
Abstract
Artificial intelligence is entering official statistics through automated coding, imputation, nowcasting from alternative data sources, and small area estimation. This article examines AI adoption through the lens of methodological transitions in survey sampling—from design-based inference through model-assisted estimation—and addresses three questions. First, what is the relationship between algorithm-assisted and model-assisted inference? We show that generalized difference estimators can incorporate machine learning predictions in the same way they incorporate parametric working models. Second, what quality framework extensions are needed for operational deployment? Drawing on vignettes from European and North American statistical offices, we identify five areas requiring development: training data documentation, algorithmic transparency, validation protocols, uncertainty characterization, and reproducibility. We argue for prequential evaluation—assessing calibration and stability over successive production cycles—as an operational practice suited to algorithm-assisted systems. Third, what institutional challenges distinguish AI from earlier transitions? We examine the public-private asymmetry in AI development: whereas twentieth-century methodological innovations emerged largely from public institutions, contemporary AI capabilities are concentrated in private technology companies. European Statistical System initiatives illustrate governance responses, but dependency risks persist. We conclude that algorithm-assisted inference can succeed, but only if it can be made auditable, reproducible, and publicly defensible.
Keywords
1. Introduction
National statistical offices are increasingly adopting artificial intelligence (AI). Machine learning (ML) is being applied to automated coding, record linkage, editing and imputation, nowcasting, and small area estimation (Dumpert 2025). These applications promise substantial efficiency gains: automated text coding can reduce the volume of manual processing and make data available earlier; nowcasting uses timely, high-frequency information to produce early estimates of indicators, often weeks ahead of standard publication schedules; and satellite imagery can support high-resolution statistics at scales for which surveys are not powered (Barreñada et al. 2022; Corral et al. 2025; ONS 2023). International coordination efforts—through the UNECE modernization program, Eurostat’s AIML4OS initiative—indicate that AI/ML methods are moving beyond isolated pilots toward coordinated capacity-building to support implementation in statistical production (UNECE 2022, 2025).
These developments raise questions that existing official statistics quality frameworks do not fully address—especially around training data provenance and reproducibility. AI methods can improve efficiency but introduce additional dependencies and new sources of uncertainty: training data dependence, algorithmic opacity, and drift over time or estimation cycles (Bommasani et al. 2022; Burrell 2016). Early contributions from Statistics Netherlands (Buelens et al. 2014) framed this as a question of whether algorithmic methods could be incorporated without compromising core values of methodological rigor and quality assessment. The tension is increased by an institutional asymmetry: while many of the twentieth-century methodological innovations emerged from public statistical institutions, the most capable AI systems (e.g., large language models and foundation models) are largely produced by private technology companies, which raises challenges for transparency, documentation, and other requirements of official statistics production (Bommasani et al. 2022).
This article examines AI adoption through the lens of the methodological transitions that have shaped survey sampling and official statistics production. First, what is the relationship between algorithm-assisted and model-assisted inference? Second, what extensions to existing quality frameworks are needed for operational deployment of AI methods in official statistics production? Third, what institutional challenges distinguish AI from earlier methodological transitions?
The article is organized as follows. Section 2 reviews the historical arc from design-based to model-assisted inference. Section 3 shows how generalized difference estimators can incorporate machine learning predictions in the same way they incorporate parametric working models. Section 4 provides empirical vignettes illustrating how AI is entering statistical production processes. Section 5 draws on the preceding sections to propose concrete extensions to existing quality frameworks. Section 6 turns to institutional challenges that shape whether these quality extensions can be implemented, including the public-private asymmetry in AI development. Section 7 discusses implications for NSO practice, and Section 8 concludes.
2. From Design-Based to Model-Assisted Inference
Design-based inference locates its randomness in the sampling mechanism and provides design-unbiased estimation under the sampling design, without requiring assumptions about the underlying population (Hansen et al. 1953). This paradigm became foundational because it aligned with institutional needs for transparency and public trust: when validity derives from the design, the statistician’s choices are visible and defensible. Porter (1995, 4–5) argues that quantification became central to modern governance because it enabled “mechanical objectivity”: decision-making justified through rule-bound procedures rather than personal judgment.
Yet pure design-based inference has limitations. Tillé et al. (2022) observe that “official statisticians are inherently reluctant to model” but note this reluctance must be balanced against practical demands for small-area estimates, timely indicators, and efficient use of auxiliary information. Model-assisted inference provides a synthesis: using models to improve precision while retaining asymptotically design-consistent inference.
Cassel et al. (1976) developed the generalized regression (GREG) family of estimators. Särndal et al. (1992) consolidated this framework, defining model-assisted estimation as the use of models as working approximations without abandoning design-based guarantees. Models are instrumental rather than foundational: they generate fitted values used in constructing the estimator, but inference is evaluated through design-based properties—notably, asymptotic unbiasedness and variance—rather than through the model’s fit.
Smith (1976) argued that credibility cannot rest solely on formal optimality; it depends on explicit validation and conventions for transparency and communication of uncertainty. Smith (1984) further emphasized that model dependence is not inherently problematic when governed by clear conventions. Subsequent developments extended the framework to nonparametric methods (Breidt and Opsomer 2017) and Bayesian approaches framed as “calibrated Bayes,” emphasizing calibration to repeated sampling performance, developed across several publications by Little (2004, 2006, 2012).
Valliant (2024) highlights how survey sampling innovations (e.g., regression estimators, calibration, small area estimation) were gradually incorporated through shared quality standards. NSOs made substantial investments in design-based methods: sampling frames, weighting procedures, variance estimation routines, training programs, and external audits. Introducing new methods is costly because it requires new routines, sensitivity analyses, and transparent documentation. The question for algorithm-assisted inference is whether similar machinery can be built around AI-based predictors.
3. Formalizing the Prediction Framework
To understand how AI extends the tradition of model-assisted inference, one can formalize official statistical production as a prediction problem. This section draws on the model-assisted survey sampling literature (Breidt and Opsomer 2017; Ranalli 2025; Särndal et al. 1992) and uses it as an organizing lens for algorithm-assisted settings.
3.1. The Prediction Problem
Let

Since only sample values are observed, estimation of
3.2. Model-Based and Model-Assisted Estimators
Suppose the population structure of the analysis variables is described by a model

where
A general form for a model-based estimator of
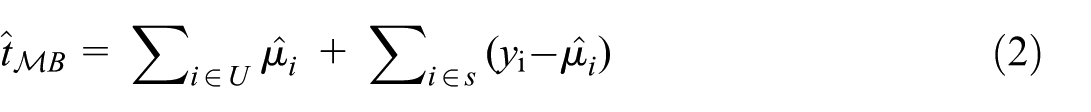
The estimator sums model predictions over the entire population and adds sample residuals as a correction. Model-assisted estimation is a hybrid that constructs estimators to be both design-consistent and model-consistent (Särndal et al. 1992). The general form is:
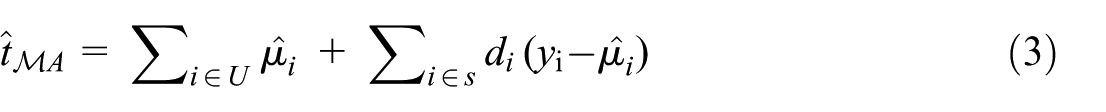
where
3.3. Algorithm-Assisted Estimation
The critical observation is that Equations (2) and (3) do not require
Let
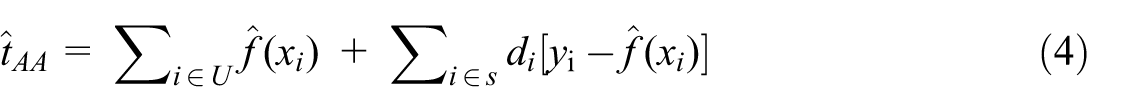
Equation (4) is mathematically identical to Equation (3); what changes is the complexity and opacity of the prediction function. When
At the same time, the intensification of model dependence has practical consequences: the properties of
3.4. AI for Measurement and Data Integration
The framework in Equations (1) to (4) applies to estimation—using AI to improve prediction of unobserved
When an LLM classifies free-text responses into occupation codes, the outcome
The relationship between
A related task is data integration: using ML to transform alternative data sources into official indicators. Let

This resembles Equation (4) but with important differences. First, Z is not a vector of auxiliary covariates known for a probability sample; it is a separate data source with its own coverage and selectivity. Second, the reference set
These measurement and integration tasks raise analogous concerns to estimation—training data dependence, opacity, instability—but they operate upstream, affecting the inputs to subsequent aggregation. The vignettes in Section 4 illustrate all three entry points: automated coding (measurement), nowcasting from alternative data (integration), and small area estimation (estimation proper).
4. Empirical Vignettes from Practice
The idea that algorithmic methods might become a distinct component of official statistics is not new. Statistics Netherlands discussion papers (e.g., Buelens et al. 2012) framed “algorithmic inference” as an extension of the design- versus model-based debate, asking whether new data sources could be incorporated without compromising core values. Related work introduced “algorithmic statistics” as outputs produced by machine procedures and argued that quality assessment must adapt accordingly (Struijs et al. 2014). These early contributions anticipated many of today’s arguments about black-box models and selectivity bias.
As Section 3 outlined, AI enters official statistics at three stages: measurement (automated coding and classification), data integration (nowcasting from alternative sources), and estimation (imputation, small area prediction). Each corresponds to a distinct component of the formal framework: coding affects the observed
4.1. Automated Coding: From Rule-Based to Neural Language Models
Automated coding of free-text survey responses—particularly occupation and industry classifications—has a long history in NSOs. What has changed is the sophistication of the underlying models.
The UK Office for National Statistics (ONS) Data Science Campus has developed ML-based pipelines for occupation (SOC) and industry (SIC) coding, which is the task of assigning standardized classification codes to free-text survey responses describing jobs and businesses. The project reported classification accuracy of approximately 85% for SOC codes and 81% for SIC codes, evaluated against expert-coded validation samples (ONS 2021). Performance is evaluated against expert-coded validation samples using two metrics: match rate (the proportion of cases the system can confidently classify, with remaining cases escalated to human coders) and matched accuracy (the proportion of auto-coded cases that are correct). The legacy rule-based tool achieved matched rates of 55% to 65% with matched accuracy above 90%; the ML approach achieved match rates of 73% to 76% with comparable or higher accuracy levels. More recent work explores LLM-based pipelines (“ClassifAI”) for complex or ambiguous job descriptions that challenge existing auto-coders (ONS 2024a).
The U.S. Census Bureau has pursued similar research. Recent work links Internal Revenue Service Form 1040 occupation write-ins with American Community Survey responses—where occupation text has been coded through autocoding and expert review—to evaluate transformer-based classification (Bryant et al. 2024). Using a BERT model, a transformer-based architecture (Vaswani et al. 2017), achieved 81% agreement with expert-coded ACS occupations when using ACS write-ins as input, but only 42% when using IRS write-ins, reflecting the noisier and less detailed nature of tax-form text. The linked-data framework provides a validation resource as coding methods evolve.
These applications share a common quality architecture: confidence thresholds define which cases are auto coded versus escalated to human review; validation samples enable ongoing monitoring of the confusion matrix C; and version control tracks model changes. The operational question is where to set thresholds: higher thresholds increase precision but reduce efficiency gains; lower thresholds increase throughput but require more post-hoc correction. This trade-off must be calibrated to domain-specific requirements.
4.2. Alternative Data Sources and Nowcasting
A second entry point for algorithm-assisted official statistics is the use of high-frequency data to improve timeliness or expand coverage. In the framework of Section 3.4, these applications estimate ĝ(Z) where Z is an alternative data source with its own coverage properties.
Research at De Nederlandsche Bank (Verbaan et al. 2017) showed that debit card transaction data can nowcast household consumption, providing estimates weeks before official national accounts figures become available.
Statistics Netherlands has also used NLP classifiers to identify “online platform” businesses from website text (Daas et al. 2024), a task for which no adequate identification method previously existed, since standard business classification systems do not include a category for online platforms.
Spain’s Statistical Office (INE) has piloted “early imputation” using statistical learning to produce preliminary business turnover indices earlier in the production cycle than traditional collection allows (Barragán et al. 2022). Validation against final survey results shows acceptable accuracy trade-offs for the timeliness gains. Statistics Canada uses gradient boosting to classify millions of scanner-data transactions to standard product codes, enabling granular price statistics at scales impossible to process manually (Laroche and Tremblay 2020). Other applications include Istat’s use of AIS ship-tracking data for maritime transport statistics where ML algorithms processing raw GPS tracks are benchmarked against traditional port surveys; administrative sources are then used to assess coverage and correct discrepancies prior to publication (Arosio et al. 2025).
These applications share a common structure. AI enables integration of data sources that would otherwise be intractable—because of volume, unstructured format, or conceptual distance from official classifications. Quality assurance remains anchored in benchmarking against reference series, explicit documentation of coverage limitations, and transparent revision policies. The formal requirement from Section 3.4 applies: because the relationship
4.3. Machine Learning for Small Area Estimation
A third entry point is estimation proper: using
5. Extending Quality Frameworks for Algorithm-Assisted Inference
Quality frameworks for official statistics address error sources across the production process. The Total Survey Error paradigm organizes these into sampling error, coverage error, nonresponse error, measurement error, and processing error (Biemer 2010; Groves and Lyberg 2010). The European Statistics Code of Practice specifies sixteen quality principles spanning institutional environment, statistical processes, and statistical output (Eurostat 2018). The Generic Statistical Business Process Model (UNECE Statistics Division 2025) provides a reference framework for describing and comparing production processes across NSOs.
Algorithm-assisted methods do not introduce entirely new categories of error—misclassification is a form of measurement error, data linkage failures are processing or coverage errors, and model drift can undermine comparability and coherence—but they change how these errors manifest and how they can be audited. Algorithmic components may automate steps that were previously governed by explicit rules or human judgment. When these steps are performed by ML models, the conventions governing them become less visible: the “rules” are learned from data rather than specified by statisticians. AI may also require additional forms of standardization—training datasets, annotation protocols, validation benchmarks—that differ from traditional investments in classification schemes and metadata. Finally, algorithmic components may be updated more frequently than traditional methods, creating practical challenges for version control and time-series comparability.
A growing literature addresses these challenges. The UNECE High-Level Group for the Modernization of Official Statistics has developed a framework for responsible AI in official statistics, emphasizing transparency, accountability, human oversight, and risk management, with concrete guidelines and examples for implementation (UNECE 2025). Methodological work has begun to formalize quality concepts for ML: Puts et al. (2025) propose a “Total Machine Learning Error” framework that enumerates error sources specific to ML—training data representativeness, measurement error in labels and features, and risks from the model and pipeline. Complementary European work maps conventional quality criteria (relevance, accuracy, comparability, coherence) to ML use cases (Dumpert 2025). These frameworks provide a starting point, but they remain at a high level of abstraction relative to production standard operating procedures, quality thresholds, and audit trails. The challenge is to translate principles into concrete production practices—the kind of institutionalized conventions that made model-assisted inference governable.
Smith’s (1976, 1984) reviews of survey sampling foundations emphasize that model dependence becomes manageable only when conventions for validation and communication are explicit and shared across the profession. For algorithm-assisted inference, this suggests that quality frameworks must move beyond checklists of desirable properties toward operational standards that can be implemented, audited, and compared across NSOs. Dawid’s (1984) prequential approach offers such operational philosophy: statistical procedures should be evaluated by their predictive performance over successive observations, assessing calibration and stability across time rather than relying on one-off claims of optimality; where probabilistic outputs are produced, proper scoring rules provide a standard tool for assessing calibration (Gneiting and Raftery 2007). For algorithm-assisted systems that are retrained and updated, prequential monitoring—using scoring rules, calibration checks, and drift detection—provides a template for continuous quality control that aligns with the production rhythms of official statistics. Building on this, we identify five areas where existing quality frameworks require extension.
We envisage these extensions as augmentations of existing quality reporting rather than separate reporting instruments. Current quality reports, such as those structured around the European Statistics Code of Practice or national quality guidelines, already address documentation of sources, methods, and limitations. The proposals below identify where those reports need additional content to cover algorithmic components, rather than calling for entirely new reporting frameworks. The goal is to embed algorithmic quality assessment within the established architecture of quality management, ensuring continuity with existing practices while also addressing the specific challenges that AI introduces.
5.1. Training Data Documentation
Quality metadata should document the provenance, coverage, and potential biases of data used to train algorithmic components. This parallels existing requirements to document sampling frames and auxiliary information but extends to training sets that may be external to the NSO and subject to different quality regimes. For LLM-based coding tools, documentation should specify labeled training corpora, annotation procedures, and the representativeness of occupational or industry text relative to the target population. For nowcasting applications, it should specify which populations and behaviors are captured by alternative data sources—and which are systematically missing. When pre-trained models are used, documentation should acknowledge what is unknown about the original training data.
This represents a new form of standardization within official statistics quality reporting. The broader ML governance literature has developed templates such as “datasheets for datasets” (Gebru et al. 2021) and “model cards” (Mitchell et al. 2019) that provide structured documentation of training data and model characteristics. These templates offer a starting point, but adapting them to official statistics contexts where representativeness, coverage, and longitudinal stability have specific meanings remains a work in progress. In practice, the allocation of documentation responsibilities will depend on the source of the training data and the nature of the algorithmic component. When NSOs use pre-trained models provided by commercial vendors, they should expect suppliers to furnish basic documentation on training data composition, preprocessing steps, and known limitations, ideally specified as part of procurement agreements. When NSOs train models on externally acquired data (e.g., administrative records or transaction data), documentation of any preprocessing performed by the data holder before transfer should be requested as part of data access. Where such documentation is unavailable, as may be the case with foundation models, NSOs should document what is unknown and assess the implications for output quality. The development of standardized templates for training data documentation, analogous to the datasheets and model cards discussed above, could facilitate this process across NSOs and support comparability of quality assessments.
5.2. Algorithmic Transparency Within the Statistical Chain
Quality reporting should specify where AI enters the statistical production chain, what tasks algorithms perform, and how algorithmic and non-algorithmic components interact. Full disclosure of proprietary model architectures may be infeasible, but users should understand the role of algorithms in producing published statistics: which steps are automated, what confidence thresholds trigger human review, and how algorithmic outputs are overridden or corrected.
This is an extension of longstanding practice in which methodological changes are documented and communicated. The challenge is that algorithmic components may be updated more frequently than traditional methods, and their effects on outputs may be less predictable. Making such updates visible through versioning, release notes, and impact assessments requires new documentation routines that most NSOs are only beginning to develop.
Two related concepts merit attention here. First, explainability, defined as the capacity to provide interpretable accounts of why an algorithm produced a particular output, is increasingly recognized as essential for accountability in automated systems (Burrell 2016). For official statistics, explainability need not require full interpretability of every model parameter; it requires that statisticians can describe, at an appropriate level of abstraction, how algorithmic components contribute to published outputs and what factors drive their predictions. The UNECE framework for responsible AI in official statistics identifies explainability as a core requirement (UNECE 2025). Second, algorithmic fairness, whether algorithmic outputs perform equitably across population subgroups, is relevant wherever AI is used in measurement or estimation. If an automated coder misclassifies occupations at systematically different rates for different demographic groups, or if a nowcasting model performs less well for certain regions or population segments, the resulting statistics may embed differential biases that are difficult to detect without explicit fairness evaluation. Quality frameworks should therefore include provisions for assessing differential performance across relevant subgroups, extending the disaggregated evaluation practices that already form part of good survey methodology.
5.3. Validation Protocols and Benchmarking
Algorithm-assisted outputs should be benchmarked against established methods where possible, assessing not only aggregate accuracy but also differential performance across domains, subgroups, and time periods. In coding applications, this implies continuous evaluation against clerical gold standards and targeted rechecks of categories where ML performance is weakest. In estimation and nowcasting, it implies systematic comparison against reference series and explicit evaluation of revision behavior.
The prequential perspective helps operationalize this: validation should be ongoing rather than one-time, with sequential monitoring of predictive distributions and calibration over repeated production cycles. This necessity is reinforced by Zhang’s (2019) observation that building the best model for estimation simultaneously reduces the ability to verify its assumptions; any covariate informative enough to serve as a diagnostic check should already be in the model—meaning that external validation infrastructure is structurally necessary. This is analogous to the continuous benchmarking that survey methodologists apply to nonresponse adjustments or small area models—but it requires infrastructure that may not yet exist for all algorithmic applications: stable gold-standard samples, longitudinal labels, and automated dashboards for error stratification by domain.
5.4. Characterizing and Communicating Uncertainty
Quality reporting should distinguish between sampling uncertainty and algorithmic uncertainty. Users should understand which uncertainty components are attributable to the sampling design and which arise from algorithmic choices and data dependencies—recognizing that these components are not always cleanly separable in integrated pipelines (UNECE 2025). In some settings, algorithm-related uncertainty can be approximated via resampling/perturbation of training data; in others—especially when using large pre-trained models or opaque pipelines—it may only be bounded through sensitivity analyses and stability checks rather than fully quantified.
In many NSO settings, sampling and algorithmic uncertainty interact—for example, when models are trained on survey samples or when survey error affects training labels. Where uncertainty cannot be fully decomposed, this limitation should be communicated explicitly, in the same spirit as model diagnostics and sensitivity analyses in model-assisted inference (Little 2012; Tzavidis 2025). The goal is not to achieve certainty but to be transparent about what is and is not known—a principle that has always governed quality reporting in official statistics, but that algorithmic opacity makes more difficult to implement.
5.5. Reproducibility and Version Control
NSOs should maintain version control for algorithmic components, enabling reproduction of historical outputs and assessment of how model updates affect published statistics. This extends existing practices for documenting methodological changes to the algorithmic domain and connects to emerging discussions of “MLOps” (machine learning operations) within statistical production. Concrete controls include logging prompts and parameters, using fixed decoding settings, maintaining frozen model endpoints, checksumming training data, and using reproducible computational environments.
Reproducibility is particularly challenging for LLM-based systems, whose outputs may vary across model versions, prompting strategies, or even random seeds. For externally provided models, reproducibility may require contractual arrangements specifying version stability and access to historical model states. The goal is to preserve the capacity to explain and audit decisions retrospectively—a capacity that traditional rule-based systems provided by construction but that must be engineered into algorithmic workflows.
These five extensions address technical and procedural dimensions of quality, but they leave open broader questions about legitimacy and trust. The impersonal procedures that Porter (1995) describes depend not only on automation but on the visibility and auditability of those procedures. If algorithmic components are opaque—whether because of technical complexity or proprietary restrictions—then the center of gravity shifts toward performance documentation and auditability of evaluation: users must trust the validation infrastructure rather than inspecting the methods directly. Whether this shift is compatible with the institutional norms of official statistics is an open question. The following section considers an additional complication: when the most capable AI systems are developed outside public statistical institutions, the conventions governing their use may be shaped by actors whose interests do not align with those of official statistics.
6. Institutional Challenges
The quality framework extensions proposed in Section 5 cannot be implemented by methodologists alone. They require collaboration between statistical methodologists, data scientists, IT specialists, and domain experts—a combination of competencies that few NSOs currently possess in integrated form. Leading offices have responded by creating dedicated data science units that work alongside traditional methodology divisions: the ONS Data Science Campus, Statistics Canada’s Data Science Division, and similar initiatives across European NSOs. A recent framework for AI readiness in NSOs emphasizes that such capacity-building is “not a one-time goal but an ongoing process” requiring attention to governance, skills, infrastructure, and delivery mechanisms (PARIS21 2025). But a more fundamental challenge concerns the origin of the AI systems themselves—and who controls the infrastructure on which algorithm-assisted official statistics will depend.
6.1. The Public-Private Asymmetry in AI Development
The methodological innovations that shaped twentieth-century official statistics emerged from public institutions. Neyman’s (1934) foundational work on probability sampling was academic. Hansen et al. (1953) codified survey practice at the US Census Bureau. The development of GREG estimators and calibration methods occurred in universities and statistical offices (Cassel et al. 1976). Small area estimation techniques were refined through collaborations between academic statisticians and national offices (Molina and Rao 2023). These methods were published openly, debated in journals, and adopted by NSOs worldwide. The intellectual infrastructure of official statistics was, in this sense, a public good.
The AI landscape differs. The most capable foundation models—large-scale systems trained on broad data that can be adapted to many tasks—originate from private technology companies. Google, Meta, OpenAI, and Anthropic train systems on proprietary data using computational resources that exceed the capacity of any statistical office (Sevilla et al. 2022). Even nominally “open” models often carry licensing restrictions, lack full documentation of training procedures, or cannot be reproduced due to computational costs (Liesenfeld et al. 2023). This asymmetry creates tensions with the quality framework proposed in Section 5. Training data documentation requires information that may be proprietary. Algorithmic transparency requires access to architectures that may be trade secrets. Reproducibility requires model weights and procedures that companies may not release.
The concern extends beyond models to data. Tillé et al. (2022) express skepticism about web scraping for official statistics, noting that “official statistics must be sustainable and that the Internet is not stable over time” and that “it would be extremely dangerous to become dependent on [the] giants of the web.” Transaction data, mobile phone records, and social media traces—the data sources that AI methods can exploit—are typically held by private companies whose commercial interests may not align with statistical purposes. Access arrangements are precarious: platforms can change APIs, impose fees, or withdraw access entirely. The general trend toward restricted data access—the “post-API age”—has been documented in the research methods literature (Freelon 2018) and was dramatically illustrated when Twitter (now X) restricted academic data access in 2023. Some jurisdictions have enacted legislation enabling statistical authorities to compel access to privately held data—the UK’s Digital Economy Act 2017 is one example—though the use of such compulsory powers raises practical and relational considerations that may limit their application.
6.2. European Responses: Building Public Infrastructure
The European Statistical System (ESS) has responded to these challenges with substantial investment in public AI/ML infrastructure. We focus on Europe as an illustrative governance ecosystem; other regions are developing different approaches, but the ESS initiatives are among the most visible and well-documented.
The ESS response is three-fold. First, shared open-source infrastructure; the AIML4OS project (Artificial Intelligence and Machine Learning for Official Statistics), launched in April 2024, is a four-year ESSnet collaboration of sixteen countries building a common platform for AI/ML tools, guidance, and sandboxes (Eurostat 2024). The project spans use cases including automated coding, editing and imputation, earth observation data, large language models, and synthetic data generation. Complementary initiatives address specific data sources and technologies. The Web Intelligence Hub provides capabilities to gather and process web content for statistical purposes, accompanied by ESS guidelines for web content retrieval, while the Smart Surveys Implementation project develops methods for combining traditional survey questions with sensor-enabled devices while ensuring privacy safeguards (Eurostat 2025). Second, enabling legislation; the revision of Regulation (EC) 223/2009 on European Statistics, which entered into force in December 2024, enables statistical authorities to access privately held data for developing and producing European statistics. Third, privacy-preserving technologies: the revised Regulation makes explicit reference to Privacy Enhancing Technologies and secure infrastructure designed to comply with data protection requirements, addressing the tension between data access and confidentiality. These European efforts represent a deliberate strategy to maintain public control over statistical infrastructure while exploiting new data sources and methods.
6.3. Persistent Risks of Dependency
Despite these efforts, risks of dependency remain. A recent OECD report on AI in government observes that “a lack of skills internal in public administrations can result in an overreliance on outsourcing” and warns that “relying too heavily on procurement relative to building internal capacities can result in a hollowing-out of government capacities” (OECD 2025). The PARIS21 framework explicitly warns against “vendor lock-in” and recommends procurement rules that preserve optionality (PARIS21 2025).
These concerns reflect broader patterns in public-sector digital transformation, where data analytics and AI capabilities are increasingly provided by private technology firms. Cloud computing migration has made many government agencies—including statistical offices—dependent on infrastructure provided by Amazon Web Services, Microsoft Azure, or Google. Even where NSOs develop AI solutions in-house, they often rely on pre-trained models or cloud-based computing resources provided by private vendors. The risk is that dependence on external systems whose design and governance are not controlled by the statistical office may limit the capacity to document, audit, and reproduce statistical outputs.
These challenges are particularly acute for statistical offices in low- and middle-income countries, which often face fragmented data systems, outdated technology, limited budgets, shortages of skilled staff, and restricted access to cloud services (PARIS21 2025). The ESS investments described above are not equally available to all statistical systems. Yet pressure to deliver on the Sustainable Development Goals with fewer resources makes AI applications attractive—automated coding, nowcasting, multilingual dissemination tools—even where institutional capacity to govern them responsibly may be limited. The risk is that AI adoption proceeds faster than the development of quality assurance infrastructure, creating dependencies that are difficult to reverse.
7. Discussion
The preceding sections examined AI in official statistics through the lens of algorithm-assisted inference—situating current developments within the methodological transitions from design-based through model-assisted approaches. The formal framework in Section 3 showed that generalized difference estimators accommodate machine learning predictions in the same way they accommodate parametric models. The vignettes in Section 4 illustrated how NSOs are already embedding AI within validation regimes that extend established quality practices. Section 5 proposed quality framework extensions, and Section 6 considered institutional challenges arising from the public-private asymmetry in AI development. Several observations emerge from this analysis.
First, formal continuity between model-assisted and algorithm-assisted methods does not imply that AI adoption is straightforward. The design-consistency result in Equation (4) requires regularity conditions—stability of the learner, bounded complexity, adequate sample size—that may not hold for all ML methods. In practice, techniques such as sample splitting and cross-fitting are often needed to ensure that the properties of
Second, the concerns raised about private-sector dependence should not be read as counsel against AI adoption. NSOs retain important advantages: legal authority to collect and access data, established relationships with respondents, expertise in measurement and uncertainty, and reputational capital built over decades of producing trusted statistics. These assets provide leverage in negotiations with technology providers and create opportunities for public-sector leadership. The European Statistical System’s investments in shared infrastructure, enabling legislation, and privacy-enhancing technologies described in Section 6 demonstrate that public institutions can shape AI development rather than merely consuming privately produced tools. The relationship between official statistics and AI can be reciprocal: statistical infrastructure (sampling frames, classification systems, quality-assured microdata) and statistical expertise (in bias, uncertainty, and representativeness) are valuable for AI development, not only the reverse.
Third, the tension between methodological opportunity and institutional risk is not unprecedented. Every major transition in official statistics—from census enumeration to sample surveys, from manual tabulation to computing, from design-based to model-assisted methods—raised analogous questions about expertise, control, and legitimacy (Brewer 2013). What distinguishes the current moment is the speed of change, the concentration of capability in a small number of private actors, and the opacity of the systems involved. The historical pattern—controversy, then gradual incorporation through the development of shared standards—suggests a template.
The private-dependence risk deserves explicit articulation. The mechanism by which external AI systems threaten quality governance operates through at least three channels. First, opacity prevents implementation of quality frameworks: if training data, model architecture, and decision logic are proprietary, then the documentation, transparency, and auditability requirements of Section 5 become infeasible. Second, vendor control over model updates creates discontinuity risk: if a provider changes a model version mid-year, the NSO may be unable to reproduce last quarter’s outputs or maintain time-series comparability—and the resulting revisions become politically exposed. Third, procurement constraints may limit methodological sovereignty: contractual restrictions on disclosure, sensitivity analysis, or public defense of methods would compromise the transparency that legitimates official statistics. These are not abstract risks; they are operational constraints that procurement and governance arrangements must address.
The practical implication is that NSOs must attend simultaneously to two agendas. The first is technical: developing the skills, infrastructure, and quality practices needed to make algorithm-assisted inference reliable. The second is institutional: ensuring that AI adoption does not erode the transparency, accountability, and public character that give official statistics their authority. These agendas are complementary. Quality frameworks that cannot be implemented because underlying systems are proprietary and opaque serve little purpose; AI systems adopted without quality governance will not sustain public trust.
7.1. Limitations
This article has several limitations. The empirical vignettes are illustrative rather than exhaustive, and they are biased toward high-income NSOs with substantial public documentation of their AI initiatives. Evidence is uneven across application domains: automated coding and nowcasting are relatively well-documented, while applications in small area estimation, disclosure control, and data editing have less accessible public reporting. Many of the initiatives described are at the pilot stage; claims about operational deployment rely on limited public information, and production realities may differ from published accounts. The quality framework extensions proposed in Section 5 are conceptual; translating them into auditable standards will require empirical work on implementation feasibility and cost. Finally, our focus on the European Statistical System as an illustrative governance ecosystem means that institutional arrangements in other regions—with different legal frameworks, capacity constraints, and relationships with technology providers—receive less attention than they deserve.
7.2. Future Research
Future research should address both the technical and institutional agendas identified above. On the technical side, four study designs would be particularly valuable. First, head-to-head comparisons of algorithm-assisted versus traditional methods across multiple countries and domains, with domain-level error reporting rather than only aggregate accuracy—assessing differential performance across subgroups, rare categories, and geographies. Second, prequential monitoring studies that track how model drift manifests in official outputs over successive production cycles, identifying what monitoring thresholds and alert systems can prevent problematic releases. Third, benchmarking under distribution shift: systematic evaluation of algorithm-assisted methods under policy-relevant changes such as classification revisions, economic shocks, or pandemic-induced behavioral shifts that stress-test the stability assumptions underlying design-consistency. Fourth, uncertainty quantification studies that develop and validate methods for decomposing and communicating the distinct contributions of sampling and algorithmic uncertainty in published statistics.
On the institutional side, comparative case studies are needed of how NSOs are navigating the public-private boundary: what contractual arrangements are being negotiated, what in-house capacities are being built, what international coordination is emerging, and how quality frameworks are being adapted in practice. Institutional ethnography of AI adoption decisions within statistical offices—examining procurement processes, internal capacity-building pathways, and the micro-politics of methodological change—would complement the macro-level analysis offered in this article. Empirical studies of AI adoption in statistical offices remain sparse.
8. Conclusion
This article argues that AI does not constitute a new inferential paradigm for official statistics. It represents the next phase in a methodological evolution from purely design-based inference through model-assisted approaches to what may now be called algorithm-assisted inference. Each transition in the history of survey methodology expanded the role of modeling assumptions in statistical production; each succeeded when accompanied by quality frameworks adequate to the new sources of uncertainty. Algorithm-assisted inference extends the prediction framework while preserving design-based guarantees—provided that regularity conditions are met and quality governance is adequate. These conditions are not trivially satisfied; techniques such as sample splitting, cross-fitting, and stability checks are often required to ensure that the properties of learned prediction functions do not undermine design-based guarantees. The vignettes in Section 4 illustrate that this formal continuity has practical implications: NSO practitioners are embedding AI within validation regimes—benchmarking, human oversight, prequential monitoring—that extend established quality practices rather than replacing them.
The additional requirements for algorithm-assisted official statistics are concrete: document training data provenance; make algorithmic roles visible within production pipelines; benchmark against established methods and monitor calibration over time; characterize and communicate uncertainty, including its algorithmic components; enforce reproducibility through version control. Implementing these requirements will bring efficiency gains while preserving what gives official statistics their distinctive authority: the capacity to make uncertainty visible, to explain methods, and to sustain trust during methodological change.
At the same time, quality frameworks alone cannot address a concern that distinguishes this transition from earlier ones. The methodological innovations of the twentieth century emerged from public institutions; the AI innovations of the twenty-first century emerge predominantly from private technology companies. If NSOs become dependent on commercial AI systems that cannot be inspected, documented, or reproduced, then the quality frameworks described here become difficult to implement. The risk is not that AI cannot work technically—the evidence suggests it can—but that AI may be adopted in ways that compromise the transparency and accountability that make official statistics trustworthy. Initiatives such as the European Statistical System’s investments in shared infrastructure, enabling legislation, and privacy-enhancing technologies demonstrate that public institutions can shape this trajectory—but such responses require sustained commitment and resources that are not universally available. A partial precedent offers some grounds for cautious optimism: over the past two decades, many NSOs became locked into production systems built on proprietary software with expensive license fees, yet the community has gradually migrated toward open-source alternatives such as R and Python. Whether community-developed tools will similarly emerge to reduce dependence on proprietary AI systems remains to be seen, but the historical pattern suggests that dependencies initially perceived as permanent can eventually be dissolved.
The history of statistics reminds us that the legitimacy of official statistics rests not only on technical correctness but on the perception that methods are impartial, transparent, and subject to disciplined quality control. Design-based inference achieved this by minimizing discretion; model-assisted inference maintained it through explicit conventions for validation and documentation. Algorithm-assisted inference will succeed on the same terms—but only if NSOs attend to institutional as well as methodological challenges. The question is not whether to adopt AI, but how to adopt it in ways that preserve the public character of official statistics. Algorithm-assisted inference will succeed only insofar as it can be made auditable, reproducible, and publicly defensible.