
Abstract
Distributed learning is a powerful tool for optimizing retention of verbal materials. We examined the effect of distributing learning on long-term memory for a melody and found strong evidence of better recall in the spaced conditions. In the current study, music students were taught a four-phrase melody in learning sessions that were massed, spaced at 2 days, or spaced at 1 week. Three weeks later, they were tested for recall. Performances were evaluated for note omissions, number of incorrect notes and intervals, and number of correct notes and intervals. Results indicated strong evidence for a spacing effect for melody learning between the massed and spaced conditions at a retention interval of 3 weeks, and no evidence of difference between the two spaced conditions. Unlike most spacing studies, memory did not improve with longer spacing between learning episodes. These results suggest that memory for a melody may rely primarily on structural constraints within the material itself. Once these constraints are understood and associated with the cue, the performance unspools. Results have implications for best practices in melodic learning and for the role of constraining cues in the retrieval of structured non-verbal material.
Melody has been part of human life since prehistory. It accompanies us from our very earliest moments. In every culture, mothers soothe infants with a lullaby. Newborn babies may recognize tunes heard while still in the womb (Partanen et al., 2013). We learn to speak through “motherese,” a wordless crooning by the parent that transmits the prosody and affective significance of language to the child (Saint-Georges et al., 2013). Given the ubiquity of melody in human activity, it is surprising to find that the best practice for learning and retaining a new melody has not yet been established. Our current study is the first to look at the effect of distributed learning on sung melody and one of the few to examine spacing effects in music. We join a small body of music studies where the stimulus materials are reproduced (i.e., sung) and not simply recognized (Halpern & Bartlett, 2010).
The central theme of this research is that melodic syntax, or the rules necessary to generate melody, creates structure that can be used to cue memory in performance. As such, it is important to understand the primary constituents of musical structure. Both tonal structure and melodic contour influence the perception of melody and its subsequent recall (Dowling, 1978; Schmuckler, 2014). Musical tonality is “the hierarchical organization of the chromatic set around a single reference pitch” (Schmuckler, 2014, p. 144). Simply put, it allows for the organization of melody according to the notes and chords of a specific key. In Western tonal music, melodies imply an underlying harmony (Patel, 2010). When an implied harmony is based on the simplest tonal formulas, transposed melodies are recognized more accurately (Cuddy et al., 1981). Scale and contour both influence melody retention (Dowling, 1978). Melodies that outline tonic triads (a chord formed of the first, third, and fifth notes of the scale) at phrase endings are remembered more accurately than melodies that do not (Boltz, 1991). The effect is shown only when the triads are used with regular patterns of accent. Modal melodies (melodies based on the notes of a scale, arranged into patterns other than major or minor) can be difficult to learn compared with melodies based on more conventional harmonic progressions (Oura & Hatano, 1988). Memory for traditional songs or ballads may be influenced by multiple constraints in the materials (Rubin, 1995, 2006; Wallace & Rubin, 1991). Recall is serial; what is sung cues what is to come. Although memory for a tune will not offer the poetic constraints offered by a song with words, melodic structure, with its regular phrase length, cadential formulas, and tonal resolution will still have a constraining effect on the choice of notes. Taken together, these constraints act as ongoing associative cues which help to determine the subsequent choice of notes.
There are several factors in melodic recall that distinguish it from word or prose recall. There is evidence that both melody learning and text learning require syntactical processing, which overlaps in the neural resources required for activation and integration (Patel, 2010). Melody learning may evoke semantic processing through activation of extramusical meaning (Koelsch, 2011), although this activation is weaker and of a much more general nature than in the learning and retrieval of text (Slevc & Patel, 2011). Memory for melody requires continuous recall according to an imposed rhythmic and melodic pattern. Furthermore, in sung recall, the procedural aspects of singing technique and the demands of music processing are engaged, and the rhythmic and pitch constraints of the melody function as a framework for retrieval (Rubin, 1995, 2006; Wallace & Rubin, 1991). This framework is presented complete at the first learning episode. Once the intervallic and rhythmic structure of the melody is learned it may be retrieved as a continuous associative unspooling where each pitch cues the next according to the learned patterns (Chaffin et al., 2015).
Singing a melody from memory involves retrieval of pitch and temporal information from long-term memory. This information, stored as episodic traces, is then sent to motor planning and implementation mechanisms that execute the articulatory and phonatory instructions (Dalla Bella, 2015; Dalla Bella & Berkowska, 2009). These traces represent exposure to the melody during the learning phase (Glenberg, 1979). Whatever cues are available at testing provide access to those traces. The cue activates components in the episodic trace that are identical to those in the cue. In more complex materials, retrieval is aided by implicit perceptual representation (Mandler, 2004; Snyder, 2016). This refers to unconscious statistical learning that structures unconscious expectation about environmental events and keeps a record of regularities in the environment (Reber, 1989). There is evidence that complex harmonic, melodic and rhythmic features may be acquired by both expert and non-expert musicians through exposure alone, without additional learning strategies (Rohrmeier & Rebuschat, 2012). Declarative cues, termed performance cues, have been described in certain types of expert music performance (Chaffin & Imreh, 2002; Ginsborg & Chaffin, 2011). Their use is primarily limited to materials that require declarative cues internalized during the learning phase to facilitate retrieval (Bach Italian Concerto, Presto; Stravinsky Ricercar, etc.). In these performances, content addressability (the ability to restart at any point in the material) is of the utmost importance to ensure memory security. Serial cuing, whereby an ongoing chain of association allows for the unspooling of the material, is not sufficient to assure smooth performance (Chaffin et al., 2015).
The spacing effect
The spacing effect refers to the boost in recall gained from distributing learning over minutes, hours, days, or months, compared with learning materials presented in one massed session (Cepeda et al., 2008, 2009; Donovan & Radosevich, 1999; Kim et al., 2019). There is considerable research looking at the effects of distributed learning on memory for word lists (Cepeda et al., 2006) and there is evidence for the positive effects of varying both the intervals between study sessions and retention intervals for memory of relatively simple cognitive tasks (Carpenter et al., 2012). In addition to the purely verbal domain, spacing effects have been shown in a variety of other modalities (Lee & Genovese, 1988), including surgical training (Spruit et al., 2015), sports (Dail & Christina, 2004), mathematics and statistics (Ebersbach & Nazari, 2020; Lyle et al., 2020), visual acuity (Kornmeier et al., 2014), and singing (Katz et al., 2021). In a typical spacing study (Figure 1), participants are presented with an initial learning session, where the material is learned to some criterion of accuracy (often 95% correct) to ensure an equal standard of learning across conditions. A review session follows an interstudy interval (ISI) with a fixed number of learning trials. The final test is at a fixed retention interval (RI), which allows the interstudy interval to be examined as a single independent variable. For convenience, the terms spacing effect and distributed practice effect are often used interchangeably.
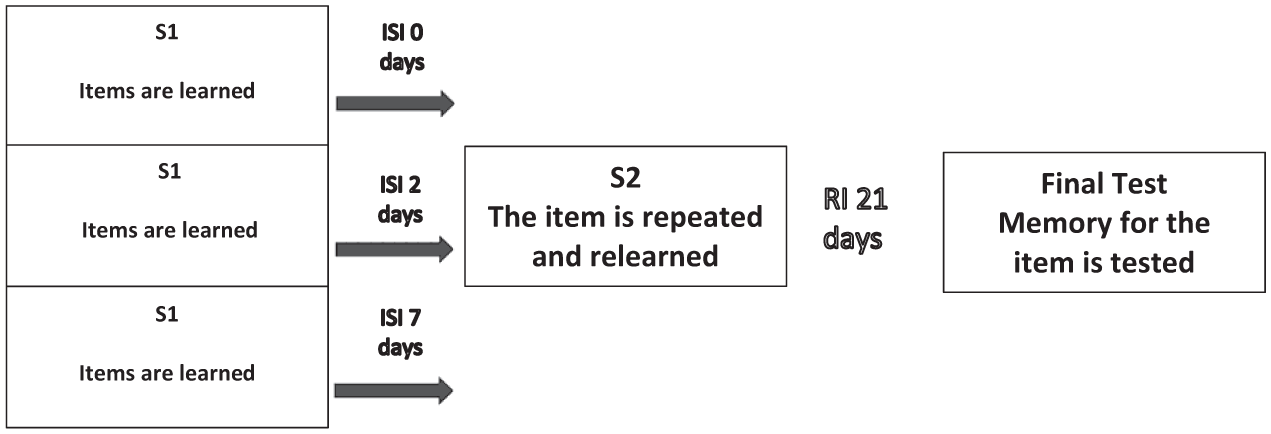
A Basic Distributed Practice Design.
Music spacing studies
Spacing effect studies using musical materials are rare. Several studies have looked at the effect of varying retention interval on memory consolidation for simple keyboard sequences (Allen, 2007; Cash, 2009; Simmons & Duke, 2006). These all used massed sessions for training. Simmons (2011) looked at memory for a nine-note keyboard figure among trained keyboard players. There were three conditions, massed and spaced at 6 and 12 hr, but the retention interval varied between experimental conditions, thereby confounding the results. As such, no conclusions regarding the effect of spacing on memory for music can be drawn. The study was also underpowered (29 participants in three conditions).
Song, with its unique cognitive profile of coordinated production of both notes and words, shows a large spacing effect in sung performance (Katz et al., 2021). Three groups of undergraduates were taught to sing a two-verse song set to a newly written melody following traditional rules of musical syntax. Lyrics followed the repetitive rhyme and metre of the traditional ballad (Wallace & Rubin, 1991). After a 3-week retention interval there was evidence for a spacing effect for syllables for the 2-day and 1-week condition compared with the massed, with evidence of no difference between the two spaced conditions. Results were consistent with the theory of multiple constraints in complex materials. The authors theorized that once the complex structure of the song was understood and associated with the initial cue, the predictable internal structure would allow for retrieval without resorting to the usual form of contextual cuing that we would expect to find in verbal materials (Cepeda et al., 2008; Glenberg, 1979). Because the notes and words were taught together, any measure of the retrieved notes would reflect word learning as well. The effect of distributed learning on melody alone thus cannot be determined from the song study. For this question, a separate melody study is required.
Spacing effect: theoretical context
The spacing effect has been explained as an interaction between encoding variability and study-phase retrieval. Most other theories (e.g., deficient processing) do not fit well with spacing gaps of days or weeks, as used in the present study (Cepeda et al., 2008, 2009). Encoding variability refers to the variability in cues available at retrieval when materials are learned over time. There are three types of cues considered to be significant in recall: contextual, structural-associative, and descriptive (Glenberg, 1979). Of these, contextual cues function largely unconsciously, based on the context of the learning environment, and are automatically encoded. Structural cues are based on the structural relationships discovered or imposed on the items to be remembered during the learning phase. They are more specific than contextual cues which are typically general in nature. Finally, descriptive cues are meanings consciously attached to the material to be remembered and are the most specific in nature. More time between subsequent presentations of the same material increases contextual variability, which in turn leads to enhanced retrieval due to the greater possibility of overlap between learning and retrieval context. A greater number of unconsciously recognized contextual cues when present at testing increase the odds of retrieving the previously learned material. Study-phase retrieval contributes to the effect by strengthening memory for items that are successfully retrieved with some effort during the learning phase (Thios & D’Agostino, 1976). Items that are easily retrieved and those that are not retrieved receive no such boost. Taken together, these factors are thought to produce the spacing effect (Delaney et al., 2010).
Current study
In this study we examine the distribution of learning events for long-term retention of a sung melody. Our theoretical perspective draws on the theory of multiple constraints as a cuing mechanism derived from the study of traditional ballads (Rubin, 1995) and encoding variability from the spacing literature. In the case of a melody, both contextual components unconsciously absorbed in the learning phase and structural components created by the musical framework may be activated when the first notes are heard. Access to the memory is predominantly controlled by the most specific components in the trace (Watkins & Watkins, 1975). As structural components are more specific than contextual components, retrieval of the melody will be predominantly controlled by whatever structural components are implied by the initial cue and the ongoing structural cues generated by the performance as it unfolds. The various structural aspects of melody (tonality, motivic patterns, rhythm, etc.) act as constraints that limit the choice of possible notes in reconstruction of the melody from memory. Globally, coherent rhythmic patterns supported by cadential structures in balanced phrases allow the notes to be chunked for recall. With massed learning, study-phase retrieval will rely on the easy retrieval of information from the first occurrence. As the gap between learning sessions increases, a reconstructive process (Glenberg, 1979) takes hold that is closer to the demands of the final memory test. This strengthens the memory trace and in verbal materials at least, makes retrieval of the material more likely for longer spacing intervals at the final test. In the present tune study, we predict that structural cues at the final test will be enough to overtake the effect of contextual variability at the more distant spacing interval. Although the absence of words structured in a poetic form may diminish the effect of structural cuing, it will not eliminate it. For this reason, contrary to the usual findings in the verbal spacing literature, where increased spacing usually leads to better memory at the final test, structural cuing will lead to an equal enhancement to memory between spaced intervals at the final test.
Hypotheses
In this study, we tested memory for a melody under three learning conditions: massed learning, where there is a minimal gap between learning sessions; spaced learning, where there is a 2-day gap; and spaced learning, where there is a 1-week gap. Our dependent variables for all hypotheses were correctly and incorrectly sung notes and intervals.
Hypothesis 1: A spacing effect between massed and spaced sessions at final retrieval. Because of the easy retrieval of the melody at the review session, and the reliance on working memory instead of long-term memory for retrieval, structural elements in the melody will be only weakly associated with the cue in the massed condition. This will lead to impaired retrieval at the final session, compared with the spaced conditions.
Hypothesis 2: No difference in memory between the two spaced conditions. Either of the two spaced conditions will allow for sufficient association between structural elements in the melody and the initial cue to enable retrieval of the melody. In this study, structural cues will be enough to overtake the effect of contextual variability at the more distant spacing intervals. Although the absence of words structured in a poetic form may diminish the effect of structural cuing, it will not eliminate it.
Hypothesis 3: Increased forgetting for the spaced conditions at the second session, when the massed and spaced conditions are compared. There are fewer shared contextual cues between initial learning and the spaced conditions. This makes retrieval more difficult for the spaced conditions.
Hypothesis 4: A difference in forgetting between the two spaced conditions, with increased forgetting for the longer gap condition. Because structural cues in the melody are only weakly associated with the stimulus material, prior to the review session, contextual variability will largely determine retrieval. At the beginning of the second learning session, where forgetting is measured, the only contextual cues associated with the target material are from the first learning session. The longer interstudy intervals in the spaced conditions mean an increasing mismatch between the contextual cues learned at the first session and the contextual cues available at retrieval the beginning of the second session, hence diminished retrieval.
Method
Transparency and openness
We report how we determined our sample size, all data exclusions, all manipulations, and all measures in the study. All data are available at https://osf.io/f4hjp/. Data were analyzed using JASP, version 0.18.3 (JASP Team, 2024), with default priors (Wagenmakers et al., 2018; for t-tests, a Cauchy distribution with a location of 0 and scale of 0.707; for ANOVAs, Jeffreys-Zellner-Siow prior, r scale fixed effects = .5; r scale random effects = 1). We chose to use default priors because they “have desirable properties, are broadly applicable, and are computationally convenient” (Rouder & Morey, 2012, p. 883). This study was approved by the York University Human Participants Research Committee, e2020-291.
Participants
When we planned our study, few or no accessible methods for a priori sample size estimation for Bayesian analyses existed (e.g., Fu et al., 2022). Thus, we aimed to run enough participants to ensure that all our major hypotheses had at least moderate evidence for the null or experimental hypothesis (i.e., 0.33 > BF10 > 3). Our prior study on song learning (Katz et al., 2021) suggested that a sample size of n = 90 would be sufficient. We planned to add additional participants after the initial round of data collection, if we were unable to find at least moderate evidence for or against our hypotheses. This is known as an open-ended sequential design (Schönbrodt & Wagenmakers, 2018). The experiment compared participants (n = 90) drawn from conservatory music students and undergraduate university students of varying levels of musical expertise. A total of 143 participants began the experiment: undergraduates from a second-year music class (n = 97) who received course credit for participation; members of a first-year ear training class in a BA program at a music conservatory (n = 11) who also received course credit for participation; undergraduates from the general university population (n = 25) who were paid participants; and candidates from a pool of exam candidates in a standardized North American music curriculum (n = 10) who were paid participants. The criterion for learning was a correct performance of the notes as determined by testers at the end of the first session. This high standard was chosen as partial compensation for the inexact nature of pitch reproduction in singing. Of the 143 participants who completed the study, 91 reached the initial learning criterion and 52 did not. In addition, sound files from one of the criterion candidates were too distorted to be coded, leaving a final total of 90 participants for analysis. The high exclusion rate (36%) may have been due to the necessarily high criterion standard.
A range of demographics were collected, which included age, gender, guardian education, results of the Profile of Music Perception Skills (PROMS) test of musical perceptual ability, Royal Conservatory of Music (RCM) grade level, and level of music performance experience. Participants were on average 20 years old (SD = 2.2, range = 16–30), 47 were female, and 43 were male, and all were native English speakers or had spoken English for 5 years or more. Participants’ guardians had 16 years of education, on average. Participants were Caucasian (n = 41), East Asian (n = 24), South Asian (n = 10), Black (n = 4), Hispanic (n = 4), or Other (n = 6). Bayesian ANOVA or Bayesian contingency table tests (as appropriate) indicated no evidence of difference between groups for individual demographics (Appendix 1, Table 3). Participants were matched between Zoom-based internet sessions and lab-based in person sessions, so that there were approximately equal ratios of participants tested on Zoom and in person for each experimental condition. A Bayesian contingency test for location indicated evidence of no difference between conditions (BF10 = 0.10). Pitch performance in online singing tests has been shown to function comparably to in-person singing tests (Tan et al., 2021). The mixed model of Zoom plus in-person testing was selected for practical considerations. In-person testing was not allowed in 2022, when testing began, due to the COVID-19 pandemic. By 2023, classes were taught in-person and we moved to in-person testing to accommodate.
Design
Participants were randomly assigned to one of the three conditions: massed, spaced at 2 days, or spaced at 1 week. They were then trained to criterion at the initial study session, followed by a review session that was either immediate (massed), or 2 days or 1 week later (spaced conditions). The final test was 3 weeks after the review session (Figure 1). All tests were cued by the first four notes of the melody, which were then dropped from analysis, leaving 48 individual notes. Measures of note accuracy (number of correctly sung notes; number of incorrectly sung notes), interval accuracy (number of correct intervals; number of incorrect intervals), and number of note omissions were the dependent variables for analysis for all hypotheses. Cents off pitch and absolute value of cents off pitch for both notes and intervals were tracked, but as a broad measure that included all notes (both correct and incorrect), they were too general to be of use. Hesitations were also recorded, although there were too few hesitations to allow for further analysis.
Materials
A four-phrase melody was newly composed by the lead researcher for testing purposes (Appendix 2). To avoid floor or ceiling effects, the melody was composed to be easy enough to learn in a single session for most participants, but difficult enough to show differences in recall after 3 weeks. Efforts were made to incorporate features in the melody that make for memorability, including a simple underlying tonal harmony (Cuddy et al., 1981; Patel, 2010); frequent use of pitches outlining basic triads at phrase endings within a regular pattern of accents (Boltz, 1991); and a completely regular phrase structure derived from traditional ballads (Rubin, 1995). Materials contained no modulations to other keys and only a brief excursion to the relative minor in the third phrase (Oura & Hatano, 1988). Stimulus materials were prepared as scores and MIDI recordings in four different keys to match the voice types of the participants. Scores were prepared using Noteflight, an online music transcription software, in the keys of F for soprano and D for alto in the treble clef, F for tenor in the tenor treble clef, and D for bass in the bass clef. In all cases, scores were notated with the syllable “doo” on each note to simplify subsequent pitch identification. MIDI recordings of the melody were generated in Noteflight in the various keys at a constant tempo of quarter note = 100 beats per second, a tempo chosen to be engaging and comfortably singable. Four different PowerPoint presentations were then prepared using the stimulus recordings and scores, according to a uniform presentation script. The script was then recorded by the lead researcher and embedded in the slides for use as instructional materials.
Procedure
The participants were all tested for voice type on presentation in the lab or Zoom session. If they were unable to match the reference keyboard pitch, they were given course credit but disqualified from further participation. Data from participants who could not recognizably sing the melody (according to the judgment of the researcher) was eliminated from analysis. Participants were first exposed to the entire melody played in the appropriate key for their voice type. Every stimulus exposure was with recording and score in the appropriate keys. They were then given three groups of learning trials: the first two phrases, the last two phrases, and all four phrases together. In the first two groups of trials, two phrases of the four-phrase stimulus were presented three times followed by a memory test cued by the starting pitch. At this point, if the participant reached criterion on the first two phrases, they were advanced to the final two phrases. If not, they continued with a maximum of three more presentations of the first two phrases alternating with cued tests. Once four tests had been given on the first two phrases, participants were advanced to the final two phrases, which were presented in the same way: three learning trials followed by a test, and then a maximum of three presentations of the stimulus, each followed by a cued test. The final group of learning trials began with a presentation of the whole melody, followed by a test cued by the first four notes of the melody. This was then followed by a maximum of three more presentations of the whole melody, each followed by a cued test. At any point in this final group of trials, if the participant reached criterion on a test, they were passed to the end of the session. Mistakes were pointed out by the researcher after every test, so that, if possible, participants would not repeat the same errors. At the end of the session, participants in the spaced conditions were thanked for their time and asked not to practice or otherwise think about the melody. Those in the massed condition went on to the second session immediately. Post hoc testing determined both equality and accuracy between all criterion tests (see Appendix 1, Table 4).
The second (review) session had a fixed number of learning trials across all conditions. The session began with a memory test to establish forgetting. All participants were then given three exposures to the stimulus and another test. Dates for the final session were confirmed, and participants were once again asked not to practice or otherwise think about the melody. The third session consisted only of the final test. All participants were directed to an online demographic questionnaire and the mini-PROMS test (Profile of Music Perception Skills; Zentner & Strauss, 2017), which they were asked to complete on their own outside the testing lab. The mini-PROMS is a well-validated 15-min version of the original PROMS battery of tests (test–retest reliability, r = .83. Criterion validity, r = .61). Results indicated evidence of no difference between groups for musical perceptual ability (BF10 = 0.12). Although testing in our study was conducted by three researchers who were aware of the experimental condition, efforts were made to ensure freedom from bias and to establish equivalence between participant groups other than for the experimental manipulation. Of the three sessions in the lab, sessions 2 and 3 followed a strict protocol determined by the slide presentation. The initial session necessitated individualized coaching to reach the criterion learning goal.
Data coding and analyses
We coded notes and intervals that were 50 cents or less off the ideal note or interval as on-pitch (i.e., correct). Being more than 50 cents off was coded as off-pitch (i.e., incorrect). As nearly as possible, objective methods of measurement were used to determine the experimental values for analysis. Participant recordings were masked by the head of the research team. Recorded sound files were analyzed in Melodyne, a commercially available sound editing program. Melodyne uses Fast Fourier Transform analysis of the waveform for acoustic segmentation, separating each audio file into separate pitches. An average pitch is then determined from stable note segments, ignoring onsets and offsets, as these are the points of maximum instability in a vocal performance (Dalla Bella, 2015; Neubäcker, 2011). Pitches were reviewed and corrected for onset time by the lead researcher, who was unaware of the experimental condition. Pitch values in note names and cents and length of any hesitation in hundredths of a second were then transcribed from the Melodyne files and entered into spreadsheets.
Results were analyzed with Bayesian ANOVAs and post hoc tests for unimodal data (number of correctly and incorrectly pitched notes, number of correctly and incorrectly pitched intervals between notes, and number of omitted notes). Of all these measures, the most relevant to our hypotheses are the number of correctly pitched intervals. Number of notes omitted is a catch-all measure, in that all notes that were not sung were part of the total. This tended to diminish the difference between experimental groups by removing notes sung incorrectly. Number of correct notes was more specific for our purposes but discounted those notes that strayed more than 50 cents from the “ideal” pitch. This meant that notes were judged incorrect where participants drifted from the underlying tonality of the melody. Number of correct intervals was the best of the measures available to us, because it compensated for pitch drift. Although this dependent variable still included a number of pitches that were more than 50 cents out of melody but judged “correct” by the researchers, it did allow out-of-melody notes where the interval relations were no more than 50 cents off. We included number of incorrect notes and number of incorrect intervals in the tables of results, although those measures did not allow for the notes and intervals that were incorrect because they were omitted.
Results
Baseline
We examined the final test of the first session to establish that all participants had learned the material equally well (Figure 2; Appendix 1, Table 4). There was evidence of no difference between groups for note omissions (BF10 = 0.14), number of correct pitches (BF10 = 0.33), number of incorrect pitches (BF10 = 0.30), number of correct intervals (BF10 = 0.11), and number of incorrect intervals (BF10 = 0.23).
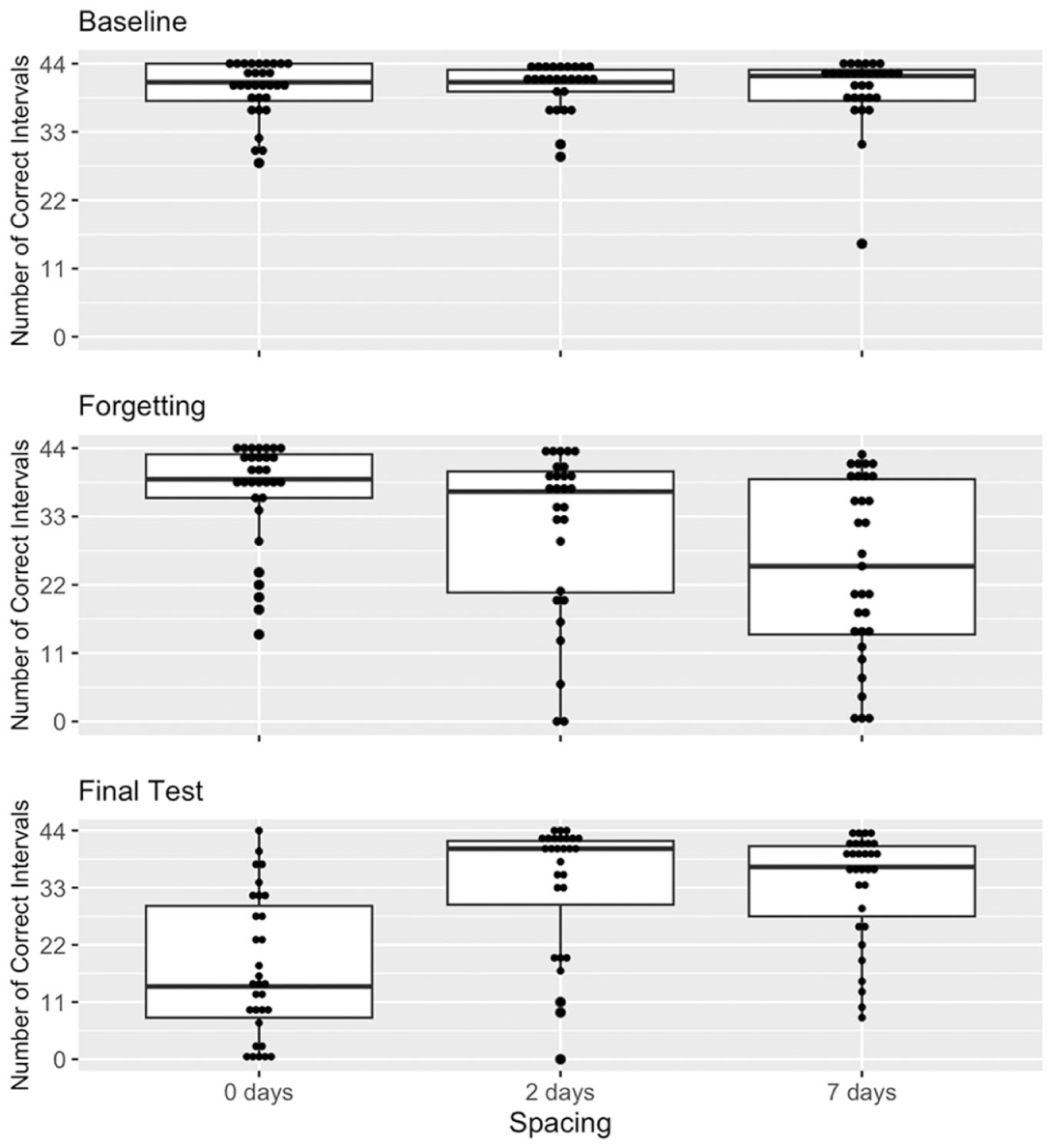
Number of Correct Intervals by Condition by Session.
Forgetting
We examined forgetting using the test at the beginning of session 2 (Figure 2). We expected that the massed group would show an advantage for note retrieval and that forgetting would be greater in the 1-week spaced condition over the 2-day condition. Results partially confirmed our predictions (Table 1). Participants omitted fewer notes and sang more correct notes and intervals in the massed condition than the spaced conditions, although evidence of increased forgetting between the two spaced conditions was inconclusive. Overall, differences between the massed and spaced conditions were due almost entirely to the difference between the massed and the 1-week condition.
Measures of Forgetting at Session 2, Test 1.
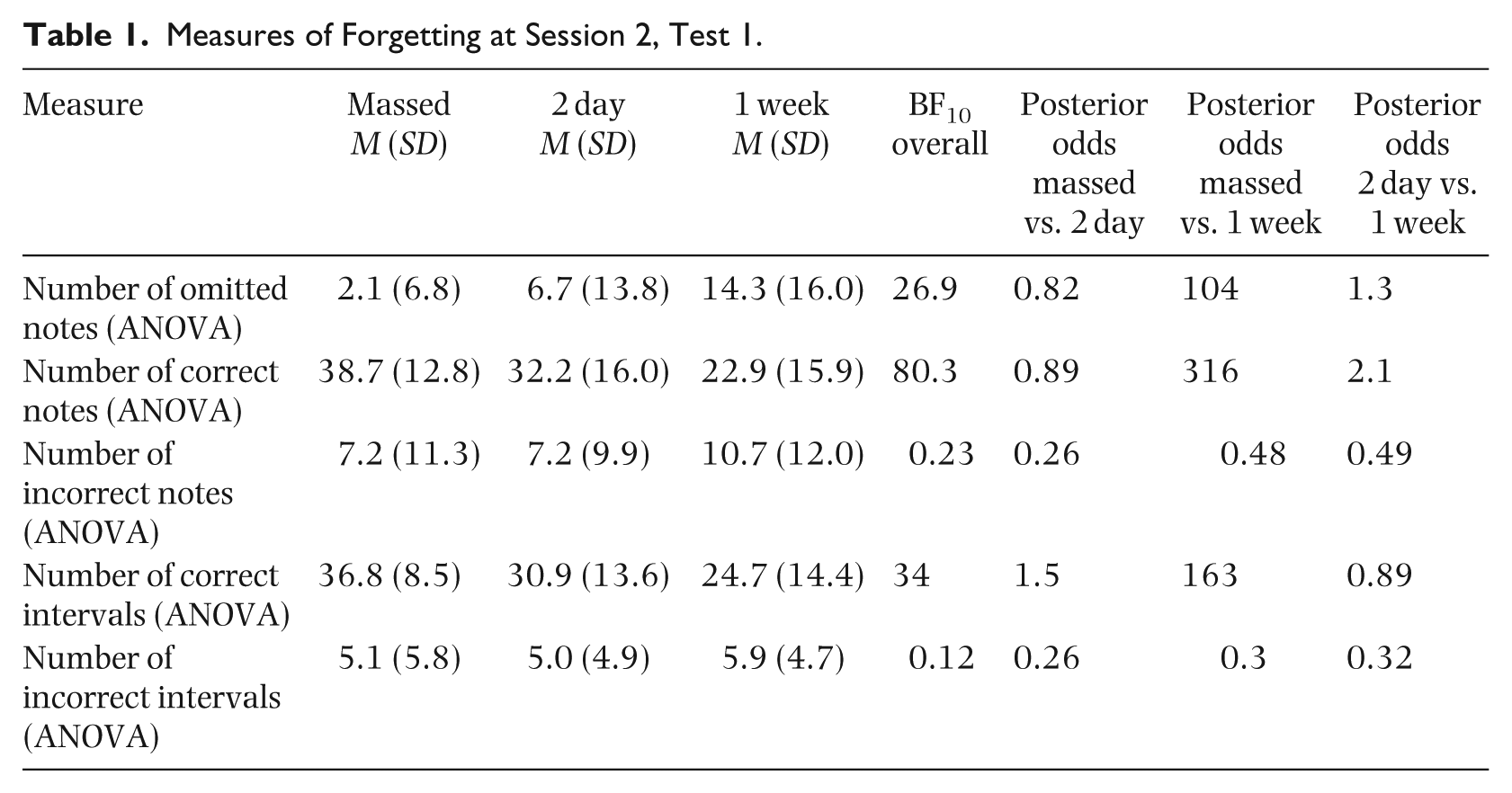
We ran ANOVAs with spacing (massed, 2 day, and 1 week) as a factor. There was strong evidence overall for increased note omissions (BF10 = 26.9), decreased number of correct notes (BF10 = 80.3), and decreased number of correct intervals (BF10 = 34.0) between conditions. There was inconclusive evidence of forgetting at the 2-day condition compared with the massed condition (note omission, BF10 = 0.82; correct notes, BF10 = 0.89; correct intervals, BF10 = 1.5) and strong evidence of forgetting for the 1-week condition compared with the massed condition (note omission, BF10 = 104; correct notes, BF10 = 316; correct intervals, BF10 = 163). There was inconclusive evidence of a difference in forgetting between the 2-day and 1-week condition (note omission, BF10 = 1.3; correct notes, BF10 = 2.1; correct intervals, BF10 = 0.89).
Final test
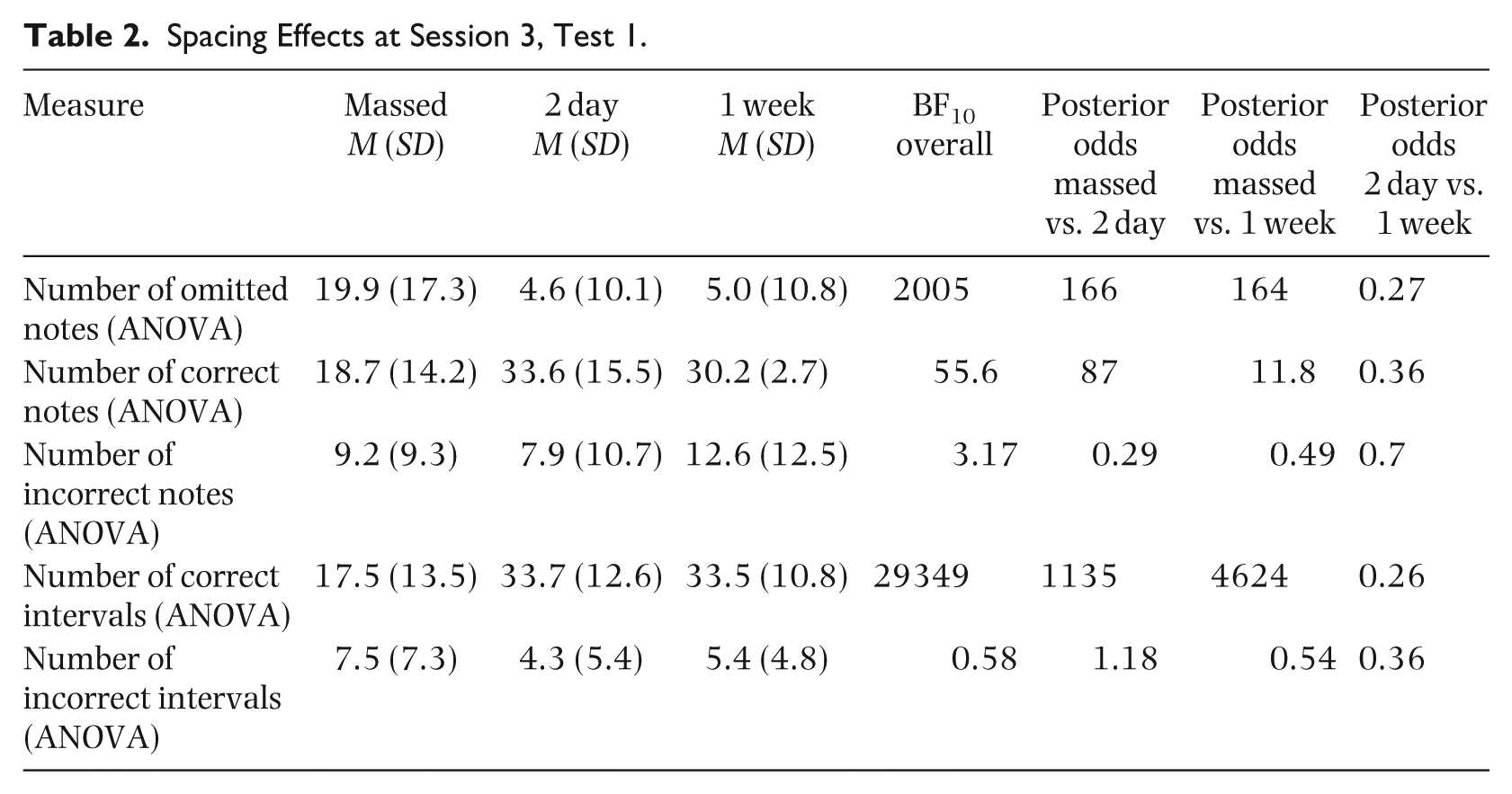
Our main goal was to show the effect of three different spacing intervals on the final test performance of a melody at a 3-week retention interval (Figure 2). We predicted that there would be a retrieval advantage for both spaced conditions over the massed and that there would be no difference between the two spaced conditions. Results confirmed our predictions (Table 2). Participants recalled fewer correct notes in the massed condition than the spaced conditions, with no increase in forgetting between the two spaced conditions. We ran ANOVAs with spacing (10 min, 2 day, and 1 week) as a factor. There was strong evidence overall for increased note omissions (BF10 = 2005), decreased number of correct notes (BF10 = 55.6), and decreased number of correct intervals (BF10 = 29349) across conditions. There was strong evidence of a spacing effect at the 2-day condition compared with the massed condition (note omission, BF10 = 166; correct notes, BF10 = 87; correct intervals, BF10 = 1135), and strong evidence of a spacing effect for the 1-week condition compared with the massed condition (note omission, BF10 = 164; correct notes, BF10 = 11.8; correct intervals, BF10 = 4624). There was evidence of no difference between the 2-day and 1-week condition (note omission, BF10 = 0.27; correct notes, BF10 = 0.36; correct intervals, BF10 = 0.26).
Spacing Effects at Session 3, Test 1.
Discussion
The findings of the present study suggest that spaced practice is an effective way to learn a melody without words. This extends the results of our previous song study (Katz et al., 2021), which also showed the positive effect of spaced learning on song. We theorized that the structural cues offered by the melody may be sufficient to allow for a comparable level of retrieval for both spaced conditions, regardless of the gap. This was borne out by the data. We did not find in either study a benefit to extending the lag between spaced practice, a finding contrary to comparable studies of verbal learning (Cepeda et al., 2006). Comparing the two spaced conditions with the 1-week condition in the melody study, there was no recall advantage for the 1-week gap over the 2-day gap. This does not mean that contextual cues played no part in recall. The phrase-by-phrase learning approach we used certainly allowed for plenty of opportunity to form contextual cues based on the learning environment. The key issue, however, is that structural cues, when present in sufficient quantity, are more specific than contextual cues and will take precedence over them in determining retrieval (Glenberg, 1979).
Where the song study exhibited a bimodal distribution of results for forgetting and for final recall, results in the melody study were unimodal. This can be understood as a further indication that the greater number of cues in the song materials allowed some participants to retrieve the entire song, where in the melody study the notes were retrieved on a phrase-by-phrase basis. As in the song study, it appears that there will be a discernable improvement in recall once some threshold between the massed and 2-day condition has been reached. It is not unreasonable to expect on further testing, that a sleep consolidation gap may account for this (Bell et al., 2014), although the exact length of the critical gap is not yet known. Because these two studies did not have a control condition using music without structural cues, we cannot claim that we have established the relative importance of structural cues in determining retrieval in highly structured materials. We have however, presented evidence that, given the limitations of our forced learning procedure, music based on traditional materials is remembered more accurately under spaced conditions. This does suggest that structural cues can be important in determining retrieval in highly structured materials, an avenue for retrieval indicated but not tested in the previous spacing literature (Glenberg, 1979).
The results for forgetting allowed us another comparison between the presence or absence of words in the stimulus. We reasoned that a melody alone would offer fewer structural cues for recall than a melody with words. As a result, in the massed condition, common contextual cues and the recency of the material in working memory led to excellent recall for both types of materials at the beginning of the second session. In the spaced conditions, the materials were only weakly associated with the initial cue, and recency was not a factor in recall. Although we expected that the greater contextual mismatch between the initial session and the increased lag should lead to more forgetting at the 1-week interval, this was only partially borne out by the evidence. While a comparison of means shows greater recall in the 2-day condition over the 1 week, it was not enough to show evidence of difference. Retrieval of structural cues in both spaced conditions may have been strong enough to allow for similar limited retrieval. A subsequent post hoc analysis on a phrase-by-phrase basis did show evidence of a difference between the two spaced conditions for correct notes in phrase four (BF10 = 8.3). Overall, when the two spaced conditions were compared, forgetting increased in a linear fashion from phrases one to four in both note omission and number of correct notes (Tables 1 and 2 Supplemental materials).
The four-phrase melody written for our study has strong internal cues related to phrase structure, tonality, metre, and internal rhythm. 1 As in the song study, there was no increase in retrieval when the 2-day and 1-week gaps were compared. This may be characteristic of highly structured materials. Once the patterns are learned and sufficiently associated with the material, much of it can be retrieved. In both studies, the melody contains a single cue (the initial four notes), which establishes rhythmic pattern, harmony, and basic tonality. This initial cue acts to initiate a series of ongoing cues that enable retrieval.
To give a more vivid comparison, we can examine spacing effects between verbal materials, song materials, and melodic materials. For verbal materials, we have chosen experiment 1 from Cepeda et al. (2009). In this study, a list of Swahili-English words was learned with gaps of 0, 1, 2, 4, 7, and 14 days, with a retention interval of 10 days. Although the retention intervals differed between the verbal and musical materials, the results still illustrate the difference in the spacing effect for low structure (associative memory for foreign-language vocabulary) and high structure (verbatim memory for song and melody) materials. The vocabulary study showed an increase in retention to a certain optimal gap, and a falling away in retention from there. This pattern has been characterized as a non-monotonic relationship (Cepeda et al., 2009), and it is consistent with findings in Ausubel (1966; text recall), Childers and Tomasello (2002; object recall), Edwards (1917; fact recall), and Glenberg and Lehmann (1980; free recall of word lists). In contrast, a non-monotonic relationship is absent in the spacing gaps of both the song and melody studies.
Our study suggests that spaced practice of melismatic or melodic music may offer some benefit to musicians. A singer given new cadenzas for a Handel aria on short notice, an instrumentalist learning new ornamentation, or a choral singer preparing a primarily melismatic Renaissance mass or motet will probably not retain the material well if they “cram” rehearsal into a single session. As with song, if there is an interval between learning sessions, recall will be substantially improved. The length of the critical spacing interval has yet to be determined, but we know that it must be somewhere between 10 min and 2 days, which were the approximate lengths of our massed and (shortest) spaced ISIs. It may also require an interval of sleep for consolidation (Bell et al., 2014). This research may also have more general implications for verbatim memory of all types, wherever materials are characterized by complex structural relations between elements.
Constraints on generality
We have mentioned the high criterion of 100% correct pitches from the end of the first session that may have contributed to the high exclusion rate for our study. The higher rate in the melody study (36%) over the song study (13%) may also be due to the greater difficulty of learning a melody without words. We have some support for this from the song study, where the first 20 min of learning were devoted to learning the melody alone. Over half of the participants were unable to learn the melody in this time. Once the words were given, most of the same participants were able to correct their melody errors. It is possible that the difficulty of learning a melody without words may be found more generally, a phenomenon worthy of further study. In addition, there may have been more inadvertent rehearsal between spaced sessions (including earworms) limiting the generalizability of the results. Finally, the method of learning (two phrases at a time) may have allowed for the increased formation of structural cues over a more ecologically valid approach.
Conclusion
This study showed that the spacing effect can be used to help memory for a melody based on traditional materials, when taught on a phrase-by-phrase basis. Like the song spacing study (Katz et al., 2021), but unlike most verbal learning studies, we did not find the inverse-U pattern where retention improves with greater spacing intervals and then decreases once an optimal ISI has been reached (Cepeda et al., 2008). Future studies should examine whether this result reflects our choice of inter-study intervals, or whether the large number of cues present in a traditional melody contributes to better memory from spacing regardless of ISI. In the future, studies of complex materials using different modalities (i.e., visual, gestural, aural, verbal) would help to identify the influence of structure on retention. A more ecologically valid learning strategy could be tested. In addition, the results could be extended to different musical genres and the analysis stratified to indicate the effect of varying levels of musical expertise. A follow-up study of song lyrics without a musical setting is also clearly indicated, examining whether the spacing effect improves memory for lyric poetry.
Supplemental Material
sj-docx-1-pom-10.1177_03057356251401906 – Supplemental material for Spaced learning and melodic memory
Supplemental material, sj-docx-1-pom-10.1177_03057356251401906 for Spaced learning and melodic memory by Joel J Katz and Melody Wiseheart in Psychology of Music
Footnotes
Appendix 1
Learning Outcomes (Session 1, Test 1): Massed, 2 Day, and 1 Week ISIs.
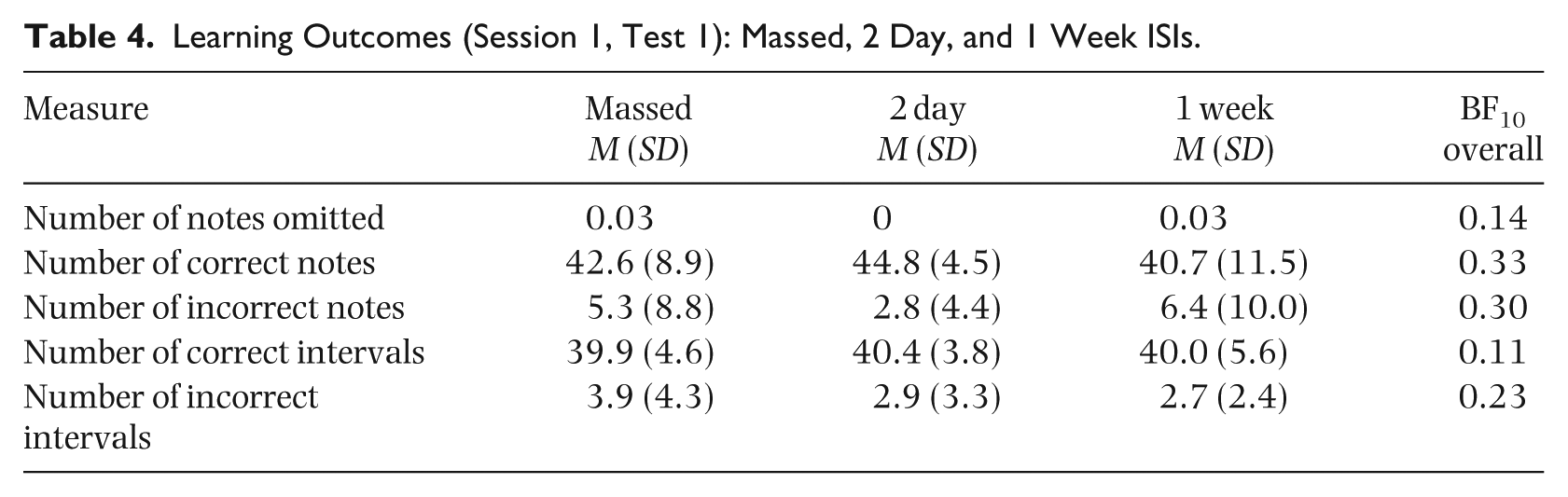
| Measure | Massed |
2 day |
1 week |
BF10 overall |
|---|---|---|---|---|
| Number of notes omitted | 0.03 | 0 | 0.03 | 0.14 |
| Number of correct notes | 42.6 (8.9) | 44.8 (4.5) | 40.7 (11.5) | 0.33 |
| Number of incorrect notes | 5.3 (8.8) | 2.8 (4.4) | 6.4 (10.0) | 0.30 |
| Number of correct intervals | 39.9 (4.6) | 40.4 (3.8) | 40.0 (5.6) | 0.11 |
| Number of incorrect intervals | 3.9 (4.3) | 2.9 (3.3) | 2.7 (2.4) | 0.23 |
Appendix 2
Author contributions
M.W. acquired funding for the project; J.J.K. and M.W. conceptualized the study; J.J.K. administered the project and conducted the research; J.J.K. and M.W. supervised the research team, curated the data, and conducted data analyses; J.J.K. wrote the original paper draft and prepared data tables; J.K.K. and M.W. reviewed and edited the paper.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Social Sciences and Humanities Research Council of Canada (grant number 435-2020-1256).
Ethical considerations
Supplemental material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.