
Abstract
Travel time prediction is vital to the development and maintainence of advanced intelligent transportation system technologies. The travel time on a road segment is dependent on various factors like dynamic traffic demands, incidents, weather conditions, and geometric factors. However, uncertainties associated with prediction performance consistency may reduce the effectiveness of such systems. To tackle these challenges, this paper proposes a hybrid deep learning algorithm-based methodology by integrating variational mode decomposition, multivariate long short-term memory, and quantile regression to predict estimates of travel time ranges instead of single-point predictions. Travel time data collected from loop detectors on motorways near the city of Dublin, Republic of Ireland were modeled. The proposed method was evaluated using various design scenarios and was found to perform efficiently in comparison with conventional deep learning algorithms.
Keywords
Travel time information in real time is the most sought-after data among travelers as it is very useful for making trip-related decisions such as route choice and departure time. It is also useful for practitioners wanting to interpret the efficiency of road segments and in managing traffic using intelligent transportation system (ITS) applications. However, travel time may vary significantly over space and time as a consequence of variations in traffic demand, capacity, incidents, roadwork, adverse weather, driving behavior, and congestion. As a result, being able to depend on extensive traffic data and recent technologies to precisely predict travel times is essential. There is plenty of literature in the domain of travel time prediction, which can be broadly classified as inductive approaches (i.e., data-driven methods) and deductive approaches (i.e., traffic flow theory-based methods). As the present study has proposed data-based modeling and prediction, the following paragraphs brief the reported studies based on inductive approaches.
Numerous studies have reported predicting travel times based on naïve methods, statistical methods, and artificial intelligence (AI)-based methods. Naïve methods ( 1 ) predict travel time by averaging over time and space selectively. Statistical approaches like time series ( 2 , 3 ) and regression methods ( 4 , 5 ) predict travel time based on correspondences among the identified limited independent variables. However, these methods are largely dependent on the correspondence between a limited amount of training and testing data. AI-based techniques such as artificial neural networks ( 6 , 7 ), support vector machines (SVMs) ( 8 , 9 ), recurrent neural networks (RNNs) ( 10 , 11 ), and convolutional neural networks (CNNs) ( 12 , 13 ) are widely used prediction techniques when there is a large amount of data available for various applications in traffic. In light of this, RNNs and CNNs have gained greater research attention in recent times, owing to their ability to model complex temporal dependencies in data. Therefore, we adopted a multivariate long short-term memory (LSTM) neural network to develop a travel time prediction method in this study. Hybrid methodologies generally delve into mode decomposition algorithms to disintegrate the original traffic data sequence into multiple subsignals. Further, hybrid models integrate one or more AI-based methods in prediction methodology to tackle the nonlinearity and nonstationarity of the traffic system. Popular mode decomposition algorithms include empirical mode decomposition (EMD) ( 14 ), empirical ensemble mode decomposition (EEMD) ( 15 ), and wavelet transform.
A few recent studies have explored hybrid models for prediction in the domain of traffic engineering. Zheng et al. proposed an EMD-based hybrid modeling framework by integrating SVM and LSTM for traffic flow prediction ( 16 ). Tian explored hybrid models by integrating EEMD with SARIMA models to perform traffic flow prediction ( 17 ). Xiu et al. developed a hybrid methodology by combining EEMD bidirectional gated recursive units (GRUs) to predict the passenger flow in the metro system, and reported a superior performance when compared with a single GRU model ( 18 ). Although most of the research on hybrid models has been based on EMD and EEMD, Sopeña et al. developed a hybrid modeling framework using variational mode decomposition (VMD) with a feedforward neural network (FFNN) for the purpose of traffic flow prediction ( 19 ). This study reported the superior performance of VMD when compared with other mode decomposition techniques using FFNN. However, the use of hybrid models like VMD has not been investigated in relation to travel time prediction. As travel time can render higher variations owing to its dynamic behavior and can be affected by various factors, adopting a hybrid model like VMD might be expected to better capture variations at different scales. Thus, the present study proposed a VMD-based hybrid modeling methodology for travel time prediction. In this study, we integrated the multivariate LSTM technique, a special type of RNN with a VMD algorithm, because LSTM has proven to be an excellent tool in time series prediction. Furthermore, to date, the combination of VMD and LSTM has not been explored. Therefore, the current methodology comprising a VMD integrated multivariate LSTM technique, was expected to improve the accuracy of the forecast while reducing the computational complexity of the prediction algorithm.
Point forecasts (i.e., a singular number that represents an estimate of an unknown variable value at a future date) cannot provide any information with respect to the uncertainty associated with the forecasts themselves, thus affecting the reliability of the prediction system. To overcome this issue, the present study utilized quantile regression (QR), a nonparametric method to identify the probabilistic estimates of prediction, known as prediction intervals (PIs). Overall, the study contributions include
Adopting a novel methodology consisting of a mode decomposition algorithm to decompose the time series data to capture the speed dynamics at different frequencies;
Formulating a hybrid prediction methodology with multiple deep learning models to predict the decomposed speed time series data to improve prediction accuracy when compared with traditional deep learning models; and
Providing an interval estimate unlike traditional models that fuses a QR-based loss function with an LSTM technique, which essentially equips the methodology by yielding reliability bounds.
To summarize, the present study proposed a travel time prediction methodology based on LSTM, a special type of RNN integrated with a mode decomposition algorithm, VMD and QR, a nonparametric approach to estimate PIs.
The remainder of this paper is organized as follows: the following section details the methodology; data collection and processing are then described, followed by presentation of the results. The final section presents our conclusions from this work.
Methodology
The present study focused on developing a hybrid deep learning model-based prediction framework to forecast the probability estimates of predicted travel time. This methodology integrated three different techniques—VMD, LSTM, and QR—to build a multi-input, single-output model while considering traffic flow and speed as inputs to predict travel time. Let
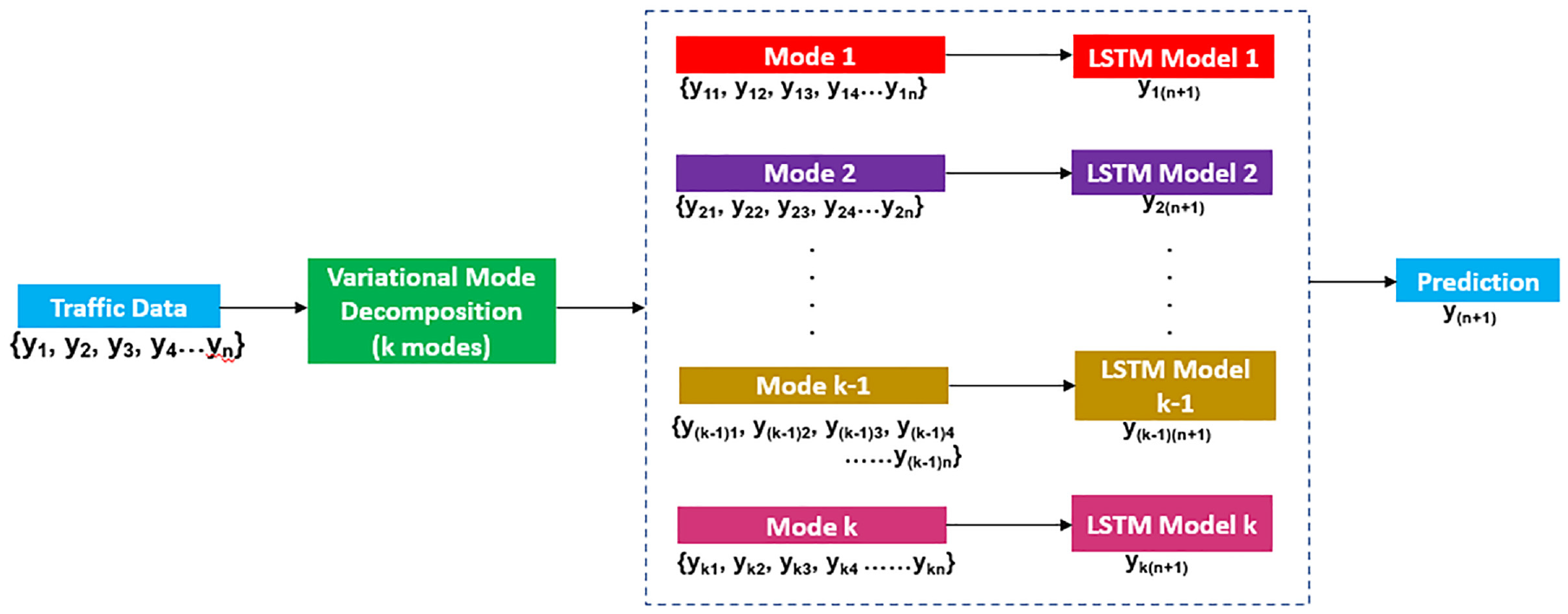
Research schema.
Variational Mode Decomposition
VMD is a nonrecursive signal processing method designed for decomposing complex nonstationary signals (
20
). The decomposition process is performed by a constrained variational problem to determine the bandwidth of each mode. This process involves three steps: 1) the Hilbert transform is used to obtain the unilateral frequency spectrum for each mode, 2) an exponential tuned to the estimated center frequencies is used to shift every mode’s frequency spectrum to baseband, and 3) the bandwidth of each mode is identified using the
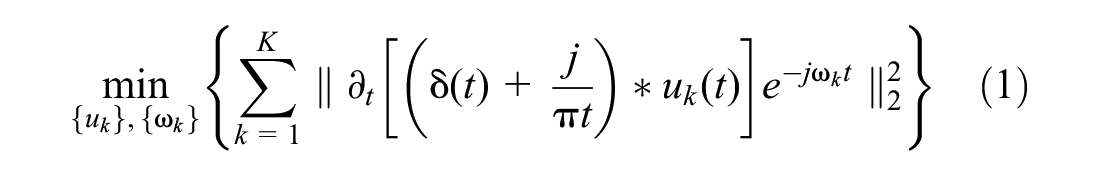
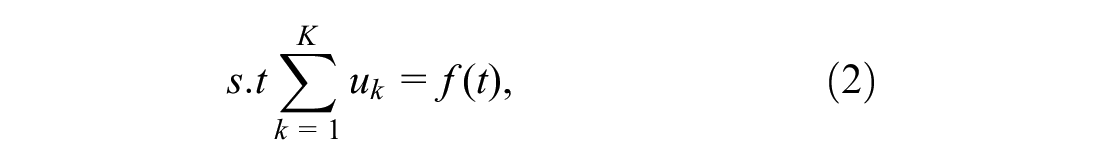
where
j is an imaginary number. This is a complex valued analytic signal,
The present study adopted the number of predefined modes
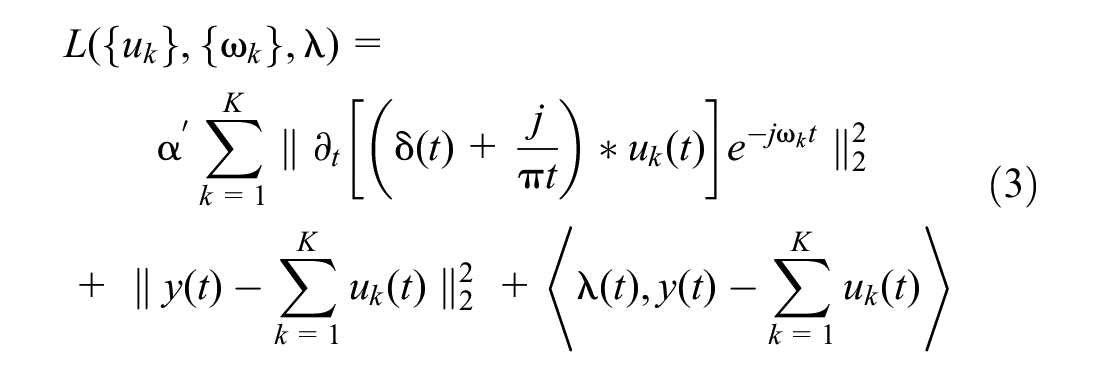
This equation can be solved using a sequence of iterative suboptimizations known as the alternate direction method of multipliers (
22
,
23
). By doing so, the modes,
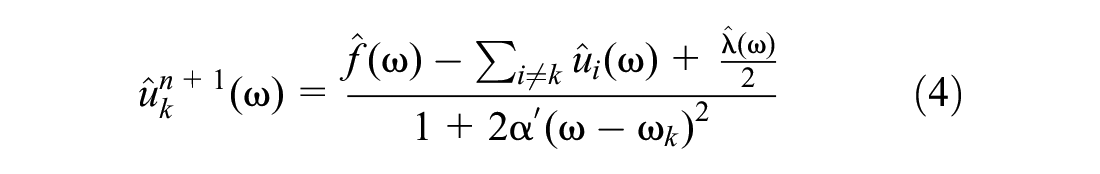
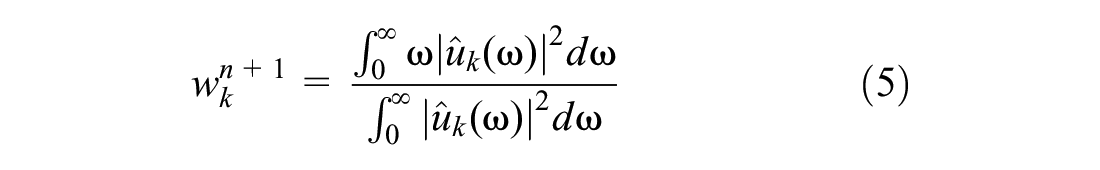
The modes are solved in the spectral domain and can be transformed back into the time domain by taking the real part of the inverse Fourier transform of the signal. In Equation 4, value
Long Short-Term Memory
LSTM networks (
24
) regulate the flow of information using three gates (i.e., forget gate,
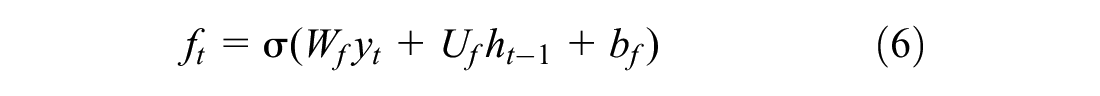
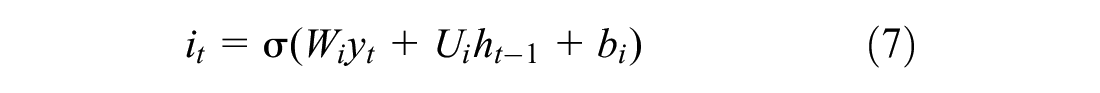
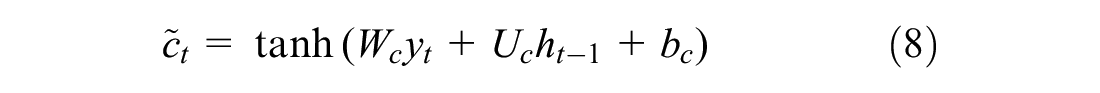
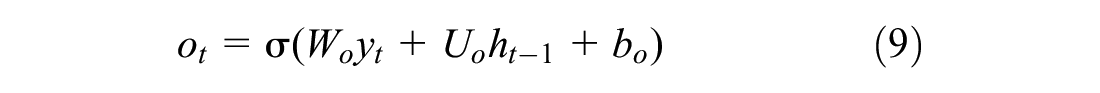
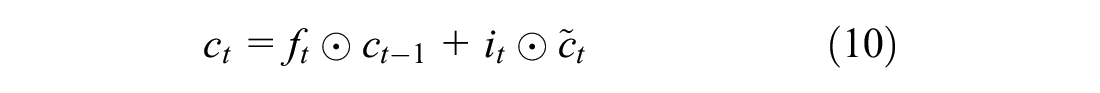
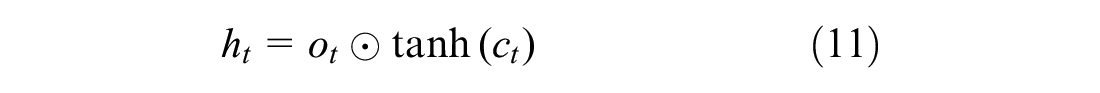
Firstly, the LSTM network decides whether the information from the previous time step is discarded or maintained by means of the forget gate,
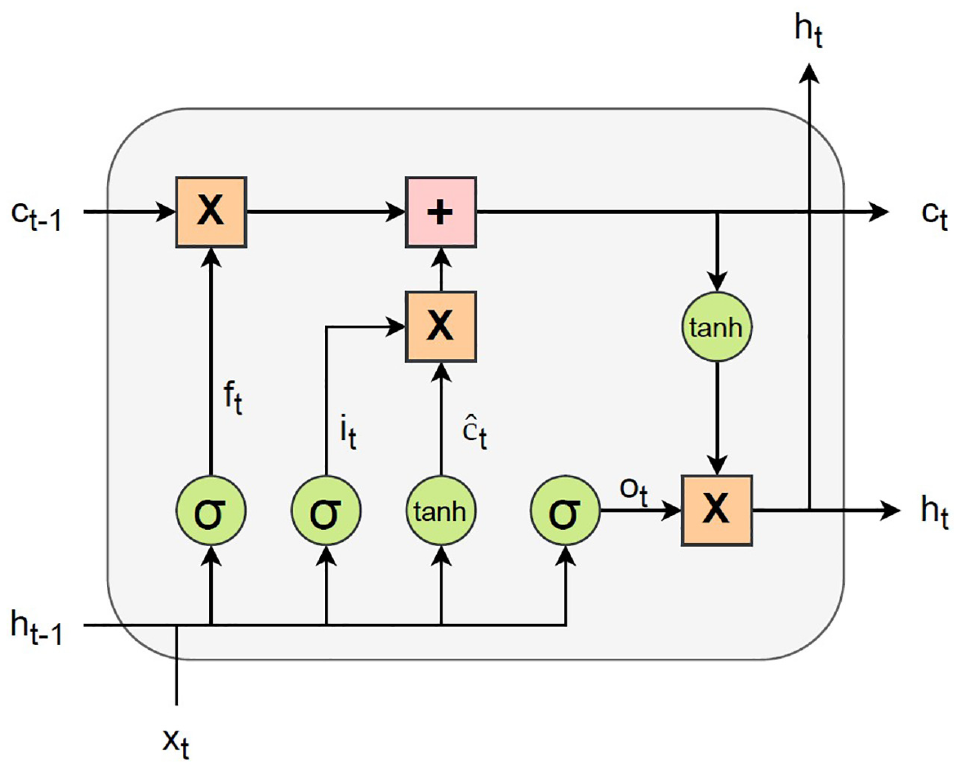
Structure of an LSTM network.
The cell state of the LSTM network is updated as shown in Equation 10, combining the elementwise product,
Quantile Regression
In this study, we implemented a QR loss function—a nonparametric approach—to estimate the PI corresponding to the lower and upper boundaries of the estimate. PI is a measure illustrating the robustness of the algorithm in relation to its ability to quote the variation within an observed dataset. The loss function is equal to
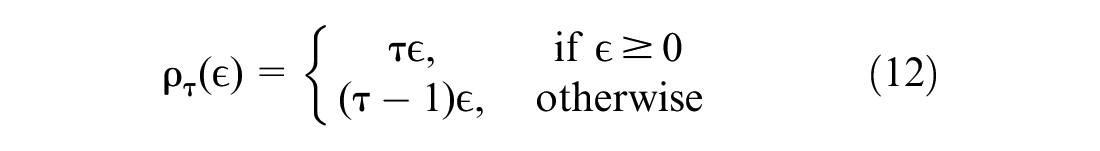
Then, the error function that must be minimized is
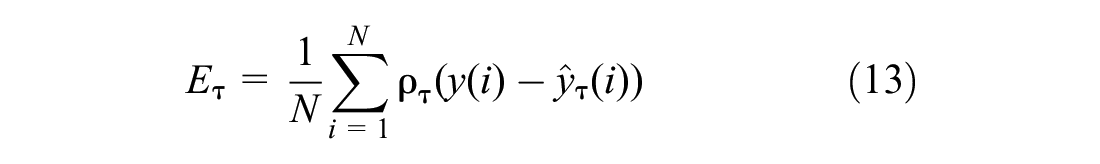
where y(i) is the target value, and
Prediction and Performance Evaluation
In this study, the accuracy of point forecasts was quantified using the mean absolute percentage error (MAPE),
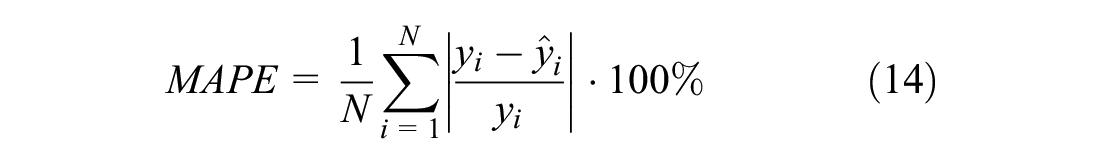
where
N = number of samples,
However, the coverage and width of the PI must also be assessed for its evaluation. For that purpose, Prediction Interval Coverage Probability (PICP) metric was considered to measure the coverage of the PI and is defined as follows:
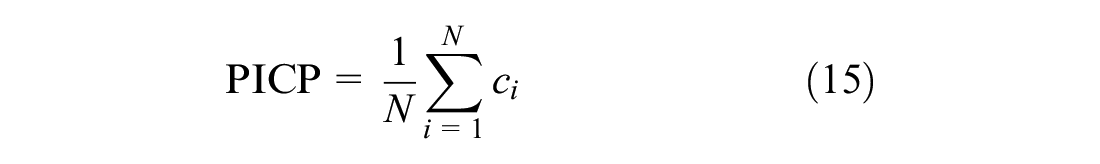
where N accounts for the number of observations, and
The present study experimented with the aforementioned methodology in four ways (as shown in Table 1) to explore the best-performing combinations. Table 1 details the model combinations and their input variables adopted for prediction. Univariate models take past observations of speed time series as input to predict future values; multivariate models take past observations of both speed and flow time series as inputs to predict future speed values. Furthermore, VMD integrated models train dedicated LSTM models to predict values for each IMF, which are combined to obtain the final predicted speed signal.
Variations of Prediction Algorithms used for Travel Time Modeling
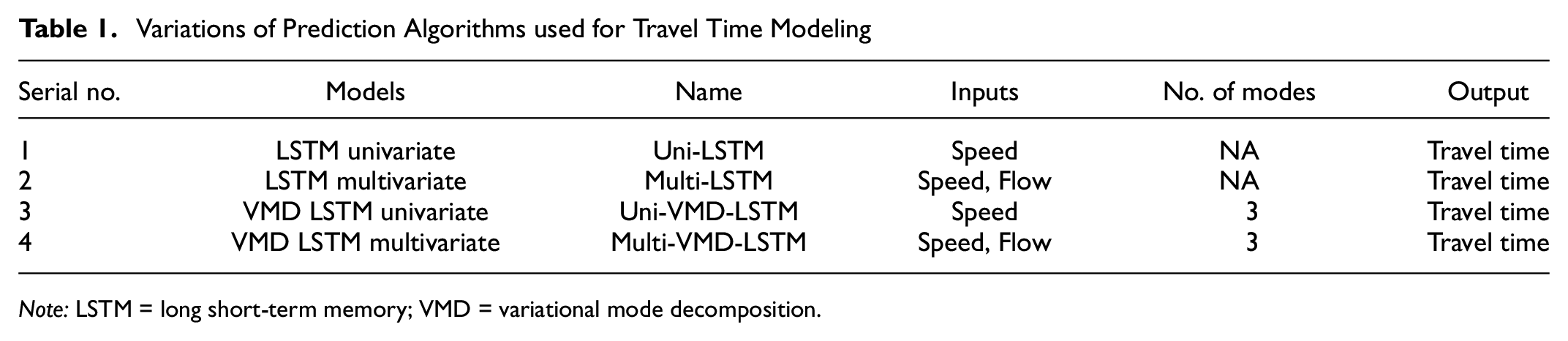
Note: LSTM = long short-term memory; VMD = variational mode decomposition.
Data Description
The data for this study were sourced from Traffic Infrastructure Ireland traffic counters ( 25 ) installed on the Irish road network. Vehicles are detected by passing over loops embedded beneath the road surface. Traffic counters provide information on the volume of traffic by time of day and by vehicle class (e.g., motorcycle, car, goods vehicles distinguished by the number of axles, etc.) with up to 12 classes being identified. In this study, we focused on six consecutive vehicle detectors located on the M50, the most prominent and busiest Irish motorway situated around the capital city, Dublin (see Figure 3). The M50 is a C-shaped, orbital, six-lane expressway corridor, with three lanes in each direction, that connects Dublin port with the M11 at Shankill, Ireland. All the other national routes radiate outwards from Dublin, their junctions beginning at the M50. The speed limit is 120 km/h and the traffic composition consists of 79.31% passenger cars, 0.2% motorbikes, 11.74% light goods vehicles, 7.89% heavy motor vehicles, 0.34% buses, and 0.525% caravans.
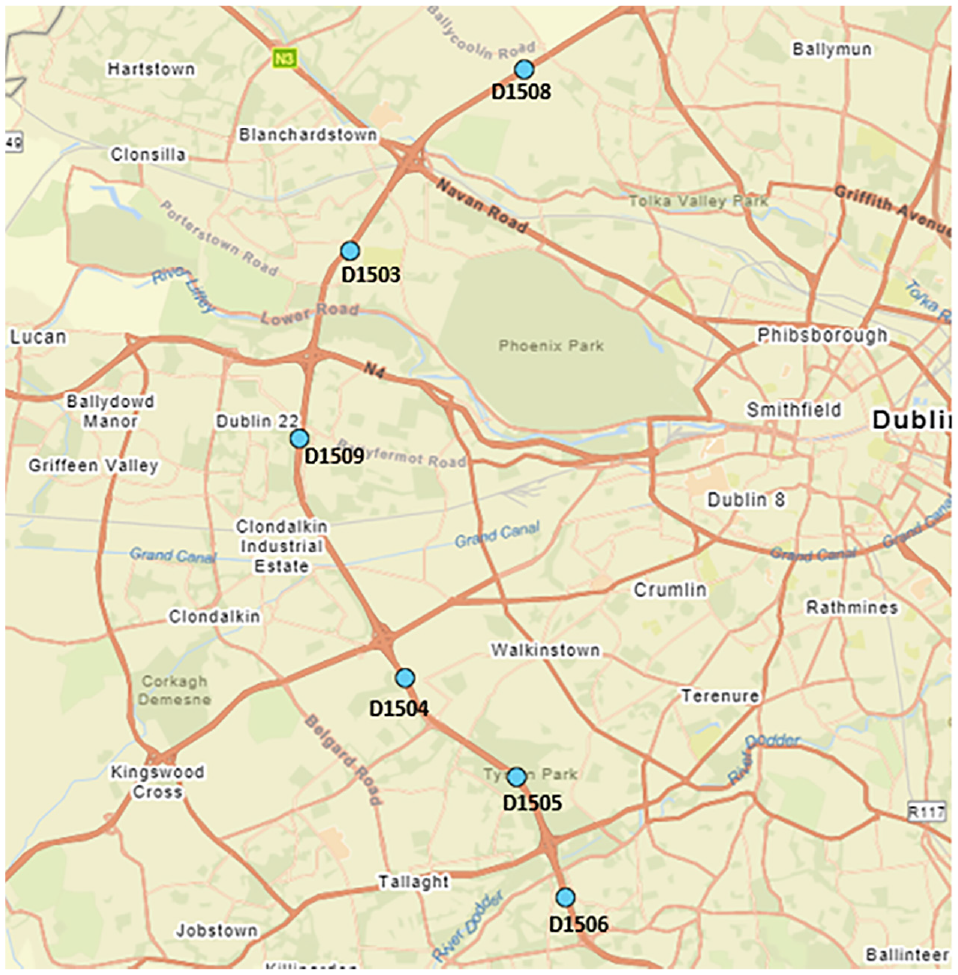
Map of test bed with the chosen detectors.
The raw data obtained were vehicle transactions consisting of time of passage, speed, vehicle type, and lane identifiers. For this study, the flow and speed values from the vehicle class “passenger cars” were considered for a period of 5 months (January to May 2019). Reserving the last month for testing (80:20 ratio), the remaining data were utilized for training and validation. The sourced data were processed in four stages: data cleaning, outlier removal, time series formation, and data imputation. Data cleaning involves extraction of the necessary information from the raw data, which consists of location-related details, lane identifiers, and vehicle identities such as tag-IDs and length, which were removed from the database to prepare the necessary inputs for the developed methodology. In the outlier removal stage, unreasonable data points that did not reflect the characteristics of the study sites were removed. Vehicle transactions with zero speed values, extremely high speed values of more than 200 km/h, and negative speed values were identified as outliers and removed from the database. Such values may have been incorrectly reported owing to sensor or communication errors.
In the next stage, the cleaned flow and speed values were processed to set up the time series. In the present study, the traffic flow and speed values observed at different times of the day were viewed as sequential data or a time series. The entire 24-h time window was divided into 5-min slots, such that we had twelve 5-min slots in an hour totaling 288 slots in a 24-h window. Further, the data were preprocessed such that at each time slot there was only one observation. In this regard, the traffic flow observation for any slot was the cumulative number of vehicles passing over the counter during a particular 5-min interval. The speed values were obtained by averaging the speeds of all the vehicles that passed over the counter during the 5-min period. Missing speed values resulting from there being no vehicles during a 5-min period were imputed by temporal substitution, in which temporally lagged observations were used for data imputation. Substitutions were designed based on the availability of data checked at different levels, such as an immediate past observation in time, and a week past observation, by taking advantage of the daily and weekly seasonality in the traffic data. This process of handling missing values is generally termed data imputation. The percentage of missing values was found to be less than 0.2% for the chosen dataset. The processed database comprised 43,488 observations in the continuous time series format with a 5-min resolution (frequency). A sample plot of processed speed and flow time series is shown in Figure 4. The descriptive statistics of the speed time series are clearly illustrated by boxplots presented in Figure 5.
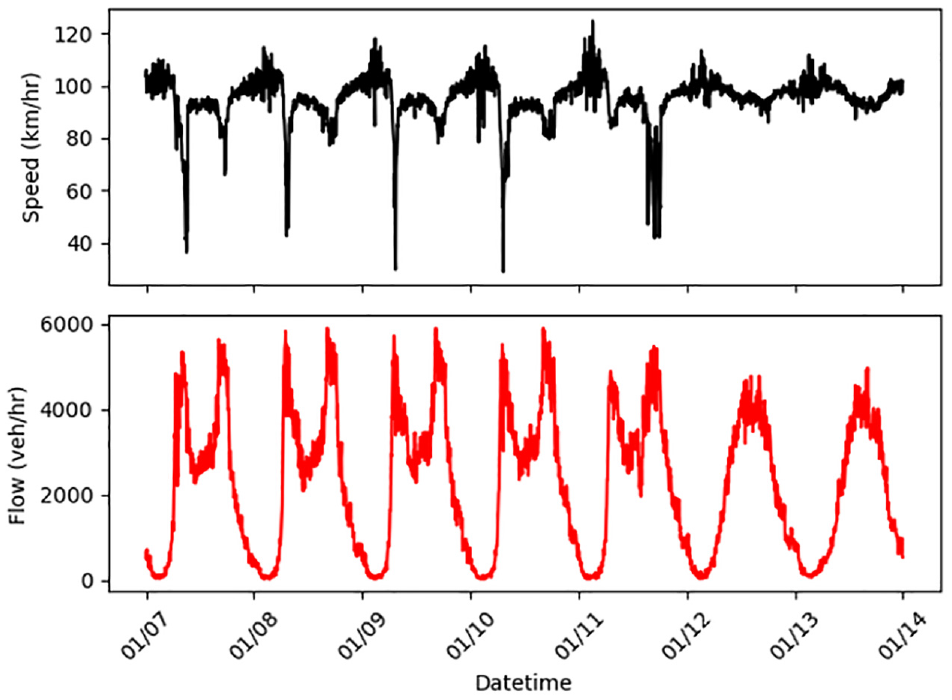
Sample plot of speed and flow time series.
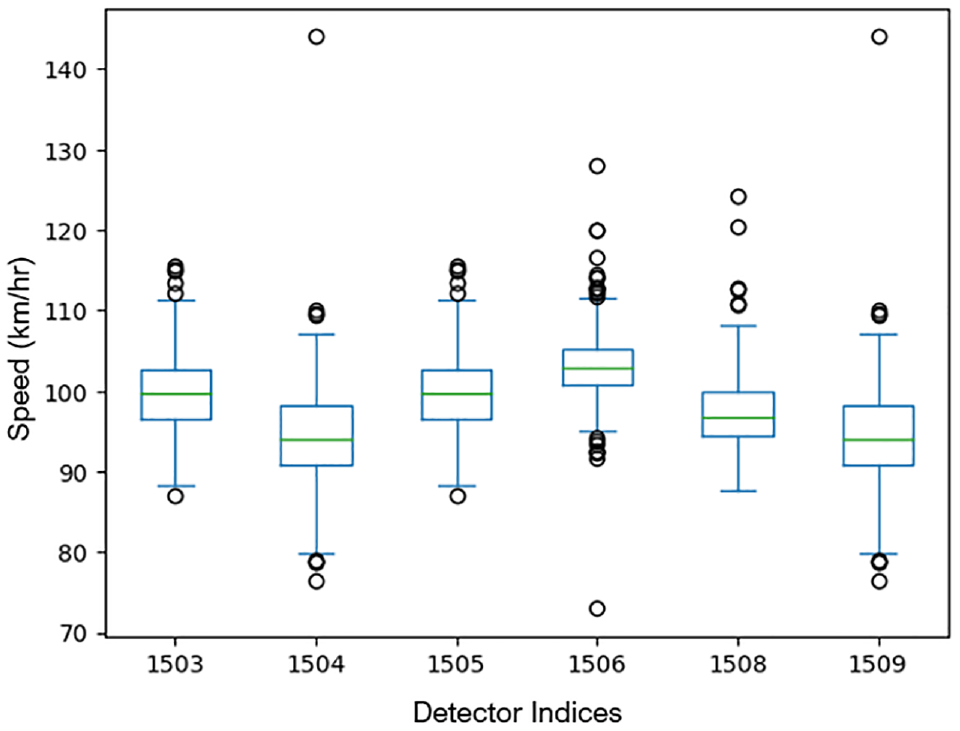
Box plot of speed sample across the considered detectors.
From Figures 4 and 5 it can be observed that the statistical characteristics of the speeds identified by each of the detectors were significantly different, despite being situated consecutively on the same motorway. On that note, Figures 4 and 5 collectively reflect the spatiotemporal variation in speed values observed on the M50. The processed speed time series was given as input to the developed variable mode decomposition algorithm, and three different band-limited IMFs (modes) were generated. A sample plot of the original speed signal and decomposed modes is shown in Figure 6.
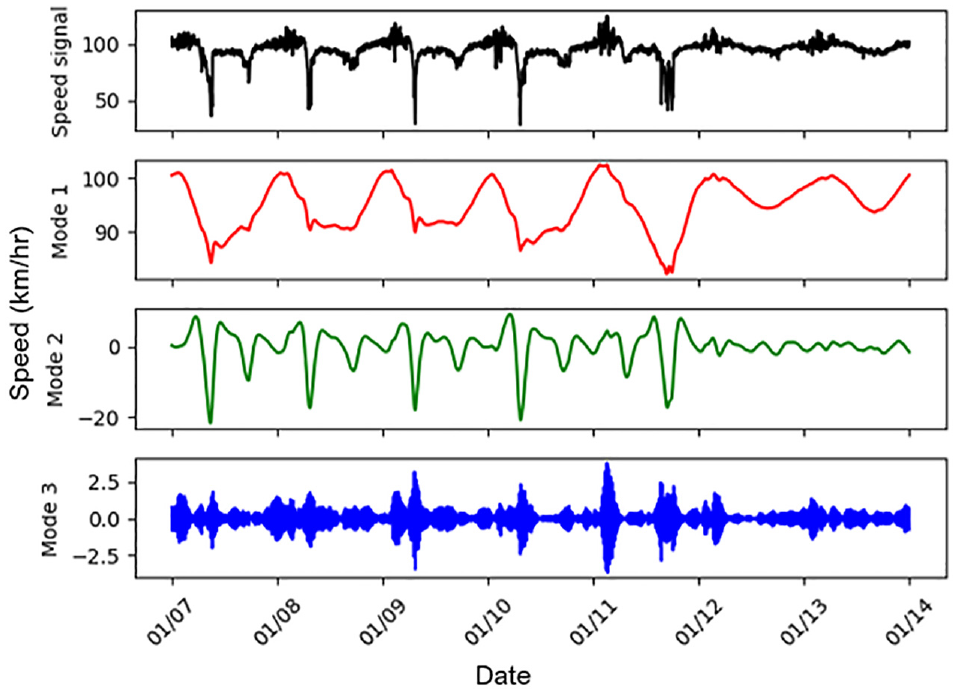
Mode decomposition of speed signal using VMD.
Further, each IMF was trained using dedicated LSTM models along with flow time series, and speed values were predicted. The present study considered 24 time-lagged observations to predict future travel time values with a 5-min horizon. In the subsequent stage, the travel time values were estimated from the predicted speed values.
Results
To explore the efficiency and performance of the developed model, the results were evaluated and compared against the benchmark models. To check the importance of the mode decomposition step during prediction, the performance of the VMD LSTM model was compared with a simple LSTM model, which takes the input without any preprocessing. To identify the advantages of considering traffic flow in travel time prediction, performances were compared between multivariate and univariate versions of the deep learning models. Overall, the four test cases (shown in Table 1) Multi-VMD-LSTM, Uni-VMD-LSTM, Multi-LSTM, and Uni-LSTM were considered and the prediction performances of all models compared.
Figure 7 shows the predicted travel time intervals of all the explored model combinations and measured travel times. It can be seen that intervals predicted by the multivariate models included all or most of the observed data points within the PIs, unlike the univariate models. It was also observed that the performance of the Multi-VMD-LSTM model was better than the other design variations, illustrating the advantage of adopting a signal processing tool like VMD when considering multiple variables. The VMD LSTM model presented a good adaptation to the data, even if some of the observations fall outside the interval.
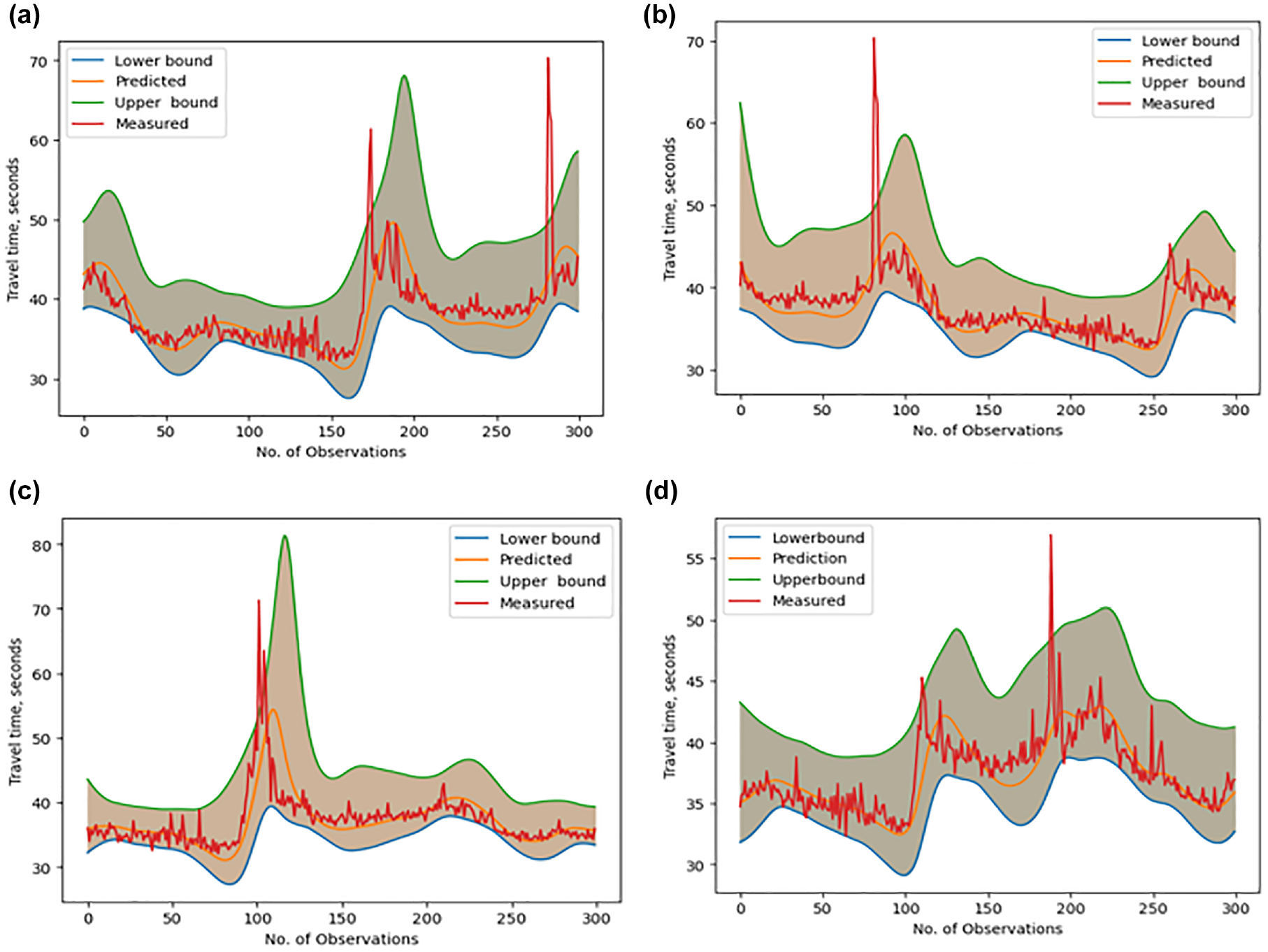
Prediction intervals across developed methods.
Figure 8 shows a comparison of PICP values across all the detectors among the four model variants. It was observed that the VMD LSTM model provided better coverage probability when compared with the LSTM models.
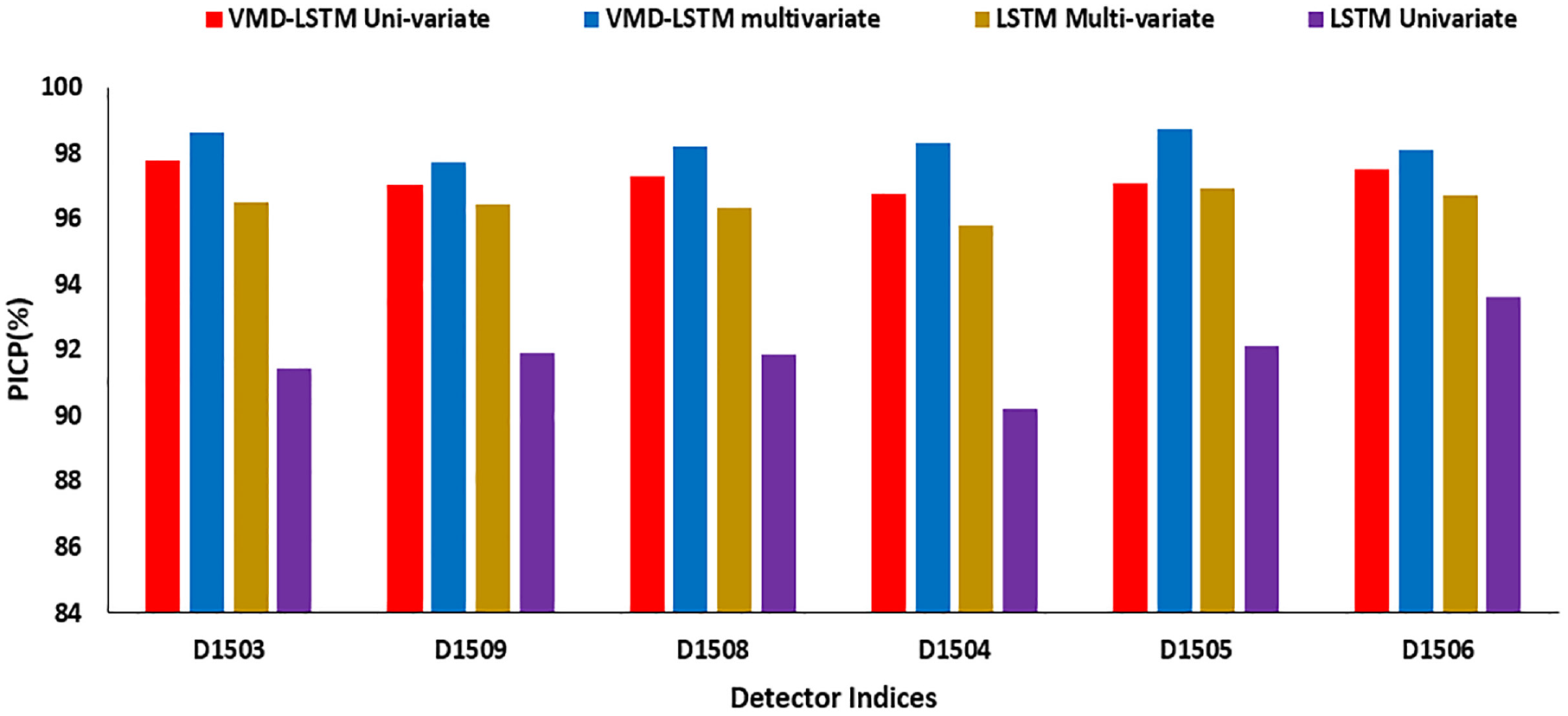
Comparison of PICP values across test detectors.
Further, the performance of all the modeled datasets considered in this study was compared to illustrate the consistency and effectiveness of the proposed methodology (Table 2). From the data presented in the table, it can be observed that the MAPE values of all the tested cases were between 3% and 6%. In the case of the six studied loop detectors, the VMD LSTM multivariate version of the proposed model outperformed the other models tested in this study. Preprocessing using the VMD proved to be the most useful addition to a conventional deep learning model such as LSTM. The use of both speed and flow in traffic prediction proved effective in the case of four detectors, whereas the other two did not show any effective improvement. This outcome was similar to model performance without the preprocessing step. Furthermore, preprocessing seemed to improve the impact of multivariate inputs.
Table of MAPE Values for all Test Cases
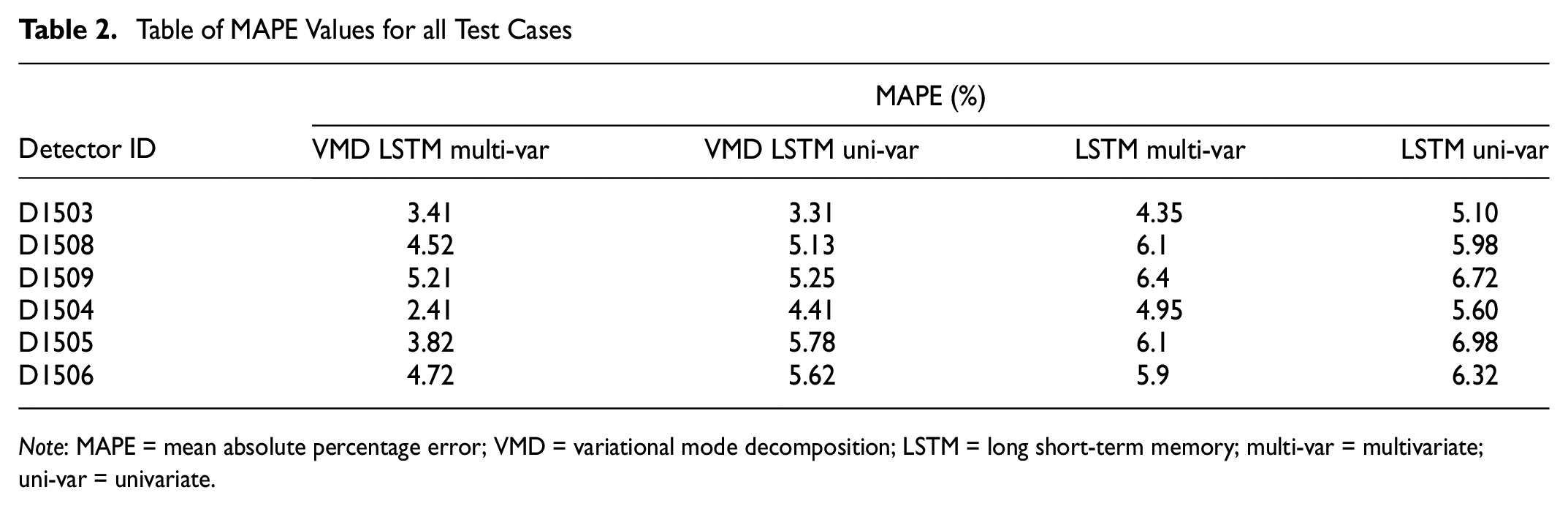
Note: MAPE = mean absolute percentage error; VMD = variational mode decomposition; LSTM = long short-term memory; multi-var = multivariate; uni-var = univariate.
Conclusion
Travel time prediction is essential to the developing and implementation of the majority of ITS applications in real time. The present study formulated a travel time prediction methodology by decomposing the input time series into multiple modes (IMFs) using VMD, and exclusive multivariate LSTM models were built for each of the IMFs, integrating QR to obtain the probabilistic intervals for the predicted travel time.
The probabilistic intervals produced the upper and lower bounds of the predicted travel time, providing a measure of uncertainty. Performance of the developed methodology was found to be efficient for both point forecasts, in which MAPE scores varied between 3% and 5%, and prediction intervals with PICP values varying between 97% and 99%. This performance was compared with simple LSTM models under univariate and multivariate cases to explore the advantages of a VMD–LSTM model combination. The results showed that the proposed method outperformed the benchmark methods in all cases, consistently showing the superiority of the developed methodology. Overall, the results showed that the VMD–LSTM–QR-based method was efficient and reliable for the purpose of travel time prediction. Furthermore, the probabilistic estimates around the point predictions (i.e., probabilistic prediction interval) acted as a measure of the robustness of the prediction algorithms and are essential for real-time implementations. Under unexpected traffic conditions during incidents, pandemics, and extreme weather events, PIs would be expected to provide meaningful bounds with which to understand the expected variations of travel time in the near future. The developed methodology would be completely transferable to any location with the availability of the aforementioned data source and initial training to learn about the model parameters. Further, the multivariate LSTM could be extended by adding suitable weather factors to develop a weather-adaptive travel time prediction system—a possible future extension to this study.
Footnotes
Author Contributions
The authors confirm their contribution to the paper as follows: study conception and design: D. Bharathi, J. M. González-Sopeña; data collection: D. Bharathi; analysis and interpretation of results: D. Bharathi; draft manuscript preparation: D. Bharathi, J. M. González-Sopeña, B. Ghosh, S. Clarke. All authors reviewed the results and approved the final version of the manuscript.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This publication emanated from research supported in part by a grant from Science Foundation Ireland (grant no. 13/RC/2077P2).