
Abstract
Recent research has shown that formal musical training has a wealth of benefits in terms of cognition, mental health, social skills, and even speech perception. Of these benefits, there is strong support for a relationship between formal musical training and an improved ability to recognize emotions in speech prosody. Given this connection, interpersonal relationships stand to benefit from improved communication efficacy, which includes an improved ability to recognize emotions in speech. Interpersonal relationships rely on successful expression and interpretation of emotions in speech. If formal musical training can improve the perception of emotions in speech, it should indirectly benefit interpersonal relationship quality. The current study collected data from 197 undergraduate students about their formal musical training and interpersonal relationship quality through an online survey. The results showed that formal musical training accounted for 8% of the difference in relationship conflict but did not benefit relationship support or depth. While musical expertise does not necessarily improve relationship quality overall, it may help reduce conflict in relationships. Further research is needed, with participants who have greater musical expertise, to clarify the relationship between formal musical training and relationship conflict.
Keywords
Formal musical training is often considered a nonessential component to basic education, but it has benefits that extend outside of the classroom; formal musical training can improve speech perception (Başkent & Gaudrain, 2016; Good et al., 2017; Lim, 2010; Lima & Castro, 2011; Musacchia et al., 2007; Schön et al., 2004; Thompson et al., 2004; Tierney et al., 2020), social skills (Cores-Bilbao et al., 2019; Kim & Kim, 2018; Lima & Castro, 2011; Thompson et al., 2004; Tierney et al., 2020), emotional intelligence (Cores-Bilbao et al., 2019; Good et al., 2017; Kim & Kim, 2018; W.-L. Lee et al., 2006; Lima & Castro, 2011; Schellenberg & Mankarious, 2012; Thompson et al., 2004), school performance (Gouzouasis et al., 2007), and decision-making ability (Hou et al., 2017). One of these benefits is an improved ability to recognize emotions being expressed in speech (Good et al., 2017; Park et al., 2015; Parsons et al., 2014; Schellenberg & Mankarious, 2012; Schön et al., 2004; Thompson et al., 2004). Understanding the emotions being expressed by another person is a fundamental feature in forming and maintaining healthy relationships (Minzenberg et al., 2006; Moeller & Kwantes, 2015; Petrovici & Dobrescu, 2014). A decreased ability to understand emotions in speech could lead to deficits in interpersonal relationships and, as a result, could cause “serious ramifications on social interactions and social development” (Jiam et al., 2017, p. 2). Therefore, there is a potential indirect benefit to interpersonal relationships from formal musical training.
Formal musical training and ability
Formal musical training can take place in various settings, with different short- and long-term goals. Some may engage in it purely for the interest in acquiring a new ability, others may be learning to develop a lifelong career as a musician. Different settings, different intentions, and different aspirations can lead to different experiences of formal music training (Schellenberg & Mankarious, 2012). Someone training with the intention of becoming a musician may put more time and effort into their practice than someone who is doing it for fun. Regardless of how one is taught, though, formal musical training refers to the practice of actively engaging in learning a new instrument, and musical ability refers to the level of acquired skill one develops over time from this training. Neither musical ability nor formal musical training can be effectively measured through the number of years trained, making a thorough measurement of both ability and training important when considering either of them in relation to non-musical concepts (Lima & Castro, 2011; Schellenberg & Mankarious, 2012; Swaminathan & Schellenberg, 2020).
Formal musical training and emotion recognition
When compared with those without formal musical training, those who have formal musical training are better at most speech-related auditory perception tasks, such as speech perception (Başkent & Gaudrain, 2016), pitch processing (Marques et al., 2007; Moreno & Besson, 2005; Schön et al., 2004), and speech processing (Juslin & Laukka, 2003; W.-L. Lee et al., 2006; Lima & Castro, 2011; Moreno & Besson, 2005; Park et al., 2015; Parsons et al., 2014; Thompson et al., 2004; Tierney et al., 2020). Even when training is short in duration, from as little as 8 weeks to 1 year, there is a significantly increased ability to perceive emotion in speech prosody (Good et al., 2017; Lima & Castro, 2011; Moreno & Besson, 2005; Park et al., 2015; Schön et al., 2004; Thompson et al., 2004). Speech prosody refers to the variation of certain sound qualities during speech, such as pitch and rhythm, which is often used to convey emotion (Lima & Castro, 2011). Thompson et al. (2004) reported improved emotion recognition in speech in those who are musically trained. In experimental settings, children with 1 year of piano lessons are better at identifying fear or anger after a year of piano lessons than their untrained peers (Thompson et al., 2004). In the same study, musically trained adults were better at identifying most emotions when compared with untrained adults, even if their training took place in childhood (Thompson et al., 2004). Musical training can improve universal language abilities, too, such as the ability to recognize a distressed infant (Parsons et al., 2014). Musicians are even able to detect pitch violations in languages that are foreign to them (Marques et al., 2007). Musicians clearly possess some ability to recognize emotions in speech beyond that of those without formal musical training but there is some debate about whether this is a result of training or some other variable.
Trimmer and Cuddy (2008) found emotional intelligence to be a better predictor of the ability to recognize emotion in speech than formal musical training or ability. One reason Trimmer and Cuddy (2008) may have had non-significant results, as pointed out by Lima and Castro (2011), is the average years of musical training that their participants had, around 6.5. In most research on this topic, participants have had an average of 12 or more years of formal musical training (Lima & Castro, 2011). The theory that higher IQ, differences in socioeconomic status or musical training contexts, and overall mental functioning are what predict speech prosody perception ability fails to account for results in experimental studies, or those who controlled for these factors, though.
Schellenberg and Mankarious (2012) found that higher functioning children, who are likely also higher in emotional intelligence, are more likely than their lower-functioning peers to take music lessons. Higher mental functioning might account for the difference in emotion recognition between musicians and those without formal musical training in previous studies (Schellenberg & Mankarious, 2012). IQ differences, socioeconomic status, and social contexts where musical training takes place (one-on-one compared to group learning) can influence emotion recognition in speech (Schellenberg & Mankarious, 2012). When Schellenberg and Mankarious (2012) controlled for these factors, the association between emotion comprehension and formal musical training essentially disappeared, but this could be related to the complexity of the measurement they chose. Nonetheless, controlling for IQ and socioeconomic status seems rather important in this context.
Swaminathan and Schellenberg (2020) controlled for IQ, socioeconomic status, and working memory and found that musical ability was a more accurate predictor of emotion recognition in speech than formal training. Formal musical training was measured by asking about duration of training, and musical ability was measured with the Montreal Battery of Evaluation of Musical Abilities (Peretz et al., 2013). Socioeconomic status was controlled for by asking the children’s parents about their income and education, the Wechsler Abbreviated Scale of Intelligence (WASI) was used to assess and control for IQ (Weschler, 1999), and working memory was measured by administering Digit Span (Swaminathan & Schellenberg, 2020). IQ and musical ability, as opposed to formal training, were the most accurate predictors of speech perception ability (Swaminathan & Schellenberg, 2020). These results suggest that the improved ability to recognize emotion in speech is a result of predisposition and not necessarily a result of training.
Other research on this topic seems to contradict these findings (W.-L. Lee et al., 2006; Lima & Castro, 2011; Marques et al., 2007; Schön et al., 2004). Emotional intelligence is likely an accurate predictor of emotion perception in speech prosody, but that does not mean musical training or ability has no impact. In addition, formal musical training itself must have some effect on musical ability and thereby improving emotion recognition in speech prosody. Despite their findings, Swaminathan and Schellenberg (2020) suggest that there is a meaningful association between musical ability and language ability. At a minimum, more clarity is needed in the relationship between formal musical training and emotion recognition in speech prosody. If there is a relationship between musical ability and language ability, then musical ability should be an accurate predictor of interpersonal relationship skills.
Another possible explanation is that the structures in the brain devoted to processing certain qualities of music, such as pitch, are domain general and can assist in processing sound qualities in speech (Lima & Castro, 2011; Schön et al., 2004). Therefore, if someone has formal musical training, processing musical qualities is improved and, as a result, so is processing similar sound qualities in speech. Brain imaging supports this theory, showing activation of similar networks when musicians process music and speech (Hyde et al., 2009; Moreno & Besson, 2005; Musacchia et al., 2007; Schön et al., 2004). Moreno and Besson (2005) found that just 8 weeks of musical training altered event-related brain potentials when processing pitch in language. Musacchia et al. (2007) discovered that musicians have a greater neural response to both music and speech than those without formal musical training. Musical training modifies subcortical structures that assist with processing of music and speech (Musacchia et al., 2007). Hyde et al. (2009) found changes in brain structure after 15 months of formal musical training in children, consequently improving some musically related auditory skills. The expression of emotion in music has remarkably similar patterns to the expression of the same emotions in speech, further supporting the theory that processing is domain general (Juslin & Laukka, 2003). The changes in speech processing, as measured through various brain imaging and event-related potential techniques, support the notion that formal musical training has some measurable benefit as a result of auditory processing plasticity.
Patel (2011, 2014) developed the OPERA hypothesis to explain the benefits of formal musical training on the processing of speech and language.
The “OPERA” hypothesis proposes that such benefits are driven by adaptive plasticity in speech-processing networks, and that this plasticity occurs when five conditions are met. These are: (1) Overlap: there is anatomical overlap in the brain networks that process an acoustic feature used in both music and speech (e.g., waveform periodicity, amplitude envelope), (2) Precision: music places higher demands on these shared networks than does speech, in terms of the precision of processing, (3) Emotion: the musical activities that engage this network elicit strong positive emotion, (4) Repetition: the musical activities that engage this network are frequently repeated, and (5) Attention: the musical activities that engage this network are associated with focused attention. (Patel, 2011, p. 1)
Patel’s (2011, 2014) hypothesis suggests that, when these conditions are met, formal musical training can promote adaptive plasticity in networks that process speech. This hypothesis might help explain the non-significant or inconsistent findings of the aforementioned research. Trimmer and Cuddy (2008), for example, did not take into consideration the frequency of repetition. Instead, Trimmer and Cuddy (2008) asked participants how often they practiced at the peak of their interest. Those who have not practiced recently, but perhaps practiced very frequently in the past, would be treated the same as someone who frequently practiced last week. A questionnaire that considers the conditions in the OPERA hypothesis may lead to more significant findings in terms of speech processing and musical ability.
Formal musical training, and ability, may also be related to interpersonal relationship qualities and factors that influence interpersonal relationships. Children who have received group music lessons show higher extraversion and sociability (Kawase et al., 2018). Group musical activity and expression may improve interpersonal relationships in children (Passanisi et al., 2015). Music-based therapies and interventions, which include a focus on rhythm and song, also yield improvements in social relationships in various populations (K. J. Lee & Lee, 2020; Passanisi et al., 2015; Sharda et al., 2018). There is clearly some relationship between music exposure beyond listening, whether it be training, analyzing, or otherwise participating in music, and the qualities of social relationships.
Emotion recognition and interpersonal relationships
Our relationships with others, interpersonal relationships, rely on many different forms of communication, some more subtle than others. One of the methods by which we communicate emotions is through speech prosody (Good et al., 2017; Juslin & Laukka, 2003; Musacchia et al., 2007; Park et al., 2015; Parsons et al., 2014; Patel, 2011, 2014; Schön et al., 2004; Swaminathan & Schellenberg, 2020; Thompson et al., 2004; Trimmer & Cuddy, 2008). Speech prosody is a subtle, yet important, method of communicating emotions and identifying the emotions expressed through speech prosody is important. Being able to recognize and understand emotions in speech prosody is essential to forming and maintaining healthy relationships (Jiam et al., 2017; Minzenberg et al., 2006; Stewart-Brown, 2005). Having healthier relationships leads to an improvement in overall well-being (Ciechanowski et al., 2005; Kenny et al., 2013; Martin & Dowson, 2009; Schutte et al., 2001; Stewart-Brown, 2005; Stoetzer et al., 2009; Zlotnick et al., 2000).
Poor or unsatisfying interpersonal relationships are associated with more emotional distress in adolescence, higher rates of depression and stress, and less motivation and engagement in school (Ciechanowski et al., 2005; Kenny et al., 2013; Martin & Dowson, 2009; Schutte et al., 2001; Stewart-Brown, 2005; Stoetzer et al., 2009; Zlotnick et al., 2000). Contrastingly, strong or satisfying interpersonal relationships often correlate with better social and emotional development, lower emotional distress, and higher overall happiness (Ciechanowski et al., 2005; Kenny et al., 2013; Martin & Dowson, 2009; Schutte et al., 2001; Stewart-Brown, 2005; Stoetzer et al., 2009; Zlotnick et al., 2000). A critical feature of speech is the expression of different emotions, which is why it is essential to forming strong, healthy interpersonal relationships (Jiam et al., 2017; Minzenberg et al., 2006; Stewart-Brown, 2005).
An increased ability to recognize emotion is associated with stronger interpersonal relationships, and decreased ability is associated with poorer interpersonal relationships (Wang et al., 2019). Children who are better at recognizing emotions form better friendships (Wang et al., 2019). Poor social emotion recognition in adults is associated with higher occurrence of suicide attempts and depression (Szanto et al., 2012). Interpersonal relationships are dependent on the successful expression and reception of emotions, as well as satisfaction, support, and a lack of conflict (Kenny et al., 2013); those who have an improved ability to express and understand emotions are much better in terms of both mental well-being and interpersonal relationships (Jiam et al., 2017; Minzenberg et al., 2006; Stewart-Brown, 2005).
Those who have mental illnesses, such as borderline personality disorder, schizophrenia, and major depressive disorder often struggle with interpersonal relationships, potentially worsening their mental well-being (Hofer et al., 2009; Minzenberg et al., 2006; Zlotnick et al., 2000). Severity of symptoms associated with mental illnesses corresponds with deficits in emotion recognition (Hofer et al., 2009). In addition, those who have stronger social relationships have a 50% lower mortality risk than those with weaker social relationships (Holt-Lunstad et al., 2010). Improving emotional recognition and, as a result, interpersonal relationships can lead to improved overall physical, mental, and social well-being for adults and adolescents.
The current study
Formal musical training has an array of benefits to cognition, including the processing of speech prosody (Başkent & Gaudrain, 2016; Good et al., 2017; Lim, 2010; Lima & Castro, 2011; Musacchia et al., 2007; Park et al., 2015; Parsons et al., 2014; Schellenberg & Mankarious, 2012; Schön et al., 2004; Thompson et al., 2004; Tierney et al., 2020). People who are better at understanding the emotions being conveyed to them in their relationships often have better relationships, and having better relationships leads to better overall health. The current study aims to clarify the relationship, if any, between musical ability and/or formal training and self-reported interpersonal relationships.
In our first research question, we examine whether formal musical training, both in years spent studying music and the extent of practice in that time, will reliably predict stronger, healthier interpersonal relationships. This question is based on the majority of discussed literature, such as Thompson et al. (2004) and Lima and Castro (2011), that suggest that improved recognition of emotional speech prosody is associated with musical expertise or formal training. Overall, previous literature has found a relationship between formal musical training and emotion recognition (Good et al., 2017; Park et al., 2015; Parsons et al., 2014; Schellenberg & Mankarious, 2012; Schön et al., 2004; Thompson et al., 2004) and better emotion recognition is associated with greater interpersonal relationship quality (Wang et al., 2019). We hypothesize that formal musical training will predict higher self-reported relationship quality.
In our second research question, we examine whether individual aspects of musical ability, acquired as a result of formal musical training, influence interpersonal relationships. This question is based on the findings of Swaminathan and Schellenberg (2020) and Trimmer and Cuddy (2008), who suggested that improved recognition of emotional speech prosody is a result of musical ability, not formal training. As previously discussed, years of formal training alone does not necessarily correlate with greater musical ability, which often depends on the amount of time engaging in practice and other music-related events outside of training (Lima & Castro, 2011; Schellenberg & Mankarious, 2012; Swaminathan & Schellenberg, 2020). We hypothesize that greater musical ability will predict stronger, healthier interpersonal relationships.
Method
Data collection and analysis plans were pre-registered through Open Science Framework, an online service that allows researchers to provide methodology, analyses, and hypotheses prior to collecting data. The Open Science Framework page for this study can be found at https://osf.io/7m9nx.
Participants
The current study collected data from 197 undergraduate students at the University of New Brunswick. One hundred sixty-nine participants identified as female, 28 identified as male, and two identified as non-binary, with an average age of 21.3 years. Two non-binary participants were excluded from the final analysis because there were not enough in the group. Sixty-eight participants had no formal training, evaluated by asking participants how many years of formal musical training they have had in their lifetime, in musical instruments or voice, and 131 had training in at least one instrument. There was an average of 2.3 years of musical training among all participants. Of the 129 participants who reported playing an instrument, 28 said that they had no formal training. Of the 101 participants who said they played an instrument and had formal training, the average length of training was 4.3 years, with a standard deviation of 2.8.
Measures
Undergraduate students completed a questionnaire online that measured musical ability, years of formal training, and the quality of their interpersonal relationships. Two different questionnaires were used to assess musical ability, extent of training, relationship qualities, and basic demographic information.
Musical ability and formal training
There are various measures that can be used to evaluate the extent of one’s musical training and ability: the Musical Sophistication Index, which incorporates various aspects of both musical training and musical ability; the Montreal Battery of Evaluation of Amusia can be used to evaluate one’s lack of musical ability (Peretz et al., 2003); the Montreal Battery of Evaluation of Musical Abilities (Peretz et al., 2013); and the music instruction scale developed by Cuddy et al. (2005). Most of these measures take into account the various aspects of musical training and ability that participants may have, accounting for any differences in their individual training and not simply asking the number of years that the participant has trained. We found Goldsmith’s Musical Sophistication Index (Gold-MSI; Müllensiefen et al., 2014) to be the most thorough for the current study because it is a reliable measure that does not require auditory tasks. In addition, the Gold-MSI has numerous subscales that break down musical ability in a useful manner.
Gold-MSI is a self-report questionnaire that provides reliable measurements for musical perceptual abilities, which evaluates the ability to accurately perceive musical differences (9 items, α = .873); musical training, which evaluates the extent of musical training (7 items, α = .903); emotions in music, which evaluates the ability to recognize emotions in music (6 items, α = .791); active engagement, which evaluates the time and money dedicated to music (9 items, α = .872); and general musical sophistication, which incorporates all of the aforementioned subscales into one measurement (18 items, α = .926). The singing abilities subscale was excluded because previous experimental research found no relationship between vocal training and emotion recognition (Thompson et al., 2004). The Gold-MSI uses a Likert-type scale that ranges from 1 (completely disagree) to 7 (completely agree). These subscales sufficiently measure both musical training, for the first research question, and musical ability, for the second research question.
Interpersonal relationship quality
Interpersonal relationship quality was measured using the Quality of Relationship Inventory (QRI; Pierce et al., 1997). The QRI is a 25-item self-report relationship inventory with three subscales: support, which is a measure of perceived social support; conflict, which measures perceived conflict in interpersonal relationships; and depth, which is a measure of the importance of interpersonal relationships, all of which have Cronbach’s alpha between .70 and .94 (Pierce et al., 1997). The QRI also uses a self-reporting format with a Likert scale ranging from 1 (not at all) to 4 (quite a bit). This inventory is directed at a specific relationship and not all relationships in general, participants were asked to choose a close relationship with a non-relative peer.
Data collection
Data were collected through Qualtrics, an online questionnaire service that allows for anonymous data collection. Participants were recruited through an undergraduate research pool signup system, which provided an anonymous link to the Qualtrics questionnaire, and were rewarded with bonus marks for a participating class. Participants provided consent to participate prior to beginning the Qualtrics questionnaire and were able to opt-out at any time. This study and the data collection procedures were reviewed and approved by the University of New Brunswick Research Ethics Board (File #044-2020).
Data analysis
Three separate hierarchical linear regressions were used for each of the QRI outcome measures (conflict, support, and depth) to test both hypotheses; in the first step, sex and age were entered; in the second step, the musical training subscale data were entered as the only predictor variable and compared with relationship quality data from the QRI subscales; in the third step, the perceptual abilities, general sophistication, active engagement, and emotions subscales, from the Gold-MSI, were added as predictor variables.
For the first research questions, relationship quality was measured with the three subscales, support, conflict, and depth, from the QRI, and musical training was operationalized through the Gold-MSI musical training subscale. Greater musical training is expected to be associated with higher quality interpersonal relationships.
For the second research question, we used similar procedures; to assess the various aspects of musical ability, we used the perceptual abilities, active engagement, general sophistication, and emotions subscales from the Gold-MSI. Greater musical ability in any of the subscales of the Gold-MSI is expected to be associated with higher quality interpersonal relationships in any of the subscales in the QRI.
G-Power, a statistical power analysis program, was used to calculate the number of participants needed for the desired power (Faul et al., 2007). A medium effect size (r = .144) was expected, based on previous, similar research (Swaminathan & Schellenberg, 2020). To achieve a power of .95, with three regressions, a minimum n of 116 was needed. To maximize power, and account for potentially unusable data, we aimed to recruit up to 200 participants.
Results
Participants (N = 206) voluntarily signed up for the questionnaire between November 17 and December 7. The responses of nine participants (4.3%) were omitted because of incomplete data.
QRI support
Table 1 shows the hierarchical multiple regression for the QRI subscale support. In the first step (ΔR2 = .027, p = .167), sex and age were entered. In the second step (ΔR2 = .001, p = .689), the musical training subscale from the MSI was added as a predictor variable, which was non-significant (B = .001, 95% CI [−.006, .009], p = .690). The emotions (B = .013, [−.008, .036], p = .235), active engagement 1 (B = −.001, [−.021, .018], p = .891), perceptual abilities (B = .010, [−.005, .026], p = .185), and general sophistication (B = −.006, [−.020, .006], p = .302) subscales were added in the third step (ΔR2 = .031, p = .542). The MSI subscales had no significant relationship with the support subscale from the QRI.
Hierarchical Multiple Regression Results for QRI Support.
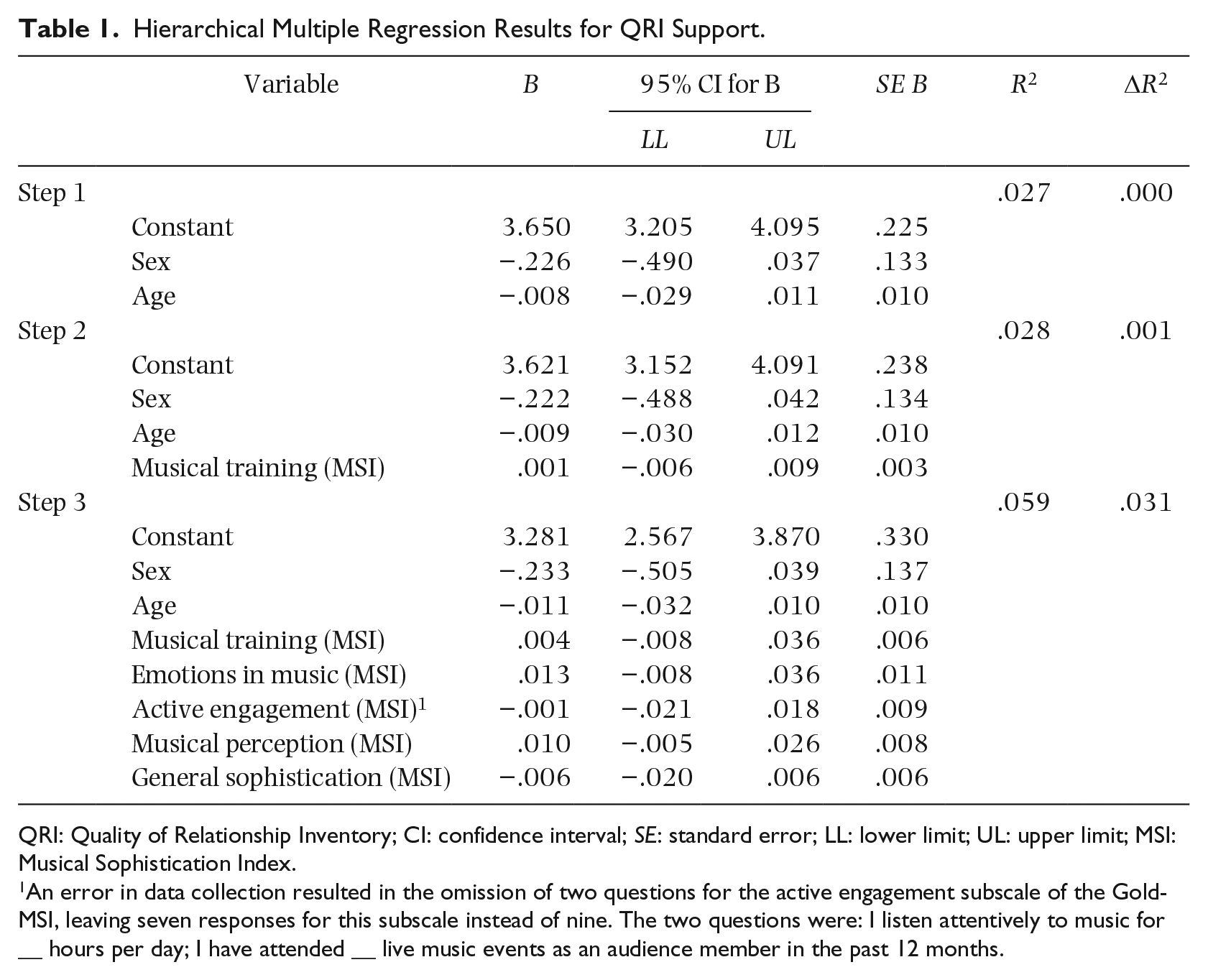
QRI: Quality of Relationship Inventory; CI: confidence interval; SE: standard error; LL: lower limit; UL: upper limit; MSI: Musical Sophistication Index.
An error in data collection resulted in the omission of two questions for the active engagement subscale of the Gold-MSI, leaving seven responses for this subscale instead of nine. The two questions were: I listen attentively to music for __ hours per day; I have attended __ live music events as an audience member in the past 12 months.
QRI conflict
Table 2 shows the hierarchical multiple regression for the QRI subscale conflict. In the first step (ΔR2 = .001, p = .888), sex and age were entered. In the second step (ΔR2 = .009, p = .136), the musical training subscale from the MSI was added as a predictor variable, which was non-significant (B = .005, [−.001, .013], p = .136). The emotions (B = −.003, [−.022, .015], p = .730), active engagement (see Note 1) (B = .011, [−.010, .032], p = .307), perceptual abilities (B = −.022, [−.038, −.007], p = .005), and general sophistication (B = .011, [−.001, .024], p = .089) subscales were added in the third step (ΔR2 = .079, p = .024). In the third step, the perceptual abilities subscale was significant and accounted for 8% of the difference in conflict. The three other MSI subscales were not significant in this model.
Hierarchical Multiple Regression Results for QRI Conflict.
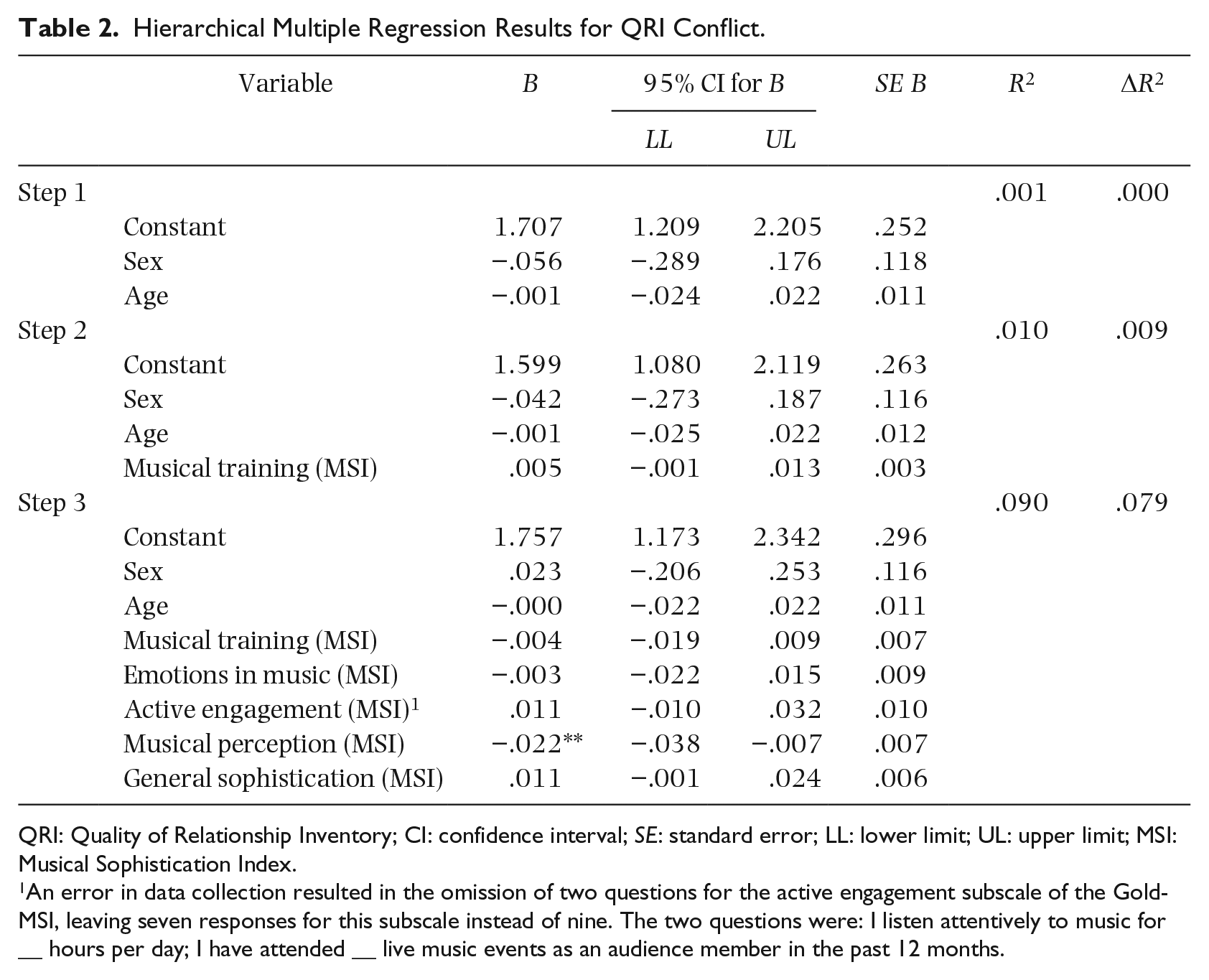
QRI: Quality of Relationship Inventory; CI: confidence interval; SE: standard error; LL: lower limit; UL: upper limit; MSI: Musical Sophistication Index.
An error in data collection resulted in the omission of two questions for the active engagement subscale of the Gold-MSI, leaving seven responses for this subscale instead of nine. The two questions were: I listen attentively to music for __ hours per day; I have attended __ live music events as an audience member in the past 12 months.
QRI depth
Table 3 shows the hierarchical multiple regression for the QRI subscale depth. In the first step, sex and age were entered (ΔR2 = .041, p = .038). In the second step (ΔR2 = .003, p = .505), the musical training subscale from the MSI was added as a predictor variable, which was non-significant (B = .003, [−.006, .012], p = .505). The emotions (B = .010, [−.011, .033], p = .332), active engagement (see Note 1) (B = .009, [−.009, .029], p = .329), perceptual abilities (B = .003, [−.014, .020], p = .714), and general sophistication (B = −.005, [−.018, .007], p = .382) subscales were added in the third step (ΔR2 = .019, p = .385). The MSI subscales had no significant relationship with the depth subscale from the QRI.
Hierarchical Multiple Regression Results for QRI Depth.
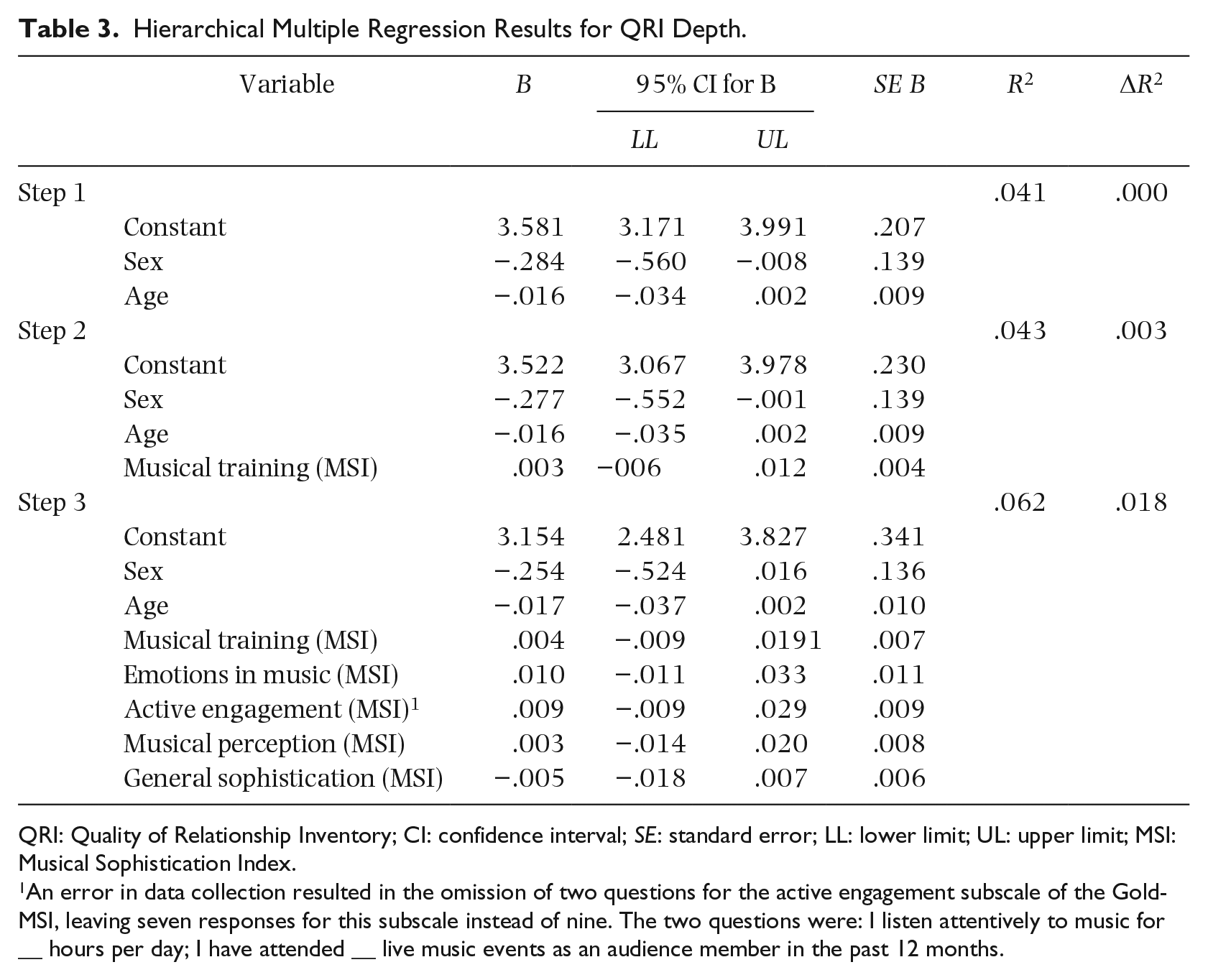
QRI: Quality of Relationship Inventory; CI: confidence interval; SE: standard error; LL: lower limit; UL: upper limit; MSI: Musical Sophistication Index.
An error in data collection resulted in the omission of two questions for the active engagement subscale of the Gold-MSI, leaving seven responses for this subscale instead of nine. The two questions were: I listen attentively to music for __ hours per day; I have attended __ live music events as an audience member in the past 12 months.
Discussion
Our first hypothesis, that musical training would correlate positively with greater relationship quality, yielded no significant results; musical training alone has no impact on the various measures of interpersonal relationship quality. Our second hypothesis, that different elements of musical training, such as perceptual abilities and overall sophistication, would correlate with greater relationship quality, was partially supported; in most cases, there was no significant relationship between the MSI subscales and the QRI subscales, with the exception of musical perceptual abilities and conflict. Greater musical perceptual ability was associated with lesser reported conflict.
There was no significant relationship between the musical training subscale of the MSI and any of the QRI subscales (depth, conflict, and support). These results do not mean that musical training is not a predictor of the ability to recognize emotions in speech; instead, these results suggest that the improved ability to recognize emotions in speech prosody, because of musical training alone, may not be strong enough to result in relationship quality differences. There are two potential explanations for this result: musical training may not influence the perception of speech prosody, which supports some previous literature (Swaminathan & Schellenberg, 2020; Trimmer & Cuddy, 2008); alternatively, the average years of musical training across participants who reported having more than 0 years of training was below a previously established minimum to detect changes in speech prosody perception (Lima & Castro, 2011). Lima and Castro (2011) suggest that there is significant difference in the results of studies with different averages of years of musical training; the average range in studies with significant results is 12 or more years, and the current study had an average, in participants who reported greater than 0 years of training, of 4.3 years. However, other studies have found results with training that has been much shorter in duration (Good et al., 2017; Lima & Castro, 2011; Moreno & Besson, 2005; Park et al., 2015; Schön et al., 2004; Thompson et al., 2004). It should be noted that the MSI subscale musical training considers various aspects of a participant’s musical training, not simply the number of years that someone has practiced. At a minimum, these results add support to the notion that there is little detectable difference in low-average (below 12 years of musical training) participants.
The remaining MSI subscales, which were used to assess the various aspects of musical ability, had no significant relationship with the QRI subscales, except for musical perception and conflict. Scores on musical perception accounted for 8% of the difference in relationship conflict scores; greater self-reported musical perceptual abilities, which is an element of musical training, was associated with less self-reported conflict in relationships. Considering the innumerable variables that influence relationship conflict, such as personality traits, upbringing, socioeconomic status, education, and substance use, 8% is a generous amount for a seemingly unrelated factor (Großmann et al., 2019; Kershaw et al., 2013; Mandal & Hindin, 2013; Rodriguez-Stanley et al., 2020). This difference is enough to justify greater research into the potential benefits and applications of musical training for those who are at greater risk for, or already exhibit, relationship conflict. These results provide some support for previous findings, which suggest that greater musical ability, not just training, is responsible for more accurate recognition of emotions in speech (Swaminathan & Schellenberg, 2020; Trimmer & Cuddy, 2008).
Limitations
There were some limitations to the study that should be considered. Due to a technical error, two questions were missing from the active engagement subscale in the data collection stage. It is possible this may have influenced the measurement of active engagement. However, this subscale was purely exploratory and not inherently linked to the main hypotheses. It is also important to consider potential mediating factors affecting musical perceptual skills: for example, musical perception may be a result of greater emotional intelligence. Someone with greater emotional intelligence may score higher on musical perceptual abilities and, consequently, lower on the conflict subscale. Future research should control for emotional intelligence, as suggested by Schellenberg and Mankarious (2012) and Swaminathan and Schellenberg (2020).
The average number of years of musical training across all participants (2.3 years) was far below what Lima and Castro (2011) suggested is a sufficient average for detecting the effects of musical training (6.5 years). The number of years of musical training across participants who reported having training, excluding those with none, was 4.3 years, still below this threshold. Future research could benefit from assessing the relationship between musical training and relationship quality in a participant pool that has a higher average. Another limitation may be the handful of questions in the MSI that ask about musical training. Some questions ask about years of musical training “including voice.” Previous literature has found that voice training does not yield the same results as instrument training (Thompson et al., 2004).
While participants were undergraduate students, generalizability is not a concern because past research has established that age has a mild effect on emotion recognition in speech prosody (Lima & Castro, 2011). However, some studies have pointed out age-related decline in some musical training and emotional prosody tasks (Lima & Castro, 2011; Müllensiefen et al., 2014). Given this research, if there is a relationship between musical training and relationship quality, it would be most noticeable in younger participants.
Finally, participants’ ability to detect emotions conveyed in speech prosody was not evaluated. While there is a strong foundation to support that those with greater musical abilities score higher in speech prosody emotion recognition, we cannot definitively say that the participants with musical training in this study had an above average ability to detect emotions in speech prosody. Future research in this area should assess participants’ ability to detect emotions in speech prosody and its potential relationship with interpersonal relationship conflict.
Conclusion
These results, while not anticipated, raise new questions and areas of inquiry. It is worth investigating the underlying mechanisms of relationship conflict and musical perceptual ability. Having an improved ability to recognize what others are expressing to you may lead to less frequent conflict, but not necessarily greater depth or support. Future research should aim to clarify the relationship between musical perceptual abilities and relationship qualities, specifically conflict.
If musical training and, as a result of it, musical perceptual abilities can reduce conflict in relationships, finding ways to teach musical perceptual abilities may indirectly benefit interpersonal relationship skills. Increased interpersonal relationship skills can be beneficial to a wide range of populations, including those suffering from mental illness and school-aged children (Hofer et al., 2009; Minzenberg et al., 2006; Szanto et al., 2012; Wang et al., 2019; Zlotnick et al., 2000). Understanding the emotions expressed by others, in any context, is a vital aspect of human communication. If musical training has the potential to reduce conflict in interpersonal relationships through its potential benefits to emotion recognition, it is worthy of further inquiry. Specifically, musical training may be used to improve emotion recognition in populations who are predisposed to poorer emotion recognition, those who struggle with interpersonal relationships, and in school-aged children to prepare them for future relationships. While this research was exploratory, future research should aim to identify the underlying mechanisms of musical training and ability on interpersonal relationships.