
Abstract
Background: There are currently no published prosthetic-related outcome measurement tools (OMT) available in the Arabic language.
Objective: The aim of this study was to translate the Prosthetic Evaluation Questionnaire (PEQ) into Arabic, ensuring cross-cultural equivalence with the original English language version.
Study Design: Psychometric property testing.
Methods: The PEQ was culturally and linguistically adapted from English to Arabic using a process of forward translation, backward translation, committee review and pre-testing. Pre-testing was carried out in a clinical trial where subjects each completed the questionnaire in Arabic and English, and underwent random probe questioning. The data were compared and analysed, using intraclass correlation (ICC) and Bland Altman plots.
Results: Seven patients gave consent and completed the study. For all nine PEQ scales, the ICC point estimate scores were above 0.8, indicating a good degree of correlation. However, for some scales, the 95% confidence interval was wide, indicating a large level of variation. The Bland Altman plots displayed a good distribution around the mean for most of the scales, although the results were affected by the small sample size.
Conclusion: The results of the analysis showed that the Arabic version of the PEQ was linguistically equivalent to the original version, although further testing with a larger sample group is recommended.
The availability of a prosthetic outcome measurement tool in Arabic will enable clinicians to collect evidence that can be used to monitor and improve patient care. As there is currently little information available about amputees in the Gulf region, this tool will be a useful resource to both clinicians and decision makers.
Keywords
Background
Outcome measurement tools (OMT) are often used as part of evidence-based practice. While there is a wide selection of health-related outcome measurement tools available, there are only a few suitable for use in a prosthetic clinical setting.
The Prosthetic Evaluation Questionnaire (PEQ) is an OMT which was developed by the Prosthetics Research Study (PRS) group to fill the need for a comprehensive self-report OMT for persons with a lower limb amputation.1,2 The PEQ is a reliable and validated self-report questionnaire which covers a broad range of topics relevant to amputee care. The tool comprises of 84 questions, most of which are scored using a visual analogue scale. The questions are used to form nine scales, which cover topics such as ambulation, frustration, social burden and well-being. Each scale is validated for internal consistency and temporal stability. The tool can be used in its entirety, or the scales can be used independently, increasing the flexibility of the PEQ as a clinical tool.1,2 The PEQ is freely available on the internet 3 and has been used in many published research activities across the world, but not in the Arabic language.
Like the majority of OMTs available for use in prosthetics, the PEQ has been developed and tested in the English language. As there is an increasing requirement to record patient progress, the need for OMTs in other languages has increased. A number of tools have been translated into other languages, however often there is little evidence of the translation techniques used or testing carried out on the new tool. An outcome measurement tool that is directly translated from the source language to the target language will, in most cases, contain errors that may distort the intent of the tool, thus affecting its quality and effectiveness.4–6 A review of the literature has shown that authors often use substandard translation techniques, or fail to report the translation methods used, when utilising an OMT in a different language. 7 In such circumstances it is likely that the translated version will not be equal to the original version, or will not be applicable for the target population. If such a tool is used alongside the original version, data contamination will occur.8,9 Froman and Owen 10 warned that a cross-cultural study can be ruined if the researcher assumes that the translated tool has the same measurement properties as the original version, without proper equivalence testing.
Arabic is currently the fourth most spoken primary language, 11 and therefore it can be assumed that there are a great number of native Arabic speaking amputees, however there is currently no published prosthetic-related OMT available in the Arabic language. This study was designed to translate the PEQ into Arabic, ensuring cross-cultural equivalence of the tool with the original English language version.
Methods
Ethical approval for this study was granted by King Fahad Medical City Internal Review Board and University of Strathclyde Ethical Committee. Permission was granted by the Prosthetic Research Study group (PRS) to translate the PEQ into Arabic.
The PEQ was translated using a method similar to that described by Guilleman, 12 and according to the recommendations made by World Health Organization. 13 The method used included the three recommended elements; planning and defining rules for the technique, conducting the translation, and checking validation of the translated tool. 9 Three techniques were used to check the quality of translation; committee approach, back-translation, and pre-testing. The translation process used is illustrated in Figure 1.
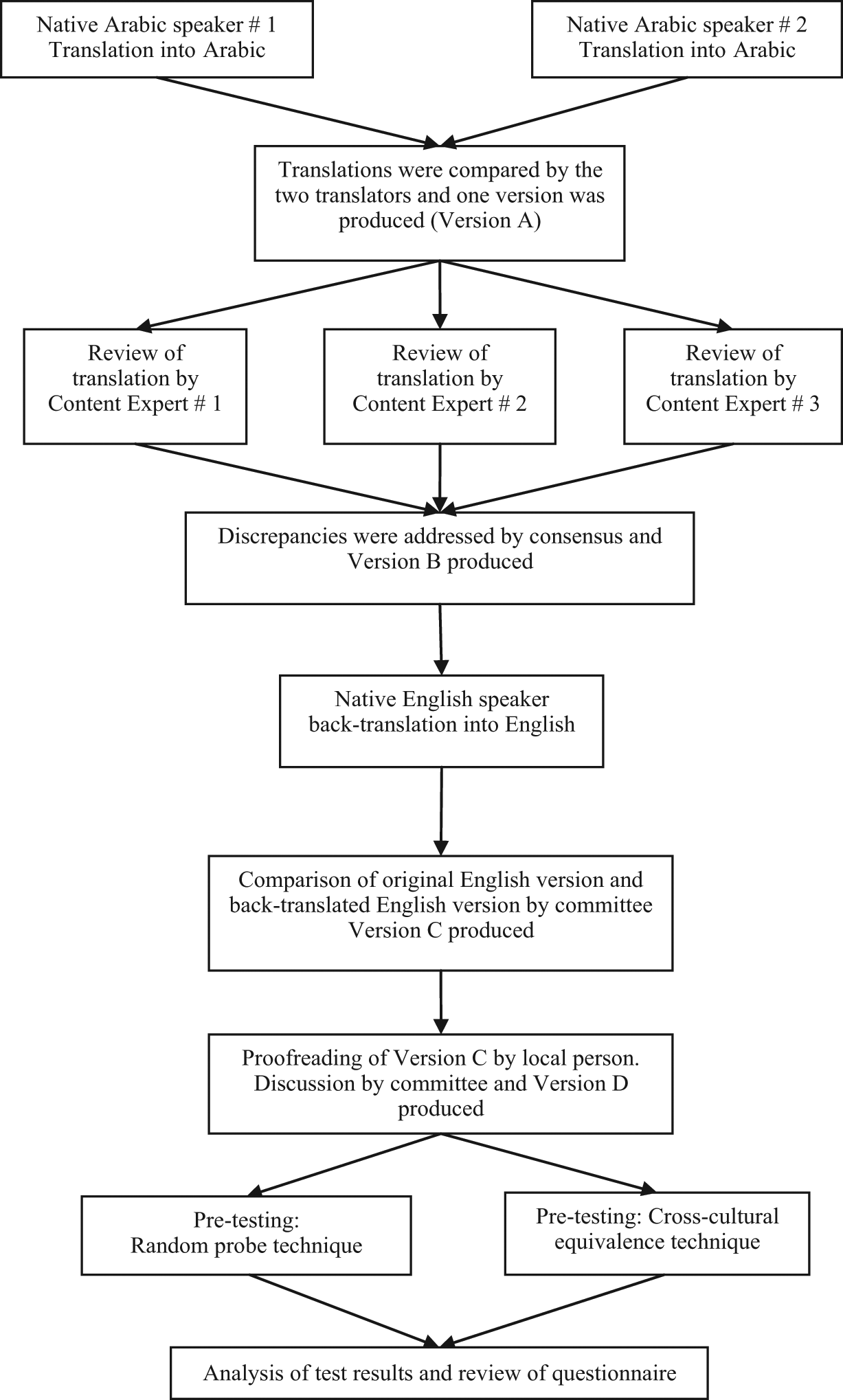
Translation process.
A translation team was established, consisting of two native Arabic speaking translators, three content experts, one native English speaking healthcare professional, the primary investigator (PI), and one Arabic speaking non-medical person. The team members were informed of the task objective, the planned technique, and their role within the team. They were briefed about the importance of conceptual equivalence and instructions were given to the team members that the original meaning of the tool should be maintained while being translated, however adaptations should be made, where appropriate, to adapt the tool for the Saudi Arabian culture. The aim of the translation was to produce a text that is easy to read, so that, for example, a 10- to 12-year-old child could understand it, preserving the meaning of the questions, but which is related to the local population.
Step 1: Conducting the translation
Two native Arabic speakers (Native Arabic speaker 1 and 2) individually translated the tool from English to Arabic. The translators selected to perform this stage were Saudi nationals who were employed full time as medical translators. They were both native Arabic speakers who had studied linguistics and completed Bachelor degrees in the UK.
Step 2: Checking the translation (committee approach)
Following completion of the individual translations, the two translators compared work and jointly produced one Arabic version of the tool (Version A).
Step 3: Checking the translation (committee approach)
Version A was reviewed individually by the three content experts. The content experts comprised of two native Arabic speaking prosthetists (one Saudi, one Palestinian) and one native Arabic speaking assistive technologist (Saudi). All three content experts were fluent in English, and had lived and studied in the UK for a minimum of five years. The content experts were instructed firstly to read Version A and judge whether it was easily understandable. After this, they were instructed to compare the translated question with the original text, to ensure that the meaning of the items were maintained, and document any issues which they observed.
Step 4: Checking the translation (committee approach)
A committee consisting of the two translators, three content experts and the primary investigator reviewed the comparisons. Discrepancies were discussed among all committee members and changes to Version A were agreed by consensus. The committee also agreed format and numbering systems at this stage of the review. The changes were made to the tool, and Version B was produced.
Step 5: Testing the translation (backwards translation)
Version B was back-translated into English by an American-Jordanian native English speaker. This translator was a healthcare worker, bilingual in English and Arabic and educated in the USA. He had no prior knowledge of the PEQ.
Step 6: Testing the translation (backwards translation, committee approach)
The back-translation was compared with the original English version of the PEQ. The principle investigator conducted this step, and then reported the findings to a committee consisting of the three content experts, the primary investigator and the native English speaking translator. The discrepancies found between the back-translated and original versions were discussed within the committee, and changes made by agreement of all members. Any changes were subsequently back-translated again until the committee were satisfied. Version C was produced.
Step 7: Testing the translation (pre-test 1)
An additional member of the team, a non-medical Arabic speaking Saudi was recruited to proofread the questionnaire and comment on its ease of understanding. Her comments were taken into account and Version D was produced.
Step 8: Testing the translation (pre-test 2)
Pre-testing was conducted through appraisal by bilingual individuals to assess the validity of the individual items and the nine PEQ scales in the Arabic version.
The patient trial was conducted in the Rehabilitation Hospital, King Fahad Medical City, Riyadh. A convenience sample was selected by screening patients attending the Rehabilitation Technology department for routine appointments. Patients who were bilingual in Arabic and English, aged over 18, and had a lower limb amputation at, or above, ankle disarticulation levels were invited to participate. Patients with recent amputations, limited cognitive ability and those undergoing gait training were excluded from the study.
After giving written consent to participate, the subjects were each given the questionnaires to complete. The subjects were pre-assigned to groups according to the order they were recruited; half the subjects completed the English version first, and half completed the Arabic version first. Each subject was required to complete the first questionnaire then return it to the investigator. Upon its return, the subjects were each given the second questionnaire and asked to repeat the process. In addition, demographic information about the subjects was recorded by the investigator. Following completion of the two questionnaires, the subjects underwent a cognitive debriefing exercise. The debriefing exercise was an individual interview where the subject was asked about their ease of understanding the Arabic version, and asked to highlight any problems which they experienced. In addition, the subject was specifically asked about 10 of the items, which had been randomly chosen, and asked to explain what they thought the question was asking, repeat the question in their own words, and describe the thoughts that came to their mind when they initially read the question (random probe technique). 14
Individual question responses were coded according to the guidelines provided by the PRS group. 15 The visual analogue scale responses were measured to the nearest millimetre, from left to right, using a ruler, and scored 0–100. The Likert scale questions were scored 0–6. The scores for the nine individual scales were calculated according to PRS guidelines, and then analysed.
The information collected from the cognitive debriefing was evaluated. The responses were then compared with the data from the two questionnaires to determine if there was a link between the problem items and the recorded results.
The data was analysed using a statistical software package, SPSS Version 17 for Mac-based computer software. The nine PEQ scales were tested using intraclass correlation (ICC) and Bland Altman plots. ICC was used to assess the linear relationship between the sets of data. When analysing the ICC, point estimates over 0.8 were interpreted as ‘good’, 0.5–0.8 as weak, and below 0.5 as poor. A high correlation however does not automatically imply that there is good agreement between two methods 16 ; therefore a second series of tests was conducted to assess the agreement between the two sets of data. A Bland Altman plot calculates the mean difference, or amount of agreement, between two sets of measures. It is constructed by plotting the differences between the measurements against the mean of the measurements. 16 The upper and lower boundaries of the limits of agreement (mean ± 1.96 × the standard deviation of the difference score), which are expected to include 95% of differences between the two measurement methods, are illustrated on the plot. 17 The spread of points within the Bland Altman plot in relation to the mean, were visually assessed to ascertain the amount of agreement between the two sets of data. A close distribution of points around the mean was interpreted as ‘good’, while a more spread out distribution was interpreted as ‘poor’. Any individual points which did not follow the general pattern and fell out with the limits of agreement were described as ‘outliers’.
Results
Committee Review of comparisons made by Bilingual Content Experts
During the Committee Review all items were discussed, and changes were made to several of the items. One of the issues discussed was the appropriateness of the word ‘phantom’ when describing pain and sensation. Some committee members stated that that Saudi people can be superstitious and often will not admit to having a ‘ghost sensation’. After much discussion it was determined that the word should be changed. Instead of ‘phantom’, the word ‘يوهم’ was used, which can be back-translated to mean ‘non-existing’.
In addition to discussing the content of the items, the committee discussed the format and numbering systems to be used in the Arabic version. It was deemed appropriate to alter the numbering of the questions in both versions to enable easier reading of the questionnaire and analysis of results. By assigning each question a number according to the section it is in, rather than the page it appears on, any confusion encountered during the printing process would be eliminated.
Results of back-translation
Discrepancies between the original English language items, and the back-translated items were found in 13 of the items. These items were discussed by the committee and appropriate changes were made to the translated version. For the majority of the items this involved only minor re-wording of the question. The revised items were then back-translated again, and the results compared by the committee.
Results of pre-test
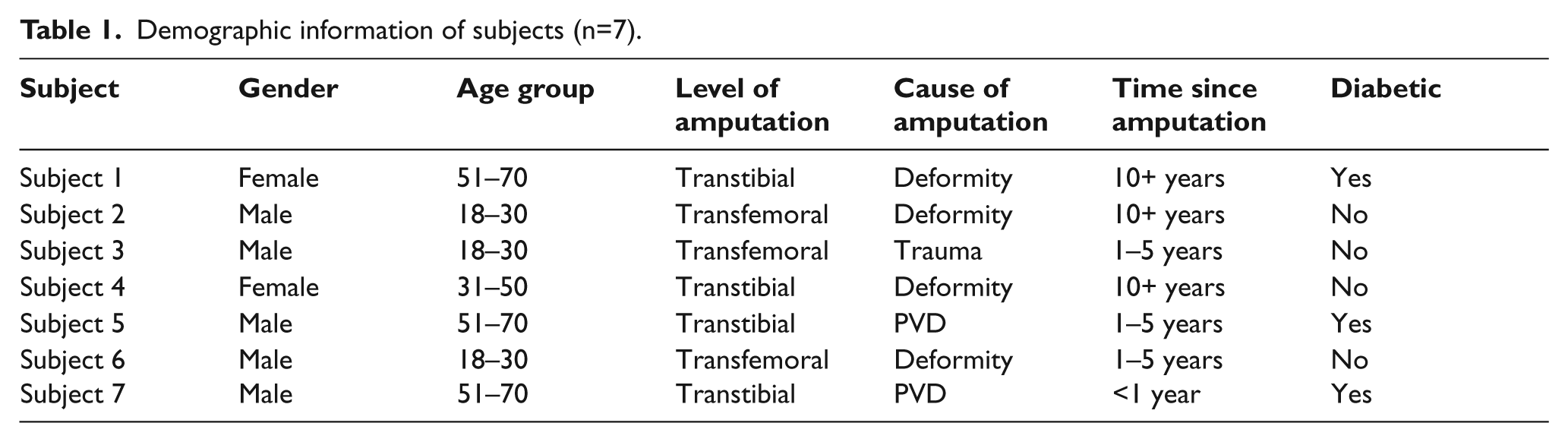
Data was collected over eight months, between February and September 2009. During this time 1,279 patients were screened for inclusion in the study. Eight patients were eligible for the study and were invited to attend. Of these, seven patients gave consent to participate and completed the study. Demographic information regarding the subjects is shown in Table 1.
Demographic information of subjects (n=7).
Testing of individual items
The results of the cognitive debriefing showed that all the subjects found the Arabic version easy to understand, and easier to complete than the English version. None of the subjects described problems answering any of the items. On analysis of the results, there was only one occurrence where a subject had recorded a response in one language but had not recorded a response in the other.
Testing of scales
The ICC point estimate scores (Table 2) for each of the nine scales were above 0.8, indicating a good level of correlation. However, for the Frustration, Perceived Response, Residual Limb Health and Social Burden scales, the 95% confidence interval was wide, indicating a large level of variation.
Results of Intra-class Correlation Testing between English and Arabic versions of the PEQ scales.
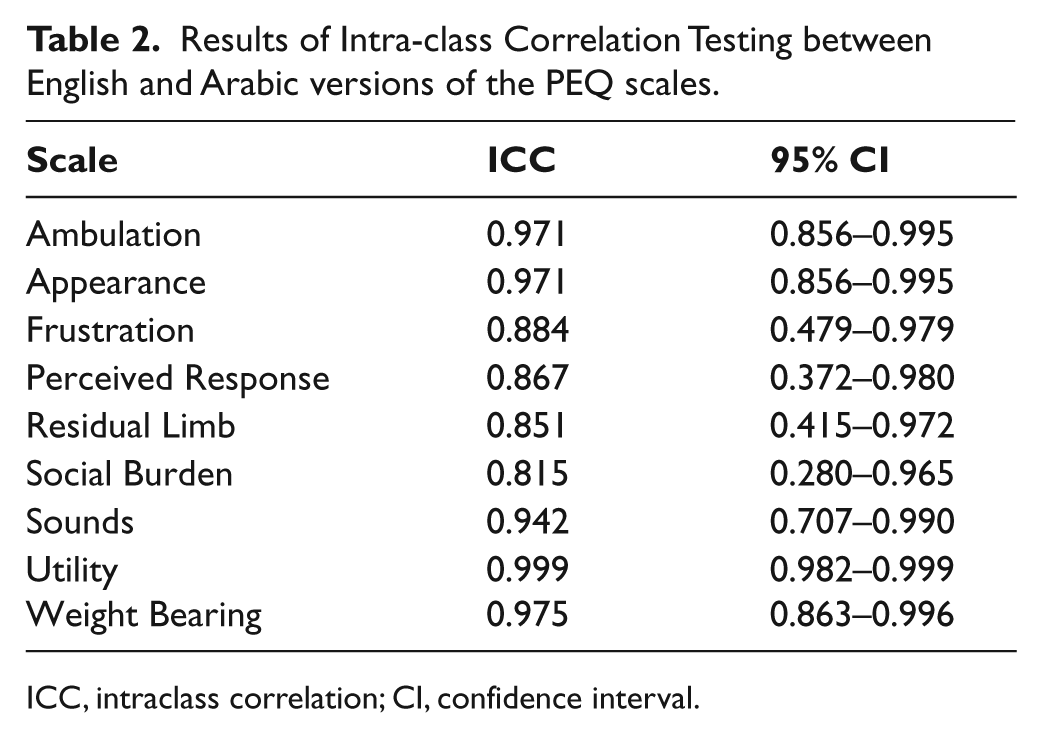
ICC, intraclass correlation; CI, confidence interval.
The distribution around the mean in the Bland Altman plots (Figure 2) was good for most of the scales, however in some cases there were outliers which, given the small sample size, affected the results. Another issue affected by the sample size were the limits of agreement which were wide for seven out of the nine scales.

Bland Altman Plots . The dashed bold lines represent the mean difference score. The dashed lines represent the limits of agreement (mean ± 1.96 × the standard deviation of the difference score). (A.) Ambulation Scale (AM), (B.) Appearance Scale (AP), (C.) Frustration Scale (FR), (D.) Perceived Response Scale (PR), (E.) Residual Limb Health Scale (RL), (F.) Social Burden Scale (SB), (G.) Sounds Scale (SO), (H.) Utility Scale (UT), (I.) Well Being Scale (WB)
Discussion
Until this exercise had been conducted, no patient-recorded OMT were available in the Arabic language, therefore, any research or monitoring of amputees had to be recorded by the prosthetist, physical therapist or physician. By creating this new tool, amputees can be more involved in their treatment. While the questionnaire was adapted specifically for the Saudi Arabian population, it is expected that the version is relevant and can be easily understood among native Arabic speakers from other communities.
The method used to translate and validate the questionnaire was lengthy and time consuming, especially compared to techniques used in similar published exercises. While there were many steps to the procedure, each had its own purpose and contributed to the development of a quality translation.
The initial development of the translated tool involved the assistance of many persons. The first translation was conducted by qualified translators with experience working in medical translation, however further knowledge of the subject was essential to produce a version of the questionnaire that was relevant and easily understood. The content experts contributed significantly to the process by suggesting alternative words and phrases, which would be more meaningful to the subjects expected to complete the questionnaire. Back-translation proved to be a vital part of the process. It was especially useful as it allowed the non-Arabic speaking PI to have knowledge of the translation. During the review of the translated and back-translated versions, many discrepancies were found, and alterations made to improve the quality of the questionnaire.
Testing of the tool was conducted using bilingual Saudi subjects. While the study sample was representative of the Saudi population in terms of gender and age, as the subjects were bilingual they may have had a higher level of education than the general population. Although this could have affected their responses to the questions, it was unlikely to affect the results of the study, which investigated the differences between responses to the same question.
Two techniques were used to test the tool; random probe questioning and bilingual testing. One disadvantage of the random probe technique that was used to test the individual items in the tool was the language barrier. As the investigator who performed this exercise does not speak Arabic, and the subjects were bilingual, the random probe interview was conducted in English. This may have affected how much information the subjects gave, as English was not their native language and perhaps they felt self-conscious speaking in that language. An improvement to this stage of validation could have been made by applying the random probe technique to a larger group of Arabic speakers, and interviewing them in Arabic. The scale testing could then have been performed separately using bilingual subjects. Pre-testing demonstrated that the method used for translation was effective as none of the subjects who completed the pre-test found any difficulty answering the items. While the subjects were all bilingual, they all reported that the Arabic version was easier to complete than the English version. This supports the opinion of Sereci, 3 that a bilingual individual will favour his native language. A disadvantage of the bilingual testing method used is that the results could be impaired by errors associated with test-retest reliability.
The test lacked power due to the small sample group which was chosen for convenience. A complete analysis of the questionnaire would have required in excess of 400 subjects which was not practical at this early stage of the tool development.
The linear analogue scales used to record most of the responses were easy to use, but time consuming to measure. An observation of the results was that often respondents would mark a similar score on the scale for each question. This was evident in both language versions and was more obvious nearer the end of the questionnaire when perhaps the subject was tiring. This observation may indicate the presence of a response set in the PEQ; where subjects respond systematically to items regardless of content. As the subjects were not observed while completing the questionnaire this cannot be confirmed. This topic has not been discussed in any of the published literature, and therefore further investigation is required in order to confirm the sensitivity of the tool.
Conclusion
The PEQ was cross-culturally adapted into the Arabic language using a process of translation, back-translation, committee review and pre-testing. The pre-testing methods used demonstrated linguistic equivalence of the Arabic and English versions. Psychometric testing of the PEQ Arabic version is required to complete the validation process.
Further outcome measurement tools should be cross-culturally adapted into Arabic to give clinicians and researchers working with the Arabic speaking population a wider number of available tools. Tools should be available for use with lower limb, upper limb and paediatric amputees.
Any persons interested in the Arabic PEQ should contact the corresponding author.
Footnotes
Acknowledgements
The authors wish to thank the Prosthetic Research Study Group for permission to translate the PEQ into Arabic, Dr Angus McFadyen for his advice with the statistical analysis, the translation team for their cooperation in the translation and adaptation process, and the subjects, without whom the study could not have been completed.
This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.
The authors declare that there is no conflict of interest.