
Abstract
Objective
To evaluate the effectiveness of machine learning (ML) models in predicting 5-year type 2 diabetes mellitus (T2DM) risk within the Chinese population by retrospectively analyzing annual health checkup records.
Methods
We included 46,247 patients (32,372 and 13,875 in training and validation sets, respectively) from a national health checkup center database. Univariate and multivariate Cox analyses were performed to identify factors influencing T2DM risk. Extreme Gradient Boosting (XGBoost), support vector machine (SVM), logistic regression (LR), and random forest (RF) models were trained to predict 5-year T2DM risk. Model performances were analyzed using receiver operating characteristic (ROC) curves for discrimination and calibration plots for prediction accuracy.
Results
Key variables included fasting plasma glucose, age, and sedentary time. The LR model showed good accuracy with respective areas under the ROC (AUCs) of 0.914 and 0.913 in training and validation sets; the RF model exhibited favorable AUCs of 0.998 and 0.838. In calibration analysis, the LR model displayed good fit for low-risk patients; the RF model exhibited satisfactory fit for low- and high-risk patients.
Conclusions
LR and RF models can effectively predict T2DM risk in the Chinese population. These models may help identify high-risk patients and guide interventions to prevent complications and disabilities.
Keywords
Introduction
Diabetes mellitus is a metabolic syndrome characterized by elevated blood glucose levels due to impaired glucose regulation. Type 2 diabetes mellitus (T2DM), the most common form of diabetes, represents 90% of cases worldwide. 1 T2DM is a chronic disease influenced by genetic and environmental factors. 2 Long-term uncontrolled T2DM can lead to complications in multiple organ systems. T2DM-related cardiovascular and renal diseases are leading causes of morbidity; the resulting disability and mortality constitute substantial economic burdens on families and society. 3
During rapid economic growth in the past three decades, diabetes prevalence has increased by tenfold in mainland China. 4 In 2013, an estimated 113.9 million Chinese adults had diabetes, whereas 493.4 million had prediabetes; these prevalences are increasing. 5 The number of people with T2DM risk is increasing due to population aging, which presents a challenge for Chinese healthcare providers. 6 To improve T2DM awareness and early intervention efforts, the Chinese Diabetes Society revised its diagnostic criteria in 2020. However, numerous individuals with T2DM are asymptomatic or lack access to routine diabetes screening; thus, 8.1% of the Chinese population with diabetes remains undiagnosed. 5 Although the economic burden remains an important aspect of diabetes, it is important to emphasize the potential for prognostic models to transform healthcare.
Machine learning (ML) has been increasingly used to predict non-communicable disease risk since the widespread emergence of artificial intelligence in the 2010s. This alternative approach to diabetes screening, diagnosis, and risk prediction has been reported elsewhere. 7 The establishment of prediction models via ML can help doctors and patients better understand disease progression, enabling appropriate preventive and therapeutic measures. The predictive abilities of ML have demonstrated accuracy and flexibility regarding T2DM. 8 However, some challenges persist in this research field, such as dataset quality and quantity, model selection and optimization, and other factors. Several ML models can help predict T2DM risk, but their reliability requires validation due to small training and testing datasets. 9 Some researchers have suggested that the performances of ML models for predicting diabetes risk are not superior to conventional risk stratification models, 10 primarily because of sample size. The previous models have some additional limitations: inconsistent performance depending on input variables and uncertain reproducibility among ethnicities and populations. Because model construction requires substantial time and resources, these limitations should be considered when developing and evaluating prediction models. Recent studies have revealed challenges regarding generalizability and performance across populations and sub-groups.9,11 Although ML has broad potential for predicting T2DM risk, some persistent issues must be addressed. We sought to improve the application of ML in predicting T2DM risk by using a larger dataset and testing the discrimination and calibration performances of four ML models (Extreme Gradient Boosting [XGBoost], support vector machine [SVM], logistic regression [LR], and random forest [RF]).
Materials and methods
Study population and data acquisition
Clinical data were collected from an open-access database of basic demographic information, past medical history, and laboratory results from 2010 to 2016, maintained by the Rich Healthcare Group. 12 These data included age, sex, body mass index (BMI), systolic and diastolic blood pressures (SBP and DBP), fasting plasma glucose (FPG), total cholesterol (TC), triglycerides (TG), high-density lipoprotein (HDL) cholesterol, low-density lipoprotein (LDL) cholesterol, alanine transaminase (ALT), aspartate aminotransferase (AST), blood urea nitrogen (BUN), serum creatinine (CR), and family history of T2DM. Family history of T2DM was defined as a diagnosis of T2DM in parents, siblings, and/or offspring at the time of data collection. Individuals who met the following Chinese Diabetes Society 2020 diagnostic criteria for diabetes 13 at the initial checkup were excluded: typical diabetic symptoms and either random plasma glucose ≥11.1 mmol/L, FPG ≥7.0 mmol/L, 2-hour oral glucose tolerance test ≥11.1 mmol/L, or glycated hemoglobin (HbA1C) ≥6.5%. Asymptomatic individuals were asked to undergo repeat testing confirmation on another day. Individuals were excluded if any follow-up data were missing within 5 years after the initial evaluation. Diagnoses of T2DM were made according to the above criteria or as recorded in the database. This study was conducted in accordance with the 2013 revision of the Helsinki Declaration. This report was written in compliance with STROBE guidelines. 14 All patient information was deidentified to ensure privacy. This retrospective study did not require formal Institutional Review Board approval because it constituted a secondary analysis of a public dataset; for the same reason, written participant consent was not required.
Selection of prognostic variables
We carefully selected 15 variables (age, sex, BMI, SBP, DBP, FPG, TC, TG, HDL cholesterol, LDL cholesterol, ALT, AST, BUN, CR, and family history of T2DM) strongly associated with T2DM risk to preserve model discrimination capacity and avoid redundancy during ML model establishment. Because the incidence of T2DM tends to increase over time, survival analysis (i.e., Cox proportional hazards regression) was used to assess time-to-event outcomes. Variable importances were ranked using a tree-based technique. 15 The data-driven selection of these variables was validated by reviewing published literature to confirm the rationale for their inclusion in the model.16–19
ML models
Statistical analysis
Statistical analyses were conducted with R software, ver. 4.2.0 (www.r-project.org). Baseline differences between the training and validation sets were analyzed using Fisher's exact test for categorical variables and the Mann–Whitney U test for continuous variables. To identify risk factors for T2DM, variables were analyzed by univariate and multivariate Cox proportional hazards regression. To evaluate ML model performances, receiver operating characteristic (ROC) curves were established; areas under the ROC (AUCs) were calculated to compare these models. 24 ML model parameters (accuracy, precision, recall, F1 score, and mean squared error )were calculated in the training and validation sets. Finally, calibration plots were generated to demonstrate correlations between predictions and observed results. 25
Results
Baseline characteristics of the study population
In total, 211,833 individuals were present in the original dataset. Among these individuals, 165,586 were excluded because of incomplete data. The training set included 32,372 individuals, whereas the validation set included 13,875 individuals. The baseline characteristics of individuals in the training and validation sets are presented in Table 1. The median ages were 43.43 and 43.53 years in the training and validation sets, respectively; both groups had a higher percentage of men (55% and 56%) than women (45% and 44%). The median BMI (23.32 kg/m2) was on the threshold for overweight in both sets, according to Chinese standards. 26 SBP and DBP were within normal ranges; however, the median SBP (119.04 mmHg and 119.28 mmHg) in both groups approached the upper limit of normal. Other metabolic panel values were consistent with international standards. Approximately 2.2% of individuals had a family history of T2DM. During the 5-year follow-up period, T2DM was diagnosed in 411 (1.3%) and 205 (1.5%) individuals in the training and validation sets, respectively.
Comparison of baseline characteristics between training and validation sets.

ALT, alanine transaminase; AST, aspartate aminotransferase; BMI, body mass index; BUN, blood urea nitrogen; DBP, diastolic blood pressure; FPG, fasting plasma glucose; HDL, high-density lipoprotein; IQR, interquartile range; LDL, low-density lipoprotein; SBP, systolic blood pressure; SD, standard deviation; TC, total cholesterol; T2DM, type 2 diabetes mellitus; TG, triglycerides.
Establishment of the prediction model
Univariate and multivariate Cox analysis identified nine independent risk factors for T2DM: FPG, age, TG, ALT, BMI, CR, DBP, sex, and family history of T2DM (all P < 001; Table 2). Other variables were excluded from the prediction model.
T2DM risk prediction via Cox proportional hazards regression modeling.

ALT, alanine transaminase; AST, aspartate aminotransferase; BMI, body mass index; BUN, blood urea nitrogen; CI, confidence interval; CR, creatinine; DBP, diastolic blood pressure; FPG, fasting plasma glucose; HDL, high-density lipoprotein; HR, hazard ratio; LDL, low-density lipoprotein; SBP, systolic blood pressure.
The feature importances of all included variables were analyzed using the XGBoost model. The importances of the variables were ranked in the following order: FPG, age, TG, ALT, BMI, CR, DBP, sex, and family history of T2DM (Figure 1). The x-axis in Figure 1 represents feature importances with positive correlations. In the next step, we subjected all ranked features to model performance evaluation.
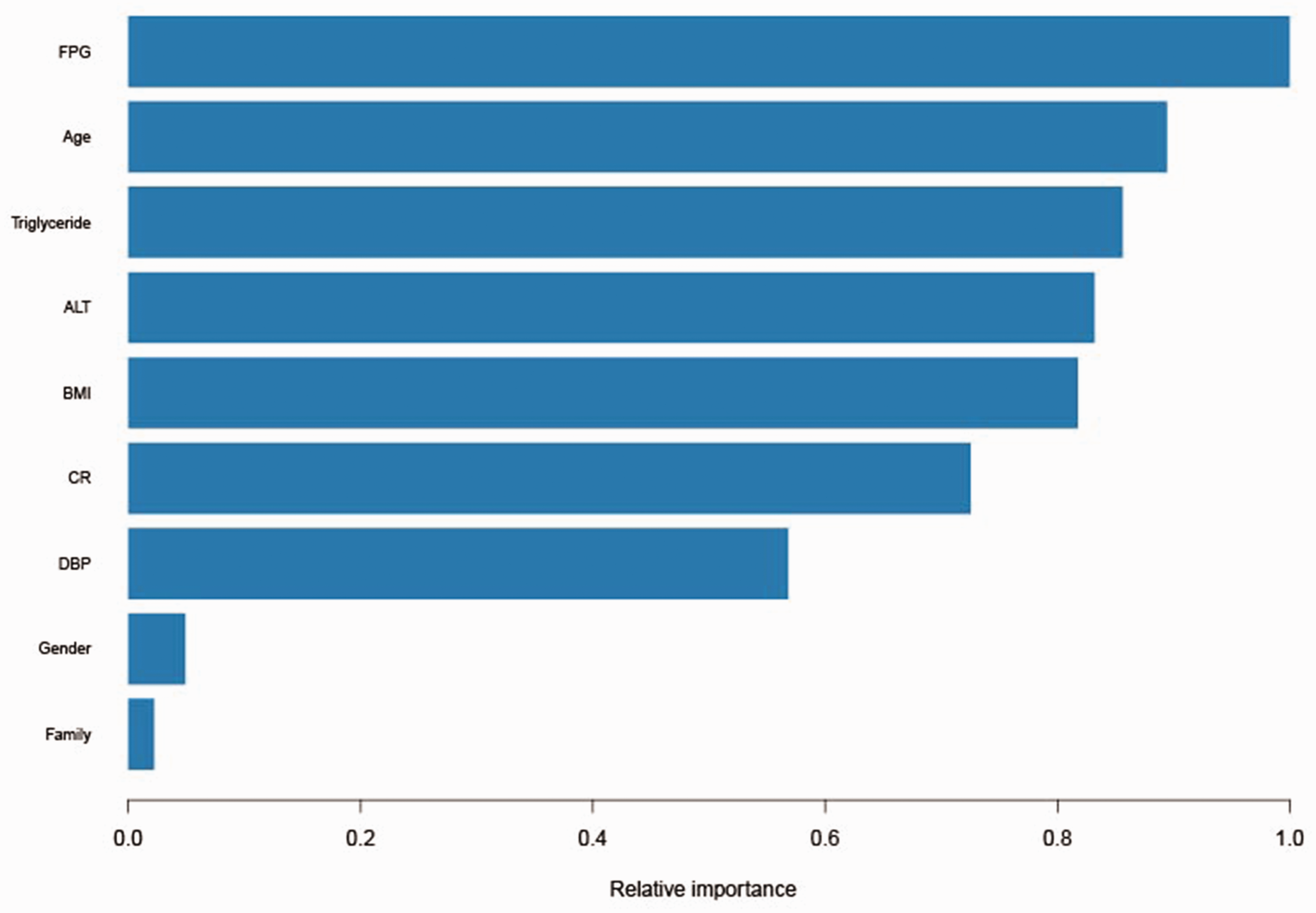
Feature importance ranking in the XGBoost model. ALT, alanine transaminase; BMI, body mass index; CR, creatinine; DBP, diastolic blood pressure; FPG, fasting plasma glucose; XGBoost, Extreme Gradient Boosting.
Discrimination and calibration performances of the four models
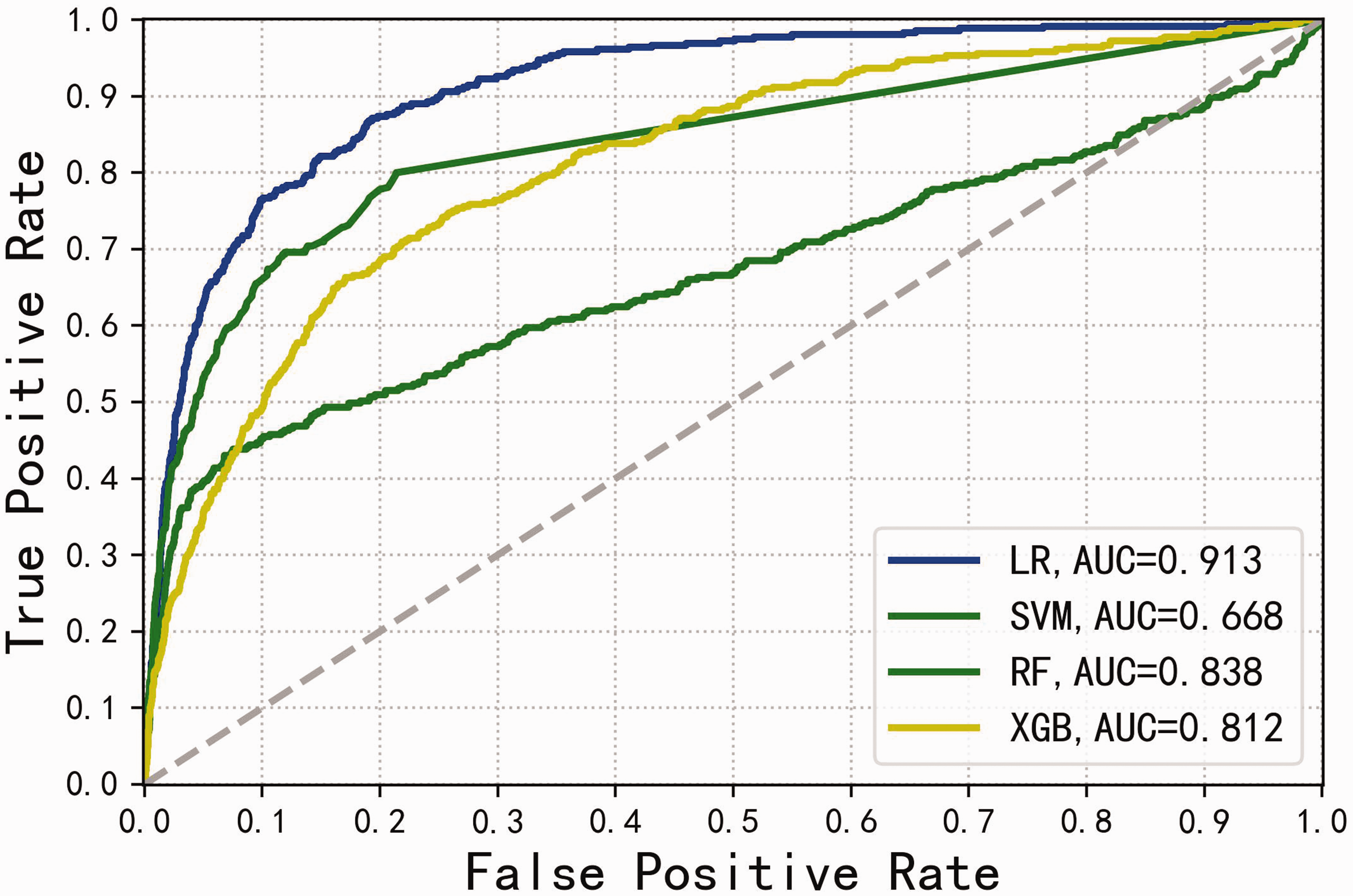
The nine variables were used to construct XGBoost, SVM, LR, and RF models. Performance evaluation of the four models revealed training set AUCs of 0.986, 0.896, 0.914, and 0.998, respectively; validation set AUCs were 0.812, 0.668, 0.913, and 0.838, respectively. These results are presented as ROC curves in Figure 2 and Figure 3. In summary, all four models showed high AUCs in the training set, but only the LR and RF models maintained favorable AUCs in the validation set.
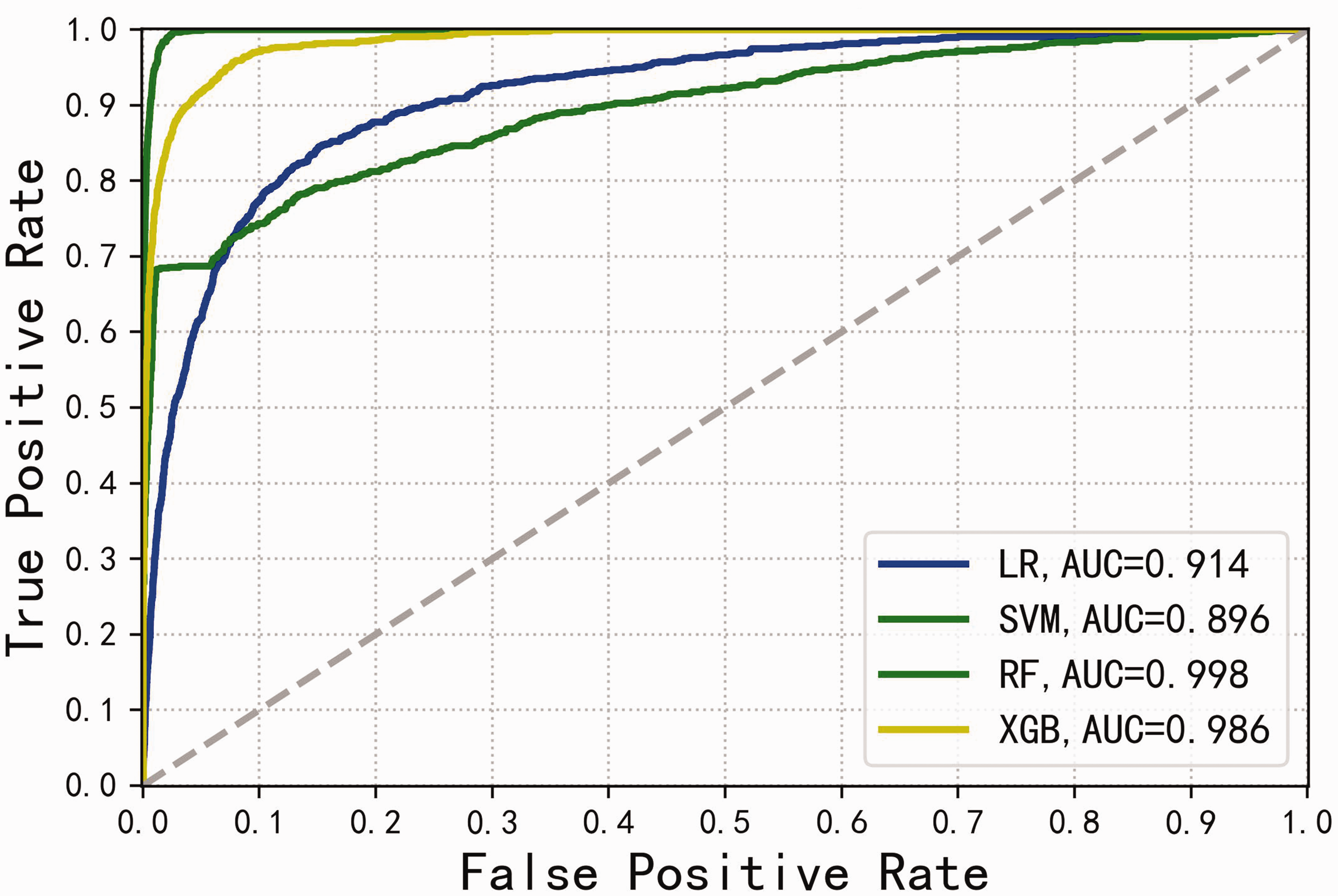
ROC curves for the four models in the training set. AUC, area under the ROC curve; LR, logistic regression; SVM, support vector machine; RF, random forest; ROC, receiver operating characteristic; XGBoost, Extreme Gradient Boosting.
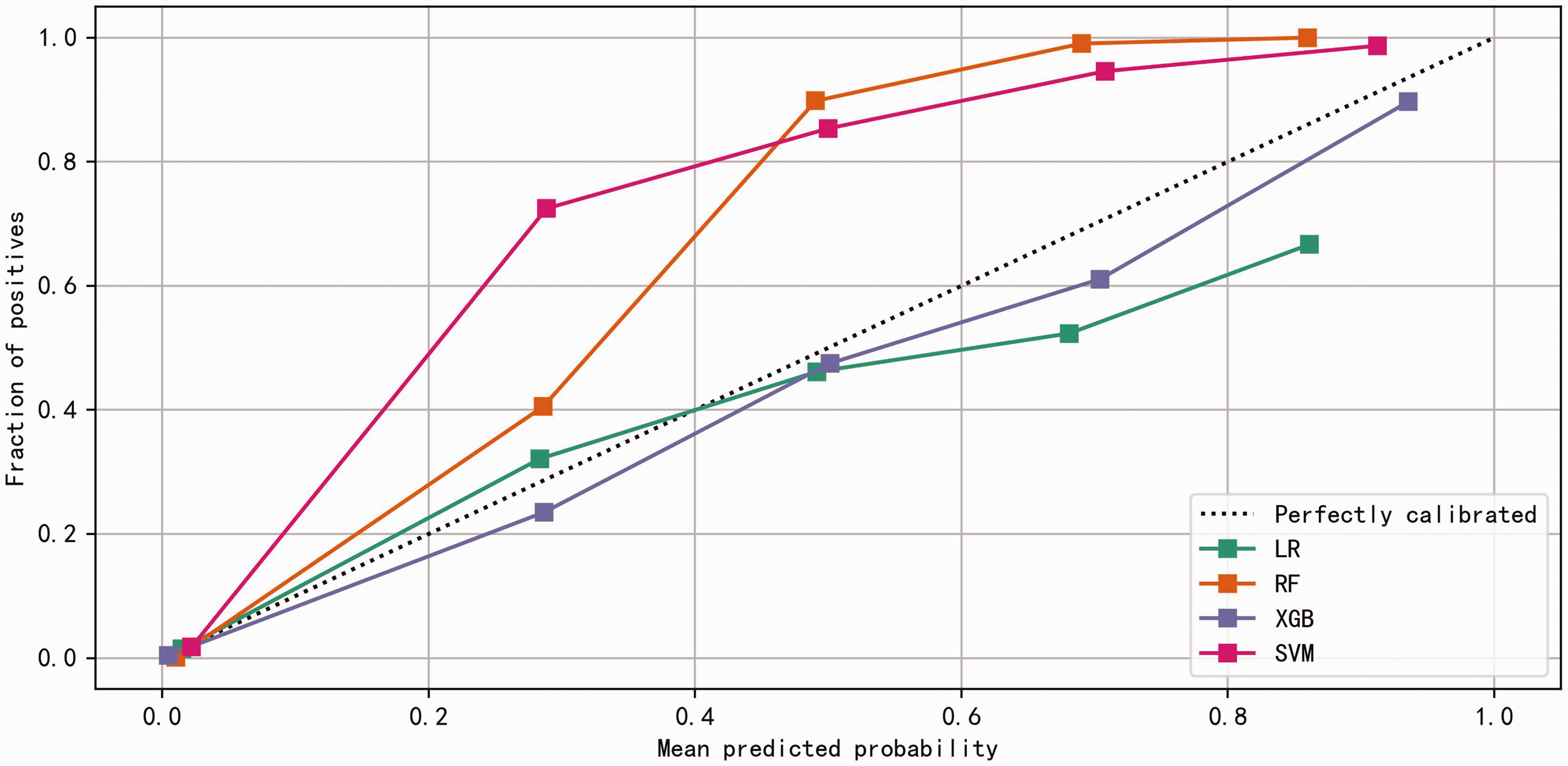
Calibration plots for the four ML models in the training set. ML, machine learning; LR, logistic regression; SVM, support vector machine; RF, random forest.
The Hosmer–Lemeshow test 27 was used for cross-validation and assessment of calibration performance among the four models. Linear agreement in training and validation sets is depicted in Figure 4 and Figure 5. The four models showed good agreement between predicted and actual results in the training set (Figure 4). In the validation set, the LR and RF models demonstrated relatively good fit, although the LR model appeared to overestimate T2DM risk in some patients (Figure 5).
ROC curves for the four models in the validation set. AUC, area under the ROC curve; LR, logistic regression; SVM, support vector machine; RF, random forest; ROC, receiver operating characteristic; XGBoost, Extreme Gradient Boosting.

Calibration plots for the four ML models in the validation set. LR, logistic regression; ML, machine learning; SVM, support vector machine; RF, random forest.
Discussion
T2DM is a common chronic metabolic disease affecting numerous individuals in China. Uncontrolled T2DM can cause irreversible complications that lead to disability and mortality. In this study, we used nine variables to construct four ML models, then evaluated their performances with real-world data. Early detection of T2DM can be achieved with accurate and uncomplicated prediction models. Therefore, we sought to identify the most favorable model that could provide guidance for T2DM prevention and management.
FPG was identified as the highest-ranking independent risk factor for T2DM. This is unsurprising because hyperglycemia is a core etiological aspect of T2DM and plays a key role in T2DM diagnosis according to all international guidelines.4,28 FPG is the primary screening factor for T2DM because of its simplicity, speed, and cost-efficiency; these characteristics are favored by primary care physicians and specialists. HbA1c, which reflects long-term plasma glucose levels, is essential for the screening, diagnosis, and monitoring of T2DM; however, it was not included in our original data due to a lack of awareness prior to changes in Chinese guidelines. 4 A meta-analysis showed that an HbA1c level of 7.0% has 97.3% (95% confidence interval: 95.3–98.4) diagnostic sensitivity for T2DM. 29 HbA1c screening should be integrated into future models as more data become available.
Age was the second highest-ranking risk factor for T2DM, according to the XGBoost model. Increasing diabetes prevalence among older adults has been identified in diverse populations across various studies. A survey of adults aged >65 years in the United States showed that the prevalence of diabetes (mainly T2DM) nearly doubled from 1994 to 2003. 30 T2DM prevalence has been predicted to increase from 16.0% in 2005 to 32.7% by the year 2050. 31 Similarly, in China, Li et al. 32 reported a high burden of T2DM and revealed that the substantial increase in mortality from 1990 to 2019 was likely related to population aging. Therefore, it is crucial to consider age as a risk factor in T2DM prediction models.
TG, ALT, and BMI were the third- to fifth-highest ranking risk factors in our feature importance analysis. The accumulation of excess body fat is closely related to insulin resistance, a primary mechanism of glucose dysregulation. TG levels are strongly correlated with diet and reflect the amount of body fat. A cohort study focusing on the combined TG-BMI metric revealed that it had a causal association with diabetes, particularly in young, middle-aged, and non-obese Chinese individuals. 33 In 2013, Kunutsor et al. 34 performed a meta-analysis of nine studies concerning the relationship between ALT and T2DM risk. Their results suggested a moderate association, although publication bias may have influenced the findings.
In this study, we used an LR model incorporating nine independent risk factors that had been identified through univariate and multivariate Cox analyses: FPG, age, TG, ALT, BMI, CR, DBP, sex, and family history of T2DM. Our LR model demonstrated robust discrimination and calibration performance in the training and validation sets. The key strengths of this model include its interpretability—clear coefficients for each predictor variable facilitate comprehension by clinicians—and strong calibration, ensuring that predicted probabilities are closely aligned with observed outcomes. Furthermore, the LR model's simplicity and transparency make it suitable for clinical practice, supporting risk assessment and guiding intervention decisions. 35 However, LR models assume a linear relationship between predictor variables and outcomes, which may be inaccurate in the context of complex non-linear relationships. Additionally, such models might not fully capture complicated interactions between variables, leading to decreased predictive accuracy relative to more flexible models such as RF.
This study also used an RF model, an ensemble learning technique, with the same nine risk factors. It displayed favorable discrimination in the training and validation sets. The RF model's advantages include its ability to manage non-linear relationships and complex interactions that are often present in medical data. The feature importance analysis component of RF models offers valuable insights into the relative contribution of individual predictor variables, helping to prioritize interventions and future research. Additionally, the ensemble nature of RF models can mitigate the risk of overfitting, enhancing their generalizability with respect to diverse medical datasets. Nevertheless, RF models lack the direct interpretability of LR models. Additional efforts may be needed to elucidate the clinical significance of feature importance rankings. Additionally, unoptimized RF models can overfit training data; thus, they require careful regularization and hyperparameter adjustments.
In summary, both LR and RF models show promise in terms of predicting T2DM risk, but each model has distinct advantages and limitations. Model selection should consider trade-offs between interpretability and predictive accuracy, as well as specific clinical requirements. Further research and validation efforts are needed to refine these models for practical clinical use. Notably, previous studies have used ML to predict T2DM risk, 17 but they included fewer participants compared with our study.
This study had some limitations. First, the original database exclusively included individuals who attended health checkups at private facilities. This aspect may have led to selection bias because such individuals were able to undergo health examinations, regardless of the funding mechanism (self-pay or employer-sponsored). High-income populations generally have greater healthcare access and reduced likelihood of delayed interventions for prediabetes. 36 Second, only four well-established ML models were compared in this study. Promising ML models have recently emerged due to increased awareness of artificial intelligence applications in the medical field. Alternative ML models, such as K-nearest neighbor, merit exploration in future studies. Finally, the follow-up period for the database in this study was limited to 5 years. Owing to the chronic nature of T2DM, patients are more likely to develop clinically significant manifestations at older ages. A longer follow-up period (i.e., 10 or 20 years) may yield more comprehensive and generalizable results.
Conclusion
We used nine variables to construct four ML models based on training and validation sets derived from real-world data. Our results showed that the LR and RF models were effective for predicting T2DM risk in the Chinese population. We believe that integrating these models into clinical practice and future research can aid clinicians and public health professionals by enabling accurate prediction of T2DM risk.
Footnotes
Acknowledgements
We thank all study participants for their donated blood samples and support.
Author contributions
HL performed statistical analysis. SD wrote the manuscript. LW, Jia L, and YD interpreted the data for analysis. Jing L, ZL, YW, LJ, and SY contributed to discussion and editing. HY and XF designed the study and revised the manuscript. HY and XF had full access to the data and final responsibility for the decision to submit for publication. All authors read and approved the final manuscript.
Data availability statement
The data that support the findings of this study are available from the corresponding author upon reasonable request.
Declaration of conflicting interest
The authors declare that there is no conflict of interest.
Funding
This study was supported by the Medical Science Research Project of Hebei Province (20231924).