
Abstract
This study aims to investigate how Brazilian institutional repositories guide subject representation in the self-archiving of their information resources. As a method, an exploratory and qualitative study was carried out with the application of an electronic exploratory analysis of repositories and an analysis of transcripts of thesis and dissertation authors’ Individual Verbal Protocols during self-archiving. The analysis of the results in the Brazilian university repository sample shows that 10 have a self-archiving policy and five include guidance to the author on subject representation and metadata quality. The transcription analysis of the authors’ Individual Verbal Protocols reveals that all authors consider keywords important for content representation. The investigation concludes that the self-archiving process is fundamental for the dissemination of scientific information and wide access to the community.
Introduction
Institutional repositories are directly responsible for disseminating academic production, together with knowledge transfer technologies. The producers of scientific knowledge are the supplying agents of the material that should be made available digitally by institutional repositories. As these changes intensify, universities’ responsibilities increase, in the continuous formation of the academic community so that it becomes familiar with the electronic/digital environment and with the self-archiving process.
Self-archiving is the depositing of an academic paper by an author-researcher in an institutional repository. For Swan (2008), researchers themselves, after publishing their scientific research, will self-archive a copy in a repository. It has been noted that self-archiving is not being widely adopted by authors for several reasons. Thus, we can understand that reducing barriers, creating incentives and establishing policies is essential (Veiga and Macena, 2015), and the establishment of policies for repositories serve to both enhance and guarantee their formation and maintenance.
Few studies have been dedicated to self-archiving in institutional repositories in the Brazilian information science literature, specifically dealing with the quality of subject representation and retrieval. Furthermore, even if a system allows self-archiving, this does not ensure its active use. To change this scenario, mandatory policies that cooperate in increasing the rate of self-archiving use should be created.
Self-archiving has a sociopolitical impact. It is the biggest challenge of open access and the solution that can generate the greatest impacts towards the universalization of access to information and scientific knowledge. The idea of self-archiving occurred for the first time in physics in 1991 through ArXiv, originally developed by Paul Ginsparg (Wikipedia, 2023a), and in computing and information science through the CiteSeerX Library in 1997, created by the researchers Lee Giles, Kurt Bollacker and Steven Laurence (Wikipedia, 2023b). The ArXiv and CiteSeerX initiatives became structurally possible in 1999 with the open access movement and the Open Archives Initiative (Van de Sompel and Lagoze, 2000).
For Van de Sompel and Lagoze (2000), self-archiving is greatly enhanced by the Open Archives Initiative protocol – an initiative that makes scientific publications available free of charge via the Internet and allows an author to gain visibility and access to papers through its search and retrieval, leading authors to be increasingly cited and known in their field of work. Furthermore, it reduces the barriers imposed by traditional publishing systems.
Self-archiving through open access repositories allows authors to make their papers accessible to the public and increase the visibility of their research. This context provided a favourable environment for the proposal for a global scientific communication, mentioned in 1994 in an online post by Stevan Harnad (1995) entitled ‘Subversive proposal’, ‘originated from a June 28 1994 Internet posting (Harnard, 1995, see Subversive Proposal (google.com)) and first presented at Network Services Conference (NSC) London, England, 28–30 November 1994 Address: Washington DC’ (University of Southampton Institutional Repository, 2017). Rodrigues (2006: 29–40) considers that such a proposal, which was deemed subversive at the time it was mentioned, might today seem both ‘fruitfully visionary and naively inadequate’. However, at a meeting in Budapest in December 2001, the utopia of free access to literature published in scientific journals was discussed. Today, this has become a reality thanks to the combination of tradition and new technologies (Rodrigues, 2006: 29–40).
Despite the obstacles, many countries have adopted self-archiving by researchers or someone from their team. In the case of Brazilian repositories, their insertion has occurred in an incipient way, as such repositories keep theses and dissertations in institutions’ information systems – generally the library, which acts as the main responsible for populating the repositories (Kuramoto, 2014).
According to Triska and Café (2001), self-archiving refers to the right an author has to send their text for publication without the mediation of third parties. Much more than just depositing a scientific paper in a repository, an author needs to know everything that involves their rights regarding the paper they have written because of the consequences of editorial control.
Some of the advantages of the self-archiving process include the rapid online availability of papers, the verification of entered metadata, enhancements in workflow efficiency, and more effective use of the human resources available in libraries. In this view, policies should encourage faculty, researchers, students and institutional staff to self-archive scientific production following the submission criteria.
For the implementation of a successful self-archiving policy, institutions must provide support and training materials so that researchers feel comfortable with the system. In addition to making deposits, institutions should be concerned with passing on to their researchers the philosophy and relevance of the open access movement to scientific information, making their researchers aware of the importance of self-archiving (Assis, 2013).
According to Leite (2009), the benefits for researchers who self-archive their production in repositories are the information and knowledge organization of the network they participate in; increasing their research visibility and impact; accountability to society; and the expansion of possibilities for dialogue among researchers who are part of the network and with society in general.
Brazil has adhered poorly to the important practice of self-archiving in institutional repositories and is still resistant to letting its authors make deposits, even when the institution has a pre-established policy in place. Thus, the mere existence of a policy is not enough to ensure full adherence to self-archiving. More effort is needed from the managers responsible for the repositories, as well as new studies that identify the difficulties with regard to adherence (Baggio and Blattmann, 2017; Veiga and Macena, 2015).
This study aims to investigate how Brazilian institutional repositories guide subject representation in the self-archiving of their information resources. It is justified by the importance of subject representation in building products where the netizen will access the information expected.
Subject representation in repositories
This section discusses information representation by keywords assigned by authors, contrasting the perspectives of natural language versus controlled language to guide its application in the context of self-archiving in repositories.
Digital repositories can be used in public and private institutions to disseminate the research produced, providing self-archiving that grants better research dissemination. Lynch (2003: 328) states that repositories is ‘a set of services the university offers to members of its community, aimed at managing and disseminating digital resources created by the institution and its members’. Furthermore, it contains an information retrieval system by document and metadata access points, which enables access to the digital document contained in the repository.
More than part of the movement of access to scientific information, self-archiving belongs to the new configuration of the Web environment as an interaction network in which netizens themselves interact and collaborate in the description of the available contents, producing, classifying and reformulating what is already available. Thus, it is understood that subject indexing is an activity with a social impact on digital environments. Even if it favours the development of more democratic institutional repositories, resulting in more representative and inclusive information representation, it is understood that internal and external policies must establish guidelines for users on how to proceed with subject representation at the time of self-archiving.
Information representation is built by people and is part of a social action – that is, ‘representations are based on social actions, reflect historical moments, theories, ideologies and cultures and, although they are close to reality, they can bring diverse “readings”‘ (Moraes and Arcello, 2000: 9). The chosen concepts are synthesized in keywords, which configure as concise representations of the documentary content.
A keyword can be defined as a word or group of words chosen in the title or text of a document, or even in documentary research, to characterize its content. In addition to indicating the theme, through the reading and analysis of the document, keywords facilitate the identification and retrieval process (Menezes et al., 2004). The keyword’s function is mainly to characterize documents to improve the location of documents, and it is one of the indexing languages. When used in a search, it begins to be applied in indexing, information retrieval, and the development of thesauri and other knowledge organization systems (Lu et al., 2019: 415).
Representation by automatic indexing allows a keyword search in which the search strategies used by the netizen at the time of the search must match the words of the catalogue so that the expected documents are found. The origin of the concept of a ‘keyword’ is unknown, but we do know that it has been linked to the interests of information retrieval since the first manual indexing initiatives (Foskett, 1973: 24), referring to keyword indexing with the aid of a computer – a concept that was established by Hans Peter Luhn and known as ‘KWIC Key-Word In Context’ (Foskett, 1973: 25). Its origin can also be explained by the proposal of ‘uniterms’, which, in the words of Chu (2010), can be seen as keywords because they are derived from original documents without any kind of vocabulary control. The uniterm index created by Mortimer Taube in 1953 comprises terms that can be post-coordinated (Foskett, 1973: 310).
A keyword is a word or expression that is ‘key’ in the representation of a text or information resource for the purposes of access and retrieval. The concept is related to the representation of the meaning of verbal or non-verbal content, and is used to identify important ideas and themes. In addition, it has a range of diverse purposes that include bibliometric studies, indexing and retrieval. Therefore, it can be considered as ‘the documentary representation with a higher degree of condensation than the title and abstract’ (Fujita and Tartarotti, 2020: 337).
The product of documentary representation, whether a keyword or a descriptor, is housed in metadata to be retrieved. Metadata is descriptions that are specifically created to represent digital information accessible on the Internet (Chu, 2010: 41). Keyword searching, on the other hand, is one of the main information retrieval techniques. Through natural language, people can describe the same thing in different ways, making the words used in the query different from those used in the documents and thereby preventing word matching and, consequently, the retrieval of relevant documents. There are other limitations, such as when a term has more than one meaning; different terms have the same meaning; or the query has a high recall, retrieving a long list of documents. Netizens with little knowledge of what they are looking for find it more difficult to formulate a query that recalls relevant documents.
Natural language is used in writing and speech; it is words that, in an organized way, convey a message from the sender to the receiver. The indexing carried out with this type of language leads to information retrieval through expressions used by the user. The reading carried out by the information professional can be performed superficially – focusing on the title, abstract or initial and final paragraphs of the text – or in a detailed manner – removing blocks of information from the text, which will also result in the selection of keywords.
Artificial, documentary or controlled language is constructed by a specialized professional; it is elaborated according to the established rules of a specific controlled vocabulary with the purpose of describing the content of a document in a simple way and the aim of storage uniformity, as well as the easy retrieval of the information. It is the information professional’s responsibility to build representation languages that best meet user demands and also adapt to the needs of different organizations in different social sectors (Tonello et al., 2012).
In the case of subject as well as other databases, it is possible to verify whether vocabulary control was used for representation in the indexing or the search. Information, to be retrieved properly, must be organized and represented in the most faithful way possible to comply with the information content of the document and the needs of the user. This process takes place through the elaboration of information products, such as summaries, classification numbers, keywords and descriptors.
Methodological procedures
In order to fulfil the objective of investigating how university repositories guide subject representation in the self-archiving of their information resources, the methodology adopted to carry out this study had a descriptive exploratory character of a qualitative nature and applied two methods: (1) an electronic exploratory analysis to survey and identify self-archiving and subject representation guidelines in Brazilian repositories and (2) an analysis of transcripts from an introspective technique called Individual Verbal Protocol applied at the moment the authors performed the self-archiving of their theses and dissertations.
Electronic exploratory analysis
For universities to give visibility to their scientific production, their institutional repositories need their operating policies or tutorials to consider the quality of subject representation. Thus, for access to be effective and netizens’ needs to be met, the process of subject representation should be clearly delimited in tutorials that guide authors during self-archiving.
The data collection, which was carried out between 13 April and 9 May 2022, involved an electronic exploratory analysis of 82 repository sites from the list of Instituto Brasileiro de Informação em Ciência e Tecnologia (IBICT) repositories previously analysed by Fujita and Tolare (2019). The selection criteria were that the repositories enabled the self-archiving of theses and dissertations and provided self-archiving tutorials. Self-archiving and guidelines for subject representation by keywords were explored on the websites of selected Brazilian repositories.
Analysis of Individual Verbal Protocol transcripts
We have carried out an analysis of the results obtained in the introspective data collection of the investigation by Fujita et al. (forthcoming), which identified how authors assigned their own keywords for their papers during the self-archiving process. For this analysis, five student participants from the graduate programmes in Information Science and Education at the Universidade Estadual Paulista Júlio de Mesquita Filho (UNESP), Marília, Brazil were interviewed on the Google Meet platform. They had recently defended their Master’s theses or doctoral dissertations, and had self-archived their work in the UNESP institutional repository through the Individual Verbal Protocol.
The Individual Verbal Protocol is an introspective technique in which authors report on everything they are thinking about the stages of the process and verbalize their questions. It was agreed that the researcher carrying out the interviews would remain silent so as not to interfere in the process, and, at the end of the procedure, three retrospective questions were asked on the observed data.
To begin the introspective data collection, the librarian responsible for the repository at the institution authorized the research. The participants submitted their papers again to contribute to the study and were informed that only their first submission would be stored in the repository, and those responsible would exclude the extra submission.
The procedures were divided into ‘before’, ‘during’ and ‘after’ the self-archiving process. In the ‘before’ stage, the scope of the research was established by outlining the context in which the repositories function, aiming to gain a deeper understanding of the self-archiving process; in addition, their policies, resolutions and tutorials were read through. First, the research theme was introduced, explaining its proposals and clarifying the participants’ questions, and before starting the submissions themselves, the participants briefly described the theme of their scientific investigation and their study, carried out an introduction, shared their screen and started the self-archiving procedures. The participants entered the repository’s electronic address and started the process. The student-author entered the repository link, set up a personal login and, during the process, went through all the necessary steps to carry out the submission of their paper.
During the recording of the interviews, the way the participants assigned their keywords for their theses or dissertations was analysed. In the subsequent procedures, an analysis of the participants’ verbalization at the time of recording and reading of the literal transcripts of their interviews was carried out.
Results
The results of the exploratory study on Brazilian repositories are presented in the following two sections: (1) an electronic exploratory analysis of self-archiving and guidelines on subject representation for authors and (2) an analysis of the Individual Verbal Protocols of the authors of theses and dissertations during self-archiving.
Electronic exploratory analysis
The electronic exploratory analysis was carried out on 82 Brazilian repository sites and identified that 10 repositories allow the self-archiving of theses and dissertations by observing the existence of an interface for authors. By exploring these interfaces, the objective was to identify the existence of tutorials with specific guidelines on subject representation for assigning keywords with or without the use of controlled vocabularies. In the following, we describe the characteristic aspects of the self-archiving or self-depositing modality in each selected repository.
Fundação Getúlio Vargas
The digital repository of the Fundação Getúlio Vargas aims to preserve and share the institution’s academic production, and to be its memory and identity. It has tutorials, videos and presentations by the institution, in addition to Ordinance No. 40/2018, entitled ‘Document Deposit Policy’. Its ordinance follows the international self-archiving standard that establishes the deposit of academic productions directly by authors. Deposits are carried out by students, professors and researchers on the repository’s website or, when necessary, by the Fundação Getúlio Vargas team, which standardizes and publishes the deposited papers. The repository uses the controlled language from the subject terminology of the National Library of Brazil and Bibliodata. Guidance to authors on self-archiving is not offered on the repository’s website.
Universidade Federal Rural da Amazônia
The institutional repository of the Universidade Federal Rural da Amazônia stores and disseminates the university’s intellectual production; has an operating policy, tutorials for registration and self-deposit, and normalization instructions; and offers training. It has a self-deposit tutorial, and its operating policy has metadata that follows international standards. In the tutorial, which is accessible on the repository’s website, there is an indication for keyword assignment with guidelines on subject representation with natural language keywords and a summary in Portuguese and English.
ARCA, Fundação Oswaldo Cruz
In ARCA, the institutional repository of the Fundação Oswaldo Cruz, the authors fill in the metadata and deposit the digital object. The institution’s libraries, together with community managers, facilitate the self-archiving process. All deposits go through the ‘aided deposit’ process – that is, the author performs self-archiving with minimal metadata and the technical team of Fundação Oswaldo Cruz librarians (trained by the manager of the ARCA communities) completes the remaining metadata. Additionally, we observed that the ARCA repository uses DeCS – Health Sciences Descriptors as a controlled language. Guidance to authors on self-archiving is not accessible on the repository’s website.
Universidade Federal de Goiás
The institutional repository of the Universidade Federal de Goiás is populated in a decentralized way. Various entities are involved: course coordination, final paper coordination, and the heads of departments or academic units. The repository allows authors to submit their own papers as long as they are in accordance with the rules established by the management committee, which are published on the institutional website. Guidance to authors on self-archiving is not accessible on the repository’s website.
Universidade Federal do Ceará
The institutional repository of the Universidade Federal do Ceará enables the self-deposit of technical scientific work by the university community in accordance with the university’s institutional policy for technical scientific information. Guidance to authors on self-archiving is not accessible on the repository’s website.
LUME, Universidade Federal do Rio Grande do Sul
LUME, the repository of the Universidade Federal do Rio Grande do Sul, offers access to digital collections (text, image, video, audio) produced at the university and other documents of interest. Its access is free but, in some cases, is restricted to community members. It uses DSpace, is compatible with the Open Archives Initiative protocol, and follows the Dublin Core metadata standard and the Corporation for National Research Initiatives’ Handle system to define permanent identifiers for each document available in the repository. Metadata registration is carried out by the author or the person responsible for the community with the final guidance of LUME’s technical team. This is a mediated self-deposit system whose guidelines for authors on self-archiving are not accessible on the repository’s website.
UNESP – Universidade Estadual Paulista Júlio de Mesquita Filho
The UNESP institutional repository has tutorials on the self-archiving of theses, dissertations, final papers, book chapters and other materials. There is a tutorial for each type of scientific production, containing an indication of keyword assignment with specific guidelines on subject representation and the use of the UNESP thesaurus for vocabulary control.
Universidade Federal de São Paulo
In the institutional repository of the Universidade Federal de São Paulo, the submission made by an author, co-author or mediator comprises the metadata registration; the students use natural language and the librarians then carry out the validation. It has accessible tutorials on the self-archiving site for undergraduate final papers, theses, dissertations and scientific articles, with an indication of keyword assignment but no guidelines on the subject representation process and use of controlled vocabulary.
Universidade Federal de Uberlândia
The institutional repository of the Universidade Federal de Uberlândia has tutorials for each stage of the self-archiving process of theses and dissertations, covering bibliographic references; the preparation of catalogue sheets; converting documents into PDFs; registration on the repository’s website; ORCID registration; the submission of professors’ descriptive memorials; and the submission of other types of materials such as journal articles, book chapters, electronic books, research reports and conference papers. It has an accessible tutorial on the academic-paper self-archiving website, with an indication of keyword assignment but no guidance on the subject representation process or the use of controlled vocabulary.
Universidade Federal da Bahia
In the institutional repository of the Universidade Federal da Bahia, a deposit can be carried out in two ways: (1) self-archiving and a mediated deposit after registration on the system or (2) authorization by the repository’s administration and validation by the University System of Libraries before it is made available. The repository has a submission tutorial and registration guidelines, in addition to two operating ordinances (No. 024/2010 and No. 159/2021) and a resolution (No. 159/2021). It has an access tutorial on the academic-paper self-archiving website, with an indication of keyword assignment but no guidance on the subject representation process or the use of controlled vocabulary.
Table 1 shows that 5 of the 10 repositories contain self-archiving tutorials – namely, those of the Universidade Federal Rural da Amazônia, Universidade Federal de São Paulo, Universidade Federal da Bahia, Universidade Federal de Uberlândia and UNESP.
Repositories with operating tutorials and guidelines for subject representation.
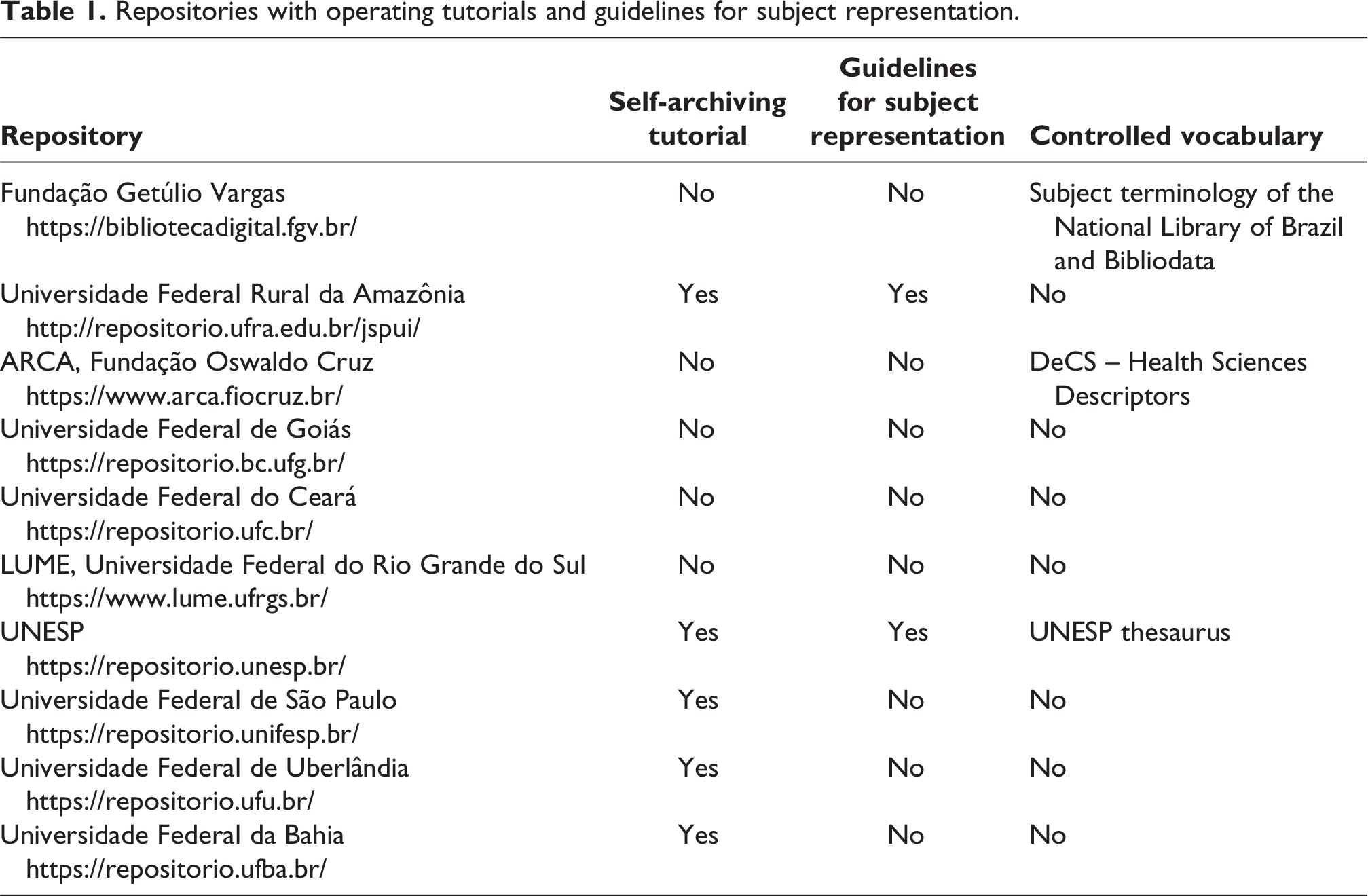
The analysis of the tutorials revealed that the first four of the Universidade Federal Rural da Amazônia Repository, UNIFESP Repository, Universidade Federal da Bahia Repository, Universidade Federal de Uberlândia - Institutional Repository, and UNESP Institutional Repository present an indication of keyword assignment without guidelines on how to represent subjects or how to use controlled vocabulary, and only the UNESP institutional repository provides guidelines on subject representation in keyword assignment and use of controlled vocabulary. The Universidade Federal Rural da Amazônia is the only university that approaches metadata quality as essential for metadata standardization and information retrieval. However, it does not have guidelines for users on how to represent a subject when self-archiving.
For De Freitas (2019: 52) and De Freitas et al. (2021: 173), self-archiving is an alternative way to share information, but they observed some resistance from authors to adhere to self-archiving practices. It was also noted, from the survey, that most university institutional repositories do not have a formalized self-archiving policy that prioritizes subject representation. Golub et al. (2014) note that, in most repositories, authors are not trained in indexing and do not receive any indexing guidelines. They caution that if suggestions are derived from an appropriate controlled vocabulary, the retrievability of articles will likely contribute to ideal precision and recall. The results of a study conducted by Tartarotti et al. (2018), which examined the presence of indexing policies in collaborative environments through a survey of those responsible for digital libraries of theses and dissertations in Brazil, revealed the absence of an indexing policy to guide and safeguard its practice of self-archiving in collaborative settings.
In general, Brazilian institutional repositories do not have a self-archiving policy that includes subject representation, which deals with the quality of the metadata in question. In this context, implementing self-archiving for treating information resources contributes to the systematic development of guidelines for indexing policie that satisfy the current requirements of information representation in digital environments and, at the same time, achieve high standards in the quality of subject indexing conducted in institutional repositories.
Analysis of Individual Verbal Protocol transcripts
The analysis of the authors’ Individual Verbal Protocol transcripts (see Table 2) reveals that all of the authors considered keywords to be important for their theses’ and dissertations’ content representation in view of the wish for them to be retrieved. One can observe the authors’ concern regarding the meaning that keywords carry when assigned, and that they need to reflect the domain of the investigated topic so that domain-specialist readers can retrieve and recognize them within the area of knowledge in which they work. Considering that the author is a domain expert, when they assign keywords, their objective is to ensure that the content of their text is retrieved and read by others, who are likewise domain specialists. Similarly, Holstrom (2019: 123) assesses the differences between the domain-expert indexer (author) and the professional indexer as follows: ‘Unlike professional indexers, who broadly consider the needs of many users, domain experts are more likely to consider the information needs and priorities of other scholars and practitioners in their field’. There are different objectives for author indexing, but vocabulary control can be added to the guidelines for subject representation. If there are no compatible descriptors, an author can decide whether a keyword is more important and specific for representing the content of their thesis or dissertation.
Analysis of Individual Verbal Protocols.
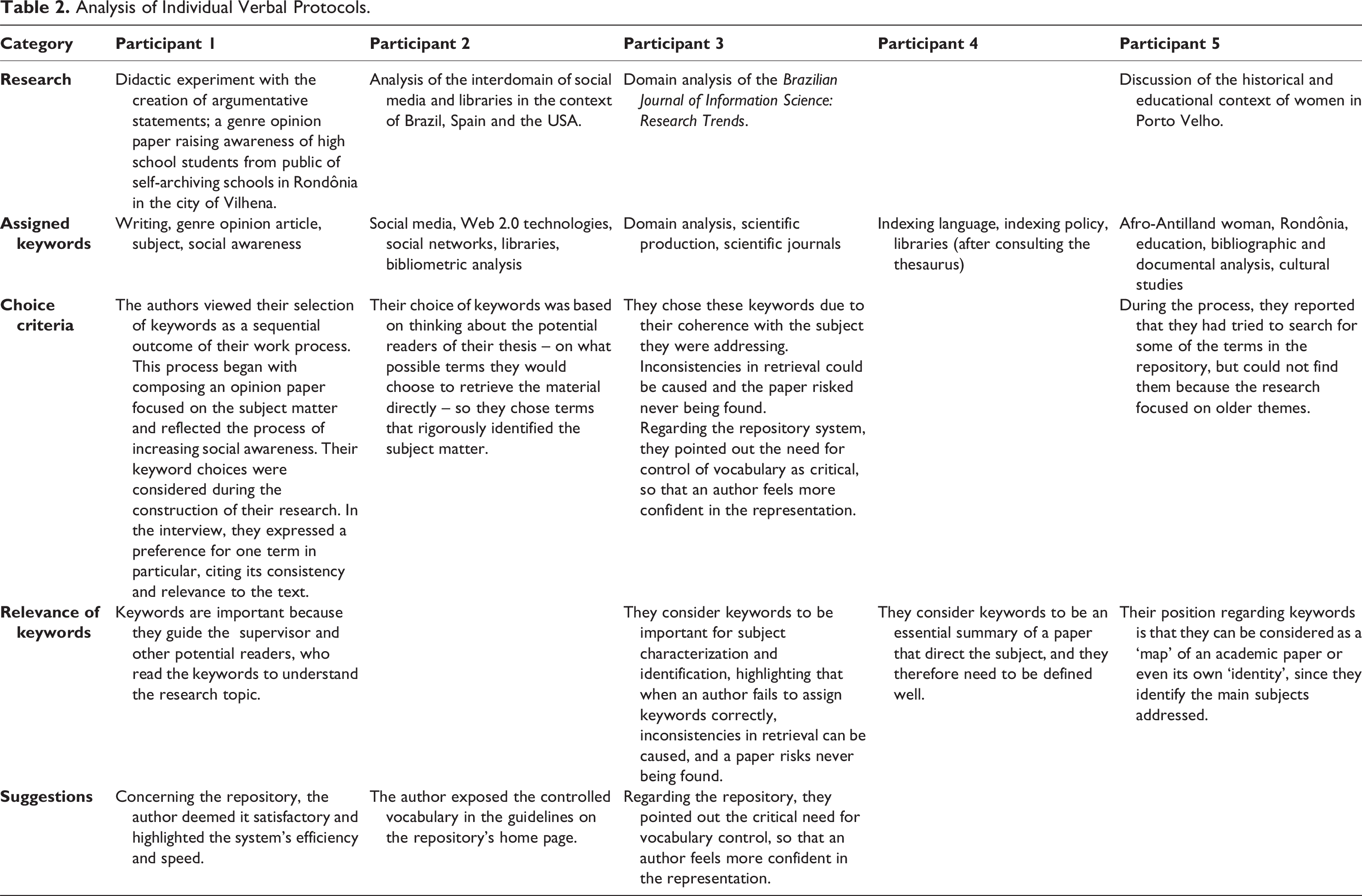
On the other hand, some authors realized the need for control and a range of specialized vocabulary to be indicated for use during keyword assignment. These results suggest that repositories need to elaborate and include guidelines on subject representation by keywords indicating the use of controlled vocabularies, as the authors of theses and dissertations highlighted the importance of representation and its effects on retrieval.
Conclusion
The investigation regarding the guidelines provided to authors for subject representation using keywords available in university repositories for the self-archiving of their information resources carried out two analyses from different yet complementary perspectives: (1) an electronic exploratory analysis to identify guidelines on subject representation in the self-archiving procedures of Brazilian repositories and (2) an analysis of authors’ introspection during subject representation in the self-archiving of their theses and dissertations in the UNESP institutional repository, which provides guidelines on subject representation using keywords.
For the authors participating in this analysis, the study concludes that keyword assignment is a relevant representation procedure when their selections are determined by considering potential readers. These keywords must be correct and coherent with the content of their theses and dissertations and, above all, function as a ‘map’ or the ‘identity’ of the academic work, capable of characterizing it and making it accessible upon retrieval. The primary concern of the authors was the accuracy, coherence and correctness of the keywords, so that they could reach other readers and researchers in their domain of expertise. This is evidenced by the fact that one of the participants even cited their own supervisor as one of their potential readers. Hence, the authors participating in the study recommended the inclusion of controlled vocabulary along with guidelines on subject representation using keywords.
This study recognizes that the authors reported extensive procedures in the process of subject representation using keywords, making them expert indexers in their area of expertise. The fact that the UNESP institutional repository has guidelines available to authors for assigning keywords to theses and dissertations highlights the importance of self-archiving and subject representation.
Self-archiving works through its authors and helps them understand the objectives of creating repositories and the importance of access to research in scientific communication. Therefore, it is essential to involve the scientific community in the development of their repositories through self-archiving. The self-archiving process encourages authors to consider the information needs of the users of institutional repositories when depositing their publications and submitting subject metadata with keywords that facilitate access to the content.
However, the analysis of self-archiving policies across the set of repositories reveals that, in relation to subject metadata, few self-archiving policies concern this aspect, even though this operation enables the development of more democratic institutional repositories, resulting in an information system oriented to the interests of the scientific visibility of their authors in favour of satisfying the more global information needs of users.
Therefore, if users incorporate vocabulary control into their self-archiving routines when entering subject metadata, and if their keywords subsequently serve for the continuous updating of controlled vocabularies, this will bridge the domain-knowledge expertise of both authors and professional indexers during the storage of information resources and their representation in metadata. This bridge will allow the organization of teams that can share decisions aimed at continuously updating controlled vocabularies in a hybrid context between natural language and controlled language. At the same time, it will make a significant contribution to the process of determining keywords with exhaustiveness, specificity, correctness and consistency in the representation of the contents of information resources, which will encourage repositories to incorporate the advances provided by vocabulary control in self-archiving routines through indexing-policy tutorials. This will be particularly valuable due to the contribution of new terms brought about by the constant scientific and technological evolution required in the development of research, which, in turn, will generate new knowledge. The compatibility of specialized languages, authors and controlled vocabularies will contribute to the scientific visibility and impact factor of publications.
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
This research was supported by the Brazilian National Council for Scientific and Technological Development.