thus becomes crucial; however, such reputation stands largely on the research output produced by researchers at the individual level. This has led to the creation of much more elaborate evaluation systems for individuals in universities than for individuals in most other organizations. These elaborate systems, which interlink the organizational and individual levels, have been fueled by regulators, market actors, and scrutinizers, as well as by universities themselves when academic leaders attempt to manage the reputation of their organizations.
Regulators and evaluations
Referring first to the top-left corner of our model in Figure 1, we note that universities are more or less dependent on regulators. In many countries, regulators stand behind universities to provide them with legitimacy and resources (cf. Hammarfelt and Hallonsten, this volume). This also implies that regulators have strong interests in monitoring whether universities are following rules as well as in assessing how they are using resources (Musselin, 2013). For regulators, accountability has become central (Hood and Dixon, 2015). However, the uncertainty associated with the three basic university tasks makes it difficult for regulators to evaluate education, research, and community interaction.
Since the late 20th century, there has been a general tendency for regulators to delegate resource allocation of universities to market actors (Amable, 2011; Lee Mudge, 2008). In this way, the number and performance of students have become the basis for allocating public funding to education (Marginson, 2006), whereas selection among project grant proposals has become the basis for distributing funding to research (Braun, 1998; Lepori, 2011). In view of these changes, Figure 3 provides an adapted model that shows how regulators (R), instead of governing universities directly, often rely on market actors (M) and market mechanisms in resource allocation (R3). At the same time, regulators also express evaluation demands (R4) on various scrutinizers (S), asking them to evaluate the output and performance of universities. Indirectly, delegating governance may give rise to select evaluations (S3) of market actors conducted by scrutinizers.
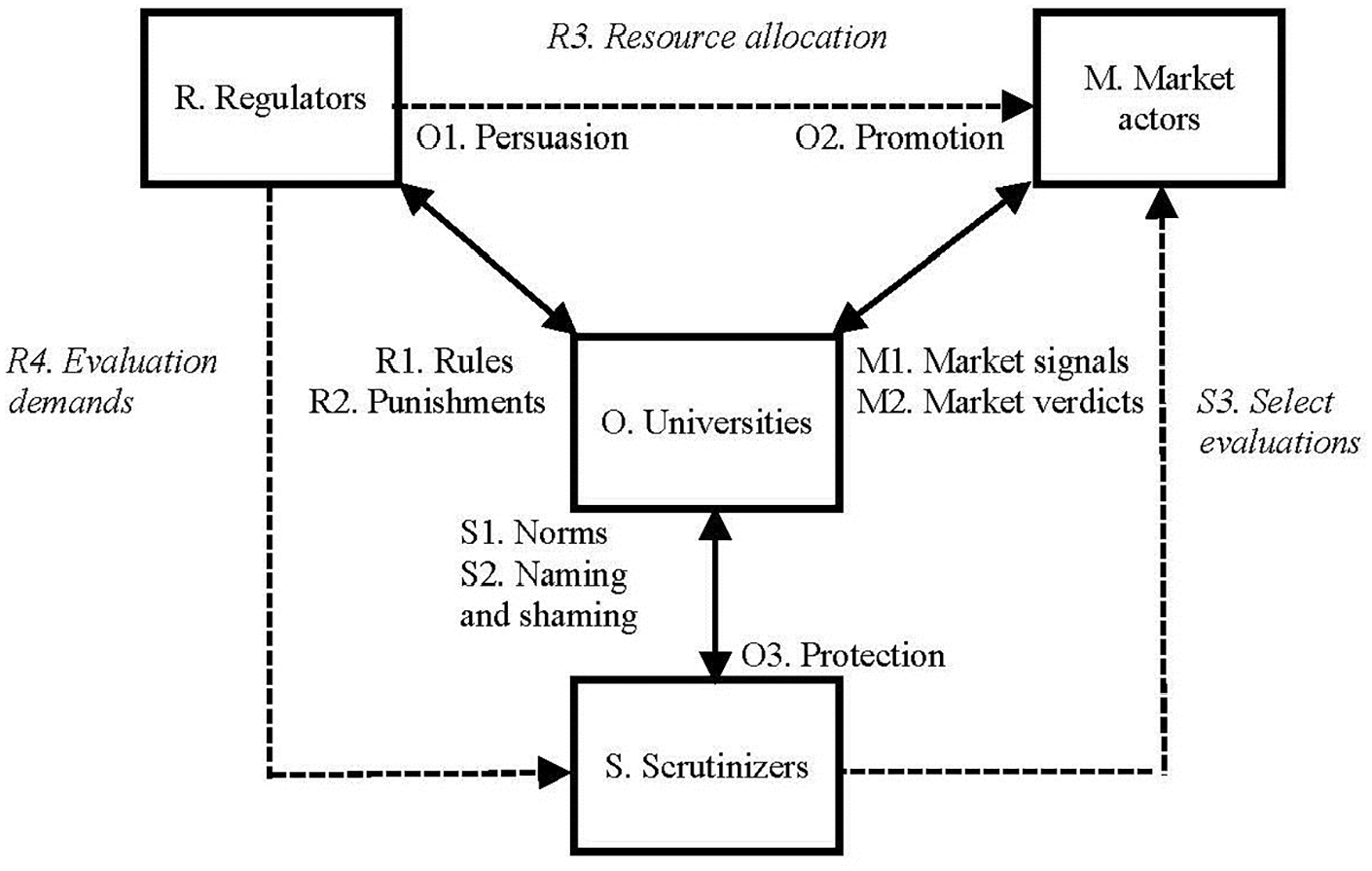
Regulators delegating university governance to market actors and scrutinizers.
With researchers having to promise spectacular scientific contributions in grant proposals, expectations surrounding such contributions have concomitantly risen (Heinze, 2008; Serrano-Velarde, 2018). This, in turn, reinforces regulator demands to evaluate the return on taxpayers’ money. Research councils, for instance, experienced clear demands to conduct evaluations in the 1980s and 1990s. Examples from Sweden include evaluations of disciplines, first conducted in the natural sciences (NFR, 1981), and, later, in the humanities and social sciences (Engwall, 1992; Öhngren, 1994). The transition from ‘management by placement’ to ‘management by expectations of performance’ (Foss Lindblad and Lindblad, 2016) has clearly increased the demand for evaluations. The introduction of new public management reforms (Hood, 1991, 1995) and the advent of audit society-driven developments (Power, 1997) have further reinforced this demand.
Regulators in the United Kingdom have been forerunners when it comes to launching evaluations (cf. Hammerfelt and Hallonsten, this volume). In 1986, at a time of retrenchment, the UK’s University Grants Committee launched an evaluation series, originally called the Research Selectivity Exercise, focusing on university research output. A similar series − called the Research Assessment Exercise (RAE) − starting in 1996, followed over the next two decades (Barker, 2007; Brassington, 2022). These evaluations engaged a large number of researchers inside and outside British universities. Researchers inside the participating universities prepared input for evaluators, whereas external researchers assessed the focal universities. As a result, evaluators proliferated: the 2001 RAE included 69 panels, each consisting of 6–20 members (Barker, 2007: 4). However, the conclusions were gloomy as evaluations suggested that the RAEs ‘largely reinforced the established order’ by means of ‘an elite system to reward research-based institutions.’ Nevertheless, it was concluded that ‘some form of national evaluation would be present for UK university research in the foreseeable future’ (Barker, 2007: 11). This has also been the case. In 2014 and 2021, the Research Excellence Framework, focusing on university research impact, replaced the RAEs. Later, in 2017, the Teaching Excellence Framework (TEF) followed for the evaluation of education (Copeland, 2017). This development demonstrates how eager British regulators have been to launch evaluations. Eventually, and in line with the predictions of neo-institutional theory (DiMaggio and Powell, 1983; Meyer and Rowan, 1977), UK evaluations have become models for regulators in other countries, such as Italy (Franceschet and Costantini, 2011) and the Netherlands (Campbell, 2003).
There are thus reasons to highlight regulators as a significant actor type for the spread of evaluations that took off gradually in the 1980s during a decade of deregulation (Lazonick, 1993; Vogel, 2018), fitting well with the idea of delegation to market actors in Figure 3. Although we may face reregulation in the future, there are also reasons to believe that regulators will remain interested in evaluations. This interest originates from the uncertainty associated with the three basic university tasks. Here, we should note that there are struggles for resources among regulators too. Ministries of education and science must show that their sector is performing well vis-à-vis other ministries. Evaluations may therefore constitute important means through which regulators seek additional resources for their areas of responsibility.
Market actors and evaluations
The top-right corner of Figure 3 underscores that student demand is crucial for all universities, irrespective of whether the education they provide is funded through taxes or tuition fees. High demand heightens opportunities to select excellent students. For universities that can charge tuition fees, high demand can also be the basis for raising fees (Garritzmann, 2016). Although many in the academic profession would prefer not to consider students as customers, they do constitute market actors considering reputation in their choice of place to study (Espeland and Sauder, 2016; Stevens, 2007). Obviously, various evaluations shape the reputation of universities. These evaluations focus on individual faculty members as well as on organizations in their entirety. The individual level is particularly clear in US universities, where local student bookstores often sell publications containing assessments of faculty members. Instead, the organizational level tends to be centered on universities in national and international contexts. Here, university rankings, which drive, and are driven by, a perception of global competition for students and faculty members (Wedlin, 2006, 2011), constitute salient tools through which universities seek to attract human and, by extension, financial resources. This notion of competitive student markets is particularly important in some higher education systems, such as the Australian, where universities have strong ambitions to attract foreign students in large numbers (Marginson, 2006). Rankings, in this sense, become means to facilitate markets in which students and universities can locate one another.
In terms of research, evaluations unfold rather differently, and the role of publishers is both important and peculiar. As market actors, publishers constitute crucial gatekeepers controlling academic journals that present research output (Powell, 1986). Researchers increasingly strive to publish in these journals to gain positions at universities and access resources from research funding bodies as well as to build reputation among peers (Münch, 2014). Publishers, in turn, work harder and harder to improve the reputation of their academic journals by announcing citation scores and advertising impact factors. It is particularly worth noting that professional associations originally founded and managed many of these journals (Engwall and Hedmo, 2016; Merton and Zuckerman, 1971). With the passage of time, however, commercial enterprises, such as Elsevier, Springer, and Wiley, have taken over the management of many, if not most, academic journals, utilizing elaborate administrative systems for submissions and reviews. These enterprises have assumed influential roles in academic publishing, thereby contributing to an increase in market pressures. Despite this commercialization, journals still rely on researchers as reviewers who select among the submitted manuscripts (Powell, 1986). Publishers and researchers thus live in a symbiotic relationship that contributes to academic sorting processes, with deep consequences for the reputation of publishers, researchers, and, by extension, the universities in which these very same researchers are active. Private financing bodies and wealthy individuals, who provide research donations, do not face similar pressures to evaluate output. However, even these bodies tend to care about their reputation. They are increasingly keen to recruit researchers as evaluators of project grant proposals.
It is clear that market actors, including students, publishers, and financing bodies, play important roles in the diffusion of evaluations. Assessments of faculty members and universities are important for the decision-making of students. Moreover, publishers function as gatekeepers selecting research output for publication in systems that, by extension, affect how universities are ranked. In addition, financing bodies conduct evaluations of proposals before granting resources to research projects. Researchers themselves play a core role in many of these evaluations.
Scrutinizers and evaluations
In terms of the lower part of Figure 3, scrutinizers are actors that govern universities through norms. Auditors constitute a prominent group of scrutinizers that communicate to the public whether universities follow specified norms (Power, 1997). Similar to corporations, universities have made themselves ‘auditable’ by adopting sophisticated accounting systems, which auditors can use in their evaluations (Hutaibat and Alhatabat, 2020; Moll and Hoque, 2011).
Media companies like Google, Elsevier, and Clarivate (earlier Thomson Reuters) constitute another prominent group of scrutinizers, providing the influential bibliometric services Google Scholar, Scopus, and Web of Science, respectively. Such services facilitate output comparisons at the individual level of researchers as well as at the organizational level of departments and universities by aggregating individual researcher output (Gläser and Laudel, 2007; Weingart, 2005). These bibliometric services gain increasing influence as they also feed into other evaluations, particularly rankings. As such, and despite the perceived relevance of rankings for attracting students, rankings also perform a general scrutinizing function among universities. This becomes clear as we consider how rankings build on assessments of research output, including publications. Among the best-known university rankings claiming to operate globally, the Academic Ranking of World Universities (ARWU) is noted for its heavy reliance on research output as a performance indicator. This ranking measures and positions universities based on Nobel Prize winners, publications, and citations (Cheng and Cai Liu, 2007). Whereas media companies provide input to the ARWU, and other similar rankings, through bibliometric services, there are also examples of rankings entirely constructed and driven by media companies themselves. Some of the most prominent examples encompass those rankings of business schools created by the Financial Times, Business Week, and Forbes.
Other prominent scrutinizers include NGOs. They can − sometimes in collaboration with the media − identify deficiencies in the educational programs and research endeavors of universities. Universities are somewhat vulnerable against actors that ask what the public receives in return for their taxes (cf. Kjöller, 2020), as the output of education, research, and community interaction often resists quantification (although many scrutinizers certainly attempt to quantify this output). Again, the uncertainty associated with the three basic tasks of universities plays a significant role here.
While the role of NGOs, auditors, and media companies as scrutinizers of universities should not be underestimated, researchers, as members of the academic profession, constitute the most significant group of scrutinizers. Although evaluations tend to generate complaints from members of professions (Abbott, 1988; Blomgren, 2003), evaluations simultaneously play a central role, as previously highlighted, in assessments of job applications, grant proposals, and scholarly manuscripts by various organizations in the academic field. What is more, when researchers conduct assessments, earlier evaluations are often cited in relation to faculty recruitments, project selections, and publication decisions (Lamont, 2009; Roumbanis, 2019). This dual situation, in which evaluations are both criticized and utilized, constitutes an example of what Spencer and Dale (1979) called ‘social deadlocks’: settings in which all involved complain about a specific problem, yet no one can or will do anything to address it.
Universities and evaluations
Finally, Figure 3 demonstrates that universities, like other organizations, practice three strategies as responses to governance pressures from regulators, market actors, and scrutinizers: persuasion, promotion, and protection, respectively. Here, responses to regulators can take the form of evaluations launched by academic leaders inside universities, and such evaluations are particularly interesting as they relate to all three strategies. Internally initiated evaluations may persuade regulators to stay away from universities (‘We can assess ourselves!’). Evaluations launched inside universities can also be ways to promote relationships with market actors that offer economic and cultural capital. Finally, internally initiated evaluations may also provide universities with protection from scrutinizers that are attentive to transgressive practices (‘We are following the norms!’).
A noticeable example of an evaluation launched inside a university is the Quality and Renewal (Kvalitet och Förnyelse [KoF]) project initiated in 2006 and 2007 by the then vice chancellor of Uppsala University, Anders Hallberg. In this project, 176 mainly international experts in 24 panels were asked to evaluate all research conducted at Uppsala University. KoF07 (Nordgren et al., 2007) was followed by similar projects in 2010−2011 (Nordgren et al., 2011) and 2017 (Malmberg, 2017). Again, in line with neo-institutional theory, these projects created stress, repercussions, and tendencies of isomorphism throughout the Swedish university field. Soon after Uppsala, two other higher education organizations, the Royal Institute of Technology and Lund University, initiated their own internal research evaluations. Later, other universities followed suit. Thus, by 2013, 11 higher education institutions in Sweden had carried out one or more internally launched evaluations (Bomark, 2017). Such projects not only required considerable efforts from evaluators, but also from researchers who prepared self-evaluation reports and site visits.
The results of these internal evaluations appear to have created disappointment among faculty members. At Uppsala University, departments that received negative feedback were obviously frustrated. However, those departments that received positive feedback were also disappointed, as they had expected more compliments and, above all, much more resources than they ultimately received (Bomark, 2016). This suggests that, as in the case of the UK’s RAE exercises, the internal effects of such evaluations on subsequent performance are doubtful. Rather, as already mentioned, internally launched evaluations may form part of university efforts to use self-assessments as persuasion toward regulators, promotion among market actors, and protection against scrutinizers.
Much as vice chancellors initiate evaluations to persuade regulators, other academic leaders, such as department heads, have sought to improve the reputation of their organizations by embarking on accreditation projects (Cret, 2011; Hedmo, 2004). Departments pay accreditors, conduct self-evaluations, and adapt to standards, particularly administrative ones, established by scrutinizers. Successful outcomes provide an entrée to what was, but perhaps no longer is, an exclusive club of screened departments that deploy their accreditations as tools in reputation-building efforts. However, as the number of accredited departments increases, the potential to employ accreditation as a reputation tool decreases. As a result, university leaders have responded by embarking on further accreditation projects. A notorious example comes from business schools, which have three prominent scrutinizers offering different types of accreditations: the British AMBA, the European EQUIS, and the North American AACSB. However, once again, as the number of business schools with triple accreditations grows, the potential to employ this ‘Triple Crown’ as a reputation-building tool also decreases. This sets off an elusive and constantly ongoing search for exclusivity as business schools attempt to distinguish themselves from other business schools.
Both accreditations and evaluations launched inside universities illustrate how academic leaders at various levels voluntarily launch evaluations that add to those already imposed by regulators, market actors, and scrutinizers. Whereas complaints regarding evaluations are common inside universities, there appears to be a gap between talk and action (Brunsson, 1989). This is evident when groups of faculty members or individual researchers complain about evaluations, but also employ a rhetoric that draws on impact factors, citation scores, and the like (Fochler et al., 2016; Rushforth and de Rijcke, 2015). Fundamental to this phenomenon is the internal competition among departments, as well as among faculties, for economic and cultural capital. The features of universities as loosely coupled systems that make them difficult to oversee and control (Weick, 1976) reinforce such competition.
Concluding discussion
The overarching question driving this special section is to identify causes and consequences of the current evaluation regime in (academic) science. In our article, we have focused on the dynamic interplay between different actors that have fueled the transformation of academia into the present evaluation regime. The actors driving this transformation, and their changing relationships, are at the center of our title ‘Who is to Blame?’ We addressed this question starting from a general model of external governance pressures on organizations, and subsequently analyzed the roles of three actor types for universities. Our analysis leads us to conclude that regulators, market actors, and scrutinizers, which govern through rules, signals, and norms, respectively, have all contributed to the development of the present evaluation regime in academia.
Regulators are doubtless to blame for the spread of evaluations. Sweeping changes, such as the introduction of new public management and the advent of audit society-driven developments, have generated regulator demands to evaluate the use of taxpayers’ money in universities. Market actors are certainly also responsible. Among them, publishers, through their academic journals, have been notorious for increasingly promoting various metrics with which to evaluate research output, including citation scores and impact factors. These evaluations more and more influence the reputation of individual researchers and, through aggregation, entire universities. Finally, scrutinizers are to blame as well. Media companies offer bibliometric services that facilitate output comparisons at various levels, while NGOs and auditors carry out assessments to evaluate performance among universities.
In addition to these three actor types exerting external governance pressures, universities themselves are also to blame. This becomes clear when we consider how researchers, as members of the academic profession, have come to play an instrumental and increasingly significant role over time by assisting regulators, market actors, and scrutinizers in their evaluations. The engagement of researchers is central for assessments of disciplines, departments, and universities as well as for evaluations of job applications, project proposals and scholarly manuscripts. Driven by career ambitions and professional struggles, present-day researchers support and enhance the use of various metrics in order to evaluate research output. Academic leaders at various levels have also played a key role in the past decade or so by launching further evaluations from inside the universities themselves. We interpret such internally initiated evaluations as preemptive responses that universities launch to persuade, promote, and protect amid governance pressures from regulators, market actors, and scrutinizers.
Regulators, market actors, and scrutinizers as well as researchers and academic leaders are thus all to blame for the development of the current evaluation regime. However, we note that, although all these actor types are culpable, none of them is guilty alone. It is in the reinforcing relationships among actors at different levels that we find the strongest processes behind the present assessment culture.
Although we have highlighted several processes fueling what seems like a never-ending barrage of evaluations in contemporary academia, we should also mention recent efforts to reform evaluations, particularly in terms of reducing the influence exerted by metrics. One such initiative is the San Francisco Declaration on Research Assessment (DORA) developed in 2012 by the American Society for Cell Biology. Ten years later, 22,000 individuals and organizations in 159 countries have signed the Declaration (DORA, 2022). Its core recommendation is clear and concise: ‘Do not use journal-based metrics, such as journal impact factors, as a surrogate measure of the quality of individual research articles, to assess an individual scientist’s contributions, or in hiring, promotion or funding decisions.’ Another recent effort to reduce the influence of metrics is the Reforming Research Assessment (RRA) initiative launched by the European University Association and Science Europe. After stakeholder consultations, the two organizations published a report in July 2022 (EUA, 2022) outlining core commitments to adopt ‘a responsible use of quantitative indicators,’ to abandon ‘inappropriate uses of the Journal Impact Factor (JIF) and h-index,’ and to avoid ‘the use of rankings of research organizations in research assessment.’ Despite these promising efforts to reduce the influence of metrics, they still appear to be widely used throughout academia. This is perhaps an expression of the lure associated with simplified measures for evaluating the research output of individual researchers as well as of entire universities.
At the same time, the DORA declaration and the RRA report do not contain any questioning of evaluations per se. The uncertainty associated with education, research, and community interaction as the three basic university tasks is likely to continue driving further evaluations. After all, universities can deploy externally and internally initiated evaluations as tools to demonstrate the prudent use of resources. Evaluations appear to be here for the long run.
Footnotes
Funding
The author(s) received financial support for the research, authorship, and/or publication of this article: from the Jan Wallander and Tom Hedelius Foundation (Grant W18-0053) and the Swedish Research Council (Grant 2019-03198).