
Abstract
Mode choice models are important for investigating how travelers will react to changes in public transportation fares and the introduction of new mobility services. The models are essentially built for a given set of mode alternatives, for which parametric utility functions for each mode are defined, and the parameters are estimated using mode choice behavior data. Therefore, the models are dependent on the target mode alternatives in the modeling step and not generalizable to other modes. This study aimed to develop a general mode choice model that can be applied to various sets of mode alternatives. We used large language models to achieve generalizability. The model input comprised sentences that represented different alternatives and variables related to choosing a travel mode. The output was a word that indicated the mode that would be selected. In this study, we created a textual dataset based on four publicly available mode choice datasets. The experimental results showed that the proposed language-based mode choice model, our proposed approach, was more versatile than the classical multinomial logit model in predicting a variety of mode alternative sets.
Keywords
Discrete choice models (DCMs) have been studied to understand and predict people’s transportation mode choices ( 1 – 4 ). These models use a linear utility function that includes variables such as travel time and fare. The function considers different factors that influence travel choices, such as travel time, cost, convenience, and personal preferences ( 4 ). However, it is usually tailored to the specific modes included in the alternative set, which makes predicting choices difficult when new modes are added or when the alternative set is entirely different. Because of the limited generalizability of the existing DCMs, data collection is necessary each time a new model is created, which restricts the model’s applicability. This study aimed to overcome this lack of generalizability by examining the potential of large language models (LLMs).
DCMs are essential for various domains. These models are used to investigate how travelers will react to changes in public transportation fares or the introduction of new mobility services. For example, they have been applied to estimate travel demand and reveal preferences for relatively new mobility services such as ride-sourcing and shared micromobility ( 5 , 6 ). Furthermore, mode choice models play an important role in activity-based demand modeling and can be used as a model of agent behavior in agent-based simulation ( 7 –10).
DCMs are often based on the assumption of random utility maximization (
11
,
12
), which assumes that when people make a choice, they choose the mode that maximizes their utility. Utility consists of several variables, x, such as travel time and monetary cost in the case of transportation mode choice, and preferences,
Building a model includes costly and resource-intensive processes such as defining mode alternatives for each use, determining utility functions, estimating model parameters, and especially collecting data, which is particularly resource-intensive. There are two types of data collection: stated preference (SP) surveys, such as questionnaires, and revealed preference (RP) surveys, in which data are collected by observing the actual behavior of travelers. Whereas SP surveys are particularly useful for analyzing the choice behavior for new mobility services, deviations from actual behavior may exist; therefore, RP surveys need to measure both information about the alternative set and the choice result. It is difficult to measure what are considered as alternatives, even though the chosen mode can be measured. Traffic assignment has been analyzed by adding a transportation mode choice model to agent-based traffic simulations ( 14 ). However, owing to the high costs of data collection, some researchers either use the default parameters of the mode choice models built into agent-based simulators, or use the results of previous modeling to hypothetically set the parameters for their target mode. Although this is a practical solution, it should be noted that it may have only limited effectiveness ( 9 ).
For creating a general mode choice model, we used language models. Specifically, we inputted sentences (prompts) that represented choices and their related variables into a language model that then outputted a word representing the chosen mode. Unlike traditional DCMs, as illustrated in Figure 1, which are limited to the alternatives used during parameter estimation, our method handles a variety of alternative sets by adjusting the prompts based on the choices and their variables. Various language models have been proposed, including encoder-only models such as BERT (bidirectional encoder representations from transformers) ( 15 ), which excel at understanding sentences; and decoder-only models such as GPT (generative pretrained transformer) ( 16 ) with larger parameters (large language models or LLMs). These language models are used for predicting transportation mode choices.
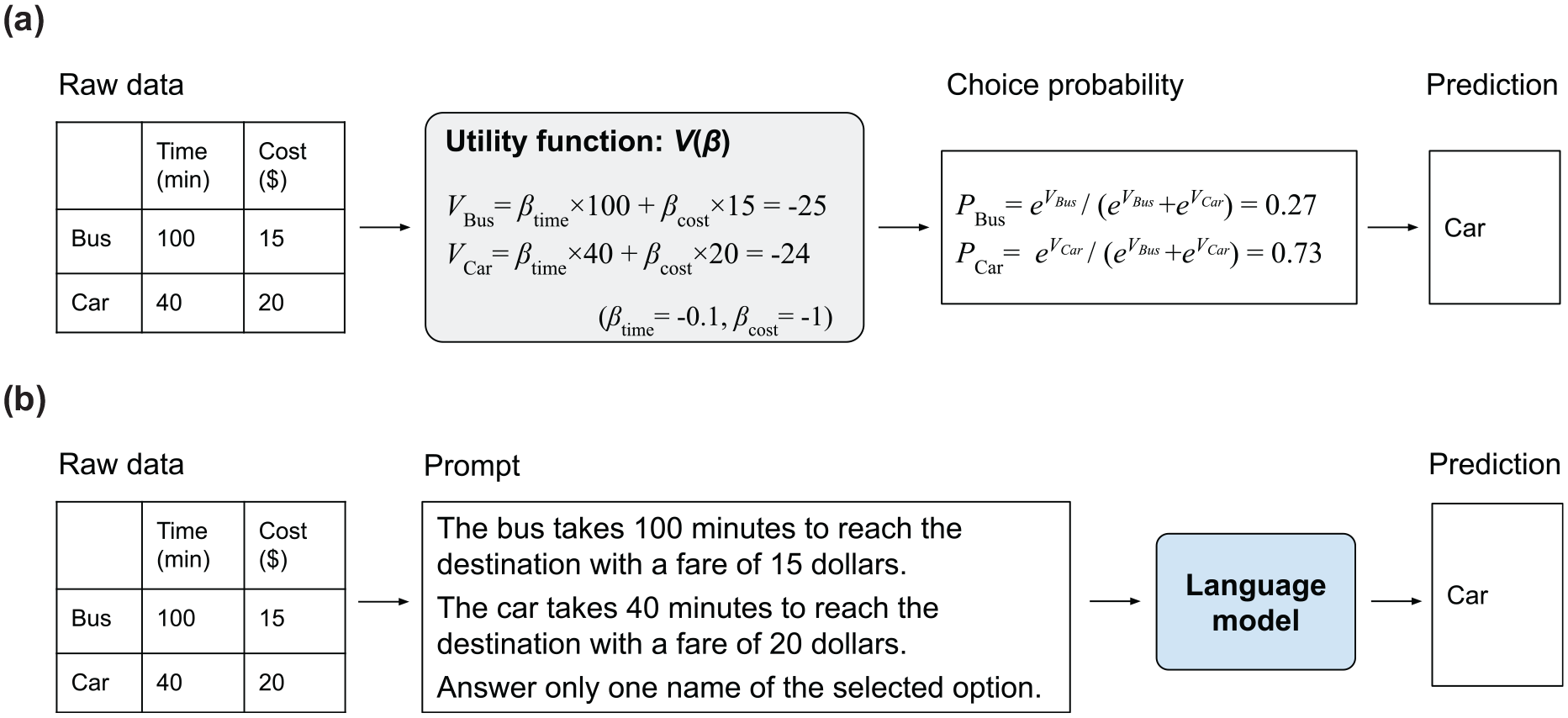
Comparison of two paradigms for the mode choice prediction task: (a) a traditional utility function-based discrete choice model and (b) the proposed language-based mode choice model.
To evaluate our models, we created a dataset based on four publicly available transportation mode choice datasets. This study aimed to verify the predictability and generalizability of the language-based mode choice model on this dataset.
Our contributions are summarized as follows:
We propose an approach to discrete choice modeling with language models.
We create a dataset of discrete choice behaviors in the form of sentences, consisting of sentences explaining the choices, based on an open dataset of discrete choice behaviors.
We verify the versatility of the language-based mode choice model in comparison with conventional DCMs on the newly created dataset.
The remainder of this paper is organized as follows. Section 2 reviews related work on DCMs and language models. Section 3 introduces the preliminaries of the study. Section 4 describes the proposed approaches. Section 5 describes the experiments on an open mode choice behavior dataset, and Section 6 summarizes the study and outlines future research opportunities.
Literature Review
This section describes the state of the art of DCMs, especially those models using machine learning. In addition, we describe related work on language models.
Existing DCMs Using Neural Networks
In recent years, research has been conducted to improve the prediction accuracy of DCMs by representing the utility functions using neural networks (NNs) (
17
–22). These studies can be divided into those in which the utility function is fully represented by NNs and those in which it is partially represented by NNs. In the former case, for example, Wang et al. modeled discrete choice behavior by training NNs that output choice probabilities for all choice variable inputs. They also proposed a method to train NNs separately for each alternative (
17
). This allowed for a nonlinear representation of the utility function and improved prediction accuracy. However, if all utility functions are represented by NNs, interpretability is lost. Therefore, a method has been proposed in which a portion of the utility function is represented by NNs, while the rest is represented by linear functions, thereby preserving interpretability. For example, one can separate the input variables into a utility function for NNs and a linear utility function, and then sum the outputs of each to obtain the final utility function value (
19
), or one can output the parameter
However, existing DCMs using NNs trained with these approaches cannot be applied to settings with other alternative sets; for example, a model trained on a dataset where the alternative set is trains or buses cannot be easily applied to a prediction task where the alternative set includes cars, buses, and walking. These models must be tuned for specific data and are not generalizable. In contrast, we make them generalizable by using a new approach that uses pretrained language models to make predictions by simply changing the input prompt according to an alternative set and variables. To the best of our knowledge, our study is the first attempt to use a language model for mode choice modeling and discrete choice modeling.
Language Models
Language models take a text as input and convert it into another text as output. Recently, language models, especially LLMs, have shown remarkable performance in various natural language processing tasks such as machine translation ( 15 , 23 ), text summarization ( 24 , 25), and question answering ( 26 , 27 ).
Our study is a question-answering task. The task of answering a single choice among multiple choices is called multiple choice question answering (MCQA). For example, a dataset, Situations with Adversarial Generations, is formatted to select a suitable subsequent sentence for a given sentence ( 27 ). This dataset is often used as a benchmark for MCQA, but the input sentence does not include a detailed description of the other choices, nor does it consider the relationship between the choices. Additionally, as the number of alternatives is basically fixed, improvements are needed for application to cases in which the number of modes changes. CommonsenseQA was created to test a model’s capability to answer questions that require commonsense knowledge ( 26 ). Although common knowledge held by LLMs is useful for predicting mode choice, this dataset is not specific to transportation mode choice and does not include numerical information such as travel times and fares.
Unlike previous natural language processing (NLP) tasks, this study examines the performance of LLM in the context of predicting transportation mode choices. Our study compares two representative language models that use transformer architecture ( 23 ): BERT and GPT. BERT is often applied to classification problems and is suitable for modeling tasks that involve choosing one mode from a predefined set of alternatives ( 15 ). Thus, BERT-based models have characteristics similar to those of existing DCMs, which results in lower generalizability. However, GPT is a text generation model that does not require predefined choices, allowing for a more versatile and general-purpose model. In this study, we compare the two models, BERT and GPT as language models.
Preliminaries
Problem Definition
We present a definition of the mode choice modeling problem. The problem is to construct a model that predicts the mode chosen by an individual traveler based on a set of possible mode alternatives, C, and attributes of alternatives,
Multinomial Logit Model
We introduce the multinomial logit model (MNL), which is a basic model of DCMs. DCMs are utility-based models that define a utility,
In an MNL, the utility function,

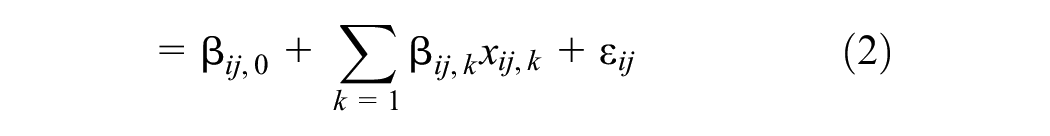
where x describes the observed attributes of the choice alternative (e.g., the price or travel time associated with the mode), and the individual sociodemographic characteristics (e.g., the individual level of income or age) (
19
).
Assuming a Gumbel distribution for the probability term, the probability that an individual i will choose mode j from an alternative set C is as follows:
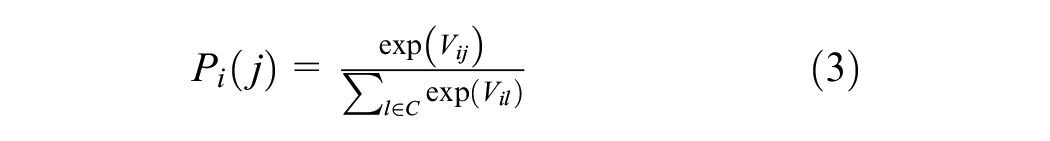
The preference parameters,
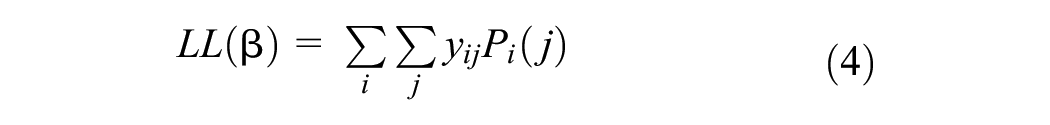
where
Language-Based Mode Choice Model
This section describes our proposed approach to language-based transportation mode choice prediction. We first describe the approach using BERT as the encoder-only model, followed by the LLM approach as the decoder-only model.
Encoder-Only Model Approach: BERT-DCM
Encoder-only models, such as BERT, are capable of extracting information from an input sequence and are suitable for tasks such as question answering and text classification that require sentence comprehension. Question answering can be used to extract an answer from a given sentence, and text classification can be used for sentiment analysis, such as movie reviews.
The task of predicting transportation mode choice is similar to question answering, in particular, MCQA, in which there are multiple alternatives. A text comprising a question and an answer is input to BERT, which outputs its validity score. This is done for all answer alternatives, and the validity scores are converted to a choice probability using a softmax function. In the case of MCQA, the number of choices in the dataset used for fine-tuning poses a strong limitation. That is, fine-tuning is performed with a fixed number of modes, therefore, improvements are needed to apply this model to infer in cases for which the number of options is different.
Therefore, to model multiple discrete choice behaviors with different numbers of options, we propose an approach, BERT-DCM, in which BERT is fine-tuned in the same setting as the binary classification (text classification) problem, and during inference, as in MCQA, sentences are entered into BERT for the number of alternatives to find the alternative with the highest validity score. An overview of BERT-DCM is shown in Figure 2.
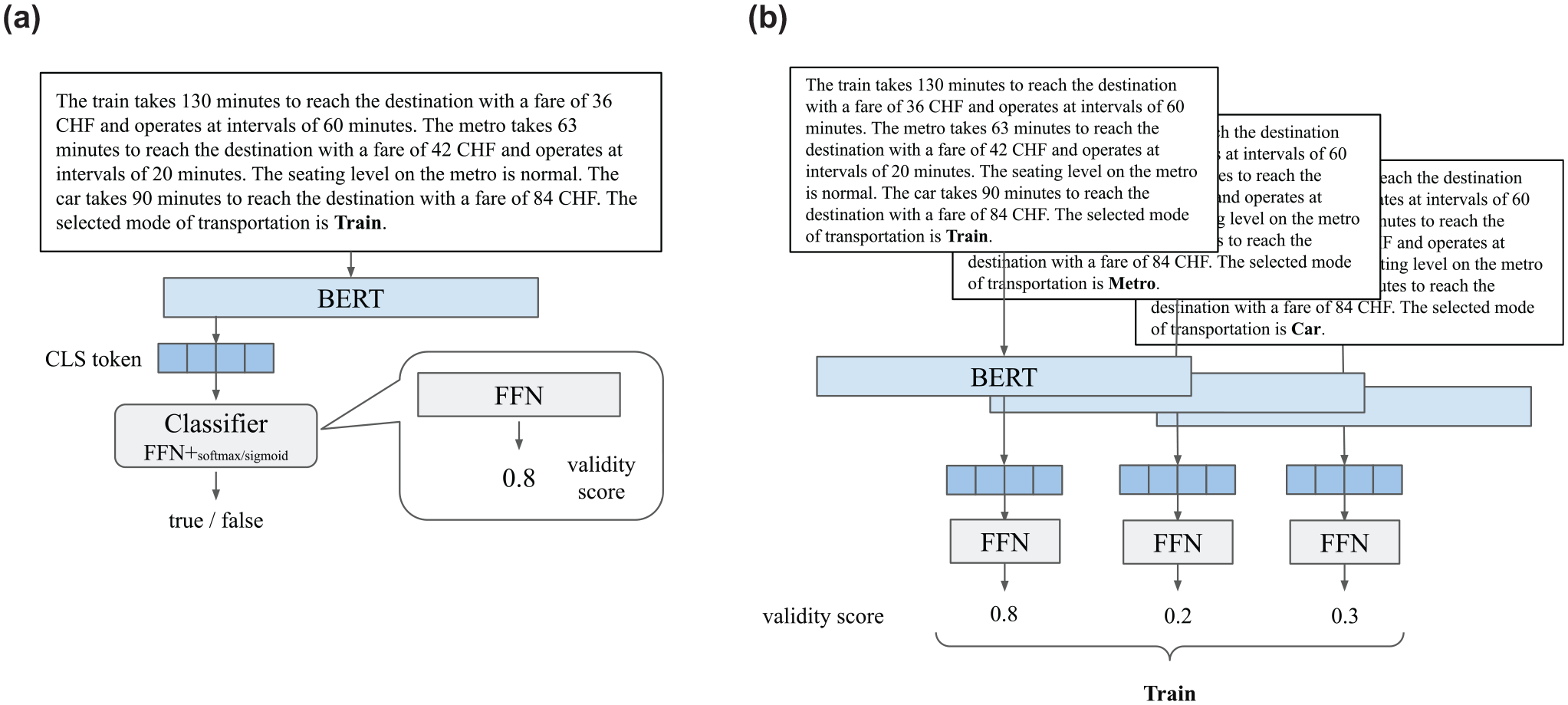
BERT-DCM approach in (a) training and (b) inference steps.
Training Step
First, the input text includes information such as fares and travel times for all target modes of transportation in natural language. At the end of the sentence, we add a sentence such as “The selected mode of transportation is mode” where mode corresponds to one of the transportation mode alternatives.
During fine-tuning, BERT is trained in a binary classification setting, determining whether the input sentences are correct or incorrect. BERT performs various tasks by dividing sentences into tokens, such as word-level tokens, and transforming them in the model. For the classification task, a special token called a CLS token is added to the beginning of the sentence; the CLS token is used as an embedding for the entire text, and the final transformed vector of the CLS token is used for classification. The final hidden state vector of the CLS tokens is transformed into a validity score by a feed-forward neural network to determine whether it is correct or incorrect.
Inference Step
When predicting transportation mode choice, sentences with different {modes} are prepared for each of the target alternatives, each of which is input into BERT, and the transportation mode with the highest validity score for each mode is used as the prediction result.
Decoder-Only Model Approach: LLMs
Decoder-only models, recently called LLMs, such as GPT, can predict the next word in the input word sequence and generate sentences by repeating the prediction autoregressively. As a method for predicting transportation mode choice, similar to BERT-DCM, LLM is inputted with sentences such as the fare and travel time for each transportation mode, and the names of possible transportation modes are output, as shown in Figure 3.

LLM-based mode choice (zero-shot prompting).
Zero-Shot Prompting
As with BERT, we used a pretrained LLM. LLMs that have been pretrained on large amounts of data can perform a variety of NLP tasks without fine-tuning. This setup without training data is called a zero-shot. Therefore, as shown in Figure 3, we must enter a description of the transportation mode and an instruction such as “Answer only one name of the selected mode.” In this study, the sentence “Alternatives are Train, Metro, Car.” was added at the end to increase the accuracy of the LLM output.
Few-Shot Prompting
LLMs are huge models with tens of billions of parameters, and owing to their large model size, they have an emergent ability that is not present in smaller models. In-context learning is one such ability that, given several examples of a task as input as shown in Figure 4, can produce the expected output without additional training or gradient updates. Furthermore, increasing the number of examples improves performance ( 28 ). Note that the input text can also include a description of personal attributes such as the age and gender of the expected traveler, for example, “The traveler is 40 years old or younger and a man. The trip purpose is business.”

Few-shot prompting.
Experiment
This section examines the generalizability of language-based mode choice models. Using a dataset of choice behavior for a set of transportation modes, we built a model and tested whether the model could successfully predict other sets of modes.
Dataset
We used four mode choice datasets that differed in the number of alternatives and the modes included. All datasets are publicly available and can be accessed from the website of Biogeme (https://biogeme.epfl.ch/), a Python library for DCM. The first was London Passenger Mode Choice (LPMC). The second was mode choice in Switzerland, which is termed Optima; the third was collected to analyze the impact of introducing high-speed rail in Switzerland and is termed Swissmetro; the fourth was mode choice in the Netherlands, which is termed Netherlands. The number of alternatives, the modes included, the variables, and the data collection methods for each dataset are summarized in Table 1.
Dataset
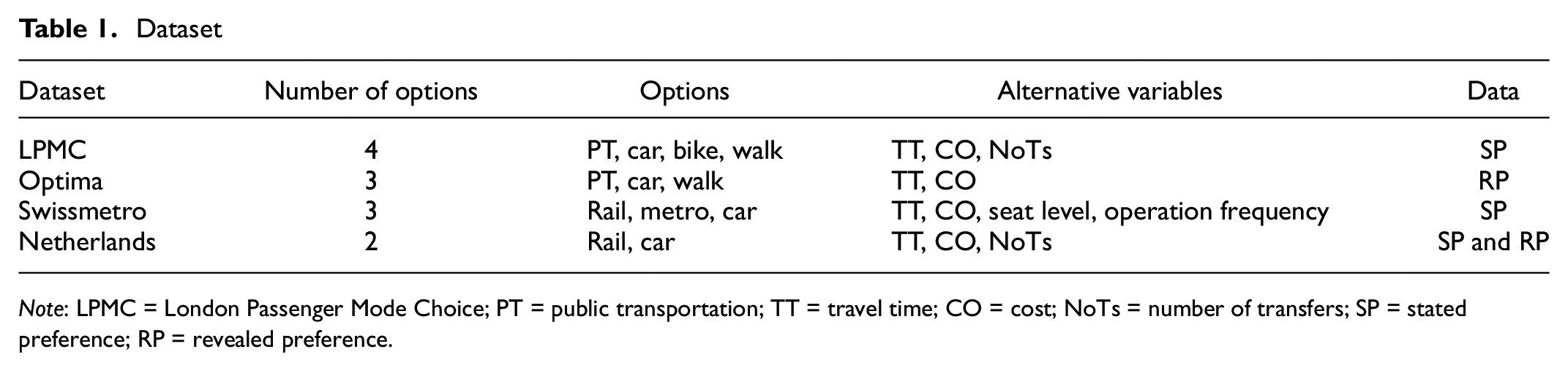
Note: LPMC = London Passenger Mode Choice; PT = public transportation; TT = travel time; CO = cost; NoTs = number of transfers; SP = stated preference; RP = revealed preference.
Each dataset included different variables, such as the service level of the transportation mode, travel time, and cost. Some datasets included the number of transfers, seating levels, and frequency of service, such as how many trains come every hour. In all the datasets, the demographic information of the travelers was collected, including age, gender, and purpose of travel
The dataset was in tabular form and contained variables such as travel time, cost for each transportation mode, and personal attributes of the chooser (traveler), for one choice behavior. These variable-only data were converted into natural language sentences. Note that we created five text styles using GPT, replaced the variable part according to each choice behavior, and created a text dataset.
Although the original amount of data in each dataset was different, we sampled the smallest amount, 1,700, from each dataset. We split the data at a ratio of 4:1, used for training and testing, respectively.
Baseline
We used MNL, which is a basic model of DCMs, as a baseline. As mentioned above, an MNL is a choice model with a utility function, which is defined as a linear sum of alternative variables and preference parameters. Here, we defined the utility function using travel time (TT) and cost (CO), variables common to all datasets, as follows:
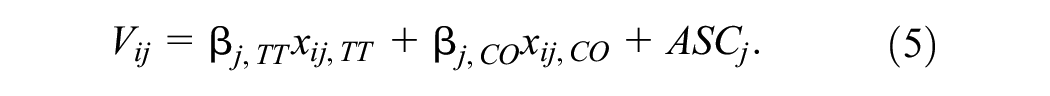
In the experiment, the parameters
Settings
The settings of the language-based mode choice models were determined as follows.
BERT-DCM
We fine-tuned the BERT model published on Huggingface (https://huggingface.co/distilbert/distilbert-base-uncased) with training data. In this case, as described above, an input sentence was created as a set of questions (explanation of TT and CO for each mode), and an answer (one of the possible modes), and fine-tuning was performed to improve the accuracy of judging whether the answer was correct. Fine-tuning was performed in an early stopping setting, in which a portion of the training data was used as validation data, and model parameters were updated until the improvement in the accuracy of the validation data stopped. We used a learning rate of
LLM
LLM had both zero- and few-shot prompting settings. In the zero-shot prompting setting, only the question text was the input text, whereas in the few-shot prompting setting, several examples were included in the input text. In the experiment, we examined the cases with 1, 3, 5, and 10 examples. The examples were randomly sampled from the training data. As the selection of which examples to use affects prediction performance, we conducted five sampling iterations and evaluated the performance using the mean and standard deviation of the result for each sample.
In this experiment, we used GPT-3.5-Turbo and GPT-4 provided by OpenAI (The specific versions used were GPT-3.5-turbo-0125 and GPT-4-0613.) GPT-3.5-Turbo is relatively inexpensive to use, and although GPT-4 is more expensive than GPT-3.5-Turbo, it has a larger number of model parameters and is more accurate for various tasks. To eliminate randomness in the output, we used the GPT parameter temperature of 0, and the seed was fixed.
In addition, we examined the impact of including personal attributes in the input text. In traditional MNL, researchers must decide manually which personal attributes (such as age, gender, or trip purpose) to include in the utility function and how to encode them. This handcrafting process is often difficult. In contrast, when using LLMs, one can simply describe the traveler in natural language (e.g., “The traveler is a man younger than 40, traveling for business”), without manually designing the utility function.
Evaluation Metrics
The predictive performance of mode choice was evaluated by accuracy and macro F1 values.
Results
We first show the estimated results of the MNL and discuss the BERT-DCM results. Thereafter, we describe the LLM results.
First, Table 2 shows the results of parameter estimation for each MNL dataset using the utility function in Equation 5. The variables for TT and CO were negative, therefore, they were not unnatural estimates, for example, an increase in TT increased utility. However, the value of time (VoT) varied widely across datasets. In particular, the estimated VoT in the Netherlands dataset was extremely low. The fitting performance of the model was also lower in the Netherlands. This was because the variables were limited to make the utility function general-purpose.
Estimated parameters of MNL
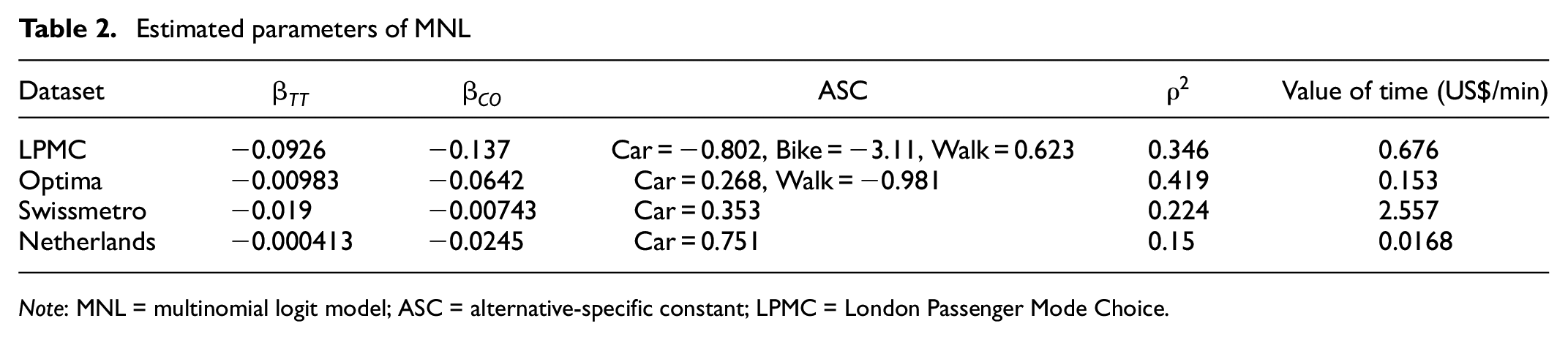
Note: MNL = multinomial logit model; ASC = alternative-specific constant; LPMC = London Passenger Mode Choice.
The results for BERT-DCM accuracy, and F1 for MNL and BERT-DCM are shown in Figures 5 and 6, respectively. The four plots in the figures show the prediction accuracy for each dataset. For example, Figure 5a shows the prediction results for LPMC data using MNL with parameters estimated for datasets such as Optima, Swissmetro, and Netherlands, as shown in Table 2. We also show the prediction results for LPMC data using the fine-tuned BERT (Figure 6a).
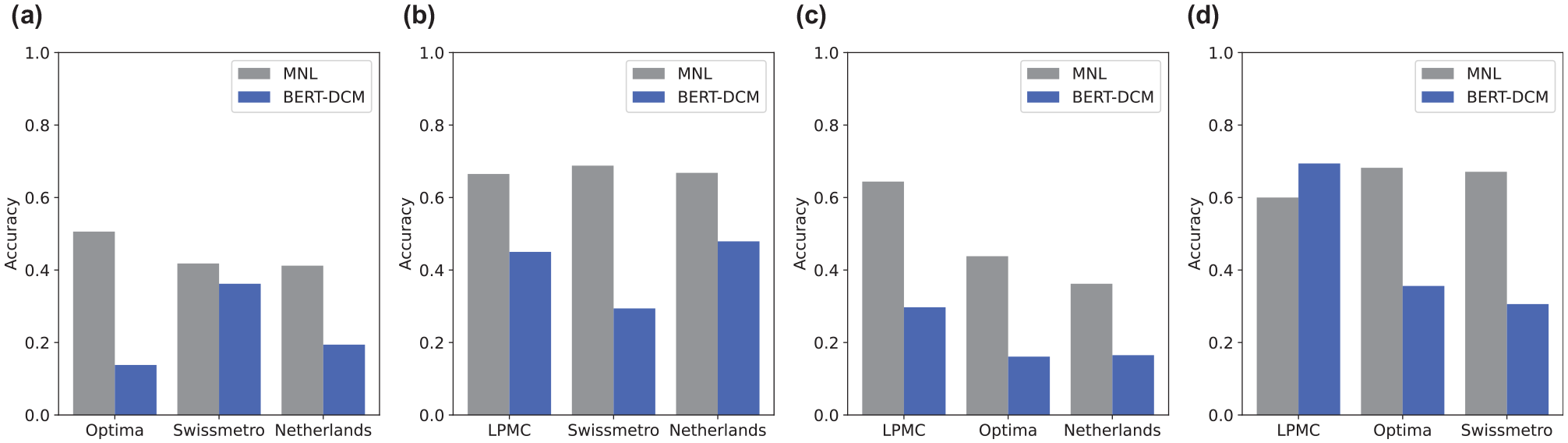
Accuracy of MNL and BERT-DCM: (a) LPMC, (b) Optima, (c) Swissmetro, and (d) Netherlands.
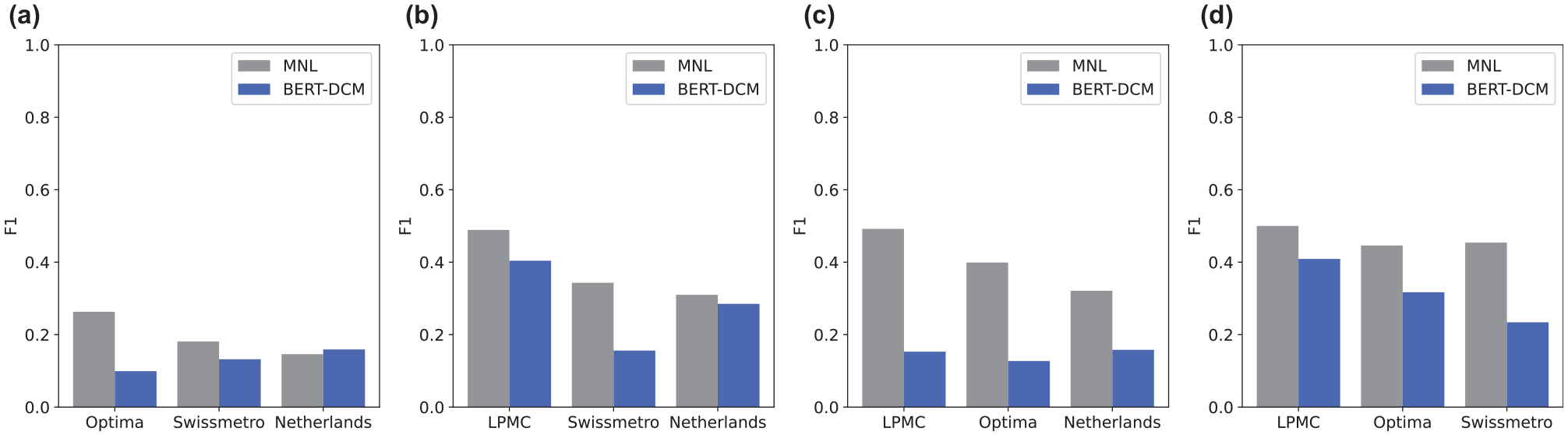
F1 score of MNL and BERT-DCM: (a) LPMC, (b) Optima, (c) Swissmetro, and (d) Netherlands.
The accuracy results showed that prediction accuracy varied depending on which dataset was used for training. Additionally, the F1 score showed that using the parameters estimated by LPMC also had the best accuracy for the other data. This indicated that training on a dataset that included as many alternatives as possible was important to create a model that could also be used to make generalized predictions on other data. Conversely, this showed that a model trained on a smaller number of choices was not sufficient when using the model on a new dataset that had more choices.
Prediction accuracy with BERT-DCM was almost always lower than with models trained on any dataset. This indicated that fine-tuning BERT did not provide the ability to make generic transportation mode choices.
The results for LLM accuracy, and F1 for LLM (GPT-3.5-Turbo and GPT-4) are shown in Figures 7 and 8, respectively. The figures show that GPT-4 had better prediction performance than GPT-3.5-Turbo; GPT-4 especially had similar or better prediction accuracy than MNL for most datasets. Furthermore, in both GPT-3.5-Turbo and GPT-4, the addition of sentences related to personal attributes contributed to the improvement in accuracy, and in GPT-4, the accuracy improved as the number of examples increased in the setting of the few-shot prompting.
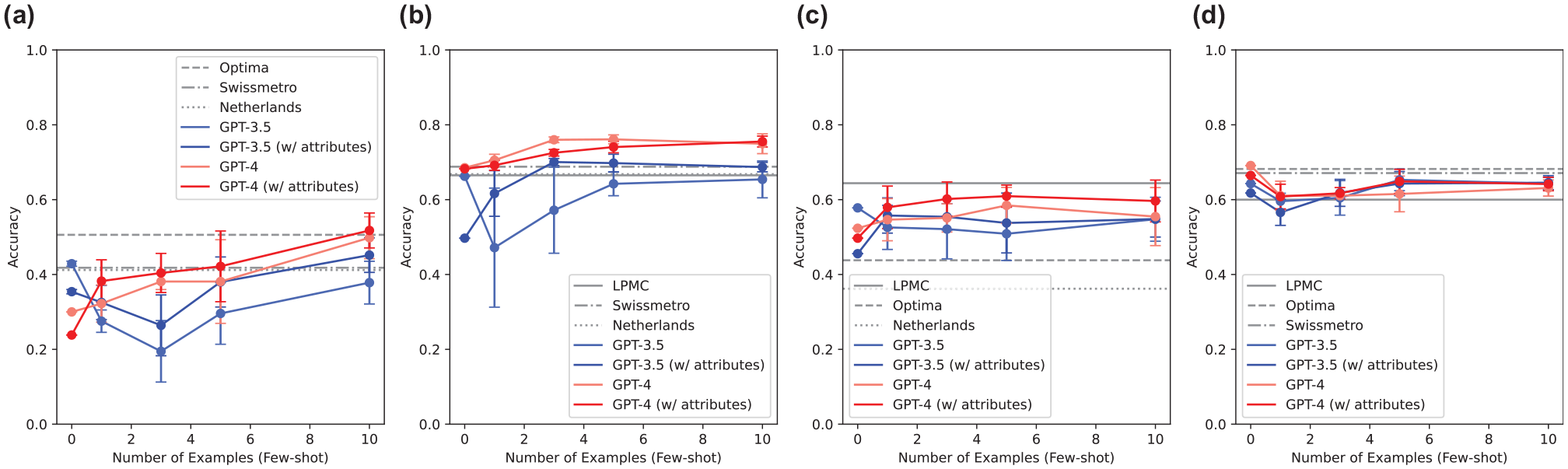
Accuracy of MNL, GPT-3.5-Turbo, and GPT-4: (a) LPMC, (b) Optima, (c) Swissmetro, and (d) Netherlands.
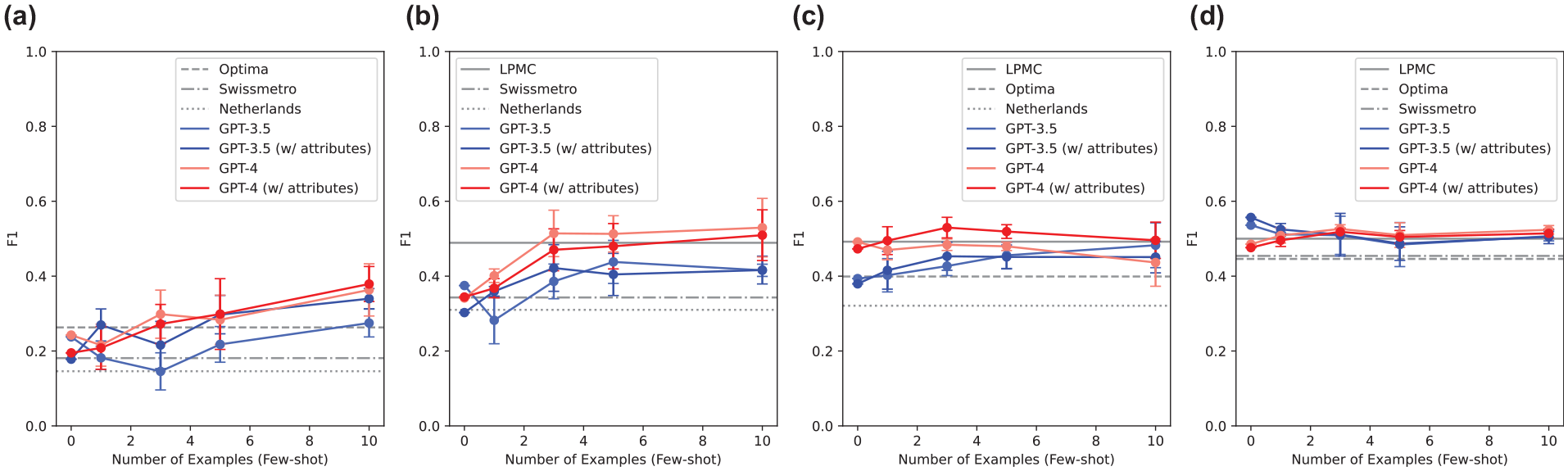
F1 score of MNL, GPT-3.5-Turbo, and GPT-4: (a) LPMC, (b) Optima, (c) Swissmetro, and (d) Netherlands.
The performance improvement with the number of examples in the prompts depended on the characteristics of the dataset, especially the number of modes; LPMC included four mode alternatives, and performance improved as the number of examples increased. However, Optima and Swissmetro had three alternatives, and although increasing the number of examples improved performance, the improvement was limited to a certain value. More interestingly, for the Netherlands, the performance worsened with the addition of more examples because the Netherlands had only two alternatives and could be predicted based on the common sense that GPT originally retained, whereas adding more examples led to a blurring of the prediction.
It should be noted that in the case of MNL, the prediction accuracy varied greatly depending on which dataset the estimated parameters used, whereas in the case of GPT-4, the prediction was stable for all datasets. This showed the generalizability of language-based mode choice prediction using LLM.
Discussion
The experimental results showed that language-based mode choice approaches, such as LLMs, can make generic predictions for various sets of transportation mode alternatives. This section mentions some aspects of the language-based mode choice approaches, such as interpretability, explainability, hallucination, pretrained data, and computational CO.
Interpretability and Explainability
This study focused on whether language-based mode choice approaches can make generic predictions for various sets of transportation mode alternatives. Therefore, the interpretability of the models, which is important in the transportation research field, was left out of the scope. However, it is necessary to explore the interpretability of this approach.
In our view, interpretability refers to the ability to understand the internal mechanisms of the model. If the mode choice model is interpretable, several economic indicators such as choice prediction, choice probability, market share, substitution patterns, elasticity of alternative, social welfare, and VoT can be obtained from the model ( 17 ). Therefore, interpretability is discussed in this paper as the possibility of calculating such economic indicators. Table 3 shows a comparison of the interpretability of the traditional DCM and LLM. LLMs generate the token that has the highest probability of following the given input, where the input sentence is represented as a sequence of tokens (words). Therefore, it is possible to make LLMs output the names of the transportation modes that are most likely to be chosen, as in our approach.
Comparison of the Interpretability of the Traditional DCM and LLM
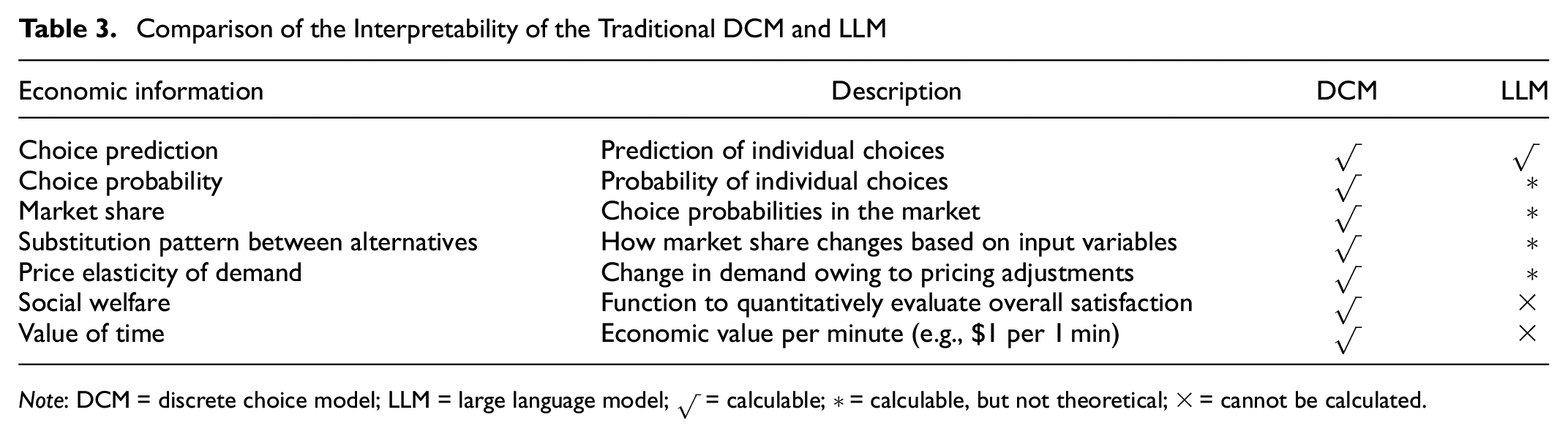
Note: DCM = discrete choice model; LLM = large language model; √ = calculable; * = calculable, but not theoretical; × = cannot be calculated.
Additionally, LLM outputs unnormalized values for each token called logits. These logits are converted into probabilities using a softmax function. Therefore, it is possible to calculate the pseudo-choice probability by extracting only the logits corresponding to the tokens (bus, train, car, etc.) in the set of transportation options and converting them using a softmax function ( 29 ). However, since these logits are not values calculated using only variables such as prices and TTs, they cannot be treated in the same way as the value of the utility function in the traditional DCMs. For this reason, it is important to note that it is not the same as the choice probability calculated using traditional DCMs.
As with choice probability, it is possible to calculate market share, substitution patterns between alternatives, and price elasticity. These indexes are calculated by repeating the operation of outputting individual choice probabilities to LLMs for the number of people in the market with changing prices for a transportation mode. However, there is no theoretical consistency in traditional DCMs. Finally, since social welfare and VoT are values calculated using the utility function value and parameters,
There is still room for improvement in the interpretability of LLMs. By analyzing the attention layers within the transformer blocks that make up models such as BERT and GPT, we can gain insights into the internal mechanisms of these models. For instance, Clark et al. examined the attention heads in a specific layer of a pretrained BERT model and found that each head focused on different linguistic patterns in the input ( 30 ). Some heads attended to the objects of verbs, whereas others focused on the determiners of nouns. This analysis helps us to understand how BERT internally represents language.
Additionally, an open-source Python framework called Attention Lens has been developed to interpret the roles of attention heads ( 31 ). It converts the output of each attention head into vocabulary tokens using head-specific learned transformations (“lenses”), enabling visualization of the information that each head uses for output. Using Attention Lens, it has been shown, for example, that certain attention heads in the GPT2-Small model often take on specialized roles such as induction heads. Induction heads seem to have the ability to learn similar patterns, which is considered to be a key factor in enabling in-context learning—and by extension, in improving prediction accuracy by extracting patterns from prompts without any fine-tuning ( 32 ). Using Attention Lens, it is possible to analyze whether such attention heads are present in a model and make LLM-based mode choice prediction more interpretable.
Explaining which input information is used by the model to produce output has been discussed in the field of deep learning, and approaches such as SHAP (SHapley Additive exPlanations) ( 33 ) and LIME (Local Interpretable Model-agnostic Explanations) ( 34 ) have emerged.
SHAP quantifies the contribution of each feature to a model’s prediction based on Shapley values, a concept from cooperative game theory that fairly distributes the total payoff among players depending on their individual contributions. In the context of machine learning, each “player” corresponds to a feature, and the Shapley value represents how much that feature contributes to the prediction by averaging over all possible feature combinations. SHAP enables the visualization of feature importance, instance-level SHAP values, and how changes in feature values affect model outputs. Recently, SHAP-based approaches have been applied to explain LLMs. For example, TokenSHAP estimates the contribution of each input token based on SHAP ( 35 ). Since LLM inputs are of variable length and often include many tokens, a Monte Carlo sampling approach is used to efficiently compute token-level contributions.
LIME is a method that approximates the relationship between the input features and the model’s output for a given instance using a simple linear regression model. It estimates the contribution of each feature to the prediction by generating a dataset through repeated sampling and prediction around the vicinity of the input instance, which is then used to train the surrogate linear model. In the case of LLMs, the input consists of a sequence of tokens. Heyen et al. applied LIME to explain the predictions of LLMs by introducing perturbations—specifically, by deleting certain input tokens and measuring the change in output to identify which tokens are most influential ( 36 ). Their analysis, which involved models of four different sizes, showed that although larger models tend to perform better, the alignment between tokens identified as important by LIME and those considered important by humans does not necessarily increase with model size. This means that even if a model becomes more accurate, it does not necessarily focus more on the tokens that humans think are important.
Unlike the traditional approach of making the black box explainable, it is possible to have LLMs output the reasons for the prediction as text. Therefore, we present several cases in which we added the sentence “And then answer why that choice,” to the end of the input prompt used in our experiments to output the predicted result of the transportation mode choice and the reason for the prediction.
We present the prompts created from the Swissmetro test samples and the corresponding GPT-4 outputs. Tables 4 and 5 illustrate examples of Case 1 with and without the personal attributes in the prompt, respectively. From the GPT-4 output shown in Table 4, it is evident that the predictions were made considering the TT and CO of the transportation modes mentioned in the prompt. Additionally, from Table 5, it is clear that the predictions considered the traveler’s income and the purpose of the trip. However, as shown in Table 6, in Case 2, GPT-4 makes an incorrect prediction. Although both Cases 1 and 2 have business as the travel purpose, the traveler in Case 1 chooses the cheapest mode, the train, whereas the traveler in Case 2 opts for the metro, which has the shortest TT. This indicates that the current LLM has limitations in weighing different factors (such as CO, time, and service frequency). However, a language-based approach using LLMs allows for the easy addition of further contextual information, which could lead to improved accuracy.
Prompt and GPT-4 Output for the Test Sample in the Swissmetro Dataset: Correct Case

Note: CHF = Swiss franc; GPT-4 = generative pretrained transformer-4.
Prompt, Including Personal Attributes Highlighted in Blue, and the GPT-4 Output for the Test Sample in the Swissmetro Dataset: Correct Case

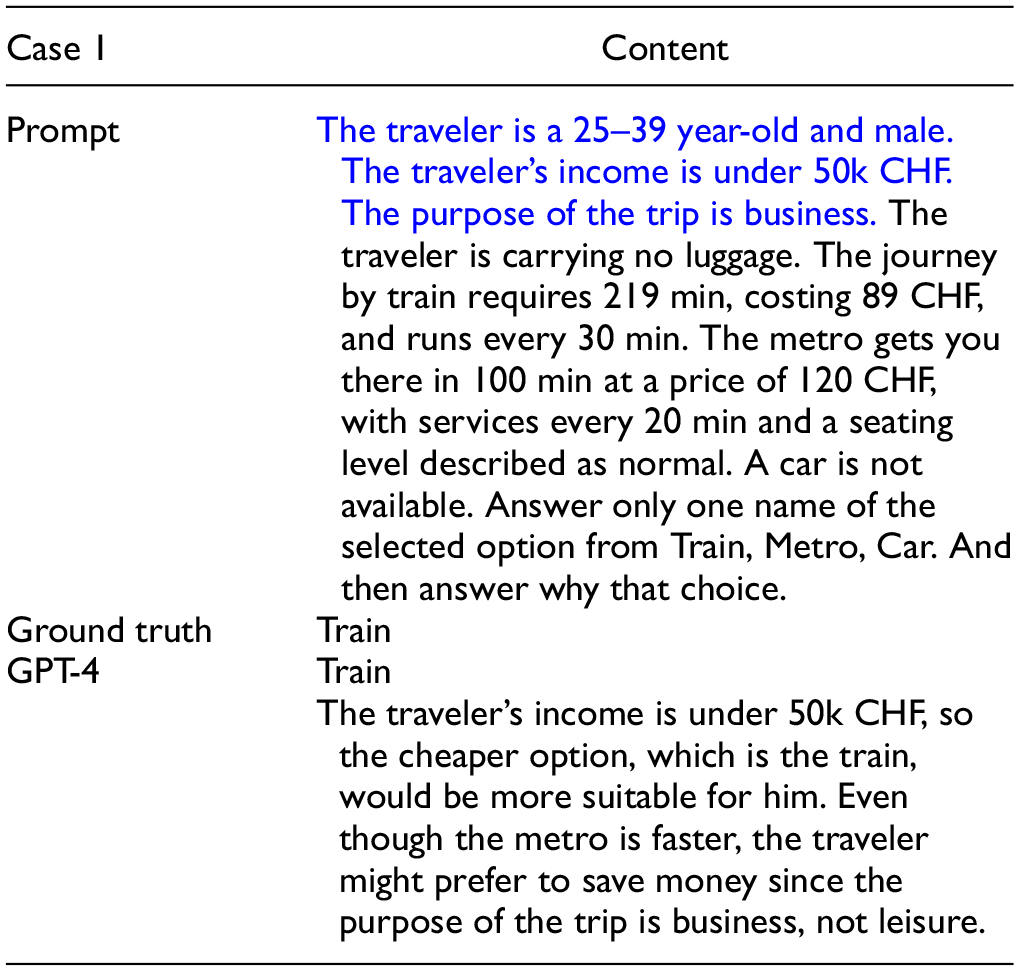
Note: CHF = Swiss franc; GPT-4 = generative pretrained transformer-4.
Prompt, Including Personal Attributes, and the GPT-4 Output for the Test Sample in the Swissmetro Dataset: Incorrect Case

Note: CHF = Swiss franc; GPT-4 = generative pretrained transformer-4.
More recently, reasoning models such as OpenAI’s o-series (e.g., o3) have emerged. These models are designed to include the rationale behind the outputs by default. The explanatory text generated with the output is called a reasoning token and provides insight into why the model arrived at a particular output.
By using these approaches, it is possible to understand which features the model considers important when predicting mode choice. For example, one can quantitatively visualize whether alternative-specific attributes such as CO and TT are more influential, or whether individual attributes such as age and trip purpose play a greater role. This enables researchers to make informed decisions about which variables to include in the input text—essentially supporting the variable selection process in the design of utility functions, as done in traditional choice modeling.
Hallucination
LLMs may generate plausible-looking statements that are irrelevant or factually incorrect, which is called “hallucination” ( 37 , 38 ). LLMs still lack the ability to control their use of internal or external knowledge accurately ( 39 ). As the same person may make a different choice in the same situation in transportation mode choice, it is difficult to guarantee what the true choice is. However, when the choice is decisive, the LLM must use knowledge correctly to make a highly accurate prediction. This is a common challenge for all domains of LLMs and one worth addressing in transportation-related tasks. Several methods for mitigating hallucinations have been proposed. For example, Sun et al. proposed a contrastive learning scheme ( 38 ). Contrastive learning is a method of deep learning that constructs feature representations by learning the similarities and differences in data. When fine-tuning an LLM or BERT, the model is trained to output positive examples (correct answers), but in Sun et al.’s method, an LLM is trained to not generate negative examples (incorrect answers) through contrastive learning and it suppresses hallucinations. There is also a method called “self-reflection” that is used to check whether the LLM output contains any hallucinations ( 40 ).
Pretrained Data
In the case of the BERT-based model, fine-tuning was performed with early stopping, in which a portion of the training data was used as validation data, and training was halted when validation accuracy no longer improved. This training setting is called early stopping and it helps prevent overfitting to the training data. In contrast, GPT was used without fine-tuning in this study, so there was no risk of overfitting to our dataset. However, the model’s performance may depend on the characteristics of the data used during pretraining, potentially introducing bias or affecting generalizability depending on the domain coverage of the pretraining corpus. LLMs such as GPT trained with excessive data on a particular domain (e.g., finance or science) reduce the generalization ability of the LLM for other domains ( 39 , 41 ). Therefore, several LLMs employ general-purpose pretrained data that provide rich text sources on a variety of topics, such as web pages, books, and conversational texts. It is important to investigate what type of LLMs and pretrained data can be useful for mode choices and other transportation-related tasks.
Computational Cost
LLMs can be used as a model for agents in multiagent simulations such as MATSim ( 42 ). For example, Liu et al. demonstrated that LLM agents can reproduce realistic travel behavior and system-level dynamics in transportation simulations, such as morning commute scenarios ( 43 ). This supports the feasibility of integrating LLMs into agent-based transportation models. Although this study provides valuable insights into the behavioral soundness of LLM agents, it involved only 40 agents. Scaling such approaches to population-level simulations poses significant computational challenges.
When using an LLM with an application programming interface (API) like GPT-4, it takes time to compute and communicate with the API. Whereas traditional DCMs can make predictions in microseconds, it takes approximately 0.75 s to make a single choice prediction with an LLM. Additionally, there is an economic cost, as API usage incurs a fee. In such cases, input/output (I/O) overhead from issuing large numbers of API requests becomes a major bottleneck. To address this, Yan et al. developed OpenCity, a scalable platform that parallelizes requests using I/O multiplexing and reduces redundancy through prompt optimization strategies ( 44 ). These improvements enabled the simulation of 10,000 agents’ daily activities in about 1 h on commodity hardware.
Another solution is to use a small-scale model that is publicly available, such as LLaMA (https://huggingface.co/meta-llama), or other distilled or quantized models, on a local computer. Although a GPU environment is required, this approach can reduce computational cost, communication overheads, and usage fees. However, there has been no systematic investigation into how the size of the LLM—ranging from large-scale models like GPT-4 to smaller, locally executable models—affects the accuracy of individual choice behavior or the emergent system-level dynamics. This remains an important direction for future research.
Conclusion
Mode choice models are dependent on the target mode alternatives in the modeling step and are not generalizable to other modes. Therefore, we proposed a novel approach by applying language models to predict mode choices based on natural language inputs describing various travel modes and associated variables. Our experiments, using datasets with both SP and RP surveys, demonstrated that the proposed language-based models were more versatile and generalizable across different scenarios compared with the traditional MNL. Furthermore, the proposed approach considers the attributes of the traveler in the form of natural language. We found that this improved the prediction accuracy in transportation mode choice behavior.
For future work, there are several areas to explore to enhance the robustness and effectiveness of language-based mode choice models. First, expanding the datasets to include more diverse and extensive scenarios could help improve the model’s ability to handle a wider range of real-world applications. Secondly, in few-shot prompting, examples are currently selected at random. In other tasks, it has been shown that selecting similar examples could improve prediction accuracy ( 45 ). Therefore, we can expect to see an improvement in accuracy in the prediction of transportation mode choice. Thirdly, integrating more complex individual attributes and contextual factors could provide deeper insights into the factors influencing mode choice decisions. Additionally, exploring the integration of these models into transportation-related applications, such as personalized travel recommendations, could offer practical benefits. Lastly, applying the LLM-based mode choice model to multiagent simulation could provide rich analyses and understanding of traffic phenomena. Since computational complexity increases with the number of agents, the computational efficiency and scalability of the model are critical issues.
Footnotes
Author Contributions
The authors confirm contribution to the paper as follows: study conception and design: R. Nishida, T. Ishigaki; data collection: R. Nishida; analysis and interpretation of results: R. Nishida, T. Ishigaki, M. Onishi; draft manuscript preparation: R. Nishida, T. Ishigaki. All authors reviewed the results and approved the final version of the manuscript.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by Japan Society for the Promotion of Science under KAKENHI (Grant no. 24K20850).
Data Accessibility Statement
The data that support the findings of this study are available from the corresponding author on reasonable request.