
Abstract
When a spoken phrase is repeated several times, listeners often report a perceptual illusion during which speech is transformed into song. The speech-to-song (STS) illusion is often attributed to prosodic elements of speech, though listeners can vary greatly in their STS experience. While previous research established robust links between music aptitude and STS, the present study asks whether other cognitive traits may also influence STS. Individual (in)sensitivity to nonverbal aspects of speech, specifically speech prosody, has been previously linked to autistic traits and emotional intelligence. We test whether the presence of autistic traits, the level of emotional intelligence and musical training, as well as syntactic complexity influence the likelihood, speed, and strength of STS among native British English listeners. The results provide evidence for the involvement of some but not all studied traits. We found sentence complexity to be interacting with a composite score of musical training, and emotional intelligence for the likelihood of STS, whereas sentence complexity influenced the strength of the transformation. These results suggest that individual listener variability may interact with the linguistic parameters of sentences in STS. Crucially, sensitivity to prosody through emotional intelligence or by the presence of autistic traits does not mediate the transformation.
Keywords
The speech-to-song (STS) illusion is a well-described phenomenon linking language and music. It was first discovered by Diana Deutsch (1995), who reported a perceptual illusion where a spoken phrase changes from being perceived as speech to song after a few repetitions. This transformation mostly appears after the third repetition of the spoken phrase (Falk et al., 2014) and cannot be “unheard”; thus it continues to be perceived as song (Groenveld et al., 2020) with memory traces of a stimuli influencing the consistency of the STS transformation (Soehlke et al., 2022). The illusion is suggested to be caused by changes in the neural circuits associated with pitch extraction, song production, and auditory–motor integration (Tierney et al., 2012) and it is thought that prosodic elements of the acoustic speech signal, such as rhythm and pitch, contribute most to a successful STS transformation (Falk et al., 2014). Although the STS illusion has attracted a range of studies (Falk et al., 2014; Graber et al., 2017; Groenveld et al., 2020; Jaisin et al., 2016; Rathcke et al., 2021; Tierney et al., 2018), there are still many mysteries surrounding this phenomenon. This includes individual differences in listeners that may increase the likelihood of perceiving STS such as individual sensitivity to speech prosody, and possibly the presence of autistic traits or the variability in emotional intelligence.
Speech prosody often refers to the musical aspects of speech (Cole, 2015; Everhardt et al., 2022; Thompson et al., 2004) and can include qualities such as a sentence’s melody through pitch and intonation, and its rhythm through stress and timing. An important function of speech prosody is to express the speaker’s emotions or intentions (Frick, 1985; Juslin & Laukka, 2001, 2003). In short, speech prosody does not relate to what one says, but to how one speaks (Everhardt et al., 2022). To recognize prosody, specific acoustic cues need to be processed by the listener, such as the fundamental frequency, and timing cues. Successful interpretation of prosody includes linking the acoustic content with socio-emotional conventions (Globerson et al., 2015).
Specific prosodic aspects of a speech signal may contribute to a successful STS transformation (Falk et al., 2014; Rathcke et al., 2021). There is, for example, a crucial role for the perceived pitch of the speaker’s voice (Rathcke et al., 2021), which is related to the fundamental frequency (F0). Stable F0 trajectories are more likely to induce an STS transformation compared with fluctuating F0 trajectories and are in fact considered to be the most salient acoustic cue of STS (Groenveld et al., 2020; Rathcke et al., 2021; Tierney et al., 2018). In addition, Rathcke et al. (2021) tested whether consonant sonority carrying phrasal prosody and pitch can impact the likelihood of perceiving STS in French and English listeners and found that high-sonority sentences and listening in a non-native language support STS transformation. Interestingly, acoustic aspects of the speech signal that may relate to specific characteristics in Western 12-tone equal temperament (12-TET; the musical tuning system most Western-enculturated participants are used to hearing), such as specific pitch intervals, do not appear to enhance the likelihood of an STS transformation (Cross et al., 1983; Falk et al., 2014; Krumhansl, 2000; Tierney et al., 2018). Thus, a musical melody can start to occur without any concrete acoustic musical elements (Rathcke et al., 2021) and depends mostly on a process of perceptual distortion through the act of repetition (Deutsch et al., 2011). With regard to rhythm, it is found that the phenomenon does not rely on isochrony within the phrase or across repetitions (Falk et al., 2014; Margulis et al., 2015; Tierney et al., 2018). Instead, it builds on small timing variations occurring through the grouping of sounds into intervocalic intervals (Falk et al., 2014).
Although acoustic parameters contribute to the likelihood of an STS transformation, there is a large deal of variability in whether a listener reports a transformation. Thus, apart from possible linguistic or acoustic differences between the spoken phrases, listener-specific characteristics, such as individual sensitivity to speech prosody, may also contribute to this variation (Rathcke et al., 2021). As prosody appears to play a role in increasing the likelihood of STS, are there any individual differences in sensitivity to prosody that may influence whether or not someone reports an STS illusion?
Due to the similarities between music and speech prosody, it is thought that perceptual skills learned through extensive musical training may help to recognize expressions carried by prosodic elements of speech (such as conveyed emotions, pragmatic intentions, or syntactic structures). A study by Thompson et al. (2004) tested whether those who have received music lessons are more sensitive to prosodic elements in speech that convey emotion. In two experiments, it was found that musically trained adults outperform untrained participants in identifying sadness, fear, or neutral emotions. In a third experiment, 6-year-olds were tested after having received 1 year of music or drama lessons, and it was confirmed that music training indeed improves a listener’s ability to identify emotions conveyed by speech prosody. Another study by Trimmer and Cuddy (2008) asked 100 university undergraduate to identify emotions in neutral speech and melodic phrases that were manipulated to express either anger, fear, joy, sadness, or a neutral expression. Their responses were correlated with their music education, emotional intelligence, musical perception, and memory and fluid intelligence. They found that emotional intelligence was linked to correctly perceiving the intended emotion of the speech and musical stimuli, and that increased perceptual auditory skills through musical training did not enhance emotion perception. Hence, emotional intelligence may help to correctly process prosodic information. Expression and perception of emotion are essential components of communication in music, but similar to variability in auditory skills; individual differences in the receptiveness of emotions and emotional intelligence exist (Resnicow et al., 2004).
Prosodic cues are not solely used to convey emotions in speech, but they also provide syntactic information and can help to disambiguate ambiguous sentences (Bennett & Elfner, 2019; Lehiste, 1973). Snedeker and Trueswell (2003) found speakers to use more prosodic cues in their speech in ambiguous contexts and in particular when sentences are syntactically more ambiguous. Hence, individual sensitivity toward prosodic cues is helpful to process emotional information conveyed by the speaker, but may also help to express syntactic constituency.
The idea that individual differences in sensitivity to prosody can contribute to STS illusions has been tested in a recent study by Tierney et al. (2021). Tierney and colleagues examined whether musical aptitude or training contribute to the strength of the illusion based on the idea that musicians may be less susceptible to auditory illusions due to interfering top–down processes (Brennan & Stevens, 2002; Craig, 1979; Davidson et al., 1987; Pressnitzer et al., 2018), but prior research has been inconclusive regarding the role of musical training and music perception skills in the likelihood and strength of the illusion (Falk et al., 2014; Vanden Bosch der Nederlanden et al., 2015). Tierney et al. (2021) found that the degree of musical training did not impact the strength of the illusion, but a range of music perception skills did. This suggests that sensitivity to the prosodic aspects in the STS illusion may be due to specific listener’s characteristics that may be related, but are not necessarily limited to music perception skills. Thus, the literature suggests there may be a role of perceptual auditory skills (such as trained musical perception skills) on the perception of STS. However, it is yet unclear how other individual traits that have been linked to prosodic sensitivity, such as autistic traits and emotional intelligence (or a combination of both), contribute to the perception of the illusion.
Apart from specific skills possibly contributing to help to distinguish prosody in speech, there are also individuals who have difficulties perceiving or processing prosodic cues and thus may not easily recognize emotions conveyed by speech. For example, it is thought that individuals with autism spectrum disorder (ASD) have impaired prosodic processing due to deficits in social communication (Globerson et al., 2015; Maslennikova et al., 2022; Rosenblau et al., 2016). A study by Rosenblau et al. (2016) tested emotional prosody recognition accuracy in individuals with ASD and controls on a behavioral and neural level and found reduced accuracy for the former compared with the latter group. Individuals with ASD showed reduced neural activity in the superior temporal sulcus, insula, and amygdala for complex compared with basic emotions and showed a stronger relation between brain activity during emotional prosody processing and accuracy in the behavioral task. Maslennikova et al. (2022) tested 4- to 6-year-old children diagnosed with ASD and typically developing (TD) peers using an electroencephalogram (EEG) paradigm where brain responses were collected to syllables with different types of emotional prosody (joy, anger, sadness, fear, and calmness). It was found that children with ASD and TD children had similar neural responses to anger and fear prosody, but differences occurred for sad and joy prosodic elements. The authors conclude that difficulties in emotional prosody recognition in children with ASD may be due to atypical neural processing of specific acoustic elements in speech, but that differences between emotions occur. Another study confirms that auditory perceptual abilities are an important aspect of why individuals with ASD may have difficulty recognizing affective prosody (Globerson et al., 2015).
If general auditory perceptual abilities are the cause of impaired prosodic processing in ASD, this should also occur in music perception, but evidence suggests that this may not be the case (DePriest et al., 2017; Jamey et al., 2019). DePriest et al. (2017) examined prosodic phrasing in ASD in speech and in music. Using behavioral and event-related potential (ERP) methods, they tested phrase boundary processing in speech and in music it differed between individuals with ASD and TD individuals. It was found that processing of musical prosodic cues is not impaired in individuals with ASD, in contrast with language prosodic cues. It is suggested that there are key differences in the way the acoustic features of language and music are integrated in the brain leading to a possible impairment of speech prosodic cues in ASD. Similarly, Jamey et al. (2019) found evidence for intact melodic and rhythmic music perception in children with ASD compared with TD children and the tested music perception skills were related to nonverbal cognitive abilities and children’s age rather than the presence of autistic traits.
Moreover, a reduced sensitivity to linguistic prosodic cues may impact processing of syntactic complexity. Studies have shown that language abilities in children with ASD are related to their syntactic skills (Peristeri et al., 2017) with spoken speech showing less syntactically complex sentences (e.g., Eigsti et al., 2007). Hence, in addition to a possible link between processing of prosodic cues in speech and emotion recognition, there may be a relation between the former and the use and recognition of complex syntax in speech.
However, a recent systematic study (Zhang et al., 2022) found that the relation between ASD and (affective) prosody recognition is not as clear-cut and that there may only be moderate differences between individuals diagnosed with ASD and TD individuals. These differences were even further reduced when publication bias was taken into account. It was concluded that there is insufficient evidence to show whether affective prosody recognition is or is not impaired in ASD. Thus, it is yet unclear whether the presence of autistic traits and emotional intelligence is linked with prosody recognition and whether this can impact the speech-to-song transformation.
This study examines whether there is a correlation between the presence of autistic traits, emotional intelligence, and the likelihood, speed, and strength of perceiving the speech-to-song illusion in English native speakers. British English adults participated in their native language in a speech-to-song experiment, whereby we measured the likelihood of perceiving the illusion, the speed at which participants perceived the illusion, and the strength of the illusion. In addition, participants filled out the AQ-10 Autism Spectrum Quotient, a quick screening tool that may indicate the possibility of someone having autistic traits, and the Trait Emotional Intelligence Questionnaire (TEI-QUE), which tests participants’ emotional intelligence. As suggested by the above literature, listeners with autistic traits may have difficulties perceiving prosodic elements in speech, hence they may be less likely to perceive the speech-to-song illusion. In contrast, those scoring high on the emotional intelligence score may be more likely to perceive the speech-to-song illusion. Depending on the presence or level of particular traits in listeners, they may adopt a different listening strategy focusing either more or less on prosodic aspects of the sentences. To test this, and based on Rathcke et al. (2021), we tested the following aspect of STS:
1. Likelihood of STS: whether participants report having perceived an STS transformation.
2. Speed of STS: if participants reported having perceived an STS transformation, and during which cycle they reported the STS.
3. Strength of STS: the strength of the song-like ratings after having perceived an STS transformation.
Apart from the AQ-10 and TEI-QUE scores, we also include a composite of musical training a participant has received as this may also impact the likelihood, speed, or strength of STS (Rathcke et al., 2021) Musical training has had mixed findings in prior studies (Falk et al., 2014; Rathcke et al., 2021; Tierney et al., 2021). Due to the aforementioned relation between prosody and syntactic complexity, the sentences were manipulated to represent differing levels of syntactic complexity.
Method
Participants
Forty-one English (Mage = 20.34, range = 18–41) speakers participated in the experiment. Participants were screened for language impairments (including dyslexia) and amusia. No professional musicians participated in the experiment. The study was approved by the ethics committee of the University of Kent and all participants gave informed consent to participate in this research and received a small payment.
Materials
Twenty-four English sentences were created which varied in sonority, in length (5–13 syllables), and in syntactic structure. The sentences were recorded by a native female speaker of British English. The specific sentences used can be found in the Supplementary Materials. The test sentences were looped with eight repetitions, each separated by a 400-ms pause. To increase the success of the STS manipulation, a mean sonority index was calculated for each sentence. Following the same procedure as Rathcke et al. (2021) each phoneme’s location was numerically coded on the phonological sonority scale (Clements, 1990) from 0 for voiceless plosives to maximally 9 for open vowels. We then calculated a mean sonority score for each sentence. Each sentence’s underlying structure was quantified to study the effect of syntactic complexity. This was based on five syntactic aspects: (1) the number of terminal syntactic nodes (3–10 in this sample); (2) the number of predicates (1 or 2); (3) the number of subordinate sentences (0 or 1); (4) the number of phrasal constituents (1–4); and (5) the presence of a garden-path effect (coded as 0–2). The presence of a garden-path effect was calculated based on whether a sentence had (1) no syntactic ambiguity (coded as 0), (2) syntactic ambiguity, but this was not expressed prosodically (coded as 1), or (3) syntactic ambiguity expressed both syntactically and prosodically (coded as 2). This then led to a composite score of syntactic complexity, which varied between 5 and 19 (M: 10.98) in this sample with a higher score representing higher syntactic complexity.
AQ-10 Autism Spectrum Quotient
To test for the presence of possible autistic traits, participants filled out the AQ-10 Autism Spectrum Quotient questionnaire (Allison et al., 2012). This is a quick screening tool that healthcare practitioners can use to screen whether an adult should be referred for further autism assessment. It is important to note that this is not a self-assessment tool or that a high score on this questionnaire automatically means a person has autism. The questionnaire consists of 10 statements with four possible choices for each statement: (1) definitely agree, (2) slightly agree, (3) slightly disagree, (4) definitely disagree. A score of 6 or more may be an indication that the person has autism, but it is important to note that this questionnaire is not sufficient to warrant a diagnosis.
TEI-QUE
Apart from the AQ-10 Autism Spectrum Quotient, participants also filled out the Trait Emotional Intelligence Questionnaire—Short Form (TEI-QUE-SF; Petrides & Furnham, 2006). This questionnaire consists of 30 items that measure global trait emotional intelligence and is based on the long form of the TEI-QUE (Petrides & Furnham, 2003). For the short version, two items of the original 15 subscales are selected based on their correlations. The SF has been validated to ensure consistency with the long version (Petrides & Furnham, 2001, 2003, 2006). Participants respond to the 30 items on a 7-point Likert scale.
Music score
Participants also filled out a questionnaire asking about their musical training, and ongoing and past musical and dancing experience. From this questionnaire, a general musicality index was derived, following previous work (Rathcke et al., 2021; Šturm & Volín, 2016). The musicality index captured an aggregate score based on years of musical training (from 0 to 18 in the present sample), current regular music practice (0 for non-active and 1 for active participants), number of musical instruments (which included singing and dancing, from 0 to 5 in the sample), and finally the age at which participants started their musical training (below the age of 10 was coded as 2, from 10 up to 20 years as 1, above 20 years as 0). The resulting musicality indices varied from minimally 0 (no musical experience) to maximally 20 (a relatively high level of musical experience). None of the participants was a professional musician. The aggregated music score was normalized and used for further analysis.
Procedure
Listeners were tested at the University of Kent, Canterbury, England. Prior to the experiment, participants filled in an online questionnaire related to their musical experience, including questions about music training, ongoing and past musical activities, instruments played (including singing), and the starting age of musical training. In addition to the musical background questionnaire, participants also filled out the AQ-10 and TEI-QUE forms.
Participants were then invited to visit the lab for the STS experiment. Participants were first asked to rate the 24 individual test sentences on a scale from 1 (clearly speech) to 8 (clearly song). These ratings functioned as the baseline of perceived song-likeness of each sentence prior to the experimental manipulation (Falk et al., 2014; Groenveld et al., 2020). Subsequently, participants finished a few distractor tasks, which was followed by the main STS task. Participants listened to the looped sentences and were asked to indicate when they heard the STS transformation by pressing a button as soon as they heard the transformation. They were clearly instructed not to press the button if they did not experience the STS transformation. After every trial, they evaluated the song-likeness of the sentence in the same format as in the baseline test.
Statistical analysis
The data were analyzed with Bayesian multilevel regression models run in the statistical program R (R Core Team, 2021) with the brms package using Stan (Bürkner, 2017, 2018; R Core Team, 2021). We tested the effects of the predictor variables (AQ-10 score and TEI-QUE score) on (1) the likelihood of STS (whether or not participants reported having perceived the transformation during repetitions coded modeled as a binomial model) and (2) the speed of STS (during which repetition cycle from 1–8 participants reported perceiving the transformation modeled as an ordinal model) and the strength of STS (based on how song-like the sentences were rated from 1 to 8, collected after repetitions and modeled as an ordinal model).
Hence, two models per STS measurement were run to test the hypotheses. Each model includes two main predictors: either AQ-10 or TEI-QUE score and music score both interacting with the sentence complexity score, and random effects for participants and sentence. All continuous variables were scaled and centered to zero. All models converged.
We used a weakly informative prior with a Student’s t-distribution and three degrees of freedom, a mean of 0 and a scale of 1. To quantify the strength of evidence for each hypothesis, we used evidence ratios which are given by the posterior probability that an effect is in the hypothesized direction divided by the posterior probability that the effect is in the opposite direction (Smit, Milne, Sarvasy, & Dean, 2022). An evidence ratio (ER) of >19 can be considered to be analogous to a p-value of <.05. Such ratios are referred to as “strong evidence” in a directional hypothesis testing using Bayesian regression.
To assess each model’s overall fit to the data, we use the McKelvey and Zavoina pseudo-R2 (McKelvey & Zavoina, 1975) following guidelines and R script by Milne and Herff (2020).
Results
Song-like ratings
Figure 1 shows the “song-like” ratings pre- and posttest averaged across all sentences. A Bayesian linear model with pre- or posttest as fixed effects and participants and sentence as random effects showed that we have strong evidence that ratings increased posttest compared with pretest (estimate = 0.41, 90% CI = [0.34, 0.47], ER = > 19,999, PP = 1.00).
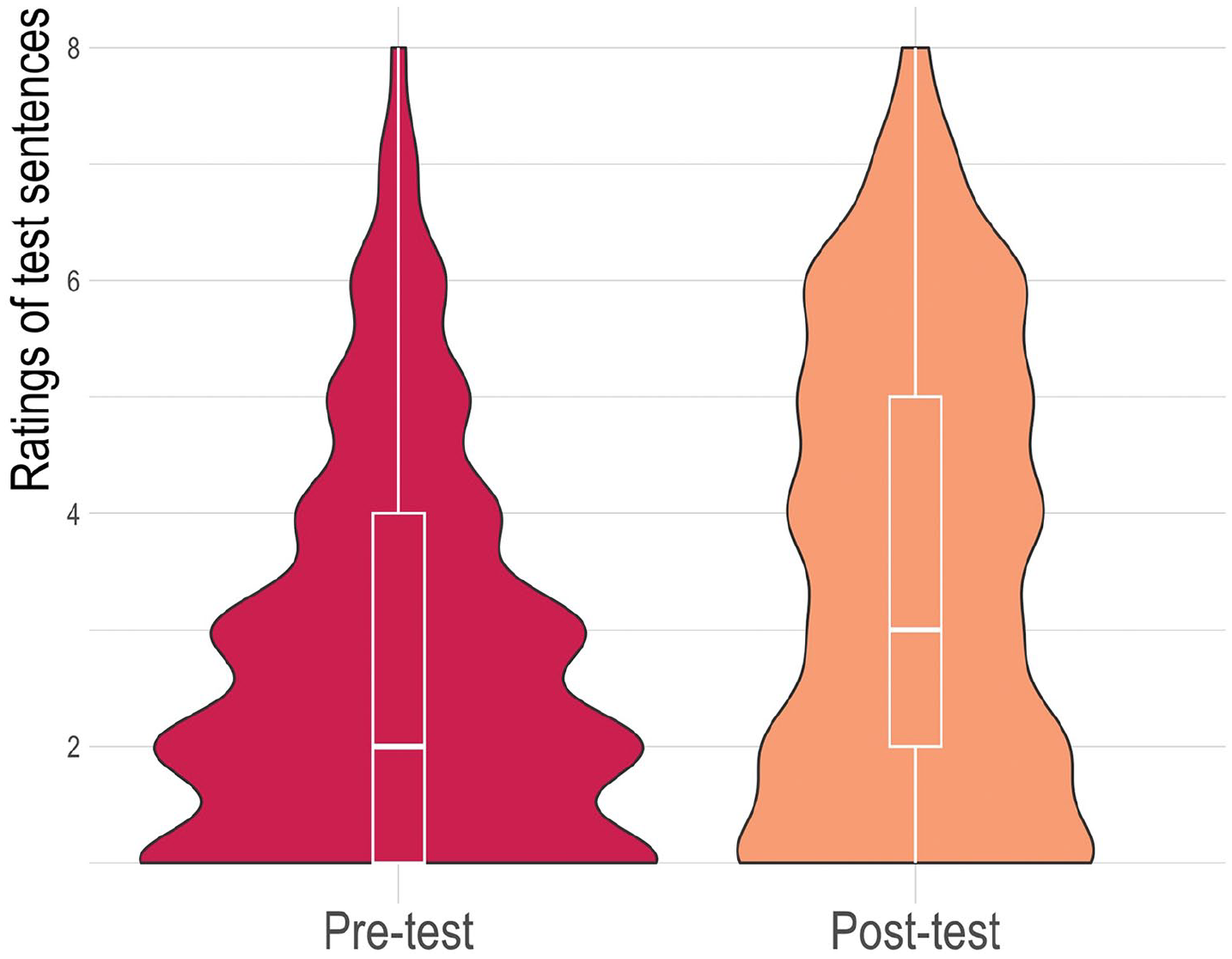
Violin Plots With Embedded Boxplots of Ratings of Test Sentences After a Single Exposure Versus After Eight Repetitions on the 8-Point Scale (1 = Clearly Speech, 8 = Clearly Song) for Both Test Languages After a (a) single exposure vs. (b) after eight repetitions.
Test scores
Figure 2 shows the distribution of the AQ-10 and TEI-QUE test scores and the correlation between the two test scores (R = –0.47, p < .001) is plotted in Figure 3. As we are interested in possible different mechanisms high scoring participants on either test may employ while perceiving the illusion, we will test the two in different models.
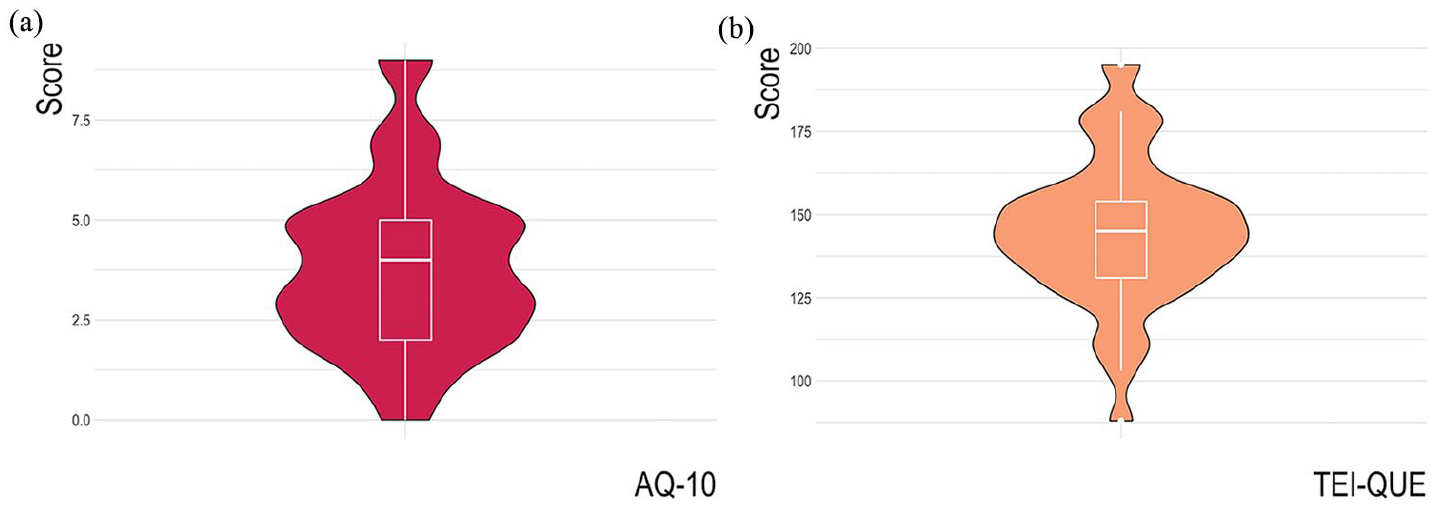
(a) Distribution of AQ-10 scores. (b) Distribution of TEI-QUE scores.
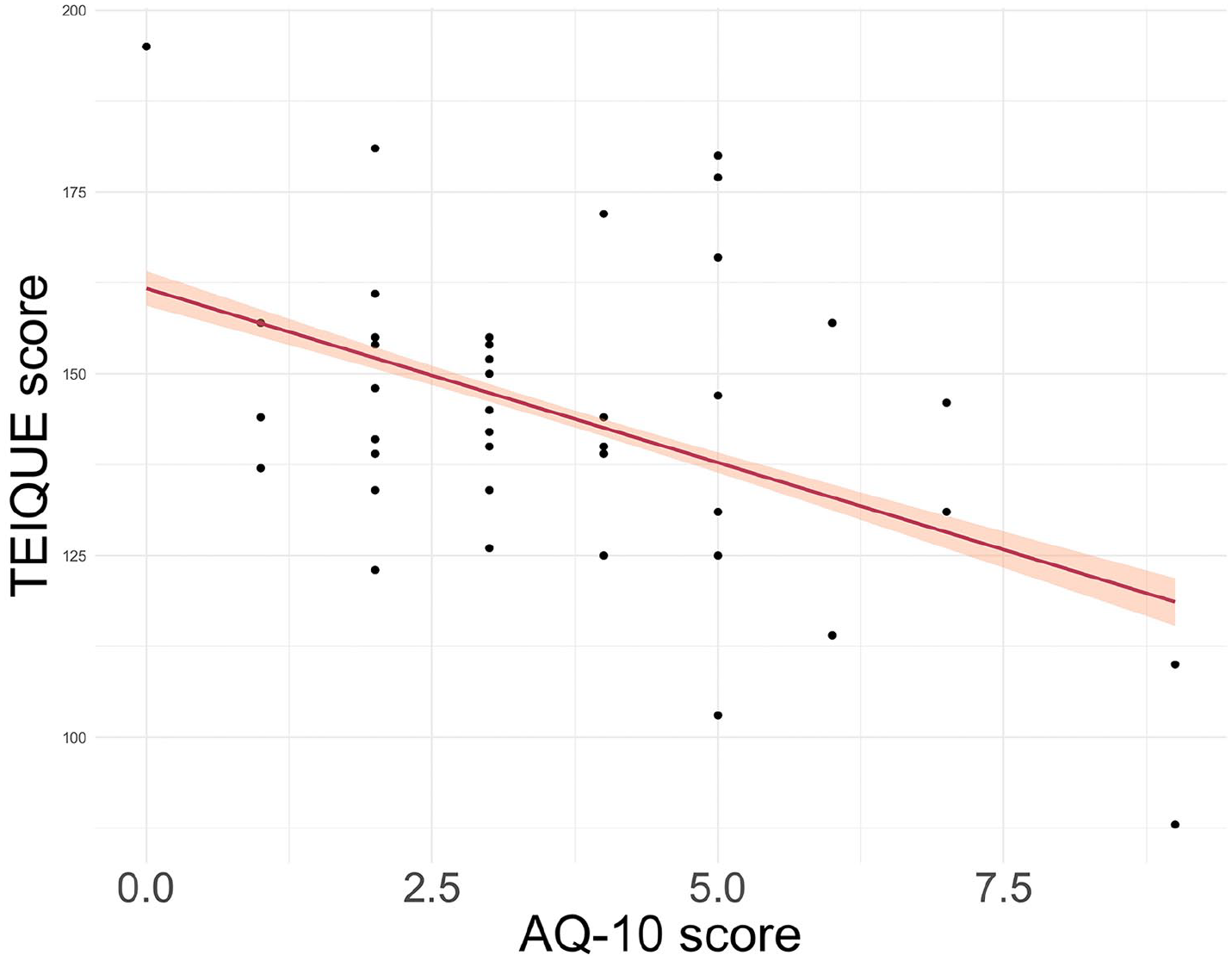
Correlation Between the AQ-10 and TEI-QUE Scores.
Likelihood of STS
We tested for the effects of the main predictors of the AQ-10 and TEI-QUE scores and possible control variables on the likelihood of perceiving STS using two different models: one with AQ-10 (Model 1) and one with TEI-QUE (Model 2) as predictor. Hypothesis testing showed that sentence complexity may negatively impact the likelihood of STS (see Table 1) and that this interacts with the music score in both the models. In other words, those with a higher music score are less impacted by sentence complexity than those with a lower music score. We also have some evidence that sentence complexity interacts with TEI-QUE with those with a higher emotional intelligence score being more impacted by sentence complexity than those with a lower emotional intelligence score. Results of the hypothesis tests are shown in Table 1. Both models have a Bayesian McKelvey–Zavoina R2 of 0.43 with 95% credibility intervals of 0.35–0.52. Thus, they explain about 43% of the variance in the data. The model outputs and conditional effects with evidence-supported hypotheses are visualized in the Supplementary Materials.
Results of the Hypothesis Tests.
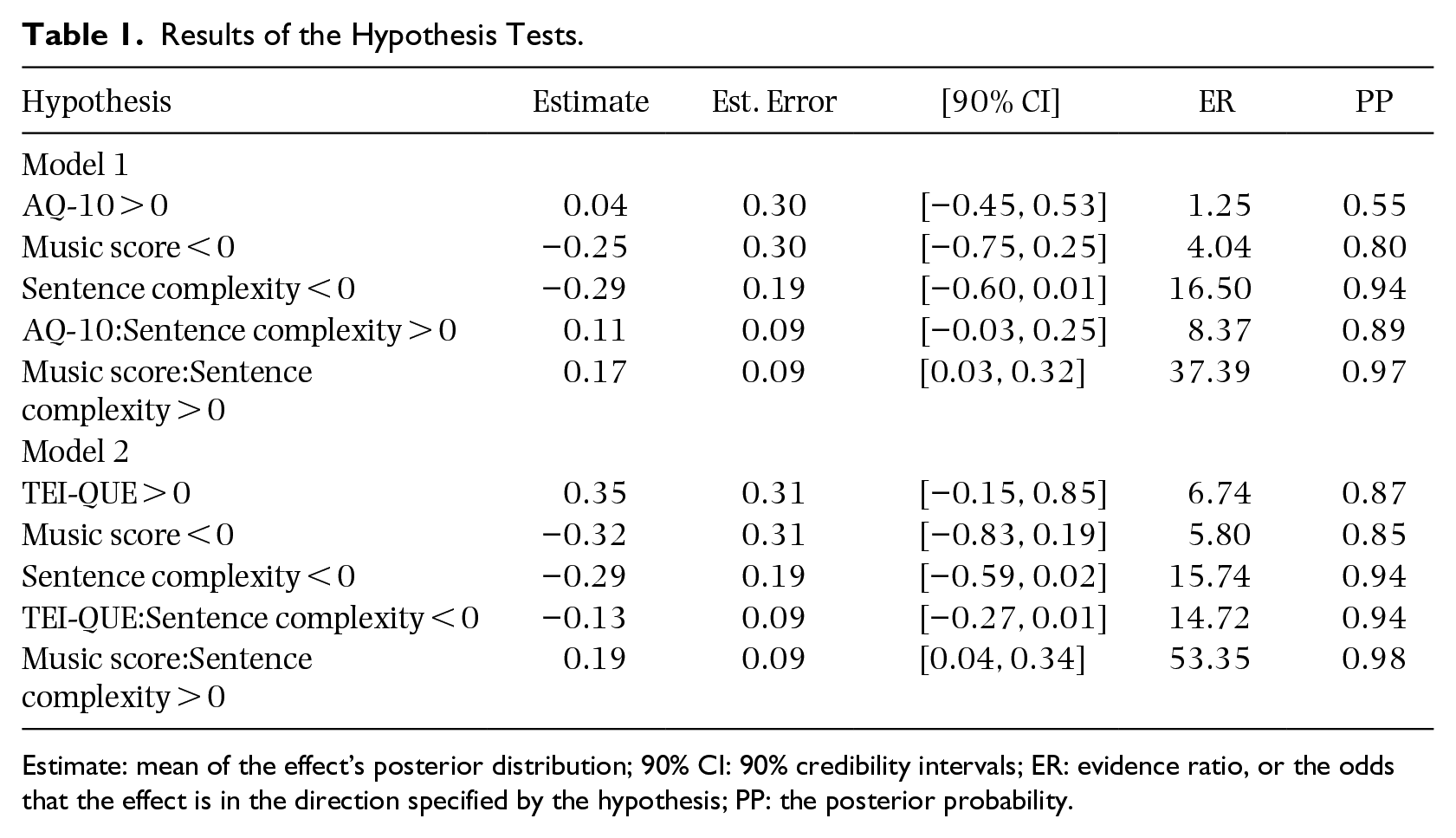
Estimate: mean of the effect’s posterior distribution; 90% CI: 90% credibility intervals; ER: evidence ratio, or the odds that the effect is in the direction specified by the hypothesis; PP: the posterior probability.
Speed of STS
The second hypothesis tests for a possible effect of the predictors on the speed of perceiving STS again in two models: one with AQ-10 (Model 1) and one with TEI-QUE (Model 2) as predictor. The response variable here is during which repetition cycle the STS was perceived and these models were run only on trials where a transformation was perceived. We find no strong evidence in support of any predicted effect or interactions on the speed of the illusion. There is only some evidence (i.e., ER = 10.38) for a negative effect of emotional intelligence on the speed of the illusion, with a large effect size (estimate = –0.41).
Results of the hypotheses tests are shown in Table 2 and both models have a Bayesian McKelvey–Zavoina R2 of 0.35 with 95% credibility intervals of 0.28–0.42. Thus, they explain about 35% of the variance in the data. The model outputs and conditional effects of the with evidence-supported hypotheses are visualized in the Supplementary Materials.
Results of the Hypothesis Tests.
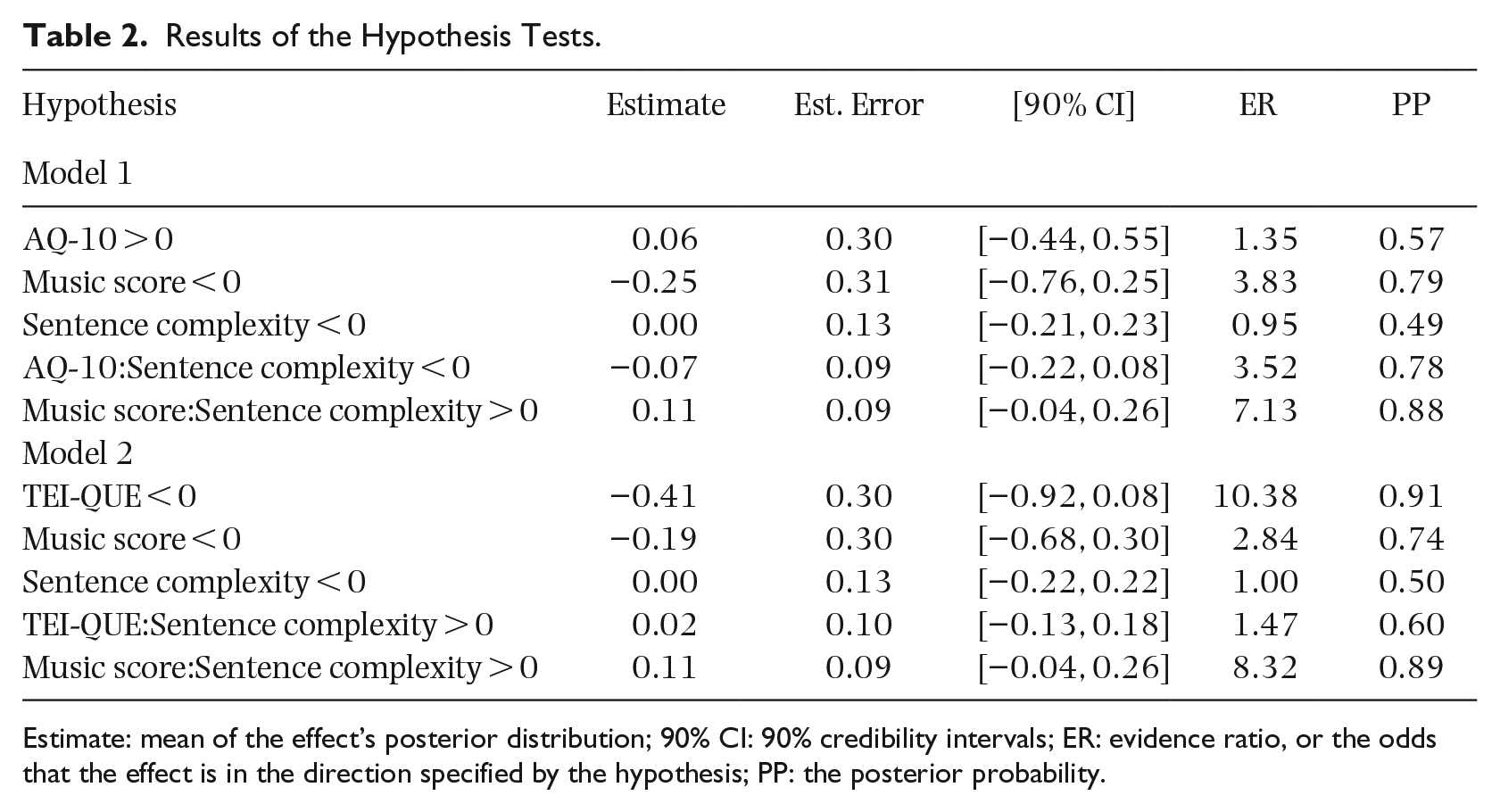
Estimate: mean of the effect’s posterior distribution; 90% CI: 90% credibility intervals; ER: evidence ratio, or the odds that the effect is in the direction specified by the hypothesis; PP: the posterior probability.
Strength of STS
Finally, we tested for a possible effect of the predictors in two models on the strength of perceiving STS as measured by the posttest song-like ratings of each sentence. These models were again run only on trials where a transformation was perceived. Hypothesis testing shows strong evidence that sentence complexity has a negative impact on the reported strength of the STS transformation in both models (see Table 3). We did not have strong evidence for any of the other predictors or the interactions; however, there is moderate evidence for an interaction between AQ-10 and sentence complexity. The models have a Bayesian McKelvey–Zavoina R2 of 0.48 with 95% credibility intervals of 0.41–0.54 and explain roughly 48% of the variance in the data. The models outputs and conditional effects for the with evidence-supported hypotheses are visualized in the Supplementary Materials.
Results of the Hypothesis Tests.
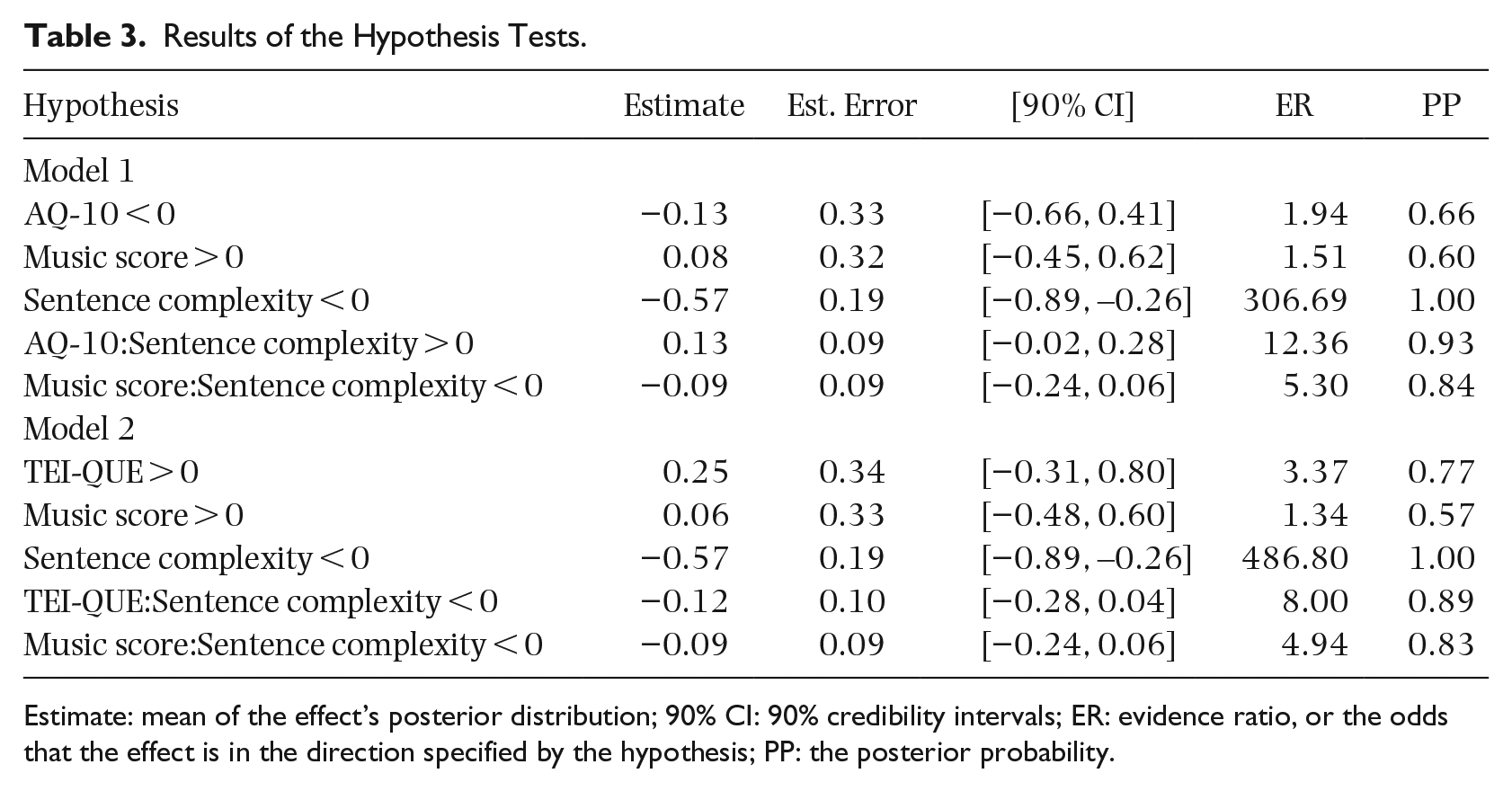
Estimate: mean of the effect’s posterior distribution; 90% CI: 90% credibility intervals; ER: evidence ratio, or the odds that the effect is in the direction specified by the hypothesis; PP: the posterior probability.
Discussion
This study investigated a potential role of autistic traits and emotional intelligence on the likelihood, strength, and speed of a speech-to-song transformation in British English native speakers. Overall, the findings show that, in addition to specific acoustic parameters of the sentences as found in prior research (e.g., Rathcke et al., 2021), listener-specific as well as sentence-specific characteristics play a role in the success of the transformation. Generally, song-like ratings went up after the experimental manipulation, meaning that the STS transformation has been successful.
Regarding the likelihood of STS, we found an interaction between sentence complexity and musical score in both the models. Listeners with a lower musical score appear to be more strongly impacted by higher sentence complexity than those with a higher musical score. This is in contrast with Rathcke et al. (2021), who found no contribution of the same music score on the likelihood, strength, or speed of STS. However, in their study, they only included music score as a covariate, whereas here it was introduced as interaction. This suggests that the presence of musical training only influences the transformation in combination with linguistic parameters, but not on its own. Similarly, as discussed in the introduction, Tierney et al. (2021) found effects for specific musical skills (such as beat perception, tonality perception, and selective attention to pitch), but not for musical training by itself, on strength of the illusion. These results combined show that predictors based on the level of musical training, whether this is a composite score or one’s total number of years of musical training, may not uncover the sensitivities or musical skills in the tested population (Smit et al., 2023). There, to further uncover the role of musical aptitude or skills on STS, specific music perception tests should be used (Smit et al., 2023; Tierney et al., 2021). We found no main effects of either the presence of autistic traits or the level of emotional intelligence on the likelihood of STS. However, we see moderate evidence of a negative interaction between emotional intelligence and sentence complexity, whereby there is a larger role of emotional intelligence on the likelihood of STS for less complex sentences, but not for more complex sentences. Again, this shows that cognitive traits or skills interact with the sentence’s linguistic or acoustic properties in a complex manner.
We then tested whether autistic traits, emotional intelligence, and music score influenced the speed of the transformation. TEI-QUE scores were negatively correlated with the speed of the transformation, but again, the evidence for this effect is moderate.
Although it is well-established that the STS is highly dependent on repetition (Falk et al., 2014; Rathcke et al., 2021; Simchy-Gross & Margulis, 2018), individual differences also play a role in how quick the transformation takes place. In prior studies (Falk et al., 2014; Rathcke et al., 2021), individual variation in the speed of the transformation has also been found, with the transformation taking place earlier when one listens to in one’s native language compared with a second language (Rathcke et al., 2021), suggesting a role of linguistic context on the speed of STS. In this study, participants were solely tested in their native language, but individual variation in emotional intelligence appears to somewhat impact the speed of the transformation, suggesting listeners may employ different listening strategies when listening to the stimuli.
As discussed by Falk et al. (2014), the speed of STS occurrence is related to the perception of the sentence’s acoustics before the repeated loops start, which may mean that listeners who use different listening strategies will perceive the transformation at a variety of locations. For example, those who focus more on bottom–up acoustic properties (such as voice timbre) may perceive the transformation later than those who focus on top–down features (such as pitch contour) (Falk et al., 2014). This could mean that those with a higher emotional intelligence score may use a top–down-focused processing strategy, thereby perceiving the transformation quicker than those using a bottom–up approach.
One cognitive mechanism that has been suggested to be of influence to STS is discussed in Castro et al. (2018). Castro et al. (2018) suggest that node structure theory (NST) may explain the connection between speech and music in this auditory illusion. In short, NST is a connectionist model describing perception and action processes through priming and activation processes of “nodes” (i.e., a piece of information that can be, but is not limited to, syllables, words, or phonemes) and has been used to explain language and memory processing (MacKay, 1987). According to Castro et al. (2018), NST can be used to explain the differences between top–down and bottom–up mechanisms on STS and indeed, it appears that top–down processes play a role in likelihood of perceiving STS (Margulis, 2013; Vanden Bosch der Nederlanden et al., 2015) and associated brain regions are activated when experiencing the auditory illusion (Heffner & Slevc, 2015). However, it can be debated whether NST is the responsible top–down mechanism behind the STS illusion as, it is to this day still unclear how the connection from a syllable node to a song percept would occur (Tierney et al., 2021). Syllable units are not likely to be the mediators between representations of linguistic and musical nature as the temporal intervals related to syllables are less likely to be susceptible to STS transformation intervocalic units (Falk et al., 2014).
Finally, we tested for the strength of the transformation. Interestingly, there was no evidence for an effect of any of the predictors related to individual characteristics of participants on the strength of the transformation. However, we find strong evidence that sentence complexity had a negative impact on the strength of STS. A similar finding was found in Castro et al. (2018). Although the likelihood and speed of STS appear to be mediated by listener-specific characteristics in combination with linguistic or acoustic parameters of the sentence, the strength of STS may be mostly influenced by sentence-specific differences, here its complexity. Listeners may use different listening strategies based on the syntactic complexity of the tested sentences, as well as on the cognitive resources available to the listener.
The speed and strength of the transformation were both analyzed exclusively on those trials during which a transformation was perceived. We acknowledge that dichotimizing the data in this way may lead to a loss of variability in the data (Smit et al., 2023), however, a prerequisite for measuring the speed and strength of STS is that a transformation needs to have taken place for a listener. Therefore, it was decided to conduct this analysis only on trials where a transformation was perceived. For a future perspective, if the interest lies purely in the song-likeness of a sentence, the full data can be analyzed. Furthermore, a future study ideally should increase their sample size so as to further increase the certainty of the tested effects.
In this study, we focused on emotional intelligence and the presence of autistic traits, but STS also appears to be moderated by other cognitive traits, such as attention and working memory (Falk et al., 2014; Rathcke et al., 2021; Tierney et al., 2021). As auditory working memory is also an important cognitive skill for the perception of music (Smit, Milne, & Escudero, 2022), future studies could focus on a possible interacting role of such cognitive traits with music perception skills on the STS transformation. Other considerations must be made when interpreting this study’s results. Regarding the tests scores on the AQ-10 and looking at the distribution of the AQ-10 scores in Figure 2(a), we find the majority of scores are in the middle two quartiles. As we tested for a possible presence of autistic traits and did not specifically recruit people based on whether they have autism or not, we did not expect to have a larger number of participants with a high score on the AQ-10. To further explore whether autism predicts the likelihood of the STS, a follow-up study could consider including participants who have been diagnosed with autism. Additionally, this result may also mean that there may be particular individual traits associated with ASD that contribute more to prosodic processing than other traits. This study used the AQ-10 test, which is a short version of a larger autism screening questionnaire. To fully understand whether there are specific individual traits aiding or inhibiting STS transformations, a larger-scale study could consider honing into specific subcategories of these questionnaires.
This study included a number of listener-specific individual differences into the study of the STS phenomenon. Here, we used three questionnaires to focus on the presence of autistic traits, emotional intelligence, and musical training. Overall, the results support the literature suggesting that the relation between the tested traits, and the perception of speech or musical prosodic cues is not straightforward and is an interplay of both listener- and sentence-specific characteristics, which can lead to different listening strategies. It is important to note that the current study was run on a monolingual population from a specific culture, thus any cross-linguistic or cross-cultural generalizations cannot be made. Future studies could focus on further delving into which specific (music) perception skills influence STS to delve deeper into the specific individual traits that contribute to the likelihood, speed, and strength of the transformation and include cross-linguistic and cross-cultural components to further investigate the acoustic and linguistic components contributing to STS.
Conclusion
This study focused on three different dimensions of the STS phenomenon: (1) its likelihood, (2) the speed of occurrence, and (3) the strength of the transformation. This multidimensional approach to the STS phenomenon enables a deeper insight into whether individual differences in the listener or in the sentence influence a successful transformation and the results show that the different dimensions of STS are impacted differently by the tested individual traits.
Supplemental Material
sj-pdf-1-pom-10.1177_03057356241256652 – Supplemental material for Beyond musical training: Individual influences on the perception of the speech-to-song illusion
Supplemental material, sj-pdf-1-pom-10.1177_03057356241256652 for Beyond musical training: Individual influences on the perception of the speech-to-song illusion by Eline A Smit and Tamara V Rathcke in Psychology of Music
Footnotes
Acknowledgements
The authors acknowledge Simone Falk and Simone Dalla Bella, whose prior work in collaboration with the second author has been instrumental for the development of the methods and analytic procedures used in this paper.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by an Excellence Strategy Grant from the University of Konstanz and the Small Research Grant from the British Academy (SG152108) to the second author.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.