
Abstract
Perimeter metering control has long been an active research topic since well-defined relationships between network productivity and usage, that is, network macroscopic fundamental diagrams (MFDs), were shown to be capable of describing regional traffic dynamics. Numerous methods have been proposed to solve perimeter metering control problems, but these generally require knowledge of the MFDs or detailed equations that govern traffic dynamics. Recently, a study applied model-free deep reinforcement learning (Deep-RL) methods to two-region perimeter control and found comparable performances to the model predictive control scheme, particularly when uncertainty exists. However, the proposed methods therein provide very low initial performances during the learning process, which limits their applicability to real life scenarios. Furthermore, the methods may not be scalable to more complicated networks with larger state and action spaces. To combat these issues, this paper proposes to integrate the domain control knowledge (DCK) of congestion dynamics into the agent designs for improved learning and control performances. A novel agent is also developed that builds on the Bang-Bang control policy. Two types of DCK are then presented to provide knowledge-guided exploration strategies for the agents such that they can explore around the most rewarding part of the action spaces. The results from extensive numerical experiments on two- and three-region urban networks show that integrating DCK can (a) effectively improve learning and control performances for Deep-RL agents, (b) enhance the agents’ resilience against various types of environment uncertainties, and (c) mitigate the scalability issue for the agents.
Keywords
Transportation researchers and practitioners often use different modeling paradigms to develop, test, and refine traffic control strategies. Microscopic modeling approaches can best represent the reality, but they are not well-suited to urban traffic control because of the complexity of these systems. The network macroscopic fundamental diagram (MFD) has recently emerged as another tool to model urban transportation systems from a regional perspective. Specifically, the MFD leverages the existence of well-defined and unimodal relationships between the average network productivity (e.g., trip completion rate) and average network usage (e.g., accumulation) on homogeneous networks to describe aggregate traffic dynamics. The presence of such relationships has been studied for a long time ( 1 – 4 ), but integrating the MFD into a framework that enables aggregate traffic dynamics modeling is a relatively recent achievement ( 5 ). Since then, extensive MFD-related research efforts have been performed, such as MFD estimation ( 6 – 9 ), the existence conditions for low-scatter MFDs ( 10 – 13 ), network instability and hysteresis phenomena ( 14 – 18 ), and others.
MFD-based modeling paradigms have facilitated the development of perimeter metering control (PMC) schemes, that is, regulating transfer flows to improve the overall network throughput. For single-region networks, the PMC problem was first studied by Daganzo ( 5 ) and further investigated by Haddad and Shraiber ( 19 ), Keyvan-Ekbatani et al. ( 20 , 21 ), and Haddad ( 22 ). Numerous research works have also examined PMC for two-region ( 23 – 28 ) and multi-region networks ( 29 – 36 ). A wide variety of methods have been proposed to solve the PMC problem, and these can be loosely categorized into model-based and data-driven approaches. Model-based methods include proportional–integral-based control ( 19 , 20 , 32 ), adaptive control ( 28 , 37 ), model predictive control (MPC) ( 24 , 25 , 30 , 31 , 38 ), and others. In particular, MPC is an advanced closed-loop control scheme that considers the possible discrepancy between the MFD prediction model and the plant (reality). It has been applied extensively in prior works and has realized state-of-the-art control performances. However, by nature of the rolling horizon design, MPC suffers from low generalizability to new plants because of its sensitivity to horizon parameters ( 39 , 40 ). More importantly, the successful application of model-based methods is contingent on relatively accurate modeling of the regional environment dynamics, a problem that is also challenging.
For these limitations, data-driven approaches have received increasing research interest recently. Examples include model-free adaptive control (MFAC) ( 33 , 34 ) and reinforcement learning (RL) methods ( 26 , 41–43). Notably, RL methods can internalize the traffic dynamics and produce control strategies from interactions with the environment, and they have been shown to be comparable to MPC ( 43 ). While remarkable, in the initial period of learning, the RL agents consistently perform worse than when no control is applied. This initial underperformance results from the agents’ completely random exploration of the entire action space, which is contrary to how someone with knowledge of the scenario (e.g., domain experts) would explore to intelligently learn about the environment. Therefore, the present paper examines how external knowledge can be integrated into RL agents to improve their learning and control performances. In particular, this paper focuses on the application of the recently developed C-RL agent in Zhou and Gayah ( 43 ) and also proposes a novel agent that builds on the Bang-Bang control policy ( 5 , 44 ) for two- and three-region PMC. Domain control knowledge (DCK) is then presented and integrated within these agents to obtained much improved performances. The DCK initially provides a “warm-start” to the learning processes by defining a set of default actions for the agents that are conditioned on the network congestion level. During the remainder of the training process, it continues to provide the default actions for the agents to explore around at each step to determine their overall control policy. By providing such information, the DCK specifies the most fruitful part of the action space for the agents to enable efficient exploration. A series of explorative experiments are conducted to determine suitable representations for DCK. The effectiveness of DCK is demonstrated via extensive numerical experiments on two- and three-region perimeter control problems, where the control outcomes, resilience to environment uncertainties, and scalability to larger problems are comprehensively examined.
The remainder of the present paper is structured as follows. The next section introduces the general formulation of PMC problems with MFDs. Subsequently, an overview is provided on the application of the C-RL agent to perimeter control, which is followed by the novel deep reinforcement learning (Deep-RL) agent proposed here and the two types of DCK. The following section presents the simulation results, and the final section summarizes the concluding remarks.
Problem Formulation
This paper considers a general PMC problem for an urban network composed of a set of
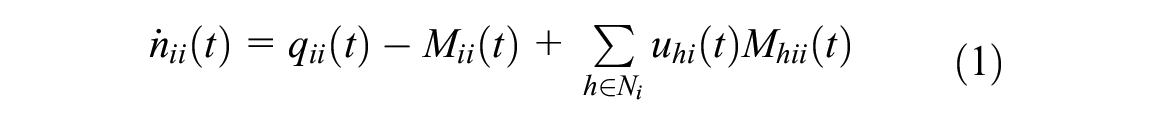
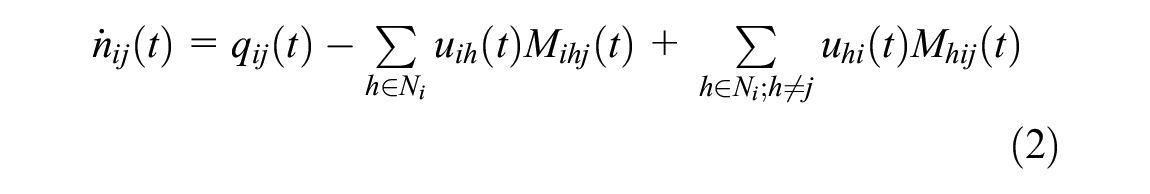
where
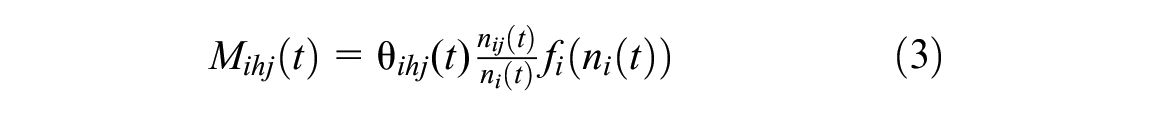
where
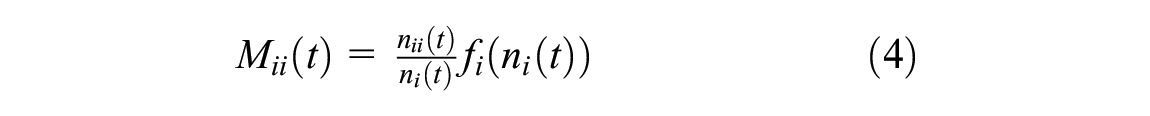
Similar to Sirmatel and Geroliminis (
49
), the networks considered in this work feature an obvious route for each origin–destination pair, in which case the route choice term can be omitted (i.e.,
The traffic dynamics presented above can be embedded into the controller designs of model-based approaches such as MPC ( 24 , 35 ). In reality, however, these dynamics are often blended with environment uncertainty that might arise in MFDs, traffic demands, or both. Concretely, the uncertainty in MFDs and traffic demand are defined as follows (similar to Zhou and Gayah [ 43 ]):
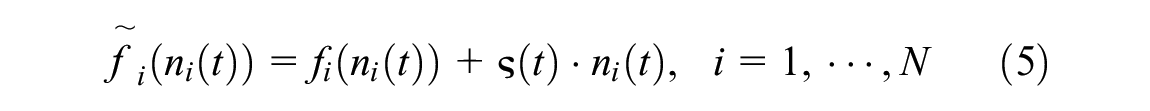
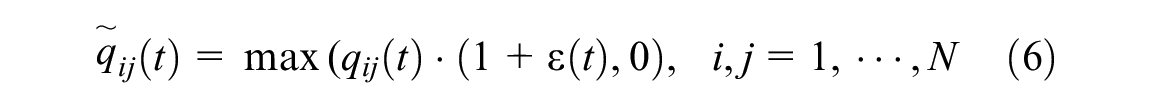
where
The objective of PMC is to maximize the network throughput, that is, the cumulative trip completion (CTC). Solving the perimeter control problem then amounts to selecting actions
Methodology
This section details the methodology adopted in this paper. The first section provides an overview of the C-RL agent applied to perimeter control. The next section proposes a novel Deep-RL agent building on the Bang-Bang control policy. The two types of DCK are then described in the last section.
C-RL for Perimeter Metering Control
RL has long been applied for traffic signal control by the transportation community ( 53 – 56 ). However, its application to PMC is fairly limited, with a few initial attempts by Su et al. ( 26 ) and Ni and Cassidy ( 41 , 42 ). Nevertheless, the solution methods in these works are still heavily reliant on full knowledge of the system dynamics. Zhou and Gayah ( 43 ) provide the first examination of completely model-free Deep-RL techniques on two-region PMC problems, where the continuous agent C-RL has exhibited comparable control performances to MPC.
The C-RL agent is built on the model-free off-policy actor–critic learning algorithm, the deep deterministic policy gradient ( 57 ). The agent has an actor that selects continuous real values for the perimeter controllers and a critic that evaluates the selected actions. For the enhancement of scalability to problems with large state and/or action spaces, both the actor and critic are constructed using neural networks. The actor parameters are updated by gradient ascent with the deterministic policy gradient ( 58 ), while the critic parameters are updated in a similar fashion to Q-learning ( 59 ). Recent advances that improve learning stability, such as experience replay ( 60 ) and the target network, are also incorporated in the C-RL agent. In addition, the agent was strengthened with the distributed learning architecture Ape-X ( 61 ), which helps collect large quantities of experiences for the agent to learn more effectively. In this work, the C-RL agent is adapted for two- and three-region control. Specifically, the tanh activation layer of the C-RL agent is replaced by a linear layer with truncated outputs such that the RL outputs still lie within [−1,1]. This is helpful, since larger variations of the actions across consecutive time steps can be achieved, whereas the tanh activation restricts such variations. In addition, when the C-RL agent is applied for three-region perimeter control, its actor network is expanded into three dense rectified linear unit (ReLU) layers with 64, 64, and 16 units.
Before applying the C-RL agent, the perimeter control problem is first formulated as a Markov decision process whose major components are state, action, and reward. The state is defined as a collection of accumulations and estimated traffic demands, the latter of which are readily available from historical observations and do not need to be accurate; see Zhou and Gayah (
43
) for the examination of such inaccuracy. The action contains a real value bounded by
Bang-Bang Type Deep-RL Controller
Following the success of Deep-RL on two-region perimeter control problems, this paper presents a novel agent building on the Bang-Bang control policy (henceforth denoted as Bang-Bang type Deep-RL [B-RL]). The Bang-Bang policy was initially proposed by Daganzo ( 5 ) and later corroborated by Ni and Cassidy ( 42 ) and Aalipour et al. ( 44 ) as the optimal form of actions for perimeter control problems. This policy only allows the perimeter controllers to alternate between the minimum and maximum values possible. In general, when the region is uncongested, the maximum controller value is selected such that the accumulation could approach the critical level to realize higher efficiency. The minimum value is chosen otherwise to prevent the region from exacerbated congestion.
The Bang-Bang policy provides an intuitive yet effective way to manage urban traffic flows at an aggregate level. Building on this policy and realizing Bang-Bang type control actions, the resulting B-RL agent can achieve promising control performances. As consistent with the Bang-Bang policy, the B-RL agent can only adopt either
Domain Control Knowledge
Integration of DCK With the C-RL Agent
The C-RL agent underperforms the no control (NC) strategy initially because of its random exploration of the entire action space, which also slows down the learning process. To combat these, this paper proposes knowledge-guided exploration strategies for the agent via the integration of DCK. Specifically, a set of default actions is provided to the agent by the DCK at each step that suggest where to explore around. These default actions are “best-guess” solutions based on general knowledge of regional traffic flow dynamics; thus, they are informed by the physical behavior of the network and how the best control policy might take shape. In this way, the agent performs its random exploration of the action space in a more guided manner since the DCK can specify the most promising exploration direction for the agents. Note that the “best-guess” default actions are not dependent on detailed information about the MFDs or origin–destination patterns.
With these in mind, the intuitions behind DCK are explained. Firstly, metering should not be imposed for a vehicle moving into regions that are very uncongested, that is, the inbound perimeter controllers should be directly set to the maximum value
With the above intuitions, the “best-guess” default action values between any pair of neighboring regions
uncongested, as represented by
near congestion, as indicated by
congested, as implied by
The values
Default Actions for the C-RL Agent

→ represents actions that are set to this value and further exploration is not needed.
~ represents that only default actions are set to this value that the agent can explore around.
C-RL = recently developed agent in Zhou and Gayah ( 43 ).
The original outputs of the C-RL agent lie within
A few clarifications are provided here for the proposed DCK. Firstly, the DCK only specifies the default actions for the agent to explore around and does not limit the range of actions the agent can take. As such, the resulting agent (denoted by C-RL+DCK) could still select all possible controller values between
Integration of DCK With the B-RL Agent
Similar to above, the DCK proposed here provides the B-RL agent with a series of default actions that can lead to the most efficient exploration of the action space. However, since the B-RL agent assumes a Bang-Bang type action space, the default actions differ from those for the C-RL agent; see Table 2.
Initial Actions for the B-RL Agent

→ represents that actions are set to this value and further exploration is not needed.
~ represents that initial actions are set to this value with a high probability
∈ represents that actions are chosen by the agent via truly random exploration.
B-RL = Bang-Bang type deep reinforcement learning.
As Table 2 shows, the regional congestion levels are defined in the same way as for the C-RL agent with the parameter
Experimental Details
In this section, numerical experiments are conducted on two- and three-region perimeter control problems. The Deep-RL agents (i.e., B-RL, C-RL, and the associated DCK agents) are applied for control of these problems, and the effectiveness of the DCK is evaluated with respect to the learning performances and control outcomes. For comparison purposes, two methods that are not learning-based, that is, MPC and NC, are also applied for control. MPC is an advanced control scheme that builds on relatively accurate modeling of the environment dynamics. Its closed-loop structure renders it applicable to scenarios with discrepancies between the prediction model and the plant (reality). Over the past decade, the MPC scheme has been extensively applied to the perimeter control problem and has achieved state-of-the-art control performances; see Haddad (
25
), Haddad et al. (
30
), Hajiahmadi et al. (
31
), Sirmatel and Geroliminis (
35
), and Ramezani et al. (
36
). In addition, see Geroliminis et al. (
24
) for computational details and Zhou and Gayah (
43
) for an overview of the MPC method. In the present work, the MPC method is implemented according to Geroliminis et al. (
24
) and Sirmatel and Geroliminis (
35
), with the parameters to be presented shortly. The NC method is included as a baseline since it simulates scenarios where no perimeter control is enforced. This strategy selects
It should be noted that, while the optimal perimeter control policy has been shown in the form of Bang-Bang ( 44 ), the Bang-Bang control policy itself is not an effective method and thus is not included for comparison here. The reasons are twofold. Firstly, under the Bang-Bang policy, most vehicles will be denied entry to a congested region as the perimeter controller will be set at the minimum value. Then, in an urban network comprised of more than one region, transfer flows will be strictly limited when all regions are congested. As a result, vehicles will be held waiting within the origin regions and congestion cannot be well distributed (or dissipate) over the whole network. Secondly, the effectiveness of the Bang-Bang policy is contingent on accurate critical accumulation information, as it acts on the congestion status of the region. With even slight underestimation of the regional production, the Bang-Bang policy will impose more-than-necessary restrictions on the transfer flows, which would adversely affect the total trip completion in the network. Therefore, to achieve sufficient perimeter control efficacy, advanced control schemes like MPC are required. In this work, though, Deep-RL methods are utilized since they do not depend on accurate knowledge of the environment; see Zhou and Gayah ( 43 ) for more discussions on this.
In all experiments, the boundary values of
Two-Region Perimeter Control
The experiment setup of two-region perimeter control is first introduced, where the main control scenario is explained on which different methods are compared. Under the main scenario, explorative experiments are then performed to determine suitable representations for the DCK. Subsequently, control results on the main scenario using different methods are described, followed by a series of robustness tests.
Experiment Setup
An urban network comprising two homogenous regions is considered here; see Figure 1a. Each region is modeled by a well-defined MFD with
(a) A two-region urban network, (b) the associated macroscopic fundamental diagrams (MFDs), and (c) estimated traffic demand profile. The scatter in (b) and (c) respectively represents the uncertainties in the MFDs and estimated traffic demands.
For the two-region control problem considered here, the MPC is implemented as per Geroliminis et al. (
24
) with both prediction and control horizons of 20, that is, the MPC method considers the traffic dynamics for 20 time steps into the future and controls for the 20 steps. The selection of the control horizon aims to provide the best possible MPC control performance. The state for all agents consists of two regional accumulations
Explorative Results
As alluded to previously, the effectiveness of the DCK might be affected by its specific representations, that is, the functional form for the default action mapping and
DCK Representation for the C-RL Agent
The functional mapping for the default actions is studied first. To this end, the default action values are preliminarily set to
(a) Different functional forms for the domain control knowledge and (b) performance curves with moving average.
To evaluate the impacts of the default actions, a range of
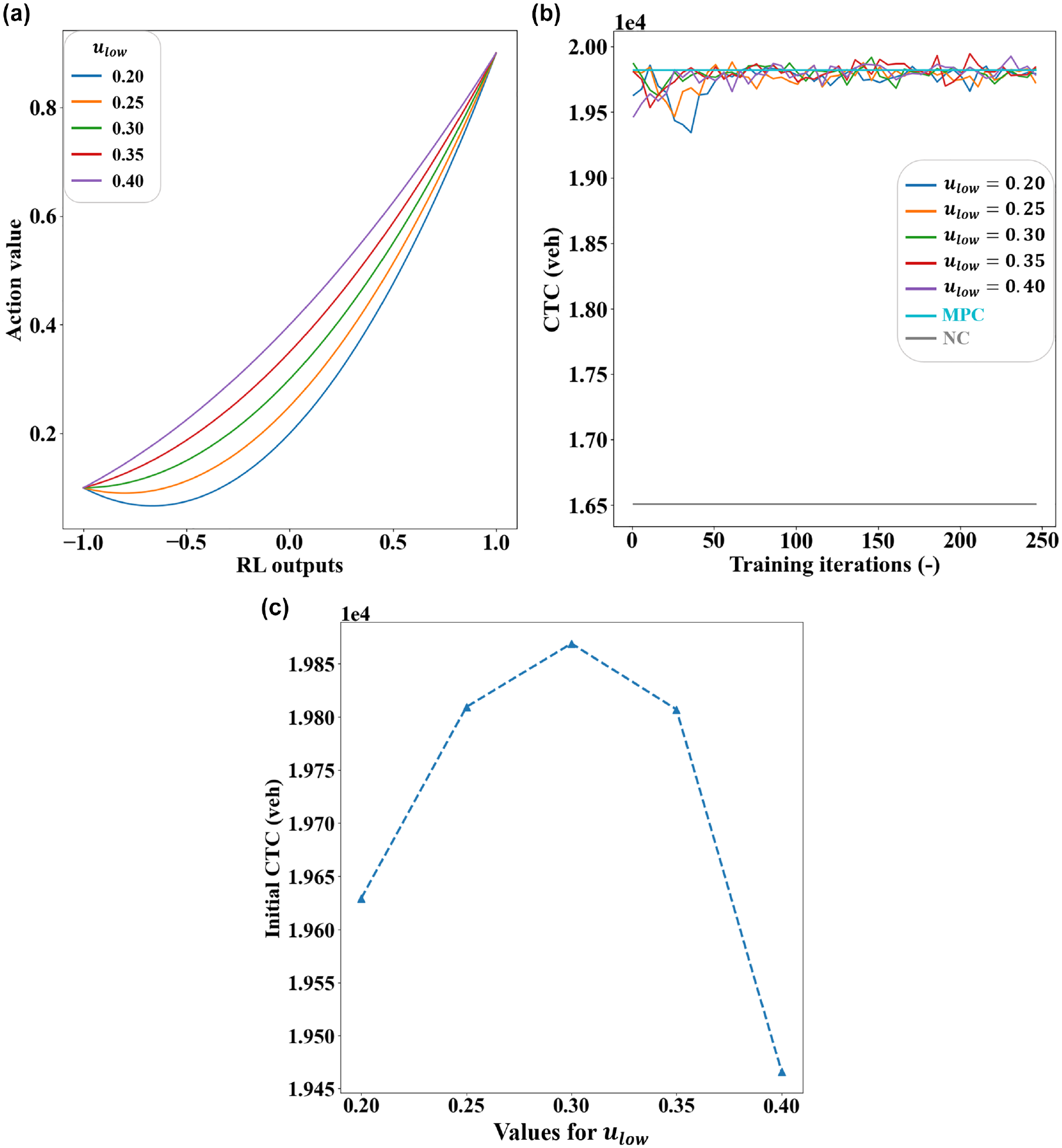
(a) Quadratic functions with different
As can be observed in Figure 3b, the learning curves tend to fluctuate less as the
To determine a suitable value for the parameter that defines the classifications of regional congestion levels, a series of experiments have been conducted using the C-RL+DCK agent for control while the
(a) Performance curves with moving average and (b) summary statistics.
DCK Representation for the B-RL Agent
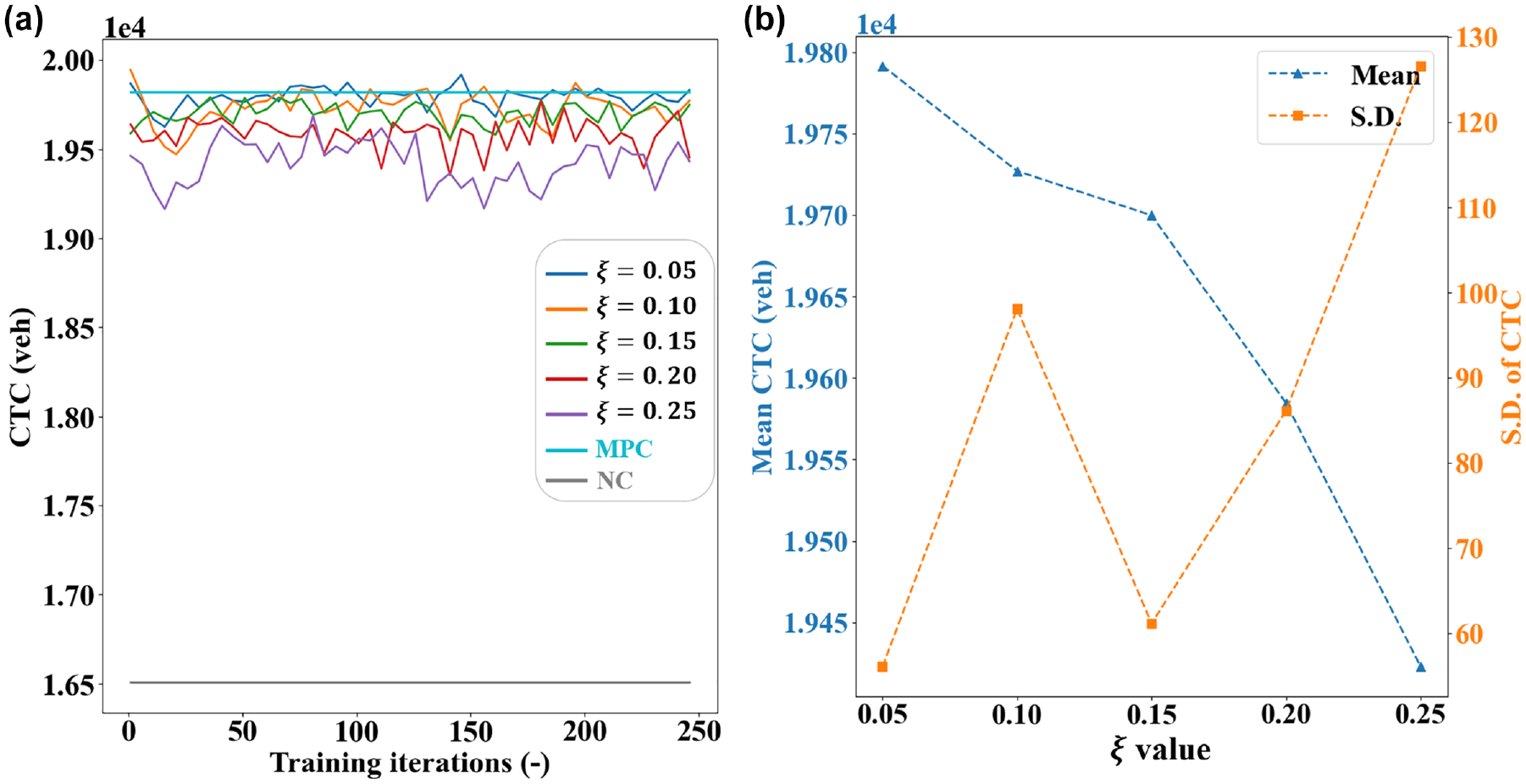
The parameter
(a) Performance curves with moving average and (b) summary statistics.
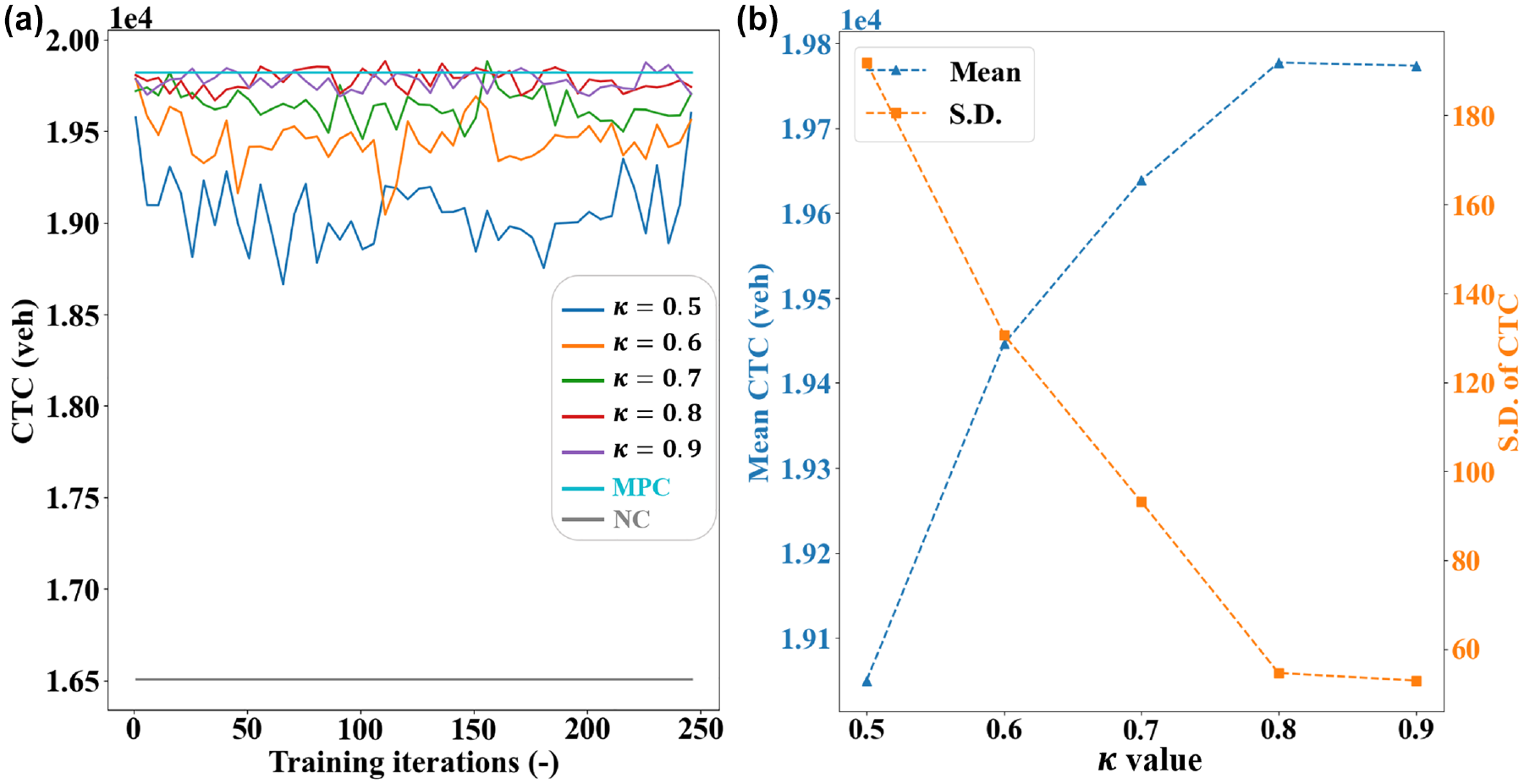
The
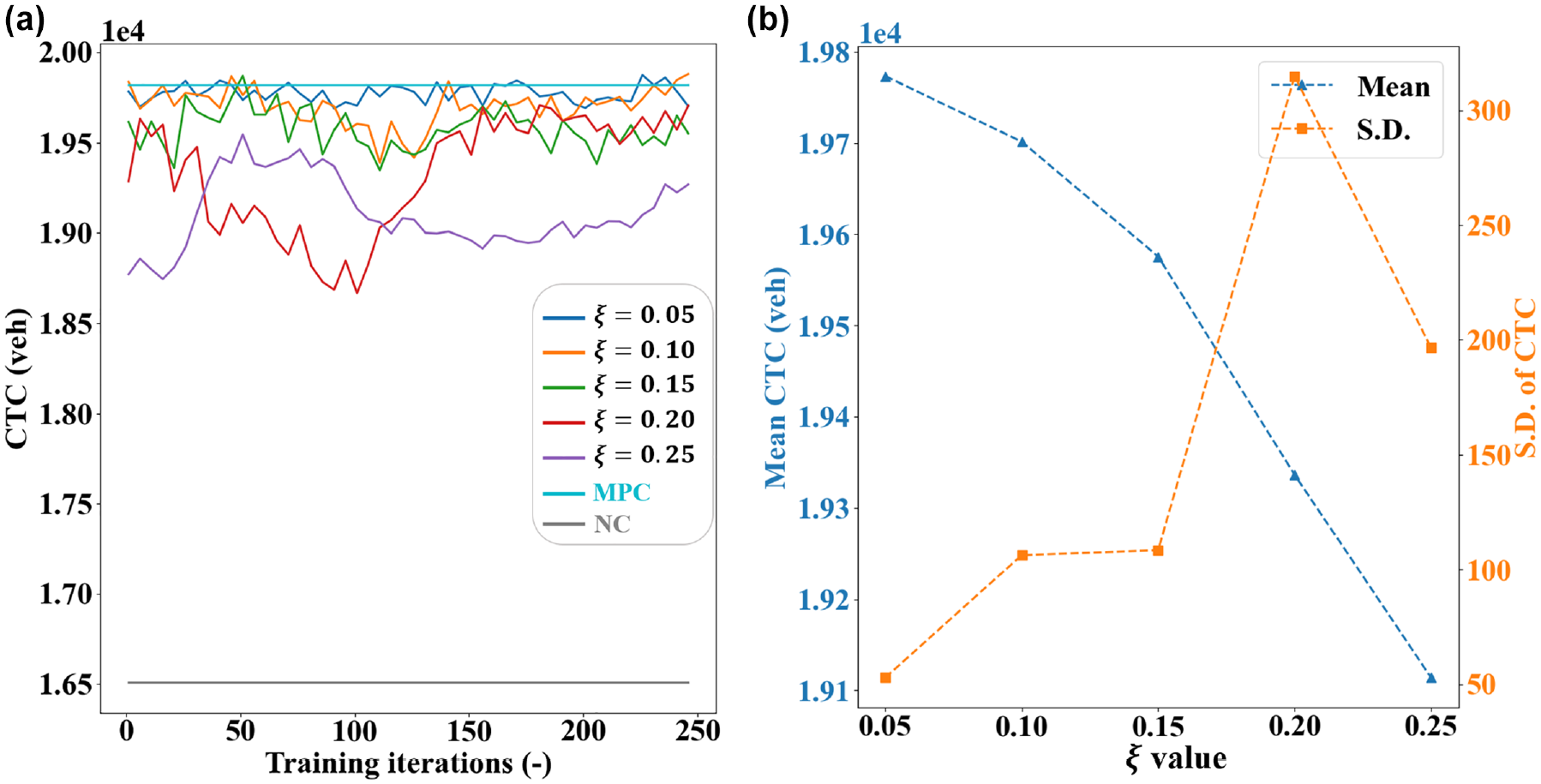
(a) Performance curves with moving average and (b) summary statistics.
To summarize, the explorative results have shown the following: (a) for the C-RL agent, the DCK should adopt the quadratic functional mapping and the parameters should be
Control Results
Integrating the DCK with the above parameterization settings, the performance curves of the six control methods are provided in Figure 7. The individual curves represent the evolution of CTC with respect to the training iterations using different solution methods. A total of four random seeds were used to train the Deep-RL agents and each seed leads to a slightly different performance curve. The darker lines in Figure 7 denote the median performances across random seeds, whereas the shaded areas represent performance bounds. Similarly, the NC and MPC are run multiple times to obtain their performance bounds; however, their performances are relatively invariant as they are not learning-based methods.
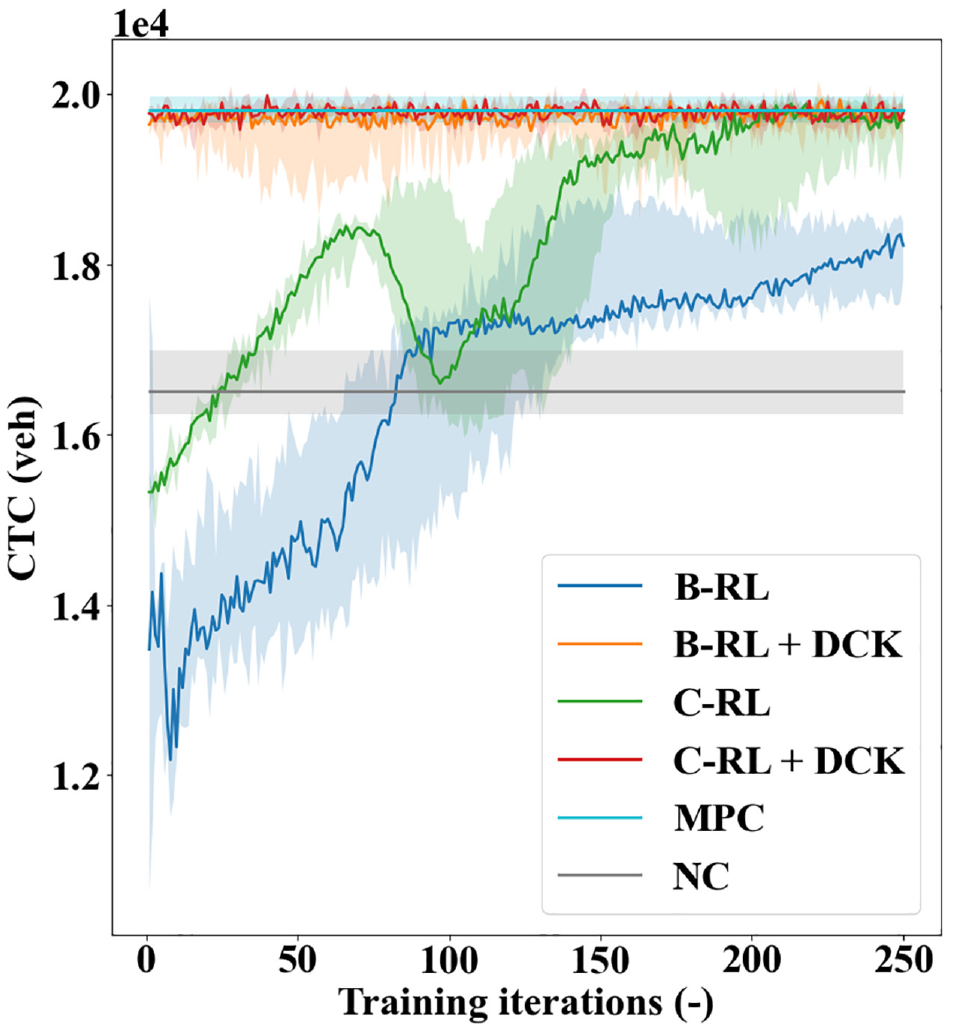
Performance curves of the six control methods on the main control scenario.
As can be observed in Figure 7, the NC method provides the lower-bound performance with respect to the final CTC values, which is expected since an unrestricted vehicle influx into the already congested city center will only exacerbate the congestion therein. In contrast, the MPC achieves a much higher CTC than the NC, indicating both the necessity and advantage of perimeter control. The C-RL agent can steadily learn, and its performance is comparable with the MPC on convergence. The B-RL agent, however, fails to compete with the MPC, although it can conduct learning to some extent. Note that the CTC values realized by both agents in the early period of learning are worse than those of the NC, which will likely not be tolerated in real-world implementations. Comparatively, the DCK agents initiate the learning processes from a high-performance point, as attributed to the advantageous default actions specified by the DCK. Importantly, the DCK can help improve the learning processes of the C-RL agent without affecting its final performances. For the B-RL agent, the DCK can elevate both its initial and final control performances. In addition, the DCK agents stabilize at the best performances much earlier than the original agents. These observations manifest the effectiveness of the DCK. While promising, these results are not unexpected, since the DCK can specify the most fruitful part of the action spaces for the agents to explore. It is worth highlighting that the DCK is not only providing a better starting point for the agents. More importantly, it is infusing a domain expertise-based exploration strategy into the learning procedure of the agents in the form of default actions at each step, which is what truly contributes to the improved performances for the agents.
To examine the effectiveness of the DCK in greater detail, control outcomes of the six methods are visualized in Figures 8 and 9, respectively, for the evolutions of accumulations and controller values of
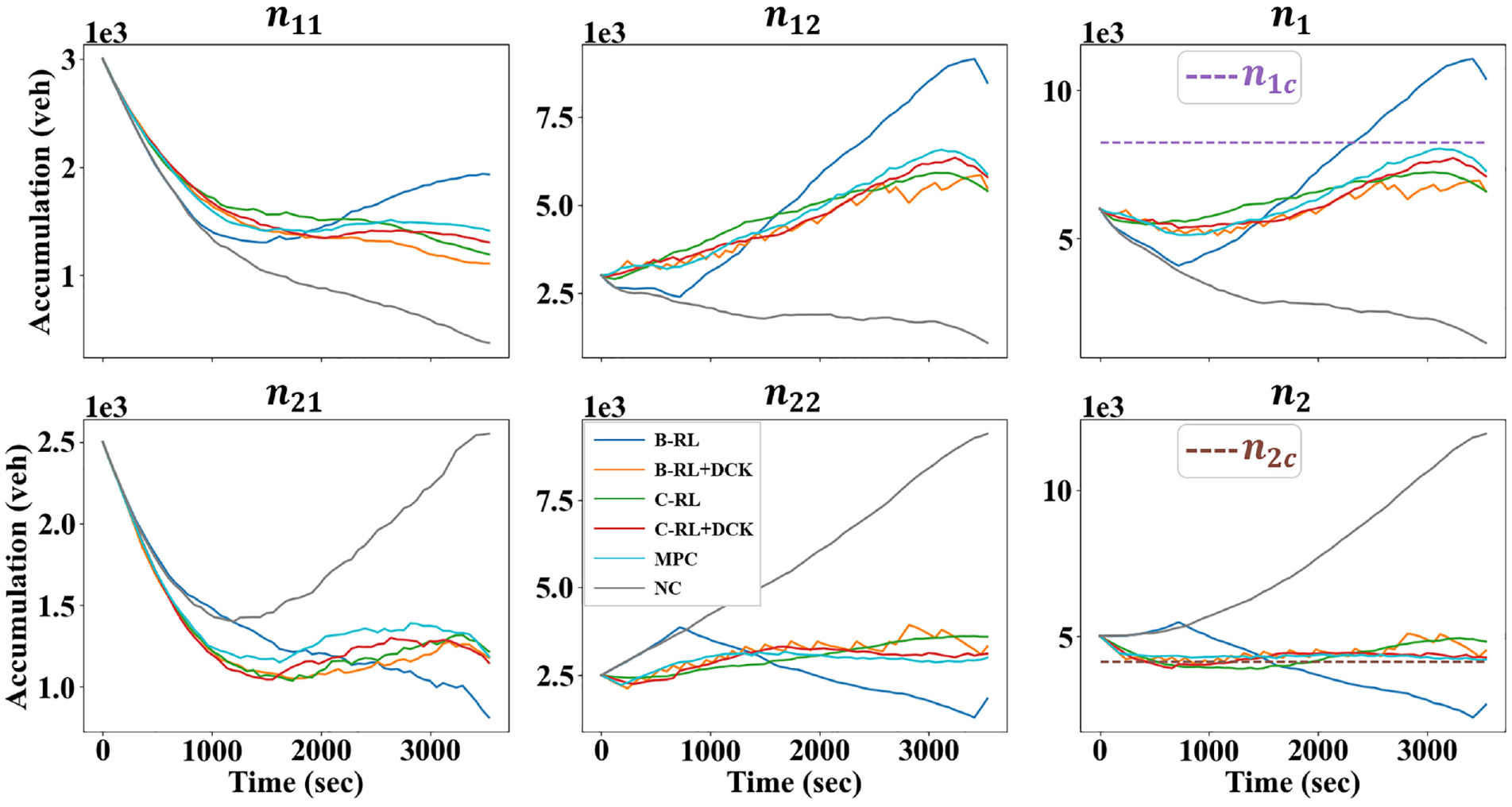
Evolutions of accumulations for different control methods.
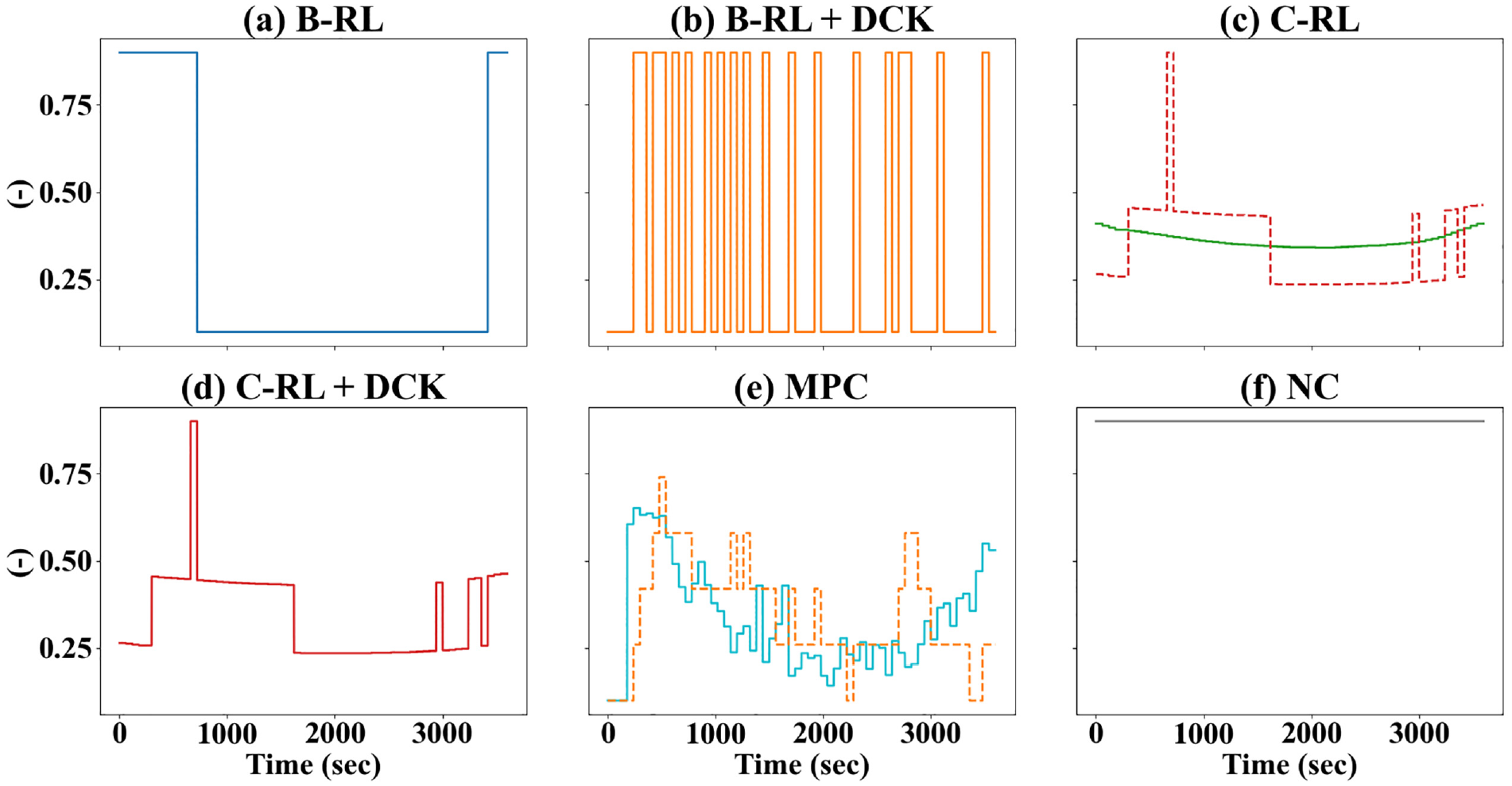
Controller values of
A few additional observations can be made from Figure 9. Firstly, the DCK can be utilized to facilitate abrupt changes in the policy. To see this, notice how the policies differ between C-RL and C-RL+DCK in Figure 9c. Concretely, during 300–1600 s,
Robustness Tests
To further demonstrate the DCK effectiveness and the resilience of the DCK agents against environment uncertainties, this section considers two more experimental scenarios with different types of uncertainties.
Measurement Noise
Building on the main scenario with uncertainties in the traffic demands and the MFDs, this test examines the resilience of the DCK agents against environment measurement noise on the accumulations. Concretely, the measurement noise considered here is in the form of
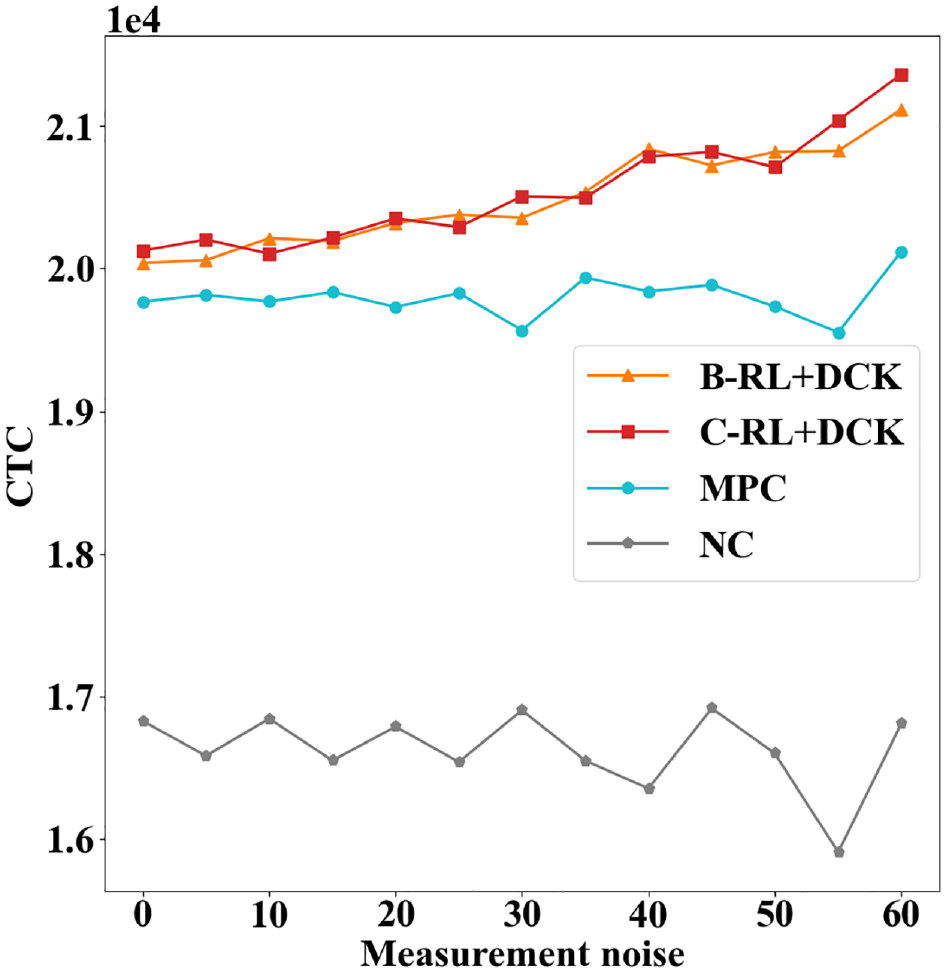
Control gains of different methods under each level of measurement noise.
Estimation Errors of the Critical Accumulation
As hinted previously, the DCK is designed based on definitions of the regional congestion levels that require the critical accumulation information, whereas estimating the critical accumulations might be prone to errors caused by multivaluedness, instability, and hysteresis phenomena (
14
–
16
). Therefore, this test examines whether the DCK can still be effective when the critical accumulations are inaccurately estimated and whether the DCK agents are resilient to such estimation errors. To this end, estimation errors ranging from −20% to 20% are tested. For example, an estimation error of −20% means the DCK classifies accumulation values of
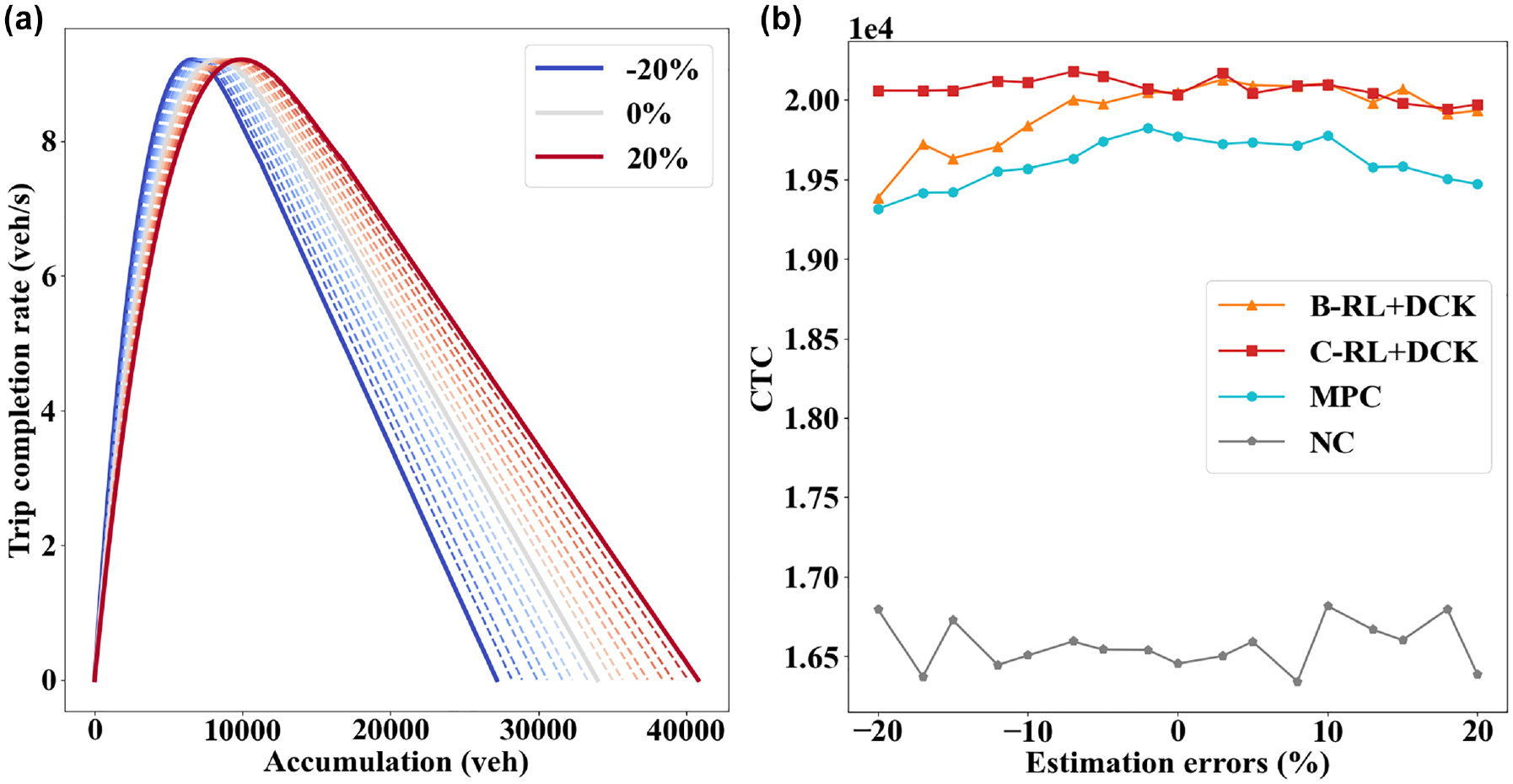
(a) Illustration of estimation errors for the model predictive control (MPC) and (b) control gains with different estimation errors.
Figure 11b provides the control gains of different methods under each level of estimation error. As can be seen, both DCK agents can always outperform the MPC despite inaccurate critical accumulation information. This is remarkable, since it shows that the effectiveness of the DCK is not contingent on precise estimations of the critical accumulations and the agent can be applied for control regardless. The B-RL+DCK agent suffers from some performance degradation when the critical accumulation is significantly under-estimated (i.e.,
In summary, the robustness tests conducted in this section show that the DCK agents are resilient to various types of environment uncertainties. This is critical for real-world applications where uncertainties can be ubiquitous in sensors and network modeling techniques.
Three-region Perimeter Control
To demonstrate the DCK effectiveness in a more general and complex setting, the three-region PMC problem is examined in this section. The experiment setup is first introduced, with extra details for the different control methods. The control results are then compared, which help illustrate the potential of DCKs in larger perimeter control problems.
Experiment Setup
The three-region network (i.e.,
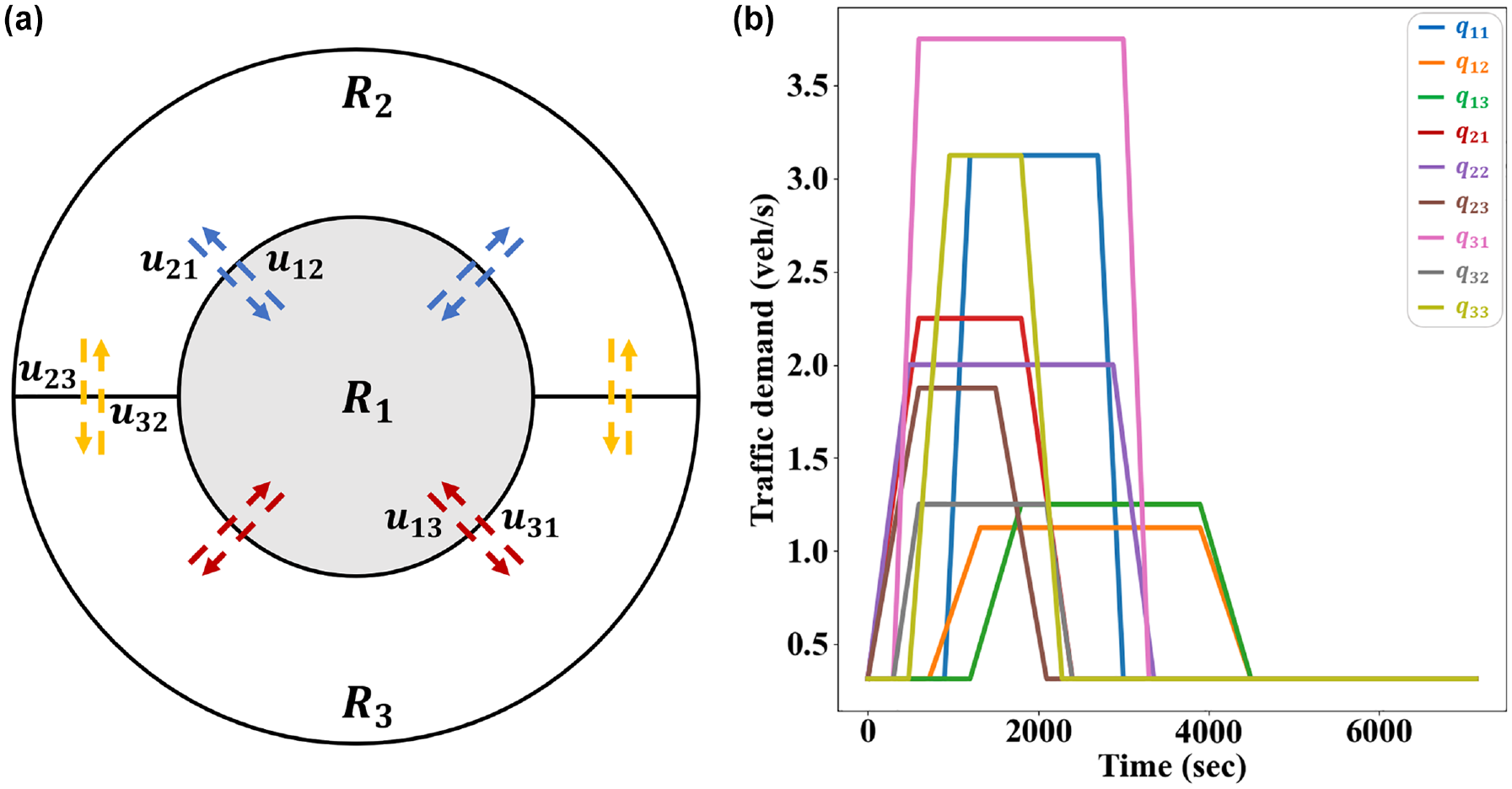
(a) A three-region urban network and (b) estimated traffic demand profile.
For this problem, the state space consists of three regional accumulations
Control Results
Figure 13 presents the performance curves of different control methods for the three-region problem. As can be seen, the B-RL fails to learn effectively and underperforms the NC method throughout its learning course. While undesirable, this is not entirely unexpected because of difficulties in exploration. Concretely, the B-RL has a 64-dimension action space (two options for each of the six controllers), and exploration in such a high-dimensional space is not conceivably tractable, which thus leads to the agent’s failure in learning. In contrast, the action space of the C-RL is only six-dimensional, with one for each perimeter controller. Therefore, the C-RL can learn to control and realize a relatively high network throughput at the end of learning. Comparing the curves between the original and the DCK agents, one may notice that the DCK agent can significantly improve the learning and control performances of both agents, although the DCK agent is proposed only for a pair of neighboring regions. This indicates that even limited or imperfect knowledge can be readily and effectively applied to enhance the learning abilities of pure Deep-RL agents, a point also demonstrated by Zhang et al. ( 63 ). Notably, the improved performances of the B-RL agent are made possible since it mainly explores around the most rewarding part of the action space with guidance provided by the DCK agent, thus greatly speeding up the learning process. As such, the DCK agent can improve the scalability of the agents to larger problems by reducing the action space that needs to be explored. Motivated by this, the DCK agents might be potentially used as a sub-component for a larger-scale perimeter controller designed for city-level traffic management, which is considered as a future extension to the present work. Finally, notice that both DCK agents can often realize higher CTC values than the MPC as training proceeds. This is reasonable, as the MPC is a model-based scheme that formulates a non-convex optimization program at each time step. For networks with an increased number of regions, the size of the formulated program increases dramatically; for example, the three-region problem has six control variables, whereas the two-region problem has only two. Consequently, the expanding solution space, coupled with the non-convex nature of the formulated program as well as the high level of environment uncertainty, renders it increasingly difficult for the MPC to derive promising control policies, which explains its slight underperformance compared with the DCK agents.
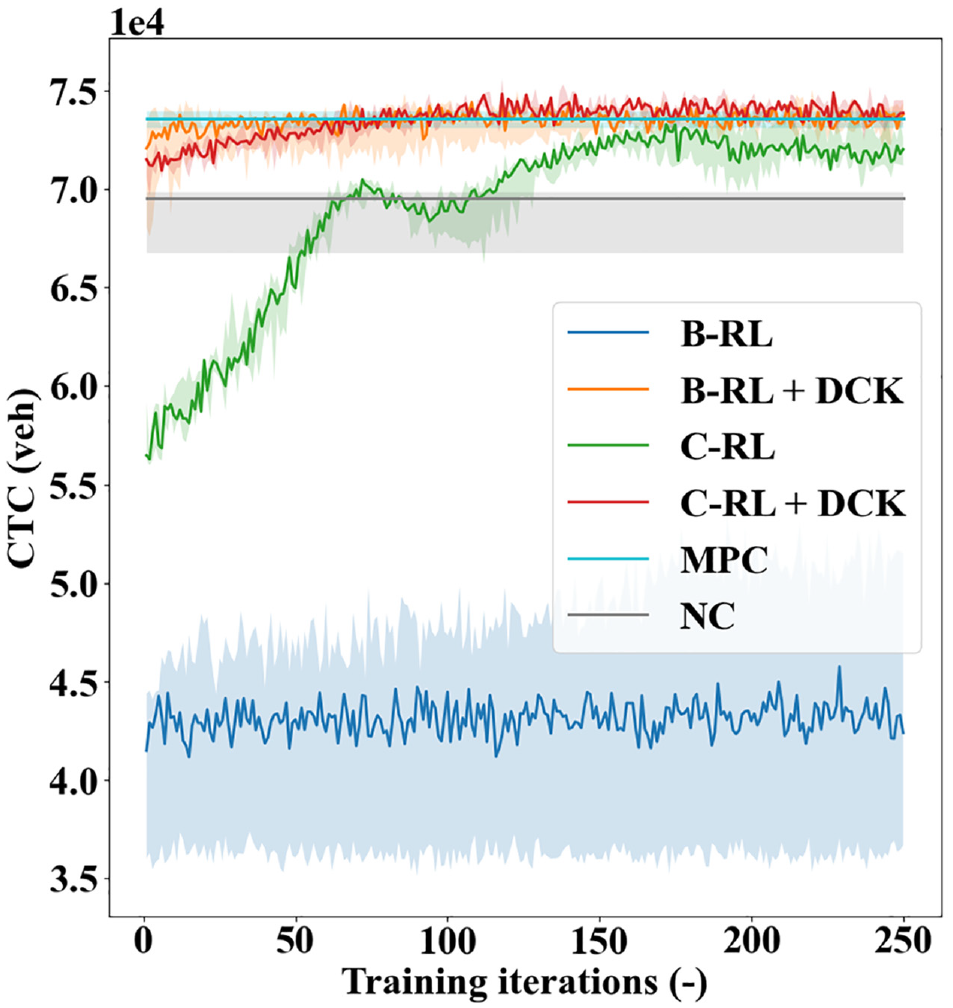
Performance curves of the six control methods for three-region control.
The control outcomes of different methods with respect to the accumulation plots are provided in Figure 14, where the critical accumulations are also included. A few observations can be made. Firstly, under the NC policy, only region 1 exhibits notable congestion, which is reasonable since the experiment scenario simulates a morning peak with high inflows into the city center. The B-RL agent, however, produces a policy that leads to severe congestion both in regions 1 and 3, which explains the poor throughput it realizes (i.e., with CTC values even lower than those of the NC). In comparison, the other methods can effectively mitigate the congestion in region 1, indicating fulfillment of the perimeter control objective, that is, to protect regions from over-congestion by distributing the vehicles across the network. To this end, notice that these methods distribute vehicles in different manners. In particular, the C-RL agent reduces but does not eliminate the congestion in the city center, while keeping both outer regions roughly uncongested. This scheme has some benefits but also some disadvantages, most notably the diminished throughput value because of congestion present in a region loaded with destinations, as opposed to the optimal AB strategy in Daganzo ( 5 ). Nevertheless, the B-RL+DCK and C-RL+DCK agents respectively trade off efficiencies in regions 2 and 3 for lessened congestion in the city center, whereas the MPC distributes vehicles throughout the network in a relatively balanced fashion. Therefore, these three methods can realize higher throughputs, since the most destination-loaded region (i.e., the city center) has accumulations near to or lower than the critical value. In addition, the similarities in the accumulation plots between the MPC and DCK agents imply that the DCK agent is indeed effective, even in larger problems.
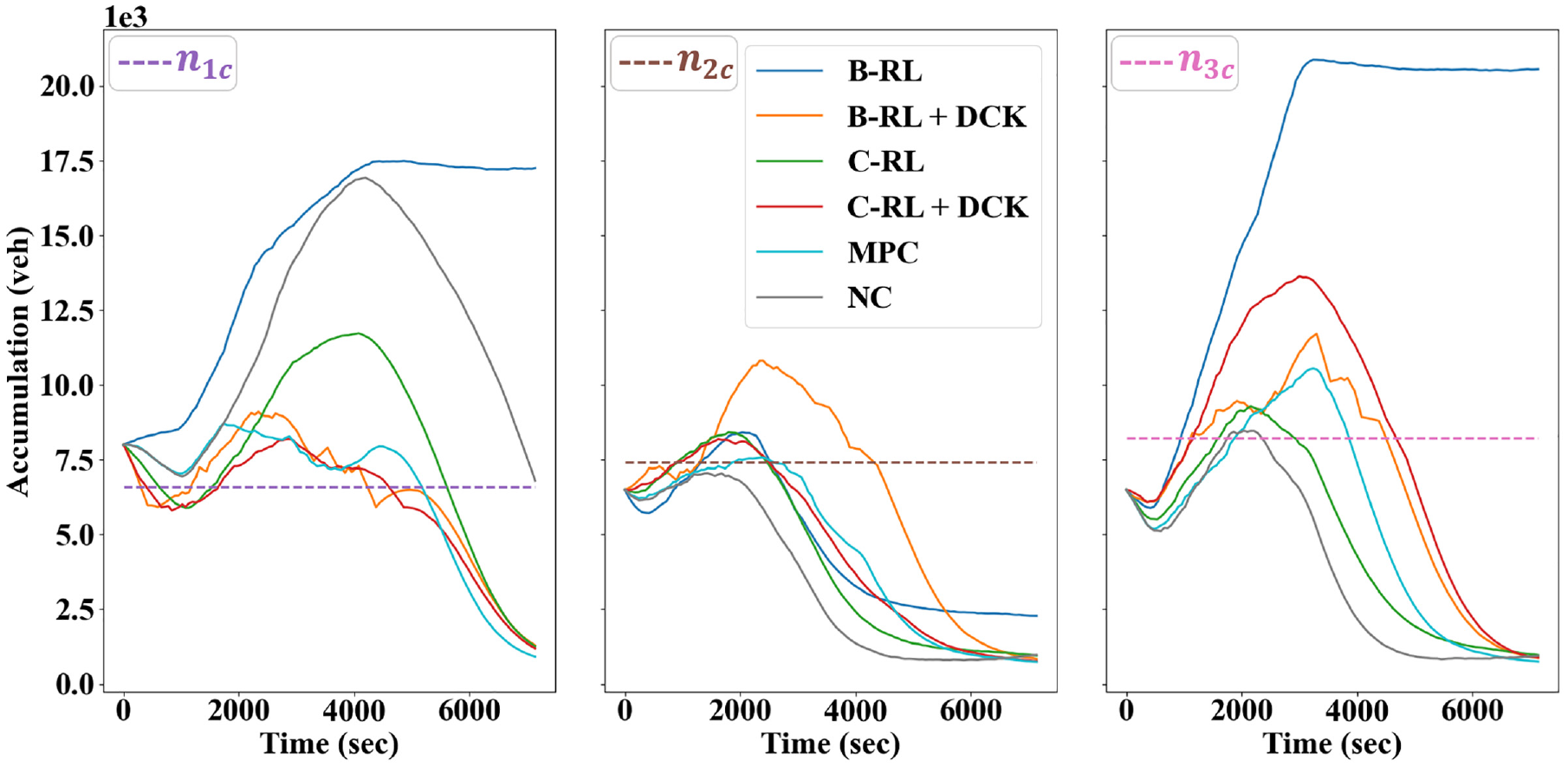
Evolutions of accumulations by different control methods.
Concluding Remarks
This paper studies the two- and three-region perimeter control problems. A novel Deep-RL agent building on the Bang-Bang policy is devised and utilized for control, together with the C-RL agent in a recent publication. The two agents exhibit initial underperformances to the NC method because of their random exploration of the entire action space. Therefore, two types of DCK based on expert-level understanding of regional congestion dynamics are presented and integrated with the agents to improve their learning and control performances. Concretely, the DCK specifies the most fruitful part of the action space for the agents to explore by providing them with a set of sensible default actions at each action-taking step. A series of explorative experiments have been conducted to derive suitable representations for the DCK. Extensive numerical experiment results have shown that the DCK can (a) improve the learning and control performances for the agents, (b) improve the agents’ resilience against various types of environment uncertainties (i.e., measurement noise of regional accumulations, estimation errors of the critical accumulations), and (c) mitigate the scalability issue for the agents. Overall, the proposed DCK agents have been shown to be capable of achieving superior learning and control performances, while in the meantime requiring little information about the environment. These results are promising for real-world applications of Deep-RL-based regional control policies. Specifically, they suggest that Deep-RL agents could be integrated with DCK in a way that will not cause worse performances than the status quo (i.e., NC) in the course of learning, which would otherwise be grounds for removing the Deep-RL agents before they could fully learn about the environment.
Note that, while the comparability between the MPC and DCK agents is the main highlight of the present paper, it is not atypical for the latter to outperform the former, particularly in scenarios with high uncertainties and problem complexity; see Figures 10, 11, and 13. As touched on previously, the MPC method is susceptible to the mismatch between the MFD prediction model and the plant, as prevalent in problems with high uncertainties. Also, in its open-loop problem, obtaining the global optimum cannot be guaranteed for the formulated high-dimensional non-convex program. These complications help explain the slight underperformance of the MPC compared with the proposed DCK agents and also justify the need to develop model-free data-driven control schemes. In this regard, note that it is computationally intensive for the MPC to solve the optimization program at every step, while the time needed to apply the pre-trained Deep-RL agents is nearly negligible. Although training the agents might take up an extended period, this could be done in a simulation platform offline. Overall, compared with the state-of-the-art MPC method, the proposed DCK agents have been shown to be capable of achieving superior performances in large perimeter control problems with high uncertainties, while in the meantime exhibiting prominent implementational efficiency at the time of application.
Future works could include developing DCK without using the critical accumulations to set the agents free from the estimation errors and to maintain the model-free property. Also, only two types of DCK are examined in this paper. It would be beneficial to research other types of DCK, for example, one that is general enough to encompass all perimeter control problems. Further, it is a research priority to evaluate the proposed methods in a microsimulation platform, as opposed to the numerical simulations conducted here. This would also establish grounds for possible real-world applications of the proposed method.
Footnotes
Author Contributions
The authors confirm contribution to the paper as follows: study conception and design: V.V. Gayah, D. Zhou; data collection: D. Zhou; analysis and interpretation of results: V.V. Gayah, D. Zhou; draft manuscript preparation: V.V. Gayah, D. Zhou. All authors reviewed the results and approved the final version of the manuscript.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by NSF Grant CMMI-1749200.