
Abstract
‘Personalized medicine’ might sound like the very antithesis of population science and public health, with the individual taking the place of the population. However, in practice, personalized medicine generates heavy investments in the population sciences – particularly in data-sourcing initiatives. Intensified data sourcing implies new roles and responsibilities for patients and health professionals, who become responsible not only for data contributions, but also for responding to new uses of data in personalized prevention, drawing upon detailed mapping of risk distribution in the population. Although this population-based ‘personalization’ of prevention and treatment is said to be about making the health services ‘data-driven’, the policies and plans themselves use existing data and evidence in a very selective manner. It is as if data-driven decision-making is a promise for an unspecified future, not a demand on its planning in the present. I therefore suggest interrogating how ‘promissory data’ interact with ideas about accountability in public health policies, and also with the data initiatives that the promises bring about. Intensified data collection might not just be interesting for what it allows authorities to do and know, but also for how its promises of future evidence can be used to postpone action and sidestep uncomfortable knowledge in the present.
Introduction
‘Personalized medicine’ is one of several names for various streams of overlapping and related ideas also known as genomic, precision, targeted, stratified or differentiated medicine (Hedgecoe, 2004; Prainsack, 2017; Reardon, 2011; Tutton, 2012). Each of these names holds several meanings and the various streams refer to complementary and sometimes competing attempts at individualizing medical treatment and prevention. During the past couple of years, many researchers and politicians have begun talking about ‘P4 Medicine’ as a catchy term to refer to the wider assemblage of personalised medicine as a matter of making medicine predictive, preventive, personalized, and participatory (Hood and Flores, 2012). As De Grandis and Halgunset (2016) argue, these are all ‘future-oriented concepts’, where their vagueness is instrumental to their political efficacy.
Personalized medicine might sound like the very antithesis of public health and the population sciences, focusing on individuals rather than populations. However, in this article I show that personalized medicine fuels heavy investments into the population health sciences and uses population data to guide individuals. Personalized medicine does not imply a shift from population to individual; rather, it generates new ways of inscribing the population in the individual and of letting individuals contribute in new ways to the population. Personalized medicine stimulates ‘intensified data sourcing’ (Hoeyer, 2016), by which I mean attempts at getting more data, of better quality, from more people – despite disagreements about uses of the data. Proponents of personalized medicine require access to data from large-scale genomic research projects, as well as data collected in the course of routine care (Green et al., 2019). Clinicians have always used patient data as learning opportunities, but initiatives aimed at personalized medicine intensify data collection and pooling – and in consequence confront patients with heightened responsibilities for contributing personal data to shared resources (Prainsack, 2015). In the Danish case I present here, data-pooling facilitates not only research and clinical experimentation with personalized treatment, but also stratification of population groups and personalized prevention targeting at-risk individuals in general practice. It shifts expectations for both general practitioners (GPs) and patients, and reconfigures ideas about health, illness and the role and nature of evidence in documenting effects of interventions.
The rise of personalized medicine should be understood in the context of changing socio-technical practices in the governance of public health, including how attributions of responsibility are made in relation to data-based decision making. Governmental accountability has long been associated with documentation, transparency and responsible means of enforcement (Bessette, 2001). Accountability denotes an institutional allocation of responsibility and systems for controlling responsibilities. Current accountability regimes need data and typically rely on what Porter (1995) calls ‘trust in numbers’. Key studies, however, have questioned the ability of quantitative data to underpin systems of responsibility (Power, 1997; Strathern, 2000; Wiener and Kayser-Jones, 1989). As data can be open to multiple interpretations, it has also been argued that data intensification can lead to a more (rather than less) ambiguous allocation of responsibility (Jerak-Zuiderent and Bal, 2011). Furthermore, there is an enduring tension between understandings of accountability as ‘from nowhere and for everyone’ (as in multi-use databases) and ‘from somewhere and for someone’ (as in everyday clinical care) (Jerak-Zuiderent, 2015: 412). This tension has increased with the digitization of medical records, because digitization facilitates easy reuse of data and allows the authorities to re-conceptualize the health records as audit tools and not just clinical memory practices (Winthereik et al., 2007). We are now facing a form of second-generation digitization, where data sharing for ever more purposes are made possible through data centralization. Personalized treatment and prevention are among the additional purposes that digitalized data centralization is aimed at facilitating.
Intensified data sourcing might also affect accountability in ways other than simply adding purposes. In fact, my key argument is that data intensification is becoming a way for public authorities to respond to a wider set of problems related to budget restraints and demographic challenges, problems for which they basically have no solutions. In this situation, data increasingly come to serve as a promise of future accountability. They should be thought of as promissory data. Instead of doing something today, authorities postpone action until more data has been accumulated. Data serve as promises of future action. Data initiatives allow authorities to present themselves as responding to problems while in effect they are merely promising future action – once enough data has allowed identification of new solutions. My point is we might misunderstand the politics of data intensification if we think it all relates to what authorities can do and know with data. In some instances, it might be just as important for authorities that data collection can be used to avoid action. They can postpone action while ‘waiting for more data’. To understand how personalized medicine reconfigures public health in Denmark we therefore need to understand how it interacts with wider initiatives of data sourcing and how data are used to hold (or, in some cases, not hold) individuals and authorities accountable for their actions.
Locating the field of personalized medicine and prevention in Denmark
Denmark is a high-income country in northern Europe with just 5.7 million inhabitants and with universal tax-financed coverage of medical care and a range of other welfare benefits. Though there are some out-of-pocket payments for pharmacy prescriptions and dental care, there is a high degree of social security (Vallgårda, 2016). Denmark is also characterized by a very elaborate IT infrastructure, digitized health services, and very elaborate national registries collecting structured data on all citizens from birth to grave (Thygesen and Ersbøll, 2011). Everyone in Denmark is allocated a personal identity number at birth or immigration. This is used in all interactions with public authorities (and for many private services). Practically all data are digitized, and thanks to the identification number they can be related to each other, not by probability (as in e.g. Scotland), but by actual reference to each individual. Many of these features also characterize the other Nordic countries and there is a form of national branding competition among them to attract international research investments with claims from each country about having unique data sources for the population sciences (Tarkkala and Tupasela, 2018; Tupasela, 2017).
‘That sounds absolutely outrageous!’ is a reaction I have had when describing the Danish registry system to academic colleagues outside the Nordic countries. Often, people have already read my descriptions, but it is only in the course of a subsequent dialogue they seem to realize the opportunities for data tracking that result from assigning each individual an identity number, which is then used in all interactions with authorities and most commercial services (sports, transport, telecommunication etc.). ‘You should write about that!’ they then say, and only when re-reading my draft do they realize what it actually means. The number assigned to each citizen at birth or upon immigration is kept in a registry that tracks the place of residence and family relations of all citizens at all times. By using the same number in all interactions with the public authorities, it is possible to track all citizens with respect to their medical diagnoses and treatments throughout life, their cause of death, and all publicly mediated services including housing, income, and education. In consequence, the whole country has been described as one big ‘cohort study’ and an ‘epidemiologist’s dream’ (Bauer, 2014; Frank, 2000, 2003). Data from public registries can be used for administrative and research purposes without informed consent, and this tracking of citizens is seen as relatively uncontroversial by the public, not least because it facilitates easy access to and coordination of services for most citizens (Hoeyer, 2018).
My investigation of personalized medicine in Denmark explores this data infrastructure and its current reconfigurations. My approach takes leads from work in science and technology studies (STS) on personalized medicine (Hedgecoe, 2004; Reardon, 2011; Tutton, 2012), big data assemblages (Cool, 2016; Hogle, 2016a, 2019), data-intensive population sciences (Ackerman et al., 2016; Bauer, 2013; Moriera and Palladino, 2011) and critical interrogations of public health (Armstrong, 2017; Bauer, 2014; Dumit, 2012). As a native Dane, most of my work could be seen as a form of ‘ethnography at home’ (Jackson, 1987), and in fact I often find myself serving as both ethnographer and data subject. When I go to the doctor and undertake everyday activities such as sport or grocery shopping, I produce the kind of data traces related to my own personal identity number that data-intensive medicine is eager to accumulate. However, participation in these mundane activities reveal little about the emerging assemblage of personalized medicine per se. I do not ‘experience’ the infrastructure, and rarely see the data. I am thus submerged in the field while also being strangely expelled from it. I am both at its centre and unable to locate it anywhere.
The problem of access reflects a more basic analytical problem: Where is the future of personalized medicine taking shape? Taking an ethnographic response to documents (Riles, 2006), I have been tracing policy papers relating to personalized medicine and their references to the scientific literature. Gradually, I have come to see policy documents, along with conferences, meetings, workshops and public hearings as places where competing futures of medicine are articulated in ways that shape the present, irrespective of the predictive value of the promises made (Brown and Michael, 2003; Fortun, 2008; Hedgecoe, 2004; Petersen, 2019). During the past three years I have participated in more than twenty conferences and meetings in Denmark on personalized medicine and big data, mostly just as an audience member but on three occasions also as speaker invited to comment on ‘ethical’ issues. Most of the conferences were advertised as academic events though some where marketed as networking opportunities aimed also at industry. At such conferences it is impossible to get an informed consent from every participant, and for ethical reasons I therefore refrain below from giving too many details that could identify speakers or commentators. One of the striking features of the conferences is the sense of convergence; there is tremendous agreement about being on the brink of something new, about needed investment, and about the considerable ‘potential’ in personalizing medicine (Taussig et al., 2013). General references to public statements at the conferences are ways of communicating this agreement in an ethically sensitive way. To further understand the data-sourcing initiatives on which personalized medicine depend, I have also undertaken interviews with people working as clinicians or data managers at the clinical or administrative level. The quotes from texts and interviews that I present in the following have all been translated from Danish, and italics have been used to indicate informants’ emphasis. 1
Seen from an international perspective, the average Dane is relatively privileged. Public debates in Denmark, however, tend to focus on crisis and the need for reform to sustain existing levels of care. A ‘good crisis’ is usually conducive for public acceptance of reform, and no doubt some stakeholders use this rhetoric consciously. Nevertheless, the national health system also faces very real problems. Contributing to the sense of urgency are expensive new treatment options and demographic transitions towards an aging population with rising rates of multimorbidity and chronic illnesses. In this mix of being at the frontier of e-health innovation and data pooling, while facing economic challenges, personalized medicine has emerged as an ambiguous figure, simultaneously representing challenge, rescue and opportunity. But to understand this properly, we first need to understand better why proponents of personalized medicine find the Danish information infrastructure for population data so attractive; that is, why does personalized medicine tend to generate demands for the types of population data that Denmark has in such abundance?
Personalized medicine means investments in intensified data sourcing
In a relatively recent but already widely-cited commentary in Nature, Nicholas Schork (2015) from the Craig Venter Institute argues that the classical Randomized Clinical Trial (RCT) is obsolete. We need a new system of approval, he suggests, aimed at cutting the expenditure associated with testing many people on few factors. Instead of the RCT, we should test few people in relation to many factors. The aim is to arrive at a form of medicine that works for the individual. He is not particularly clear on how statistics should work with many factors and low numbers, and says little about how to acquire general insights into unique conditions (Abettan, 2016). The idea of predictions at the level of the individual has long been seen as statistically absurd by biostatisticians (Henderson and Keiding, 2005). From an STS perspective, Tutton (2014: 56) argues that individualization cannot mean finding the right treatment for the individual per se; it must imply assigning individuals to new groups. This would imply that personalization in assessments of medical effect is more like a continuation of the gradual developments of the RCT that have come to take into account differences in gender, race and age (Epstein, 2003). However, Schork (2015) not only envisages new ways of grouping trial subjects; he also wants to begin ‘transforming everyday clinical care into solid N-of-1 trials’ (p. 611). In other words, Schork suggests that data should be harvested in the course of daily treatment, and that all patients should be regarded as research participants (Hogle, 2016b). 2 With N-of-1 trials in daily clinical practice, Schork thus imagines individuals contributing to the population in the hope that population data can guide their own and other patients’ treatment. Such plans necessitate a centralized IT infrastructure for health data (Carusi, 2016). Heavy investments in collection, storage and use of health data are therefore key components of the personalized medicine agenda (Prainsack, 2015).
In the period 2007–2013, the European Union (EU) invested 1 billion Euros in personalized medicine just within the 7th Framework Programme. On top of this came corporate and national research investments. To facilitate access to the needed data, the EU also funded harmonization of biobanks and data infrastructures to allow easier pooling of data (General Secretariat of the Council, 2016). In 2015, the Council of the EU furthermore adopted a strategy paper on personalized medicine according to which member states should work to ‘support the standardisation and networking of biobanks to combine and share resources’ and ‘promote the interoperability of electronic health records to facilitate their use for public health and research’ (General Secretariat of the Council, 2015: 7). In January 2019, the EU invested an additional 21 million Euros in the construction of an interoperable electronic health record through the Horizon 2020 program (and invited STS scholars on board to help make the prototype ‘citizen centred’; see Smart4Health, 2019). One of the data specialists I interviewed had some experience with previous attempts in this field and stated that while the full integration of European medical records will never work in practice, the political ambition is nevertheless clear. In the United Kingdom, the then Prime Minister Cameron personally worked to establish the 100K Genome Project to promote personalized medicine through genome sequencing and centralized access to health data supported through massive investments in e-health to ensure easy secondary uses of health data (Department of Health & Social Care, 2017). In the United States, personalized medicine was strongly supported by Senator, later President, Obama, leading to the Personalized Medicines Initiative receiving $215 million on the President’s 2016 Budget (Fox, 2015; White House Office of the Press Secretary, 2015). More importantly, he had already ensured investments of more than 30 billion USD in interoperability of electronic health records through the stimulus package following the financial crisis (Watcher, 2017). As part of these efforts, systems are being developed in the United States to provide ‘secure access to the electronic health care information of more than 125 million patients’ (U.S. Food and Drug Administration, 2013: 40). Personalized medicine is thus closely intertwined with creating access to population data.
Denmark is no exception in this regard, but here politicians take pride in already having a well-developed digital data infrastructure. Personalized medicine has therefore become one of several agendas for which existing health data have come to be seen as an important resource. In 2013, the Organisation for Economic Co-operation and Development (OECD, 2013) wrote a report in which it pointed out that ‘the goldmine [of Danish data] is only partly exploited’ (p. 18). The OECD report has since been referenced in a series of other reports, legal proposals and government plans arguing a need for an enhanced health data access and use. Following the OECD report, the Government asked the multinational consultancy group Deloitte to advise on how to optimize health data use. Pollock and Williams (2010) point to the role of consultancies as ‘promissory organisations’ that shape the economy of innovation with self-fulfilling prophecies; in this case, the report really did shape the direction of the investments to come. Deloitte (2014) suggested that centralizing data flows would facilitate easier data (re-)use and described the overall purpose as a matter of ‘supporting a culture in the health services, where the point of departure for medical and health economic actions is based on data and knowledge about what works’ (p. 6). It sounds like a laudable idea to build on knowledge about what works, but the report itself is unfortunately a poor example in this regard, as I will discuss below. Commissioned consultancy reports such as Deloitte’s represent an interesting genre, claiming authoritative insights and thriving on a language of ‘recommendations’ but rarely delivering references or other forms of documentation (Brenneis, 2006; Christiansen, 2010). The OECD and Deloitte reports serve more as sources of authority than as sources of documentation. What has this authority been used for and which types of knowledge does it hide?
Centralizing the data infrastructure: Data reuse and its blind spots
The Deloitte and OECD reports were used when arguing for a need to establish an independent National Board of Health Data and to instigate a number of initiatives aimed at centralization of Danish health databases (Lundbergh et al., 2013; Ministeriet for Sundhed og Forebyggelse, 2014; Sundhedsdata Styrelsen, 2017). A range of policy papers continued to communicate this commitment to infrastructural change focused on enhanced accessibility to health data for ‘secondary purposes’; that is, for non-clinical purposes (Ministeriet for Sundhed og Forebyggelse, 2013; Registerforskningsudvalget, 2013). Following up on these initiatives, the Danish Regions developed a general policy aimed at ‘optimizing health data usage’ (Danske Regioner, 2015c), again focusing on reuse of data for purposes other than treatment of the individual patient. In 2016, a national strategy for personalized medicine, also emphasizing centralized access to health data, was adopted by both the Ministry of Health and the Danish Regions (Sundheds- og Ældreministeriet and Danske Regioner, 2016). In 2016, the commitment to enhanced data sourcing was written into the shared budget agreements between the three levels of Danish government: ‘The Government, the Municipalities and the Danish Regions have agreed to continue the ambitious agenda of digitization’, with a clarification that the new strategy aims at ‘development of the data-supported public sector and centralized public [fællesoffentlige] digital infrastructures’ (Finansministeriet, 2016: 23–24). In 2016, they also agreed ‘that personalized medicine in the form of using genetic and other forms of molecular information constitute a potentially important element in the development of future offers in the health services’ (Regeringen and Danske Regioner, 2016: 10). To this end, and with the national strategy for personalized medicine, a new National Genome Centre was funded with 100 million DKK in 2017–2020. The money was given with the explicit hope of facilitating additional private research donations (see more about the envisioned large-scale project below). In many ways, bioinformatics is now seen as the way to finally deliver on all the old promises of genomics that never really materialized (Salter and Salter, 2017). New promises can be made by adding enhanced IT data infrastructure to genomics. The abundance of Danish health data is in this way now used to reinvigorate the promise of genomics. Promises have social lives and change over time; but while promises continue to relate to the future, their political power operates in the presence, as Hedgecoe (2004) argues.
All of these policies consistently emphasize reuse of data and the establishment of centralized access points. For example, several agencies work to pool data from the very detailed Danish quality assurance databases to open them up for multiple purposes; the National Board of Health Data requested copies of these data that are otherwise kept at the Regional level. One woman, who I here call Mona and who has worked for years with quality databases at the Regional level, explained her perception of the ambitions in this way: Now they want to pool the data, and then you’ve suddenly got, so to say, a hell of a lot information about all citizens in Denmark. There might be ten [citizens] who are not registered somewhere, but then they must be born abroad, really … Then combining all these data sources we can actually have sort of a constant state-of-health registry, which provides us with a real-time picture of the state of health in the population: How many smoke, what do people weigh, how much do they exercise?
Mona found it worrisome that she could not identify a clear purpose for this centralization. Besides personalized medicine, Mona had heard mention of using data for new forms of personalized prevention strategies, and for calculating remuneration of public hospitals according to health outcome measures (so-called ‘value-based healthcare’). With data pooling, she noted, you can easily identify those in need of prevention: ‘For example, the fattest women live in [the city of] Randers, and they really do, and then I guess it could be relevant for Randers to know.’ But she then returned to the absence of a clear purpose, remarking that all this data pooling could make her feel a little uncomfortable and remind her of ‘“Big Brother” … The reason I am a tiny bit worried is that they can’t say why they want all this data. They just want it.’ I do not pursue the issue of surveillance here (Lyon, 2019; Zuboff, 2019). I use these quotes primarily to show how population databases still allow singling out individuals – and to illustrate the scale of the data pooling and how diffuse the purposes remain for many of the involved. 3 The purposes should materialize in an unspecified future.
If data reuse is supposed to facilitate decisions ‘based on data and knowledge about what works’, as the Deloitte (2014) report suggests, it is remarkable how these policies avoid particular forms of existing knowledge about the typical effects of data reuse and data pooling. It is well-known that reuse of data for new purposes tends to affect data validity and thereby the usefulness for ‘primary purposes’ (Jirotka et al., 2013; Markus, 2001). That is, data reuse necessitates standardization, which inflicts new forms of hidden data errors, and reuse can have looping effects when health professionals change their mode of documentation in response to learning that data is used to monitor their behaviour (Wadmann et al., 2018, 2013). Such STS-oriented insights are consistently ignored in the policy papers. Hence, the quest for ‘evidence’ through data integration, which we see in the Deloitte report and the other policies, chooses particular forms of evidence and disregards others (Wiener and Kayser-Jones, 1989).
Mobilizing a sense of need for ‘personalized medicine’
During the scientific conferences on personalized medicine I have attended, researchers and politicians seek to mobilize commitments, not so much through the use of data, but through narratives. Again and again I have heard speakers refer to the story of President Kennedy ‘putting a man on the moon’ to argue the need for political commitment in relation to ‘personalized medicine’. Similarly, speakers refer to the business school narrative of ‘burning platforms’ (a metaphor of fire at an oilrig, often used in management courses to signal immediacy of action) and to the latest fashion in innovation, ‘disruptive technologies’. Disruption is a term used to explain the sudden death of certain technologies: Kodak, for example, did not manage to foresee a shift to digital cameras. Paradoxically, these narratives are employed to argue the need for data sourcing so that future decisions can build on data rather than stories. The burden of evidence rests with the future; in the present a good narrative will do.
What is it policymakers and researchers seek to mobilize funding for? In their ‘action plan’ for personalized medicine (Danske Regioner, 2015b), the Danish Regions endorsed a project strategy of whole genome sequencing of thousands of citizens, in the expectation that the work would be financed primarily through a donation from the private Novo Nordic Foundation (Pedersen, 2015). The specific project plan contains few details (Skøtt et al., 2015). Though it is expected to raise several billion Danish kroner of research investments, it is a policy document without a clear project protocol. In 2018, the foundation nevertheless decided to donate one billion DKK (149 million USD) to the construction of sequencing and supercomputing facilities nested within the publically controlled National Genome Centre.
What these documents miss in terms of specificity, they make up for in terms of the gravity with which they argue the need for investments in personalized medicine. One graphic in particular, which I discuss in detail below, serves this purpose. It is consistently presented not only in reports, but also at conferences and in workshops, sometimes by several speakers during the same event – to the point where it is introduced with variations of ‘you probably all know this figure’, and often with the heading: ‘The burning platform’ (see Image 1).

A photo from one of the conferences displaying The Graphic (reproduced on the left) that lists ‘Share of patients who gain no benefit from drugs’ (referencing the FDA report).
The Graphic lists ‘the share of patients who gain no benefit from drugs’ in relation to nine diseases. It is said, for example, that 43% of diabetes patients and 75% of cancer patients gain no benefit from existing treatment options. It is an astonishing set of claims, not least considering that patients do live with diabetes (and other diseases on the list) for many years.
This stated lack of evidence for existing treatments is said to explain why we need personalized medicine. A more pressing point, in my view, is that The Graphic itself lacks evidence. The Danish report from 2015, in which it first appears, references a Food and Drug Administration (FDA) report from 2013 as source (U.S. Food and Drug Administration, 2013). The FDA report (and a very similar graphic) was used by President Obama to promote personalized medicine in the United States (Fox, 2015). The FDA sounds like an authoritative source, but the report merely references an article from 2001 in support of the claims contained in The Graphic (Spear et al., 2001). One could have expected more recent documentation, perhaps, on which to build the future of medicine. When reading the 2001 article, however, the evidence base dwindles even more. The 2001 study presents no methodological explanation, and actually just lists some numbers in a table in relation to an argument about what it would take to develop pharmacogenetic tests (see Senn, 2014 for criticism from a statistician). Furthermore, there are some interesting leaps in each translation. The 2001 article referred to ‘[r]esponse rates of patients to a major drug for a selected group of therapeutic areas’, whereas FDA uses the caption ‘for whom drugs are ineffective’. The leap from ‘response rates to a major drug’ (drug in singular) to the FDA coinage ‘for whom drugs are ineffective’ (drugs in plural) to the Danish claim about ‘no benefit’ is remarkable (see Table 1). In essence, this means that the claim that there is no evidence for the effect of existing treatments is being made without supporting evidence.
A systematic comparison of statements in the graphic(s).
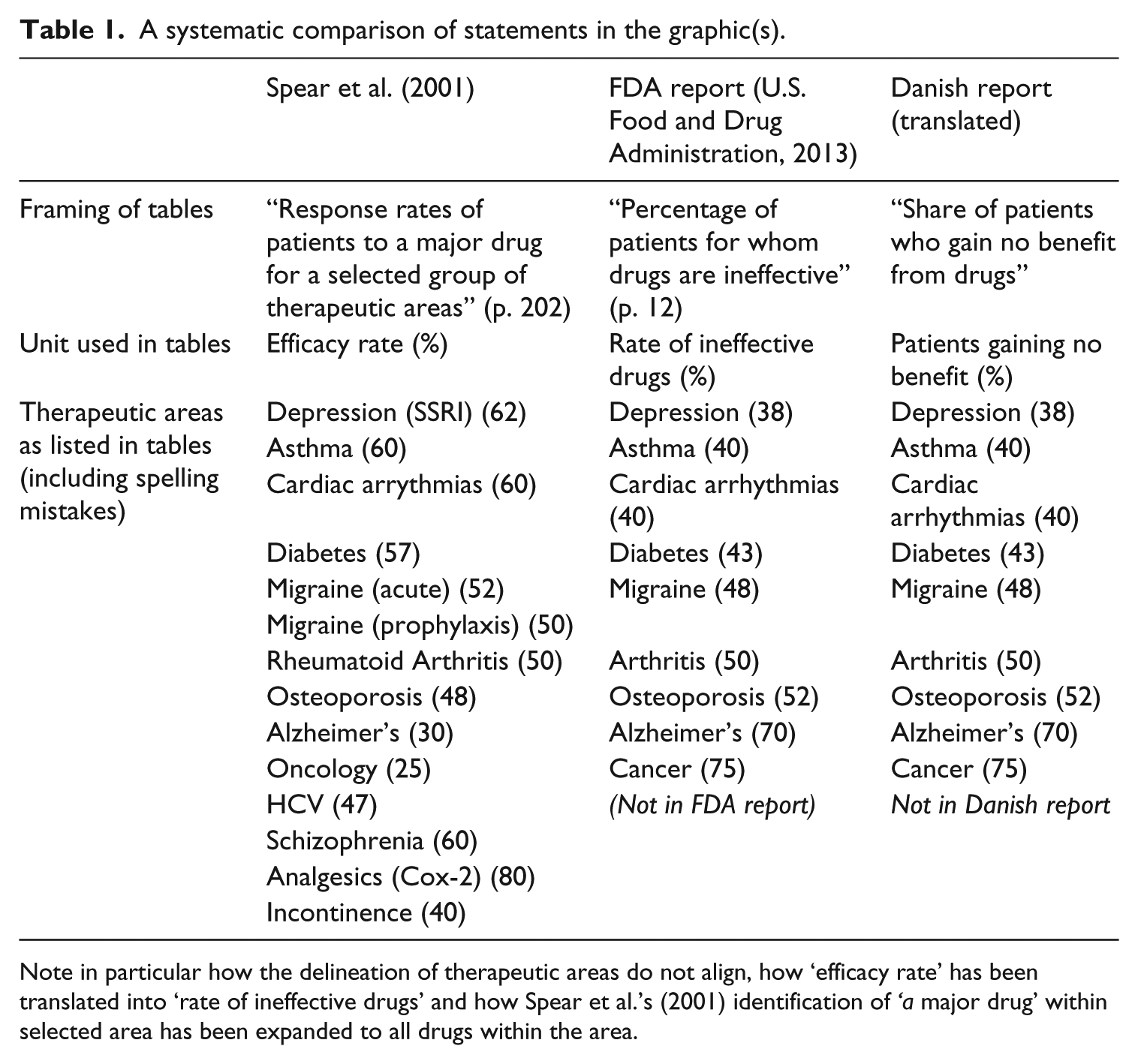
Note in particular how the delineation of therapeutic areas do not align, how ‘efficacy rate’ has been translated into ‘rate of ineffective drugs’ and how Spear et al.’s (2001) identification of ‘a major drug’ within selected area has been expanded to all drugs within the area.
As I realized that there was a lack of empirical support for The Graphic, I took the opportunity during a conference break to remark to a speechwriter for one of the politicians who had just used this graphic that they ought to stop using it. To my surprise, she replied, ‘But it illustrates the problem so well’. While I first could not agree that it illustrated anything, I have now come to think that it illustrates how proponents of data sourcing initiatives do not need evidence in support when arguing their case: They can make do with a narrative that merely appears to rest on data and a promise of better evidence in the future. Instead of using displays of data and evidence to make politics and biomedicine accountable, accountability is here directed toward the potential future outcome (a supposedly great project), rather than faithful representation of what is already known.
In October 2016 a reference group of Danish scientific experts delivered a report on personalized medicine that finally seemed to have at least wondered about the accuracy of The Graphic. The experts added a footnote to it: It is noted that The Graphic builds on older and not fully compatible data for each area of disease, therefore it cannot be said to be fully documented and probably misses the significant progress in treatment in recent years based partly on the introduction of new personalized/stratified drugs (Sundheds- og Ældreministeriet, 2016: 6).
Note, however, that what first looks like acknowledgement of the lack of scientific support turns out to reinstate the assumption that it builds on evidence (although this might be outdated) and ends with the claim that ‘personalized/stratified drugs’ do deliver better results. Uncertainty about past knowledge is used to argue the need for future certainty.
I have dwelled at length on The Graphic to illustrate how scientists become complicit in a paradoxical evidence-free pursuit of evidence. The absence of interest in understanding the problem (the evidence base today) in order to promote a solution (personalized genomic medicine) involves a particular temporality. The solution is basically just a promise for the future, but it is so grand that it becomes unnecessary to probe the problems supposedly haunting the present. And, really, why should scientists who are working in the nexus of science and policy want to debunk a figure that might help raise billions of research funding for a large-scale data-gathering project?
At one of the conferences I attended, I heard a researcher ask critical questions and complain that large-scale, top-down initiated projects of this type could get funded without proper scientific evaluation. It was a rare exception to what is otherwise a strikingly homogenous scene of enthusiastic debates about the potential of personalized medicine. However, one of the key actors at the administrative level in the Danish Regions silenced the critique saying: ‘In my experience, scientists always grumble, but once the music is playing, they turn towards the orchestra.’ He seems to have construed a new version of the old saying, ‘he who pays the piper calls the tune’ – and considering the general lack of interest among researchers in challenging the politically presented ‘evidence’, he seems to have had a point.
Despite all these reservations, it would be foolish to assume there are no valid scientific arguments for embarking on large-scale projects aimed at a more data-intensive form of research. Yet, the political process does not depend on such arguments. The quest for centralized data sourcing that is said to be ‘supporting a culture in the health services, where the point of departure for medical and health economic actions is based on data and knowledge about what works’ (Deloitte, 2014) is itself remarkably resistant to existing data and knowledge. This is no less true when it comes to the political promises related to the economic effects of an investment in personalized medicine. It is to these promises I now turn.
Make money or save money?
At conferences, politicians respond to the current sense of crisis of escalating healthcare budgets, claiming that personalized medicine will do two good things for the economy: It will generate new revenue in the private pharmaceutical industry (make money) and cut expenditure in the public healthcare sector (save money). It is apparently both a business opportunity and a response to rising healthcare expenditure. Both promises are present also in consultancy reports (Deloitte, 2014) and the public action plans and policy papers (Danske Regioner, 2015a, 2015c). 4 There is, however, a striking paradox at play. Denmark is a welfare state where the public sector that hopes to make savings also pays for the services that the private sector is expected to make money on. Again, ‘personalized’ medicine serves as a vague but appealing buzzword (Vincent, 2014) onto which both ambitions can be projected and their conflict ignored. Furthermore, the cost of data sourcing is rarely considered in relation to personalized medicine. I interviewed a data analyst, Liselotte, who wrote off the costs associated with data collection: ‘Basically, I couldn’t care less [jeg er fløjtende ligeglad] about the economy from where I’m sitting … I just want [the data] that I need at my disposal.’ None of the data analysts I interviewed were aware of anyone counting the costs associated with collecting the data they used. In official reports and financial bills listing such costs they typically figure as ‘investments’, which implies a future return. Hence, economic aspects of data sourcing are, again, embedded in a particular temporality. Promissory data can be claimed to involve potential future savings and gains in ways that overrule concerns about the expenses related to data collection in the present.
In pursuit of future economic growth – the aim of making money – the Danish Regions commissioned a report from a consultancy named DAMVAD to outline the financial prospects in case of an investment in personalized medicine (DAMVAD Analytics, 2016). Just like the OECD and Deloitte reports discussed above, this report serves more as a source of authority than a form of documentation, giving few references or verifiable calculations. It states that with few companies in the area, personalized medicine is not an obvious focus for public investment; however, because of the abundance of available health data in Denmark, it is an area of ‘great potential’. This potential, apparently, does not need further proof (Taussig et al., 2013).
The means by which personalized medicine is to rescue the state from escalating healthcare costs – help save money – are similarly undefined and diffuse. The escalating costs leading to the current crisis in healthcare expenses partly reflect increased activity (due to changing demographics and treatment expectations) and rising costs of pharmaceutical products. In some cases, such as cancer treatments, the higher prices are directly related to drug regimens associated with ‘personalized medicine’ (Annas, 2014). It is partly the rare and the ‘tailored’ treatments that put strains on hospital budgets (COWI, 2009; Sonne, 2016). At one conference, during a plenary discussion, I therefore commented from my place in the audience that personalized medicine could not both save public money and make private money, but I was told from the podium by a prominent politician that my ‘thinking was much too narrow’, and that savings would come from, for example, ‘a quick return for patients to the job market’. However, even this argument suffers when considering that at least 68% of the most expensively treated patients causing strains on budgets are on permanent welfare and will never return to a job (Region Sjælland, 2014).
Praise of prevention as a source of cost-saving is also recurrent in reports and action plans. Prima facie, this sounds reasonable. However, the life-expectancy in most high-income countries has been going up (indicating a better state of public health), without the cost of the health services decreasing (Vallgårda et al., 2014): Better health might not necessarily mean cheaper health. A group of Dutch health economists (van Baal et al., 2008), have even argued that prevention of smoking and obesity in modern welfare states does not limit expenditure because people will survive to get more expensive long-lasting disease patterns. As they note: ‘The underlying mechanism is that there is a substitution of inexpensive, lethal diseases toward less lethal, and therefore more costly, diseases’ (van Baal et al., 2008: 245).
My point is not to dispute the potential gains from personalizing medicine and prevention. Rather, it is that the politicians who so enthusiastically emphasize a need for intensified data sourcing to reach these gains do little to engage existing data and knowledge when articulating the economic implications of their proposed investments. What is more, some politicians apparently doubt that personalized medicine will imply higher prices and levels of healthcare costs. Yet this was considered an unquestionable fact by the industry representatives with whom I have been speaking. Several of them even considered it a key threat to innovation, should the public sector refuse to pay the escalating prices. Dumit (2012) has described earlier strategies of mass pharmaceuticalization as a way to ensure consistently high annual growth rates in the pharmaceutical sector, but my interlocutors in the industry suggest that there is a limit to the number of drugs the average citizen can take (not least granted the current problematization of the damages of polypharmacy). Therefore, they see a need to focus on higher prices instead to sustain continued growth rates. With personalized medicine as one possible solution to the growth problem, Hedgecoe (2004: 122) noted more than a decade ago the industry’s dislike of cost-effectiveness analyses in this field. Over lunch at one of the recent high-profile conferences, I joined the table of the representatives from the pharmaceutical company sponsoring the event. I quickly realized that they all worked in marketing and that there were no participating company scientists. When I asked them why they sponsored this type of event, they explained how the whole pricing system is being reconfigured, and that many of their new products were of value to so few people that unless it was possible to create ‘a sense of need for “personalization” among clinicians and in the public’, they simply would not be able to charge a price that made innovation worthwhile. Conferences on personalized medicine, then, are used to orchestrate this sense of need (see also Wu, 2016).
At other events, industry representatives explained their support of personalized medicine conferences as a means to ensure their access to healthcare data, so that they could develop more precise diagnostic tools and treatments. If they are to make money, access to the raw material of personalized medicine – population data – was necessary. Teis, a man I interviewed about his work with data integration through a national e-health portal, explained how some big Danish companies now wanted the authorities to facilitate the upload of data streams from so-called wearables (including the iPhone) to the public platform. This would allow citizen-generated data to be linked to public data using the personal identity number (and thereby a calculus of the segments of the population from whom the data stem). The companies hope that this form of big data might assist the approval process for new drugs by delivering data on the effect of drugs outside the trial settings, while authorities hope that such links can in turn deliver what is now increasingly referred to as ‘real-world evidence’ of drug effect.
Teis, in fact, has a different vision. He hopes it can also serve as tools for citizens: ‘We have to have some algorithms that analyse the data streams [from wearables]. Draw out insights, save those insights, and give those insights back to the citizen.’ This he sees as the essence of personalized medicine, citizens contributing to the population and simultaneously learning about themselves from population data. From Teis’ perspective, the public health system will break down if people do not learn to control their own health. Once a data infrastructure of this kind is in place, Teis assumes that data can be used by companies and clinicians too. In fact, it is probably the easiest way to get approval. Though the companies expect to use such data to prove the worth of more expensive products, Teis doubts this outcome; on the contrary, he hopes to prove that more expensive drugs do not fare better.
In a welfare state like Denmark, data-intensive personalized medicine in this way operates in a space created by an ambivalent state of crisis (escalating costs and healthcare needs) and opportunity (industry interests). To retain the privilege of health, wealth and universal access to care, the state now frames data on its citizens as assets (Sadowski, 2019; Vezyridis and Timmons, 2017). The value of these assets lies in future use. As described above, data are also seen as essential to realizing the other Ps in P4 medicine: predictive, preventive and participatory technologies. In the Deloitte (2014) report that gave rise to the restructuring of the data infrastructure, several of the competing ambitions are combined in a remarkable bullet point stating the following aims for data centralization (in a language no less peculiar in Danish than in its translation): Targeted support of interconnecting [tværgående] coordination as well as citizens’ own involvement in the management of their own disease holds great potential in terms of limiting the need for activity in the health services through prevention and changed division of labour with the citizens. This could be supported by systematically identifying [udsøgning] the citizens who could benefit hereof. The implementation of citizen-directed programs can contribute to address inequality in health (Deloitte, 2014: 46).
The pleonasm, ‘interconnecting coordination’ and what in Danish is in fact a neologism, ‘udsøgning’, which I have translated simply as ‘identifying’ (though it does not have the same secret-service-surveillance connotations) are part of this characteristic consultancy jargon that elevates plain statements about patients needing to care for themselves to slightly obscure truths. Again, the consultancy report manages to state a potential with no references, no data and no argumentation in its support. Nevertheless, this aim was immediately imported into a government health policy program called ‘The Sooner the Better’ [Jo før, jo bedre] (Regeringen, 2014) with a program ‘investment’ of 5 billion DKK in the period 2015–2018. Thought of as ‘investments’, the costs associated with data might be concrete burdens in the present, lifted only through an unspecific future promise of savings.
Personalized medicine is thus expected to make money by making persons contribute data that can attract investments, and then save money by using the same data to enhance treatment opportunities and to identify the most costly citizens before they become very ill, to present them with responsibilities for life-style changes (see also Broer and Pickersgill, 2015). I now turn to these new forms of personalized prevention in which Teis, Deloitte and Government policies invest so much hope. In doing so, I address how the promise of using population data to target individuals is made while selectively picking and choosing from existing knowledge about effective public health interventions.
Personalized prevention: Making those ‘at risk’ do their share
The stated aim of the government programme ‘The Sooner, the Better’ was ‘earlier diagnosis, better treatment, and more years in good health for all’ (Regeringen, 2014). One of the programme’s methods, in line with Deloitte’s (2014) recommendation, calls for data-analysis to deliver ‘targeted health check-ups … and support to the most complex and vulnerable patients’ (p. 22). Furthermore, it was pointed out that physicians in general practice ‘need new IT-based tools to support them in detecting citizens with a high risk of chronic illness [so that they can conduct] a targeted health examination’ (p. 25). It is in many ways a classic biopolitical move to ask GPs to use population data to identify high-risk citizens, who are then encouraged to assume responsibility for their own health (Foucault, 1994; Rose, 2007). It is, however, more than that. It is indicative of a new political organization: GPs have not previously been allowed to use population databases to identify and reach out to citizens who have not themselves requested medical assistance. ‘The Sooner, the Better’ thereby introduces a radical shift in the role of the GPs. Rather than waiting for sick people to ask for help, they must seek out at-risk individuals and make them realize that they will one day have a problem. GPs are self-employed in Denmark, but citizens can use them for free, as the expense is covered by the Danish Regions. Partly for this reason, it has always been a basic principle that GPs should not initiate contact with patients because they could use it to boost their business. The Danish health system, with its universal access to care, was set up in a period with a focus on treatment and cure, where the obligation resting on the sick was to follow the advice of the system until the point of recovery (Parsons, 1951). The personalized data-intensive identification thereby forms part of a wider shift in not only healthcare tasks, but also in the responsibilities of GPs and citizens.
This type of personalized medicine can be said to address inequality in health using data-intensive methods to identify and target those with the most pressing need. Though congruent at some level with the US and British versions that put the concept of personalized medicine on the international agenda (Hedgecoe, 2004; Hogle, 2016a; Macfall, 2019; Reardon, 2011), this type of ‘personalization’ still takes on a form of its own. In Denmark, for example, no one stands to lose access to health or insurance eligibility; in fact, they can expect to receive more, rather than less, attention. The emphasis on ‘solidarity’ in the Danish system instead implies an unequal distribution of the obligation to change (Prainsack, 2014). That is, it is those citizens who are living with the most risk factors who are the most obliged to change their life-style. The ‘personalized’ fight against inequality in health then becomes a personal responsibility for conforming to the norm, very personal indeed (Árnason, 2012). In this way, the potential future ill-health of ‘costly’ individuals’ makes them accountable in the present to the wider Danish population.
This Danish type of personalized prevention provides little room for taking into account personal circumstances and preferences (Prainsack, 2014). Though personalized medicine once emerged as a term in the early 20th century to challenge the increased reliance of statistical evidence, today it has become almost synonymous with data-intensive medicine (Tutton, 2014). The person as a carrier of values and experiences has been transformed into a source of data and a target for intervention. In an interview with my colleague Sarah Wadmann and me, a Danish GP commented on the current shift towards computer-based medical advice. She complained that there was no need for a doctor anymore, just a computer, before saying with real agitation in her voice: I think it’s bloody annoying that they act as if they have a monopoly on, you know, this ‘personalized medicine’. Really, it’s such an abuse, it’s as if we’re sort of molesting [voldtager] the meaning of the word, right? ’Cause it’s, God damn it, not what the rest of us mean with ‘personal’ attention, right? We don’t mean statistical average!
Data-intensive methods and decision-support systems clearly provide important medical tools, but this GP also sees them as intervening in her perception of good care – in effect undermining personalization.
While medical examinations may lead to more treatment for those targeted by the algorithms for risk identification, the effect of medical examinations on the health of those identified is contested. 5 This is also the case in relation to preventive counselling on behavioural change. In fact, existing studies mostly indicate that this has a limited effect (Hollands et al., 2016; Jørgensen et al., 2014). The majority of citizens targeted suffer from complex combinations of social inequalities, not lack of advice (Marmot et al., 2010). Furthermore, it is striking that concurrent with the introduction of data-driven ‘targeted’ prevention, the very same groups targeted in this manner in Denmark have had their social and unemployment benefits reduced. ‘Data-driven decision-making’ thereby glosses over the grim reality that those who are facing health inequalities as a result of systematically tightened structural constraints are offered an hour of medical counselling in what could perhaps be called a classic example of responsibilization (c.f. Kerr et al., 2019), not because of but despite existing studies and ‘knowledge about what works’.
GPs have become mediators in this process of responsibilization in the Danish version of personalized medicine. Therefore, it is also interesting that a recent study of a GP-mediated preventive intervention program in Denmark found that GPs often decide to not even mention life-style factors such as smoking to their patients because they do not expect any effect, and fear negative implications for patients’ confidence in them (Broholm-Jørgensen et al., 2017). As Green and Vogt (2016) argue, if we take all social factors into consideration then it is a very long way from the ideal of P4 medicine to practical implementation. Still, the promise made by proponents of P4 is that with proper data sourcing, we will know the effect – after implementation – despite uncertainties in the present.
In sum, personalized data-intensive medicine operates in a remarkable tension between ambitions of participatory approaches empowering individuals (using population data to identify and guide individuals) and standardized population data (making individuals conform to averages). Irrespective of existing studies indicating the limited effect of the chosen measures, it thrives on a promise of future effects which are in turn dependent on a responsibilization of those currently deemed at risk.
Conclusion
The development of personalized medicine takes multiple forms. As a buzzword, it is sufficiently vague to allow different individuals and institutions to project competing hopes and expectations onto it. One thing is clear, however: Novel regimens of personalized medicine do not imply abandoning large numbers and the methods of the population health sciences. On the contrary, personalized medicine requires bigger datasets than ever before. The ‘laboratories of personalized medicine’ are replete with population data. When such datasets are constructed and put into use, personalized medicine acquires nationally specific forms in reflection of existing healthcare systems and political and economic structures. To understand what personalized medicine produces locally, we therefore need to follow their translations in specific settings.
The Danish story of mobilizing massive investments in a new research area could be told as a classic narrative of the formation and facilitation of political alliances (Czarniawska, 2005; Vincent, 2014). To raise funds you need to raise expectations (Brown and Michael, 2003), and it is hardly surprising that the boundaries between scientific evidence and political processes become blurry in the articulation of such arguments (Hoeyer et al., 2019; Weiss, 1986). In relation to personalized medicine, I nevertheless find it striking how groups of researchers, clinicians and policymakers coalesce in their pursuit of future sources of evidence, while demonstrating tenuous relationships with existing evidence. In the Danish assemblages created around personalized medicine, it is as if data serve more as a promise for the future than as inscriptions of the past. In this turmoil of politicized uses of ‘evidence’, there is a special role for STS to exert a form of data-engaged resistance from within. Rather than accepting a reduction of knowledge to questions of power, there is an important task in tracing knowledge claims through their cycles of production, use and re-appropriation by new actors for new purposes. But this is not enough. STS needs to explore policy processes as sites of particular forms of knowledge production with political effects in need of scrutiny in their own right. If policymakers today pick and choose among different forms of knowledge depending on their agendas, and if they prefer a quick consultancy report and a popular narrative about placing ‘a man on the moon’ to substantial data analysis, we should probably not expect their future decision-making processes to become altogether different. But this is not the key question. What we need to ask is instead what all the promises of future evidence produce in the present.
One important but rarely acknowledged effect of data promises is, I suggest, postponement. Once a policymaker makes a call for ‘more data’, it becomes legitimate to postpone action until the data have been collected. By claiming that it is better to wait until more data have been accumulated, data promises thus generate a form of temporal disruption of public accountability. Talk about the ‘potential’ of future data-intensive methods allows the prospects of future knowledge to overrule what we know already, and thereby what we could already do – in the present. Responsibility becomes redefined: It is responsible to delay the use of available tools for limiting inequality in health, while it becomes irresponsible not to pursue data for future use. Simultaneously, the implementation of unproven prevention schemes is legitimized because future data might prove their value. Current scientific doubts can thereby be sidestepped and action endorsed while making the claim that it is evidence-based medicine. In doing so, the temporality of the models that were traditionally referenced in public policy are disrupted because the effects of data sourcing are supposed to become evident only after implementation. Data become promissory. Promises embody a particular form of accountability through the obligations that they implicitly or explicitly reference. With promises of future gains, the welfare state can portray itself as caring for the future of the vulnerable and poor, rather than their present. In this context, data-as-promise, or what I call ‘promissory data’, is – politically speaking – a more powerful resource than data-as-evidence. The risk in all of this is that the terms of care come to resemble what Biehl (2016) has called a ‘fabulation of power’, a narrative that disregards existing knowledge to sustain a myth of governance that has the eradication of inequality as a primary objective. Faced with such fabulations, data per se seem relatively powerless and unfit to hold authorities accountable – unless critical observers learn to reintegrate data in new counternarratives as a form of data-engaged resistance. My discussion of Table 1 may serve as a humble attempt of doing that.
If we acknowledge that there are no easy solutions to the multi-rooted ‘crisis’ associated with escalating healthcare costs, and that the relevant forms of knowledge for any major social problem will always be contested, we might now appreciate this element of the appeal of personalized medicine and the wider field of big data. Promissory data deliver legitimate postponement of action – and fill the waiting time with a genuine and serious task: data compilation. It is even possible for policymakers to portray themselves as siding with key values of accountable governance – dedication to evidence and care for those in need – without actually doing anything and while ignoring contemporary controversies and uncomfortable insights. Mostly, data collection can be associated with goals that few oppose, not least because the realization of these goals remains vaguely situated in the future. When proponents of personalization attack the legitimacy of structural prevention aimed at mass health, for example, they are in-line with a critique that has also been made in STS (Dumit, 2012). And who wants to argue against the construction of a better evidence-base and more effective treatments? Still, STS needs to keep scrutinizing whether policymakers are replacing mass health, not with ‘tailor-made medicine’, but with new data-intensive technologies of control and responsibilization.
The quest for personalized medicine currently interacts with forms of data-sourcing that imply that citizens should serve as data subjects and contribute to population goals (Garrety et al., 2013; Green and Vogt, 2016; Vezyridis and Timmons, 2017). While citizens incur this responsibility in the present, the authorities postpone their own responsibility for ensuring good use of data to the future. Therefore, personalized medicine does not imply a shift from population to individual; instead, its data-intensive methods generate new temporal organizations of accountability and new ways of inscribing the population in the individual while letting individuals contribute to the population. Public health is reconfigured in the process.
Footnotes
Acknowledgements
Previous versions of this work were presented at 4S in Barcelona, the AAA in Minneapolis, at Sheffield University, and at the Digital Healthcare Workshop, Nottingham University. I would like to thank the organizers and audiences of these events for comments. I would also like to thank informants and good colleagues from or associated with these events and the ERC project. In particular, I would like to thank Maria Olejaz, Henriette Langstrup, Linda Hogle, Martyn Pickersgill, Susanne Bauer, Mette N Svendsen, Sara Green, Kean Birch, Mark Vardy and Sergio Sismondo who all helped me develop the argument. My student assistant Lea Larsen also deserves a special note of appreciation for taking care of numerous tedious tasks.
Funding
This project has received funding from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreement number 682110).
Notes
Author biography
![]() ).
).