
Abstract
We tested how induced emotions and Turkish makam recognition are influenced by participation in an ear training class and whether either is influenced by the temperament system employed. The ear training class was attended by 19 music students and was based on the Hicaz makam presented as a between-subjects factor in either unfamiliar Turkish original temperament (OT, pitches unequally divided into 24 intervals) or familiar Western equal temperament (ET, pitches equally divided into 12 intervals). Before and after the class, participants listened to 20 music excerpts from five different Turkish makams (in both OT and ET versions). Emotion induction was assessed via the 25-item version of Geneva Emotion Music Scales (GEMS-25), and participants were also asked to identify the makam that was present in the excerpt. The unfamiliar OT was experienced as less vital and more uneasy before the ear training class, and recognition of the Hicaz makam increased after ear training classes (independent of the temperament system employed). Results suggest that unfamiliar temperament systems are experienced as less vital and more uneasy. Furthermore, being exposed to this temperament system for just 1 hr does not seem to be enough to change participants’ mental representations of it or their emotional responses to it.
There are various musical characteristics that are associated with cognitive processing of and emotional meaning in music. For instance, happy music tends to be higher in pitch, whereas sad music is often associated with lower pitch (Juslin & Laukka, 2003a). Accordingly, numerous studies have been conducted which test the emotional qualities and recognition performance of music parameters, including tonal, syntactic, and rhythmic features (Dowling, 1984; Gabrielsson & Lindström, 2010; Juslin & Timmers, 2010; Loui, Wessel, & Kam, 2010). Despite being the foundation of syntactic pitch relations, from a pitch position in an octave to the musical phrase, to the best of our knowledge, the emotional qualities of temperament systems and the role of temperament systems on recognition performance have not yet been studied before.
In music theory, temperament systems are referred by different terms such as tuning systems or scale systems. Throughout this article, we are going to use the term temperament systems to be consistent with the historical distinction between pure intervals and tempered intervals (Rasch, 1983). Temperament systems describe culturally determined and idealized pitch relations (Kopiez, 2003). Usually, these pitch relations are based on consonance (Bibby, 2003) and differ regarding the partition of the pitch continuum. For example, in Western culture, the most common temperament system is the 12-tone equal-tempered system in which an octave is divided into 12 successive pitch spaces, each sounding half of the whole tone. The most noticeable differences among temperament systems from different cultures are the subdivision of a whole tone. For instance, the Indian Shruti 22 note system dominantly uses 22 divided pitches in an octave, and in this approach, one whole step is formed by five unequally divided (from ratio 1:1 to 9:8) pitches.
In this study, we aimed to explore the role of temperament systems on emotion induction and recognition performance by presenting an unfamiliar musical syntax in familiar and unfamiliar temperament systems. For this reason, we chose Turkish makam music, which is traditionally performed in an unequally divided 24-interval temperament system. In Turkish makam music, in comparison with the Western equal temperament (ET) system, a whole step is divided into nine equal steps (with the Holdrian Comma), and a half step is divided into four equal steps. Each of these steps is called a coma—the smallest interval unit of the Turkish makam music system. As shown in Table 1, the original temperament (OT) system (known as Arel-Ezgi-Uzdilek) uses unequal intervals, meaning that the notes used are not divided equally within the octave. This means that not all nine comas that exist in a whole step are used.
The original Turkish temperament system interval names.
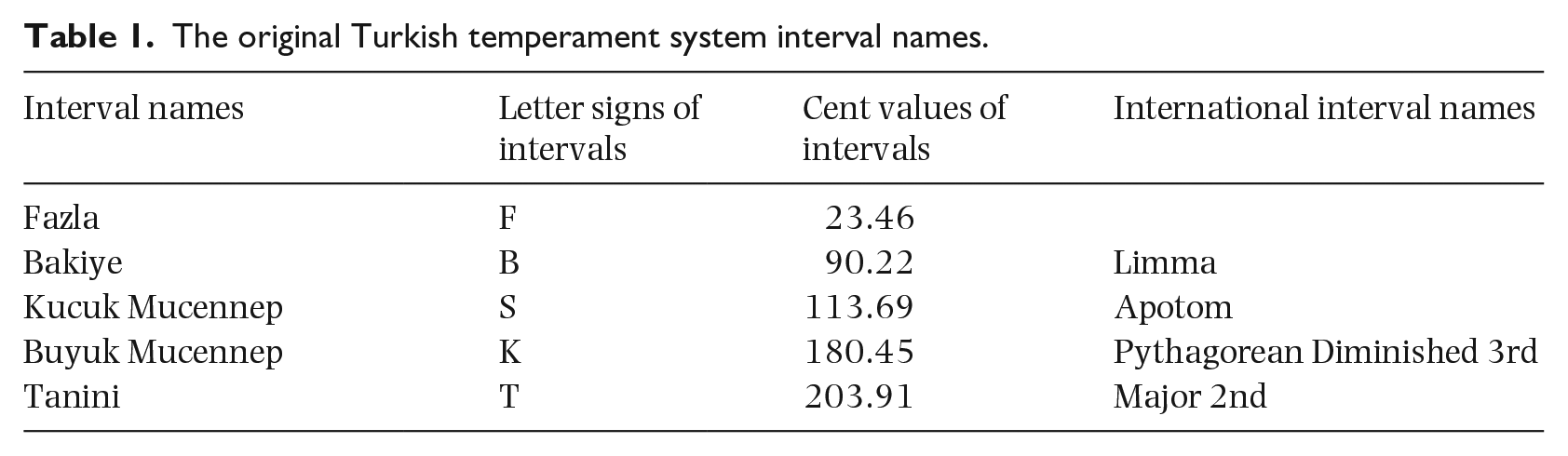
In Western music, a scale is produced by obtaining a new tetrachord (a pitch set which includes four notes and three interval units) above another tetrachord. However, Turkish makam music uses trichords, tetrachords, and pentachords to produce scales, and those chords are given names for their “flavor” or melodic character at the note where they move melodically.
Another vital component of Turkish music is the makam itself. A makam is a melodic texture consisting of progressions, directionality, tonal and temporary centers, and cadences. It usually compares with the concept of a scale. From a perceptual perspective, makams contain additional melodic patterns which aid recognition of their emotional expressivity, in addition to providing a sense of tonic and dominant (Bozkurt, 2008; Yarman & Karaosmanoglu, 2014).
Temperament systems were studied particularly with respect to performance intonation (Kopiez, 2003; Loosen, 1995; Vurma & Ross, 2006). For instance, Loosen (1995) studied the preferred tuning systems by musicians and non-musicians through scales. He compared three different temperament systems (Pythagorean, 12 equal-tempered and just intonation) through a computer-generated diatonic C Major scale. Accordingly, temperament system preferences have been differentiated in accordance with participants’ played instruments (where their more familiar system was preferred), and non-musicians showed no significant preference differences. Accordingly, these results indicate the relevance of learning and familiarity in the experience of temperament systems. Much research also examined tonal hierarchy sensitivity and expectations through familiar–unfamiliar stimuli pairings with familiar–unfamiliar participant pairings (Castellano, Bharucha, & Krumhansl, 1984; Curtis & Bharucha, 2009; Demorest, Morrison, Jungbluth, & Beken, 2008; Eerola, Louhivuori, & Lebaka, 2009). However, most of these cross-cultural studies, despite including comparative evaluations of pitch and melodic structures, did not include the temperament system as an experimental factor. Here, mostly, the 12-interval ET system was used, or no explicit details about which temperament system was used were reported.
Previous research shows that the acquisition of musical knowledge begins from the prenatal period (Partanen, Kujala, Tervaniemi, & Huotilainen, 2013) and differs based on the cultural background of a listener (McDermott, Schultz, Undurraga, & Godoy, 2016; Patel & Demorest, 2013). Despite some contradictory findings and theories, the theory of auditory statistical learning (Vapnik, 1998) provides the most comprehensive set of explanations for listeners’ musical mental representations. Accordingly, the theory of statistical learning predicts that listeners acquire musical knowledge about statistical regularities in music through passive exposure to them (Huron, 2006). Based on this knowledge, listeners form expectations that can be violated or confirmed while listening to music.
Statistical learning in music has been studied in many ways, including research on tonal (Creel, 2011), melodic (Cuddy & Lunney, 1995; Tillmann, Bharucha, & Bigand, 2000), and rhythmic (Barwick, 2002; Schultz, Stevens, Keller, & Tillmann, 2013) expectations. Furthermore, the role of expectation violations has also been tested within cross-cultural contexts (Balkwill & Thompson, 1999; Curtis & Bharucha, 2009; Demorest et al., 2008; Lynch, Eilers, Oller, Urbano, & Wilson, 1991; Krumhansl & Shepard, 1979; Polak, London, & Jacoby, 2016; Raman & Dowling, 2016). Several authors have suggested that moments of melodic expectation violations are linked to emotional responses to music (Huron, 2006; Meyer, 1956; Narmour, 1990) and recognition performance in music (Boltz, Schulkind, & Kantra, 1991), as violations of expectations might be perceived as arousal-inducing and emotional and might cause better recall performance. Egermann, Pearce, Wiggins, and McAdams (2013) were able to confirm the hypothetical link between expectation and emotion: Accordingly, those musical events that were statistically difficult to predict for a computational algorithm (simulating statistical learning in listeners) lead to increases in continuous arousal ratings, a decrease in valence ratings, and increases in physiological arousal.
Aims and research questions
We aimed to show that temperament systems might play a relevant role in mental pitch representations and hence expectations. This suggestion is based on our proposal that temperament systems act as an ecosystem of all possible musical pitch relations and expectations. Accordingly, in this exploratory study, our underlying research questions were the following:
RQ1. Does the temperament system in which a Turkish makam is presented influence a listener’s emotional response to it?
RQ2. Are listeners able to recognize a Turkish makam after attending an ear training, and does this recognition depend on the temperament system employed in the training?
RQ3. Do listeners’ emotional responses to the unfamiliar temperament system change through exposure to ear training?
We, therefore, predict that unfamiliar temperament systems lead to different emotional responses compared with familiar temperament systems (due to an increase in pitch-based expectation violations). Furthermore, in line with the theory of statistical learning, we hypothesize that listeners’ cognitive and emotional responses change through exposure to the temperament systems in ear training.
Method
Experimental design
We employed a mixed between- and within-factorial design in this study. A pre-training experiment examined participants’ emotional responses to five unfamiliar makams presented in their OT system and an adapted ET version of them. In addition to that, we also tested whether participants were able to identify the name of the makam correctly.
Subsequently, participants were randomly assigned to one of two different 1-hr-long ear training class that focused on the general features of the Hicaz makam. One version of the training employed the 24-interval OT system and another the 12-interval ET system. In a subsequent post-training experiment, all participants rated the emotional responses to the same makam excerpts once more that were presented in the pre-experiment and completed another makam identification task.
Participants
Nineteen music students who were enculturated in the Western temperament system participated in this study (mean age = 23 years, SD = 4.8 years, 10 males; formal music education M = 11 years, SD = 5 years). Except for one (excluded from analysis), all other participants were unfamiliar with makam music.
Musical stimuli
We asked five Turkish makam music experts to suggest makams and two songs per makam that match the nine different emotional qualities of the 25-item version of Geneva Emotional Music Scales (GEMS-25) first-order factors (Zentner, Grandjean, & Scherer, 2008). Despite some overlap across experts’ suggestions, there was no full agreement on makam and emotion pairings among experts. However, we chose a total of five makams from those suggested by experts: Hicaz, Huseyni, Mahur, Saba, and Mustear Makams and two songs according to these makams.
Accordingly, we selected two excerpts per makam and created its OT and ET versions. To produce 12-interval ET versions, we adapted the makams, which were originally in the 24-interval OT based on the nearest pitch principle.
In addition to that, to test for a potential effect of timbre (not shown here), we created three different versions of each stimulus using three different instruments (see Table 2 for full stimulus characteristics), resulting in a total of 60 stimuli. All stimuli were monophonic and were created via Mus2 Turkish notation and Finale software. To eliminate the effects of other structural features on emotion induction, temperament versions of all excerpts did not include any accentuation or articulation.
Stimulus characteristics.
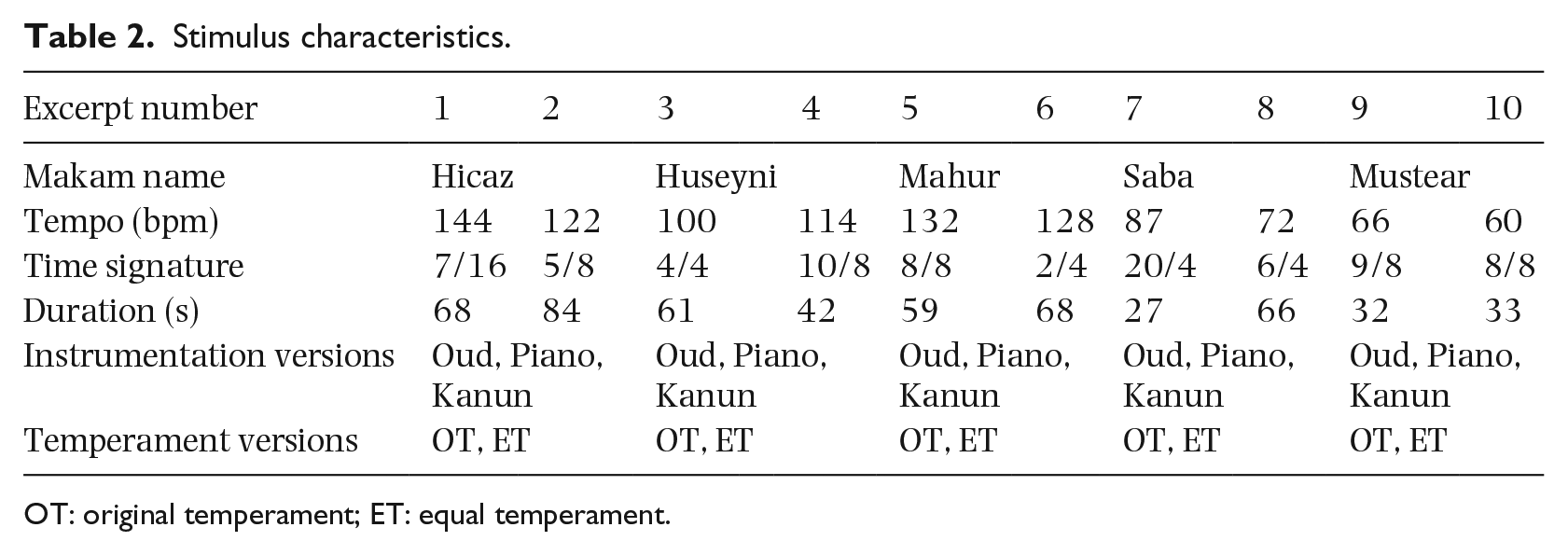
OT: original temperament; ET: equal temperament.
Procedure
The pre-training experiment was conducted in a listening laboratory and embedded in an online questionnaire. Here, participants were asked to rate their emotional response retrospectively to each stimulus presented in random order, using the GEMS-25 questionnaire (Zentner et al., 2008). Each instrumentation version was only randomly presented once to each participant, creating an additional between-subjects factor. As it did not significantly influence participants’ emotional responses, we are not presenting the related results here. Furthermore, they were asked to identify the name of the makam from a list of 10 different makams or select an “I do not know” option. To increase absorption in music, participants wore active noise cancellation headphones. All the experiment sessions lasted approximately 25 min per participant.
Subsequently, participants were randomly assigned to one of two groups to attend a 1-hr-long ear training class. One participant group received a music-theoretical introduction to the Hicaz makam in OT and the other group in ET. Both ear training sessions were run in a normal classroom setting and were about 1-hr-long. On the day after the ear training sessions, all participants participated in the same listening experiment like the one before attending the class.
Ear training classes and content
We selected Hicaz makam as the makam taught in the ear training (Figure 1). The ear training classes were devised based on the demands of the temperament system. The focus of both classes was to expose participants to the features of the selected makam. To do this, we used Hicaz makam’s traditionally defined syntactic movement characters. We created and used some well-known solfeggios which were based on tetrachord and pentachordal components of the Hicaz makam. The class was based on a gradual approach and started from basic four-note tetrachord solfeggio to a full characteristic of Hicaz makam solfeggio. To be consistent with participants’ formally taught ear training methods, we did not use solmization in vocalizations. Instead of solmization, all participants vocalized solfeggios with a “na” syllable. Participants were also familiarized with some theoretical and cultural features of Turkish makam music. Except for the use of a different temperament system, all ear training materials were identical in both classes which were also taught by the same teacher to eliminate any teaching style differences.

Hicaz Makam Example in the Original Temperament and Equal Temperament.
Results
Effect of temperament system and makam type in the pre-experiment
To reduce the number of dependent variables and increase the interpretability of results, we reduced the GEMS-25 questionnaire to the three underlying second-order factors Sublimity (combining Wonder, Transcendence, Tenderness, Nostalgia, Peacefulness), Vitality (combining Power and Joyful Activation), and Unease (Tension and Sadness) by producing a mean score for each second-order factor. We then employed a hierarchical linear modeling procedure to test for significant effects on these three emotion factors (using the Mixed procedure in SPSS). All estimations are based on restricted maximum likelihood with compound symmetry heterogeneous covariance structure (which produced overall the best Akaike information criterion [AIC] fit indices).
Figure 2(a) presents the mean intensity of the second-order sublimity factor in the pre-training experiment (before the ear training class) separated by stimulus temperament system and makam type. According to our hierarchical linear model, neither temperament system, F(1, 153) = 0.23, p = .64, nor makam type, F(4, 153) = 1.47, p = .21, influenced experienced sublimity. The interaction between temperament system and makam type was also not significant, F(4, 153) = 0.51, p = .73.
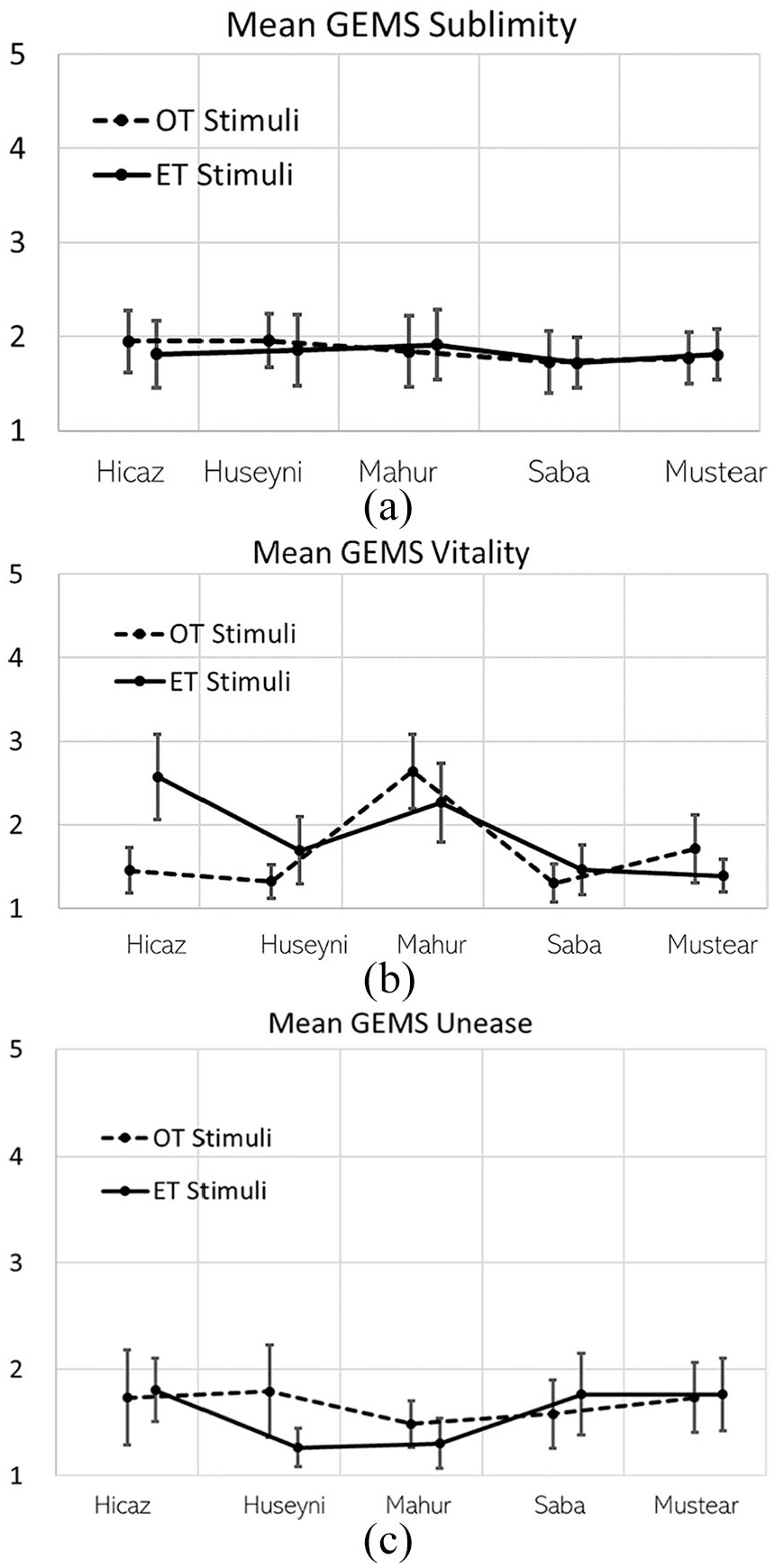
Mean Intensity of Second-Order GEMS Factors in Pre-Experiment Separated by Stimulus Temperament System and Makam Type With 95% CI: (a) Sublimity, (b) Vitality, and (c) Unease.
Figure 2(b) presents the mean intensity of the second-order vitality factor in the pre-training experiment separated by stimulus temperament system and makam type. According to our model, temperament system, F(1, 153) = 6.80, p < .01, and makam type, F(4, 153) = 28.47, p < .001, influenced vitality significantly. The interaction between temperament system and makam type was also significant, F(4, 153) = 13.29, p < .001. The Hicaz and Mahur makams were experienced as more vital than all other three makams. The vitality ratings of all makams also differed in accordance with their temperament system. While generally ET makam versions were mostly experienced as more vital than their OT versions (apart from the Mahur and Mustear makam), this effect appeared to be strongest for the Hicaz makam: Fixed-effects estimates indicate that the ET version was experienced as significantly more vital, b = 1.44, t = 5.27, p < .001, compared with the OT version.
Figure 2(c) presents the mean intensity of the second-order uneasiness factor separated by stimulus temperament system and makam type. According to our linear model, the temperament system did not, F(1, 153) = 1.66, p = .20, but makam types did, F(4, 153) = 4.53, p < .001, influence uneasiness significantly. The interaction between temperament system and makam type was also significant, F(4, 153) = 3.50, p < .01. This indicates that ET version of the Huseyni makam was experienced as less uneasy than its original version.
Effect of ear training and temperament system on Hicaz makam recognition
We asked our participants the name of the makam presented in the pre- and post-training experiments. We expected that there was an increase in Hicaz makam recognition performance after the ear training, and we tested whether this depended on the temperament systems employed in the training and listening experiments. To test this, we used a generalized linear mixed model with the probability of recognizing the Hicaz makam correctly as an outcome variable. Only the experimental factor time was significant, F = 6.678, p < .01, indicating that, generally, the recognition rate improved after the ear training class (Figure 3). However, no other experimental factors or interactions were significant, indicating that recognition performance did not depend on the temperament system employed in the ear training class or for stimulus presentation (see Appendix 1).
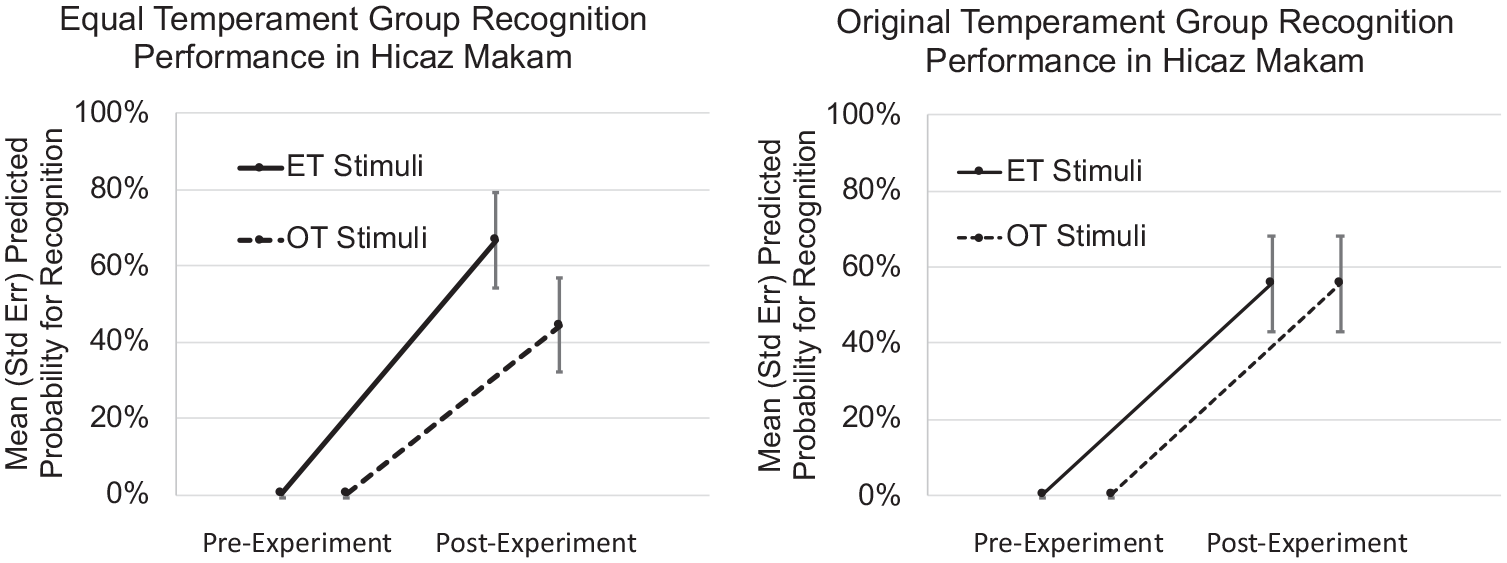
Predicted Hicaz Makam Recognition Probability Separated by Time (Pre- vs. Post-Experiment), Ear Training Type, and Stimulus Temperament System.
Effect of ear training on emotional experience of Hicaz makam
As we noticed a change in participants’ ability to recognize the previously unfamiliar Hicaz makam, we then subsequently tested whether the ear training leads to any associated changes in their emotional experience of this makam. For this reason, we again estimated a linear mixed model for each of the three second-order GEMS factor ratings, using only data for the Hicaz makam. We excluded the other makams from the modeling approach. The first justification behind this is the only potential hypothesis of change for makam was for Hicaz. Furthermore, exploratory analyses (not shown here) for other makams indicate that any of the other makams’ emotional impacts did not change as a function of the ear training and temperament system.
Even though Figure 4(a) indicates that the experience of sublimity might have decreased after the ear training for the OT participant group (which is also indicated by a non-significant trend in the interaction of the factor time and ear training group), no experimental factor and no interaction were significant when modeling sublimity (see Appendix 2).
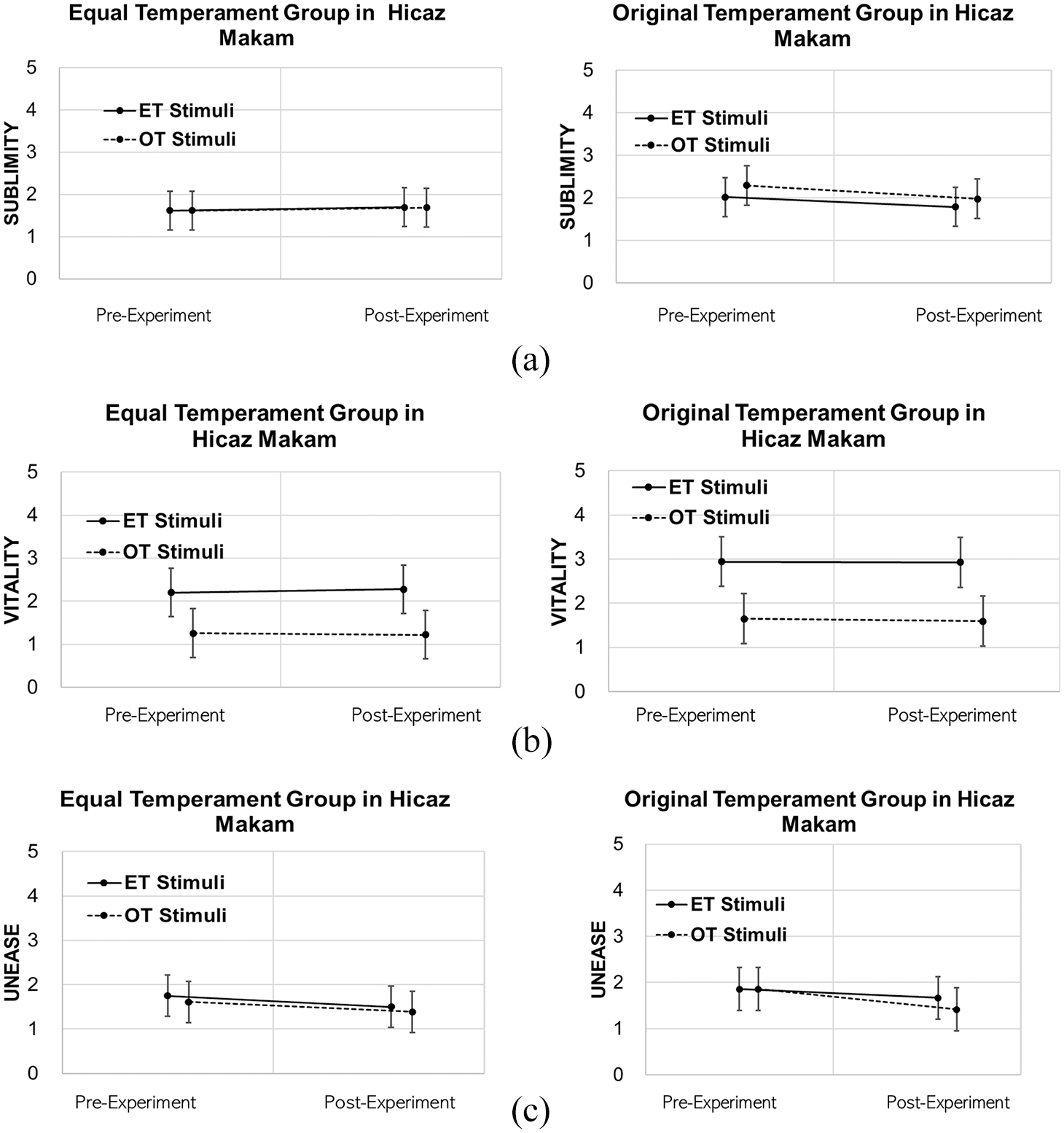
Mean Experience of Three Second-Order GEMS Factors for Hicaz Makam Separated by Time (Pre- vs. Post-Experiment), Ear Training Type, and Stimulus Temperament System With 95% CI: (a) Sublimity, (b) Vitality, and (c) Unease.
Figure 4(b) shows again (like in the pre-training experiment) that, generally, the ET was experienced as more vital than the original, F(1, 48) = 74.910, p < .001. However, all other factors and interactions were not significant (see Appendix 3).
For the experience of unease, only the time factor was significant, indicating that, generally, exposure to the makam decreased the experience of this feeling (Figure 4(c)); no other factor or interaction was significant (Appendix 4).
Discussion
We tested the effects of temperament systems on emotion induction and recognition performance through adapting an unfamiliar temperament system to a familiar temperament system. The results demonstrate that different makams induced different emotions, and the intensity of these emotional qualities also changed according to the presented temperament system (RQ1). As expected, recognition rates of the Hicaz makam increased from pre- to post-experiment (RQ2). However, this increase did not depend on the temperament system employed in the training or listening experiment. Being exposed to the Hicaz makam during the ear training did decrease the experience of its uneasiness (comparing ratings in pre- and post-experiment). However, this change did not also depend on the tuning system employed (RQ3).
Previous cross-cultural music cognition studies showed that musical expectations are biased by culture (Demorest, Morrison, Nguyen, & Bodnar, 2016). Demorest and colleagues hypothesized that listeners in an out-of-culture memory task might attempt to use in-culture schemata to organize culturally unfamiliar music rather than a new, more appropriate construct. This idea is supported by findings like those of Curtis and Bharucha (2009), who presented listeners with music stimuli that exploited their cultural biases, leading to incorrect recall responses for culturally unfamiliar music. Demorest et al. (2008) compared American with Turkish participants, and they found a positive effect of in-culture familiar music characteristics on music memory performance. In the pre-training experiment, our participants also had less cognitive schemata available to process the OT stimuli (compared with their ET versions). Therefore, without any OT temperament schemata, the OT versions might have been experienced as less vital and less positive. Furthermore, we only observed an increase in general cognitive schemata for makam syntax as a result of the ear training, indicated by an increase in the makam recognition rate. Here, we did not observe a benefit of stimuli where temperament of stimuli was congruent.
We also only observed a general, temperament-independent decrease in the experience of uneasiness for the Hicaz makam. This general reduction of unpleasant feelings after exposure might also be similar to the mere exposure effect, described by Zajonc (1968), which has been shown in music (e.g., Halpern & Müllensiefen, 2008; Mungan, Akan, & Bilge, 2019; Peretz, Gaudreau, & Bonnel, 1998). We assume that the duration of the exposure in the 1-hr-long class might not have been long enough also to change listeners’ mental representation of the temperament system employed. Therefore, the latter variable showed no visible effects on post-experiment responses.
In terms of emotion studies in music, the pitch factor is a more ambiguous structural factor than factors such as tempo and loudness, as its relationship with emotion is less clearly defined (Gabrielsson & Lindström, 2010). Therefore, studying the emotional qualities of temperament systems in different cultural contexts might give new insights into understanding how a pitch is linked to emotion. Our study shows that, generally, unfamiliar temperament systems are experienced as less vital and more uneasy. Furthermore, being exposed to this temperament system for just 1 hr does not seem to be enough to change participants’ mental representations of it or their emotional responses to it. Further longitudinal experiments with larger sample size would need to be conducted, where the amount of exposure is substantially increased. This research could also introduce an additional experimental factor by also recruiting participants from Turkey who should have a generally higher cultural familiarity with makam music. This would allow differentiating long-term cultural exposure differences from short-term exposure differences through the ear training class (OT vs. ET). Nevertheless, the study presented here, to our best knowledge, is the first experiment to show that temperament systems have an effect on emotion induction, illustrating their general psychological relevance for understanding our everyday experienced responses to music.
Footnotes
Appendix
Fixed effects for unease factor responses to Hicaz makam (pre- and post-experiment).
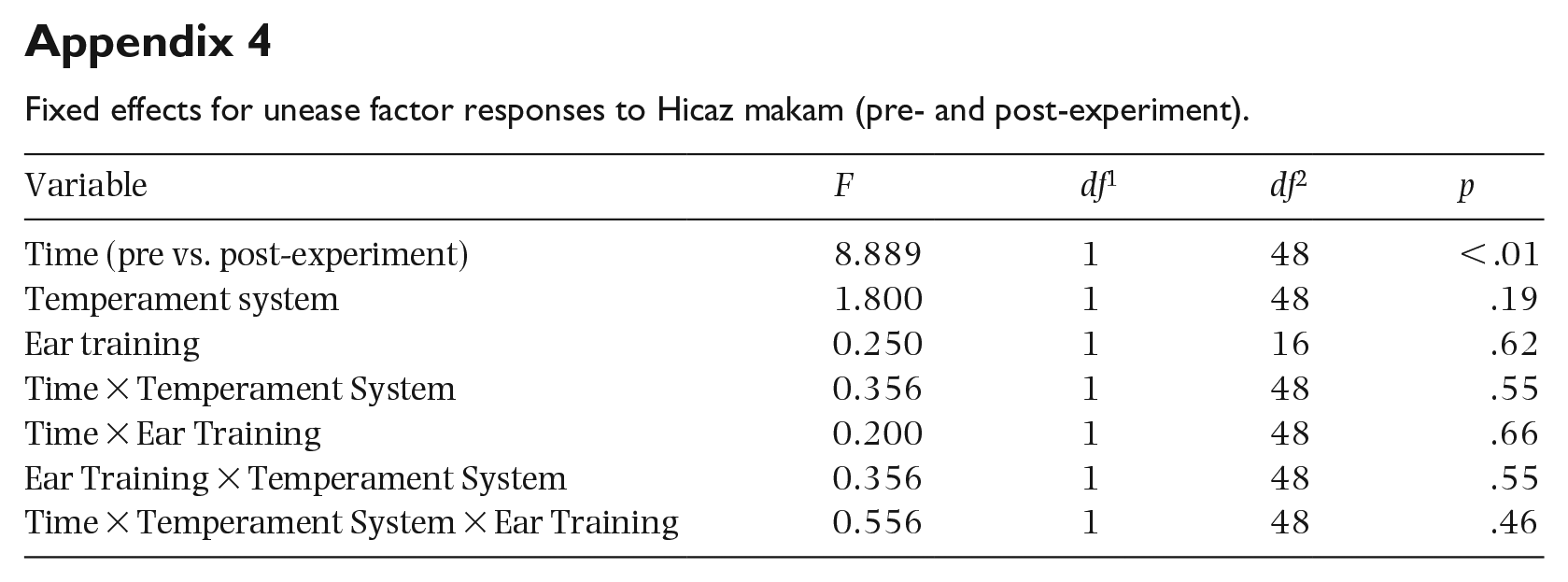
| Variable | F | df 1 | df 2 | p |
|---|---|---|---|---|
| Time (pre vs. post-experiment) | 8.889 | 1 | 48 | < .01 |
| Temperament system | 1.800 | 1 | 48 | .19 |
| Ear training | 0.250 | 1 | 16 | .62 |
| Time × Temperament System | 0.356 | 1 | 48 | .55 |
| Time × Ear Training | 0.200 | 1 | 48 | .66 |
| Ear Training × Temperament System | 0.356 | 1 | 48 | .55 |
| Time × Temperament System × Ear Training | 0.556 | 1 | 48 | .46 |
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.