
Abstract
In a previous study, we found that musical learning of novices was equally accurate (in terms of playing the correct rhythms and pitches) when learning in a solo or duo setting. Intrigued by these findings, we conducted a follow-up experiment investigating whether the learning outcomes differed in subjective terms as perceived by listeners judging the performances. Here, expert musicians were asked to discern whether melodies learned under conditions of synchrony, turn-taking, or imitation were likely learned individually or with a partner. In addition, they evaluated the learners’ proficiency in playing the melodies, assessing expressiveness, the clarity of their articulation and phrasing, as well as the overall coherence of the performances. Listeners showed differential responses to both the learning condition and the pairing (solo or duo) in which the melodies were learned. Although the outcome did not yield salient-enough results for significant clusters of responses to emerge, our findings could inspire future research to delve into the question of discernible signatures between individual and group musical learning by adopting a longitudinal approach.
Over the last few decades, several studies have investigated musicians’ usage of a wide range of expressive strategies during performance, to make each interpretation unique. These strategies can consist of shaping parameters, such as phrasing, dynamics, and articulation, (see, e.g., Demos et al., 2016; Fabian et al., 2014; Palmer, 1996, 1997; Timmers, 2003, 2005). As reported by Doğantan-Dack (2014), this research orientation has a long history, stretching back to early work on musical expressiveness in performance put forward by Seashore (1938) and Lussy (1874). This scholarly tradition considers expert musicians to be able to strike a remarkable balance between providing an accurate and recognizable performance of the music and delivering distinctive artistic outputs by manipulating different musical parameters (see Héroux, 2016). Indeed, beyond improved technical skills, expert musicians have been shown to also possess a wider range of interpretations than music students (Repp, 1990). That said, it should be noted that novice musicians and learners can also engage with, and cultivate, a variety of interpretative skills since their earliest learning experiences. Accordingly, a number of contributions have suggested that children display a natural tendency to develop a personal musical style (Imberty, 1983); that music students often conceive of expressiveness as an inherent quality of musicking (Schiavio et al., 2019); that young musicians can be taught to perform music expressively through a dialogic approach based on enquiry and discussion (Meissner & Timmers, 2020); and that, on a more general level, achieving independent expressive competences might be one of the main goals of musical learning, both in individual and in collaborative contexts (Borgo, 2007; Elliott, 2005; Griffiths, 2017).
Because of its focus on expressive creativity through interaction, learning music together with others has recently been explored as a particularly valuable pedagogical setting. This learning modality may help students enhance their creative and musical skills as well as benefit from an increased sense of social and musical inclusion (Burnard et al., 2008). Such insights have prompted researchers to reflect on the differences and continuities between musical pedagogies based on individual and group learning (Brandler & Peynircioglu, 2015; Schiavio, Biasutti, et al., 2020; see also Hanken, 2016; Nielsen et al., 2018). A recent study (Schiavio, Stupacher, et al., 2020) examined how well novice musicians, either solo or in pairs, were able to reproduce, on a digital piano, a set of short target melodies presented via dedicated instructional videos in three learning conditions: synchrony, turn-taking, and imitation. In the synchronization condition, participants reproduced the melody in synchrony with a video (solo group) or their assigned partner (duo group). The turn-taking condition involved the participant playing in alternation with the computer (solo group) or with the other participant (duo group). In the imitation condition, participants imitated a video performance shown on the computer (solo group) or imitated their partner who reproduced a video performance (duo group). Solo participants were instructed to learn the melodies in these conditions by engaging with the videos, whereas pairs were invited to perform the same tasks interacting with each other. Analyzing the temporal and melodic accuracy with which the target melodies were performed by participants, it was found that in both groups (solo and duo), learning in synchrony and by turn-taking gave rise to significantly better results when compared to imitation. Learning individually likewise did not significantly differ from learning with a partner when looking at the subjective ratings (e.g., enjoyment, satisfaction, confidence about learning, etc.) that participants reported after taking part in the study.
Since these results were obtained when analyzing the objective properties of the participants’ musical outcomes, and their felt, subjective learning experiences (i.e., via questionnaires), it remains an open question whether differences between solo and duo musical learning might be differentially appreciated from a perceiver’s standpoint. For instance, when listeners are invited to pay particular attention to expressiveness (Clarke, 1988), articulation and phrasing (Doğantan-Dack, 2012) or coherence (Zbikowski, 1999), new subtle nuances may be disclosed, potentially leading to a richer musical experience. Can this aid listeners to distinguish between musical excerpts learned individually and together with others? The present research addresses this question by reporting on a new exploratory study in which expert musicians were invited to evaluate the short musical excerpts performed by the novice learners of the study by Schiavio, Stupacher, et al. (2020) and compare them to the target melodies these learners were invited to learn. We expected that relevant differences between solo and duo conditions might be observed, that is, that listeners would distinguish between musical outcomes learned individually or with a partner. We based this prediction on the hypothesis that interacting with others while learning shapes one’s musicking. This perspective is prominent in contemporary music scholarship influenced by embodied and interactive approaches to cognition (see, e.g., Moran, 2014; Reybrouck, 2021; van der Schyff et al., 2022). These approaches emphasize how the reciprocal influence between individuals and their environment can foster creativity and positive experiences when making and learning music (e.g., Nijs, 2019; Sawyer, 2003). Specifically, a number of scholars have recently argued that prioritizing collaboration in contexts where learners can learn from each other as well as from a teacher can yield significant benefits in terms of facilitating skill acquisition, fostering trust, and promoting social understanding (see Borgo, 2007; Schiavio & Nijs, 2022). By contrast, in research looking at expert musicians, empirical evidence comparing expressivity in group versus solo conditions has pointed toward the potentially constraining aspects of performing in a group, leading musicians to reduce expressive variations (Bishop & Goebl, 2020).
Either way, we speculate that an interactive musical experience might foster distinctive stylistic characteristics that may not always be captured by the analysis of quantifiable parameters (such as pitch and temporal accuracy; though possibly of others which we have not evaluated), but which nevertheless may be picked up by attentive listeners. 1 Previous research has shown the challenges in predicting perceived similarity between performances based on measured characteristics (e.g., Timmers, 2005), indicating instead the relevance of communication of musical intentions and interpretations. Rather than perceiving exact deviations in timing, dynamics, rhythm or pitch, listeners have been shown to be sensitive to communicative aspects of performances, such as its degree of expressivity (Kendall & Carterette, 1990) and its manner of phrasing and articulation (Palmer, 1996). With respect to differences between duo versus solo performances, we expect these to emerge based on performers’ engagement with both covert and overt forms of bodily activity (Brown & Martinez, 2007; Cross, 2010), and through motor resonance with the sounding performance (Overy & Molnar-Szakacs, 2009; Patel & Iversen, 2014). In addition, two studies conducted by De Poli et al. (2014) and Schubert & Kreutz (2014) explored participants’ evaluations of computer-assisted music performances across various dimensions, such as accuracy, emotional content, and coherence of the performed style. 2 While the dimensions examined in these studies align with our own, the studies did not specifically address perceptual distinctions between stimuli generated individually versus those created collaboratively with another peer. For this reason, when designing the present study we were specifically interested in what qualitative differences may emerge between listening to musical excerpts performed independently or as a dyad. We see joint learning as a context where motivation and role-modeling play an important role, possibly leading to more coherence and stability (Bishop & Goebl, 2020) as well as creative emergence (Pennill & Breslin, 2022).
To examine these predictions, we asked our participants to rate all the melodies played by the learners of the previous study, in light of five questions. The first one explicitly asked whether, according to the listener, the melody had been learned alone or with a partner; the second referred to how well the melody had been learned when compared to the target stimulus. While these questions were posed to elicit answers that might be more easily examined in light of the data reported in the work of Schiavio, Stupacher, et al., 2020 (from now on labeled “the original study”) and its experimental manipulations, the three following questions referred instead to the musical dimensions discussed above (i.e., expressiveness, phrasing and articulation, and coherence). In asking these questions, we aimed at gaining richer insight into which set of subjective parameters may distinguish between musical outcomes learned individually versus with a partner.
Methods
Participants
Participants for the present experiment were recruited using the Prolific platform (www.prolific.co). Inclusion criteria were: (1) having more than 5 years of experience in playing a musical instrument and (2) holding an undergraduate, graduate, or doctorate degree in music. A total of 20 participants took part in the study (10 men, 10 women; age: M = 24.9 years, SD = 4.23). The number of years of musical training was recorded for each participant (M = 14.1, SD = 4.56). A sample size of 20 participants has been shown to be promising in reaching a high inter-rater reliability, even in complex and subjective assessment situations typical of creativity ratings (Ceh et al., 2022). All procedures were approved by the Ethical Committee at the University of Graz and were in accordance with the statements of the Declaration of Helsinki. Participants were monetarily compensated for their involvement in the study and provided written informed consent. None of the participants had participated in the original study.
Stimuli
Three short melodies were composed by author AS for the original study, all involving a limited set of pitches (F♯, G♯, and A♯) in different orders, styles, and rhythms. The melodies were performed by a professional pianist on a digital piano (Yamaha Clavinova CLP370) and were recorded using the software Reaper64. These recordings constituted the “target melodies” that participants were asked to reproduce under various conditions in the original study. Participants learned these melodies either on their own (solo group) or paired up (duo group). Furthermore, learning occurred under one of three learning conditions: synchronization, turn-taking, and imitation. Each condition had a unique short melody to learn and perform in that condition. Performances of 36 participants (18 groups) in the “duo” condition and 18 participants in the “solo” condition were recorded, for a total of 162 recordings collected (i.e., 54 per learning condition/melody. Participants of the rating study were asked to rate each of the recordings (“reproduced melodies”) in a rating trial (162 trials in total). The average (mean ± SD) duration of a melody was 16.8 ± 4.29 s.
Procedure
The task was implemented using the jsPsych JavaScript framework (de Leeuw, 2015) and administered online using Pavlovia (www.pavlovia.org). Online participants were invited to listen to pairings of target melodies and reproduced melodies and rate each reproduced melody on a number of musical dimensions. Each trial consisted of a screen containing two playback buttons (for the current target melody and the current reproduced melody) and five questions. Between the different trials presented to any one participant, all combinations of available target and reproduced melodies were covered (presentation order: latter nested, in sequence, within the former). The five questions (and rating options) presented within each trial were:
(A) Do you think the melody was learned individually or with a partner? (“Individually” . . . “Together”)
(B) How well do you think the performed melody was learned? (“Not well at all” . . . . “Extremely well”)
(C) Please evaluate the expressiveness of the performed melody (“Very bad” . . . “Excellent”)
(D) Please evaluate the musical phrasing and articulation of the performed melody (“Very bad” . . . “Excellent”)
(E) Please evaluate the overall musical coherence of the performed melody (“Very bad” . . . . “Excellent”)
Question (A) was rated on a quasi-continuous (21-step) confidence rating scale, presented to participants as horizontal line with a moving slider. Questions (B)–(E) were rated on 10-point Likert-type scales. We opted not to use a Likert-type scale for Question (A) as we expected this question to be hard for participants to decisively answer. With a quasi-continuous scale, we wanted to be able to measure more subtle variations in participant’s responses. A linear transformation was applied prior to the analyses, to equalize scale ranges across all five questions. The order of questions was shuffled between trials. Each participant ran through 162 rating trials, one for each reproduced melody. Data analyses exclusively employed these five ratings as dependent variables. Trials’ response times (RTs) were only used to define and exclude outliers (see the “Outlier removal” section). The entire rating task lasted around 1.5 hr on average (ca. 33 s per melody).
Data analyses
Outlier removal
We defined as “outliers” trials whose total RT was suspiciously low, measured from the onset of the trial screen to the onset of participants clicking on the “Next melody” button. Specifically, we defined the playback duration of the reproduced melody as the RT threshold. We did not include an upper bound on RTs (i.e., exclude participants who took too long with the task), since the task provided no opportunities for breaks, and we wished to allow for the possibility of participants taking arbitrary breaks within the duration of certain trials. Such outliers were excluded on a per trial basis, which amounted to 9.72% of the trials.
Linear mixed-effects models
To check for the effect of conditions on ratings, we fitted linear mixed-effects models, separately for each rating. We used the fitlme function in MATLAB (Mathworks Inc., MA), with the formula: ratings ~ pairing + learning + repNumber + training + (1|id_rater) + (1|id_melody)
where the fixed-effects were the pairing condition (solo/duo), learning condition (imitation/synchronization/turn-taking), trial repetition number (1/2/3), and participant’s number of years of musical training (continuous).
Dimensionality reduction
Given the high dimensionality of the data set (five different ratings per trial), we aimed to remove redundant information and arrive at a parsimonious explanation of our data. With dimensionality reduction, the aim is to “embed” high-dimensional data into lower-dimensional data (2D or 3D), which can be visualized and interpreted, for instance, by observing emerging clusters that align with experimental manipulations. To this aim, we used tSNE (t-Distributed Stochastic Neighbor Embedding), a machine learning approach to dimensionality reduction which, unlike more traditional methods like principal component analysis (PCA), usefully retains local rather than global variance (Belkina et al., 2019; Hinton & Roweis, 2002). tSNE can be used together with several distance metrics, and by way of an exploratory analysis, we compared three different metrics (the Euclidean, Chebyshev, and Mahalanobis distances), aiming to find which yielded a better separation of our reproduced melodies, as classified (by the tSNE algorithm) in accordance with our two pairing conditions and our three learning conditions. We used for this the tsne function in MATLAB. The Euclidean, Chebyshev, and Mahalanobis distances are mathematical measures used to quantify the similarity or dissimilarity between objects or data points in various contexts. They respectively incorporate the straight-line distance, the maximum difference, and the covariance structure of the data.
Intra-class correlations
Intra-class correlations (ICCs) are descriptive statistics that can be used when measurements are made on units organized into groups (McGraw & Wong, 1996). They describe how strongly units in the same group resemble each other. We used ICCs to assess how consistent the participants’ scores were to each other, for each of the five ratings. We treated all observations as coming from two different groups, on the basis of the pairing condition. To evaluate whether participants answered each question in a consistent manner, we computed the average ICC using the ICC(2, k) form (Koo & Li, 2016; Shrout & Fleiss, 1979), computed in MATLAB using the ICC function. 3 We considered its output to be a measure of inter-rater reliability, as it corresponds effectively to a two-way random effects model for consistency (McGraw & Wong, 1996). Since ICCs give a composite of intra- and inter-observer variability, their results are difficult to interpret when observers are not interchangeable. 4 Alternative measures, such as Cohen’s kappa statistic are more suitable measures of agreement among non-exchangeable observers. However, in this case, we assume our participants are interchangeable.
Logistic regression
We created, separately for each of the three learning conditions, a logistic binomial model of the probability of a reproduced melody having been performed solo or duo, as a function of the five ratings, specified in the model individually (i.e., with no interaction terms). Using fitglm in MATLAB, the generalized linear regression model was specified as follows: logit(pairing) ~ 1 + A + B + C + D + E Distribution = Binomial
where A–E were ratings for the five questions.
Variance Inflation Factors
We computed variance inflation factors (VIFs) across the five questions, to check the degree to which these variables are multicollinear. This returns a single number per target. That is, for each of our five questions, its VIF estimates to what degree its data is accounted for by the data in the other four questions. VIFs range from 1 upward, and indicate what percentage of the variance (i.e., the standard error squared) is inflated for each coefficient. For example, a VIF of 1.9 means the variance of a particular coefficient is 90% greater than what would be expected if there was no multicollinearity at all, that is, no correlation with other predictors (VIF = 1). As a rule of thumb, VIFs between 1 and 5 indicate moderately correlated variables, and VIFs greater than 5, highly correlated variables (Everitt & Skrondal, 2010).
Results
Rating distributions
Figure 1 shows the distributions of ratings for reproduced melodies under the various (learning and pairing) conditions, and in response to the five ratings concerning musical dimensions.
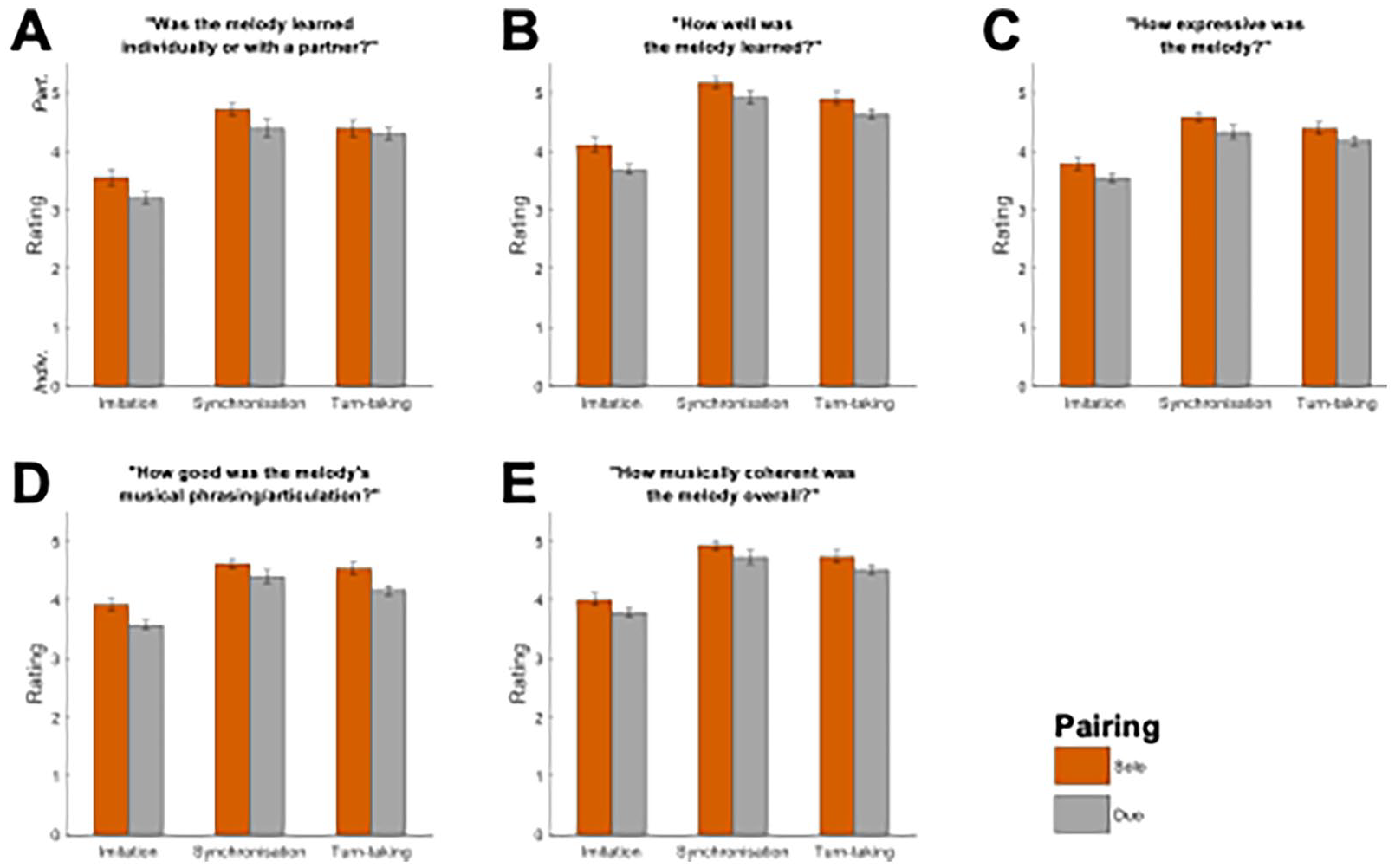
Ratings Across Conditions.
Linear mixed-effects models
Coefficients for the estimated linear mixed-effects models are given in Table 1. These results suggest that both the pairing and the learning conditions significantly influenced ratings given in response to each of the five questions, while musical training did not, likely due to a ceiling effect.
Results of Linear Mixed-Effects Models.
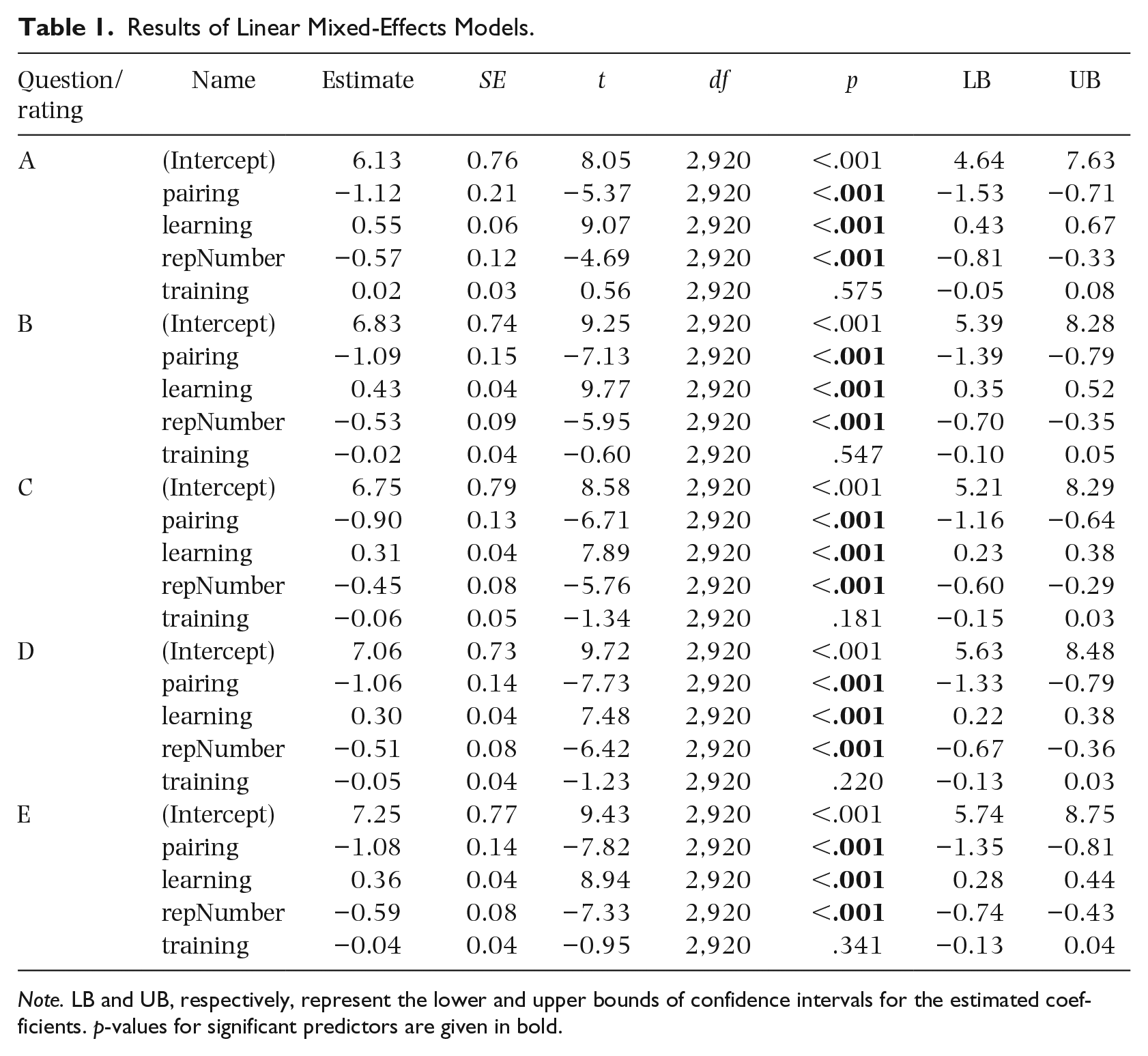
Note. LB and UB, respectively, represent the lower and upper bounds of confidence intervals for the estimated coefficients. p-values for significant predictors are given in bold.
Dimensionality reduction
Figure 2 depicts the result of applying tSNE to our ratings, classifying by pairing condition and by learning condition, in two dimensions. Visually, it can be seen that no clusters form to separate the melodies according to their ratings, a result we later also explore statistically. A three-dimensional embedding yielded similar results to the 2D embedding pictured.
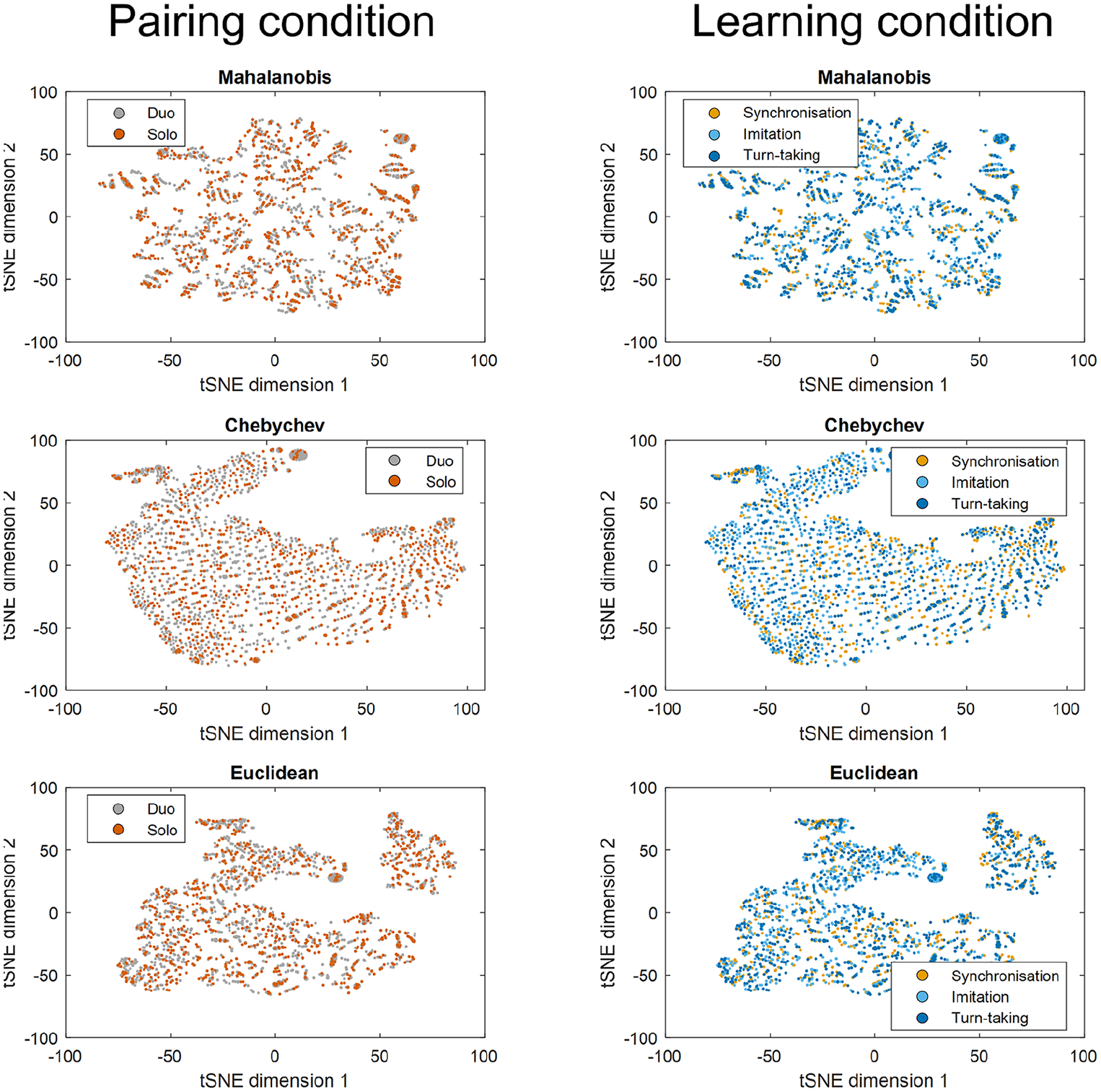
Dimensionality Reduction.
Intra-class correlations
Table 2 reports confidence intervals for estimated ICCs, and corresponding hypothesis tests, performed for the null hypothesis that ICC = 0. The ICCs for Questions A and C are indicative of a good to excellent inter-rater reliability, and Questions B, D, and E reach an overall excellent inter-rater reliability (Koo & Li, 2016). Thus, our expert raters showed a very high consistency and coherence in their assessments.
Intra-Class Correlations, of the Type ICC(2, k).
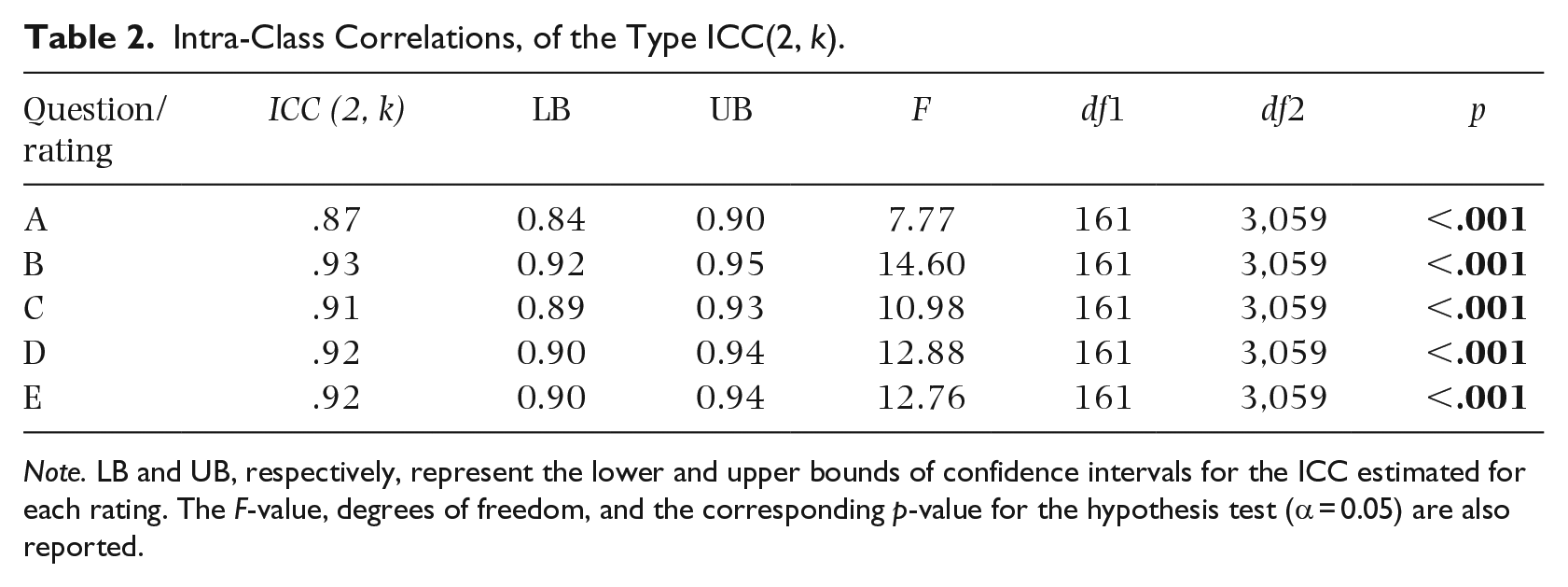
Note. LB and UB, respectively, represent the lower and upper bounds of confidence intervals for the ICC estimated for each rating. The F-value, degrees of freedom, and the corresponding p-value for the hypothesis test (α = 0.05) are also reported.
Logistic regression
Only the model for the first learning condition, imitation, was significant (p<0.05), meaning it differed statistically from a trivial (constant) model, in its attempt to predict pairing condition (solo or duo) on the basis of the five regressors. Within this model, the two questions that constituted significant regressors were B and E, that is, the judgment regarding how well participants reproduced the melodies they were invited to learn and the overall coherence of their performances. Reproduction quality was negatively associated with pairing, whilst coherence showed a positive association. The model for the turn-taking condition approached significance (p = .056; see Table 3), Question D (which refers to phrasing and articulation) being its sole significant regressor showing a negative relationship with pairing.
Results of Logistic Regression.
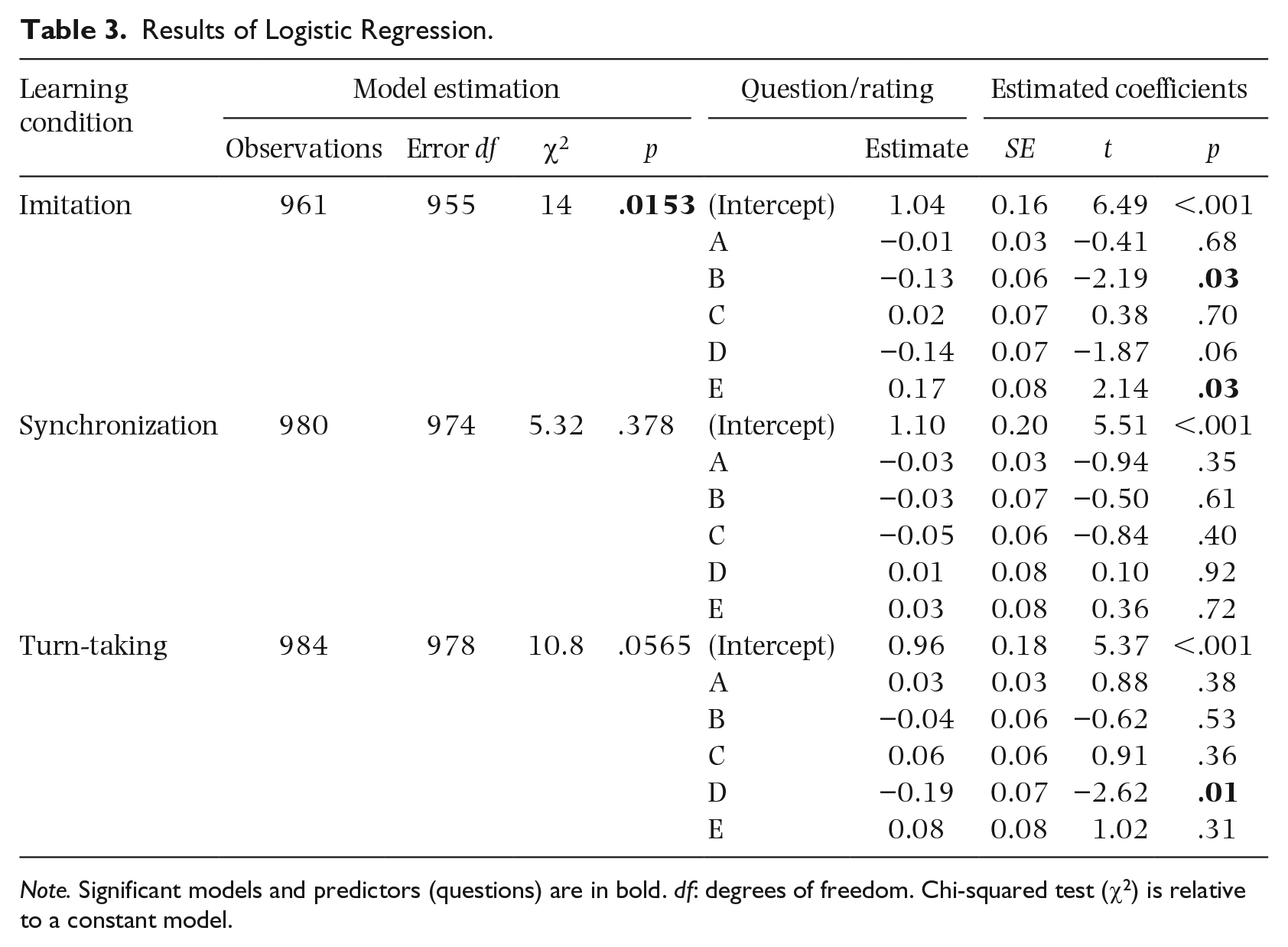
Note. Significant models and predictors (questions) are in bold. df: degrees of freedom. Chi-squared test (χ2) is relative to a constant model.
Variance Inflation Factors
For the five ratings, the obtained VIFs were, respectively: 1.7, 4.0, 3.5, 4.7, and 5.5. Since all factors are below 10 (and also considering the sample size), we did not worry about serious collinearity problems in the regression analyses (Miles, 2014). Moreover, this suggests that Rating A, concerning the pairing of the performed melody (learned individually versus with a partner), contained the most “signal,” that is, the highest amount of unique subjective information.
Discussion and conclusion
The present study examined whether expert musicians, when focusing on subtle musical nuances that may not be captured by straightforward measurements of pitch and tempo accuracy (Schiavio, Stupache, et al., 2020), can distinguish between musical excerpts learned by novices individually or in pairs.
By asking five questions related to different musical dimensions, we found that our participants responded differentially to the learning condition (synchrony, turn-taking, and imitation) and pairing (solo and duo) with which the melodies were learned. However, this result was not salient enough to let us observe significant clusters of responses, as depicted in Figure 2. Distinguishing between musical outcomes performed in different learning conditions and pairings, in other words, was no easy task for our participants. This may be due to various factors. First, learners were asked to reproduce a melody, so that, it is possible that their creativity was not fully engaged by the task, restricting differences in group processes or individual performances to emerge. This still allows for the possibility that with a greater degree of creative freedom, the pairing effect would have been more salient in the ratings, potentially giving rise to distinguishable response clusters. Such a reasoning is supported by recent work in creativity research exploring how creative potential and flexibility are often limited when relying on habits, existing patterns, or when agents cannot move “past old ideas ‘inside the box’” (Ibáñez de Aldecoa et al., 2021; see also Storm & Angello, 2010). Second, the interaction between musical partners in the original study was quite short (maximum 12 min per learning condition)—perhaps not enough to leave a significant “trace” in the way the melodies were played. A third reason for the lack of clear distinction between the two conditions could be that solo and duo contexts may both be conducive to development in their own ways. Individual contexts necessitate less to align performance with others and may therefore, at least initially, be less inhibiting.
These last two points align well with existing research that explores the efficacy of pedagogical settings emphasizing mutual trust, open discussion, and peer collaboration in fostering skill development over the course of a program (Robinson & Kakela, 2006; Schiavio & Nijs, 2022). With this in mind, it is crucial to recognize that the type of musical interaction that takes place in such contexts cannot be reduced to a passive process. Instead, it demands active engagement and cooperation with others, fostering the gradual development of trust and the establishment of connections over time. Instrumental pedagogy that involves peer-to-peer interaction can thus benefit from structured opportunities to sustain engaging interactions over extended periods. By doing so, the necessary conditions can be created to facilitate learning and foster expressive performance. This sustained interaction may give rise to musical stimuli with more distinct characteristics that can be associated with either individual or duo modes of learning. Indeed, if we consider the perception of music as an active process of creative re-creation, reliant on continuous bodily grounded and exploratory processes that aim to establish a novel and appropriate engagement with the environment (Schiavio et al., 2022; see also Baroni, 2006), then a more robust and prolonged interaction may promote modes of listening that consistently resonate with the intersubjective features inherent in the musical stimulus, allowing listeners to more consistently recognize said (social) relationships.
To gain richer insight into solo versus duo contexts for skill development, future studies may need to consider longitudinal approaches, where differences between individual and duo learning could be explored over the long term. This might involve looking at both quantifiable parameters (e.g., pitch and temporal accuracy, and expressive variation) and at the learners’ subjective experiences, integrating quantitative and qualitative approaches in a rich variety of ways (see West, 2014). In using a longitudinal approach, it will be of interest to examine the development over time in solo and duo learning across phases of rehearsal that may include exploration, transition, and consolidation (Pennill, 2019).
Probably, the most interesting finding of the present study emerges from the logistic regression: on one hand, we do not have hard evidence that our participants could discriminate directly whether a piece was learned individually or together. On the other hand, when it comes to musical outcomes learned via imitation, then certain rated characteristics do in fact bear an awareness of the pairing condition. In particular, with increasing scores in Rating B (“How well do you think the performed melody was learned?”), the probability decreases that the musical excerpt evaluated was learned in duo. Hence, the probability increases that the melody belonged to the solo group. Conversely, with increased ratings in E (“Please evaluate the overall musical coherence of the performed melody”), the probability increases that the melody belonged to the duo group. Note that this response pattern is associated with melodies learned via imitation only. In the original study, the melodies learned in this condition featured more errors when compared to those learned through the other learning conditions. Remarkably, this effect was almost always present for both solo and duo pairings: learning by imitation, in other words, generally yielded less accurate musical outcomes when novices were asked to reproduce target melodies both individually and collectively. It is therefore plausible that our raters were able to capitalize on such a difference between learning conditions, giving rise to results that resonate with those reported in the original study. And indeed, this would appear to be the case, as Questions B and E relate to how well the melodies were learned and perceived as coherent, respectively—parameters perhaps more associable with (yet not reducible to) general performance quality than others.
Looking more closely at the findings of the original study, some important details emerge that may further clarify the results obtained in the present contribution. There, temporal accuracy in the solo group was the only parameter not giving rise to a significant effect; consequently, no differences were found between learning conditions or pairings in that regard (see Schiavio, Stupacher, et al., 2020 for details). Said differently, when participants learned melodies individually, imitating musical and motor patterns provided by an instructional video was—for temporal accuracy—no less efficient than learning in turn-taking or in synchrony with the video. This might help explain why, in the present study, the increase of Rating B (How well do you think the performed melody was learned?), was associated with the probability that the melody was learned without a musical partner: raters may have been particularly focused on the temporal cues of the heard melodies (see Repp, 1992, 1999), linking fewer temporal deviations in the target melodies to more accuracy and less coherence (see also Quinn & Watt, 2006).
We now discuss how, for musical excerpts learned via imitation, an increase in rating E (Please evaluate the overall musical coherence of the performed melody) was simultaneously associated with the probability that the melody belonged to the duo group. Why would a category, such as musical coherence be linked to duo learning, in the imitation condition only? Let us first clarify that previous literature may have treated coherence slightly differently from how we have conceived of such a notion for the present study. Consider, for example, the study by Geake (1997), which demonstrated that perception of a sequence of pitch fluctuations involves some direct awareness of its structural coherence. In that study, coherence was defined in terms of the autocorrelation function of the melodic sequence—that is, its level of redundancy. 5 Such an understanding of coherence based on melodic variability, however, is not consistent with how the term was employed in the present study: evaluating the melodic patterns’ “fixed” structural properties was not the main goal of our raters, who were instead invited to focus on the uniqueness of a given musical excerpt—one that is achieved through the consistent use of expressive, dynamic, or phrasing performative strategies. In that specific sense, therefore, coherence is predicated at a lower level of granularity when compared to expressiveness as well as articulation and phrasing. This arguably places coherence on a continuum with the other “general” quality defined by Rating B. As mentioned earlier, indeed, these two dimensions (coherence and how well the melodies were performed) might speak better than others to more general performative dimensions.
With this in mind, we suggest that the temporal signature for the solo group in the imitation condition highlighted above (i.e., the absence of a significant difference between learning conditions) might have indirectly led our raters to note those temporal deviations that are more consistently present in the melodies reproduced by the duo group, taking such temporal cues as indicative of more coherence. Now, recall that in the original study the imitation condition generally gave rise to more mistakes when compared to others. It is possible that, since quantitative analyses offered in the original study only looked at the number of mistakes but not at their quality, qualitatively similar mistakes committed by the same learner during one performance could become particularly significant for our raters, fostering a perceived sense of coherence in the reproduced melody. 6 Although this interpretation remains quite speculative, it still appears consistent with the possibility that such temporal fluctuations represent genuine errors on part of the novices, rather than intentional performative choices. If that were the case, our evaluators could have classified them as expressive nuances or as specific articulation or phrasing solutions. Instead, these temporal deviations remain subtle enough to modulate the perceived coherence of the piece, without, however, becoming essential factors with respect to other parameters.
The present work has some limitations: because our participants were music experts, we tended to assume that our definitions of “expressiveness,” “articulation and phrasing,” and “coherence” would be unequivocally understood, albeit with expected individual differences essential to critical appraisal of such subjective dimensions. Future work that wishes to examine whether our findings could be replicated with novice participants as raters might therefore ensure that clear working definitions are provided in advance to all participants. Also, the inclusion of different types of differences between performances makes it hard to interpret the cause of observed effects. Moreover, there may be some adjustment in terms of expectation of what constitutes expressiveness or coherence in the context of performances by novice musicians. It should also be noted that in the original study the tasks through which melodies were learned involved instructional videos. As such, researchers interested in this topic could complement our findings by systematically exploring (in both solo and duos situations) more in-person learning contexts, examining whether the presence of the teacher could give rise to different outcomes. Such a possibility resonates well with recent work by Meissner and Timmers (2020), which suggests that instructional strategies based on teacher-pupil dialogue might be particularly useful in fostering expressiveness across weekly instrumental music tuition. The key role of teachers in supporting musical development and flourishing is also well documented in literature exploring how instructors’ gestures and bodily movements facilitate learning in different contexts (Simones, 2019; Zhukov, 2012).
In conclusion, while we could not find a corroboration of our main hypothesis, the present study yields intriguing results that could inspire future work to investigate in further detail the complex dynamics of individual and collective musical skill acquisition.
Footnotes
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: AS acknowledges the support of the Austrian Science Fund (FWF), by which this research was funded (project number P32460). For the purposes of open access, the author has applied a CC BY public copyright licence to any Author Accepted Manuscript version arising from this submission. Funding throughout the duration of this project was also received by the STARS programme of the University of Padova (grant awarded to TP), and earlier by the European Commission’s MSCA framework (“Seal of Excellence” awarded to TP).