
Abstract
Theory behind neighbourhood effects suggests that people’s spatial context potentially affects individual outcomes across multiple scales and geographies. We argue that neighbourhood effects research needs to break away from the ‘tyranny’ of neighbourhood and consider alternative ways to measure the wider sociospatial context of people, placing individuals at the centre of the approach. We review theoretical and empirical approaches to place and space from diverse disciplines, and explore the geographical scopes of neighbourhood effects mechanisms. Ultimately, we suggest how microgeographic data can be used to operationalise sociospatial context, where data pragmatism should be supplanted by a theory-driven data exploration.
Keywords
I Introduction
Current research linking the residential context to individual outcomes is inconclusive with regard to the strength and importance of neighbourhood effects, and the mechanisms behind them (Van Ham et al., 2012). The literature often highlights several methodological challenges for quantitative neighbourhood effects research, including bias caused by the non-random selection of people into neighbourhoods, and the endogeneity of neighbourhood characteristics: in other words, a correlation between variables used to explain the neighbourhood effect and the error term of the model. Both are major obstacles in determining ‘real’ causal relationships between spatial contexts and individual outcomes (see Manski, 1993). However, this paper focuses on the more fundamental issue of the definition of neighbourhood itself – an important challenge as yet given surprisingly little attention (Galster, 2001; Lupton, 2003; Van Ham and Manley, 2012).
Early investigations into neighbourhood effects used ethnographic research methods, observing life in specific neighbourhoods (see, for instance, Wilson, 1987; Wacquant and Wilson, 1989). Although the neighbourhood was the starting point of enquiry, the focus was on the sociospatial structures within local communities rather than in the neighbourhood itself. Although secondary data and quantitative methods were also used by some early scholars investigating neighbourhood effects (Lewis, 1966), the quantitative study really took off during the late 1990s, spurred by the increasing availability of microdata and computing power. This allowed researchers to model the effects of living in deprived neighbourhoods on individual outcomes, for example by using data from the 1990s Moving to Opportunity program (Katz et al., 2001; Leventhal and Brooks-Gunn, 2003).
While ethnographic research generally focused on a named and identifiable neighbourhood and local reputation, quantitative research needed geocoded individual level microdata linked to the characteristics of a diverse range of neighbourhoods, across a whole city, region or even country. As a result, most quantitative studies on neighbourhood effects use a data-driven definition of neighbourhood – the administrative neighbourhood boundaries which were readily available in the data. These administrative neighbourhoods, which may not appropriately reflect a ‘residential neighbourhood’ at all, are often the only aspect of the sociospatial context of people which is recorded in data. This is no surprise, as administrative neighbourhoods are used for the delivery of policy and the collection of (census) data based upon the political and social needs of the state, rather than based on underlying social processes that administrative units are said to delineate (Manley et al., 2006; Jones et al., 2018).
The pragmatism to adopt administrative neighbourhoods means that much quantitative research on neighbourhood effects has been driven by data availability rather than driven by theoretical considerations (Jencks and Mayer, 1990; Sampson et al., 2002). It is unrealistic to presume that a single spatial entity can adequately capture all relevant characteristics of the sociospatial context which might influence individual outcomes (Raudenbush and Sampson, 1999; Galster, 2001; Nicotera, 2007). Of course, all across the social sciences, complex phenomena have been studied using simplified assumptions about human behaviour and the urban environment, often because of the lack of appropriate data and analytic tools (Kwan, 2000). Indeed, a reduction from the complexity of the real world is required in order to say something meaningful. However, if we start from a theoretical perspective, it becomes clear that many of the assumed causal mechanisms studied as ‘neighbourhood effects’ actually reflect effects from multiple contexts with differing temporal and spatial scopes. Crucially, the residential administrative neighbourhood is only one of these scopes (Sampson et al., 2002; Galster, 2012).
To move forward, we propose a thought experiment: Rather than being driven by data availability, what if we start from theory and specify the data required from that perspective? Moreover, since quantitative research on neighbourhood effects depends on data availability, once we have considered the data requirements, how can research benefit from the increasing availability of microgeographic secondary data? With the availability of richer spatial data, quantitative studies have started to consider a larger number of spatial scales, which shed new light on multiple spatial contexts which affect people (Andersson and Musterd, 2010). Recently, alternative approaches to zonation, particularly in the form of bespoke neighbourhoods (or egohoods), centred around each person, have emerged (Johnston et al., 2000; Petrović et al., 2018). So far, microgeographic data have enabled the move away from fixed single scale administrative neighbourhood boundaries to bespoke multiscale spatial contexts (see Andersson and Malmberg, 2014).
Within the context of our thought experiment, this paper discusses how microgeographic data can be used to operationalise sociospatial contexts within the theoretical framework of neighbourhood effects. We discuss three conceptual issues, starting with the most fundamental one, how place and space have traditionally been conceptualised in different disciplines studying neighbourhood effects. We then focus on theoretical neighbourhood effects mechanisms and their relevant geographies (Galster, 2012), which leads to hypotheses on idealised spatial units for testing specific contextual effects. To operationalise these spatial units, we need to know more about the nature of spatial data and how to use them to explore social processes, and this is the third conceptual issue discussed. Building on these three conceptual issues (concepts of place and space, geography of neighbourhood effects mechanisms, and the nature of spatial data), we consider the operationalisation of sociospatial contexts in quantitative empirical studies of neighbourhood effects. We review selected studies which use different approaches to the geography of neighbourhood effects, ranging from fixed bounded administrative neighbourhoods to a multiscale representation of the sociospatial context (Andersson and Malmberg, 2014; Petrović et al., 2018). Ultimately, we discuss how microgeographic data can further improve the neighbourhood effects research.
II Modifiable geographies of neighbourhood effects
1 Concepts of space and place
Concepts of space and place have played a role in various disciplines dealing with neighbourhood effects, such as geography, sociology, criminology, economics and health studies. Here we briefly discuss concepts of space and place, starting from the perspective of health studies, which brings together epidemiology, geography and sociology (Curtis and Rees Jones, 1998; Tunstall et al., 2004; Cummins et al., 2007). The distinction between space and place in health geography suggests that space is where a location is, and place relates to what that location is (see Tunstall et al., 2004). The notion of place, therefore, reflects the social and physical attributes of particular spaces and moves us beyond a Euclidean notion of space, as a dimension in which phenomena are distributed, to a more nuanced structure. On the one hand, this view of place as an interpretation of space invokes a study which ‘can be as rich as the study of time through social history’ (Tunstall et al., 2004: 6). On the other hand, such a distinction between place and space can relegate space to a mere geometric notion. The view of space as a residual dimension, a flat surface, has been criticised by human geographers, particularly Doreen Massey (see, e.g., Massey, 2005). Space is, according to Massey, a cut through time, connecting stories and biographies and things existing at the same time, and therefore a dimension of simultaneity and multiplicity. Space presents us with the existence of others and, therefore, with the question of ‘the social’ (Massey, 2005). Throughout geographical analysis, these notions of place and space (place/space distinction and dynamic, unbounded space) have been invoked within analytical frameworks – the former for focusing on specific places as local contexts, and the latter for dynamising and unbinding space as one integrated spatial context.
A discussion on space and place in understanding neighbourhood effects also includes a distinction between context, as a measure of social environment, and composition as an individual level factor (Pickett and Pearl, 2001). This distinction has advanced health geography, supporting the relevance of place for individual health in addition to individual level effects (Duncan et al., 1998; Diez Roux, 2002). However, the ‘relational approach’ questions the strict distinction between context and composition, because the characteristics of people and the places they live in are interrelated (Macintyre et al., 2002; Cummins et al., 2007), and social space is in fact a product of our relations and connections with each other (Massey, 2005). Authors such as Curtis and Rees Jones (1998) and Bernard et al. (2007), referring to Giddens’ (1984) structuration theory, emphasise the mutual relationships between social structures and people’s behaviour, which means that neighbourhood structures have a strong influence on individuals, but also individual behaviour shapes neighbourhood contexts. The relational approach precludes places from having fixed characteristics and defines them as ‘dynamic and constantly evolving entities’ with positive and negative consequences for their residents (Cummins et al., 2007), playing at multiple spatial scales.
Spatial scale is strongly related to discussions on space and place in the field of neighbourhood effects and beyond (Smith, 2000; Brenner, 2001). Debates on place in health geography draw attention to distinct characteristics of places and the relations between the spatial and the social, often at a micro scale. Neighbourhood scale is, however, still undertheorised, despite some studies operationalising places at different scales (Tunstall et al., 2004). Different disciplines have focused on different spatial scales. While health geography has focused on smaller scales, following the concept of place, other disciplines, such as criminology, have more gradually moved from the macro to the micro. During the 19th century, crime was frequently studied at the regional and city levels (see Weisburd et al., 2008), and mid-20th century Chicago sociologists shifted the focus to neighbourhoods and communities, particularly by developing the concept of social disorganisation (Thomas, 1966; Park, 1967). Theoretical perspectives continued to focus on even smaller spatial scales, such as specific locations within neighbourhoods (Eck and Weisburd, 2015), through the introduction of the ‘routine activities’ perspective (Cohen and Felson, 1979) as well as the ‘crime pattern theory’, where place is explicitly taken into account as a ‘backcloth’ of human behaviour (Brantingham and Brantingham, 1993).
Which scales of spatial context are relevant for understanding social phenomena is not immediately clear. Suttles (1972) has argued that urban households identify four scales of neighbourhoods, starting from the block, where children can play without supervision, up to an entire sector of the city. While this rather general overview needs to be adapted for specific settings, such as city size and urban form, the multiplicity of scales is an ever-present issue in defining neighbourhood, which is more complex than a bounded unit at a single spatial scale. However, the predominant view of the neighbourhood remains a ‘geographically bound unit’, even by authors emphasising social connections as a criterion for defining neighbourhoods (Chaskin, 1995). In contrast, Massey (1994) conceptualises neighbourhood as a set of overlapping social networks with various spatial extents. Because social connections are not strictly bounded in space, neighbourhoods are inherently fuzzy entities which are difficult to define and to operationalise. The fuzziness of boundaries is important not only for small-scale neighbourhoods but also because of the lack of true (or fixed) sets of regions at the macro scale (Isard, 1956; Altman, 1994).
Fuzzy neighbourhoods are overlapping spaces as opposed to mutually exclusive discrete units. Neighbourhoods imbricate not only because of social, but also organisational, political and economic processes (Logan and Molotch, 2007). The overlapping of community boundaries implies that residents do not see the city as divided into mutually exclusive local areas with hard borders, but they see a multitude of overlapping neighbourhoods simultaneously (Hunter, 1974). Although community and neighbourhood are distinct concepts (Hunter, 1974; Sampson, 2004), this is not crucial at this point, particularly given the emphasis on the social dimension of neighbourhood. If communities, as not necessarily spatial entities, overlap in space, this is also true for neighbourhoods, which are by definition spatial. Within the neighbourhood effects literature, the concept of overlapping fuzzy neighbourhoods has been made operational as ‘bespoke neighbourhoods’ or ‘egocentric neighbourhoods’ (Johnston et al., 2000). A bespoke neighbourhood is an area surrounding an individual, starting from a very small spatial unit, and as a consequence, bespoke neighbourhoods of multiple individuals overlap. The corresponding concept of ‘egohoods’ (Hipp and Boessen, 2013) introduced an important conceptual turn in the spatial analysis of crime, which has a very long tradition of using non-overlapping units with administratively defined boundaries (Weisburd et al., 2008).
Bespoke neighbourhoods at multiple scales are a key to understanding the relationships between (adjacent) neighbourhoods, particularly through the notion of spatial spillovers. Spillover effects between neighbourhoods have, so far, received less attention than the corresponding concept of spillovers in economics (Dietz, 2002). Exceptionally, Sampson et al. (1999) identified spatial externalities as a product of collective practices in one neighbourhood benefiting surrounding areas. Although the term ‘neighbourhood’ is usually associated with an autonomous bounded area, the interest in spillover characteristics of neighbourhoods suggests that the spatial context is much more complex than just an independent coexistence of adjacent neighbourhoods. Lupton (2003) identified the following three key issues in conceptualising the spatial context in the neighbourhood effects research: the complex relationships between places and people living there, the issue of neighbourhood boundaries, and the relationship of one neighbourhood to another. Overlapping spaces at multiple spatial scales can address all three issues more competently than a single bounded spatial unit.
Ultimately, the concepts discussed above are pervaded by the relationship between space and time. Both space and time are multiscalar, and both are crucial for measuring exposure to context, with two key temporal perspectives. The first is the heterogeneity of places which people are exposed to during their daily space-time paths (Hägerstrand, 1970), including the residential, but also school, work and other environments (Van Ham and Tammaru, 2016). The second is ‘spatial times’ (Massey, 2005), which incorporate influences of different places on an individual during their lifecourse – a sequence of neighbourhoods forming an individual’s neighbourhood history (Van Ham et al., 2014). Contextual effects arise from multiple spatial and temporal domains as well as linkages and interactions between them. Underlying mechanisms are very diverse, but if we know what mechanism we are examining, we can hypothesise about its spatial and temporal scope.
2 Mechanisms of contextual effects and their spatial scope
The neighbourhood context is thought to influence a broad spectrum of individual life outcomes, including health, education and socioeconomic status, and people respond to (changes in) context in different ways (Sampson, 2012). There is no single neighbourhood effects theory, as the term covers a multitude of processes (Sampson et al., 2002). Galster (2012) categorised the assumed mechanisms behind neighbourhood effects into four categories: social-interactive, environmental, geographical, and institutional mechanisms. Dependent on the outcome under study, some spatial processes are more relevant than others, and, accordingly, some spatial contexts have greater importance than others.
Social-interactive mechanisms include, for example, peer effects on an individual’s behaviour and attitudes, local social norms, social networks, social cohesion and control (Galster, 2012). These mechanisms require (potential) contact and interaction between people, and as such are likely to play out on a very local scale. We can generally assume that peer group effects operate at the small spatial scale, such as a block or several streets (Van Ham and Manley, 2012), and that residents feel more socially integrated in their own ‘street’ than further away (Taylor and Brower, 1985).
Environmental mechanisms, such as exposure to air or water pollutants, are the most difficult to capture within discretely defined imposed neighbourhood boundaries. Besides ecological (toxic) conditions of environment, these mechanisms include exposure to violence, and physical conditions, such as the quality of public space and noise pollution (Galster, 2012). Particularly in large cities, the geography of health impacts shifts from the neighbourhood level to city level, or even to regional dimensions of air and water pollution, so that environmental burdens are increasingly displaced to greater scales (Sorensen and Okata, 2011). Conversely, the impact of contaminated land, often a factor in brown field building, may be highly localised and specific.
Geographic mechanisms refer to the neighbourhood’s location relative to larger-scale political and economic structures, and includes public services, as well as the spatial mismatch between neighbourhoods and job opportunities (Galster, 2012). Although the mismatch originates as a driver of unemployment of African-Americans in the United States (Kain, 1968), physical proximity to jobs is equally relevant in Europe (Van Ham et al., 2001; Gobillon et al., 2011). However, the scale of the mismatch depends on the local setting, since the scale at which a mechanism operates may vary between places and over time (Manley et al., 2006; Van Ham and Manley, 2012).
The fourth type of mechanisms identified by Galster (2012) were institutional mechanisms, including the interface between neighbourhood residents and vital markets related to physical conditions in the neighbourhood, local education, healthcare and other institutions to which residents have access, but also stigmatisation (Galster, 2012). Neighbourhood reputation and stigmatisation is associated with well-known, even officially defined neighbourhoods, or areas of specific types of housing or residents’ ethnic backgrounds. Mechanisms which relate to access or exposure to people, resources, or harms can be better served by bespoke measures of neighbourhood characteristics rather than by administrative neighbourhood boundaries.
Neighbourhood effects research is often used to design policies to reduce negative outcomes. The spatial contexts in which these policies are implemented are often invoked as the analytical frame for empirical research. However, neighbourhood effects mechanisms are not about officially defined administrative neighbourhoods, but about a variety of spatial contexts across fuzzy space. The fuzziness of space is bi-directional. It arises from both the overlapping individual contexts of multiple people, and the fact that individuals may belong to multiple contextual scales, which Galster and Sharkey (2017) term the spatial opportunity structure. Moreover, different people can be influenced by the neighbourhood in different ways or degrees (Bernard et al., 2007; Small and Feldman, 2012), due to different activity spaces (Kwan, 1999) or different relations to the neighbourhood during their life course (Ellen and Turner, 1997; Forrest and Kearns, 2001). Therefore, the conceptualisations of neighbourhood in neighbourhood effects research should more closely match the underlying mechanisms. This implies that the term ‘spatial context effects’ more closely matches what we try to understand than the term ‘neighbourhood effects’.
3 The nature of spatial data and social processes
Social processes occur regardless of the administrative boundaries within which data are normally collected (Manley et al., 2006; Jones et al., 2018). While many spatial scales and zonation schemes are theoretically possible, study areas are not analogous to samples in statistics which are randomly drawn from the set of all possible study areas (Longley et al., 1999). On the contrary, spatial data is often autocorrelated, meaning that the value of an observation is similar to those of nearby observations. This ‘special’ feature of spatial data (Anselin, 1989) counteracts a basic statistical principle of observation independence. Spatial autocorrelation is, however, not a nuisance, but a means to understand social processes. As long ago as the 1930s, Stephan (1934) wrote that ‘[d]ata of geographic units are tied together, like bunches of grapes, not separate, like balls in an urn’, and crucially that ‘by virtue of their very social character, persons, groups and their characteristics are interrelated and not independent’. In spatiotemporal processes, such as neighbourhood effects, ‘nearby’ and ‘distant’ need to be identified both spatially and temporally (see above on space and time being multiscalar). What happens in a location at one point in given time is related to events in nearby locations and at nearby times, although the transition to nearby spaces and times need not be linear (Goodchild, 2004).
Spatial dependence has traditionally been used to identify clusters. Pioneering work included mapping hot spots of disease in epidemiology and health geography, where small-area data have long been available (Cuzick and Elliott, 1992), as well as crime mapping in empirical research and practice of criminology (Weisburd and McEwen, 2015). Mapping clusters reveals that spatial dependency does not occur everywhere equally. Spatial heterogeneity is, therefore, another ‘special’ feature of spatial data (Anselin, 1995), such that we need to consider local characteristics of places, not universal generalities (Getis, 1999). In this respect, geographically weighted regression (GWR) examines how regression parameters vary across space (Brunsdon et al., 1996; Fotheringham et al., 2003). Both spatial autocorrelation and spatial heterogeneity are scale-dependent, as while smaller spatial units have their micro-characteristics, they are also simultaneously part of larger structures with macro characteristics. Spatial scale is a lens through which we can analyse spatial homogeneity and heterogeneity.
The modifiable areal unit problem (MAUP) is an important consequence of spatial heterogeneity (Openshaw and Taylor, 1979; Openshaw, 1984). MAUP refers to the phenomenon that the results of analyses depend on the scale of spatial units chosen, as well as on the precise zonation of the units at a single scale on the ground. Relatedly, we can conceptualise two aspects of scale. The first relates to the scale at which social structures exist and over which the processes operate and is known as the phenomenon scale. This contrasts with the second, the analysis scale, which relates to the size of the units at which these phenomena are empirically measured and analysed (Montello, 2001). Whilst it might seem trivial to suggest that analysis scale should correspond to the phenomenon scale from the research and policy perspective, often they do not. Compared to the natural sciences, research regarding scale in social sciences has been less explicit and precise (Gibson et al., 2000). Matching the phenomenon and analysis spatial representation of social processes is associated with a high degree of uncertainty in space and time, as defined within the uncertain geographic context problem (Kwan, 2012). As a consequence, available spatial data often do not match the mechanisms behind neighbourhood effects that we want to study and understand.
III From neighbourhood effects to sociospatial context research
The literature has often treated neighbourhoods a-spatially, or implemented only discrete parts of the theoretical concerns we outline. Where a neighbourhood is given sufficient conceptual space, it remains a nuisance rather than a fundamental focus of the research question. Besides critiquing this pragmatic approach, we point out some theoretically-informed examples operationalising sociospatial contexts, which can be applied more widely.
Opposing concepts of neighbourhood include ‘objective’ and perceived neighbourhoods, fixed and bespoke neighbourhoods, single-scale and multiscale neighbourhoods, homogeneous and heterogeneous neighbourhoods (see reviews by Nicotera, 2007; Chaix et al., 2009). Small-sample qualitative studies and large-sample quantitative studies fundamentally differ in exploring sociospatial context. Qualitative studies reveal information that quantitative studies of large populations are unable to explore, particularly with regard to residents’ perceptions of neighbourhoods. Neighbourhood boundaries imposed by an outsider researcher neglect residents’ experiences, which can be relevant for individual outcomes. In contrast, large-sample quantitative studies require simplified assumptions about neighbourhood size and boundaries, but yield more generalisable and comparable results. The generalisation of neighbourhood related findings can be problematic.
Qualitative surveys reveal that residents differ in their assessment of the neighbourhood, whereby assessments of some neighbourhood characteristics, such as social disorder, are more easily aggregated from multiple responses than other characteristics, such as social interactions (Coulton et al., 1996). Additionally to qualitative methods, including discussion groups or interviews (Davidson et al., 2008), geographic information systems (GIS) are increasingly used to assess residents’ perceptions of neighbourhood size and boundaries (Lohmann and McMurran, 2009). In a study of low-income communities in 10 cities in the USA, Coulton et al. (2013) found that neighbourhoods delineated from GIS maps drawn by respondents are smaller than typical census tracts, but larger than those gained from residents’ answers on an ordinal scale or qualitative questions. GIS-based studies result in different conclusions regarding whether and which sociodemographic characteristics of people determine how they perceive their neighbourhoods (see, e.g., Lee and Campbell, 1997; Orford and Leigh, 2014). This mirrors different settings in which the studies are conducted, in addition to different methods used.
Large-sample quantitative studies can also learn from this and pay more attention to various spatial settings and individual sociodemographics. Individual heterogeneity arising from ethnographic research has been identified as very useful for quantitative studies of neighbourhood effects (Small and Feldman, 2012), but these two types of research are still rarely combined. Furthermore, as Chaix et al. (2009) note, methods used to delineate perceived neighbourhoods can also be used for objectively experienced neighbourhoods, which may be more informative in understanding individual outcomes, given that contextual effects rely on exposure and interaction. Methods for detecting objectively experienced neighbourhoods use location-aware technologies such as GPS and mobile phone tracking to find activity spaces (Ahas et al., 2010; Chaix et al., 2013). While these methods have relaxed spatial and temporal constraints (Shaw, 2010), delicately measuring exposure in space and time, they have also intensified ethical issues in data collection.
When data on activity spaces are not available, empirical studies sometimes compare administrative units at different spatial scales. These studies demonstrate the relevance of spatial scale, particularly the constraints of the lack of small-area data for representing local contexts. For example, Prouse et al. (2014) in their study on income inequality in Halifax, Nova Scotia (Canada), criticised the coarse scale of the census tracts as a predominant proxy for neighbourhoods. Instead, the authors suggested that in smaller cities dissemination areas, as defined within census tracts, following distinctive features such as roads or waterways and encompassing 400 to 700 people, are more useful. This conclusion appreciates not only spatial scale but also urban form, specifically distinguishing between bigger and smaller cities. However, we should not focus on micro-geographies to the detriment of larger spatial structures.
Moving beyond the administrative unit, neighbourhood effects studies increasingly compare different spatial scales by aggregating the smallest available units to higher scales using ‘bespoke neighbourhoods’ (Bolster et al., 2007; Stein, 2014; Veldhuizen et al., 2015). Bespoke neighbourhoods tackle the fact that people living on the edge of an administrative neighbourhood might associate themselves with, or be influenced by, the adjacent neighbourhood. Exploring spatial scale of bespoke neighbourhoods has the potential to advance our understanding of the wider residential context. This was illustrated by Petrović et al. (2018), who constructed bespoke neighbourhoods at 101 spatial scales, ranging from the very micro (100 by 100 meter grids) to very large spatial units. They showed that multiscale understandings of spatial context differ between locations within one city, but also between cities with different urban forms. So far, most neighbourhood effects studies have investigated within-neighbourhood effects – the effect of the neighbourhood in which someone lives – whereas few studies have considered neighbourhood as being embedded in a wider spatial context (Graif et al., 2016), the influence of ‘neighbouring neighbourhoods’ (Bolster et al., 2007), or adjacent neighbourhoods forming an extra-local context (Sampson, 2001). When analysing this wider context and spatial autocorrelation, crucially, urban form also needs to be considered (Petrović et al., 2018).
As discussed earlier, it is not only space that is multiscalar but also time, and we need to understand contextual effects in a multiscalar space-time framework. For example, Van Ham et al. (2014) studied the intergenerational effects of neighbourhood in Sweden by reconstructing individual neighbourhood histories from the moment of leaving the parental home. They showed that growing up in a deprived neighbourhood increases the likelihood of living in a similar neighbourhood later in life. And Hedman et al. (2015) showed that the childhood neighbourhood affected individual income up to 17 years after leaving the parental home. Wodtke et al. (2011) showed that longer term exposure to deprived neighbourhoods has a strong effect on school outcomes, and that the effects of social exposures have long temporal lags.
The lack of appropriate data sometimes leads to the conclusion that the MAUP, or geography in general, are irrelevant for individual outcomes. For example, Brännström (2005) did not find effects of either census areas or parishes on individual income and receipt of social assistance in Sweden. As noted by Andersson and Musterd (2010), both of these spatial units are heterogeneous and may obscure processes occurring at smaller spatial scales. Looking into these smaller scales is increasingly possible through the availability of microgeographic data in the form of small grid cells, and further differentiation of spatial scales was achieved by starting with grid cells and aggregating them to larger scales of bespoke neighbourhoods (Östh et al., 2014; Petrović et al., 2018). Thus, microgeographic data make it possible for researchers to move away from predefined (administrative) neighbourhoods to spatial contexts which are both individualised and multiscalar (in space and time). This development signals a turn from the study of neighbourhood effects to the study of sociospatial contextual effects.
IV The role of microgeographic data in future contextual effects research
Microgeographic data include spatial data with a fine spatial resolution, such as point data or areal data for regularly shaped (grids) or irregularly shaped polygons, e.g. census tracts. These data can come from various sources, including (government) registers or large-scale surveys. According to the fractal principle, ‘all geographic phenomena reveal more detail with finer spatial resolution, at predictable rates’ (Goodchild, 2004: 711). As such, the ‘special’ features of spatial data – spatial autocorrelation and spatial heterogeneity (Anselin, 1995, see Section 2.3.) – should be recognised, not as problems but as opportunities (Fotheringham et al., 2000). In this respect, microgeographic data offer numerous opportunities to advance research into contextual effects.
1 Spatial and relational thinking
Analytic tools and techniques in neighbourhood effects research often treat spatial units in the same way as any other variables. Three basic ways of dealing with spatial data include using regular statistical methods and ignoring spatial dependence; acknowledging that spatial dependence exists and trying to remove it to justify using aspatial methods; and taking spatial autocorrelation explicitly into account and explaining it from a theoretical perspective. The latter approach benefits the neighbourhood effects research, although even spatial statistics often treat this spatial dependence as a nuisance and something that should be corrected, rather than as an important source of information. The increasing availability of microgeographic data motivates social scientists to think about how they represent sociospatial context and how to integrate spatial analysis in their research.
In comparison with the natural sciences, the social sciences have been slower to exploit GIS although the spatial dimension is no less important for social than for natural processes. Maps can be found in early social science, but many disciplines moved away from these roots, developing other methodologies (Steinberg and Steinberg, 2005). Current trends in data science make mapping particularly relevant, because visualisation helps elucidate complex spatiotemporal patterns. GIS has not been sufficiently reconciled with neighbourhood effects studies. An exception is the work of Knaap (2017), who mapped the spatial opportunity structure to link the geography of opportunity with the mechanisms of neighbourhood effects. GIS expresses geography as a series of layers, capturing unique but related features. The spatial opportunity structure (Galster and Sharkey, 2017) is similarly organised as a series of contextual characteristics, such as ethnic and income compositions. Methods such as geographically weighted regression (GWR) can be used to operationalise spatial context by the interaction of multiple contextual characteristics, as well as the characteristics themselves in nearby locations. This can be a useful exploratory tool, which gives specific results for different locations rather than a single universal result.
Relational theory suggests that space can be understood only through relations. This includes subjective relations between people as well as individual spatial perceptions of neighbourhood, but also ‘objective’ relations as functional distances to schools, healthcare or other services. Relational perspectives on place emphasise the position of places relative to each other (Cummins et al., 2007). There is no spatial knowledge without metric information about distance and relative locations of places (Montello, 1998). Furthermore, conditions in one neighbourhood are not independent of conditions in adjacent neighbourhoods, which makes spatial autocorrelation the fundamental tenet of the research question. Finally, the connections between physically distant places, including mobility trajectories of people or regional labour markets, may also be important for individual outcomes. Distances and spatial relations can be more accurately measured using microgeographic data.
Precise measures of locations come not only from recording people’s residential locations using population registers or census data, but also from following people’s mobility using new technologies such as mobile sensing. Whilst innovative, this development also increases privacy concerns (Campbell et al., 2008). For instance, De Montjoye et al. (2018) proposed four models for the privacy-conscientious use of mobile phone data for research, including limited release, pre-computed indicators and synthetic data, remote access and question-and-answer. Some of the models can be applied to other types of sensitive data, such as health data, although none of these models cuts through the complexity of the use of sensitive data for research (De Montjoye et al., 2018). Privacy issues particularly concern the increasing linking of different sources of (sensitive) data, such as administrative records, survey data or areal imagery.
2 Fuzzy and bounded space
Neighbourhoods are ‘geographic objects with indeterminate boundaries’ (Burrough and Frank, 1996). Imposed boundaries matter to different extents for various neighbourhood effects mechanisms or for the same mechanism in different settings. For example, administratively defined neighbourhoods with high shares of ethnic minorities may be stigmatised, as might areas abutting asylum centres, but the extent of these areas may not coincide with administrative units. Different types of bounded and fuzzy spaces drive individual residential histories so that while people may rely on officially defined neighbourhoods such as school districts when selecting potential neighbourhoods, they may also pay attention to (functional) distances to transportation sites or other services. When moving into the neighbourhood, exposure to others depends less on administrative boundaries and more on proximity, so that the relevant contexts become even fuzzier. Microgeographic data makes it possible to better understand bounded spaces, for instance heterogeneity in ethnic compositions or housing types within administrative units, but also fuzzy spaces of potential or actual exposure to context.
Individual exposure to context can be better represented with exposure surfaces in a ‘moving window’ defined at multiple spatial scales rather than fixed spatial units. For example, if a small area where an individual lives is surrounded by a markedly different larger area, this is masked when the two areas are combined into a large single unit. With the moving window this does not happen (Jones et al., 2018). Exposure surfaces via a moving window can also move us beyond discrete-space modelling. For neighbourhood effects (which are by definition spatial processes), the commonly used fixed effects model completely removes space, leaving neighbourhood as an isolated unit (Bell et al., 2018). Moreover, the use of an individual as their own control unit in a fixed effects model denies group level effects and assumes independence of outcomes across areas, rendering the question of neighbourhood effects meaningless. Two basic ways to take spatial dependence into account are hierarchical structures of space in multilevel models, and spillovers captured in spatial econometric models. Both approaches can be related to how social processes work, recognising not only the coexistence, but also the interdependence, of multiple spatial scales. Additionally, very small areas, close to exact geographic coordinates, also offer possibilities for continuous-space modelling. The continuous treatment of space can reveal the spatial distribution of outcomes and the scale of spatial variations, in contrast to measuring characteristics of the neighbourhood in a more traditional, bounded, sense which may obscure or underestimate the effect of context as a more complex spatiotemporal category (Cummins et al., 2007).
Many individual outcomes depend on duration of exposure to different places, such as the residential neighbourhood and school for education outcomes, or residence and workplace for labour market or health outcomes. Therefore, microgeographic data can also improve the connection between time and space. We can adapt spatial scale to the temporal scope we are interested in, for example by using micro-locations for exposures on daily space-time paths, or larger scales for long-term exposure to, say, poverty. While administrative units precisely define a neighbourhood boundary, the location of an individual within that area remains unknown. Microgeographic data can reveal the location of an individual more precisely, while the boundaries of their multiple neighbourhoods are fuzzier. Thus, to measure multiple spatial scales, the question become where to set thresholds.
3 Thresholds in fuzzy space
Thresholds exist even in a fuzzy space. Without limits, there can be neither difference nor identity (Abrahamsson, 2018). Setting thresholds in bespoke neighbourhoods using microgeographic data is particularly challenging, both because of the individual character of the neighbourhood and because of the fuzzy space. Bespoke neighbourhoods are usually based on distance or population counts. Population based bespoke neighbourhoods can be constructed from geographical coordinates for each individual. Using micro-scale grid cells, small increments in distance can be more accurately applied than small increments in population, because grid cells themselves are created based on distance. Even irregularly shaped spatial units can be used, although they are more challenging for delineating both distance and population.
The choice between specific techniques for delineating bespoke neighbourhoods is not solely a technical issue, but a theoretical one as well. On the one hand, some institutions or services are located based on the population served, which justifies the population count thresholds. Elsewhere, the area over which these people are distributed is important, because distance determines accessibility and exposure. For example, direct residential environments and exposure to first neighbours are normally associated with short distances regardless of the number of neighbours, although the density of neighbourhood can also affect social processes. Furthermore, since the same number of people can be distributed over very different areas, population size alone is not sufficient to characterise large scale contexts. In addition to distance, local patterns of land use (e.g. housing, play area, transportation infrastructure, etc.) can assist in setting thresholds in fuzzy space.
Considering multiple spatial scales in a fuzzy space has been achieved by using spatial profiles, which consist of a range of bespoke neighbourhoods from micro to macro scales. Based on the egocentric framework (see Lee et al., 2008), Spielman and Logan (2013) created profiles of individual buildings, which show how the surrounding social compositions change with scale. Petrović et al. (2018) created distance profiles of exposure to sociospatial context at a range of 101 spatial scales and measured the variability of the distance profiles across scales. While in some locations the context changed gradually, abrupt changes in other distance profiles revealed ‘social cliffs’ (Dean et al., 2018; Petrović et al., 2018). Uncovering these marked sociospatial changes is relevant for neighbourhood effects research, because micro locations and local changes in exposure are often at the core of the theory, but in the empirical research they have often been studied through a proxy of too coarsely bounded spatial units. Fuzziness of space as well as changes and limits in the fuzzy space have received more attention in studying natural than social phenomena (see Burrough and Frank, 1996; Fisher, 2000). However, in identifying the extent of a mountain from the perspective of different people, Fisher et al. (2004) dealt with similar issues, particularly spatial scale. The methods which they used to identify morphometric classes (peaks, slopes, channels and ridges) of a mountain could also identify ‘social cliffs’, ‘social cleavages’ and other classes of exposure surfaces in urban settings. These methods can be used to further develop the concept of distance profiles representing sociospatial context.
Regardless of the metrics (e.g. distance, population counts, travel time) used to delineate bespoke neighbourhoods, the smaller the scale, the more ‘bespoke’ neighbourhoods can be, and the bigger the scale, the more ‘shared’ and overlapping neighbourhoods are. The multiscale bespoke neighbourhood perspective, therefore, draws attention to both local peculiarities and extreme contextual conditions on the one hand, and large-scale shared contexts on the other hand. This is what the theoretical approaches to neighbourhood effects mechanisms ask for and how sociospatial context is likely to be operationalised in the future more often, given the increasing availability of microgeographic data.
V Structuring the uncertainty of sociospatial context
The overview of theoretical concepts of space and place and mechanisms of spatial contextual effects, as well as the review of the empirical literature, were permeated by issues of spatial scale and boundaries in fuzzy space. This, combined with the immense possibilities of microgeographic data, leads to uncertainty in the operationalisation of sociospatial context. Empirical studies which address the issue of spatial scale sometimes note that there are no theoretical guides as to the scale at which contextual effects operate (see, e.g., Plum and Knies, 2015). In this section, we bring some structure to the relationship between contextual mechanisms and spatial scales. Although uncertainty in the operationalisation of sociospatial context cannot be avoided, it can be structured in a way that shows which mechanism is most likely to operate at which scales, as well as on which factors this likeliness depends.
Figure 1 shows a matrix of contextual mechanisms and spatial scales. The density shows the likely relevance of a specific scale for a specific mechanism. For example, while peer group effects normally operate at a small spatial scale, school districts extend to larger scales. Some mechanisms may operate at multiple scales simultaneously, particularly processes like stigmatisation. While labour market factors generally operate at larger spatial scales, the exact extent of local labour markets varies across regions. With a single spatial scale, we run the risk of cutting through various mechanisms, capturing relevant scales for some and less relevant scales for other mechanisms, represented with horizontal lines in Figure 1.
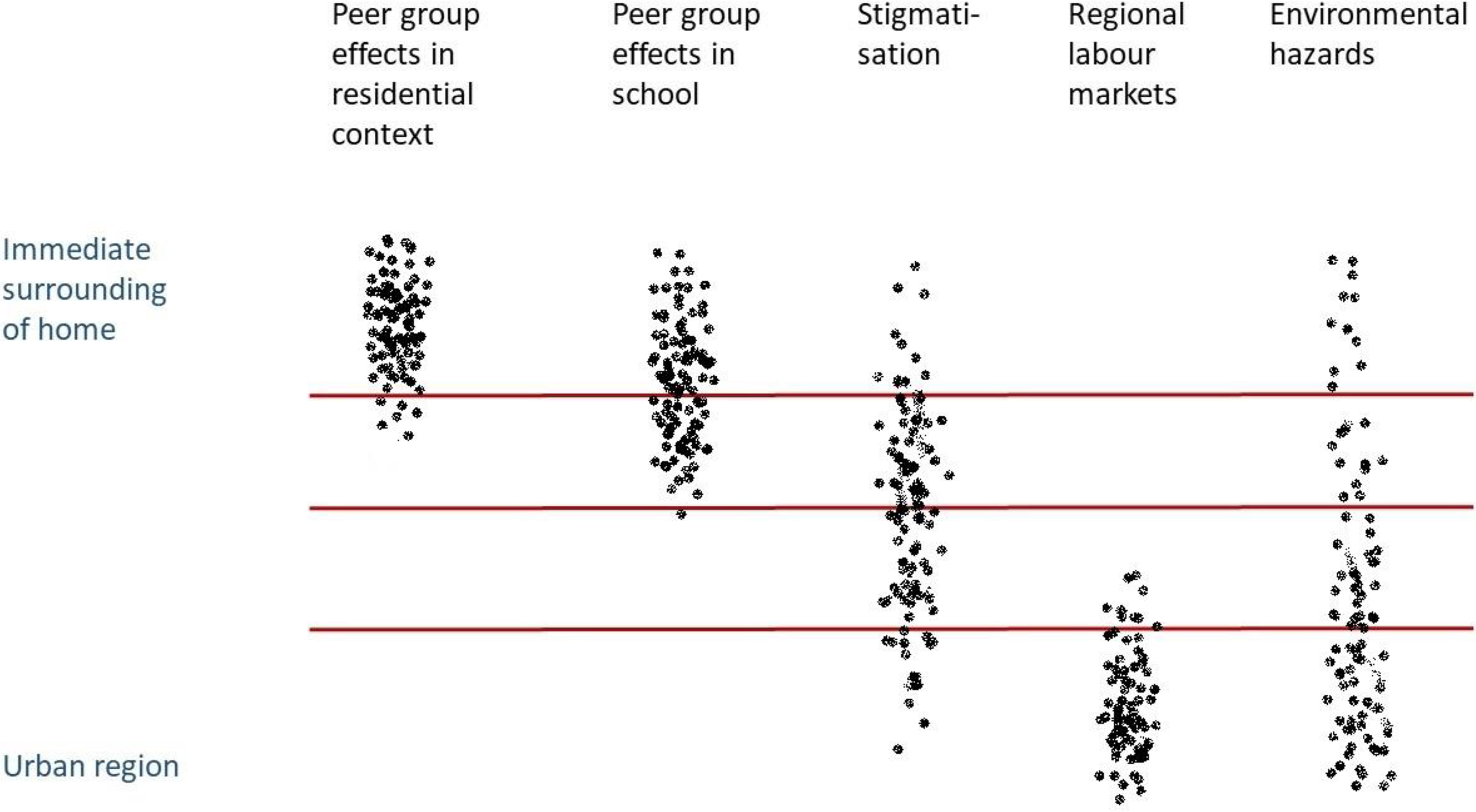
Spatial scales of contextual mechanisms.
Which scale is the most relevant also depends on the sociodemographic characteristics of people and the urban setting, which can be illustrated with an example: One child grows up in a street with poor neighbours, but in a middle-class district, and goes to a middle-class school. Another child goes to the same school and lives in the same urban district, but in a street with richer neighbours. Both children live in the same urban region so their spatial contexts are shared at some scales and distinct at others, and they include interactions between individual, family, neighbourhood, city and regional level factors.
Ultimately, neighbourhood effects research should be reconciled with more individual- and family-oriented perspectives on human development, by recognising the key lower-level context – the family, and its mediating position between an individual and the neighbourhood (Lee, 2001; Hedman et al., 2019), as well as the interaction of other factors, such as genes, with the environment (see e.g. Boardman et al., 2013). Although technology has become increasingly important in the social domain, many forms of social life remain spatially organised. Many types of behaviours are spatially concentrated, so that even individuals who use the internet the most concentrate in certain neighbourhoods (Sampson, 2012).
General hypotheses about specific mechanisms and their spatial scope are as important as the knowledge of the spatial and temporal setting. Theory can inspire qualitative studies in various settings, based on which hypotheses for quantitative studies can be formulated. Ethnographic studies, therefore, have an intermediate role between theory and quantitative studies – to help generate clearer and more specific hypotheses, but also to provide qualitative data which can be linked with administrative records. The way to implement the theory of contextual mechanisms in quantitative studies would then be firstly, to formulate general hypothesis, for distinguishing between different mechanisms, e.g. peer group effects operate at a smaller spatial scale than stigmatisation (see Figure 1); secondly, to analyse the spatial and temporal setting, e.g. stigmatisation takes larger spatial scope in a big city and increases over time as the concentration of poverty increases; thirdly, to formulate specific and nuanced hypotheses regarding affected people, e.g. people from the neighbourhood with different vocations or of different age are affected in different ways.
VI Conclusions
In this paper, we built on conceptual and empirical work related to neighbourhood effects, to raise spatial awareness and integrate knowledge from various disciplines, particularly because spatial data are increasingly detailed and more accessible to researchers. We identified increasing interest in spatial scale and bespoke neighbourhoods, but also discordances between the theoretical approaches to contextual effects and the empirical research. Therefore, we proposed ways in which microgeographic data can further advance contextual effects research. The first is that data should remind us that contextual effects research is about the space around us, and that we should adopt a spatial perspective from approaches which actively use it, such as GIS. Second, with microgeographic data we can implement the concepts of fuzzy space. Concomitantly, we should not forget landmarks or boundaries which are easily recognised, and we should use different concepts of space (fuzzy and bounded) when appropriate. Third, fuzzy space, and particularly its thresholds, need to be further explored using microgeographic data, for example in the form of spatial profiles. Spatial profiles show that MAUP is not a mere problem, but also a resource for studying a range of spatial scales of context.
Quantitative research depends on the synchronised availability of good-quality data, well-formulated hypotheses which can be expressed in mathematical terms, analytic tools and techniques, and technology to facilitate the analysis (Haining, 2003). Formulating hypotheses is a crucial initial step, ideally the main determinant in the choice of appropriate spatial data. Theoretical approaches to the mechanisms of neighbourhood effects should guide these hypotheses, where, for example, social mechanisms generally differ from institutional mechanisms in both spatial scale and zonation schemes. The hypotheses can be refined by exploring spatial patterns of area characteristics, e.g. housing types or poverty concentrations in different (parts of) cities and with the results of qualitative research of the study area. Crucially, microgeographic data put a wider variety of scaling and zonation schemes into practice and, therefore, make it feasible to follow theoretical approaches to neighbourhood effects and bring back spatial thinking into neighbourhood effects research.
A parallel between theorising place and space and the availability of spatial data can be drawn from the health geography or criminology, where the concept of place was given more attention compared to other (sub)disciplines within the neighbourhood effects research (see also a similar observation by Haining, 2003). Further parallels can be drawn between theoretical approaches such as peer group effects, spatial spillovers or the relational approach, on the one hand, and the nature of spatial data, notably spatial autocorrelation, on the other hand, which are often considered separately, either studying social theory or technical properties of spatial data. By linking theoretical and spatial analysis approaches, the grounding for neighbourhood effects research increases, as does our knowledge about phenomenon scale. Together, this can then inform analysis scale. The role of microgeographic data is then to better link the phenomenon and the analysis scale, as well as to give attention to both micro-locations and large-scale urban, institutional and economic structures.
A parallel also exists between geographic objects with fuzzy boundaries in physical and human geography. Geography, the most spatial of disciplines (Massey, 1995), should enrich the neighbourhood effects research by facilitating zonation systems that are less arbitrary and can capture various mechanisms of contextual effects more accurately than predefined administrative areas. Also, methods used in physical geography to operationalise geographic phenomena which are fuzzy for scale reasons (Fisher et al., 2004) can be used to dynamise space and make it relevant for the broad social science. Using microgeographic data, neighbourhood effects research can give more attention to location, distance and exposure, spatial dependence and heterogeneity, taking into account multiple neighbourhood membership. Microgeographic data move us from the autonomous bounded spatial units to continuous space, in which neighbourhoods are much fuzzier than is generally assumed, and where spatial contextual effects should be investigated rather than ‘neighbourhood’ effects.
Using standard administrative units has for a long time been a defining feature of neighbourhood effects research. This is understandable as many datasets require specific geographies to be used. However, the increasingly availability of microgeographic data is helping social scientists to better understand sociospatial context and arrive at clearer conclusions about contextual effects. The variety of spatial contexts that are possible to study using microgeographic data should not only remain alternative ways of operationalisation of neighbourhoods. Instead, they should become a paradigm of the spatial contextual research. Where the neighbourhood effects literature argues for more attention to the definition of neighbourhood, we even go one step further, and argue that in order for neighbourhood effects research to move on, we need to break away from the tyranny of neighbourhood, and consider the effects of the broader sociospatial context of people.
Footnotes
Acknowledgements
We would like to thank the editor, Professor Pauline McGuirk, the anonymous editor two and three anonymous reviewers for their suggestions to improve the original version of the manuscript. We would also like to thank Professor Mark Stephens for his suggestions at the New Housing Researchers Colloquium in Dublin 2016.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research leading to these results has received funding from the European Research Council under the European Union's Seventh Framework Programme (FP/2007-2013) / ERC Grant Agreement n. 615159 (ERC Consolidator Grant DEPRIVEDHOODS, Socio-spatial inequality, deprived neighbourhoods, and neighbourhood effects).