
Abstract
As a result of the emergence of the internet, semantic web and social media, netizens have been able to create digital footprints on scholarly, commercial or non-scholarly platforms. However, it remains a mystery as to what happens to the data created by ordinary users of digital platforms, whether they create text, visuals, sounds or multimedia files. Despite the privatization and commoditization of digital spaces by informational capitalism, austerity policies across the globe have led to deterioration and diminishing of physical public spaces and infrastructure for providing services. This article seeks to explore the concept of data capitalism amidst rising surveillance capitalism and suggests ways through which libraries can protect the interests of their users against data capitalism.
Introduction
Conceptual framework
The study will be guided by Zuboff's (2015) surveillance capitalism theory that outspreads from her observations of the novel development of Google's profit model. Zuboff (2015) explores how Google opted not to use the traditional fee-for-service model to produce profit but instead initiated a method which would turn the orthodox consumer into a new source of profit through a targeted advertising strategy (Chisita et al., 2024). The above-mentioned initiative involved harvesting individual data from users to build highly accurate profiles of them to enhance the company's ability to efficaciously market to them (Zuboff, 2015). According to Zuboff (2015), Google's innovation was premised on the notion that by collecting mass amounts of this data exhaust, they could collate and combine them to create accurate user profiles (Zuboff, 2015). A huge amount of detailed data is generated by digital platforms on the World Wide Webb (WWW), such as, retail and e-commerce, mobile telecommunications and smart infrastructure systems, and such data include consumer preferences, patterns of behaviour, beliefs and hopes (Cinnamon, 2017). Big Data encompasses dissimilar categories of crude data, for example, public data, private data, data exhaust, community data and self-quantification data exhaust which must be proccessed and distilled to produce valuable insights and While Big Data refers to data generated online through user interactions, it is also genegerated through offline sources, for example, retail, healthcrare, public services, research data and intrernet of things (local communication protocols) (George et al., 2014). This study will focus on data exhaust, which refers to data collected for a different purpose but can be recombined with other data sources to create new sources of value; for example, when individuals adopt and use new technologies, they generate ambient data as by-products of their everyday activities. The other sources of data exhaust include data generated by individuals as they go about their daily lives relating to commerce, health care or social interaction and information-seeking behaviour, which can be used to infer people's needs, desires or intentions (George et al., 2014). Zuboff (2015) acknowledged that the exploitation of data exhaust was pioneered by Google, and the strategy has now become the dominant rationality of accretion of data use, as well as the economic driver of the tech industry as evidenced by its adaptation by social media companies (Zuboff, 2015).
The second theory supporting the study is Lyon's (2007) comprehensive notion of surveillance, and his more specific conception of ‘surveillance culture’. Lyon (2007) defined surveillance as ‘the focused, systematic and routine attention to personal details for purposes of influence, management, protection or direction’ (Lyon, 2007: 14). A revised version of Lyon's surveillance theory (2018) noted how surveillance had become an integral part of social media. Stiegler (2013) and Chisita et al. (2024) bemoaned the pitfalls of digital technical systems for giving impetus to the data economy whereby human beings are identified by the quantum of the information they provide ‘voluntarily’, either at work or through leisure, to support data capitalism and the surveillance economy at the expense of freedom.
As an alternative to examining the extension of surveillance into our culture from the economic perspective, one can examine the concept of ‘platform capitalism’ by Srnicek, which argues that platform businesses like Facebook, Uber, Amazon and AirBnB (Eliot, 2022; Srnicek, 2016) do not own the means of production, such as the cars in Uber, the products in Amazon, the rooms in AirBnB or the data in Facebook. Instead, it is the goal of the aforementioned platform companies to have the minimum involvement in the actual service itself while collecting profit through the wide scale use of the platform that connects consumers to the product (Srnicek, 2016). With regard to data, platform capitalists are able to collect massive amounts of data on their users due to their economies of scale, which they attempt to use to make their platforms ever more efficient and profitable, by leveraging the data to improve or make new products (Srnicek, 2016).
Statement of the problem
In the contemporary era, data have emerged as a pivotal asset akin to the historical significance of traditional factors of production in propelling economic growth across successive centuries. This analogy was prominently featured in a comprehensive exposé on Big Data titled ‘The World's Most Valuable Resource’, prominently showcased on the cover of the May 2017 edition of The Economist (2017) (Fuchs, 2019). The narrative posited therein equated data to the transformative force of oil during the early 20h century, underscoring its prospective role in driving global development in the 21st century. Despite assertions suggesting that the advent of Big Data facilitates novel avenues for knowledge acquisition and fosters innovative applications, this discourse emphasizes a critical inquiry into the awareness among data generators regarding the fate of their data within the intricate web of the internet.
Concerns are raised regarding the unethical exploitation of data by multinational corporations, particularly pertaining to privacy violations and unauthorized utilization of personal data. The phenomenon of surveillance capitalism epitomizes this issue wherein data extraction, analysis and monetization are facilitated through perpetual tracking and monitoring of users’ online activities (Lutz et al., 2020). This surreptitious acquisition of user preferences, behaviours and intimate details is leveraged to mould perceptions, influence decisions and exert control over actions, thereby perpetuating a system of data capitalism.
The proliferation of datafication, characterized by the escalating digitization of various aspects of daily life, has amplified the significance of data in governmental administration and commercial operations (van Dijck, 2014). This study endeavours to elucidate the dynamics of data capitalism and its ramifications for users of online communication platforms. The failure to apprise users of the inherent risks associated with online communication may precipitate detrimental consequences for individual and collective well-being, particularly exacerbated by the expanding global user base of the internet.
Scholars such as Young and Quan-Haase (2013) posit a privacy calculus model to elucidate the privacy paradox wherein users weigh the perceived benefits against the anticipated risks of online transactions. In this context, libraries assume a pivotal role as custodians of professional and academic integrity, tasked with educating users and safeguarding their rights to privacy in the digital realm. The preservation of privacy constitutes a foundational tenet enshrined within codes of ethics such as the ‘Code of Ethics for Librarians and Other Information Workers’ of the International Federation of Library Associations and Institutions (IFLA, 2022) and the ‘Code of Ethics’ of the American Library Association (ALA, 2017), alongside its ‘Library Bill of Rights’ (ALA, 2006). Legislative measures enacted by nation-states further underscore the imperative of safeguarding data usage within legal frameworks.
Aims of the research
The study aims to ensure a comprehensive exploration of the challenges posed by data capitalism and the surveillance economy, and to identify actionable solutions that libraries can adopt to protect their users’ privacy and rights.
Justification of the study
The study is highly relevant and timely, particularly considering the COVID-19 pandemic, which significantly increased global internet usage, and consequently propelled the issue of data capitalism to the forefront of academic and public discourse. During the lockdown periods, individuals worldwide were compelled to rely extensively on the internet for communication, interaction and work, leading to a notable surge in the use of internet services, video conferencing tools and content delivery platforms (Branscombe, 2020). The post COVID-19 pandemic era has seen a massive increase in the use of the internet in public and private institutions.
This digital shift has brought to light several pressing issues associated with the post-pandemic era, such as the escalating use of digital technologies, the rise of work-from-home employment models, the proliferation of gig workers and the intensification of workplace surveillance and technological stress (Pandey and Pal, 2020). The pandemic has catalysed a dramatic increase in the adoption of video- and audio-conferencing tools, making remote work a norm and leading educational institutions to integrate platforms like Zoom, Google Meet and Microsoft Teams into their operations (The New York Times, 2020).
Understanding how data are utilized in this new digital landscape is crucial for internet users, as it can significantly impact their privacy and security. This study aims to shed light on these issues, providing valuable insights that will benefit internet users by enhancing their awareness of data practices. Furthermore, the study will be beneficial for policymakers, especially legislators tasked with crafting laws to protect internet users from potential exploitation by data capitalists. By addressing these critical concerns, the research will contribute to the development of more informed and effective policies that safeguard user privacy and data security in an increasingly digital world.
In the epoch of digital governance, online undertakings have transformed into a veritable commodity for a clandestine and secretive network establishment targeting to exploit and ambush the intricacies of private lives (Bollier, 2024). This research will investigate the prevalent business model of digital surveillance, where individual information is methodically tracked, packaged and sold in a manner to create a concealed internet ecosystem that raises concerns about privacy invasion, breach of confidentiality and ethical boundaries (Nechushtai, 2019). Hayles (2012) argued that lives have changed to a point where a lack of phone signal or an internet connection, or even a low battery, can make us feel lost, disoriented and unable to work, or even make us think that we missing something. The pervasive nature of digital technology has its merits and demerits as will be explored in the subsequent sections.
Research questions
The study will be guided by the following research questions:
How can the concept of data capitalism be comprehensively defined and explained, including its characteristics, mechanisms and impacts on society? How does data capitalism undermine privacy of internet users? What is the role of libraries in protecting the privacy of users in online communication? What are effective recommendations for protecting internet users from the privacy risks associated with data capitalism?
Research methodology
The methodological approach adopted herein predominantly entails a meticulous and exhaustive scrutiny of extant scholarly literature across diverse modalities, including articles, monographs, reports and various online and offline repositories of knowledge using a narrative literature review. A narrative review, unlike systematic reviews, does not have guidelines such as PRISMA (preferred reporting items for systematic reviews and meta-analyses) statements (Ferrari, 2015). In NRs, the goal is to identify and summarize what has been published previously, to avoid duplications, and to identify new research areas not yet addressed (Ferrari, 2015). There can be several questions addressed by NRs, and the selection criteria may not be explicitly outlined, so subjectivity in study selection is the main weakness associated with NRs that could lead to bias (Ferrari, 2015). The focus of this study is centred on the phenomena of data capitalism and the surveillance economy by probing the multifaceted dimensions and implications of the aforementioned concepts. Furthermore, considerable attention is directed towards elucidating the envisioned role of libraries in safeguarding individual privacy amidst the burgeoning digital milieu. This methodological framework is underpinned by a commitment to comprehensively survey and synthesize existing discourse, thereby laying a robust foundation for the ensuing theoretical and empirical analyses.
This research is situated within the interpretive philosophical paradigm, focusing on the phenomenon of data capitalism within the context of the surveillance economy. Emphasizing the comprehension of social phenomena, meanings and interpretations, this paradigm guides the investigation into the intricate dynamics of data capitalism.
In alignment with this philosophical stance, the methodology employed in this study predominantly involves a systematic review of existing literature. This approach entails a meticulous and comprehensive examination of previously published research encompassing articles, books, reports and other pertinent sources of information available both online and offline. Through this methodological lens, the aim is to synthesize and analyse the wealth of knowledge already documented on the subject matter.
The primary objectives of this research encompass an exploration of the nature and extent of data capitalism, particularly its implications for the erosion of internet users’ privacy. Additionally, the study delves into the role of libraries as crucial actors in safeguarding the privacy of users engaged in online communication. Finally, the research endeavours to provide actionable recommendations aimed at mitigating the adverse effects of data capitalism on internet users, thereby fostering a more secure online environment.
By adopting an interpretive philosophical perspective and employing a rigorous review of existing literature, this study seeks to contribute to a deeper understanding of data capitalism within the contemporary landscape of the surveillance economy.
These criteria encompass considerations such as the temporal scope of the literature, preference for peer-reviewed publications, the diversity of report types, geographical coverage and the inclusion of supplementary resources beyond conventional academic outlets.
Literature review
West (2019) highlighted that the evolution of modern data capitalism began in earnest during the mid-1990s, in the years leading up to the dot-com boom characterised by the speculative investment bubble. As outlined above, the 1990s were a period of technological and economic transformation for the emerging internet industry, during which, companies shifted from understanding the internet primarily as a marketplace for the sale of goods to one that placed greater emphasis on technology's role in generating and storing user data. According to Pandey and Pal (2020), cloud, internet-of-things (IoT), blockchain, artificial intelligence (AI) and machine learning (ML) are some of the most popular technologies adopted by organizations in their transformation processes.
Zuboff's (2015) concept of surveillance capitalism articulates the idea of a new subspecies of capitalism whereby profits are derived from unilaterally surveilling and modifying human behaviour (Zuboff, 2016). West (2019) traced the evolution of data capitalism to the corporate logic that underpins mass data collection, which has historical origins in the efforts to quantify human behaviour to cultivate a culture of teamwork and improve organisational performance. Herbst (1993) reports that in the late 17th century, mathematical methods were applied to social problems in order to gain a better understanding of the world around us. As West (2019) states, during that period, the Dutch East India Company (DEIC) used censuses of residents to translate ‘foreign’ cultural aspects into intelligible, quantifiable categories that Western colonizers could use for social control. The commercial credit reporting system began in the 19th century.
The use of the internet and other technological advancements according to Schiller (1999: 14) serve as the basis for digital capitalism whereby web-based networks universalise and widen participation in the capitalist economy. In Dean's view (2016), communicative capitalism is characterized by pulling users into the ‘circuit of exploitation’, through which we all become members of the cybertariat: ‘Under communicative capitalism most of us can’t avoid producing for capitalism, our basic communicative activities are enclosed in circuits as raw materials for capital accumulation’ (Dean, 2016: 17–18).
Charitsis et al. (2018) noted that Google's success is underpinned by the organization's ability to extract and analyse more and more data, the personalisation of all contractual, commercial relationships and services and making marketing experimental. Furthermore, Zuboff (2015) argued that Google uses its business model to accumulate as much information about users as possible, and then repackages and commoditizes the data to sell to potential buyers for profit.
Bolin (2024) captures the associations between four dissimilar dynamics (see Figure 1). According to the author, each dynamic is partially within but also partway external of data capitalism as a system, because not all technological dynamics are subsumed by capitalism, and not all social dynamics are drawn into profit-motivated actions (e.g., social relations within the family mainly lie outside of capitalism). To unpack Bolin’s (2024) model it is vital to analyse how the variables relate to each other. Cohen (2019) states that the economic variable is the most central component of data capitalism due to its focus on the investment imperative, maximum profit and the constant drive towards perpetual economic growth, based on the legal regulation of private ownership.
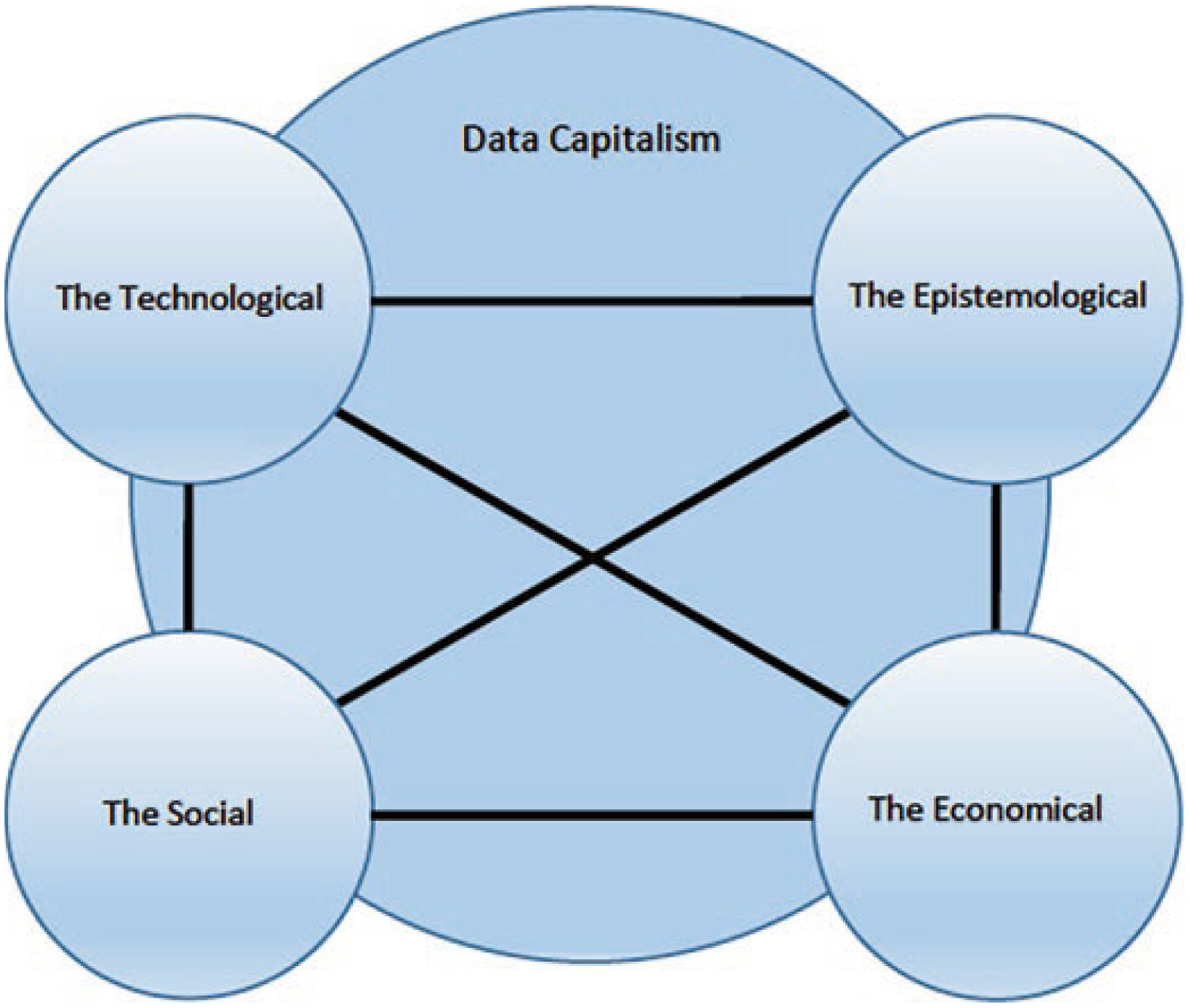
Value dynamics in data capitalism.
First, Bolin (2016) states that the media and communication industries employ three basic business models, namely a text-based, an audience-based and a service-based model.
The text-based model emphasizes the monetization of copies of media texts in exchange for economic value (money). This models 15th century Guttenberg revolution, when the print technology made it possible to mass produce written texts for monetary value. The audience-based model focuses on commercial advertising, whereby media producers sell their readers’ or viewers attention to advertisers (and others) who wish to reach audiences with commercial (or political) information. The service-based model is related to the telecommunications sector, where telephone companies traditionally offer a service for customers to communicate with distant connections through mobile networks for a fee or for a subscription, or both.
Second, data capitalism and the datafication of society postulate a technologically driven process concentrated on the ‘quantification and potential tracking of all kinds of human behaviour and sociality through online media technologies’ (van Dijck, 2014: 198). Technology and knowledge are thus intimately related, and knowledge has always been a central feature in the advancement of capitalism across its many modes (Braman, 2012).
Third, the epistemological dimension is closely linked to the technological dynamics of data capitalism and it based on the notion that knowledge follows an epistemological dynamic focused on progressively erudite means of gaining intelligence about social subjects who are viewed as consumers of products and services, including media and cultural products. Castells (1996: 34) argued that epistemology and ways of gaining knowledge have always been fundamental constituents in the development of new techniques for governing the environment, and they became popular towards the Second Industrial Revolution in the mid-1800s.
Fourth, the social dynamic originating from those who generate data at various instances in practices of production and consumption has become forcefully incorporated into those practices of production and consumption, becoming a fundamental feature of data capitalism (Bolin, 2024). The domain of the social, however, is centred on social values such as belonging, recognition, identity and sociality, rather than the profit motive, for example, the economic imperative (Bolin, 2024).
A study by Lane (2010) noted that commercial credit reporting agencies developed surveillance networks in the 19th century to assess and monitor the creditworthiness of American businesses. These networks evolved by the 1870s into intricate systems that tracked individuals to provide consumer credit. Data systematization was labour-intensive, which led to the use of technology such as file systems, punch cards and networks of information exchange among credit managers to quantify information about people (Lauer, 2010). The introduction of database computing substantially augmented corporations’ capacity to collect and file data about individuals, leading to a boom in the scientization of the public. A growth in the use of surveys and polls in the 1950s and 1960s sought to render the post-war ‘mass society’ intelligible as a consumer public to researchers, political pollsters and marketers (Igo, 2007). By the 1980s, processes to collect data about consumers were largely automatic through the recording of consumer transactions such as credit card purchases and telephone calls. The practice of data collection had become a deeply embedded function of direct marketing (Lauer, 2012).
In the Digital spaces, personal information is tracked, collated and traded and this confirms that business organizations such as data brokers engage in organized tracking and collation of personal information, including online behavioural patterns, predilections, tendencies and locations. They generate comprehensive datasets and pools of information that they monetize to boost the flourishing industry of data brokerage (Dinev and Hart, 2006; Loi et al., 2022).
The extracted data are evaluated and manipulated by expert data scientists, psychologists and those who study human behaviour and such datasets are useful to comprehend and influence human behaviour thus facilitating the exploitation of vulnerabilities and emotions of internet users for strategic purposes (Clarke, 1994).
Sophisticated algorithms are also designed to predict and envisage users’ decisions, choices and actions based on online history and search strategy and this creates a predictive or analytical framework that advertisers, social media platforms and politicians leverage in order to reach their target audience (Brayne, 2017). Data companies operate in the shadow of internet ecosystems, orchestrating the buying and selling of personal information in a realm hidden from public scrutiny (Deibert, 2013).
Advertisers, social media and politicians are the beneficiaries of the datasets generated by information brokers because the acquired information is used to target campaigns, manipulate public opinion and influence decision-making (Papakyriakopoulos et al., 2018). Acquiring this information entails espionage and infiltration into personal lives, which is a violation of privacy that has legal and ethical implications. Digital surveillance questions the limits of confidentiality and invasion of privacy, which has implications for civil liberties (Henschke, 2017).
Legal framework for the protection of personal information
In an epoch where personal information is progressively digitized and susceptible to unauthorized access, the need for vigorous data protection measures has become vita for many governments globally. Identifying this, Nigeria has taken a noteworthy step by proposing the ‘Bill for an Act to Provide a Legal Framework for the Protection of Personal Information’ (Federal Republic of Nigeria, 2023). The aim of the legislation is to institute a Nigeria Data Protection Commission to regulate the handling of personal information, bringing with it a range of potential implications for individuals, businesses and the broader digital landscape (Abdulrauf and Fombad, 2017). The Nigerian Data Protection Regulation (NDPR, 2019) obliges data controllers to set up firewalls, encryption technologies and adapt continuous capacity building to upskill staff with neccessary knowledge to protect personal data from these threats in the form of misuse. Abdulrauf and Fombad (2017) argued that access to the internet, as well as freedom of expression, should be upgraded to fundamental constitutional rights, along with the right to reasonable expectation of privacy of personal information on the internet, among other ancillary rights. On the other hand, Zimbabwe enacted the Cyber and Data Protection Act (2022: Chapter 12: 7) with the aim of ensuring effective cyber protection. By increasing cyber security, this Act aims to build confidence and trust in the secure use of information and communication technologies by data controllers, their representatives and the subjects of data (Zimbabwe Cyber and Data Protection Act 2022: Chapter 12: 7). The aforementioned Zimbabwean Act covers cyber offences relating to computer systems, computer data, data storage mediums (Part 1); data codes and devices relating to electronic communications and materials (Part 2); and offences against children and procedural law (Part 3). It should be noted that the Act does not explicitly mention data capitalism. However, the Act obliges data controllers or data processors to ensure that personal information be administered in harmony with the right to privacy of the data subject(s). Unlike Nigeria’s and Zimbabwe's data protection laws, the Ghana Data Protection Act (2012: Act 843) obliges data collection agents, including libraries, to protect the personal information of library patrons.
The surveillance of personal data in the form of digital capitalism has also been used by data brokers for commercial predictability leading to economic gain through the use of predictive analytics to shape market strategies, influence consumer behaviour and manipulate consumer preferences, habits and patterns for economic advantage (Zuboff, 2023).
In view of the preceding statement, data privacy advocates should focus on creating awareness regarding the repercussions of digital surveillance and advocate for stringent regulations, guidelines, protocols and technological solutions to safeguard and protect users from needless invasions into their digital lives (Prinsloo and Slade, 2014).
In the advent of the internet, the semantic web and social media, netizens have created digital footprints through content creation on, scholarly (academic social networking sites), commercial or non-academic platforms (social network sites). Nevertheless, it remains unclear what happens to the data created by users of digital platforms whether in textual, visual, audio or multimedia files. Regardless of the privatization and commoditization of digital spaces by informational capitalism, austerity policies across the globe have led to the deterioration and diminishing of physical public spaces and infrastructure for service provision. Neoliberal policies seek to abolish collective institutions, including youth clubs, unions and libraries. In order for librarians to facilitate commoning, they themselves must reflect upon their conduct in ways that are consistent with ‘the art of democratic living’ (Quan, 2017: p.174), irrespective of the authority they exercise. This article seeks to evaluate the concept of data capitalism in the midst of rising surveillance capitalism and to suggest ways through which libraries can protect the interests of their users against bureaucracy and data capitalism. Throughout the article, data capitalism is examined in relation to the role played by data scientists, who are crucial in capturing, translating and modifying human experiences through and into digital technologies, performing key operations associated with the surveillance capitalism phenomenon (Couldry and Mejias, 2019; Zuboff, 2019).
The article explored how libraries can deal with data capitalism as institutions imbued with a philosophy or epistemology of democratic access and ethos that upholds the privacy and the confidentiality of users’ digital footprints, and to withstand the evil menace of data capitalism. The article employed the interpretive paradigm involving a qualitative research approach to untangle the implications of data capitalism on a noble profession that is fighting for its survival in the crude and veiled world of data capitalism in the age of the internet.
Library advocacy and intervention
The connection of data capitalism and the surveillance economy comes with remarkable challenges relating to privacy, security and the commodification of personal data. Libraries, as institutions dedicated to the dissemination of knowledge and the protection of intellectual freedom, can play a crucial role in addressing these issues (Lamdan, 2019). Bignoli et al. (2021) accused libraries of complicity in the surveillance capitalism crisis through aiding and abetting data manipulation to disadvantage vulnerable users, especially students in higher education. Data collection through poorly regulated and ubiquitous means by highly profitable analytics and technology companies intersects with the marginalization of vulnerable racial and social groups as a result of the surveillance capitalism crisis (Bignoli et al., 2021). Besides being sites of academic and vendor surveillance, libraries are also complicit in campus-wide or even larger corporate data collection (Salo, 2021). While libraries are rarely the vector force behind such initiatives, as any campus unit looking to prove its worth, they often capitulate without effective resistance when challenged with such a demand (Bignoli et al., 2021).
The adoption of proctoring systems by higher education institutions to guard against cheating during the COVID-19 pandemic era gave impetus to data capitalism in the form of crisis surveillance. This was done under the pretext that academic institutions needed to ensure academic integrity since students were assumed to be cheating. Through algorithmic proctoring, as well as through many other technologies like it, students are abandoned in favour of undemocratic approaches like discriminatory exclusion, the use of a pedagogy of punishment, underming privacy to data, and emphasis on technology as the only solution to social problems (technological solutionism) (Swauger, 2020). While technology holds greater promises in the form of opportunities, it is important to note that there is a dark side that information professionals as defenders of the information/knowledge revolution should guard against and this can be solved by conducting more research and enlightening vulnerable citizens, who are also netizens of the cyber-world and cyber-proletariats of the techno-driven world.
As protectors of intellectual freedom, libraries and related establishments must take a preemptive posture in advocating privacy rights in the midst of digital surveillance (DeBrabander, 2020). This can be achieved through implementing comprehensive privacy policies, legislative intervention and engagement with stakeholders and enlightening users through educational outreach and in this way, libraries can serve as symbols of hope for privacy advocacy and nurturing a digital environment that respects the fundamental rights of all individuals (Payton and Claypoole, 2023).
Libraries as social and academic establishments can organize digital literacy programmes designed to teach users and the wider community on how to traverse the digital landscapes in a safer manner without risking exposure to privacy violations. Such innovative projects will include helping people understand privacy settings and online tracking so they can make informed decisions when sharing personal information (Calzada and Marzal, 2013).
Libraries can support and promote the use of technologies that highlight and promote user privacy tools and techniques such as encrypted applications and browser extensions that block trackers (Van Zoonen, 2016). Encrypted applications protect data by converting it inti a secure format that can be read by a user with the proper decryption key and this safeguards library data.
The library as an institution can be an example to other related institutions by deploying systems that will ensureg that library systems and databases are protected and secured, with user privacy guaranteed. Libraries can also implement encryption procedures that frequently update security protocols to shield patron information from unauthorized access.
Allied with the above, libraries can collaborate to promote advocacy efforts and team up with like-minded organizations to stimulate ethical data practices (Seth et al., 2022).
By taking these actions, libraries can actively contribute to mitigating the negative impacts of data capitalism and the surveillance economy, championing privacy rights and fostering an informed and empowered user base.
What is the role of libraries in protecting the privacy of users in online communication?
Libraries can play a pivotal role by protecting the privacy of patrons, especially in online communication, because it is vital to ensure that users are able to access information and resources without compromising their personal data (Al-Suqri et al., 2020). Additional to other responsibilities of libraries, it is equally important that they observe strict guidelines on the confidentiality of patrons’ records. This comprises protecting information relating to the borrowing history, resource and reserve requests and any other personally identifiable information (PII) associated with library services (Neuhaus, 2003).
Libraries should enable the implementation of encryption protocols and secure connections to protect information from unauthorized access (Halevi and Shoup, 2013), educate users about online privacy and security through training and workshops (Tummon and McKinnon, 2018) and conduct consistent privacy audits to gauge the effectiveness of privacy protection measures (Jolley, 2023).
It is expected that libraries should also act as protectors of user privacy in the digital age, implementing robust policies, technologies and educational initiatives to ensure that individuals can access information freely and confidentially while maintaining their privacy in online communication (McKinnon and Turp, 2022).
Recommendations and conclusions
Users of libraries deserve the right to privacy, security and confidentiality when they volunteer information during registration and use of library databases. Libraries should feel secure to utilise library systems without any fear of losing their right to privacy, security and confidentiality (Al-Suqri et al., 2020). The study suggests makes the following recommendations: 1. Along with their other responsibilities, it is equally important for libraries to observe strict guidelines on the confidentiality of patrons’ records. This comprises protecting user's information relating to the borrowing history, transactional logs, resource utilisation and reserve requests and any other services provided by libraries (Neuhaus, 2003). 2. Libraries should enable the implementation of encryption protocols and secure connections to protect information from unauthorized access (Halevi and Shoup, 2013), educate users about online privacy and security through training and workshops (Tummon and McKinnon, 2018) and conduct consistent privacy audits to gauge the effectiveness of privacy protection measures (Jolley, 2023).
It is expected that libraries should also act as protectors of user privacy in the digital age, implementing robust policies, technologies and educational initiatives to ensure that individuals can access information freely and confidentially while maintaining their privacy in online communication (McKinnon and Turp, 2022).
Further research directions and conclusions
Future research should focus on how users’ rights to privacy and protection can be upheld when using web-based library resources. The emergence of data capitalism necessitates library and information professionals to work with other key stakeholders, including internet service providers (ISP), government, regulatory bodies, internet users and data brokers (independent information practitioners). It is imperative to rethink and restrategize new models of data capitalism that protect the right to user privacy. Data surveillance may be permissible for security reasons, for example, to prevent money laundering, but it is imperative to ensure that it does not impinge on or undermine constitutional rights. The role of librarians in educating users on the safe use of the internet should be considered as a high priority considering that data have become a highly sought out commodity by data vendors. It would be a disservice to internet users if librarians allowed data vendors to trample on their rights for the sake of profit. Maintaining user trust in the digital world will help to enhance the credibility and usefulness of the library and information profession in the dynamic information landscape.
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.