
Abstract
ChatGPT's large language model, GPT-4V, has been trained on vast numbers of image-text pairs and is therefore capable of processing visual input. This model operates very differently from current state-of-the-art neural networks designed specifically for face perception and so I chose to investigate whether ChatGPT could also be applied to this domain. With this aim, I focussed on the task of face matching, that is, deciding whether two photographs showed the same person or not. Across six different tests, ChatGPT demonstrated performance that was comparable with human accuracies despite being a domain-general ‘virtual assistant’ rather than a specialised tool for face processing. This perhaps surprising result identifies a new avenue for exploration in this field, while further research should explore the boundaries of ChatGPT's ability, along with how its errors may relate to those made by humans.
In November 2022, OpenAI's ChatGPT was released to the public and we were in awe of its ability to tell jokes and do our assignments for us. However, with its fabricated citations (Walters & Wilder, 2023) and overuse of words like ‘delves’ and ‘significant’ (Kobak et al., 2024), we soon realised that our fear of artificial intelligence and the impending ‘rise of the machines’ may have been a tad premature. Here, with the latest advances as of September 2023, I argue that perhaps a little fear may still be warranted.
ChatGPT's newest large language model (LLM) – GPT-4V(ision) – can process visual input. Preceding models relied on extensive training with text data sourced from the internet, allowing them to learn the structure within these data. Now, through exposure to vast numbers of image-text pairs, the latest model can ‘see’, recognise and interpret uploaded images. Crucially, if any future Terminator is going to be successful in its mission, it will need to discriminate between people to target key members of the resistance. Therefore, I wanted to determine how well ChatGPT performed with face images in particular, building on previous research showing human levels of accuracy when identifying mental states from only the eye region of faces (Elyoseph et al., 2024).
Face matching involves deciding whether two photos depict the same person or two different people. This can be challenging when the faces are unfamiliar since the photos themselves lack information regarding how appearance can vary as a function of lighting, expression, hairstyle and so on (Hancock et al., 2000). Researchers have created several such tasks, varying in both trial difficulty and how unconstrained or controlled the images are, and so I tested ChatGPT on a selection of these (see Figure 1), with the results presented in Table 1. 1

An example from the Glasgow Face Matching Test, showing ChatGPT's correct response.
Human and ChatGPT performance on several tests of face matching.
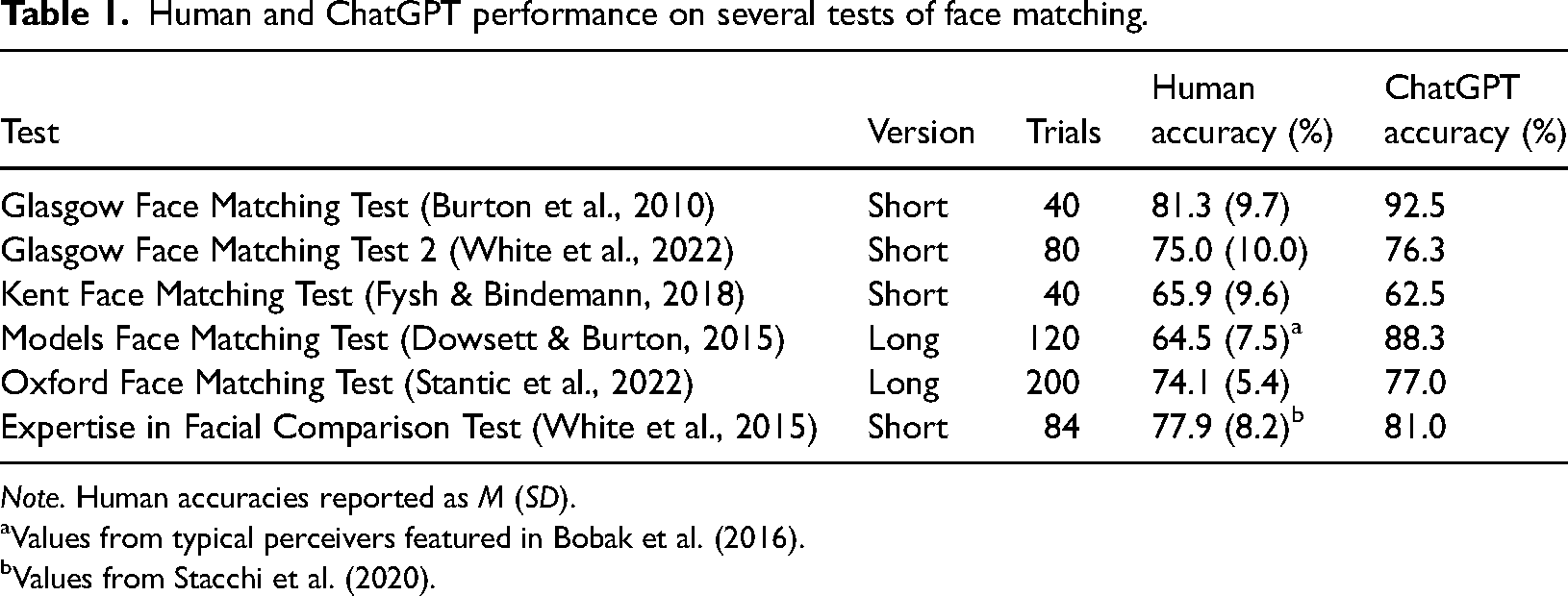
Note. Human accuracies reported as M (SD).
aValues from typical perceivers featured in Bobak et al. (2016).
bValues from Stacchi et al. (2020).
I found that ChatGPT's performance was comparable with human abilities, making it less accurate than state-of-the-art deep convolutional neural networks (DCNNs; National Institute of Standards and Technology, 2024; Phillips et al., 2018). However, the difference is that ChatGPT is based on a transformer neural network, first converting images into text-like representations. Crucially, ChatGPT can interpret any image rather than being limited to a specific domain (unlike DCNNs) and is freely available for use by Terminators (and the general public).
Having shown that ChatGPT demonstrates competent face matching abilities, further study might investigate the underlying process. For instance, are some facial features (e.g., the eyes) more heavily weighted during comparisons? Are some transformations (e.g., head rotation, expression change) more difficult to handle? How do ChatGPT's errors relate to human decisions? The possibilities for combining LLMs and face perception research are numerous and represent an exciting new avenue for exploration. Indeed, by probing the nature of its internal representations, we may uncover both similarities and differences with human face processing, resulting in new insights much like those emerging from research with DCNNs (e.g., Parde et al., 2019). In the meantime, while August 29, 1997 (aka ‘Judgement Day’) passed without incident, I recommend caution as we continue to witness the evolution of ChatGPT in the near future.
Footnotes
Author Contribution(s)
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.