
Abstract
We contribute to the Science in the Forest, Science in the Past series by investigating the specific practices of “data science”, a set of contemporary methods associated with large-scale data processing infrastructure that shares many characteristics with artificial intelligence technologies. We offer a critical history of data science in relation to the engagement of Western publics with environmental policy through “citizen science”, and contrast those developments with the authors’ different experiences and perspectives of applying aspects of data science and citizen science in collaboration with local communities in South America and Africa.
Introduction
Investment in and reliance on digital computing technologies have become central to many forms of institutionalised scientific research. Data-intensive scientific discovery has been described as a “Fourth Paradigm” (Hey et al. 2009), and is promoted by technologists as succeeding pre-digital eras of direct observation and analytic generalisation. Our contribution to “Science in the Forest, Science in the Past” considers this contemporary advocacy of data science, via a critical investigation that draws both on history of the field (as we explain, a comparatively recent past) alongside cross-cultural perspectives from the forests of Africa and South America.
We interrogate data science in relation to the closely cognate field of artificial intelligence (AI), which at the time of writing threatens to disrupt conceptions of knowledge across many domains of professional practice. We have a particular interest in the way that AI algorithms are trained through the appropriation of human labour, for example when open public resources or volunteer effort are recruited to work alongside professional scientists to collect and interpret “crowd-sourced” datasets. This tendency within data science can be compared to the mechanisms of data extraction, exploitation and inequality that underpin the internet economy driving AI research, described by Couldry and Mejias (2019, 2020) as “data colonialism” for the ways that these dynamics echo earlier infrastructures of enclosure, extraction and exploitation of physical resources.
In addition to the economic implications of data as a commodity for global science and industry, we consider the ways that data science follows AI in reconfiguring knowledge and knowledge work. Blackwell (2023) has claimed that AI functions as a branch of literature, constructing new representations of what it means to be human. The programming languages and database schemas of data science, while not intended to be literary, indeed define what it is possible for scientists to know, just as the language in which literature is written defines the conceptual space that literature can explore. In campaigning for literature to be written in his own and other African languages, Ngũgĩ wa Thiong'o argued that writing in one's own language was essential for decolonisation of the mind (Thiong'o 1986). We, therefore, explore the relationship between the technical Western “languages” of data science, 1 and the alternative ways of knowing often characterised as Indigenous knowledge (or IK) (Bidwell et al. 2022).
Data science and planetary health
A key focus in this edition of the Science in the Forest, Science in the Past series, as articulated by Geoffrey Lloyd, is ideas and practices related to health and well-being, including conceptions of the body, the self in relation to the world and its inhabitants, states of being, normalcy and deviations from the normal, and intelligence however manifested. From the perspective of data science, the health of the human population is an increasingly data-intensive area of research. Public health has been concerned with statistical data from the time of Florence Nightingale and Jon Snow (Palmer 1977) through to the daily statistical updates of the Covid-19 pandemic (Spiegelhalter and Masters 2021). At the leading edges of health research, statistical genomics and protein modelling are used to quantify and calculate the normal functions of a healthy human body as well as problematic deviations, and the “quantified self” movement has conceived human well-being as a data commodity available for commercial exploitation (Couldry and Mejias 2020).
However, in our own contribution to this collection, echoing the attention given by Professor Lloyd to the world and its inhabitants, we are especially concerned with the health of the planet rather than humans as individuals (cf. Gabrys 2020a; Horton and Lo 2015; Whitmee et al. 2015). Within this exploration of planetary health and environments, we consider the relationships and intersections between digital technology and environmental data science, and how they influence forests as inhabited sites and objects of scientific study. We thus engage with the rubric of science in the forest to question how contemporary data science generates and engages with diverse knowledges and practices of forests.
Western-led policy recognises biodiversity and carbon-storage as two examples of how forests contribute to planetary health, through the interrelation of environmental and human flourishing. However these instrumental Western views of the forest present a regrettably dramatic contrast to the knowledge and traditions of those who live in forests of the Global South, where it may never have occurred to treat the health of humans and of forests as separable in the first place (Green 2012; Adom 2018). International agreements and obligations reward nations in the South for the contribution of their forest ecosystems to carbon credits and biodiversity, following commercial dynamics that we return to discuss later in this article (Beauman 2022). But these practices are data-intensive and require extensive monitoring and reporting mechanisms to demonstrate the health of forests. Meanwhile, multiple other data practices materialise in and in relation to forest spaces, whether through participatory monitoring, Indigenous archives, or counter-mapping projects (Gabrys et al. 2022).
We illustrate our reflections on these themes by reference to four data science projects undertaken by the authors, involving a diverse range of collaborators in both Global South and Northern institutions. The most extended of these sections, coming at the end of this paper, considers the infrastructure being developed and deployed by Joycelyn Longdon, to record and analyse environmental acoustic data in a forest in Ghana. Our collaborators in this continuing project are Prof Emmanuel Achaemong, Head of the Department of Silviculture and Forest Management at Kwame Nkrumah University of Science and Technology (KNUST) in Ghana, and Dr Adham Ashton-Butt of the British Trust for Ornithology. In order to contrast that forest setting to environmental data science practices in the North, we start with a brief critical history of the development of data science in association with citizen science, via the observation of birds and acoustic recording of birdsong. Recording and observation are differently configured in the way that Jennifer Gabrys’ earlier collaborative research in citizen sensing is now developing through a Smart Forests initiative in locations including Chile, India, Indonesia, the US and EU. We describe a third project, presenting a contrast to the embedding of sensing infrastructure within the forest, turning to the remote sensing of forest environments from satellites, in which Longdon investigated international efforts to monitor deforestation in the Democratic Republic of Congo. In the last of the projects we describe experiments with reconnecting satellite imagery to local communities, in Alan Blackwell's collaboration with educators working in a city bordering a biosphere reserve in Ethiopia.
The colonialism of data science
This paper interrogates and problematises the ambitions of data science in the forest. At once a marketing catchphrase, a profession and a new academic discipline, data science is contributing to the establishment of many funding initiatives, degree programmes, congresses and peer-reviewed publication venues (Provost and Fawcett 2013; Cao 2016; Jat et al. 2021). What are the social-political consequences of data science as informed by commercial interests of historically deforested yet wealthy nations on one side, and on the other, those in the Global South whose remaining forests are often threatened by the dynamics of colonial capitalism?
If data science is implicated in the global infrastructure of exploitative labour, colonial oppression, and wealth extraction (Couldry and Mejias 2019), do we simply join the queue of critical commentators elaborately describing the workings of digital injustice? Should we direct our gaze toward the environmental costs of the data industry itself, including mineral extraction and the resources used to power data centres (Gabrys 2014; Hogan 2015); or to the whistleblowers and conscientious objectors within the data science and AI industries (Bender et al. 2021; Lannelongue, Grealey and Inouye 2021)? Despite these urgent and important questions, our intention here is not to echo or amplify these approaches. Instead, our research focus is motivated by ethnographic and participatory concerns that consider how data can be understood and practised in alternative ways from within the forest, and in relation to the concerns of forest dwellers.
We write at a time when there is widespread attention to the contributions of “Indigenous knowledge” (Ulloa 2017; Latulippe and Klenk 2020). The value of IK is framed within international consensus on environmental health and conservation, as expressed in the Sustainable Development Goals, governed through international law, and measured by scientific bodies such as the UN Environmental Program's World Conservation Monitoring Centre (Ingwall-King, Gangur and Mistry 2020). Moreover, the diminishment of IK would only compound the irrecoverable loss of ecological and genetic biodiversity (e.g. Barrera-Bassols and Zinck 2003; Yahaya 2012; Adom 2018).
Nevertheless, there are many reasons for the people who live in or adjacent to forests to be cautious of such international interest in their “knowledge”. Colonial extraction of Indigenous knowledge has been notoriously inequitable, including in the use of intellectual property law to confiscate or appropriate the medicinal knowledge of traditional healing plants through patenting of valuable species without compensation to those who “invented” their medicinal application, or to the traditional owners of the land where those species grow (Mooney 1980; Leach and Davis 2012). The very concept of fieldwork has been characterised as fundamentally extractive (Nhemachena, Mlambo and Kaundjua 2016), while the residual inequities of conduct in colonial research institutions have been used to fuel populist resistance to public health crises (Green 2012) rather than integrating the expertise of local populations in contributing to new conceptual frameworks (Mavhunga 2018).
The relationship between data and knowledge that is presumed in Western conceptions of “knowledge work”, “knowledge industries”, “knowledge-based systems”, and “knowledge engineering” demonstrates how data communications and processing technologies have become an infrastructure that both shape and privilege the epistemological cultures within which they arise (Bidwell 2021). The very notion of “intellectual property”, as elaborated in the Western-led international frameworks of copyright and patent laws, can seem meaningless or profoundly unethical in comparison to traditional conceptions of knowledge. As explained by Barry Barclay (2005), in his proposal for an alternative framework of mana tuturu in the spiritual guardianship of Māori taonga (cultural treasures), the application of copyright law to such treasures can be compared to the doctrines of settler colonialism under which existing traditional law was held to have no status in court because of its assumed inferiority to the European laws of the colonising power. Movements to develop Indigenous data sovereignty are articulating different approaches both to the infrastructures and practices of data, and to the epistemes that data practices support and extend (Kukutai and Taylor 2016; see also Westbury et al. 2022). Engagement with local communities via digital technologies demands epistemic accountability to avoid the potential for a person's meanings, contributions and communicative practices to be undervalued, excluded, silenced, misrepresented or systematically distorted (Bidwell 2021). Our goal in this paper is to explore how data sciences and data practices are shaped, and can potentially be re-shaped by attending to these diverse infrastructures that are within and in relation to forest environments.
A critical technical practice of data science
This article is a sequel to papers that Alan Blackwell has presented at two previous Science in the Forest, Science in the Past workshops. Both reflected on the status of AI as a science, responding to the fertile epistemological traditions brought by other contributors, and considering AI both as a product of its past and as an enterprise situated in a particular contemporary landscape that resists characterisation in relation to science in the forest. The first of those papers, Objective Functions, Deep Learning and Random Forests, questioned the epistemological and cultural foundations of AI, advocating a contextualized, qualitative and interpretive social science of “big data”, and leading to a published paper that interrogated (In)humanity and Inequity in Artificial Intelligence (Blackwell 2019). The second of Blackwell's SFSP contributions proposed an agenda for Ethnographic Artificial Intelligence (Blackwell 2021), introducing the plans for his own fieldwork in Ethiopia, Namibia and Uganda, cut short by the Covid-19 pandemic, but leading to publication with his Ethiopian colleagues on Inventing Artificial Intelligence in Ethiopia (Blackwell, Damena and Tegegne 2021) as discussed further below.
The overall orientation of the new work that we present in this paper, as with the earlier SFSP contributions by Blackwell, is associated with an agenda known as Critical Technical Practice (which we abbreviate to CTP), originally proposed by Philip Agre in 1997, in his compelling personal reflections on Lessons Learned in Trying to Reform AI. As subsequently quoted, Agre had become convinced that AI researchers in computer science departments were engaged in covert philosophy, whereas his own goal was to make the philosophy overt. This required him “to stop thinking the way that AI people think, and to start thinking the way that social scientists think”.
CTP can be understood in part as a concerted response to the high modernism of the twentieth century cybernetic programme, which originally aspired to a future of interacting with computers as “man-machine symbiosis” (Licklider 1960), a modernism now signified by the Bauhaus aesthetic that has become ubiquitous in the products of Microsoft, Apple, Google's Android and their global licensees and competitors. Although the modernist drivers of the information economy have become wholly embedded in international late-colonial business and policy (Mhlambi and Tiribelli 2023), academic computer science has more recently responded with a comparatively postmodern approach to this rational view of computation, through a “second wave” of research in human-computer interaction (HCI) exemplified by a turn to the social in the work of Lucy Suchman (2007) among others familiar to Agre, and a third wave incorporating the ironic and pastiche elements of practice-led Critical Design (Bardzell et al. 2012).
Many reflective practitioners in computer science research have adopted Agre's CTP as a banner for particular ways of proceeding as academics, although not so much in the mainstream of AI research where Agre developed his concerns (indeed, many current AI researchers have never encountered Agre, or any other critique from 25 years ago), but certainly in the field of HCI, where the phrase is associated with those who work on the boundaries of user experience design and science and technology studies, including the present authors, but also leading critical voices in the field, for example Dourish et al. (2004). This community of reflective practitioners see themselves both as designers and social scientists, engaged in research practices where making, even craft, is itself a source of knowledge, to be understood among the social settings of technical construction, everyday use, and critical reception.
In bringing these intellectual concerns of HCI researchers to our forest sites in Africa and South America, we hope to remain alert to the fact that postmodern responses to the modernist agenda of computational sciences and technologies reflect European and Western preoccupations, not necessarily the predominant concerns of the Global South. Decoloniality can itself be a response to modernity, which would take CTP in a very different direction (Mignolo and Walsh 2018). But as observed by Kwame Anthony Appiah, the postmodern impulse to distance oneself from ancestors need not be presumed as a priority for African philosophers, especially where these theories are implicated (as is HCI) in the cultural trade of world capitalism (Appiah 1993, 149). There is active debate over whether AI could ever be decolonised, given its origins in eugenics and racist models of intelligence (Adams 2021), and approaches to decolonial thinking in HCI are still under active development (e.g. Bidwell and Winschiers-Theophilus 2015; Awori et al. 2016).
Data science versus artificial intelligence
The term “Data Science” was practically unknown as recently as 2008 (see Figure 1), and certainly not ready for critical inspection when Philip Agre was trying to reform AI in the 1990’s. In most practical uses, “data science” could be directly replaced by the traditional term “statistics”, since both its purpose and practitioners are the same, and indeed many of today's leading data scientists previously described themselves as statisticians.
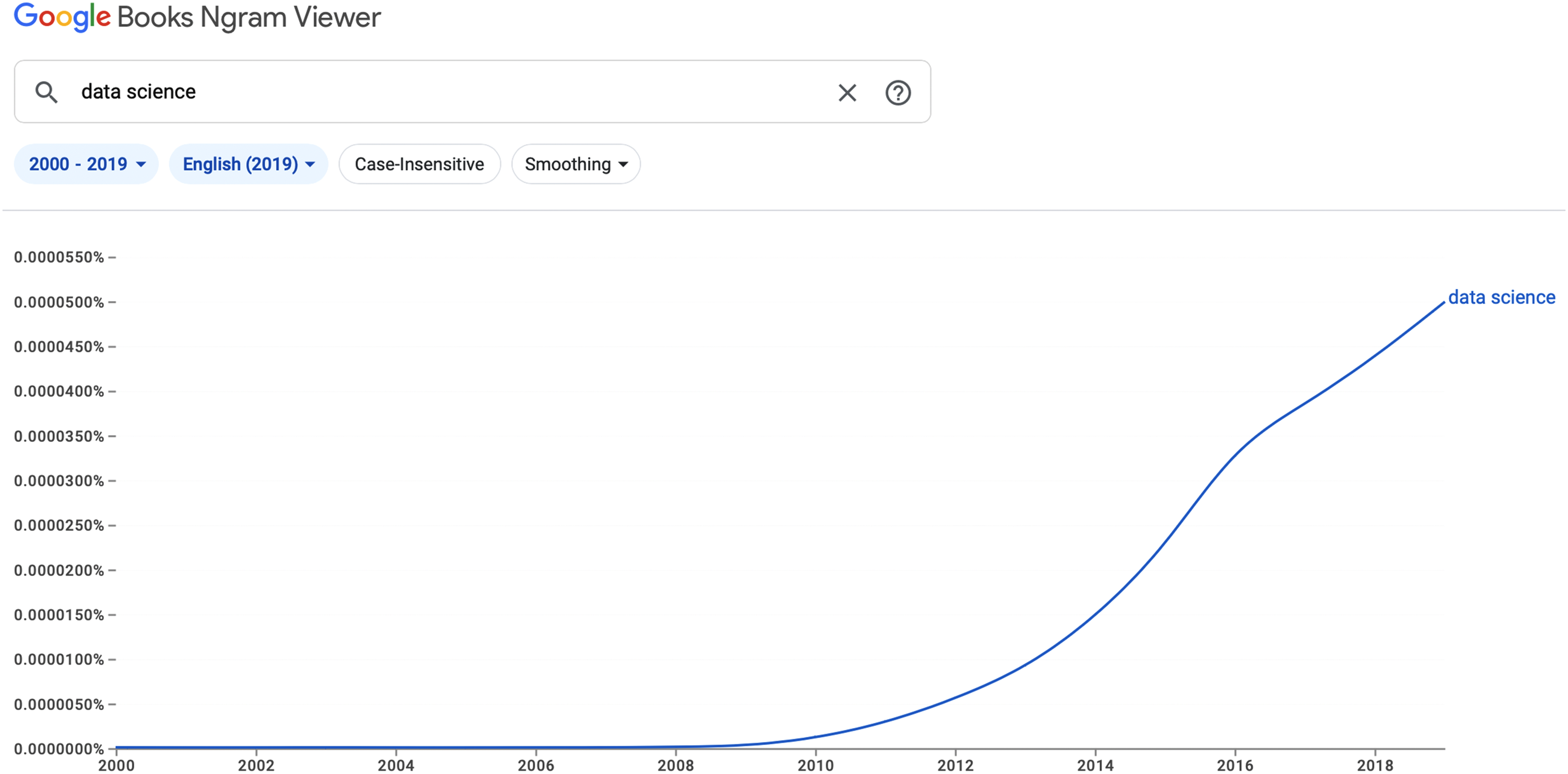
The rise of “Data Science” since 2000.
However the ambitions of “data science” as a promotional term do extend beyond those of statistics, aspiring to the status of scientific knowledge in itself, rather than (as was almost always the case for research statisticians) in the service of another discipline. This shift has come about, as with the revival of interest in AI over the past 20 years, through dramatic advances in the class of algorithms referred to as “machine learning”. Machine learning methods have proven particularly effective in the automated processing of extremely large quantities of data, moving beyond familiar statistical domains like epidemiology to include large corpora of text and digital images that could not previously have been processed numerically using statistical methods. As we explain below, applications of machine learning in forests are growing to include many different modalities of data — certainly traditional statistical reporting of quantitative measurements, but also digitised images and sound recordings.
A casual observation of contemporary studies in computer science, as seen in many universities, is that although students are initially excited by the prospects of humanoid robots or new intelligent life, in practice they focus on the technical application of machine learning algorithms. After acquiring those skills, most do not proceed to the careers imagined by science fiction, but are employed to apply machine learning algorithms to business problems under the banner of data science. Rather than exploring the nature of intelligence, much data science and machine learning deals with mathematical problems that are familiar from high school mathematics, such as making predictions on the basis of trends and correlations. As argued in Blackwell's (2021) previous presentation to SFSP, imitation of human intelligence by “predicting” what humans have said before, as in the recently notorious ChatGPT, is a kind of pastiche, plagiarism or parody of hidden human work (cf. Bender et al. 2021; Blackwell 2024), itself often commissioned from ghost workers in Africa or elsewhere in the Global South (Gray and Suri 2019; Rowe 2023).
In the remainder of this paper, our goal is to problematise the enterprise of data science in relation to cultures and environments other than its home ground of AI research and statistical governance. The rhetorical claim implicit in the promotional phrase “data science” seems to assume a kind of meta-scientific status, in which quantification has become a science in itself, independent of what is being counted (Blackwell 2022). However, the doubtful epistemological basis of such a claim can be somewhat obscured by appeal to “artificial intelligence”, through which actual knowledge is claimed to arise directly (through computation) from numerical data. Taking data science to the forest is, we hope, an opportunity to challenge such claims.
A key concern is that the computational regimes of data science may exacerbate the replacement or devaluing of traditional and Indigenous knowledge. While there have been a few experiments in integrating traditional modes of observation and reasoning into a statistical machine learning framework (e.g. Masinde and Bagula 2011), it is more commonly the case that Western scientific framing can undermine or replace traditional knowledge (Adom 2016; Kosoe, Osei-Wusu Adjei and Diawuo 2020). Treating Indigenous knowledge as abstract data can easily lose its contextual and cultural significance (Awori, Vetere and Smith 2015). Furthermore, Indigenous knowledge practices are already appropriate and sustainable, in contrast to “modern” alternatives that require expensive apparatuses and special training (Yahaya 2012).
Citizen-data infrastructures
Before we proceed to describe our own fieldwork, this section examines the Western frame from which our research concerns have emerged. Research undertaken in a computer science department, with a focus on eco-acoustic data, would routinely be associated with the historical adoption of machine learning methods for analysis of birdsong by ornithologists (e.g. Stowell and Plumbley 2010; Nicholson 2016; Priyadarshani, Marsland and Castro 2018). We therefore wish to stay alert to the sociotechnical dynamics within which public imagination is married to technical resources in such methods, identifying and responding to the mainstream approaches and narratives of Western data science.
In Western imaginations of forest conservation, birdsong in particular can function as a signifier of ecological biodiversity, as skilfully employed by Rachel Carson in the title of her classic 1962 polemic Silent Spring. Public support for conservation science is often mobilised through enthusiasm for birds and birdsong, for example in the Cambridge Conservation Initiative, a supporter of our own research, which includes among its partner organisations charities such as Birdlife International, the British Trust for Ornithology (BTO), and the Royal Society for the Protection of Birds (RSPB). Later in this paper, we discuss the capture and analysis of audio data in a forest in Ghana, in a project collaborating with BTO and Ghanaian researchers 2 , although noting that the popular appreciation of birdsong in the gardens and countryside of Europe and North America should not be taken to mean that birdsong is considered the preeminent feature of an ecological soundscape in West Africa.
Longstanding organisations such as the RSPB (est. 1889) and its US counterpart the Audubon Society (est. 1905 3 ) have mobilised public participation in scientific data collection through large-scale observational surveys such as the RSPB Big Garden Birdwatch that has taken place annually since 1979. In the US, the phrase “citizen science” was coined in the mid-1990s to describe a project of the Cornell ornithology lab, whose founder Arthur Allen had convened evening seminars to raise public awareness about ornithology since the 1950’s (Bhattacharjee 2005). The distinctive opportunity for wider public engagement through the internet was recognised by Cornell ornithologist Rick Bonney (2008), who started to talk about citizen science following a project in 1995 that distributed a bird observation survey (on paper), inviting members of the public to send their responses by email (Gura 2013). The Cornell lab has continued to innovate in the use of digital communications for collecting observational data, now via its eBird app (Sullivan et al. 2009), but also coordinates advocacy for citizen science across many disciplines, via platforms such as Citizen Science Central and the Citizen Science Association.
The most dramatic recruitment of volunteer enthusiasts as unpaid research assistants for data science was achieved in the Galaxy Zoo project (Raddick et al. 2010) established to label the immense quantities of data arriving from the Hubble space telescope. Without dwelling on the reference to environmental commodification suggested by the “Zoo” metaphor, the Zooniverse infrastructure now coordinated by the Citizen Science Alliance is used by research teams in many scientific domains to coordinate large-scale processes for sending images, collecting responses, checking labels by comparing judgments of different volunteers and so on.
Recruiting humans to make isolated intelligent decisions, as component elements within an engineering data processing infrastructure, had already been pioneered in commercial contexts with Amazon Mechanical Turk (AMT), which as claimed by Blackwell in his previous SFSP contributions represents the disguised operating principle of all so-called intelligent AI systems, whose intelligence is constructed by collecting and replaying human judgements (Blackwell 2021). The exploitative nature of such arrangements is generally avoided through euphemisms such as “crowd-sourcing”, a term that has been used not only as a marketing term for systems like AMT, but sometimes as a near-synonym for citizen science. These ambitions seem reminiscent of early optimistic enthusiasm for direct democracy through the global internet, later revealed to be a new source of misinformation and oppression, just as the flexible labour underpinning social media and AI is now being criticised as creating an underclass of “ghost workers” (Gray and Suri 2019).
Despite (or perhaps in response to) the problematic use of citizen science as a euphemistic cover for minimal-cost research labour through crowd-sourcing, there have been projects that emphasise the status of the “citizen” as political agent rather than purely low-cost labour. For example, the Cornell team have developed the overlapping interests of amateur bird watchers with those who engage in conservation volunteering, and even in community political action promoting conservation priorities for planning and regulation in their residential neighbourhoods (Cooper et al. 2007). A vast range of citizen science and citizen sensing research has engaged with how these practices can reorient the power dynamics of knowledge production, the production of data, and the mobilisation of evidence to support democratic and pluralistic worlds (e.g. Irwin 1995; Ottinger 2010; Gabrys, Pritchard and Barratt 2016; Storksdieck et al. 2016; Oliver et al. 2017; Gabrys 2022a).
The purposeful entangling of science, technology and politics by advocates of citizen science goes beyond the dynamics that are apparent from science studies, for example, enlisting volunteers as instrumental allies in scientific work (Latour 1987), extending to the role of these internet applications as media platforms. These platforms can be a political tool to be used in aligning public discourse toward the scientific evidence and priorities of the researchers, and applied to causes ranging from biodiversity preservation as studied by Latour in the Amazon, to climate change mitigation, with consequences that Latour had not anticipated (Rojas 2015).
Data science and citizen science thus come together in a sociotechnical infrastructure where the technologies of observation and recording are entangled with human labour of interpretation, including the perceived value of certain species rather than others as signifiers of biodiversity, conservation priorities, and planetary health. Unsurprisingly, ornithologists such as the Cornell laboratory have taken this opportunity to invest in machine learning methods, while birdsong is seen as an attractive application domain in which to test and demonstrate machine learning algorithms (Gaunt et al. 2005). The epistemological commitments of the classical neural network, in which samples of complex data are classified by reference to “ground truth” labels of a training set, seems ideally suited to the simple prerequisites of studying avian utterances. Bird species have distinctive songs, an objectively certified hierarchy is available in the form of Linnean classification, and ample volunteer labour is available to annotate recorded sample recordings with the species that produced them.
The application of these methods in the field is, unfortunately, less straightforward, for example when multiple species of bird are vocalising at the same time, other sounds complicate the recording, or the volunteer observers might not be sufficiently skilled in attributing sounds to the correct species (Herman 2020). As a result, the most successful demonstrations of neural networks for many years were those that employed recordings of individual birds, captured in the controlled setting of a laboratory recording studio.
Nevertheless, the confluence of public interest and goodwill, the metonymic significance of birds and their song, and the technical opportunities offered by field recording technologies and neural network algorithms have resulted in an embedding of these Western priorities and values into the knowledge infrastructure that might be deployed around the forest. As critical technical practitioners, the brief historical commentary above has demonstrated our commitment to interrogating and unsettling the epistemological and political commitments that have been embedded in scientific infrastructure, re-centring publics as fundamental to the technical project, rather than incidental participants or recipients. The remainder of this paper illustrates these dynamics through four examples of our own practice-based research, drawn from different stages of project development. Each reflects a particular set of data science and sensing technologies, but in relation to the practices of the “forest” rather than the imagination and ideals of Western data scientists.
Classifying forest through data practices
Joycelyn Longdon's research is supported by the UK Research Councils as one of a cohort of students in the Cambridge Centre for Doctoral Training on AI for Environmental Risk (AI4ER). This Centre is one of 14 that were established across various UK universities in 2018, with the objective of developing research skills in AI (seen as a national priority for economic development (Hall and Pesenti 2017)), while addressing practical problems that will both validate the potential impact of AI technologies and make progress toward solving those problems through the expected value of the technology itself. This is, of course, an approach to science funding that simultaneously advances a research question on behalf of the scientists receiving the funding (what is the potential value of AI?), while also predicated on the answer to this question (that AI will be more effective than other possible research investments toward solving the problems of environmental risk). The resulting expectation is that every project carried out in this Centre, and in others like it, should demonstrate that AI is an effective way of addressing whatever problems that particular Centre has been created to address.
As a result, most projects at the AI4ER Centre have clear engineering objectives, able to be solved through the application of technology that is understood to be effective rather than offering speculative enquiry. In practice, and as already explained, this requires the objective methods of data science rather than the subjective imagination of AI (Blackwell 2023). In the first year of the 4-year AI4ER degree programme, students develop and demonstrate their data science skills in a mini-project related to environmental risk. In Longdon's case, this project for her MRes also related to forests, though the short time available makes it impractical for MRes students to actually collect data from a forest. Instead, the data for these data science projects must be reused from other research projects, in the hope that better data science methods will discover new patterns in the data that were not already apparent to those who originally collected and analysed it.
Longdon, as with many other students in this situation, based her MRes project on the archives of data collected by the Landsat programme that has been jointly managed by NASA and the US Geological Survey since the 1970’s. Data collected by Landsat 7 over the past 20 years takes photographs of every part of the Earth, with each individual pixel corresponding to an area of 30 by 30 metres. The colour of each pixel includes the familiar RGB (red, green, blue) of digital photographs, but also several infrared bands. Data collected from satellite images (often referred to as “remote sensing” among specialists) is particularly convenient when, as in the case of Landsat, the US government-funded scientific outputs are made freely available for anyone to access. As a result, much of the satellite imagery currently familiar through commercial products such as Google Earth is derived from Landsat data. Google also makes the Landsat data more conveniently available to academic researchers who have limited budgets, through free access to the Google Earth Engine that stores archived images from Landsat, and provides data science algorithms, visualisation tools, and processing resources. Although the role of Google as a corporate sponsor is not investigated further in our work here, we note with interest that the familiar product Google Earth itself started as a proposal to investigate deforestation (then called “Google Tree”), and that scholars have traced the artifice involved in the construction of the cloudless “Pretty Earth Image” (Sansone Ruiz 2023).
It is not unusual for Landsat data, together with Google Earth Engine, to be used for projects that address environmental risks. Longdon's MRes project was one of many that considered how satellite images could be used to remotely sense deforestation, by observing when particular 30m by 30m pixels, that had previously been the colour of green forest, changed to become another colour. In principle, this seems straightforward, but in practice, the relationship of changes in the satellite image to the things one might experience within the forest is extremely complex, and might not be unambiguous evidence of deforestation. Most vegetation constantly changes its colour, according to seasons. One might compare a specific week of one year to a specific week of another (if only the seasons were so conveniently aligned in an era of changing climate), except for the fact that heavily forested areas are also often covered by cloud, meaning that the reference location in the critical week of the previous year might often have been inconveniently hidden from the satellite. Furthermore, a technical fault that historically afflicted part of the Landsat equipment means that there are large stripes of missing data in several years, especially across the parts of central Africa where Longdon planned to locate her case study in the Democratic Republic of Congo.
A further substantial problem is how to “train” the machine-learning classifier that recognises one colour of pixel as representing forest, and another not. These algorithms rely on training sets labelled with “ground truth” observations of what actual vegetation growing on that particular 30 m by 30 m piece of ground has resulted in the colour of that pixel. In practice, training data is constructed by drawing boundaries on a map, based on local geographic knowledge of the boundaries of forest reserves, urban settlements, agricultural communities and so on. At the time of Longdon's Master's research, the most accurate training data for previous training of Landsat classifiers had been amassed elsewhere, while land use surveys from the DRC had reported on a 300 m grid 4 , with only one human judgement for every 100 points on the Landsat image. By careful selection of 5 land cover classes (Cropland, Shrubland, Forest, Urban and Water) from among the original 37, Longdon was able to train her machine learning classifier to demonstrate reasonable consistency of automated satellite observation with other measures of deforestation (Longdon 2021).
Of course, the transformation of forest into farmland does not happen accidentally, and the enterprise of constructing objective remote sensing measures to detect such transformations is a political enterprise. Longdon had chosen to study the Mai Ndombe region because it had come to the attention of an environmental campaigning group monitoring the effectiveness of the REDD+ (Reducing Emissions from Deforestation and Forest Degradation) carbon offset and credit schemes (Ickowitz et al. 2015). The question of whether a photographic pixel captured in one place and time is, or is not, considered to be a pixel of forest, thus has direct financial and political consequences in other places and times. For a country subject to economic exploitation and political unrest, there is substantial motivation to have the satellite images look the way that they should. If agricultural cultivation happens to be carried out under the forest canopy where it cannot be seen from a satellite, it produces economic value while still attracting environmental incentives, regardless of the actual ecological consequences. Even more problematic, much native “forest” is not dense tropical canopies, but savannah or other kinds of natural vegetation that may be indistinguishable from local cultivation practices. Detecting deforestation in such circumstances, defined as a clear change of labels from forest to not-forest, involves AI that is interpretive as much as objective. Not only must every pixel have an agreed interpretation at a single point of time, but change in the colours of these pixels over time may or may not be evidence of humans modifying forests. Sometimes pixels become less green, then more green again, from one year to the next. Official audits rely on specifying thresholds of how sudden the change must be, with a constraint that the change should not be reversed the next year (as often happens), and all are subject to the uncertainties already mentioned of cloud cover, technical failures, approximate ground truth labels and so on.
A critical technical practice perspective resists the tempting privilege of remote sensing as a view from on high, using images in which humans are literally invisible, and technical gaps are taken to reflect the absence of any knowledge. Instead, the perspective of the critical technical practitioner acknowledges the dangers of surveillance-as-science, ensuring that science about the forest is always fully engaged with science in the forest. These dynamics, relating the research site of the forest-laboratory to the global commodification of carbon capture industry, have already been documented in the Brazilian Amazon context where the REDD+ programme was initiated (Rojas 2015).
Bringing satellite data down to Earth
While the use of satellite imagery as a mechanism for enforcement of forest preservation is a potent metaphor for the decontextualisation of observation through remote sensing, with the resulting potential for data science to reinforce neocolonial economic arrangements, there is no reason in principle why such data should not be re-connected to the locations being observed. A project undertaken by Alan Blackwell, in collaboration with colleagues in Ethiopia and the UK, extended the methods developed in Longdon's MRes project to a specific conservation context and local community. Blackwell's collaboration with AI researchers in Bahir Dar Ethiopia had previously identified the opportunity for an alternative approach to AI that they described as “broad learning” (Blackwell, Damena and Tegegne 2021), for its emphasis on including wider contexts and populations, as a contrast to the “deep learning” methods that have been developed through the extractive and exploitative commodification of data (Blackwell 2023).
Bahir Dar University (BDU) is located on the shore of Lake Tana, celebrated in the BDU motto as Wisdom at the Source of the Blue Nile. Lake Tana is the largest body of water in Ethiopia, and also a UNESCO Biosphere Reserve (Wondie 2018), meaning that in addition to being one of the longest-established technology research centres in Ethiopia, BDU has major research programmes dedicated to sustainable agriculture, fishery management, and conservation of the lake and its surroundings. One of the greatest environmental threats for Lake Tana is invasive water hyacinth, which has spread over much of the coastal surface area (Tewabe et al. 2017), and is clearly visible from satellites (Asmare et al. 2020), making it an appropriate focus for our exploration of placing satellite observation data within the context of local science and learning.
Blackwell worked with students and colleagues 5 in a technical exploration of whether the sociotechnical infrastructure of classifying Landsat images could be combined with some simple principles of citizen science, at a level appropriate for advanced secondary school students in Ethiopia. With a special focus on one of the Ethiopian STEM Center schools that had been established for talented students to interact with academics from local universities like BDU, the goal of this curriculum development project was for students to develop an understanding of machine learning-based data science alongside more embodied observation of the environmental neighbourhood of their school. Cropped versions of Landsat 8 images were created, so that file sizes were small enough directly to be downloaded and processed on school computers. Rather than building classifiers using standardised and sanitised ground truth datasets, the proposed lesson plans included field trips along the lake shore for students to collect their own observations, photographing water hyacinth at specific locations they and their families in the local community could report with the recently released Amharic-language version of the what3words app.
Although deployment of this curriculum was disrupted by the Covid pandemic and armed conflict in Ethiopia, lesson plans and a pilot implementation demonstrated that commodity mobile phones and school computers can offer both local agency and a more sophisticated appreciation of how observational evidence informs environmental policy (Sanchez-Ricol 2021). Where Western school curricula have traditionally taught probability and statistics with gambling apparatus such as coins, dice and cards, this project was one of a series that have related machine learning pedagogy to practical applications in African contexts (Blackwell et al. 2021; Attahiru, Hall Maudslay and Blackwell 2022; Mutua and Blackwell 2023).
This experiment in broad learning was completely reliant both on globalised infrastructures (Landsat, Google Earth Engine, Android phones, what3words), and also on the agenda of the STEM centre that associated development opportunities with technical and scientific education (our collaborator Dr Tesfa Tegegne, the principal of the STEM centre, was also the director of the BDU research centre in ICT for development). These tensions between global trends in technology research on one hand, and local autonomy and agency on the other, permeate AI research (Blackwell, Damena and Tegegne 2021), but the next case studies explore ways in which closer engagement with the forest unsettles that technically-driven perspective.
Smart forests
Gabrys's research on Smart Forests investigates the digitalisation of forest environments, especially for the purposes of managing and mitigating environmental change. Within the scope of data production and data science, many environments are becoming “smart” through digital technologies such as the Internet of Things, which would sense environments and actuate changes (Gabrys 2020b). Data-oriented technologies ranging from remote sensing to situated sensors, Lidar and robots, camera traps and participatory apps, are generating, circulating, and contributing to actions for governing forest environments. Data practices and data sciences then contribute to different social-political effects, depending upon who is involved in using digital technologies, generating data, and acting on evidence. As the Smart Forests research project has demonstrated, power inequalities can arise across actors such as big tech companies in the Global North and forest communities in the Global South, or across environmental policymakers and commercial tech firms with different objectives and commitments to addressing environmental change (Gabrys et al. 2022). The “datafication” of forest environments involves selecting, mobilising, and sustaining particular forest worlds, which can come at the expense of others. Forests become bounded and stabilised as objects of scientific enquiry by the sensing and data infrastructures that monitor and observe them, more than ever within the concerns for global deforestation and carbon sequestration. Using inventive digital practices, fieldwork, participatory workshops and mapping, the Smart Forest research project studies the transformation of forests and forest communities through digital technologies. Through case studies, the project analyses how forest technologies are transforming practices of observing, mitigating, participating in, and regulating environmental change.
Part of this approach to developing inventive research methods has involved designing a participatory open-data platform, the Smart Forests Atlas, which invites extended stakeholder networks to contribute to documenting, commenting on, and connecting through forest initiatives that attend to digital technology interventions. With four “way-finding” devices, including logbooks, stories, a map, and a radio, the Atlas composes forest data into particular narrative forms that reorient more statistical engagements with data. It also unfolds through a set of “digital gardening” techniques that allow for pluralistic and multi-directional data practices across participants (Westerlaken, Gabrys and Urzedo 2022). This further allows for a more-than-human approach to forest data, where digital technologies can tune into other forest worlds (Gabrys 2022b).
Across the Smart Forests research collective, individual case studies are taking place across India, Indonesia, the Netherlands, and Chile. With the latter case, the question arises as to what counts as data, and why data matters for addressing issues of forest loss, monocultures, and wildfires. Working across social sciences, creative practice, ecology, and computation, the South American case study especially considers how different sensing practices compose different forest worlds, which can create data-infused forms of knowledge, but also other ways of experiencing and contributing to forests that exceed a data-focused project. Viewing the forest through a plurality of entities and digital channels is a response to human-centred sciences of the forest, and in particular, the kinds of dynamic that are now motivating Longdon's initial investigations as described in the next section.
Data science infrastructure in and for the forest
We introduced the mode of our joint enquiry in relation to Agre's prescription of a Critical Technical Practice for AI research (Agre 1997). Agre's concern, in trying to “reform AI”, was to encourage his technical colleagues to recognise and acknowledge the philosophical nature of their work. This remains an urgent problem for AI researchers today, whose day-to-day work might be devoted to relatively mundane statistical data science, but who continue to be motivated by fundamental questions in theory of mind, without necessarily having the opportunity to become familiar with the intellectual precedents that could better formulate those questions. However, it is also important to acknowledge the second element of Agre's prescription, which was to advocate philosophical enquiry that did have an empirical base in technical practice. Many of the insights that have been achieved from AI arise precisely from the engineering enterprise of testing some theory of mind by implementing it.
In this final case study, we describe the starting point for an ongoing project, in which Longdon's PhD research will involve the practical design of software and hardware infrastructure that takes data science to a specific forest context and community.
This research seeks to understand what the dynamic of technical practice means for data science in the forest. The anxieties of Western intellectuals, whether dismissing the mundane physical realisation of concepts, or perhaps embarrassed by the greater technical dexterity of their laboratory technicians or the more practical relevance of engineering industry, are of little concern in an African forest. More importantly, there is no real need to draw a distinction between the practical (so-called “indigenous”) knowledge of people who live in forests and the practical craft knowledge of people who work in laboratories (Agrawal 1995), other than to reinforce colonial relations.
Furthermore, we might ask what is data science the science of? The name of the field suggests that this is the science of data itself, irrespective of what might be being counted or measured, just as AI is not the intelligence of any particular organism or person, but rather intelligence without a body, able to be re-embodied in a machine without threat to the generality of the research findings, effectively a body without race, gender, or physical ability, universally privileged (Hayles 1999). The science of data in itself, like the study of disembodied intelligence, is to some extent an exercise of metaphysical epistemology. As suggested by Agre, such investigations should be conducted both in the awareness of these metaphysical claims (perhaps attending particularly to the question of embodiment as Agre's own AI research did), and also grounded in the practical accomplishments of what is actually being made. In this case study, these practical accomplishments refer to the work of citizen-science politics and data science practices as Joycelyn “takes data science to a specific forest context and community”, engaging with a forest-fringe community, not far from Kumasi in Ghana, where she is a visiting student in the department of silviculture at the Kwame Nkrumah University of Science and Technology (KNUST).
In an initial phase of fieldwork, she has discussed with the community the potential use of unattended audio recording devices (specifically designed for use in field ecology), to collect bioacoustic data over reasonably long periods of time. The lineage of such recording equipment evolved from the traditions of Western conservation research that we have discussed earlier in this paper, should be clear. At the same time, the potential implications of surveillance and extraction are equally clear to the forest community, to her scientific hosts in Ghana, and to her collaborators. Sensitive negotiation of such questions is a central element of critical technical practice.
The historical narratives of citizen science and data science are already problematic in multiple ways, as we have discussed. But they are particularly problematic when we juxtapose the disembodied and euphemistic global aspirations of the internet “crowd” and “cloud” with the real places and people of forests. While the Citizen Science Association might invite inspection of who owns data or benefits from its use, the practices of crowd-sourcing are far more entangled with the economic and political realities of surveillance capitalism, ghost labour and racist technology than can be openly questioned from the research centres of the USA or UK.
The work of Jerome Lewis, Muki Haklay, Claire Ellul and their colleagues in the Extreme Citizen Science (ExCiteS) group at UCL have been addressing this problem directly in their work, building in particular on Lewis's extended fieldwork with hunter-gatherers in the Congo Basin (Lewis 2012, 2014). That project employed digital infrastructure for field observation and data labelling, in some ways resembling the crowd-sourced volunteer projects of the Global North, but oriented toward far more direct citizen action. In forest regions of the Congo that were subject to commercial logging, a (pre-smartphone) GPS application was created in collaboration with the local community in the forest. This customised mobile device (created at a time before the smartphone “app”) allowed hunter-gatherers in the Congo Basin to represent their own understanding of specific trees and places in ways that could become digitally attested, and placed alongside other forms of evidence to be considered in negotiation, permission, compensation, and all the other complexities of technologised forest exploitation.
This practical science in the physically present forest raises obvious questions that arise from both the technical practice and the embodied physicality, just as in the work of Gabrys and colleagues in their investigation of Smart Forests. Is the relationship between forest and data a question of measurement, extraction, or surveillance? All of these are routine critical questions when digital technologies are deployed in Western contexts. In a lower-middle income country such as Ghana, how do the economic opportunities associated with data science differ from the apparatus of surveillance capitalism that has attracted so much attention in the West? How do the AI mechanics of data collection and labelling as seen in the remote analysis of satellite imagery relate to the practices of those who know and understand this specific forest, and to the specific time and place in which a sound is heard? Are the boundaries between data and media that have been negotiated between (for example) those who interact via Twitter and those who interact via the Zooniverse or eBird still valid or even relevant in this location? Can Joycelyn's distinct Cambridge lives as social media climate activist and audio data statistician still be distinct as she works with sensors in the Ghanaian forest?
At this formative stage of Joycelyn's research, we can illustrate some of these issues by considering a specific technical aspect of her field research, namely AudioMoth acoustic sensors, serving as a rather constrained case study.
AudioMoths are small, open-source, customisable and programmable acoustic sensors (Hill et al. 2018) used in bio- and eco-acoustic studies. Compared to other available sensors, AudioMoths have increased energy efficiency. This efficiency results in a lower device cost of $84 in comparison to other acoustic sensors on the market powered by solar panels, such as Song Meters, which cost $499 at the lower end. Price point was one of the main motivations behind the choice of AudioMoth. With project longevity an important consideration for this research, the accessibility and ease of maintenance of the equipment being used, by the forest community and academic collaborators with constrained resources, was of utmost importance.
These sensors are employed across a range of conservation studies, as a biodiversity monitoring toolkit including studies on land and in water. However, just as “the cloud” disguises the real tangibility of the internet, the ideas of passivity or automation disguise the sheer amount of human labour that goes into “automated sensing”. This level of labour is, of course, much less than in purely manual field measurement and observation, but even automated sensors are not wholly autonomous.
As an example, consider the practical consequences of how important temporality is in acoustic sensing. Conservationists and data scientists conventionally structure their observations over periods of time. Automated schedules not only make data organisation and analysis more efficient than manual activation, but also allow researchers to only record at times that have the most animal diversity or activity.
Many products are available to provide automated remote data collection, but unlike other more expensive sensors that have the ability to be remotely programmed through mobile apps, the AudioMoth requires significant labour from community members who must manually program the sensors through wired connection with a PC or computer. There is the added complexity that when a sensor is serviced, (e.g. replacing batteries and memory cards once they are either depleted or full), the sensor returns to its default settings. As a result, the sensors cannot simply be serviced in place to replenish these hardware elements, but need to be removed, re-programmed, and redeployed. In the context of the forest in which Longdon was working, with steep incline and uneven terrain, and with work being conducted in the rainy season, this required returning to the village to re-programme all of the sensors, under cover in the community church, before redeployment.
The temporal limitations imposed by the finite battery and memory card life directly impact the recording schedule and the labour needed to support it. For example, taking the average lifespan of an AA battery and the time at which a 64GB memory card would become full, a continuous 24-h recording schedule required servicing and reprogramming every 6 days. During Joycelyn's initial period of field research, two sensors were deployed a 40 min walking distance apart. When scaled to a larger network, as planned for subsequent fieldwork in order to obtain more rich biodiversity data from a range of ecological settings, the practical logistics will become a non-trivial task, and will have direct influence on the research questions. For example, if the sensor is set to record for three hours at the dawn chorus, the servicing schedule would be reduced to every 28 days. An additional consideration is that regions with higher biodiversity are located deeper in the forest, at further distances from the village, covering steeper terrain and more dense foliage, meaning that even the previous 40 min walk between sensors might not be achievable.
These considerations, which might seem relatively trivial in the context of a well-funded laboratory staffed by professional technicians, become central and critical factors in other communities and locations. As mundane annoyances in the life of the working field ecologist, they may be ever-present, perhaps to be solved once the lucky scientist scores a large enough grant to buy solar-powered mobile-configured automatic field stations (and sensibly chooses a field site having both sufficient cellphone coverage, while also remote and obscured enough to avoid theft or damage). But in our own case, the practical questions of sensors-in-context unavoidably draws attention to the embodied provenance of data. Data science in Western business contexts already involves disproportionate effort in “data-wrangling” – cleaning and formatting the source files in order that they can be processed by machine learning algorithms. But the embodiment of sensors within this setting and this community means that data is not only retrospectively abstracted from the relative comfort of a data scientist's desk, but integrated into experiences of journeying through landscape – as Nicola Bidwell observed in her daily walks while deploying community networking infrastructure in Southern Africa, such knowledge is integrated “alongly” through narratives of wayfaring (as described by Ingold (2016)), rather than abstracted into epistemologies of colonial control and surveillance (Bidwell et al. 2022).
Toward data science in the future
This paper has described an intersection of important contemporary concerns, that we hope offers a novel set of questions within the longer series of investigations into Science in the Forest, Science in the Past. By looking inside the technical practices of the environmental data scientist, we highlight the ways that knowledge is being constructed in the forest-as-environment. Importantly, we question the status of data science as a universalised foundation of research and policy, if seen as an exercise of AI, aspiring to knowledge that is produced mechanically as a by-product of quantification through sensors.
In particular, this project engages with the way that the internationalised scientific community, aligned in the pursuit of planetary health around the Sustainable Development Goals, and in the work of conservation NGOs, often proceeds through negotiated or presumed consensus on the types and nature of scientific knowledge. This consensus is in turn reinforced by the commercially standardised technical infrastructure of data capture, storage, communication and processing. Any attempt to explore or describe alternative types of data leads at best to a regrettable othering of the knowledge systems that are contrasted with this infrastructure, and at worst an elision, omission or outright deletion of data that appears invalid.
We also acknowledge the close entanglement and implications of data science with the global technology industry, and the ways that the products and infrastructures our research has relied on may serve to bolster or even “greenwash” the very structures that we set out to question. This ever-present danger exposes us, along with many of our Western colleagues, to Aimé Césaire's condemnation of abstract philosophical enquiry as “goitrous academics, wreathed in dollars and stupidity […] all of them tools of Capitalism” (Césaire 1950/2000, 54).
Nevertheless, we believe that these relations between artificial knowledge, digital media, sensing infrastructure, geographic locations and diverse peoples, offer important challenges to our future understanding of forests and of science in this era of climate crisis. At a time of growing public concern about the consequences that AI technologies may have for education, public discourse and the creative professions in the West, African thinkers suggest that ecological conservation should itself be considered as another fundamental element of AI ethics (Nandutu, Atemkeng and Okouma 2023). We should also be alert to the fact that some Western “ethical” fears for AI, such as the pseudo-Christian eschatology of a messianic Singularity (Bostrom 2014; Davis 2015), may themselves be considerably less rational than the science of African forests (Wiredu 1976/1997).
If environmental data science did serve as the channel by which the ethics of AI became more attentive to the health of the planet, would the languages of the West (or even Western programming languages) be the most appropriate basis for the ethical vocabulary we will need? For example, as noted by Nanjala Nyabola (2021), the data protection law of Kenya is only defined in English, because there is no word for data protection in the official language Kiswahili. Where human relations with their environment are concerned, African languages may already have superior ways of describing the relevant concepts, as in Mavhunga's use of terms from the Zimbabwean language and culture to analyse the scientific interactions between sleeping sickness and the tsetse fly (Mavhunga 2018). Lesley Green argues for the importance of attending to technology, from the context of Africa, because it is technology that brings knowledge objects into being (Green 2012). We are depressingly familiar with the undesirable function of AI as a technology of race (Benjamin 2020), where information systems have reproduced the metaphysical thingification of African people already observed by Aimé Césaire (1950/2000). Yet Achille Mbembe (2017) urges us to remember that Europe is not the whole world, but only a part of it, and that a European metaphysics inevitably reduces the universal to its own dimensions. It is precisely this danger of data science that we wish to avoid, by constructing this science in the forest, before the ambitions of data science, or indeed the forest itself, are condemned to the past.
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Cambridge Centre for Doctoral Training in AI for Environmental Risk; Evolution Education Trust; Cambridge Conservation Institute; UK Global Challenges Research Fund; European Research Council Horizon 2020 grant No. 866006.